⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-28 更新
SyncAnimation: A Real-Time End-to-End Framework for Audio-Driven Human Pose and Talking Head Animation
Authors:Yujian Liu, Shidang Xu, Jing Guo, Dingbin Wang, Zairan Wang, Xianfeng Tan, Xiaoli Liu
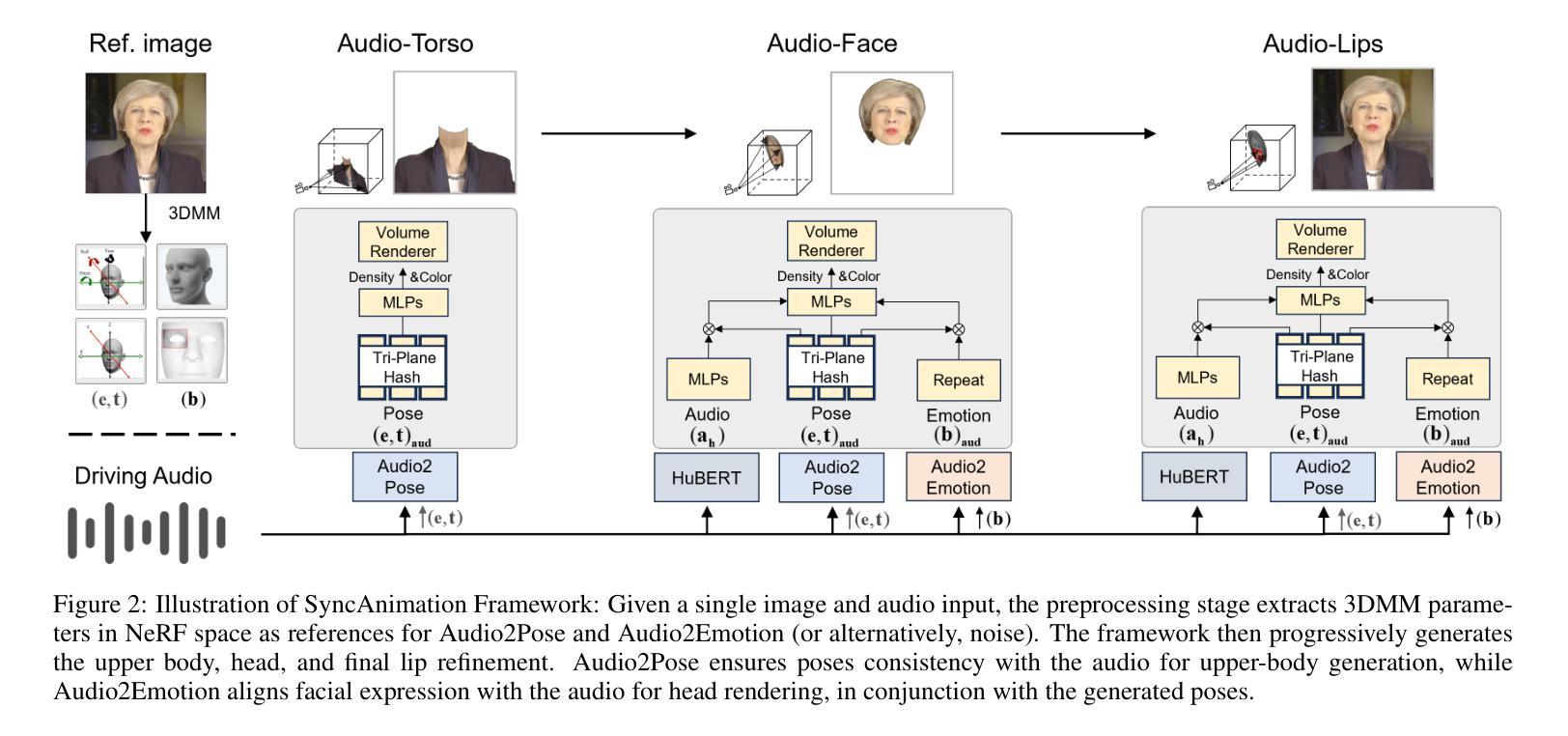
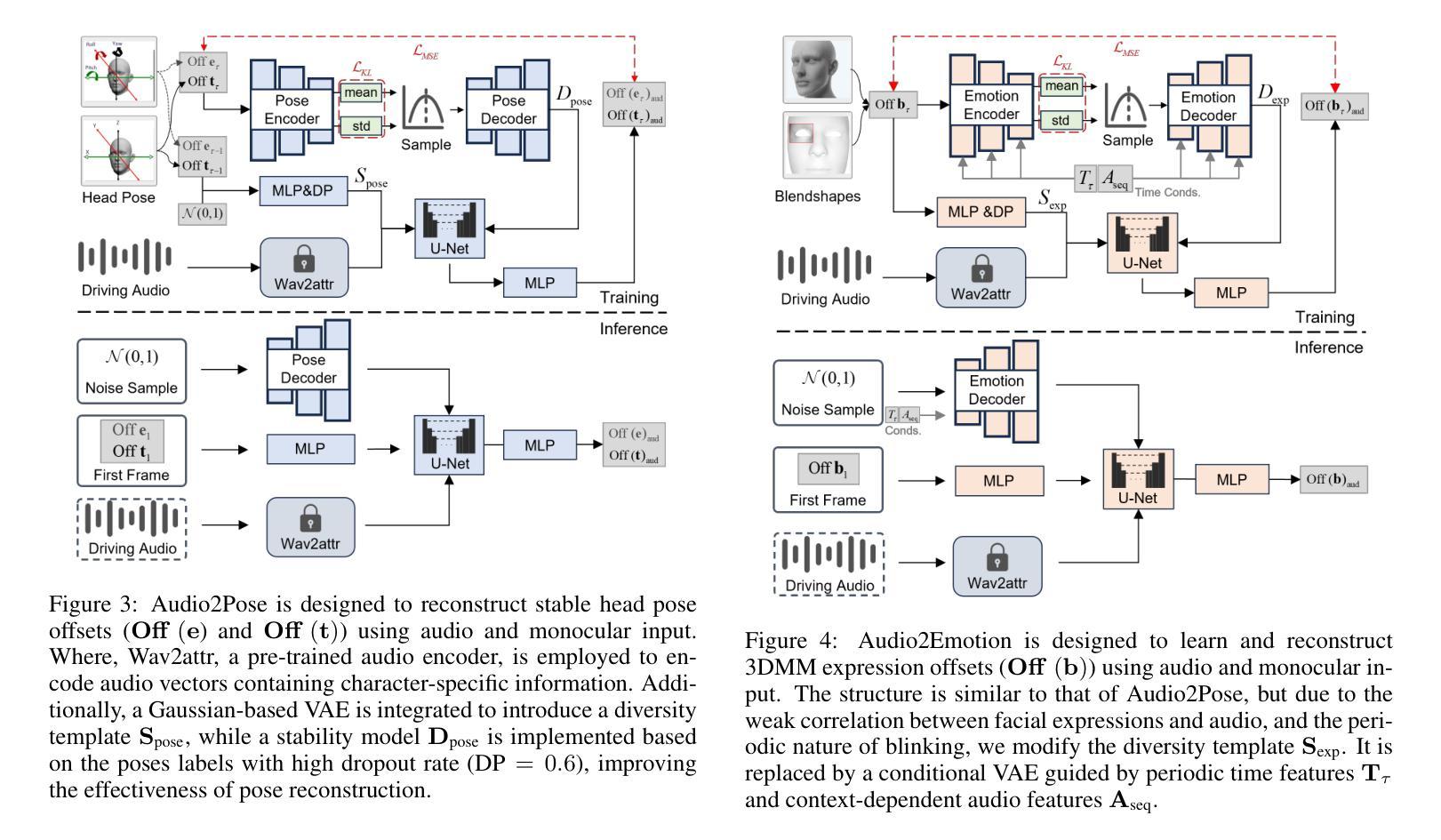
Generating talking avatar driven by audio remains a significant challenge. Existing methods typically require high computational costs and often lack sufficient facial detail and realism, making them unsuitable for applications that demand high real-time performance and visual quality. Additionally, while some methods can synchronize lip movement, they still face issues with consistency between facial expressions and upper body movement, particularly during silent periods. In this paper, we introduce SyncAnimation, the first NeRF-based method that achieves audio-driven, stable, and real-time generation of speaking avatar by combining generalized audio-to-pose matching and audio-to-expression synchronization. By integrating AudioPose Syncer and AudioEmotion Syncer, SyncAnimation achieves high-precision poses and expression generation, progressively producing audio-synchronized upper body, head, and lip shapes. Furthermore, the High-Synchronization Human Renderer ensures seamless integration of the head and upper body, and achieves audio-sync lip. The project page can be found at https://syncanimation.github.io
生成由音频驱动的虚拟人物仍然存在巨大挑战。现有方法通常需要很高的计算成本,并且常常缺乏足够的面部细节和逼真度,使得它们不适用于需要高实时性能和视觉质量的应用。虽然一些方法可以实现唇部同步,但它们仍然面临面部表情和上半身动作之间的一致性问题的挑战,尤其是在无声时期尤为明显。在本文中,我们介绍了SyncAnimation,这是一种基于NeRF的方法,通过结合通用的音频到姿势匹配和音频到表情同步,实现了音频驱动的、稳定的、实时的说话虚拟人物生成。通过集成AudioPose Syncer和AudioEmotion Syncer,SyncAnimation实现了高精度的姿势和表情生成,逐步生成与音频同步的头部、上身和唇部形状。此外,“高同步人类渲染器”确保头部和上身的无缝集成,实现唇部音频同步。项目页面可访问:https://syncanimation.github.io。
论文及项目相关链接
PDF 11 pages, 7 figures
Summary
本文介绍了基于NeRF技术的音频驱动动画生成方法SyncAnimation,它能实时生成稳定的语音动画。通过结合音频到姿态的匹配和音频到表情的同步,实现了高精度的姿态和表情生成,同时保证了头部和上半身的无缝集成,实现了音频同步的嘴唇动作。
Key Takeaways
- SyncAnimation是基于NeRF技术的音频驱动动画生成方法。
- 现有方法在计算成本、面部细节和真实性方面存在缺陷,不适用于高实时性能和高视觉质量的应用。
- SyncAnimation通过结合音频到姿态的匹配和音频到表情的同步,实现了高精度的动画生成。
- AudioPose Syncer和AudioEmotion Syncer的组合使用是SyncAnimation的核心。
- SyncAnimation能生成音频同步的头部和上半身动作。
- High-Synchronization Human Renderer确保了头部和上半身的无缝集成。
点此查看论文截图

GS-LiDAR: Generating Realistic LiDAR Point Clouds with Panoramic Gaussian Splatting
Authors:Junzhe Jiang, Chun Gu, Yurui Chen, Li Zhang
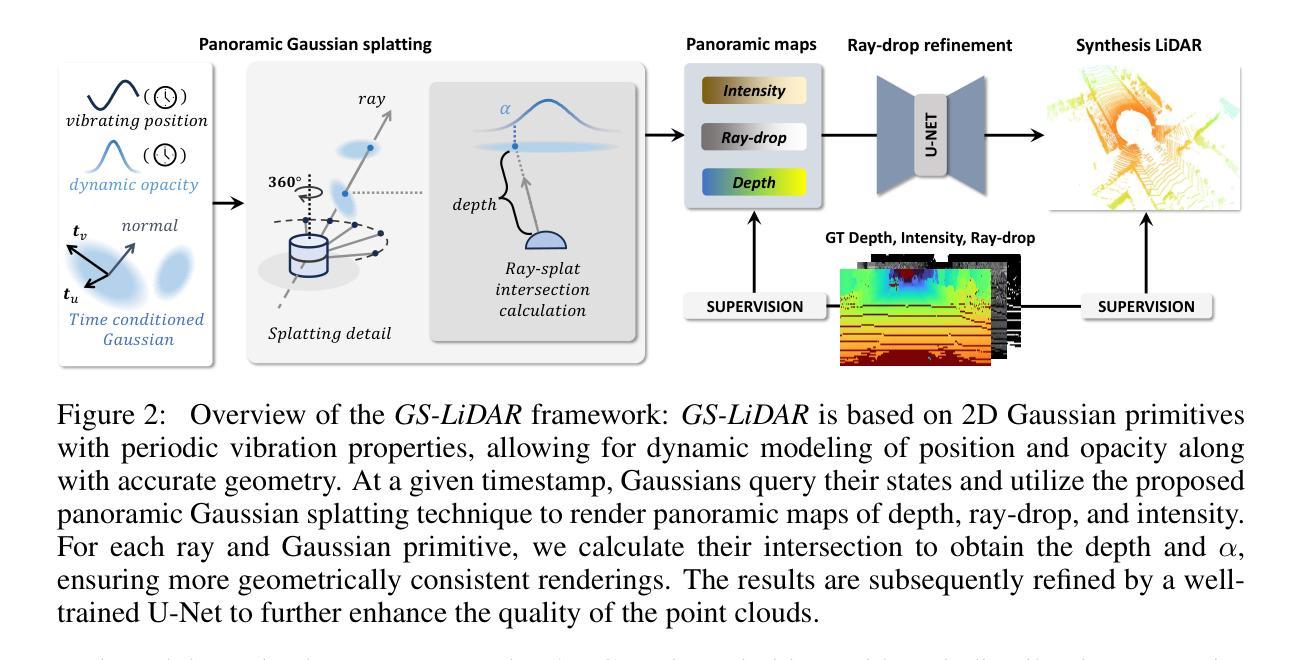
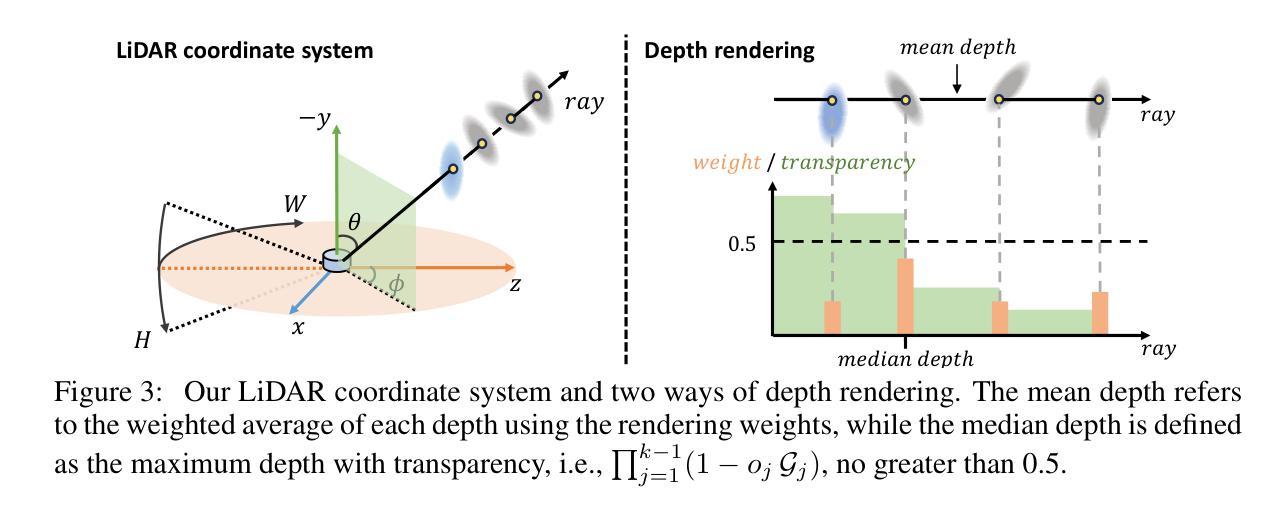
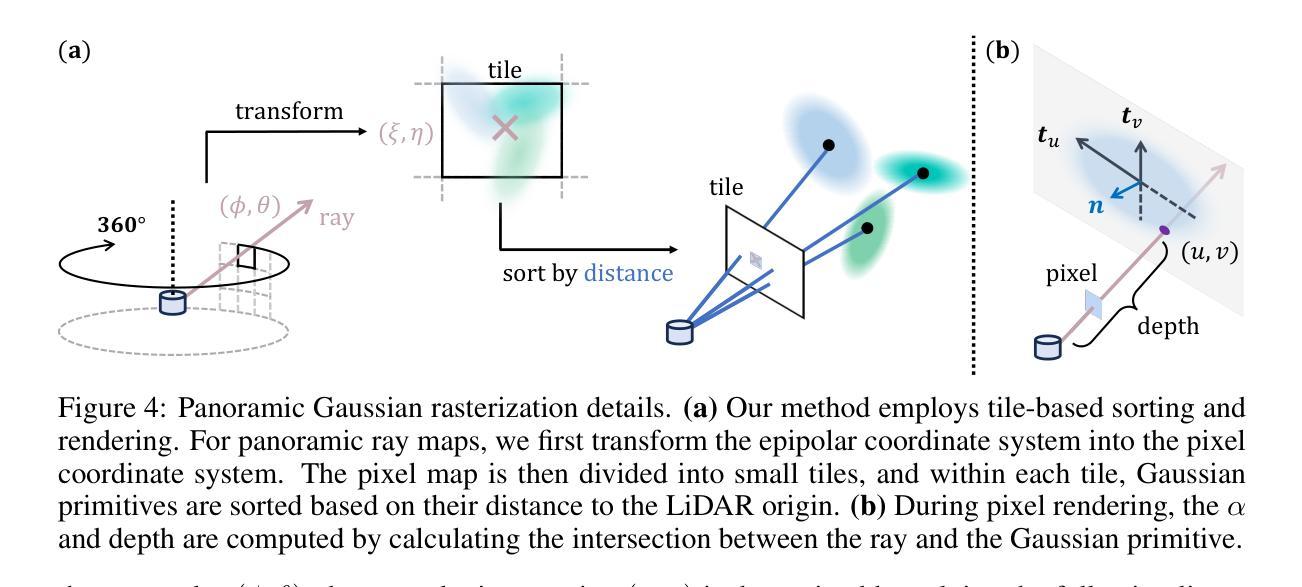
LiDAR novel view synthesis (NVS) has emerged as a novel task within LiDAR simulation, offering valuable simulated point cloud data from novel viewpoints to aid in autonomous driving systems. However, existing LiDAR NVS methods typically rely on neural radiance fields (NeRF) as their 3D representation, which incurs significant computational costs in both training and rendering. Moreover, NeRF and its variants are designed for symmetrical scenes, making them ill-suited for driving scenarios. To address these challenges, we propose GS-LiDAR, a novel framework for generating realistic LiDAR point clouds with panoramic Gaussian splatting. Our approach employs 2D Gaussian primitives with periodic vibration properties, allowing for precise geometric reconstruction of both static and dynamic elements in driving scenarios. We further introduce a novel panoramic rendering technique with explicit ray-splat intersection, guided by panoramic LiDAR supervision. By incorporating intensity and ray-drop spherical harmonic (SH) coefficients into the Gaussian primitives, we enhance the realism of the rendered point clouds. Extensive experiments on KITTI-360 and nuScenes demonstrate the superiority of our method in terms of quantitative metrics, visual quality, as well as training and rendering efficiency.
激光雷达视点合成(NVS)作为激光雷达模拟领域的一项新任务应运而生,其可从新的视角提供有价值的模拟点云数据,有助于自动驾驶系统。然而,现有的激光雷达NVS方法通常依赖于神经辐射场(NeRF)作为其三维表示,这在训练和渲染方面都带来了很大的计算成本。此外,NeRF及其变体是为对称场景设计的,使得它们不适合驾驶场景。为了解决这些挑战,我们提出了GS-激光雷达(GS-LiDAR)框架,这是一种用于生成真实激光雷达点云的新型框架,具有全景高斯喷射技术。我们的方法采用具有周期性振动特性的二维高斯基元,能够精确重建驾驶场景中静态和动态元素的几何形状。我们还引入了一种新型全景渲染技术,具有明确的射线喷射交点,由全景激光雷达监督指导。通过将强度和射线下降球谐(SH)系数纳入高斯基元中,我们提高了渲染点云的真实性。在KITTI-360和nuScenes上的大量实验表明,我们的方法在定量指标、视觉质量以及训练和渲染效率方面都表现出优越性。
论文及项目相关链接
Summary
本文介绍了LiDAR新型视图合成(NVS)任务在LiDAR模拟领域的新兴发展。针对现有LiDAR NVS方法依赖神经辐射场(NeRF)带来的计算和渲染成本高以及不适合驾驶场景的问题,提出了一种新的框架GS-LiDAR,使用全景高斯平铺技术生成逼真的LiDAR点云。该框架采用具有周期性振动特性的2D高斯基元,可精确重建驾驶场景中的静态和动态元素。此外,引入了一种新型全景渲染技术,通过明确的射线平铺交点,在全景LiDAR监督指导下进行。通过结合强度和射线下降球面谐波(SH)系数的高斯基元,增强了渲染点云的真实性。在KITTI-360和nuScenes上的实验表明,该方法在定量指标、视觉质量以及训练和渲染效率方面均表现优越。
Key Takeaways
- LiDAR新型视图合成(NVS)是LiDAR模拟领域的新任务,能为自动驾驶系统提供有价值的模拟点云数据。
- 现有LiDAR NVS方法依赖神经辐射场(NeRF),计算与渲染成本较高,且对驾驶场景适应性差。
- GS-LiDAR框架使用全景高斯平铺技术生成逼真的LiDAR点云,采用2D高斯基元并引入周期性振动特性,能精确重建驾驶场景元素。
- GS-LiDAR引入全景渲染技术,通过射线平铺交点实现,受全景LiDAR监督。
- 结合强度和射线下降球面谐波(SH)系数的高斯基元,增强了点云的真实性。
- 在KITTI-360和nuScenes数据集上的实验表明,GS-LiDAR在定量指标、视觉质量以及效率方面均优于现有方法。
点此查看论文截图