⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-01 更新
A Video-grounded Dialogue Dataset and Metric for Event-driven Activities
Authors:Wiradee Imrattanatrai, Masaki Asada, Kimihiro Hasegawa, Zhi-Qi Cheng, Ken Fukuda, Teruko Mitamura
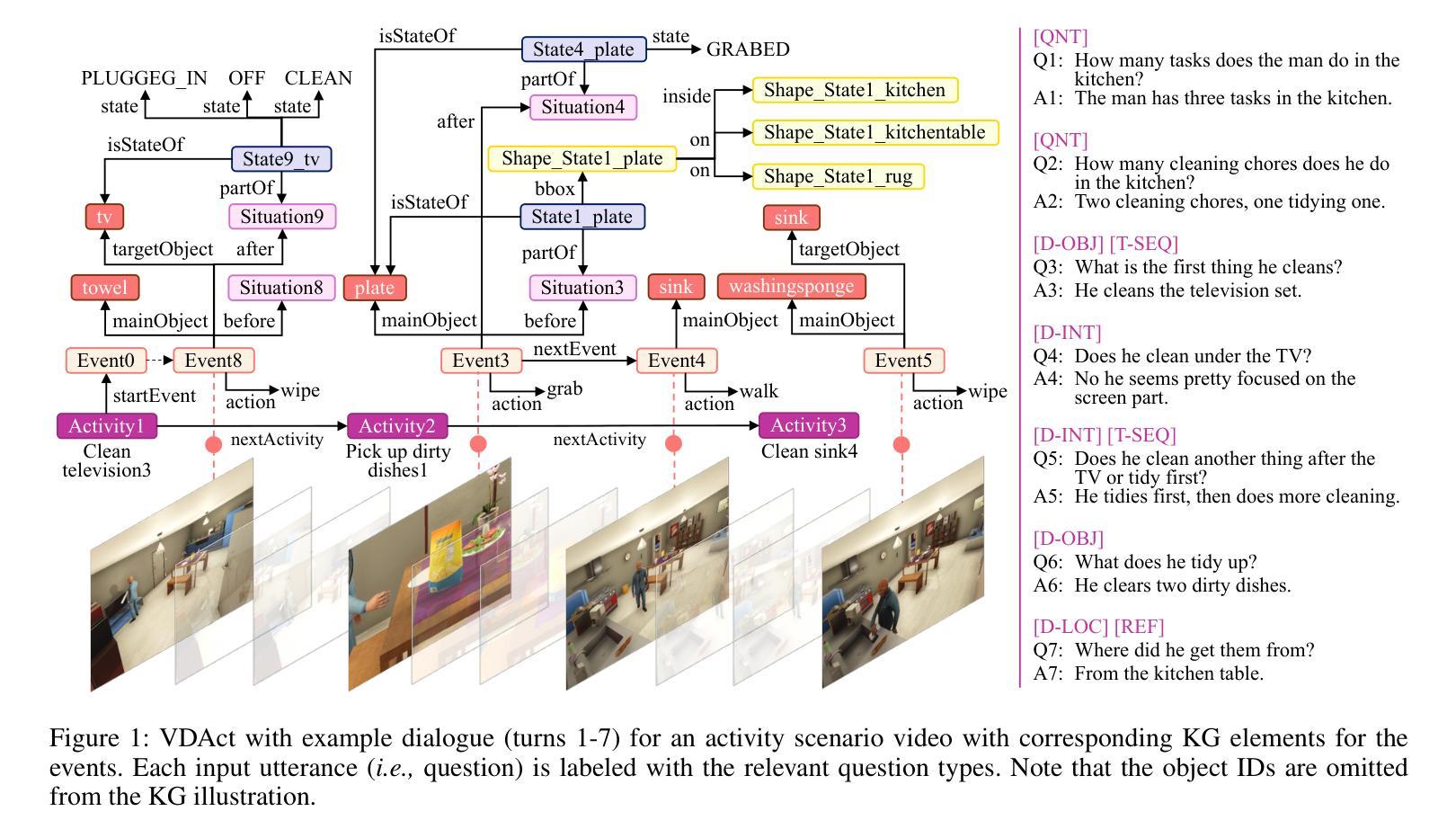
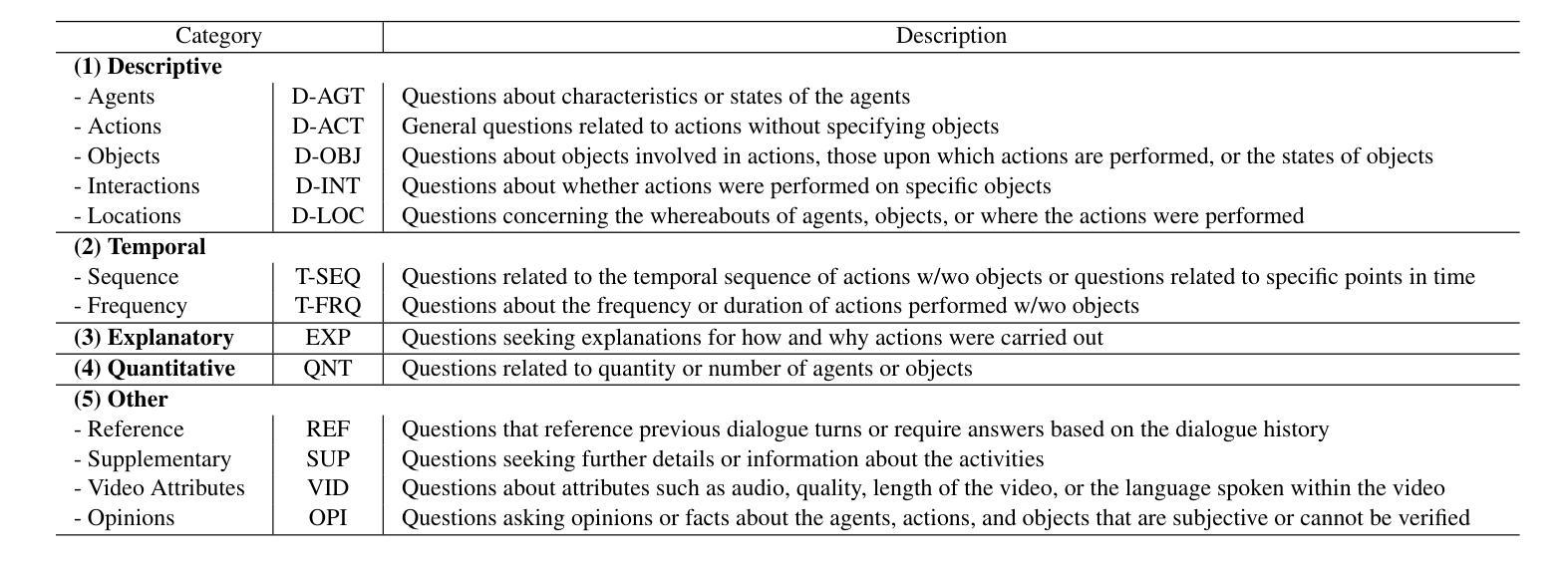
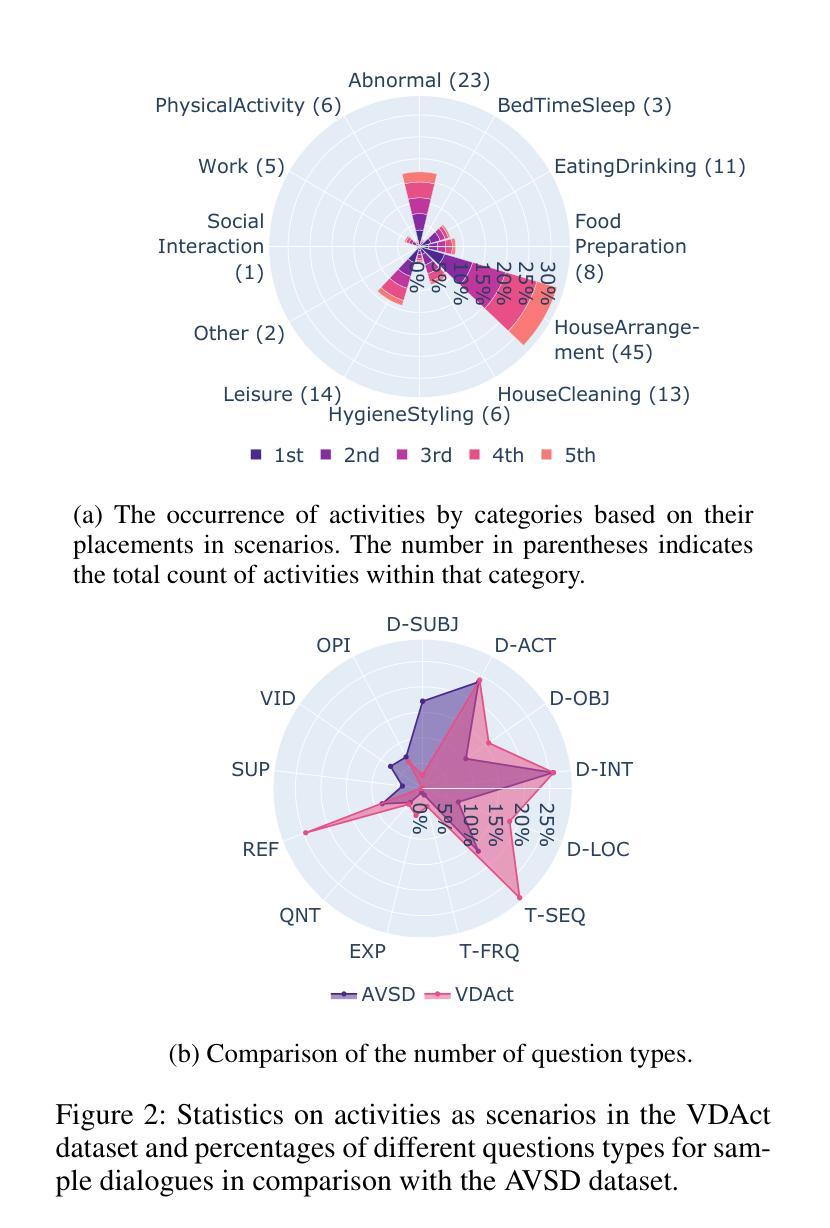
This paper presents VDAct, a dataset for a Video-grounded Dialogue on Event-driven Activities, alongside VDEval, a session-based context evaluation metric specially designed for the task. Unlike existing datasets, VDAct includes longer and more complex video sequences that depict a variety of event-driven activities that require advanced contextual understanding for accurate response generation. The dataset comprises 3,000 dialogues with over 30,000 question-and-answer pairs, derived from 1,000 videos with diverse activity scenarios. VDAct displays a notably challenging characteristic due to its broad spectrum of activity scenarios and wide range of question types. Empirical studies on state-of-the-art vision foundation models highlight their limitations in addressing certain question types on our dataset. Furthermore, VDEval, which integrates dialogue session history and video content summaries extracted from our supplementary Knowledge Graphs to evaluate individual responses, demonstrates a significantly higher correlation with human assessments on the VDAct dataset than existing evaluation metrics that rely solely on the context of single dialogue turns.
本文介绍了VDAct数据集,这是一组基于视频的事件驱动活动对话数据集,以及专门为此任务设计的基于会话情境的评估指标VDEval。与现有数据集不同,VDAct包含更长的、更复杂的视频序列,这些视频序列描绘了各种各样的基于事件的活动,需要先进的上下文理解才能准确生成响应。该数据集包含3000个对话,超过3万个问答对,源于具有多样化活动场景的1000个视频。由于活动场景的广泛性和问题类型的多样性,VDAct显示出明显的挑战性特征。关于最新视觉基础模型的实证研究突出了它们在解决我们数据集上某些问题类型时的局限性。此外,VDEval结合了对话会话历史和我们附加知识图谱中提取的视频内容摘要,以评估单个响应,与只依赖于单个对话回合情境的现有评估指标相比,它在VDAct数据集上的人类评估中显示出更高的相关性。
论文及项目相关链接
PDF Accepted at AAAI2025
Summary
VDAct数据集包含3000个对话和超过3万个问答对,基于视频对话活动设计,强调对事件驱动活动的上下文理解。VDAct挑战在于其活动场景多样性和问题类型广泛。此外,论文提出了VDEval评估指标,该指标结合了对话会话历史和视频内容摘要,比现有指标更能准确评估单个响应的质量。
Key Takeaways
- VDAct数据集强调对事件驱动活动的上下文理解,包含更长的视频序列和多样化活动场景。
- VDAct数据集包含大量对话和问答对,为视频对话任务提供丰富资源。
- VDEval评估指标结合了对话会话历史和视频内容摘要,提高了响应质量评估的准确性。
- VDEval相较于现有单一对话上下文评估指标,更能反映人类评估的共识。
- VDAct数据集广泛涵盖不同类型的问题,展现出挑战性。
- 视频对话任务需要先进的视觉基础模型来应对挑战。
点此查看论文截图




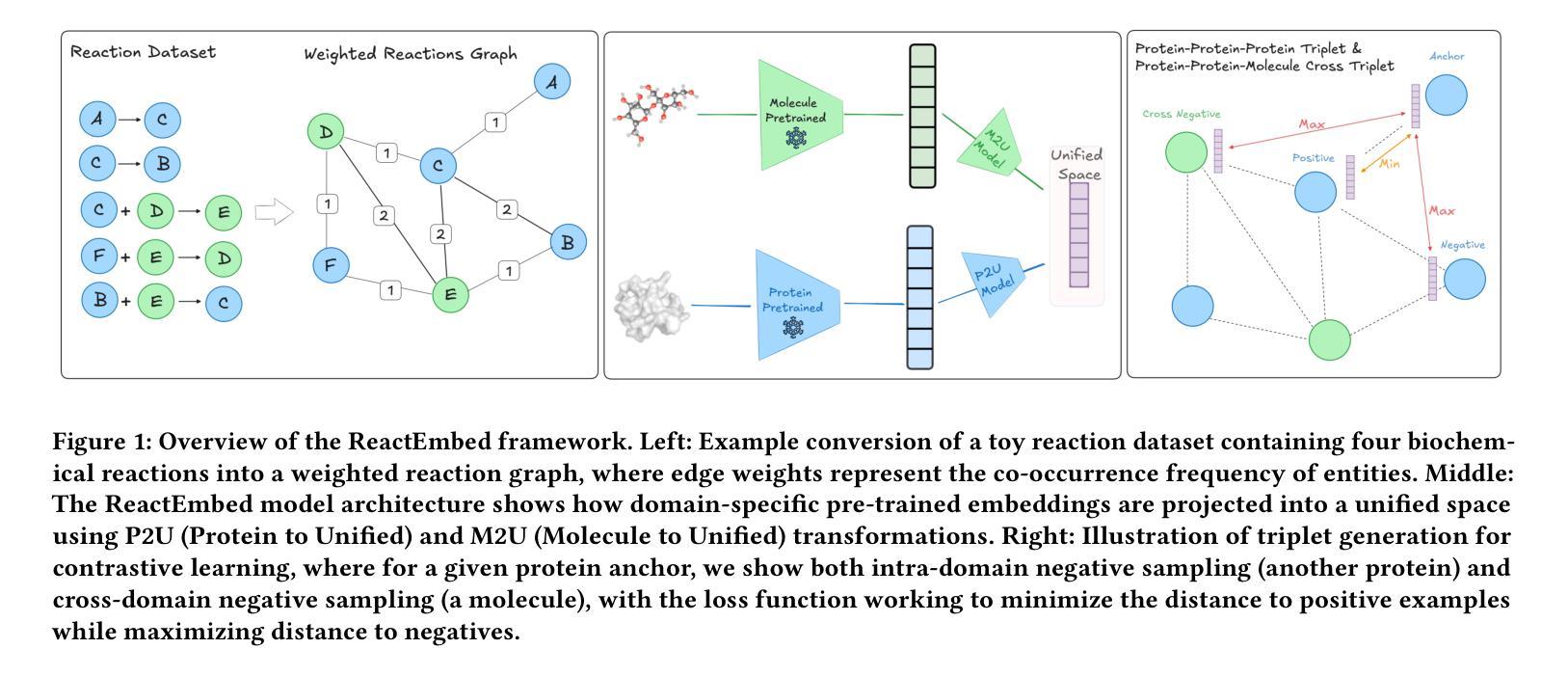
ReactEmbed: A Cross-Domain Framework for Protein-Molecule Representation Learning via Biochemical Reaction Networks
Authors:Amitay Sicherman, Kira Radinsky
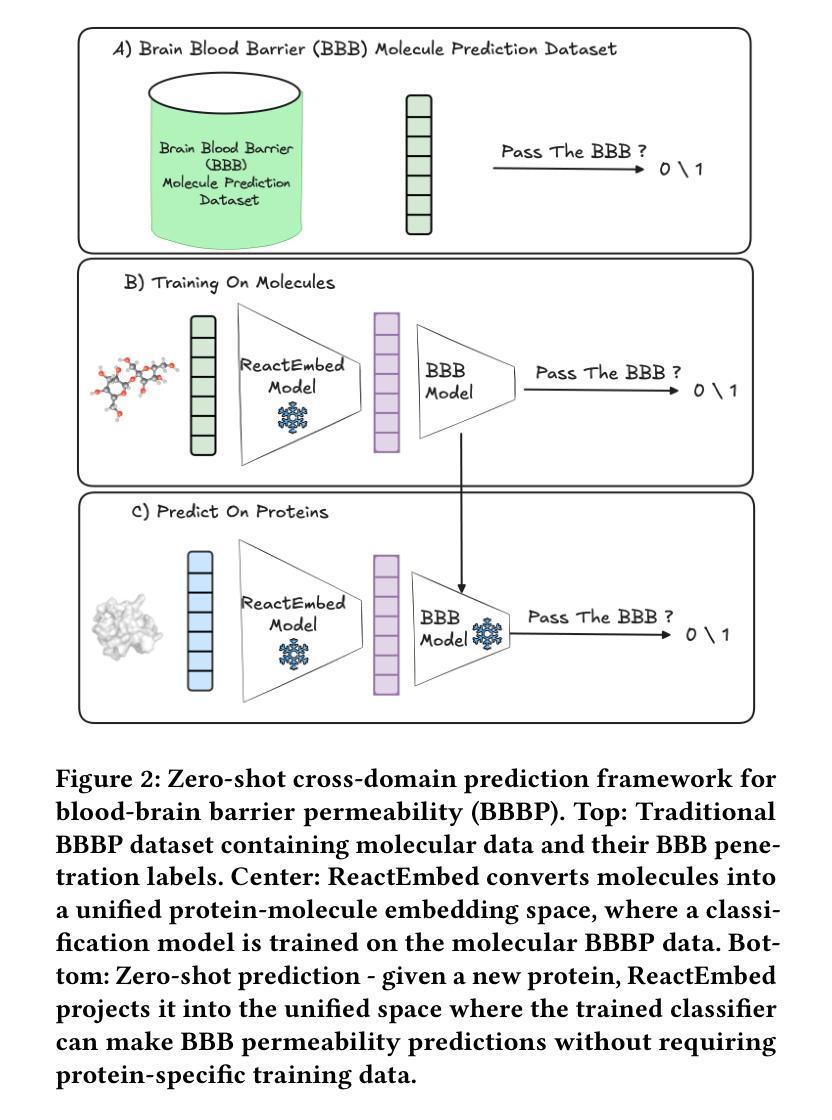
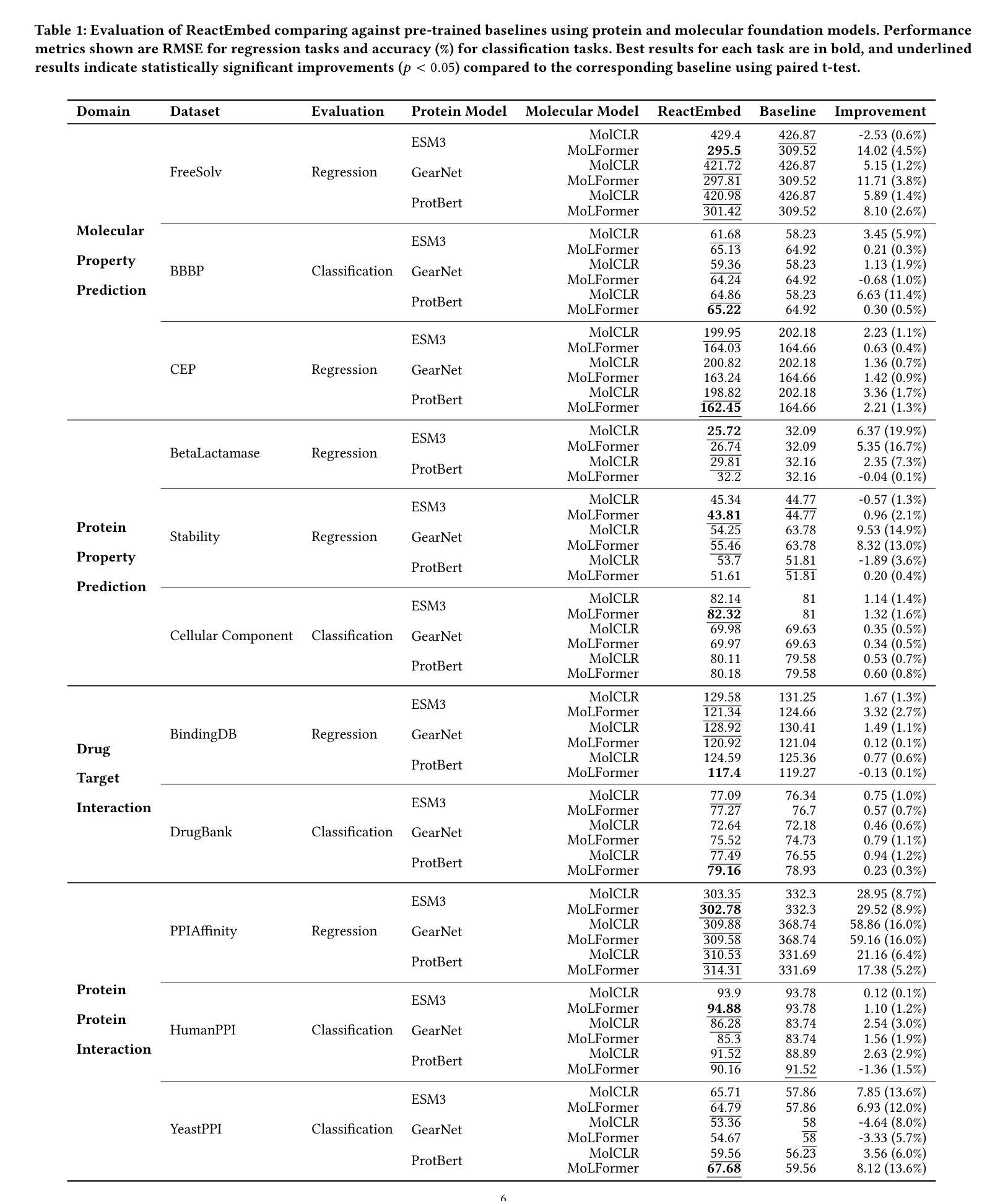
The challenge in computational biology and drug discovery lies in creating comprehensive representations of proteins and molecules that capture their intrinsic properties and interactions. Traditional methods often focus on unimodal data, such as protein sequences or molecular structures, limiting their ability to capture complex biochemical relationships. This work enhances these representations by integrating biochemical reactions encompassing interactions between molecules and proteins. By leveraging reaction data alongside pre-trained embeddings from state-of-the-art protein and molecule models, we develop ReactEmbed, a novel method that creates a unified embedding space through contrastive learning. We evaluate ReactEmbed across diverse tasks, including drug-target interaction, protein-protein interaction, protein property prediction, and molecular property prediction, consistently surpassing all current state-of-the-art models. Notably, we showcase ReactEmbed’s practical utility through successful implementation in lipid nanoparticle-based drug delivery, enabling zero-shot prediction of blood-brain barrier permeability for protein-nanoparticle complexes. The code and comprehensive database of reaction pairs are available for open use at \href{https://github.com/amitaysicherman/ReactEmbed}{GitHub}.
计算生物学和药物发现的挑战在于创建能够捕捉蛋白质和分子内在属性及其相互作用的全面表征。传统方法通常侧重于单模态数据,如蛋白质序列或分子结构,这限制了它们捕捉复杂生物化学关系的能力。这项工作通过整合包含分子和蛋白质之间相互作用在内的生化反应来增强这些表征。我们借助反应数据和最先进的蛋白质和分子模型的预训练嵌入,开发了一种通过对比学习创建统一嵌入空间的新方法ReactEmbed。我们在各种任务上评估了ReactEmbed,包括药物-靶点相互作用、蛋白质-蛋白质相互作用、蛋白质属性预测和分子属性预测,它始终超越了所有当前的最先进模型。值得注意的是,我们通过成功实施基于脂质纳米颗粒的药物输送展示了ReactEmbed的实际效用,能够实现蛋白质-纳米颗粒复合物的血脑屏障渗透性的零样本预测。反应对的代码和综合数据库可在GitHub上免费使用:https://github.com/amitaysicherman/ReactEmbed。
论文及项目相关链接
Summary
该文指出计算生物学和药物发现面临的挑战在于如何创建能全面反映蛋白质和分子内在属性和相互作用的表示方法。传统方法往往局限于单模态数据,难以捕捉复杂的生物化学关系。本文开发了一种名为ReactEmbed的新方法,通过结合反应数据并利用先进的蛋白质和分子模型预训练嵌入技术,构建了一个统一嵌入空间。ReactEmbed在不同任务上的表现均超越现有最佳模型,并在脂质纳米粒子药物输送中得到成功应用,能够实现对蛋白质纳米粒子复合物血脑屏障通透性的零样本预测。相关代码和反应对数据库已在GitHub上公开使用。
Key Takeaways
- 计算生物学和药物发现的挑战在于创建全面反映蛋白质和分子内在属性和相互作用的表示方法。
- 传统方法主要关注单模态数据,限制了捕捉复杂生物化学关系的能力。
- ReactEmbed方法通过结合反应数据,利用先进蛋白质和分子模型的预训练嵌入技术,构建了一个统一的嵌入空间。
- ReactEmbed在多种任务上表现超越现有最佳模型,包括药物-靶标相互作用、蛋白质-蛋白质相互作用、蛋白质属性预测和分子属性预测。
- ReactEmbed成功应用于脂质纳米粒子药物输送,可实现蛋白质纳米粒子复合物血脑屏障通透性的零样本预测。
- ReactEmbed的代码和反应对数据库已公开在GitHub上供使用。
点此查看论文截图