⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-01 更新
Free-T2M: Frequency Enhanced Text-to-Motion Diffusion Model With Consistency Loss
Authors:Wenshuo Chen, Haozhe Jia, Songning Lai, Keming Wu, Hongru Xiao, Lijie Hu, Yutao Yue
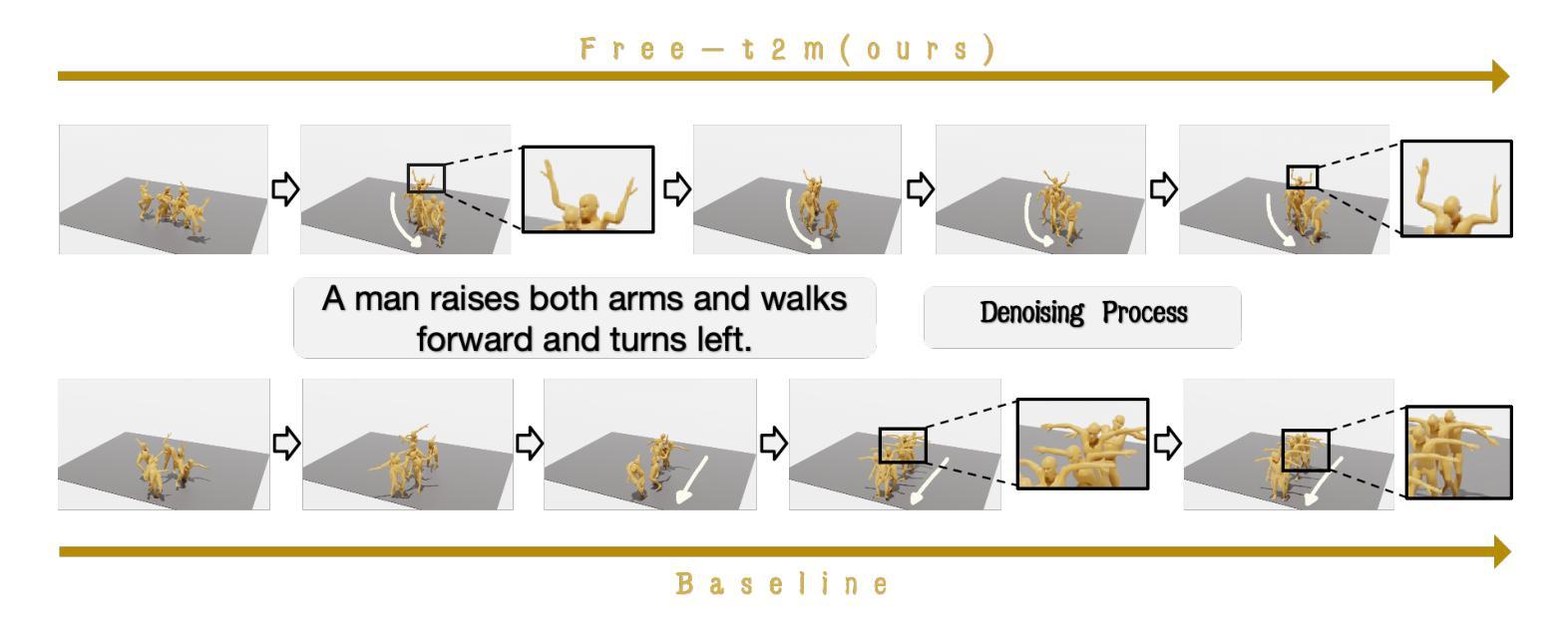
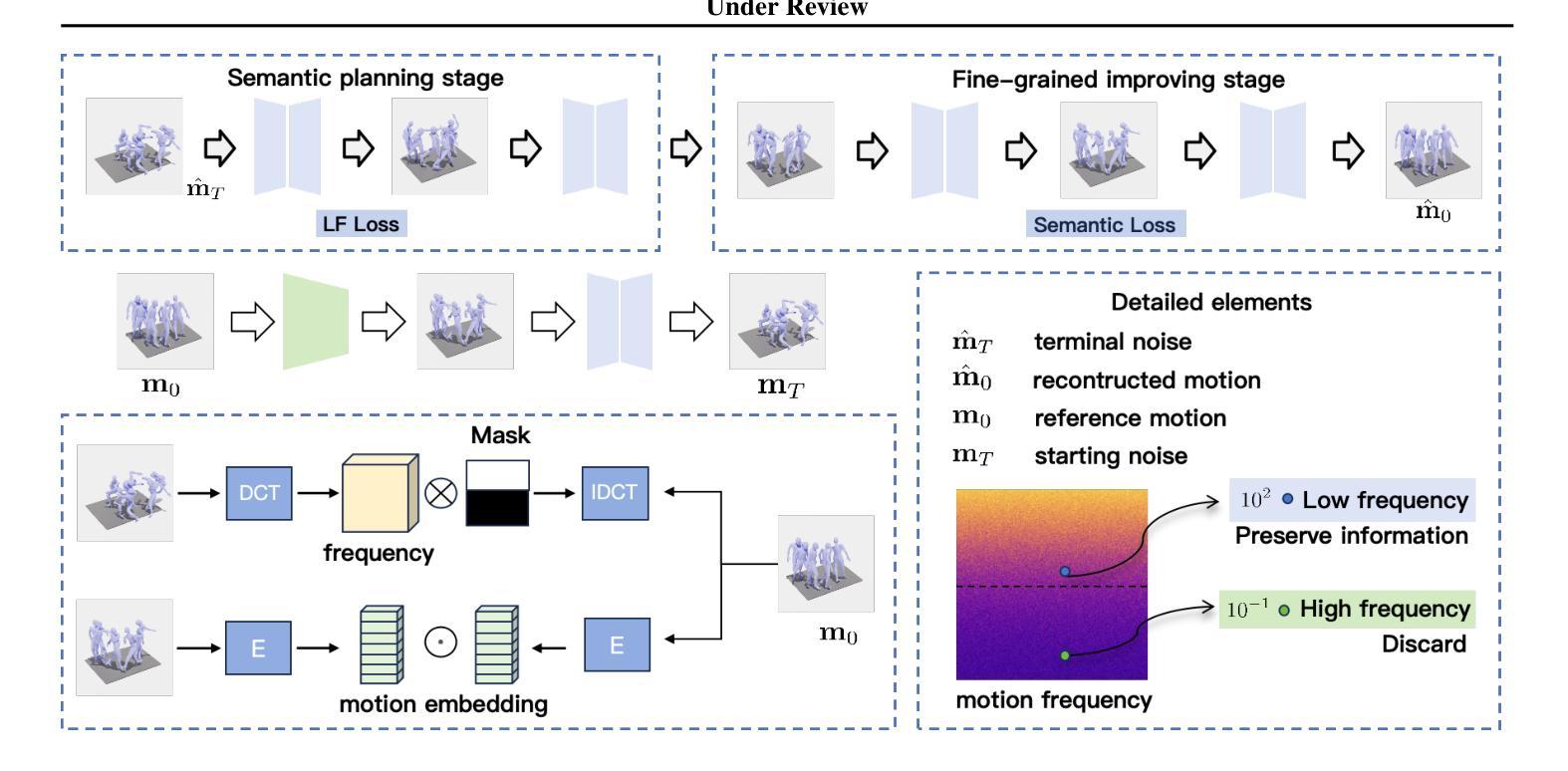
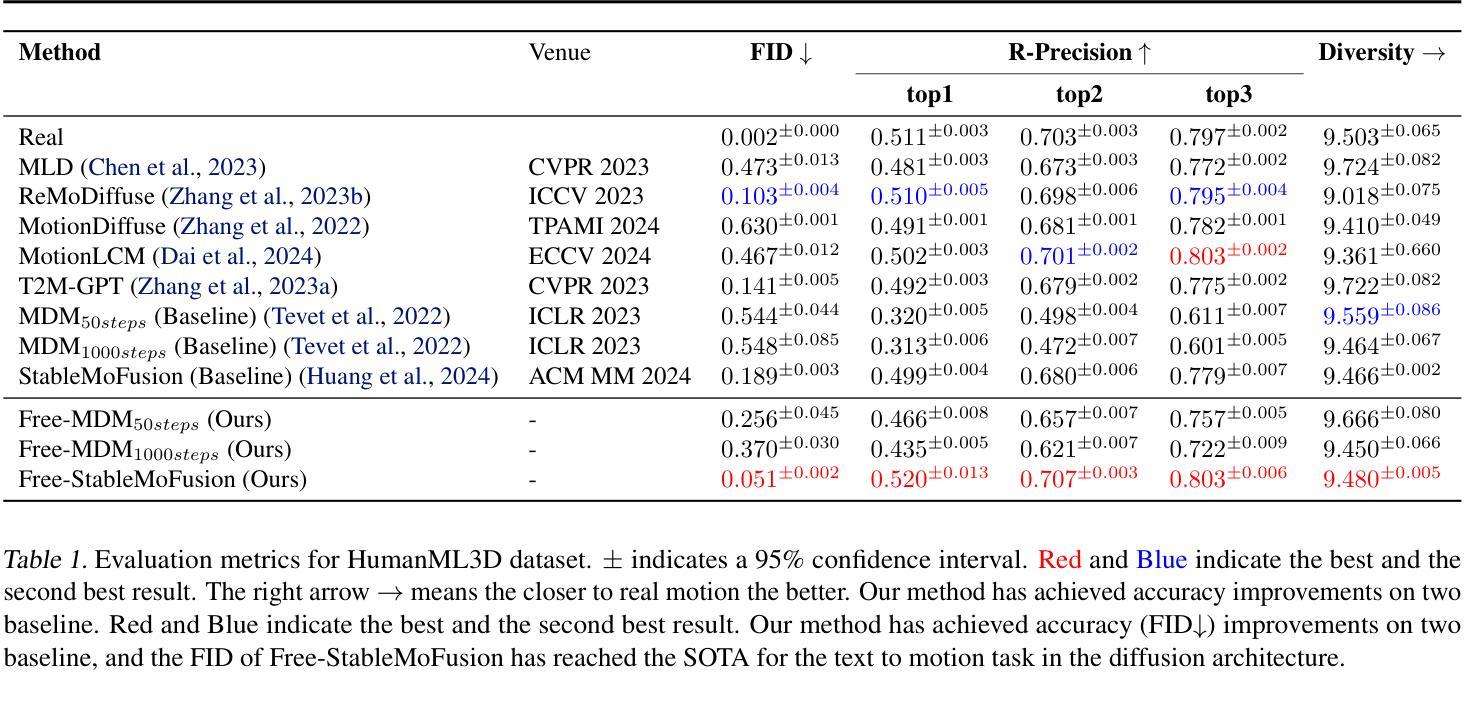
Rapid progress in text-to-motion generation has been largely driven by diffusion models. However, existing methods focus solely on temporal modeling, thereby overlooking frequency-domain analysis. We identify two key phases in motion denoising: the semantic planning stage and the fine-grained improving stage. To address these phases effectively, we propose Frequency enhanced text-to-motion diffusion model (Free-T2M), incorporating stage-specific consistency losses that enhance the robustness of static features and improve fine-grained accuracy. Extensive experiments demonstrate the effectiveness of our method. Specifically, on StableMoFusion, our method reduces the FID from 0.189 to 0.051, establishing a new SOTA performance within the diffusion architecture. These findings highlight the importance of incorporating frequency-domain insights into text-to-motion generation for more precise and robust results.
文本到动作生成的快速发展在很大程度上得益于扩散模型。然而,现有方法只专注于时间建模,从而忽略了频域分析。我们确定了动作去噪中的两个关键阶段:语义规划阶段和精细改进阶段。为了有效解决这两个阶段,我们提出了Frequency enhanced text-to-motion diffusion model(Free-T2M),它结合了针对特定阶段的一致性损失,增强了静态特征的稳健性,提高了精细粒度的准确性。大量实验证明了我们的方法的有效性。具体来说,在StableMoFusion上,我们的方法将FID从0.189降低到0.051,在扩散架构中建立了新的最佳性能。这些发现强调了将频域见解融入文本到动作生成中的重要性,以获得更精确和更稳健的结果。
论文及项目相关链接
Summary
文本对文本到动作生成的研究进展进行了介绍,指出虽然扩散模型取得了快速进展,但现有方法主要关注时序建模,忽略了频域分析的重要性。针对这一问题,本文提出了结合两个阶段一致性损失的频率增强文本到动作扩散模型(Free-T2M),该模型在语义规划阶段和精细改善阶段进行了针对性的改进,并通过广泛的实验证明了方法的有效性。其在StableMoFusion数据集上将FID得分从0.189降低到0.051,实现了扩散架构内的最佳性能。这凸显了将频域分析融入文本到动作生成中的重要性,以实现更准确和稳健的结果。
Key Takeaways
- 文本到动作生成领域存在仅关注时序建模的问题,忽略了频域分析的重要性。
- 提出了一种新的频率增强文本到动作扩散模型(Free-T2M)。
- Free-T2M模型结合两个阶段一致性损失,针对语义规划阶段和精细改善阶段进行改进。
- 该模型在StableMoFusion数据集上实现了显著的性能提升,FID得分从0.189降低到0.051。
- Free-T2M模型展示了结合频域分析在文本到动作生成中的重要性。
- 方法的有效性通过广泛的实验得到了证明。
点此查看论文截图