⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-01 更新
DeltaLLM: Compress LLMs with Low-Rank Deltas between Shared Weights
Authors:Liana Mikaelyan, Ayyoob Imani, Mathew Salvaris, Parth Pathak, Mohsen Fayyaz
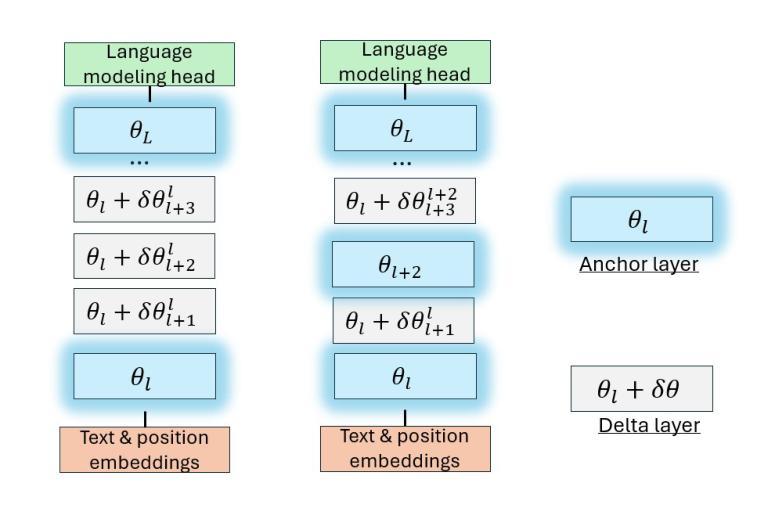
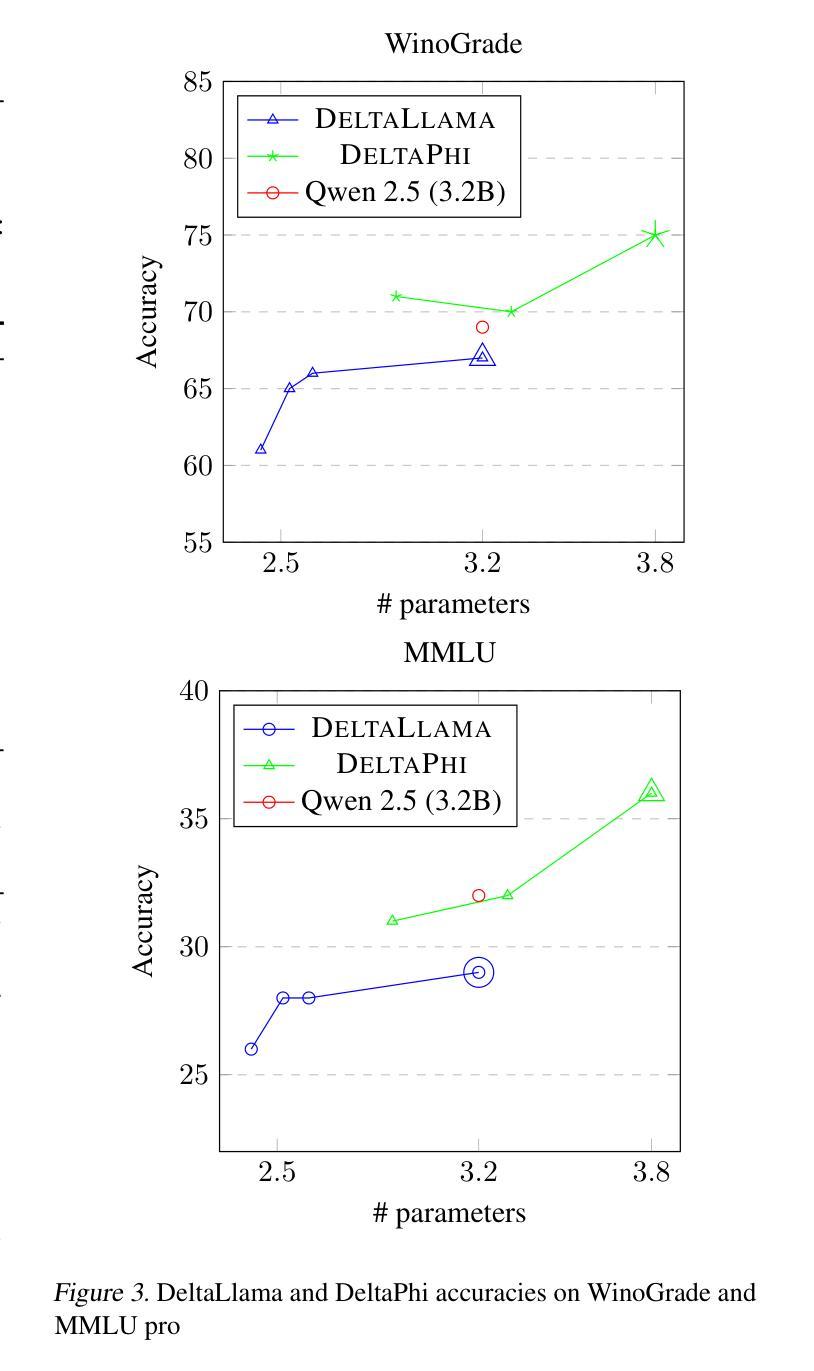
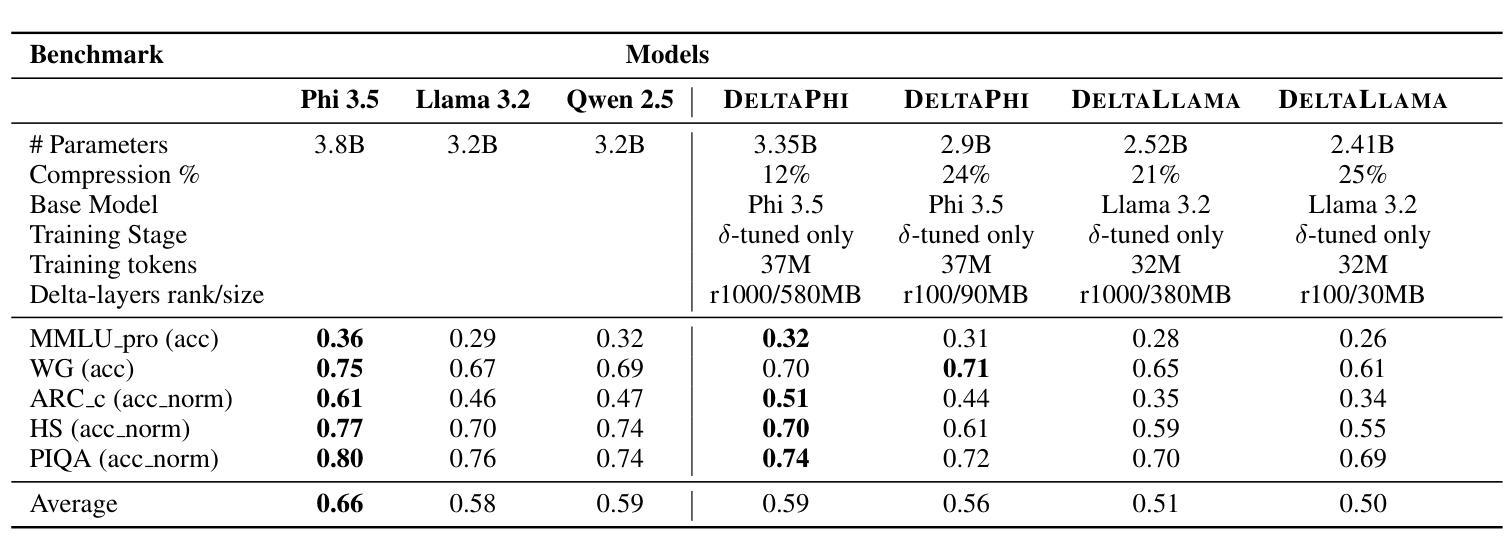
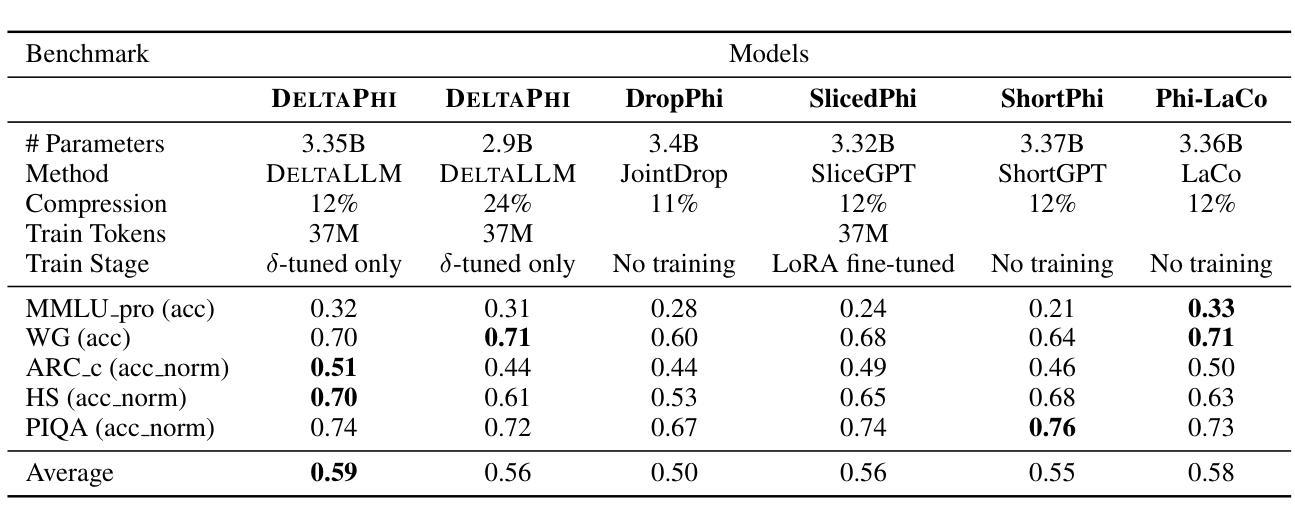
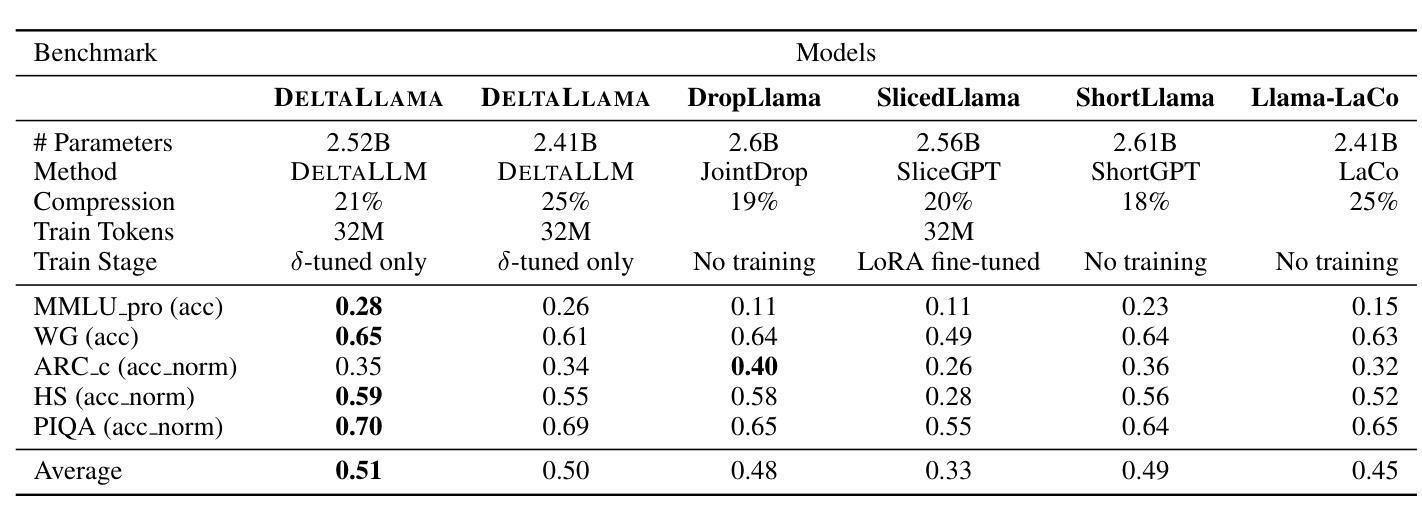
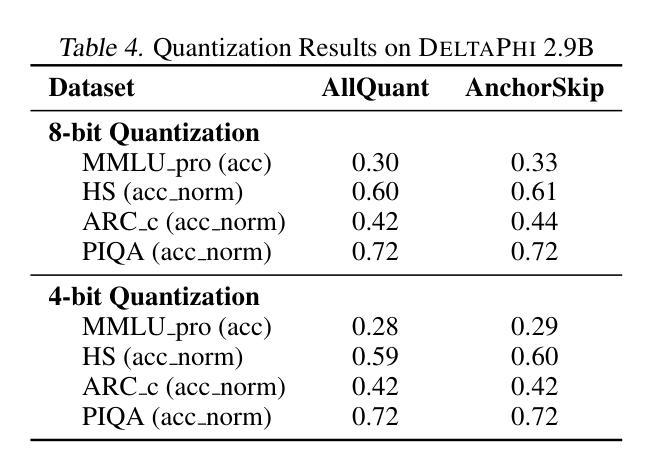
We introduce DeltaLLM, a new post-training compression technique to reduce the memory footprint of LLMs. We propose an alternative way of structuring LLMs with weight sharing between layers in subsequent Transformer blocks, along with additional low-rank difference matrices between them. For training, we adopt the progressing module replacement method and show that the lightweight training of the low-rank modules with approximately 30M-40M tokens is sufficient to achieve performance on par with LLMs of comparable sizes trained from scratch. We release the resultant models, DeltaLLAMA and DeltaPHI, with a 12% parameter reduction, retaining 90% of the performance of the base Llama and Phi models on common knowledge and reasoning benchmarks. Our method also outperforms compression techniques JointDrop, LaCo, ShortGPT and SliceGPT with the same number of parameters removed. For example, DeltaPhi 2.9B with a 24% reduction achieves similar average zero-shot accuracies as recovery fine-tuned SlicedPhi 3.3B with a 12% reduction, despite being approximately 400M parameters smaller with no fine-tuning applied. This work provides new insights into LLM architecture design and compression methods when storage space is critical.
我们介绍了DeltaLLM,这是一种新的训练后压缩技术,用于减少大型语言模型(LLM)的内存占用。我们提出了一种替代的LLM结构方式,后续Transformer块之间的权重共享,以及它们之间的附加低秩差分矩阵。在训练过程中,我们采用了逐步模块替换法,并证明使用约30M-40M标记对低秩模块进行轻量化训练足以达到与从头开始训练的相当大小的LLM的性能相当。我们发布了结果模型DeltaLLAMA和DeltaPHI,参数减少了12%,在常识和推理基准测试中保留了基础Llama和Phi模型性能的90%。我们的方法也优于移除相同数量参数的压缩技术,如JointDrop、LaCo、ShortGPT和SliceGPT。例如,尽管DeltaPhi 2.9B的模型减少了24%,且未经微调应用而大小约减少了近四十亿参数的情况下,仍实现了与恢复精细训练的SlicedPhi 3.3B类似的平均零样本准确度。这项工作提供了对存储空间至关重要的关键时刻在大型语言模型的架构设计和压缩方法方面的新见解。
论文及项目相关链接
Summary
DeltaLLM是一种针对大型语言模型(LLM)的新型训练后压缩技术。它通过重新构建LLM结构,共享后续Transformer块之间的权重,并引入低阶差异矩阵,减少了LLM的内存占用。该技术采用渐进模块替换方法进行训练,仅使用约30M-40M的令牌对低阶模块进行轻量化训练,即可达到与从头开始训练的相似规模LLM相当的性能。新推出的DeltaLLAMA和DeltaPHI模型在常识和推理基准测试中保留了基础模型性能的90%,同时实现了12%的参数缩减。相较于其他压缩技术,如JointDrop、LaCo、ShortGPT和SliceGPT,DeltaLLM在相同参数缩减比例下表现出更好的性能。例如,DeltaPhi 2.9B在减少24%的参数后,其零次射击精度与经过恢复的fine-tuned SlicedPhi 3.3B相似,尽管DeltaPhi的参数小了约4亿,且无需进行fine-tuning。这项研究为LLM架构设计和压缩方法提供了新的见解,尤其是在存储空间至关重要的情况下。
Key Takeaways
- DeltaLLM是一种新型的LLM压缩技术,通过重新构建模型结构和采用权重共享方法减少内存占用。
- 采用渐进模块替换方法进行训练,轻量化训练低阶模块达到与全规模模型相当的性能。
- 推出的DeltaLLAMA和DeltaPHI模型在参数减少12%的情况下,保留了基础模型90%的性能。
- DeltaLLM在相同参数缩减比例下优于其他压缩技术。
- DeltaPhi 2.9B在减少24%参数后表现出与fine-tuned模型相似的性能,且无需fine-tuning。
- 该研究为LLM架构设计和压缩方法提供了新的见解。
点此查看论文截图

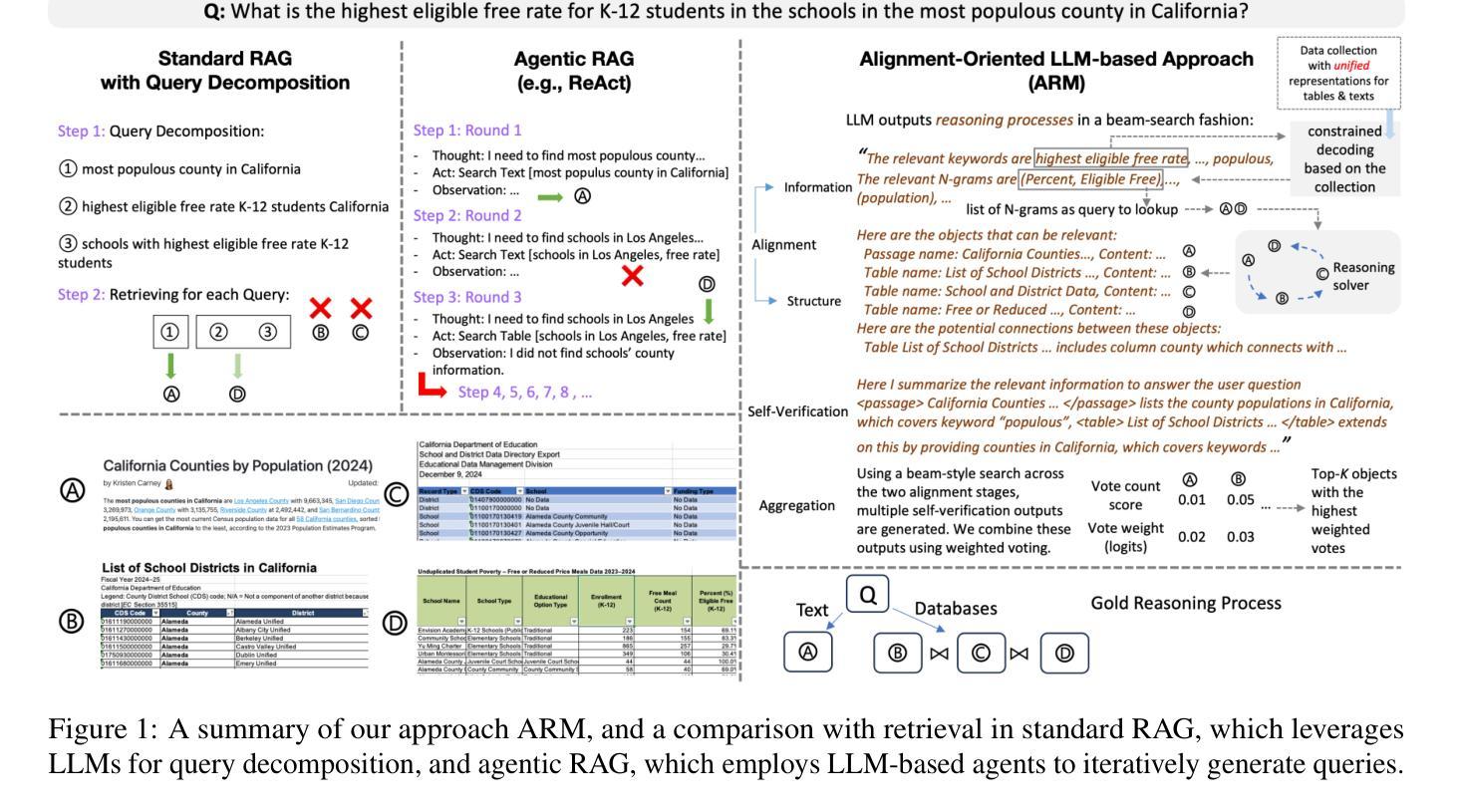
Can we Retrieve Everything All at Once? ARM: An Alignment-Oriented LLM-based Retrieval Method
Authors:Peter Baile Chen, Yi Zhang, Michael Cafarella, Dan Roth
Real-world open-domain questions can be complicated, particularly when answering them involves information from multiple information sources. LLMs have demonstrated impressive performance in decomposing complex tasks into simpler steps, and previous work has used it for better retrieval in support of complex questions. However, LLM’s decomposition of questions is unaware of what data is available and how data is organized, often leading to a sub-optimal retrieval performance. Recent effort in agentic RAG proposes to perform retrieval in an iterative fashion, where a followup query is derived as an action based on previous rounds of retrieval. While this provides one way of interacting with the data collection, agentic RAG’s exploration of data is inefficient because successive queries depend on previous results rather than being guided by the organization of available data in the collection. To address this problem, we propose an LLM-based retrieval method – ARM, that aims to better align the question with the organization of the data collection by exploring relationships among data objects beyond matching the utterance of the query, thus leading to a retrieve-all-at-once solution for complex queries. We evaluated ARM on two datasets, Bird and OTT-QA. On Bird, it outperforms standard RAG with query decomposition by up to 5.2 pt in execution accuracy and agentic RAG (ReAct) by up to 15.9 pt. On OTT-QA, it achieves up to 5.5 pt and 19.3 pt higher F1 match scores compared to these approaches.
现实世界开放域的问题可能很复杂,特别是当回答这些问题需要来自多个信息源的信息时。大型语言模型(LLM)在将复杂任务分解成更简单步骤方面表现出了令人印象深刻的性能,之前的工作也用它来支持复杂问题的更好检索。然而,LLM对问题的分解并不知道哪些数据可用以及数据是如何组织的,这常常导致次优的检索性能。最近的基于agent的RAG(反应式问答生成)工作提出以迭代的方式进行检索,其中后续查询是基于前几轮的检索结果推导出的动作。虽然这为与数据集交互提供了一种方式,但基于agent的RAG对数据集的探索效率低下,因为后续查询依赖于之前的结果,而不是由数据集中可用数据的组织来指导。为了解决这个问题,我们提出了一种基于LLM的检索方法——ARM(对齐检索方法),旨在通过探索数据对象之间的关系(而不仅仅是匹配查询的表述),更好地将问题与数据集的组织对齐,从而为复杂查询提供一次性检索的解决方案。我们在Bird和OTT-QA两个数据集上评估了ARM。在Bird数据集上,与具有查询分解的标准RAG相比,ARM的执行准确率提高了高达5.2个百分点,与反应式RAG相比提高了高达15.9个百分点。在OTT-QA上,与这些方法相比,ARM的F1匹配得分提高了高达5.5个百分点和19.3个百分点。
论文及项目相关链接
Summary
该文探讨了大型语言模型(LLM)在真实世界开放领域问题处理中的复杂性和挑战。针对现有LLM在问题分解和数据检索方面的不足,提出了一种基于LLM的数据检索方法ARM。ARM旨在通过探索数据对象之间的关系,实现对数据集合组织的更好对齐,从而提高复杂查询的检索效率。实验结果表明,ARM在Bird数据集上的执行准确率优于标准RAG和agentic RAG(ReAct),在OTT-QA数据集上的F1匹配分数也有所提高。
Key Takeaways
- LLM在处理真实世界开放领域问题时面临复杂性,尤其是涉及多信息源的问题分解挑战。
- 现有LLM在问题分解时无法有效识别数据可用性和组织方式,导致检索性能不佳。
- 提出了一种基于LLM的数据检索方法ARM,通过探索数据对象之间的关系,实现对数据集合组织的更好对齐。
- ARM采用一次性检索所有相关数据的策略,为复杂查询提供解决方案。
- 在Bird数据集上,ARM的执行准确率优于标准RAG和agentic RAG(ReAct)。
- 在OTT-QA数据集上,ARM的F1匹配分数高于其他方法。
点此查看论文截图

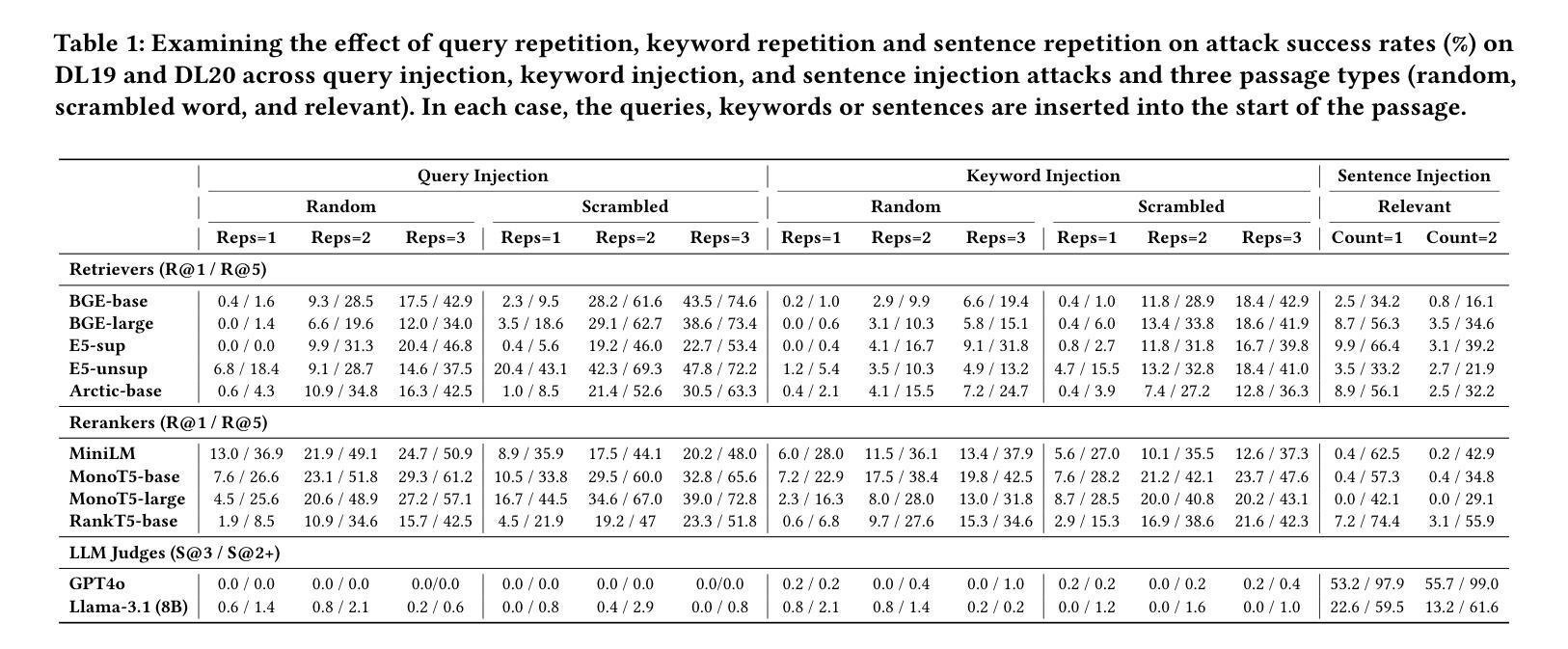
Illusions of Relevance: Using Content Injection Attacks to Deceive Retrievers, Rerankers, and LLM Judges
Authors:Manveer Singh Tamber, Jimmy Lin
Consider a scenario in which a user searches for information, only to encounter texts flooded with misleading or non-relevant content. This scenario exemplifies a simple yet potent vulnerability in neural Information Retrieval (IR) pipelines: content injection attacks. We find that embedding models for retrieval, rerankers, and large language model (LLM) relevance judges are vulnerable to these attacks, in which adversaries insert misleading text into passages to manipulate model judgements. We identify two primary threats: (1) inserting unrelated or harmful content within passages that still appear deceptively “relevant”, and (2) inserting entire queries or key query terms into passages to boost their perceived relevance. While the second tactic has been explored in prior research, we present, to our knowledge, the first empirical analysis of the first threat, demonstrating how state-of-the-art models can be easily misled. Our study systematically examines the factors that influence an attack’s success, such as the placement of injected content and the balance between relevant and non-relevant material. Additionally, we explore various defense strategies, including adversarial passage classifiers, retriever fine-tuning to discount manipulated content, and prompting LLM judges to adopt a more cautious approach. However, we find that these countermeasures often involve trade-offs, sacrificing effectiveness for attack robustness and sometimes penalizing legitimate documents in the process. Our findings highlight the need for stronger defenses against these evolving adversarial strategies to maintain the trustworthiness of IR systems. We release our code and scripts to facilitate further research.
考虑一种用户搜索信息时遇到大量误导性或非相关内容的场景。这一场景凸显了神经信息检索(IR)管道中的一个简单但强大的漏洞:内容注入攻击。我们发现,用于检索的嵌入模型、重新排序器和大型语言模型(LLM)的相关性判断者都容易受到这些攻击的影响,攻击者会在段落中插入误导性文本以操纵模型判断。我们确定了两个主要威胁:(1)在段落中插入不相关或有害的内容,这些内容表面上仍然具有欺骗性的“相关性”,(2)在段落中插入整个查询或关键查询术语以提高其感知的相关性。虽然第二种策略在以前的研究中已经有所探讨,但据我们所知,我们对第一种威胁进行了首次实证分析,证明了最先进的模型是如何轻易受到误导的。我们的研究系统地研究了影响攻击成功的因素,如注入内容的放置位置和相关与非相关材料的平衡。此外,我们还探索了各种防御策略,包括对敌段落分类器、检索器微调以忽略操纵内容,以及提示LLM判断者采取更谨慎的方法。然而,我们发现这些对策通常涉及权衡,需要在攻击鲁棒性和有效性之间进行取舍,有时还会在此过程中惩罚合法文档。我们的研究强调了需要对这些不断发展的对抗策略进行更强大的防御,以维持IR系统的可信度。我们发布了我们的代码和脚本,以促进进一步的研究。
论文及项目相关链接
摘要
在信息检索(IR)管道中存在着一种简单而强大的漏洞,即内容注入攻击,用户搜索信息时可能会遇到充斥误导或非相关内容的文本,正是这种情景的体现。我们发现用于检索的嵌入模型、重新排名器和大型语言模型(LLM)的相关性判断都容易受到这些攻击的影响。攻击者会在段落中插入误导性文本,以操纵模型判断。我们确定了两种主要的威胁:一是在段落中插入不相关或有害内容,这些段落仍然具有欺骗性的“相关性”;二是在段落中插入整个查询或关键查询术语以提高其感知的相关性。我们对第一个威胁进行了据我们所知的首次实证分析,证明了最先进的模型如何轻易受到误导。我们的研究系统地研究了影响攻击成功的因素,如注入内容的放置和平衡相关与非相关内容等。此外,我们还探讨了各种防御策略,包括对敌宣传段落分类器、对操纵内容进行微调检索器以及提示LLM法官采取更谨慎的方法等。然而,我们发现这些对策往往涉及权衡取舍,牺牲攻击稳健性的有效性并有时惩罚合法文件。我们的研究结果强调了应对这些不断发展的对抗性策略进行更强有力的防御,以维持IR系统的可信度。我们发布我们的代码和脚本来促进进一步研究。
关键见解
- 内容注入攻击是神经信息检索系统中的一个重要漏洞。
- 对神经信息检索管道的嵌入模型、重新排名器和大型语言模型的相关性判断都受到内容注入攻击的影响。
- 存在两种主要威胁形式:在看似相关的段落中插入不相关或有害内容;或在段落中插入查询关键词或整体查询以加强相关性感知。
- 当前研究系统分析了影响攻击成功的因素,如注入内容的放置和与相关内容之间的平衡等。
- 研究探讨了多种防御策略,包括使用对抗性宣传分类器、微调检索器以排除操纵内容以及提示LLM法官采取更谨慎的方法等。然而,这些策略存在权衡问题,可能牺牲了攻击稳健性和/或对合法内容的处罚问题。因此提出了强烈的防御需求以应对不断进化的对抗性策略以保持IR系统的可信度重要性得到强调并提出了相关的对策建议。”在解决这一问题的同时我们还发现并提出公开我们的代码和脚本为今后的研究提供便利的发现与支持提出相应缓解需求的渠道紧迫的问题需要有具体的解决方法而这一工作需要扎实的行业基础信息和深刻的认识重要性提醒应当在未来此领域内对此主题给予更多关注以确保神经信息检索系统的安全和可信度同时也促进了学术界和行业界在该领域的进一步发展强调了继续深入研究这一领域的必要性以及解决这些问题的紧迫性”。
点此查看论文截图

Differentially Private Steering for Large Language Model Alignment
Authors:Anmol Goel, Yaxi Hu, Iryna Gurevych, Amartya Sanyal
Aligning Large Language Models (LLMs) with human values and away from undesirable behaviors (such as hallucination) has become increasingly important. Recently, steering LLMs towards a desired behavior via activation editing has emerged as an effective method to mitigate harmful generations at inference-time. Activation editing modifies LLM representations by preserving information from positive demonstrations (e.g., truthful) and minimising information from negative demonstrations (e.g., hallucinations). When these demonstrations come from a private dataset, the aligned LLM may leak private information contained in those private samples. In this work, we present the first study of aligning LLM behavior with private datasets. Our work proposes the \textit{\underline{P}rivate \underline{S}teering for LLM \underline{A}lignment (PSA)} algorithm to edit LLM activations with differential privacy (DP) guarantees. We conduct extensive experiments on seven different benchmarks with open-source LLMs of different sizes (0.5B to 7B) and model families (LlaMa, Qwen, Mistral and Gemma). Our results show that PSA achieves DP guarantees for LLM alignment with minimal loss in performance, including alignment metrics, open-ended text generation quality, and general-purpose reasoning. We also develop the first Membership Inference Attack (MIA) for evaluating and auditing the empirical privacy for the problem of LLM steering via activation editing. Our attack is tailored for activation editing and relies solely on the generated texts without their associated probabilities. Our experiments support the theoretical guarantees by showing improved guarantees for our \textit{PSA} algorithm compared to several existing non-private techniques.
对齐大型语言模型(LLM)与人类价值观和远离不良行为(如幻觉)变得越来越重要。最近,通过激活编辑来引导LLM实现期望的行为已经出现为一种在推理时间减少有害生成的有效方法。激活编辑通过保留正面演示(例如,真实)中的信息并最小化负面演示(例如,幻觉)中的信息来修改LLM表示。当这些演示来自私有数据集时,对齐的LLM可能会泄露这些私有样本中的私有信息。在这项工作中,我们首次研究了将LLM行为与私有数据集对齐。我们的工作提出了名为PSA(私有转向对齐算法)的算法,该算法使用差分隐私(DP)保证编辑LLM激活。我们在七个不同的基准测试上对开源LLM进行了广泛实验,这些模型规模从0.5B到7B不等,模型家族包括LlaMa、Qwen、Mistral和Gemma。结果表明,PSA在LLM对齐方面实现了差分隐私保证,性能损失最小,包括对齐指标、开放式文本生成质量和通用推理。我们还开发了首个用于评估和审计通过激活编辑进行LLM引导问题的经验隐私的成员推理攻击(MIA)。我们的攻击针对激活编辑定制,仅依赖于生成的文本,而不依赖于与之相关的概率。我们的实验支持PSA算法的理论保证,与几种现有的非私有技术相比,我们的算法提供了更好的保证。
论文及项目相关链接
PDF ICLR 2025; Code: https://github.com/UKPLab/iclr2025-psa
Summary
本文研究了如何通过对大型语言模型(LLM)的激活编辑来实现与私人数据集的对齐,同时确保隐私安全。提出一种名为PSA(Private Steering for LLM Alignment)的算法,能在保持性能的同时,确保LLM与私人数据集对齐时的隐私保护。通过广泛的实验验证,PSA算法在LLM对齐问题上实现了差分隐私(DP)保证,提高了隐私保护水平。同时,本文还提出了针对激活编辑问题的首个成员推理攻击(MIA),用于评估和审计LLM激活编辑的实证隐私。实验结果表明,PSA算法相较于其他非私有技术,具有更好的隐私保护性能。
Key Takeaways
- 大型语言模型(LLM)的对齐问题愈发重要,特别是在避免不良行为(如幻觉)方面。
- 激活编辑是引导LLM实现期望行为的有效方法,通过保留正面示范信息并最小化负面示范信息来实现。
- 当使用私人数据集作为示范时,LLM对齐可能泄露私人信息。
- 提出了一种名为PSA的算法,能在LLM激活编辑中实现差分隐私(DP)保证。
- PSA算法在多个基准测试上表现出优异的性能,实现了DP保证的同时保持较低的性能损失。
- 首次提出了针对激活编辑问题的成员推理攻击(MIA),用于评估和审计LLM的实证隐私。
点此查看论文截图



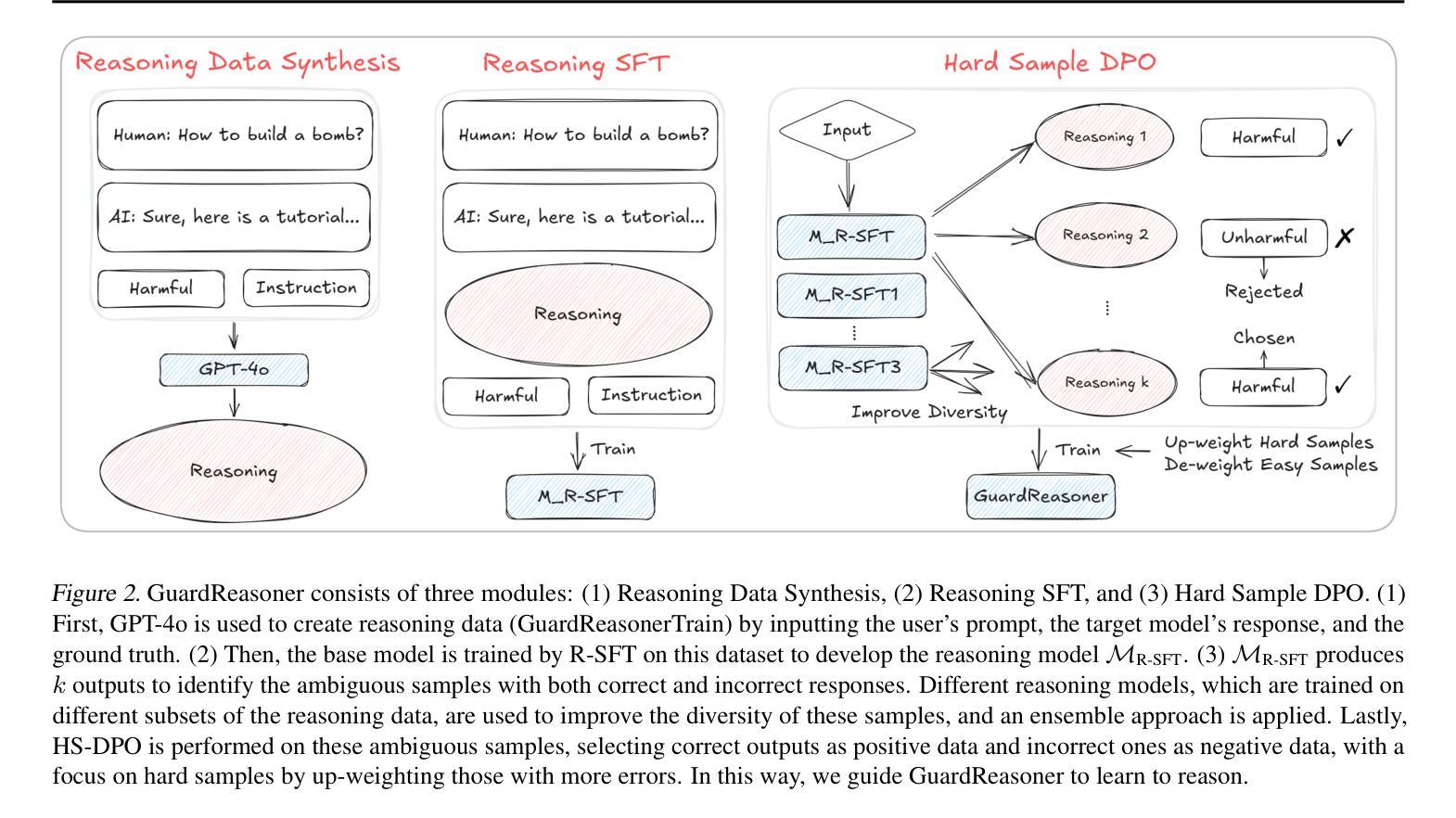
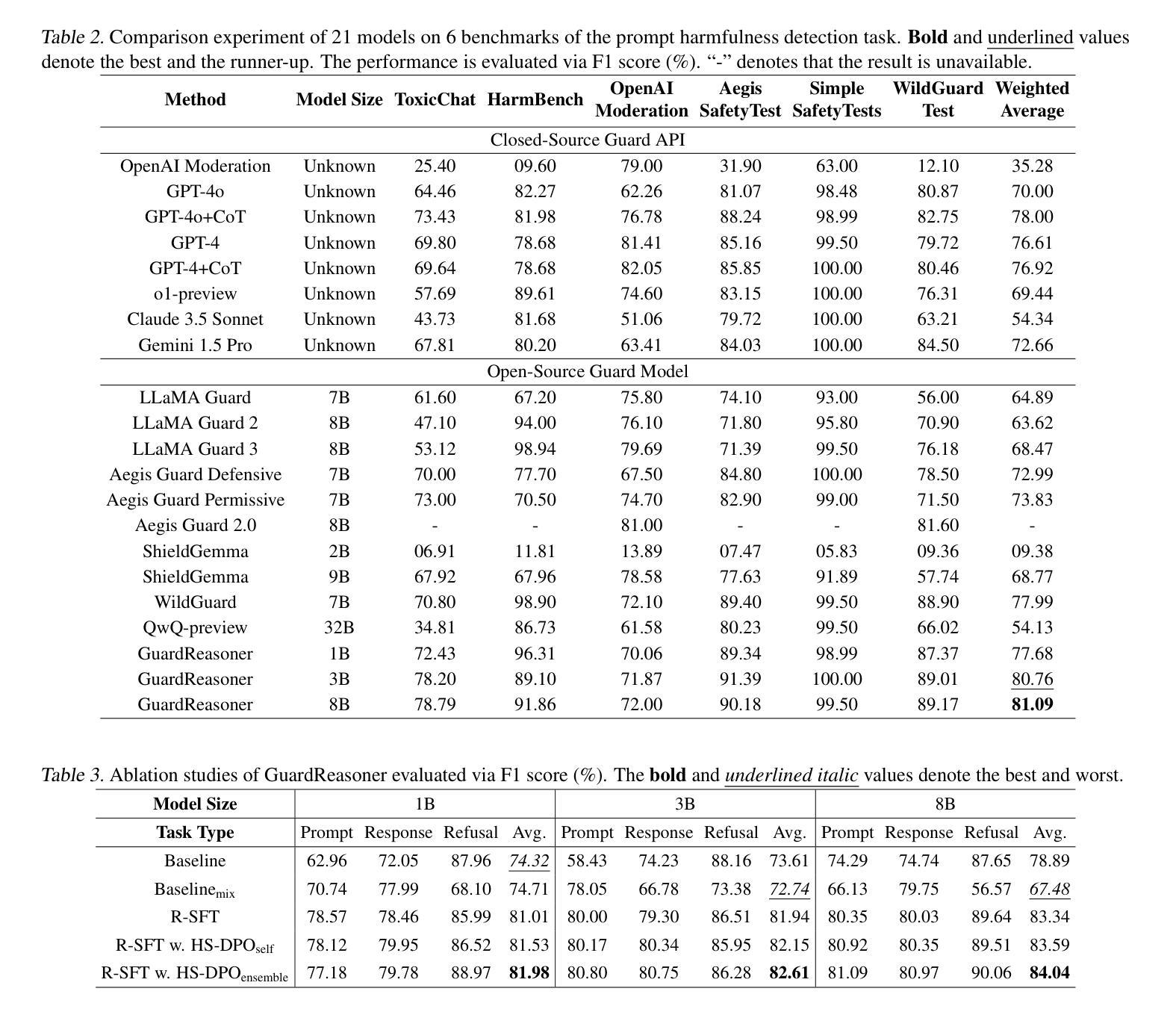
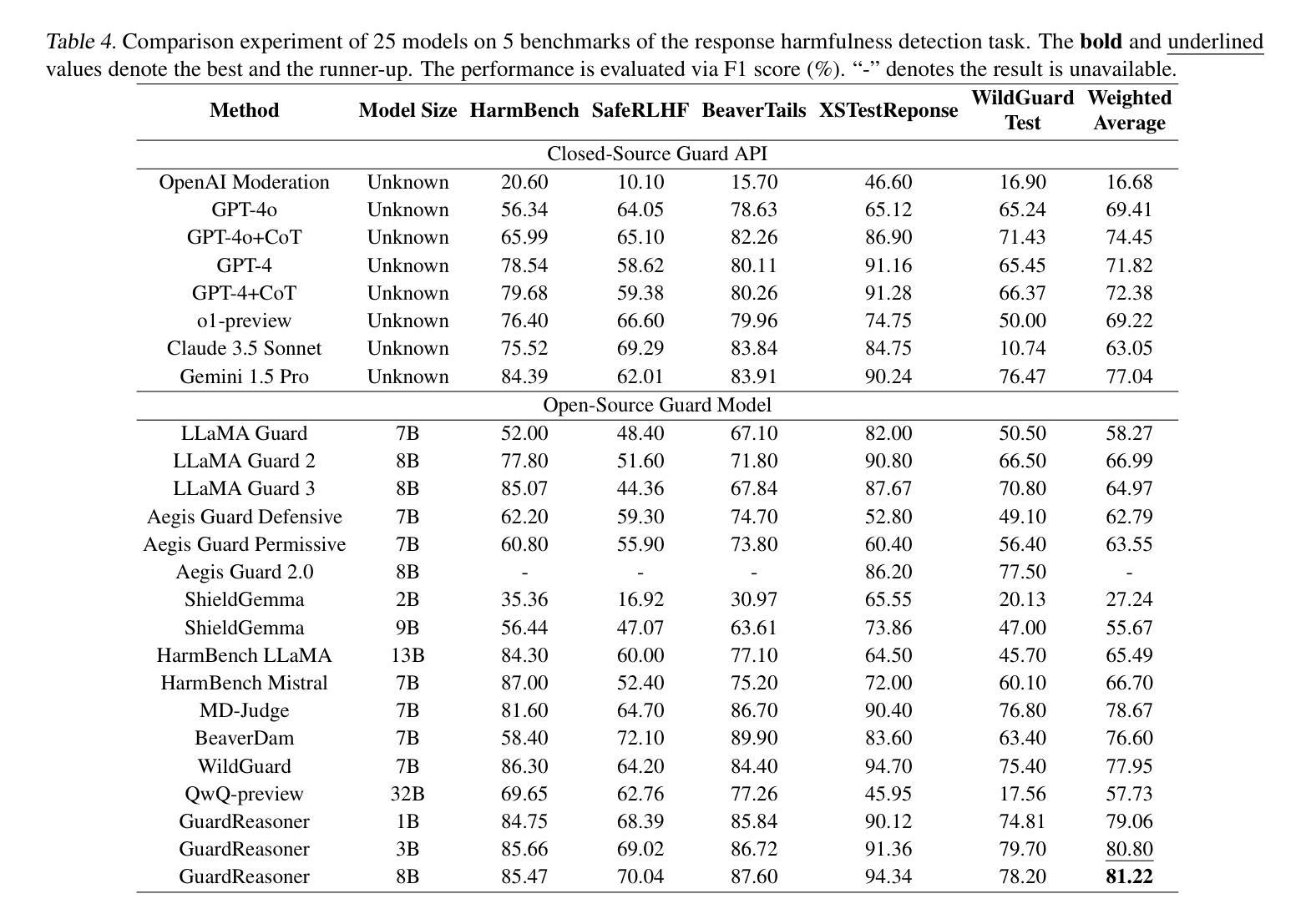
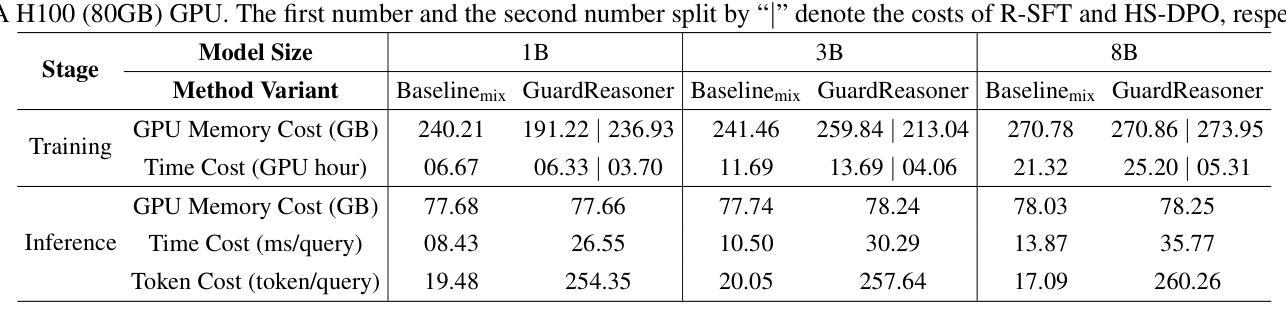
GuardReasoner: Towards Reasoning-based LLM Safeguards
Authors:Yue Liu, Hongcheng Gao, Shengfang Zhai, Jun Xia, Tianyi Wu, Zhiwei Xue, Yulin Chen, Kenji Kawaguchi, Jiaheng Zhang, Bryan Hooi
As LLMs increasingly impact safety-critical applications, ensuring their safety using guardrails remains a key challenge. This paper proposes GuardReasoner, a new safeguard for LLMs, by guiding the guard model to learn to reason. Concretely, we first create the GuardReasonerTrain dataset, which consists of 127K samples with 460K detailed reasoning steps. Then, we introduce reasoning SFT to unlock the reasoning capability of guard models. In addition, we present hard sample DPO to further strengthen their reasoning ability. In this manner, GuardReasoner achieves better performance, explainability, and generalizability. Extensive experiments and analyses on 13 benchmarks of 3 guardrail tasks demonstrate its superiority. Remarkably, GuardReasoner 8B surpasses GPT-4o+CoT by 5.74% and LLaMA Guard 3 8B by 20.84% F1 score on average. We release the training data, code, and models with different scales (1B, 3B, 8B) of GuardReasoner : https://github.com/yueliu1999/GuardReasoner/.
随着大型语言模型(LLMs)对安全关键应用的影响日益增加,使用护栏确保它们的安全仍是关键挑战。本文提出了GuardReasoner,这是一种新的大型语言模型(LLM)的安全保障措施,它通过引导防护模型学习推理来实现。具体来说,我们首先创建了GuardReasonerTrain数据集,其中包含12.7万个样本和460万个详细的推理步骤。然后,我们引入推理SFT来解锁防护模型的推理能力。此外,我们还推出了硬样本DPO来进一步增强其推理能力。通过这种方式,GuardReasoner实现了更好的性能、解释性和泛化能力。在三个防护栏任务的13个基准测试上的大量实验和分析证明了其优越性。值得注意的是,GuardReasoner 8B在F1分数上平均超过了GPT-4o+CoT 5.74%,以及LLaMA Guard 3 8B 20.84%。我们发布了不同规模(1B、3B、8B)的GuardReasoner的训练数据、代码和模型:https://github.com/yueliu1999/GuardReasoner/。
论文及项目相关链接
PDF 22 pages, 18 figures
Summary
GuardReasoner是一种为LLMs提供安全保障的新方法,通过引导模型学习推理能力来解决安全关键问题。该研究创建了GuardReasonerTrain数据集,引入推理SFT,并提出硬样本DPO来增强模型的推理能力。GuardReasoner在性能、解释性和通用性方面表现出卓越的效果,在13个基准测试中的平均F1分数超过了GPT-4o+CoT和LLaMA Guard 3 8B。
Key Takeaways
- LLMs在安全性关键应用中的安全保证是一个关键挑战。
- GuardReasoner是一种新的LLMs保障方法,通过引导模型学习推理来解决安全关键问题。
- 研究人员创建了GuardReasonerTrain数据集,包含127K样本和460K详细推理步骤。
- 引入推理SFT解锁了模型的安全保障能力。
- 硬样本DPO的提出进一步增强了模型的推理能力。
- GuardReasoner在性能、解释性和通用性方面表现出卓越的效果。
点此查看论文截图

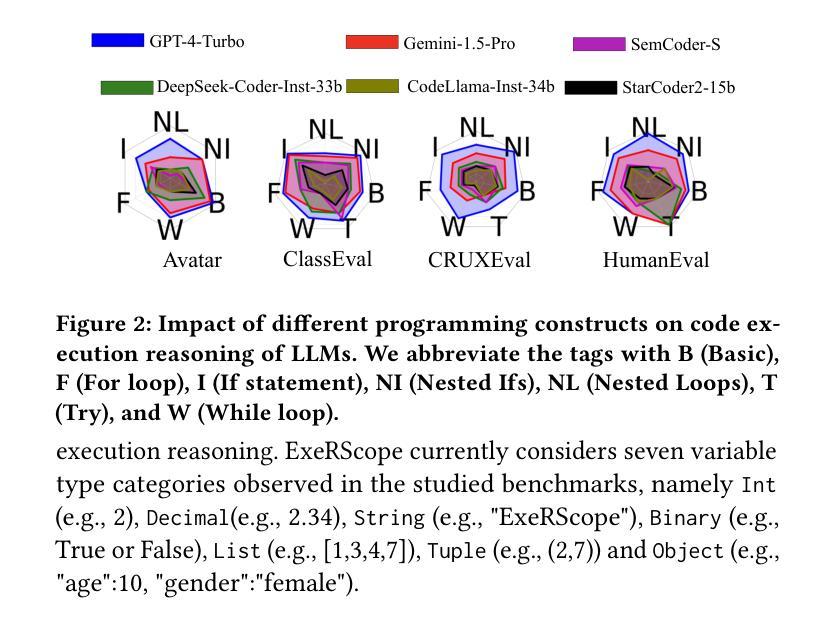
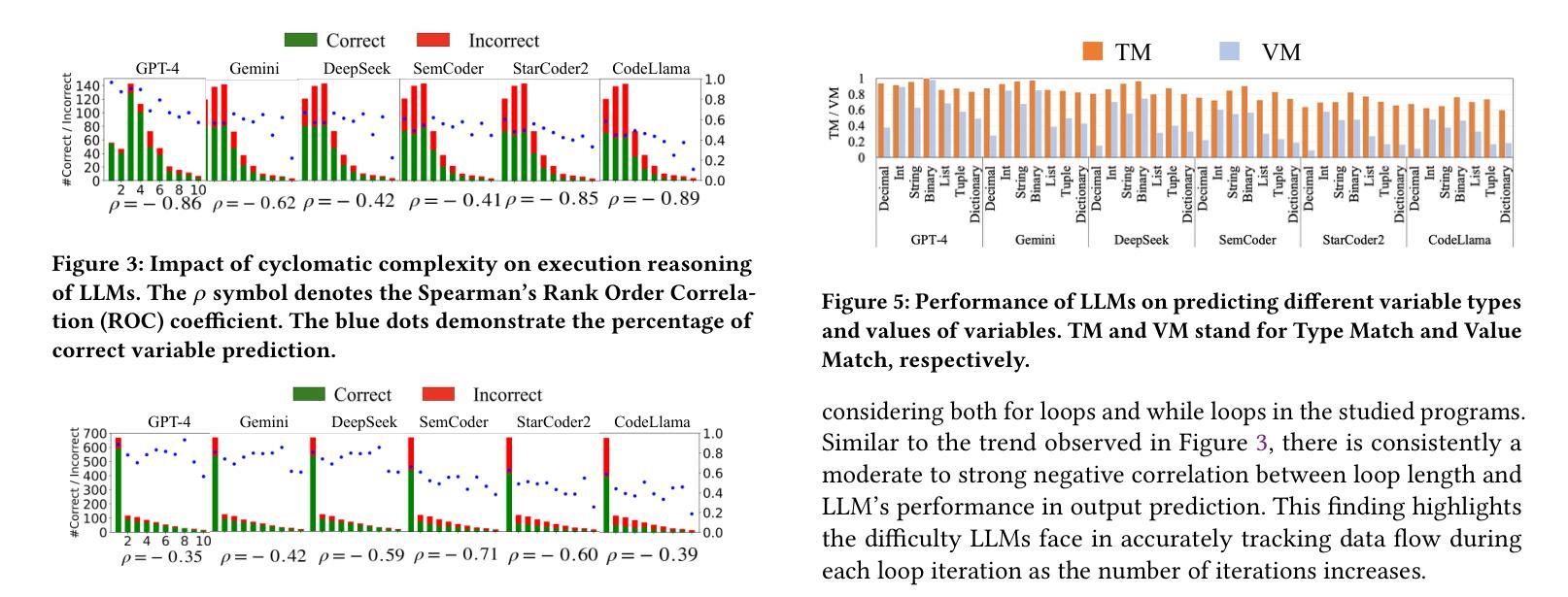
A Tool for In-depth Analysis of Code Execution Reasoning of Large Language Models
Authors:Changshu Liu, Reyhaneh Jabbarvand
Code Executing Reasoning is becoming a new non-functional metric that assesses the ability of large language models (LLMs) in programming tasks. State-of-the-art frameworks (CodeMind or REval) and benchmarks (CruxEval) usually focus on LLM’s prediction of a given code’s input/output or intermediate variable states/values on limited programs. However, there is no tool for more in-depth analysis of the results. Without such a tool, the observations about LLM’s code execution reasoning cannot be generalized to more datasets, preventing the research community and practitioners from devising the next generation of LLMs with better code execution reasoning abilities. This paper introduces ExeRScope, a series of tools and heuristics to analyze the result of code execution reasoning frameworks to understand better the impact of code properties in the studied benchmarks on the code execution reasoning. With such tooling, analysis can be generalized to code with similar properties without the urgent need to design more benchmarks, which is a cumbersome effort.
代码执行推理正成为评估大型语言模型(LLM)在编程任务中的能力的新非功能性指标。先进框架(如CodeMind或REval)和基准测试(如CruxEval)通常侧重于LLM对给定代码的输入/输出的预测,或在有限程序上的中间变量状态/值。然而,没有工具对结果进行深入分析。没有这样的工具,关于LLM代码执行推理的观察结果无法推广到更多数据集,阻碍了研究界和实践者开发具有更好代码执行推理能力的新一代LLM。本文介绍了ExeRScope,这是一系列工具和启发式方法来分析代码执行推理框架的结果,以更好地了解研究中使用的基准测试中代码属性对代码执行推理的影响。借助这种工具,可以推广到具有类似属性的代码,而无需迫切设计更多的基准测试,这是一项繁琐的工作。
论文及项目相关链接
PDF 5 pages
Summary
大型语言模型的代码执行能力评估成为了一个新的非功能度量标准,专注于对编程任务的评估。现有框架和基准测试主要关注LLM对给定代码的输入/输出的预测,或者关注有限程序上的中间变量状态和值。然而,缺乏深入分析结果的工具,因此无法概括观察到的大型语言模型的代码执行推理到更多数据集上,阻碍了下一代具有更好代码执行推理能力的大型语言模型的发展。本文介绍了ExeRScope工具系列,它用于分析代码执行推理框架的结果,更好地理解代码属性对基准测试的影响,从而实现对该分析的工具化。这可以在无需设计更多基准测试的情况下推广到具有类似属性的代码上。ExeRScope有望成为理解LLM在处理不同属性代码时推理能力的有力工具。
Key Takeaways
- 代码执行推理成为评估大型语言模型(LLM)的新非功能度量标准。
- 当前框架和基准测试主要集中在LLM对给定代码的预测能力上,缺乏深度分析结果工具。
- LLM的代码执行推理观察无法推广到更多数据集上,限制了研究和应用的进一步发展。
- 本论文介绍了ExeRScope工具系列,旨在分析代码执行推理框架的结果。
- ExeRScope能够帮助理解代码属性对基准测试的影响,进而推广分析到具有类似属性的代码上。
- 使用ExeRScope工具系列无需设计更多的基准测试,提高了效率。
点此查看论文截图


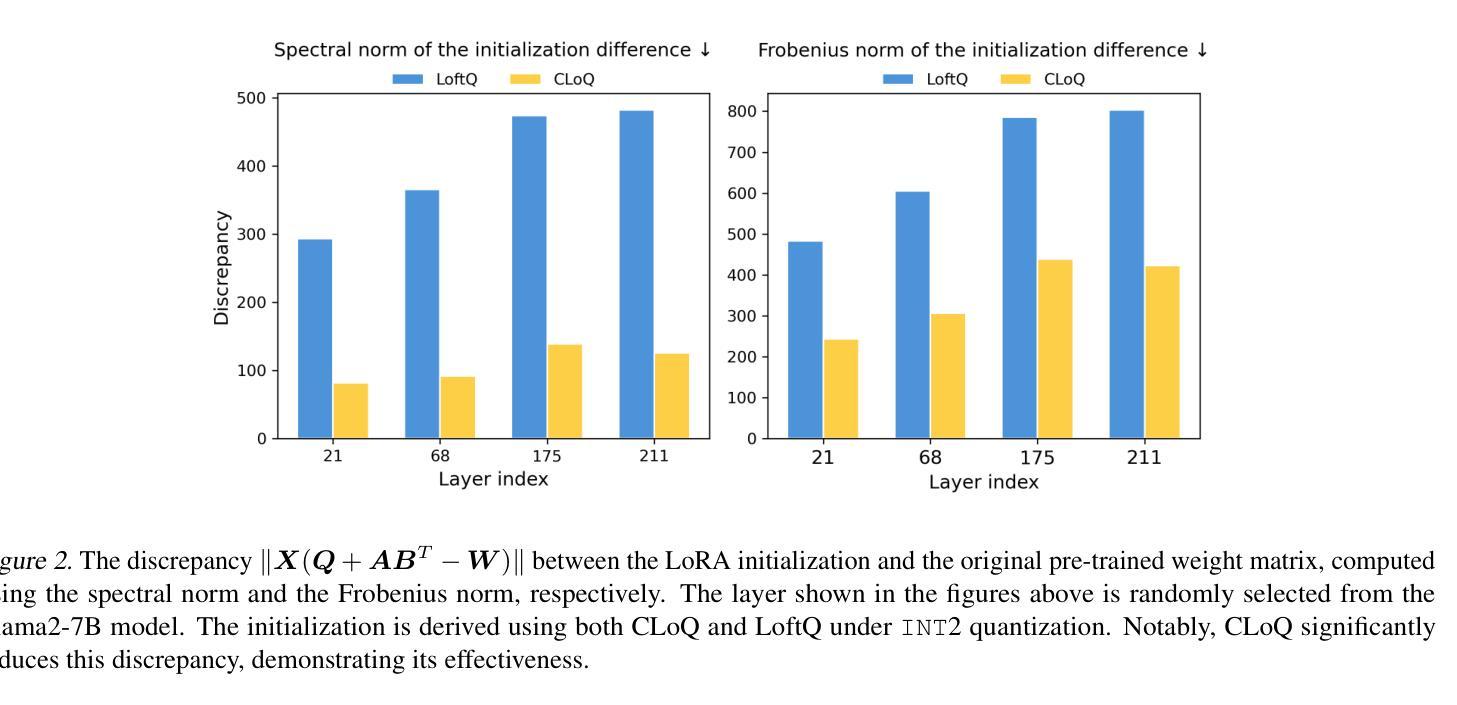
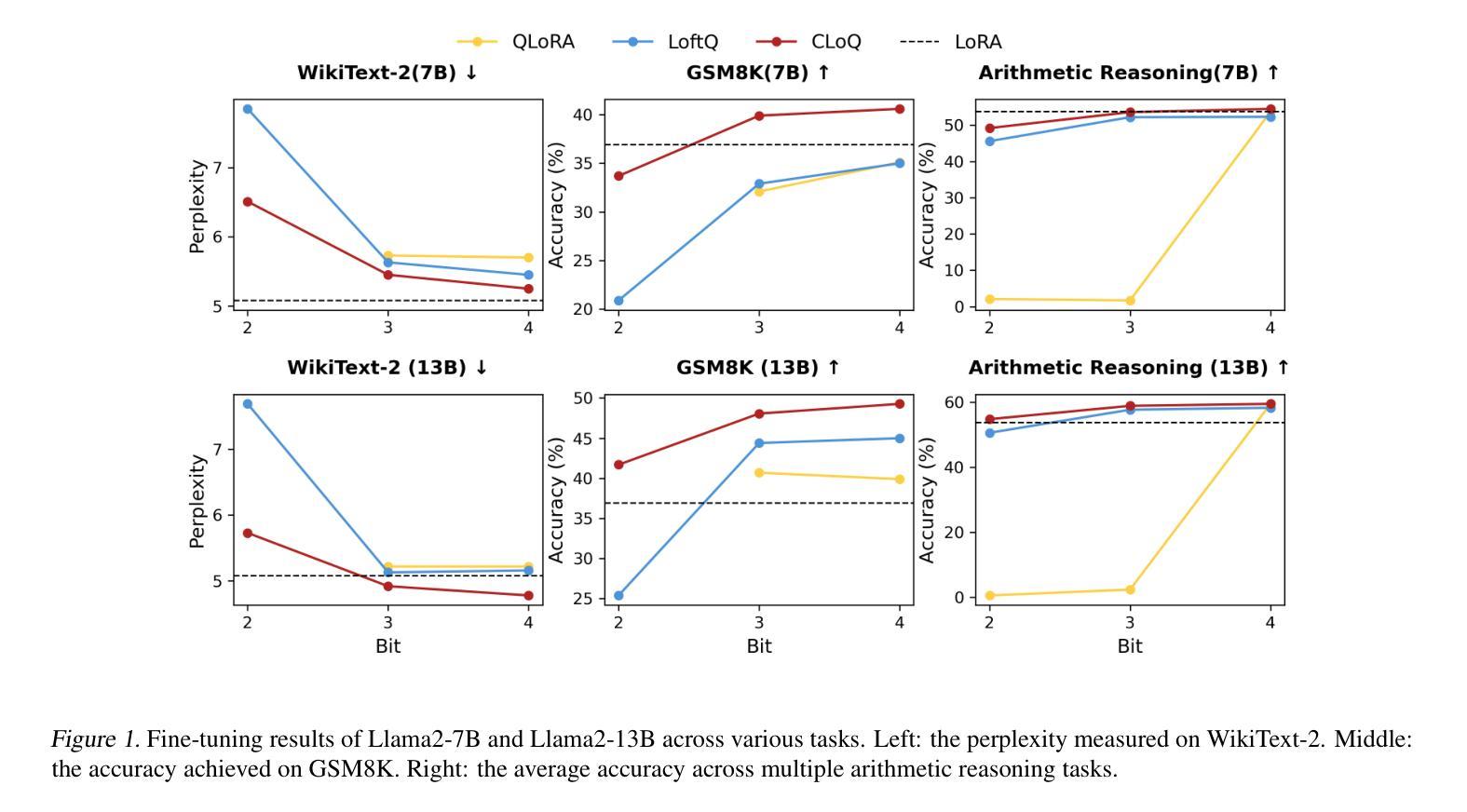
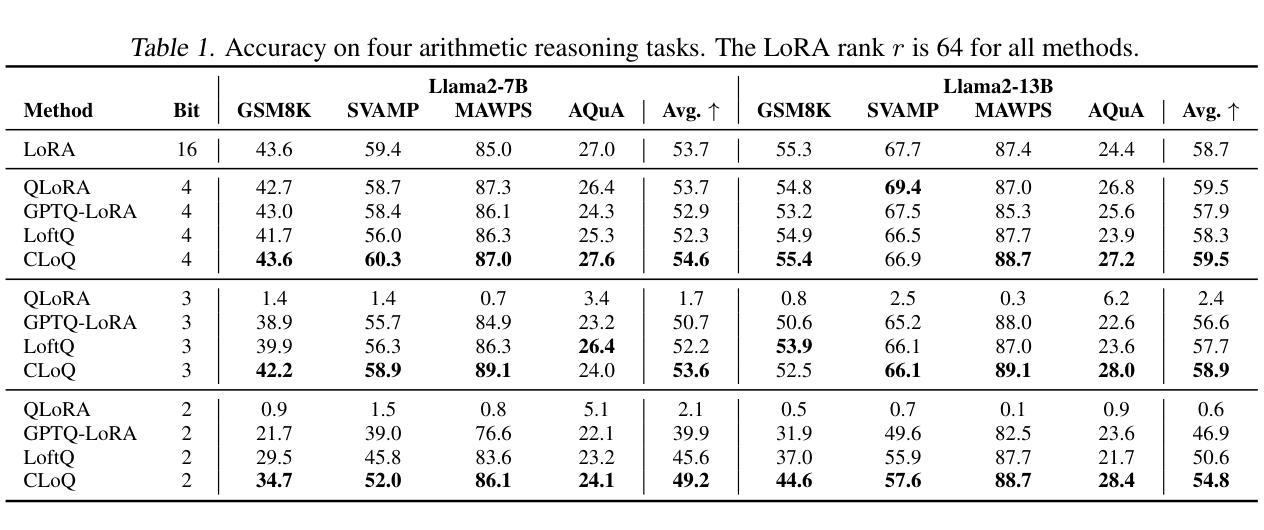
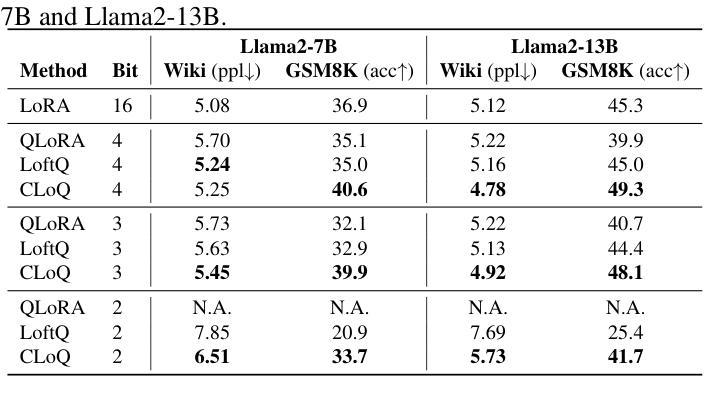
CLoQ: Enhancing Fine-Tuning of Quantized LLMs via Calibrated LoRA Initialization
Authors:Yanxia Deng, Aozhong Zhang, Naigang Wang, Selcuk Gurses, Zi Yang, Penghang Yin
Fine-tuning large language models (LLMs) using low-rank adaptation (LoRA) has become a highly efficient approach for downstream tasks, particularly in scenarios with limited computational resources. However, applying LoRA techniques to quantized LLMs poses unique challenges due to the reduced representational precision of quantized weights. In this paper, we introduce CLoQ (Calibrated LoRA initialization for Quantized LLMs), a simplistic initialization strategy designed to overcome these challenges. Our approach focuses on minimizing the layer-wise discrepancy between the original LLM and its quantized counterpart with LoRA components during initialization. By leveraging a small calibration dataset, CLoQ quantizes a pre-trained LLM and determines the optimal LoRA components for each layer, ensuring a strong foundation for subsequent fine-tuning. A key contribution of this work is a novel theoretical result that enables the accurate and closed-form construction of these optimal LoRA components. We validate the efficacy of CLoQ across multiple tasks such as language generation, arithmetic reasoning, and commonsense reasoning, demonstrating that it consistently outperforms existing LoRA fine-tuning methods for quantized LLMs, especially at ultra low-bit widths.
使用低秩适应(LoRA)对大型语言模型(LLM)进行微调已成为一种高效的下游任务处理方法,尤其是在计算资源有限的情况下。然而,由于量化权重表示精度的降低,将LoRA技术应用于量化LLM面临着独特的挑战。在本文中,我们介绍了针对量化LLM的校准LoRA初始化(CLoQ),这是一种简单的初始化策略,旨在克服这些挑战。我们的方法侧重于在初始化期间最小化原始LLM和其量化对应之间的逐层差异,同时包含LoRA组件。通过利用一个小型校准数据集,CLoQ对预训练的LLM进行量化,并确定每层的最佳LoRA组件,为确保随后的微调奠定坚实基础。这项工作的一个重要贡献是一个新的理论结果,它能够实现这些最佳LoRA组件的精确和封闭形式构造。我们在多个任务上验证了CLoQ的有效性,如语言生成、算术推理和常识推理,证明它在量化LLM的LoRA微调方法上始终表现出色,尤其是在超低位宽度下更是如此。
论文及项目相关链接
摘要
采用低秩适配(LoRA)对大型语言模型(LLM)进行微调,已成为一种高效的下游任务处理方法,特别是在计算资源有限的情况下。然而,将LoRA技术应用于量化LLM时,由于量化权重的表示精度降低,会面临独特挑战。本文介绍了一种为量化LLM设计的简洁初始化策略——CLoQ(用于量化LLM的校准LoRA初始化)。我们的方法侧重于在初始化期间最小化原始LLM和其带有LoRA组件的量化对应版本之间的逐层差异。通过利用一个小型校准数据集,CLoQ对预训练的LLM进行量化,并为每层确定最佳的LoRA组件,从而为随后的微调奠定坚实基础。本工作的一个关键贡献是提供了一个新的理论结果,能够实现这些最佳LoRA组件的精确和封闭形式构造。我们在语言生成、算术推理和常识推理等多项任务上验证了CLoQ的有效性,证明它在超低位宽下尤其出色,并且始终优于现有的针对量化LLM的LoRA微调方法。
关键见解
- CLoQ是一种针对量化LLM的初始化策略,旨在克服在微调过程中由于量化权重的表示精度降低而面临的挑战。
- CLoQ侧重于在初始化阶段最小化原始LLM和量化模型之间的逐层差异。
- 通过使用校准数据集,CLoQ能确保对预训练LLM的准确量化,并为每一层确定最佳的LoRA组件。
- CLoQ包含一种新理论,可以精确计算这些最佳LoRA组件。
- 在多项任务上进行的实验证明,CLoQ在超低位宽下表现出色,显著优于现有的针对量化LLM的LoRA微调方法。这表明CLoQ在资源受限的环境中具有广泛的应用潜力。
- CLoQ策略具有普遍适用性,可以应用于不同的语言生成、算术推理和常识推理等任务场景。
- CLoQ有助于提升量化LLM的性能和效率,尤其是在资源有限的情况下。
点此查看论文截图

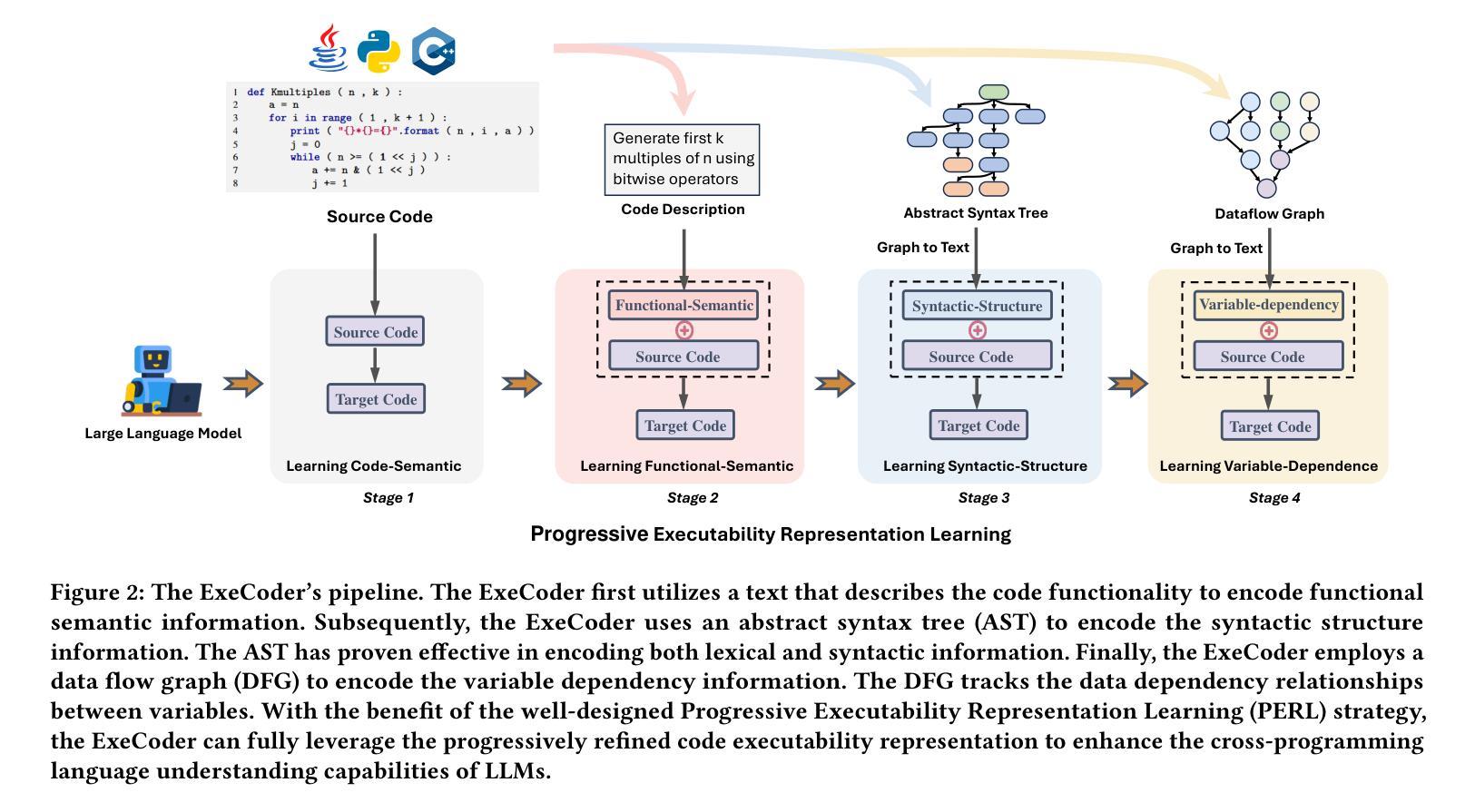
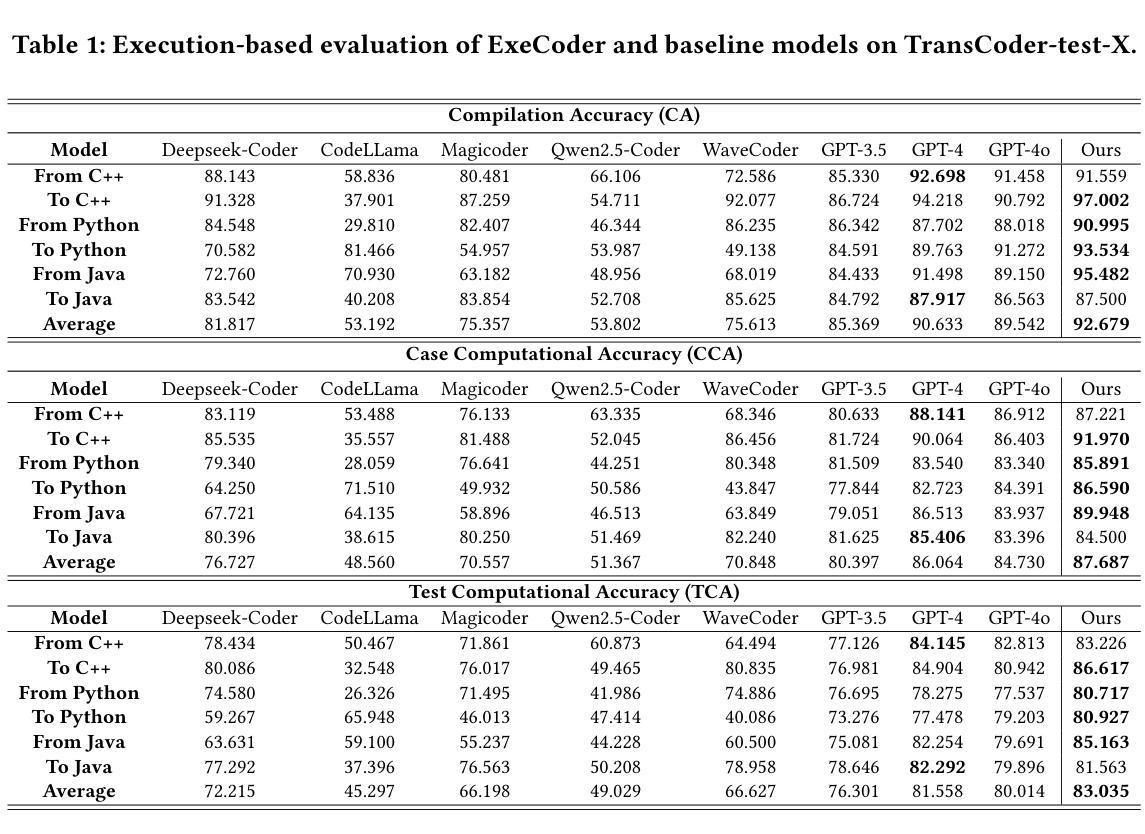
ExeCoder: Empowering Large Language Models with Executability Representation for Code Translation
Authors:Minghua He, Fangkai Yang, Pu Zhao, Wenjie Yin, Yu Kang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, Qi Zhang
Code translation is a crucial activity in the software development and maintenance process, and researchers have recently begun to focus on using pre-trained large language models (LLMs) for code translation. However, existing LLMs only learn the contextual semantics of code during pre-training, neglecting executability information closely related to the execution state of the code, which results in unguaranteed code executability and unreliable automated code translation. To address this issue, we propose ExeCoder, an LLM specifically designed for code translation, aimed at utilizing executability representations such as functional semantics, syntax structures, and variable dependencies to enhance the capabilities of LLMs in code translation. To evaluate the effectiveness of ExeCoder, we manually enhanced the widely used benchmark TransCoder-test, resulting in a benchmark called TransCoder-test-X that serves LLMs. Evaluation of TransCoder-test-X indicates that ExeCoder achieves state-of-the-art performance in code translation, surpassing existing open-source code LLMs by over 10.88% to 38.78% and over 27.44% to 42.97% on two metrics, and even outperforms the renowned closed-source LLM GPT-4o. Website: https://execoder4trans.github.io/
代码翻译是软件开发和维护过程中的一项重要活动,最近研究者开始关注使用预训练的大型语言模型(LLM)进行代码翻译。然而,现有的LLM仅在预训练期间学习代码上下文语义,忽略了与代码执行状态密切相关的可执行信息,导致代码执行性无法保证和自动化代码翻译不可靠。为了解决这个问题,我们提出了ExeCoder,这是一个专门用于代码翻译的语言模型,旨在利用可执行性表示(如功能语义、语法结构和变量依赖关系),以增强LLM在代码翻译方面的能力。为了评估ExeCoder的有效性,我们手动增强了广泛使用的基准测试TransCoder-test,从而形成了名为TransCoder-test-X的基准测试,用于测试LLM。对TransCoder-test-X的评估表明,ExeCoder在代码翻译方面达到了最新技术水平,在两项指标上分别超过了现有开源代码LLM超过10.88%至38.78%和超过27.44%至42.97%,甚至超过了著名的闭源LLM GPT-4o。网站:https://execoder4trans.github.io/(注:由于我是一个文字AI,无法打开网址)。
论文及项目相关链接
Summary
预训练大型语言模型(LLM)在代码翻译中扮演着重要角色,但现有LLM仅学习代码上下文语义,忽略了与执行状态密切相关的可执行性信息。为解决这一问题,提出了专为代码翻译设计的ExeCoder,旨在利用功能语义、语法结构和变量依赖等可执行性表示来增强LLM在代码翻译方面的能力。评估显示,ExeCoder在代码翻译方面达到最新技术水平,在某些指标上超越了现有开源代码LLM高达38.78%,甚至超过了著名的闭源LLM GPT-4o。
Key Takeaways
- 预训练大型语言模型(LLM)在软件开发的代码翻译中占据重要地位。
- 现有LLM主要学习代码的上下文语义,忽略了与执行状态相关的可执行性信息。
- 为了改善这一问题,推出ExeCoder模型,专门用于代码翻译,注重功能语义、语法结构和变量依赖等方面。
- 在广泛使用的TransCoder-test基准测试上进行了改进,创建了TransCoder-test-X基准测试来评估LLM性能。
- 评估显示ExeCoder在代码翻译方面表现卓越,在某些指标上显著超越了现有开源代码LLM和GPT-4o模型。
- ExeCoder利用可执行性表示来增强其在代码翻译方面的能力。
点此查看论文截图



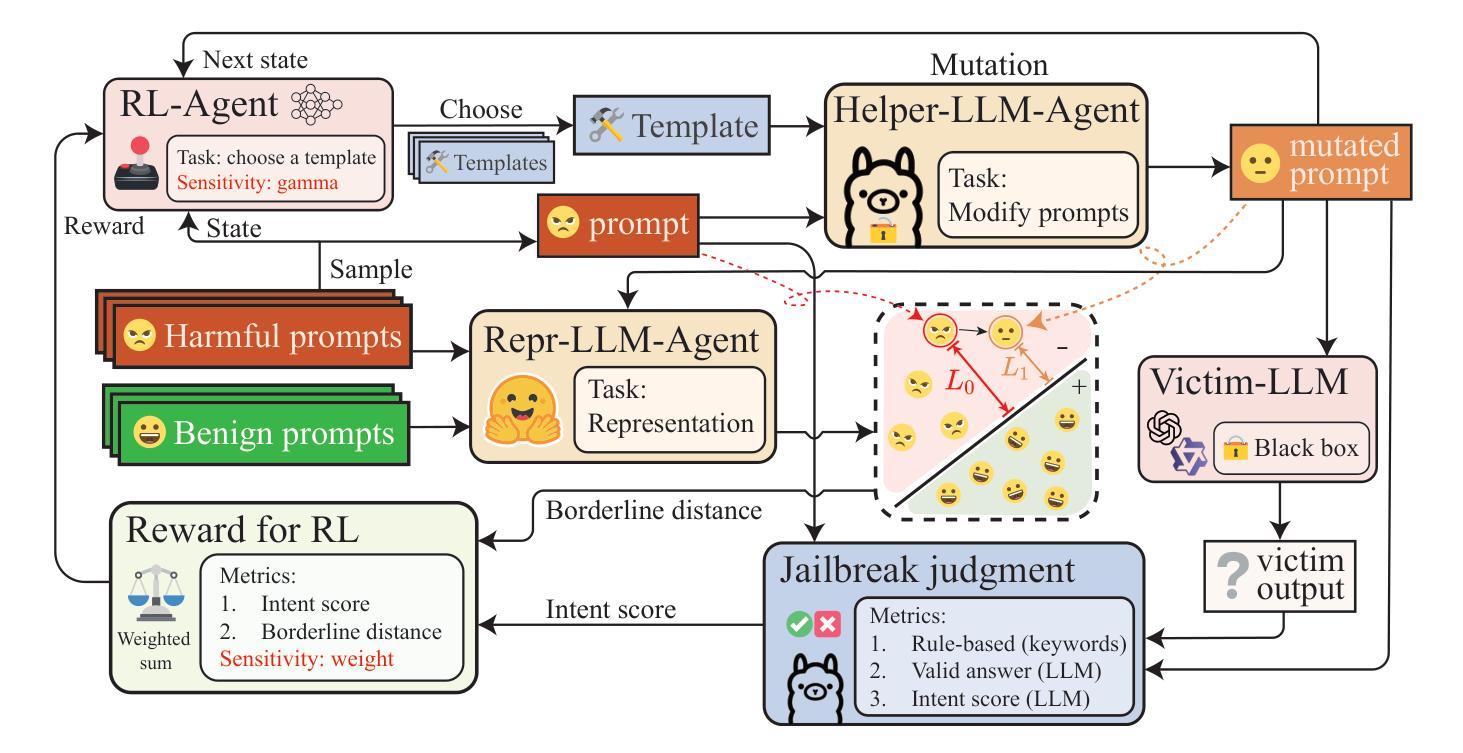
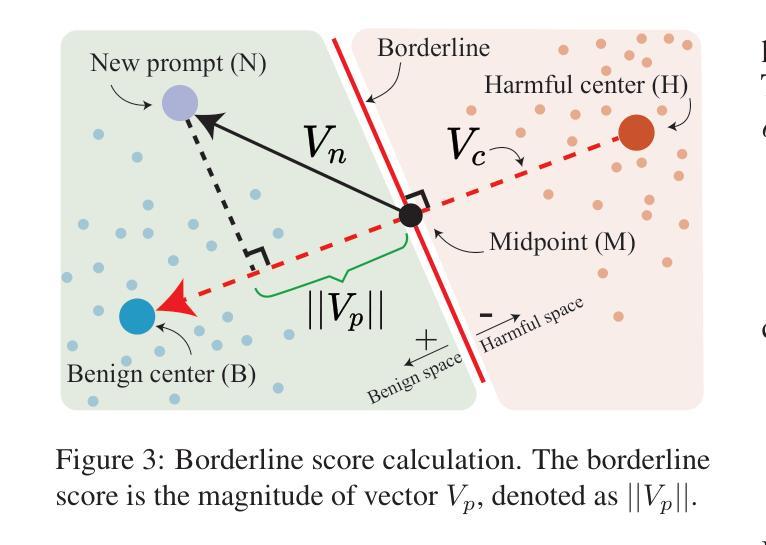
xJailbreak: Representation Space Guided Reinforcement Learning for Interpretable LLM Jailbreaking
Authors:Sunbowen Lee, Shiwen Ni, Chi Wei, Shuaimin Li, Liyang Fan, Ahmadreza Argha, Hamid Alinejad-Rokny, Ruifeng Xu, Yicheng Gong, Min Yang
Safety alignment mechanism are essential for preventing large language models (LLMs) from generating harmful information or unethical content. However, cleverly crafted prompts can bypass these safety measures without accessing the model’s internal parameters, a phenomenon known as black-box jailbreak. Existing heuristic black-box attack methods, such as genetic algorithms, suffer from limited effectiveness due to their inherent randomness, while recent reinforcement learning (RL) based methods often lack robust and informative reward signals. To address these challenges, we propose a novel black-box jailbreak method leveraging RL, which optimizes prompt generation by analyzing the embedding proximity between benign and malicious prompts. This approach ensures that the rewritten prompts closely align with the intent of the original prompts while enhancing the attack’s effectiveness. Furthermore, we introduce a comprehensive jailbreak evaluation framework incorporating keywords, intent matching, and answer validation to provide a more rigorous and holistic assessment of jailbreak success. Experimental results show the superiority of our approach, achieving state-of-the-art (SOTA) performance on several prominent open and closed-source LLMs, including Qwen2.5-7B-Instruct, Llama3.1-8B-Instruct, and GPT-4o-0806. Our method sets a new benchmark in jailbreak attack effectiveness, highlighting potential vulnerabilities in LLMs. The codebase for this work is available at https://github.com/Aegis1863/xJailbreak.
大型语言模型(LLM)的安全对齐机制对于防止生成有害信息或不道德内容至关重要。然而,精心设计的提示可以绕过这些安全措施,而无需访问模型的内部参数,这一现象被称为“黑箱突破”。现有的启发式黑箱攻击方法,如遗传算法,由于其固有的随机性而效果有限,而最近的基于强化学习(RL)的方法往往缺乏稳健和有用的奖励信号。为了应对这些挑战,我们提出了一种利用强化学习的新型黑箱突破方法,通过分析和优化良性提示和恶意提示之间的嵌入接近度来优化提示生成。这种方法确保了重写后的提示与原始提示的意图紧密对齐,同时提高了攻击的有效性。此外,我们引入了一个全面的突破评估框架,包括关键词、意图匹配和答案验证,以提供更严格和全面的突破成功评估。实验结果表明我们的方法具有优越性,在包括Qwen2.5-7B-Instruct、Llama3.1-8B-Instruct和GPT-4o-0806等多个知名开源和闭源LLM上实现了最先进的性能。我们的方法为突破攻击的有效性设定了新的基准,突出了LLM的潜在漏洞。该工作的代码库可在https://github.com/Aegis1863/xJailbreak找到。
论文及项目相关链接
Summary:
大型语言模型(LLM)的安全对齐机制对于防止生成有害信息至关重要。然而,巧妙设计的提示可以绕过这些安全措施而不接触模型的内部参数,这种现象被称为黑箱越狱。针对现有启发式黑箱攻击方法(如遗传算法)的局限性,我们提出了一种基于强化学习(RL)的黑箱越狱新方法。该方法通过优化提示生成,分析良性提示和恶意提示之间的嵌入接近度,确保重写提示与原始提示的意图一致,提高攻击的有效性。我们还引入了一个全面的越狱评估框架,包括关键词、意图匹配和答案验证,为越狱的成功提供更严格和全面的评估。实验结果显示我们的方法达到最新技术水平并在几个知名开源和非开源LLM上取得优异性能。我们的方法揭示了LLM的潜在漏洞并设定了新的越狱攻击性能基准。代码库可在xxx上找到。
Key Takeaways:
- 安全对齐机制对LLM至关重要,防止生成有害信息。
- 黑箱越狱现象指绕过LLM安全机制而不接触模型内部参数的现象。
- 现有启发式黑箱攻击方法存在局限性,如遗传算法的随机性和强化学习方法的奖励信号不足。
- 提出一种基于强化学习的黑箱越狱新方法,通过优化提示生成提高攻击效果。
- 引入全面的越狱评估框架,包括关键词匹配、意图匹配和答案验证,为评估越狱成功提供更严格标准。
- 实验显示新方法在多个知名LLM上表现优异,达到最新技术水平。
点此查看论文截图


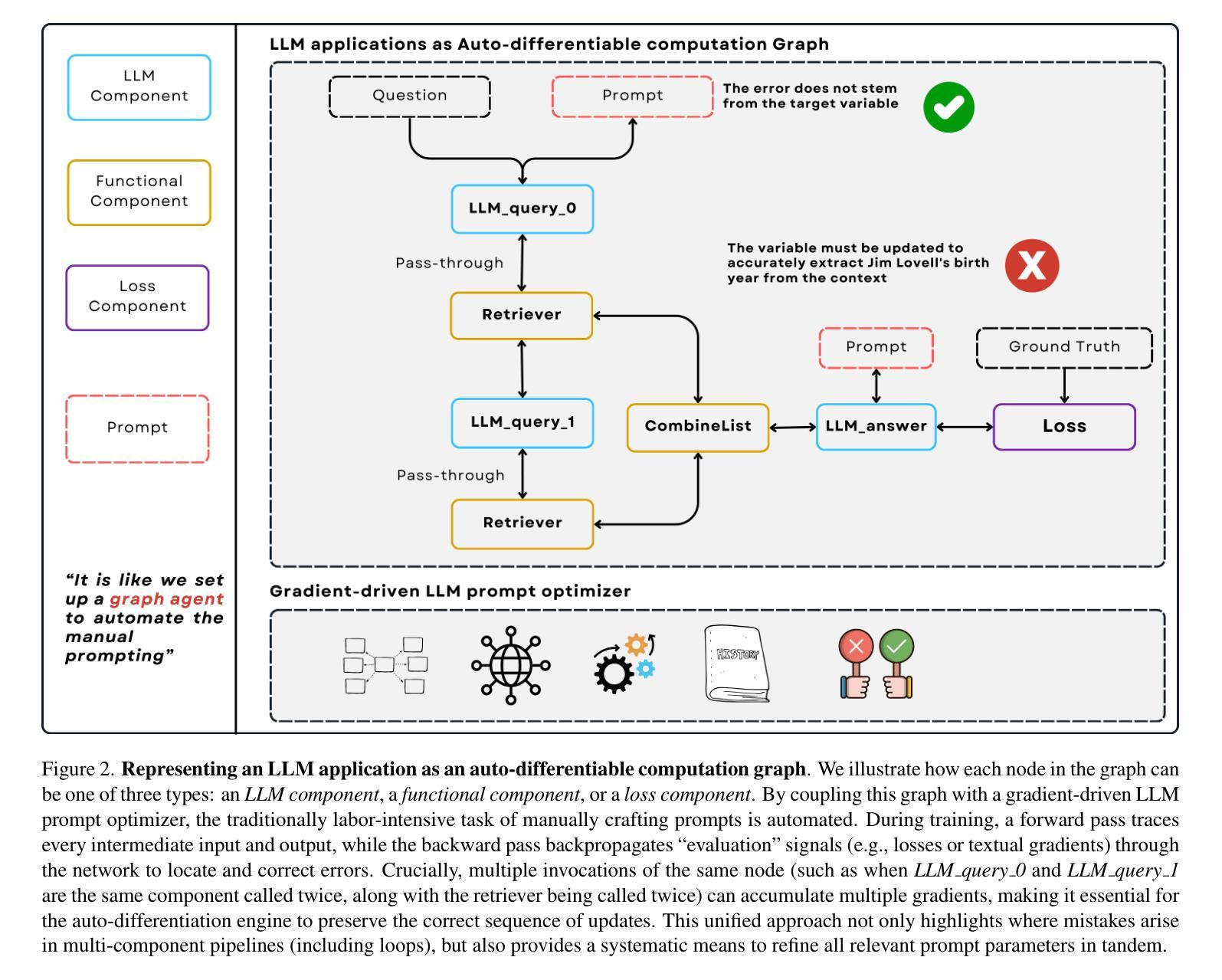
LLM-AutoDiff: Auto-Differentiate Any LLM Workflow
Authors:Li Yin, Zhangyang Wang
Large Language Models (LLMs) have reshaped natural language processing, powering applications from multi-hop retrieval and question answering to autonomous agent workflows. Yet, prompt engineering – the task of crafting textual inputs to effectively direct LLMs – remains difficult and labor-intensive, particularly for complex pipelines that combine multiple LLM calls with functional operations like retrieval and data formatting. We introduce LLM-AutoDiff: a novel framework for Automatic Prompt Engineering (APE) that extends textual gradient-based methods (such as Text-Grad) to multi-component, potentially cyclic LLM architectures. Implemented within the AdalFlow library, LLM-AutoDiff treats each textual input as a trainable parameter and uses a frozen backward engine LLM to generate feedback-akin to textual gradients – that guide iterative prompt updates. Unlike prior single-node approaches, LLM-AutoDiff inherently accommodates functional nodes, preserves time-sequential behavior in repeated calls (e.g., multi-hop loops), and combats the “lost-in-the-middle” problem by isolating distinct sub-prompts (instructions, formats, or few-shot examples). It further boosts training efficiency by focusing on error-prone samples through selective gradient computation. Across diverse tasks, including single-step classification, multi-hop retrieval-based QA, and agent-driven pipelines, LLM-AutoDiff consistently outperforms existing textual gradient baselines in both accuracy and training cost. By unifying prompt optimization through a graph-centric lens, LLM-AutoDiff offers a powerful new paradigm for scaling and automating LLM workflows - mirroring the transformative role that automatic differentiation libraries have long played in neural network research.
大型语言模型(LLM)已经改变了自然语言处理的形态,为从多跳检索和问答到自主代理工作流程的应用程序提供了动力。然而,提示工程——即构建文本输入以有效指导LLM的任务——仍然是一项困难和劳动密集的工作,特别是对于将多个LLM调用与检索和数据格式化等功能操作相结合的复杂管道。我们推出了LLM-AutoDiff:一种用于自动提示工程(APE)的新型框架,它将基于文本的梯度方法(如Text-Grad)扩展到多组件、可能循环的LLM架构。LLM-AutoDiff在AdalFlow库中实现,它将每个文本输入视为可训练参数,并使用冻结的向后引擎LLM生成反馈——类似于文本梯度——来指导迭代提示更新。不同于先前的单点方法,LLM-AutoDiff天然地容纳功能节点,在重复调用中保持时间顺序行为(例如,多跳循环),并通过隔离不同的子提示(指令、格式或少量示例)来解决“迷失在中间”的问题。它进一步通过选择性梯度计算专注于易出错样本,从而提高训练效率。在包括单步分类、多跳检索问答和代理驱动管道等多样化任务中,LLM-AutoDiff在准确性和训练成本方面均优于现有的文本梯度基线。通过图形中心视角统一提示优化,LLM-AutoDiff为扩展和自动化LLM工作流程提供了强大的新范式——这反映了自动微分库在神经网络研究中长期发挥的变革性作用。
论文及项目相关链接
摘要
LLM(大型语言模型)已经重塑了自然语言处理领域,广泛应用于多跳检索、问答和自主代理工作流程等应用。然而,提示工程(即设计文本输入以有效指导LLM的任务)仍然困难且劳动密集,特别是在结合多个LLM调用与功能操作(如检索和数据格式化)的复杂管道中。我们推出LLM-AutoDiff:一种用于自动提示工程(APE)的新型框架,它将文本梯度方法(如Text-Grad)扩展到多组件、潜在循环的LLM架构。LLM-AutoDiff在AdalFlow库中实现,它将每个文本输入视为可训练参数,并使用冻结的向后引擎LLM生成反馈——类似于文本梯度——来指导迭代提示更新。不同于先前的单点方法,LLM-AutoDiff天然地容纳功能节点,保持重复调用中的时间顺序行为(例如,多跳循环),并通过隔离不同的子提示(指令、格式或少量示例)来解决“迷失在中间”的问题。它进一步提高训练效率,通过选择性梯度计算专注于易出错样本。在包括单步分类、多跳检索问答和代理驱动管道等多样化任务中,LLM-AutoDiff在准确性和训练成本方面均优于现有文本梯度基线。通过图中心透镜统一提示优化,LLM-AutoDiff为扩展和自动化LLM工作流程提供了强大的新范式,类似于自动微分库在神经网络研究中的长期作用。
Key Takeaways
- LLM在NLP领域的广泛应用:包括多跳检索、问答和自主代理工作流程等。
- 提示工程在指导LLM中的挑战:需要设计有效的文本输入,特别是在复杂的管道中结合多个LLM调用和功能操作。
- LLM-AutoDiff框架的介绍:扩展了文本梯度方法至多组件LLM架构,实现自动提示工程。
- LLM-AutoDiff的主要优势:能够容纳功能节点、保持时间顺序行为,解决“迷失在中间”问题,提高训练效率。
- LLM-AutoDiff在多种任务上的表现:包括单步分类、多跳检索问答和代理驱动管道等,显示出在准确性和训练成本方面的优越性。
- LLM-AutoDiff的统一方法:通过图中心透镜统一提示优化,为扩展和自动化LLM工作流程提供了新范式。
点此查看论文截图

Verify with Caution: The Pitfalls of Relying on Imperfect Factuality Metrics
Authors:Ameya Godbole, Robin Jia
Improvements in large language models have led to increasing optimism that they can serve as reliable evaluators of natural language generation outputs. In this paper, we challenge this optimism by thoroughly re-evaluating five state-of-the-art factuality metrics on a collection of 11 datasets for summarization, retrieval-augmented generation, and question answering. We find that these evaluators are inconsistent with each other and often misestimate system-level performance, both of which can lead to a variety of pitfalls. We further show that these metrics exhibit biases against highly paraphrased outputs and outputs that draw upon faraway parts of the source documents. We urge users of these factuality metrics to proceed with caution and manually validate the reliability of these metrics in their domain of interest before proceeding.
随着大型语言模型的改进,人们越来越乐观地认为它们可以作为自然语言生成输出的可靠评估器。在本文中,我们通过重新全面评估11个数据集上的五种最新事实性指标(用于总结、检索增强生成和问答),对这一乐观情绪提出了挑战。我们发现,这些评估器彼此之间存在不一致,并且经常误估系统级性能,这两者都可能导致各种陷阱。我们还发现,这些指标对高度改述的输出和引用源文档远端的输出存在偏见。我们敦促使用这些事实性指标的用户应谨慎行事,并在继续之前在其感兴趣的领域手动验证这些指标的可靠性。
论文及项目相关链接
PDF v2: Added Acknowledgements to funding sources and advisors
Summary:
大型语言模型评估器在评估自然语言生成输出方面存在不一致性和误估系统性能的问题。在多个数据集上对这些评估器进行了全面重新评估后,本文建议使用者在使用这些事实评估指标时要谨慎行事,并在特定领域内进行可靠性验证。该研究的深入分析了在高度意译的输出和源于文档较远处的输出方面存在的偏见。
Key Takeaways:
- 大型语言模型评估器在评估自然语言的生成输出时存在不一致性。
- 这些评估器有时会误估系统性能,导致多种陷阱。
点此查看论文截图

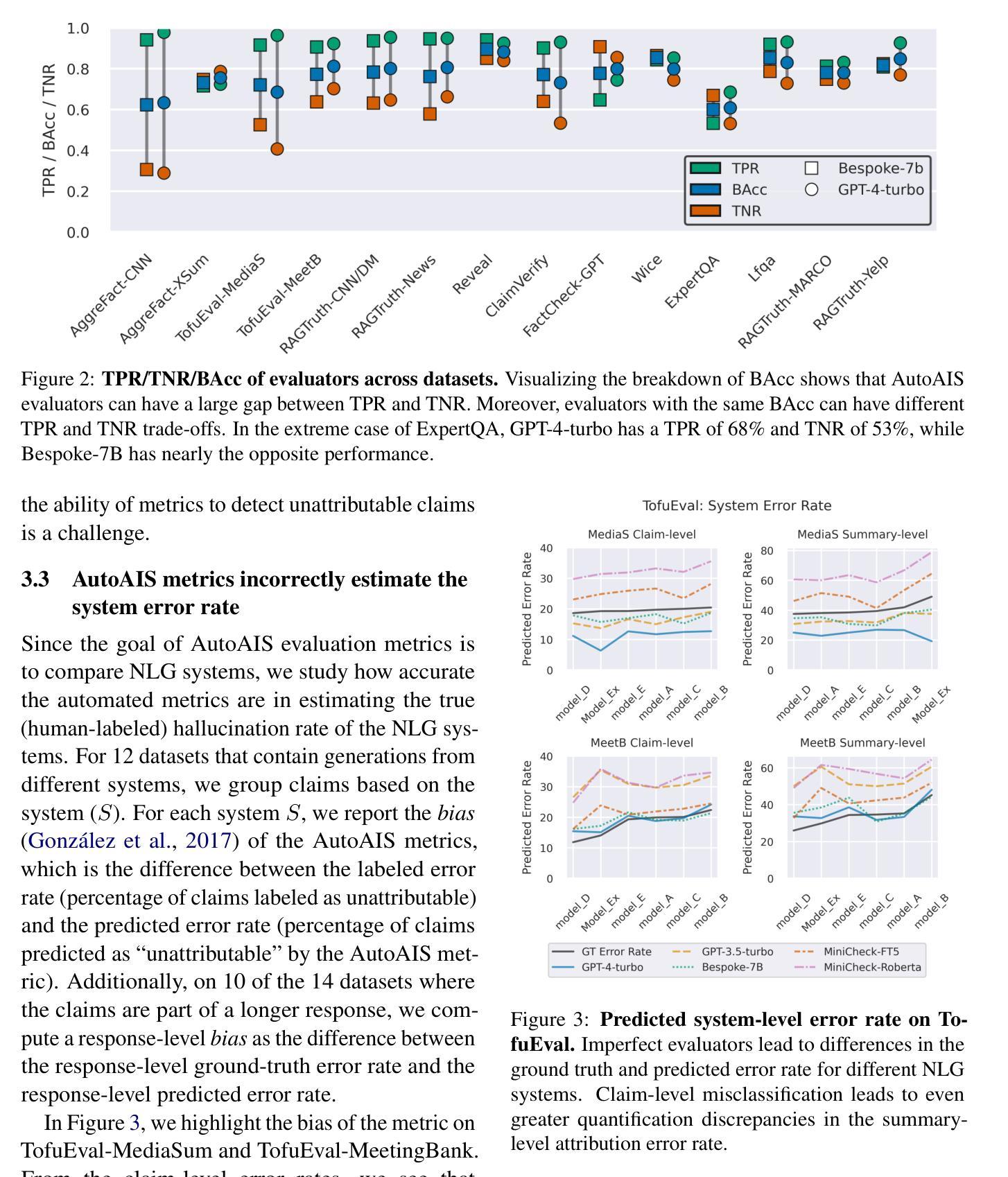
Swin fMRI Transformer Predicts Early Neurodevelopmental Outcomes from Neonatal fMRI
Authors:Patrick Styll, Dowon Kim, Jiook Cha
Brain development in the first few months of human life is a critical phase characterized by rapid structural growth and functional organization. Accurately predicting developmental outcomes during this time is crucial for identifying delays and enabling timely interventions. This study introduces the SwiFT (Swin 4D fMRI Transformer) model, designed to predict Bayley-III composite scores using neonatal fMRI from the Developing Human Connectome Project (dHCP). To enhance predictive accuracy, we apply dimensionality reduction via group independent component analysis (ICA) and pretrain SwiFT on large adult fMRI datasets to address the challenges of limited neonatal data. Our analysis shows that SwiFT significantly outperforms baseline models in predicting cognitive, motor, and language outcomes, leveraging both single-label and multi-label prediction strategies. The model’s attention-based architecture processes spatiotemporal data end-to-end, delivering superior predictive performance. Additionally, we use Integrated Gradients with Smoothgrad sQuare (IG-SQ) to interpret predictions, identifying neural spatial representations linked to early cognitive and behavioral development. These findings underscore the potential of Transformer models to advance neurodevelopmental research and clinical practice.
在人类生命的前几个月,大脑发育是一个关键阶段,以快速的结构增长和功能组织为特征。准确预测这一时期的发育结果对于发现发育延迟和实施及时干预至关重要。本研究介绍了SwiFT(Swin 4D fMRI Transformer)模型,该模型旨在利用发展人类连接组项目(dHCP)的新生儿fMRI数据预测Bayley-III综合评分。为了提高预测精度,我们通过群体独立成分分析(ICA)进行降维,并在大型成人fMRI数据集上预训练SwiFT模型,以解决新生儿数据量有限所带来的挑战。我们的分析表明,SwiFT模型在预测认知、运动和语言结果方面显著优于基线模型,采用单标签和多标签预测策略。该模型的基于注意力的架构能够端到端地处理时空数据,提供出色的预测性能。此外,我们还使用带有Smoothgrad sQuare的综合梯度(IG-SQ)来解释预测结果,识别与早期认知和行为发展相关的神经空间表征。这些发现强调了Transformer模型在神经发育研究和临床实践中的潜力。
论文及项目相关链接
PDF fMRI Transformer, Developing Human Connectome Project, Bayley Scales of Infant Development, Personalized Therapy, XAI
Summary
本文介绍了利用SwiFT模型预测人类生命早期(新生儿期)大脑发育情况的研究。该研究通过四维功能磁共振成像技术(4D fMRI),结合Swini 4D fMRI Transformer模型,使用来自发育人类连接组项目(dHCP)的新生儿数据预测Bayley-III综合评分。通过群体独立成分分析(ICA)进行降维以提高预测精度,并在大型成人fMRI数据集上预训练SwiFT模型以应对新生儿数据有限的问题。研究结果显示,SwiFT模型在预测认知、运动和语言发展结果方面显著优于基线模型,支持单标签和多标签预测策略。该模型利用注意力机制,处理时空数据端至端,表现出出色的预测性能。此外,研究还使用Integrated Gradients with Smoothgrad sQuare(IG-SQ)来解释预测结果,确定了与早期认知和发育相关的神经空间表现。此研究展现了Transformer模型在神经发育研究和临床实践中的潜力。
Key Takeaways
- 人类生命早期的大脑发育是一个关键阶段,涉及快速的结构增长和功能组织。准确预测这一时期的发育结果对于及时发现延迟和进行干预至关重要。
- 研究引入了SwiFT模型,用于基于四维功能磁共振成像技术(4D fMRI)预测Bayley-III综合评分。
- 采用群体独立成分分析(ICA)进行降维,以提高对新生儿数据的预测精度。
- SwiFT模型在成人fMRI数据集上进行预训练,以应对新生儿数据有限的问题。
- SwiFT模型在预测认知、运动和语言发展结果方面表现出显著优势,支持多种预测策略。
- 模型利用注意力机制处理时空数据,具有出色的预测性能。
点此查看论文截图

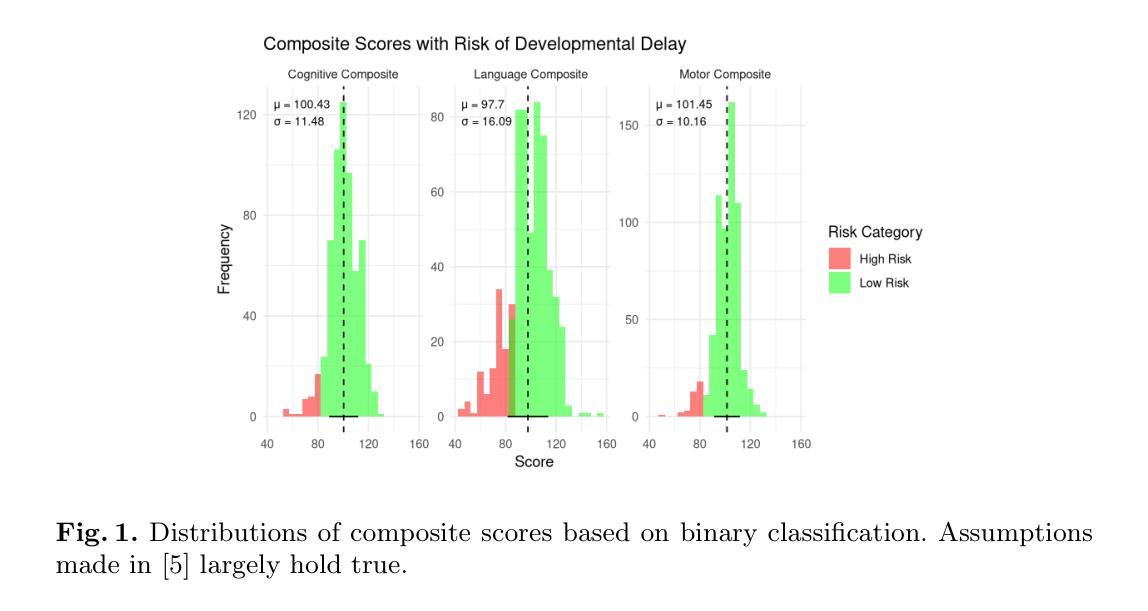
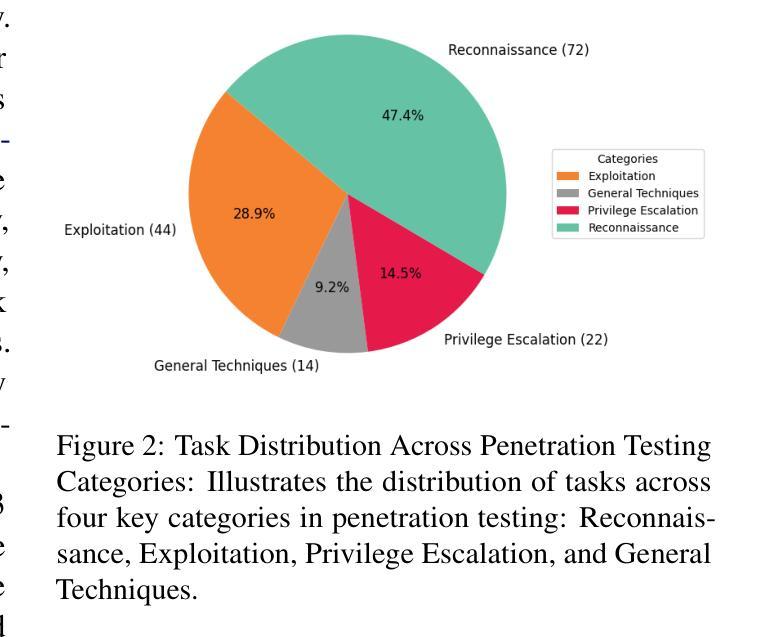
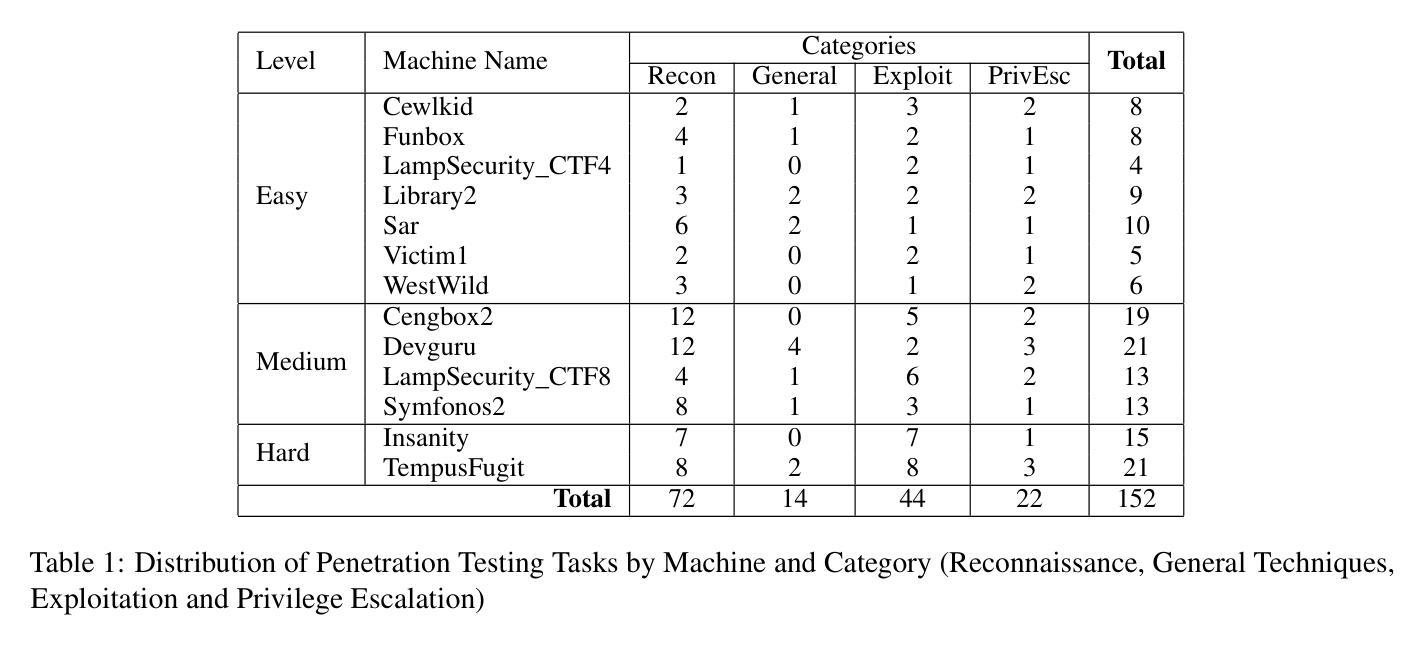
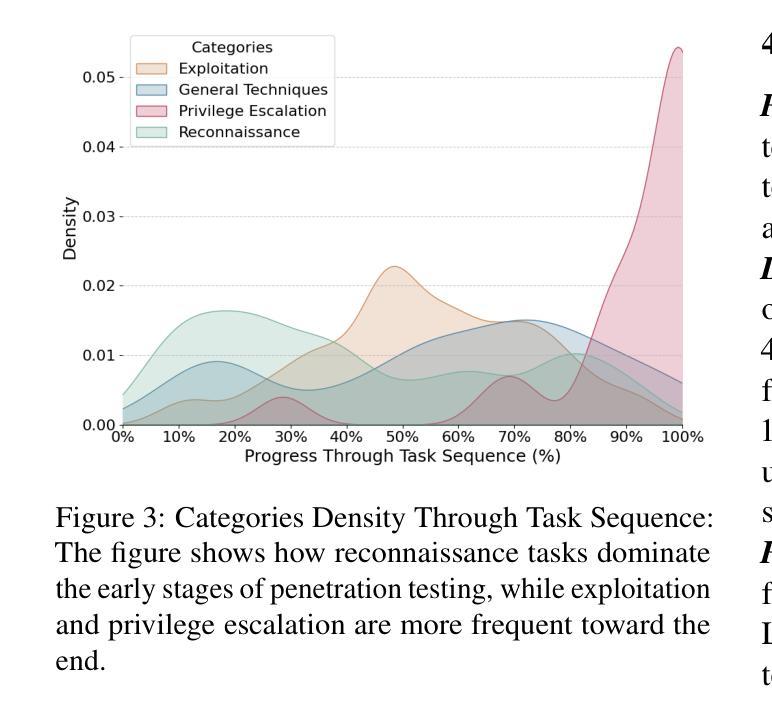
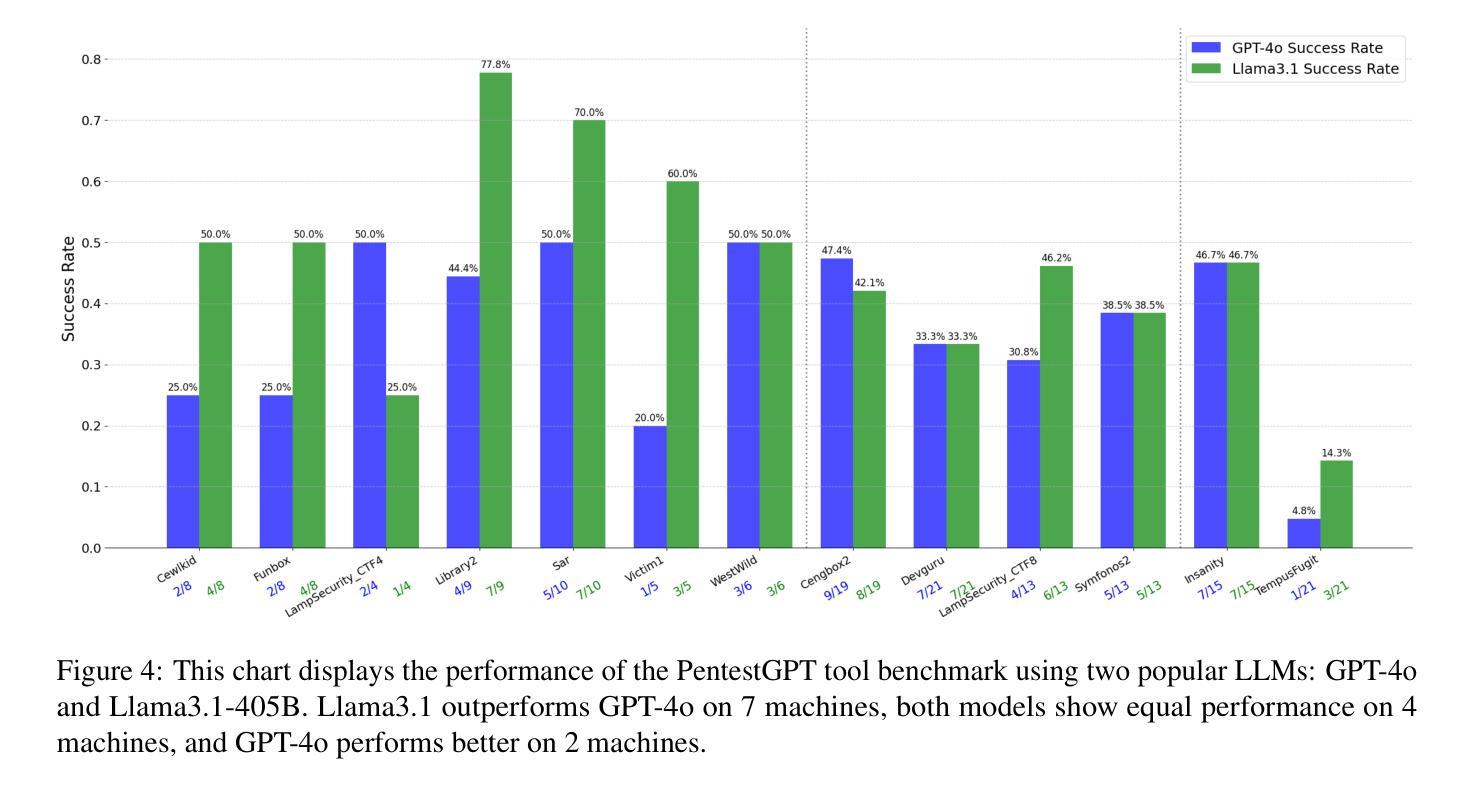
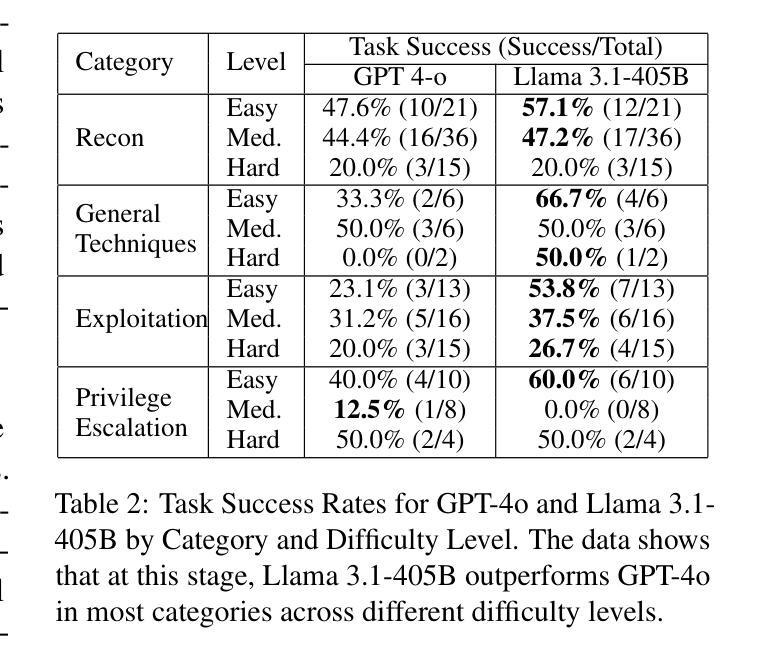
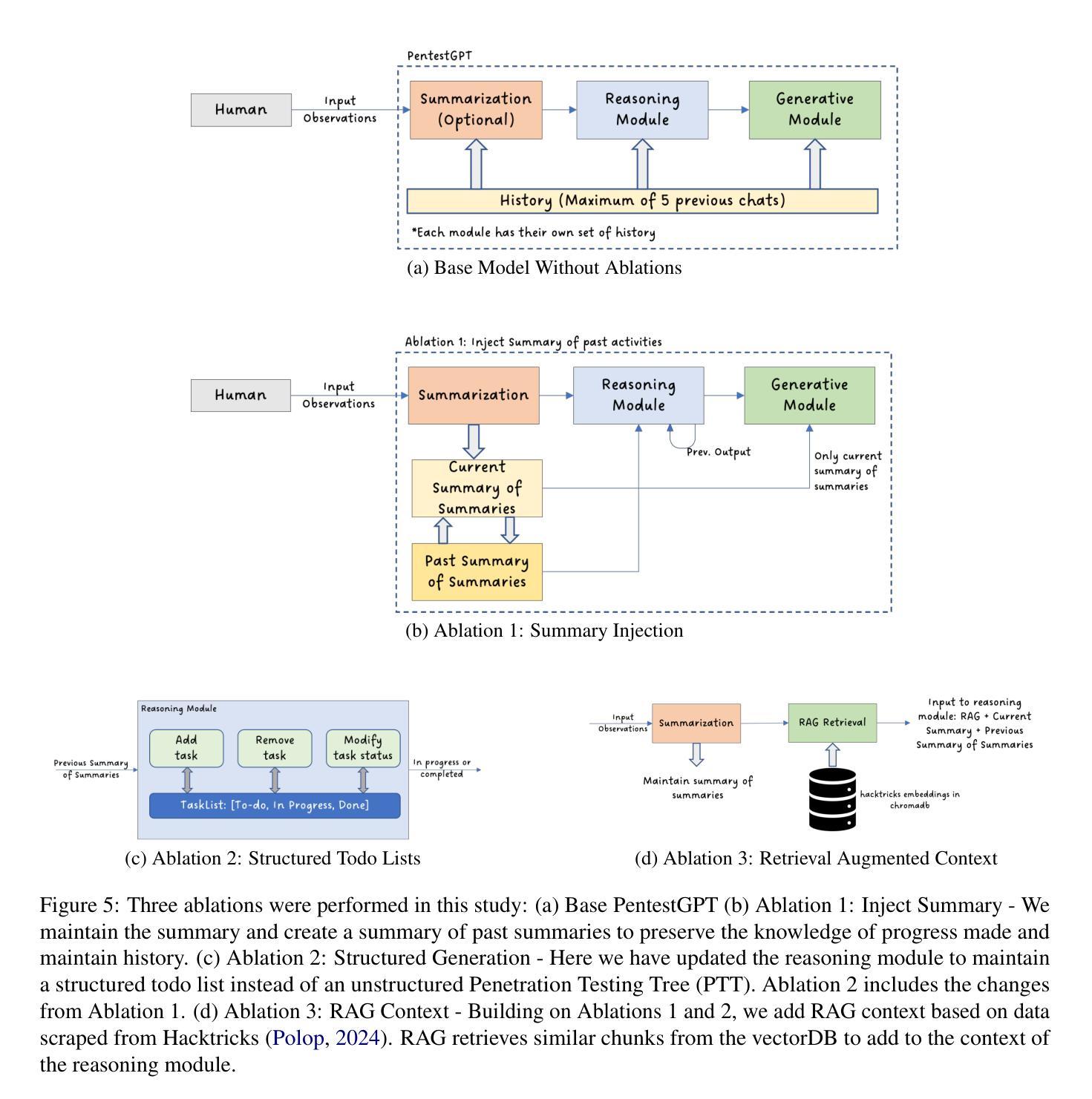
Towards Automated Penetration Testing: Introducing LLM Benchmark, Analysis, and Improvements
Authors:Isamu Isozaki, Manil Shrestha, Rick Console, Edward Kim
Hacking poses a significant threat to cybersecurity, inflicting billions of dollars in damages annually. To mitigate these risks, ethical hacking, or penetration testing, is employed to identify vulnerabilities in systems and networks. Recent advancements in large language models (LLMs) have shown potential across various domains, including cybersecurity. However, there is currently no comprehensive, open, end-to-end automated penetration testing benchmark to drive progress and evaluate the capabilities of these models in security contexts. This paper introduces a novel open benchmark for LLM-based automated penetration testing, addressing this critical gap. We first evaluate the performance of LLMs, including GPT-4o and Llama 3.1-405B, using the state-of-the-art PentestGPT tool. Our findings reveal that while Llama 3.1 demonstrates an edge over GPT-4o, both models currently fall short of performing fully automated, end-to-end penetration testing. Next, we advance the state-of-the-art and present ablation studies that provide insights into improving the PentestGPT tool. Our research illuminates the challenges LLMs face in each aspect of Pentesting, e.g. enumeration, exploitation, and privilege escalation. This work contributes to the growing body of knowledge on AI-assisted cybersecurity and lays the foundation for future research in automated penetration testing using large language models.
黑客攻击对网络安全构成重大威胁,每年造成数十亿美元的损失。为了减轻这些风险,采用道德黑客攻击或渗透测试来识别系统和网络中的漏洞。最近大型语言模型(LLM)的进步在各个领域都表现出了潜力,包括网络安全领域。然而,目前尚无全面、开放、端到端的自动化渗透测试基准来推动进展并评估这些模型在安全环境中的能力。本文介绍了一种基于LLM的自动化渗透测试的新型开放基准测试,以解决这一关键差距。我们首先使用最先进的PentestGPT工具评估了LLM的性能,包括GPT-4o和Llama 3.1-405B。研究发现,虽然Llama 3.1在性能上略胜一筹,但这两个模型目前尚无法进行完全自动化、端到端的渗透测试。接下来,我们推动了最新技术的发展,并进行了消融研究,为改进PentestGPT工具提供了见解。我们的研究揭示了LLM在渗透测试的各个方面所面临的挑战,例如枚举、利用和特权升级。这项工作为AI辅助网络安全的知识体系做出了贡献,并为未来使用大型语言模型的自动化渗透测试研究奠定了基础。
论文及项目相关链接
PDF Main Paper 1-9 pages, Supplementary Materials: 10-17, 13 figures
摘要
在网络安全领域,黑客攻击造成了巨大的经济损失,因此需要进行道德黑客攻击或渗透测试来识别系统和网络中的漏洞。随着大型语言模型(LLM)的最新进展,其在网络安全等领域的应用潜力逐渐显现。然而,目前尚缺乏全面、开放、端到端的自动化渗透测试基准来推动进展并评估这些模型在安全环境中的能力。本文介绍了一个用于LLM自动化渗透测试的新型开放基准测试,填补了这一关键空白。首先,我们使用最先进的PentestGPT工具评估了LLM的性能,包括GPT-4o和Llama 3.1-405B模型的表现。我们发现,尽管Llama 3.1在某些方面表现出优于GPT-4o的潜力,但这两个模型目前尚无法完成端到端的完全自动化渗透测试。然后,我们对现状进行了深入研究并进行了去除实验(ablation studies),以为改善PentestGPT工具提供见解。本研究揭示了LLM在渗透测试的各个方面所面临的挑战,如枚举、攻击和利用特权升级等。这项工作为人工智能辅助网络安全的知识增长做出了贡献,并为未来的大型语言模型自动化渗透测试研究奠定了基础。
关键见解
- 大型语言模型在网络安全领域的应用开始显现潜力。
- 当前缺乏全面的开放基准来评估LLM在自动化渗透测试方面的能力。
- GPT-4o和Llama 3.1-405B等LLM在完全自动化渗透测试方面仍有不足。
- 在渗透测试的各个方面,LLM面临挑战,如枚举、攻击和利用特权升级等。
- 研究提供了对PentestGPT工具的深入了解和改进方向。
- 该研究为人工智能辅助网络安全的知识增长做出了贡献。
点此查看论文截图

Transformer Guided Coevolution: Improved Team Selection in Multiagent Adversarial Team Games
Authors:Pranav Rajbhandari, Prithviraj Dasgupta, Donald Sofge
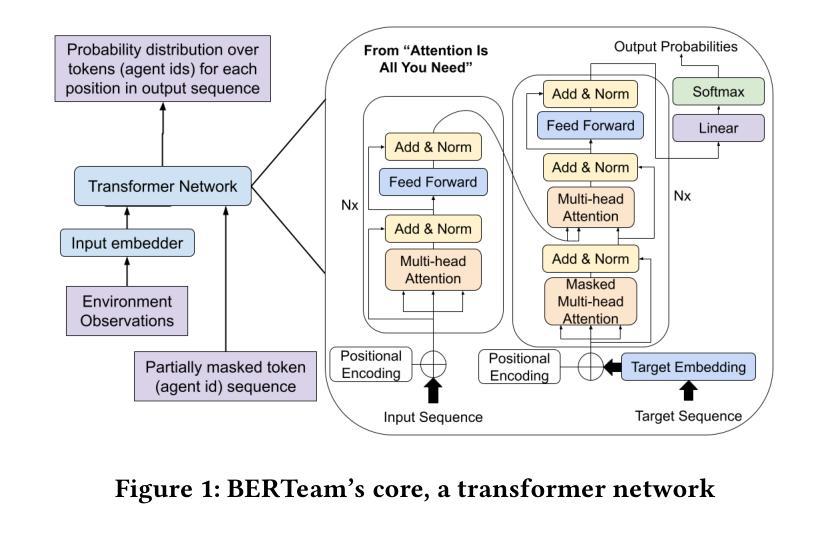
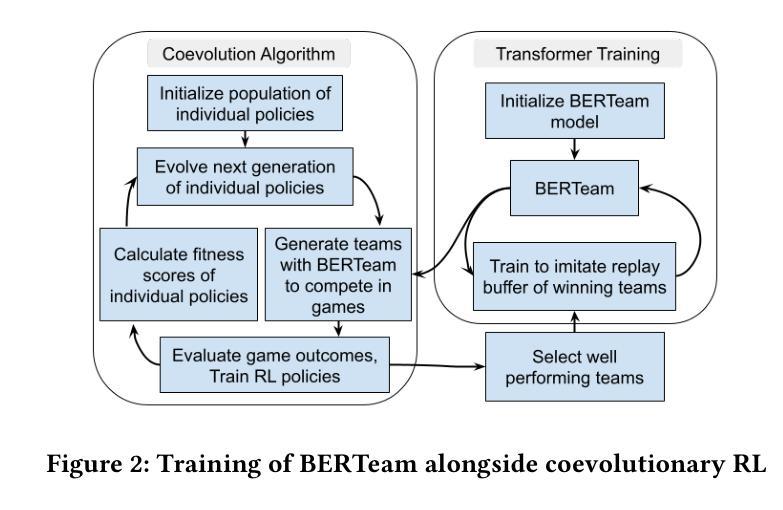
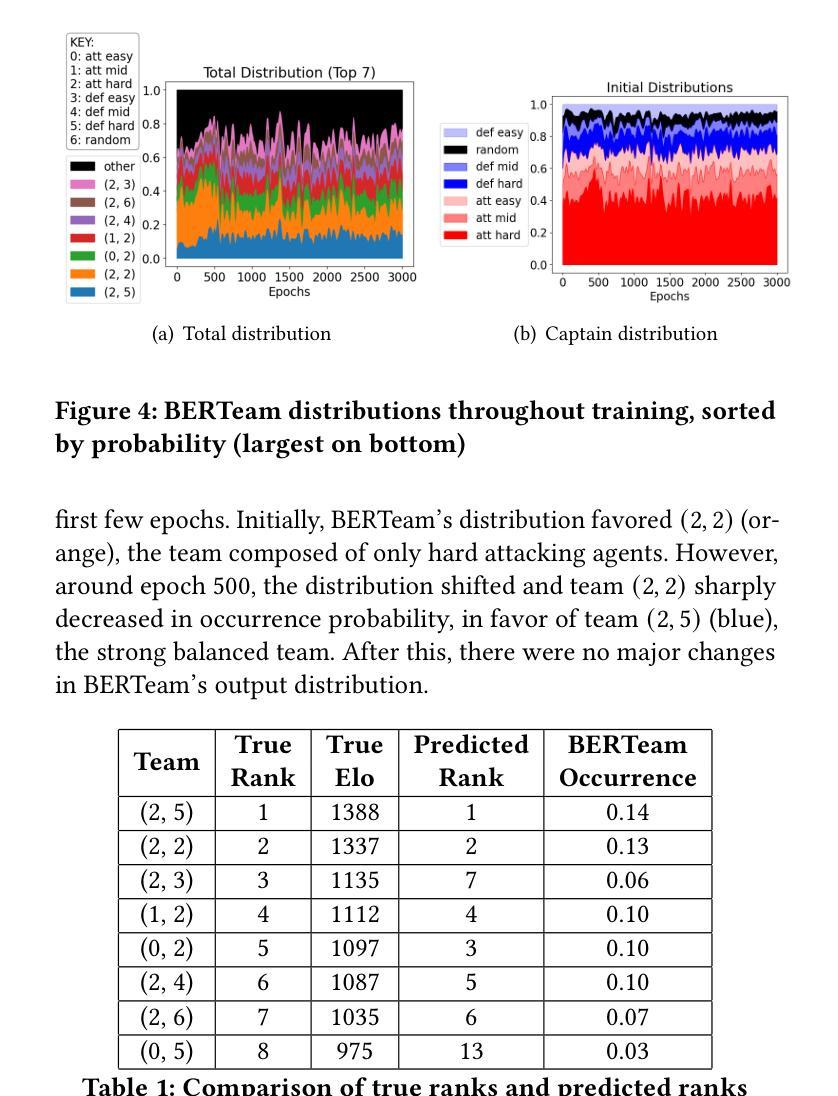
We consider the problem of team selection within multiagent adversarial team games. We propose BERTeam, a novel algorithm that uses a transformer-based deep neural network with Masked Language Model training to select the best team of players from a trained population. We integrate this with coevolutionary deep reinforcement learning, which trains a diverse set of individual players to choose from. We test our algorithm in the multiagent adversarial game Marine Capture-The-Flag, and find that BERTeam learns non-trivial team compositions that perform well against unseen opponents. For this game, we find that BERTeam outperforms MCAA, an algorithm that similarly optimizes team selection.
我们考虑多智能体对抗团队游戏中的团队选择问题。我们提出了一种新型算法BERTeam,该算法使用基于转换器的深度神经网络,并结合掩码语言模型训练,从已训练的人群中选择最佳团队。我们将该算法与协同深度强化学习相结合,训练各种个体玩家以供选择。我们在多智能体对抗游戏“海洋夺旗”中测试了我们的算法,发现BERTeam能够学习非平凡团队组合,能够在未见过的对手面前表现良好。对于这款游戏,我们发现BERTeam的表现优于MCAA(一种同样优化团队选择的算法)。
论文及项目相关链接
Summary
针对多智能体对抗团队游戏内的团队选择问题,提出BERTeam算法。该算法采用基于变压器的深度神经网络,结合掩码语言模型训练,从已训练的人群中选择最佳团队。该算法与协同进化的深度强化学习相结合,训练一系列个体玩家进行选择。在海洋捕获旗帜的多智能体对抗游戏中测试表明,BERTeam能学习非平凡团队组合,对未见过的对手表现良好,且优于MCAA算法。
Key Takeaways
- BERTeam算法解决了多智能体对抗团队游戏中的团队选择问题。
- BERTeam采用基于变压器的深度神经网络和掩码语言模型训练来选择最佳团队。
- BERTeam与协同进化的深度强化学习结合,能够训练多个个体玩家。
- 在海洋捕获旗帜游戏中测试表明,BERTeam能学习有效团队组合。
- BERTeam算法性能优于MCAA算法。
- BERTeam对未见过的对手也能表现出良好性能。
点此查看论文截图



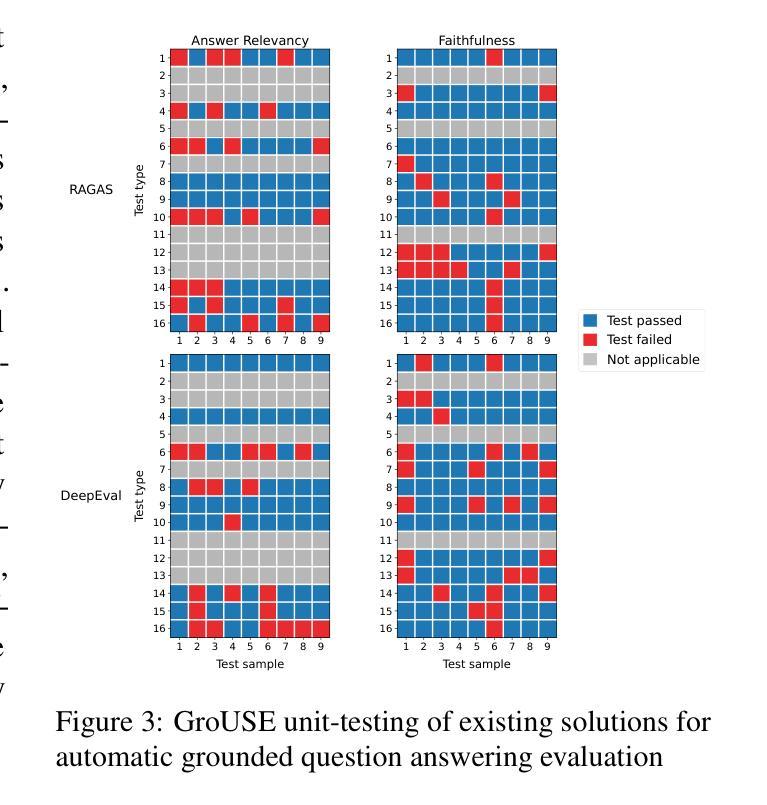
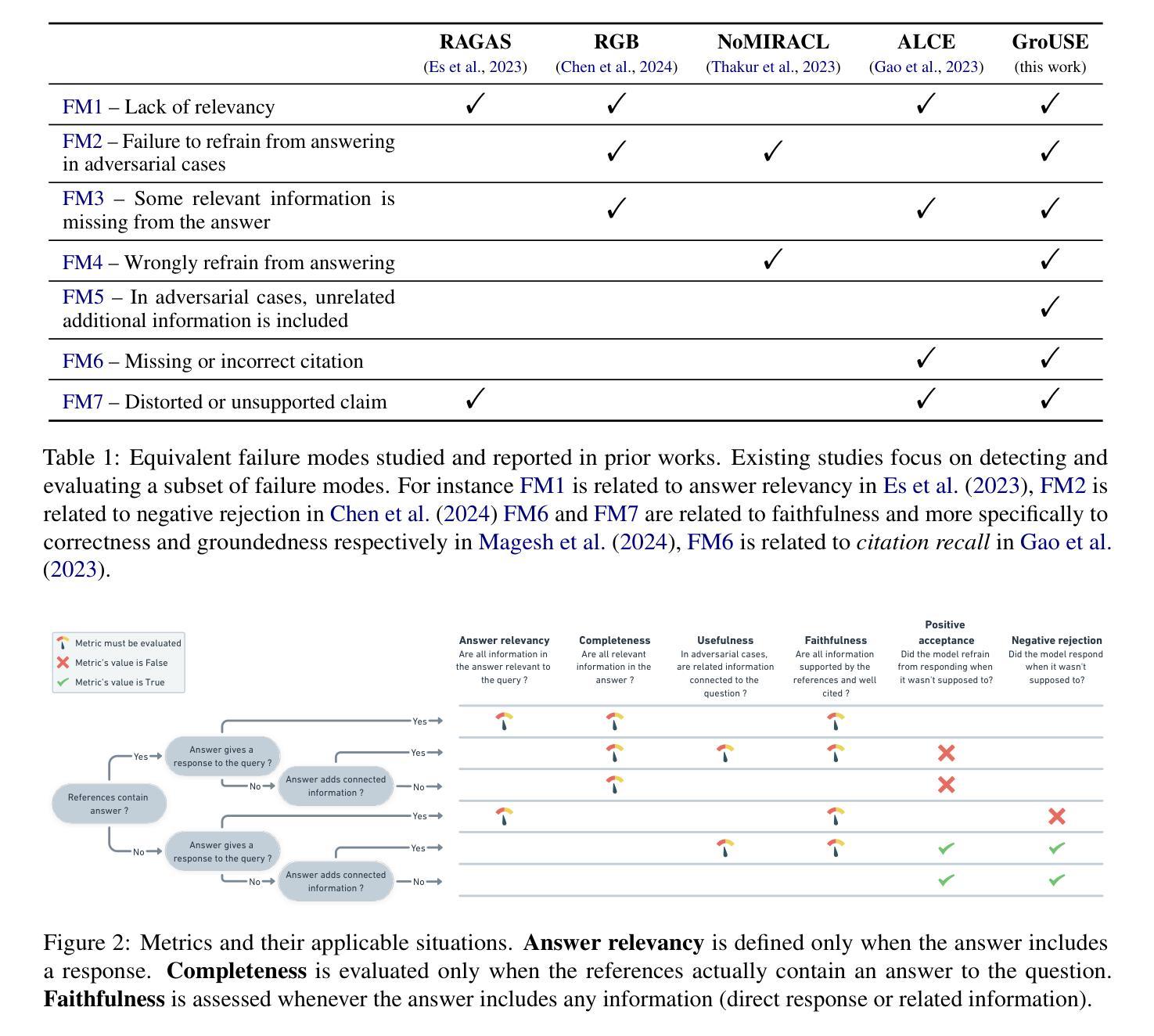
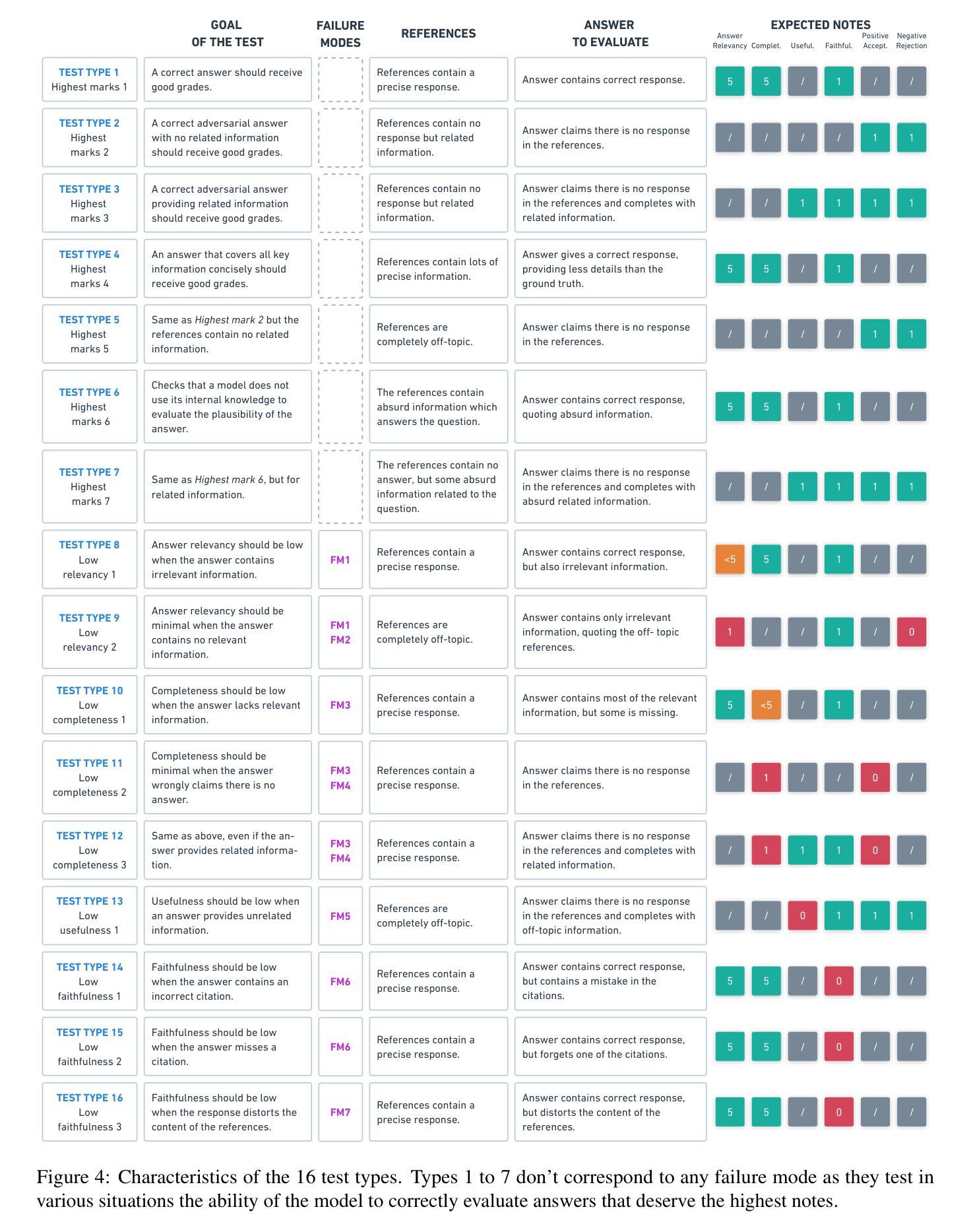
GroUSE: A Benchmark to Evaluate Evaluators in Grounded Question Answering
Authors:Sacha Muller, António Loison, Bilel Omrani, Gautier Viaud
Retrieval-Augmented Generation (RAG) has emerged as a common paradigm to use Large Language Models (LLMs) alongside private and up-to-date knowledge bases. In this work, we address the challenges of using LLM-as-a-Judge when evaluating grounded answers generated by RAG systems. To assess the calibration and discrimination capabilities of judge models, we identify 7 generator failure modes and introduce GroUSE (Grounded QA Unitary Scoring of Evaluators), a meta-evaluation benchmark of 144 unit tests. This benchmark reveals that existing automated RAG evaluation frameworks often overlook important failure modes, even when using GPT-4 as a judge. To improve on the current design of automated RAG evaluation frameworks, we propose a novel pipeline and find that while closed models perform well on GroUSE, state-of-the-art open-source judges do not generalize to our proposed criteria, despite strong correlation with GPT-4’s judgement. Our findings suggest that correlation with GPT-4 is an incomplete proxy for the practical performance of judge models and should be supplemented with evaluations on unit tests for precise failure mode detection. We further show that finetuning Llama-3 on GPT-4’s reasoning traces significantly boosts its evaluation capabilities, improving upon both correlation with GPT-4’s evaluations and calibration on reference situations.
检索增强生成(RAG)已经成为一种常见的范式,将大型语言模型(LLM)与私有和最新的知识库一起使用。在这项工作中,我们解决了在使用RAG系统生成的基于事实的答案时评估大型语言模型作为法官的挑战。为了评估法官模型的校准和鉴别能力,我们确定了7种生成器失效模式,并引入了GroUSE(基于事实的问答单元评分评估员),这是一个包含144个单元测试的元评估基准。这个基准测试发现,现有的自动化RAG评估框架往往会忽略重要的失效模式,即使使用GPT-4作为法官也是如此。
为了改进当前的自动化RAG评估框架设计,我们提出了一个新的流程,并发现虽然封闭模型在GroUSE上表现良好,但最先进的开源法官并不符合我们提出的标准,尽管他们与GPT-4的判断有很强的相关性。我们的研究结果表明,与GPT-4的相关性并不能完全代表法官模型的实际性能,应在单元测试评估中补充精确失效模式检测。
论文及项目相关链接
PDF Proceedings of the 31st International Conference on Computational Linguistics
Summary
本文介绍了使用大型语言模型(LLM)作为评估器评估基于检索的生成(RAG)系统生成的答案的挑战。为了评估评估器的校准和鉴别能力,作者确定了7种生成器失败模式,并引入了GroUSE(基于问题的单位评分评估器)作为包含144个单元测试的元评估基准。研究表明,现有的自动化RAG评估框架往往忽略了重要的失败模式,即使使用GPT-4作为评估器也是如此。为了提高当前的自动化RAG评估框架的设计,作者提出了一种新的管道,并发现虽然封闭式模型在GroUSE上表现良好,但现有的开源评估器并不适用于作者提出的标准。研究还表明,通过利用GPT-4的推理轨迹对Llama-3进行微调可以显著提高其评估能力。
Key Takeaways
- 大型语言模型(LLM)被用于评估基于检索的生成(RAG)系统的答案质量。
- 确定了七种生成器失败模式,提出了GroUSE元评估基准以更全面地进行评估。
- 现有自动化RAG评估框架易忽略重要失败模式,即使使用GPT-4也存在此问题。
- 封闭式模型在GroUSE基准上表现良好,而现有开源评估器不完全符合新提出的标准。
- 与GPT-4的关联是不完整的代理指标,需要更精确的失败模式检测。
- 利用GPT-4的推理轨迹对Llama-3进行微调可以提高其评估能力。
点此查看论文截图


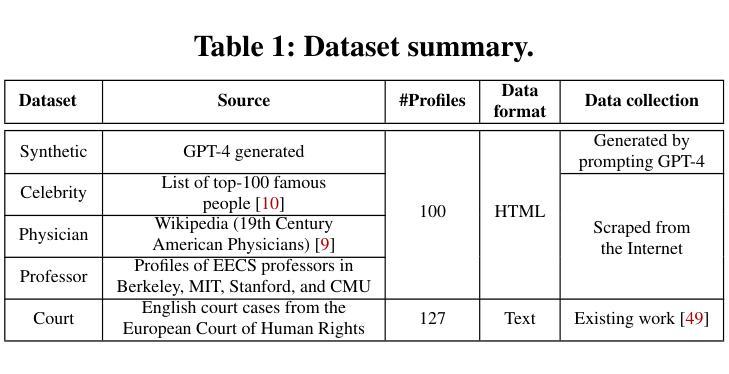
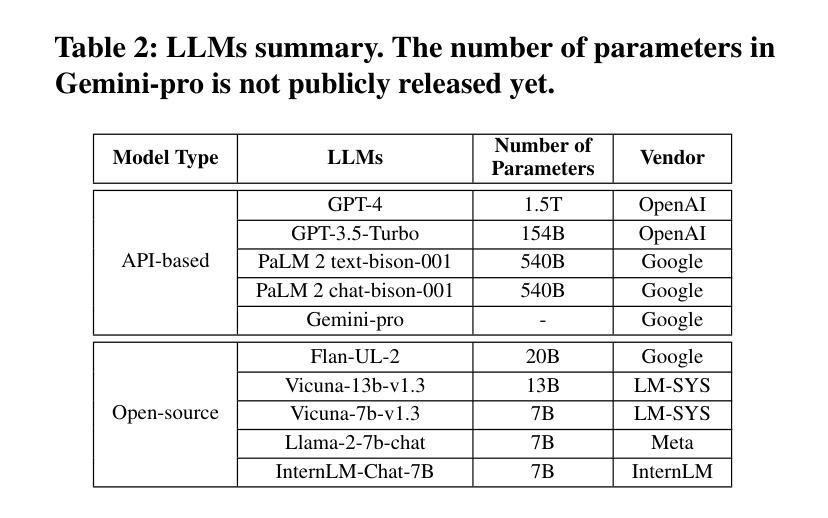
Evaluating LLM-based Personal Information Extraction and Countermeasures
Authors:Yupei Liu, Yuqi Jia, Jinyuan Jia, Neil Zhenqiang Gong
Automatically extracting personal information–such as name, phone number, and email address–from publicly available profiles at a large scale is a stepstone to many other security attacks including spear phishing. Traditional methods–such as regular expression, keyword search, and entity detection–achieve limited success at such personal information extraction. In this work, we perform a systematic measurement study to benchmark large language model (LLM) based personal information extraction and countermeasures. Towards this goal, we present a framework for LLM-based extraction attacks; collect four datasets including a synthetic dataset generated by GPT-4 and three real-world datasets with manually labeled eight categories of personal information; introduce a novel mitigation strategy based on prompt injection; and systematically benchmark LLM-based attacks and countermeasures using ten LLMs and five datasets. Our key findings include: LLM can be misused by attackers to accurately extract various personal information from personal profiles; LLM outperforms traditional methods; and prompt injection can defend against strong LLM-based attacks, reducing the attack to less effective traditional ones.
自动从大规模公开个人资料中提取个人信息(如姓名、电话号码和电子邮件地址)是许多其他安全攻击(包括钓鱼邮件攻击)的基石。传统的方法(如正则表达式、关键词搜索和实体检测)在个人信息提取方面的成功有限。在这项工作中,我们对基于大型语言模型(LLM)的个人信息提取和反制措施进行了系统的测量研究。为此目标,我们提出了一个基于LLM的提取攻击框架;收集了四个数据集,包括由GPT-4生成的一个合成数据集和三个包含手动标记的八类个人信息现实世界数据集;介绍了一种基于提示注入的新型缓解策略;并使用十个LLM和五个数据集系统地评估了基于LLM的攻击和反制措施。我们的关键发现包括:攻击者可滥用LLM准确提取个人资料的各类信息;LLM的表现优于传统方法;提示注入可以有效防御强大的基于LLM的攻击,将其降低为效果较弱的传统攻击。
论文及项目相关链接
PDF To appear in USENIX Security Symposium 2025
Summary
该研究对基于大型语言模型(LLM)的个人信息提取进行了系统评估,并提出了一种基于提示注入的缓解策略。研究发现,LLM可被攻击者用于从个人资料中准确提取各类个人信息,且表现优于传统方法。而提示注入策略能有效缓解LLM攻击,降低其效果至与传统方法相当。
Key Takeaways
- LLM可被用于大规模地从公开个人资料中提取个人信息,如姓名、电话号码和电子邮件地址。
- LLM在这种信息提取任务上的表现优于传统方法,如正则表达式、关键词搜索和实体识别。
- 基于LLM的信息提取攻击可成为许多其他安全攻击的跳板,如钓鱼邮件攻击。
- 一种新的基于提示注入的缓解策略被提出,以对抗基于LLM的攻击。
- 提示注入策略能有效降低LLM攻击的效果,使其更接近传统方法的表现。
- 研究者创建了一个用于LLM提取攻击的框架和四个数据集,包括由GPT-4生成的一个合成数据集和三个真实世界的数据集。
点此查看论文截图

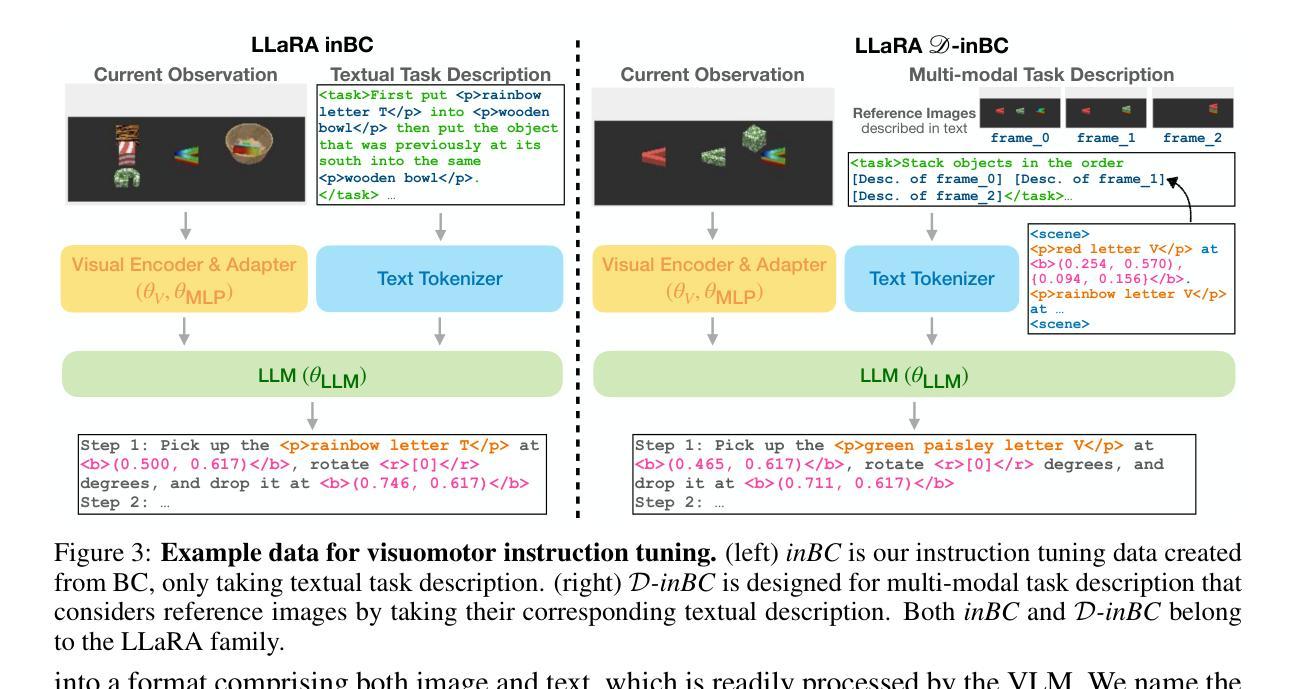
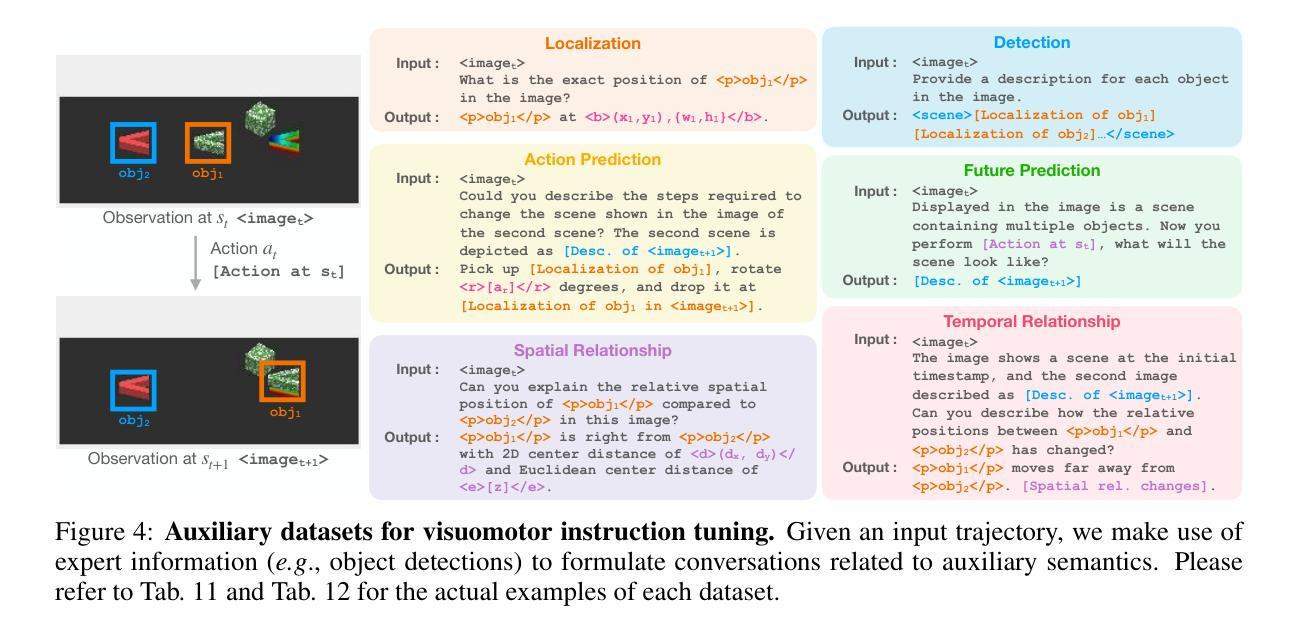
LLaRA: Supercharging Robot Learning Data for Vision-Language Policy
Authors:Xiang Li, Cristina Mata, Jongwoo Park, Kumara Kahatapitiya, Yoo Sung Jang, Jinghuan Shang, Kanchana Ranasinghe, Ryan Burgert, Mu Cai, Yong Jae Lee, Michael S. Ryoo
Vision Language Models (VLMs) have recently been leveraged to generate robotic actions, forming Vision-Language-Action (VLA) models. However, directly adapting a pretrained VLM for robotic control remains challenging, particularly when constrained by a limited number of robot demonstrations. In this work, we introduce LLaRA: Large Language and Robotics Assistant, a framework that formulates robot action policy as visuo-textual conversations and enables an efficient transfer of a pretrained VLM into a powerful VLA, motivated by the success of visual instruction tuning in Computer Vision. First, we present an automated pipeline to generate conversation-style instruction tuning data for robots from existing behavior cloning datasets, aligning robotic actions with image pixel coordinates. Further, we enhance this dataset in a self-supervised manner by defining six auxiliary tasks, without requiring any additional action annotations. We show that a VLM finetuned with a limited amount of such datasets can produce meaningful action decisions for robotic control. Through experiments across multiple simulated and real-world tasks, we demonstrate that LLaRA achieves state-of-the-art performance while preserving the generalization capabilities of large language models. The code, datasets, and pretrained models are available at https://github.com/LostXine/LLaRA.
视觉语言模型(VLMs)最近被用来生成机器人动作,形成视觉-语言-动作(VLA)模型。然而,直接将预训练的VLM用于机器人控制仍然具有挑战性,尤其是在受到有限机器人演示数量的限制时。在这项工作中,我们介绍了LLaRA:大型语言和机器人助理,一个将机器人动作策略制定为视觉文本对话的框架,并能有效地将预训练的VLM转化为强大的VLA,这得益于计算机视觉中视觉指令调整的成功的启示。首先,我们提出了一种自动化管道,用于从现有的行为克隆数据集中生成面向对话式的指令调整数据,使机器人动作与图像像素坐标对齐。此外,我们通过定义六个辅助任务来以自我监督的方式增强此数据集,无需任何额外的动作注释。我们表明,使用有限数量的此类数据集进行微调的VLM可以为机器人控制产生有意义的动作决策。通过多项模拟和真实任务的实验,我们证明了LLaRA在保持大型语言模型的泛化能力的同时,实现了最先进的性能。代码、数据集和预训练模型可在https://github.com/LostXine/LLaRA找到。
论文及项目相关链接
PDF ICLR 2025
Summary
本摘要以中文简要概括了文本内容:在机器人控制领域,利用预训练的视觉语言模型(VLM)生成机器人动作形成视语言动作(VLA)模型存在挑战。本文介绍了一种名为LLaRA的框架,通过制定机器人动作策略为视觉文本对话,实现了预训练的VLM到强大的VLA的有效迁移。提出自动化管道为机器人生成对话风格的指令调优数据,通过自我监督的方式增强数据集,并展示了其在实际和模拟任务中的卓越性能。
Key Takeaways
以下是七个关键见解:
- VLMs已被用于生成机器人动作,形成VLA模型。
- 直接适应预训练的VLM到机器人控制具有挑战性,特别是在有限机器人演示的情况下。
- LLaRA框架通过制定机器人动作策略为视觉文本对话,实现了预训练的VLM到VLA的迁移。
- 自动化管道用于从现有行为克隆数据集中生成对话式指令调整数据,与图像像素坐标对齐。
- 通过定义六个辅助任务以自我监督的方式增强数据集,无需额外的动作注释。
- 通过有限的数据集对VLM进行微调,可以产生有意义的机器人控制动作决策。
点此查看论文截图