⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-29 更新
A Training-free Synthetic Data Selection Method for Semantic Segmentation
Authors:Hao Tang, Siyue Yu, Jian Pang, Bingfeng Zhang
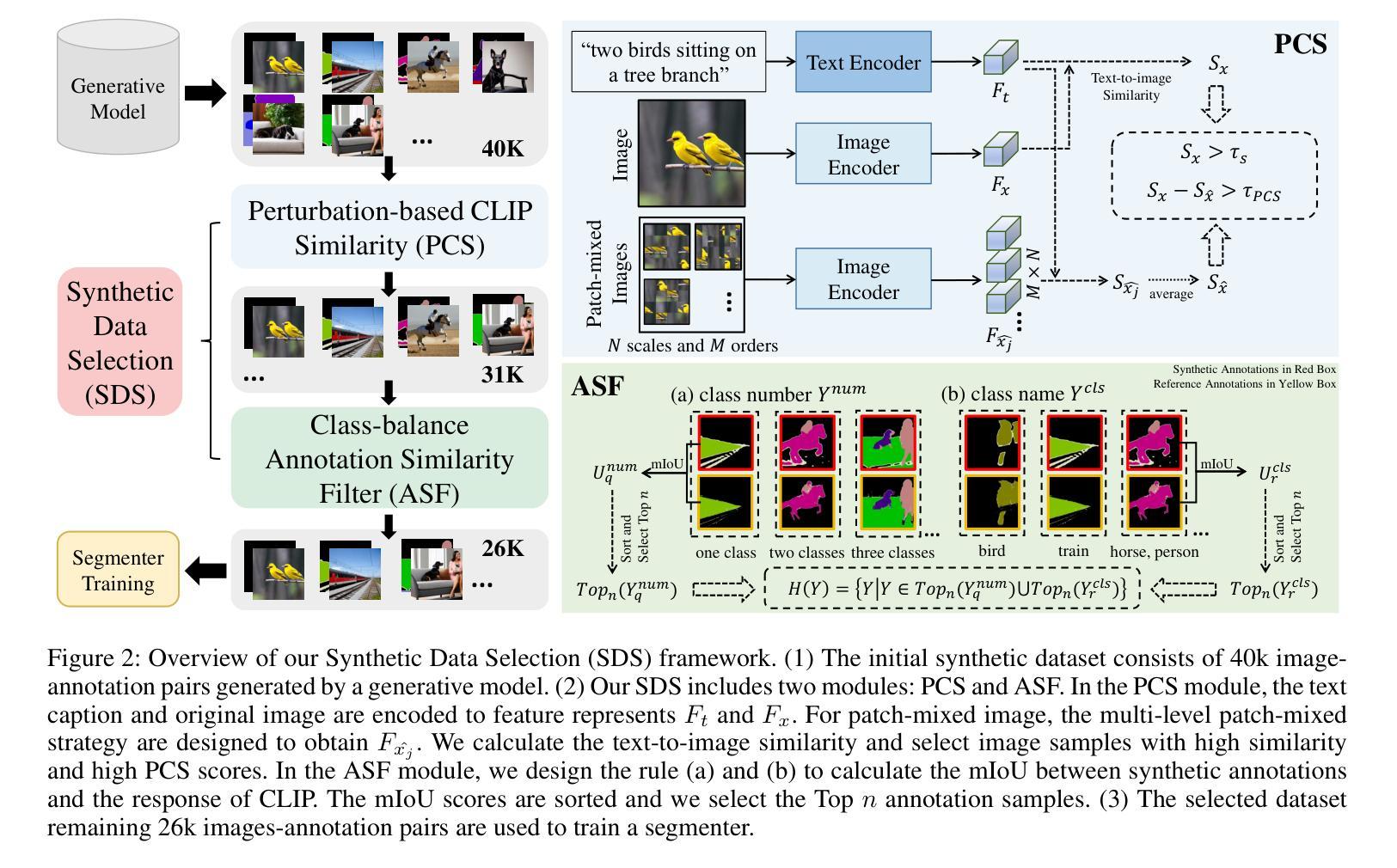
Training semantic segmenter with synthetic data has been attracting great attention due to its easy accessibility and huge quantities. Most previous methods focused on producing large-scale synthetic image-annotation samples and then training the segmenter with all of them. However, such a solution remains a main challenge in that the poor-quality samples are unavoidable, and using them to train the model will damage the training process. In this paper, we propose a training-free Synthetic Data Selection (SDS) strategy with CLIP to select high-quality samples for building a reliable synthetic dataset. Specifically, given massive synthetic image-annotation pairs, we first design a Perturbation-based CLIP Similarity (PCS) to measure the reliability of synthetic image, thus removing samples with low-quality images. Then we propose a class-balance Annotation Similarity Filter (ASF) by comparing the synthetic annotation with the response of CLIP to remove the samples related to low-quality annotations. The experimental results show that using our method significantly reduces the data size by half, while the trained segmenter achieves higher performance. The code is released at https://github.com/tanghao2000/SDS.
使用合成数据训练语义分割器因其易于获取和大量存在的特点而备受关注。大多数之前的方法侧重于生成大规模合成图像注释样本,然后使用所有这些样本对分割器进行训练。然而,这种解决方案仍存在主要挑战,因为不可避免地会出现质量较差的样本,使用它们来训练模型会损害训练过程。在本文中,我们提出了一种利用CLIP的无训练合成数据选择(SDS)策略,用于选择高质量样本以构建可靠的合成数据集。具体来说,给定大量的合成图像注释对,我们首先设计了一种基于扰动的CLIP相似性(PCS)来测量合成图像的可靠性,从而移除低质量图像样本。然后,我们通过比较合成注释与CLIP的响应,提出了类平衡注释相似性过滤器(ASF),以消除与低质量注释相关的样本。实验结果表明,使用我们的方法可以将数据量减半,同时训练的分割器性能更高。代码已发布在https://github.com/tanghao2000/SDS。
论文及项目相关链接
PDF Accepted to AAAI 2025
Summary
利用合成数据训练语义分割器已备受关注。针对使用低质量样本训练模型的问题,本文提出了一种无需训练的合成数据选择策略SDS,结合CLIP技术筛选高质量样本构建可靠的合成数据集。通过设计基于扰动的CLIP相似度测量和类平衡标注相似性过滤器,有效去除低质量图像和标注样本。实验结果显示,使用此方法可将数据量减半,同时训练出的分割器性能更高。
Key Takeaways
- 利用合成数据训练语义分割器是当前研究的热点。
- 低质量样本对训练过程产生负面影响。
- 提出了一种无需训练的合成数据选择策略SDS。
- 通过设计基于扰动的CLIP相似度测量,去除低质量图像样本。
- 引入类平衡标注相似性过滤器,去除低质量标注样本。
- 实验结果显示,使用此方法能显著减少数据量并提高分割器性能。
点此查看论文截图



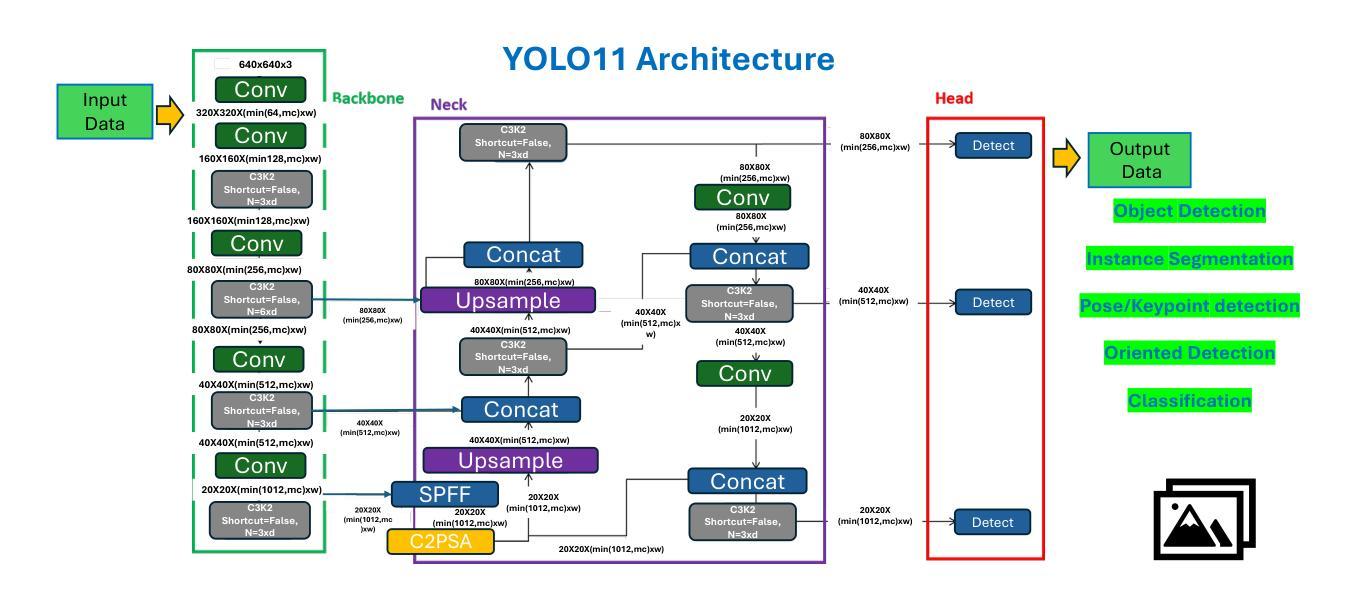
Comparing YOLOv11 and YOLOv8 for instance segmentation of occluded and non-occluded immature green fruits in complex orchard environment
Authors:Ranjan Sapkota, Manoj Karkee
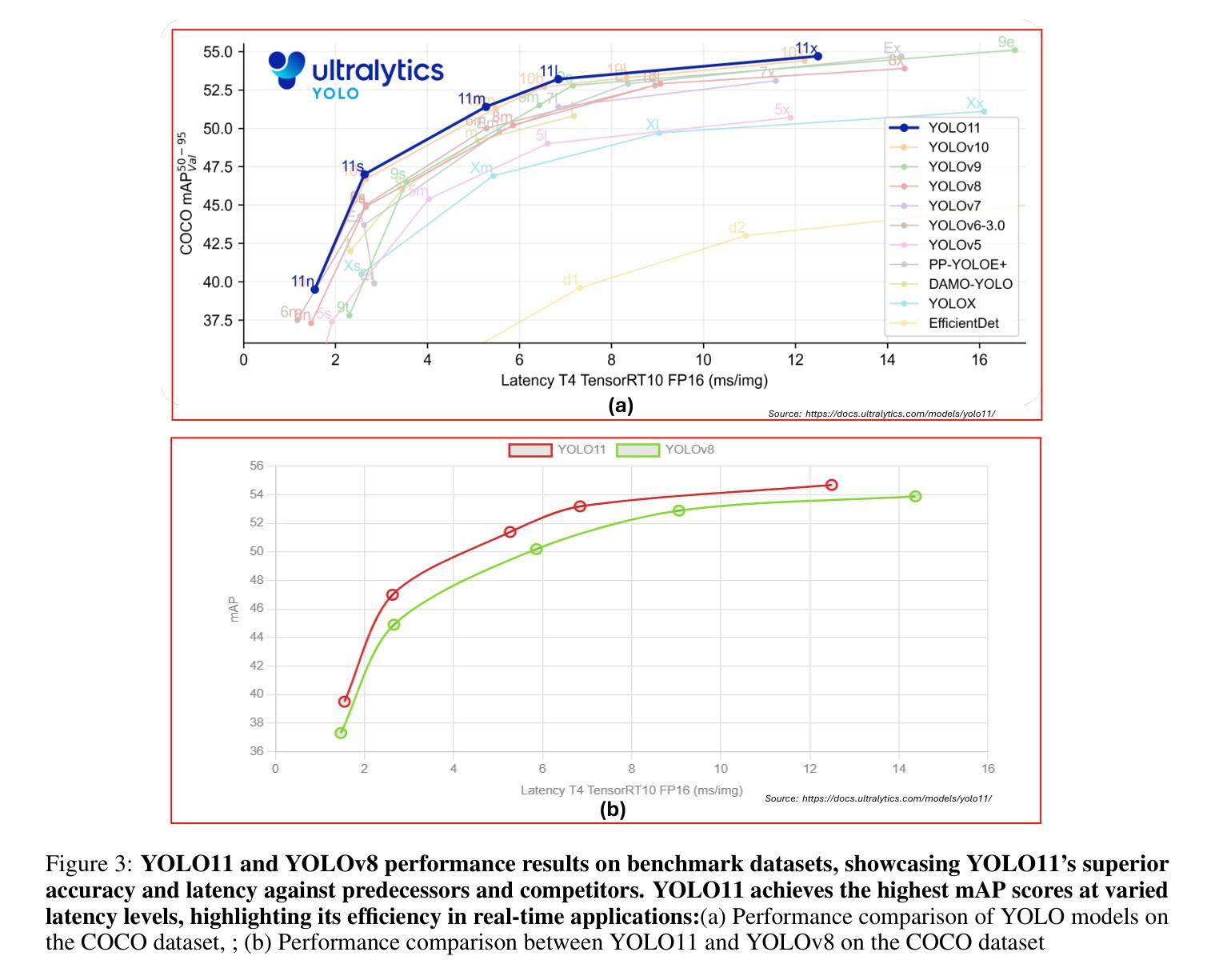
This study conducted a comprehensive performance evaluation on YOLO11 (or YOLOv11) and YOLOv8, the latest in the “You Only Look Once” (YOLO) series, focusing on their instance segmentation capabilities for immature green apples in orchard environments. YOLO11n-seg achieved the highest mask precision across all categories with a notable score of 0.831, highlighting its effectiveness in fruit detection. YOLO11m-seg and YOLO11l-seg excelled in non-occluded and occluded fruitlet segmentation with scores of 0.851 and 0.829, respectively. Additionally, YOLOv11x-seg led in mask recall for all categories, achieving a score of 0.815, with YOLO11m-seg performing best for non-occluded immature green fruitlets at 0.858 and YOLOv8x-seg leading the occluded category with 0.800. In terms of mean average precision at a 50% intersection over union (mAP@50), YOLOv11m-seg consistently outperformed, registering the highest scores for both box and mask segmentation, at 0.876 and 0.860 for the “All” class and 0.908 and 0.909 for non-occluded immature fruitlets, respectively. YOLO11l-seg and YOLOv8l-seg shared the top box mAP@50 for occluded immature fruitlets at 0.847, while YOLO11m-seg achieved the highest mask mAP@50 of 0.810. Despite the advancements in YOLO11, YOLOv8n surpassed its counterparts in image processing speed, with an impressive inference speed of 3.3 milliseconds, compared to the fastest YOLO11 series model at 4.8 milliseconds, underscoring its suitability for real-time agricultural applications related to complex green fruit environments. (YOLOv11 segmentation)
本研究对YOLO11(或YOLOv11)和YOLOv8这两款“You Only Look Once”(YOLO)系列的最新产品进行了全面的性能评估,重点评估了它们在果园环境中对未成熟绿苹果的实例分割能力。YOLO11n-seg在所有类别中获得了最高的掩膜精度,达到了显著的0.831分,这凸显了其在水果检测方面的有效性。YOLO11m-seg和YOLO11l-seg在非遮挡和遮挡的幼果分割方面表现出色,分别获得了0.851和0.829的分数。此外,YOLOv11x-seg在所有类别的掩膜召回率方面表现出色,获得了0.815的分数,其中YOLO11m-seg在非遮挡的未成熟绿幼果方面表现最佳,达到了0.858分,而YOLOv8x-seg在遮挡类别中领先,获得了0.800的分数。在平均精度均值(mAP@50)方面,YOLOv11m-seg表现一直较好,在“全部”类别中,框和掩膜分割的最高分数分别为0.876和0.860,非遮挡未成熟幼果的分数分别为0.908和0.909。YOLO11l-seg和YOLOv8l-seg在遮挡的未成熟幼果的框mAP@50上并列第一,得分为0.847,而YOLO11m-seg在掩膜mAP@50上表现最佳,得分为0.810。尽管YOLO11有所进步,但在图像处理速度方面,YOLOv8n超越了其他模型,其推理速度达到了惊人的3.3毫秒,而最快的YOLO11系列模型为4.8毫秒,这表明它非常适合与复杂的绿色水果环境相关的实时农业应用。(YOLOv11分割)
论文及项目相关链接
PDF 16 Pages, 10 Figures, 3 Tables
Summary:
最新一代YOLO系列的实例分割性能被详细评估,特别是在果园环境下对未成熟绿色苹果的检测能力。在评估指标上,YOLOv系列表现出色,如YOLO11n-seg在各类别中的mask精度达到最高值(0.831),成为果实检测方面的翘楚。此外,YOLOv系列还在不同的场景类别(如非遮挡和遮挡的果实)中展现出卓越性能。在mAP@50方面,YOLOv系列模型同样表现优异。尽管YOLOv8在图像处理速度上超越YOLO11系列,具备更快的推理速度(3.3毫秒),使其成为复杂绿色果实环境下实时农业应用的理想选择。该研究对农业智能化中的视觉检测应用具有积极意义。
Key Takeaways:
- YOLO系列的最新版本在果园环境下对未成熟绿色苹果的实例分割能力进行了全面评估。
- YOLO系列模型在不同类别中展现出色的mask精度,特别是YOLO11n-seg在各类别中达到最高值(0.831)。
- YOLO系列模型在非遮挡和遮挡条件下的性能评估也有卓越表现。其中YOLO11m-seg在非遮挡的未成熟绿色果实中表现最佳。
- 在mAP@50评估标准下,YOLO系列模型表现出色,尤其是YOLOv系列。
- YOLOv8模型具备更快的推理速度(3.3毫秒),适用于实时农业应用,特别是在复杂的绿色果实环境中。
- 研究为农业智能化领域的视觉检测应用提供了积极进展。研究中的高性能模型和方法可能为未来智能农业领域提供更精确的视觉识别和数据处理能力打下基础。这对于自动化果树林管理等具有实用价值的应用具有重大意义。例如提升种植者生产效率,实现精细农业实践等。
点此查看论文截图