⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-28 更新
Attribute-based Visual Reprogramming for Image Classification with CLIP
Authors:Chengyi Cai, Zesheng Ye, Lei Feng, Jianzhong Qi, Feng Liu
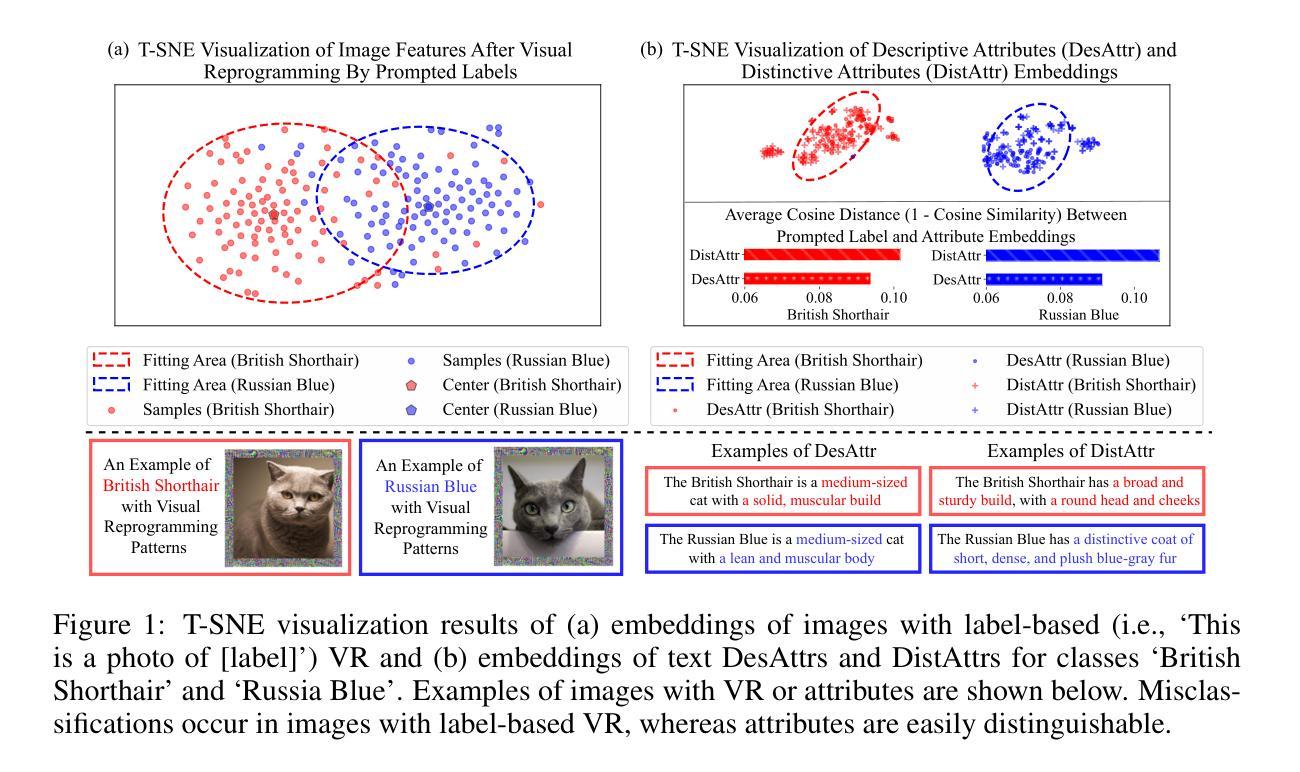
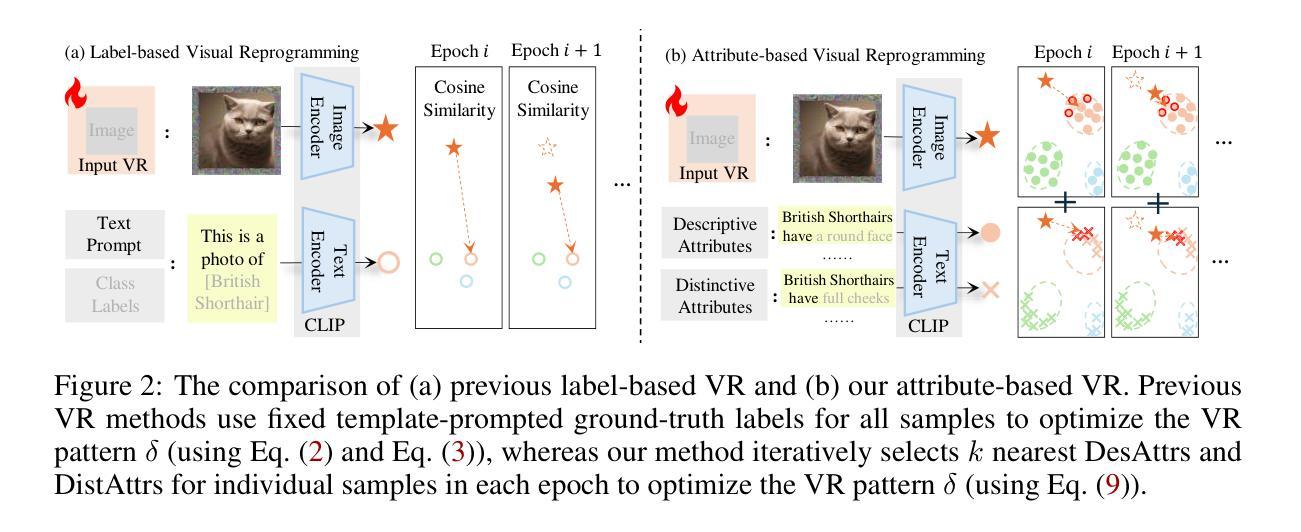
Visual reprogramming (VR) reuses pre-trained vision models for downstream image classification tasks by adding trainable noise patterns to inputs. When applied to vision-language models (e.g., CLIP), existing VR approaches follow the same pipeline used in vision models (e.g., ResNet, ViT), where ground-truth class labels are inserted into fixed text templates to guide the optimization of VR patterns. This label-based approach, however, overlooks the rich information and diverse attribute-guided textual representations that CLIP can exploit, which may lead to the misclassification of samples. In this paper, we propose Attribute-based Visual Reprogramming (AttrVR) for CLIP, utilizing descriptive attributes (DesAttrs) and distinctive attributes (DistAttrs), which respectively represent common and unique feature descriptions for different classes. Besides, as images of the same class may reflect different attributes after VR, AttrVR iteratively refines patterns using the $k$-nearest DesAttrs and DistAttrs for each image sample, enabling more dynamic and sample-specific optimization. Theoretically, AttrVR is shown to reduce intra-class variance and increase inter-class separation. Empirically, it achieves superior performance in 12 downstream tasks for both ViT-based and ResNet-based CLIP. The success of AttrVR facilitates more effective integration of VR from unimodal vision models into vision-language models. Our code is available at https://github.com/tmlr-group/AttrVR.
视觉重编程(VR)通过向输入添加可训练的噪声模式,将预训练的视觉模型重新用于下游图像分类任务。当应用于视觉语言模型(例如CLIP)时,现有的VR方法遵循视觉模型(例如ResNet、ViT)中使用的相同流程,将真实标签插入固定文本模板中以引导VR模式的优化。然而,这种基于标签的方法忽视了CLIP可以利用的丰富信息和多样化的属性导向文本表示,这可能导致样本的错误分类。在本文中,我们针对CLIP提出了基于属性的视觉重编程(AttrVR),利用描述性属性(DesAttrs)和区分性属性(DistAttrs),分别代表不同类别的常见和独特特征描述。此外,由于同一类别的图像在VR后可能会反映出不同的属性,AttrVR会迭代地使用每个图像样本的k个最近DesAttrs和DistAttrs来优化模式,从而实现更动态和样本特定的优化。理论上,AttrVR被证明可以减少类内方差,增加类间分离。实际上,它在基于ViT和ResNet的CLIP的12个下游任务中实现了卓越的性能。AttrVR的成功促进了从单模态视觉模型到视觉语言模型的VR的更有效集成。我们的代码可在https://github.com/tmlr-group/AttrVR上找到。
论文及项目相关链接
Summary
本文提出一种基于属性的视觉重编程(AttrVR)方法,用于CLIP模型。该方法利用描述性属性和区分性属性,分别表示不同类别的通用和独特特征描述。AttrVR通过迭代优化,使用每个图像样本的k近邻DesAttrs和DistAttrs来细化模式,实现更动态和样本特定的优化。理论上,AttrVR可以降低类内方差,增加类间分离。在ViT和ResNet的CLIP模型的下游任务中,AttrVR实现了优越的性能。
Key Takeaways
- Visual Reprogramming (VR)技术通过添加可训练的噪声模式来重用预训练的视觉模型,用于下游图像分类任务。
- 现有VR方法在应用至视觉语言模型(如CLIP)时,遵循与视觉模型相同的流程,使用固定的文本模板插入真实类别标签来指导优化VR模式。
- 传统的基于标签的方法忽视了CLIP可挖掘的丰富信息和多样化的属性导向文本表示,可能导致样本误分类。
- 本文提出的AttrVR方法利用描述性属性(DesAttrs)和区分性属性(DistAttrs),分别表示不同类别的通用和独特特征描述。
- AttrVR通过迭代优化,使用每个图像样本的k近邻DesAttrs和DistAttrs来细化模式,使优化更加动态和样本特定。
- 理论上,AttrVR能降低类内方差,增加类间分离。
- 在多个下游任务中,AttrVR对基于ViT和ResNet的CLIP模型实现了优越的性能。
点此查看论文截图

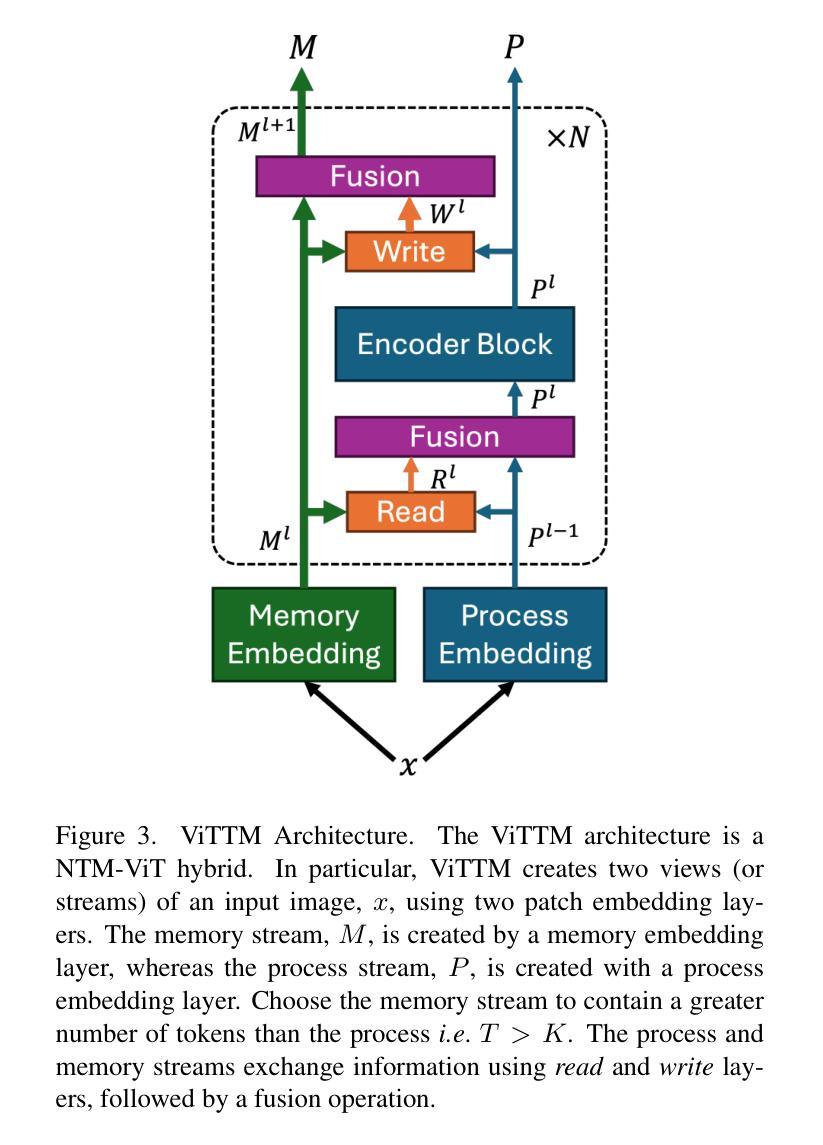
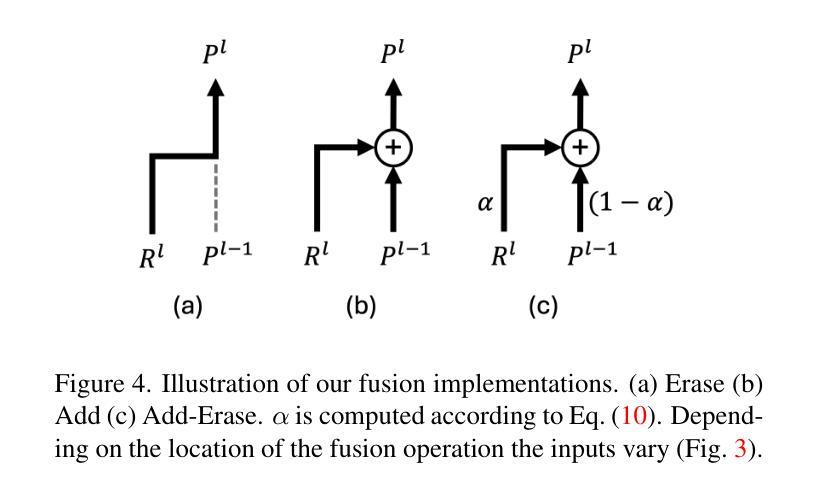
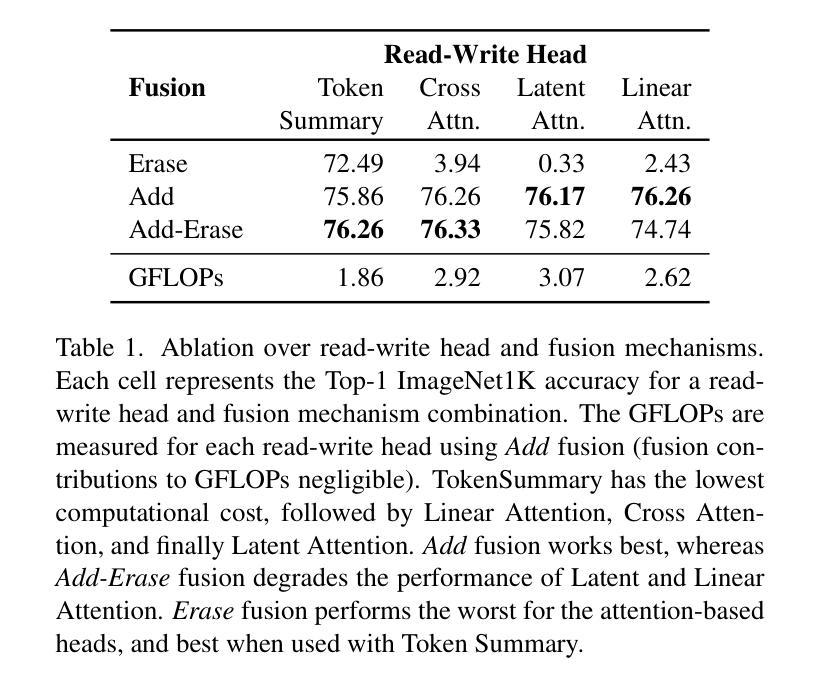
Token Turing Machines are Efficient Vision Models
Authors:Purvish Jajal, Nick John Eliopoulos, Benjamin Shiue-Hal Chou, George K. Thiruvathukal, James C. Davis, Yung-Hsiang Lu
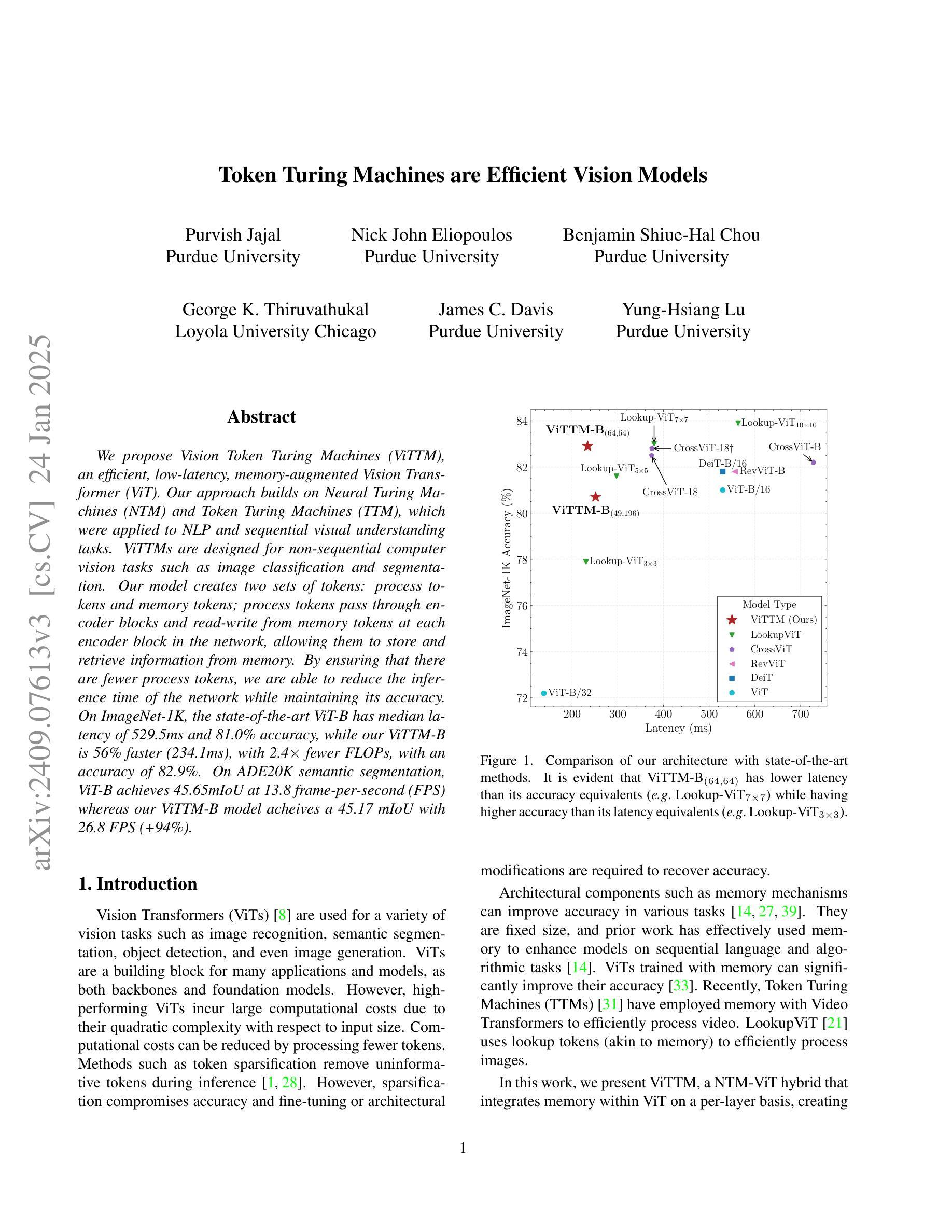
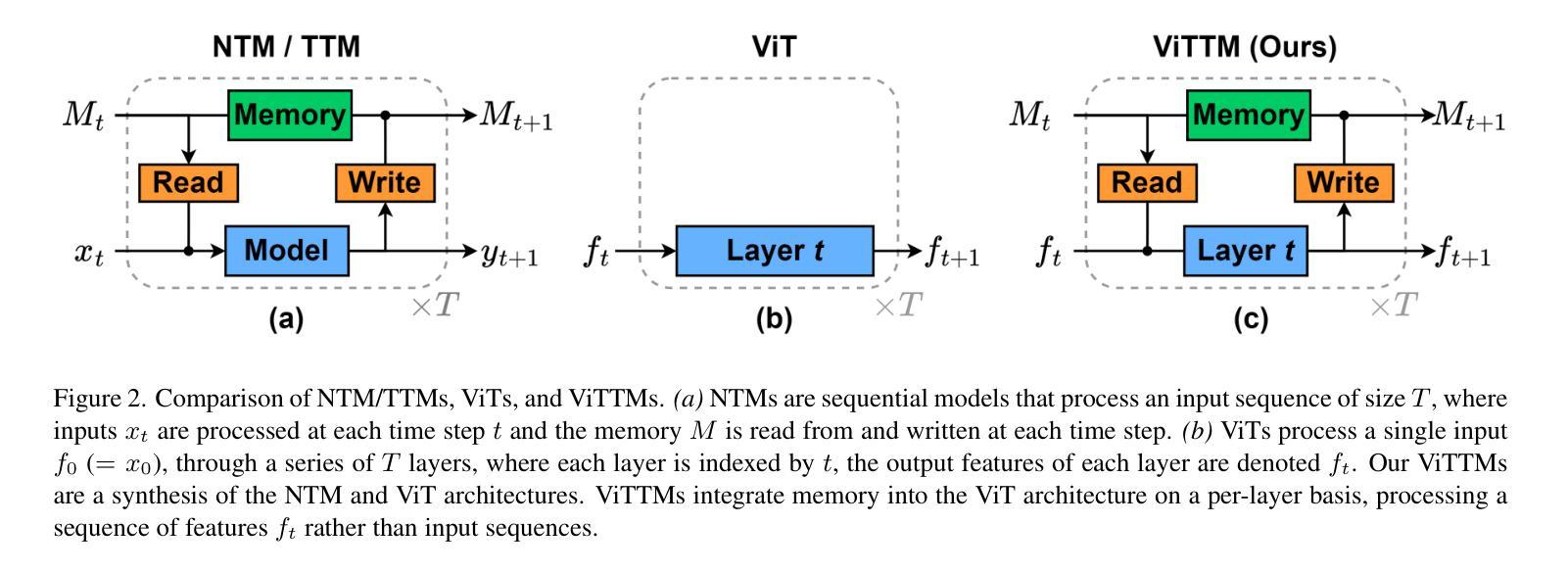
We propose Vision Token Turing Machines (ViTTM), an efficient, low-latency, memory-augmented Vision Transformer (ViT). Our approach builds on Neural Turing Machines and Token Turing Machines, which were applied to NLP and sequential visual understanding tasks. ViTTMs are designed for non-sequential computer vision tasks such as image classification and segmentation. Our model creates two sets of tokens: process tokens and memory tokens; process tokens pass through encoder blocks and read-write from memory tokens at each encoder block in the network, allowing them to store and retrieve information from memory. By ensuring that there are fewer process tokens than memory tokens, we are able to reduce the inference time of the network while maintaining its accuracy. On ImageNet-1K, the state-of-the-art ViT-B has median latency of 529.5ms and 81.0% accuracy, while our ViTTM-B is 56% faster (234.1ms), with 2.4 times fewer FLOPs, with an accuracy of 82.9%. On ADE20K semantic segmentation, ViT-B achieves 45.65mIoU at 13.8 frame-per-second (FPS) whereas our ViTTM-B model acheives a 45.17 mIoU with 26.8 FPS (+94%).
我们提出了Vision Token Turing Machines(ViTTM),这是一种高效、低延迟、内存增强的Vision Transformer(ViT)。我们的方法建立在神经图灵机和令牌图灵机的基础上,后者被应用于自然语言处理和序列视觉理解任务。ViTTM被设计用于非序列计算机视觉任务,如图像分类和分割。我们的模型创建了两组令牌:处理令牌和内存令牌;处理令牌通过编码器块,并从内存令牌在网络中每个编码器块进行读写,允许它们从内存中存储和检索信息。通过确保处理令牌的数目少于内存令牌,我们能够减少网络的推理时间,同时保持其准确性。在ImageNet-1K上,最先进的ViT-B具有529.5毫秒的中位延迟和81.0%的准确度,而我们的ViTTM-B快56%(234.1毫秒),FLOPs减少2.4倍,准确率达到了82.9%。在ADE20K语义分割任务上,ViT-B以每秒13.8帧的速度达到45.65 mIoU,而我们的ViTTM-B模型以每秒26.8帧的速度达到45.17 mIoU(+94%)。
论文及项目相关链接
PDF Accepted to WACV 2025
Summary
本文提出了Vision Token Turing Machines(ViTTM),这是一种高效、低延迟、内存增强的Vision Transformer(ViT)。ViTTM设计用于非序列计算机视觉任务,如图像分类和分割。它通过创建两组令牌:处理令牌和内存令牌,以及在每个编码器块中从内存令牌读写,来存储和检索信息。通过确保处理令牌少于内存令牌,可以在保持准确性同时减少网络推理时间。在ImageNet-1K上,ViTTM-B比先进的ViT-B更快,准确性更高。在ADE20K语义分割任务上,ViTTM-B模型也表现出更高的帧率。
Key Takeaways
- Vision Token Turing Machines (ViTTM) 是一种基于神经图灵机(Neural Turing Machines)和令牌图灵机(Token Turing Machines)的新型模型,用于计算机视觉任务。
- ViTTM针对非序列计算机视觉任务,如图像分类和分割进行了优化。
- ViTTM通过创建处理令牌和内存令牌两组令牌来工作,处理令牌能够在网络的每个编码器块中读写内存令牌。
- 通过确保处理令牌少于内存令牌,ViTTM能够在保持准确性的同时减少网络推理时间。
- 在ImageNet-1K数据集上,ViTTM-B模型相较于先进的ViT-B模型更快且更准确。
- 在ADE20K语义分割任务上,ViTTM-B模型表现出更高的帧率,且保持了良好的准确性。
点此查看论文截图
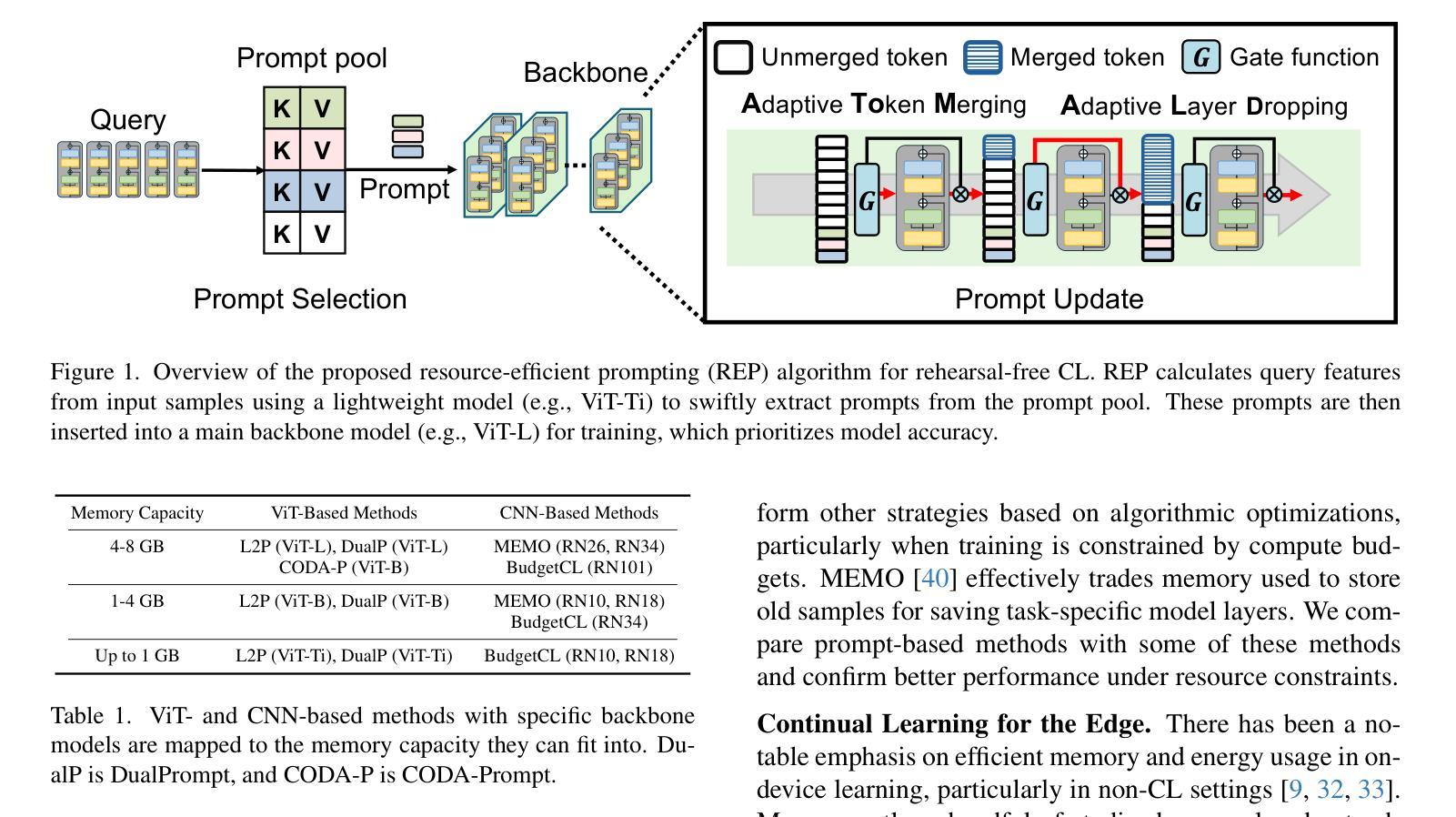
REP: Resource-Efficient Prompting for Rehearsal-Free Continual Learning
Authors:Sungho Jeon, Xinyue Ma, Kwang In Kim, Myeongjae Jeon
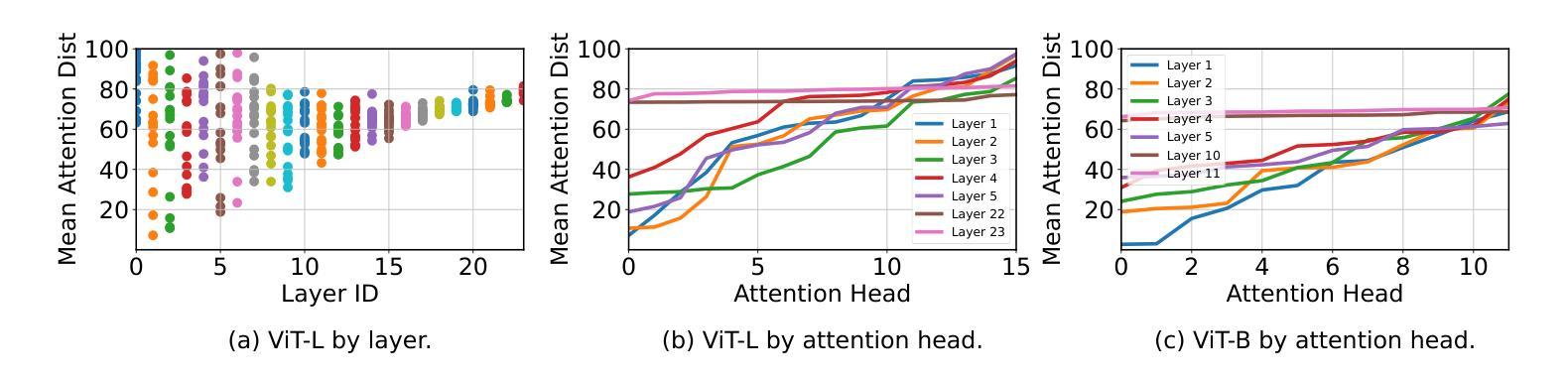
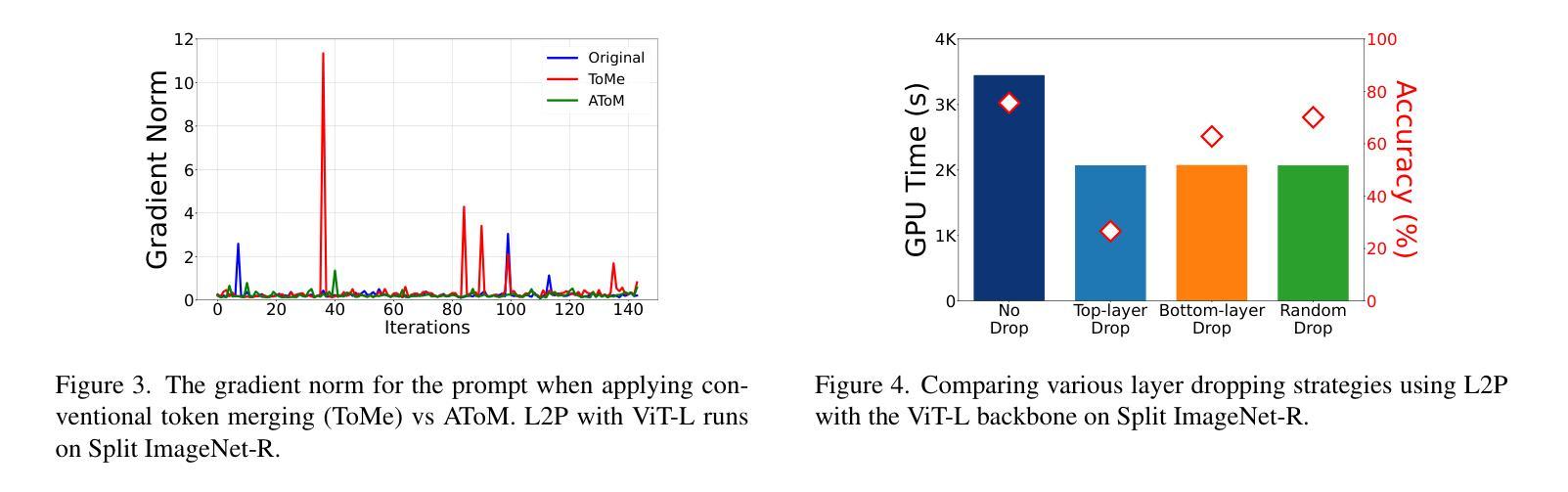
Recent rehearsal-free methods, guided by prompts, generally excel in vision-related continual learning (CL) scenarios with continuously drifting data. To be deployable on real-world devices, these methods must contain high resource efficiency during training. In this paper, we introduce Resource-Efficient Prompting (REP), which targets improving the resource efficiency of prompt-based rehearsal-free methods. Our key focus is on avoiding catastrophic trade-offs with accuracy while trimming computational and memory costs during prompt learning. We achieve this by exploiting swift prompt selection that enhances input data using a carefully provisioned model, and by developing adaptive token merging (AToM) and layer dropping (ALD) algorithms for the prompt updating stage. AToM and ALD perform selective skipping across the data and model dimensions without compromising task-specific features while learning new tasks. We validate REP’s superior resource efficiency over current state-of-the-art ViT- and CNN-based methods through extensive experiments on three image classification datasets.
最近的无复述方法,在提示的引导下,通常在视觉相关的持续学习(CL)场景中表现优异,并且这些数据是持续漂移的。要在实际设备上进行部署,这些方法必须在训练期间具有高资源效率。在本文中,我们介绍了资源高效提示(REP),旨在提高基于提示的无复述方法的资源效率。我们的重点是避免在提示学习期间出现严重影响准确率的权衡,同时减少计算和内存成本。我们通过利用快速提示选择来实现这一点,该选择使用精心准备的模型增强输入数据,并开发用于提示更新阶段的自适应令牌合并(AToM)和层丢弃(ALD)算法。AToM和ALD在数据模型和任务特定特征学习期间进行选择性跳过,而不会损害新任务的学习。我们通过在三张图像分类数据集上进行的大量实验验证了REP相较于当前最先进的ViT和CNN方法的高级资源效率。
论文及项目相关链接
Summary
本文介绍了资源高效提示方法(REP),旨在提高基于提示的无排练方法的资源效率,重点关注在避免准确性的灾难性妥协的同时,缩减计算和内存成本。通过利用快速提示选择和开发自适应令牌合并(AToM)和层丢弃(ALD)算法进行提示更新,实现在数据维度和模型维度上的选择性跳过而不影响任务特定特征的同时学习新任务。经过在三个图像分类数据集上的广泛实验验证,REP在资源效率上优于当前最先进的ViT和CNN方法。
Key Takeaways
- 引入资源高效提示方法(REP),旨在提高基于提示的无排练方法的资源效率。
- 避免与准确性的灾难性妥协,同时减少计算和内存成本。
- 利用快速提示选择增强输入数据。
- 开发自适应令牌合并(AToM)和层丢弃(ALD)算法进行提示更新。
- AToM和ALD算法能够在数据维度和模型维度上实现选择性跳过。
- REP方法经过在多个图像分类数据集上的广泛实验验证。
- REP在资源效率上优于当前最先进的ViT和CNN方法。
点此查看论文截图