⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-30 更新
DiffSplat: Repurposing Image Diffusion Models for Scalable Gaussian Splat Generation
Authors:Chenguo Lin, Panwang Pan, Bangbang Yang, Zeming Li, Yadong Mu
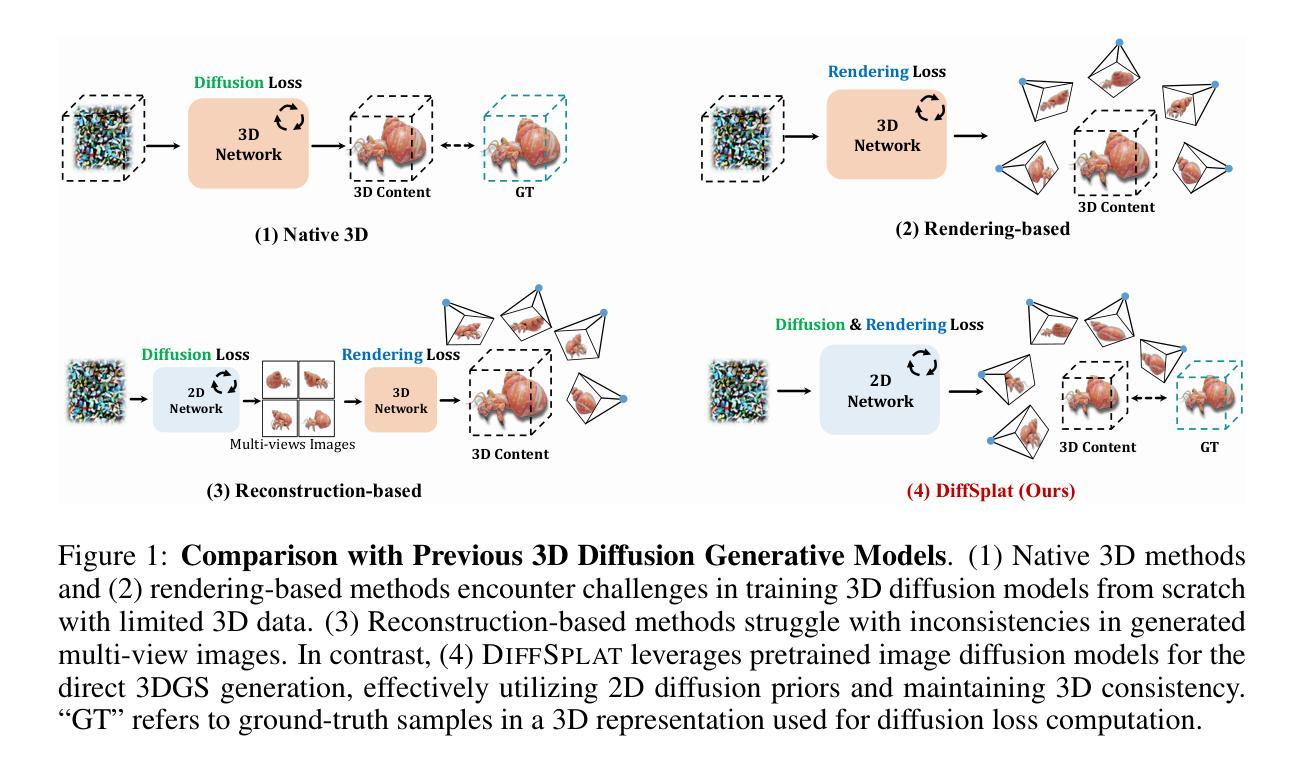
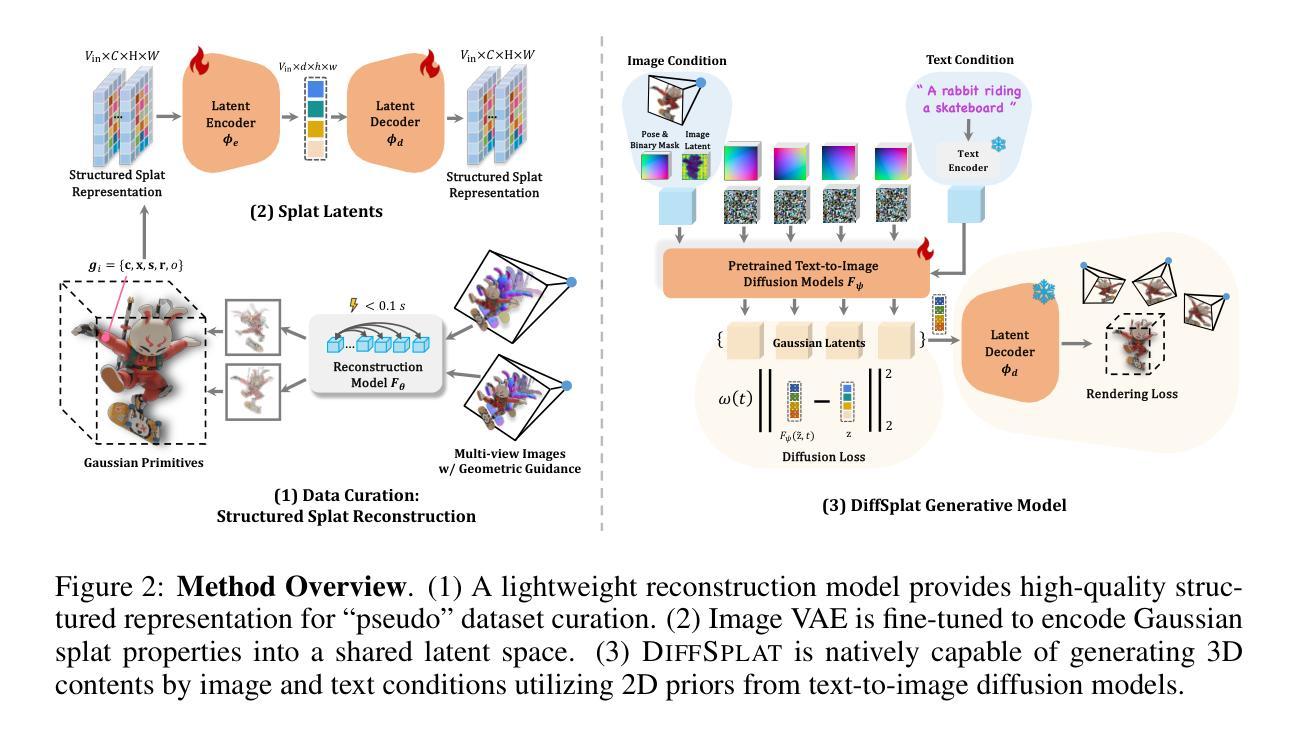
Recent advancements in 3D content generation from text or a single image struggle with limited high-quality 3D datasets and inconsistency from 2D multi-view generation. We introduce DiffSplat, a novel 3D generative framework that natively generates 3D Gaussian splats by taming large-scale text-to-image diffusion models. It differs from previous 3D generative models by effectively utilizing web-scale 2D priors while maintaining 3D consistency in a unified model. To bootstrap the training, a lightweight reconstruction model is proposed to instantly produce multi-view Gaussian splat grids for scalable dataset curation. In conjunction with the regular diffusion loss on these grids, a 3D rendering loss is introduced to facilitate 3D coherence across arbitrary views. The compatibility with image diffusion models enables seamless adaptions of numerous techniques for image generation to the 3D realm. Extensive experiments reveal the superiority of DiffSplat in text- and image-conditioned generation tasks and downstream applications. Thorough ablation studies validate the efficacy of each critical design choice and provide insights into the underlying mechanism.
近期,从文本或单一图像生成3D内容的进步面临有限的高质量3D数据集和由二维多视角生成造成的不一致性问题。我们引入了DiffSplat,这是一种新型的三维生成框架,它通过驯服大规模文本到图像扩散模型来原生生成三维高斯点集。它与之前的三维生成模型不同,通过有效利用大规模网络二维先验知识的同时在统一模型中保持三维一致性。为了引导训练,我们提出了一个轻量级的重建模型,以立即生成多视角高斯点网格来实现大规模数据集的数据采集。结合这些网格上的常规扩散损失,引入了一种三维渲染损失,以促进任意视角下的三维连贯性。其与图像扩散模型的兼容性使得能够无缝地将许多用于图像生成的技术适应到三维领域。大量实验表明,DiffSplat在文本和图像条件生成任务以及下游应用中表现出卓越的性能。详尽的消融研究验证了每个关键设计选择的有效性,并提供了对潜在机制的洞察。
论文及项目相关链接
PDF Accepted to ICLR 2025; Project page: https://chenguolin.github.io/projects/DiffSplat
Summary
最近文本或单图像生成三维内容的进展受限于高质量三维数据集缺乏以及二维多视角生成的不一致性。我们引入DiffSplat,一种新型三维生成框架,通过驯服大规模文本到图像扩散模型,原生生成三维高斯斑点。它与之前的三维生成模型不同,在统一模型中有效利用网络规模的二维先验信息,同时保持三维一致性。为了引导训练,我们提出了一种轻量级重建模型,可立即生成用于可扩展数据集整合的多视角高斯斑点网格。结合这些网格上的常规扩散损失,引入三维渲染损失,以促进任意视角之间的三维连贯性。与图像扩散模型的兼容性使能够无缝地将许多图像生成技术适应到三维领域。大量实验表明,DiffSplat在文本和图像条件生成任务以及下游应用中表现卓越。彻底的消融研究验证了每个关键设计选择的有效性,并提供了对内在机制的洞察。
Key Takeaways
- DiffSplat是一种新型三维生成框架,可以从文本或单图像生成三维内容。
- 它通过驯服大规模文本到图像扩散模型原生生成三维高斯斑点。
- DiffSplat利用网络规模的二维先验信息,同时保持三维一致性。
- 提出了一种轻量级重建模型来引导训练,并生成多视角高斯斑点网格。
- 常规扩散损失与三维渲染损失相结合,促进任意视角之间的三维连贯性。
- DiffSplat与图像扩散模型兼容,可无缝适应许多图像生成技术到三维领域。
点此查看论文截图

LinPrim: Linear Primitives for Differentiable Volumetric Rendering
Authors:Nicolas von Lützow, Matthias Nießner
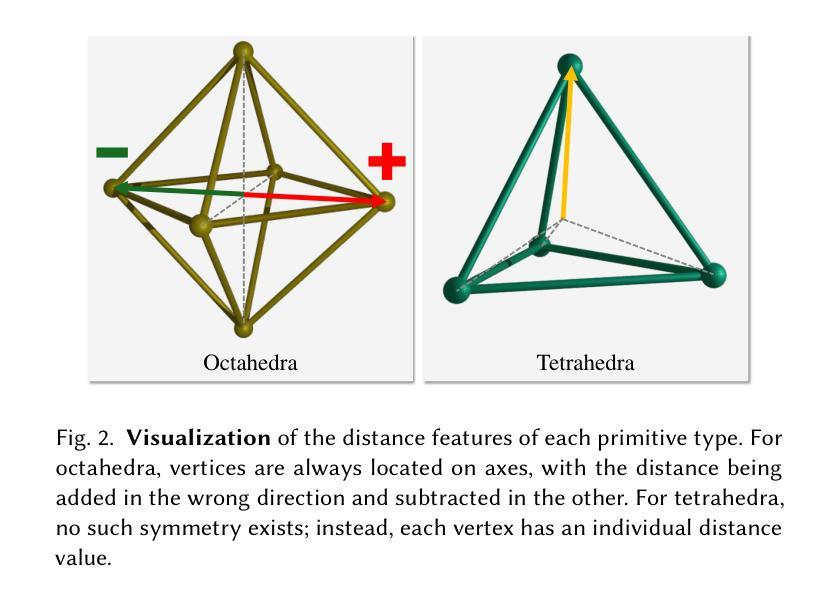
Volumetric rendering has become central to modern novel view synthesis methods, which use differentiable rendering to optimize 3D scene representations directly from observed views. While many recent works build on NeRF or 3D Gaussians, we explore an alternative volumetric scene representation. More specifically, we introduce two new scene representations based on linear primitives-octahedra and tetrahedra-both of which define homogeneous volumes bounded by triangular faces. This formulation aligns naturally with standard mesh-based tools, minimizing overhead for downstream applications. To optimize these primitives, we present a differentiable rasterizer that runs efficiently on GPUs, allowing end-to-end gradient-based optimization while maintaining realtime rendering capabilities. Through experiments on real-world datasets, we demonstrate comparable performance to state-of-the-art volumetric methods while requiring fewer primitives to achieve similar reconstruction fidelity. Our findings provide insights into the geometry of volumetric rendering and suggest that adopting explicit polyhedra can expand the design space of scene representations.
体积渲染已成为现代新型视图合成方法的中心,这些方法使用可微渲染来直接优化从观察到的视角表示的3D场景。虽然许多最新作品建立在NeRF或3D高斯模型之上,但我们探索了一种替代的体积场景表示。更具体地说,我们引入两种基于线性原始图形——八面体和四面体——的场景表示方法,二者均定义由三角形面界定的均匀体积。这一公式与基于标准网格的工具自然对齐,为下游应用提供了最小的额外开销。为了优化这些原始图形,我们提出了一种可在GPU上高效运行的可微栅格化器,允许端到端的基于梯度的优化,同时保持实时渲染能力。通过对真实世界数据集的实验,我们展示了与最先进体积方法相当的性能表现,同时以较少的原始图形达到相似的重建保真度。我们的研究为体积渲染的几何结构提供了洞察,并表明采用明确的多面体可以扩大场景表示的设计空间。
论文及项目相关链接
PDF Project page: https://nicolasvonluetzow.github.io/LinPrim ; Project video: https://youtu.be/P2yeHwmGaeM
Summary
本文探索了基于线性原始体素的新型场景表示方法,采用八面体和四面体两种新型体素表示,以三角形面定义均匀体积。为提高优化效率,提出可微分的栅格化器,可在GPU上高效运行,实现端到端的梯度优化,同时保持实时渲染能力。实验表明,该方法性能与最先进的体积方法相当,达到相似的重建保真度所需的原始体素较少。该研究为体积渲染的几何研究提供了新的见解。
Key Takeaways
- 提出了一种新型的基于线性原始体素的场景表示方法,使用八面体和四面体作为体素形式。
- 通过引入新型体素形式与标准的网格工具自然对齐,减少下游应用的开销。
- 提出了一种高效的GPU上可微分的栅格化器(rasterizer),用于优化这些原始体素并实现实时渲染能力。
- 实验表明,该方法在真实世界数据集上的性能与最先进的体积渲染方法相当。
- 该方法用更少的原始体素达到相似的重建保真度。
- 研究提供了关于体积渲染几何学的深入理解。
点此查看论文截图




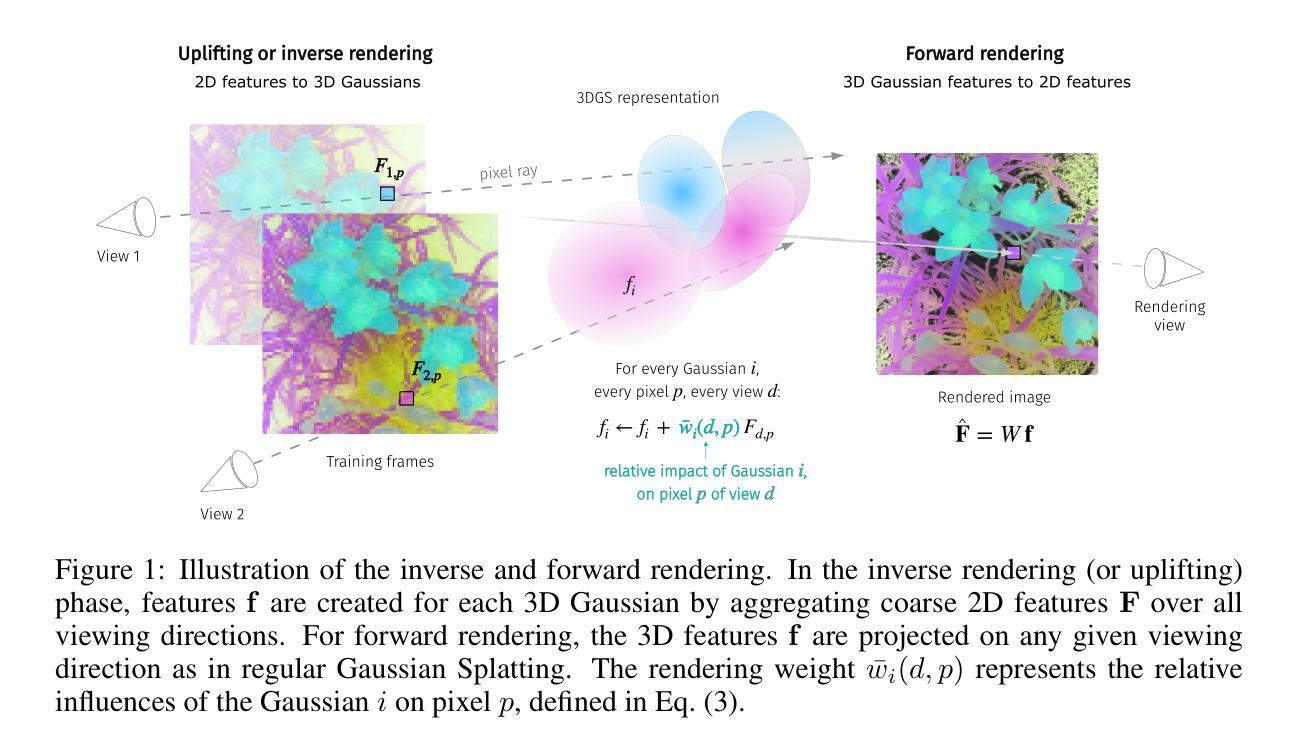
LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes
Authors:Juliette Marrie, Romain Menegaux, Michael Arbel, Diane Larlus, Julien Mairal
We address the problem of extending the capabilities of vision foundation models such as DINO, SAM, and CLIP, to 3D tasks. Specifically, we introduce a novel method to uplift 2D image features into Gaussian Splatting representations of 3D scenes. Unlike traditional approaches that rely on minimizing a reconstruction loss, our method employs a simpler and more efficient feature aggregation technique, augmented by a graph diffusion mechanism. Graph diffusion refines 3D features, such as coarse segmentation masks, by leveraging 3D geometry and pairwise similarities induced by DINOv2. Our approach achieves performance comparable to the state of the art on multiple downstream tasks while delivering significant speed-ups. Notably, we obtain competitive segmentation results using generic DINOv2 features, despite DINOv2 not being trained on millions of annotated segmentation masks like SAM. When applied to CLIP features, our method demonstrates strong performance in open-vocabulary object localization tasks, highlighting the versatility of our approach.
我们致力于扩展诸如DINO、SAM和CLIP等视觉基础模型在3D任务上的能力。具体来说,我们引入了一种新颖的方法,将二维图像特征提升为三维场景的高斯分裂表示。不同于传统方法依赖于最小化重建损失,我们的方法采用更简单、更高效的特征聚合技术,辅以图扩散机制。图扩散通过利用三维几何和由DINOv2产生的配对相似性来完善三维特征,如粗略分割掩膜。我们的方法在多个下游任务上实现了与最新技术相当的性能,同时提供了显著的速度提升。值得注意的是,即使DINOv2没有像SAM那样在数百万个标注的分割掩膜上进行训练,我们仍然使用通用的DINOv2特征获得了具有竞争力的分割结果。当应用于CLIP特征时,我们的方法在开放词汇对象定位任务中表现出强大的性能,凸显了我们方法的通用性。
论文及项目相关链接
PDF Project page: https://juliettemarrie.github.io/ludvig
Summary
该文本主要介绍了如何将二维图像特征提升到三维场景的高斯投影表示。提出一种新方法,通过图扩散机制简化特征聚合技术,不依赖传统的重建损失最小化方法。该方法可以在多个下游任务上实现与最新技术相当的性能,并显著提高速度。此外,即使在没有经过数百万个分割掩膜训练的DINOv2特征下,也能获得具有竞争力的分割结果。当应用于CLIP特征时,该方法在开放词汇对象定位任务中表现出强大的性能。
Key Takeaways
- 该文本提出了将二维图像特征提升到三维场景的高斯投影表示的新方法。
- 与传统方法不同,该方法采用更简单、更高效的特征聚合技术,并结合图扩散机制进行改进。
- 图扩散机制能够利用三维几何和由DINOv2产生的配对相似性来优化三维特征,如粗分割掩膜。
- 该方法在多个下游任务上的性能与最新技术相当,并且提供显著的速度提升。
- 在未经过大量分割掩膜训练的DINOv2特征下,该方法仍然能获得具有竞争力的分割结果。
- 当应用于CLIP特征时,该方法在开放词汇对象定位任务中表现出强大的性能,凸显了其通用性。
点此查看论文截图