⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-30 更新
PackDiT: Joint Human Motion and Text Generation via Mutual Prompting
Authors:Zhongyu Jiang, Wenhao Chai, Zhuoran Zhou, Cheng-Yen Yang, Hsiang-Wei Huang, Jenq-Neng Hwang
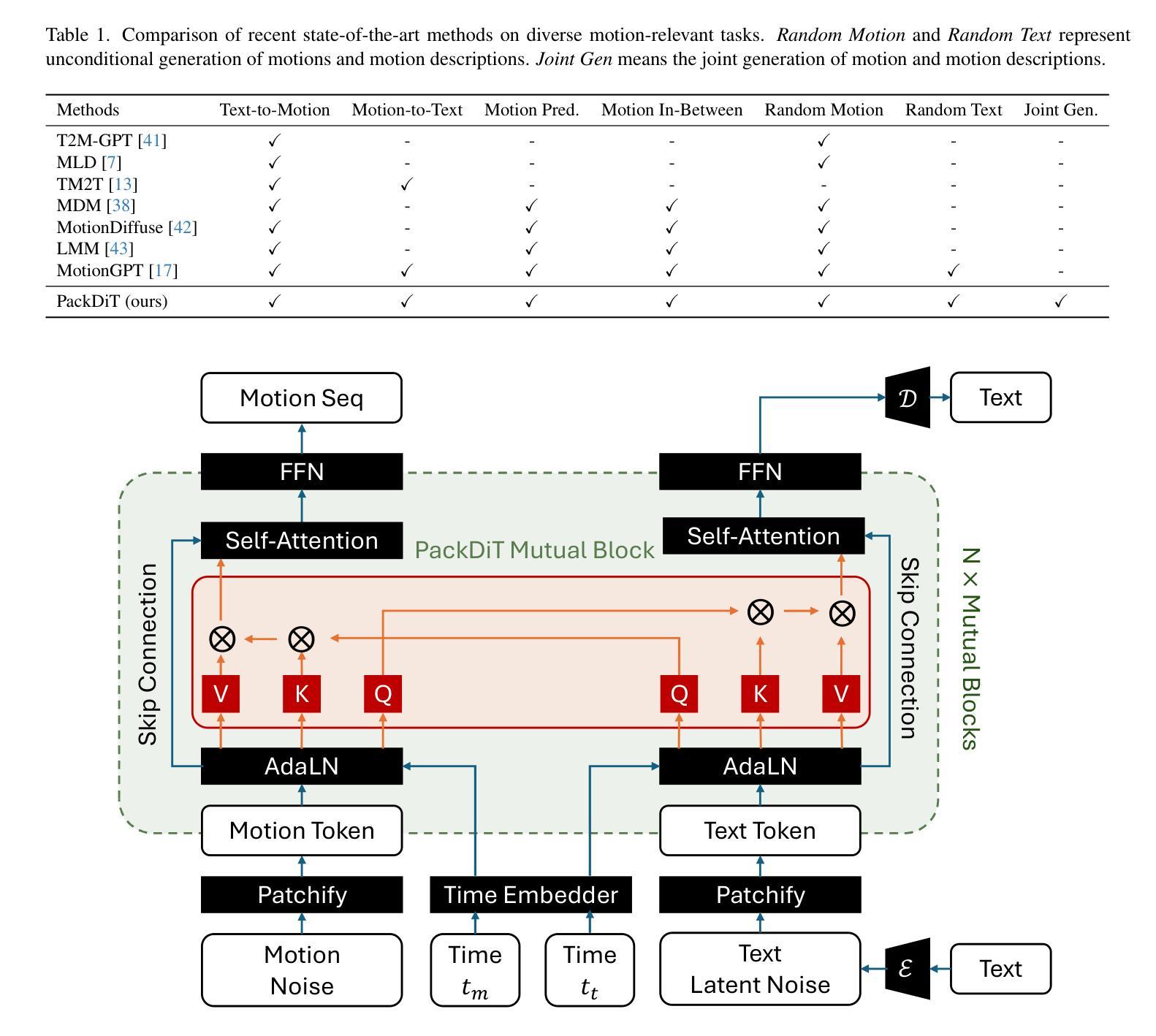
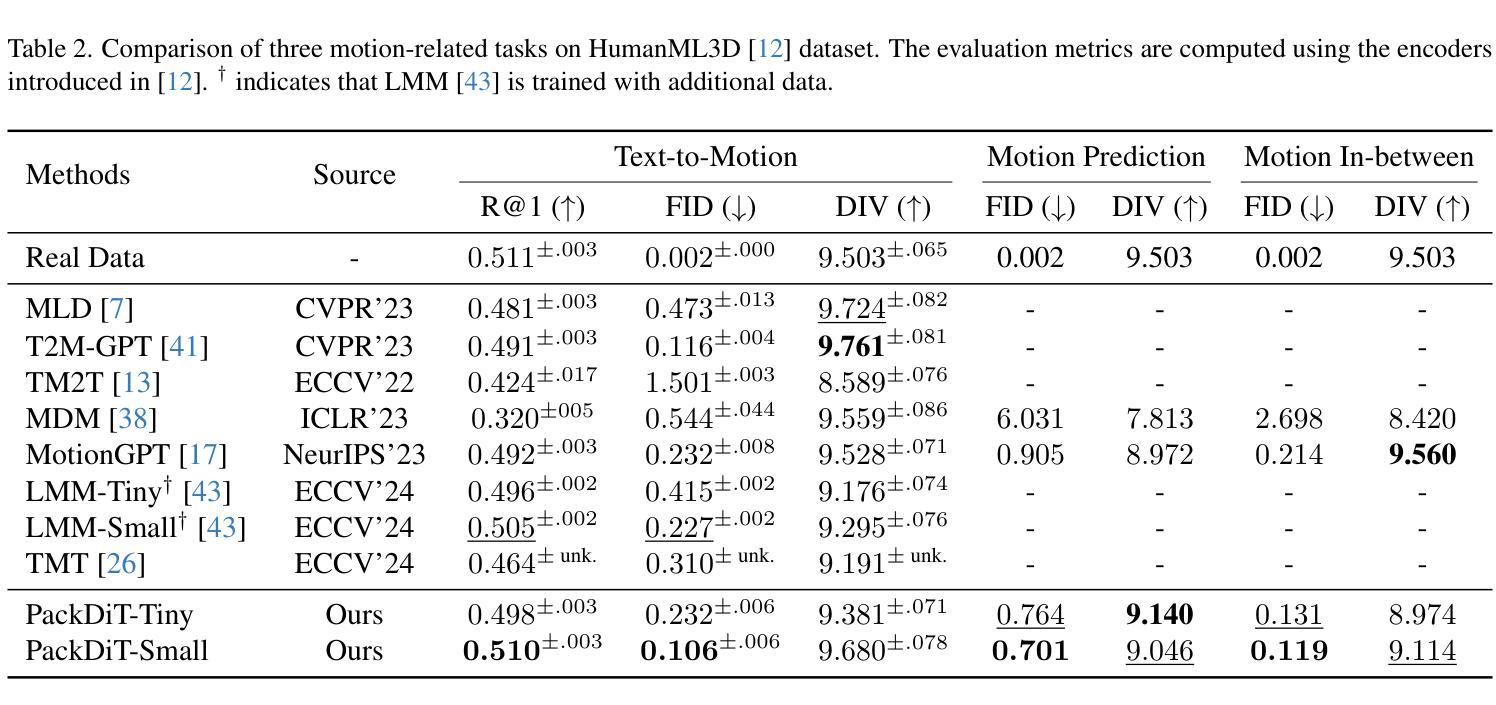
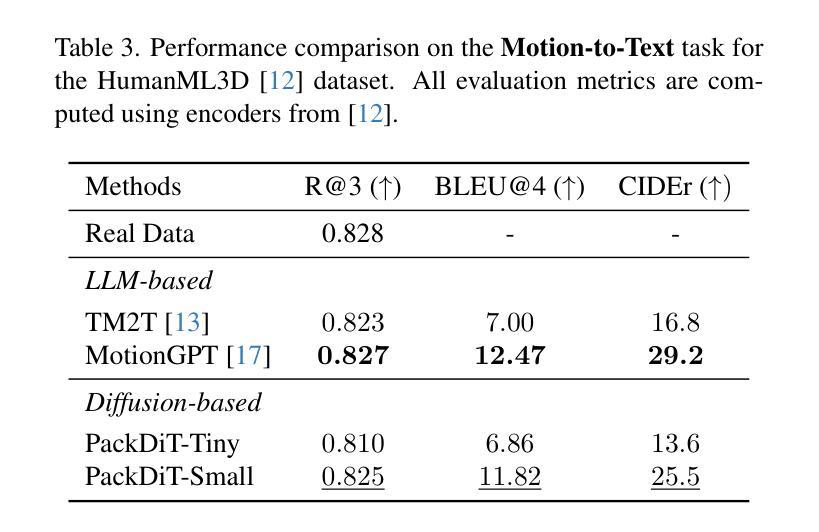
Human motion generation has advanced markedly with the advent of diffusion models. Most recent studies have concentrated on generating motion sequences based on text prompts, commonly referred to as text-to-motion generation. However, the bidirectional generation of motion and text, enabling tasks such as motion-to-text alongside text-to-motion, has been largely unexplored. This capability is essential for aligning diverse modalities and supports unconditional generation. In this paper, we introduce PackDiT, the first diffusion-based generative model capable of performing various tasks simultaneously, including motion generation, motion prediction, text generation, text-to-motion, motion-to-text, and joint motion-text generation. Our core innovation leverages mutual blocks to integrate multiple diffusion transformers (DiTs) across different modalities seamlessly. We train PackDiT on the HumanML3D dataset, achieving state-of-the-art text-to-motion performance with an FID score of 0.106, along with superior results in motion prediction and in-between tasks. Our experiments further demonstrate that diffusion models are effective for motion-to-text generation, achieving performance comparable to that of autoregressive models.
随着扩散模型的出现,人类运动生成已经取得了显著的进步。最近的研究主要集中在根据文本提示生成运动序列,这通常被称为文本到运动的生成。然而,运动与文本的双向生成,使运动到文本和文本到运动的任务得以进行,却很少被探索。这种能力对于对齐不同的模态并支持无条件生成至关重要。在本文中,我们介绍了PackDiT,这是第一个基于扩散的生成模型,可以同时执行多种任务,包括运动生成、运动预测、文本生成、文本到运动、运动到文本和联合运动文本生成。我们的核心创新是利用相互块来无缝地集成不同模态的多个扩散变压器(DiT)。我们在HumanML3D数据集上训练PackDiT,取得了最先进的文本到运动的性能,FID得分为0.106,在运动预测和其他中间任务中也取得了卓越的结果。我们的实验进一步证明,扩散模型对于运动到文本的生成同样有效,性能可与自回归模型相媲美。
论文及项目相关链接
Summary
随着扩散模型的出现,人类运动生成已经取得了显著进展。最近的研究主要集中在基于文本提示生成运动序列,即文本到运动的生成。然而,能够实现运动到文本和文本到运动双向生成的技术尚未得到广泛探索。这种能力对于对齐不同模式和支持无条件生成至关重要。本文介绍了PackDiT,这是一个基于扩散的生成模型,能够同时执行多种任务,包括运动生成、运动预测、文本生成、文本到运动、运动到文本以及联合运动文本生成。我们的核心创新是利用相互块来无缝集成不同模态的多个扩散变压器(DiTs)。我们在HumanML3D数据集上训练PackDiT,实现了领先的文本到运动性能,FID分数为0.106,并且在运动预测和中间任务中也取得了卓越的结果。我们的实验进一步证明,扩散模型对于运动到文本的生成也是有效的,其性能可与自回归模型相媲美。
Key Takeaways
- 扩散模型在人类运动生成领域取得了显著进展。
- 最近的研究主要关注基于文本提示的运动序列生成(文本到运动)。
- 双向的运动与文本生成(运动到文本和文本到运动)尚未得到广泛研究。
- PackDiT模型是第一个能够执行多种任务的扩散模型,包括运动生成、预测、文本生成以及联合运动文本生成等。
- PackDiT利用相互块集成多个扩散变压器(DiTs)来实现跨不同模态的无缝集成。
- 在HumanML3D数据集上训练的PackDiT实现了领先的文本到运动性能,并且FID分数为0.106。
点此查看论文截图