⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-01 更新
Leveraging LLM Agents for Automated Optimization Modeling for SASP Problems: A Graph-RAG based Approach
Authors:Tianpeng Pan, Wenqiang Pu, Licheng Zhao, Rui Zhou
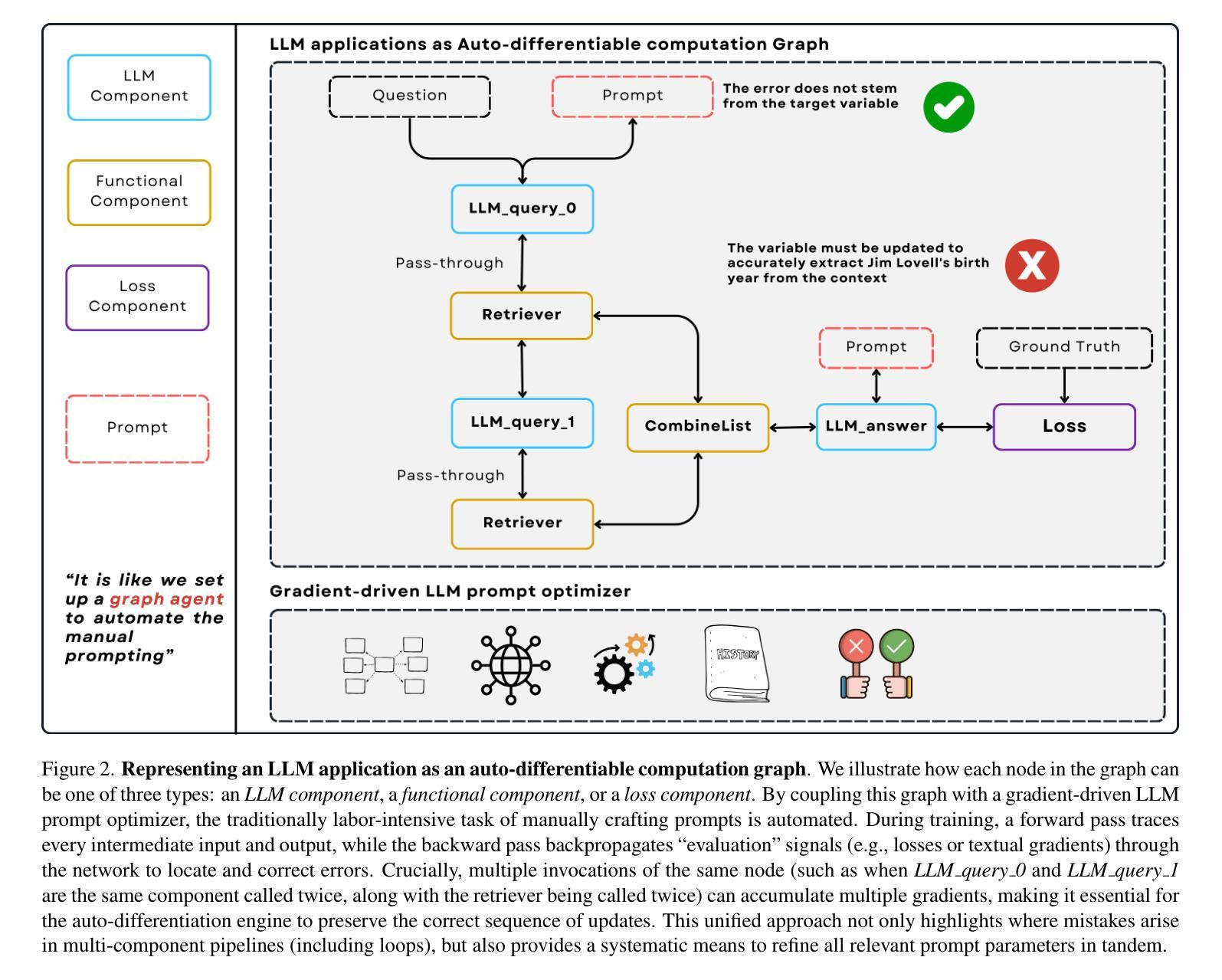
Automated optimization modeling (AOM) has evoked considerable interest with the rapid evolution of large language models (LLMs). Existing approaches predominantly rely on prompt engineering, utilizing meticulously designed expert response chains or structured guidance. However, prompt-based techniques have failed to perform well in the sensor array signal processing (SASP) area due the lack of specific domain knowledge. To address this issue, we propose an automated modeling approach based on retrieval-augmented generation (RAG) technique, which consists of two principal components: a multi-agent (MA) structure and a graph-based RAG (Graph-RAG) process. The MA structure is tailored for the architectural AOM process, with each agent being designed based on principles of human modeling procedure. The Graph-RAG process serves to match user query with specific SASP modeling knowledge, thereby enhancing the modeling result. Results on ten classical signal processing problems demonstrate that the proposed approach (termed as MAG-RAG) outperforms several AOM benchmarks.
随着大型语言模型(LLM)的快速发展,自动化优化建模(AOM)已经引起了广泛的关注。现有的方法主要依赖于提示工程,利用精心设计的专家响应链或结构化指导。然而,基于提示的技术在传感器阵列信号处理(SASP)领域表现不佳,主要是由于缺乏特定领域的专业知识。为了解决这一问题,我们提出了一种基于检索增强生成(RAG)技术的自动化建模方法,主要包括两个主要组成部分:多代理(MA)结构和基于图的RAG(Graph-RAG)过程。MA结构针对架构AOM过程进行定制,每个代理的设计都基于人类建模程序的原则。Graph-RAG过程用于将用户查询与特定的SASP建模知识相匹配,从而提高建模结果。对十个经典信号处理问题的结果证明,所提出的方法(称为MAG-RAG)优于多个AOM基准。
论文及项目相关链接
Summary
自动化优化建模(AOM)在大语言模型(LLM)的快速发展中引起了广泛关注。针对传感器阵列信号处理(Sasp)领域中缺乏特定领域知识的问题,提出了一种基于检索增强生成(RAG)技术的自动化建模方法。该方法包括两个主要组成部分:多智能体(MA)结构和基于图的RAG过程(Graph-RAG)。实验结果表明,所提出的MAG-RAG方法在多个经典信号处理方法上的表现优于几个自动化建模基准方法。
Key Takeaways
- AOM在大语言模型领域受到广泛关注。
- 当前方法主要依赖提示工程,但在传感器阵列信号处理领域表现不佳。
- 提出了一种基于检索增强生成技术的自动化建模方法来解决此问题。
- 该方法包括两个主要组成部分:多智能体结构和基于图的RAG过程。
- 多智能体结构针对架构AOM过程进行定制,每个智能体基于人类建模原理设计。
- 基于图的RAG过程旨在匹配用户查询与特定的传感器阵列信号处理建模知识。
点此查看论文截图


RepoAudit: An Autonomous LLM-Agent for Repository-Level Code Auditing
Authors:Jinyao Guo, Chengpeng Wang, Xiangzhe Xu, Zian Su, Xiangyu Zhang
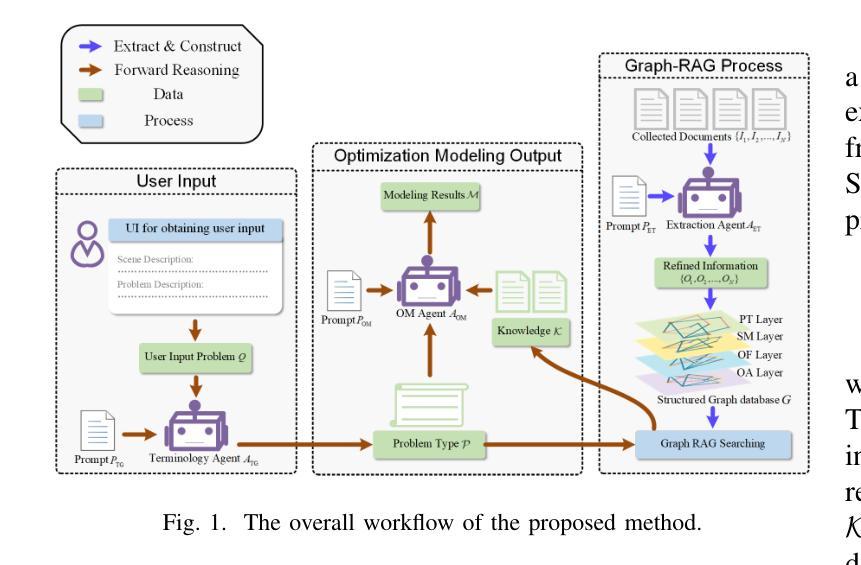
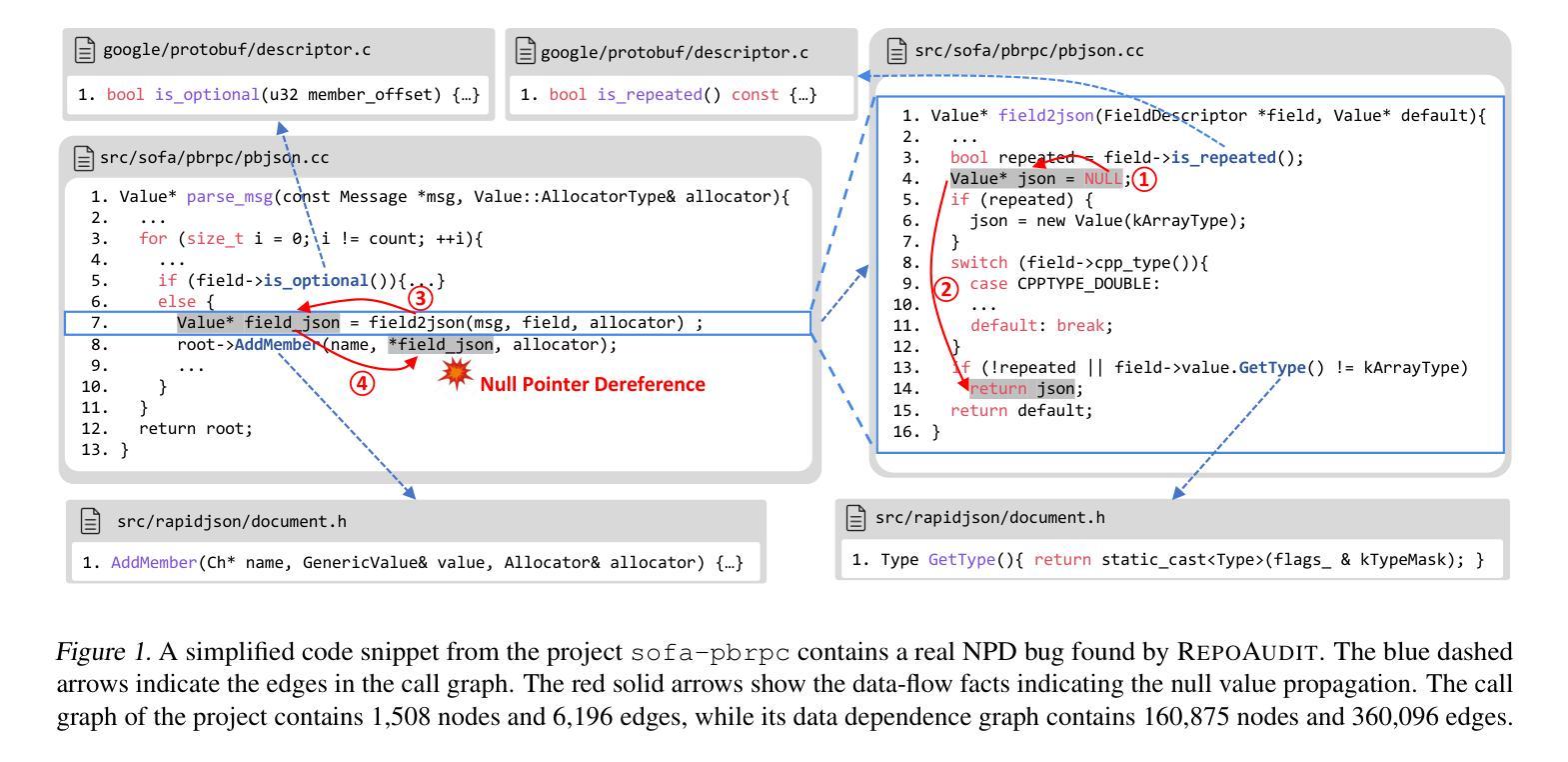
Code auditing is a code review process with the goal of finding bugs. Large Language Models (LLMs) have shown substantial potential in this task, offering the ability to analyze programs without compilation and enabling customized bug detection following specified prompts. However, applying LLMs to repository-level code auditing presents notable challenges. The inherent context limits and hallucinations of LLMs can lead to the low quality of bug reports. Meanwhile, the large size of software repositories introduces substantial time and token costs, hindering efficiency and scalability in real-world scenarios. This work introduces an autonomous LLM-agent, RepoAudit, designed to enable precise and efficient repository-level code auditing. Equipped with the agent memory, RepoAudit explores the code repository on demand, analyzing data-flow facts along different feasible program paths in individual functions. It also introduces the validator to check the data-flow facts for hallucination mitigation and examine the satisfiability of path conditions of potential buggy paths, which enables RepoAudit to discard false positives in the code auditing. Our experiment shows that RepoAudit powered by Claude 3.5 Sonnet successfully finds 38 true bugs in 15 real-world systems, consuming 0.44 hours and $2.54 per project on average.
代码审计是一种旨在发现错误的代码审查过程。大型语言模型(LLM)在此任务中显示出巨大的潜力,提供了无需编译即可分析程序的能力,并且能够根据特定提示进行定制化的错误检测。然而,将LLM应用于仓库级别的代码审计却面临诸多挑战。LLM的固有上下文限制和幻觉可能导致错误报告的质量低下。同时,软件仓库的大规模引入了大量的时间和令牌成本,阻碍了现实世界场景中的效率和可扩展性。
这项工作引入了一种自主LLM代理RepoAudit,旨在实现精确高效的仓库级别代码审计。配备有代理内存,RepoAudit按需探索代码仓库,分析单个函数中不同可行程序路径的数据流事实。它还引入了验证器,以减少幻觉并检查数据流事实,并检查潜在错误路径的路径条件的可满足性,这使得RepoAudit能够在代码审计中剔除误报。我们的实验表明,由Claude 3.5 Sonnet驱动的RepoAudit成功在15个真实系统中找到了38个真实错误,平均每个项目耗时0.44小时,花费2.54美元。
论文及项目相关链接
PDF 19 pages, 8 tables, 5 figures, 3 listings
Summary
代码审计旨在发现错误,大型语言模型(LLM)在此任务中显示出巨大潜力,可分析程序而不进行编译,并根据特定提示进行自定义错误检测。然而,将LLM应用于仓库级代码审计存在挑战。LLM的固有上下文限制和幻觉可能导致错误报告质量低下。同时,软件仓库的大规模增加了时间和令牌成本,阻碍了现实世界场景中的效率和可扩展性。本研究引入了一种自主LLM代理RepoAudit,旨在实现精确有效的仓库级代码审计。RepoAudit配备了代理内存,可按需探索代码仓库,分析单个函数中不同可行程序路径的数据流事实。它还引入了验证器,以减少幻觉并检查数据流事实,并检查潜在错误路径的条件可满足性,这使RepoAudit能够在代码审计中剔除误报。实验表明,由Claude 3.5 Sonnet驱动的RepoAudit成功在15个真实系统中找到38个真实错误,平均每个项目消耗0.44小时和2.54美元。
Key Takeaways
- 代码审计的目标是为了发现错误。
- 大型语言模型(LLM)在代码审计任务中具有巨大潜力。
- LLM在应用于仓库级代码审计时面临挑战,如上下文限制和幻觉问题。
- RepoAudit是一个自主LLM代理,可实现精确有效的仓库级代码审计。
- RepoAudit配备了代理内存,可按需探索代码仓库,并分析数据流事实。
- RepoAudit引入了验证器来减少幻觉并检查数据流事实的可行性。
点此查看论文截图


B3C: A Minimalist Approach to Offline Multi-Agent Reinforcement Learning
Authors:Woojun Kim, Katia Sycara
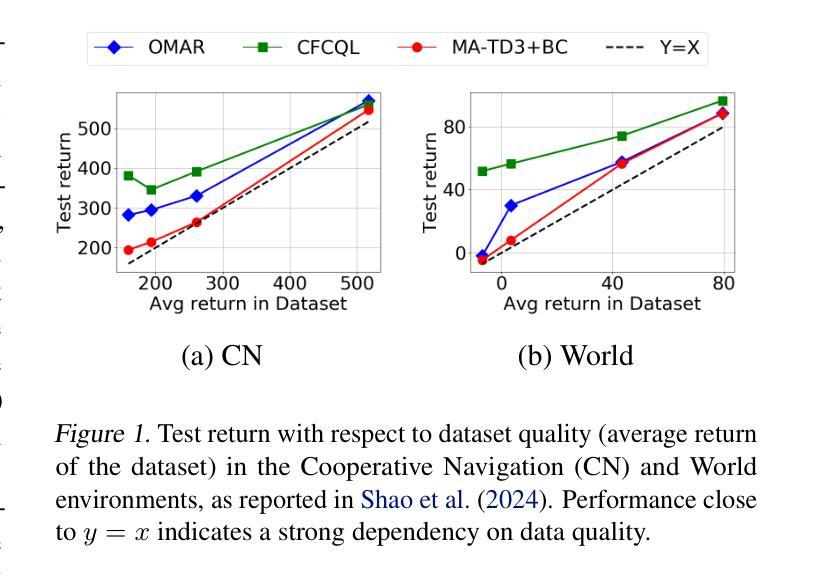
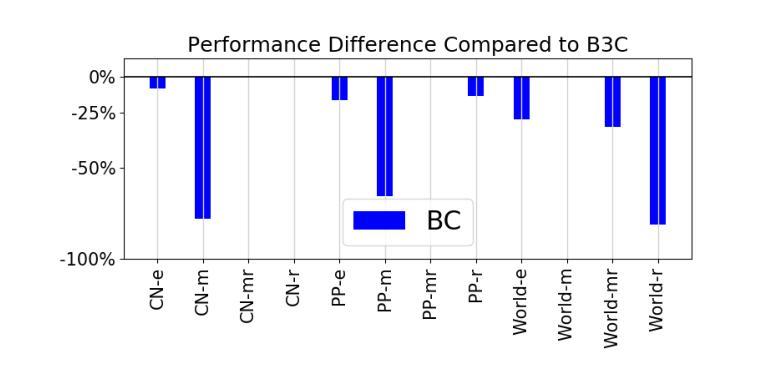
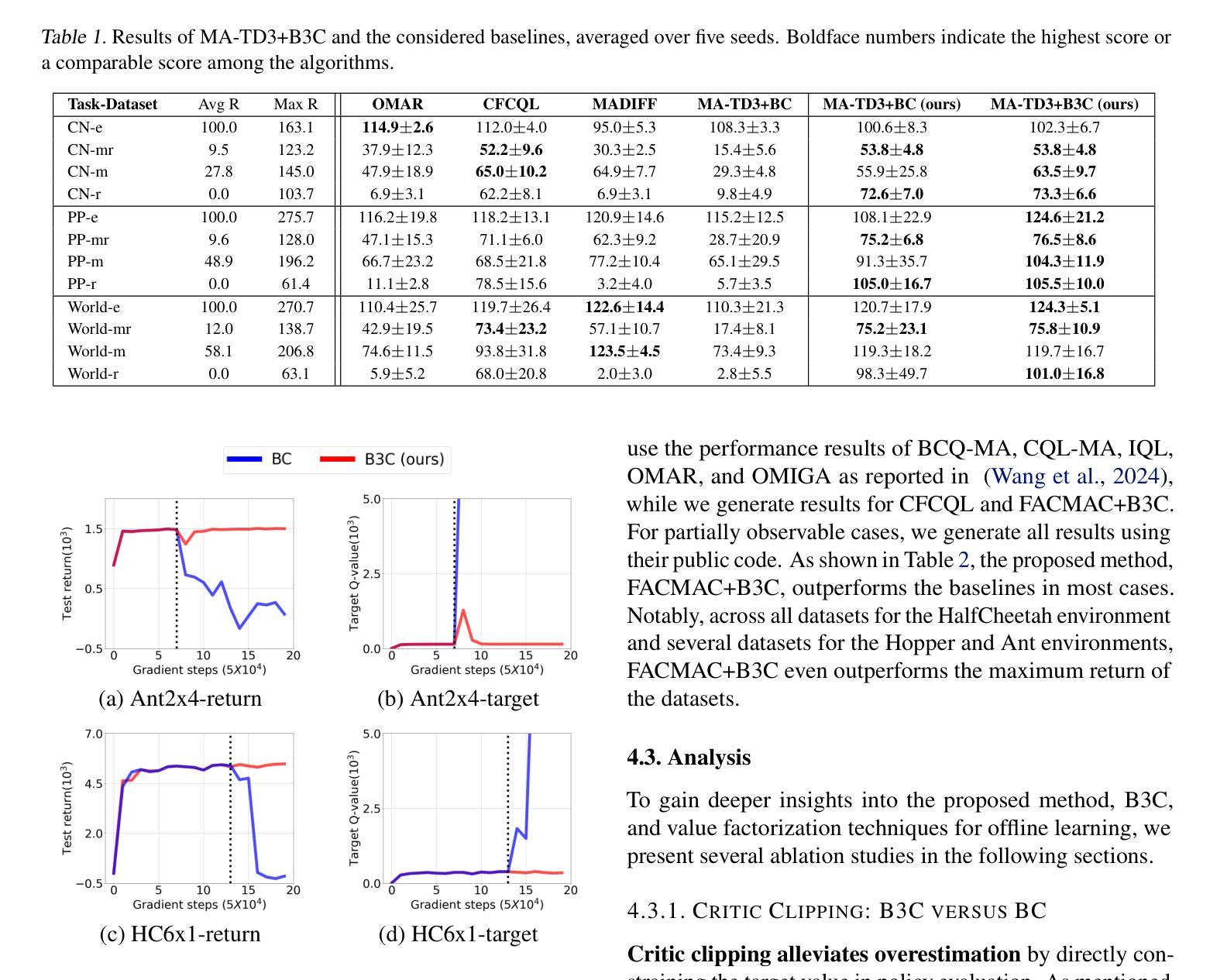
Overestimation arising from selecting unseen actions during policy evaluation is a major challenge in offline reinforcement learning (RL). A minimalist approach in the single-agent setting – adding behavior cloning (BC) regularization to existing online RL algorithms – has been shown to be effective; however, this approach is understudied in multi-agent settings. In particular, overestimation becomes worse in multi-agent settings due to the presence of multiple actions, resulting in the BC regularization-based approach easily suffering from either over-regularization or critic divergence. To address this, we propose a simple yet effective method, Behavior Cloning regularization with Critic Clipping (B3C), which clips the target critic value in policy evaluation based on the maximum return in the dataset and pushes the limit of the weight on the RL objective over BC regularization, thereby improving performance. Additionally, we leverage existing value factorization techniques, particularly non-linear factorization, which is understudied in offline settings. Integrated with non-linear value factorization, B3C outperforms state-of-the-art algorithms on various offline multi-agent benchmarks.
在离线强化学习(RL)中,由于在策略评估时选择未观察到的动作而导致的过度估计是主要挑战。在单智能体环境中,一种极简主义的方法——向现有的在线RL算法添加行为克隆(BC)正则化,已被证明是有效的;然而,这种方法在多智能体环境中的研究还不够。特别是,由于多智能体环境中存在多个动作,过度估计问题变得更加严重,导致基于BC正则化的方法容易遭受过度正则化或评论家发散的问题。为了解决这一问题,我们提出了一种简单而有效的方法,即带有评论家剪辑的行为克隆正则化(B3C)。该方法基于数据集的最大回报值对策略评估中的目标评论家值进行剪辑,并提高了基于RL目标的权重相对于BC正则化的限制,从而提高性能。此外,我们利用现有的价值分解技术,特别是离线环境中尚未充分研究的非线性分解技术。与非线性价值分解相结合,B3C在多种离线多智能体基准测试上优于最新算法。
论文及项目相关链接
Summary
在离线强化学习中,由于策略评估时选择未见动作导致的过度估计是主要挑战。在单智能体环境中采用极简主义方法——在现有在线强化学习算法中添加行为克隆(BC)正则化已被证明是有效的,但在多智能体环境中这种方法的研究较少。特别是,由于存在多个动作,过度估计在多智能体环境中变得更糟,基于BC正则化的方法很容易受到过度正则化或评论家偏离的影响。为了解决这一问题,我们提出了一种简单有效的方法,即行为克隆正则化与评论家剪辑(B3C),该方法基于数据集的最大回报剪辑目标评论家值,并提高了在BC正则化上RL目标的权重限制,从而提高性能。此外,我们还利用现有的价值分解技术,特别是离线环境中尚未研究的非线性分解技术。与非线性价值分解相结合,B3C在多种离线多智能体基准测试中表现优于最新算法。
Key Takeaways
- 离线强化学习中存在因选择未见动作导致的过度估计挑战。
- 在多智能体环境中,基于行为克隆(BC)正则化的方法容易受过度正则化或评论家偏离影响。
- 提出了一种新的方法B3C(行为克隆正则化与评论家剪辑),通过剪辑目标评论家值并调整RL目标与BC正则化的权重来解决上述问题。
- B3C方法能提高性能,并在多种离线多智能体基准测试中表现优于最新算法。
- 非线性价值分解技术在离线多智能体强化学习中潜力巨大,与B3C结合可进一步提高性能。
- B3C方法适用于离线强化学习场景,对于实际应用中数据的有限性和不完整性具有较好的适应性。
点此查看论文截图

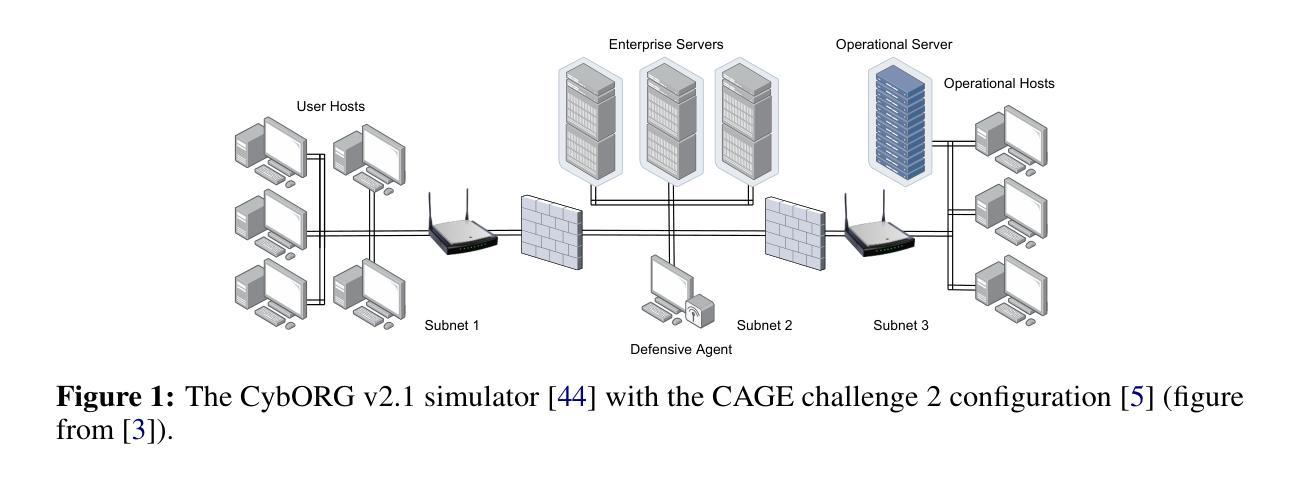
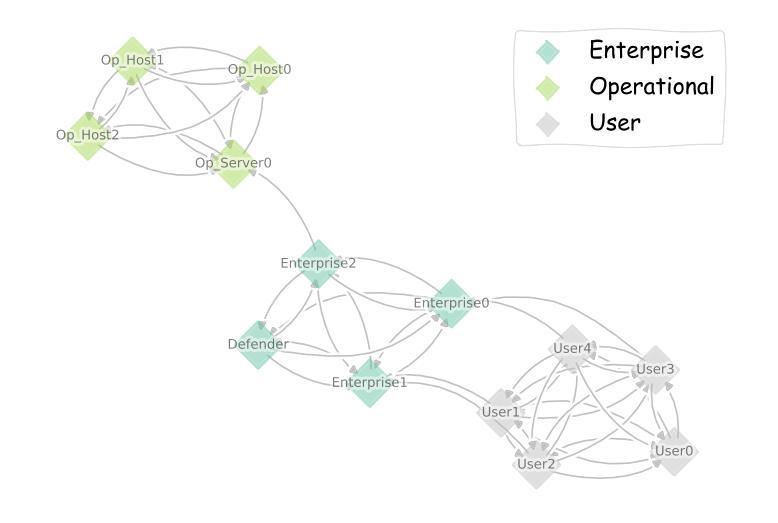
An Attentive Graph Agent for Topology-Adaptive Cyber Defence
Authors:Ilya Orson Sandoval, Isaac Symes Thompson, Vasilios Mavroudis, Chris Hicks
As cyber threats grow increasingly sophisticated, reinforcement learning (RL) is emerging as a promising technique to create intelligent and adaptive cyber defense systems. However, most existing autonomous defensive agents have overlooked the inherent graph structure of computer networks subject to cyber attacks, potentially missing critical information and constraining their adaptability. To overcome these limitations, we developed a custom version of the Cyber Operations Research Gym (CybORG) environment, encoding network state as a directed graph with realistic low-level features. We employ a Graph Attention Network (GAT) architecture to process node, edge, and global features, and adapt its output to be compatible with policy gradient methods in RL. Our GAT-based approach offers key advantages over flattened alternatives: robust policies capable of handling dynamic network topology changes, generalisation to networks of varying sizes beyond the training distribution, and interpretable defensive actions grounded in tangible network properties. We demonstrate the effectiveness of our low-level directed graph observations by training GAT defensive policies that successfully adapt to changing network topologies. Evaluations across networks of different sizes, but consistent subnetwork structure, show our policies achieve comparable performance to policies trained specifically for each network configuration. Our study contributes to the development of robust cyber defence systems that can better adapt to real-world network security challenges.
随着网络威胁日益复杂,强化学习(RL)作为一种有前景的技术,正逐渐崭露头角,用于创建智能和自适应的网络安全防御系统。然而,大多数现有的自主防御代理忽略了计算机网络在遭受网络攻击时的固有图形结构,可能会丢失关键信息并限制了其适应性。为了克服这些局限性,我们开发了自定义版本的网络安全研究健身房(CybORG)环境,将网络状态编码为有向图,并具备逼真的低级特征。我们采用图注意力网络(GAT)架构来处理节点、边缘和全局特征,并将其输出调整为与强化学习中的策略梯度方法兼容。我们的基于GAT的方法相对于扁平化替代方案具有关键优势:能够处理动态网络拓扑变化的稳健策略、推广到训练分布之外的各种网络大小,以及基于实际网络属性的可解释的防御行动。我们通过训练GAT防御策略来展示低级别有向图观测的有效性,该策略能够成功适应变化中的网络拓扑。在不同大小的网络上进行的评估,但具有一致的子网结构,表明我们的策略在实现针对每种网络配置的特定训练策略方面表现出相当的性能。我们的研究为开发能够更好适应现实网络安全挑战的稳健网络安全防御系统做出了贡献。
论文及项目相关链接
Summary
强化学习(RL)在创建智能自适应网络安全防御系统方面显示出巨大潜力,但大多数现有自主防御代理忽略了计算机网络的固有图形结构,可能遗漏关键信息并限制其适应性。为克服这些局限性,我们开发了定制版的CybORG环境,将网络状态编码为带有现实低级特征的定向图,并使用图注意力网络(GAT)架构处理节点、边和全局特征,并使其输出与RL中的策略梯度方法兼容。与平面替代方案相比,我们的GAT方法具有处理动态网络拓扑更改的能力、对超出训练分布的网络大小进行概括的能力以及基于实际网络属性的可解释防御行动的优势。
Key Takeaways
- 强化学习在网络安全防御系统中展现出巨大潜力,尤其是应对日益复杂的网络威胁。
- 当前自主防御代理忽视了计算机网络的图形结构,这可能影响防御系统的效能和适应性。
- 我们通过CybORG环境开发了一种基于图的方法,该方法能够处理网络状态并识别关键低级特征。
- 采用图注意力网络(GAT)架构处理网络中的节点、边和全局特征。
- GAT方法具有处理动态网络拓扑更改的能力,并能对不同大小的网络进行概括。
- 与平面方法相比,GAT方法提供的防御策略更可解释,基于实际网络属性。
点此查看论文截图


Beyond Browsing: API-Based Web Agents
Authors:Yueqi Song, Frank Xu, Shuyan Zhou, Graham Neubig
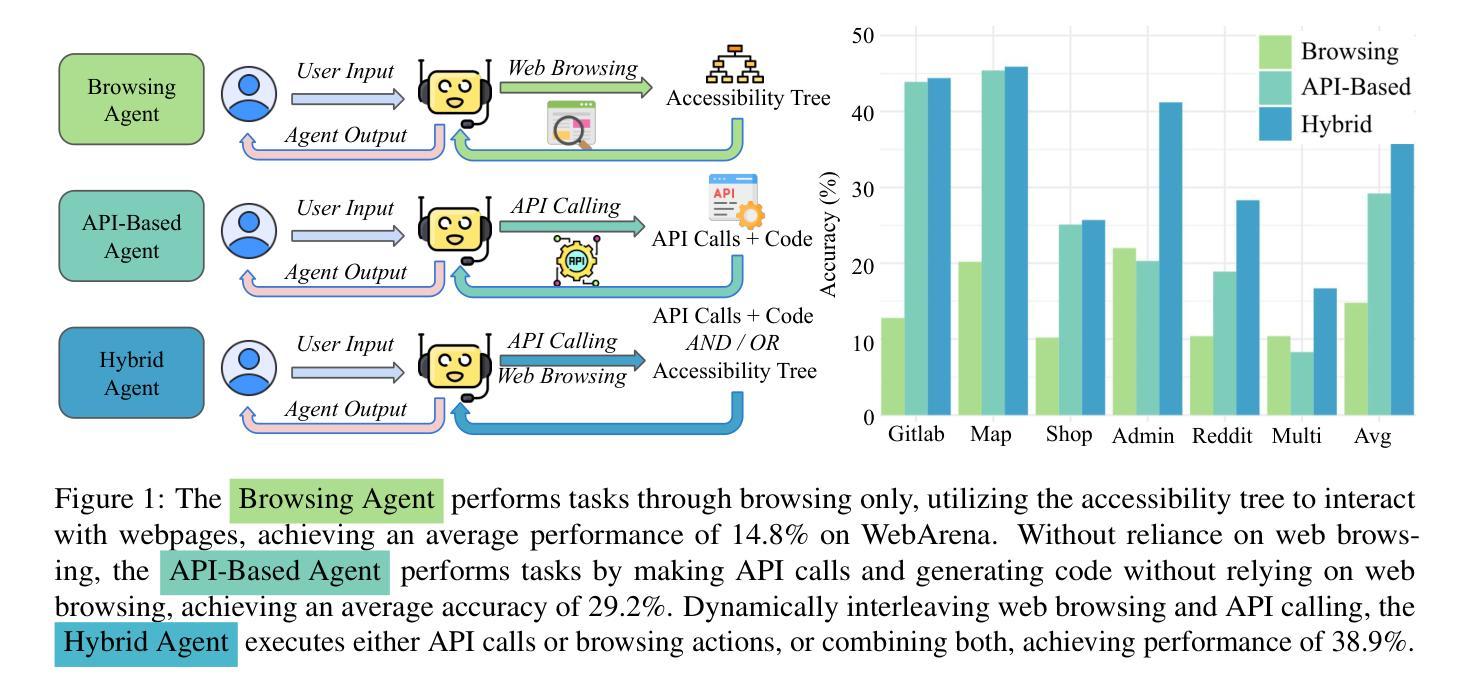
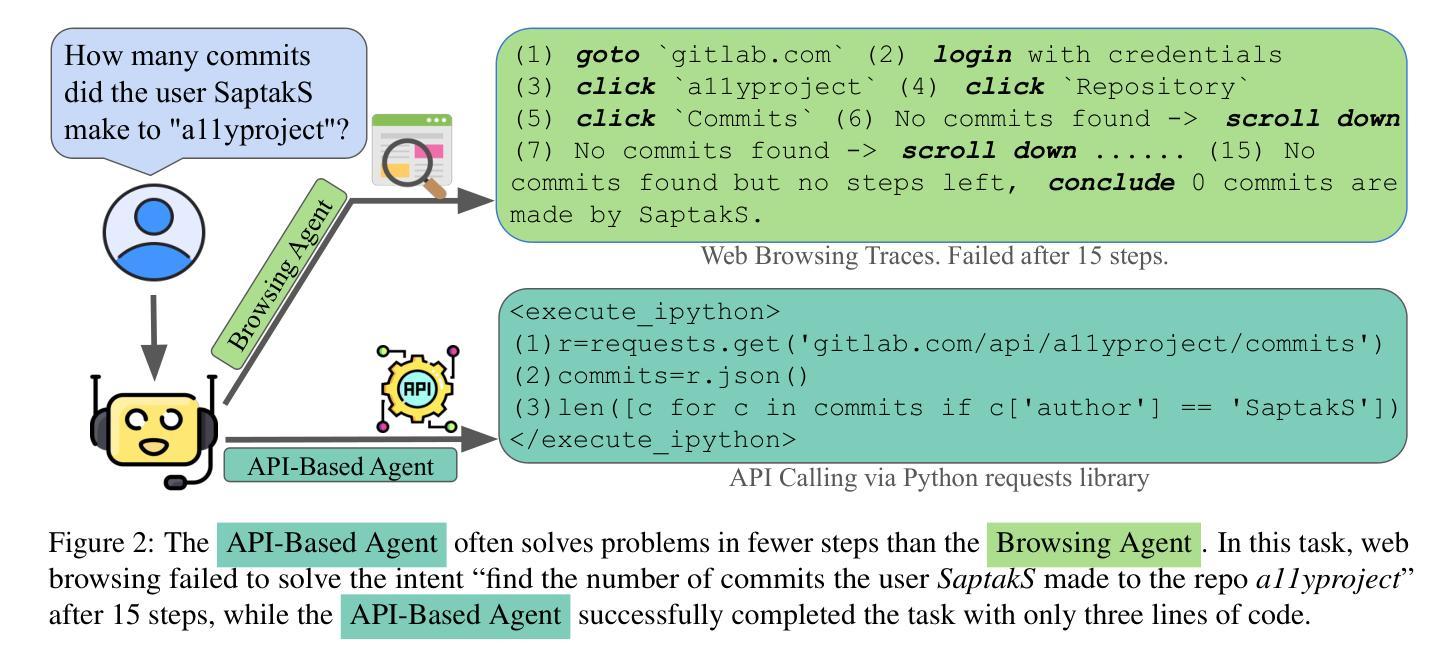
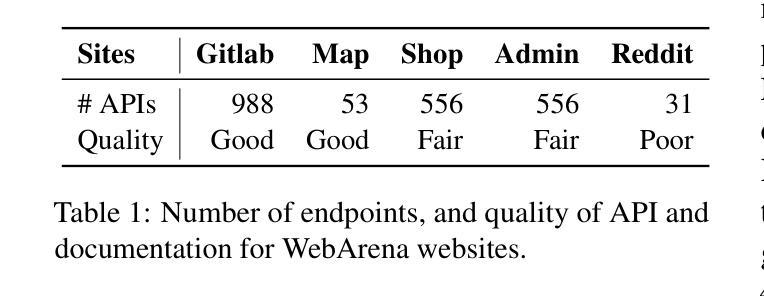
Web browsers are a portal to the internet, where much of human activity is undertaken. Thus, there has been significant research work in AI agents that interact with the internet through web browsing. However, there is also another interface designed specifically for machine interaction with online content: application programming interfaces (APIs). In this paper we ask – what if we were to take tasks traditionally tackled by browsing agents, and give AI agents access to APIs? To do so, we propose two varieties of agents: (1) an API-calling agent that attempts to perform online tasks through APIs only, similar to traditional coding agents, and (2) a Hybrid Agent that can interact with online data through both web browsing and APIs. In experiments on WebArena, a widely-used and realistic benchmark for web navigation tasks, we find that API-based agents outperform web browsing agents. Hybrid Agents out-perform both others nearly uniformly across tasks, resulting in a more than 20.0% absolute improvement over web browsing alone, achieving a success rate of 35.8%, achiving the SOTA performance among task-agnostic agents. These results strongly suggest that when APIs are available, they present an attractive alternative to relying on web browsing alone.
网络浏览器是通往互联网的门户,大部分人类活动都在这里进行。因此,在AI代理通过互联网浏览与互联网交互方面已经存在大量的研究工作。然而,还有一个专门为机器与在线内容交互而设计的接口:应用程序编程接口(API)。在这篇论文中,我们提出一个问题——如果我们采用传统上由浏览代理处理的任务,并给AI代理访问API的机会会怎样?为此,我们提出了两种类型的代理:(1)一种只通过API执行在线任务的API调用代理,类似于传统的编码代理;(2)一种可以通过网页浏览和API与在线数据进行交互的混合代理。在WebArena的实验中,WebArena是一个广泛用于网页导航任务的现实基准测试,我们发现基于API的代理表现优于网页浏览代理。混合代理几乎在所有任务上都表现得比其他代理更好,相对于仅使用网页浏览而言,其绝对改进超过了20.0%,成功率达到了35.8%,在任务无关的代理中取得了最新技术水平。这些结果强烈表明,当可用时,API成为仅依赖网页浏览的具有吸引力的替代方案。
论文及项目相关链接
PDF 24 pages, 6 figures
Summary
网络浏览器是通向互联网的门户,人类大部分活动都在这里进行。因此,在通过网页浏览与互联网交互的AI代理方面,已经进行了大量的研究工作。然而,还有一个专门为机器与在线内容交互而设计的界面:应用程序编程接口(API)。本文探讨了一个问题——如果我们采用传统上由浏览代理处理的任务,并给AI代理提供API访问权限会怎样?为此,我们提出了两种类型的代理:(1)API调用代理,它试图仅通过API执行在线任务,类似于传统的编码代理;(2)混合代理,它可以通过网页浏览和API与在线数据进行交互。在WebArena这一广泛使用和现实的网页导航任务基准测试上的实验表明,基于API的代理表现优于网页浏览代理。混合代理几乎在所有任务上都表现出比其它代理更好的性能,相较于仅使用网页浏览有20.0%以上的绝对改进,成功率达到35.8%,在任务无关代理中取得了最新技术性能。这些结果强烈表明,当可用时,API提供了一个吸引人的替代方案,不再仅仅依赖网页浏览。
Key Takeaways
- 网络浏览器是互联网的主要入口,AI代理与其交互已成为研究热点。
- 应用程序编程接口(API)是专为机器与在线内容交互而设计的界面。
- 提出两种新型AI代理:API调用代理和混合代理。
- API调用代理仅通过API执行在线任务。
- 混合代理结合网页浏览和API交互,表现出卓越性能。
- 在WebArena基准测试上,基于API的代理表现优于网页浏览代理。
- 混合代理统一优于其他代理,成功率达到35.8%,取得最新技术性能。
点此查看论文截图