⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-31 更新
Technical report on label-informed logit redistribution for better domain generalization in low-shot classification with foundation models
Authors:Behraj Khan, Tahir Syed
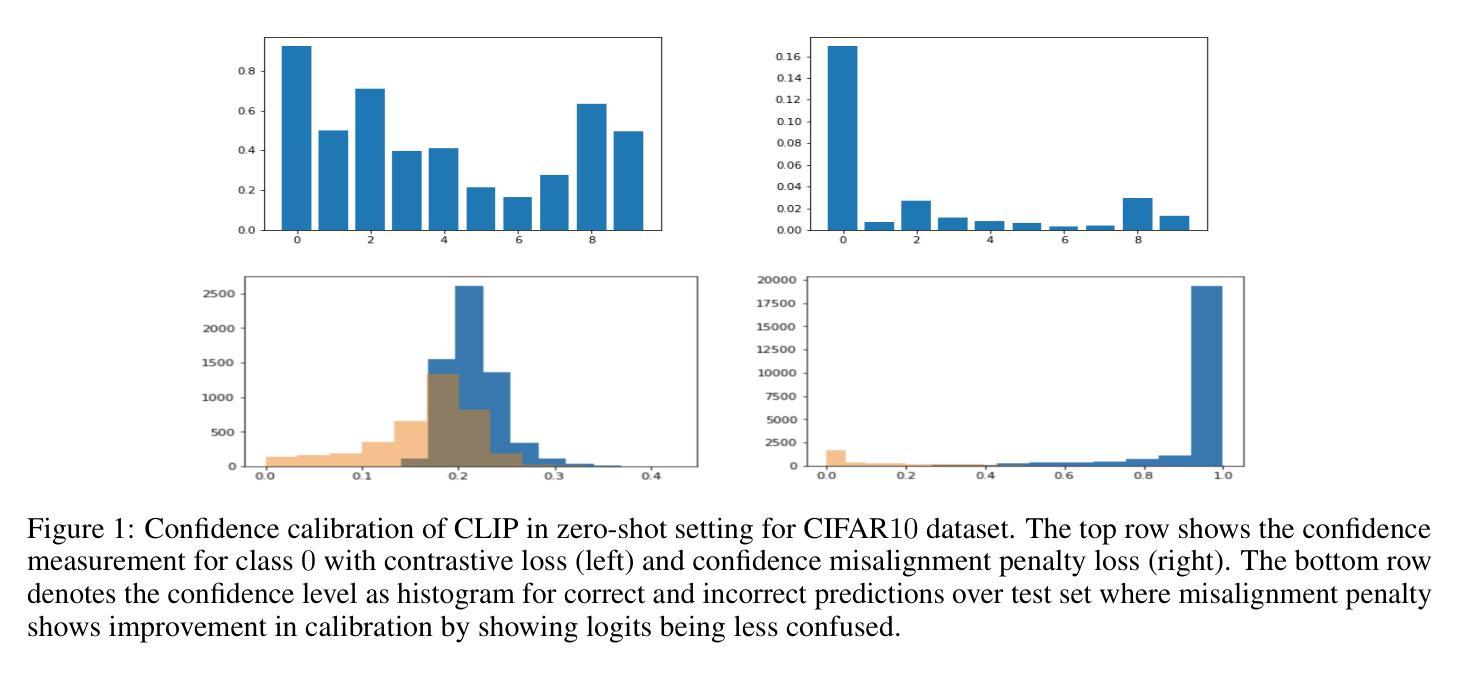
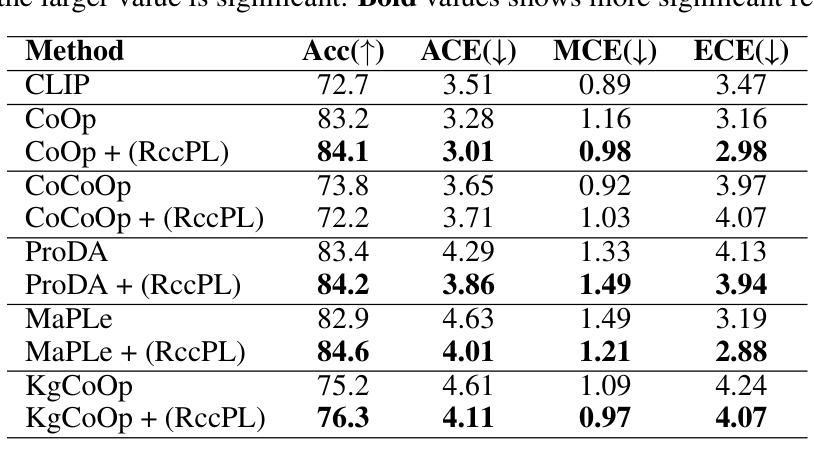
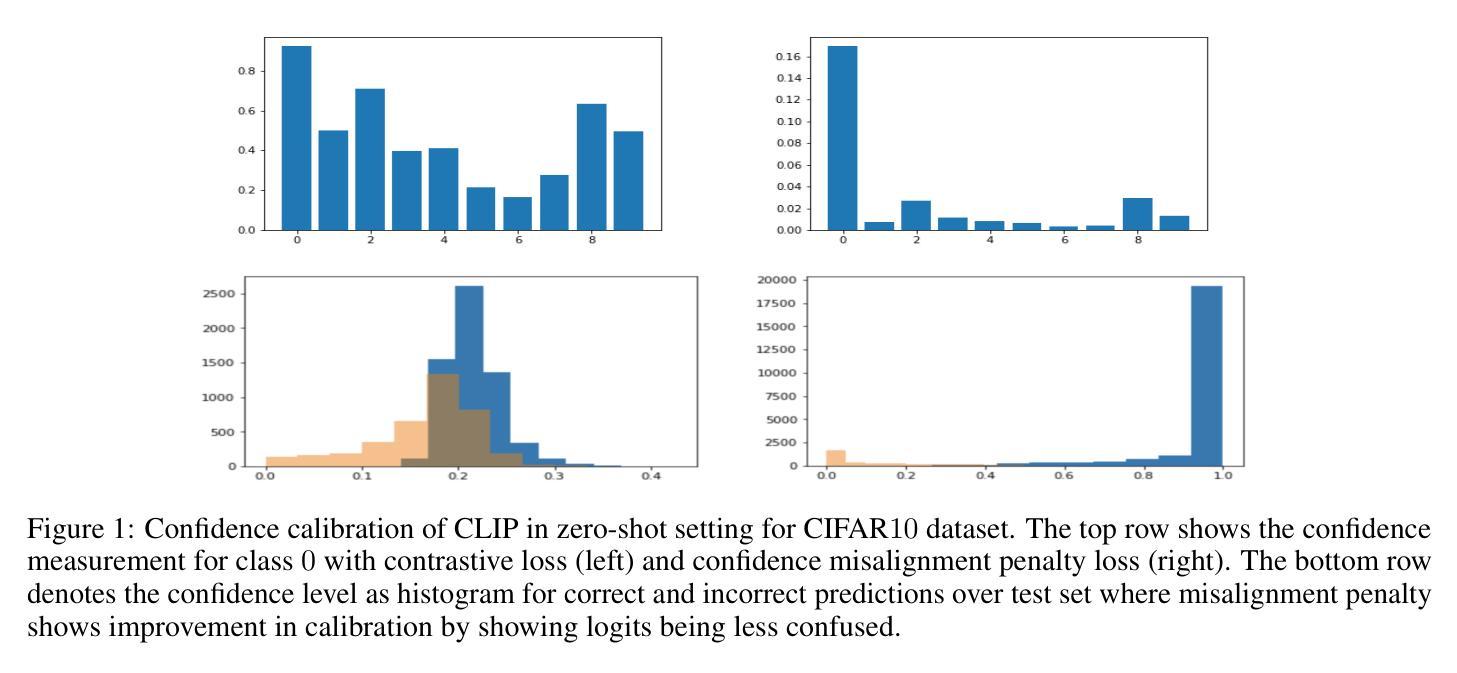
Confidence calibration is an emerging challenge in real-world decision systems based on foundations models when used for downstream vision classification tasks. Due to various reasons exposed, logit scores on the CLIP head remain large irrespective of whether the image-language pairs reconcile. It is difficult to address in data space, given the few-shot regime. We propose a penalty incorporated into loss objective that penalizes incorrect classifications whenever one is made during finetuning, by moving an amount of log-likelihood to the true class commensurate to the relative amplitudes of the two likelihoods. We refer to it as \textit{confidence misalignment penalty (CMP)}. Extensive experiments on $12$ vision datasets and $5$ domain generalization datasets supports the calibration performance of our method against stat-of-the-art. CMP outperforms the benchmarked prompt learning methods, demonstrating average improvement in Expected Calibration Error (ECE) by average $6.01$%, $4.01$ % at minimum and $9.72$% at maximum. Anonymized sample source code for this paper can be found at: \url{https://anonymous.4open.science/r/icml25-C5CB/readme.txt}
置信度校准是在基于基础模型的现实世界决策系统中,用于下游视觉分类任务时的一个新兴挑战。由于各种原因,CLIP头部的logit分数仍然很大,无论图像-语言对是否协调一致。在少量样本的情况下,很难在数据空间解决这一问题。我们提出了一种结合到损失目标中的惩罚机制,每当在微调过程中出现错误分类时,它会根据两个可能性的相对幅度,将一部分对数似然转移到真实类别上。我们将其称为“置信度不匹配惩罚(CMP)”。在12个视觉数据集和5个领域泛化数据集上的大量实验支持了我们的方法与最新技术的校准性能。CMP优于基准提示学习方法,在预期校准误差(ECE)上平均提高了6.01%,最低提高4.01%,最高提高9.72%。本论文的匿名样本源代码可在此找到:https://anonymous.4open.science/r/icml25-C5CB/readme.txt
论文及项目相关链接
Summary
模型微调过程中出现的置信度校准问题在真实世界的决策系统中是一大挑战。该问题在基于基础模型的下游视觉分类任务中尤为突出。本文提出了一种解决此问题的方法,即在损失函数中增加一个惩罚项——置信度不匹配惩罚(CMP)。它通过移动与两个似然相对幅度相当的似然对数量来对错误分类进行惩罚。在多个视觉数据集和领域泛化数据集上的实验支持了该方法相较于最新技术的校准性能。CMP在预期校准误差(ECE)方面平均提高了6.01%,最小提高4.01%,最大提高9.72%,优于基准提示学习方法。
Key Takeaways
- 置信度校准在基于基础模型的下游视觉分类任务中是重要挑战。
- 模型在微调过程中存在对图像-语言对和解的忽视问题。
- 提出了一种称为“置信度不匹配惩罚(CMP)”的方法来解决这个问题,它通过修改损失函数中的惩罚项来工作。
- CMP将错误的分类似然量转移到真实类别,以惩罚错误的分类。
- CMP在多个视觉数据集和领域泛化数据集上的实验表现优于最新的技术。
- CMP在预期校准误差(ECE)方面取得了显著的改进。
点此查看论文截图