⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-28 更新
HERMES: A Unified Self-Driving World Model for Simultaneous 3D Scene Understanding and Generation
Authors:Xin Zhou, Dingkang Liang, Sifan Tu, Xiwu Chen, Yikang Ding, Dingyuan Zhang, Feiyang Tan, Hengshuang Zhao, Xiang Bai
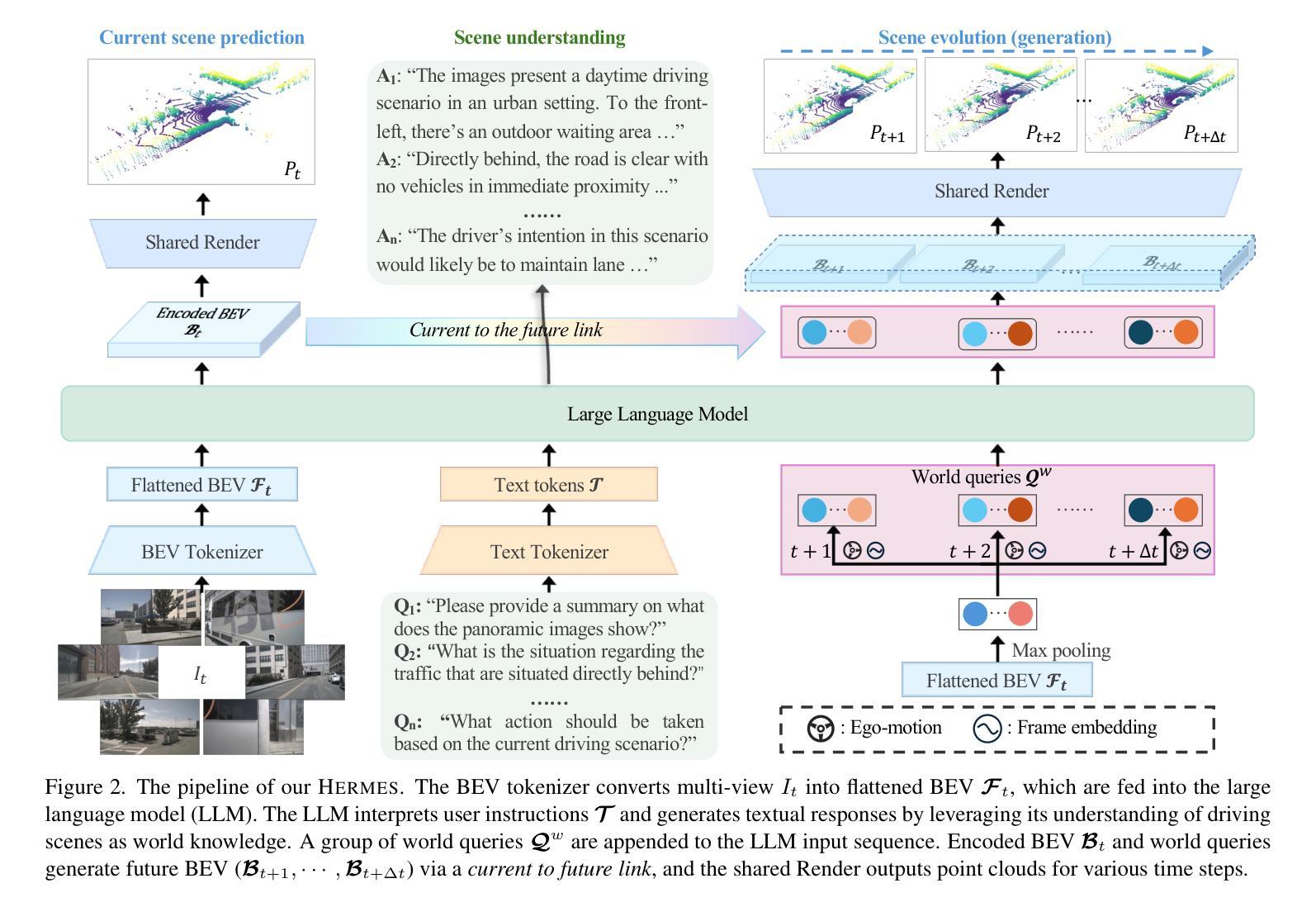
Driving World Models (DWMs) have become essential for autonomous driving by enabling future scene prediction. However, existing DWMs are limited to scene generation and fail to incorporate scene understanding, which involves interpreting and reasoning about the driving environment. In this paper, we present a unified Driving World Model named HERMES. We seamlessly integrate 3D scene understanding and future scene evolution (generation) through a unified framework in driving scenarios. Specifically, HERMES leverages a Bird’s-Eye View (BEV) representation to consolidate multi-view spatial information while preserving geometric relationships and interactions. We also introduce world queries, which incorporate world knowledge into BEV features via causal attention in the Large Language Model (LLM), enabling contextual enrichment for understanding and generation tasks. We conduct comprehensive studies on nuScenes and OmniDrive-nuScenes datasets to validate the effectiveness of our method. HERMES achieves state-of-the-art performance, reducing generation error by 32.4% and improving understanding metrics such as CIDEr by 8.0%. The model and code will be publicly released at https://github.com/LMD0311/HERMES.
驾驶世界模型(DWM)通过实现未来场景预测,已成为自动驾驶不可或缺的技术。然而,现有的DWM仅限于场景生成,无法融入场景理解,这涉及到对驾驶环境的解释和推理。在本文中,我们提出了一种统一的驾驶世界模型——赫尔墨斯(HERMES)。我们通过一个统一框架无缝集成了驾驶场景中的3D场景理解和未来场景演变(生成)。具体来说,赫尔墨斯利用鸟瞰图(BEV)表示法来整合多视图空间信息,同时保留几何关系和交互作用。我们还引入了世界查询,通过大型语言模型(LLM)中的因果注意力,将世界知识融入BEV特征,为理解和生成任务提供上下文丰富性。我们在nuScenes和OmniDrive-nuScenes数据集上进行了综合研究,以验证我们的方法的有效性。赫尔墨斯达到了最先进的性能,降低了生成错误率32.4%,并提高了理解指标,如CIDEr提高了8.0%。模型和代码将在https://github.com/LMD0311/HERMES公开发布。
论文及项目相关链接
PDF Work in progress. The code will be available at https://github.com/LMD0311/HERMES
Summary
HERMES是一种统一驾驶世界模型,实现了对驾驶场景的理解与未来场景的生成。它通过鸟瞰视图表示法整合多视角空间信息,并引入世界查询功能,借助大型语言模型的因果注意力机制,实现对场景理解与生成的上下文丰富。在nuScenes和OmniDrive-nuScenes数据集上的研究表明,HERMES在生成和理解任务上均达到了领先水平。
Key Takeaways
- HERMES是一个统一驾驶世界模型,集成了驾驶场景理解和未来场景生成的功能。
- HERMES使用鸟瞰视图表示法来整合多视角空间信息并保留几何关系和交互。
- 世界查询功能通过大型语言模型的因果注意力机制融入世界知识,丰富了理解和生成任务的上下文。
- HERMES在nuScenes和OmniDrive-nuScenes数据集上进行了综合研究验证其有效性。
- HERMES实现了先进的性能,减少了生成错误并提高了理解指标。
- HERMES模型和代码将在公开平台上发布,便于其他研究者使用和改进。
点此查看论文截图

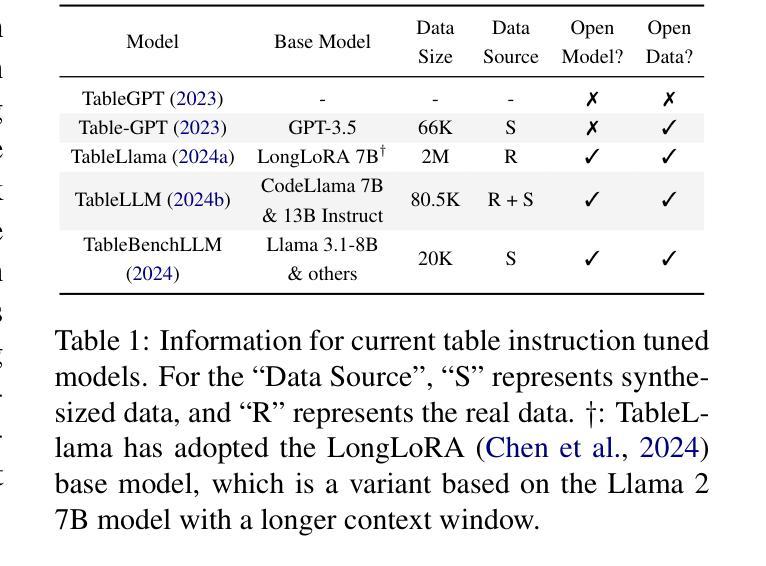
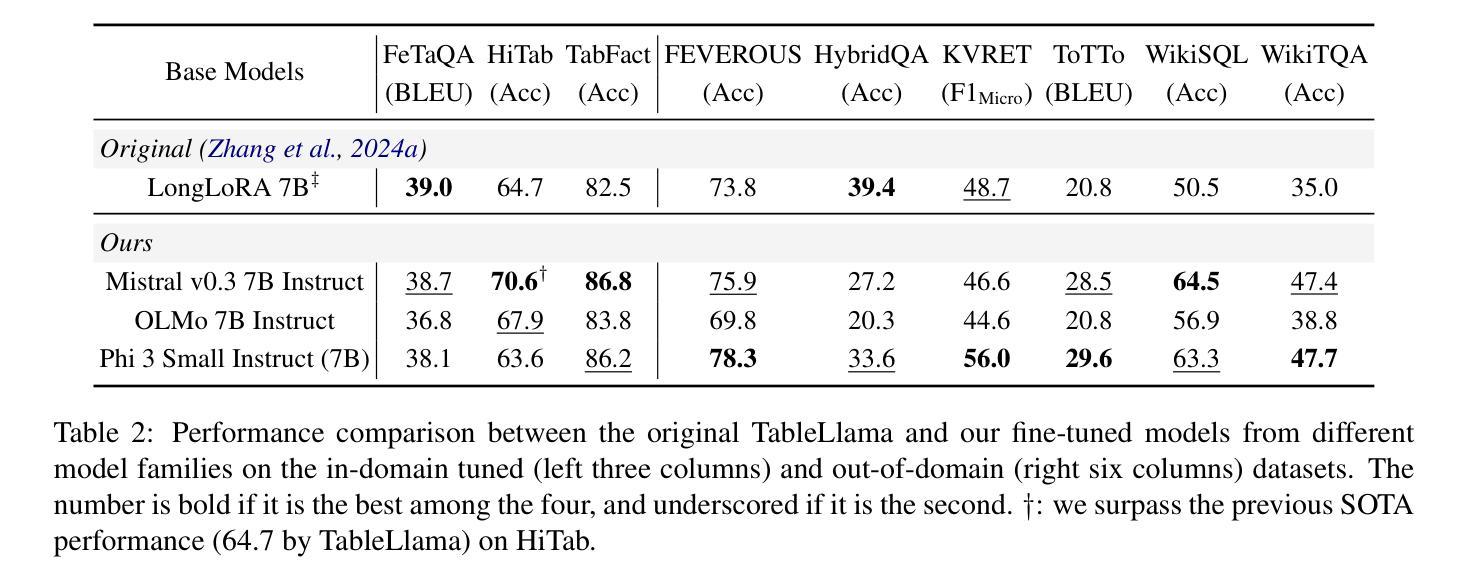
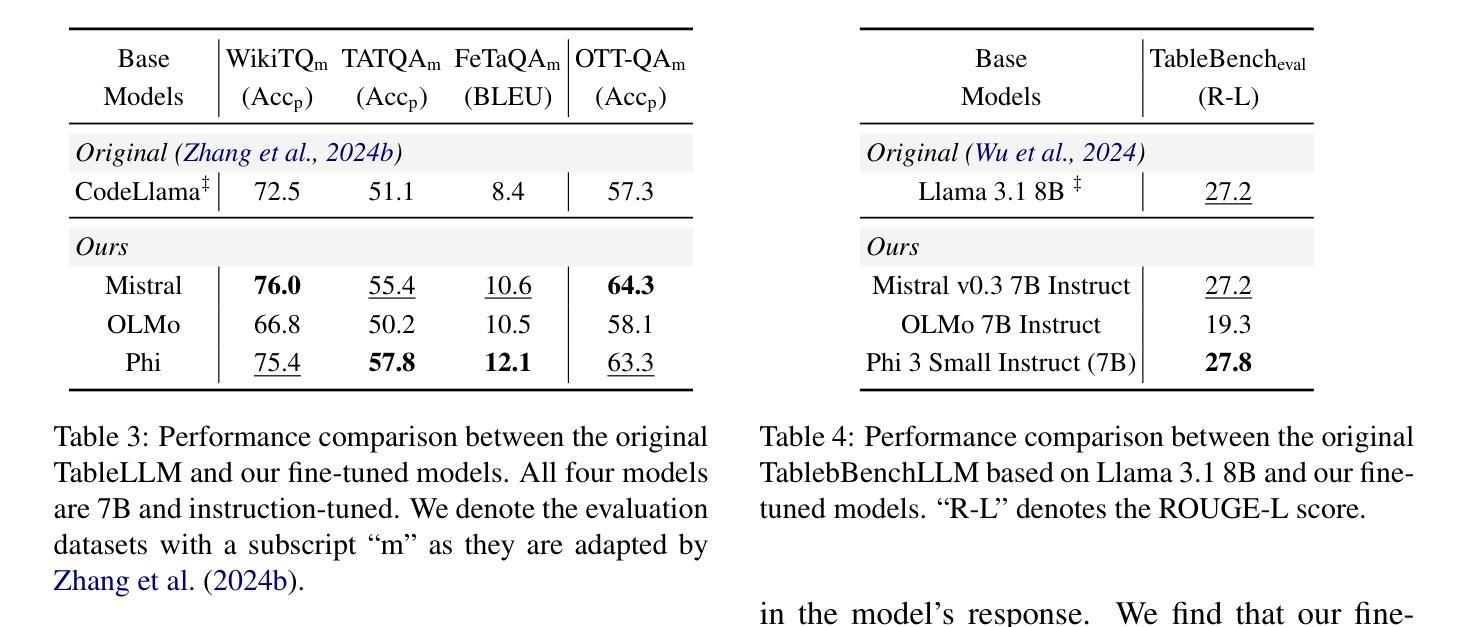
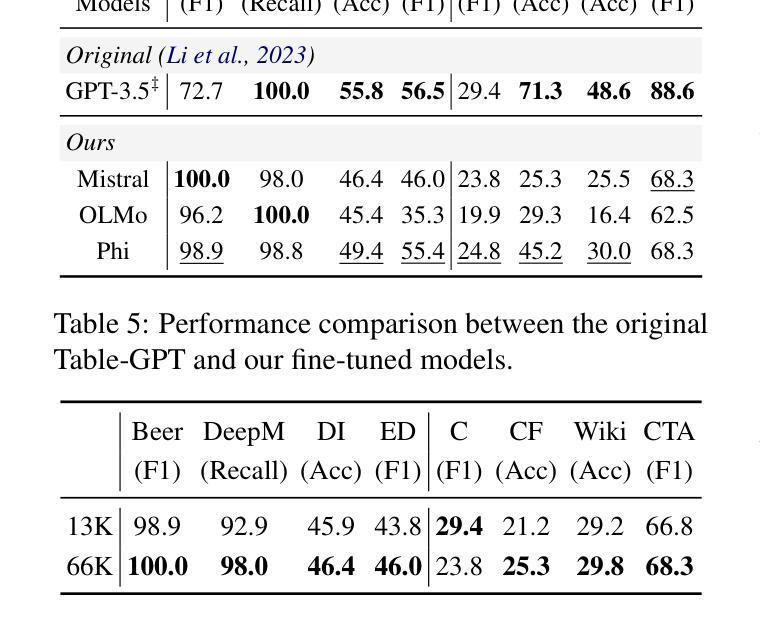
Towards Better Understanding Table Instruction Tuning: Decoupling the Effects from Data versus Models
Authors:Naihao Deng, Sheng Zhang, Henghui Zhu, Shuaichen Chang, Jiani Zhang, Alexander Hanbo Li, Chung-Wei Hang, Hideo Kobayashi, Yiqun Hu, Patrick Ng
Recent advances in natural language processing have leveraged instruction tuning to enhance Large Language Models (LLMs) for table-related tasks. However, previous works train different base models with different training data, lacking an apples-to-apples comparison across the result table LLMs. To address this, we fine-tune base models from the Mistral, OLMo, and Phi families on existing public training datasets. Our replication achieves performance on par with or surpassing existing table LLMs, establishing new state-of-the-art performance on Hitab, a table question-answering dataset. More importantly, through systematic out-of-domain evaluation, we decouple the contributions of training data and the base model, providing insight into their individual impacts. In addition, we assess the effects of table-specific instruction tuning on general-purpose benchmarks, revealing trade-offs between specialization and generalization.
自然语言处理领域的最新进展已经利用指令微调来增强大型语言模型(LLM)在表格相关任务上的性能。然而,之前的工作使用不同的基础模型和训练数据,缺乏对不同表格LLM结果的直接比较。为了解决这一问题,我们在现有的公开训练数据集上对来自Mistral、OLMo和Phi家族的基础模型进行了微调。我们的复制模型性能与现有的表格LLM相当或更胜一筹,在表格问答数据集Hitab上建立了新的最新技术水平。更重要的是,通过系统的域外评估,我们解耦了训练数据和基础模型的贡献,深入了解它们各自的影响。此外,我们还评估了表格特定指令微调对通用基准测试的影响,揭示了专业化和通用化之间的权衡。
论文及项目相关链接
Summary
自然語言處理的最新進展利用指令調整來提升大型語言模型(LLM)在表格相關任務上的性能。然而,先前的研究使用不同的基礎模型和訓練數據,缺乏對結果表格LLM的公平比較。為解決此問題,我們對Mistral、OLMo和Phi家族的基礎模型進行微調,使用現有的公共訓練數據集。我們的復現性能與現有表格LLM相當或更優,在表格問題回答數據集Hitab上樹立了新的最新技術水平。更重要的是,我們通過系統的跨域評估,解耦了訓練數據和基礎模型的貢獻,深入了解它們各自的影響。此外,我們還評估了表格特定指令調整對通用基準測試的影響,揭示了專業化和泛化之間的權衡。
Key Takeaways
- 自然语言处理的最新进展通过指令调整增强了LLM在表格任务上的性能。
- 之前的研究在基模型与训练数据上存在差异,缺乏公平比较。
- 研究人员对Mistral、OLMo和Phi家族的基模型进行了微调,达到或超越了现有表格LLM的性能。
- 在Hitab数据集上树立了新的技术标杆。
- 通过系统跨域评估,研究解耦了训练数据和基模型的贡献。
- 评估了表格特定指令调整对通用基准测试的影响。
点此查看论文截图

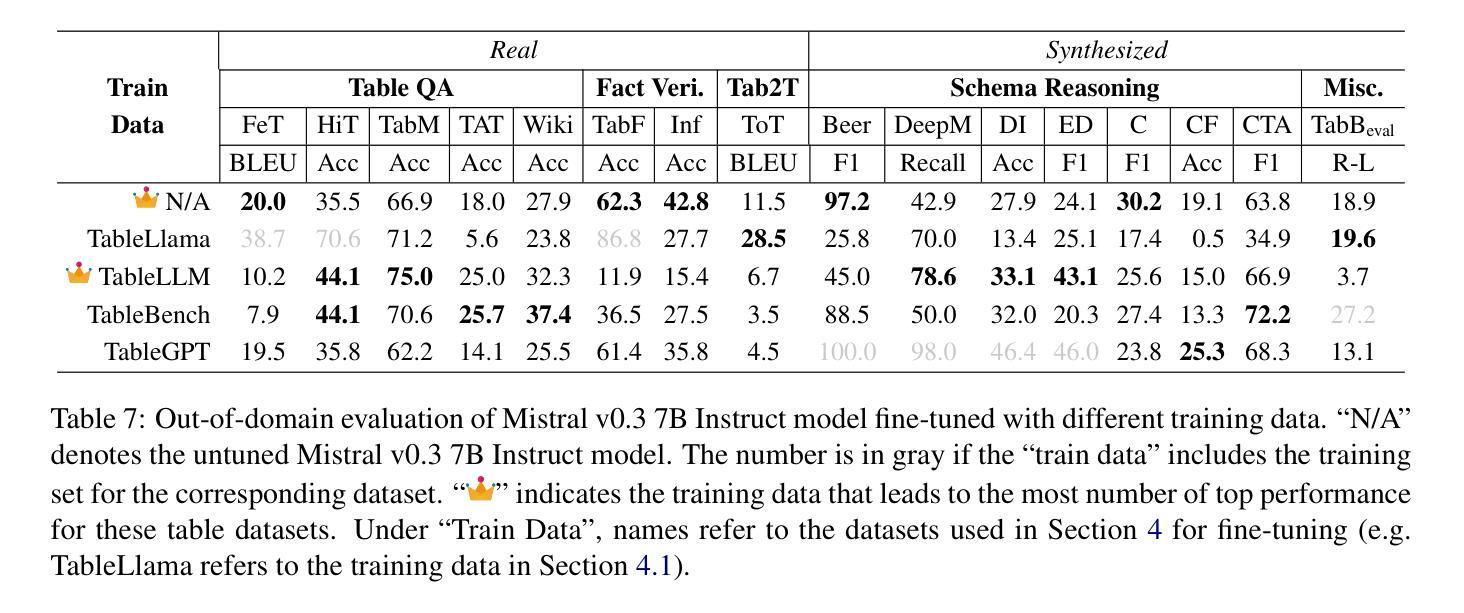

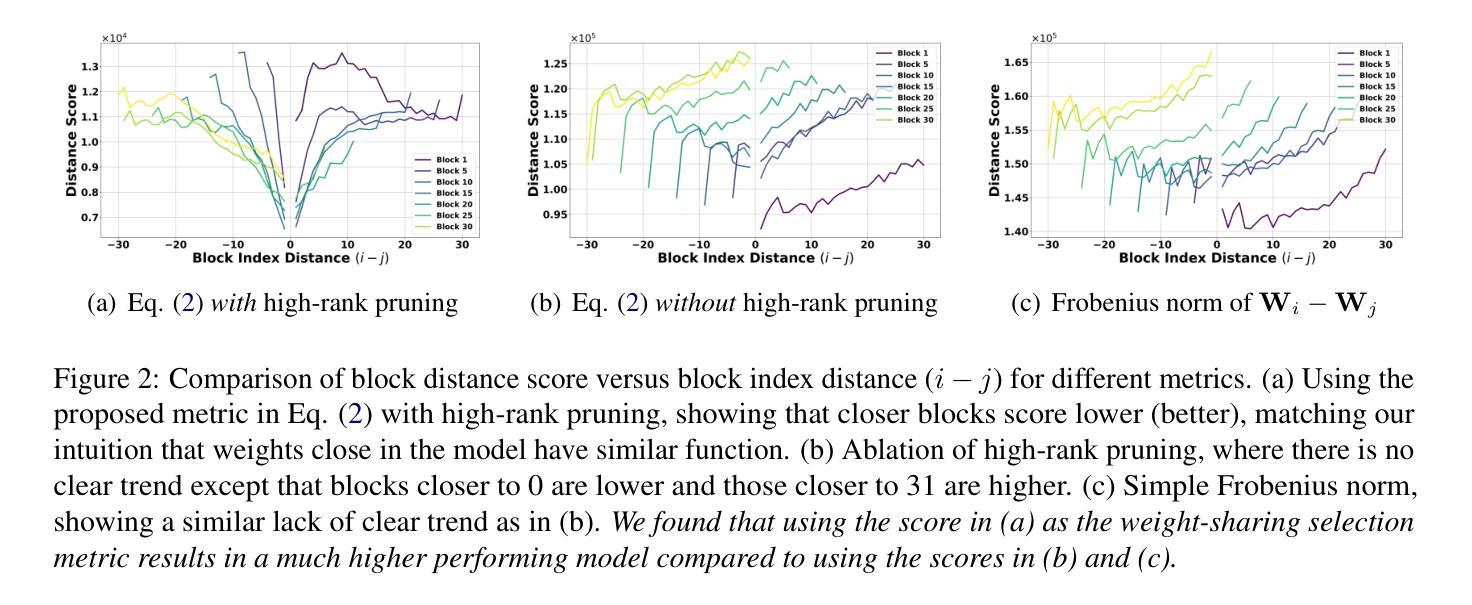
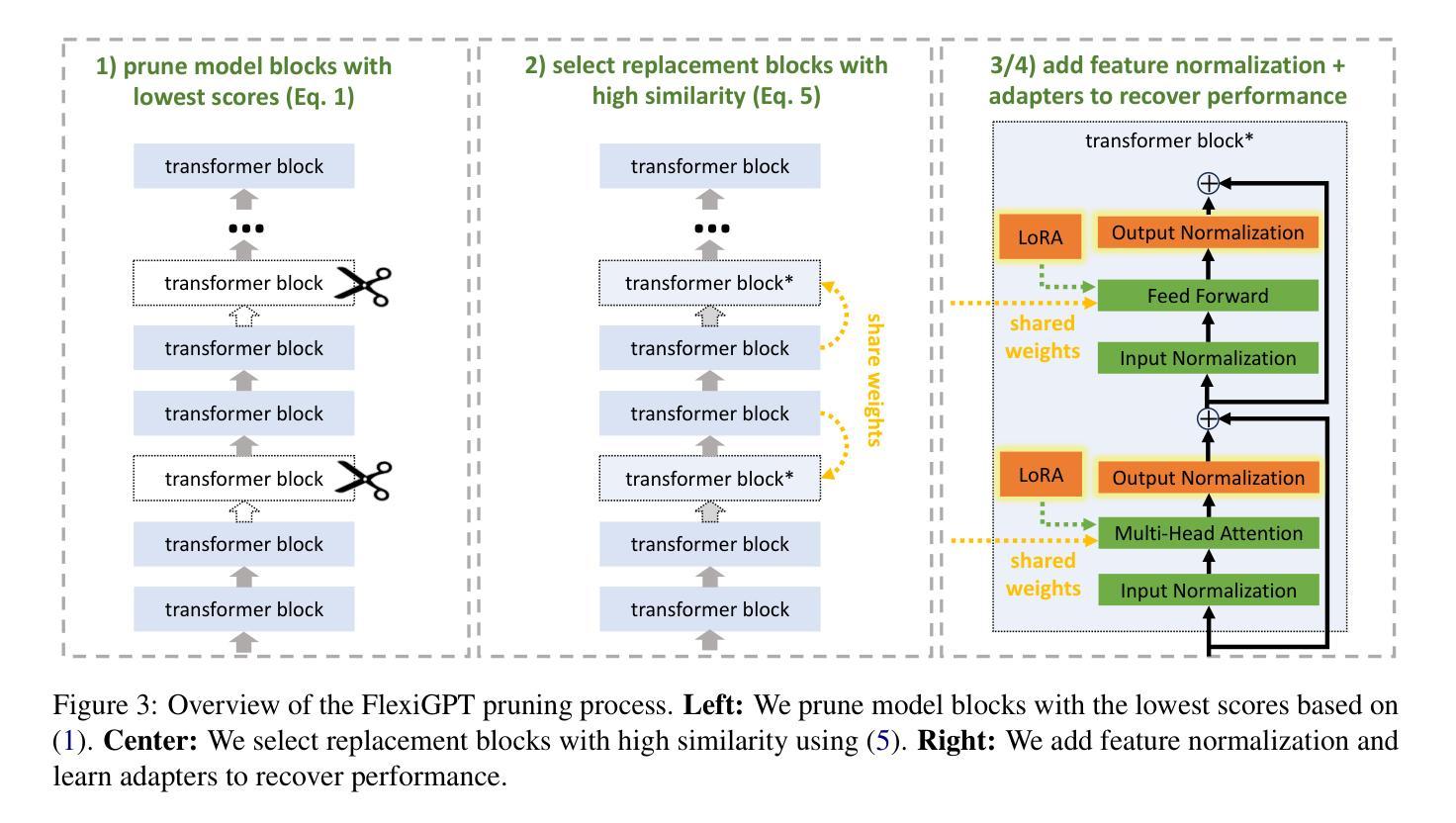
FlexiGPT: Pruning and Extending Large Language Models with Low-Rank Weight Sharing
Authors:James Seale Smith, Chi-Heng Lin, Shikhar Tuli, Haris Jeelani, Shangqian Gao, Yilin Shen, Hongxia Jin, Yen-Chang Hsu
The rapid proliferation of large language models (LLMs) in natural language processing (NLP) has created a critical need for techniques that enable efficient deployment on memory-constrained devices without compromising performance. We present a method to prune LLMs that selectively prunes model blocks based on an importance score and replaces them with a low-parameter replacement strategy. Specifically, we propose a principled metric to replace each pruned block using a weight-sharing mechanism that leverages unpruned counterparts from the model and block-specific low-rank adapters. Furthermore, we facilitate the learning of these replacement blocks with output feature normalization and an adapter initialization scheme built on low-rank SVD reconstructions. Empirical evaluations demonstrate substantial performance gains over existing methods, achieving state-of-the-art performance on 5/6 benchmarks for a compression rate of 30% and 6/6 benchmarks for a compression rate of 40%. We also demonstrate that our approach can extend smaller models, boosting performance on 6/6 benchmarks using only ~0.3% tokens of extended training with minimal additional parameter costs.
自然语言处理(NLP)中大型语言模型(LLM)的迅速增殖,产生了对能够在内存受限设备上高效部署而又不影响性能的技术的高度需求。我们提出了一种选择性地对模型块进行修剪的方法,该方法基于重要性评分进行修剪,并用低参数替换策略进行替换。具体来说,我们提出了一种有原则的度量标准,以替换每个修剪过的块,采用权重共享机制并利用模型中未修剪的对应部分和特定的低秩适配器来实现。此外,我们通过输出特征归一化和基于低秩SVD重构的适配器初始化方案,促进了这些替换块的学习。经验评估表明,与现有方法相比,我们的方法取得了显著的性能提升,在压缩率为3.5的情况下在六个基准测试中取得最高成绩。我们也证明了我们的方法可以将小型模型扩展应用到实践当中,仅仅通过扩展训练集的数据内容词的占比即可显著提升模型的性能表现且仅带来极少数的额外参数成本。
论文及项目相关链接
PDF Accepted to NAACL 2025 - Main Conference
Summary
大型语言模型(LLM)在自然语言处理(NLP)中的迅速普及,对在内存受限设备上高效部署而又不影响性能的技术提出了迫切需求。本文提出了一种选择性修剪LLM的方法,该方法基于重要性评分选择性地修剪模型块,并用低参数替换策略进行替换。我们提出了一种有原则的指标,用权重共享机制替换每个修剪过的块,该机制利用模型中的未修剪对应部分和块特定的低秩适配器。此外,我们还通过输出特征归一化和基于低秩SVD重建的适配器初始化方案,促进了这些替换块的学习。实证评估表明,相较于现有方法,我们的方法在所有六个基准测试中都实现了显著的性能提升,在压缩率为30%的情况下达到了五分之六的基准测试的最佳性能,在压缩率为40%的情况下达到了全部六个基准测试的最佳性能。此外,我们的方法还可以扩展小型模型,在仅使用约0.3%的扩展训练令牌和极小的额外参数成本的情况下,在全部六个基准测试中提升了性能。
Key Takeaways
- 大型语言模型(LLM)需要高效部署在内存受限设备上的技术。
- 提出了一种基于重要性评分的选择性修剪LLM的方法。
- 使用了权重共享机制来替换修剪过的模型块。
- 通过输出特征归一化和低秩SVD重建的适配器初始化方案,促进了替换块的学习。
- 在多个基准测试中实现了显著的性能提升,包括在压缩模型和提高小型模型性能方面。
- 压缩率达到30%和40%时,性能达到了或超越了现有方法。
点此查看论文截图

The Karp Dataset
Authors:Mason DiCicco, Eamon Worden, Conner Olsen, Nikhil Gangaram, Daniel Reichman, Neil Heffernan
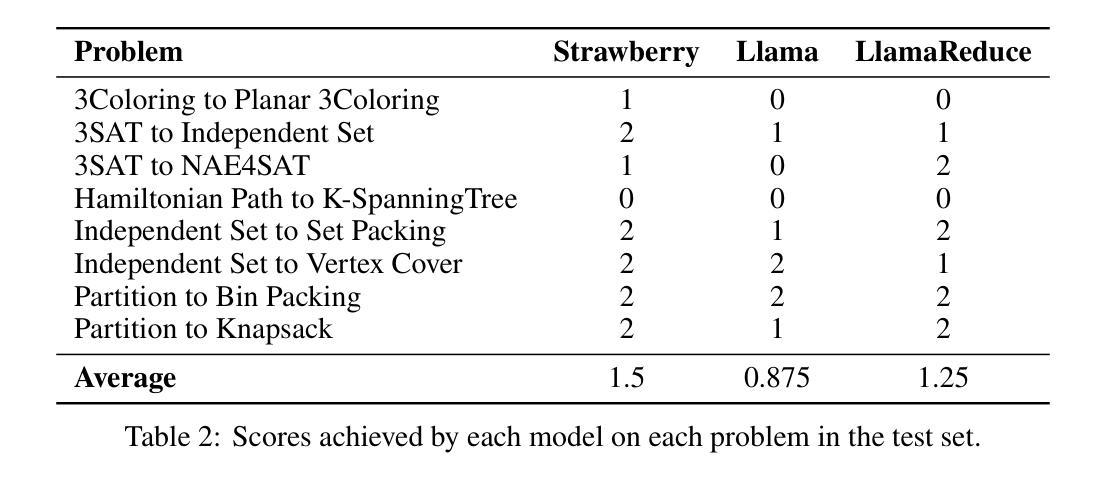
Understanding the mathematical reasoning capabilities of Large Language Models (LLMs) is a central topic in the study of artificial intelligence. This new domain necessitates the creation of datasets of reasoning tasks for both training and benchmarking the performance of LLMs. To this end, we introduce the Karp dataset: The first dataset composed of detailed proofs of NP-completeness reductions. The reductions vary in difficulty, ranging from simple exercises of undergraduate courses to more challenging reductions from academic papers. We compare the performance of state-of-the-art models on this task and demonstrate the effect of fine-tuning with the Karp dataset on reasoning capacity.
理解大型语言模型(LLM)的数学推理能力是人工智能研究的核心话题。这一新领域需要创建用于训练和评估LLM性能的推理任务数据集。为此,我们推出了Karp数据集:由NP完全性归约的详细证明组成的首个数据集。归约的难易程度各不相同,从本科课程的简单练习到学术论文中的更具挑战性的归约。我们比较了最先进模型在此任务上的性能,并展示了使用Karp数据集对推理能力进行微调的效果。
论文及项目相关链接
PDF Accepted to the 4th workshop on mathematical reasoning and AI at NeurIPS 2024
Summary:
介绍了理解大型语言模型(LLM)数学推理能力的重要性,以及为此需要创建用于训练和评估LLM性能的推理任务数据集。为此目的,引入了Karp数据集,它是首个包含NP完全性归约的详细证明的数据集。归约的难易程度不同,涵盖了从本科课程的简单练习到学术论文中的挑战性归约。此外还比较了最先进模型在此任务上的性能,并展示了使用Karp数据集微调对推理能力的影响。
Key Takeaways:
- 大型语言模型(LLM)的数学推理能力是人工智能研究中的核心话题。
- Karp数据集是首个包含NP完全性归约的详细证明的数据集。
- Karp数据集中的归约难度不同,包括从简单的本科课程练习到复杂的学术论文归约。
- 通过对最新模型在此任务上的性能进行比较,揭示了模型之间的差距。
- 展示了使用Karp数据集进行微调对模型推理能力的积极影响。
- 该数据集为评估和训练LLM的推理能力提供了重要资源。
点此查看论文截图


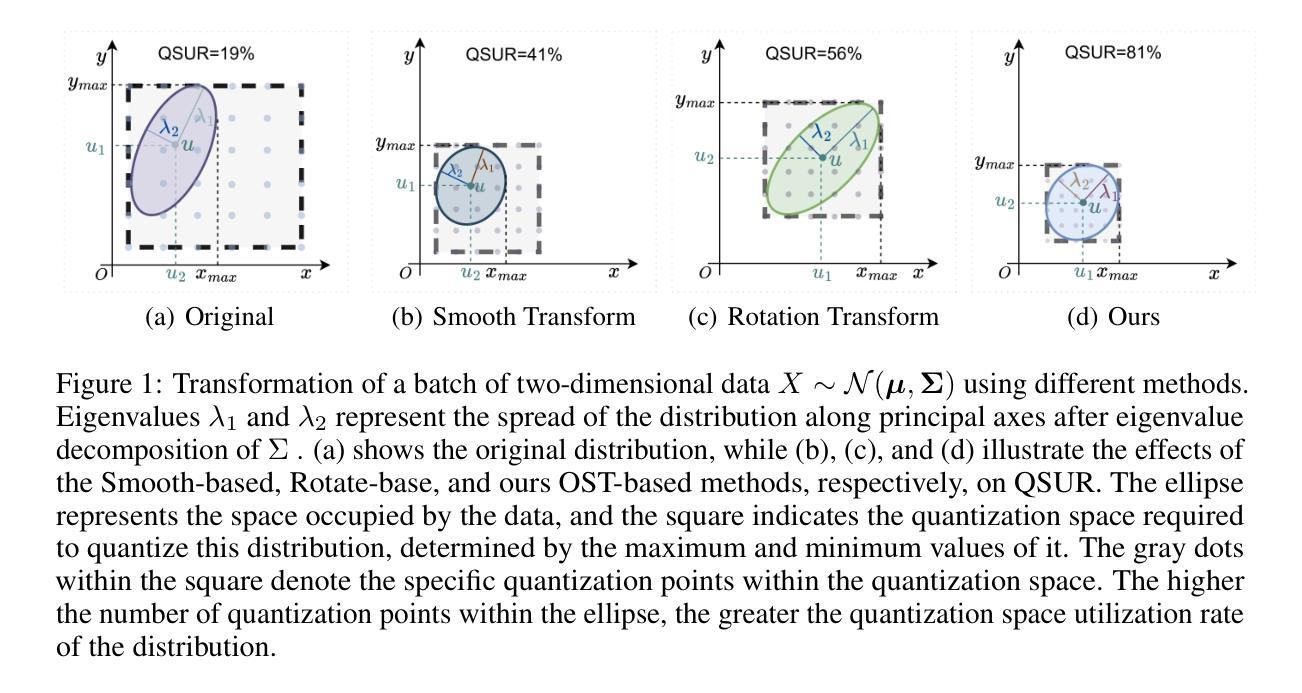
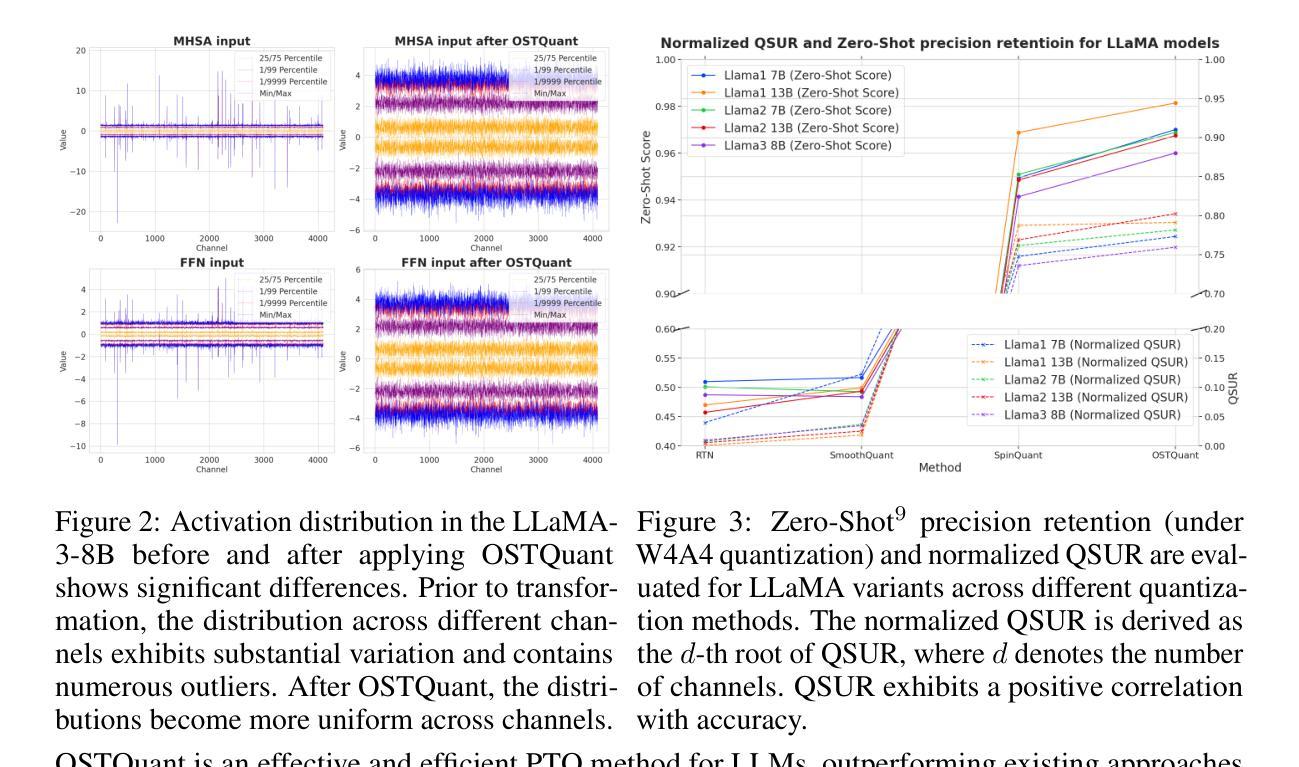
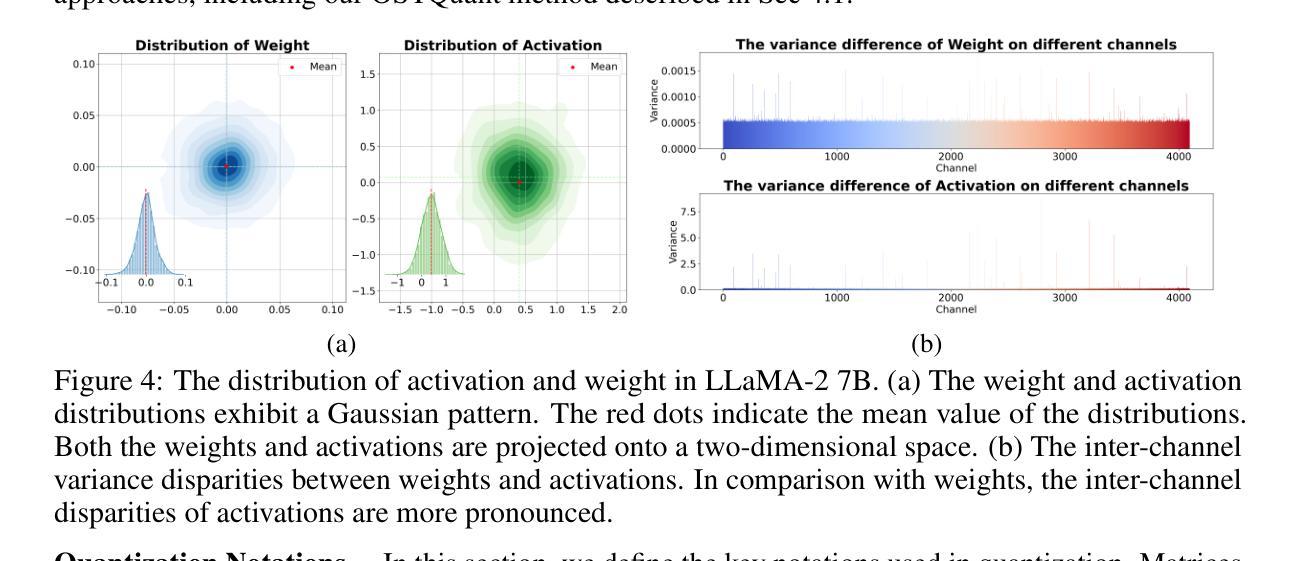
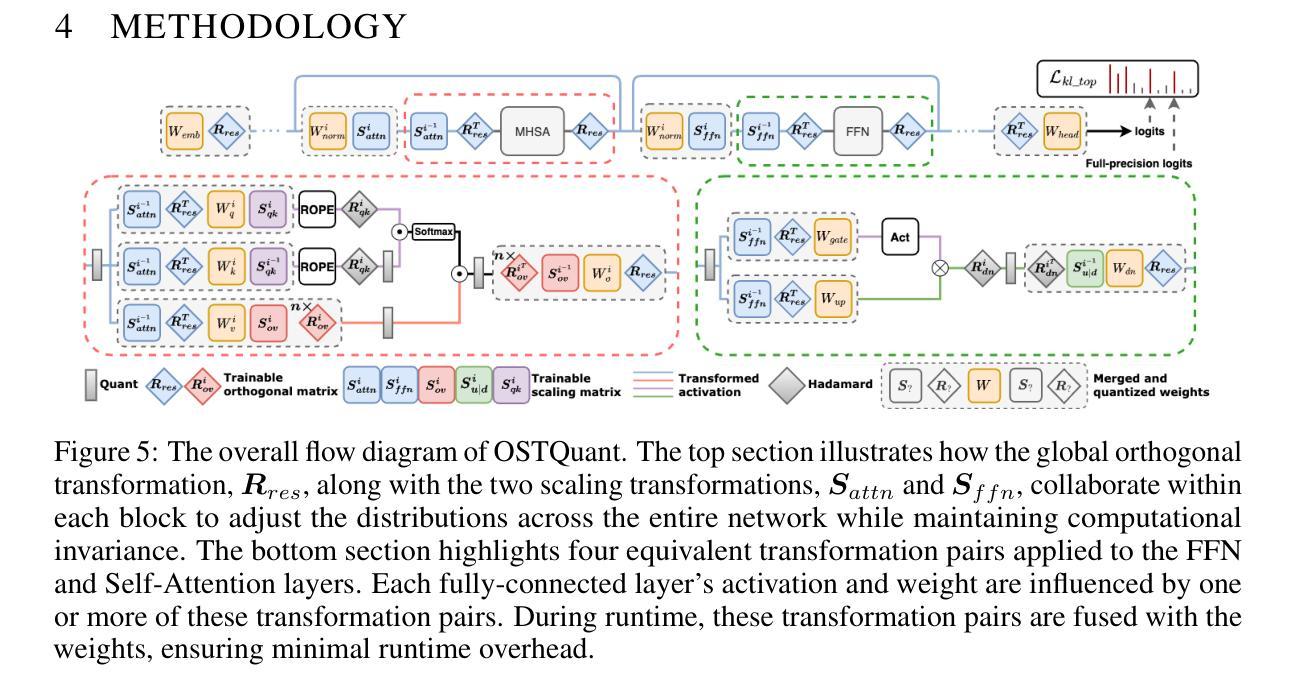
OstQuant: Refining Large Language Model Quantization with Orthogonal and Scaling Transformations for Better Distribution Fitting
Authors:Xing Hu, Yuan Cheng, Dawei Yang, Zukang Xu, Zhihang Yuan, Jiangyong Yu, Chen Xu, Zhe Jiang, Sifan Zhou
Post-training quantization (PTQ) has emerged as a widely adopted technique for compressing and accelerating Large Language Models (LLMs). The major challenge in LLM quantization is that uneven and heavy-tailed data distributions can expand the quantization range, thereby reducing bit precision for most values. Recent methods attempt to eliminate outliers and balance inter-channel differences by employing linear transformations; however, they remain heuristic and are often overlook optimizing the data distribution across the entire quantization space.In this paper, we introduce Quantization Space Utilization Rate (QSUR), a novel metric that effectively assesses the quantizability of transformed data by measuring the space utilization of the data in the quantization space. We complement QSUR with mathematical derivations that examine the effects and limitations of various transformations, guiding our development of Orthogonal and Scaling Transformation-based Quantization (OSTQuant). OSQuant employs a learnable equivalent transformation, consisting of an orthogonal transformation and a scaling transformation, to optimize the distributions of weights and activations across the entire quantization space. Futhermore, we propose the KL-Top loss function, designed to mitigate noise during optimization while retaining richer semantic information within the limited calibration data imposed by PTQ. OSTQuant outperforms existing work on various LLMs and benchmarks. In the W4-only setting, it retains 99.5% of the floating-point accuracy. In the more challenging W4A4KV4 configuration, OSTQuant reduces the performance gap by 32% on the LLaMA-3-8B model compared to state-of-the-art methods. \href{https://github.com/BrotherHappy/OSTQuant}{https://github.com/BrotherHappy/OSTQuant}.
后训练量化(PTQ)已成为广泛采用的技术,用于压缩和加速大型语言模型(LLM)。LLM量化的主要挑战在于,不均匀和重尾的数据分布可能会扩大量化范围,从而降低大多数值的位精度。最近的方法试图通过采用线性变换来消除异常值并平衡跨通道的差异,但它们仍然是启发式的,并且经常忽略优化整个量化空间中的数据分布。在本文中,我们引入了量化空间利用率(QSUR)这一新指标,它通过测量量化空间中数据的空间利用率来有效地评估转换数据的量化能力。我们结合QSUR与数学推导,研究各种变换的影响和局限性,从而引导我们开发基于正交和缩放变换的量化(OSTQuant)。OSQuant采用一种可学习的等效变换,包括正交变换和缩放变换,以优化整个量化空间中权重和激活值的分布。此外,我们提出了KL-Top损失函数,旨在优化过程中减少噪声,同时保留PTQ所施加的有限校准数据中的丰富语义信息。OSTQuant在各种LLM和基准测试上的表现均优于现有工作。在仅使用W4的情况下,它保留了99.5%的浮点精度。在更具挑战性的W4A4KV4配置中,OSTQuant在LLaMA-3-8B模型上相较于最新方法减少了32%的性能差距。相关代码链接:https://github.com/BrotherHappy/OSTQuant。
论文及项目相关链接
PDF 10 Pages
摘要
本文介绍了针对大型语言模型(LLMs)的后训练量化(PTQ)技术中的新型量化方法。文章提出了量化空间利用率(QSUR)这一新指标,以评估变换数据的可量化性。此外,还引入了正交和缩放变换基量化(OSTQuant),采用可学习的等效变换来优化权重和激活在整个量化空间中的分布。同时,提出了KL-Top损失函数,旨在减少优化过程中的噪声,并在有限的校准数据下保留更丰富的语义信息。OSTQuant在各种LLMs和基准测试上的表现均优于现有工作。在W4-only设置下,它保留了99.5%的浮点精度。在更具挑战性的W4A4KV4配置中,OSTQuant在LLaMA-3-8B模型上将性能差距减少了32%,与最新方法相比具有显著优势。
关键见解
- 介绍了针对大型语言模型(LLM)的后训练量化(PTQ)技术的新型量化方法。
- 提出量化空间利用率(QSUR)这一新指标,以评估变换数据的可量化程度。
- 引入正交和缩放变换基量化(OSTQuant),优化权重和激活在量化空间中的分布。
- 提出KL-Top损失函数,以减少优化过程中的噪声并保留更丰富语义信息。
- OSTQuant在各种基准测试上的表现优于现有方法。
- 在W4-only设置下,OSTQuant保留的浮点精度高达99.5%。
- 在更具挑战性的W4A4KV4配置中,OSTQuant显著缩小了与最新方法的性能差距。
点此查看论文截图