⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-29 更新
Multi-Agent Geospatial Copilots for Remote Sensing Workflows
Authors:Chaehong Lee, Varatheepan Paramanayakam, Andreas Karatzas, Yanan Jian, Michael Fore, Heming Liao, Fuxun Yu, Ruopu Li, Iraklis Anagnostopoulos, Dimitrios Stamoulis
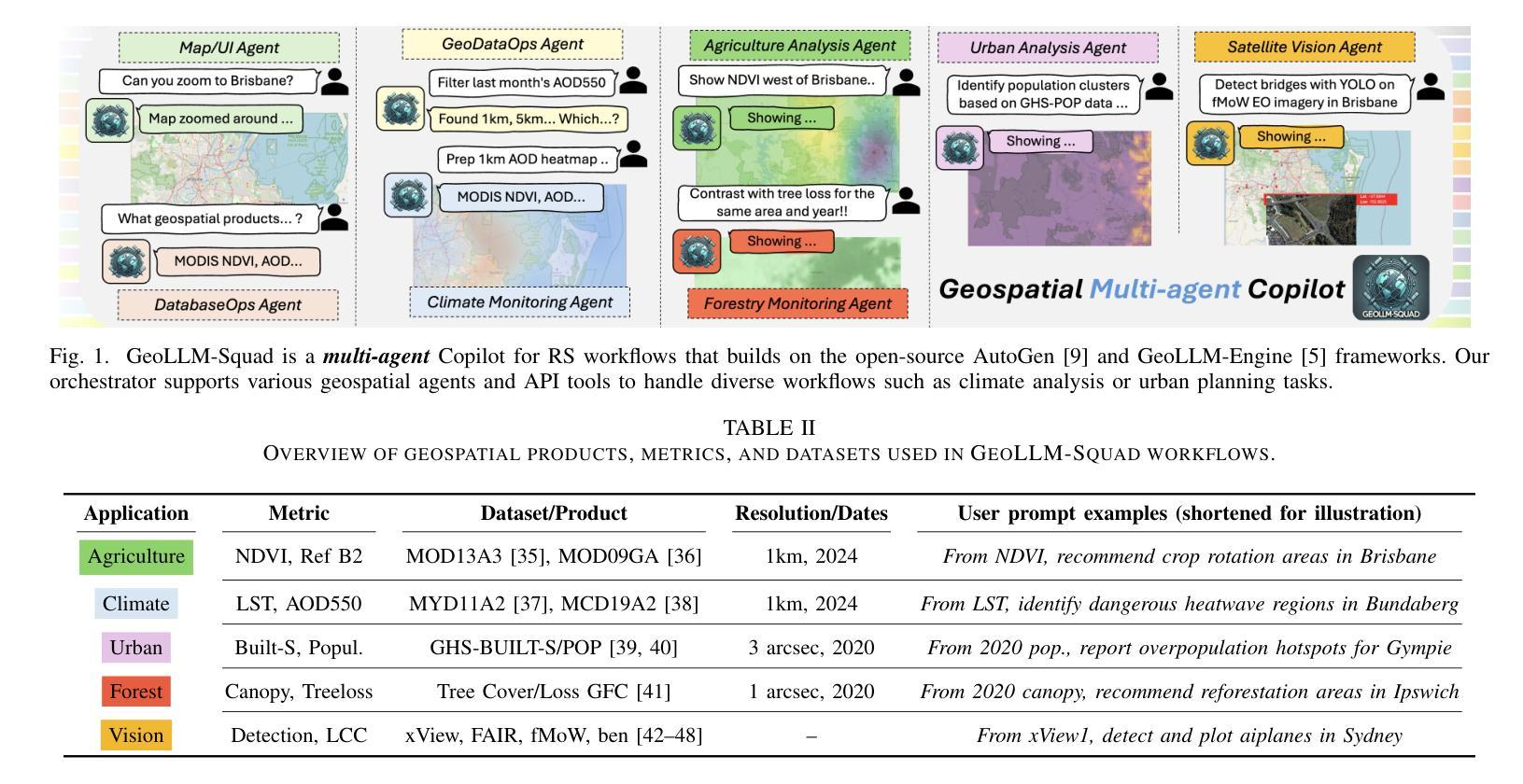
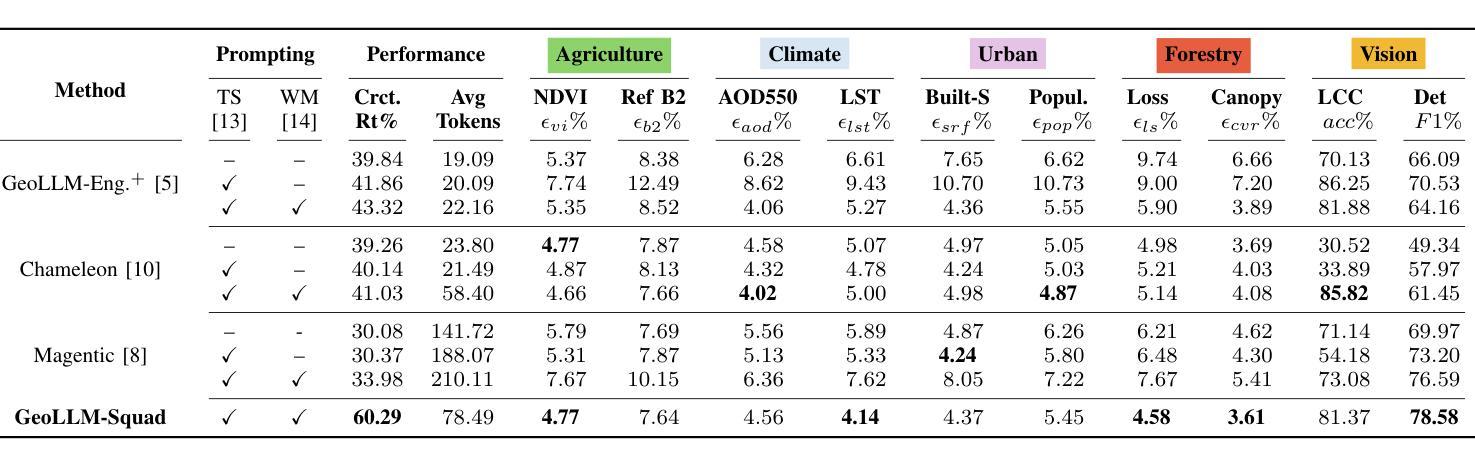
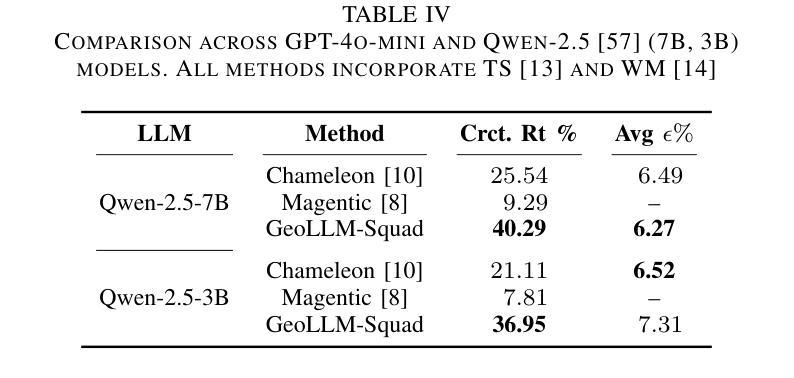
We present GeoLLM-Squad, a geospatial Copilot that introduces the novel multi-agent paradigm to remote sensing (RS) workflows. Unlike existing single-agent approaches that rely on monolithic large language models (LLM), GeoLLM-Squad separates agentic orchestration from geospatial task-solving, by delegating RS tasks to specialized sub-agents. Built on the open-source AutoGen and GeoLLM-Engine frameworks, our work enables the modular integration of diverse applications, spanning urban monitoring, forestry protection, climate analysis, and agriculture studies. Our results demonstrate that while single-agent systems struggle to scale with increasing RS task complexity, GeoLLM-Squad maintains robust performance, achieving a 17% improvement in agentic correctness over state-of-the-art baselines. Our findings highlight the potential of multi-agent AI in advancing RS workflows.
我们提出了GeoLLM-Squad,这是一个地理空间Copilot,它引入了遥感(RS)工作流中的新型多智能体范式。与依赖单一大型语言模型(LLM)的现有单智能体方法不同,GeoLLM-Squad通过将遥感任务委派给专业子智能体,将智能体的编排与地理空间任务解决分开。我们的工作建立在开源的AutoGen和GeoLLM-Engine框架之上,能够实现模块化集成各种应用,涵盖城市监测、林业保护、气候分析和农业研究等领域。我们的结果表明,虽然单智能体系统在处理日益复杂的遥感任务时难以扩展,但GeoLLM-Squad能够保持稳健的性能,在最新基线的基础上提高了17%的智能正确性。我们的研究突出了多智能体人工智能在推进遥感工作流中的潜力。
论文及项目相关链接
Summary
基于多代理的GeoLLM-Squad系统被提出,用于遥感工作流程中的新型远程检测。与传统依赖单一大型语言模型的方案不同,该系统将任务分发至专门的子代理来完成。通过开源的AutoGen和GeoLLM-Engine框架,该方案可模块化集成各种应用,如城市监测、林业保护、气候分析和农业研究等。实验结果证明,在遥感任务复杂性增加时,GeoLLM-Squad相对于现有技术提高了高达17%的正确率。
Key Takeaways
- GeoLLM-Squad引入了一种新型的多代理范式用于遥感工作。
- 该系统解决了现有单一大型语言模型在处理复杂遥感任务时的局限性。
- GeoLLM-Squad实现了模块化的应用集成,涵盖城市监测、林业保护等多个领域。
- 系统性能稳健,相较于当前主流技术提高了约17%的代理正确性。
- GeoLLM-Squad的基础是开源的AutoGen和GeoLLM-Engine框架。
点此查看论文截图


Will Systems of LLM Agents Cooperate: An Investigation into a Social Dilemma
Authors:Richard Willis, Yali Du, Joel Z Leibo, Michael Luck
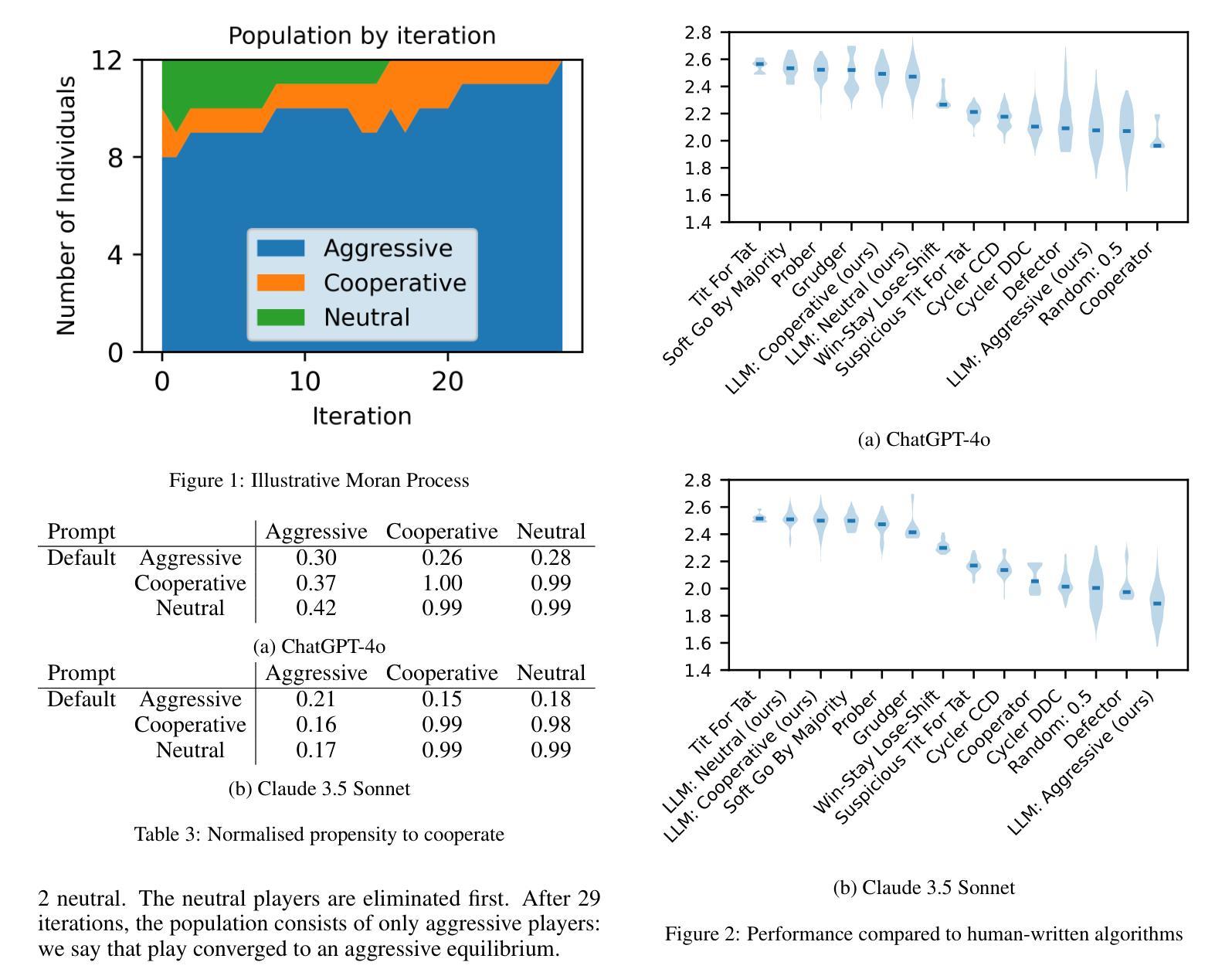
As autonomous agents become more prevalent, understanding their collective behaviour in strategic interactions is crucial. This study investigates the emergent cooperative tendencies of systems of Large Language Model (LLM) agents in a social dilemma. Unlike previous research where LLMs output individual actions, we prompt state-of-the-art LLMs to generate complete strategies for iterated Prisoner’s Dilemma. Using evolutionary game theory, we simulate populations of agents with different strategic dispositions (aggressive, cooperative, or neutral) and observe their evolutionary dynamics. Our findings reveal that different LLMs exhibit distinct biases affecting the relative success of aggressive versus cooperative strategies. This research provides insights into the potential long-term behaviour of systems of deployed LLM-based autonomous agents and highlights the importance of carefully considering the strategic environments in which they operate.
随着自主代理(autonomous agents)越来越普及,理解其在战略互动中的集体行为至关重要。本研究调查了社会困境中大型语言模型(LLM)代理系统的新兴合作倾向。不同于之前的研究中LLM输出的个体行为,我们提示采用最新技术的LLM为反复博弈的囚徒困境生成完整策略。我们运用进化博弈论,模拟具有不同战略倾向(攻击性、合作性或中立性)的代理群体,并观察它们的进化动态。我们的研究发现,不同的LLM表现出不同的偏见,影响攻击与合作的相对成功策略。本研究揭示了已部署的LLM基础自主代理系统的潜在长期行为,并强调了仔细考虑其运营的战略环境的重要性。
论文及项目相关链接
PDF 7 pages (10 including references), 4 figures
Summary
随着自主代理人的普及,理解其在战略交互中的集体行为至关重要。本研究调查了大型语言模型代理系统在社交困境中的新兴合作倾向。不同于以往只关注LLM个体行为的输出,我们提示最先进的LLM生成重复囚徒困境的完整策略。通过演化博弈理论,我们模拟不同策略倾向的代理人群体(侵略性、合作性或中立性),并观察其演化动态。研究发现不同LLM表现出不同的偏见,影响侵略与合作策略的相对成功。该研究为部署的LLM自主代理系统的潜在长期行为提供了见解,并强调了考虑其运营战略环境的重要性。
Key Takeaways
- 大型语言模型代理在社交困境中展现出新兴合作倾向。
- 与以往研究不同,本研究关注LLM在重复囚徒困境中的完整策略生成。
- 采用演化博弈理论模拟不同策略倾向的代理人群体。
- 不同LLM在战略交互中表现出不同的偏见。
- 侵略性和合作性策略的相对成功受LLM偏见影响。
- 该研究揭示了部署的LLM自主代理系统的潜在长期行为。
- 考虑到战略环境对LLM自主代理的影响至关重要。
点此查看论文截图


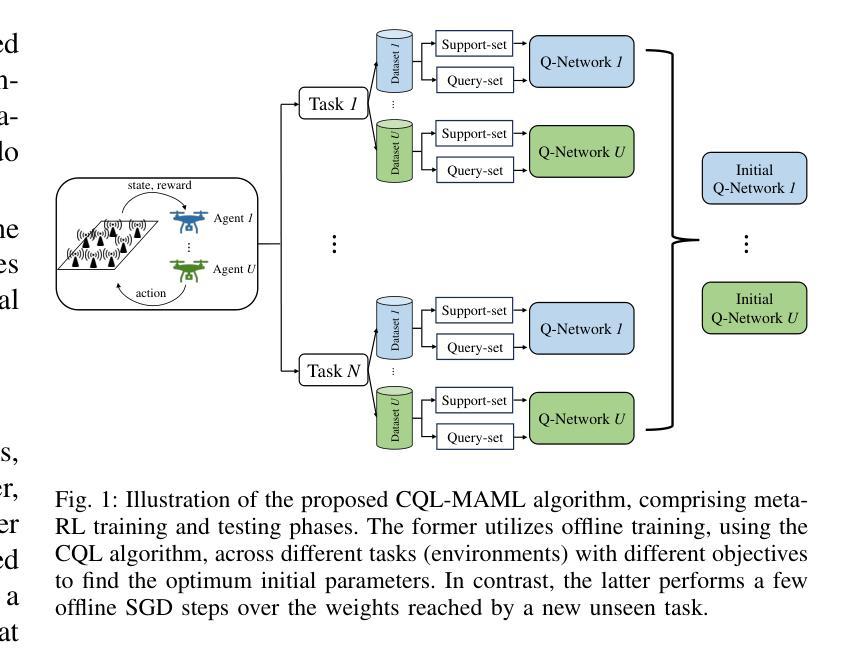
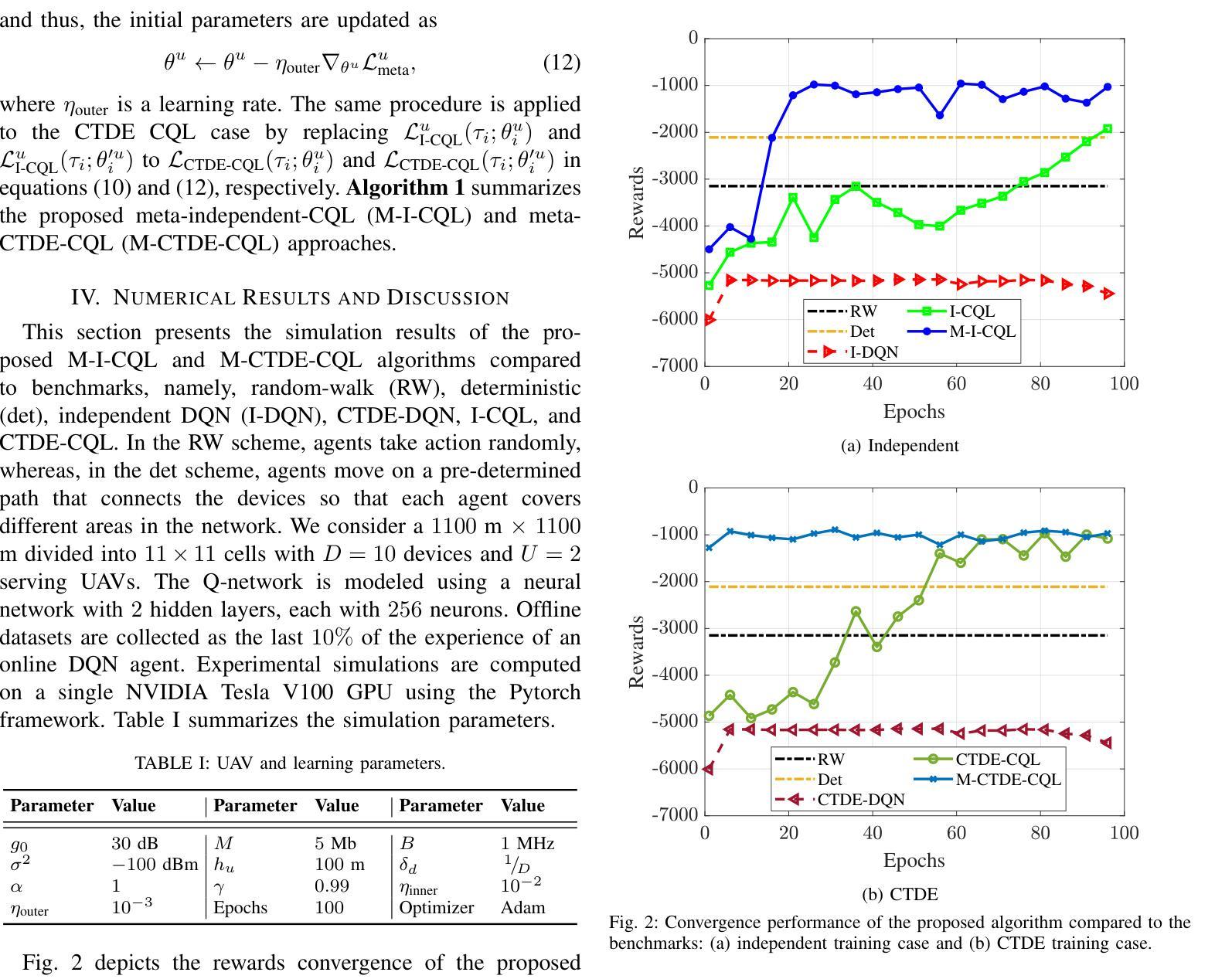
Multi-Agent Meta-Offline Reinforcement Learning for Timely UAV Path Planning and Data Collection
Authors:Eslam Eldeeb, Hirley Alves
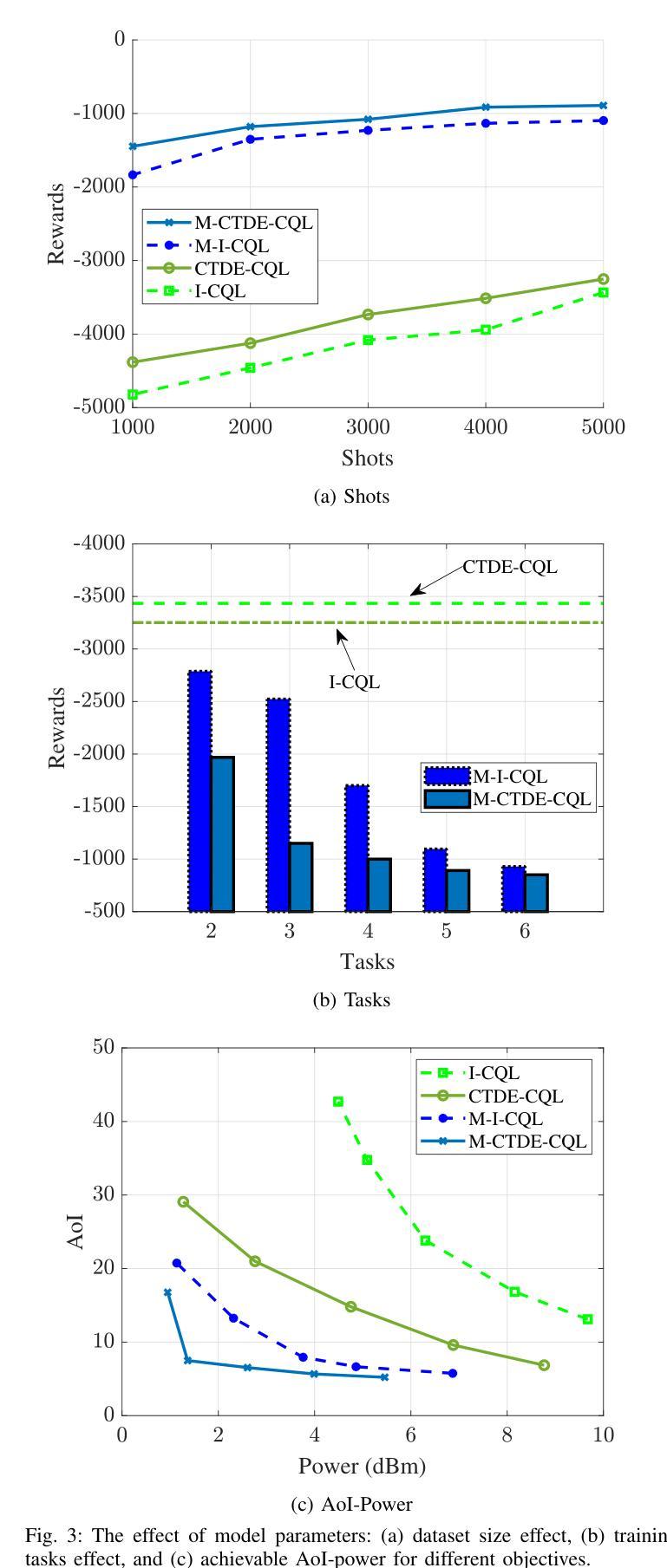
Multi-agent reinforcement learning (MARL) has been widely adopted in high-performance computing and complex data-driven decision-making in the wireless domain. However, conventional MARL schemes face many obstacles in real-world scenarios. First, most MARL algorithms are online, which might be unsafe and impractical. Second, MARL algorithms are environment-specific, meaning network configuration changes require model retraining. This letter proposes a novel meta-offline MARL algorithm that combines conservative Q-learning (CQL) and model agnostic meta-learning (MAML). CQL enables offline training by leveraging pre-collected datasets, while MAML ensures scalability and adaptability to dynamic network configurations and objectives. We propose two algorithm variants: independent training (M-I-MARL) and centralized training decentralized execution (M-CTDE-MARL). Simulation results show that the proposed algorithm outperforms conventional schemes, especially the CTDE approach that achieves 50 % faster convergence in dynamic scenarios than the benchmarks. The proposed framework enhances scalability, robustness, and adaptability in wireless communication systems by optimizing UAV trajectories and scheduling policies.
多智能体强化学习(MARL)已被广泛应用于无线通信领域的高性能计算和复杂数据驱动决策。然而,传统的MARL方案在实际场景中面临许多障碍。首先,大多数MARL算法是在线的,这可能会带来安全隐患且不太实用。其次,MARL算法具有环境特定性,意味着网络配置更改需要模型重新训练。本文提出了一种新型的元离线MARL算法,该算法结合了保守Q学习(CQL)和模型不可知元学习(MAML)。CQL通过利用预先收集的数据集进行离线训练,而MAML确保了对动态网络配置和目标的可扩展性和适应性。我们提出了两种算法变体:独立训练(M-I-MARL)和集中式训练分布式执行(M-CTDE-MARL)。仿真结果表明,所提出的算法优于传统方案,尤其是CTDE方法,在动态场景中实现了比基准测试快50%的收敛速度。通过优化无人机轨迹和调度策略,所提出的框架提高了无线通信系统的可扩展性、鲁棒性和适应性。
论文及项目相关链接
Summary
强化学习在多智能体系统(Multi-Agent Reinforcement Learning,简称MARL)中广泛用于高性能计算和无线领域的数据驱动决策。然而,传统的MARL方案在现实场景中面临诸多挑战。本文提出了一种结合保守Q学习(CQL)和模型不可知元学习(MAML)的元离线MARL算法。CQL利用预先收集的数据集进行离线训练,而MAML确保了对动态网络配置和目标的适应性和可扩展性。仿真结果表明,该算法优于传统方案,特别是CTDE方法在动态场景中的收敛速度提高了50%。该框架通过优化无人机轨迹和调度策略,提高了无线通信系统的可扩展性、鲁棒性和适应性。
Key Takeaways
- 多智能体强化学习(MARL)在无线领域的高性能计算和复杂数据驱动决策中有广泛应用。
- 传统MARL方案在现实场景中存在在线训练不安全、不实际的问题。
- 本文提出了一种元离线MARL算法,结合保守Q学习(CQL)和模型不可知元学习(MAML)。
- CQL允许离线训练,利用预先收集的数据集;MAML确保对动态网络配置和目标的适应性和可扩展性。
- 提出了两种算法变体:独立训练(M-I-MARL)和集中训练分散执行(M-CTDE-MARL)。
- 仿真结果显示,所提算法优于传统方案,特别是在动态场景中的收敛速度。
点此查看论文截图


Harnessing Diverse Perspectives: A Multi-Agent Framework for Enhanced Error Detection in Knowledge Graphs
Authors:Yu Li, Yi Huang, Guilin Qi, Junlan Feng, Nan Hu, Songlin Zhai, Haohan Xue, Yongrui Chen, Ruoyan Shen, Tongtong Wu
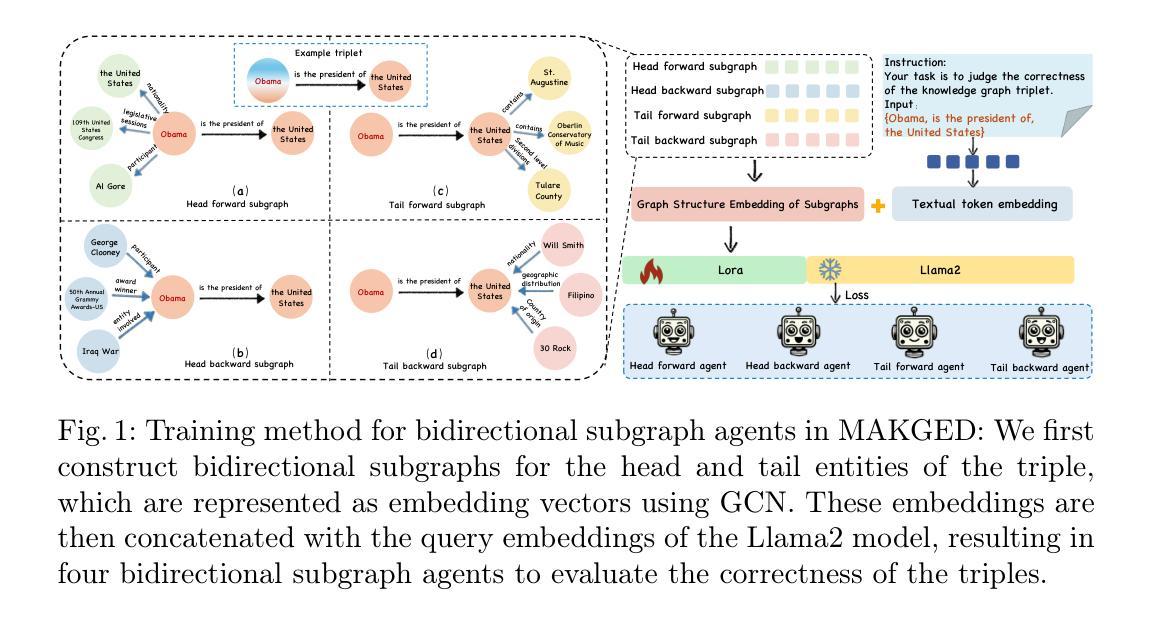
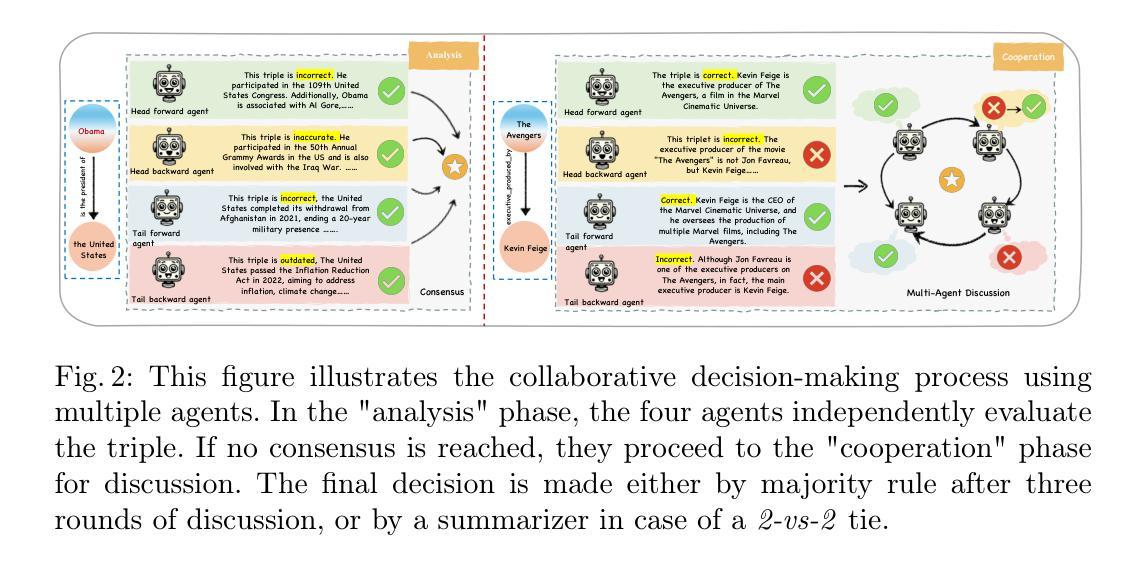
Knowledge graphs are widely used in industrial applications, making error detection crucial for ensuring the reliability of downstream applications. Existing error detection methods often fail to effectively leverage fine-grained subgraph information and rely solely on fixed graph structures, while also lacking transparency in their decision-making processes, which results in suboptimal detection performance. In this paper, we propose a novel Multi-Agent framework for Knowledge Graph Error Detection (MAKGED) that utilizes multiple large language models (LLMs) in a collaborative setting. By concatenating fine-grained, bidirectional subgraph embeddings with LLM-based query embeddings during training, our framework integrates these representations to produce four specialized agents. These agents utilize subgraph information from different dimensions to engage in multi-round discussions, thereby improving error detection accuracy and ensuring a transparent decision-making process. Extensive experiments on FB15K and WN18RR demonstrate that MAKGED outperforms state-of-the-art methods, enhancing the accuracy and robustness of KG evaluation. For specific industrial scenarios, our framework can facilitate the training of specialized agents using domain-specific knowledge graphs for error detection, which highlights the potential industrial application value of our framework. Our code and datasets are available at https://github.com/kse-ElEvEn/MAKGED.
知识图谱在工业应用中得到了广泛应用,因此错误检测对于确保下游应用的可靠性至关重要。现有的错误检测方法往往不能有效地利用细粒度子图信息,仅依赖于固定图结构,且决策过程缺乏透明度,导致检测性能不佳。在本文中,我们提出了一种用于知识图谱错误检测的多智能体框架(MAKGED),该框架在协作环境中利用多个大型语言模型(LLM)。通过训练过程中细粒度双向子图嵌入与基于LLM的查询嵌入的连接,我们的框架将这些表示集成在一起,产生四个专业智能体。这些智能体利用来自不同维度的子图信息进行多轮讨论,从而提高错误检测精度,并确保透明的决策过程。在FB15K和WN18RR上的大量实验表明,MAKGED优于最新方法,提高了知识图谱评估的准确性和稳健性。对于特定的工业场景,我们的框架可以利用领域特定的知识图谱训练专业智能体进行错误检测,这凸显了我们框架潜在的工业应用价值。我们的代码和数据集可在https://github.com/kse-ElEvEn/MAKGED获得。
论文及项目相关链接
Summary
知识图谱在工业应用中的错误检测至关重要。现有方法未能有效利用细粒度子图信息,且决策过程缺乏透明度。本文提出一种基于多智能体的知识图谱错误检测框架(MAKGED),结合细粒度子图嵌入与大型语言模型查询嵌入。通过训练生成四个专业智能体,利用不同维度的子图信息参与多轮讨论,提高错误检测准确性和决策透明度。实验表明,MAKGED优于现有方法,可提高知识图谱评估的准确性和稳健性,具有工业应用潜力。
Key Takeaways
- 知识图谱在工业应用中的错误检测很重要,影响下游应用的可靠性。
- 现有错误检测方法未能有效利用细粒度子图信息,决策过程缺乏透明度。
- 本文提出基于多智能体的知识图谱错误检测框架(MAKGED)。
- MAKGED结合细粒度子图嵌入和大型语言模型查询嵌入,生成四个专业智能体。
- 这些智能体利用不同维度的子图信息进行多轮讨论,提高错误检测准确性和决策透明度。
- 实验证明,MAKGED优于现有方法,提高知识图谱评估的准确性和稳健性。
点此查看论文截图

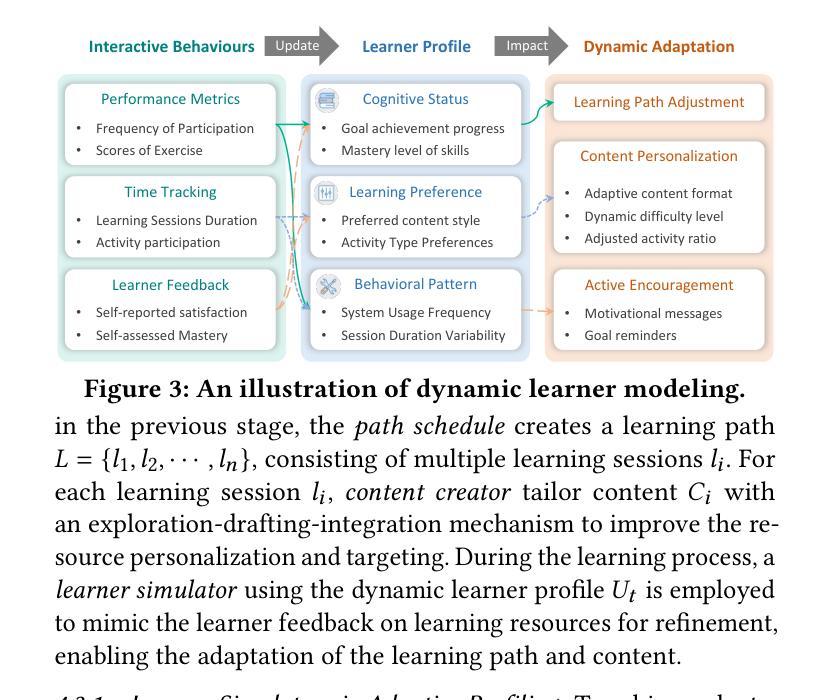
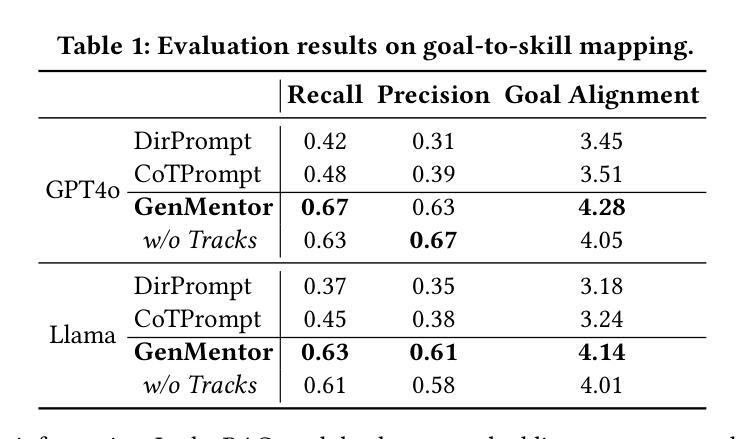
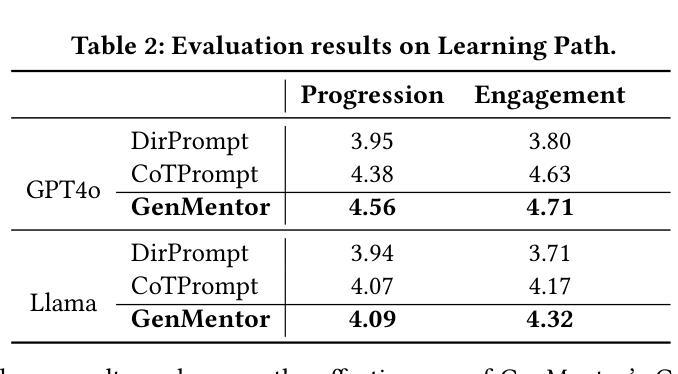
LLM-powered Multi-agent Framework for Goal-oriented Learning in Intelligent Tutoring System
Authors:Tianfu Wang, Yi Zhan, Jianxun Lian, Zhengyu Hu, Nicholas Jing Yuan, Qi Zhang, Xing Xie, Hui Xiong
Intelligent Tutoring Systems (ITSs) have revolutionized education by offering personalized learning experiences. However, as goal-oriented learning, which emphasizes efficiently achieving specific objectives, becomes increasingly important in professional contexts, existing ITSs often struggle to deliver this type of targeted learning experience. In this paper, we propose GenMentor, an LLM-powered multi-agent framework designed to deliver goal-oriented, personalized learning within ITS. GenMentor begins by accurately mapping learners’ goals to required skills using a fine-tuned LLM trained on a custom goal-to-skill dataset. After identifying the skill gap, it schedules an efficient learning path using an evolving optimization approach, driven by a comprehensive and dynamic profile of learners’ multifaceted status. Additionally, GenMentor tailors learning content with an exploration-drafting-integration mechanism to align with individual learner needs. Extensive automated and human evaluations demonstrate GenMentor’s effectiveness in learning guidance and content quality. Furthermore, we have deployed it in practice and also implemented it as an application. Practical human study with professional learners further highlights its effectiveness in goal alignment and resource targeting, leading to enhanced personalization. Supplementary resources are available at https://github.com/GeminiLight/gen-mentor.
智能辅导系统(ITS)通过提供个性化的学习体验,已经彻底改变了教育方式。然而,随着以达成特定目标为目的的学习在专业环境中变得越来越重要,现有ITS系统往往难以提供这种有针对性的学习体验。在本文中,我们提出了GenMentor,这是一个由大型语言模型驱动的多智能体框架,旨在在ITS内部提供以目标为导向的个性化学习。GenMentor首先通过精确地将学习者的目标映射到所需技能来使用经过微调的大型语言模型,该模型在特定的目标到技能数据集上进行训练。在确定了技能差距后,它使用不断发展的优化方法,结合学习者的多维度状态的全面动态档案,规划出高效的学习路径。此外,GenMentor通过探索-起草-整合机制来定制学习内容,以满足个别学习者的需求。广泛自动和人类评估证明了GenMentor在学习指导和内容质量方面的有效性。此外,我们已经将其部署在实践中,并开发为应用程序。与专业学习者进行的实际人类研究进一步突显了其在目标对齐和资源定位方面的有效性,从而增强了个性化。辅助资源可在https://github.com/GeminiLight/gen-mentor找到。
论文及项目相关链接
PDF Accepted by WWW 2025 (Industry Track)
Summary
智能辅导系统(ITS)已经通过提供个性化学习体验实现了教育的革新。然而,随着职业环境中以达成特定目标为目的的学习日益重要,现有ITS在提供此类有针对性的学习体验方面往往力不从心。本文提出了GenMentor系统,这是一个由大型语言模型驱动的多智能体框架,旨在在ITS中实现以目标为导向的个性化学习。GenMentor首先通过精确映射学习者目标与所需技能,利用经过微调的大型语言模型来确定技能差距。然后,它使用一种不断发展的优化方法,根据学习者的多维动态状态来规划高效的学习路径。此外,GenMentor还通过探索-起草-整合机制来定制学习内容,以满足个人需求。大量自动化和人类评估结果表明,GenMentor在学习指导和内容质量方面非常有效。此外,我们已经在实践中部署了它并将其开发为应用程序。与专业学习者的实际人类研究进一步突出了其在目标对齐和资源定位方面的有效性,从而实现了增强的个性化。
Key Takeaways
- 智能辅导系统(ITS)已经实现了教育的个性化革新,但在提供目标导向的学习体验方面存在挑战。
- GenMentor是一个多智能体框架,旨在通过大型语言模型(LLM)技术解决这一问题。
- GenMentor能准确映射学习者目标与所需技能,并确定技能差距。
- 该系统使用优化方法为学习者规划高效学习路径,并考虑学习者的多维动态状态。
- GenMentor通过探索-起草-整合机制定制学习内容,以满足个人需求。
- 自动化和人类评估证明了GenMentor在学习指导和内容质量方面的有效性。
- GenMentor已在实践中部署,并作为应用程序实现,与专业学习者的研究突出了其在目标对齐和资源定位方面的优势,增强了个性化学习。
点此查看论文截图

Expert-Free Online Transfer Learning in Multi-Agent Reinforcement Learning
Authors:Alberto Castagna
Reinforcement Learning (RL) enables an intelligent agent to optimise its performance in a task by continuously taking action from an observed state and receiving a feedback from the environment in form of rewards. RL typically uses tables or linear approximators to map state-action tuples that maximises the reward. Combining RL with deep neural networks (DRL) significantly increases its scalability and enables it to address more complex problems than before. However, DRL also inherits downsides from both RL and deep learning. Despite DRL improves generalisation across similar state-action pairs when compared to simpler RL policy representations like tabular methods, it still requires the agent to adequately explore the state-action space. Additionally, deep methods require more training data, with the volume of data escalating with the complexity and size of the neural network. As a result, deep RL requires a long time to collect enough agent-environment samples and to successfully learn the underlying policy. Furthermore, often even a slight alteration to the task invalidates any previous acquired knowledge. To address these shortcomings, Transfer Learning (TL) has been introduced, which enables the use of external knowledge from other tasks or agents to enhance a learning process. The goal of TL is to reduce the learning complexity for an agent dealing with an unfamiliar task by simplifying the exploration process. This is achieved by lowering the amount of new information required by its learning model, resulting in a reduced overall convergence time…
强化学习(RL)允许智能代理通过不断从观察到的状态采取行动并从环境中获得奖励的反馈来优化其在任务中的表现。RL通常使用表格或线性逼近器来映射最大化奖励的状态-行动组合。将RL与深度神经网络(DRL)相结合,显著提高了其可扩展性,并使其能够解决比以前更复杂的问题。然而,DRL也继承了RL和深度学习两者的缺点。与像表格方法这样更简单的RL政策表示相比,DRL在类似的州行动对上提高了泛化能力,但它仍然要求代理充分探索州行动空间。此外,深度方法需要更多的训练数据,随着神经网络复杂性和规模的增加,所需数据量也在上升。因此,深度RL需要很长时间来收集足够的代理环境样本并成功学习基础策略。此外,任务的微小变化往往会使得之前获得的知识无效。为了解决这些不足,引入了迁移学习(TL),它允许使用来自其他任务或代理的外部知识来增强学习过程。TL的目标是通过简化探索过程,降低代理处理不熟悉任务的学习复杂性。这是通过减少其学习模型所需的新信息量来实现的,从而缩短了整体的收敛时间…
论文及项目相关链接
PDF PhD Thesis
Summary
强化学习(RL)通过让智能代理从观察到的状态采取行动并从环境中获得奖励反馈来优化任务性能。RL通常使用表格或线性逼近器来映射状态-动作组合,以最大化奖励。结合深度神经网络(DRL)显著提高了其可扩展性,并能够解决比传统RL更复杂的问题。然而,DRL也继承了RL和深度学习的一些缺点。尽管DRL在与其他简单的RL策略表示(如表格方法)相比时,在类似状态-动作对上具有更好的概括性,但它仍然要求代理充分探索状态-动作空间。此外,深度方法需要更多的训练数据,数据量随着神经网络复杂性和规模的增加而增加。因此,深度强化学习需要大量的时间收集足够的代理环境样本并成功学习基础策略。为解决这些问题,引入了迁移学习(TL),可以利用其他任务或代理的外部知识来提高学习过程。迁移学习的目标是降低代理处理不熟悉任务的复杂性,简化探索过程。通过减少学习模型所需的新信息量来实现这一目标,从而减少整体收敛时间。
Key Takeaways
- 强化学习(RL)允许智能代理通过不断尝试动作和接收环境反馈奖励来优化任务性能。
- 结合深度神经网络(DRL)增强了强化学习的可扩展性,并解决了更复杂的任务。
- DRL面临探索状态-动作空间的挑战,需要代理充分探索。
- 深度方法需要大量的训练数据,随着神经网络复杂性和规模的增加,数据量也在增加。
- 深度强化学习需要长时间收集足够的代理环境样本并成功学习基础策略。
- 迁移学习(TL)利用其他任务或代理的外部知识来提高学习过程。
点此查看论文截图

Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement Learning
Authors:Yiqun Chen, Lingyong Yan, Weiwei Sun, Xinyu Ma, Yi Zhang, Shuaiqiang Wang, Dawei Yin, Yiming Yang, Jiaxin Mao
Retrieval-augmented generation (RAG) is extensively utilized to incorporate external, current knowledge into large language models, thereby minimizing hallucinations. A standard RAG pipeline may comprise several components, such as query rewriting, document retrieval, document filtering, and answer generation. However, these components are typically optimized separately through supervised fine-tuning, which can lead to misalignments between the objectives of individual modules and the overarching aim of generating accurate answers in question-answering (QA) tasks. Although recent efforts have explored reinforcement learning (RL) to optimize specific RAG components, these approaches often focus on overly simplistic pipelines with only two components or do not adequately address the complex interdependencies and collaborative interactions among the modules. To overcome these challenges, we propose treating the RAG pipeline as a multi-agent cooperative task, with each component regarded as an RL agent. Specifically, we present MMOA-RAG, a Multi-Module joint Optimization Algorithm for RAG, which employs multi-agent reinforcement learning to harmonize all agents’ goals towards a unified reward, such as the F1 score of the final answer. Experiments conducted on various QA datasets demonstrate that MMOA-RAG improves the overall pipeline performance and outperforms existing baselines. Furthermore, comprehensive ablation studies validate the contributions of individual components and the adaptability of MMOA-RAG across different RAG components and datasets. The code of MMOA-RAG is on https://github.com/chenyiqun/MMOA-RAG.
检索增强生成(RAG)被广泛应用于将外部、当前的知识融入大型语言模型,从而最小化幻觉。标准的RAG流程可能包含多个组件,如查询重写、文档检索、文档过滤和答案生成。然而,这些组件通常通过有监督的微调进行单独优化,这可能导致各个模块的目标与问答(QA)任务中生成准确答案的总体目标之间存在不匹配。尽管最近的努力已经探索了使用强化学习(RL)来优化特定的RAG组件,但这些方法通常专注于过于简单的管道,只有两个组件,或者没有充分解决模块之间的复杂依赖关系和协作交互。为了克服这些挑战,我们提出将RAG流程视为多代理合作任务,并将每个组件视为RL代理。具体来说,我们提出了MMOA-RAG(用于RAG的多模块联合优化算法),它采用多代理强化学习来协调所有代理的目标,以达成统一的奖励,如最终答案的F1分数。在不同问答数据集上进行的实验表明,MMOA-RAG提高了整体流程的性能,并优于现有基线。此外,全面的消融研究验证了各个组件的贡献以及MMOA-RAG在不同RAG组件和数据集上的适应性。MMOA-RAG的代码位于https://github.com/chenyiqun/MMOA-RAG。
论文及项目相关链接
Summary
该文本介绍了使用多模块协同优化的方法来优化基于检索的辅助生成模型(RAG)性能的相关研究。针对当前独立优化各模块可能导致的目标不一致问题,该研究提出将RAG的各个组件视为多智能体进行协同任务。具体来说,使用多智能体强化学习协调各个组件的目标以统一奖励为优化方向,并在多种问答数据集上验证所提出的方法能够提升整体性能。有关该研究的代码已经上传至GitHub仓库。
Key Takeaways
- RAG模型广泛应用于大型语言模型中以融入外部实时知识,减少幻觉现象。
- RAG模型包含多个组件如查询重写、文档检索等,但通常这些组件是通过监督微调单独优化的。
- 这种单独优化可能导致各组件目标与整体目标生成准确答案之间的不一致性。针对该问题,提出了一种多模块协同优化的新方法MMOA-RAG。
- MMOA-RAG将RAG的各个组件视为多智能体进行协同任务,并采用多智能体强化学习来协调各组件的目标。
- 实验表明,MMOA-RAG能提高整体性能并优于现有基准测试。此外,全面的消融研究验证了各组件的贡献以及MMOA-RAG在不同数据集上的适应性。
- 该研究的代码已上传至GitHub仓库以供公众访问和使用。这对于研究者和开发者来说是一个很好的资源。
点此查看论文截图

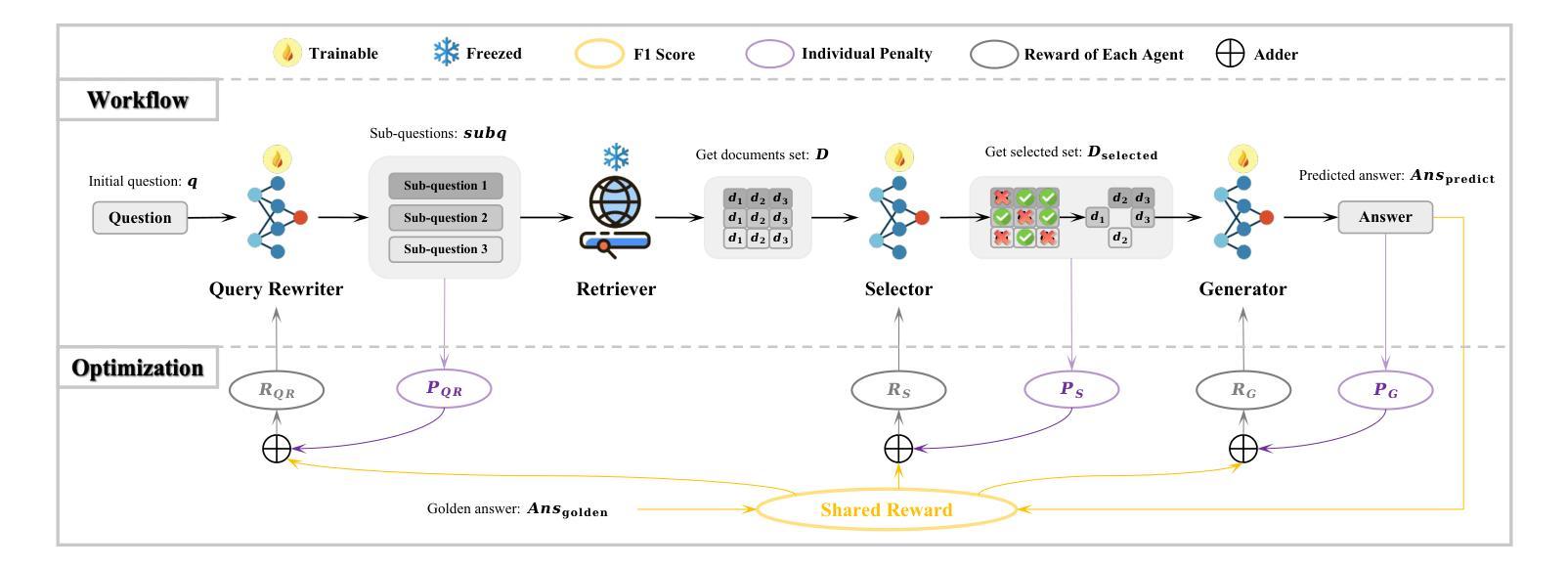
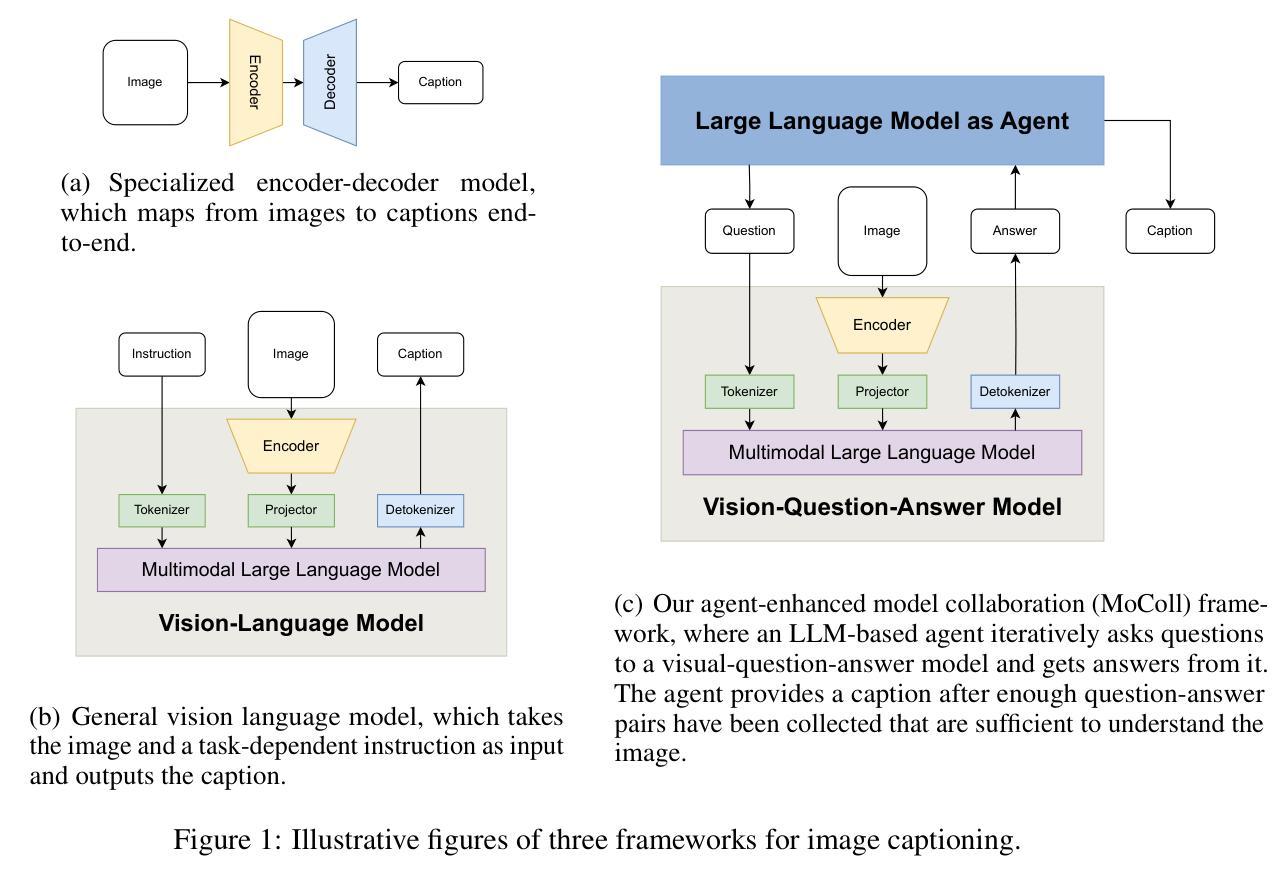
MoColl: Agent-Based Specific and General Model Collaboration for Image Captioning
Authors:Pu Yang, Bin Dong
Image captioning is a critical task at the intersection of computer vision and natural language processing, with wide-ranging applications across various domains. For complex tasks such as diagnostic report generation, deep learning models require not only domain-specific image-caption datasets but also the incorporation of relevant general knowledge to provide contextual accuracy. Existing approaches exhibit inherent limitations: specialized models excel in capturing domain-specific details but lack generalization, while vision-language models (VLMs) built on large language models (LLMs) leverage general knowledge but struggle with domain-specific adaptation. To address these limitations, this paper proposes a novel agent-enhanced model collaboration framework, which we call MoColl, designed to effectively integrate domain-specific and general knowledge. Specifically, our approach is to decompose complex image captioning tasks into a series of interconnected question-answer subtasks. A trainable visual question answering (VQA) model is employed as a specialized tool to focus on domain-specific visual analysis, answering task-specific questions based on image content. Concurrently, an LLM-based agent with general knowledge formulates these questions and synthesizes the resulting question-answer pairs into coherent captions. Beyond its role in leveraging the VQA model, the agent further guides its training to enhance its domain-specific capabilities. Experimental results on radiology report generation validate the effectiveness of the proposed framework, demonstrating significant improvements in the quality of generated reports.
图像描述是计算机视觉和自然语言处理领域的交叉任务,具有广泛的应用范围。对于生成诊断报告等复杂任务,深度学习模型不仅需要特定领域的图像描述数据集,还需要融入相关的通用知识以提供上下文准确性。现有方法存在固有局限性:专业模型擅长捕捉特定领域的细节,但缺乏泛化能力;而基于大型语言模型的视觉语言模型(VLMs)利用通用知识,但在特定领域的适应性方面却遇到困难。为了克服这些局限性,本文提出了一种新型代理增强模型协作框架,我们称之为MoColl,旨在有效地整合特定领域知识和通用知识。具体来说,我们的方法是将复杂的图像描述任务分解为一系列相互关联的问答子任务。我们采用可训练的视觉问答(VQA)模型作为专业工具,专注于特定领域的视觉分析,根据图像内容回答特定任务的问题。同时,具有通用知识的基于LLM的代理负责制定这些问题,并将得到的问题答案对综合成连贯的描述。除了发挥对VQA模型的利用作用外,代理还进一步指导其训练,以增强其在特定领域的专业能力。在放射学报告生成方面的实验验证了所提出框架的有效性,显示出生成的报告质量显著提高。
论文及项目相关链接
Summary
图像描述是计算机视觉和自然语言处理领域的核心任务之一,广泛应用于各种领域。针对诊断报告生成等复杂任务,深度学习模型不仅需要特定的图像描述数据集,还需要融入相关的通用知识以提供上下文准确性。现有方法存在局限性:专业模型擅长捕捉特定领域的细节,但缺乏泛化能力;而基于大型语言模型的视觉语言模型(VLMs)虽然可以利用通用知识,但在特定领域的适应性上却遇到困难。为解决这些问题,本文提出了一种新型代理增强模型协作框架MoColl,旨在有效整合特定领域知识和通用知识。该方法通过将复杂的图像描述任务分解为一系列相互关联的问题回答子任务来达成目标。使用可训练的视觉问答(VQA)模型作为专业工具,专注于特定领域的视觉分析,根据图像内容回答任务特定问题。同时,具有通用知识的LLM代理制定这些问题并将问题答案对合成为连贯的描述。除了利用VQA模型外,代理还进一步指导其训练以增强其特定领域的能力。在放射学报告生成方面的实验验证了该框架的有效性,显示出生成的报告质量显著提高。
Key Takeaways
- 图像描述是计算机视觉和自然语言处理领域的核心任务,涉及多种应用领域。
- 现有方法在处理复杂任务时存在局限性,专业模型缺乏泛化能力,而视觉语言模型在特定领域适应性上困难。
- MoColl框架结合了特定领域知识和通用知识来解决这个问题。
- 通过将图像描述任务分解为问题回答子任务来提高模型性能。
- VQA模型用于捕捉特定领域的视觉细节,而LLM代理负责利用通用知识合成连贯的描述。
- 代理不仅利用VQA模型,还指导其训练以增强特定领域的能力。
点此查看论文截图

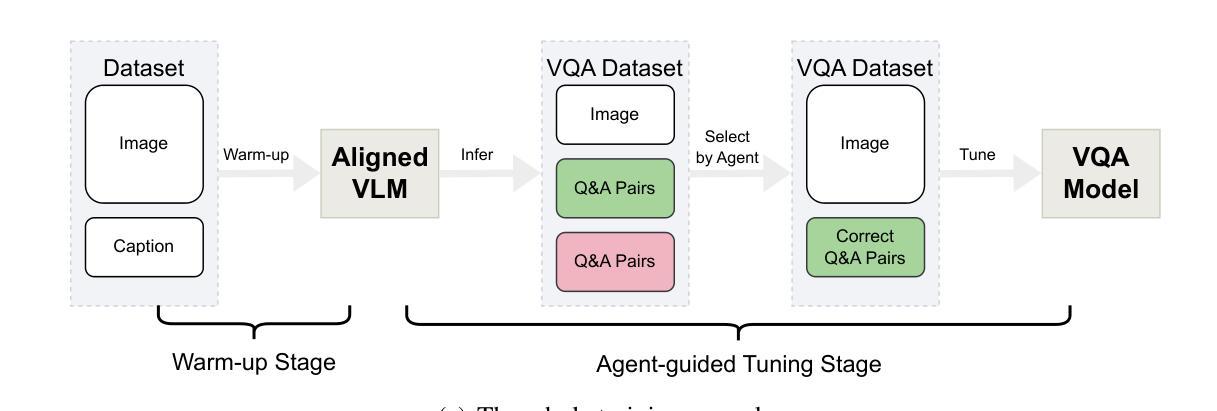
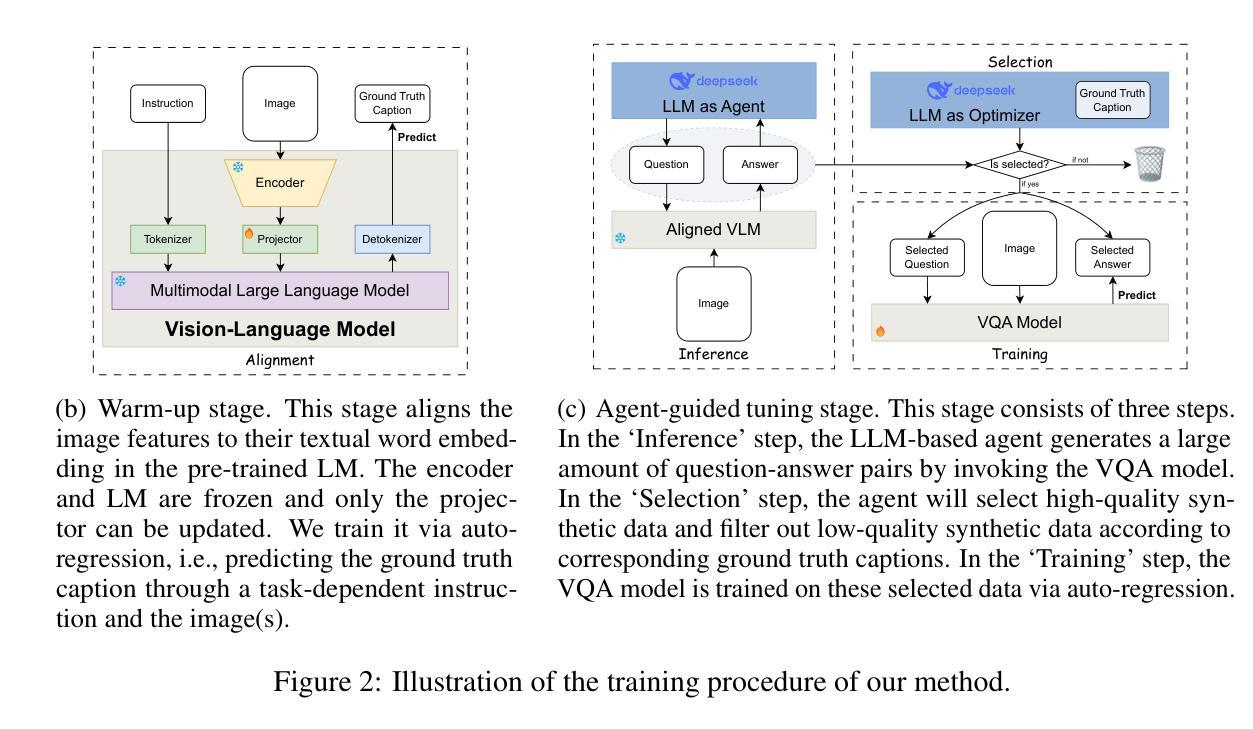
WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning
Authors:Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Wenyi Zhao, Yu Yang, Xinyue Yang, Jiadai Sun, Shuntian Yao, Tianjie Zhang, Wei Xu, Jie Tang, Yuxiao Dong
Large language models (LLMs) have shown remarkable potential as autonomous agents, particularly in web-based tasks. However, existing LLM web agents heavily rely on expensive proprietary LLM APIs, while open LLMs lack the necessary decision-making capabilities. This paper introduces WebRL, a self-evolving online curriculum reinforcement learning framework designed to train high-performance web agents using open LLMs. WebRL addresses three key challenges in building LLM web agents, including the scarcity of training tasks, sparse feedback signals, and policy distribution drift in online learning. Specifically, WebRL incorporates 1) a self-evolving curriculum that generates new tasks from unsuccessful attempts, 2) a robust outcome-supervised reward model (ORM), and 3) adaptive reinforcement learning strategies to ensure consistent improvements. We apply WebRL to transform open Llama-3.1 and GLM-4 models into proficient web agents. On WebArena-Lite, WebRL improves the success rate of Llama-3.1-8B from 4.8% to 42.4%, and from 6.1% to 43% for GLM-4-9B. These open models significantly surpass the performance of GPT-4-Turbo (17.6%) and GPT-4o (13.9%) and outperform previous state-of-the-art web agents trained on open LLMs (AutoWebGLM, 18.2%). Our findings demonstrate WebRL’s effectiveness in bridging the gap between open and proprietary LLM-based web agents, paving the way for more accessible and powerful autonomous web interaction systems.
大型语言模型(LLM)作为自主代理人在网页任务中表现出了显著潜力。然而,现有的LLM网络代理人严重依赖于昂贵的专有LLM API,而开源LLM缺乏必要的决策能力。本文介绍了WebRL,这是一种自我进化的在线课程强化学习框架,旨在利用开源LLM训练高性能的网络代理人。WebRL解决了构建LLM网络代理人的三个关键挑战,包括训练任务的稀缺性、反馈信号的稀疏性以及在线学习中的策略分布漂移。具体来说,WebRL结合了1)一种自我进化的课程,可以从失败的尝试中生成新任务,2)一种稳健的结果监督奖励模型(ORM),以及3)自适应强化学习策略,以确保持续改进。我们将WebRL应用于将开源的Llama-3.1和GLM-4模型转化为熟练的网络代理人。在WebArena-Lite上,WebRL将Llama-3.1-8B的成功率从4.8%提高到42.4%,并将GLM-4-9B的成功率从6.1%提高到43%。这些开源模型的性能显著超过了GPT-4 Turbo(17.6%)和GPT-4o(13.9%)的表现,并且优于之前在开源LLM上训练的最佳网络代理人(AutoWebGLM,18.2%)。我们的研究结果表明,WebRL在弥合开源和专有LLM基于的网页代理人之间的差距方面非常有效,为更易于访问和更强大的自主网页交互系统铺平了道路。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025
Summary
LLMs作为自主代理人在网页任务中展现出巨大潜力,但依赖昂贵的专有LLM API且开放式LLMs缺乏决策能力。本文提出WebRL框架,一个自我进化的在线课程强化学习框架,旨在利用开放式LLMs训练高性能网页代理人。WebRL解决了构建LLM网页代理人的三个关键挑战,包括训练任务的稀缺性、反馈信号的稀疏性以及在线学习中的策略分布漂移。实验证明,WebRL能成功将开源的Llama-3.1和GLM-4模型转化为熟练的网页代理人,显著提高成功率。
Key Takeaways
- LLMs在web任务中表现出强大的自主性。
- 现有LLM web代理人严重依赖昂贵的专有API。
- 开放式LLMs缺乏必要的决策能力。
- WebRL是一个自我进化的在线课程强化学习框架,旨在解决LLM网页代理人的挑战。
- WebRL解决了训练任务稀缺、反馈信号稀疏和在线学习中的策略分布漂移问题。
- WebRL能成功将开源LLMs转化为高效的网页代理人。
点此查看论文截图

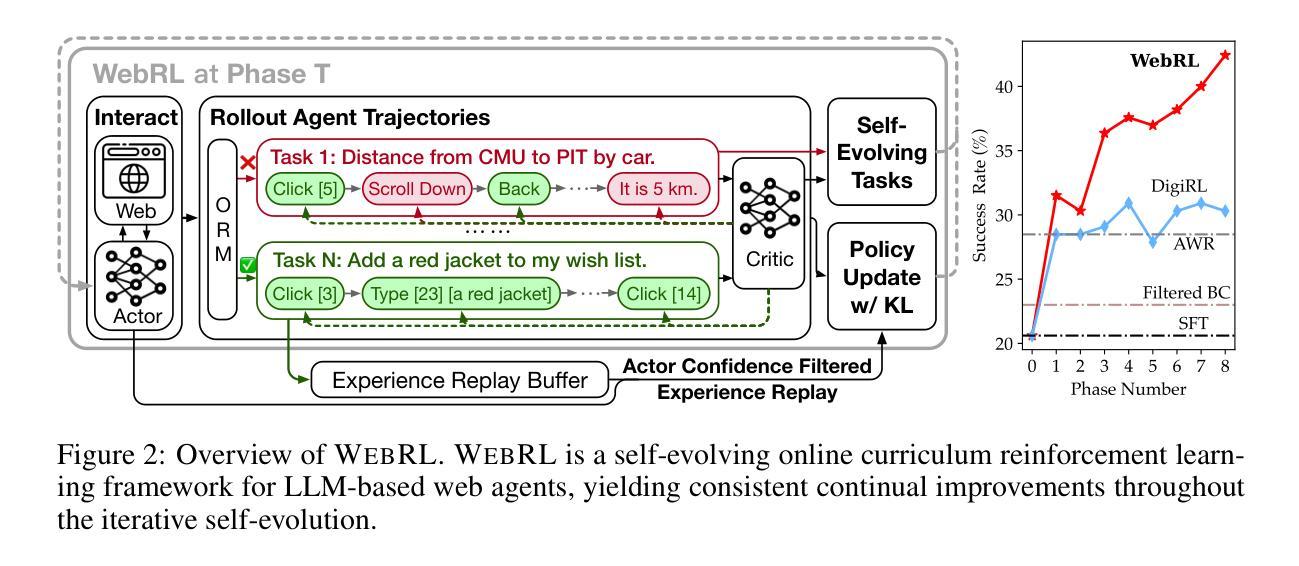
Knowledge Graph Enhanced Language Agents for Recommendation
Authors:Taicheng Guo, Chaochun Liu, Hai Wang, Varun Mannam, Fang Wang, Xin Chen, Xiangliang Zhang, Chandan K. Reddy
Language agents have recently been used to simulate human behavior and user-item interactions for recommendation systems. However, current language agent simulations do not understand the relationships between users and items, leading to inaccurate user profiles and ineffective recommendations. In this work, we explore the utility of Knowledge Graphs (KGs), which contain extensive and reliable relationships between users and items, for recommendation. Our key insight is that the paths in a KG can capture complex relationships between users and items, eliciting the underlying reasons for user preferences and enriching user profiles. Leveraging this insight, we propose Knowledge Graph Enhanced Language Agents(KGLA), a framework that unifies language agents and KG for recommendation systems. In the simulated recommendation scenario, we position the user and item within the KG and integrate KG paths as natural language descriptions into the simulation. This allows language agents to interact with each other and discover sufficient rationale behind their interactions, making the simulation more accurate and aligned with real-world cases, thus improving recommendation performance. Our experimental results show that KGLA significantly improves recommendation performance (with a 33%-95% boost in NDCG@1 among three widely used benchmarks) compared to the previous best baseline method.
语言代理最近被用来模拟人类行为和用户项目交互,为推荐系统提供推荐。然而,当前的语言代理模拟无法理解用户和项目之间的关系,导致用户配置文件不准确和推荐效果不佳。在这项工作中,我们探讨了知识图谱(KG)在推荐中的实用性。知识图谱包含了用户和项目之间广泛而可靠的关系。我们的关键见解是,知识图谱中的路径可以捕捉用户和项目之间的复杂关系,激发用户偏好的根本原因并丰富用户配置文件。利用这一见解,我们提出了知识图谱增强语言代理(KGLA),这是一个统一语言代理和知识图谱的推荐系统框架。在模拟推荐场景中,我们将用户和项目定位在知识图谱内,并将知识图谱路径整合为自然语言描述融入模拟中。这允许语言代理相互交互并发现其交互背后的充足理由,使模拟更加准确并与真实情况相符,从而提高推荐性能。我们的实验结果表明,与之前的最佳基线方法相比,KGLA显著提高了推荐性能(在三个广泛使用的基准测试中,NDCG@1提升了33%-95%)。
论文及项目相关链接
Summary
知识图谱增强语言代理(KGLA)利用知识图谱(KG)中的用户与物品之间的关系,提高了推荐系统的准确性。通过模拟用户与物品在知识图谱中的位置,将知识图谱路径作为自然语言描述融入模拟中,使语言代理交互更具理性,提高了推荐性能。
Key Takeaways
- 语言代理被用于模拟推荐系统中的用户行为和用户-物品互动,但现有模拟无法理解用户与物品之间的关系。
- 知识图谱(KG)包含用户与物品之间广泛可靠的关系,对于推荐系统具有实用性。
- 知识图谱中的路径可以捕捉用户与物品之间的复杂关系,揭示用户偏好的根本原因并丰富用户资料。
- 提出的KGLA框架结合了语言代理和知识图谱,提高了推荐系统的模拟准确性,使其更贴近真实世界案例。
- KGLA通过融入知识图谱路径的自然语言描述,使语言代理交互更具理性。
- 实验结果表明,KGLA在三个广泛使用的基准测试上,相较于之前最佳基线方法,推荐性能提升了33%-95%的NDCG@1。
点此查看论文截图



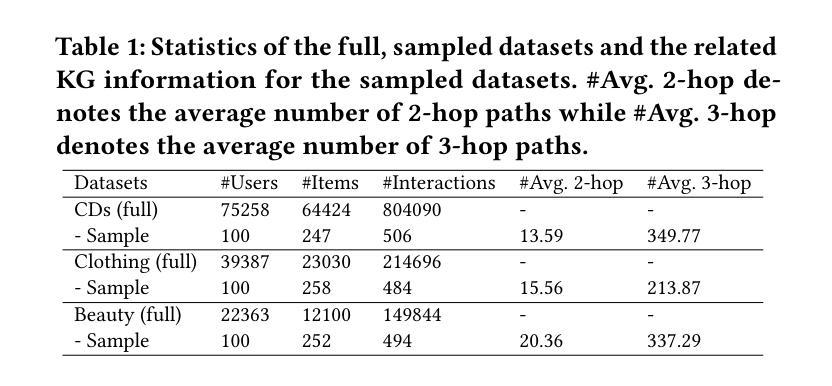
Agent Skill Acquisition for Large Language Models via CycleQD
Authors:So Kuroki, Taishi Nakamura, Takuya Akiba, Yujin Tang
Training large language models to acquire specific skills remains a challenging endeavor. Conventional training approaches often struggle with data distribution imbalances and inadequacies in objective functions that do not align well with task-specific performance. To address these challenges, we introduce CycleQD, a novel approach that leverages the Quality Diversity framework through a cyclic adaptation of the algorithm, along with a model merging based crossover and an SVD-based mutation. In CycleQD, each task’s performance metric is alternated as the quality measure while the others serve as the behavioral characteristics. This cyclic focus on individual tasks allows for concentrated effort on one task at a time, eliminating the need for data ratio tuning and simplifying the design of the objective function. Empirical results from AgentBench indicate that applying CycleQD to LLAMA3-8B-INSTRUCT based models not only enables them to surpass traditional fine-tuning methods in coding, operating systems, and database tasks, but also achieves performance on par with GPT-3.5-TURBO, which potentially contains much more parameters, across these domains. Crucially, this enhanced performance is achieved while retaining robust language capabilities, as evidenced by its performance on widely adopted language benchmark tasks. We highlight the key design choices in CycleQD, detailing how these contribute to its effectiveness. Furthermore, our method is general and can be applied to image segmentation models, highlighting its applicability across different domains.
训练大型语言模型以获取特定技能仍然是一项具有挑战性的工作。传统的训练方法常常面临数据分布不平衡和客观功能不足的问题,这些问题与特定任务的性能不太吻合。为了解决这些挑战,我们引入了CycleQD这一新方法,它利用质量多样性框架,通过算法的循环适应、基于模型合并的交叉和基于SVD的突变来实现。在CycleQD中,每个任务的性能指标轮流作为质量度量,而其他指标则作为行为特征。这种对单个任务的循环关注允许每次集中精力于一个任务,从而消除了对数据比率调整的需求,并简化了目标函数的设计。来自AgentBench的经验结果表明,将CycleQD应用于LLAMA3-8B-INSTRUCT基础模型,不仅能使它们在编码、操作系统和数据库任务上超越传统的微调方法,而且在这些领域实现了与GPT-3.5-TURBO相当的性能,尽管GPT-3.5-TURBO可能包含更多的参数。关键的是,这种增强的性能是在保留稳健的语言能力的情况下实现的,这从其流行的语言基准任务中的表现就可以得到证明。我们强调了CycleQD中的关键设计选择,详细说明了这些是如何促进其有效性的。此外,我们的方法是通用的,可应用于图像分割模型,突显其在不同领域的应用性。
论文及项目相关链接
PDF To appear at the 13th International Conference on Learning Representations (ICLR 2025)
Summary
大型语言模型的特定技能获取训练仍然是一项挑战。传统训练方法常常面临数据分布不平衡和客观函数与任务特定性能不匹配的问题。为解决这些问题,我们提出了CycleQD方法,该方法利用质量多样性框架,通过算法的循环适应、基于模型合并的交叉和基于SVD的突变来实现。CycleQD中,每个任务的性能指标轮流作为质量度量,而其他指标则作为行为特征。这种对单个任务的循环关注允许每次集中精力于一个任务,从而消除了对数据比率调整的需求,并简化了目标函数的设计。实验结果表明,将CycleQD应用于LLAMA3-8B-INSTRUCT基础模型,不仅在编码、操作系统和数据库任务上超越了传统微调方法,而且在这些领域实现了与GPT-3.5-TURBO相当的性能,尽管GPT-3.5-TURBO可能包含更多的参数。关键的是,这种增强性能的同时保持了强大的语言功能,这由其在广泛采用的语言基准任务上的表现所证明。我们还强调了CycleQD中的关键设计选择,详细说明了这些选择如何促进其有效性。此外,我们的方法是通用的,可应用于图像分割模型,凸显其在不同领域的应用性。
Key Takeaways
- 大型语言模型的特定技能获取训练存在挑战,传统方法面临数据分布和客观函数的问题。
- CycleQD方法利用质量多样性框架,通过循环适应算法、模型合并交叉和SVD突变来解决这些问题。
- CycleQD关注单个任务的循环,简化目标函数设计,并消除数据比率调整的需求。
- 在编码、操作系统和数据库任务上,CycleQD超越了传统方法,性能与GPT-3.5-TURBO相当。
- CycleQD在广泛的语言基准任务上表现优秀,证明了其保持强大语言功能的能力。
- CycleQD的关键设计选择对于其有效性至关重要,包括质量度量和行为特征的设定。
点此查看论文截图


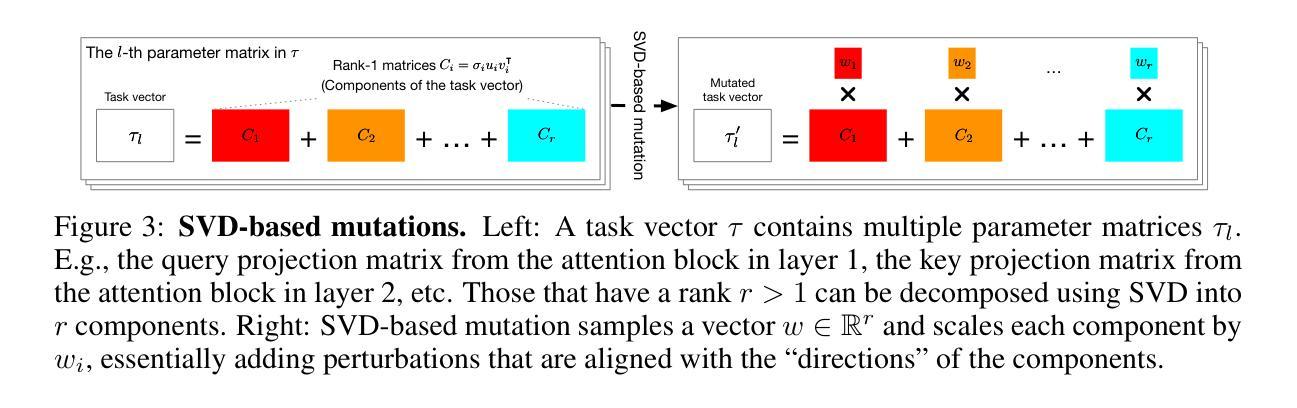
Explaining Decisions of Agents in Mixed-Motive Games
Authors:Maayan Orner, Oleg Maksimov, Akiva Kleinerman, Charles Ortiz, Sarit Kraus
In recent years, agents have become capable of communicating seamlessly via natural language and navigating in environments that involve cooperation and competition, a fact that can introduce social dilemmas. Due to the interleaving of cooperation and competition, understanding agents’ decision-making in such environments is challenging, and humans can benefit from obtaining explanations. However, such environments and scenarios have rarely been explored in the context of explainable AI. While some explanation methods for cooperative environments can be applied in mixed-motive setups, they do not address inter-agent competition, cheap-talk, or implicit communication by actions. In this work, we design explanation methods to address these issues. Then, we proceed to establish generality and demonstrate the applicability of the methods to three games with vastly different properties. Lastly, we demonstrate the effectiveness and usefulness of the methods for humans in two mixed-motive games. The first is a challenging 7-player game called no-press Diplomacy. The second is a 3-player game inspired by the prisoner’s dilemma, featuring communication in natural language.
近年来,代理(agents)已经能够无缝地通过自然语言进行交流,并在涉及合作与竞争的环境中导航,这一事实可能引发社会困境。由于合作与竞争的交织,理解代理在这种环境中的决策制定具有挑战性,人类从获得解释中受益。然而,这种环境和场景在可解释人工智能的上下文中很少被探索。虽然一些合作环境的解释方法可以应用于混合动机设置,但它们并不解决代理间的竞争、廉价对话或通过行动进行的隐性沟通。在这项工作中,我们设计了解释方法来解决这些问题。然后,我们继续建立普遍性,并证明这些方法在三种具有截然不同属性的游戏中的应用。最后,我们在两个混合动机的游戏中证明了这些方法对人类的有效性和实用性。第一个是一款名为“不施加压力的外交”的7人游戏,充满挑战。第二个是受囚徒困境启发的3人游戏,以自然语言沟通为特征。
论文及项目相关链接
PDF To be published in AAAI 2025
Summary
本文探讨了智能代理在包含合作与竞争元素的环境中面临的社交难题,如决策制定、解释方法和应用场景等。针对混合动机下的解释难题,设计了专门的解释方法并进行了验证。同时介绍了该工作在多种不同性质游戏中的实际应用效果,证明了方法的通用性和有效性。人类在该研究中被用作参与主体评估性能的关键成员,在不同的合作竞争场景下对该方法进行实际应用评估,比如一种无压力外交的游戏和一个由自然语言驱动的囚犯困境启发的游戏等场景。同时提出了一种策略交互模式。这一总结体现了研究工作的深度与广度,并且以简洁明了的方式概括了核心要点。希望这个总结能够帮助读者快速理解本文的主要内容和创新点。总的来说,本文研究具有重要的理论意义和实践价值。相信这项研究将在人工智能领域中引发广泛的关注和应用探索。例如可以通过扩大对博弈中的自然语言的建模规模和对大规模社交网络环境的支持能力,以改善未来的应用体验和提高社交机器人的能力水平等角度入手来进一步深化本项研究。
Key Takeaways
- 智能代理需要应对合作与竞争并存的环境,引入社交难题,对人类和代理决策造成挑战。这一背景引发了解释方法的需求以协助人类理解智能代理的行为模式以及进行最优决策。
- 当前研究中解释方法的应用范围有限,特别是在混合动机环境下的解释方法尚待完善,存在对廉价对话和隐性沟通的挑战。本研究设计了解释方法来应对这些问题。
点此查看论文截图

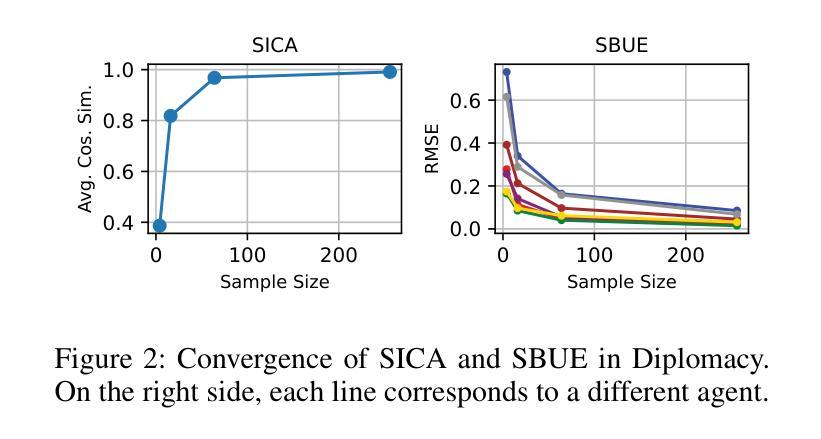
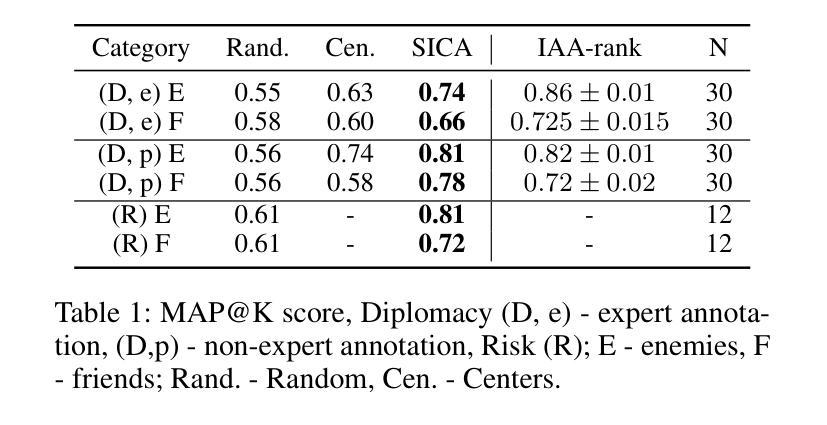

Grounded Language Agent for Product Search via Intelligent Web Interactions
Authors:Moghis Fereidouni, Adib Mosharrof, A. B. Siddique
The development of agents powered by large language models (LLMs) to accomplish complex high-level user intents, has attracted significant attention recently. However, employing LLMs with billions of parameters (e.g., GPT-4) may incur substantial costs on top of handcrafting extensive prompts. To address this, we introduce a Grounded Language Agent for Intelligent Web Interactions, named GLAINTEL. GLAINTEL employs Flan-T5 as its backbone and is flexible in training in various settings: unsupervised learning, supervised learning, and unsupervised domain adaptation. Specifically, we tackle both the challenge of learning without human demonstrations and the opportunity to leverage human demonstrations effectively when those are available. Additionally, we explore unsupervised domain adaptation for cases where demonstrations are limited to a specific domain. Experimental evaluations across diverse setups demonstrate the effectiveness of GLAINTEL in unsupervised settings, outperforming in-context learning-based approaches that employ larger models with up to 540 billion parameters. Surprisingly, behavioral cloning-based methods that straightforwardly use human demonstrations do not outperform unsupervised variants of GLAINTEL. Additionally, we show that combining human demonstrations with reinforcement learning-based training yields results comparable to methods utilizing GPT-4. The code is available at: https://github.com/MultifacetedNLP/WebAgents-Unsupervised.
基于大型语言模型(LLM)的代理发展,以完成复杂的高级用户意图,最近引起了广泛关注。然而,使用具有数十亿参数的大型语言模型(例如GPT-4)除了需要大量手工制作的提示外,还可能产生巨大成本。为了解决这一问题,我们推出了一个名为GLAINTEL的智能化网络交互接地语言代理。GLAINTEL采用Flan-T5作为其主干,在各种设置(无监督学习、监督学习和无监督域适应)中进行训练时表现出灵活性。具体来说,我们解决了没有人类演示时的学习挑战,并抓住了在有可用的人类演示时有效利用这些演示的机会。此外,我们还探索了演示仅限于特定领域的情况下的无监督域适应。在多种设置下的实验评估表明,GLAINTEL在无监督环境中的有效性,超越了使用更大模型的基于上下文学习的方法,这些模型的参数高达540亿。令人惊讶的是,直接使用人类演示的行为克隆方法并没有超越GLAINTEL的无监督版本。此外,我们还表明,将人类演示与基于强化学习的训练相结合,所产生的结果与利用GPT-4的方法相当。相关代码可访问:https://github.com/MultifacetedNLP/WebAgents-Unsupervised。
论文及项目相关链接
PDF 9 pages
Summary
基于大型语言模型(LLMs)的代理开发,用于实现复杂的高级用户意图,已引起广泛关注。为解决使用大型语言模型的高成本问题,推出了名为GLAINTEL的智能互动语言代理。GLAINTEL以Flan-T-Based为其骨干架构,并灵活适应多种训练场景,包括无监督学习、监督学习和无监督域适应。其应对挑战之一是无需人类演示进行学习,同时在有人类演示的情况下有效加以利用。针对演示限于特定领域的场景,GLAINTEL还探索了无监督域适应。在多样化的实验环境下,GLAINTEL在无监督环境下的表现效果显著,超过了基于上下文的较大模型学习模型,表现出良好的表现性能。特别的是,结合了人类演示与强化学习训练的方法产生的结果与GPT-4相当。代码已公开在GitHub上。
Key Takeaways
- 大型语言模型(LLMs)代理的发展吸引了广泛关注,用于实现复杂的高级用户意图。
- GLAINTEL是一个智能互动语言代理,以Flan-T-Based作为其骨干架构,能灵活适应不同的训练场景。
- GLAINTEL可以解决在没有人类演示的情况下进行学习的问题,并能有效利用人类演示。
- GLAINTEL在无监督域适应方面进行了探索,适用于演示限于特定领域的场景。
- 在多样化的实验环境下,GLAINTEL在无监督环境下的表现效果显著,超过了基于上下文的较大模型学习模型。
- 结合人类演示与强化学习训练的方法产生的结果与GPT-4相当。
点此查看论文截图

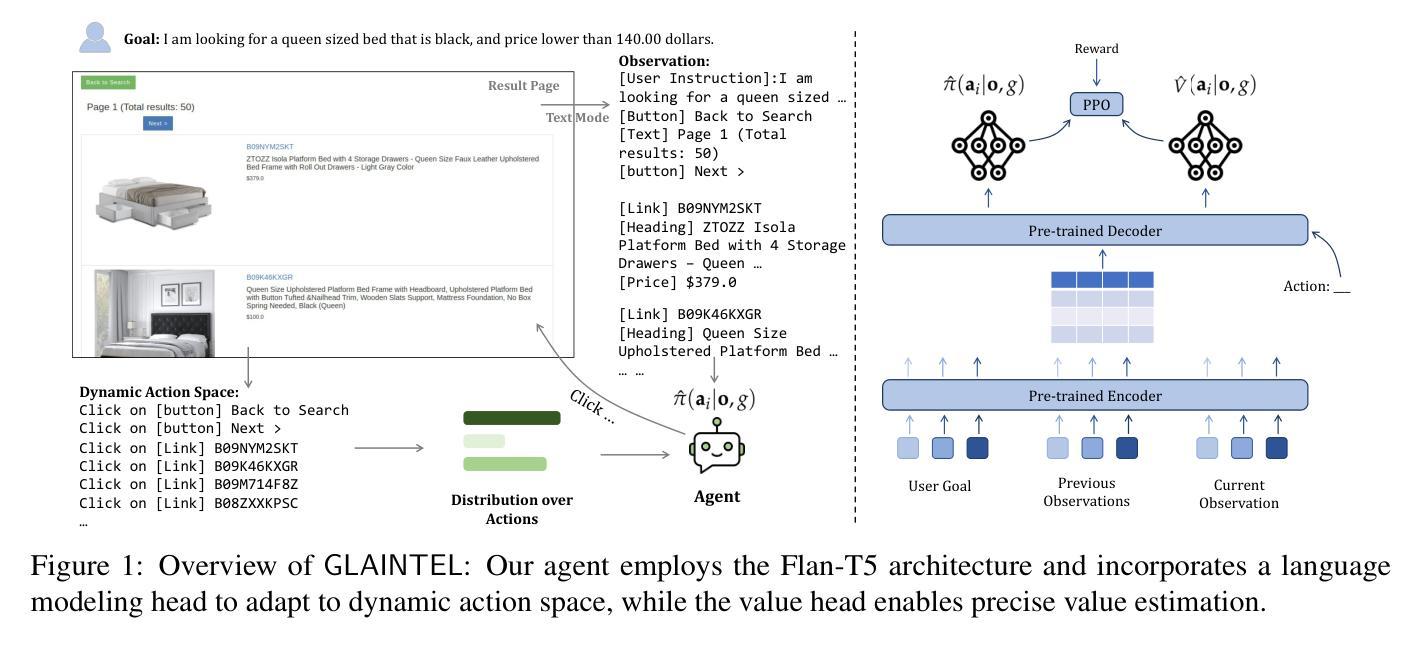
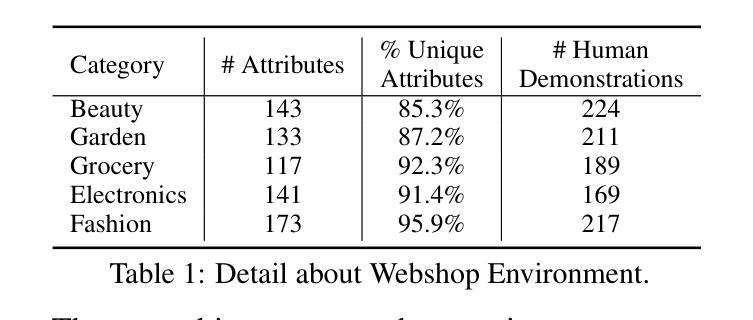
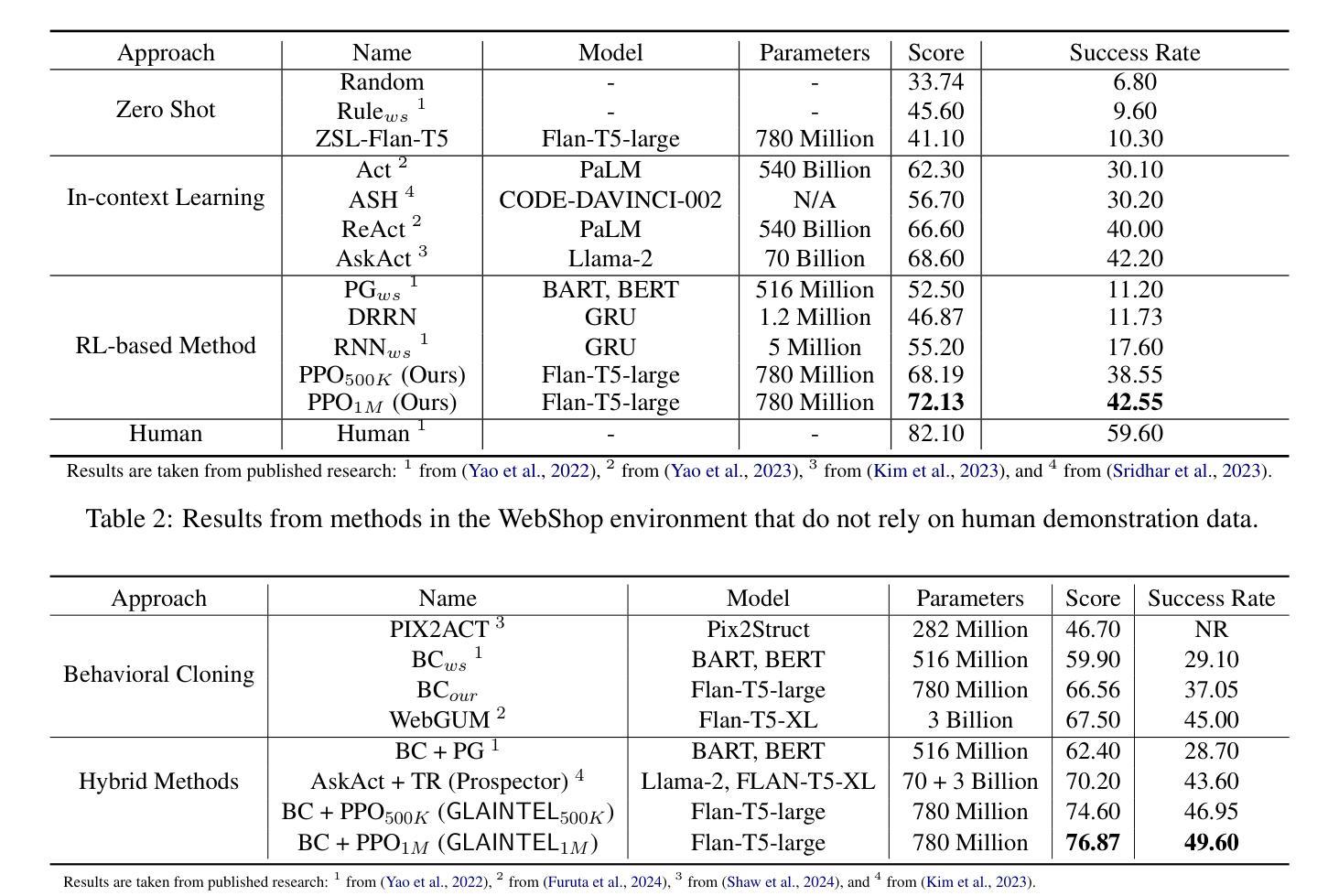
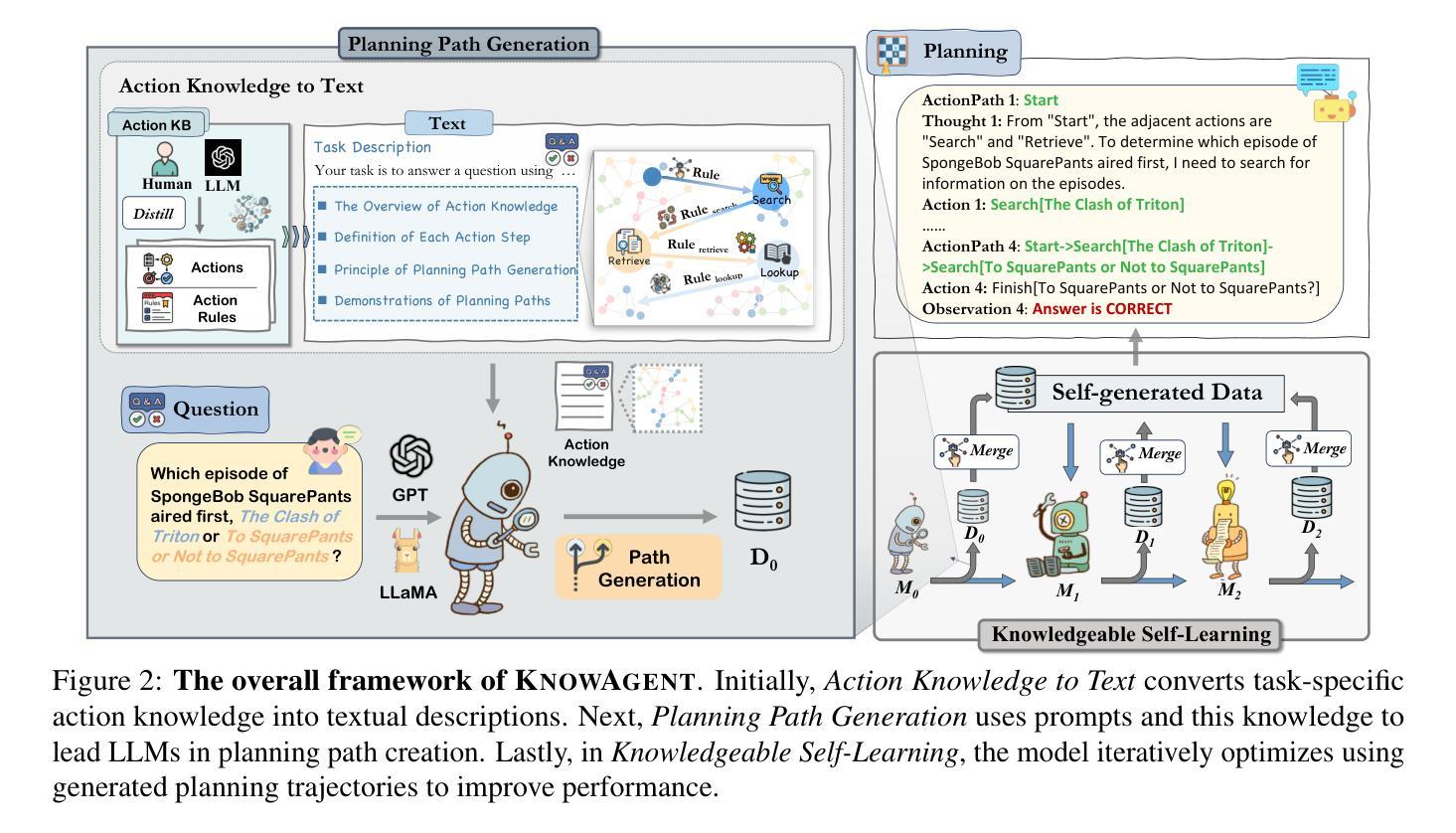
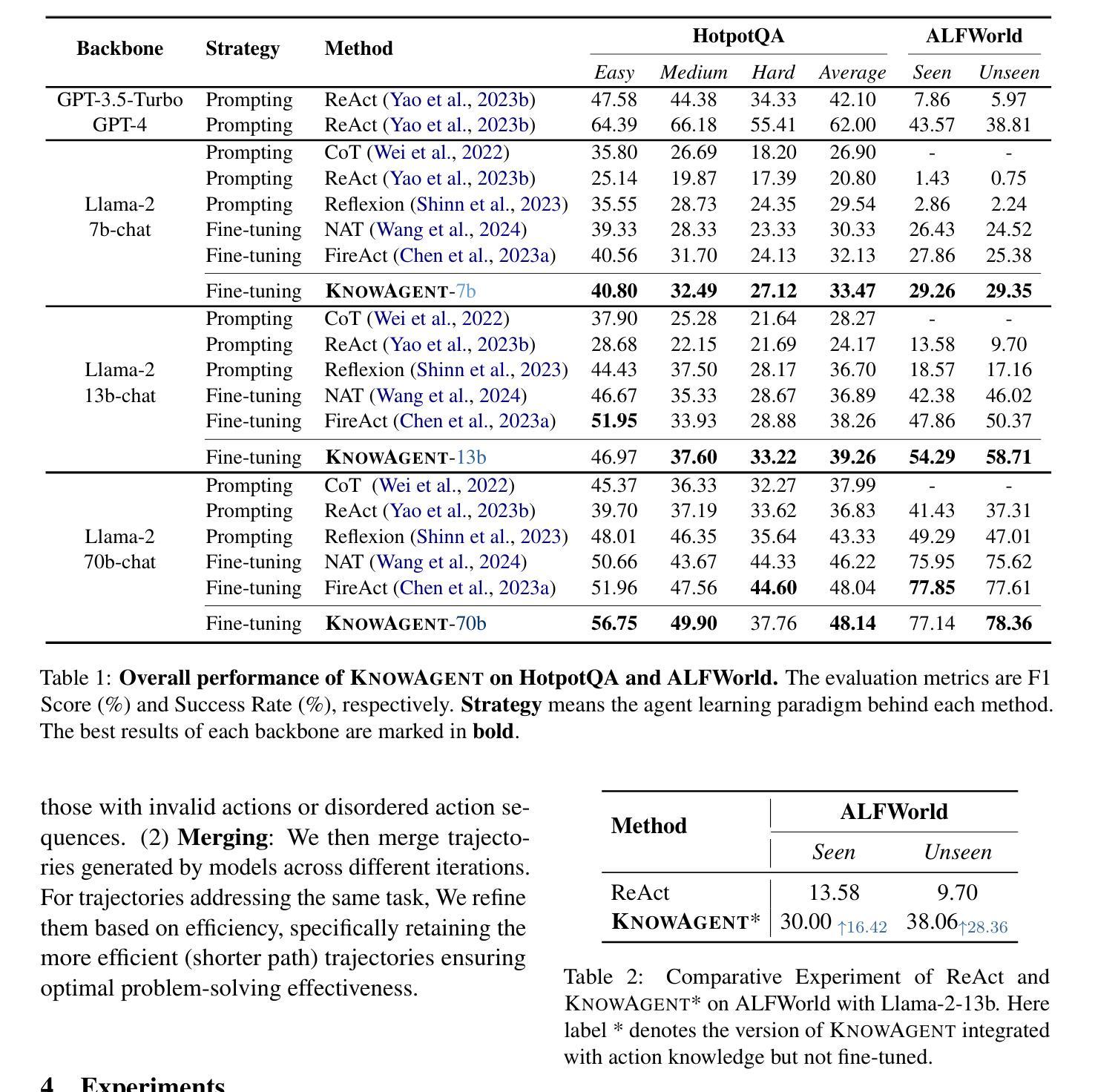
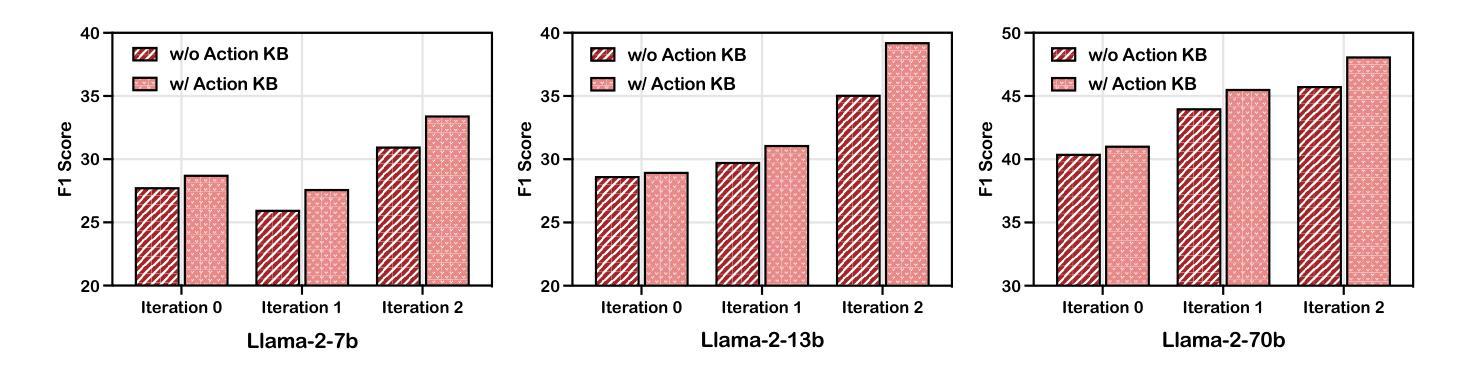
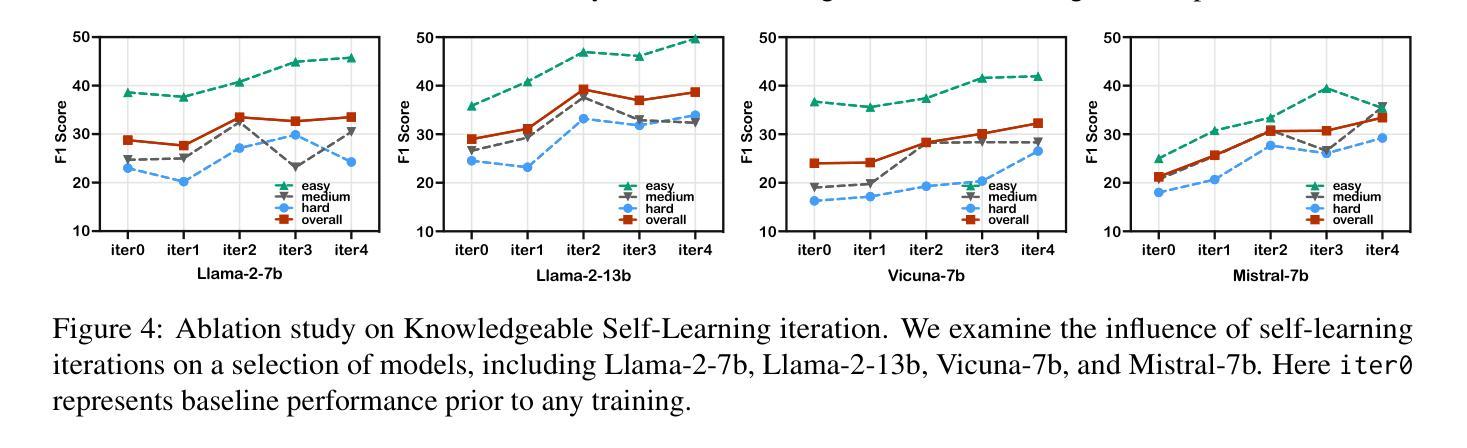
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
Authors:Yuqi Zhu, Shuofei Qiao, Yixin Ou, Shumin Deng, Ningyu Zhang, Shiwei Lyu, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen
Large Language Models (LLMs) have demonstrated great potential in complex reasoning tasks, yet they fall short when tackling more sophisticated challenges, especially when interacting with environments through generating executable actions. This inadequacy primarily stems from the lack of built-in action knowledge in language agents, which fails to effectively guide the planning trajectories during task solving and results in planning hallucination. To address this issue, we introduce KnowAgent, a novel approach designed to enhance the planning capabilities of LLMs by incorporating explicit action knowledge. Specifically, KnowAgent employs an action knowledge base and a knowledgeable self-learning strategy to constrain the action path during planning, enabling more reasonable trajectory synthesis, and thereby enhancing the planning performance of language agents. Experimental results on HotpotQA and ALFWorld based on various backbone models demonstrate that KnowAgent can achieve comparable or superior performance to existing baselines. Further analysis indicates the effectiveness of KnowAgent in terms of planning hallucinations mitigation. Code is available in https://github.com/zjunlp/KnowAgent.
大规模语言模型(LLMs)在复杂的推理任务中展现出了巨大的潜力,但在应对更高级的挑战时,尤其是在通过生成可执行动作与环境进行交互时,它们的表现却不尽如人意。这种不足主要源于语言模型中缺乏内置的动作知识,导致在任务解决过程中无法有效地指导规划轨迹,进而产生规划幻觉。为了解决这一问题,我们引入了KnowAgent,这是一种通过融入明确动作知识来增强LLM规划能力的新型方法。具体来说,KnowAgent采用动作知识库和知识自我学习策略来约束规划过程中的动作路径,从而实现更合理的轨迹合成,提升语言代理的规划性能。在HotpotQA和基于不同骨干模型的ALFWorld上的实验结果表明,KnowAgent可以达到或超越现有基准线的性能。进一步的分析表明,KnowAgent在缓解规划幻觉方面非常有效。代码可访问 https://github.com/zjunlp/KnowAgent。
论文及项目相关链接
PDF NAACL 2025 Findings. Project page: https://zjunlp.github.io/project/KnowAgent/ Code: https://github.com/zjunlp/KnowAgent
Summary
大型语言模型(LLMs)在复杂推理任务中展现出巨大潜力,但在应对更高级挑战时,尤其是在通过生成可执行动作与环境互动方面存在不足。此不足主要源于语言模型中缺乏内置的动作知识,无法有效指导任务解决过程中的规划轨迹,导致规划幻觉。为解决这个问题,我们提出KnowAgent,这是一种通过融入明确动作知识来提升LLM规划能力的新方法。KnowAgent采用动作知识库和知识自我学习策略来约束规划过程中的动作路径,实现更合理的轨迹合成,从而提升语言代理的规划性能。在HotpotQA和ALFWorld上的实验结果表明,KnowAgent的性能与现有基线相比具有竞争力或更优秀。KnowAgent在缓解规划幻觉方面表现出有效性。相关代码可访问:https://github.com/zjunlp/KnowAgent。
Key Takeaways
- 大型语言模型(LLMs)在复杂推理任务中表现出色,但在处理更高级挑战时存在缺陷,特别是在与环境交互方面。
- 缺陷的根源在于LLM缺乏内置的动作知识,无法有效指导任务解决过程中的规划轨迹。
- KnowAgent是一种通过融入明确动作知识提升LLM规划能力的方法。
- KnowAgent采用动作知识库和知识自我学习策略来约束规划过程中的动作路径。
- KnowAgent实现了更合理的轨迹合成,提升了语言代理的规划性能。
- 在HotpotQA和ALFWorld上的实验表明,KnowAgent性能优越,与现有方法相比具有竞争力。
点此查看论文截图


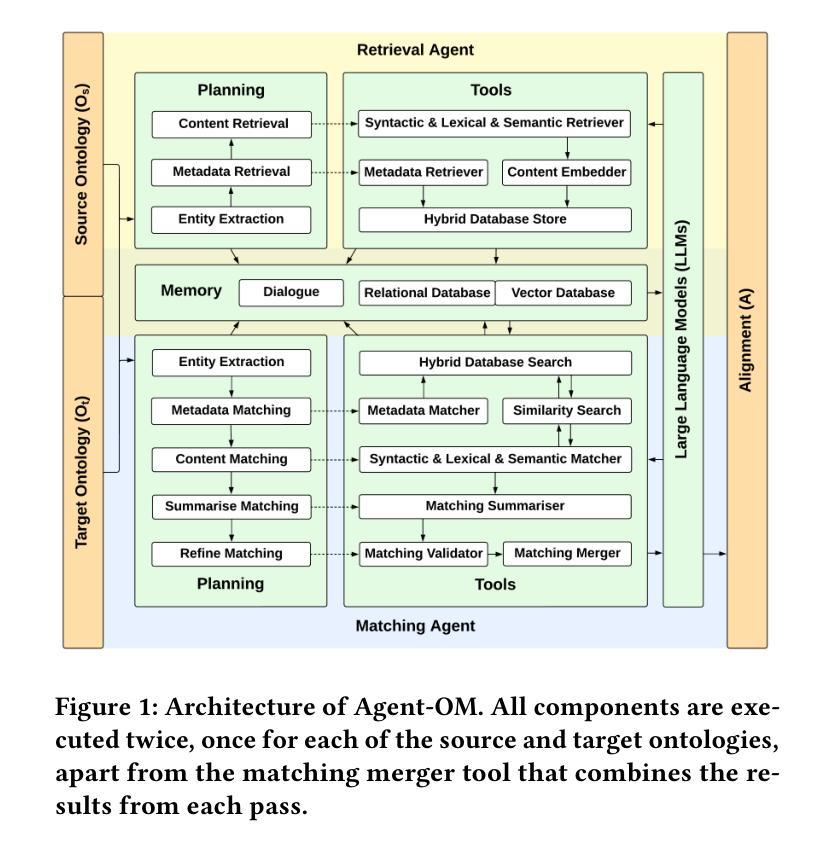
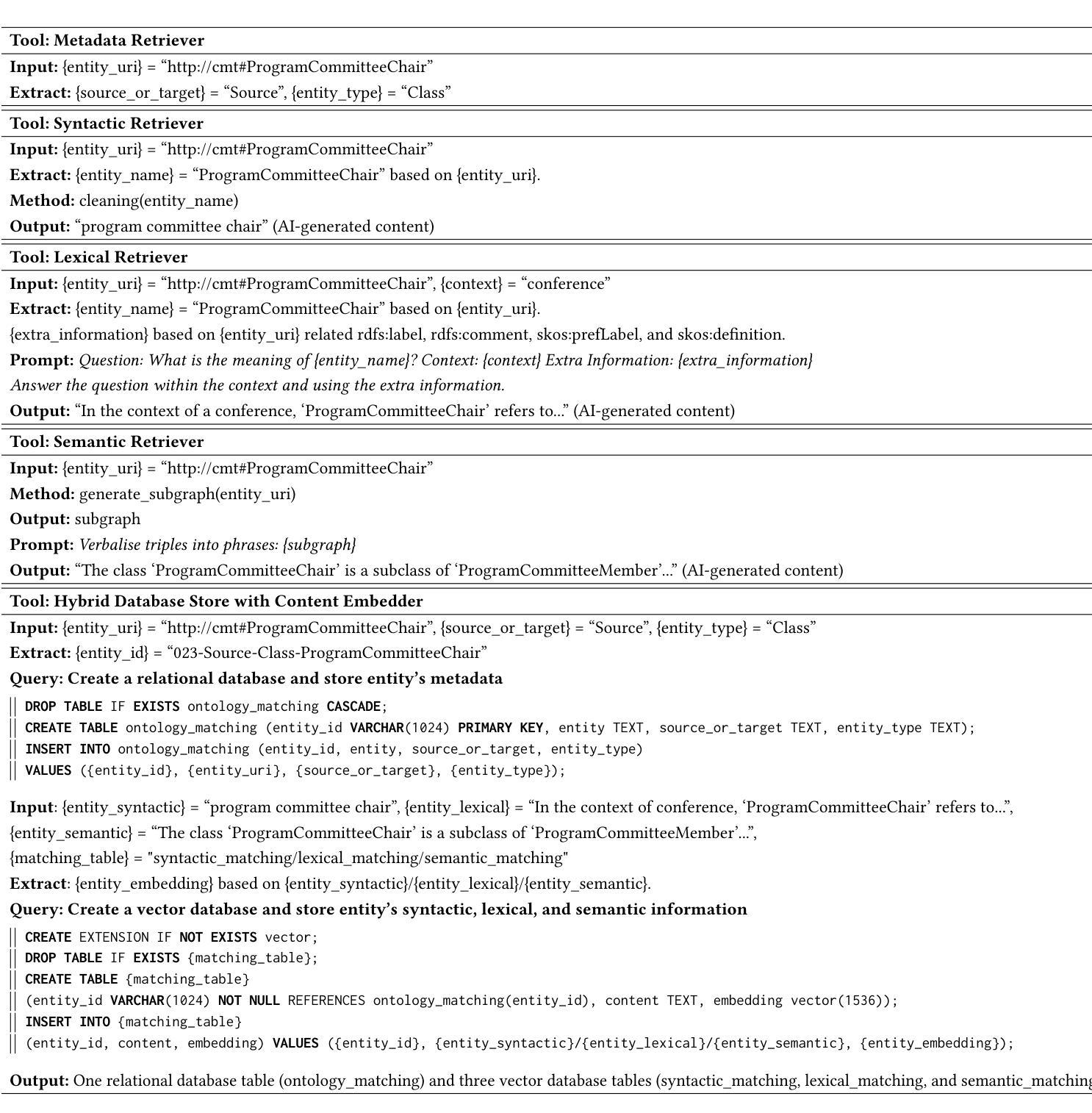
Agent-OM: Leveraging LLM Agents for Ontology Matching
Authors:Zhangcheng Qiang, Weiqing Wang, Kerry Taylor
Ontology matching (OM) enables semantic interoperability between different ontologies and resolves their conceptual heterogeneity by aligning related entities. OM systems currently have two prevailing design paradigms: conventional knowledge-based expert systems and newer machine learning-based predictive systems. While large language models (LLMs) and LLM agents have revolutionised data engineering and have been applied creatively in many domains, their potential for OM remains underexplored. This study introduces a novel agent-powered LLM-based design paradigm for OM systems. With consideration of several specific challenges in leveraging LLM agents for OM, we propose a generic framework, namely Agent-OM (Agent for Ontology Matching), consisting of two Siamese agents for retrieval and matching, with a set of OM tools. Our framework is implemented in a proof-of-concept system. Evaluations of three Ontology Alignment Evaluation Initiative (OAEI) tracks over state-of-the-art OM systems show that our system can achieve results very close to the long-standing best performance on simple OM tasks and can significantly improve the performance on complex and few-shot OM tasks.
本体匹配(OM)能够在不同的本体之间实现语义互操作性,并通过对齐相关实体解决其概念上的异质性。目前,OM系统主要有两种流行的设计范式:传统的基于知识的专家系统和较新的基于机器学习的预测系统。虽然大型语言模型(LLM)和LLM代理已经彻底改变了数据工程,并且已经在许多领域得到了创造性的应用,但它们在OM中的潜力仍然被低估。本研究引入了一种基于代理的LLM设计范式的新型OM系统。考虑到利用LLM代理进行OM面临的若干特定挑战,我们提出了一个通用框架,即Agent-OM(用于本体匹配的代理),它由两个用于检索和匹配的Siamese代理和一组OM工具组成。我们的框架在一个概念验证系统中实现。对三个本体对齐评估倡议(OAEI)赛道的最先进OM系统的评估表明,我们的系统在简单OM任务上的结果非常接近长期以来的最佳性能,并且在复杂和少量OM任务上可以显著提高性能。
论文及项目相关链接
PDF 19 pages, 12 figures, 3 tables
Summary
基于本体匹配的OM系统能通过两种流行设计范例实现语义互通性,但还存在潜在的挖掘不足的问题。这项研究利用语言大模型和相应的实体智能体设计了一种新型的OM系统,并通过使用一套工具集来解决各种挑战。评价显示,该系统的性能接近于长期以来的最佳表现,并在复杂和少样本的OM任务上显著提高性能。
Key Takeaways
点此查看论文截图