⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-31 更新
LEKA:LLM-Enhanced Knowledge Augmentation
Authors:Xinhao Zhang, Jinghan Zhang, Fengran Mo, Dongjie Wang, Yanjie Fu, Kunpeng Liu
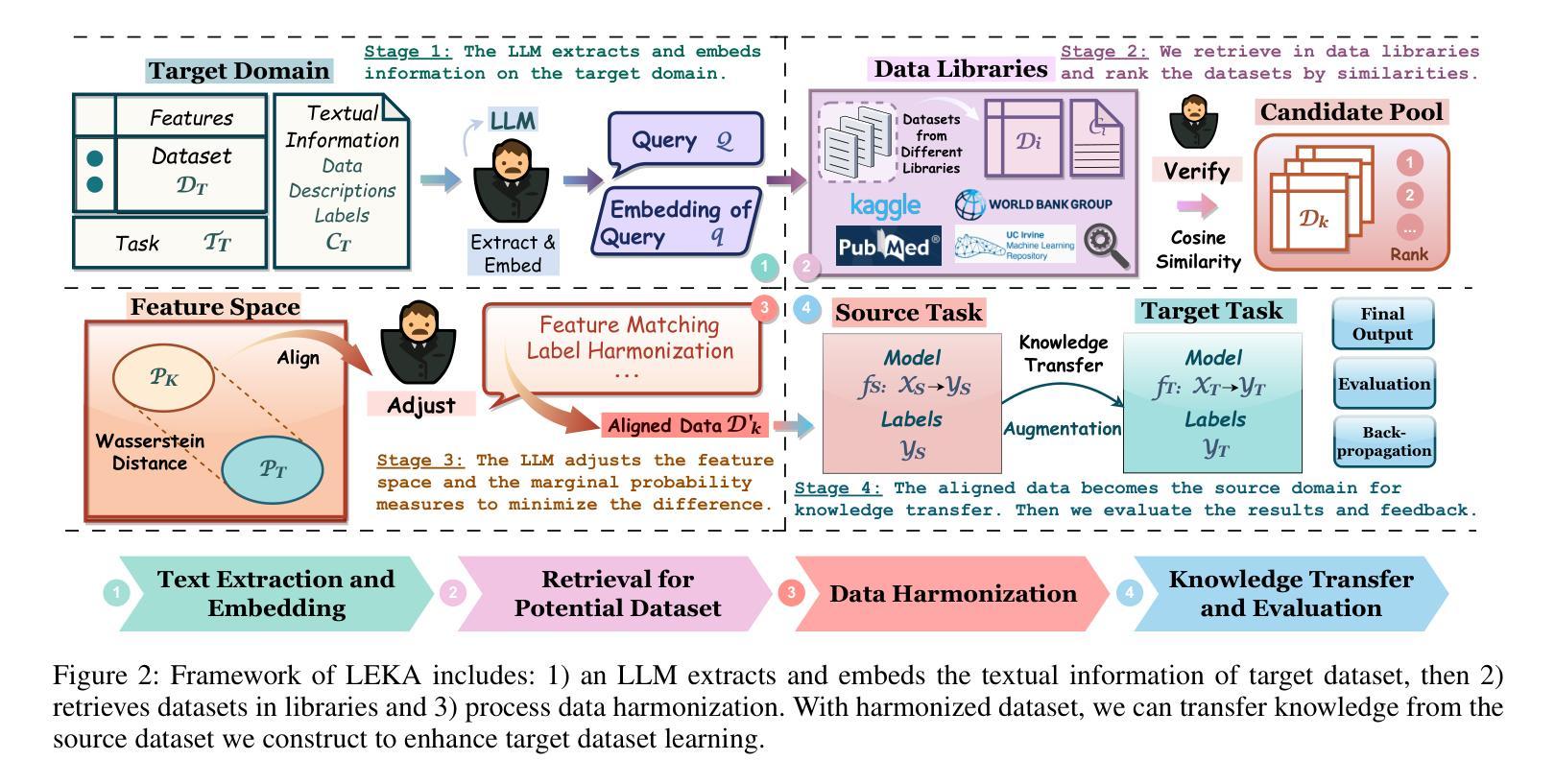
Humans excel in analogical learning and knowledge transfer and, more importantly, possess a unique understanding of identifying appropriate sources of knowledge. From a model’s perspective, this presents an interesting challenge. If models could autonomously retrieve knowledge useful for transfer or decision-making to solve problems, they would transition from passively acquiring to actively accessing and learning from knowledge. However, filling models with knowledge is relatively straightforward – it simply requires more training and accessible knowledge bases. The more complex task is teaching models about which knowledge can be analogized and transferred. Therefore, we design a knowledge augmentation method LEKA for knowledge transfer that actively searches for suitable knowledge sources that can enrich the target domain’s knowledge. This LEKA method extracts key information from textual information from the target domain, retrieves pertinent data from external data libraries, and harmonizes retrieved data with the target domain data in feature space and marginal probability measures. We validate the effectiveness of our approach through extensive experiments across various domains and demonstrate significant improvements over traditional methods in reducing computational costs, automating data alignment, and optimizing transfer learning outcomes.
人类在类比学习和知识迁移方面表现出卓越的能力,更重要的是,人类拥有识别合适知识来源的独特理解力。从模型的角度来看,这是一个有趣的挑战。如果模型能够自主检索对迁移或决策有用的知识来解决新问题,它们将实现从被动获取知识到主动访问和学习知识的转变。然而,填充模型的知识相对简单,只需更多的训练和可访问的知识库即可。更复杂的任务是教会模型哪些知识可以进行类比和迁移。因此,我们设计了一种名为LEKA的知识增强方法用于知识迁移,该方法可以积极搜索合适的能丰富目标领域知识的知识来源。这种LEKA方法从目标领域的文本信息中提取关键信息,从外部数据库检索相关数据,并在特征空间和边缘概率度量中将检索到的数据与目标领域数据进行协调。我们通过在不同领域的广泛实验验证了我们的方法的有效性,并在降低计算成本、自动化数据对齐和优化迁移学习结果方面显示出对传统方法的显著改进。
论文及项目相关链接
Summary
人类擅长类比学习和知识迁移,并能独特地识别适当的知识来源。模型若能自主检索有用的知识来解决迁移或决策问题,将从被动获取转变为主动访问和学习知识。设计了一种名为LEKA的知识增强方法,用于知识迁移,该方法能积极搜索合适的知识来源以丰富目标领域的知识。通过从目标领域提取关键信息、从外部数据库检索相关数据以及在特征空间和边际概率度量中将检索的数据与目标领域数据进行协调,实现知识增强。通过实验验证,该方法在减少计算成本、自动化数据对齐和优化迁移学习结果方面显著优于传统方法。
Key Takeaways
- 人类擅长类比学习和知识迁移,能识别适当的知识来源。
- 模型自主检索知识对解决迁移和决策问题至关重要,需要从被动获取向主动访问和学习转变。
- 设计了LEKA知识增强方法用于知识迁移,能积极搜索并丰富目标领域的知识。
- LEKA方法通过提取目标领域的关键信息,检索外部数据并进行协调,实现知识增强。
- LEKA方法在减少计算成本、自动化数据对齐方面优于传统方法。
- LEKA方法能有效优化迁移学习结果。
点此查看论文截图

Leveraging Multimodal LLM for Inspirational User Interface Search
Authors:Seokhyeon Park, Yumin Song, Soohyun Lee, Jaeyoung Kim, Jinwook Seo
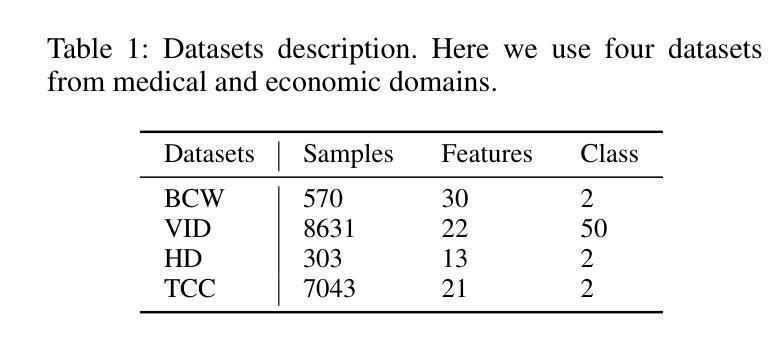
Inspirational search, the process of exploring designs to inform and inspire new creative work, is pivotal in mobile user interface (UI) design. However, exploring the vast space of UI references remains a challenge. Existing AI-based UI search methods often miss crucial semantics like target users or the mood of apps. Additionally, these models typically require metadata like view hierarchies, limiting their practical use. We used a multimodal large language model (MLLM) to extract and interpret semantics from mobile UI images. We identified key UI semantics through a formative study and developed a semantic-based UI search system. Through computational and human evaluations, we demonstrate that our approach significantly outperforms existing UI retrieval methods, offering UI designers a more enriched and contextually relevant search experience. We enhance the understanding of mobile UI design semantics and highlight MLLMs’ potential in inspirational search, providing a rich dataset of UI semantics for future studies.
灵感搜索是探索设计以启发新的创造性工作的重要过程,在手机用户界面(UI)设计中起着至关重要的作用。然而,探索广阔的UI参考空间仍然是一个挑战。现有的基于人工智能的UI搜索方法往往会忽略目标用户或应用程序情绪等关键语义。此外,这些模型通常需要视图层次结构等元数据,从而限制了它们的实际应用。我们使用多模态大型语言模型(MLLM)从移动UI图像中提取和解释语义。我们通过形成性研究确定了关键的UI语义,并开发了一个基于语义的UI搜索系统。通过计算和人类评估,我们证明我们的方法显著优于现有的UI检索方法,为UI设计师提供更丰富、语境更相关的搜索体验。我们增强了移动UI设计语义的理解,突出了大型语言模型在灵感搜索中的潜力,并为未来的研究提供了丰富的UI语义数据集。
论文及项目相关链接
PDF In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ‘25)
Summary
移动用户界面设计灵感搜索对于寻找新创意至关重要,然而现有的AI用户界面搜索方法缺乏针对目标用户和应用程序氛围等重要语义的理解,并且通常需要视图层次结构等元数据。通过使用多模态大型语言模型,我们从移动用户界面图像中提取并解释语义信息,开发了一种基于语义的用户界面搜索系统。通过计算和人类评估,我们证明了该方法显著优于现有用户界面检索方法,为UI设计师提供更丰富和上下文相关的搜索体验。这项研究增强了我们对移动用户界面设计语义的理解,并突出了多模态大型语言模型在灵感搜索中的潜力。
Key Takeaways
- 移动用户界面设计灵感搜索具有挑战性,但探索设计的巨大空间对于新创意至关重要。
- 现有AI用户界面搜索方法缺乏对目标用户和应用程序氛围等重要语义的理解。
- 多模态大型语言模型能够提取和解释移动用户界面图像中的语义信息。
- 基于语义的用户界面搜索系统通过计算和人类评估,证明其在用户界面检索方面的优越性。
- 该研究增强了我们对移动用户界面设计语义的理解。
- 多模态大型语言模型在灵感搜索中具有巨大潜力,可以为UI设计师提供更丰富和上下文相关的搜索体验。
点此查看论文截图


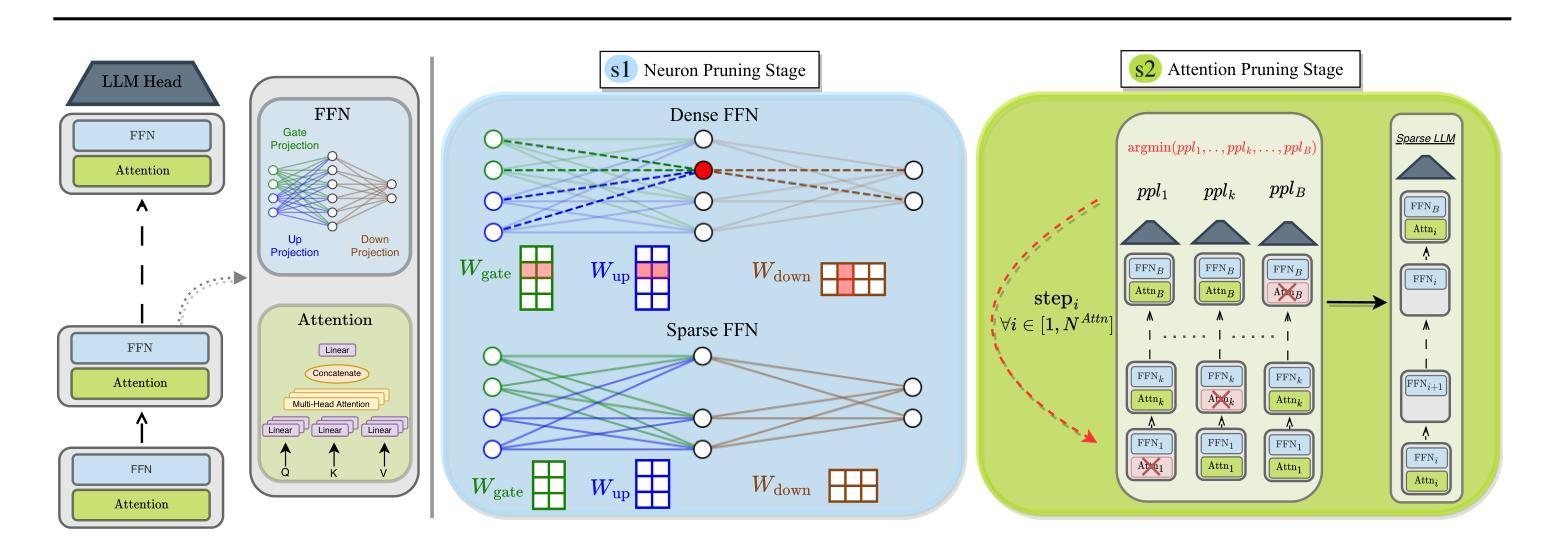
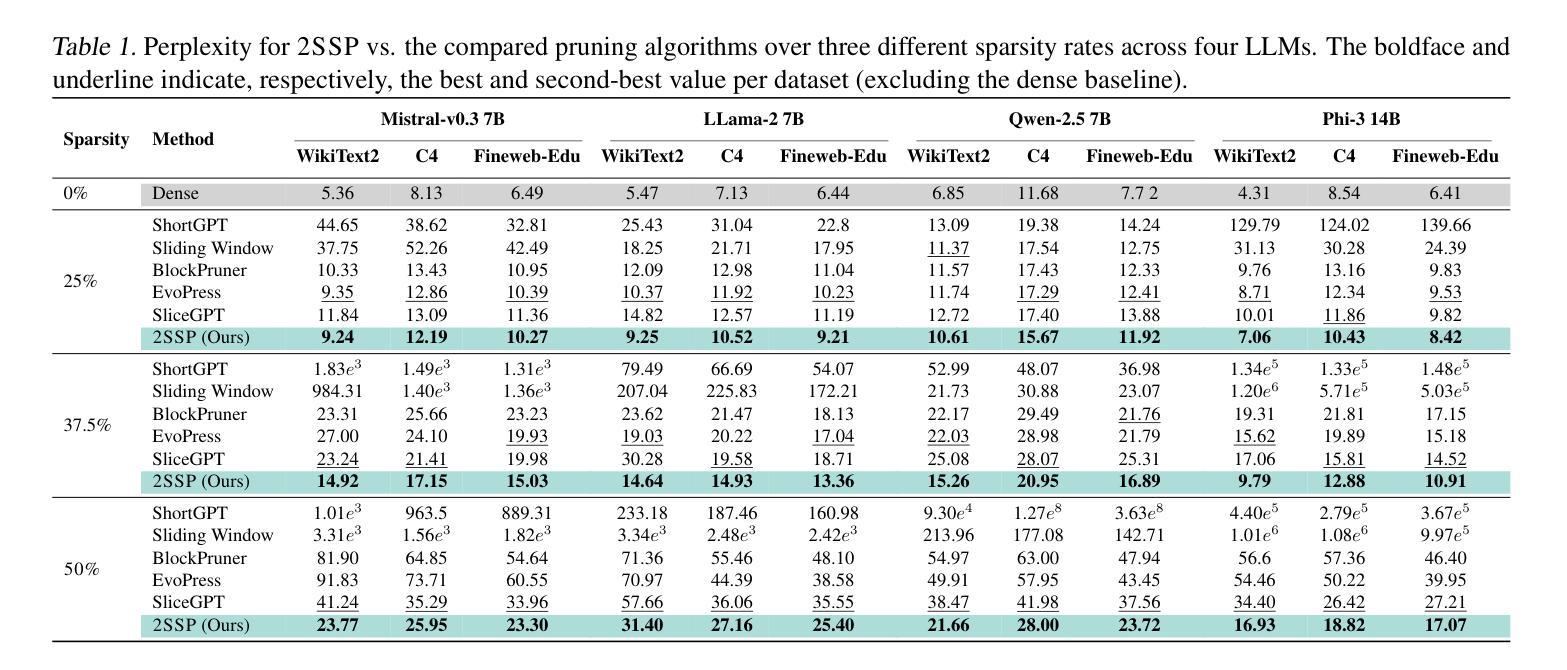
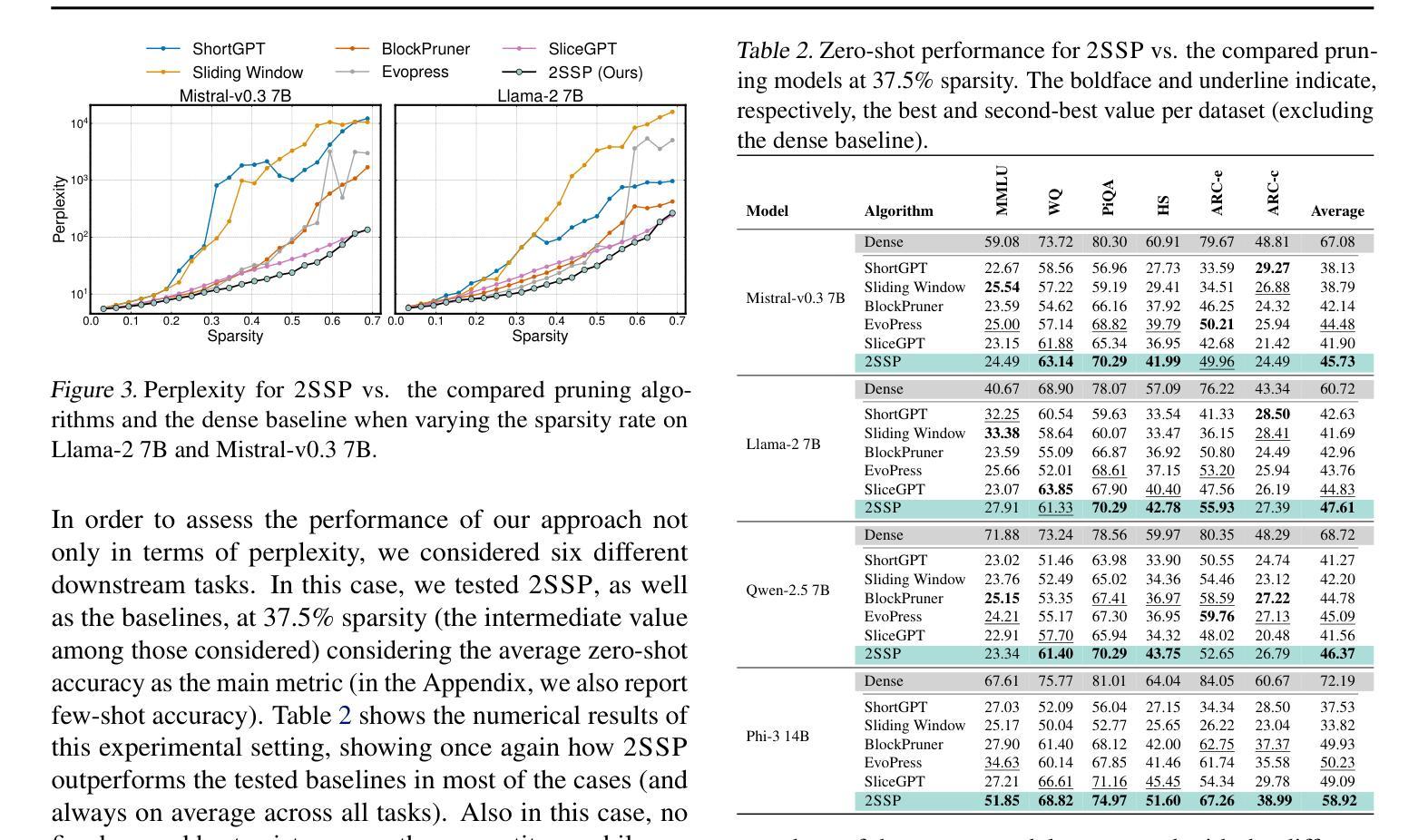
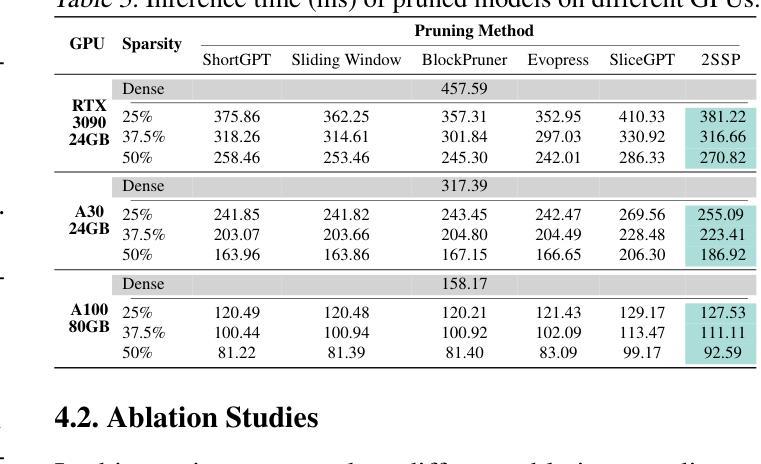
2SSP: A Two-Stage Framework for Structured Pruning of LLMs
Authors:Fabrizio Sandri, Elia Cunegatti, Giovanni Iacca
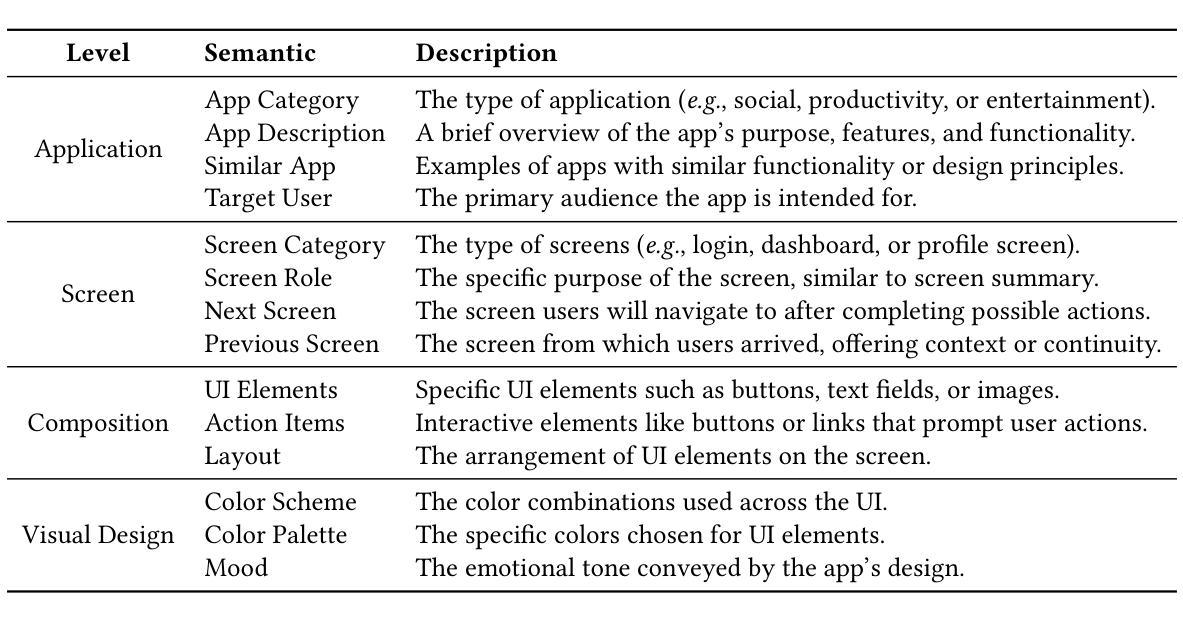
We propose a novel Two-Stage framework for Structured Pruning (2SSP) for pruning Large Language Models (LLMs), which combines two different strategies of pruning, namely Width and Depth Pruning. The first stage (Width Pruning) removes entire neurons, hence their corresponding rows and columns, aiming to preserve the connectivity among the pruned structures in the intermediate state of the Feed-Forward Networks in each Transformer block. This is done based on an importance score measuring the impact of each neuron over the output magnitude. The second stage (Depth Pruning), instead, removes entire Attention submodules. This is done by applying an iterative process that removes the Attention submodules with the minimum impact on a given metric of interest (in our case, perplexity). We also propose a novel mechanism to balance the sparsity rate of the two stages w.r.t. to the desired global sparsity. We test 2SSP on four LLM families and three sparsity rates (25%, 37.5%, and 50%), measuring the resulting perplexity over three language modeling datasets as well as the performance over six downstream tasks. Our method consistently outperforms five state-of-the-art competitors over three language modeling and six downstream tasks, with an up to two-order-of-magnitude gain in terms of pruning time. The code is available at available at \url{https://github.com/FabrizioSandri/2SSP}.
我们提出了一种针对大型语言模型(LLM)进行结构化剪枝的新型两阶段框架(2SSP),该框架结合了两种不同剪枝策略,即宽度剪枝和深度剪枝。第一阶段(宽度剪枝)会移除整个神经元及其对应的行和列,旨在保留前馈网络中每个Transformer块中间状态的修剪结构之间的连接性。这是基于一个重要性分数进行的,该分数衡量每个神经元对输出幅度的影响。第二阶段(深度剪枝)则移除整个注意力子模块。这是通过应用一个迭代过程来完成的,该过程会移除对给定指标(在我们的案例中为困惑度)影响最小的注意力子模块。我们还提出了一种新型机制来平衡两个阶段相对于所需全局稀疏率的稀疏率。我们在四个LLM家族、三种稀疏率(25%、37.5%和50%)下测试了2SSP,测量了三个语言建模数据集上的困惑度以及六个下游任务上的性能。我们的方法在三套语言建模和六个下游任务上均优于五种最先进的竞争对手,并且在剪枝时间上取得了高达两个数量级的收益。代码可在https://github.com/FabrizioSandri/2SSP获取。
论文及项目相关链接
Summary
本文提出了一种针对大型语言模型(LLM)的两阶段结构化剪枝(2SSP)框架,结合了宽度剪枝和深度剪枝两种策略。第一阶段宽度剪枝移除整个神经元及其对应的行列,旨在保留前馈网络中剪枝结构的连通性。第二阶段深度剪枝则移除注意力子模块,通过迭代过程移除对给定指标(在本研究中为困惑度)影响最小的子模块。该框架在四个LLM家族和三种稀疏率上进行了测试,并在三个语言建模数据集和六个下游任务上进行了评估,证明其优于五种现有方法,剪枝时间提高了两个数量级。代码已公开。
Key Takeaways
- 2SSP框架结合了宽度剪枝和深度剪枝两种策略,用于大型语言模型(LLM)的剪枝。
- 第一阶段宽度剪枝旨在保留前馈网络中剪枝结构的连通性。
- 第二阶段深度剪枝通过迭代过程移除对给定指标(如困惑度)影响最小的注意力子模块。
- 2SSP框架在多个LLM家族、稀疏率、语言建模数据集和下游任务上的表现均优于其他五种现有方法。
- 2SSP框架的剪枝时间有显著提高,达到了两个数量级的提升。
- 框架的代码已经公开,便于他人使用和研究。
- 该方法为提高LLM的效率和性能提供了新的思路。
点此查看论文截图

Hybrid Graphs for Table-and-Text based Question Answering using LLMs
Authors:Ankush Agarwal, Ganesh S, Chaitanya Devaguptapu
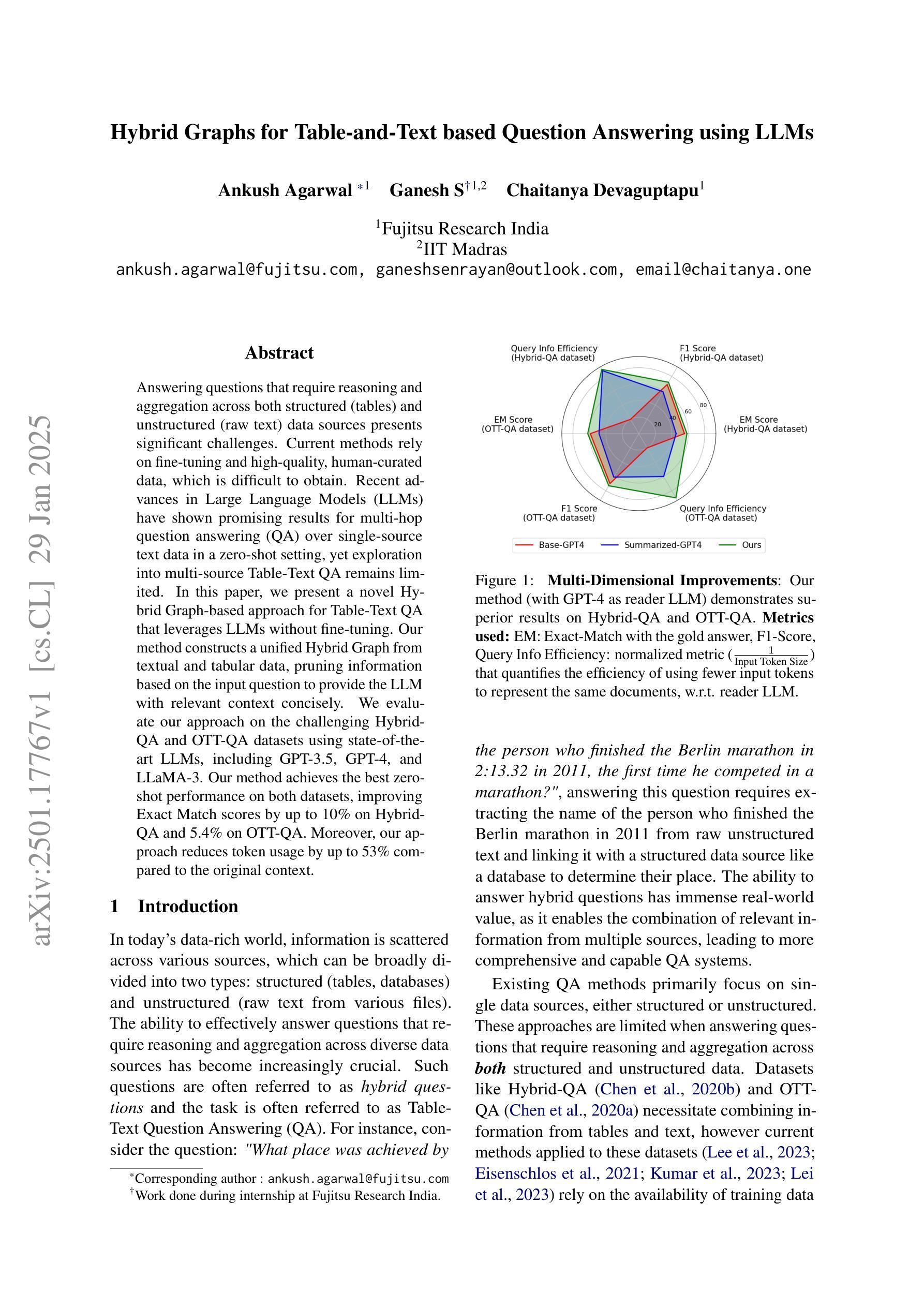
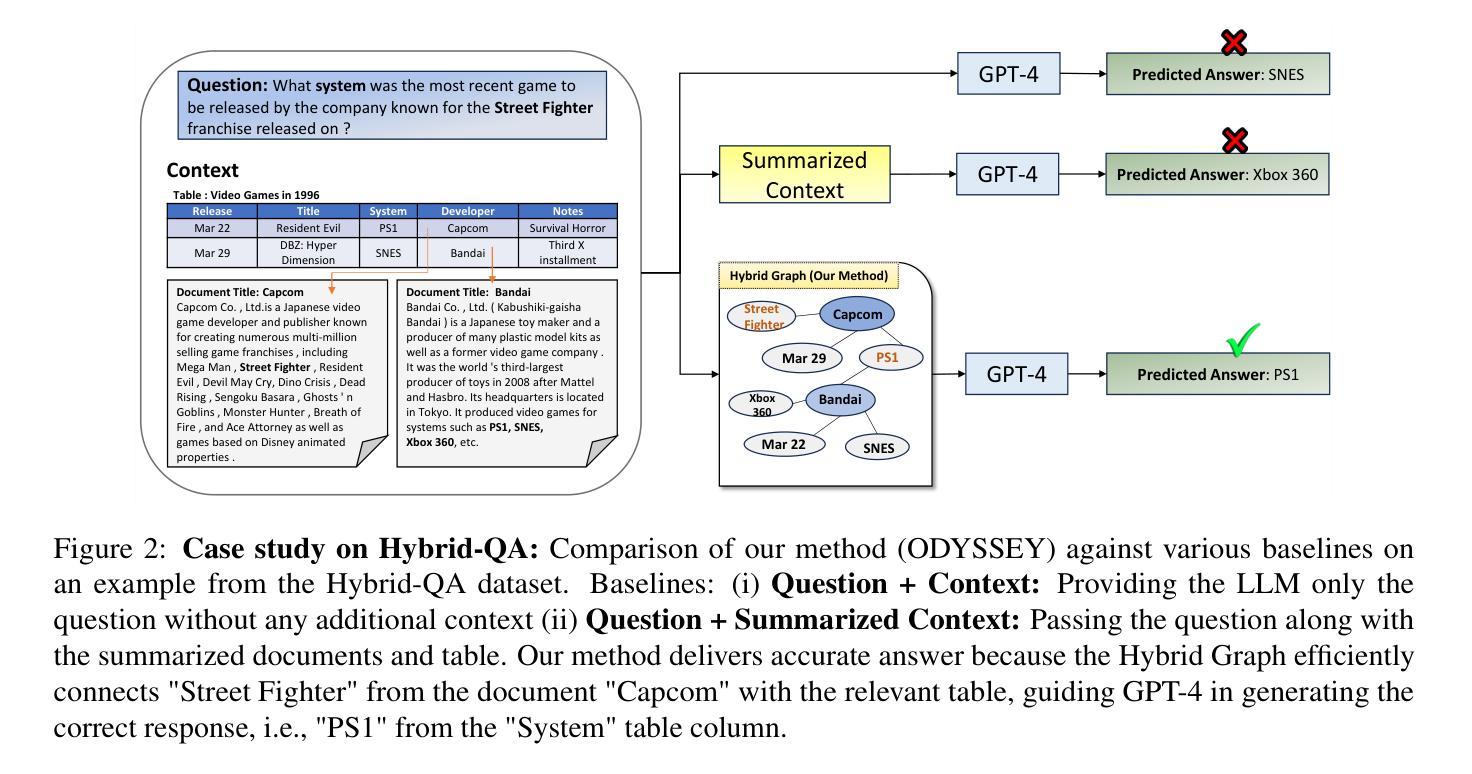
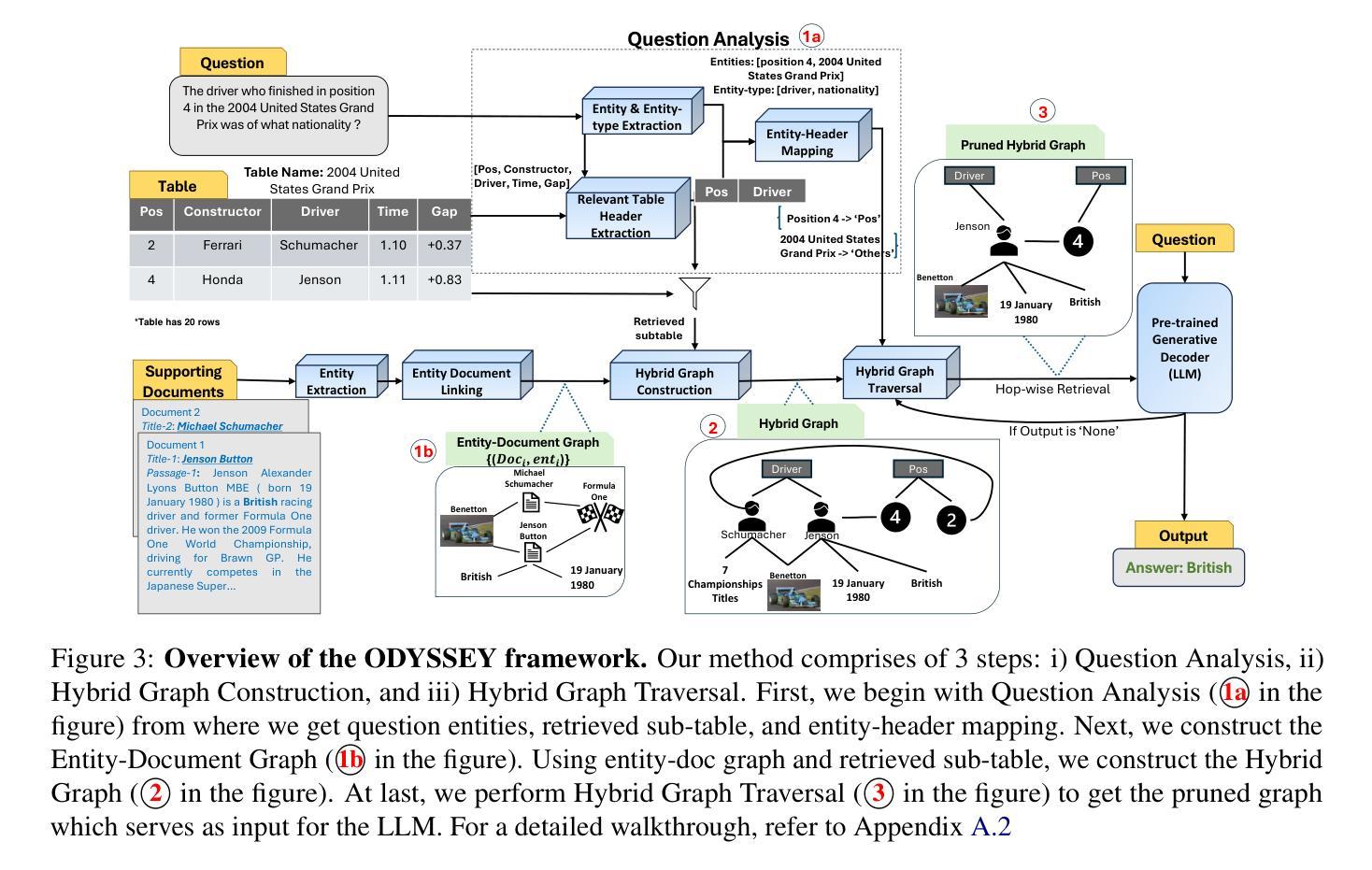
Answering questions that require reasoning and aggregation across both structured (tables) and unstructured (raw text) data sources presents significant challenges. Current methods rely on fine-tuning and high-quality, human-curated data, which is difficult to obtain. Recent advances in Large Language Models (LLMs) have shown promising results for multi-hop question answering (QA) over single-source text data in a zero-shot setting, yet exploration into multi-source Table-Text QA remains limited. In this paper, we present a novel Hybrid Graph-based approach for Table-Text QA that leverages LLMs without fine-tuning. Our method constructs a unified Hybrid Graph from textual and tabular data, pruning information based on the input question to provide the LLM with relevant context concisely. We evaluate our approach on the challenging Hybrid-QA and OTT-QA datasets using state-of-the-art LLMs, including GPT-3.5, GPT-4, and LLaMA-3. Our method achieves the best zero-shot performance on both datasets, improving Exact Match scores by up to 10% on Hybrid-QA and 5.4% on OTT-QA. Moreover, our approach reduces token usage by up to 53% compared to the original context.
回答涉及跨结构化(表格)和非结构化(原始文本)数据源推理和聚合的问题存在重大挑战。当前的方法依赖于精细调整和高质量的人工编制数据,这些数据很难获得。最近大型语言模型(LLM)的进步在单源文本数据的多跳问答(QA)中显示出有前途的结果,为零样本设置下,但对多源表文本问答的探索仍然有限。在本文中,我们提出了一种基于混合图表的表文本问答新方法,该方法利用LLM而无需精细调整。我们的方法从文本和表格数据中构建了一个统一的混合图,根据输入问题精简信息,为LLM提供简洁的上下文。我们在具有挑战性的Hybrid-QA和OTT-QA数据集上使用了最先进的LLM进行评估,包括GPT-3.5、GPT-4和LLaMA-3。我们的方法在这两个数据集上都实现了零样本的最佳性能,在Hybrid-QA上精确匹配分数提高了高达10%,在OTT-QA上提高了5.4%。此外,我们的方法与原始上下文相比,令牌使用量减少了高达53%。
论文及项目相关链接
PDF Accepted at NAACL 2025 Main Track
Summary
基于LLM的混合图方法在跨表格和文本数据源的多源问答任务中展现出卓越性能。该方法无需微调,通过构建统一混合图,将文本和表格数据整合,根据问题精简信息,为LLM提供简洁的相关上下文。在Hybrid-QA和OTT-QA数据集上的实验表明,该方法在零样本场景下表现最佳,提高Exact Match得分高达10%和5.4%。此外,该方法减少了高达53%的令牌使用量。
Key Takeaways
- LLMs在跨表格和文本数据源的多源问答任务中面临挑战。
- 当前方法依赖高质量的人为整理数据,获取困难。
- 最新LLM技术在零样本设置下的单源文本数据多跳问答中显示出希望。
- 提出了一种基于混合图的新方法,无需微调即可处理表文本QA。
- 该方法整合文本和表格数据,构建统一混合图。
- 根据问题精简信息,为LLM提供简洁的相关上下文。
点此查看论文截图

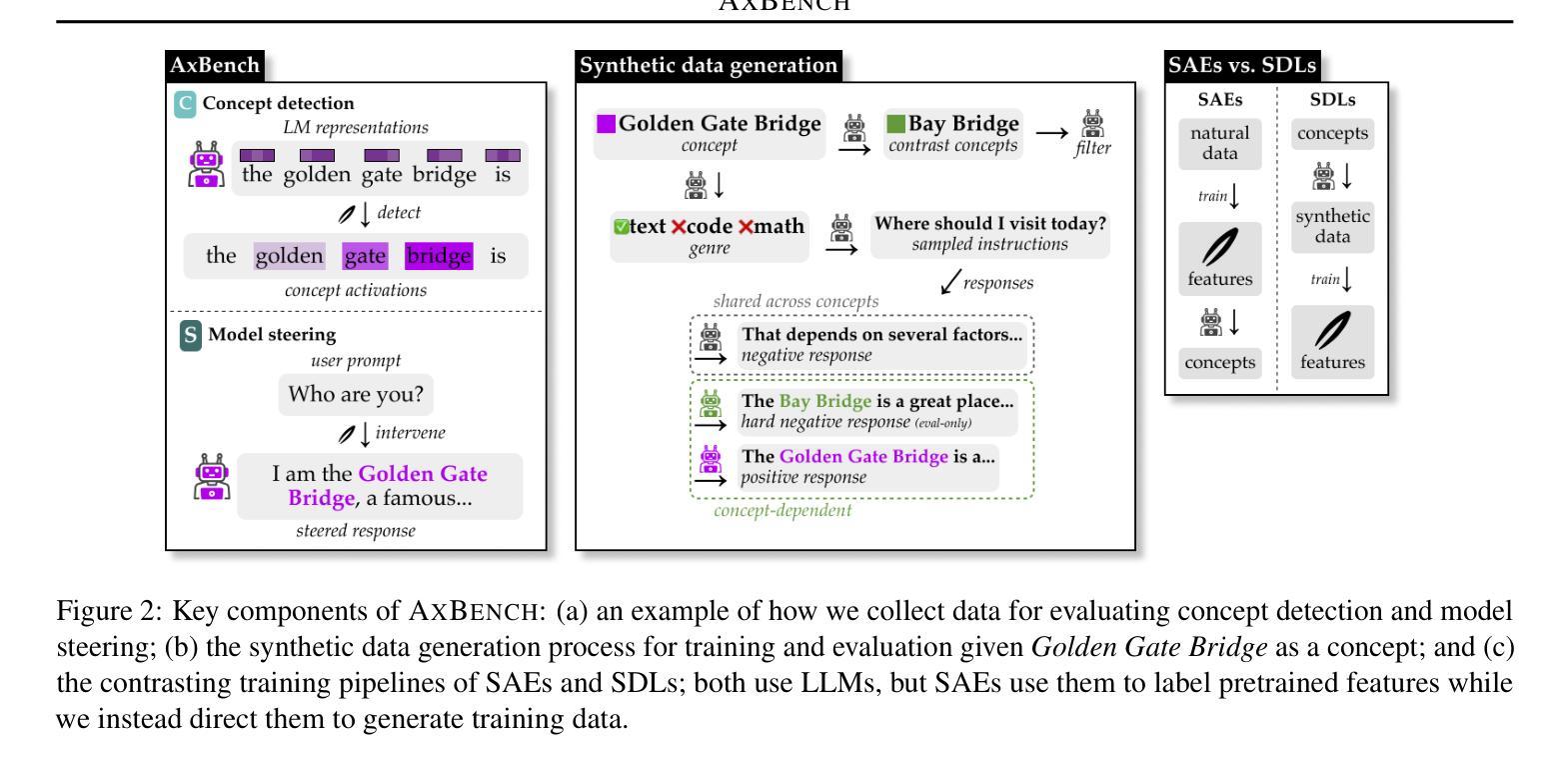
AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders
Authors:Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D. Manning, Christopher Potts
Fine-grained steering of language model outputs is essential for safety and reliability. Prompting and finetuning are widely used to achieve these goals, but interpretability researchers have proposed a variety of representation-based techniques as well, including sparse autoencoders (SAEs), linear artificial tomography, supervised steering vectors, linear probes, and representation finetuning. At present, there is no benchmark for making direct comparisons between these proposals. Therefore, we introduce AxBench, a large-scale benchmark for steering and concept detection, and report experiments on Gemma-2-2B and 9B. For steering, we find that prompting outperforms all existing methods, followed by finetuning. For concept detection, representation-based methods such as difference-in-means, perform the best. On both evaluations, SAEs are not competitive. We introduce a novel weakly-supervised representational method (Rank-1 Representation Finetuning; ReFT-r1), which is competitive on both tasks while providing the interpretability advantages that prompting lacks. Along with AxBench, we train and publicly release SAE-scale feature dictionaries for ReFT-r1 and DiffMean.
精细控制语言模型输出对于安全和可靠性至关重要。提示和微调被广泛用于实现这些目标,但解释性研究人员也提出了各种基于表示的技术,包括稀疏自动编码器(SAE)、线性人工层析成像、监督控制向量、线性探针和表示微调。目前,还没有对这些提议进行直接比较的基准测试。因此,我们引入了AxBench,这是一个用于控制和概念检测的大规模基准测试,并报告了在Gemma-2-2B和9B上的实验。对于控制任务,我们发现提示表现优于所有现有方法,其次是微调。在概念检测方面,基于表示的方法(如均值差异法)表现最好。在这两项评估中,SAE都不具备竞争力。我们引入了一种新型的弱监督表示方法(Rank-1表示微调;ReFT-r1),它在两个任务上都表现良好,同时提供了提示所缺乏的解读优势。我们训练了用于ReFT-r1和DiffMean的SAE规模特征字典并公开发布,以便与AxBench一起使用。
论文及项目相关链接
Summary
本文主要介绍了语言模型输出精细控制的重要性和方法,包括提示、微调等常用方法以及基于表示的技术,如稀疏自动编码器(SAE)、线性人工断层扫描等。由于缺乏直接比较这些方法的基准测试,作者引入了AxBench基准测试,用于控制和概念检测。实验表明,提示在所有现有方法中表现最佳,其次是微调。在概念检测方面,基于表示的方法如差异均值表现最佳。作者还提出了一种新型的弱监督表示方法——ReFT-r1,在两项任务中均表现出竞争力,同时提供了提示所缺乏的可解释性优势。
Key Takeaways
- 语言模型输出的精细控制对于安全和可靠性至关重要。
- 现有方法如提示和微调被广泛用于实现这一目标。
- 基于表示的技术,如稀疏自动编码器(SAE)和线性人工断层扫描也被用于控制语言模型输出。
- 目前缺乏直接比较这些方法的基准测试。
- 引入AxBench基准测试用于控制和概念检测。
- 在实验评估中,提示在现有方法中表现最佳,其次是微调。
点此查看论文截图

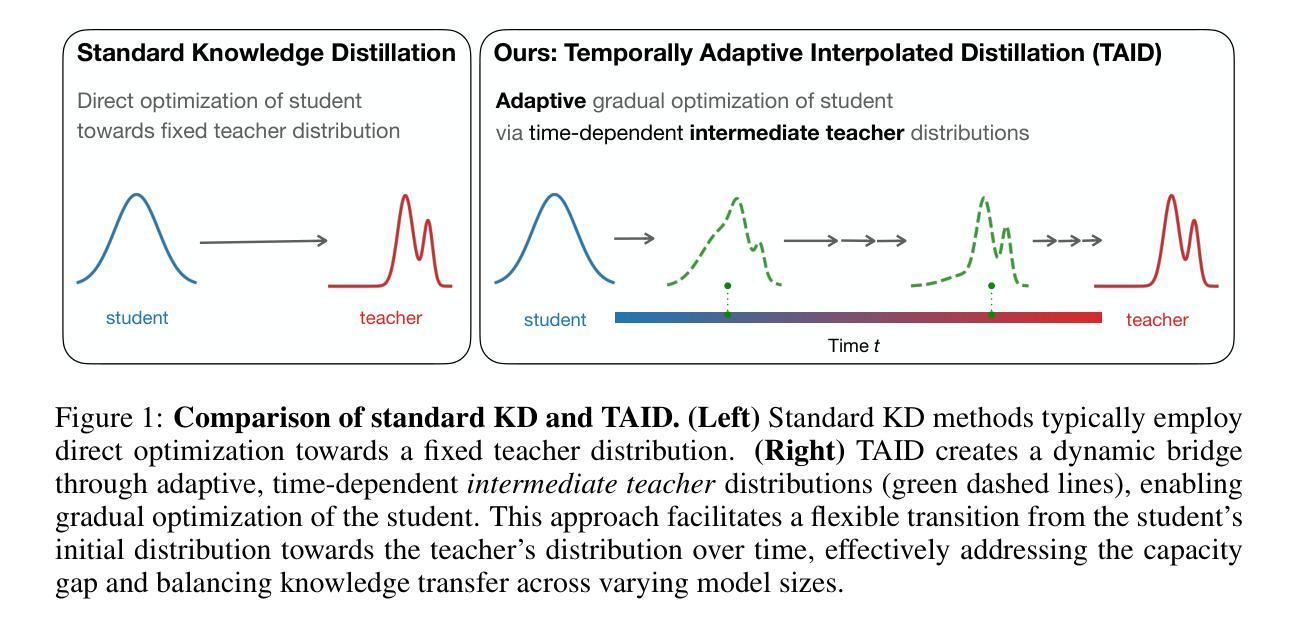
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
Authors:Makoto Shing, Kou Misaki, Han Bao, Sho Yokoi, Takuya Akiba
Causal language models have demonstrated remarkable capabilities, but their size poses significant challenges for deployment in resource-constrained environments. Knowledge distillation, a widely-used technique for transferring knowledge from a large teacher model to a small student model, presents a promising approach for model compression. A significant remaining issue lies in the major differences between teacher and student models, namely the substantial capacity gap, mode averaging, and mode collapse, which pose barriers during distillation. To address these issues, we introduce $\textit{Temporally Adaptive Interpolated Distillation (TAID)}$, a novel knowledge distillation approach that dynamically interpolates student and teacher distributions through an adaptive intermediate distribution, gradually shifting from the student’s initial distribution towards the teacher’s distribution. We provide a theoretical analysis demonstrating TAID’s ability to prevent mode collapse and empirically show its effectiveness in addressing the capacity gap while balancing mode averaging and mode collapse. Our comprehensive experiments demonstrate TAID’s superior performance across various model sizes and architectures in both instruction tuning and pre-training scenarios. Furthermore, we showcase TAID’s practical impact by developing two state-of-the-art compact foundation models: $\texttt{TAID-LLM-1.5B}$ for language tasks and $\texttt{TAID-VLM-2B}$ for vision-language tasks. These results demonstrate TAID’s effectiveness in creating high-performing and efficient models, advancing the development of more accessible AI technologies.
因果语言模型已经展现出显著的能力,但它们的规模对在资源受限环境中的部署构成了重大挑战。知识蒸馏是一种广泛使用的技术,可以从大型教师模型转移到小型学生模型,这为模型压缩提供了有前景的方法。一个主要的剩余问题在于教师和学生模型之间的巨大差异,即显著的能力差距、模式平均和模式崩溃,这些在蒸馏过程中构成了障碍。为了解决这些问题,我们引入了”时间自适应插值蒸馏法(TAID)”,这是一种新型的知识蒸馏方法,通过自适应中间分布动态插值学生和教师的分布,从学生的初始分布逐渐转向教师的分布。我们提供了理论分析,证明了TAID在防止模式崩溃方面的能力,并通过经验证明了它在解决能力差距、平衡模式平均和模式崩溃方面的有效性。我们的综合实验表明,TAID在各种模型和架构的大小、指令调整和预训练场景中均表现出卓越的性能。此外,我们通过开发两个最先进的紧凑基础模型:用于语言任务的”TAID-LLM-1.5B”和用于视觉语言任务的”TAID-VLM-2B”,展示了TAID的实际影响。这些结果证明了TAID在创建高性能和高效模型方面的有效性,推动了更可访问的AI技术的发展。
论文及项目相关链接
PDF To appear at the 13th International Conference on Learning Representations (ICLR 2025)
Summary
知识蒸馏是一种从大模型到小模型的转移知识技术,但仍存在显著的问题,例如教师与学生模型间巨大的能力差距、模式平均化和模式崩溃。为此,本文提出一种新的知识蒸馏方法——暂时自适应插值蒸馏(TAID),它通过自适应中间分布动态插值学生和教师的分布,逐步从学生初始分布转向教师分布。本文理论分析了TAID防止模式崩溃的能力,并通过实验验证了其在解决能力差距、平衡模式平均和模式崩溃方面的有效性。此外,TAID还在多种模型和架构的大小、预训练场景以及开发两个紧凑基础模型TAID-LLM-1.5B和TAID-VLM-2B中展现出卓越性能。这些成果证明了TAID在创建高性能、高效模型方面的有效性,推动了更普及的AI技术的发展。
Key Takeaways
- 知识蒸馏在模型压缩中具有潜力,但面临教师和学生模型间的能力差距、模式平均化和模式崩溃等问题。
- 引入新的知识蒸馏方法——暂时自适应插值蒸馏(TAID),通过动态插值学生和教师的分布来解决上述问题。
- TAID具有防止模式崩溃的理论分析能力,并通过实验验证了其在解决能力差距方面的有效性。
- TAID在多种模型和架构中表现优越,适用于指令调优和预训练场景。
- 开发两个紧凑基础模型TAID-LLM-1.5B和TAID-VLM-2B,为语言任务和视觉语言任务提供高性能解决方案。
- TAID创造了高效模型,推动了AI技术的发展。
点此查看论文截图


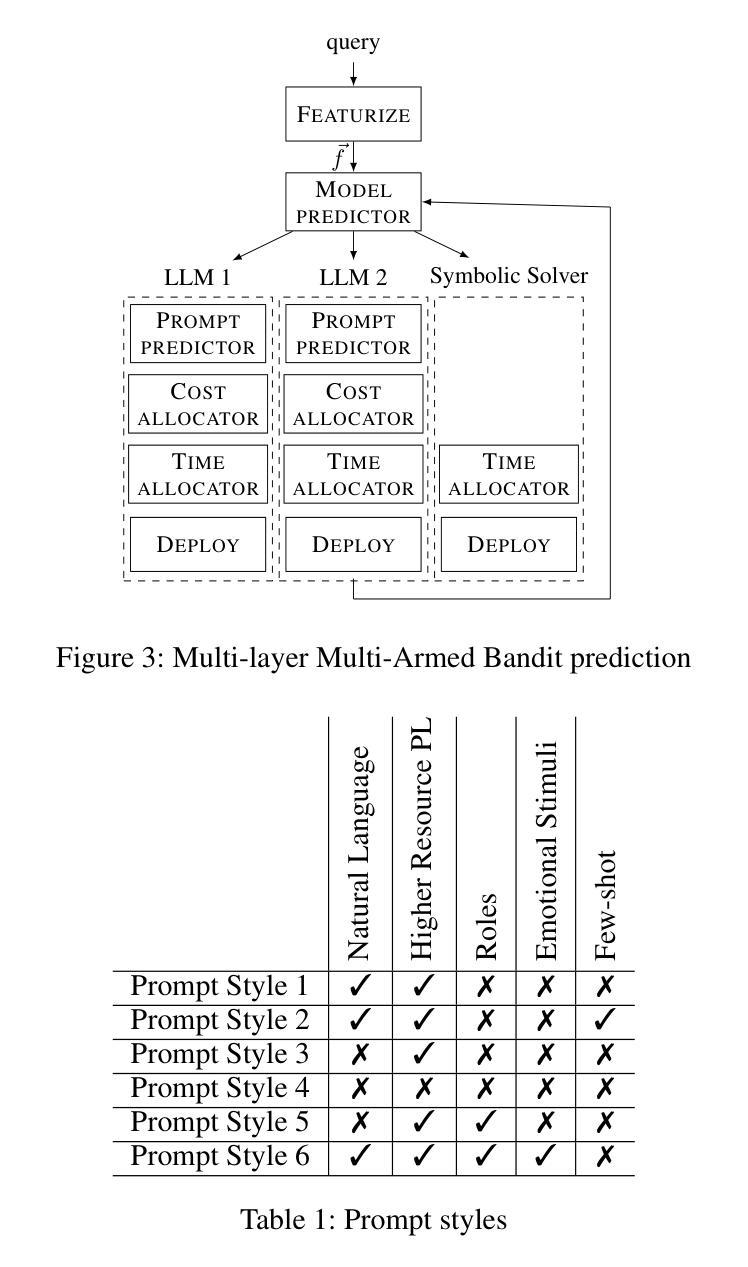
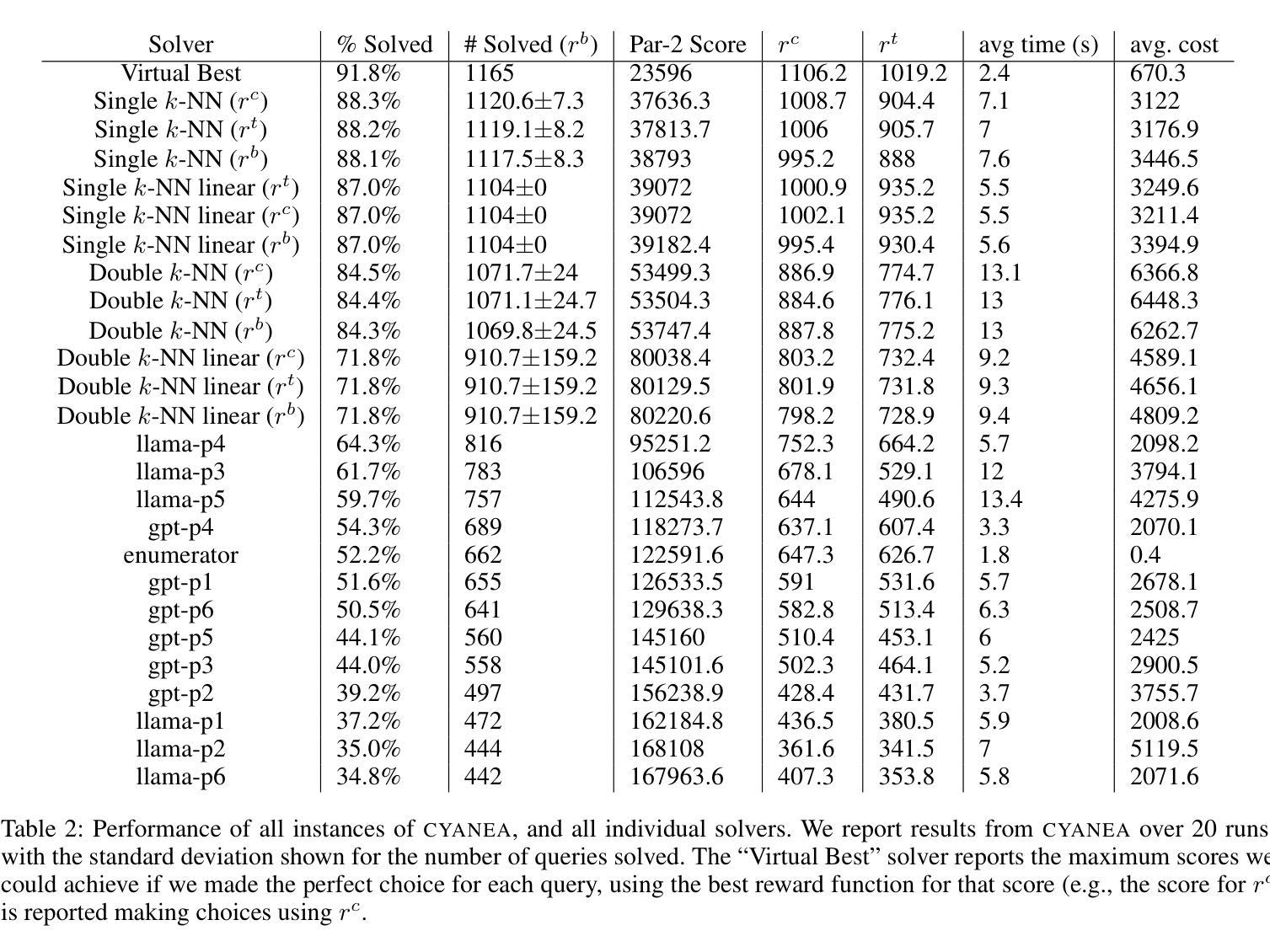
Online Prompt Selection for Program Synthesis
Authors:Yixuan Li, Lewis Frampton, Federico Mora, Elizabeth Polgreen
Large Language Models (LLMs) demonstrate impressive capabilities in the domain of program synthesis. This level of performance is not, however, universal across all tasks, all LLMs and all prompting styles. There are many areas where one LLM dominates, one prompting style dominates, or where calling a symbolic solver is a better choice than an LLM. A key challenge for the user then, is to identify not only when an LLM is the right choice of solver, and the appropriate LLM to call for a given synthesis task, but also the right way to call it. A non-expert user who makes the wrong choice, incurs a cost both in terms of results (number of tasks solved, and the time it takes to solve them) and financial cost, if using a closed-source language model via a commercial API. We frame this choice as an online learning problem. We use a multi-armed bandit algorithm to select which symbolic solver, or LLM and prompt combination to deploy in order to maximize a given reward function (which may prioritize solving time, number of synthesis tasks solved, or financial cost of solving). We implement an instance of this approach, called CYANEA, and evaluate it on synthesis queries from the literature in ranking function synthesis, from the syntax-guided synthesis competition, and fresh, unseen queries generated from SMT problems. CYANEA solves 37.2% more queries than the best single solver and achieves results within 4% of the virtual best solver.
大型语言模型(LLM)在程序合成领域展现出了令人印象深刻的能力。然而,这种表现并非在所有任务、所有LLM以及所有提示风格中都是普遍的。在许多领域,一个LLM会占据主导,一种提示风格会占据主导,或者调用符号求解器是一个比LLM更好的选择。因此,用户面临的关键挑战是,不仅要识别何时选择LLM作为求解器以及针对给定的合成任务调用哪个LLM是恰当的,而且还要以正确的方式调用它。非专家用户如果做出了错误的选择,不仅会从结果(解决的任务数量和所需的时间)上付出代价,如果使用商业API的闭源语言模型,还会产生经济成本。我们将这种选择框架作为一个在线学习问题。我们使用多臂老虎机算法来选择要部署的符号求解器或LLM和提示组合,以最大化给定的奖励函数(可能优先考虑解决时间、解决的任务数量或解决的经济成本)。我们实现了这种方法的一个实例,称为CYANEA,并对其在排名函数合成中的合成查询、语法指导的合成竞赛以及来自SMT问题的新鲜未见过的查询进行了评估。CYANEA比最佳单一求解器解决了37.2%以上的查询,并取得了与虚拟最佳求解器相差4%的结果。
论文及项目相关链接
PDF Accepted at the 39th AAAI Conference on Artificial Intelligence (AAAI-25) Main Track
Summary
大型语言模型(LLM)在程序合成领域表现出令人印象深刻的能力,但其性能并非普遍适用于所有任务、所有LLM和所有提示风格。关键挑战在于用户需要识别何时使用LLM作为求解器是最佳选择,以及如何正确调用适当的LLM来完成给定的合成任务。我们将其选择作为一个在线学习问题,并使用多臂老虎机算法来选择部署哪种符号求解器或LLM和提示组合,以最大化给定的奖励函数。我们实施了一种称为CYANEA的方法,并在排名函数合成、语法指导合成竞赛以及由SMT问题生成的新鲜未见查询上对其进行了评估。CYANEA比最佳单一求解器解决了更多的查询问题,并取得了接近虚拟最佳求解器的结果。
Key Takeaways
- LLM在程序合成领域具有显著能力,但性能因任务、LLM和提示风格而异。
- 用户面临的挑战是识别何时以及如何使用LLM进行最佳求解。
- 将此选择视为在线学习问题,使用多臂老虎机算法进行优化。
- CYANEA方法实施用于选择适当的求解器或LLM及提示组合。
- CYANEA在多个评估中表现出优于单一求解器的性能,接近虚拟最佳求解器。
点此查看论文截图



Planning Anything with Rigor: General-Purpose Zero-Shot Planning with LLM-based Formalized Programming
Authors:Yilun Hao, Yang Zhang, Chuchu Fan
While large language models (LLMs) have recently demonstrated strong potential in solving planning problems, there is a trade-off between flexibility and complexity. LLMs, as zero-shot planners themselves, are still not capable of directly generating valid plans for complex planning problems such as multi-constraint or long-horizon tasks. On the other hand, many frameworks aiming to solve complex planning problems often rely on task-specific preparatory efforts, such as task-specific in-context examples and pre-defined critics/verifiers, which limits their cross-task generalization capability. In this paper, we tackle these challenges by observing that the core of many planning problems lies in optimization problems: searching for the optimal solution (best plan) with goals subject to constraints (preconditions and effects of decisions). With LLMs’ commonsense, reasoning, and programming capabilities, this opens up the possibilities of a universal LLM-based approach to planning problems. Inspired by this observation, we propose LLMFP, a general-purpose framework that leverages LLMs to capture key information from planning problems and formally formulate and solve them as optimization problems from scratch, with no task-specific examples needed. We apply LLMFP to 9 planning problems, ranging from multi-constraint decision making to multi-step planning problems, and demonstrate that LLMFP achieves on average 83.7% and 86.8% optimal rate across 9 tasks for GPT-4o and Claude 3.5 Sonnet, significantly outperforming the best baseline (direct planning with OpenAI o1-preview) with 37.6% and 40.7% improvements. We also validate components of LLMFP with ablation experiments and analyzed the underlying success and failure reasons. Project page: https://sites.google.com/view/llmfp.
虽然大型语言模型(LLM)最近在解决规划问题方面展现出了强大的潜力,但在灵活性和复杂性之间存在权衡。作为零启动规划者本身,LLM仍然无法直接为复杂的规划问题(如多约束或长期任务)生成有效的计划。另一方面,许多旨在解决复杂规划问题的框架通常依赖于特定任务的准备性工作,例如特定于任务的上下文示例和预先定义的评论家/验证器,这限制了它们的跨任务泛化能力。在本文中,我们通过观察许多规划问题的核心在于优化问题来解决这些挑战:在目标受到约束(决策的先决条件和影响)的情况下搜索最优解(最佳计划)。利用LLM的常识、推理和编程能力,这为基于LLM的通用规划方法打开了可能性。受此观察的启发,我们提出了LLMFP,这是一个通用框架,它利用LLM从规划问题中提取关键信息,并将其正式制定为优化问题并解决,无需特定任务的示例。我们将LLMFP应用于9个规划问题,从多约束决策制定到多步骤规划问题,并证明LLMFP在GPT-4o和Claude 3.5 Sonnet上平均达到了83.7%和86.8%的最优率,显著优于最佳基线(使用OpenAI o1-preview的直接规划方法),提高了37.6%和40.7%。我们还通过消融实验验证了LLMFP的组件,并分析了其成功和失败的根本原因。项目页面:https://sites.google.com/view/llmfp。
论文及项目相关链接
PDF 57 pages, 25 figures, 15 tables
Summary
大型语言模型(LLM)在解决规划问题上展现了潜力,但在灵活性与复杂性之间存在权衡。LLM作为零规划者,尚不能直接为复杂规划问题生成有效方案。现有框架常依赖特定任务的预备工作,限制了跨任务泛化能力。本研究观察到规划问题的核心在于优化问题,并提出LLMFP框架,利用LLM捕捉规划问题的关键信息,并将其形式化为优化问题。在多个任务上的实验显示,LLMFP显著优于基线方法。
Key Takeaways
- LLM在解决规划问题时存在灵活性与复杂性之间的权衡。
- LLM尚不能直接生成复杂规划问题的有效方案。
- 现有框架解决复杂规划问题常依赖任务特定预备工作,限制了其跨任务泛化能力。
- 规划问题的核心在于寻找满足约束的最优解决方案。
- LLMFP框架利用LLM的常识、推理和编程能力,以通用方式解决规划问题。
- LLMFP在多个任务上的实验表现优于基线方法。
- LLMFP的成功与失败原因得到了实验验证和分析。
点此查看论文截图

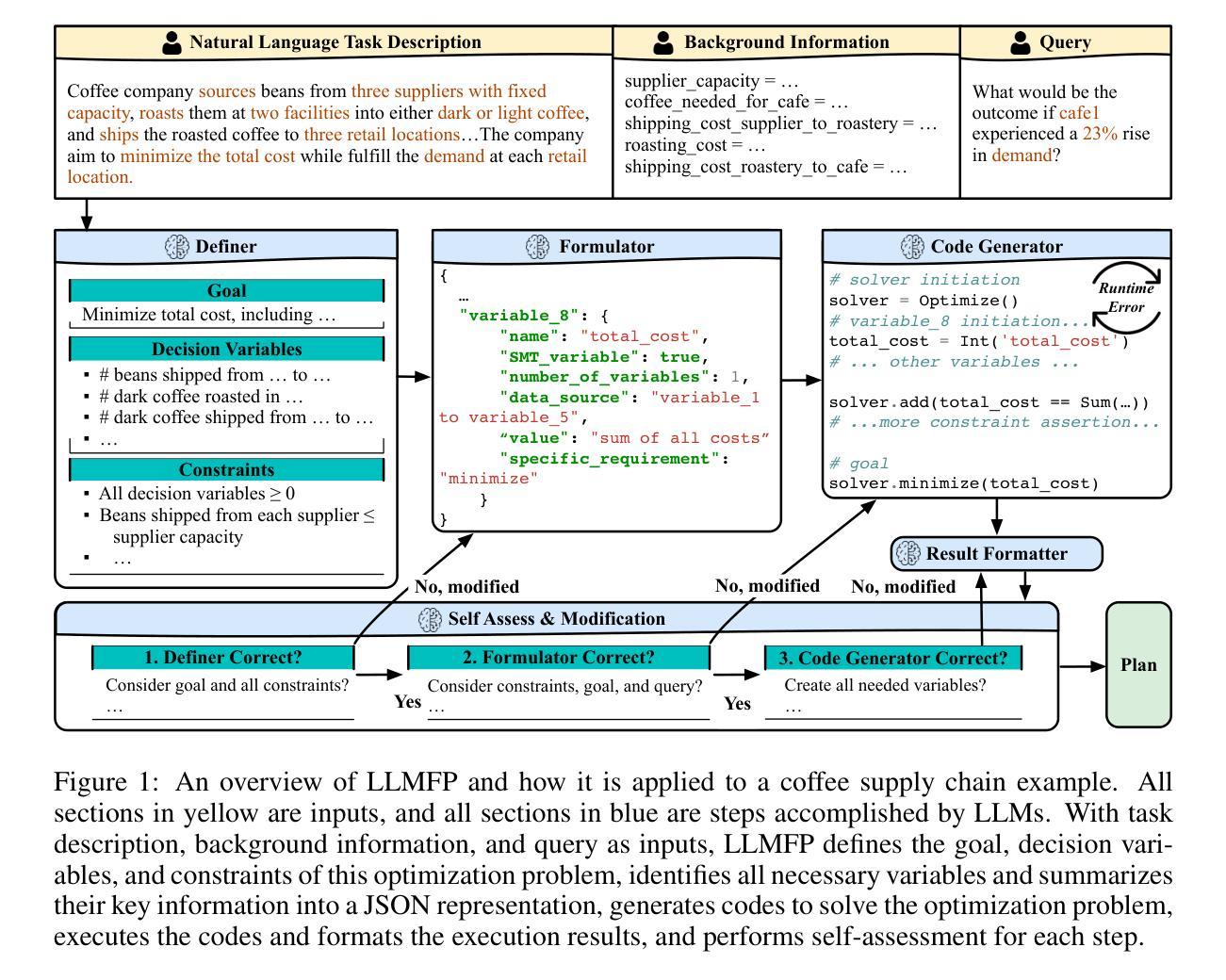

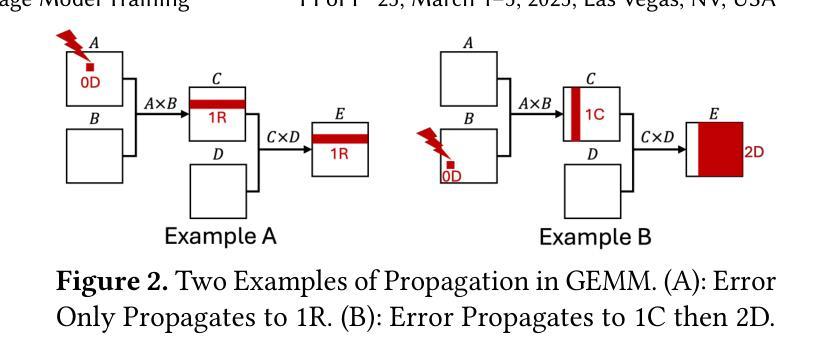
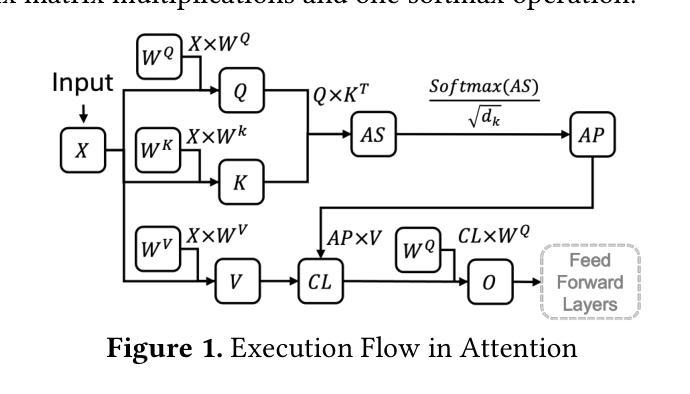
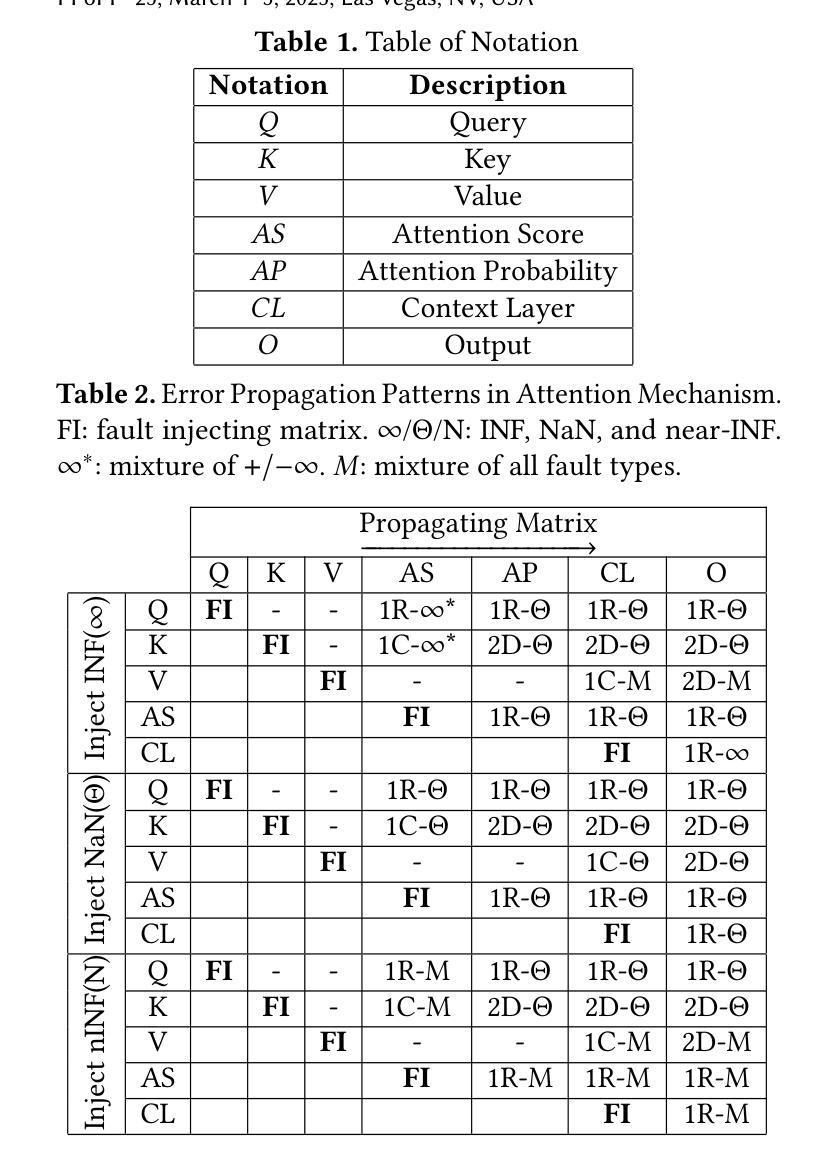
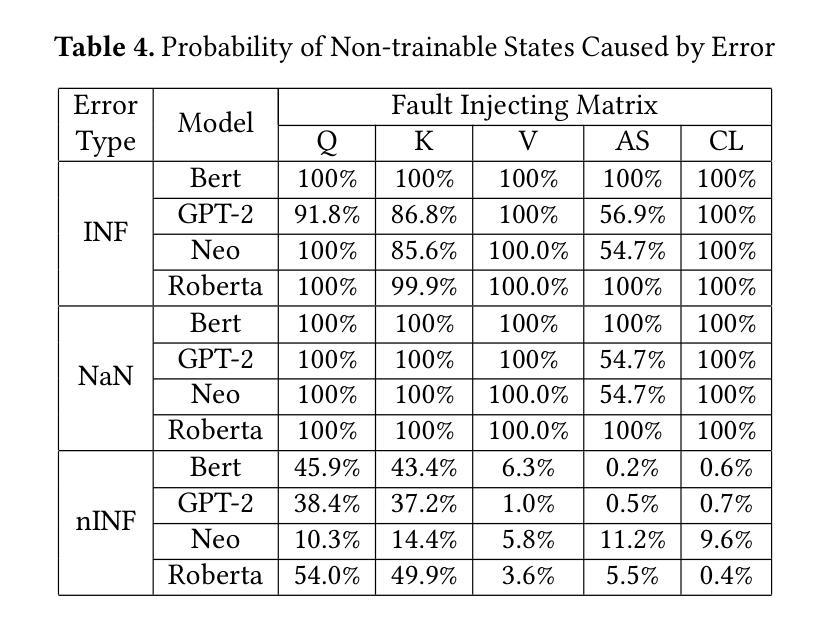
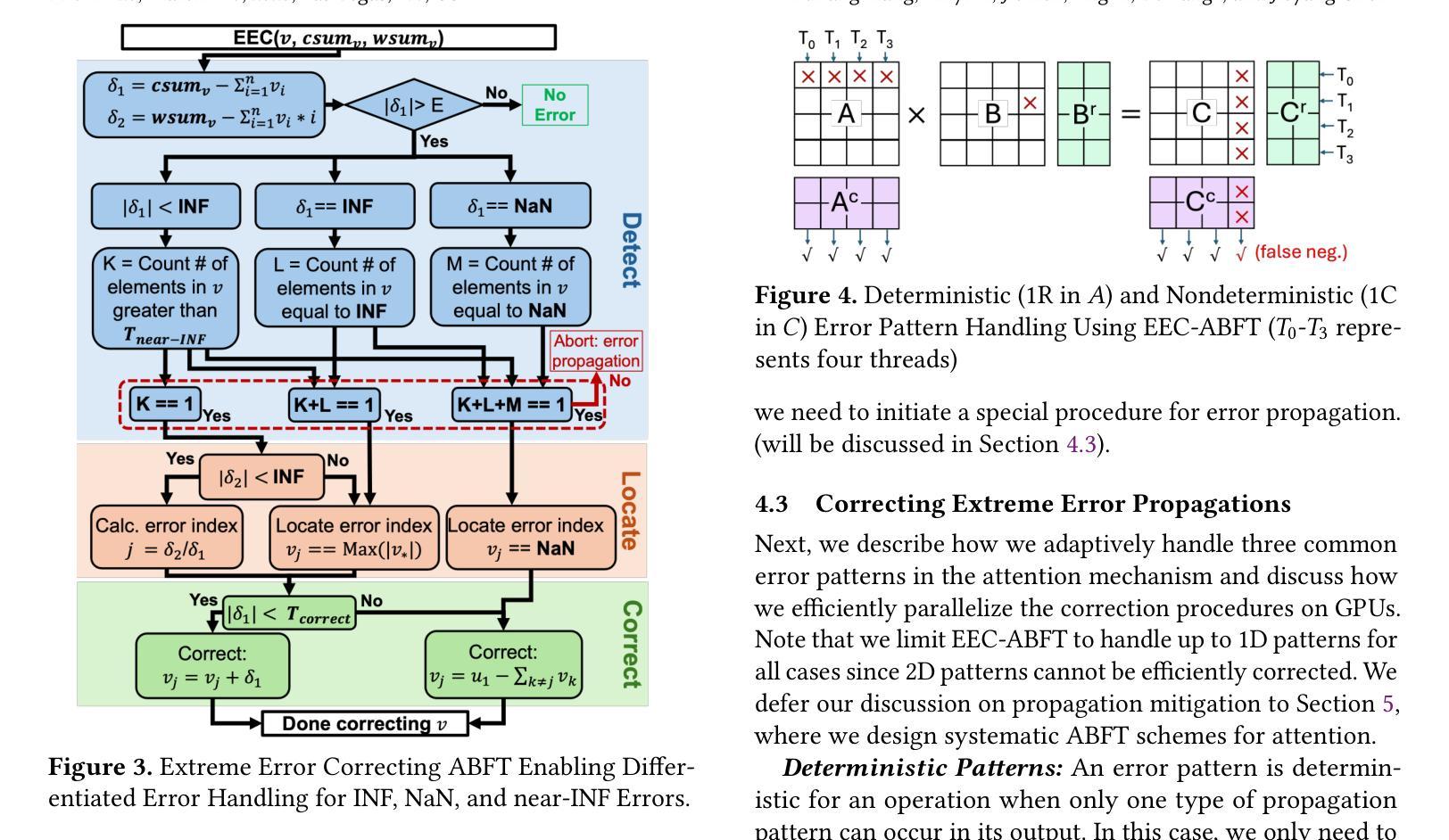
ATTNChecker: Highly-Optimized Fault Tolerant Attention for Large Language Model Training
Authors:Yuhang Liang, Xinyi Li, Jie Ren, Ang Li, Bo Fang, Jieyang Chen
Large Language Models (LLMs) have demonstrated remarkable performance in various natural language processing tasks. However, the training of these models is computationally intensive and susceptible to faults, particularly in the attention mechanism, which is a critical component of transformer-based LLMs. In this paper, we investigate the impact of faults on LLM training, focusing on INF, NaN, and near-INF values in the computation results with systematic fault injection experiments. We observe the propagation patterns of these errors, which can trigger non-trainable states in the model and disrupt training, forcing the procedure to load from checkpoints. To mitigate the impact of these faults, we propose ATTNChecker, the first Algorithm-Based Fault Tolerance (ABFT) technique tailored for the attention mechanism in LLMs. ATTNChecker is designed based on fault propagation patterns of LLM and incorporates performance optimization to adapt to both system reliability and model vulnerability while providing lightweight protection for fast LLM training. Evaluations on four LLMs show that ATTNChecker incurs on average 7% overhead on training while detecting and correcting all extreme errors. Compared with the state-of-the-art checkpoint/restore approach, ATTNChecker reduces recovery overhead by up to 49x.
大型语言模型(LLM)在各种自然语言处理任务中表现出了卓越的性能。然而,这些模型的训练计算密集且容易出错,特别是在基于转换器的LLM中起到关键作用的注意力机制。在本文中,我们研究了故障对LLM训练的影响,重点关注计算结果中的无穷大(INF)、非数字(NaN)和接近无穷大的值,并通过系统的故障注入实验进行研究。我们观察了这些错误的传播模式,这些错误可能会触发模型中的不可训练状态并中断训练,迫使程序从检查点加载。为了减轻这些故障的影响,我们提出了ATTNChecker,这是第一种针对LLM中注意力机制的基于算法的容错(ABFT)技术。ATTNChecker的设计基于LLM的故障传播模式,并融入了性能优化,以适应系统可靠性和模型脆弱性,同时为快速LLM训练提供轻量级保护。对四种LLM的评估表明,ATTNChecker在训练过程中的平均开销为7%,同时能够检测和纠正所有极端错误。与最新的检查点/恢复方法相比,ATTNChecker将恢复开销减少了高达49倍。
论文及项目相关链接
Summary
大型语言模型(LLM)在多个自然语言处理任务中展现出卓越性能,但其训练计算量大且易出错,特别是基于transformer的LLM中的注意力机制。本文通过故障注入实验研究了故障对LLM训练的影响,并观察到错误传播模式可能导致模型不可训练状态并中断训练。为缓解这些故障的影响,本文提出了针对LLM注意力机制的算法级容错技术ATTNChecker。ATTNChecker根据LLM的故障传播模式设计,融入了性能优化以适应系统可靠性和模型脆弱性,同时为快速LLM训练提供轻量级保护。评估显示,ATTNChecker平均训练开销为7%,可检测并修正所有极端错误。相较于当前先进的检查点恢复方法,ATTNChecker恢复开销降低了高达49倍。
Key Takeaways
- LLM在自然语言处理任务中具有出色表现,但其训练计算量大且存在易错点,特别是在注意力机制方面。
- 故障注入实验用于研究故障对LLM训练的影响,揭示了错误传播模式可能导致模型进入不可训练状态。
- ATTNChecker是首个针对LLM注意力机制的算法级容错技术,旨在减轻故障对训练的影响。
- ATTNC福CKER基于LLM的故障传播模式设计,融合了性能优化以适应系统可靠性和模型脆弱性。
- ATTNC福CKER提供了轻量级的保护,以确保快速LLM训练。
- 评估显示,ATTNChecker在训练过程中的平均开销为7%,并能有效检测及修正所有极端错误。
点此查看论文截图

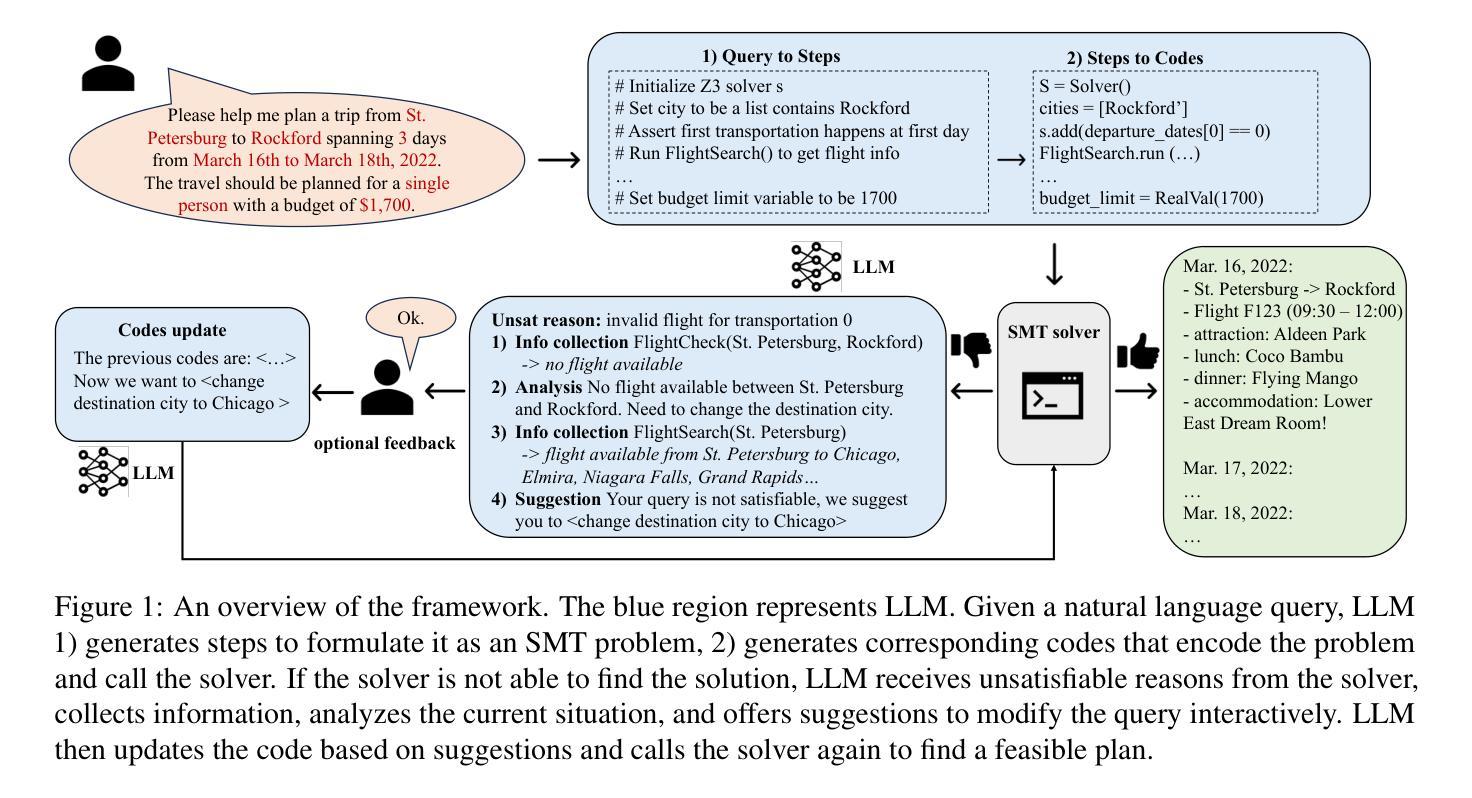
Large Language Models Can Solve Real-World Planning Rigorously with Formal Verification Tools
Authors:Yilun Hao, Yongchao Chen, Yang Zhang, Chuchu Fan
Large Language Models (LLMs) struggle to directly generate correct plans for complex multi-constraint planning problems, even with self-verification and self-critique. For example, a U.S. domestic travel planning benchmark TravelPlanner was proposed in Xie et al. (2024), where the best LLM OpenAI o1-preview can only find viable travel plans with a 10% success rate given all needed information. In this work, we tackle this by proposing an LLM-based planning framework that formalizes and solves complex multi-constraint planning problems as constrained satisfiability problems, which are further consumed by sound and complete satisfiability solvers. We start with TravelPlanner as the primary use case and show that our framework achieves a success rate of 93.9% and is effective with diverse paraphrased prompts. More importantly, our framework has strong zero-shot generalizability, successfully handling unseen constraints in our newly created unseen international travel dataset and generalizing well to new fundamentally different domains. Moreover, when user input queries are infeasible, our framework can identify the unsatisfiable core, provide failure reasons, and offers personalized modification suggestions. We show that our framework can modify and solve for an average of 81.6% and 91.7% unsatisfiable queries from two datasets and prove with ablations that all key components of our framework are effective and necessary. Project page: https://sites.google.com/view/llm-rwplanning.
大型语言模型(LLM)在解决复杂的、具有多重约束的规划问题时,即使在具备自我验证和自批能力的情况下,也难以直接生成正确的规划方案。例如,在谢等人提出的美国国内旅行规划基准测试TravelPlanner中(Xie et al., 2024),即使提供所有必要信息,最佳LLM OpenAI o1-preview也只能以10%的成功率找到可行的旅行计划。在这项工作中,我们通过提出一个基于LLM的规划框架来解决这个问题,该框架将复杂的、具有多重约束的规划问题形式化为约束可满足性问题,并进一步通过健全和完整的可满足性求解器进行求解。我们以TravelPlanner作为主要用例进行展示,证明我们的框架成功率达到了93.9%,并在多样化的同义换词提示下取得了良好效果。更重要的是,我们的框架具有较强的零样本泛化能力,能够成功处理我们新创建的未见国际旅行数据集中所包含的新增未见约束,并在新的根本不同领域进行良好的泛化。此外,当用户输入的查询不可行时,我们的框架可以识别出不满足要求的核心部分、提供失败原因以及个性化的修改建议。我们展示,我们的框架可以对两个数据集的不可满足查询进行平均达到81.6%和91.7%的修改并解决,并通过消融实验证明我们框架的所有关键组成部分都是有效且必要的。项目页面:https://sites.google.com/view/llm-rwplanning。
论文及项目相关链接
PDF 50 pages, 6 figures, 8 tables
Summary
大型语言模型(LLM)在处理复杂的带有多种约束的规划问题时,即便具备自我验证与自我批判的能力,仍难以直接生成正确的计划。例如,在Xie等人提出的TravelPlanner美国国内旅行规划基准测试中,最佳LLM OpenAI o1-preview即使获得所有必要信息,也只能以10%的成功率找到可行的旅行计划。本研究通过提出一个基于LLM的规划框架来解决这一问题,该框架将复杂的带有多种约束的规划问题形式化为约束可满足性问题,并使用健全且完整的可满足性求解器来解决。以TravelPlanner为主要用例,我们的框架成功率为93.9%,并在多样化的改述提示中表现出良好的效果。更重要的是,我们的框架具有很强的零样本泛化能力,能够成功处理我们新创建的无约束国际旅行数据集,并在全新且根本不同的领域实现良好的泛化。此外,在用户输入的查询不可行时,我们的框架可以识别出不满足核心条件的原因,并提供个性化的修改建议。实验证明,我们的框架平均可以解决81.6%和91.7%的来自两个数据集的不满足要求的查询,并通过分析证明框架的所有关键组成部分都是有效且必要的。
Key Takeaways
- LLM在处理复杂的多约束规划问题时存在困难,直接生成正确计划的成功率较低。
- 提出一个基于LLM的规划框架,将复杂的多约束规划问题形式化为约束可满足性问题并求解。
- 以TravelPlanner为主要用例,框架成功率高,并表现出良好的泛化能力。
- 框架具备零样本泛化能力,可处理未见过的国际旅行数据集。
- 当用户查询不可行时,框架能识别核心问题并提供修改建议。
- 框架对不满足要求的查询具有较高的解决率。
点此查看论文截图