⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-30 更新
Modulating CNN Features with Pre-Trained ViT Representations for Open-Vocabulary Object Detection
Authors:Xiangyu Gao, Yu Dai, Benliu Qiu, Hongliang Li
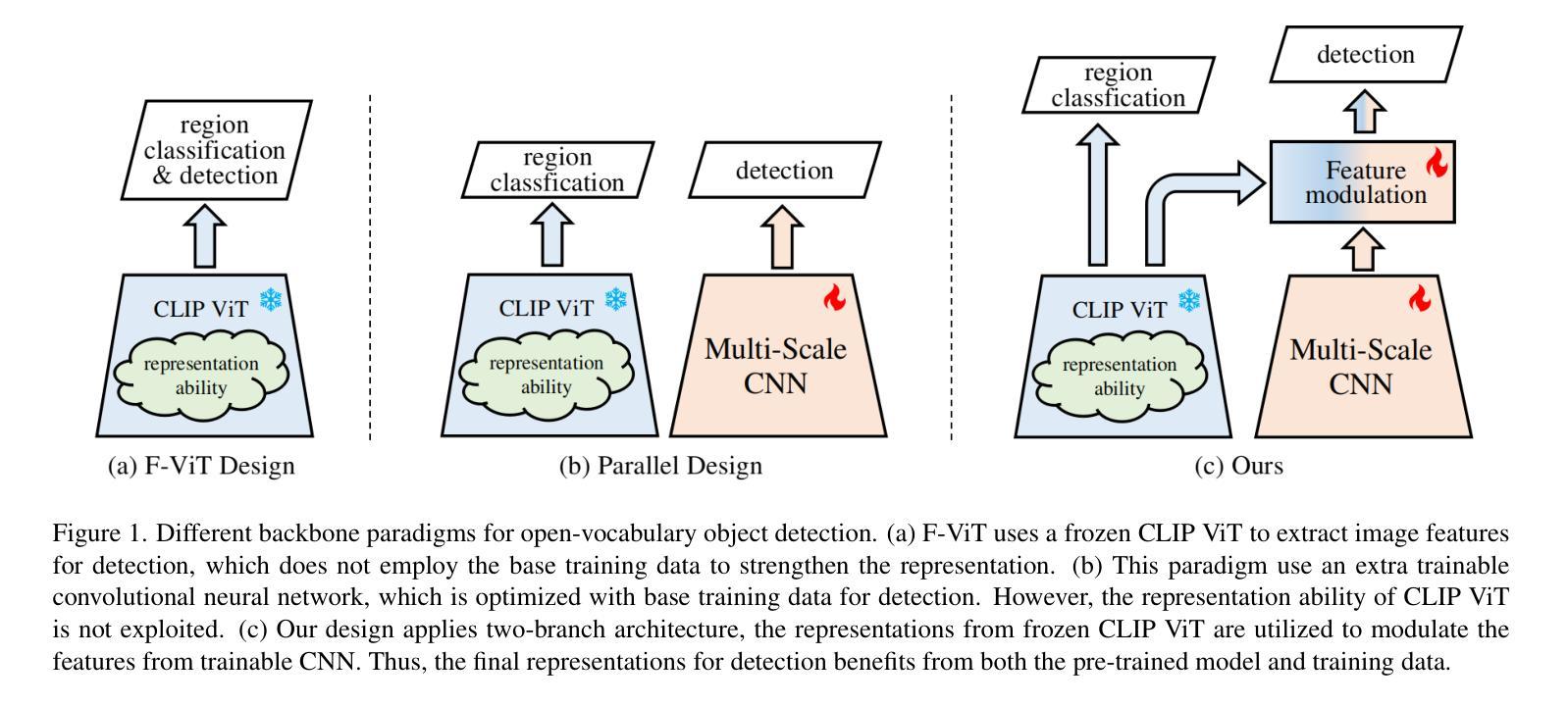
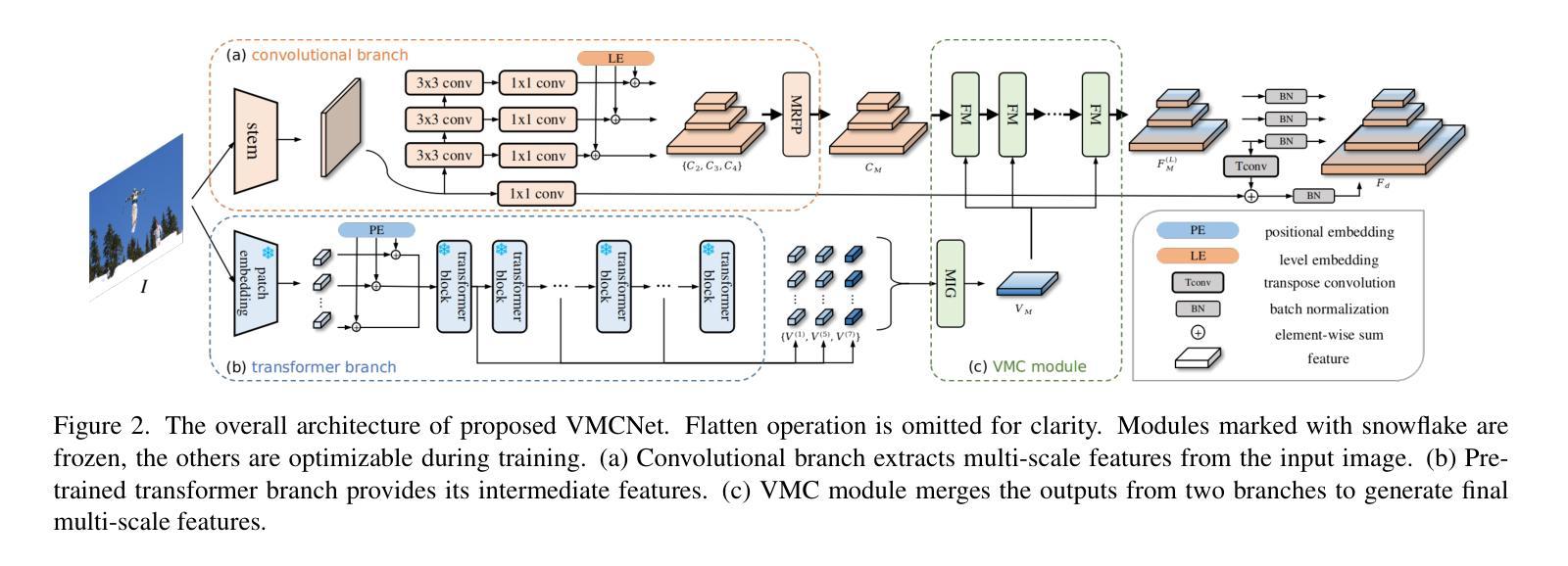
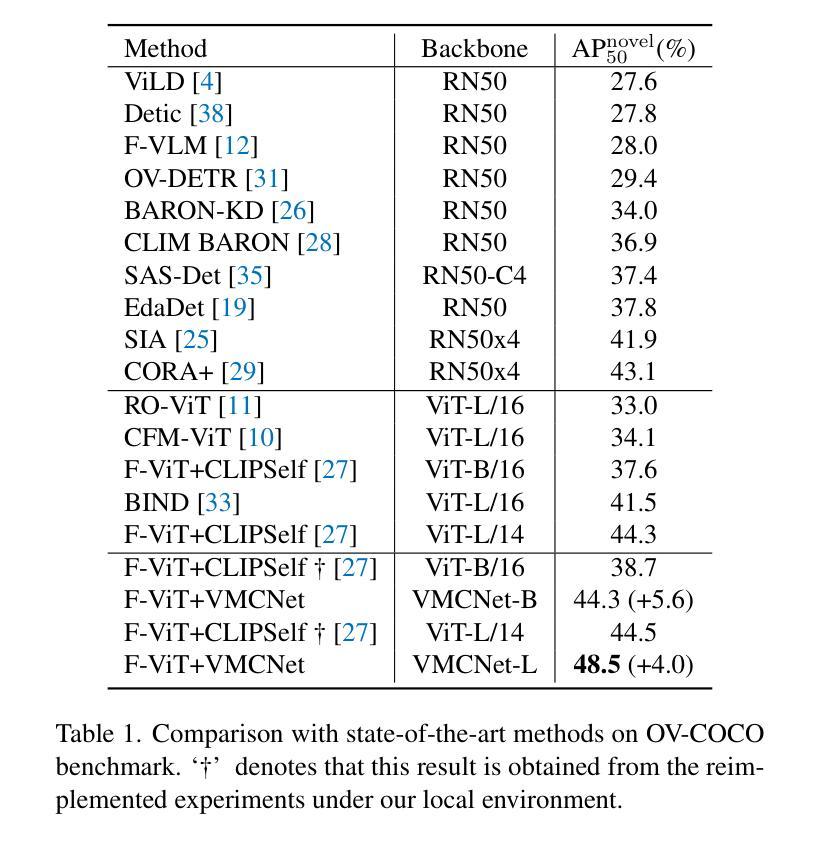
Owing to large-scale image-text contrastive training, pre-trained vision language model (VLM) like CLIP shows superior open-vocabulary recognition ability. Most existing open-vocabulary object detectors attempt to utilize the pre-trained VLM to attain generative representation. F-ViT uses the pre-trained visual encoder as the backbone network and freezes it during training. However, the frozen backbone doesn’t benefit from the labeled data to strengthen the representation. Therefore, we propose a novel two-branch backbone network design, named as ViT-Feature-Modulated Multi-Scale Convolutional network (VMCNet). VMCNet consists of a trainable convolutional branch, a frozen pre-trained ViT branch and a feature modulation module. The trainable CNN branch could be optimized with labeled data while the frozen pre-trained ViT branch could keep the representation ability derived from large-scale pre-training. Then, the proposed feature modulation module could modulate the multi-scale CNN features with the representations from ViT branch. With the proposed mixed structure, detector is more likely to discover novel categories. Evaluated on two popular benchmarks, our method boosts the detection performance on novel category and outperforms the baseline. On OV-COCO, the proposed method achieves 44.3 AP${50}^{\mathrm{novel}}$ with ViT-B/16 and 48.5 AP${50}^{\mathrm{novel}}$ with ViT-L/14. On OV-LVIS, VMCNet with ViT-B/16 and ViT-L/14 reaches 27.8 and 38.4 mAP$_{r}$.
由于大规模图像文本对比训练,预训练的视觉语言模型(如CLIP)表现出卓越的开放词汇识别能力。大多数现有的开放词汇对象检测器试图利用预训练的VLM来获得生成表示。F-ViT使用预训练的视觉编码器作为主干网络,并在训练期间冻结它。然而,冻结的主干网络不能从标记数据中受益,无法加强表示能力。因此,我们提出了一种新的双分支主干网络设计,称为ViT特征调制多尺度卷积网络(VMCNet)。VMCNet由可训练卷积分支、冻结的预训练ViT分支和特征调制模块组成。可训练的CNN分支可以使用标记数据进行优化,而冻结的预训练ViT分支可以保持从大规模预训练中获得的表示能力。然后,所提出的特征调制模块可以调制来自ViT分支的多尺度CNN特征。通过提出的混合结构,检测器更有可能发现新类别。在两个流行的基准测试上,我们的方法在新型类别检测性能上有所提升并超越了基线。在OV-COCO上,所提方法使用ViT-B/16达到44.3 AP_{50}^{novel},使用ViT-L/14达到48.5 AP_{50}^{novel}。在OV-LVIS上,VMCNet与ViT-B/16和ViT-L/14分别达到了27.8和38.4的mAP_{r}。
论文及项目相关链接
Summary
预训练视觉语言模型如CLIP具有出色的开放词汇识别能力,通过大规模图像文本对比训练达成。现有开放词汇目标检测器多尝试利用预训练VLM获得生成表示。F-ViT使用预训练视觉编码器作为主干网络并在训练时冻结。但冻结的主干网络无法从标记数据中受益以增强表示能力。为此,我们提出一种新型的两分支主干网络设计,名为ViT特征调制多尺度卷积网络(VMCNet)。VMCNet包含一个可训练的卷积分支、一个冻结的预训练ViT分支和特征调制模块。可训练的CNN分支可利用标记数据进行优化,而冻结的预训练ViT分支则保持从大规模预训练中获得的表现能力。特征调制模块能够调制来自ViT分支的多尺度CNN特征。通过这种混合结构,检测器更可能发现新类别。在流行的基准测试中,我们的方法在新型类别检测性能上有所提升并超越了基线。在OV-COCO上,使用ViT-B/16的方法达到44.3 AP50novel,使用ViT-L/14的方法达到48.5 AP50novel。在OV-LVIS上,VMCNet使用ViT-B/16和ViT-L/14分别达到了27.8和38.4的mAPr。
Key Takeaways
- 预训练视觉语言模型(VLM)如CLIP具有出色的开放词汇识别能力,得益于大规模图像文本对比训练。
- 现有开放词汇目标检测器尝试利用预训练VLM获得生成表示。
- F-ViT使用预训练视觉编码器作为主干网络,但在训练过程中无法从标记数据中受益。
- 提出的VMCNet包含可训练的卷积分支、冻结的预训练ViT分支和特征调制模块。
- 可训练的CNN分支利用标记数据优化,而预训练ViT分支保持大规模预训练的表现能力。
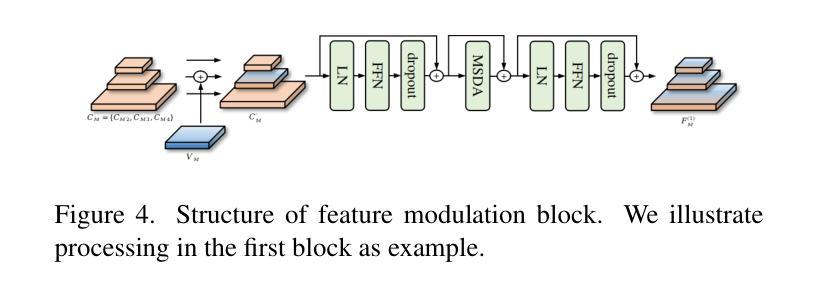
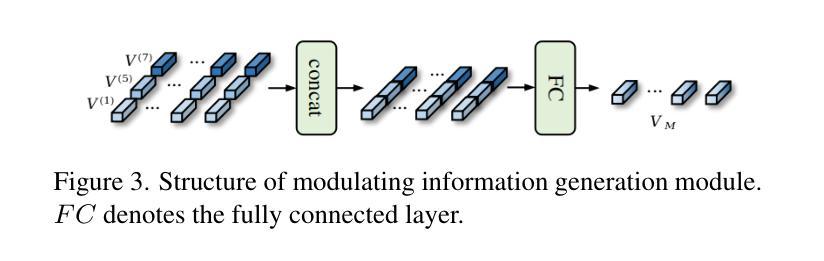
- 特征调制模块能够结合来自ViT分支和CNN分支的特征,增强检测性能。
点此查看论文截图