⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-05 更新
Laser: Efficient Language-Guided Segmentation in Neural Radiance Fields
Authors:Xingyu Miao, Haoran Duan, Yang Bai, Tejal Shah, Jun Song, Yang Long, Rajiv Ranjan, Ling Shao
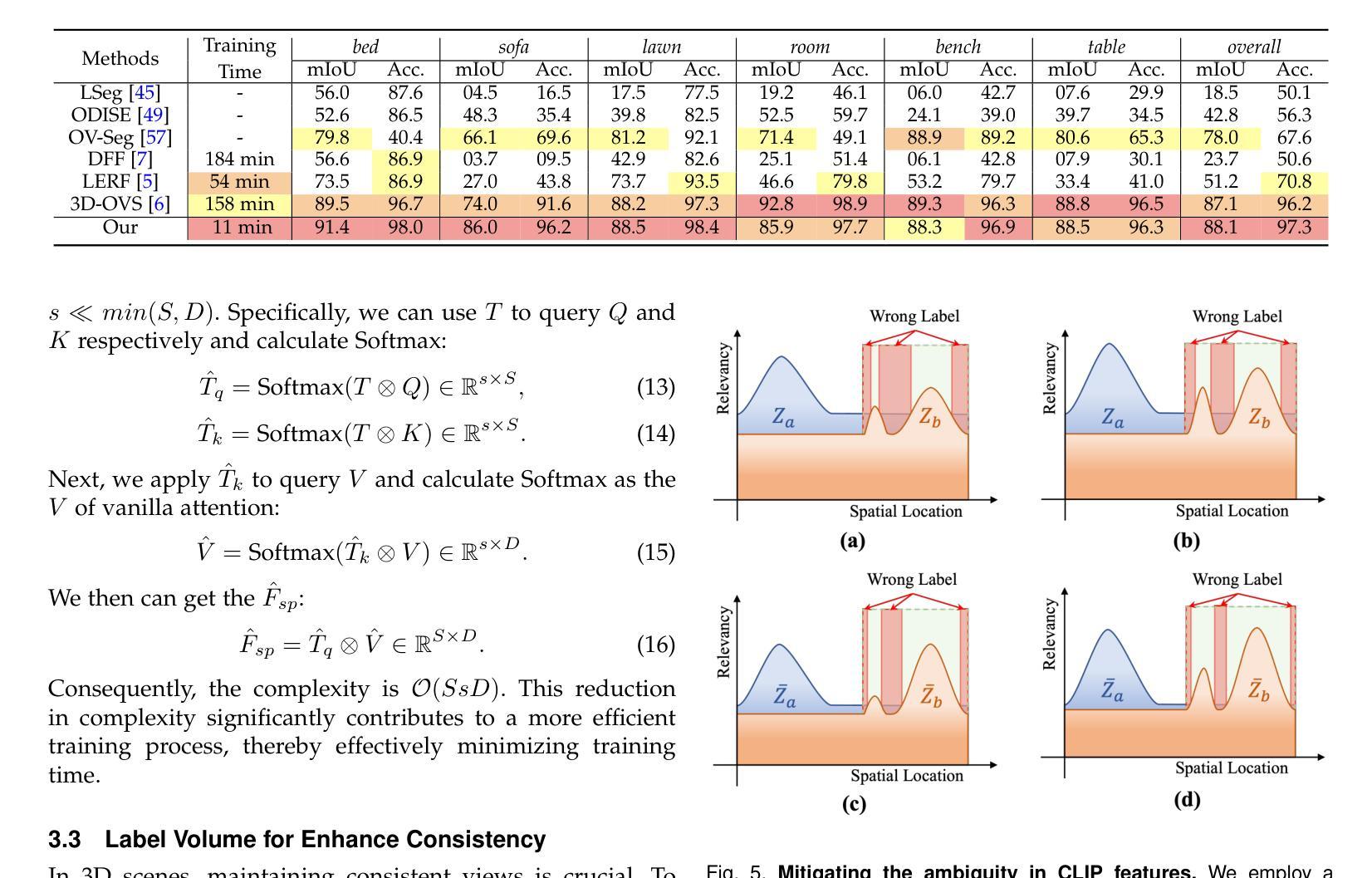
In this work, we propose a method that leverages CLIP feature distillation, achieving efficient 3D segmentation through language guidance. Unlike previous methods that rely on multi-scale CLIP features and are limited by processing speed and storage requirements, our approach aims to streamline the workflow by directly and effectively distilling dense CLIP features, thereby achieving precise segmentation of 3D scenes using text. To achieve this, we introduce an adapter module and mitigate the noise issue in the dense CLIP feature distillation process through a self-cross-training strategy. Moreover, to enhance the accuracy of segmentation edges, this work presents a low-rank transient query attention mechanism. To ensure the consistency of segmentation for similar colors under different viewpoints, we convert the segmentation task into a classification task through label volume, which significantly improves the consistency of segmentation in color-similar areas. We also propose a simplified text augmentation strategy to alleviate the issue of ambiguity in the correspondence between CLIP features and text. Extensive experimental results show that our method surpasses current state-of-the-art technologies in both training speed and performance. Our code is available on: https://github.com/xingy038/Laser.git.
在这项工作中,我们提出了一种利用CLIP特征蒸馏的方法,通过语言指导实现高效的3D分割。不同于以往依赖于多尺度CLIP特征的方法,它们在处理速度和存储需求方面存在限制。我们的方法旨在通过直接有效地蒸馏密集CLIP特征来优化工作流程,从而实现使用文本对3D场景进行精确分割。为此,我们引入了一个适配器模块,并通过自我交叉训练策略缓解密集CLIP特征蒸馏过程中的噪声问题。此外,为了提高分割边缘的准确性,这项工作提出了一种低阶瞬态查询注意力机制。为了确保在不同视角下相似颜色的分割一致性,我们通过标签体积将分割任务转化为分类任务,这显著提高了颜色相似区域的分割一致性。我们还提出了一种简化的文本增强策略,以减轻CLIP特征与文本之间对应模糊性的问题。大量的实验结果表明,我们的方法在训练速度和性能方面都超越了当前的最先进技术。我们的代码可在以下网址找到:https://github.com/xingy038/Laser.git。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence
Summary
本工作提出一种利用CLIP特征蒸馏的方法,通过语言指导实现高效的3D分割。与依赖多尺度CLIP特征的前人方法不同,我们的方法旨在通过直接有效地蒸馏密集CLIP特征来优化工作流程,从而实现使用文本的3D场景精确分割。我们引入适配器模块,并通过自我交叉训练策略减轻密集CLIP特征蒸馏过程中的噪声问题。为提高分割边缘的准确性,本工作提出了一种低阶瞬时查询注意力机制。为确保在不同视角下相似颜色的分割一致性,我们将分割任务通过标签体积转化为分类任务,这显著提高了在颜色相似区域的分割一致性。我们还提出了简化的文本增强策略,以减轻CLIP特征与文本之间对应模糊的问题。实验结果证明,我们的方法在训练速度和性能上均超越了当前先进技术。
Key Takeaways
- 引入CLIP特征蒸馏方法,实现高效3D分割。
- 提出直接蒸馏密集CLIP特征以优化工作流程。
- 引入适配器模块和自交叉训练策略以减轻特征蒸馏中的噪声问题。
- 采用低阶瞬时查询注意力机制提高分割边缘准确性。
- 通过标签体积将分割任务转化为分类任务,提高颜色相似区域的分割一致性。
- 提出简化的文本增强策略,解决CLIP特征与文本对应模糊的问题。
点此查看论文截图

Deformable Beta Splatting
Authors:Rong Liu, Dylan Sun, Meida Chen, Yue Wang, Andrew Feng
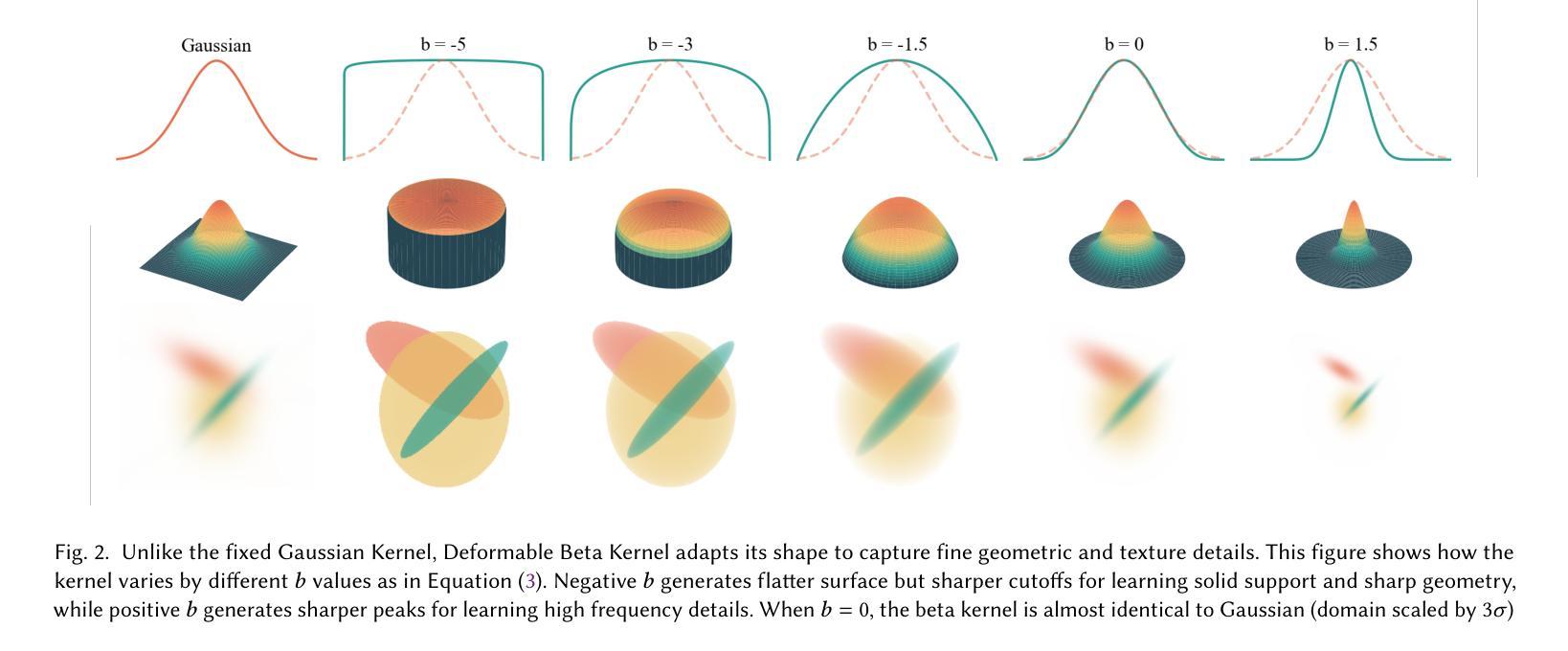
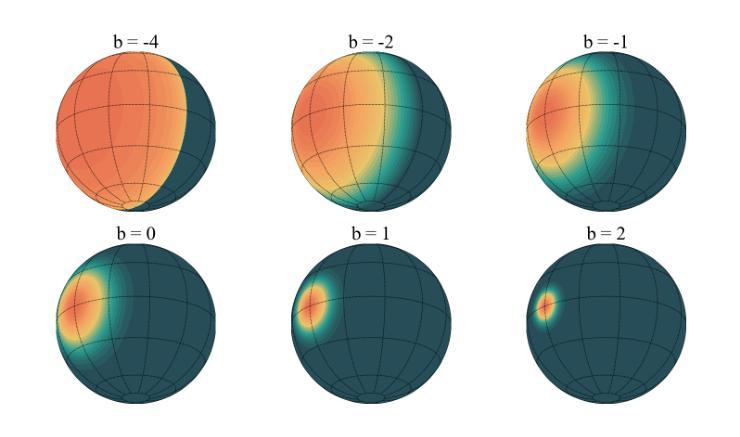
3D Gaussian Splatting (3DGS) has advanced radiance field reconstruction by enabling real-time rendering. However, its reliance on Gaussian kernels for geometry and low-order Spherical Harmonics (SH) for color encoding limits its ability to capture complex geometries and diverse colors. We introduce Deformable Beta Splatting (DBS), a deformable and compact approach that enhances both geometry and color representation. DBS replaces Gaussian kernels with deformable Beta Kernels, which offer bounded support and adaptive frequency control to capture fine geometric details with higher fidelity while achieving better memory efficiency. In addition, we extended the Beta Kernel to color encoding, which facilitates improved representation of diffuse and specular components, yielding superior results compared to SH-based methods. Furthermore, Unlike prior densification techniques that depend on Gaussian properties, we mathematically prove that adjusting regularized opacity alone ensures distribution-preserved Markov chain Monte Carlo (MCMC), independent of the splatting kernel type. Experimental results demonstrate that DBS achieves state-of-the-art visual quality while utilizing only 45% of the parameters and rendering 1.5x faster than 3DGS-based methods. Notably, for the first time, splatting-based methods outperform state-of-the-art Neural Radiance Fields, highlighting the superior performance and efficiency of DBS for real-time radiance field rendering.
3D高斯采样(3DGS)已经通过实现实时渲染技术推动了辐射场重建的发展。然而,它对高斯核处理几何的依赖以及使用低阶球面谐波(SH)进行颜色编码,限制了其捕捉复杂几何和多样色彩的能力。我们引入了可变形Beta采样(DBS),这是一种可变形且紧凑的方法,增强了几何和颜色的表示。DBS用可变形的Beta核替换了高斯核,提供了有界支持和自适应频率控制,以更高的保真度捕捉精细的几何细节,同时实现更好的内存效率。此外,我们将Beta核扩展到颜色编码,这有助于改进漫反射和镜面成分的表示,与基于SH的方法相比,产生了更优越的结果。而且,不同于依赖高斯属性的先前稠密化技术,我们从数学上证明,仅调整正则化不透明度就能确保分布保留的马尔可夫链蒙特卡洛(MCMC)独立于采样核类型。实验结果表明,DBS达到了最先进的视觉质量,同时仅使用3DGS方法的45%参数,并且渲染速度提高了1.5倍。值得注意的是,基于采样的方法首次超越了最先进的神经辐射场,突显了DBS在实时辐射场渲染中的卓越性能和效率。
论文及项目相关链接
Summary:可变形Beta斑块(DBS)技术的引入,改进了三维高斯斑块(3DGS)在几何和颜色编码上的限制,提升了实时渲染质量。通过用可变形Beta核替换高斯核,实现了更精确的几何细节捕捉和更好的内存效率。同时,将Beta核扩展到颜色编码,改进了漫反射和镜面成分的表达效果。调整正则化不透明度确保了分布保留的马尔可夫链蒙特卡洛(MCMC),无需依赖斑块核类型。实验结果表明,DBS方法在保证参数和渲染速度优势的同时实现了最佳视觉效果。这一技术的运用将斑块法提升到了前所未有的高度,超越了现有的神经辐射场渲染技术。
Key Takeaways:
- 可变形Beta斑块(DBS)技术改进了三维高斯斑块在几何和颜色编码上的限制。
- 使用可变形Beta核实现更精确的几何细节捕捉和更好的内存效率。
- Beta核的扩展优化了颜色编码,改进了漫反射和镜面成分的表达效果。
- 调整正则化不透明度可确保分布保留的马尔可夫链蒙特卡洛(MCMC),实现更高效渲染。
- 实验结果显示,DBS在参数使用上仅占用45%,渲染速度提升1.5倍,同时实现最佳视觉效果。
点此查看论文截图


VoD-3DGS: View-opacity-Dependent 3D Gaussian Splatting
Authors:Mateusz Nowak, Wojciech Jarosz, Peter Chin
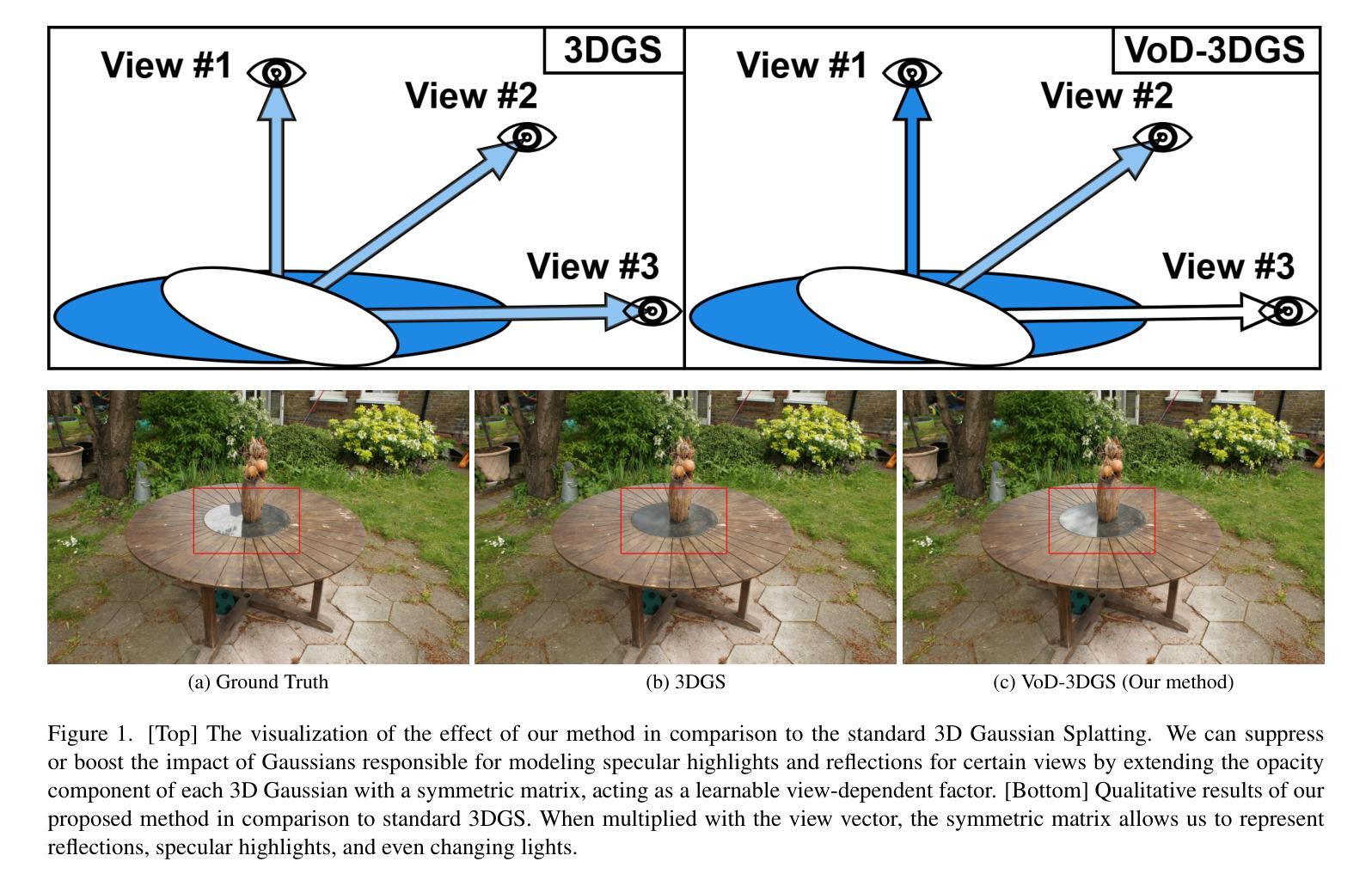
Reconstructing a 3D scene from images is challenging due to the different ways light interacts with surfaces depending on the viewer’s position and the surface’s material. In classical computer graphics, materials can be classified as diffuse or specular, interacting with light differently. The standard 3D Gaussian Splatting model struggles to represent view-dependent content, since it cannot differentiate an object within the scene from the light interacting with its specular surfaces, which produce highlights or reflections. In this paper, we propose to extend the 3D Gaussian Splatting model by introducing an additional symmetric matrix to enhance the opacity representation of each 3D Gaussian. This improvement allows certain Gaussians to be suppressed based on the viewer’s perspective, resulting in a more accurate representation of view-dependent reflections and specular highlights without compromising the scene’s integrity. By allowing the opacity to be view dependent, our enhanced model achieves state-of-the-art performance on Mip-Nerf, Tanks&Temples, Deep Blending, and Nerf-Synthetic datasets without a significant loss in rendering speed, achieving >60FPS, and only incurring a minimal increase in memory used.
从图像重建3D场景是一项具有挑战性的任务,因为光线与表面之间的交互方式取决于观察者的位置和表面材质。在经典计算机图形学中,材质可分为漫反射或镜面反射,与光线的交互方式不同。标准的3D高斯拼贴模型在表示视角相关内容方面存在困难,因为它无法区分场景中的物体与其与镜面表面交互的光线,从而产生高光或反射。在本文中,我们提出通过引入额外的对称矩阵来扩展3D高斯拼贴模型,以增强每个3D高斯的不透明度表示。这一改进允许根据观察者的角度抑制某些高斯值,从而更准确地表示视角相关的反射和高光,同时不损害场景的完整性。通过允许不透明度依赖于视角,我们改进后的模型在Mip-NeRF、Tanks&Temples、深度混合和NeRF合成数据集上实现了最先进的性能,渲染速度没有明显损失,达到>60FPS,并且仅增加了很少的内存使用。
论文及项目相关链接
Summary
本文提出扩展3D高斯拼贴模型,通过引入额外的对称矩阵以增强每个3D高斯的不透明度表示。改进允许根据观察者视角抑制某些高斯,从而更准确地表示视角相关的反射和高光,同时保持场景的完整性。在不显著降低渲染速度的情况下,增强模型在Mip-NeRF、Tanks&Temples、Deep Blending和NeRF合成数据集上实现最先进的性能。
Key Takeaways
- 论文扩展了传统的3D高斯拼贴模型,引入额外的对称矩阵以增强不透明度表示。
- 改进允许根据观察者视角抑制某些高斯,更准确地表示视角相关的反射和高光。
- 增强模型在不损失场景完整性的情况下,实现了对视角相关反射和高光的更精确表示。
- 与现有技术相比,该模型在多个数据集上实现了最先进的性能。
- 增强模型在保持较高渲染速度(>60FPS)的同时,仅增加了少量的内存使用。
- 该模型对于处理不同光照条件下的表面材料具有优势,可以更好地模拟真实世界中的光照交互。
点此查看论文截图

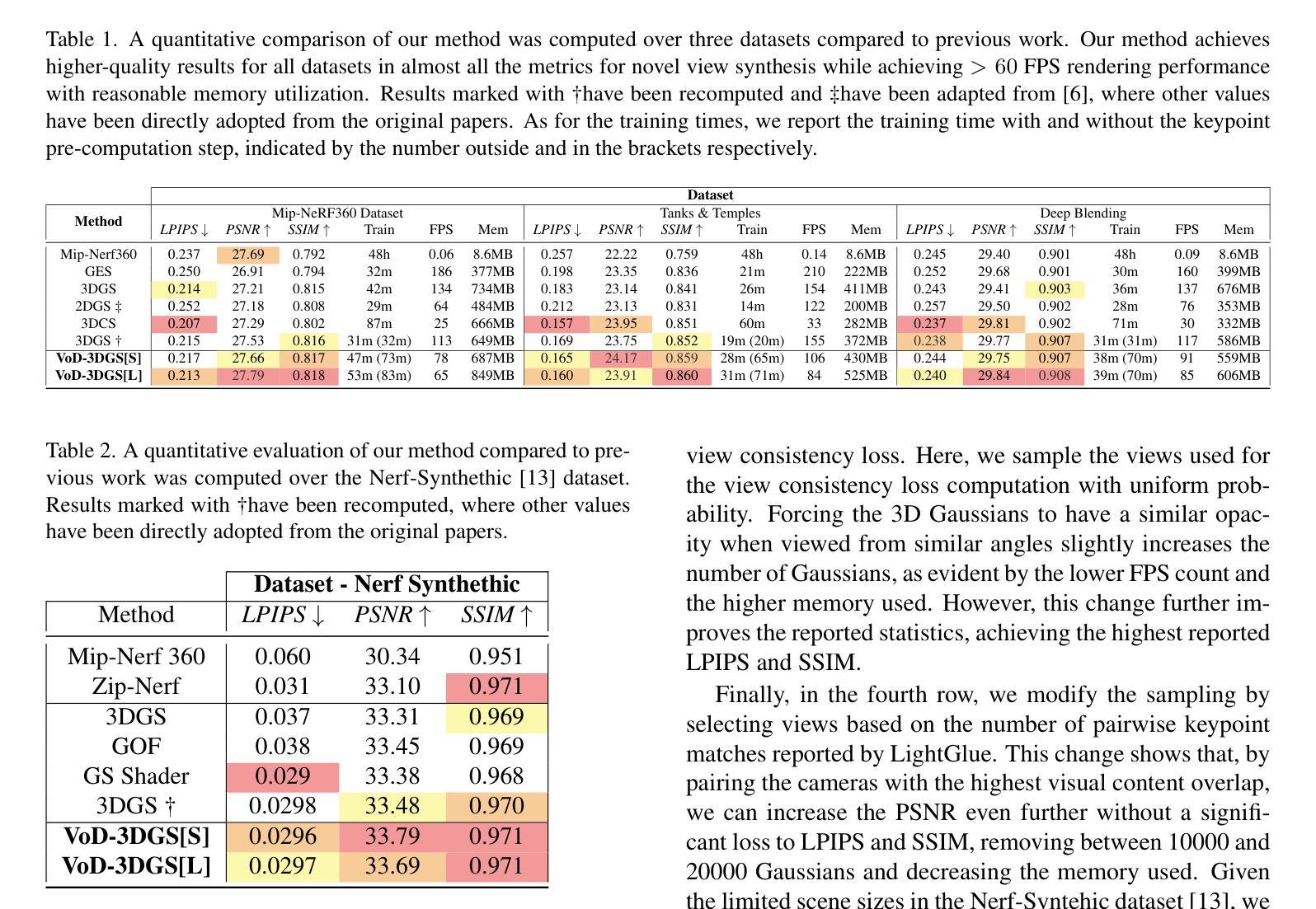
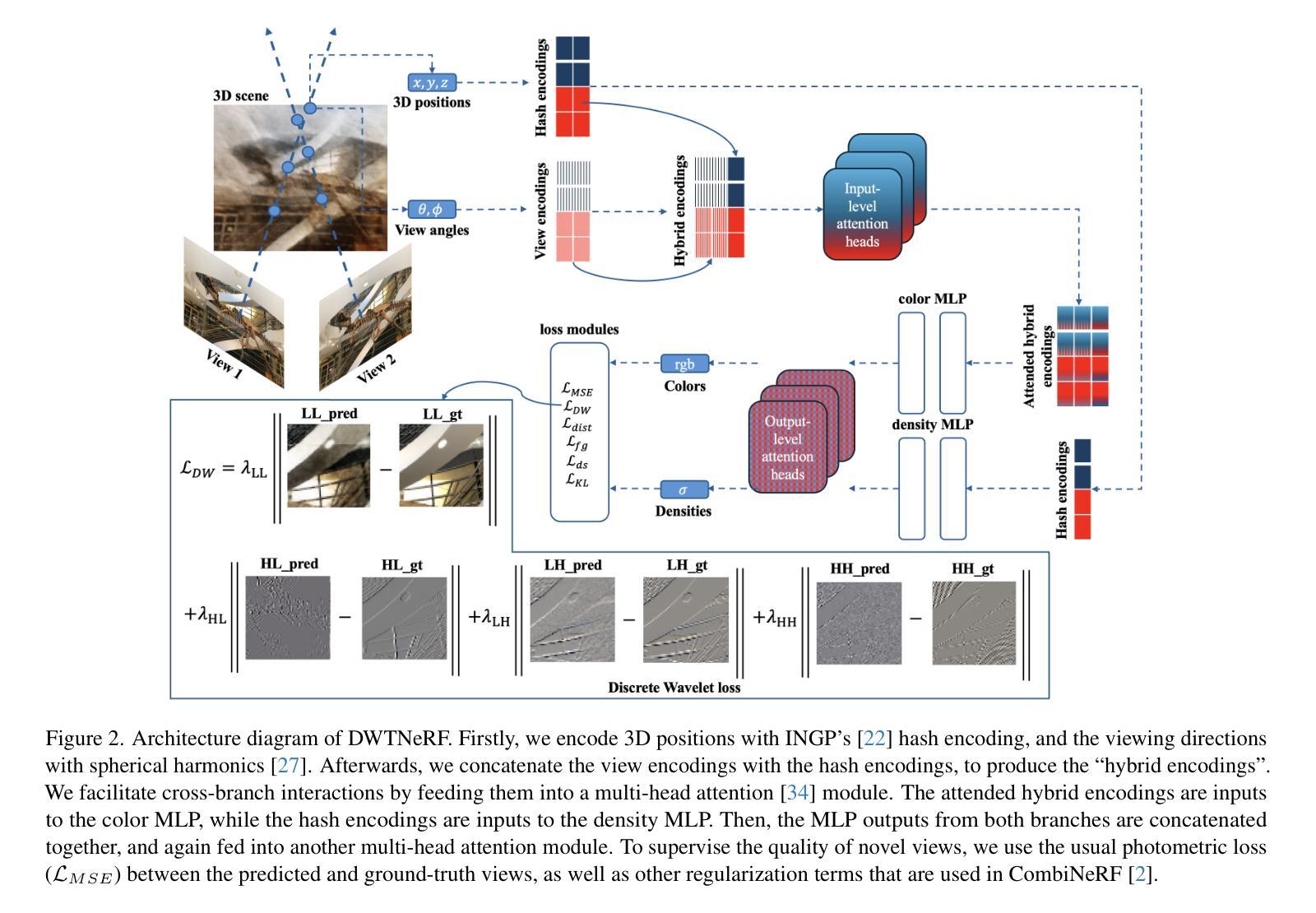
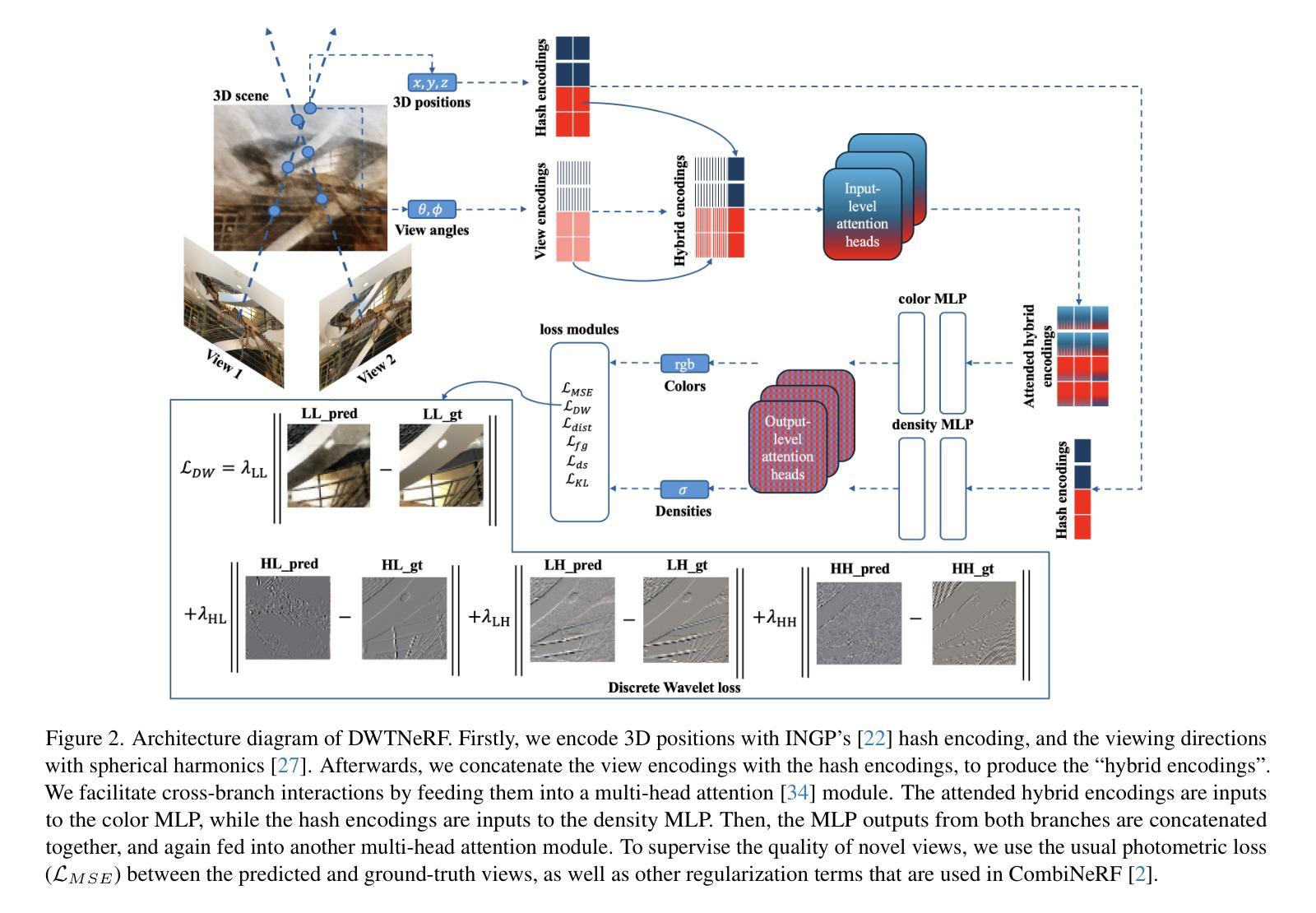
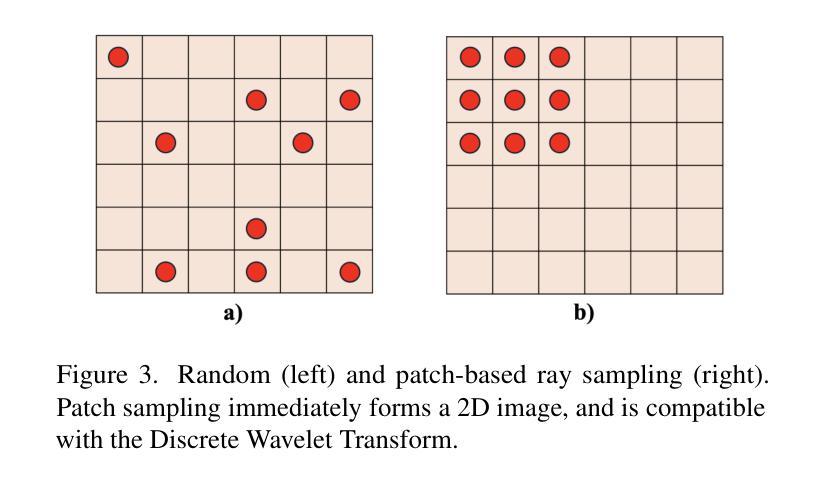
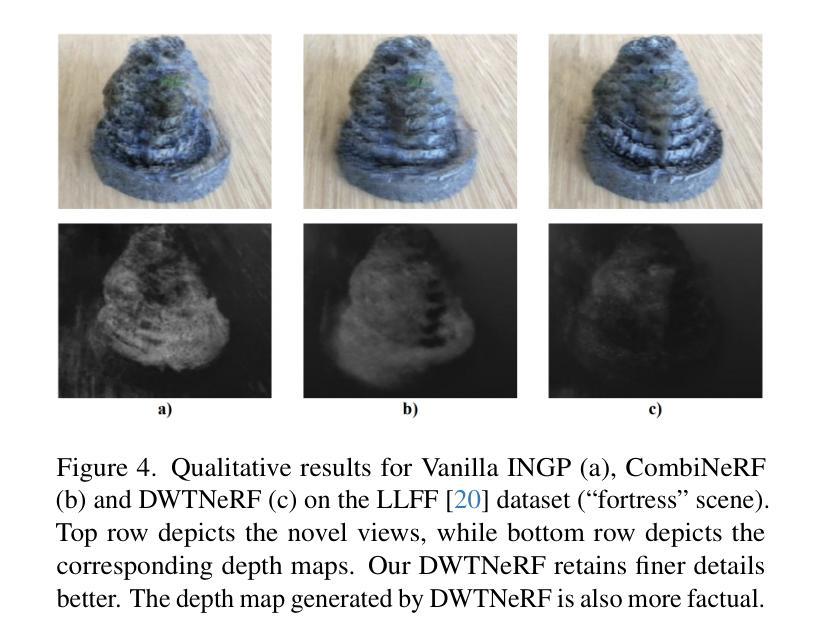
DWTNeRF: Boosting Few-shot Neural Radiance Fields via Discrete Wavelet Transform
Authors:Hung Nguyen, Blark Runfa Li, Truong Nguyen
Neural Radiance Fields (NeRF) has achieved superior performance in novel view synthesis and 3D scene representation, but its practical applications are hindered by slow convergence and reliance on dense training views. To this end, we present DWTNeRF, a unified framework based on Instant-NGP’s fast-training hash encoding. It is coupled with regularization terms designed for few-shot NeRF, which operates on sparse training views. Our DWTNeRF additionally includes a novel Discrete Wavelet loss that allows explicit prioritization of low frequencies directly in the training objective, reducing few-shot NeRF’s overfitting on high frequencies in earlier training stages. We also introduce a model-based approach, based on multi-head attention, that is compatible with INGP, which are sensitive to architectural changes. On the 3-shot LLFF benchmark, DWTNeRF outperforms Vanilla INGP by 15.07% in PSNR, 24.45% in SSIM and 36.30% in LPIPS. Our approach encourages a re-thinking of current few-shot approaches for fast-converging implicit representations like INGP or 3DGS.
神经辐射场(NeRF)在新型视图合成和3D场景表示方面取得了卓越的性能,但其实际应用受到了收敛速度慢和依赖密集训练视图的影响。为此,我们提出了DWTNeRF,这是一个基于Instant-NGP快速训练哈希编码的统一框架。它与针对少样本NeRF设计的正则化术语相结合,可在稀疏训练视图上运行。我们的DWTNeRF还包括一种新型离散小波损失,允许在训练目标中直接明确优先处理低频,从而减少早期训练阶段中少样本NeRF对高频的过拟合。我们还介绍了一种基于多头注意力的模型方法,该方法与INGP兼容,对架构更改敏感。在3次拍摄的LLFF基准测试中,DWTNeRF在PSNR上较Vanilla INGP高出15.07%,在SSIM上高出24.45%,在LPIPS上高出36.30%。我们的方法鼓励重新思考当前针对快速收敛隐式表示(如INGP或3DGS)的少样本方法。
论文及项目相关链接
PDF 17 pages, 13 figures, 8 tables
Summary
NeRF技术在新型视图合成和3D场景表示方面表现出卓越性能,但实际应用中存在收敛缓慢和依赖密集训练视图的问题。为解决这些问题,提出了DWTNeRF框架,结合了Instant-NGP的快速训练哈希编码和针对稀疏训练视图设计的正则化术语。DWTNeRF还包括一种新的离散小波损失,允许在训练目标中明确优先处理低频信息,减少早期训练阶段对高频的过拟合。在3次拍摄的LLFF基准测试中,DWTNeRF较Vanilla INGP在PSNR上提高了15.07%,在SSIM上提高了24.45%,在LPIPS上提高了36.30%。该研究鼓励重新思考当前快速收敛隐式表示(如INGP或3DGS)的少数镜头方法。
Key Takeaways
- NeRF技术在视图合成和3D场景表示上表现出卓越性能,但实际应用中面临收敛慢和依赖密集训练视图的问题。
- DWTNeRF框架结合了Instant-NGP的快速训练哈希编码,提高了NeRF的实用性。
- DWTNeRF引入了针对稀疏训练视图的正则化术语,增强了其性能。
- 离散小波损失允许DWTNeRF在训练目标中优先处理低频信息,减少早期训练阶段对高频的过拟合。
- 在LLFF基准测试中,DWTNeRF显著优于Vanilla INGP,显示出其优越性。
- DWTNeRF的研究鼓励对快速收敛隐式表示的少数镜头方法进行重新思考。
点此查看论文截图


Developing Cryptocurrency Trading Strategy Based on Autoencoder-CNN-GANs Algorithms
Authors:Zhuohuan Hu, Richard Yu, Zizhou Zhang, Haoran Zheng, Qianying Liu, Yining Zhou
This paper leverages machine learning algorithms to forecast and analyze financial time series. The process begins with a denoising autoencoder to filter out random noise fluctuations from the main contract price data. Then, one-dimensional convolution reduces the dimensionality of the filtered data and extracts key information. The filtered and dimensionality-reduced price data is fed into a GANs network, and its output serve as input of a fully connected network. Through cross-validation, a model is trained to capture features that precede large price fluctuations. The model predicts the likelihood and direction of significant price changes in real-time price sequences, placing trades at moments of high prediction accuracy. Empirical results demonstrate that using autoencoders and convolution to filter and denoise financial data, combined with GANs, achieves a certain level of predictive performance, validating the capabilities of machine learning algorithms to discover underlying patterns in financial sequences. Keywords - CNN;GANs; Cryptocurrency; Prediction.
本文利用机器学习算法对金融时间序列进行预测和分析。流程始于使用降噪自编码器对主合约价格数据进行随机噪声波动的过滤。然后,一维卷积对过滤后的数据进行降维并提取关键信息。经过过滤和降维的价格数据被输入到生成对抗网络(GANs)中,其输出作为全连接网络的输入。通过交叉验证,训练模型以捕获先于大幅价格波动的特征。该模型预测实时价格序列中重大价格变动的可能性和方向,在高预测准确率时刻进行交易。实证结果表明,结合生成对抗网络(GANs),使用自编码器和卷积对金融数据进行过滤和去噪,可以实现一定程度的预测性能,验证了机器学习算法在发现金融序列中潜在模式方面的能力。关键词——卷积神经网络(CNN)、生成对抗网络(GANs)、加密货币、预测。
论文及项目相关链接
PDF The paper was accepted by 2024 4th International Conference on Artificial Intelligence, Robotics, and Communication(ICAIRC 2024)
Summary:本文利用机器学习算法对金融时间序列进行预测与分析。通过降噪自编码器过滤原始合约价格数据中的随机噪声波动,一维卷积降低数据维度并提取关键信息。经过处理和降维的价格数据被输入生成对抗网络,其输出再作为全连接网络的输入。通过交叉验证,训练模型捕捉先于大幅价格波动的特征,预测实时价格序列中重大价格变动的可能性和方向,在高预测准确率时刻进行交易。实证结果表明,结合自编码器、卷积和生成对抗网络,机器学习算法具有一定的预测性能,验证了其在发现金融序列潜在模式的能力。
Key Takeaways:
- 利用降噪自编码器过滤金融时间序列数据中的随机噪声。
- 通过一维卷积降低数据维度并提取关键信息。
- 生成对抗网络(GANs)用于处理过滤和降维后的价格数据。
- 通过全连接网络进行预测,捕捉先于大幅价格波动的特征。
- 模型能预测重大价格变动的可能性和方向。
- 实证结果表明结合自编码器、卷积和GANs的机器学习算法具有预测性能。
- 机器学习算法能够发现金融序列的潜在模式。
点此查看论文截图


HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Authors:Artem Sevastopolsky, Philip-William Grassal, Simon Giebenhain, ShahRukh Athar, Luisa Verdoliva, Matthias Niessner
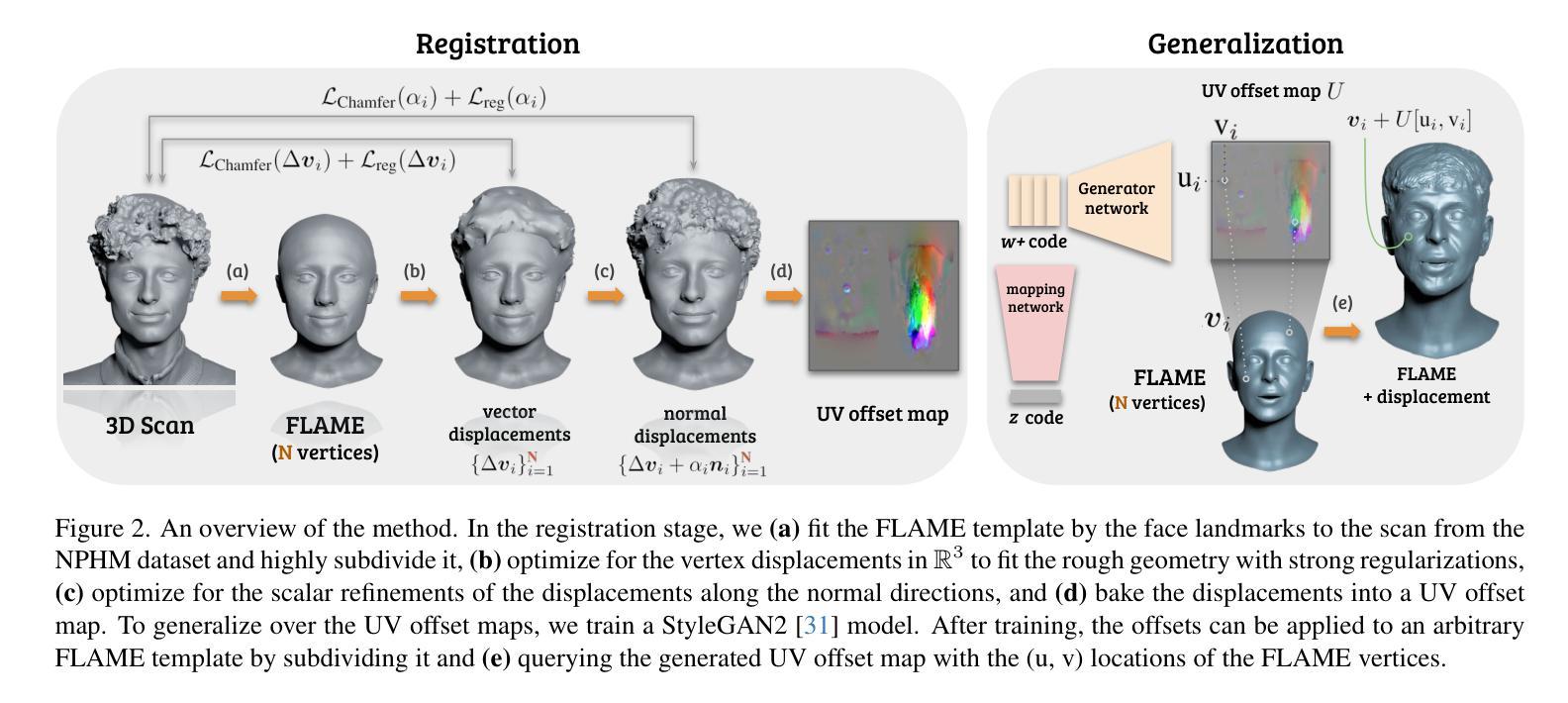
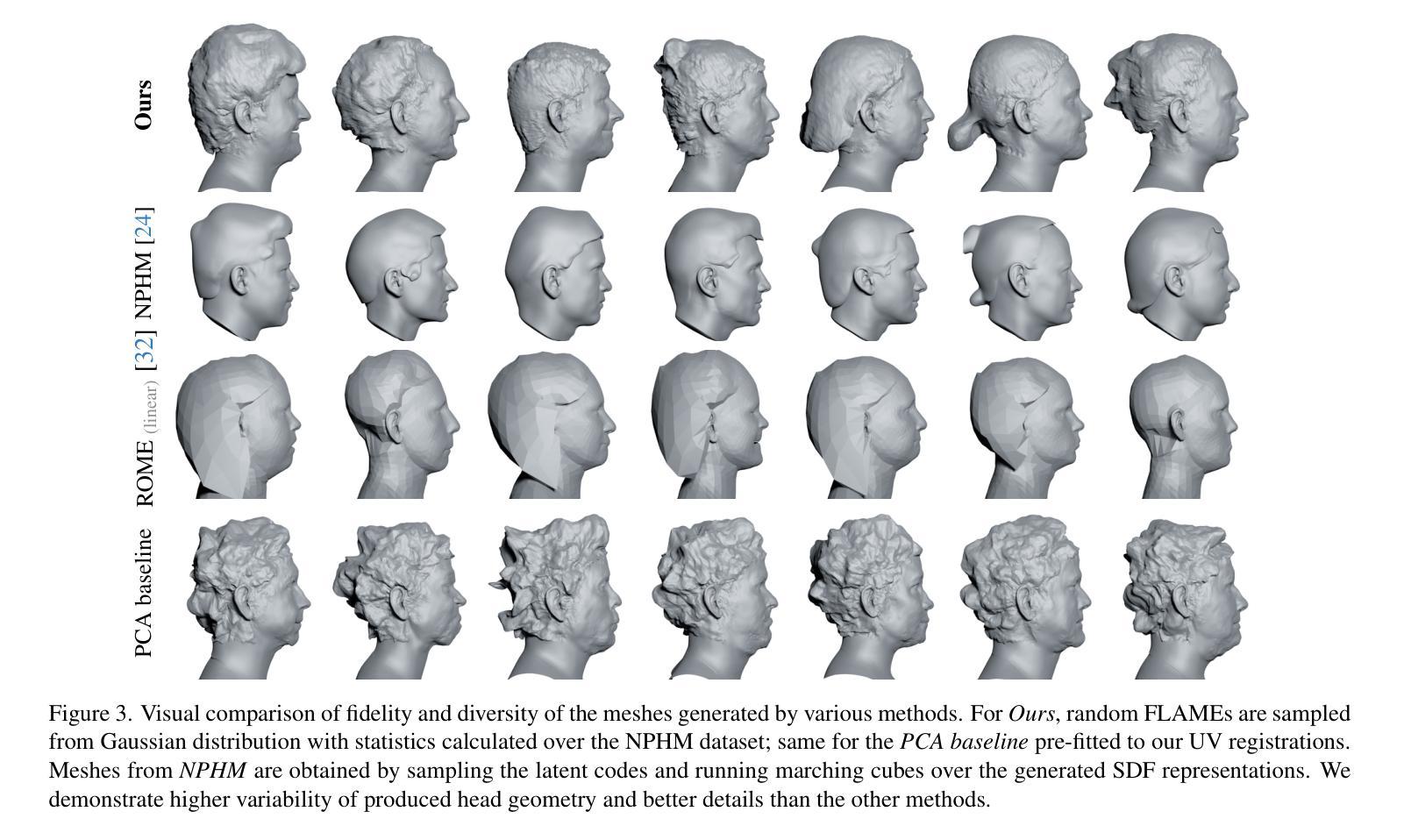
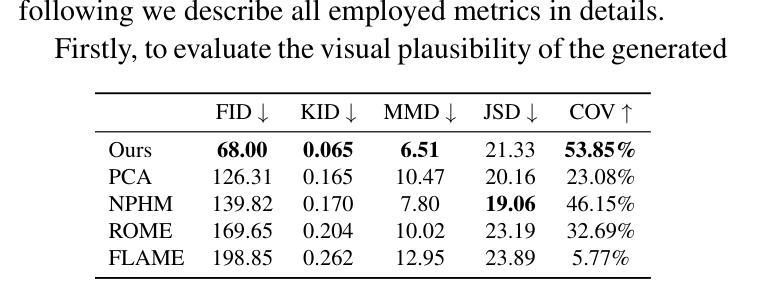
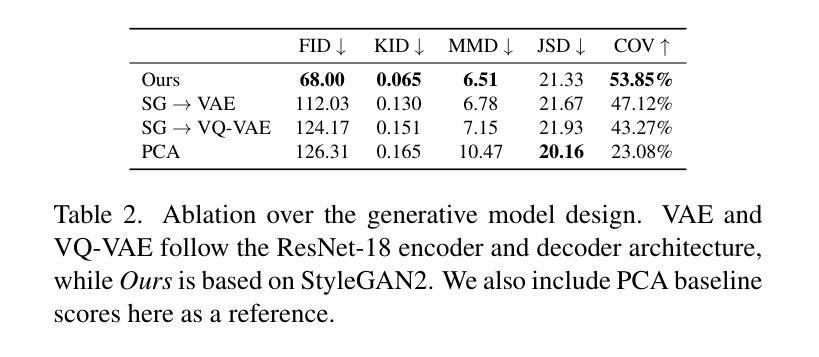
Current advances in human head modeling allow the generation of plausible-looking 3D head models via neural representations, such as NeRFs and SDFs. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g., coming from a depth sensor, while preserving a high level of detail is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM, simultaneously allowing explicit animation and high-detail preservation. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model to generalize over the UV maps of displacements, which we later refer to as HeadCraft. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify the regions semantically. We demonstrate the results of unconditional sampling, fitting to a scan and editing. The project page is available at https://seva100.github.io/headcraft.
当前的人头建模技术进展允许通过神经表示(如NeRF和SDF)生成逼真的3D头模型。然而,构建具有明确控制动画的高保真头模型仍然是一个问题。此外,基于部分观察(例如来自深度传感器的数据)完成头几何结构,同时保持高水平的细节对现有方法来说常常是困难的。我们引入了一种基于关节式3DMM的详细3D头网格生成模型,可以同时实现明确的动画和高细节保留。我们的方法分为两个阶段进行训练。首先,我们将参数化头模型与顶点位移注册到最近引入的NPHM数据集的每个网格上,该数据集包含准确的3D头扫描数据。估计的位移被烘焙到手工制作的UV布局中。其次,我们训练StyleGAN模型以概括位移的UV地图,我们稍后将其称为HeadCraft。参数模型的分解和高质量顶点位移使我们能够动画化模型并语义地修改区域。我们展示了无条件采样的结果、扫描适配和编辑。项目页面可在https://seva100.github.io/headcraft访问。
论文及项目相关链接
PDF 2nd version includes updated method and results. Project page: https://seva100.github.io/headcraft. Video: https://youtu.be/uBeBT2f1CL0. 24 pages, 21 figures, 3 tables
Summary
基于NeRF和SDF等神经表示方法,当前的人头建模技术可以生成逼真的3D头模。然而,在保持高度细节的同时,根据部分观察(如深度传感器数据)构建完整的高保真头模以及实现明确的动画控制仍是现有方法的难题。我们引入了一种基于关节式3DMM的详细3D头模生成模型,可同时实现明确的动画控制和细节保留。我们的方法分为两个阶段进行训练:首先,我们将参数化头模与顶点位移注册到准确的3D头扫描NPHM数据集网格上;然后,我们训练StyleGAN模型以概括位移的UV贴图。这种分解参数模型和高质量顶点位移的方法使我们能够动画模型和语义地修改区域。我们展示了无条件采样、贴合扫描和编辑的结果。
Key Takeaways
- 当前的人头建模技术能够利用神经表示方法生成逼真的3D头模。
- 构建完整的高保真头模,同时保持高度细节和明确的动画控制仍是挑战。
- 引入了一种基于关节式3DMM的详细3D头模生成模型,实现了明确的动画控制和细节保留。
- 方法分为两个阶段进行训练:注册参数化头模和训练StyleGAN模型以概括位移的UV贴图。
- 通过分解参数模型和高质量顶点位移,能够动画模型和语义地修改区域。
- 展示了无条件采样、贴合扫描和编辑的结果。
- 该项目的网页地址是https://seva100.github.io/headcraft。
点此查看论文截图