⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-06 更新
VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks
Authors:Lawrence Jang, Yinheng Li, Charles Ding, Justin Lin, Paul Pu Liang, Dan Zhao, Rogerio Bonatti, Kazuhito Koishida
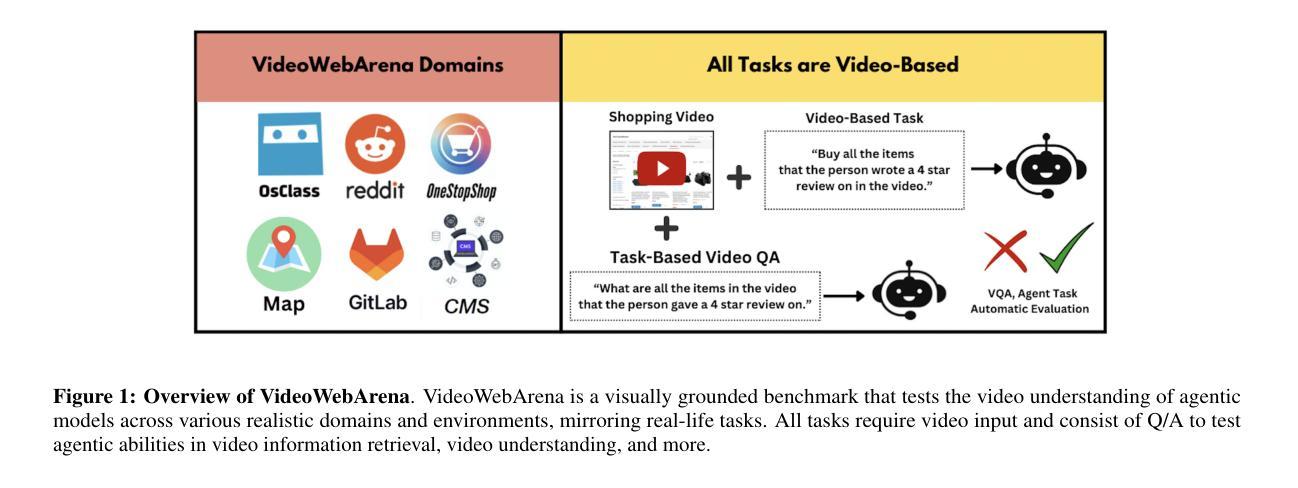
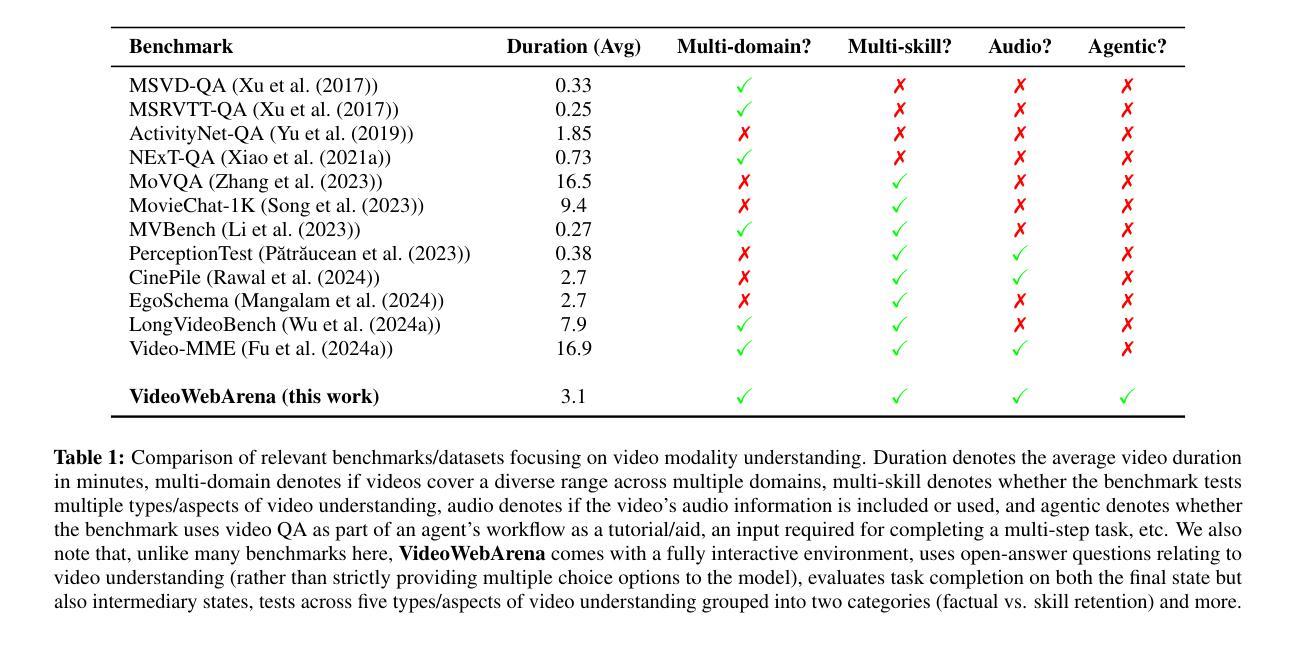
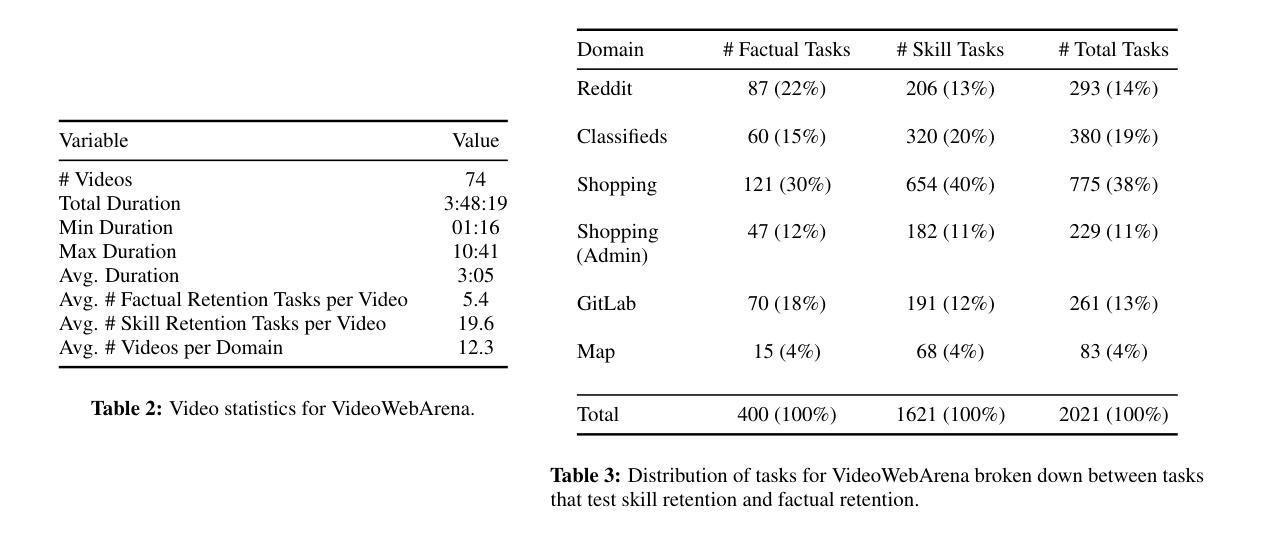
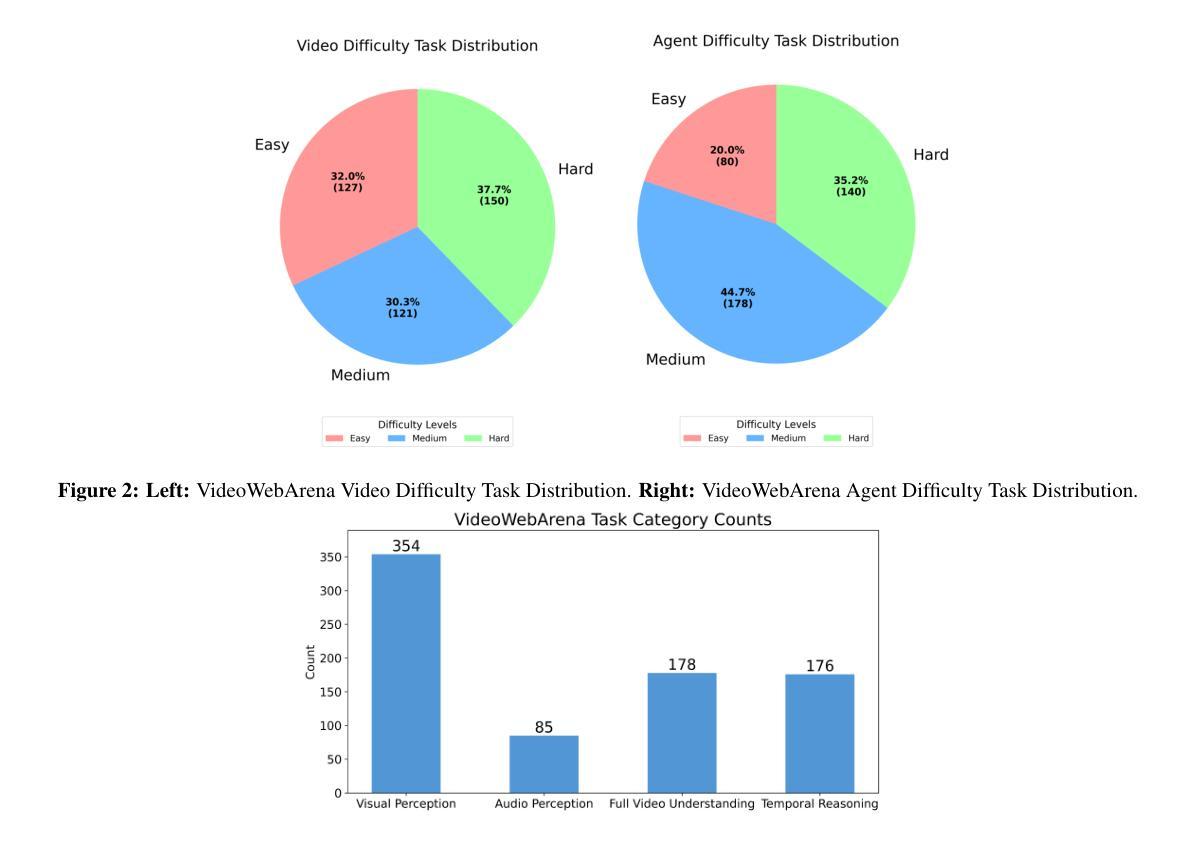
Videos are often used to learn or extract the necessary information to complete tasks in ways different than what text and static imagery alone can provide. However, many existing agent benchmarks neglect long-context video understanding, instead focusing on text or static image inputs. To bridge this gap, we introduce VideoWebArena (VideoWA), a benchmark for evaluating the capabilities of long-context multimodal agents for video understanding. VideoWA consists of 2,021 web agent tasks based on manually crafted video tutorials, which total almost four hours of content. For our benchmark, we define a taxonomy of long-context video-based agent tasks with two main areas of focus: skill retention and factual retention. While skill retention tasks evaluate whether an agent can use a given human demonstration to complete a task efficiently, the factual retention task evaluates whether an agent can retrieve instruction-relevant information from a video to complete a task. We find that the best model achieves 13.3% success on factual retention tasks and 45.8% on factual retention QA pairs, far below human performance at 73.9% and 79.3%, respectively. On skill retention tasks, long-context models perform worse with tutorials than without, exhibiting a 5% performance decrease in WebArena tasks and a 10.3% decrease in VisualWebArena tasks. Our work highlights the need to improve the agentic abilities of long-context multimodal models and provides a testbed for future development with long-context video agents.
视频通常用于以不同于文本和静态图像的方式学习或提取完成任务所需的信息。然而,许多现有的代理基准测试忽视了长语境视频理解,而是专注于文本或静态图像输入。为了弥补这一差距,我们引入了VideoWebArena(VideoWA),这是一个用于评估长语境多媒体代理视频理解能力的基准测试。VideoWA由基于手工制作的视频教程的2021个网络代理任务组成,总内容几乎为四个小时。在我们的基准测试中,我们定义了长语境视频代理任务分类,重点有两个领域:技能保持和事实保持。技能保持任务评估代理是否能够使用给定的人类演示来有效地完成任务,而事实保持任务评估代理是否能够从视频中检索与指令相关的信息来完成任务。我们发现,最佳模型在事实保持任务上达到13.3%的成功率,在事实保持问答对上达到45.8%,远低于人类的73.9%和79.3%。在技能保持任务上,长上下文模型在教程方面的表现不如没有教程,在WebArena任务中性能下降5%,在VisualWebArena任务中下降10.3%。我们的工作强调了提高长语境多媒体模型代理能力的重要性,并为未来长语境视频代理的开发提供了测试平台。
论文及项目相关链接
摘要
视频理解是理解和处理视频内容的关键过程,通过视频学习或提取完成任务所需的信息与传统的文本和静态图像方式不同。然而,现有的代理基准测试常常忽视对长上下文视频理解的研究,而更侧重于文本或静态图像输入。为了填补这一空白,我们引入了VideoWebArena(VideoWA)基准测试,用于评估长上下文多媒体代理的视频理解能力。VideoWA包含基于手工制作的视频教程的2021个网络代理任务,总时长近四个小时。我们的基准测试定义了一个长上下文视频代理任务分类学,其中包括两个主要领域:技能保持和事实保持。技能保持任务评估代理是否可以利用给定的演示有效地完成任务,而事实保持任务则评估代理是否可以从视频中检索与指令相关的信息来完成任务。最好的模型在事实保持任务上取得了13.3%的成功率,问答对上的成功率为45.8%,远低于人类的73.9%和79.3%。在技能保持任务上,长上下文模型在教程中的表现不如没有教程的情况,WebArena任务性能下降5%,VisualWebArena任务性能下降则达10.3%。我们的工作凸显了需要改进长上下文多媒体模型在代理能力方面的不足,并为未来长上下文视频代理的发展提供了测试平台。
关键见解
- 视频理解是理解和处理视频内容的关键过程,对于学习或完成任务的方式不同于文本和静态图像。
- 现有的代理基准测试常常忽视对长上下文视频理解的研究。
- VideoWebArena(VideoWA)基准测试旨在评估长上下文多媒体代理的视频理解能力。
- VideoWA包含基于手工制作的视频教程的多个网络代理任务,涵盖各种视频理解挑战。
- 定义了两个主要的长上下文视频代理任务领域:技能保持和事实保持。
- 最好的模型在事实保持任务上的表现远不及人类,凸显出长上下文多媒体模型在代理能力方面的不足。
- 在技能保持任务上,长上下文模型在有教程的情况下表现较差,性能出现明显下降。
点此查看论文截图