⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-28 更新
Scene Understanding Enabled Semantic Communication with Open Channel Coding
Authors:Zhe Xiang, Fei Yu, Quan Deng, Yuandi Li, Zhiguo Wan
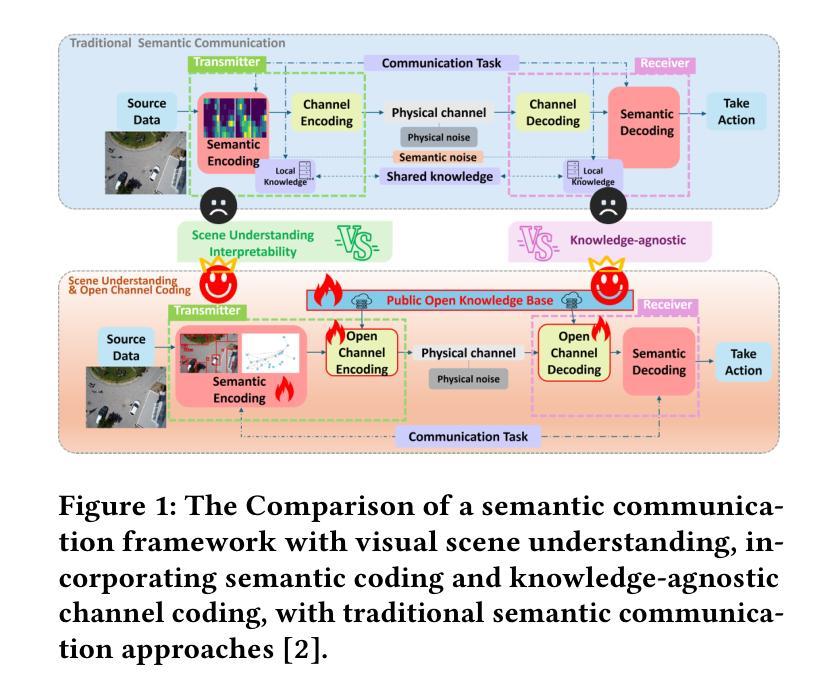
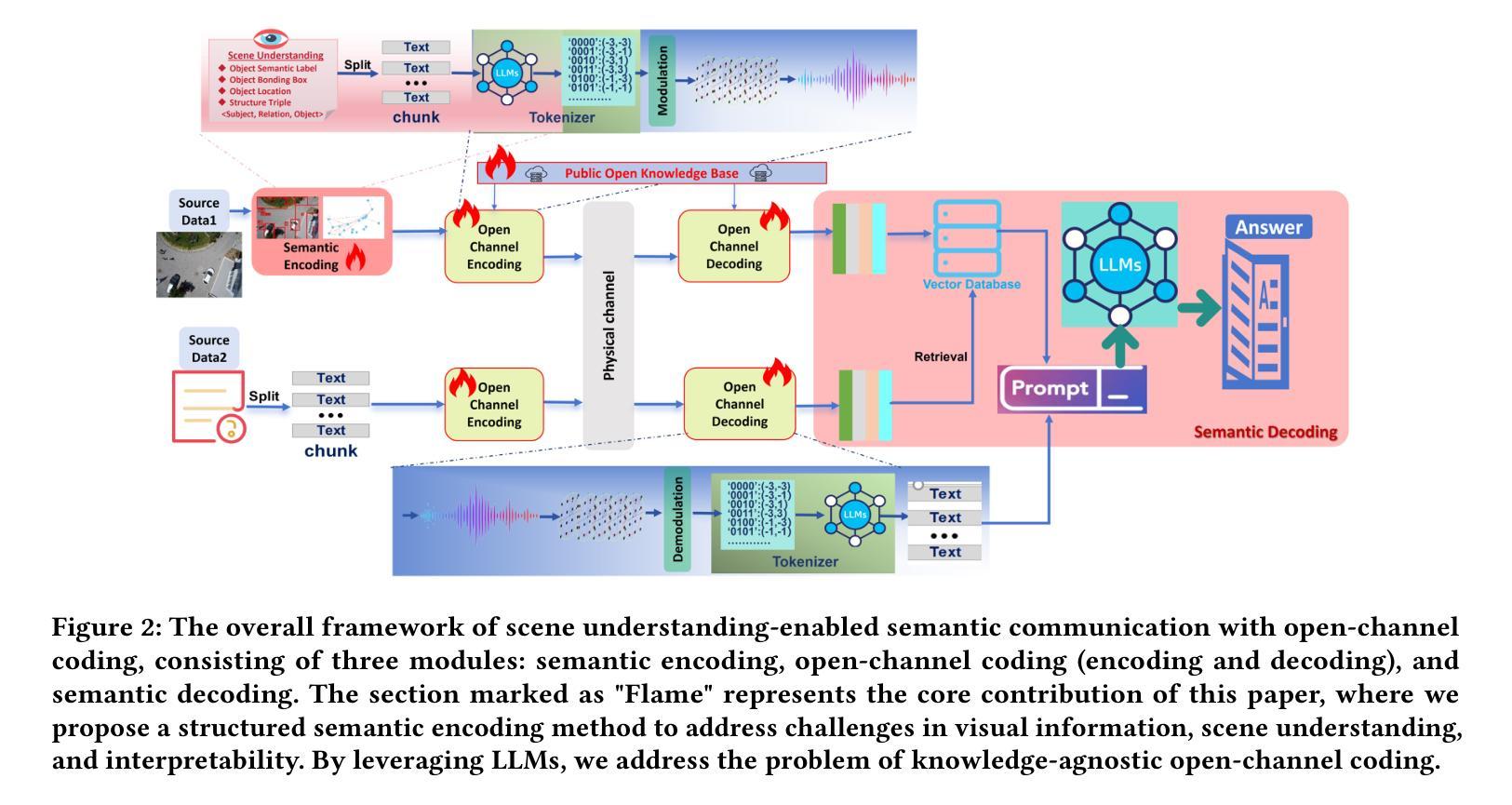
As communication systems transition from symbol transmission to conveying meaningful information, sixth-generation (6G) networks emphasize semantic communication. This approach prioritizes high-level semantic information, improving robustness and reducing redundancy across modalities like text, speech, and images. However, traditional semantic communication faces limitations, including static coding strategies, poor generalization, and reliance on task-specific knowledge bases that hinder adaptability. To overcome these challenges, we propose a novel system combining scene understanding, Large Language Models (LLMs), and open channel coding, named \textbf{OpenSC}. Traditional systems rely on fixed domain-specific knowledge bases, limiting their ability to generalize. Our open channel coding approach leverages shared, publicly available knowledge, enabling flexible, adaptive encoding. This dynamic system reduces reliance on static task-specific data, enhancing adaptability across diverse tasks and environments. Additionally, we use scene graphs for structured semantic encoding, capturing object relationships and context to improve tasks like Visual Question Answering (VQA). Our approach selectively encodes key semantic elements, minimizing redundancy and improving transmission efficiency. Experimental results show significant improvements in both semantic understanding and efficiency, advancing the potential of adaptive, generalizable semantic communication in 6G networks.
随着通信系统从符号传输转向有意义的信息传达,第六代(6G)网络强调语义通信。这种方法优先考虑高级语义信息,提高跨文本、语音和图像等多种模式的稳健性并减少冗余。然而,传统语义通信面临一些局限性,包括静态编码策略、推广能力不佳以及依赖特定任务的知识库,阻碍了适应性。为了克服这些挑战,我们提出了一种结合场景理解、大型语言模型(LLM)和开放频道编码的新型系统,名为OpenSC。传统系统依赖于固定的领域特定知识库,限制了其推广能力。我们的开放频道编码方法利用共享、公开可用的知识,实现灵活的自适应编码。这一动态系统减少了对于静态特定任务数据的依赖,提高了在不同任务和环境中的适应能力。此外,我们使用场景图进行结构化语义编码,捕捉对象关系和上下文,改进如视觉问答(VQA)等任务。我们的方法选择性地编码关键语义元素,减少冗余并提高了传输效率。实验结果表明在语义理解和效率方面都有显著提高,推动了6G网络中自适应、可推广的语义通信的潜力。
论文及项目相关链接
Summary
本文探讨了在通信系统中从符号传输向有意义信息传输转变的背景下,第六代网络强调语义通信的重要性。传统语义通信存在静态编码策略、缺乏通用性以及依赖特定任务知识库的局限性。为此,本文提出了一种结合场景理解、大型语言模型和开放通道编码的新型系统OpenSC。该系统利用公开共享的知识库,实现灵活自适应编码,减少了对静态特定任务的依赖,提高了跨任务和环境的适应性。此外,通过场景图进行结构化语义编码,捕捉对象关系和上下文信息,提高视觉问答等任务性能。实验结果表明,该方法在语义理解和效率方面取得了显著改善,为6G网络中自适应、通用语义通信的发展提供了潜力。
Key Takeaways
- 6G网络强调语义通信,专注于高层次的语义信息,提高稳健性并减少冗余。
- 传统语义通信面临静态编码策略、缺乏通用性和对特定任务知识库的依赖等挑战。
- OpenSC系统结合场景理解、大型语言模型和开放通道编码,克服了这些挑战。
- OpenSC利用公开共享的知识库,实现灵活自适应编码,增强跨任务和环境的适应性。
- 通过场景图进行结构化语义编码,提高视觉问答等任务性能。
- 实验结果表明OpenSC在语义理解和效率方面显著改善。
点此查看论文截图

Enhancing Intelligibility for Generative Target Speech Extraction via Joint Optimization with Target Speaker ASR
Authors:Hao Ma, Rujin Chen, Ruihao Jing, Xiao-Lei Zhang, Ju Liu, Xuelong Li
Target speech extraction (TSE) isolates the speech of a specific speaker from a multi-talker overlapped speech mixture. Most existing TSE models rely on discriminative methods, typically predicting a time-frequency spectrogram mask for the target speech. However, imperfections in these masks often result in over-/under-suppression of target/non-target speech, degrading perceptual quality. Generative methods, by contrast, re-synthesize target speech based on the mixture and target speaker cues, achieving superior perceptual quality. Nevertheless, these methods often overlook speech intelligibility, leading to alterations or loss of semantic content in the re-synthesized speech. Inspired by the Whisper model’s success in target speaker ASR, we propose a generative TSE framework based on the pre-trained Whisper model to address the above issues. This framework integrates semantic modeling with flow-based acoustic modeling to achieve both high intelligibility and perceptual quality. Results from multiple benchmarks demonstrate that the proposed method outperforms existing generative and discriminative baselines. We present speech samples on our demo page.
目标语音提取(TSE)从多说话人重叠的语音混合中分离出特定说话人的语音。现有的大多数TSE模型依赖于判别方法,通常预测目标语音的时间-频率谱图掩膜。然而,这些掩膜中的缺陷往往导致目标语音或非目标语音的过抑制或抑制不足,从而降低了感知质量。相比之下,生成方法基于混合和目标说话人线索重新合成目标语音,实现更高的感知质量。然而,这些方法往往忽视了语音的可懂度,导致重新合成的语音中的语义内容发生改变或丢失。受Whisper模型在目标说话人语音识别中的成功启发,我们提出了一种基于预训练Whisper模型的生成TSE框架,以解决上述问题。该框架将语义建模与基于流的声学建模相结合,以实现高可懂度和感知质量。来自多个基准测试的结果表明,所提出的方法优于现有的生成型和判别型基准方法。我们在演示页面上提供了语音样本。
论文及项目相关链接
PDF demo: https://aisaka0v0.github.io/GenerativeTSE_demo/
Summary
本文介绍了一种基于预训练Whisper模型的目标语音提取(TSE)框架,该框架结合了语义建模和基于流的声学建模,旨在提高目标语音的智力和感知质量。该框架能够从多说话人重叠语音混合物中分离出目标说话人的语音,相比现有的生成式和判别式方法,具有更好的性能。
Key Takeaways
- 目标语音提取(TSE)是从多说话人重叠语音混合物中分离出特定说话人语音的任务。
- 现有TSE模型大多采用判别方法,通过预测时间-频率谱图掩膜来提取目标语音,但这种方法存在掩膜不完美的问题,可能导致目标语音或非目标语音的过抑制/欠抑制,影响感知质量。
- 生成式方法通过重新合成目标语音来提高感知质量,但往往忽视了语音的清晰度。
- 提出的基于预训练Whisper模型的目标TSE框架结合了语义建模和基于流的声学建模,旨在实现高清晰度和感知质量。
- 该框架受到Whisper模型在目标说话人语音识别方面的成功的启发。
- 通过对多个基准的测试,证明该方法优于现有的生成式和判别式基线。
点此查看论文截图

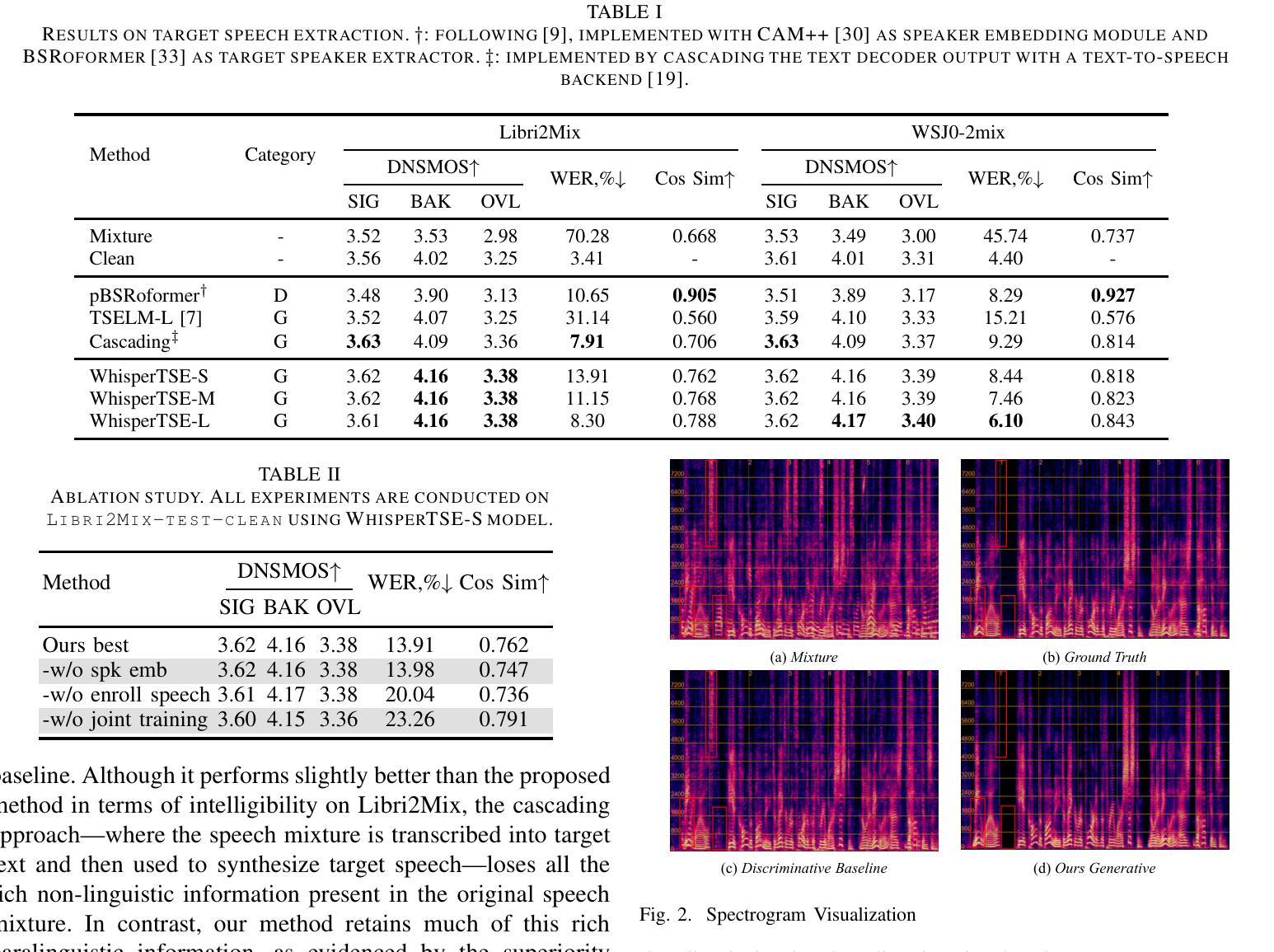
FireRedASR: Open-Source Industrial-Grade Mandarin Speech Recognition Models from Encoder-Decoder to LLM Integration
Authors:Kai-Tuo Xu, Feng-Long Xie, Xu Tang, Yao Hu
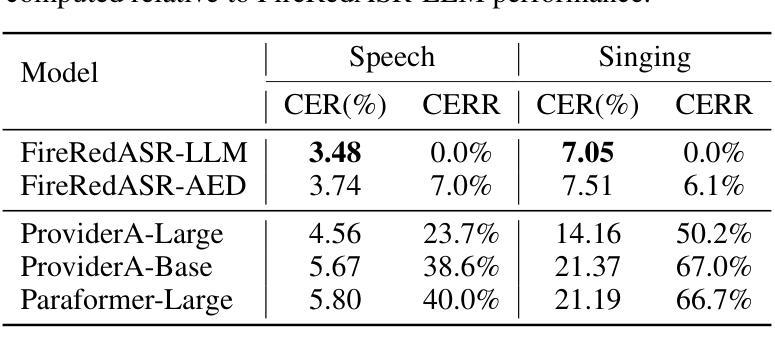
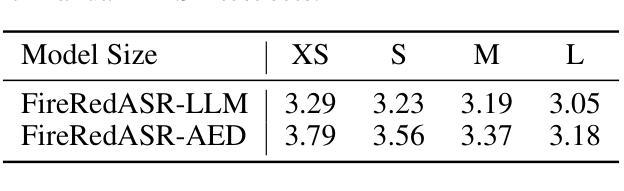
We present FireRedASR, a family of large-scale automatic speech recognition (ASR) models for Mandarin, designed to meet diverse requirements in superior performance and optimal efficiency across various applications. FireRedASR comprises two variants: FireRedASR-LLM: Designed to achieve state-of-the-art (SOTA) performance and to enable seamless end-to-end speech interaction. It adopts an Encoder-Adapter-LLM framework leveraging large language model (LLM) capabilities. On public Mandarin benchmarks, FireRedASR-LLM (8.3B parameters) achieves an average Character Error Rate (CER) of 3.05%, surpassing the latest SOTA of 3.33% with an 8.4% relative CER reduction (CERR). It demonstrates superior generalization capability over industrial-grade baselines, achieving 24%-40% CERR in multi-source Mandarin ASR scenarios such as video, live, and intelligent assistant. FireRedASR-AED: Designed to balance high performance and computational efficiency and to serve as an effective speech representation module in LLM-based speech models. It utilizes an Attention-based Encoder-Decoder (AED) architecture. On public Mandarin benchmarks, FireRedASR-AED (1.1B parameters) achieves an average CER of 3.18%, slightly worse than FireRedASR-LLM but still outperforming the latest SOTA model with over 12B parameters. It offers a more compact size, making it suitable for resource-constrained applications. Moreover, both models exhibit competitive results on Chinese dialects and English speech benchmarks and excel in singing lyrics recognition. To advance research in speech processing, we release our models and inference code at https://github.com/FireRedTeam/FireRedASR.
我们推出了FireRedASR,这是一系列针对普通话的大规模自动语音识别(ASR)模型,旨在满足各种应用中对卓越性能和最佳效率的需求。FireRedASR包含两个版本:
FireRedASR-LLM:旨在实现最新技术性能,实现无缝端到端语音交互。它采用Encoder-Adapter-LLM框架,利用大型语言模型(LLM)的能力。在公开普通话基准测试中,FireRedASR-LLM(8.3亿参数)的平均字符错误率(CER)达到3.05%,超越了最新技术水平的3.33%,相对CER降低了8.4%。它在多源普通话ASR场景中(如视频、直播和智能助理)表现出优异的泛化能力,相对于工业级基线有24%-40%的CERR。
FireRedASR-AED:旨在平衡高性能和计算效率,并作为基于LLM的语音模型中的有效语音表示模块。它利用基于注意力的Encoder-Decoder(AED)架构。在公开普通话基准测试中,FireRedASR-AED(11亿参数)的平均CER为3.18%,虽然略逊于FireRedASR-LLM,但仍然优于具有超过12亿参数的最新技术水平模型。其体积更小,适合资源受限的应用。此外,这两个模型在汉语方言和英语语音基准测试中表现出竞争力,并在歌曲歌词识别方面表现出色。为推动语音识别研究的发展,我们在https://github.com/FireRedTeam/FireRedASR上发布了我们的模型和推理代码。
论文及项目相关链接
Summary
火狐红团队提出了名为FireRedASR的普通话自动语音识别模型系列,包括面向高性能需求的FireRedASR-LLM和面向高效计算需求的FireRedASR-AED两种变体。FireRedASR-LLM采用Encoder-Adapter-LLM框架,实现先进性能,并在公开普通话基准测试中实现了平均字符错误率为3.05%的优异表现,较最新国家水平降低8.4%。FireRedASR-AED则采用Attention-based Encoder-Decoder架构,在保持紧凑模型大小的同时实现了良好的性能。两个模型均展现出在中国方言和英语语音基准测试中的竞争力,并在歌词识别方面表现尤为出色。相关研究资源已发布于https://github.com/FireRedTeam/FireRedASR以供研究使用。
Key Takeaways
- FireRedASR是一个大规模的普通话自动语音识别模型系列,包含两个变体:FireRedASR-LLM和FireRedASR-AED。
- FireRedASR-LLM采用Encoder-Adapter-LLM框架,旨在实现卓越性能并具备出色的泛化能力,相较于最新国家水平降低相对字符错误率约8%。
- FireRedASR-AED专注于平衡性能与计算效率,适合资源受限的应用场景。
- 两个模型在公开普通话基准测试中表现出色,并在多种场景下展示其泛化能力。
- 模型在歌词识别方面展现出色的性能。
- 模型对中国方言和英语语音基准测试同样具有良好的竞争力。
点此查看论文截图

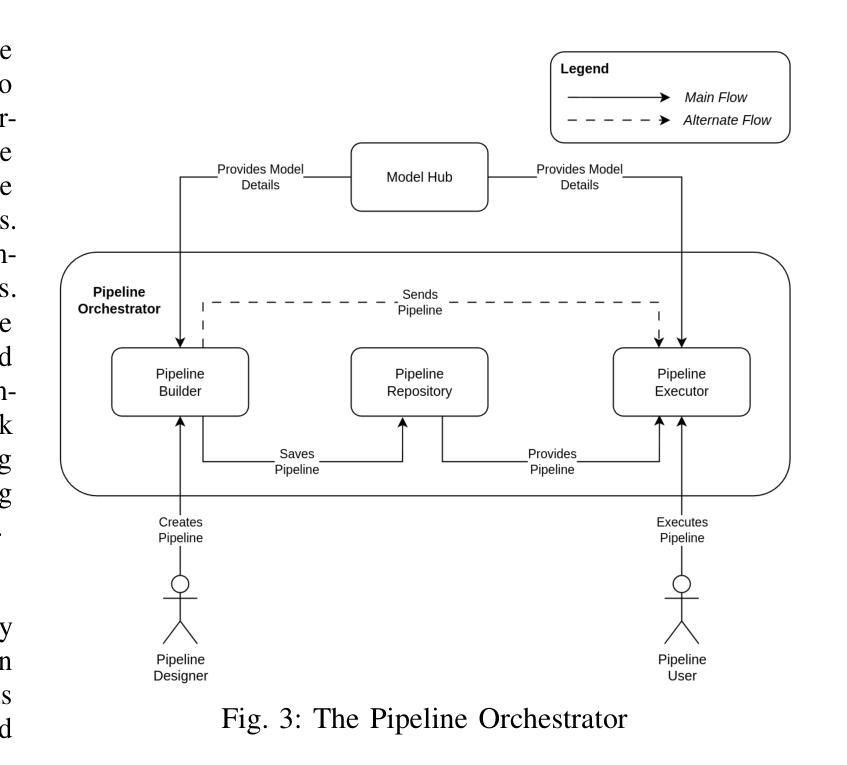
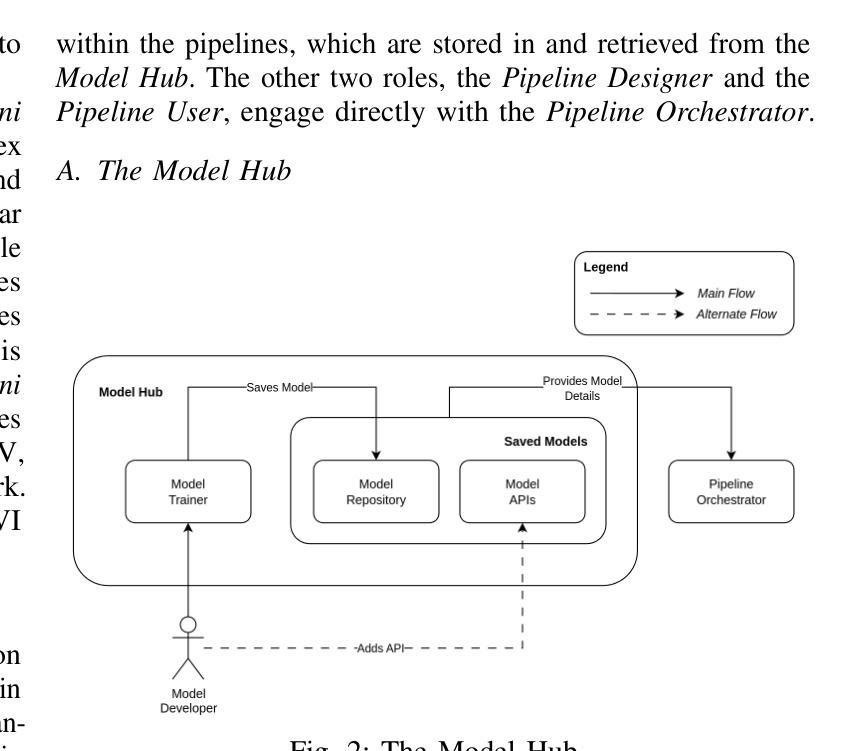
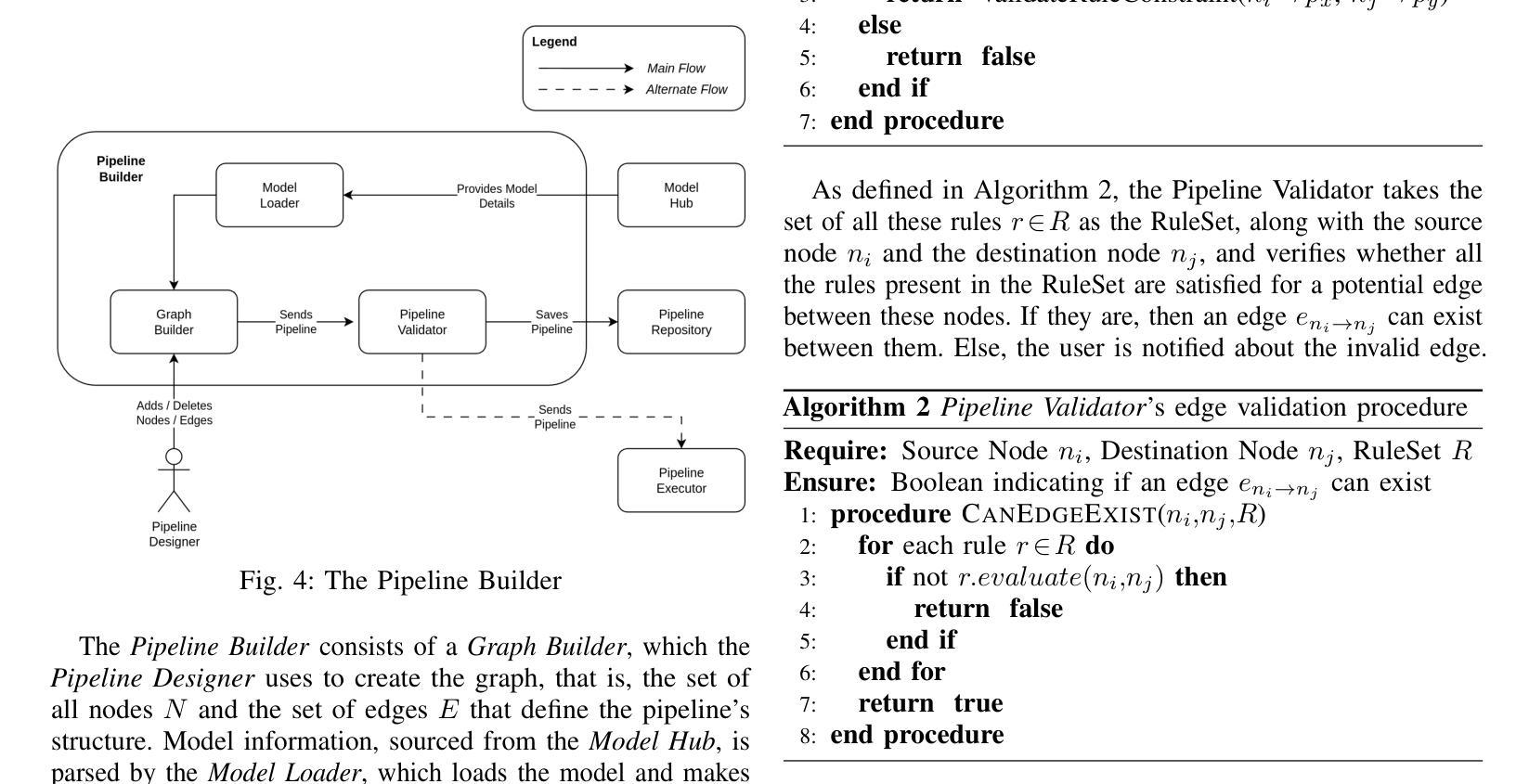
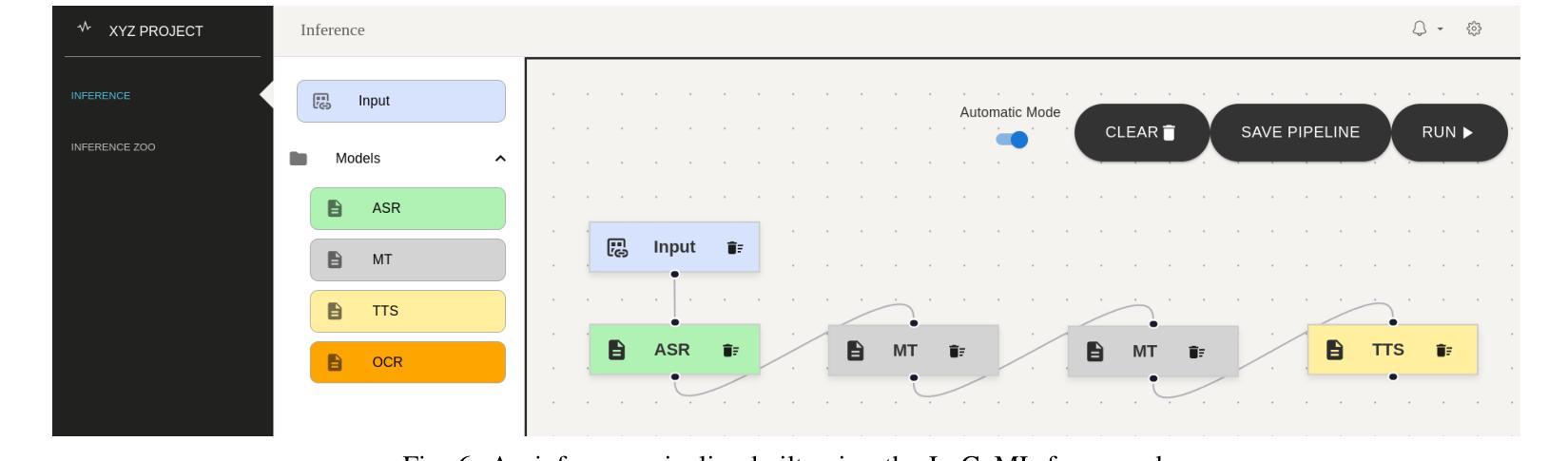
LoCoML: A Framework for Real-World ML Inference Pipelines
Authors:Kritin Maddireddy, Santhosh Kotekal Methukula, Chandrasekar Sridhar, Karthik Vaidhyanathan
The widespread adoption of machine learning (ML) has brought forth diverse models with varying architectures, and data requirements, introducing new challenges in integrating these systems into real-world applications. Traditional solutions often struggle to manage the complexities of connecting heterogeneous models, especially when dealing with varied technical specifications. These limitations are amplified in large-scale, collaborative projects where stakeholders contribute models with different technical specifications. To address these challenges, we developed LoCoML, a low-code framework designed to simplify the integration of diverse ML models within the context of the \textit{Bhashini Project} - a large-scale initiative aimed at integrating AI-driven language technologies such as automatic speech recognition, machine translation, text-to-speech, and optical character recognition to support seamless communication across more than 20 languages. Initial evaluations show that LoCoML adds only a small amount of computational load, making it efficient and effective for large-scale ML integration. Our practical insights show that a low-code approach can be a practical solution for connecting multiple ML models in a collaborative environment.
机器学习的广泛应用带来了各种具有不同架构和数据要求的模型,为将这些系统整合到实际应用中带来了新的挑战。传统解决方案往往难以管理连接异构模型的复杂性,尤其是在处理不同的技术规格时。这些限制在大型协作项目中被放大,利益相关者会贡献具有不同技术规格的模型。为了解决这些挑战,我们开发了LoCoML,这是一个低代码框架,旨在简化在“梵语项目”背景下多种机器学习模型的集成。“梵语项目”是一个大规模倡议,旨在整合人工智能驱动的语言技术,如自动语音识别、机器翻译、文本到语音和光学字符识别,以支持超过20种语言之间的无缝通信。初步评估显示,LoCoML只增加了少量的计算负载,使其对于大规模机器学习集成既高效又有效。我们的实践见解表明,在协作环境中连接多个机器学习模型时,低代码方法可能是一种实用的解决方案。
论文及项目相关链接
PDF The paper has been accepted for presentation at the 4th International Conference on AI Engineering (CAIN) 2025 co-located with 47th IEEE/ACM International Conference on Software Engineering (ICSE) 2025
Summary
ML模型的广泛应用带来了多样化的模型,具有不同的架构和数据要求,为将这些系统整合到实际应用中带来了新的挑战。传统的解决方案在处理连接异构模型的复杂性时常常表现不佳,特别是在处理不同的技术规格时。在大型协作项目中,这些局限性尤为突出,各利益相关者贡献的模型具有不同的技术规格。为解决这些挑战,研究者们开发了LoCoML低代码框架,旨在简化在Bhashini项目背景下不同ML模型的集成工作。该项目旨在整合AI驱动的语言技术,如语音识别、机器翻译、语音转文本和光学字符识别等,支持超过二十种语言的无缝交流。初步评估表明,LoCoML仅增加了少量的计算负载,对于大规模ML集成而言既高效又有效。研究团队的实际见解表明,在协作环境中连接多个ML模型时,低代码方法是一种实用的解决方案。
Key Takeaways
- 机器学习模型的广泛应用带来了多样性,对实际应用中的模型集成带来了新的挑战。
- 传统解决方案在连接异构模型时存在局限性,特别是在处理不同技术规格时。
- LoCoML是一个低代码框架,旨在简化在大型项目(如Bhashini项目)中不同机器学习模型的集成工作。
- Bhashini项目是一个旨在整合多种AI驱动的语言技术的大型项目,支持超过二十种语言的无缝交流。
- LoCoML在初步评估中表现出了高效性和有效性,仅增加了少量的计算负载。
- 低代码方法在实际应用中展现出了连接多个机器学习模型的实用性。
点此查看论文截图


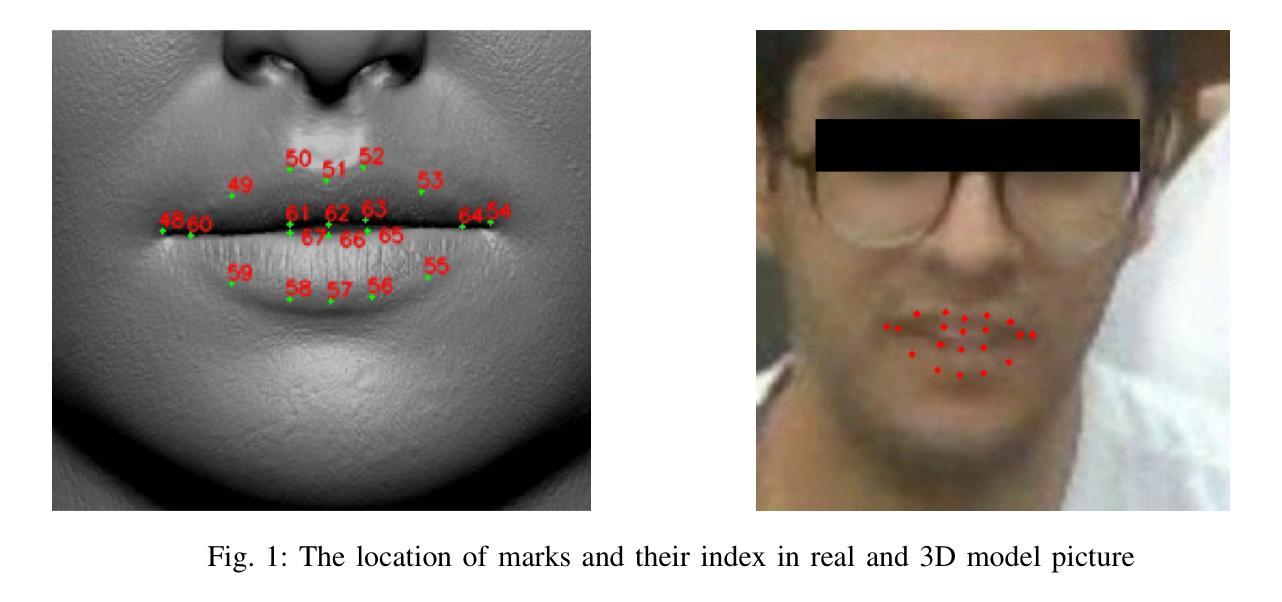
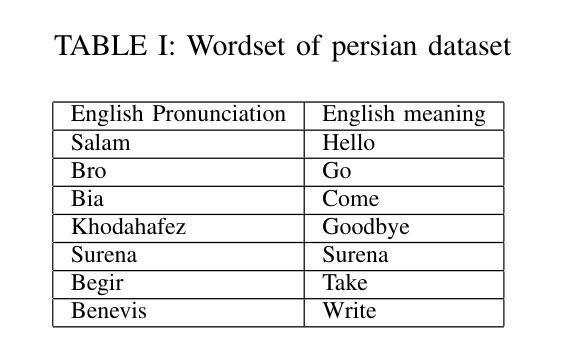
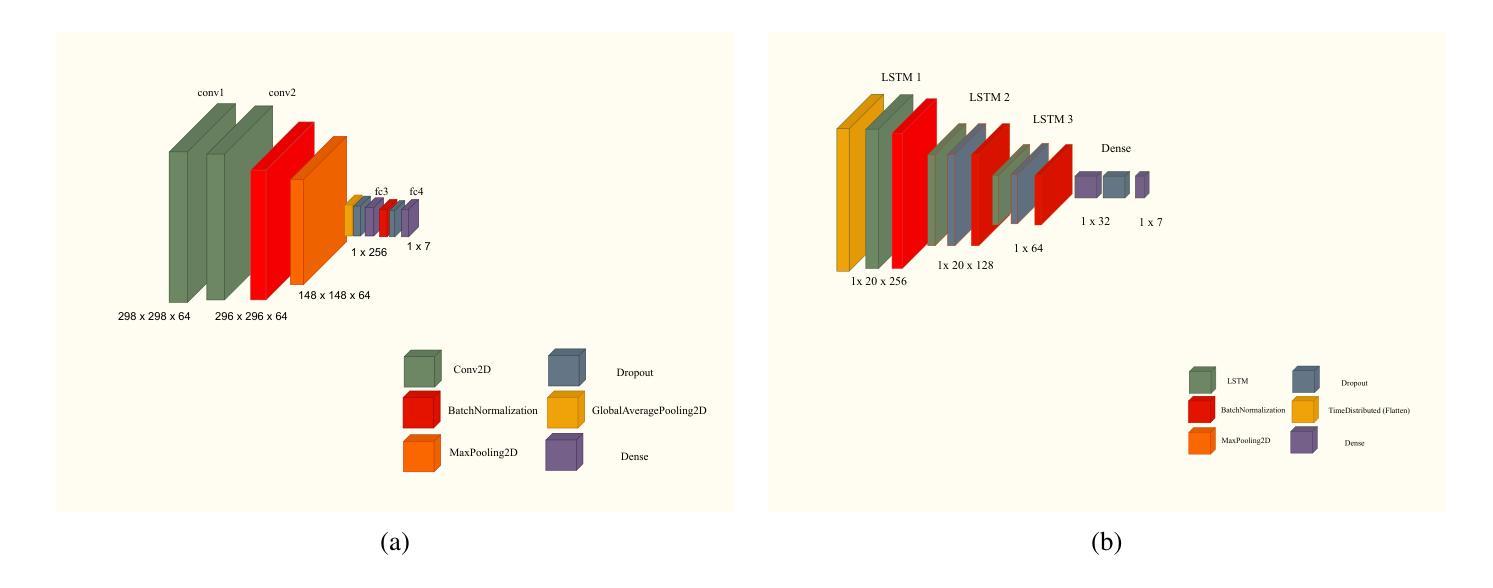
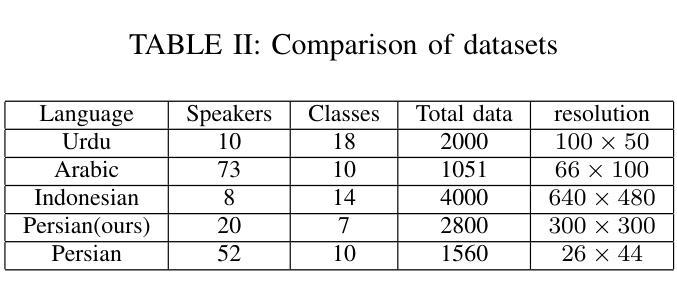
Integrating Persian Lip Reading in Surena-V Humanoid Robot for Human-Robot Interaction
Authors:Ali Farshian Abbasi, Aghil Yousefi-Koma, Soheil Dehghani Firouzabadi, Parisa Rashidi, Alireza Naeini
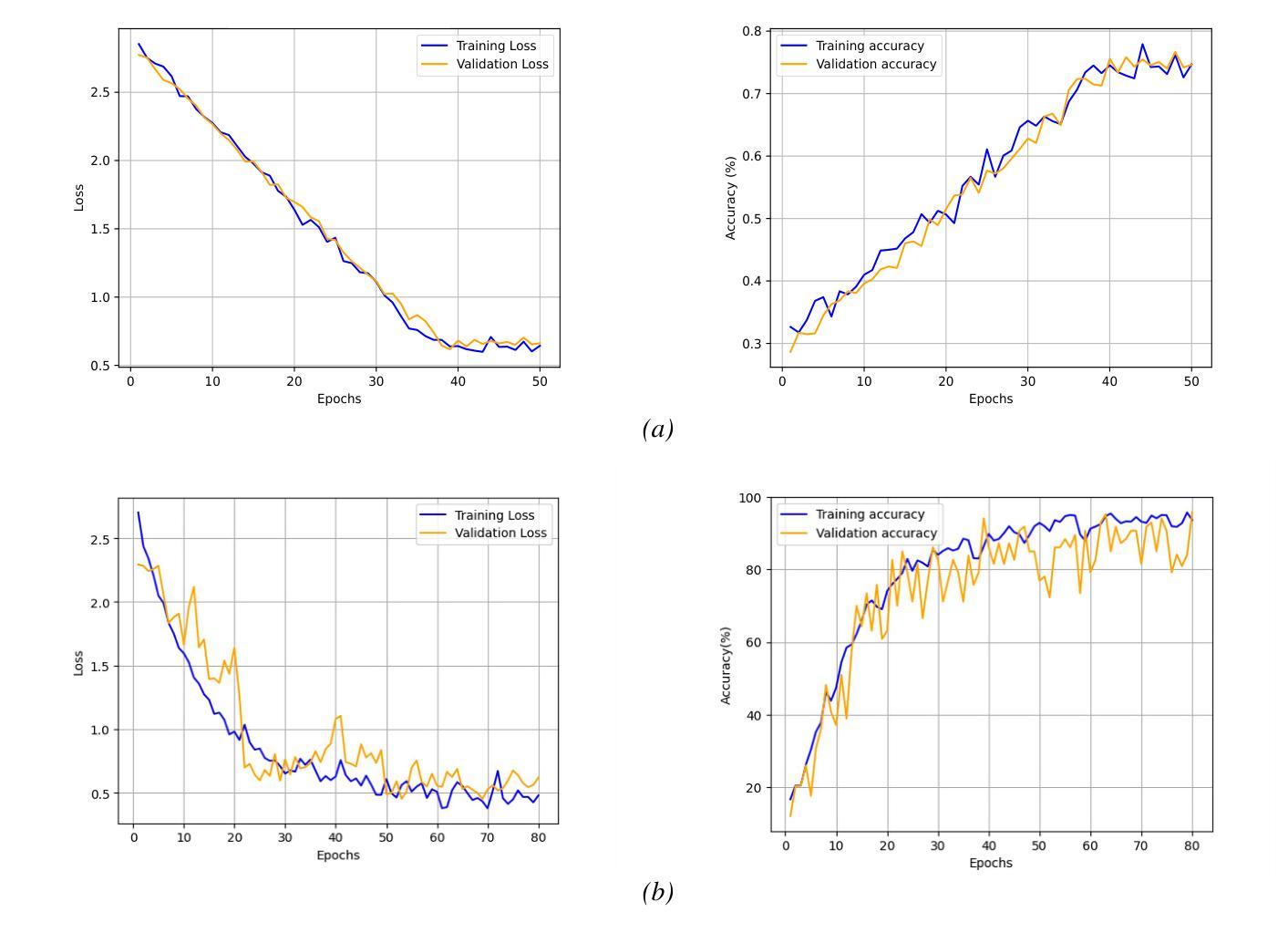
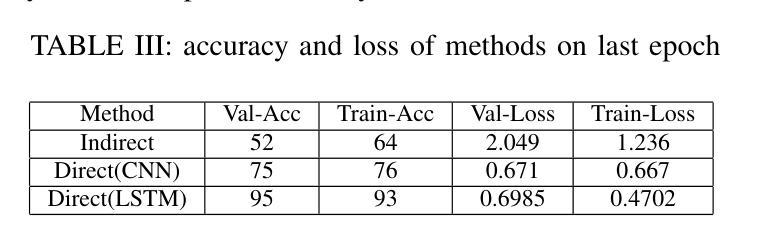
Lip reading is vital for robots in social settings, improving their ability to understand human communication. This skill allows them to communicate more easily in crowded environments, especially in caregiving and customer service roles. Generating a Persian Lip-reading dataset, this study integrates Persian lip-reading technology into the Surena-V humanoid robot to improve its speech recognition capabilities. Two complementary methods are explored, an indirect method using facial landmark tracking and a direct method leveraging convolutional neural networks (CNNs) and long short-term memory (LSTM) networks. The indirect method focuses on tracking key facial landmarks, especially around the lips, to infer movements, while the direct method processes raw video data for action and speech recognition. The best-performing model, LSTM, achieved 89% accuracy and has been successfully implemented into the Surena-V robot for real-time human-robot interaction. The study highlights the effectiveness of these methods, particularly in environments where verbal communication is limited.
唇读对于社交环境中的机器人至关重要,能提升它们理解人类沟通的能力。这项技能使机器人在拥挤的环境中能更轻松地交流,特别是在护理和客户服务角色中。通过生成波斯语唇读数据集,本研究将波斯语唇读技术融入Surena-V人形机器人,提升其语音识别能力。研究探索了两种互补方法:一种使用面部地标追踪的间接方法和一种利用卷积神经网络(CNN)和长短时记忆(LSTM)网络的直接方法。间接方法专注于追踪关键面部地标,尤其是嘴唇周围的部位,以推断动作;而直接方法处理原始视频数据进行动作和语音识别。表现最佳的LSTM模型达到了80%的准确率,并已成功实现在Surena-V机器人进行实时人机互动的应用。该研究突显了这些方法的有效性,特别是在口头沟通受限的环境中更是如此。
论文及项目相关链接
Summary:
唇读对于机器人在社交环境中的沟通至关重要,能提高机器人理解人类沟通的能力。通过生成波斯语唇读数据集,本研究将波斯语唇读技术集成到Surena-V人形机器人中,提升其语音识别能力。研究探索了两种互补方法:一种是通过面部地标追踪的间接方法,另一种是利用卷积神经网络(CNN)和长短期记忆(LSTM)网络的直接方法。LSTM模型表现最佳,准确率达到89%,并已成功应用于Surena-V机器人进行实时人机交互。该研究突显了这些方法在口语沟通受限环境中的有效性。
Key Takeaways:
- 唇读对于机器人在社交环境中的沟通至关重要。
- 生成了波斯语唇读数据集以集成到机器人中。
- 探索了两种互补方法:间接方法和直接方法。
- 间接方法关注面部地标的追踪,特别是嘴唇。
- 直接方法处理原始视频数据进行动作和语音识别。
- LSTM模型表现最佳,准确率为89%。
点此查看论文截图