⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-30 更新
ASTRAL: Automated Safety Testing of Large Language Models
Authors:Miriam Ugarte, Pablo Valle, José Antonio Parejo, Sergio Segura, Aitor Arrieta
Large Language Models (LLMs) have recently gained attention due to their ability to understand and generate sophisticated human-like content. However, ensuring their safety is paramount as they might provide harmful and unsafe responses. Existing LLM testing frameworks address various safety-related concerns (e.g., drugs, terrorism, animal abuse) but often face challenges due to unbalanced and obsolete datasets. In this paper, we present ASTRAL, a tool that automates the generation and execution of test cases (i.e., prompts) for testing the safety of LLMs. First, we introduce a novel black-box coverage criterion to generate balanced and diverse unsafe test inputs across a diverse set of safety categories as well as linguistic writing characteristics (i.e., different style and persuasive writing techniques). Second, we propose an LLM-based approach that leverages Retrieval Augmented Generation (RAG), few-shot prompting strategies and web browsing to generate up-to-date test inputs. Lastly, similar to current LLM test automation techniques, we leverage LLMs as test oracles to distinguish between safe and unsafe test outputs, allowing a fully automated testing approach. We conduct an extensive evaluation on well-known LLMs, revealing the following key findings: i) GPT3.5 outperforms other LLMs when acting as the test oracle, accurately detecting unsafe responses, and even surpassing more recent LLMs (e.g., GPT-4), as well as LLMs that are specifically tailored to detect unsafe LLM outputs (e.g., LlamaGuard); ii) the results confirm that our approach can uncover nearly twice as many unsafe LLM behaviors with the same number of test inputs compared to currently used static datasets; and iii) our black-box coverage criterion combined with web browsing can effectively guide the LLM on generating up-to-date unsafe test inputs, significantly increasing the number of unsafe LLM behaviors.
大型语言模型(LLM)由于其能够理解和生成复杂的人类内容而受到关注。然而,确保它们的安全至关重要,因为它们可能会提供有害和不安全的回应。现有的LLM测试框架解决了各种与安全相关的问题(例如,毒品、恐怖主义、虐待动物),但由于数据集不平衡和过时,常常面临挑战。在本文中,我们介绍了ASTRAL,这是一个能够自动生成和执行测试用例(即提示)以测试LLM安全性的工具。首先,我们引入了一种新的黑盒覆盖标准,以生成在安全类别(如不同风格和说服性写作技巧)之间平衡和多样化的不安全测试输入。其次,我们提出了一种基于LLM的方法,利用检索增强生成(RAG)、少数提示策略和网页浏览来生成最新的测试输入。最后,与当前的LLM测试自动化技术类似,我们利用LLM作为测试裁决者来区分安全和不安全的测试输出,从而实现全自动化测试方法。我们对知名的LLM进行了广泛评估,揭示了以下关键发现:i)GPT3.5在作为测试裁决者时表现出比其他LLM更优越的性能,能够准确检测不安全的响应,甚至超越更新近的LLM(例如GPT-4),以及专门用于检测不安全LLM输出的LLM(如LlamaGuard);ii)结果证实,我们的方法可以覆盖近两倍的不安全LLM行为,与使用相同数量的测试输入相比静态数据集;iii)我们的黑盒覆盖标准与网页浏览相结合,可以有效地指导LLM生成最新的不安全测试输入,从而显著增加不安全LLM的行为数量。
论文及项目相关链接
Summary
大规模语言模型(LLMs)能够理解和生成复杂的人类内容,受到广泛关注。然而,确保其安全性至关重要,因为它们可能会提供有害和不安全的回应。现有LLM测试框架解决了各种安全相关问题,但仍面临不平衡和过时数据集的挑战。本文介绍了一种名为ASTRAL的工具,它可以自动生成并执行测试用例以测试LLMs的安全性。首先,我们提出了一种新颖的黑盒覆盖标准来生成平衡和多样化的不安全测试输入,涵盖多种安全类别和语言写作特征。其次,我们提出了一种基于LLM的方法,利用检索增强生成(RAG)、少镜头提示策略和网页浏览来生成最新的测试输入。最后,我们利用LLMs作为测试仲裁者来区分安全和不安全测试输出,从而实现全自动测试方法。对知名LLMs的广泛评估揭示了以下关键发现。
Key Takeaways
- ASTRAL工具通过自动生成并执行测试用例来测试LLMs的安全性,解决了现有测试框架面临的不平衡和过时数据集的问题。
- 引入黑盒覆盖标准来生成平衡和多样化的不安全测试输入,涵盖多种安全类别和语言特征。
- 利用LLM结合检索增强生成(RAG)和少镜头提示策略生成最新测试输入。
- GPT3.5作为测试仲裁者表现优异,能准确检测不安全回应,甚至超越GPT-4等更新模型以及针对不安全LLM输出的检测工具LlamaGuard。
- 结果表明,与现有静态数据集相比,使用相同数量的测试输入时,该方法可以检测到近两倍的不安全LLM行为。
- 结合黑盒覆盖标准和网页浏览可有效引导LLM生成最新的不安全测试输入,显著提高检测到的不安全LLM行为数量。
- 该方法具有广泛的应用前景,可应用于评估LLM在各种场景中的安全性表现。
点此查看论文截图







Few Edges Are Enough: Few-Shot Network Attack Detection with Graph Neural Networks
Authors:Tristan Bilot, Nour El Madhoun, Khaldoun Al Agha, Anis Zouaoui
Detecting cyberattacks using Graph Neural Networks (GNNs) has seen promising results recently. Most of the state-of-the-art models that leverage these techniques require labeled examples, hard to obtain in many real-world scenarios. To address this issue, unsupervised learning and Self-Supervised Learning (SSL) have emerged as interesting approaches to reduce the dependency on labeled data. Nonetheless, these methods tend to yield more anomalous detection algorithms rather than effective attack detection systems. This paper introduces Few Edges Are Enough (FEAE), a GNN-based architecture trained with SSL and Few-Shot Learning (FSL) to better distinguish between false positive anomalies and actual attacks. To maximize the potential of few-shot examples, our model employs a hybrid self-supervised objective that combines the advantages of contrastive-based and reconstruction-based SSL. By leveraging only a minimal number of labeled attack events, represented as attack edges, FEAE achieves competitive performance on two well-known network datasets compared to both supervised and unsupervised methods. Remarkably, our experimental results unveil that employing only 1 malicious event for each attack type in the dataset is sufficient to achieve substantial improvements. FEAE not only outperforms self-supervised GNN baselines but also surpasses some supervised approaches on one of the datasets.
使用图神经网络(GNNs)检测网络攻击最近取得了令人鼓舞的结果。大多数利用这些技术的最先进的模型都需要有标签的示例,这在许多真实场景中很难获得。为了解决这一问题,无监督学习和自监督学习(SSL)作为减少对有标签数据依赖的有趣方法而出现。然而,这些方法更倾向于产生异常检测算法,而不是有效的攻击检测系统。本文介绍了FEAE(少数边缘已足够),这是一种基于图神经网络的架构,采用自监督学习和小样本学习(FSL)进行训练,以更好地区分假阳性异常值和实际攻击。为了最大化小样本示例的潜力,我们的模型采用了一种混合自监督目标,结合了基于对比和基于重建的SSL的优点。通过利用只有少数标记的攻击事件(表示为攻击边缘),FEAE在两个著名的网络数据集上的性能表现具有竞争力,与监督和无监督方法相比均有不俗表现。值得一提的是,我们的实验结果表明,在数据集中每种攻击类型只使用1个恶意事件就足以实现重大改进。FEAE不仅超越了自监督GNN基线,而且在其中一个数据集上甚至超过了某些监督方法。
论文及项目相关链接
PDF This is the version of the author, accepted for publication at IWSEC 2024. Published version available at https://link.springer.com/chapter/10.1007/978-981-97-7737-2_15
Summary
基于图神经网络(GNNs)的网络安全攻击检测方法已经取得显著的成果。现有的高级模型主要依赖于标记数据,在真实环境中很难获得。针对此问题,研究者提出了无监督学习和自监督学习(SSL)方法,以减少对标记数据的依赖,但倾向于产生异常检测算法而非有效的攻击检测系统。本文介绍了一种基于SSL和少量学习(FSL)的GNN架构FEAE,通过最小化标注攻击事件的数目,FEAE可以区分出误报异常和实际攻击事件。该架构使用结合了对比和重建的混合自监督目标来提高有限示例的性能。通过在两个知名网络数据集上进行实验,FEAE在性能上超过了监督和无监督方法。特别地,实验结果显示只需每个攻击类型使用一次恶意事件就能实现显著的提升。FEAE不仅超越了自监督的GNN基线,还在其中一个数据集上超越了某些监督方法。
Key Takeaways
- GNNs在网络安全攻击检测中展现出良好效果。
- 当前模型对标记数据高度依赖,真实环境中获取困难。
- 无监督学习和SSL方法被提出以解决对标记数据的依赖问题。
- 这些方法主要产生异常检测算法,而非高效的攻击检测系统。
- FEAE架构结合SSL和少量学习(FSL),以提高对有限样本的学习性能。
- FEAE使用混合自监督目标,结合了对比和重建方法。
点此查看论文截图


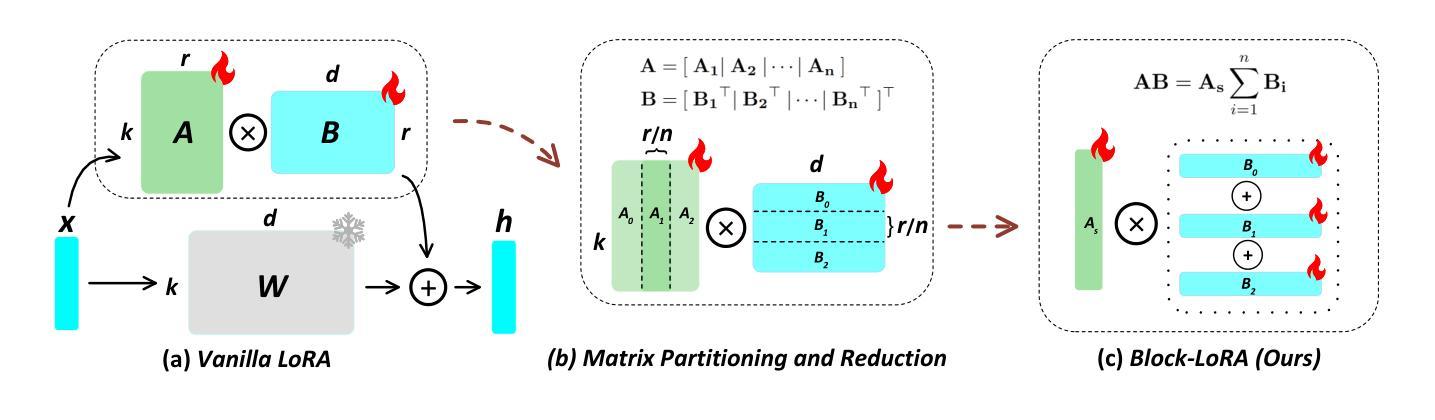
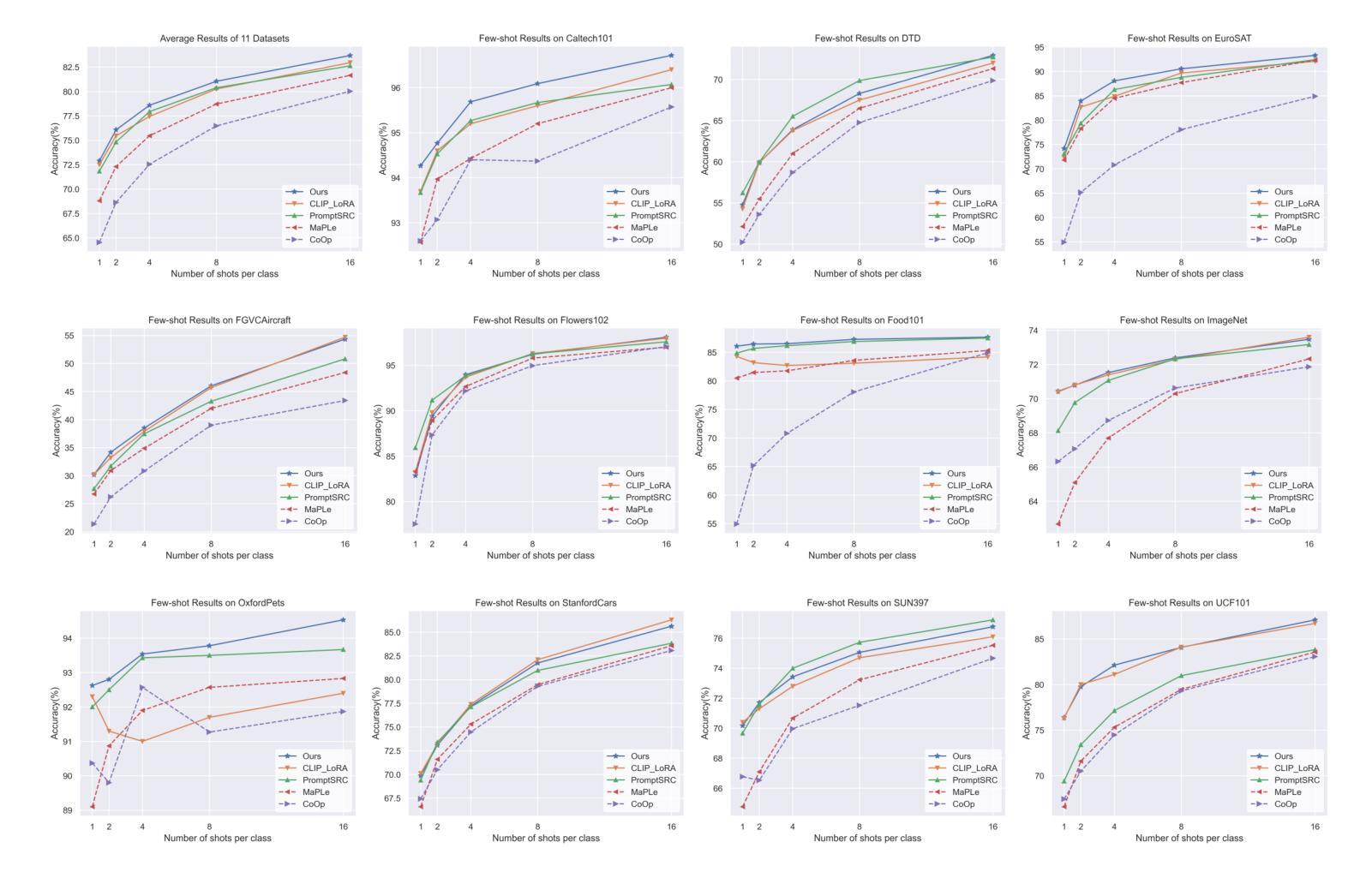
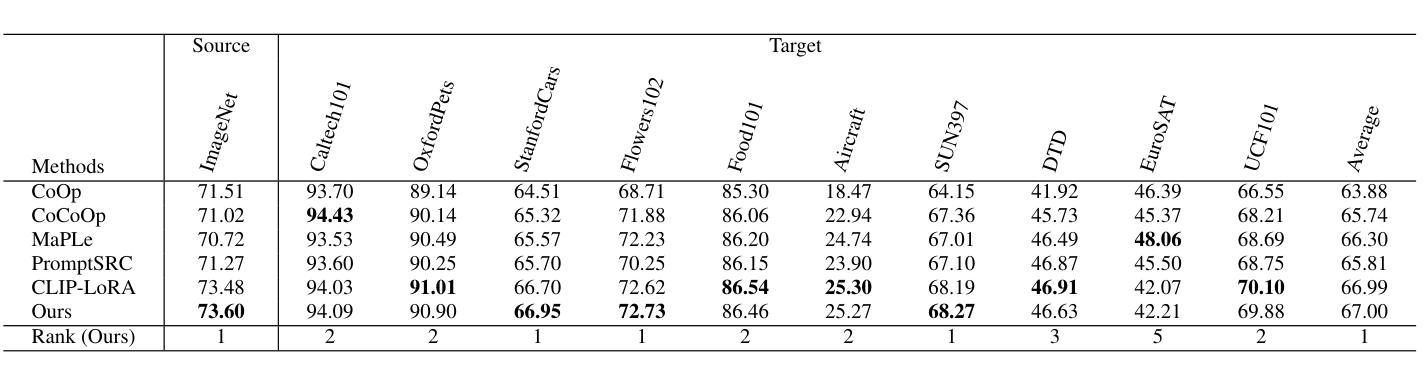
One Head Eight Arms: Block Matrix based Low Rank Adaptation for CLIP-based Few-Shot Learning
Authors:Chunpeng Zhou, Qianqian Shen, Zhi Yu, Jiajun Bu, Haishuai Wang
Recent advancements in fine-tuning Vision-Language Foundation Models (VLMs) have garnered significant attention for their effectiveness in downstream few-shot learning tasks.While these recent approaches exhibits some performance improvements, they often suffer from excessive training parameters and high computational costs. To address these challenges, we propose a novel Block matrix-based low-rank adaptation framework, called Block-LoRA, for fine-tuning VLMs on downstream few-shot tasks. Inspired by recent work on Low-Rank Adaptation (LoRA), Block-LoRA partitions the original low-rank decomposition matrix of LoRA into a series of sub-matrices while sharing all down-projection sub-matrices. This structure not only reduces the number of training parameters, but also transforms certain complex matrix multiplication operations into simpler matrix addition, significantly lowering the computational cost of fine-tuning. Notably, Block-LoRA enables fine-tuning CLIP on the ImageNet few-shot benchmark using a single 24GB GPU. We also show that Block-LoRA has the more tighter bound of generalization error than vanilla LoRA. Without bells and whistles, extensive experiments demonstrate that Block-LoRA achieves competitive performance compared to state-of-the-art CLIP-based few-shot methods, while maintaining a low training parameters count and reduced computational overhead.
最近,对视觉语言基础模型(VLMs)进行微调方面的最新进展已引起人们对其在下游小样本学习任务中有效性的广泛关注。虽然这些最新方法表现出了一些性能改进,但它们通常存在训练参数过多和计算成本过高的缺点。为了解决这些挑战,我们提出了一种基于块矩阵的低秩自适应框架,称为Block-LoRA,用于在下游小样本任务上对VLMs进行微调。Block-LoRA受到最近低秩适应(LoRA)工作的启发,它将LoRA的原始低秩分解矩阵划分为一系列子矩阵,同时共享所有下投影子矩阵。这种结构不仅减少了训练参数的数量,而且将某些复杂的矩阵乘法运算转换为更简单的矩阵加法,从而显著降低了微调的计算成本。值得注意的是,Block-LoRA能够在使用单个24GB GPU的情况下,对ImageNet小样本基准测试进行CLIP微调。我们还表明,Block-LoRA具有比传统LoRA更严格的一般化误差界限。没有额外的修饰,大量实验证明,Block-LoRA与基于CLIP的小样本方法相比具有竞争力,同时保持较低的训练参数数量和减少的计算开销。
论文及项目相关链接
PDF Under Review
Summary
近期对视觉语言基础模型(VLMs)的微调技术取得了显著进展,这引起了人们对下游少样本学习任务的关注。尽管这些方法表现出了一定的性能提升,但它们常常面临训练参数过多和计算成本高昂的问题。为解决这些挑战,我们提出了一种基于块矩阵的低秩适应框架——Block-LoRA,用于在下游少样本任务上微调VLMs。Block-LoRA通过引入块矩阵分解减少训练参数数量,并简化了复杂矩阵乘法运算,从而降低了计算成本。实验表明,Block-LoRA在ImageNet少样本基准测试上实现了有竞争力的性能表现,并具有更低的训练参数和计算开销。
Key Takeaways
- 近期对视觉语言基础模型的微调技术取得了进展,引起了对少样本学习任务的关注。
- 现有方法面临训练参数过多和计算成本高昂的挑战。
- 提出了一种基于块矩阵的低秩适应框架——Block-LoRA,用于微调VLMs。
- Block-LoRA通过块矩阵分解减少训练参数数量,并简化计算。
- Block-LoRA在ImageNet少样本基准测试上表现有竞争力。
- Block-LoRA具有更低的训练参数和计算开销。
点此查看论文截图


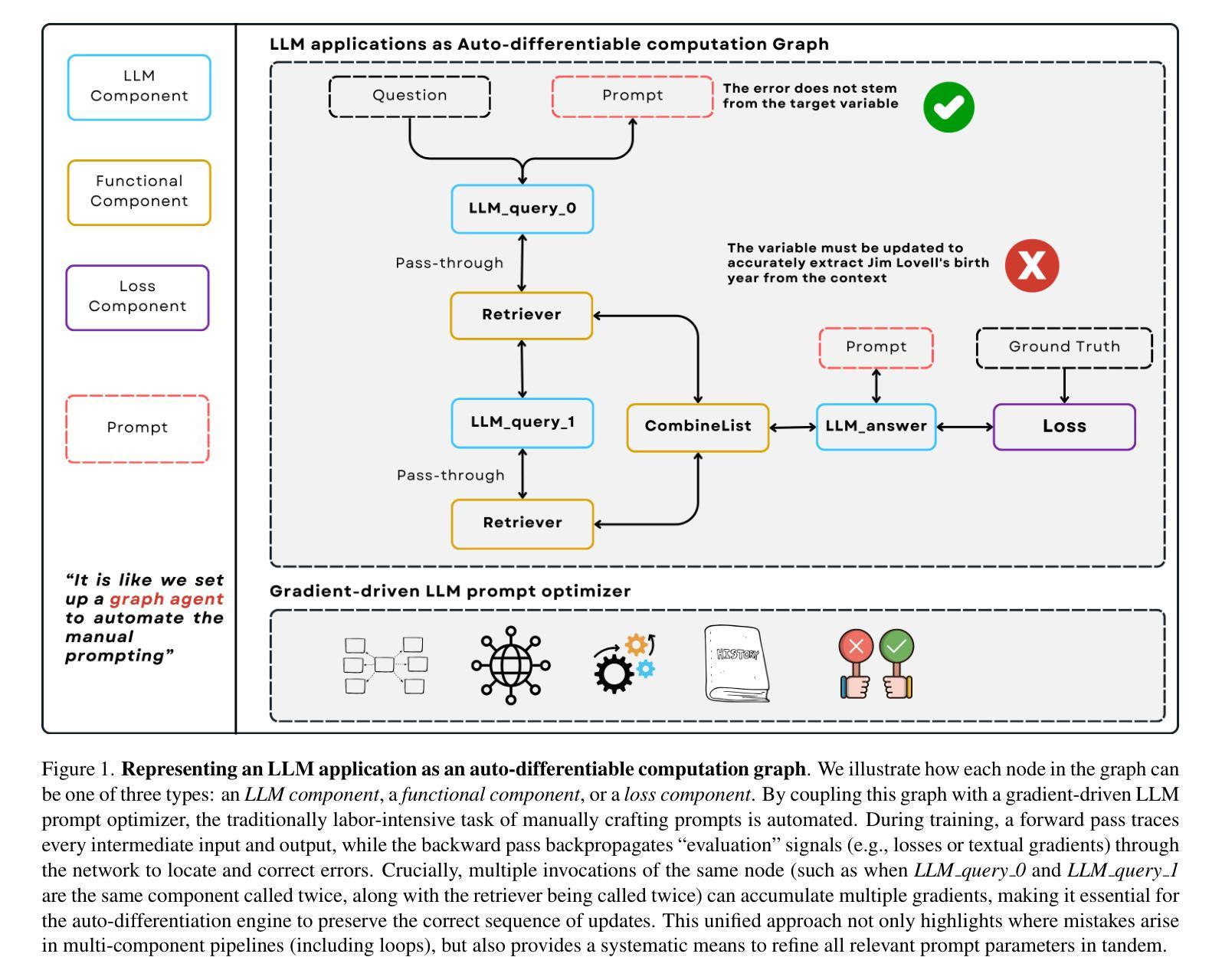
Auto-Differentiating Any LLM Workflow: A Farewell to Manual Prompting
Authors:Li Yin, Zhangyang Wang
Large Language Models (LLMs) have reshaped natural language processing, powering applications from multi-hop retrieval and question answering to autonomous agent workflows. Yet, prompt engineering – the task of crafting textual inputs to effectively direct LLMs – remains difficult and labor-intensive, particularly for complex pipelines that combine multiple LLM calls with functional operations like retrieval and data formatting. We introduce LLM-AutoDiff: a novel framework for Automatic Prompt Engineering (APE) that extends textual gradient-based methods (such as Text-Grad) to multi-component, potentially cyclic LLM architectures. Implemented within the AdalFlow library, LLM-AutoDiff treats each textual input as a trainable parameter and uses a frozen backward engine LLM to generate feedback-akin to textual gradients – that guide iterative prompt updates. Unlike prior single-node approaches, LLM-AutoDiff inherently accommodates functional nodes, preserves time-sequential behavior in repeated calls (e.g., multi-hop loops), and combats the “lost-in-the-middle” problem by isolating distinct sub-prompts (instructions, formats, or few-shot examples). It further boosts training efficiency by focusing on error-prone samples through selective gradient computation. Across diverse tasks, including single-step classification, multi-hop retrieval-based QA, and agent-driven pipelines, LLM-AutoDiff consistently outperforms existing textual gradient baselines in both accuracy and training cost. By unifying prompt optimization through a graph-centric lens, LLM-AutoDiff offers a powerful new paradigm for scaling and automating LLM workflows - mirroring the transformative role that automatic differentiation libraries have long played in neural network research.
大型语言模型(LLM)已经重塑了自然语言处理领域,推动了从多跳检索和问答到自主代理工作流程的各种应用。然而,提示工程——即设计文本输入以有效指导LLM的任务——仍然很困难且劳动密集型,特别是对于结合多个LLM调用与检索和数据格式化等功能的复杂管道。我们推出了LLM-AutoDiff:一种用于自动提示工程(APE)的新型框架,它将基于文本的梯度方法(如Text-Grad)扩展到多组件、可能循环的LLM架构。LLM-AutoDiff在AdalFlow库中实现,它将每个文本输入视为可训练参数,并使用冻结的向后引擎LLM生成反馈来指导迭代提示更新,类似于文本梯度。不同于先前的单点方法,LLM-AutoDiff天然适应功能节点,在重复调用中保持时间顺序行为(例如,多跳循环),并通过隔离不同的子提示(指令、格式或少量示例)来解决“迷失在中间”的问题。它通过选择性梯度计算来重点关注易出错样本,进一步提高训练效率。在包括单步分类、多跳检索问答和代理驱动管道等各种任务中,LLM-AutoDiff在准确率和训练成本方面均优于现有的文本梯度基线。通过以图为中心的视角统一提示优化,LLM-AutoDiff为扩展和自动化LLM工作流程提供了强大的新范式,这与自动微分库在神经网络研究中长期发挥的变革性作用相呼应。
论文及项目相关链接
Summary
大型语言模型(LLM)在自然语言处理领域的应用广泛,包括多跳检索、问答和自主代理工作流程等。然而,提示工程(即有效指导LLM的文本输入制作任务)仍然困难且劳动密集,特别是在结合多个LLM调用与功能操作(如检索和数据格式化)的复杂管道中。我们推出LLM-AutoDiff,一种用于自动提示工程(APE)的新型框架,它将文本梯度方法扩展到多组件、潜在循环的LLM架构。LLM-AutoDiff将每个文本输入视为可训练参数,并使用冻结的逆向引擎LLM生成反馈,以指导迭代提示更新。它不同于先前的单点方法,天然适应功能节点,保持重复调用中的时间顺序行为(如多跳循环),并通过隔离不同子提示(指令、格式或少量示例)来解决“迷失在中间”的问题。通过选择性梯度计算专注于易出错样本,提高训练效率。在包括单步分类、多跳检索问答和代理驱动管道等多样化任务中,LLM-AutoDiff在准确性和训练成本方面均优于现有文本梯度基线。通过统一的图形中心视角整合提示优化,LLM-AutoDiff为扩展和自动化LLM工作流程提供了强大的新范式。
Key Takeaways
- LLM在自然语言处理领域的应用广泛,但提示工程仍然是一个挑战。
- LLM-AutoDiff是一个用于自动提示工程的框架,适用于多组件和潜在循环的LLM架构。
- LLM-AutoDiff将文本输入视为可训练参数,并使用冻结的逆向引擎LLM生成反馈。
- 与先前的单点方法不同,LLM-AutoDiff适应功能节点,并保持时间顺序行为。
- LLM-AutoDiff通过隔离子提示解决“迷失在中间”的问题,并提高训练效率。
- LLM-AutoDiff在多样任务中表现优异,包括单步分类、多跳检索问答和代理驱动管道。
点此查看论文截图


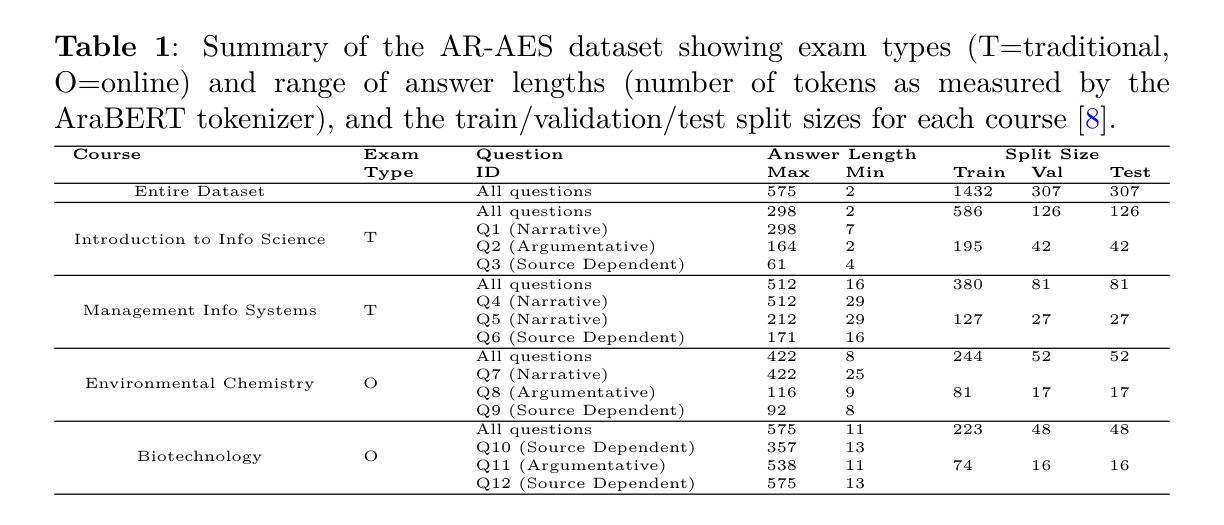
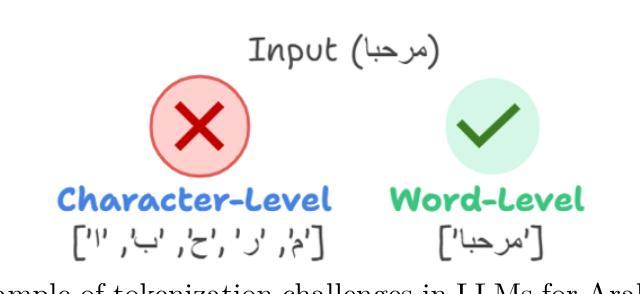
How well can LLMs Grade Essays in Arabic?
Authors:Rayed Ghazawi, Edwin Simpson
This research assesses the effectiveness of state-of-the-art large language models (LLMs), including ChatGPT, Llama, Aya, Jais, and ACEGPT, in the task of Arabic automated essay scoring (AES) using the AR-AES dataset. It explores various evaluation methodologies, including zero-shot, few-shot in-context learning, and fine-tuning, and examines the influence of instruction-following capabilities through the inclusion of marking guidelines within the prompts. A mixed-language prompting strategy, integrating English prompts with Arabic content, was implemented to improve model comprehension and performance. Among the models tested, ACEGPT demonstrated the strongest performance across the dataset, achieving a Quadratic Weighted Kappa (QWK) of 0.67, but was outperformed by a smaller BERT-based model with a QWK of 0.88. The study identifies challenges faced by LLMs in processing Arabic, including tokenization complexities and higher computational demands. Performance variation across different courses underscores the need for adaptive models capable of handling diverse assessment formats and highlights the positive impact of effective prompt engineering on improving LLM outputs. To the best of our knowledge, this study is the first to empirically evaluate the performance of multiple generative Large Language Models (LLMs) on Arabic essays using authentic student data.
本文研究了当前先进的大型语言模型(LLM),包括ChatGPT、Llama、Aya、Jais和ACEGPT,在阿拉伯自动作文评分(AES)任务中使用AR-AES数据集的有效性。它探索了各种评估方法,包括零样本、少样本上下文学习和微调,并通过提示中包含的标记指南研究了指令遵循能力的影响。实施了一种混合语言提示策略,将英语提示与阿拉伯内容相结合,以提高模型的理解力和性能。在测试的模型中,ACEGPT在整个数据集上表现最强,达到0.67的二次加权kappa(QWK),但被一个较小的基于BERT的模型以0.88的QWK超越。该研究确定了LLM在处理阿拉伯语时面临的挑战,包括分词复杂性和更高的计算需求。不同课程之间的性能差异强调了需要能够适应各种评估格式的模型,并突出了有效提示工程对改善LLM输出的积极影响。据我们所知,这项研究是首次实证评估多个生成式大型语言模型(LLM)在阿拉伯作文上的表现,使用了真实的学生数据。
论文及项目相关链接
PDF 18 pages
Summary
该研究发现评估了包括ChatGPT、Llama、Aya、Jais和ACEGPT在内的当前先进技术的大型语言模型在阿拉伯自动作文评分任务中的有效性。该研究使用了AR-AES数据集,探讨了零样本、少样本上下文学习和微调等评估方法,并考察了模型遵循指令能力的影响。通过混合语言提示策略(整合英语提示和阿拉伯内容),提高了模型的理解和性能。在测试中,ACEGPT在数据集上表现最佳,二次加权κ值达到0.67,但仍被基于BERT的小型模型超越,后者二次加权κ值为0.88。该研究指出了大型语言模型在处理阿拉伯语时面临的挑战,包括令牌化复杂性和更高的计算需求。不同课程之间的性能变化强调了需要能够适应不同评估格式的模型,并突出了有效提示工程对改善大型语言模型输出的积极影响。据我们所知,这是首次使用真实学生数据实证评估多个生成式大型语言模型在阿拉伯作文上的表现。
Key Takeaways
- 大型语言模型在阿拉伯自动作文评分任务中的有效性得到评估。
- 多种评估方法,包括零样本、少样本上下文学习和微调被探讨。
- ACEGPT在数据集上表现良好,但仍有提升空间。
- 混合语言提示策略提高了模型的理解和性能。
- 基于BERT的小型模型在某些评估指标上超越了大型语言模型。
- 大型语言模型在处理阿拉伯语时面临挑战,如令牌化复杂性和高计算需求。
点此查看论文截图

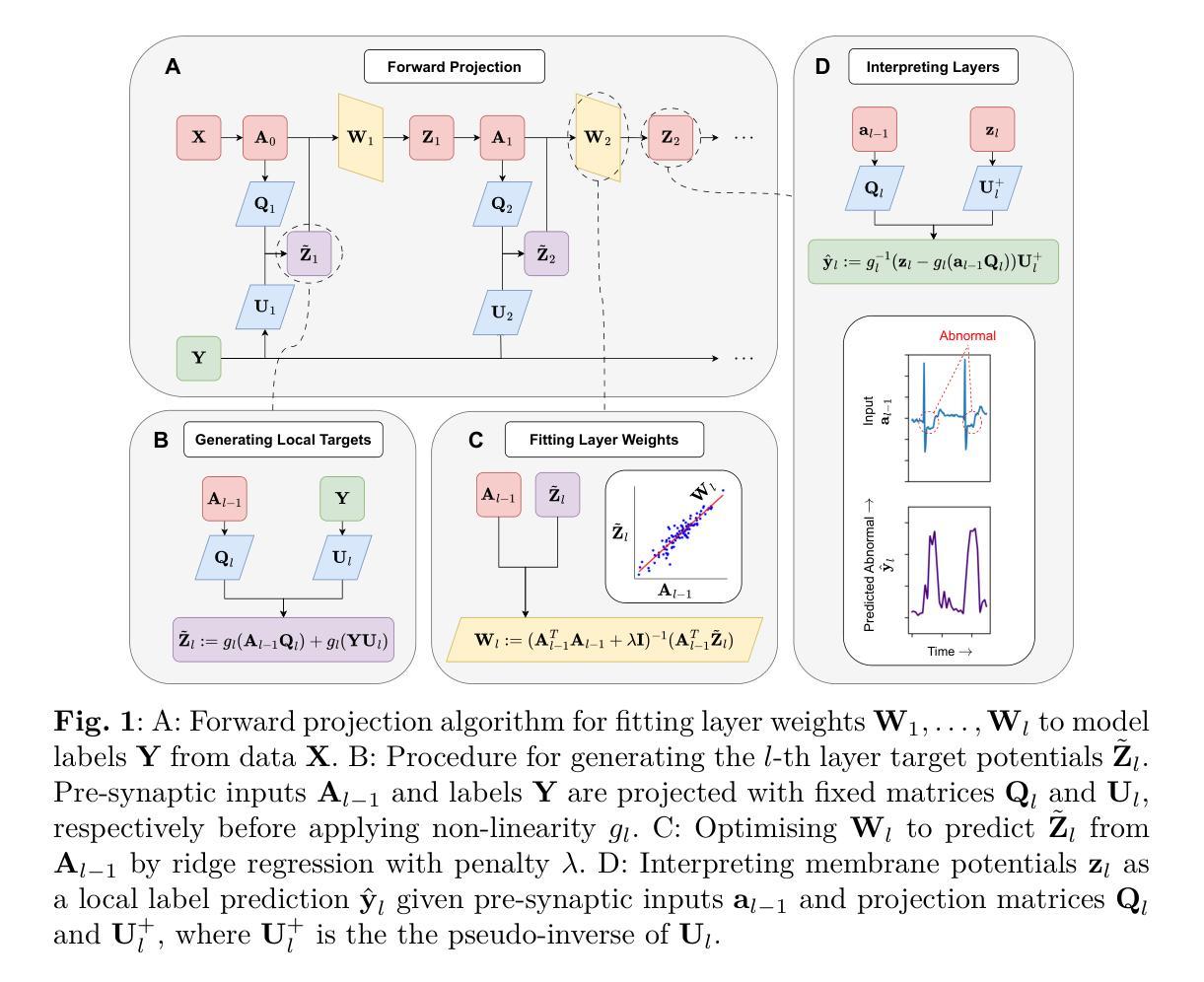
Closed-Form Feedback-Free Learning with Forward Projection
Authors:Robert O’Shea, Bipin Rajendran
State-of-the-art methods for backpropagation-free learning employ local error feedback to direct iterative optimisation via gradient descent. In this study, we examine the more restrictive setting where retrograde communication from neuronal outputs is unavailable for pre-synaptic weight optimisation. To address this challenge, we propose Forward Projection (FP). This novel randomised closed-form training method requires only a single forward pass over the entire dataset for model fitting, without retrograde communication. Target values for pre-activation membrane potentials are generated layer-wise via nonlinear projections of pre-synaptic inputs and the labels. Local loss functions are optimised over pre-synaptic inputs using closed-form regression, without feedback from neuronal outputs or downstream layers. Interpretability is a key advantage of FP training; membrane potentials of hidden neurons in FP-trained networks encode information which is interpretable layer-wise as label predictions. We demonstrate the effectiveness of FP across four biomedical datasets. In few-shot learning tasks, FP yielded more generalisable models than those optimised via backpropagation. In large-sample tasks, FP-based models achieve generalisation comparable to gradient descent-based local learning methods while requiring only a single forward propagation step, achieving significant speed up for training. Interpretation functions defined on local neuronal activity in FP-based models successfully identified clinically salient features for diagnosis in two biomedical datasets. Forward Projection is a computationally efficient machine learning approach that yields interpretable neural network models without retrograde communication of neuronal activity during training.
当前最先进的无反向传播学习方法采用局部误差反馈来指导通过梯度下降法的迭代优化过程。在这项研究中,我们探讨了更严格的设置环境,即当神经元输出的逆向通信无法用于突触前权重优化时的情况。为了应对这一挑战,我们提出了“前向投影”(FP)方法。这种新型随机闭合形式的训练方法仅需对整个数据集进行一次前向传递即可完成模型拟合,无需逆向通信。目标值通过突触前输入的非线性投影和标签逐层生成。局部损失函数通过闭合形式的回归对突触前输入进行优化,无需神经元输出或下游层的反馈。可解释性是FP训练的关键优势;FP训练后的网络中隐藏神经元的膜电位编码的信息可以按层解读为标签预测。我们在四个生物医学数据集上展示了FP的有效性。在少量样本学习任务中,FP产生的模型比通过反向传播优化的模型更具泛化能力。在大样本任务中,FP模型的泛化能力与基于梯度下降的局部学习方法相当,但仅需进行一次前向传播步骤,大大加快了训练速度。在FP模型上定义的解读函数成功识别了两个生物医学数据集中用于诊断的临床重要特征。前向投影是一种计算效率高的机器学习方法,可在训练过程中无需神经元活动的逆向通信,生成可解释的神经网络模型。
论文及项目相关链接
PDF 26 pages, 5 figures
Summary
本文提出了一种名为Forward Projection(FP)的新型随机闭式训练方法,该方法在无需逆向神经元输出进行预突触权重优化的限制条件下,仅通过单次前向传播即可完成模型拟合。FP通过逐层生成目标预激活膜电位值,并利用闭式回归对预突触输入进行局部损失函数优化,无需神经元输出的反馈或下游层级的信息。FP训练的优势在于其解释性,隐藏层神经元的膜电位编码的信息在逐层上可解读为标签预测。在四个生物医学数据集上,FP在少样本学习任务中表现出更高的模型泛化能力,在大样本任务中其泛化能力与基于梯度下降的地方学习方法相当,但只需进行一次前向传播,实现了训练速度的显著加速。此外,基于FP模型的解释函数能够成功识别两个生物医学数据集中的临床显著特征,为诊断提供帮助。总体而言,Forward Projection是一种计算高效的机器学习方式,能够在训练过程中无需神经元活动的逆向通信,生成可解释性强的神经网络模型。
Key Takeaways
- Forward Projection (FP) 是一种新型的随机闭式训练方法,仅需单次前向传播即可完成模型拟合,无需逆向通信。
- FP通过逐层生成目标预激活膜电位值,利用闭式回归优化局部损失函数。
- FP提高模型解释性,隐藏层神经元的膜电位编码的信息可解读为标签预测。
- 在少样本学习任务中,FP表现出更高的模型泛化能力。
- 在大样本任务中,FP的泛化能力与基于梯度下降的方法相当,但训练速度更快。
- 基于FP模型的解释函数能识别临床显著特征,有助于诊断。
点此查看论文截图

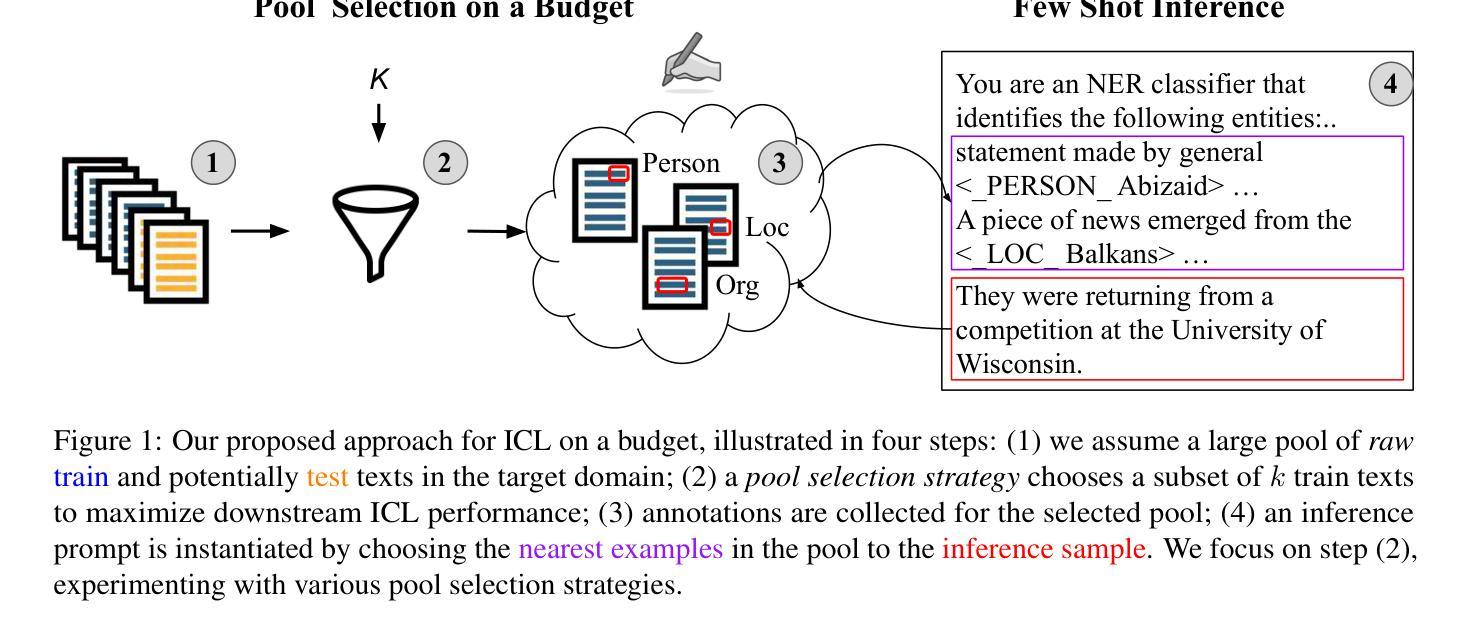
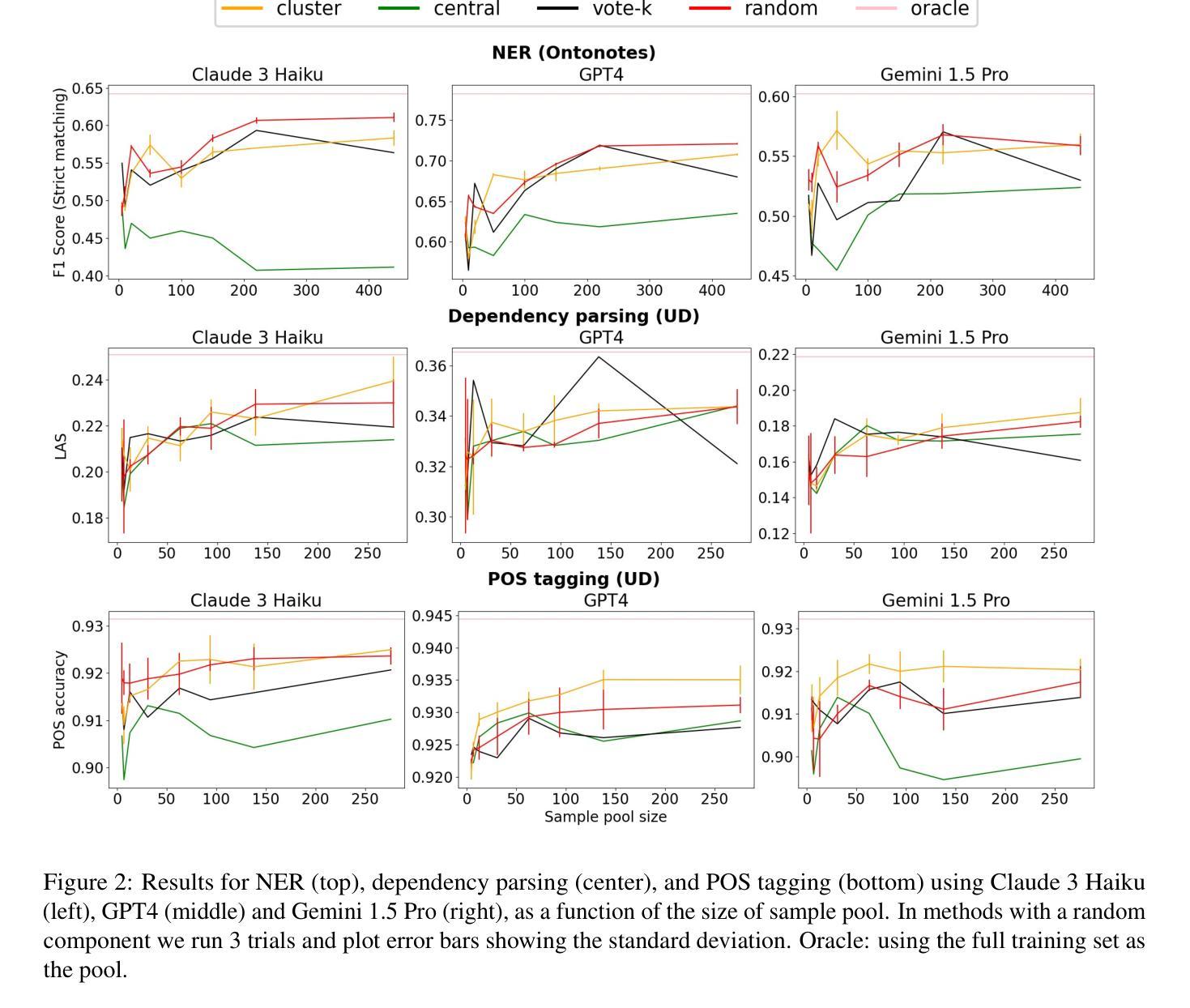
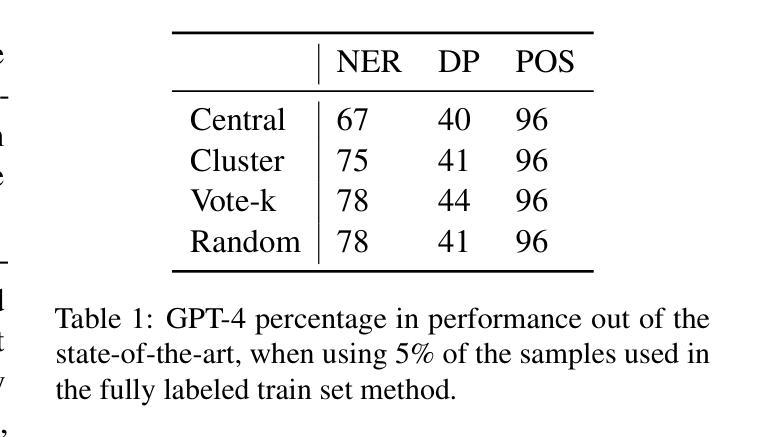
In-Context Learning on a Budget: A Case Study in Token Classification
Authors:Uri Berger, Tal Baumel, Gabriel Stanovsky
Few shot in-context learning (ICL) typically assumes access to large annotated training sets. However, in many real world scenarios, such as domain adaptation, there is only a limited budget to annotate a small number of samples, with the goal of maximizing downstream performance. We study various methods for selecting samples to annotate within a predefined budget, focusing on token classification tasks, which are expensive to annotate and are relatively less studied in ICL setups. Across various tasks, models, and datasets, we observe that no method significantly outperforms the others, with most yielding similar results, including random sample selection for annotation. Moreover, we demonstrate that a relatively small annotated sample pool can achieve performance comparable to using the entire training set. We hope that future work adopts our realistic paradigm which takes annotation budget into account.
少样本上下文学习(ICL)通常假设可以访问大型注释训练集。然而,在许多现实世界场景中,如域适应,注释样本的预算有限,目标是最大化下游性能。我们研究了在预定预算内选择样本进行注释的各种方法,重点关注令牌分类任务,这些任务注释成本高昂,在ICL设置中相对研究较少。在各种任务、模型和数据集上,我们观察到没有一种方法显著优于其他方法,大多数方法的结果相似,包括随机样本选择进行注释。此外,我们证明了一个相对较小的注释样本池可以实现与使用整个训练集相当的性能。我们希望未来的工作能采用我们考虑注释预算的现实主义范式。
论文及项目相关链接
Summary
在有限的标注预算下,针对token分类任务,研究不同的样本标注选择方法对于提高下游性能至关重要。本研究发现不同方法和模型在标注样本选择上表现相似,即使是随机选择也有较好结果。少量标注样本即可达到与使用整个训练集相近的性能。建议未来研究考虑标注预算的现实情况。
Key Takeaways
- 研究关注于在有限的标注预算下,如何选择样本进行标注,以最大化下游性能。
- 针对token分类任务,这些任务在标注时成本较高,在ICL设置中的研究相对较少。
- 研究发现不同标注样本选择方法表现相似,包括随机样本选择。
- 即使使用相对较小的标注样本池,也可以实现与使用整个训练集相当的性能。
- 未来的研究应该考虑标注预算的现实情况,以更贴近实际应用场景。
- 此研究对于如何在资源有限的情况下优化模型性能提供了有价值的见解。
点此查看论文截图