⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-01 更新
Technical report on label-informed logit redistribution for better domain generalization in low-shot classification with foundation models
Authors:Behraj Khan, Tahir Syed
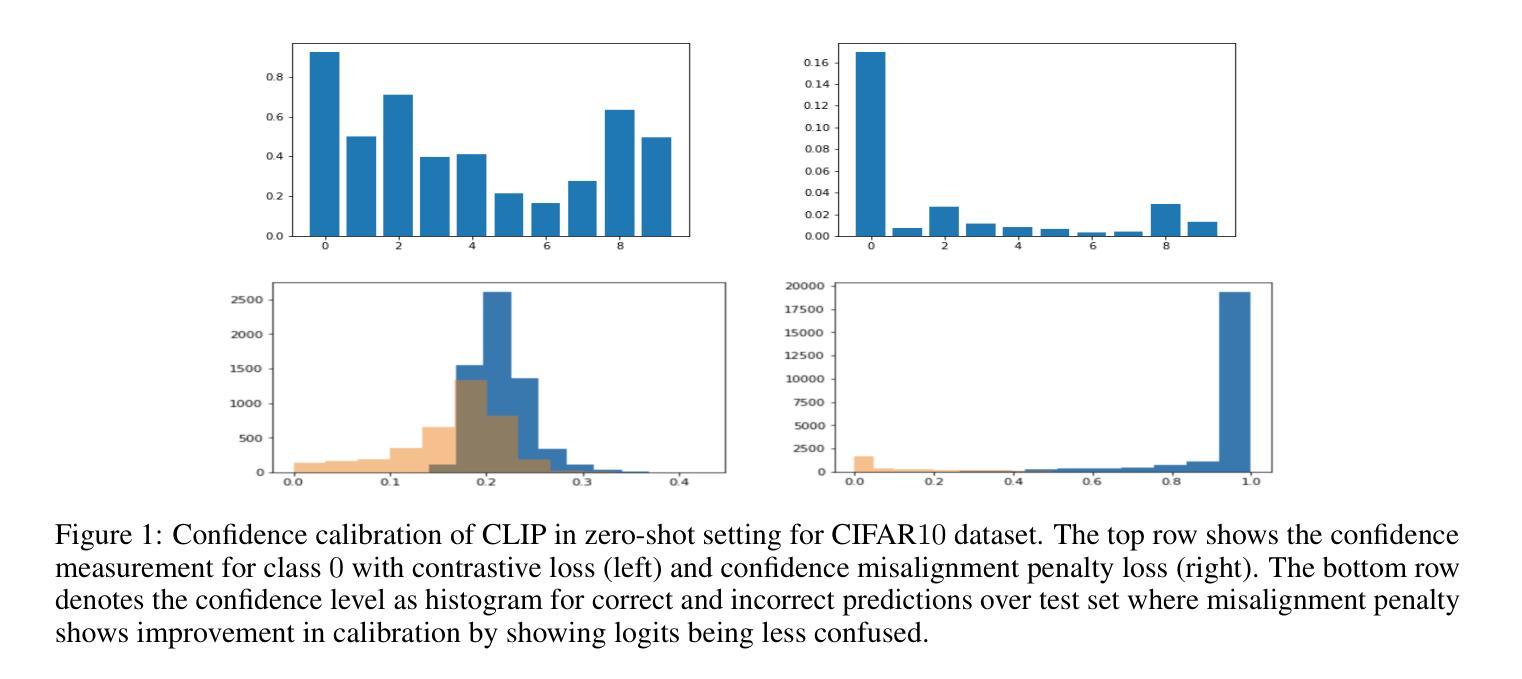
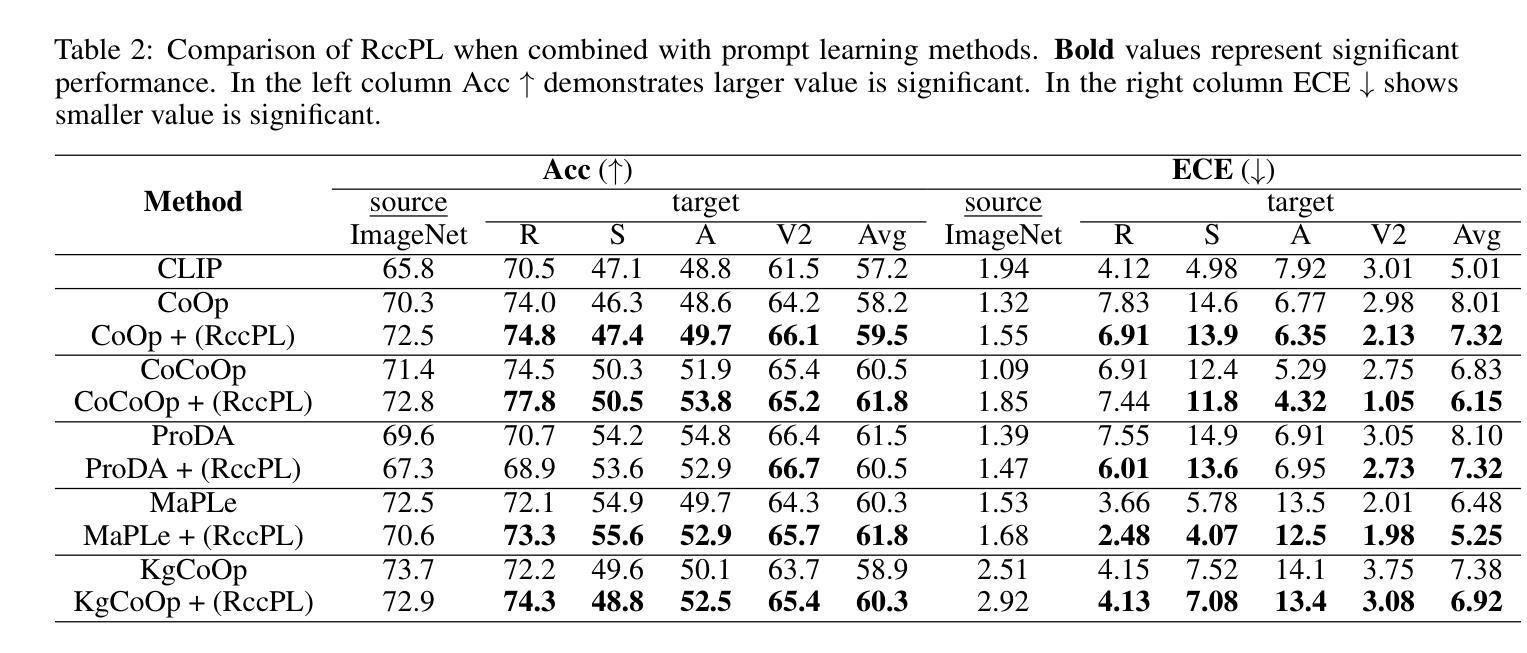
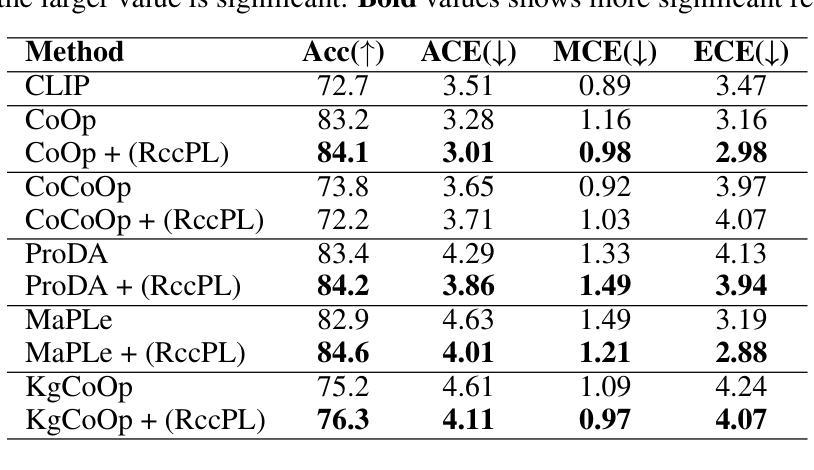
Confidence calibration is an emerging challenge in real-world decision systems based on foundations models when used for downstream vision classification tasks. Due to various reasons exposed, logit scores on the CLIP head remain large irrespective of whether the image-language pairs reconcile. It is difficult to address in data space, given the few-shot regime. We propose a penalty incorporated into loss objective that penalizes incorrect classifications whenever one is made during finetuning, by moving an amount of log-likelihood to the true class commensurate to the relative amplitudes of the two likelihoods. We refer to it as \textit{confidence misalignment penalty (CMP)}. Extensive experiments on $12$ vision datasets and $5$ domain generalization datasets supports the calibration performance of our method against stat-of-the-art. CMP outperforms the benchmarked prompt learning methods, demonstrating average improvement in Expected Calibration Error (ECE) by average $6.01$%, $4.01$ % at minimum and $9.72$% at maximum.
在基于基础模型的现实世界决策系统中,当用于下游视觉分类任务时,置信度校准是一个新兴的挑战。由于各种原因,无论图像语言对是否协调,CLIP头部的logit分数仍然很大。在少量样本的情况下,很难在数据空间中进行解决。我们提出了一种结合到损失目标中的惩罚,该惩罚在微调过程中每当出现错误分类时都会进行惩罚,通过将与两个可能性的相对幅度相当的似然性移动到真实类别来实现。我们将其称为“置信度不匹配惩罚(CMP)”。在12个视觉数据集和5个领域泛化数据集上的大量实验支持我们的方法与最新技术相比的校准性能。CMP优于基准提示学习方法,在预期校准误差(ECE)方面平均提高了6.01%,最低提高了4.01%,最高提高了9.72%。
论文及项目相关链接
Summary
基于预训练模型进行下游视觉分类任务时,置信度校准成为一项挑战。在少量样本下,由于种种原因导致logit分数难以反映图像语言对的实际一致性。为解决这一问题,我们提出了一种损失目标中的惩罚机制,即当微调时出现错误分类时,根据两个可能性的相对幅度,将部分对数似然转移到真实类别上。我们称之为置信度不匹配惩罚(CMP)。在多个视觉数据集和领域泛化数据集上的实验表明,该方法在标准测试方法上的校准性能优于当前最佳水平。CMP在预期校准误差(ECE)方面平均提高了6.01%,最小提高4.01%,最大提高9.72%。
Key Takeaways
- 置信度校准在基于预训练模型的现实决策系统中是一个新兴挑战。
- Logit分数难以反映图像语言对的实际一致性,尤其在少量样本情况下。
- 提出了一种新的损失目标中的惩罚机制——置信度不匹配惩罚(CMP)。
- CMP通过移动对数似然到真实类别来惩罚错误的分类。
- CMP在多个视觉数据集和领域泛化数据集上的实验表现优异。
- CMP相较于现有的提示学习方法有更佳的表现。
点此查看论文截图

LLM-AutoDiff: Auto-Differentiate Any LLM Workflow
Authors:Li Yin, Zhangyang Wang
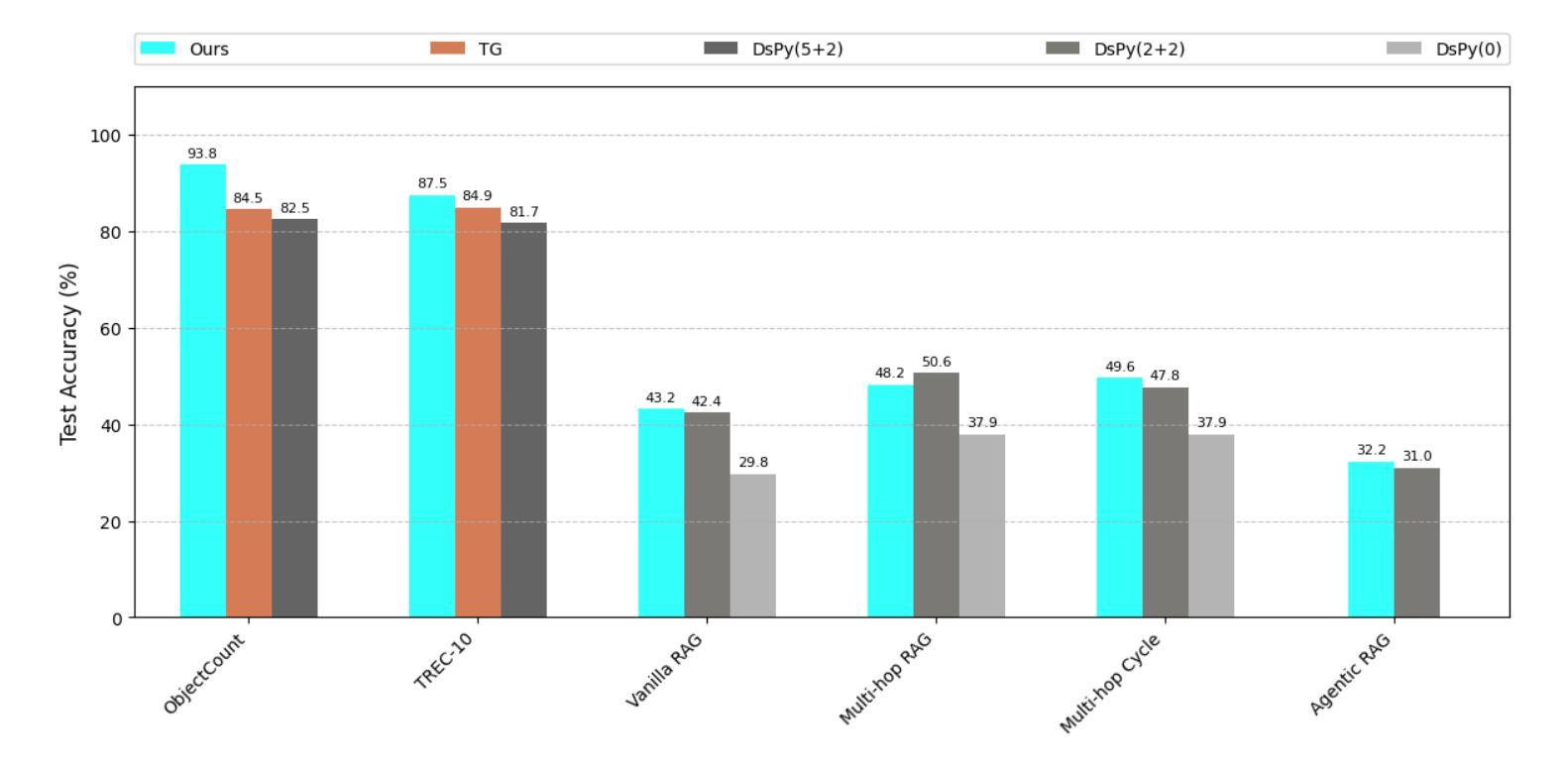
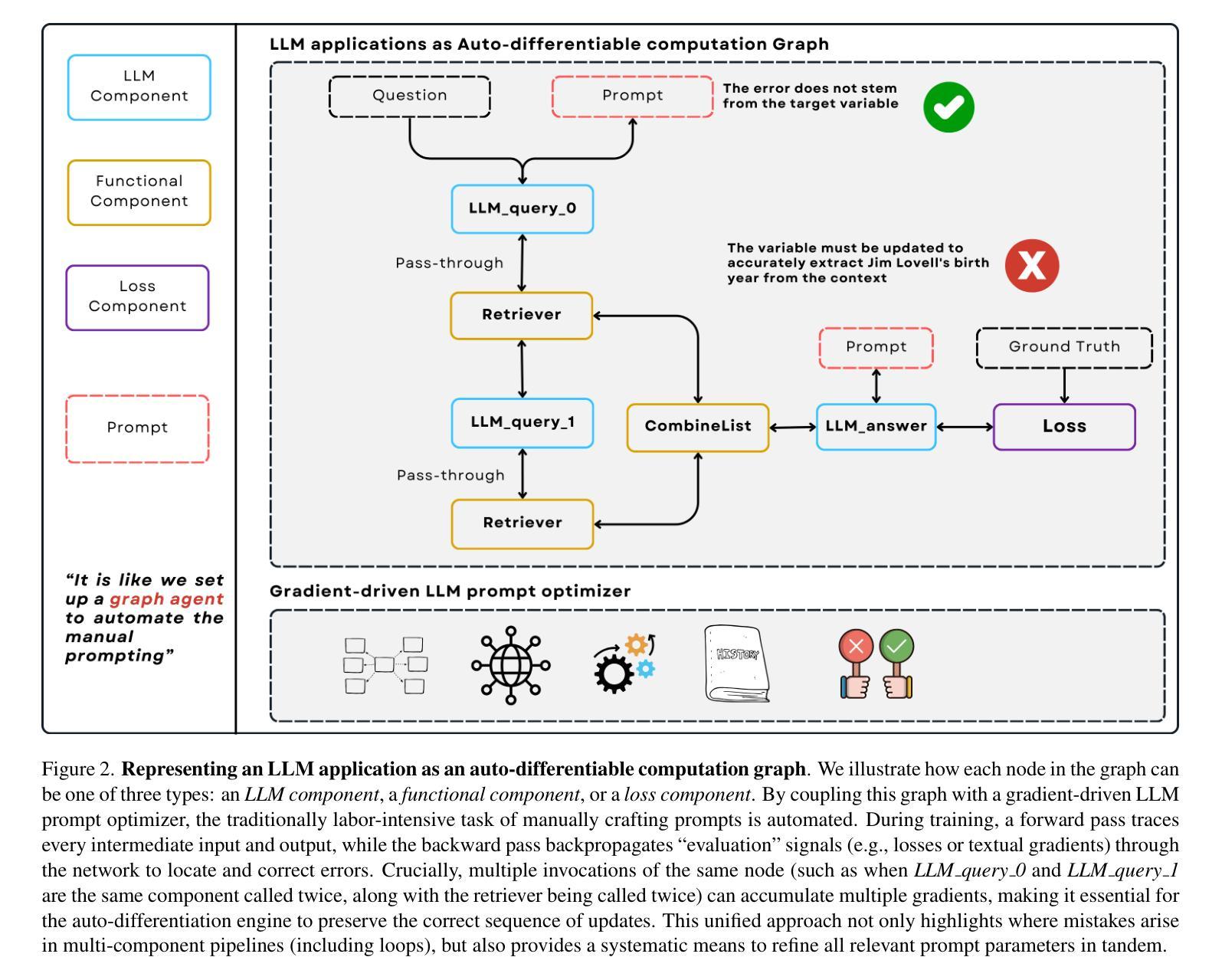
Large Language Models (LLMs) have reshaped natural language processing, powering applications from multi-hop retrieval and question answering to autonomous agent workflows. Yet, prompt engineering – the task of crafting textual inputs to effectively direct LLMs – remains difficult and labor-intensive, particularly for complex pipelines that combine multiple LLM calls with functional operations like retrieval and data formatting. We introduce LLM-AutoDiff: a novel framework for Automatic Prompt Engineering (APE) that extends textual gradient-based methods (such as Text-Grad) to multi-component, potentially cyclic LLM architectures. Implemented within the AdalFlow library, LLM-AutoDiff treats each textual input as a trainable parameter and uses a frozen backward engine LLM to generate feedback-akin to textual gradients – that guide iterative prompt updates. Unlike prior single-node approaches, LLM-AutoDiff inherently accommodates functional nodes, preserves time-sequential behavior in repeated calls (e.g., multi-hop loops), and combats the “lost-in-the-middle” problem by isolating distinct sub-prompts (instructions, formats, or few-shot examples). It further boosts training efficiency by focusing on error-prone samples through selective gradient computation. Across diverse tasks, including single-step classification, multi-hop retrieval-based QA, and agent-driven pipelines, LLM-AutoDiff consistently outperforms existing textual gradient baselines in both accuracy and training cost. By unifying prompt optimization through a graph-centric lens, LLM-AutoDiff offers a powerful new paradigm for scaling and automating LLM workflows - mirroring the transformative role that automatic differentiation libraries have long played in neural network research.
大型语言模型(LLM)已经重塑了自然语言处理领域,推动了从多跳检索和问答到自主代理工作流程的各种应用。然而,提示工程——即设计文本输入以有效指导LLM的任务——仍然很困难且劳动密集型,特别是对于结合多个LLM调用与功能操作(如检索和数据格式化)的复杂管道。我们介绍了LLM-AutoDiff:一种用于自动提示工程(APE)的新型框架,它将基于文本的梯度方法(如Text-Grad)扩展到多组件、可能循环的LLM架构。LLM-AutoDiff在AdalFlow库中实现,它将每个文本输入视为可训练参数,并使用冻结的逆向LLM生成反馈,类似于文本梯度,以指导迭代提示更新。与先前的单一节点方法不同,LLM-AutoDiff天然地容纳功能节点,在重复调用中保留时间顺序行为(例如多跳循环),并通过隔离不同的子提示(指令、格式或少量示例)来解决“迷失在中间”的问题。它通过专注于容易出错的样本并选择性计算梯度,进一步提高了训练效率。在包括单步分类、多跳检索问答和代理驱动管道的各种任务中,LLM-AutoDiff在准确性和训练成本方面均优于现有的文本梯度基线。通过图形中心视角统一提示优化,LLM-AutoDiff为扩展和自动化LLM工作流程提供了强大的新范式,这与自动微分库在神经网络研究中扮演的长期变革性角色相呼应。
论文及项目相关链接
Summary
大型语言模型(LLM)在自然语言处理领域的应用已经发生了变革,涉及多跳检索、问答和自主代理工作流程等。然而,提示工程(即有效指导LLM的文本输入制作任务)对于复杂的结合多个LLM调用与功能操作(如检索和数据格式化)的管道而言仍然困难且劳动密集。我们推出LLM-AutoDiff,一个用于自动提示工程(APE)的新型框架,它将文本梯度方法扩展到多组件、可能循环的LLM架构。LLM-AutoDiff将每个文本输入视为可训练参数,并使用冻结的向后引擎LLM生成反馈,类似于文本梯度,引导迭代提示更新。相较于先前的单点方法,LLM-AutoDiff天然容纳功能节点、保留重复调用中的时间顺序行为(如多跳循环),并通过隔离不同子提示解决“迷失在中间”的问题。通过选择性梯度计算专注于易错样本,进一步提高训练效率。在包括单步分类、多跳检索问答和代理驱动管道等多样化任务中,LLM-AutoDiff在准确性和训练成本方面均优于现有文本梯度基线。通过统一的图形中心视角整合提示优化,LLM-AutoDiff为扩展和自动化LLM工作流程提供了强大的新范式。
Key Takeaways
- LLMs已经改变了自然语言处理的格局,并广泛应用于多种应用。
- 提示工程是指导LLMs的有效文本输入的任务,对于复杂的管道而言仍然具有挑战。
- LLM-AutoDiff是一个新型框架,用于自动提示工程,扩展了文本梯度方法至多组件LLM架构。
- LLM-AutoDiff将文本输入视为可训练参数,并使用冻结的向后引擎LLM生成反馈,类似于文本梯度。
- LLM-AutoDiff能够容纳功能节点、保留时间顺序行为,并解决“迷失在中间”的问题。
- LLM-AutoDiff通过选择性梯度计算提高训练效率,关注易错样本。
点此查看论文截图