⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-28 更新
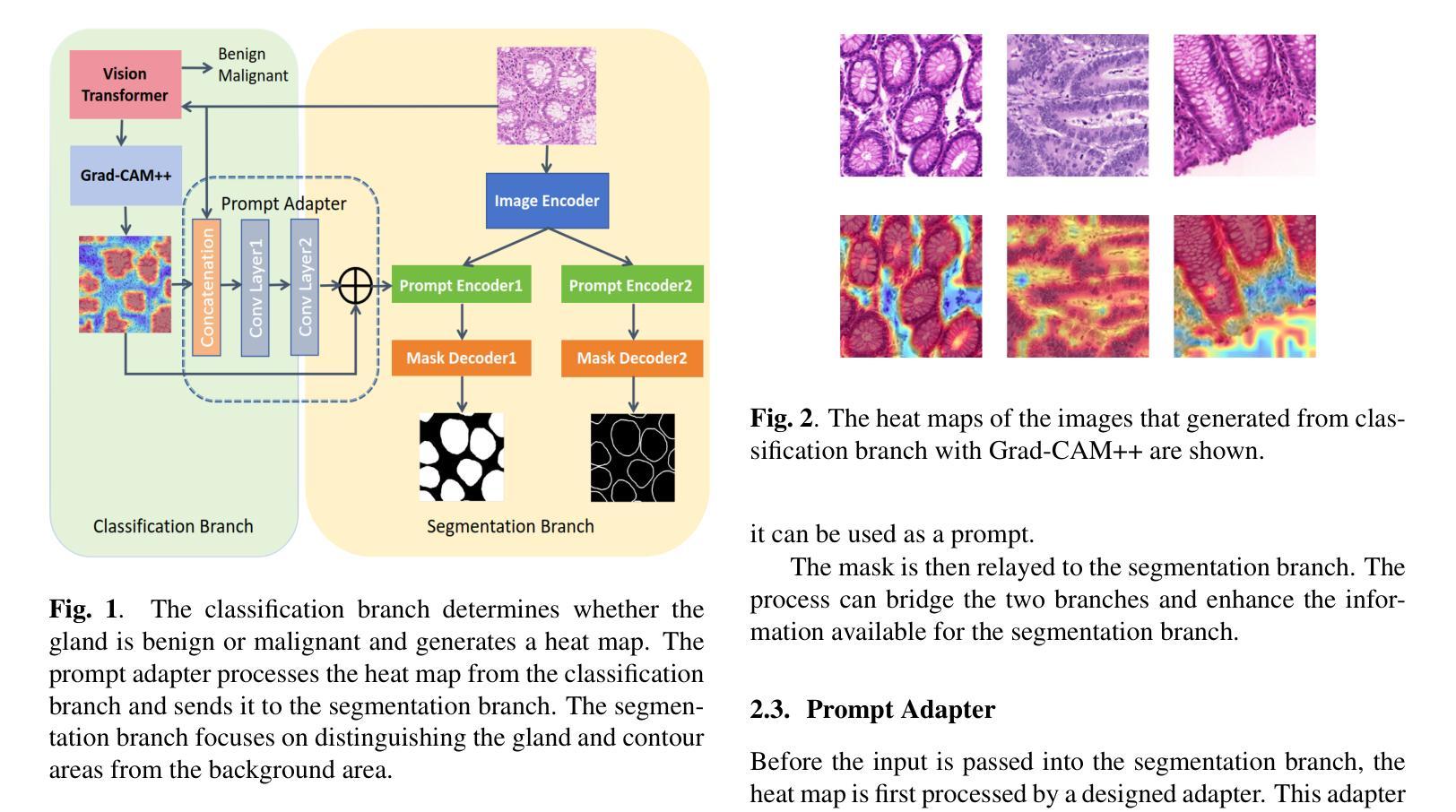
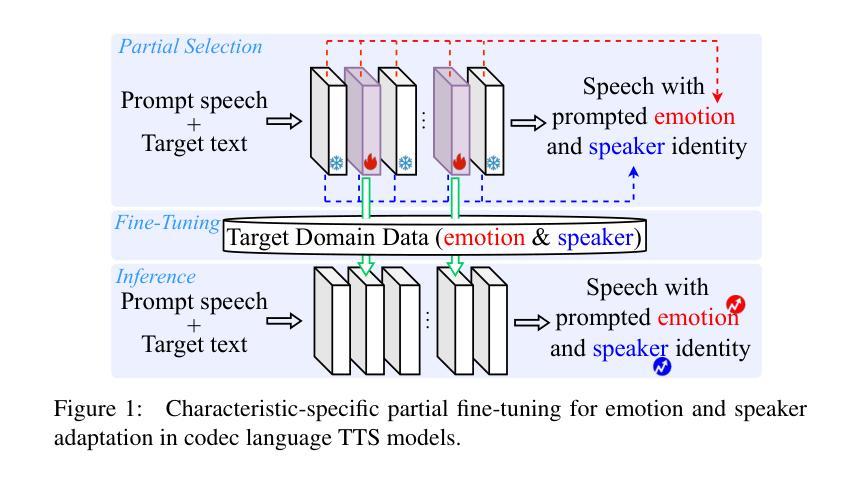
Characteristic-Specific Partial Fine-Tuning for Efficient Emotion and Speaker Adaptation in Codec Language Text-to-Speech Models
Authors:Tianrui Wang, Meng Ge, Cheng Gong, Chunyu Qiang, Haoyu Wang, Zikang Huang, Yu Jiang, Xiaobao Wang, Xie Chen, Longbiao Wang, Jianwu Dang
Recently, emotional speech generation and speaker cloning have garnered significant interest in text-to-speech (TTS). With the open-sourcing of codec language TTS models trained on massive datasets with large-scale parameters, adapting these general pre-trained TTS models to generate speech with specific emotional expressions and target speaker characteristics has become a topic of great attention. Common approaches, such as full and adapter-based fine-tuning, often overlook the specific contributions of model parameters to emotion and speaker control. Treating all parameters uniformly during fine-tuning, especially when the target data has limited content diversity compared to the pre-training corpus, results in slow training speed and an increased risk of catastrophic forgetting. To address these challenges, we propose a characteristic-specific partial fine-tuning strategy, short as CSP-FT. First, we use a weighted-sum approach to analyze the contributions of different Transformer layers in a pre-trained codec language TTS model for emotion and speaker control in the generated speech. We then selectively fine-tune the layers with the highest and lowest characteristic-specific contributions to generate speech with target emotional expression and speaker identity. Experimental results demonstrate that our method achieves performance comparable to, or even surpassing, full fine-tuning in generating speech with specific emotional expressions and speaker identities. Additionally, CSP-FT delivers approximately 2x faster training speeds, fine-tunes only around 8% of parameters, and significantly reduces catastrophic forgetting. Furthermore, we show that codec language TTS models perform competitively with self-supervised models in speaker identification and emotion classification tasks, offering valuable insights for developing universal speech processing models.
最近,情感语音生成和说话人克隆在文本到语音(TTS)领域引起了极大的兴趣。随着基于大规模数据集训练的编解码器语言TTS模型的开源,适应这些通用的预训练TTS模型以生成具有特定情感表达和目标说话人特征的声音已成为备受关注的课题。常见的方法,如完全微调(full fine-tuning)和基于适配器的微调(adapter-based fine-tuning),往往忽视了模型参数对情感和说话人控制的特定贡献。在微调期间对所有参数一视同仁,特别是当目标数据的内容多样性相对于预训练语料库有限时,会导致训练速度减慢以及发生灾难性遗忘的风险增加。为了应对这些挑战,我们提出了一种特性特定的局部微调策略,简称CSP-FT。首先,我们使用加权和法分析预训练编解码器语言TTS模型中不同Transformer层对生成语音中的情感和说话人控制的贡献。然后,我们选择性地对具有最高和最低特性特定贡献的层进行微调,以生成具有目标情感表达和说话人身份的语音。实验结果表明,我们的方法在生成具有特定情感表达和说话人身份的语音方面的性能与全微调相比具有竞争力,甚至在某些情况下表现更好。此外,CSP-FT提供大约两倍的训练速度,仅微调约8%的参数,并显著减少了灾难性遗忘。此外,我们还证明了编解码器语言TTS模型在说话人识别和情绪分类任务上的表现与自监督模型相当,这为开发通用语音处理模型提供了宝贵的见解。
论文及项目相关链接
PDF 13 pages
摘要
在文本转语音(TTS)领域,情感语音生成和语音克隆近期备受关注。随着大规模参数训练的编码语言TTS模型的开源,适应这些通用预训练TTS模型以生成具有特定情感表达和目标说话人特征的语音已成为研究热点。本文提出一种特性特定的局部微调策略(简称CSP-FT),解决现有方法在面对目标数据内容多样性有限时的训练速度慢和灾难性遗忘风险增加的问题。首先,采用加权和法分析预训练编码语言TTS模型中不同Transformer层对生成语音情感和说话人控制的贡献。然后,选择性地对具有最高和最低特性特定贡献的层进行微调,以生成具有目标情感表达和说话人身份的语音。实验结果表明,该方法在生成具有特定情感表达和说话人身份的语音方面的性能可与全微调相匹敌,甚至更优。此外,CSP-FT提供约两倍的培训速度,仅微调约8%的参数,并显著降低灾难性遗忘。同时,本文展示了编码语言TTS模型在说话人识别和情绪分类任务上的竞争力,为开发通用语音处理模型提供了有价值的见解。
关键见解
- 情感语音生成和语音克隆在TTS领域中备受关注。
- 预训练TTS模型的适应性问题,特别是生成具有特定情感和说话人特征的语音。
- 现有方法在面对有限内容多样性的目标数据时,存在训练速度慢和灾难性遗忘风险。
- 提出CSP-FT策略,通过加权和法分析不同Transformer层的特性贡献,进行选择性微调。
- CSP-FT在生成具有特定情感表达和说话人身份的语音方面表现出色,可与全微调相匹敌,甚至更优。
- CSP-FT提供更快的训练速度,降低参数微调量和灾难性遗忘风险。
点此查看论文截图

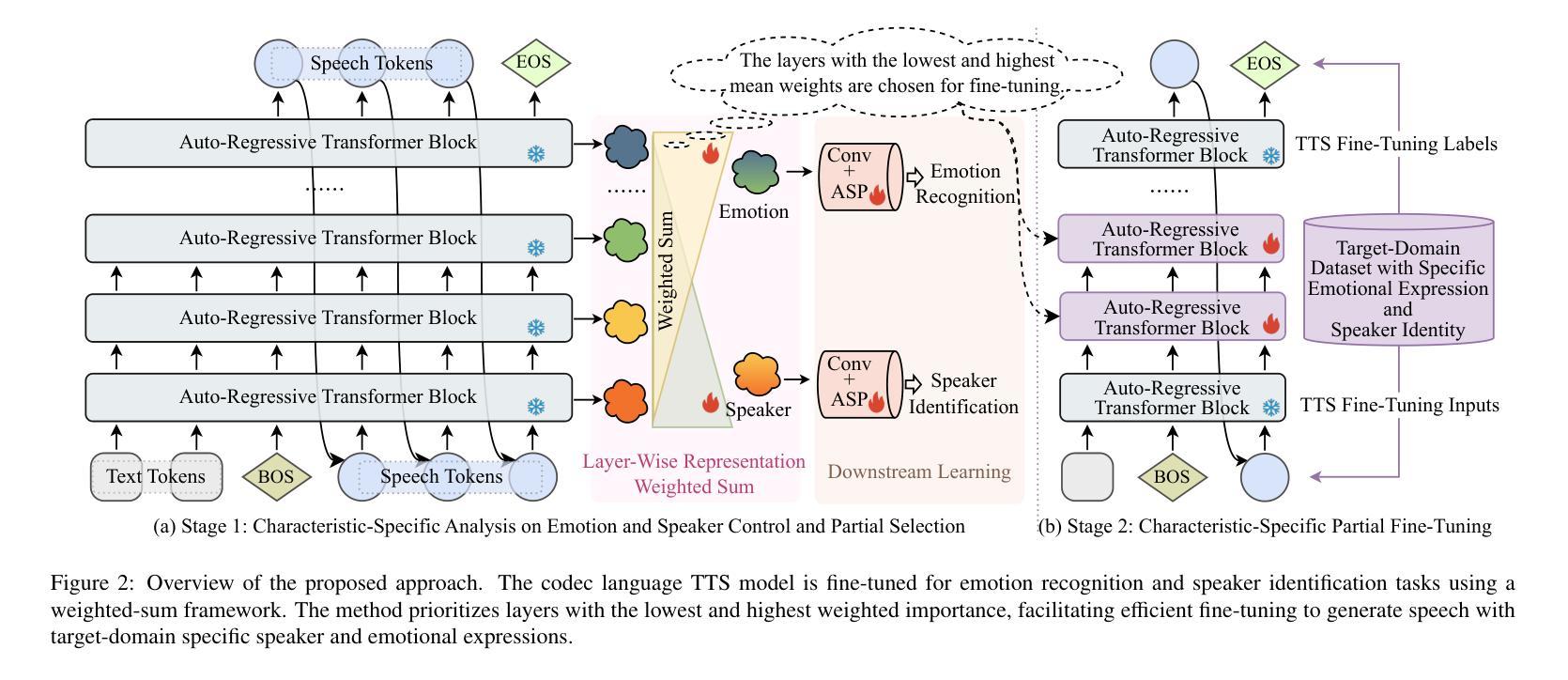

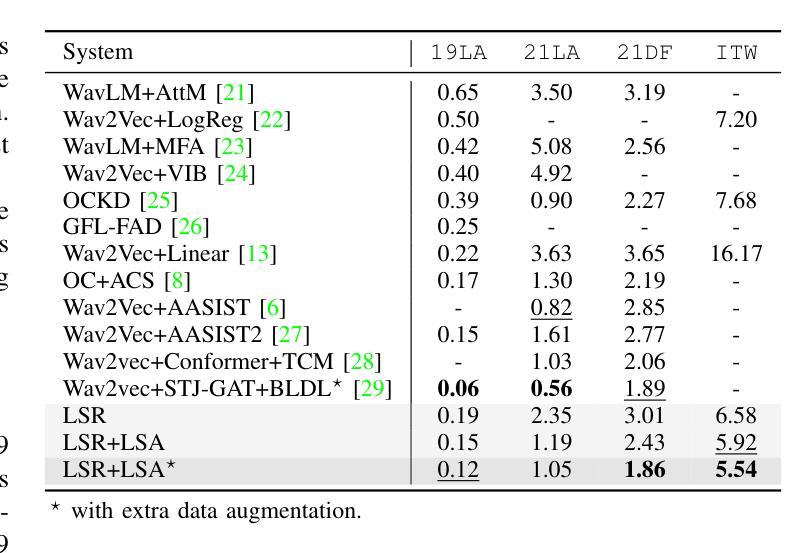
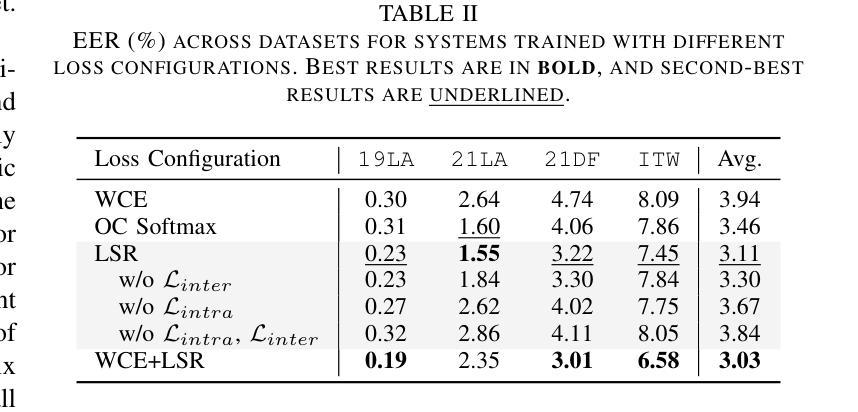
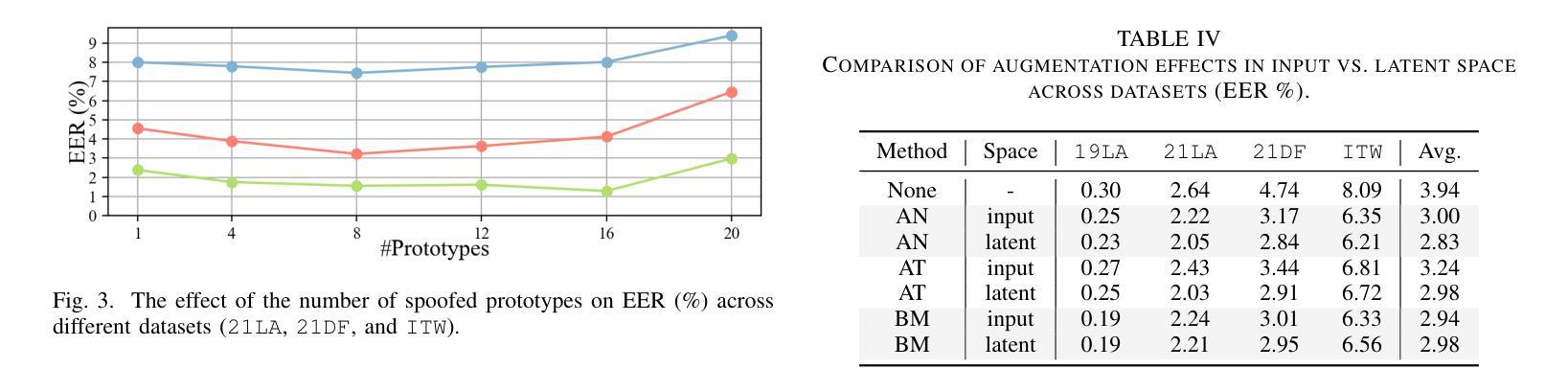
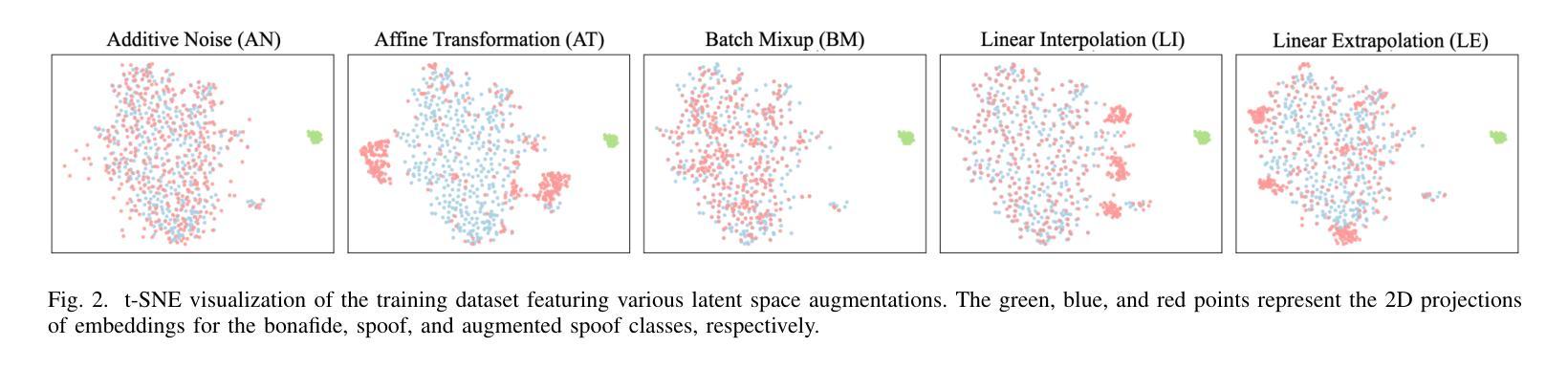
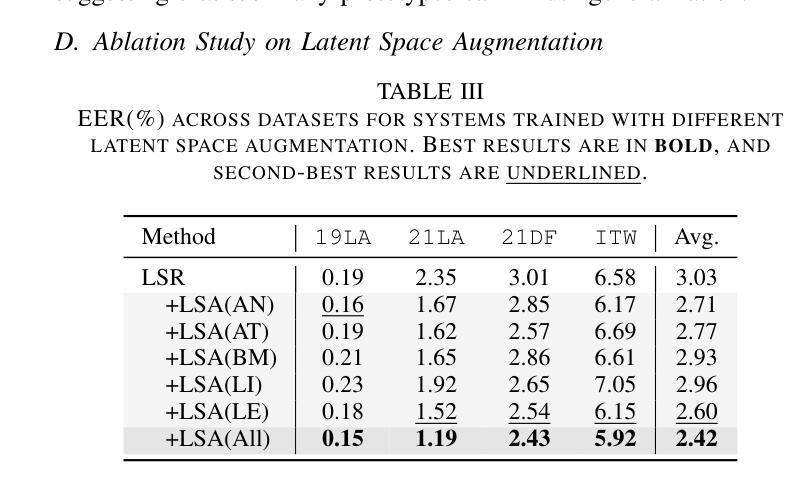
Generalizable Audio Deepfake Detection via Latent Space Refinement and Augmentation
Authors:Wen Huang, Yanmei Gu, Zhiming Wang, Huijia Zhu, Yanmin Qian
Advances in speech synthesis technologies, like text-to-speech (TTS) and voice conversion (VC), have made detecting deepfake speech increasingly challenging. Spoofing countermeasures often struggle to generalize effectively, particularly when faced with unseen attacks. To address this, we propose a novel strategy that integrates Latent Space Refinement (LSR) and Latent Space Augmentation (LSA) to improve the generalization of deepfake detection systems. LSR introduces multiple learnable prototypes for the spoof class, refining the latent space to better capture the intricate variations within spoofed data. LSA further diversifies spoofed data representations by applying augmentation techniques directly in the latent space, enabling the model to learn a broader range of spoofing patterns. We evaluated our approach on four representative datasets, i.e. ASVspoof 2019 LA, ASVspoof 2021 LA and DF, and In-The-Wild. The results show that LSR and LSA perform well individually, and their integration achieves competitive results, matching or surpassing current state-of-the-art methods.
随着语音合成技术(如文本到语音(TTS)和语音转换(VC))的进展,检测深度伪造语音变得越来越具有挑战性。欺骗对抗措施通常难以有效地推广,尤其是在面对未知攻击时。为了解决这一问题,我们提出了一种将潜在空间细化(LSR)和潜在空间扩充(LSA)相结合的新策略,以提高深度伪造检测系统的一般化能力。LSR为欺骗类引入了多个可学习的原型,对潜在空间进行细化,以更好地捕捉欺骗数据中的复杂变化。LSA通过直接在潜在空间应用扩充技术,进一步实现了欺骗数据表示的多样化,使模型能够学习更广泛的欺骗模式。我们在四个代表性数据集上评估了我们的方法,即ASVspoof 2019 LA、ASVspoof 2021 LA和DF以及In-The-Wild数据集。结果表明,LSR和LSA单独表现良好,它们的结合达到了具有竞争力的结果,匹配或超越了当前最先进的方法。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
文本介绍了语音合成技术(如文本转语音和语音转换)的进步使得检测深度伪造语音越来越具有挑战性。为解决此问题,提出一种结合潜在空间细化(LSR)和潜在空间扩充(LSA)的策略,以提高假冒检测系统的泛化能力。LSR通过引入多个可学习的伪造类别原型来细化潜在空间,以更好地捕捉伪造数据中的细微变化。LSA通过在潜在空间直接应用扩充技术进一步实现伪造数据表示的多样化,使模型能够学习更广泛的欺骗模式。经过四项具有代表性的数据评估证明该策略表现良好。
Key Takeaways
- 语音合成技术的快速发展使得检测深度伪造语音越来越困难。
- 目前反欺骗措施在泛化方面存在挑战,特别是在面对未知攻击时。
- 提出了一种新的策略,结合了潜在空间细化(LSR)和潜在空间扩充(LSA)来提高假冒检测系统的泛化能力。
- LSR通过引入多个可学习的伪造类别原型来细化潜在空间,更好地捕捉伪造数据的细微变化。
- LSA通过直接在潜在空间应用扩充技术实现伪造数据表示的多样化。
- 该策略在四个代表性的数据集上进行了评估,包括ASVspoof 2019 LA、ASVspoof 2021 LA和DF以及In-The-Wild数据集。
点此查看论文截图

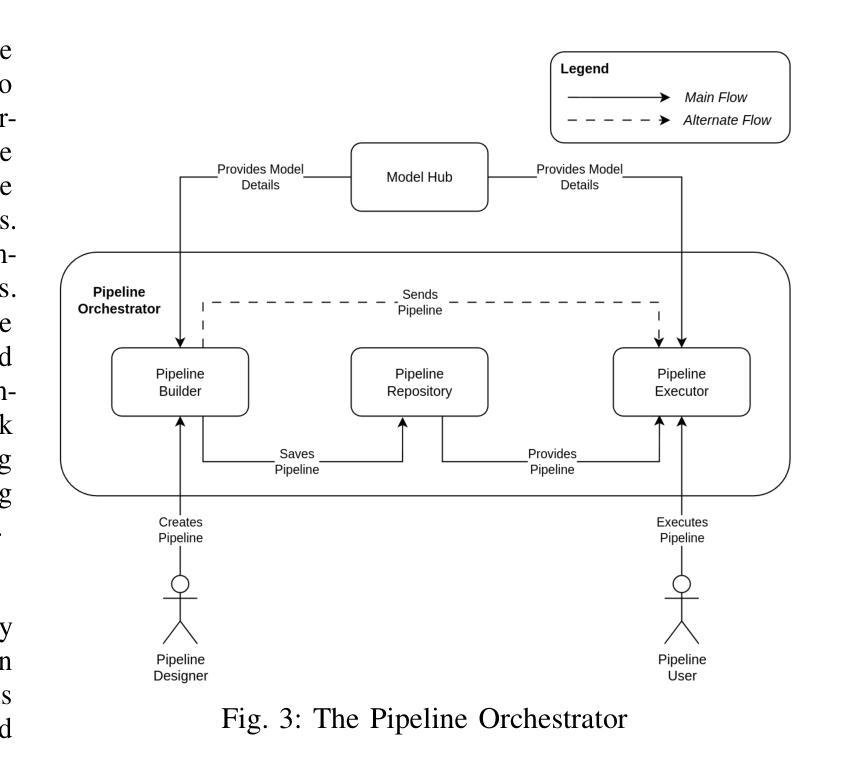
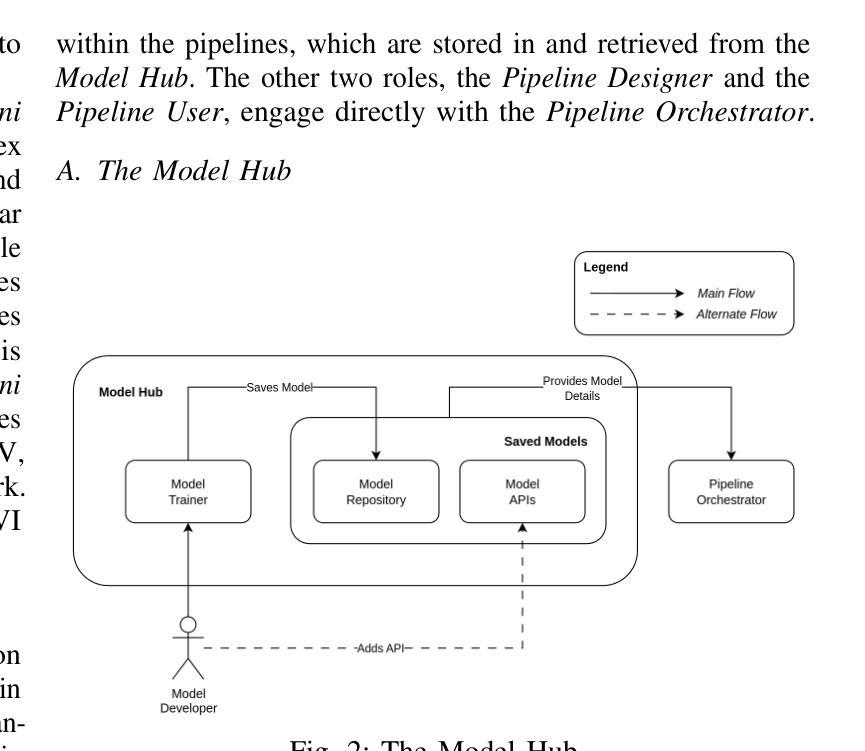
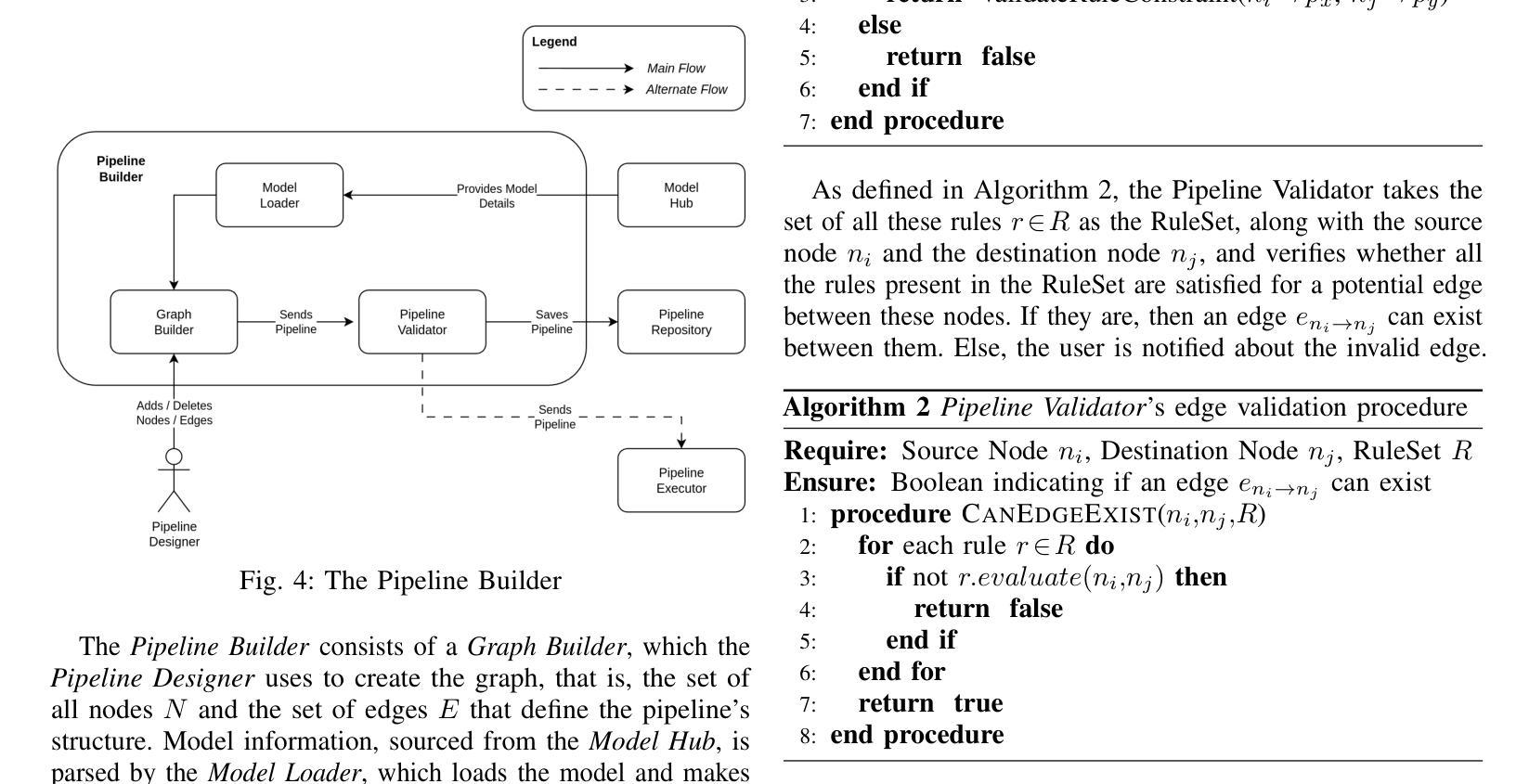
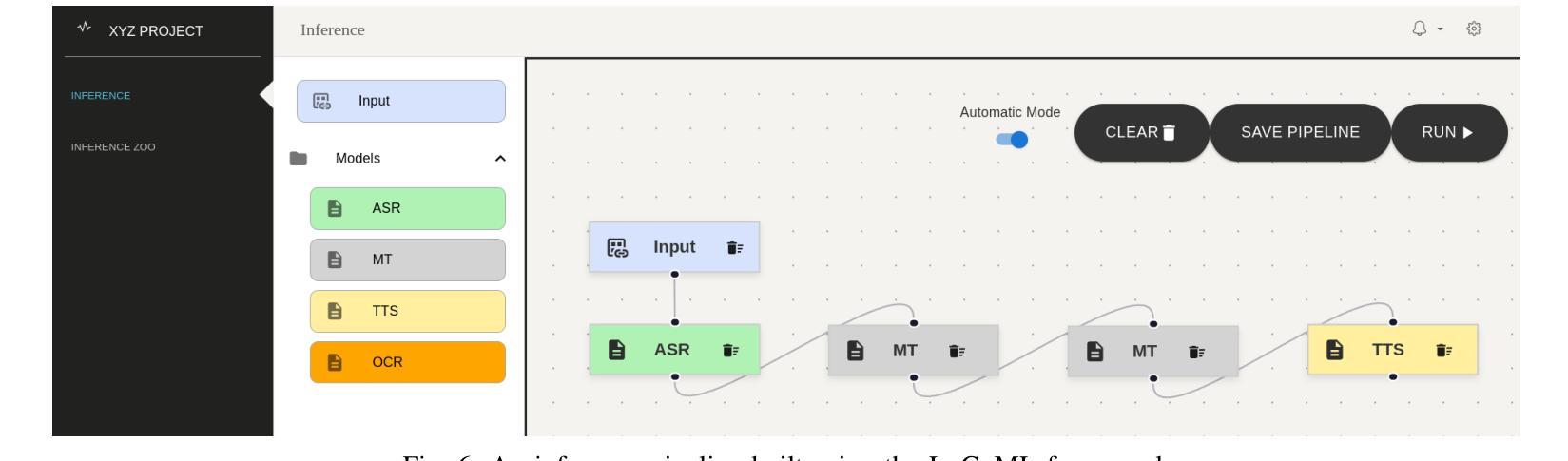
LoCoML: A Framework for Real-World ML Inference Pipelines
Authors:Kritin Maddireddy, Santhosh Kotekal Methukula, Chandrasekar Sridhar, Karthik Vaidhyanathan
The widespread adoption of machine learning (ML) has brought forth diverse models with varying architectures, and data requirements, introducing new challenges in integrating these systems into real-world applications. Traditional solutions often struggle to manage the complexities of connecting heterogeneous models, especially when dealing with varied technical specifications. These limitations are amplified in large-scale, collaborative projects where stakeholders contribute models with different technical specifications. To address these challenges, we developed LoCoML, a low-code framework designed to simplify the integration of diverse ML models within the context of the \textit{Bhashini Project} - a large-scale initiative aimed at integrating AI-driven language technologies such as automatic speech recognition, machine translation, text-to-speech, and optical character recognition to support seamless communication across more than 20 languages. Initial evaluations show that LoCoML adds only a small amount of computational load, making it efficient and effective for large-scale ML integration. Our practical insights show that a low-code approach can be a practical solution for connecting multiple ML models in a collaborative environment.
机器学习的广泛应用带来了各种具有不同架构和数据要求的模型,为将这些系统整合到实际应用程序中带来了新的挑战。传统解决方案往往难以应对连接异构模型的复杂性,尤其是在处理不同技术规格时更是如此。在大规模协作项目中,这些局限性被放大了,利益相关者会贡献具有不同技术规格的模型。为了解决这些挑战,我们开发了LoCoML,这是一个低代码框架,旨在简化在“梵诗丽项目”背景下整合各种机器学习模型的工作。“梵诗丽项目”是一个旨在整合人工智能驱动的语言技术的大规模倡议,如语音识别、机器翻译、文本转语音和光学字符识别等,以支持超过2 0种语言之间的无缝通信。初步评估表明,LoCoML的计算负载非常小,对于大规模机器学习整合来说非常高效且实用。我们的实践见解表明,低代码方法可以是一个协作环境中连接多个机器学习模型的实际解决方案。
论文及项目相关链接
PDF The paper has been accepted for presentation at the 4th International Conference on AI Engineering (CAIN) 2025 co-located with 47th IEEE/ACM International Conference on Software Engineering (ICSE) 2025
摘要
LoCoML是一个低代码框架,旨在简化不同机器学习模型在大型合作项目中的集成工作。框架通过应用简单的代码段配置技术规则而不是常规集成工具方法来实现。针对不同的语言技术和多达数十种模型的集成提供了高效的解决方案,使项目开发者可以在项目中更有效地进行工作协调和资源利用。其能在减少复杂性的同时实现高性能。初期评估表明,LoCoML对计算负载的增加非常小,适合大规模集成机器学习应用。实践见解表明,在协作环境中连接多个机器学习模型时,低代码方法是一种实用的解决方案。
关键见解
- LoCoML是一个低代码框架,用于简化不同机器学习模型在大型项目中的集成工作。
- 该框架旨在解决传统解决方案在连接不同技术规格的异质模型时面临的挑战。
- LoCoML设计用于应对多种语言技术和多种模型的集成需求,为开发者提供便利和高效性。
- LoCoML框架允许在项目中更有效地协调工作和利用资源。
- LoCoML减少了集成的复杂性,同时保证了高性能。
- 初步评估显示,LoCoML对计算负载的增加很小,适合大规模集成机器学习应用。
- 实践表明,在协作环境中连接多个机器学习模型时,低代码方法是一种有效的解决方案。
点此查看论文截图