⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-05 更新
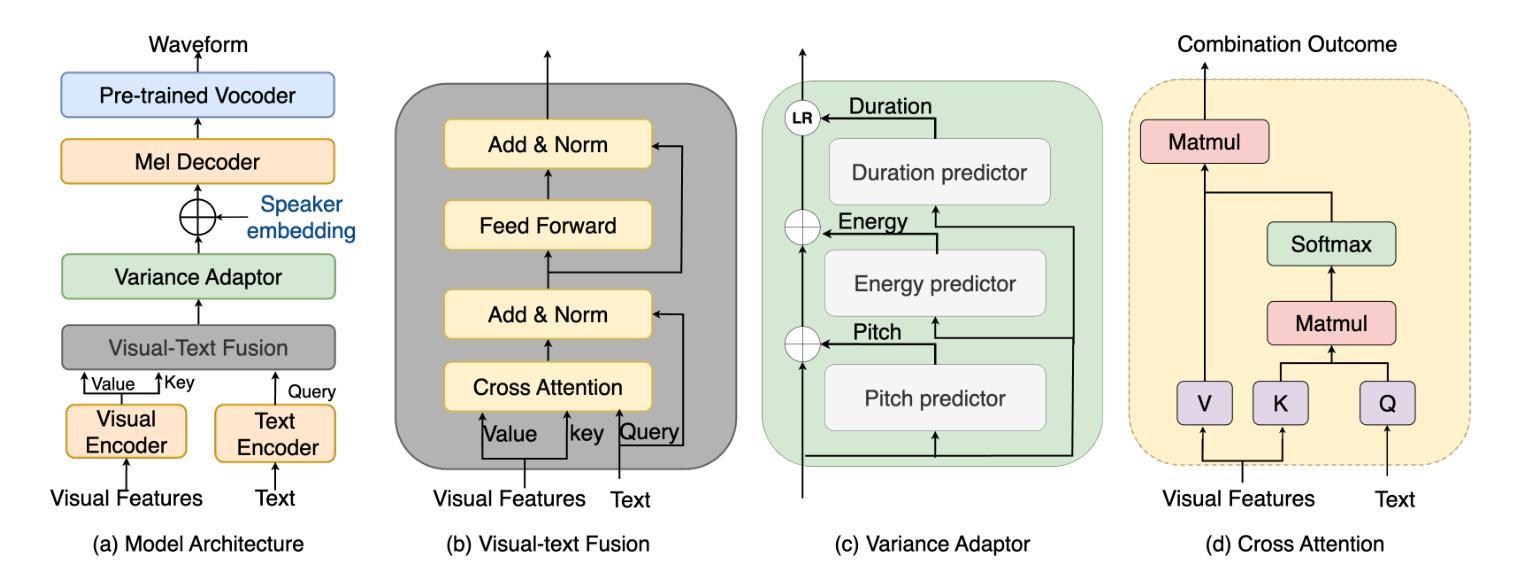
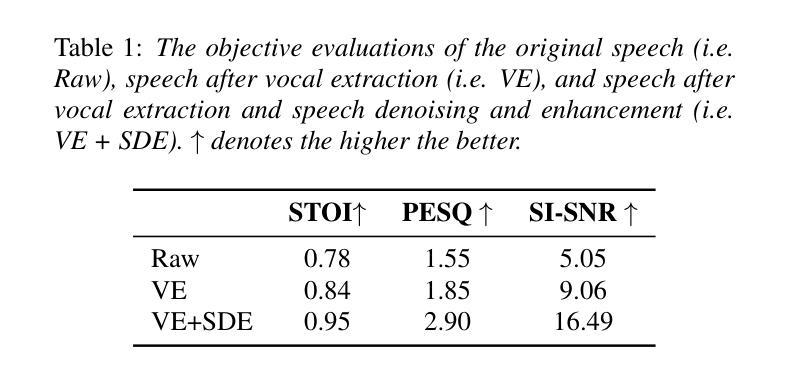
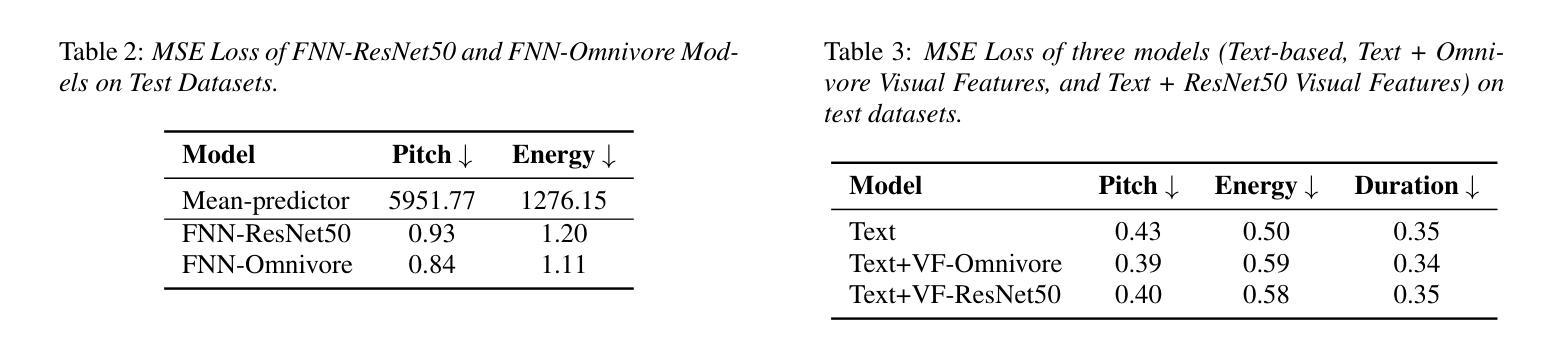
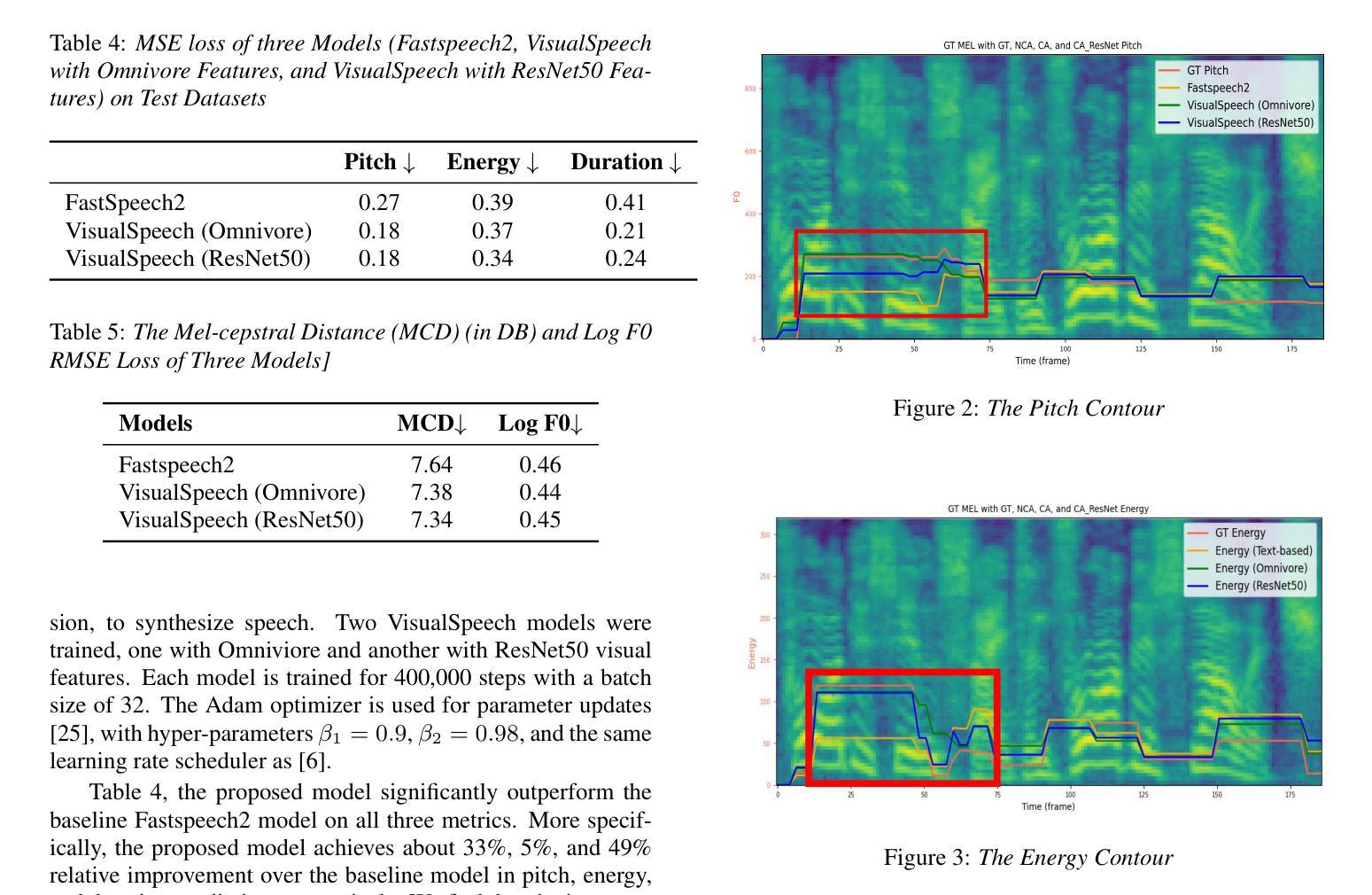
VisualSpeech: Enhance Prosody with Visual Context in TTS
Authors:Shumin Que, Anton Ragni
Text-to-Speech (TTS) synthesis faces the inherent challenge of producing multiple speech outputs with varying prosody from a single text input. While previous research has addressed this by predicting prosodic information from both text and speech, additional contextual information, such as visual features, remains underutilized. This paper investigates the potential of integrating visual context to enhance prosody prediction. We propose a novel model, VisualSpeech, which incorporates both visual and textual information for improved prosody generation. Empirical results demonstrate that visual features provide valuable prosodic cues beyond the textual input, significantly enhancing the naturalness and accuracy of the synthesized speech. Audio samples are available at https://ariameetgit.github.io/VISUALSPEECH-SAMPLES/.
文本转语音(TTS)合成面临从单一文本输入产生多个具有不同韵律的语音输出的固有挑战。虽然之前的研究通过从文本和语音预测韵律信息来解决这个问题,但额外的上下文信息,如视觉特征,仍未得到充分利用。本文探讨了整合视觉上下文以增强韵律预测潜力的可能性。我们提出了一种新型模型VisualSpeech,该模型结合了视觉和文本信息,以改进韵律生成。经验结果表明,视觉特征提供了文本输入之外的宝贵韵律线索,可显著提高合成语音的自然度和准确性。音频样本可在https://ariameetgit.github.io/VISUALSPEECH-SAMPLES/找到。
论文及项目相关链接
Summary
该论文探索了整合视觉上下文信息以提升TTS中语音韵律预测的可能性。提出一种新型模型VisualSpeech,结合视觉和文本信息,改善韵律生成效果。实验结果表明,视觉特征提供有价值的韵律线索,超越文本输入,显著增强合成语音的自然度和准确性。
Key Takeaways
- TTS合成面临从单一文本输入产生多种语音输出的挑战。
- 此前的研究已经通过预测文本和语音的韵律信息来应对这一挑战。
- 视觉特征等额外上下文信息在TTS中的潜力尚未得到充分利用。
- 本论文提出整合视觉上下文信息以增强TTS的韵律预测。
- 新型模型VisualSpeech结合视觉和文本信息,改善韵律生成。
- 实证结果表明,视觉特征对提升语音合成的自然度和准确性有重要作用。
点此查看论文截图

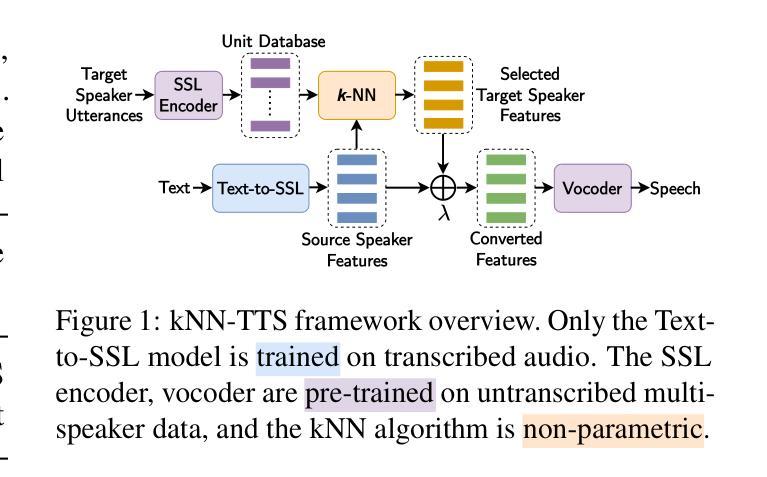
kNN Retrieval for Simple and Effective Zero-Shot Multi-speaker Text-to-Speech
Authors:Karl El Hajal, Ajinkya Kulkarni, Enno Hermann, Mathew Magimai. -Doss
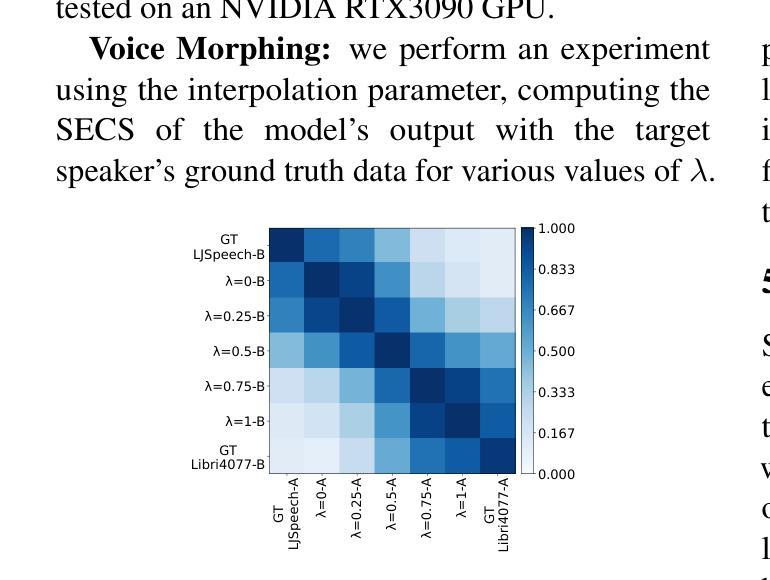
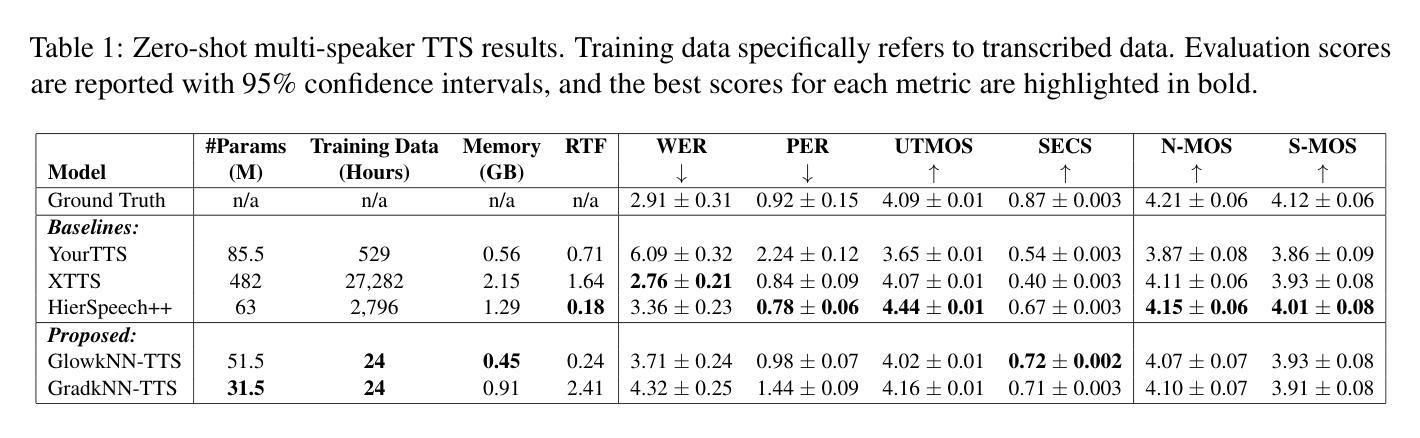
While recent zero-shot multi-speaker text-to-speech (TTS) models achieve impressive results, they typically rely on extensive transcribed speech datasets from numerous speakers and intricate training pipelines. Meanwhile, self-supervised learning (SSL) speech features have emerged as effective intermediate representations for TTS. Further, SSL features from different speakers that are linearly close share phonetic information while maintaining individual speaker identity. In this study, we introduce kNN-TTS, a simple and effective framework for zero-shot multi-speaker TTS using retrieval methods which leverage the linear relationships between SSL features. Objective and subjective evaluations show that our models, trained on transcribed speech from a single speaker only, achieve performance comparable to state-of-the-art models that are trained on significantly larger training datasets. The low training data requirements mean that kNN-TTS is well suited for the development of multi-speaker TTS systems for low-resource domains and languages. We also introduce an interpolation parameter which enables fine-grained voice morphing. Demo samples are available at https://idiap.github.io/knn-tts
尽管最近的零样本多说话人文本到语音(TTS)模型取得了令人印象深刻的结果,但它们通常依赖于来自多个说话者的大量转录语音数据集和复杂的训练管道。同时,自监督学习(SSL)语音特征作为TTS的有效中间表示形式已经出现。此外,来自不同说话者的SSL特征,在线性接近的情况下,会共享语音信息同时保持个体说话者的身份。在这项研究中,我们引入了kNN-TTS,这是一个简单有效的零样本多说话人TTS框架,它使用检索方法,利用SSL特征之间的线性关系。客观和主观评估表明,我们的模型仅在单个说话者的转录语音上进行训练,其性能与在更大训练数据集上训练的最新模型相当。低训练数据要求意味着kNN-TTS非常适合用于低资源领域和语言的多说话人TTS系统的开发。我们还引入了一个插值参数,可以实现精细的语音变形。演示样本可在https://idiap.github.io/knn-tts查看。
论文及项目相关链接
PDF Accepted at NAACL 2025
Summary
文本介绍了基于SSL特征的零样本多说话者TTS模型的最新研究成果。该模型使用检索方法利用SSL特征之间的线性关系,具有训练数据需求低的优点,能够在语音合成领域实现与大量训练数据集训练的先进模型相当的性能表现。模型还引入了插值参数,可以实现精细的语音转换功能。更多样例演示可访问链接。
Key Takeaways
- 该研究提出了kNN-TTS模型,是一个用于零样本多说话者TTS的有效框架。
- kNN-TTS利用SSL特征的线性关系,通过检索方法实现语音合成。
- 模型仅需要单一说话者的转录语音数据进行训练,即可达到与大量训练数据集训练的先进模型相当的性能表现。
- kNN-TTS适用于低资源领域和多语种的多说话者TTS系统开发。
- 模型引入了插值参数,实现了精细的语音形态变化功能。
- kNN-TTS的客观和主观评估结果均表现出其优良性能。
点此查看论文截图