⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-29 更新
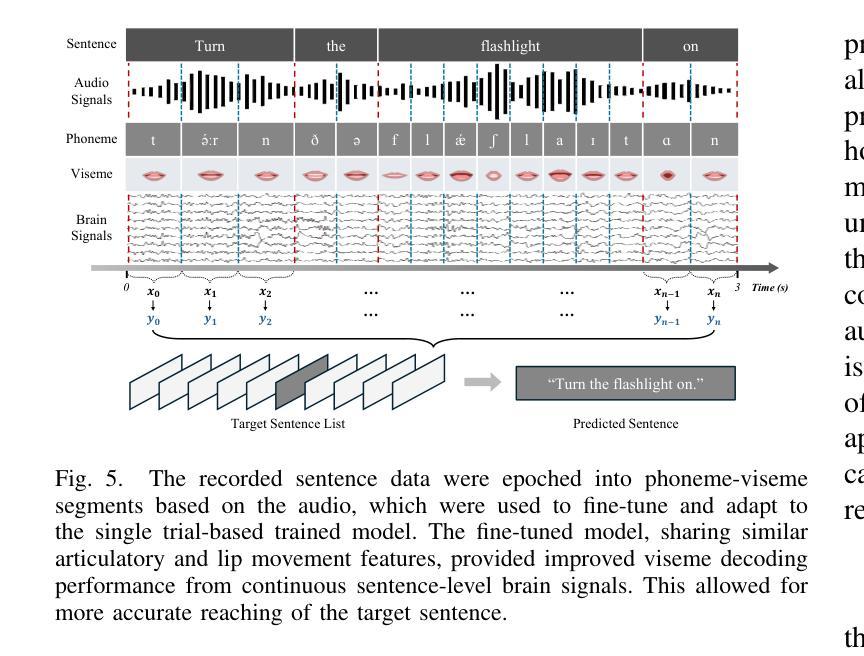
Towards Dynamic Neural Communication and Speech Neuroprosthesis Based on Viseme Decoding
Authors:Ji-Ha Park, Seo-Hyun Lee, Soowon Kim, Seong-Whan Lee
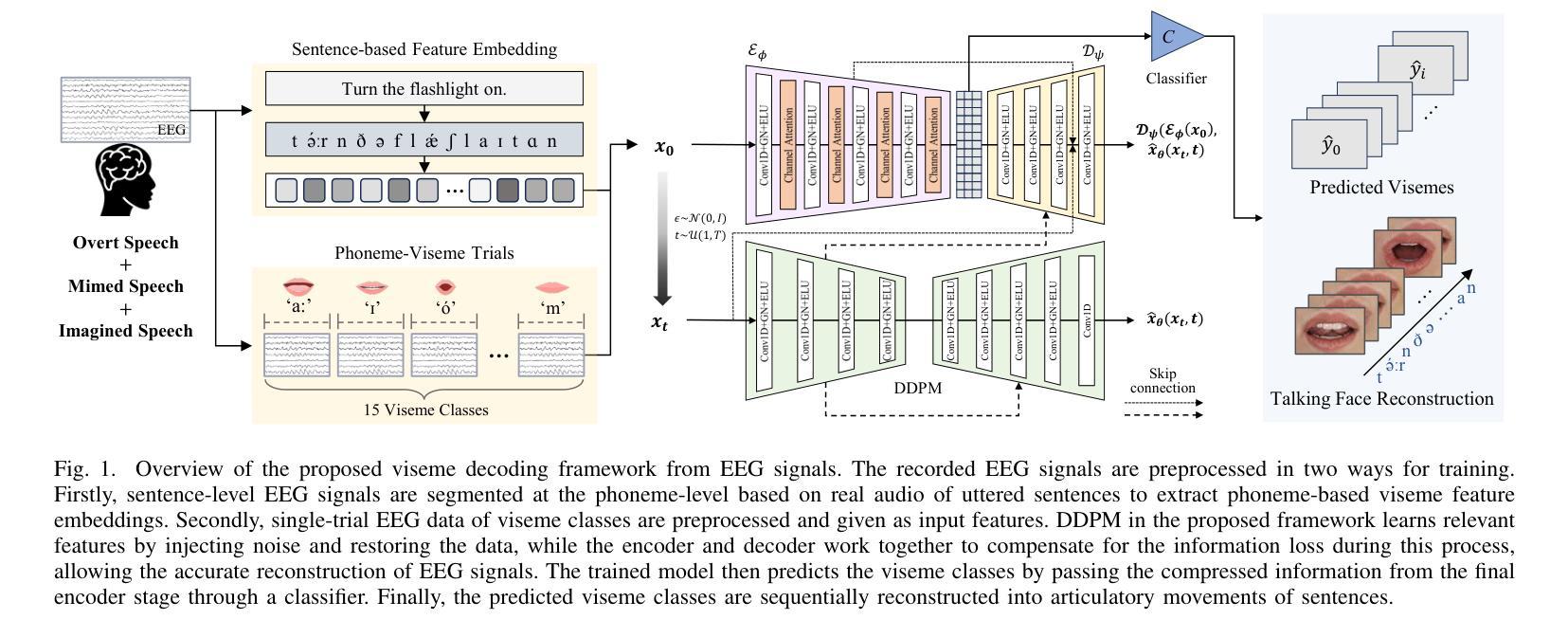
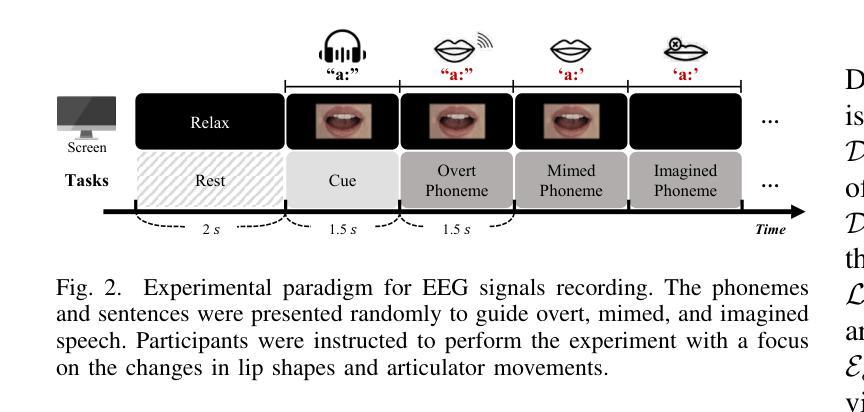
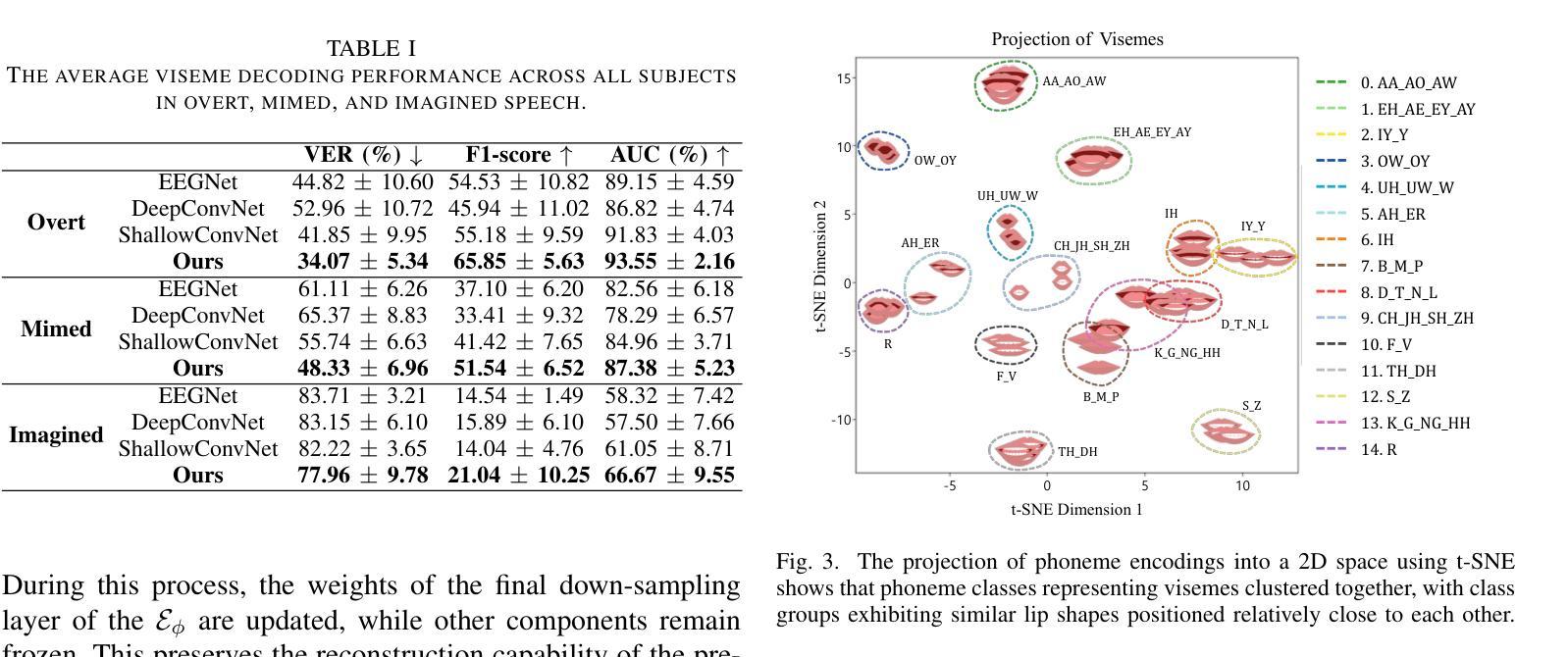
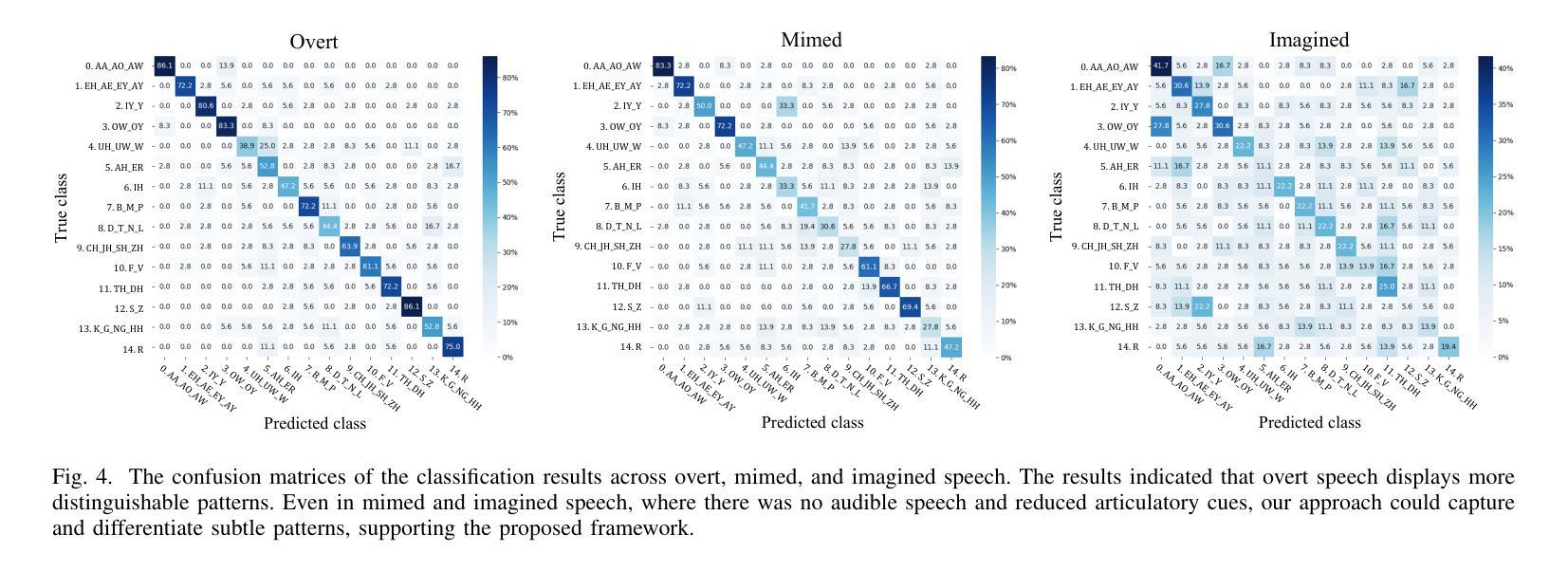
Decoding text, speech, or images from human neural signals holds promising potential both as neuroprosthesis for patients and as innovative communication tools for general users. Although neural signals contain various information on speech intentions, movements, and phonetic details, generating informative outputs from them remains challenging, with mostly focusing on decoding short intentions or producing fragmented outputs. In this study, we developed a diffusion model-based framework to decode visual speech intentions from speech-related non-invasive brain signals, to facilitate face-to-face neural communication. We designed an experiment to consolidate various phonemes to train visemes of each phoneme, aiming to learn the representation of corresponding lip formations from neural signals. By decoding visemes from both isolated trials and continuous sentences, we successfully reconstructed coherent lip movements, effectively bridging the gap between brain signals and dynamic visual interfaces. The results highlight the potential of viseme decoding and talking face reconstruction from human neural signals, marking a significant step toward dynamic neural communication systems and speech neuroprosthesis for patients.
从人类神经信号中解码文本、语音或图像,对于患者而言,其作为神经假肢具有巨大的潜力,对于普通用户而言,其作为创新沟通工具也前景广阔。尽管神经信号包含关于语音意图、动作和语音详情的各种信息,但从中生成信息输出仍然具有挑战性,目前主要集中在解码短意图或产生碎片化输出。在这项研究中,我们开发了一个基于扩散模型的框架,从与语音相关的非侵入性脑信号中解码视觉语音意图,以促进面对面神经沟通。我们设计了一个实验,将各种音素整合起来,训练每个音素的唇形动作特征(visemes),旨在从神经信号中学习相应的唇形形成表征。通过对孤立的试验和连续的句子进行唇形动作特征解码,我们成功地重建了连贯的唇动,有效地填补了脑信号和动态视觉界面之间的鸿沟。结果突出了从人类神经信号中解码唇形动作特征和重建说话人脸的潜力,标志着朝着动态神经沟通系统和语音神经假肢迈出了重要的一步。
论文及项目相关链接
PDF 5 pages, 5 figures, 1 table, Name of Conference: 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing
Summary
本文探索了基于扩散模型解码人类神经信号的视觉语音意图的潜力。研究设计了一种实验方法,通过训练神经信号中的不同音素对应的唇形表达,成功重建连贯的唇动,从而实现了脑信号与动态视觉界面的联接。这一发现对于神经通讯系统和语音神经康复有重大意义。
Key Takeaways
- 研究领域:文本专注于利用扩散模型从人类神经信号中解码视觉语音意图。
- 实验设计:设计实验以训练不同音素对应的唇形表达,旨在从神经信号中学习相应唇形的表现。
- 成功解码:从孤立的试验和连续的句子中解码唇形运动,成功重建连贯的唇动。
- 突破点:实现了脑信号与动态视觉界面的联接,填补了两者之间的鸿沟。
- 潜在应用:这一发现对于动态神经通讯系统和语音神经康复有重大意义。
- 技术创新:采用扩散模型进行解码,提高了从神经信号中获取信息的准确性。
点此查看论文截图