⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-29 更新
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
Authors:Xiang Yue, Yueqi Song, Akari Asai, Seungone Kim, Jean de Dieu Nyandwi, Simran Khanuja, Anjali Kantharuban, Lintang Sutawika, Sathyanarayanan Ramamoorthy, Graham Neubig
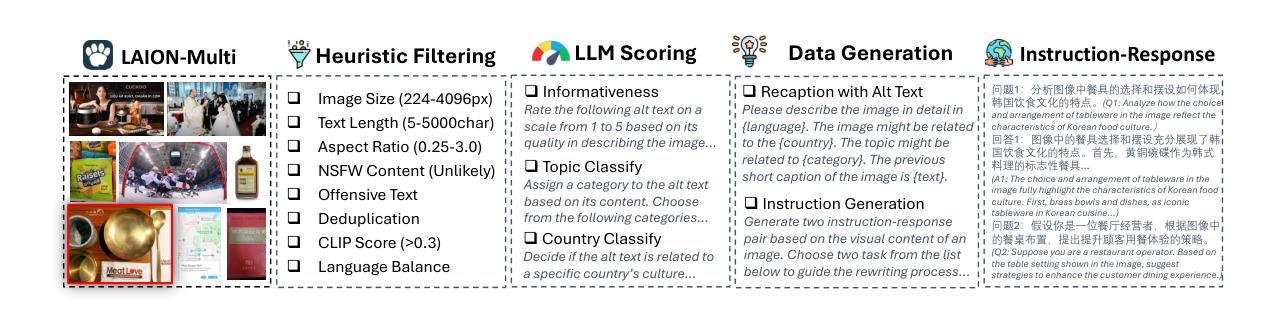
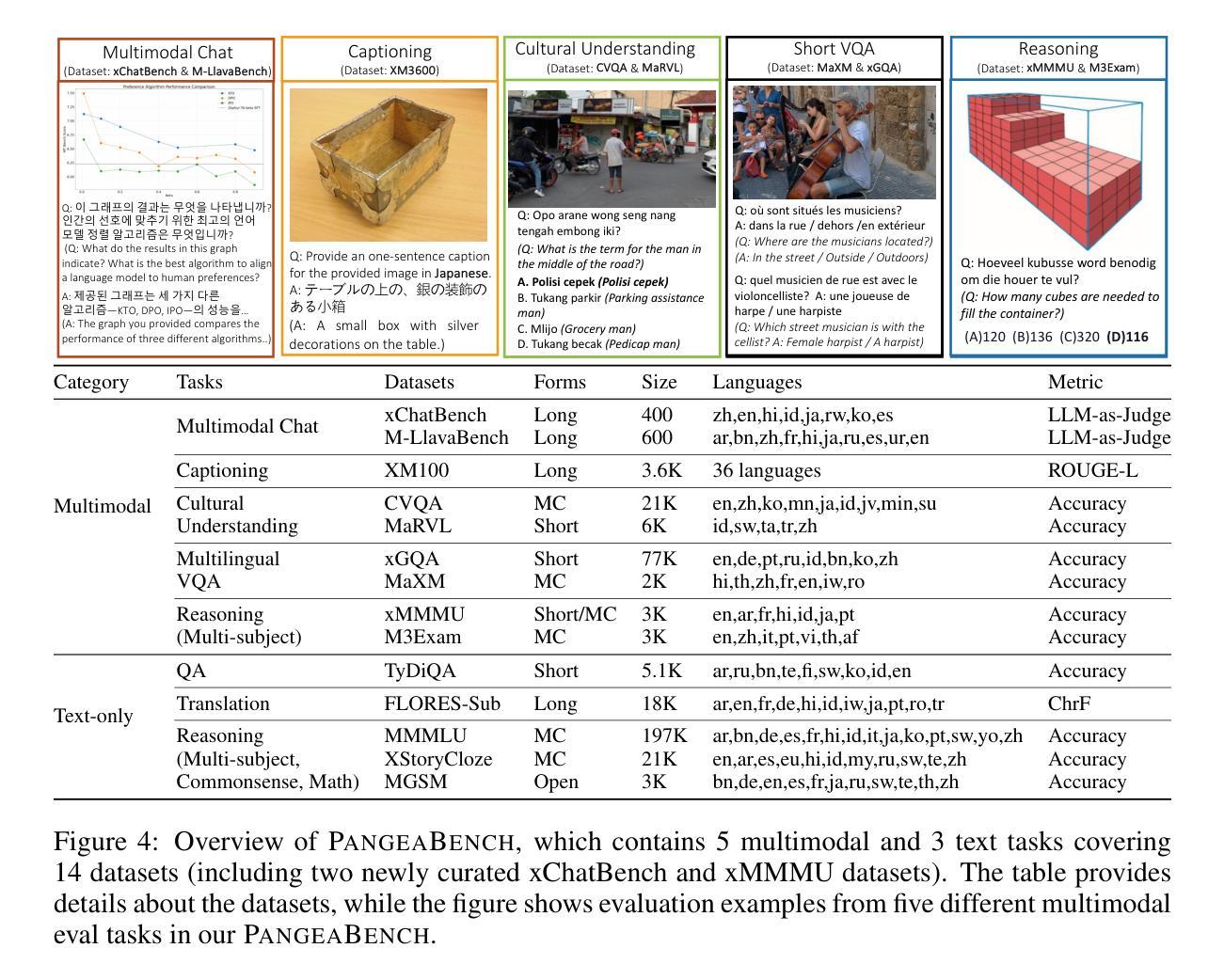
Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and western-centric datasets and tasks, leaving most of the world’s languages and diverse cultural contexts underrepresented. This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features: 1) high-quality English instructions, 2) carefully machine-translated instructions, and 3) culturally relevant multimodal tasks to ensure cross-cultural coverage. To rigorously assess models’ capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts. Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance. We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.
尽管最近多模态大型语言模型(MLLMs)取得了进展,但它们的开发主要集中于英语和西方中心的数据集和任务上,导致世界上大多数语言和多样化的文化背景代表性不足。本文介绍了Pangea,这是一个在PangeaIns上训练的多语言多模态大型语言模型,PangeaIns是一个包含39种语言的多样化600万指令数据集。PangeaIns的特点包括:1)高质量的英语指令,2)精心机器翻译的指令,以及3)文化相关的多模态任务,以确保跨文化覆盖。为了严格评估模型的能力,我们推出了PangeaBench,这是一个全面的评估套件,包含覆盖47种语言的14个数据集。结果表明,在多种语言和多样化的文化背景下,Pangea在性能上显著优于现有的开源模型。此外,消融研究进一步揭示了英语数据比例、语言流行度和多模态训练样本数量对整体性能的重要性。我们完全开源我们的数据、代码和训练检查点,以促进包容性强健的多语言MLLMs的发展,推动更广泛的语言和文化领域的公平和可访问性。
论文及项目相关链接
PDF 54 pages, 27 figures
Summary
本文介绍了一个名为Pangea的多语种多模态大型语言模型,该模型在包含39种语言的PangeaIns数据集上进行训练。PangeaIns数据集包含高质量英语指令、机器翻译指令和文化相关多模态任务,以确保跨文化覆盖。为了严格评估模型的能力,引入了PangeaBench评估套件,包含14个数据集和覆盖47种语言。结果表明,Pangea在多语种环境和多元文化背景下显著优于现有开源模型。此外,本文还通过消去研究揭示了英语数据比例、语言普及率和多模态训练样本数量对整体性能的重要性。为了促进包容性和稳健的多语种多模态大型语言模型的发展,本文公开了数据集、代码和训练检查点,推动更广泛的语言和文化领域的公平性和可访问性。
Key Takeaways
- Pangea是一个多语种多模态的大型语言模型,训练数据涵盖39种语言,旨在解决现有模型主要集中在英语和西方中心数据集的问题。
- PangeaIns数据集包含高质量英语指令、机器翻译指令和文化相关多模态任务,确保跨文化覆盖。
- PangeaBench评估套件用于严格评估模型能力,涵盖14个数据集和47种语言。
- Pangea在多语种环境和多元文化背景下的性能显著优于现有开源模型。
- 英语数据比例、语言普及率和多模态训练样本数量对模型整体性能有重要影响。
- 该研究公开了数据集、代码和训练检查点,以促进包容性和稳健的多语种多模态大型语言模型的发展。
点此查看论文截图