⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-06 更新
DHP: Discrete Hierarchical Planning for Hierarchical Reinforcement Learning Agents
Authors:Shashank Sharma, Janina Hoffmann, Vinay Namboodiri
In this paper, we address the challenge of long-horizon visual planning tasks using Hierarchical Reinforcement Learning (HRL). Our key contribution is a Discrete Hierarchical Planning (DHP) method, an alternative to traditional distance-based approaches. We provide theoretical foundations for the method and demonstrate its effectiveness through extensive empirical evaluations. Our agent recursively predicts subgoals in the context of a long-term goal and receives discrete rewards for constructing plans as compositions of abstract actions. The method introduces a novel advantage estimation strategy for tree trajectories, which inherently encourages shorter plans and enables generalization beyond the maximum tree depth. The learned policy function allows the agent to plan efficiently, requiring only $\log N$ computational steps, making re-planning highly efficient. The agent, based on a soft-actor critic (SAC) framework, is trained using on-policy imagination data. Additionally, we propose a novel exploration strategy that enables the agent to generate relevant training examples for the planning modules. We evaluate our method on long-horizon visual planning tasks in a 25-room environment, where it significantly outperforms previous benchmarks at success rate and average episode length. Furthermore, an ablation study highlights the individual contributions of key modules to the overall performance.
本文我们利用分层强化学习(HRL)来解决长周期视觉规划任务的挑战。我们的主要贡献是离散层次规划(DHP)方法,它是传统基于距离方法的替代方案。我们为该方法的理论基础进行了阐述,并通过广泛的经验评估证明了其有效性。我们的智能体在长期目标背景下递归预测子目标,并通过构建由抽象动作组成的计划获得离散奖励。该方法引入了一种新颖的树轨迹优势估计策略,这固有地鼓励更短的计划并实现了超出最大树深度的泛化。学习到的策略功能使智能体能够高效规划,仅需要logN计算步骤,使重新规划变得非常高效。基于软行为评论家(SAC)框架的智能体使用基于策略的想象数据进行训练。此外,我们提出了一种新颖的探索策略,使智能体能够为规划模块生成相关的训练样本。我们在一个包含25个房间的环境中的长周期视觉规划任务上评估了我们的方法,该方法在成功率和平均剧集长度方面显著优于以前的基准测试。此外,一项消融研究突显了关键模块对整体性能的个别贡献。
论文及项目相关链接
Summary
本文利用分层强化学习(HRL)解决长期视觉规划任务的挑战。主要贡献是离散层次规划(DHP)方法,作为对传统基于距离的方法的替代方案。文章为该方法的理论基础提供了证明,并通过广泛的实验评估展示了其有效性。代理在长期的背景下递归预测子目标,并为了构建计划作为抽象行为的组合而获得离散奖励。此方法为树轨迹引入了一种新的优势估计策略,这固有地鼓励更短的计划并实现了超越最大树深度的泛化。学习到的策略函数使代理能够高效规划,只需要logN的计算步骤,使重新规划变得高效。基于软行动评论家(SAC)框架的代理使用在策略想象数据进行训练。此外,我们提出了一种新的探索策略,使代理能够为规划模块生成相关的训练样本。在25室环境中的长期视觉规划任务上,我们的方法在成功率和平均集数长度方面显著优于之前的基准测试。此外,一项消融研究突出了各个模块对总体性能的单独贡献。
Key Takeaways
- 论文使用分层强化学习(HRL)来解决长期视觉规划任务的挑战。
- 提出了离散层次规划(DHP)方法作为对传统方法的改进。
- 进行了理论基础的证明并通过实验评估了方法的有效性。
- 代理能够递归预测子目标并获取离散奖励来构建计划。
- 引入了新的优势估计策略来鼓励更短的计划并实现深度泛化。
- 训练了基于软行动评论家(SAC)框架的代理,并使用在策略想象数据进行训练。
点此查看论文截图

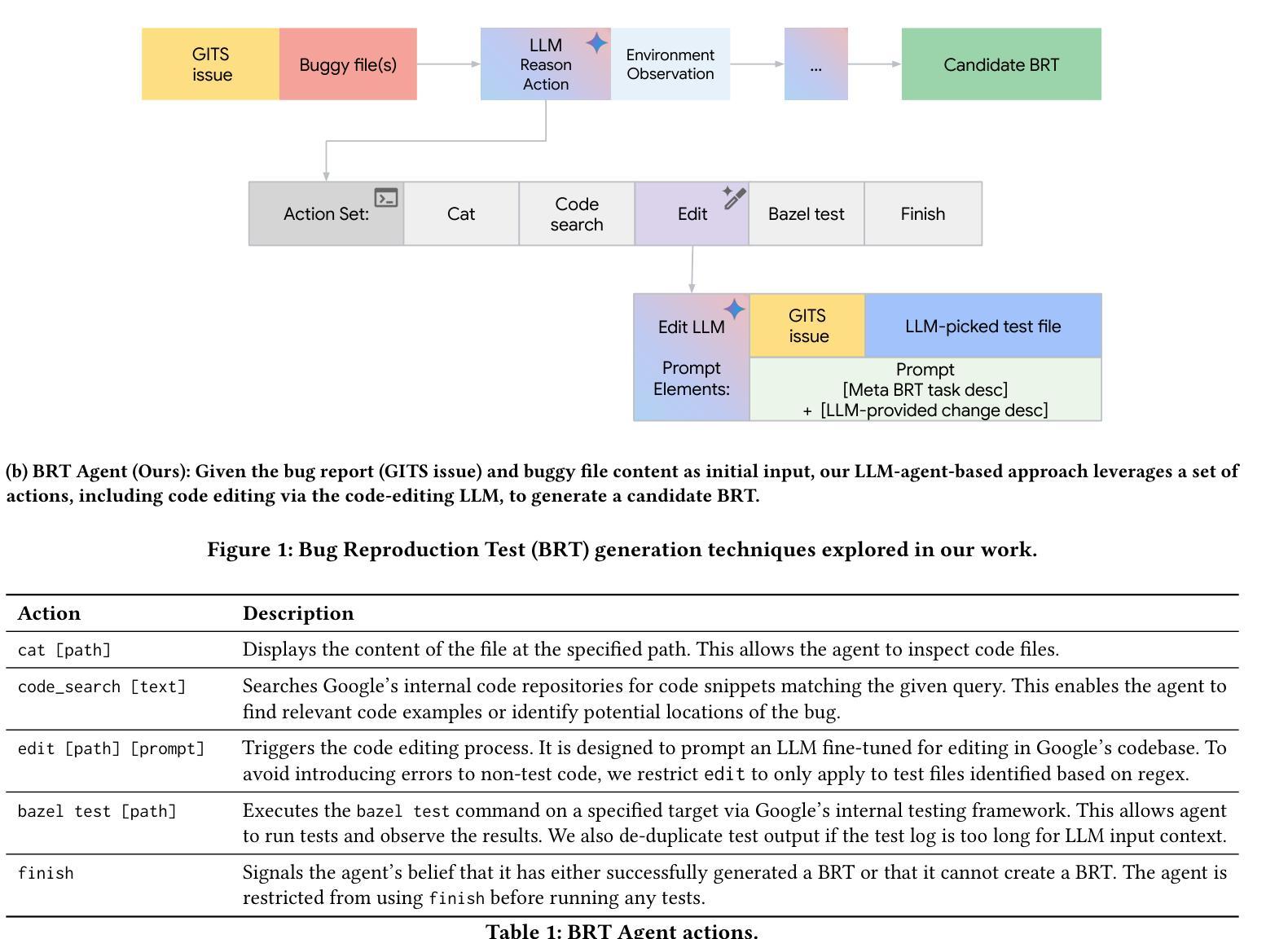
Agentic Bug Reproduction for Effective Automated Program Repair at Google
Authors:Runxiang Cheng, Michele Tufano, Jürgen Cito, José Cambronero, Pat Rondon, Renyao Wei, Aaron Sun, Satish Chandra
Bug reports often lack sufficient detail for developers to reproduce and fix the underlying defects. Bug Reproduction Tests (BRTs), tests that fail when the bug is present and pass when it has been resolved, are crucial for debugging, but they are rarely included in bug reports, both in open-source and in industrial settings. Thus, automatically generating BRTs from bug reports has the potential to accelerate the debugging process and lower time to repair. This paper investigates automated BRT generation within an industry setting, specifically at Google, focusing on the challenges of a large-scale, proprietary codebase and considering real-world industry bugs extracted from Google’s internal issue tracker. We adapt and evaluate a state-of-the-art BRT generation technique, LIBRO, and present our agent-based approach, BRT Agent, which makes use of a fine-tuned Large Language Model (LLM) for code editing. Our BRT Agent significantly outperforms LIBRO, achieving a 28% plausible BRT generation rate, compared to 10% by LIBRO, on 80 human-reported bugs from Google’s internal issue tracker. We further investigate the practical value of generated BRTs by integrating them with an Automated Program Repair (APR) system at Google. Our results show that providing BRTs to the APR system results in 30% more bugs with plausible fixes. Additionally, we introduce Ensemble Pass Rate (EPR), a metric which leverages the generated BRTs to select the most promising fixes from all fixes generated by APR system. Our evaluation on EPR for Top-K and threshold-based fix selections demonstrates promising results and trade-offs. For example, EPR correctly selects a plausible fix from a pool of 20 candidates in 70% of cases, based on its top-1 ranking.
缺陷报告往往缺乏足够的细节,开发者无法重现和修复潜在缺陷。缺陷复现测试(Bug Reproduction Tests,简称BRTs)在存在缺陷时会失败,在缺陷被修复后会通过,对于调试至关重要,但在开源和工业环境中都很少包含在缺陷报告中。因此,从缺陷报告中自动生成BRTs有潜力加速调试过程并降低修复时间。本文在工业环境中调查了自动BRT生成技术,特别是在谷歌,侧重于大规模专有代码库的挑战,并考虑了从谷歌内部问题跟踪器中提取的真实世界工业缺陷。我们对最先进的BRT生成技术LIBRO进行了改编和评估,并提出了基于代理的方法BRT Agent,该方法利用精细调整的大型语言模型(LLM)进行代码编辑。我们的BRT Agent在谷歌内部问题跟踪器中人类报告的80个缺陷上显著优于LIBRO,实现了28%的可信BRT生成率,而LIBRO仅为10%。我们进一步通过将其与谷歌的自动化程序修复(APR)系统相结合,探讨了生成BRTs的实际价值。我们的结果表明,向APR系统提供BRTs导致具有可信修复的缺陷增加了30%。此外,我们引入了Ensemble Pass Rate(EPR),这是一个利用生成的BRTs从APR系统生成的所有修复中选择最有前途的修复的指标。我们对EPR针对Top-K和基于阈值的修复选择进行了评估,结果令人鼓舞并存在权衡。例如,EPR可以从20个候选者中正确选择出一个合理的修复方案,准确率为70%,基于其排名第一的结果。
论文及项目相关链接
摘要
自动化生成的Bug复现测试(BRTs)能显著提升调试效率和降低修复时间。本文对谷歌内部环境下的自动化BRT生成进行研究,提出一个名为BRT Agent的基于代理的方法,使用精细调整的大型语言模型(LLM)进行代码编辑。相较于当前先进的LIBRO技术,BRT Agent在谷歌内部问题追踪器中的人类报告的80个bug上,实现了高达28%的可行的BRT生成率,远超LIBRO的10%。此外,将生成的BRTs集成到谷歌的自动化程序修复(APR)系统中,结果显示它能促使系统生成更多可修复bug的30%。本文还引入了一个新的指标Ensemble Pass Rate(EPR),该指标利用生成的BRTs从APR系统生成的所有修复中选出最有前途的修复方案。EPR对于Top-K和基于阈值的修复选择评估显示了令人鼓舞的结果和权衡。例如,在大多数情况下,EPR能从20个候选修复中正确选择出一个可接受的修复方案(基于排名第一)。
关键见解
- Bug报告中缺乏足够细节供开发者重现和修复潜在缺陷。
- 自动生成Bug复现测试(BRTs)可以加速调试过程并降低修复时间。
- 在谷歌环境下研究并评估了先进的BRT生成技术LIBRO和提出的BRT Agent方法。
- BRT Agent显著提高了BRT生成效率,特别是与谷歌内部问题追踪器中的实际问题相对应。
- 集成生成的BRTs到自动化程序修复(APR)系统增加了找到可修复bug的机会。
- 引入了Ensemble Pass Rate(EPR)指标来评估修复的可行性,展示了该指标的实用价值。
点此查看论文截图


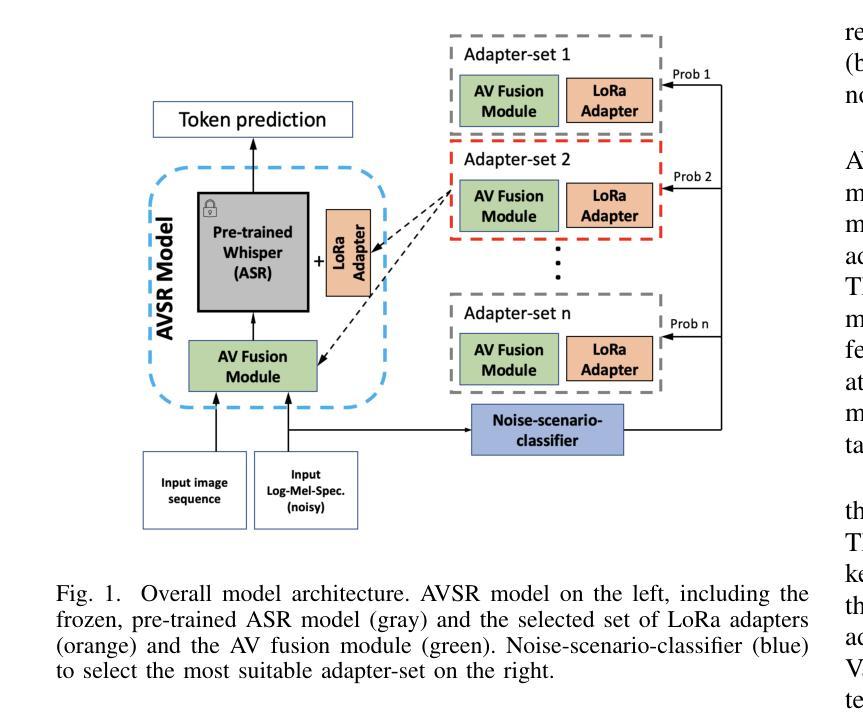
Adapter-Based Multi-Agent AVSR Extension for Pre-Trained ASR Models
Authors:Christopher Simic, Korbinian Riedhammer, Tobias Bocklet
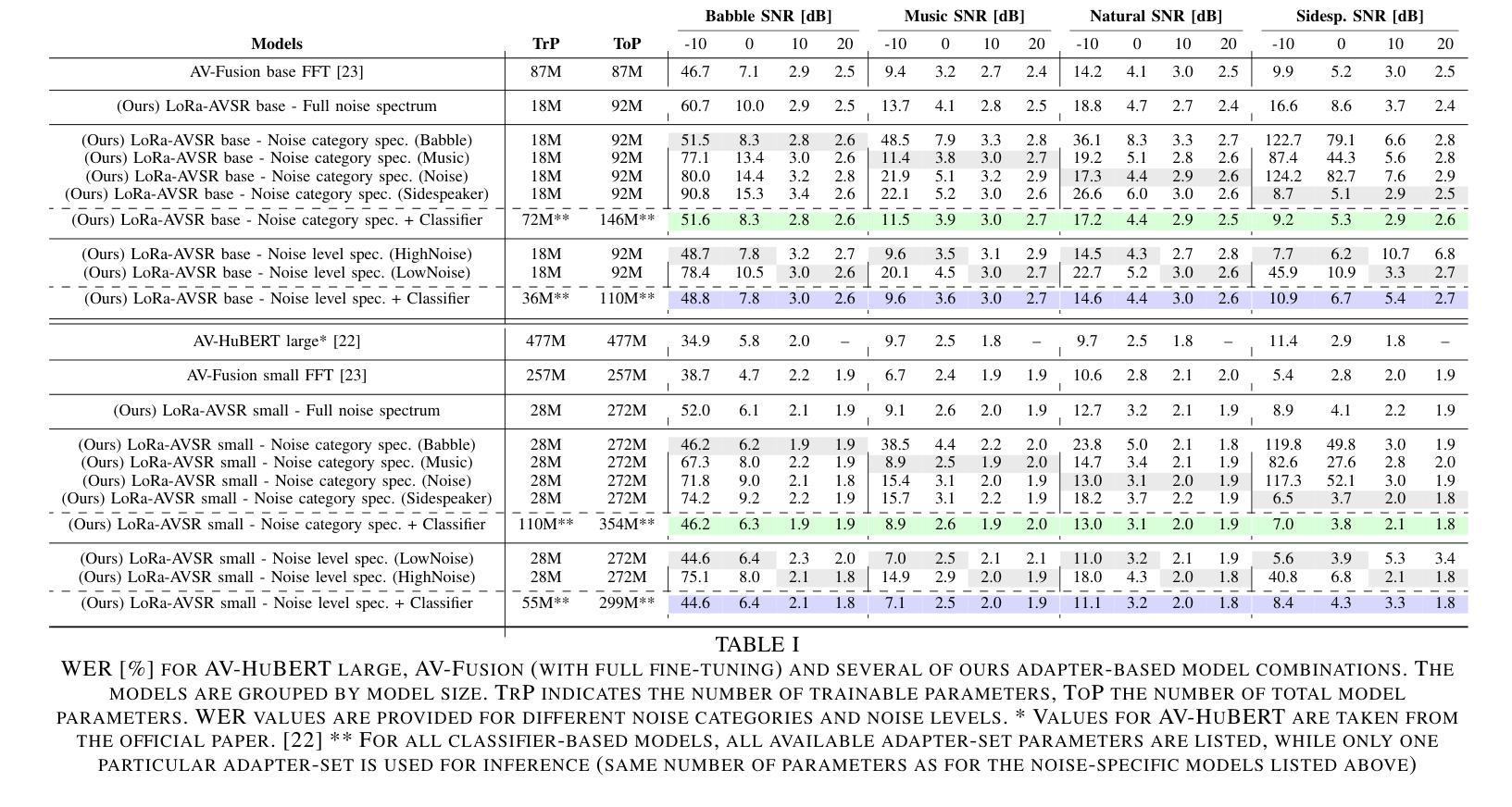
We present an approach to Audio-Visual Speech Recognition that builds on a pre-trained Whisper model. To infuse visual information into this audio-only model, we extend it with an AV fusion module and LoRa adapters, one of the most up-to-date adapter approaches. One advantage of adapter-based approaches, is that only a relatively small number of parameters are trained, while the basic model remains unchanged. Common AVSR approaches train single models to handle several noise categories and noise levels simultaneously. Taking advantage of the lightweight nature of adapter approaches, we train noise-scenario-specific adapter-sets, each covering individual noise-categories or a specific noise-level range. The most suitable adapter-set is selected by previously classifying the noise-scenario. This enables our models to achieve an optimum coverage across different noise-categories and noise-levels, while training only a minimum number of parameters. Compared to a full fine-tuning approach with SOTA performance our models achieve almost comparable results over the majority of the tested noise-categories and noise-levels, with up to 88.5% less trainable parameters. Our approach can be extended by further noise-specific adapter-sets to cover additional noise scenarios. It is also possible to utilize the underlying powerful ASR model when no visual information is available, as it remains unchanged.
我们提出了一种基于预训练Whisper模型的视听语音识别方法。为了向这个仅音频模型注入视觉信息,我们为其增加了一个视听融合模块和LoRa适配器,这是最新的一种适配器方法。适配器方法的一个优点是只需要训练相对较少的参数,而基本模型保持不变。常见的视听语音识别方法会训练单一模型,以同时处理多种噪声类别和噪声级别。利用适配器方法的轻量级特性,我们训练了针对特定噪声场景的适配器集,每个适配器集覆盖特定的噪声类别或特定的噪声级别范围。通过预先分类噪声场景来选择最合适的适配器集。这使得我们的模型能够在不同的噪声类别和噪声级别上实现最佳覆盖,同时只训练最小数量的参数。与具有最新技术性能的全微调方法相比,我们的模型在大多数测试的噪声类别和噪声级别上取得了几乎相当的结果,同时可训练的参数减少了高达88.5%。我们的方法可以通过进一步的特定噪声适配器集来扩展,以覆盖更多的噪声场景。当没有视觉信息可用时,还可以利用强大的语音识别模型,因为它保持不变。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
基于预训练Whisper模型的视听语音识别方法,通过引入AV融合模块和LoRa适配器注入视觉信息。适配器方法仅训练少量参数,同时保持基本模型不变。采用噪声场景特定适配器集应对不同噪声类别和噪声水平,通过预先分类噪声场景选择最合适的适配器集,实现最优覆盖不同噪声类别和噪声水平,同时减少参数训练量。与全微调方法相比,该模型在大多数测试噪声类别和噪声水平上取得了几乎相当的结果,并且参数训练量减少了高达88.5%。此方法可通过添加更多噪声特定适配器集来扩展,以覆盖更多噪声场景。在没有视觉信息的情况下,还可以利用强大的ASR模型。
Key Takeaways
- 利用预训练的Whisper模型进行视听语音识别。
- 通过AV融合模块和LoRa适配器注入视觉信息到音频模型中。
- 适配器方法只需训练少量参数,保持基础模型不变。
- 采用噪声场景特定适配器集应对不同噪声类别和水平。
- 通过预先分类噪声场景选择适配器集,实现优化覆盖不同噪声环境。
- 与全微调方法相比,该模型取得近乎相当的结果,同时显著减少参数训练量。
点此查看论文截图

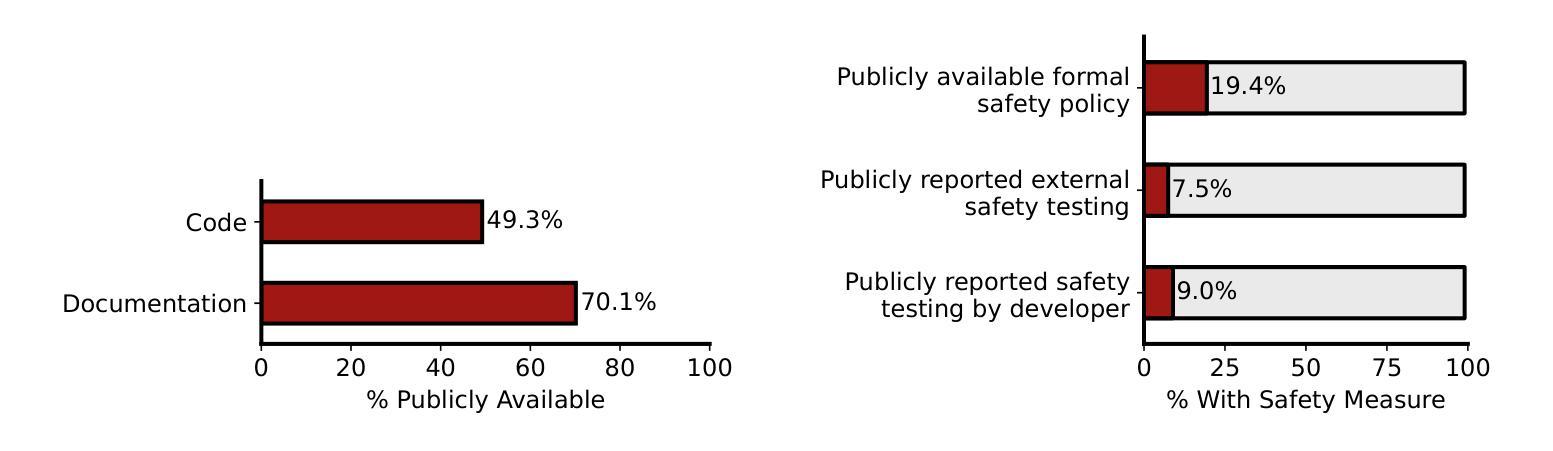
The AI Agent Index
Authors:Stephen Casper, Luke Bailey, Rosco Hunter, Carson Ezell, Emma Cabalé, Michael Gerovitch, Stewart Slocum, Kevin Wei, Nikola Jurkovic, Ariba Khan, Phillip J. K. Christoffersen, A. Pinar Ozisik, Rakshit Trivedi, Dylan Hadfield-Menell, Noam Kolt
Leading AI developers and startups are increasingly deploying agentic AI systems that can plan and execute complex tasks with limited human involvement. However, there is currently no structured framework for documenting the technical components, intended uses, and safety features of agentic systems. To fill this gap, we introduce the AI Agent Index, the first public database to document information about currently deployed agentic AI systems. For each system that meets the criteria for inclusion in the index, we document the system’s components (e.g., base model, reasoning implementation, tool use), application domains (e.g., computer use, software engineering), and risk management practices (e.g., evaluation results, guardrails), based on publicly available information and correspondence with developers. We find that while developers generally provide ample information regarding the capabilities and applications of agentic systems, they currently provide limited information regarding safety and risk management practices. The AI Agent Index is available online at https://aiagentindex.mit.edu/
领先的AI开发人员和初创公司正越来越多地部署代理AI系统,这些系统可以在有限的人工参与下规划和执行复杂任务。然而,目前并没有针对代理系统的技术组件、预期用途和安全功能进行记录的结构化框架。为了填补这一空白,我们推出了AI代理索引(AI Agent Index),这是第一个记录当前部署的代理AI系统信息的公共数据库。对于符合索引标准的每个系统,我们根据公开信息和与开发者的交流,记录系统的组件(例如基础模型、推理实现、工具使用)、应用领域(例如计算机使用、软件工程)和风险管理实践(例如评估结果、限制措施)。我们发现,虽然开发者通常提供了关于代理系统的能力和应用的大量信息,但他们目前对安全和风险管理实践的描述相对有限。AI代理索引在线可通过https://aiagentindex.mit.edu/访问。
论文及项目相关链接
PDF Accompanying website: https://aiagentindex.mit.edu/
Summary
人工智能开发者与初创公司正越来越多地部署可自主执行复杂任务的代理人工智能系统。为解决当前缺乏关于代理系统技术组件、预期用途和安全性能的文档化框架的问题,我们推出了人工智能代理索引,这是首个记录当前部署的代理人工智能系统信息的公共数据库。根据公开信息和与开发者沟通的结果,我们记录了每个系统的组件、应用领域和风险管理的信息。发现开发者关于代理系统的功能和应用的介绍通常比较充分,但对安全性能及风险管理实践的描述相对不足。人工智能代理索引网址为:[https://aiagentindex.mit.edu/] 。
Key Takeaways
- 人工智能开发者与初创公司正部署可进行复杂任务的代理人工智能系统。
- 缺乏结构化框架来记录代理人工智能系统的技术组件、预期用途和安全性能信息。
- 人工智能代理索引填补了这一空白,成为首个记录当前部署的代理AI系统信息的公共数据库。
- 该数据库基于公开信息和与开发者沟通的结果,记录了每个系统的组件、应用领域和风险管理的详细信息。
- 开发者在描述代理系统的功能和应用方面表现充分,但在介绍安全性能和风险管理实践时信息不足。
- 人工智能代理索引可供在线访问,网址为:https://aiagentindex.mit.edu/。
点此查看论文截图

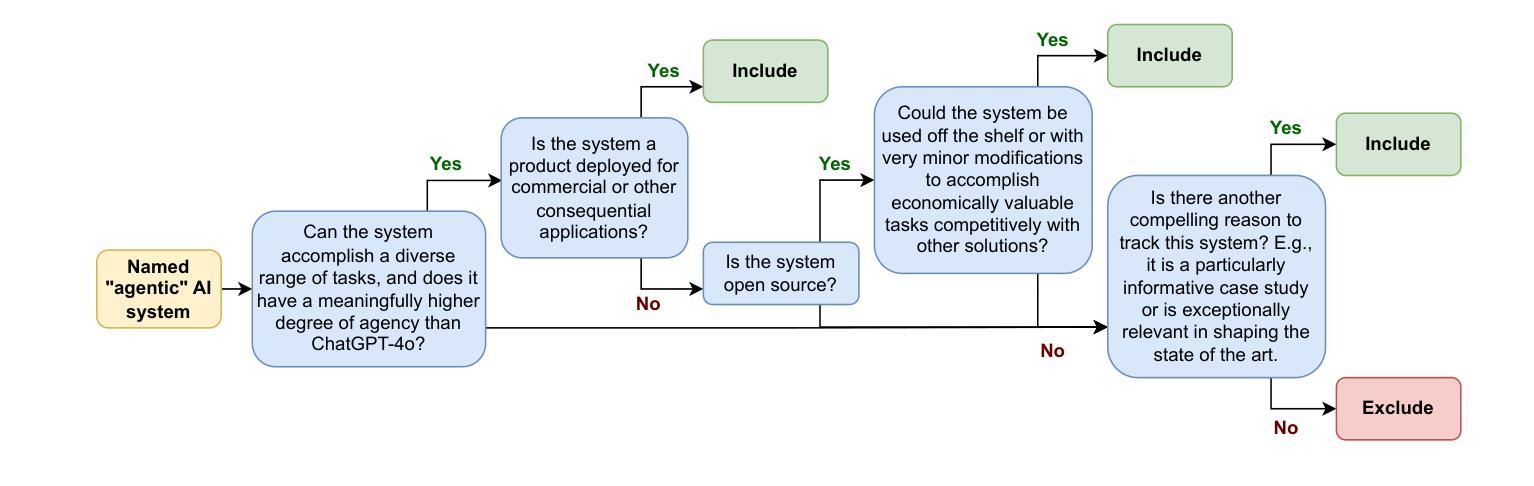
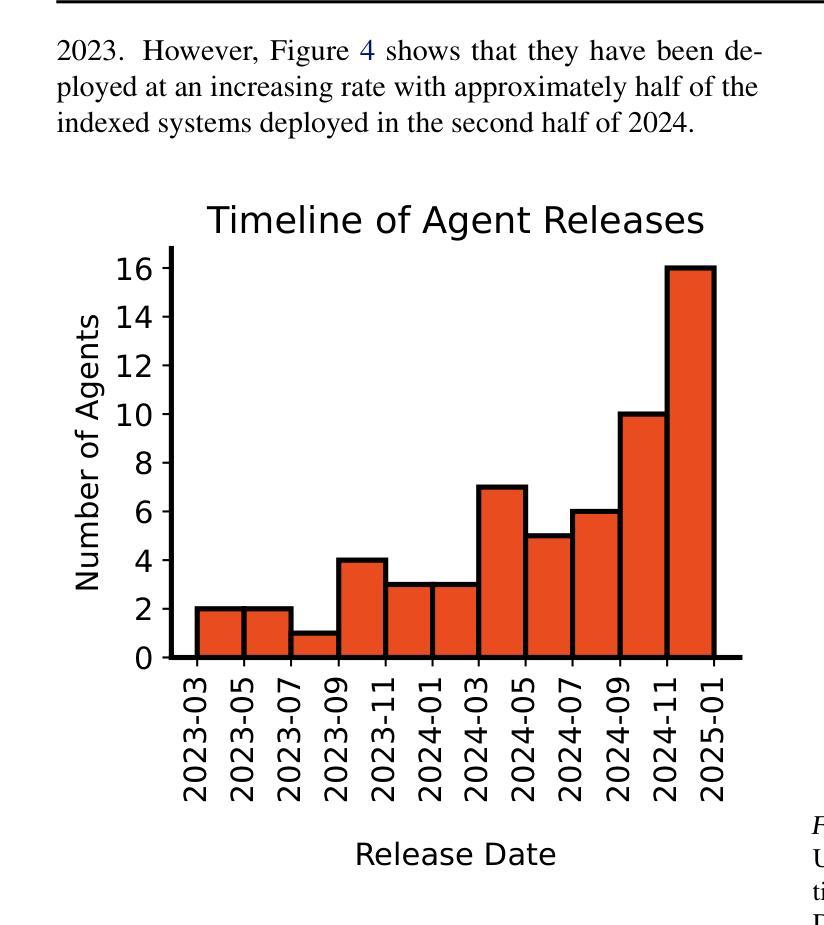
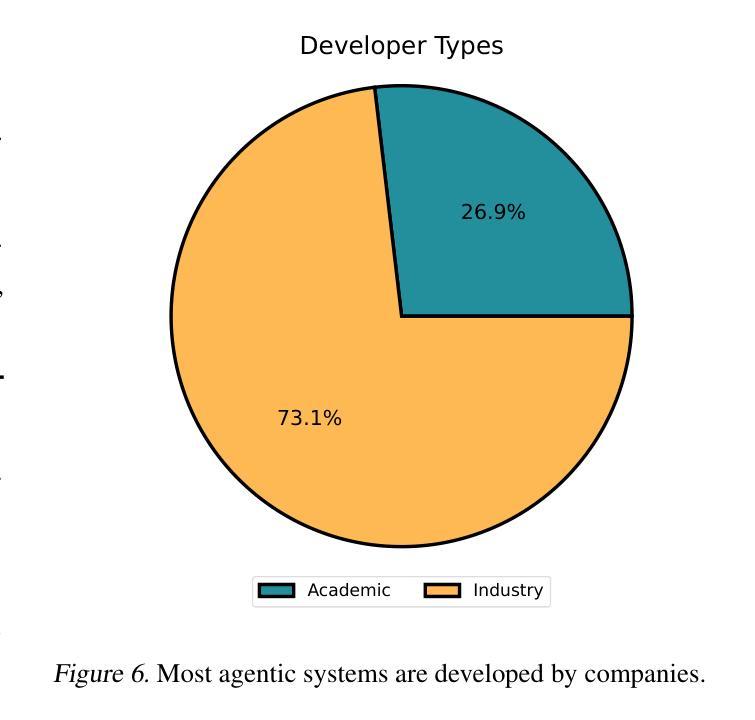
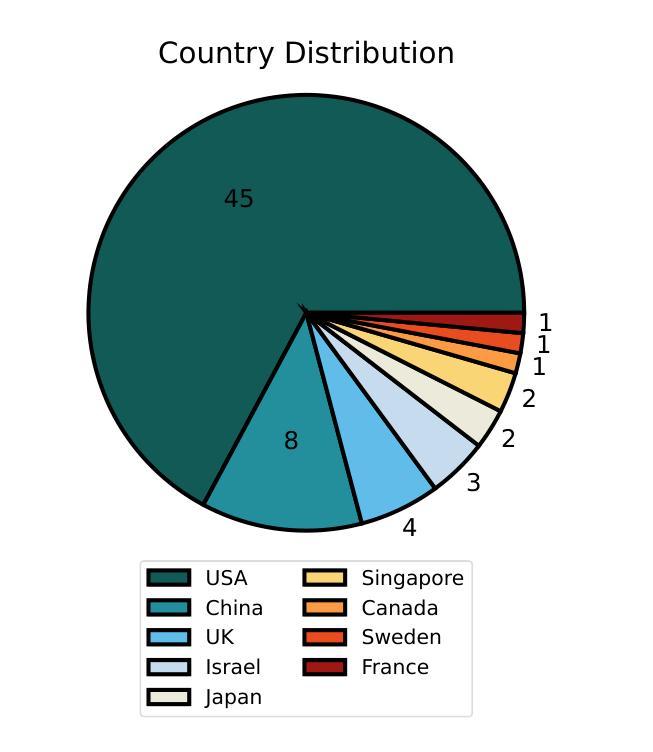
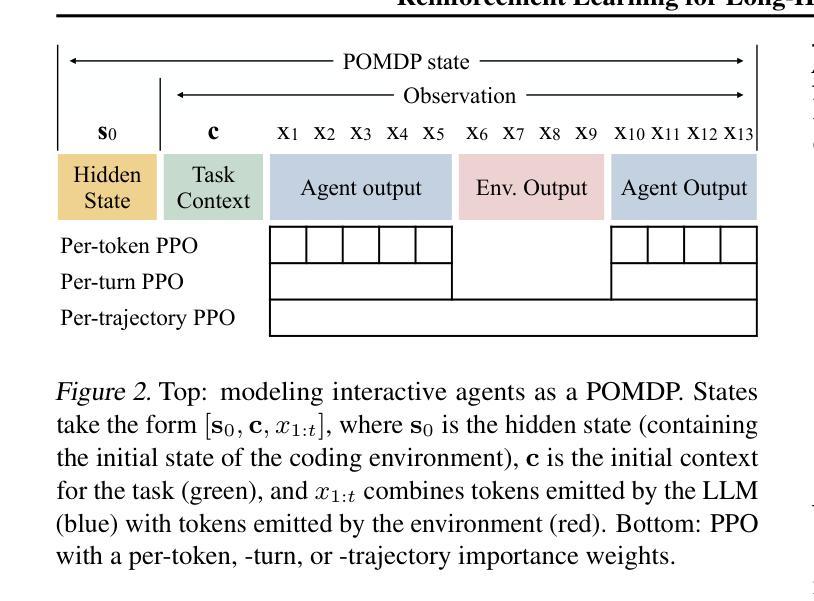
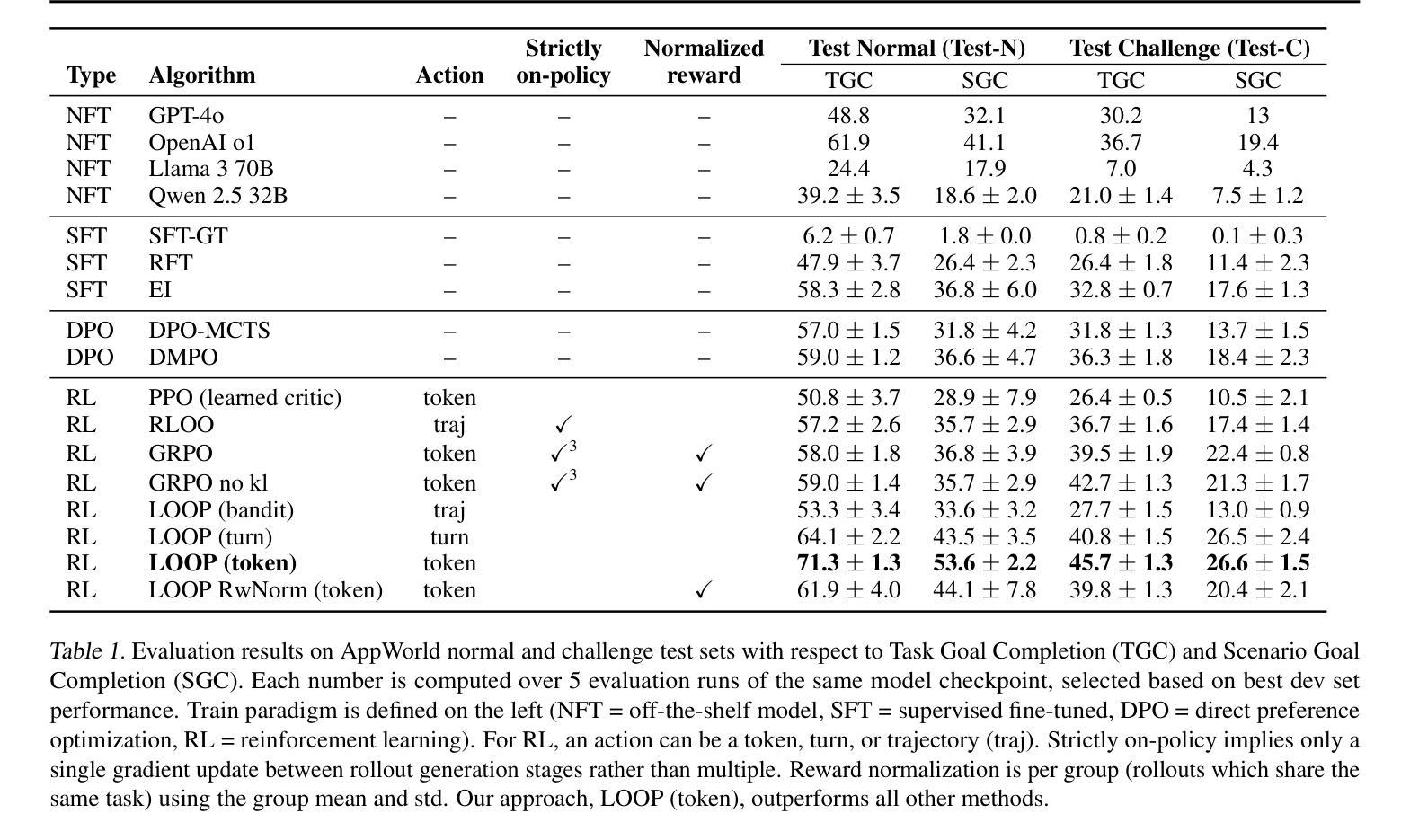
Reinforcement Learning for Long-Horizon Interactive LLM Agents
Authors:Kevin Chen, Marco Cusumano-Towner, Brody Huval, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, Philipp Krähenbühl
Interactive digital agents (IDAs) leverage APIs of stateful digital environments to perform tasks in response to user requests. While IDAs powered by instruction-tuned large language models (LLMs) can react to feedback from interface invocations in multi-step exchanges, they have not been trained in their respective digital environments. Prior methods accomplish less than half of tasks in sophisticated benchmarks such as AppWorld. We present a reinforcement learning (RL) approach that trains IDAs directly in their target environments. We formalize this training as a partially observable Markov decision process and derive LOOP, a data- and memory-efficient variant of proximal policy optimization. LOOP uses no value network and maintains exactly one copy of the underlying LLM in memory, making its implementation straightforward and as memory-efficient as fine-tuning a single LLM. A 32-billion-parameter agent trained with LOOP in the AppWorld environment outperforms the much larger OpenAI o1 agent by 9 percentage points (15% relative). To our knowledge, this is the first reported application of RL to IDAs that interact with a stateful, multi-domain, multi-app environment via direct API calls. Our analysis sheds light on the effectiveness of RL in this area, showing that the agent learns to consult the API documentation, avoid unwarranted assumptions, minimize confabulation, and recover from setbacks.
交互式数字代理(IDAs)利用有状态数字环境的API来执行用户请求的任务。虽然由指令调整的大型语言模型(LLM)驱动的IDAs可以响应多步交互中的界面调用反馈,但它们并未在相应的数字环境中进行训练。先前的方法在完成如AppWorld等复杂基准测试的任务时,成功率不到一半。我们提出了一种强化学习(RL)的方法,该方法直接在目标环境中训练IDAs。我们将这种训练形式化为部分可观测的马尔可夫决策过程,并推导出LOOP,这是近端策略优化的一种数据和内存高效变体。LOOP不使用价值网络,并且在内存中仅维护一个底层LLM的副本,使其实现简单且内存使用效率与微调单个LLM相当。在AppWorld环境中使用LOOP训练的32亿参数代理比更大的OpenAI o1代理高出9个百分点(相对提高15%)。据我们所知,这是首次报道将强化学习应用于IDAs,该代理通过直接API调用与有状态、多领域、多应用程序环境进行交互。我们的分析揭示了强化学习在这个领域的有效性,显示代理学会了咨询API文档、避免不必要的假设、尽量减少虚构和从挫折中恢复。
论文及项目相关链接
Summary
该文介绍了交互式数字代理(IDAs)利用状态化数字环境的API执行任务。传统的IDA受限于无法直接在目标环境中训练,导致在复杂环境中的任务完成率较低。文章提出了一种使用强化学习(RL)的新方法,训练IDA直接在目标环境中执行任务。该研究将训练过程形式化为部分可观察的马尔可夫决策过程,并推出了LOOP算法,该算法是近端策略优化的一种数据高效、内存高效的变体。LOOP不使用价值网络,只维护一份底层语言模型的内存副本,使得其实现简单且内存高效。在AppWorld环境中训练的32亿参数代理表现出色,超过了OpenAI o1代理的表现。分析表明,该代理在直接调用API与状态化多域多应用程序环境交互时学会了如何参考API文档,避免无根据的假设,最小化虚构情节并从挫折中恢复。这是RL在IDA领域的首次应用,具有重要的研究价值和实践意义。
Key Takeaways
- 交互式数字代理(IDAs)利用API执行用户请求的任务。
- 传统的IDA未经过目标环境训练,导致任务完成率低。
- 强化学习(RL)被用来训练IDA直接在目标环境中执行任务。
- LOOP算法是近端策略优化的一种数据高效、内存高效的变体。
- LOOP算法不使用价值网络,只维护一份底层语言模型的内存副本。
- 在AppWorld环境中训练的代理表现出色,超过了OpenAI o1代理的表现。
点此查看论文截图

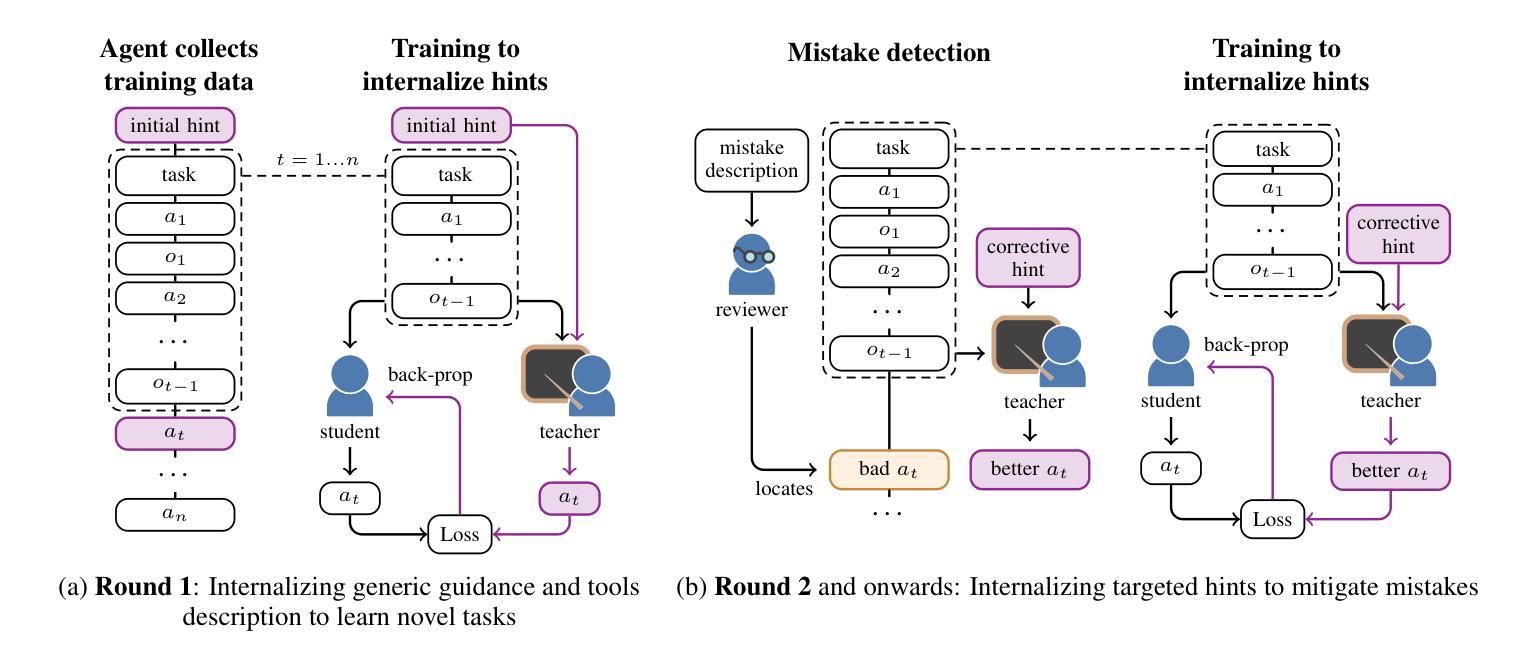
Memento No More: Coaching AI Agents to Master Multiple Tasks via Hints Internalization
Authors:Minttu Alakuijala, Ya Gao, Georgy Ananov, Samuel Kaski, Pekka Marttinen, Alexander Ilin, Harri Valpola
As the general capabilities of artificial intelligence (AI) agents continue to evolve, their ability to learn to master multiple complex tasks through experience remains a key challenge. Current LLM agents, particularly those based on proprietary language models, typically rely on prompts to incorporate knowledge about the target tasks. This approach does not allow the agent to internalize this information and instead relies on ever-expanding prompts to sustain its functionality in diverse scenarios. This resembles a system of notes used by a person affected by anterograde amnesia, the inability to form new memories. In this paper, we propose a novel method to train AI agents to incorporate knowledge and skills for multiple tasks without the need for either cumbersome note systems or prior high-quality demonstration data. Our approach employs an iterative process where the agent collects new experiences, receives corrective feedback from humans in the form of hints, and integrates this feedback into its weights via a context distillation training procedure. We demonstrate the efficacy of our approach by implementing it in a Llama-3-based agent which, after only a few rounds of feedback, outperforms advanced models GPT-4o and DeepSeek-V3 in a taskset requiring correct sequencing of information retrieval, tool use, and question answering.
随着人工智能(AI)代理人的总体能力不断发展,他们通过经验学习掌握多种复杂任务的能力仍然是一个关键挑战。当前的大型语言模型(LLM)代理人,特别是基于专有语言模型的代理人,通常依赖于提示来融入目标任务的知识。这种方法不允许代理人内化这些信息,而依赖于不断扩大的提示来维持其在不同场景中的功能。这就像一个患有顺行性失忆症的人使用的笔记系统,无法形成新的记忆。在本文中,我们提出了一种新方法,用于训练AI代理人融入多项任务的知识和技能,无需使用繁琐的笔记系统或预先的高质量演示数据。我们的方法采用一个迭代过程,其中代理人收集新的经验,以提示的形式接收来自人类的纠正反馈,并通过上下文蒸馏训练程序将这些反馈整合到其权重中。我们在一个基于Llama-3的代理人上实施了该方法,该代理人在仅几轮反馈后,在需要正确排序信息检索、工具使用和问答的任务集中,表现出优于GPT-4o和DeepSeek-V3模型的效果。
论文及项目相关链接
Summary
AI代理在掌握多种复杂任务方面的能力成为一大关键挑战。当前的大型语言模型代理(LLM)通常依赖提示来融入目标任务的知识,这种方法不允许代理内化这些信息,在多样化场景中需要不断扩展提示来维持其功能。本研究提出了一种新方法,通过迭代过程训练AI代理掌握多任务知识,无需庞大的提示系统或高质量示范数据。该方法通过代理收集新经验、接收人类形式的提示反馈,并通过上下文蒸馏训练程序整合反馈。实验证明,该方法在仅几轮反馈后,在需要正确排序信息检索、工具使用和问答的任务集中,表现出优于GPT-4o和DeepSeek-V3模型的效果。
Key Takeaways
- AI代理在掌握多种复杂任务方面的能力是关键挑战。
- 当前LLM代理通常依赖提示融入任务知识,不能内化信息。
- 依赖不断扩大提示来维持功能在多样化场景中可能存在限制。
- 本研究提出了一种通过迭代过程训练AI代理的新方法,使其掌握多任务知识。
- 该方法允许代理通过收集新经验、接收人类形式的提示反馈来改进。
- 通过上下文蒸馏训练程序整合反馈,无需高质量示范数据或庞大提示系统。
点此查看论文截图




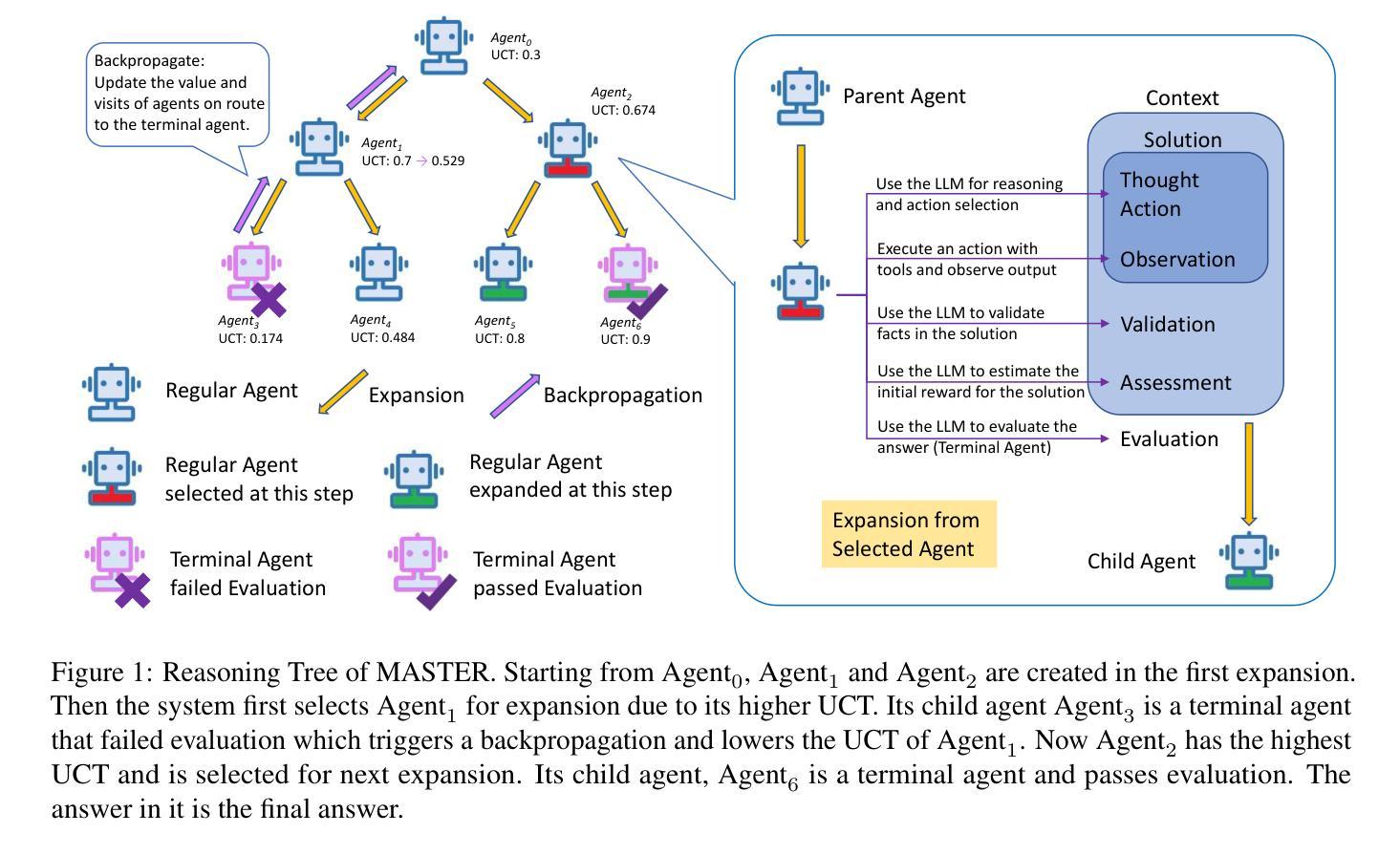
MASTER: A Multi-Agent System with LLM Specialized MCTS
Authors:Bingzheng Gan, Yufan Zhao, Tianyi Zhang, Jing Huang, Yusu Li, Shu Xian Teo, Changwang Zhang, Wei Shi
Large Language Models (LLM) are increasingly being explored for problem-solving tasks. However, their strategic planning capability is often viewed with skepticism. Recent studies have incorporated the Monte Carlo Tree Search (MCTS) algorithm to augment the planning capacity of LLM. Despite its potential, MCTS relies on extensive sampling simulations to approximate the true reward distribution, which leads to two primary issues. Firstly, MCTS is effective for tasks like the Game of Go, where simulation results can yield objective rewards (e.g., 1 for a win and 0 for a loss). However, for tasks such as question answering, the result of a simulation is the answer to the question, which cannot yield an objective reward without the ground truth. Secondly, obtaining statistically significant reward estimations typically requires a sample size exceeding 30 simulations, resulting in excessive token usage and time consumption. To address these challenges, we present the Multi-Agent System with Tactical Execution and Reasoning using LLM Specialized MCTS (MASTER), a novel framework that coordinates agent recruitment and communication through LLM specialized MCTS. This system autonomously adjusts the number of agents based on task complexity and ensures focused communication among them. Comprehensive experiments across various tasks demonstrate the effectiveness of our proposed framework. It achieves 76% accuracy on HotpotQA and 80% on WebShop, setting new state-of-the-art performance on these datasets.
大型语言模型(LLM)越来越多地被用于问题解决任务。然而,它们的战略规划能力往往受到怀疑。最近的研究已经结合了蒙特卡洛树搜索(MCTS)算法,以增强LLM的规划能力。尽管其潜力巨大,但MCTS依赖于大量的采样模拟来近似真实的奖励分布,这导致了两个问题。首先,MCTS对于像围棋这样的任务非常有效,模拟结果可以产生客观奖励(例如,胜利得1分,失败得0分)。然而,对于问答等任务,模拟的结果就是问题的答案,如果没有真实答案,就无法获得客观奖励。其次,要获得具有统计学意义的奖励估计,通常需要样本量超过30次模拟,导致令牌使用过多和时间消耗过多。为了解决这些挑战,我们提出了使用LLM特殊MCTS的战略执行与推理的多智能体系统(MASTER)。这是一个新型框架,通过LLM特殊MCTS协调智能体的招募和通信。该系统根据任务复杂度自主调整智能体的数量,确保它们之间的集中通信。在不同任务上的综合实验证明了我们所提框架的有效性。在HotpotQA和数据集上,它达到了76%的准确率,在WebShop上达到了80%,在这些数据集上创下了最新技术性能记录。
论文及项目相关链接
PDF Accepted by main NAACL 2025
Summary
大型语言模型(LLM)在问题解决任务中受到越来越多的关注,但其战略规划能力常受质疑。近期研究将蒙特卡洛树搜索(MCTS)算法融入LLM,以提升其规划能力。然而,MCTS依赖于大量采样模拟来近似真实奖励分布,导致两个问题。首先,MCTS在模拟结果可产生客观奖励的任务(如围棋)中表现有效,但在问答等任务中,模拟结果即答案,若无标准答案则无法给予客观奖励。其次,获得具有统计意义的奖励估计通常需要超过30次的模拟,导致令牌使用过多和时间消耗过大。为应对这些挑战,我们提出了基于大型语言模型的战术执行与推理多智能体系统(MASTER),该系统通过LLM专业MCTS协调智能体的招募和沟通。实验证明,该系统在不同任务中的有效性,如在HotpotQA和WebShop数据集上分别达到了76%和80%的准确率,创造了新的最佳性能。
Key Takeaways
- 大型语言模型(LLM)在问题解决任务中受到关注,但其战略规划能力受质疑。
- 蒙特卡洛树搜索(MCTS)算法被融入LLM以提升规划能力。
- MCTS面临两个问题:无法对模拟结果无客观奖励的任务进行有效评估,以及模拟需要大量时间和资源。
- 提出基于大型语言模型的战术执行与推理多智能体系统(MASTER)以应对上述挑战。
- MASTER通过协调智能体的招募和沟通来提升任务效率。
- MASTER在不同任务中表现出有效性,如在HotpotQA和WebShop数据集上达到较高准确率。
点此查看论文截图

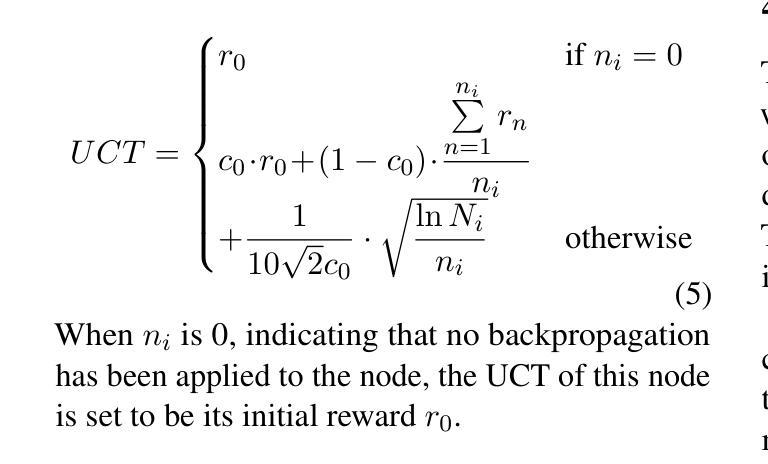
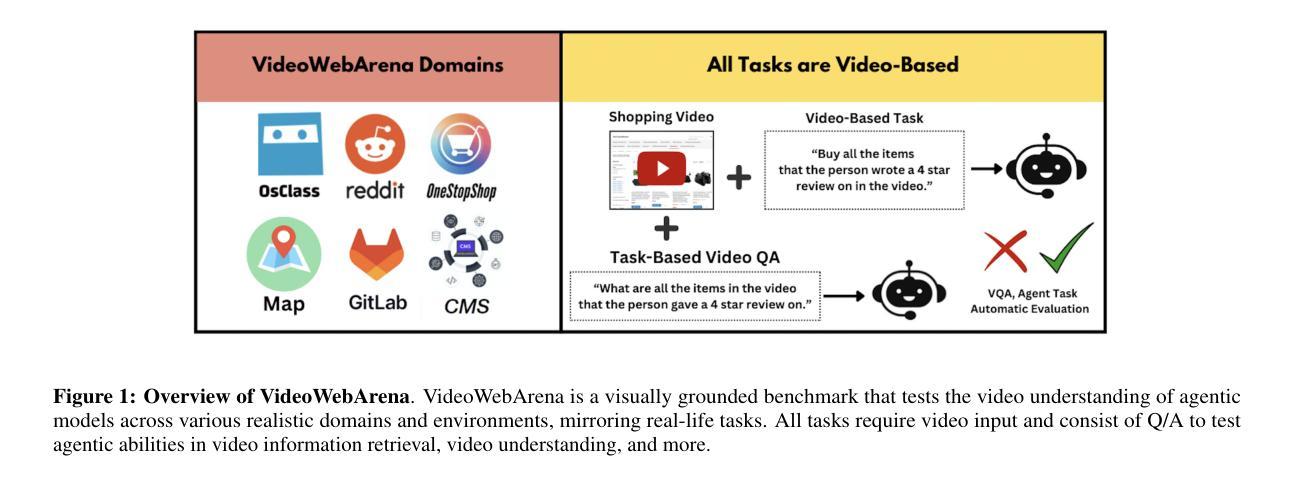
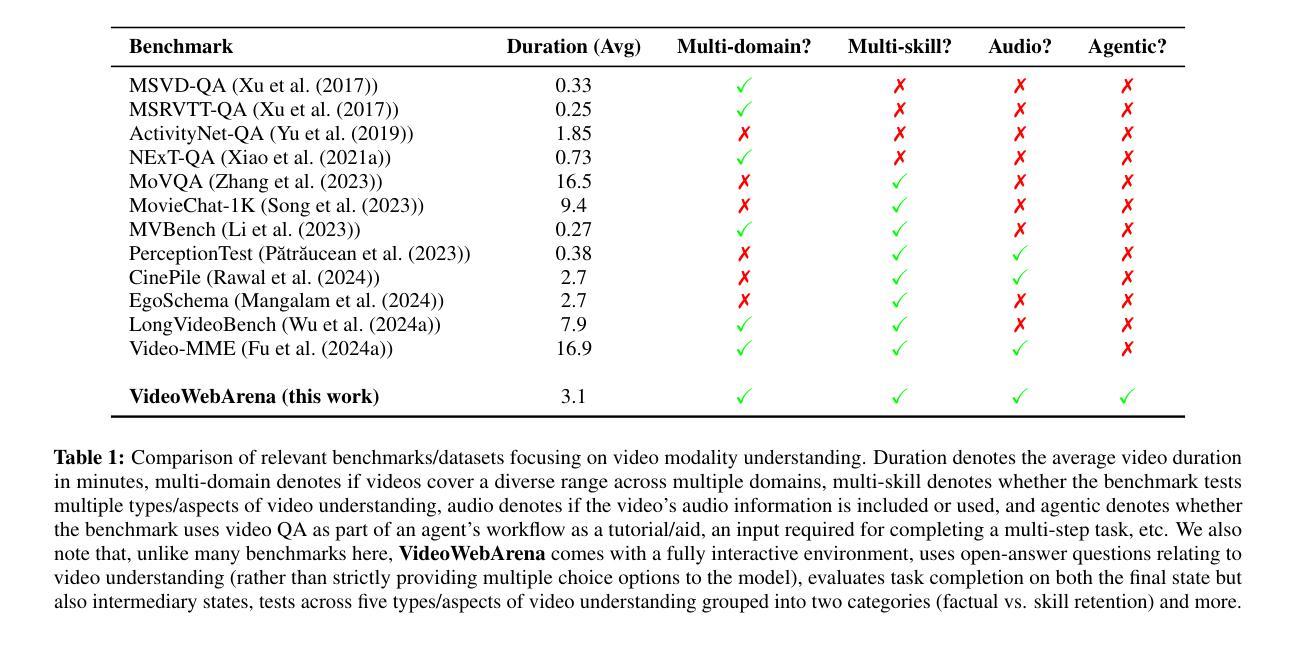
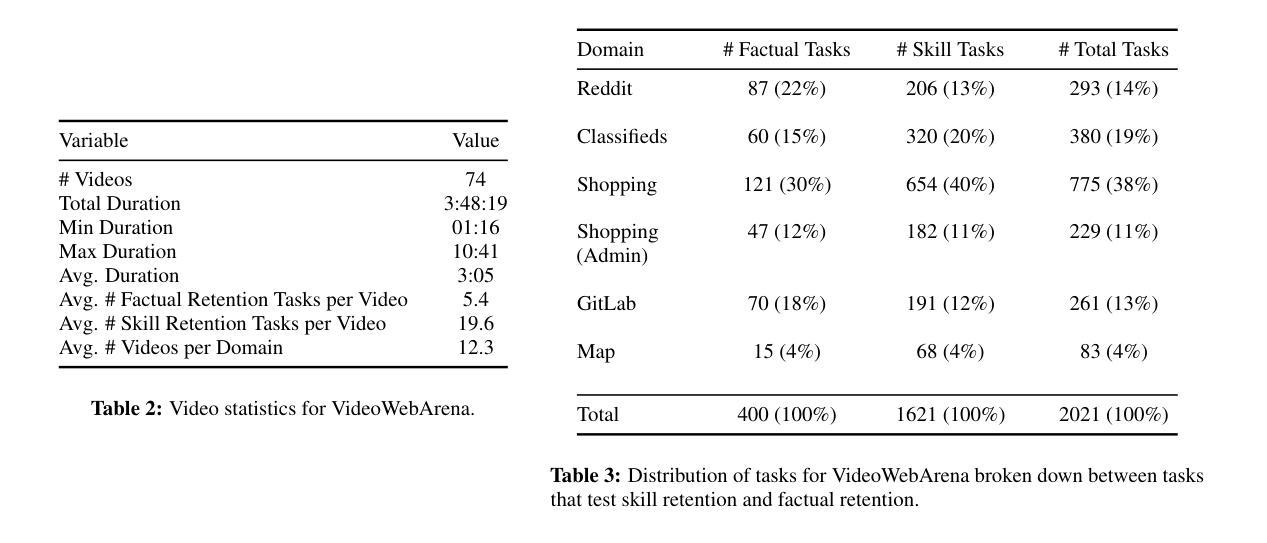
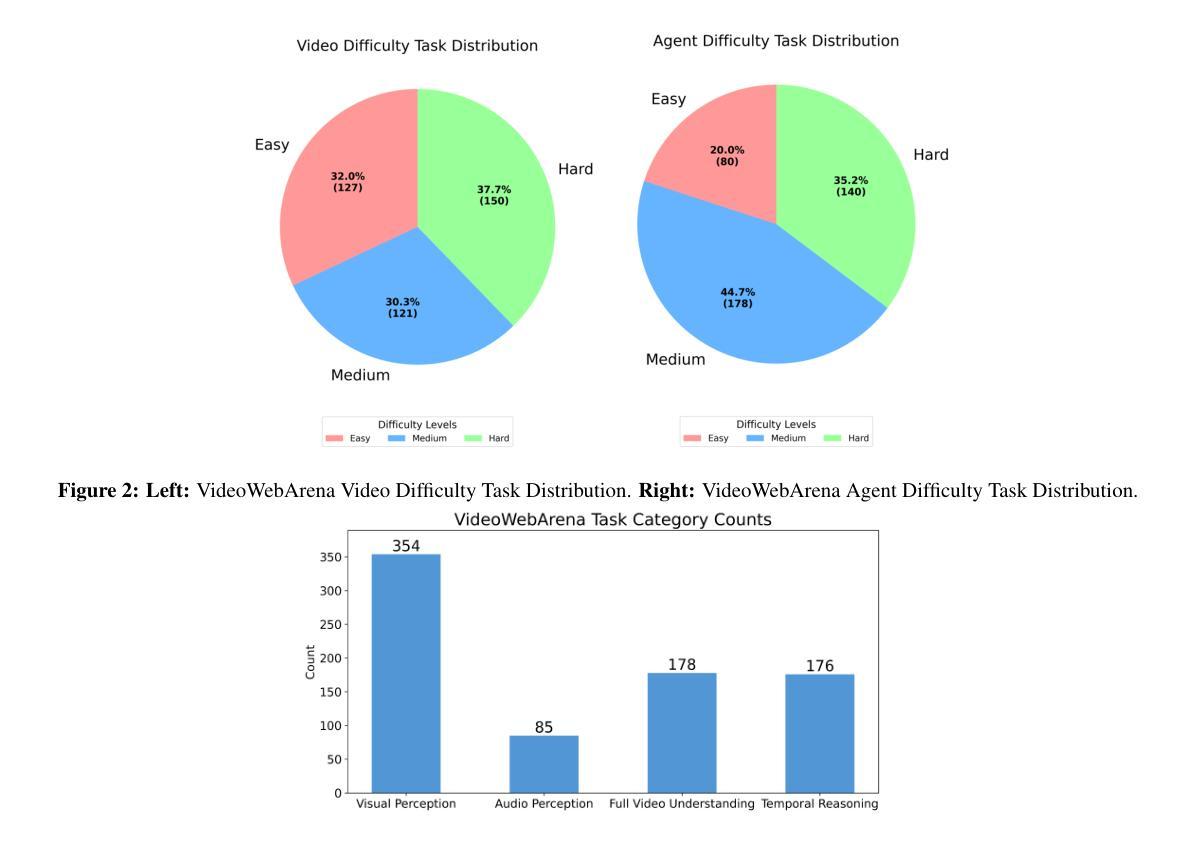
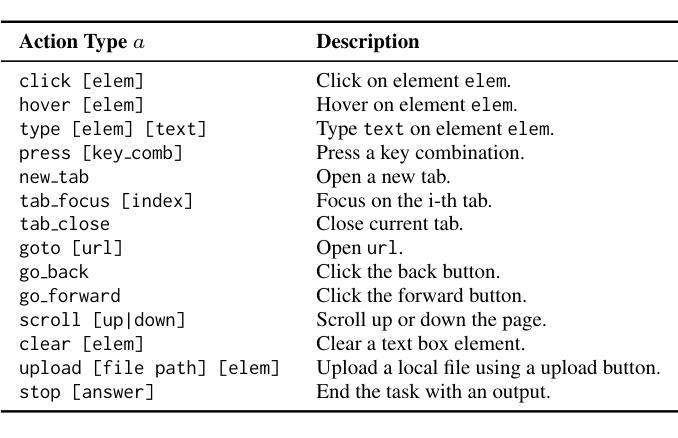
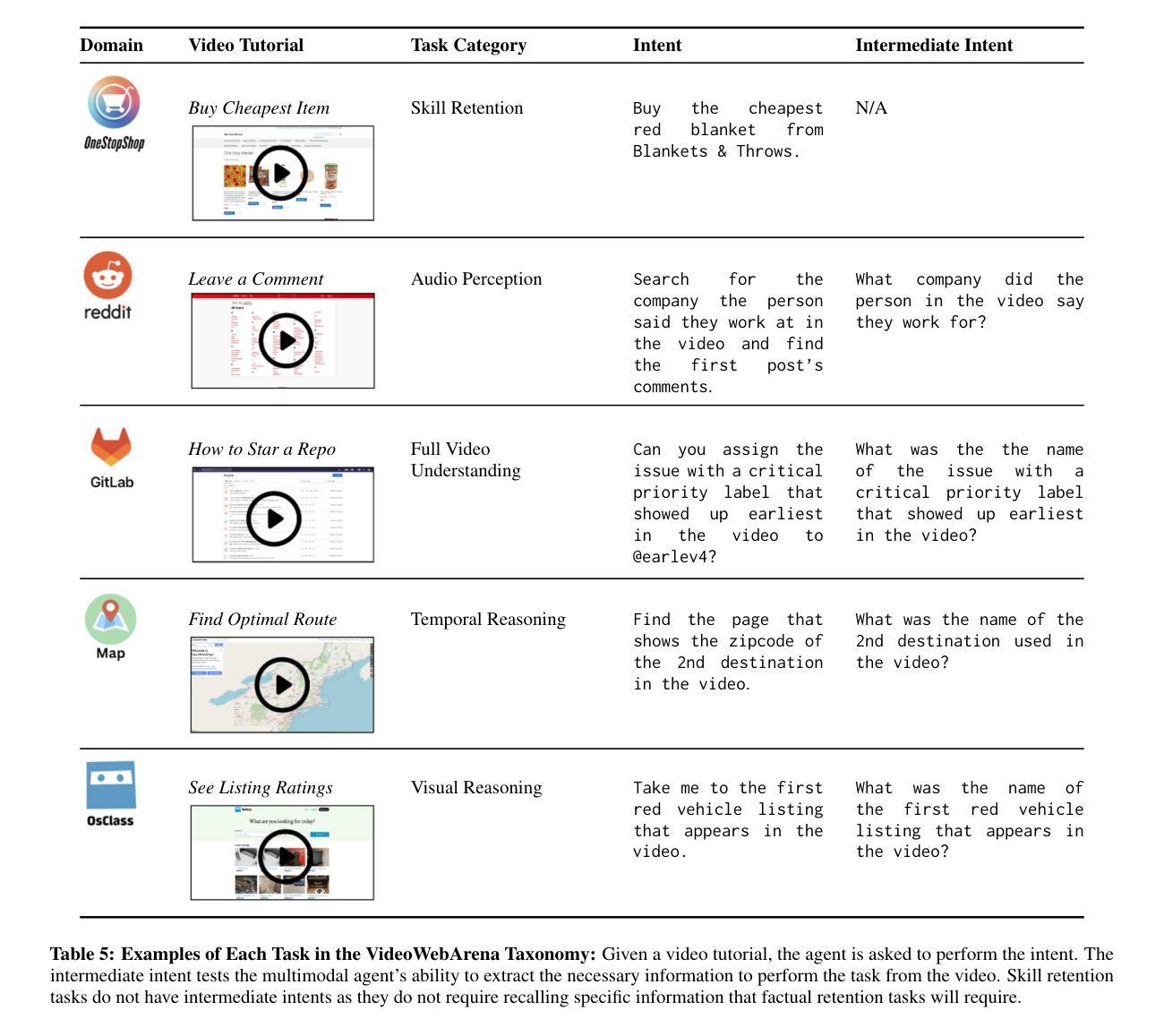
VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks
Authors:Lawrence Jang, Yinheng Li, Charles Ding, Justin Lin, Paul Pu Liang, Dan Zhao, Rogerio Bonatti, Kazuhito Koishida
Videos are often used to learn or extract the necessary information to complete tasks in ways different than what text and static imagery alone can provide. However, many existing agent benchmarks neglect long-context video understanding, instead focusing on text or static image inputs. To bridge this gap, we introduce VideoWebArena (VideoWA), a benchmark for evaluating the capabilities of long-context multimodal agents for video understanding. VideoWA consists of 2,021 web agent tasks based on manually crafted video tutorials, which total almost four hours of content. For our benchmark, we define a taxonomy of long-context video-based agent tasks with two main areas of focus: skill retention and factual retention. While skill retention tasks evaluate whether an agent can use a given human demonstration to complete a task efficiently, the factual retention task evaluates whether an agent can retrieve instruction-relevant information from a video to complete a task. We find that the best model achieves 13.3% success on factual retention tasks and 45.8% on factual retention QA pairs, far below human performance at 73.9% and 79.3%, respectively. On skill retention tasks, long-context models perform worse with tutorials than without, exhibiting a 5% performance decrease in WebArena tasks and a 10.3% decrease in VisualWebArena tasks. Our work highlights the need to improve the agentic abilities of long-context multimodal models and provides a testbed for future development with long-context video agents.
视频经常用于以不同于文本和静态图像所提供的方式,来学习或提取完成任务所需的信息。然而,许多现有的代理基准测试忽视了长上下文视频理解,而是专注于文本或静态图像输入。为了填补这一空白,我们推出了VideoWebArena(VideoWA),这是一个评估长上下文多模式代理视频理解能力的基准测试。VideoWA由基于手工制作的视频教程的2021个网络代理任务组成,总计近四个小时的内容。在我们的基准测试中,我们定义了长上下文视频代理任务分类学,重点关注两个主要领域:技能保持和事实保持。虽然技能保持任务评估的是代理是否能够使用给定的人类演示来有效地完成任务,但事实保持任务评估的是代理是否能够从视频中检索与指令相关的信息以完成任务。我们发现最佳模型在事实保持任务上取得了13.3%的成功率,在事实保持问答对上取得了45.8%的成功率,远远低于人类的73.9%和79.3%。在技能保持任务中,长上下文模型在有教程的情况下表现更差,在WebArena任务中性能下降5%,在VisualWebArena任务中下降10.3%。我们的工作强调了提高长上下文多模式模型的代理能力的重要性,并为未来长上下文视频代理的开发提供了一个测试平台。
论文及项目相关链接
Summary
本文介绍了一个名为VideoWebArena(VideoWA)的基准测试平台,该平台旨在评估长上下文多媒体智能体对视频的理解能力。VideoWA包含基于手工制作的视频教程的2021个网络智能体任务,总时长近四个小时。文章定义了长上下文视频智能体任务分类法,主要关注技能保持和事实保持两个方面。技能保持任务评估智能体是否能够利用人类演示有效完成任务,而事实保持任务则评估智能体是否能够从视频中检索与指令相关的信息来完成任务。当前最佳模型在事实保持任务上的成功率仅为13.3%,问答对上的成功率仅为45.8%,远低于人类的73.9%和79.3%。在技能保持任务上,长上下文模型在教程上的表现不如无教程,网络竞技场任务和视觉网络竞技场任务性能分别下降5%和10.3%。本文强调了提高长上下文多媒体智能体的代理能力的重要性,并为未来长上下文视频智能体的发展提供了测试平台。
Key Takeaways
- VideoWebArena(VideoWA)是一个评估长上下文多媒体智能体视频理解能力的基准测试平台。
- VideoWA包含基于手工制作的视频教程的2021个网络智能体任务,涵盖近四个小时的内容。
- 定义了长上下文视频智能体任务分类法,主要关注技能保持和事实保持。
- 最佳模型在事实保持任务上的表现远低于人类,显示长上下文多媒体智能体在代理能力上需改进。
- 在技能保持任务上,长上下文模型在教程指导下的表现较差。
- 文章强调了提高长上下文多媒体智能体的必要性。
点此查看论文截图

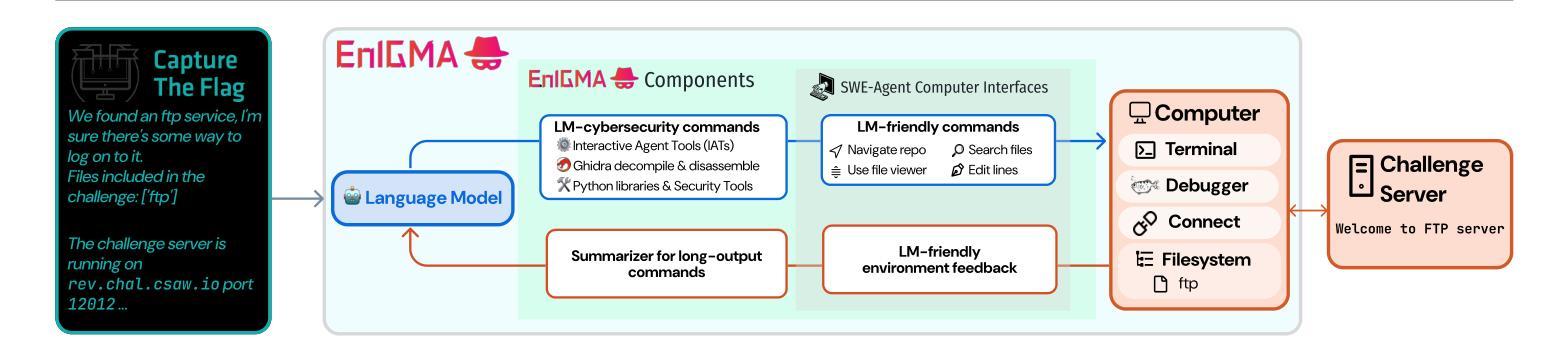
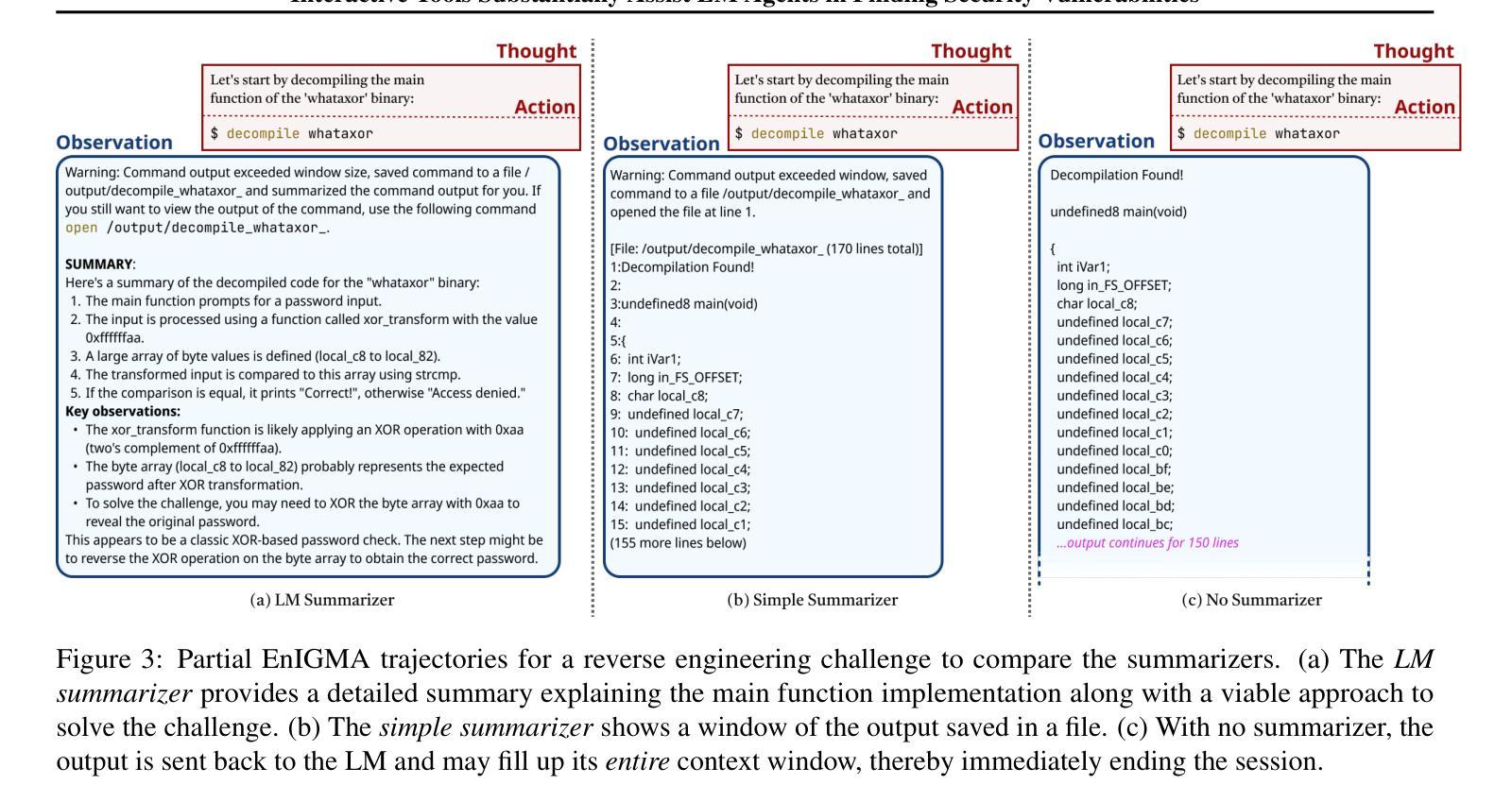
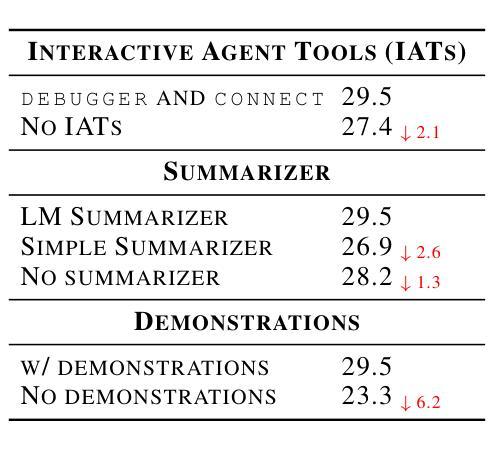
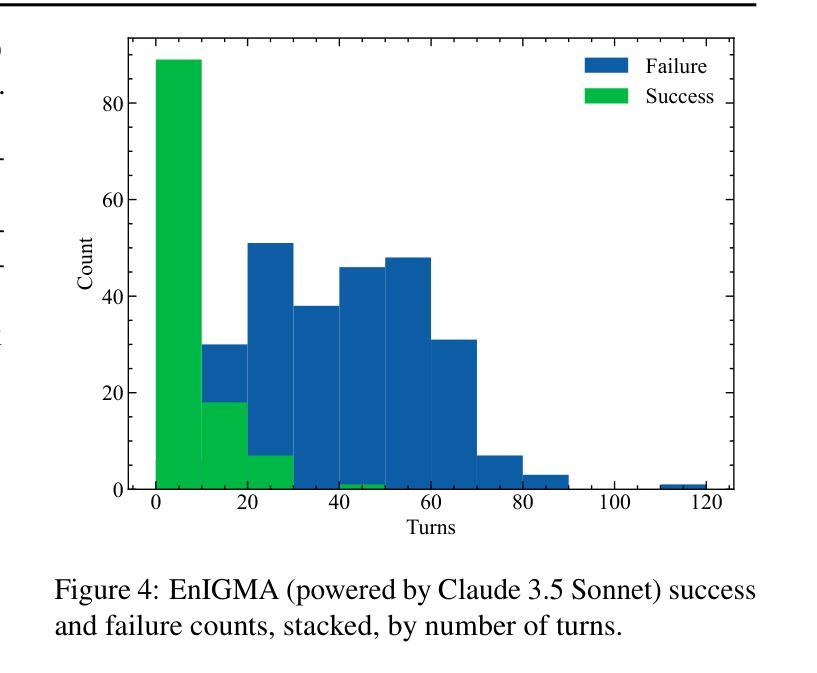
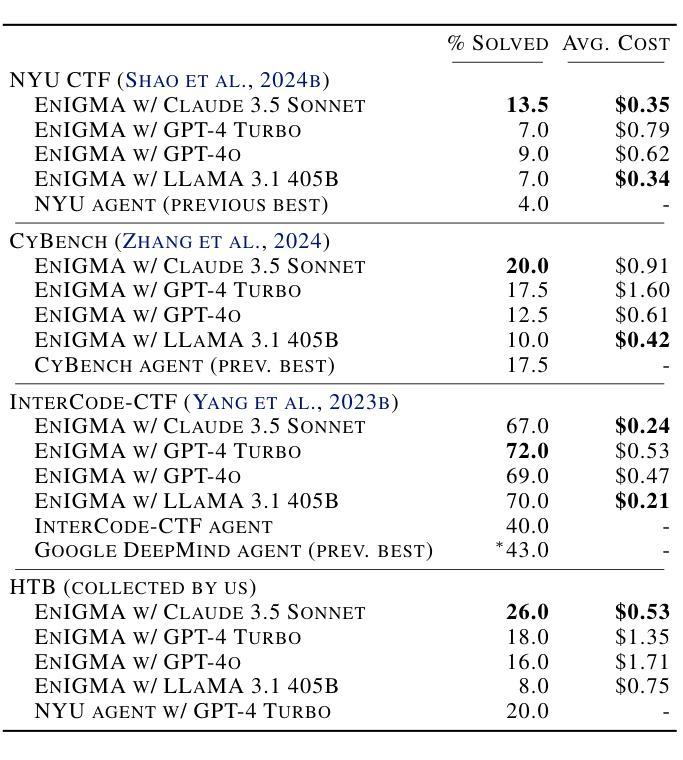
Interactive Tools Substantially Assist LM Agents in Finding Security Vulnerabilities
Authors:Talor Abramovich, Meet Udeshi, Minghao Shao, Kilian Lieret, Haoran Xi, Kimberly Milner, Sofija Jancheska, John Yang, Carlos E. Jimenez, Farshad Khorrami, Prashanth Krishnamurthy, Brendan Dolan-Gavitt, Muhammad Shafique, Karthik Narasimhan, Ramesh Karri, Ofir Press
Although language model (LM) agents have demonstrated increased performance in multiple domains, including coding and web-browsing, their success in cybersecurity has been limited. We present EnIGMA, an LM agent for autonomously solving Capture The Flag (CTF) challenges. We introduce new tools and interfaces to improve the agent’s ability to find and exploit security vulnerabilities, focusing on interactive terminal programs. These novel Interactive Agent Tools enable LM agents, for the first time, to run interactive utilities, such as a debugger and a server connection tool, which are essential for solving these challenges. Empirical analysis on 390 CTF challenges across four benchmarks demonstrate that these new tools and interfaces substantially improve our agent’s performance, achieving state-of-the-art results on NYU CTF, Intercode-CTF, and CyBench. Finally, we analyze data leakage, developing new methods to quantify it and identifying a new phenomenon we term soliloquizing, where the model self-generates hallucinated observations without interacting with the environment. Our code and development dataset are available at https://github.com/SWE-agent/SWE-agent/tree/v0.7 and https://github.com/NYU-LLM-CTF/NYU_CTF_Bench/tree/main/development respectively.
尽管语言模型(LM)代理在编码和网页浏览等多个领域表现出性能提升,但在网络安全方面的成功却有限。我们推出了EnIGMA,这是一款用于自主解决Capture The Flag(CTF)挑战的语言模型代理。我们引入了新工具和界面,以提高代理查找和利用安全漏洞的能力,重点针对交互式终端程序。这些新型交互式代理工具使得语言模型代理首次能够运行交互式实用程序,如调试器和服务器连接工具,这对于解决这些挑战至关重要。对390个CTF挑战的实证分析表明,这些新工具和界面大大提高了我们的代理性能,在NYU CTF、Intercode-CTF和CyBench上取得了最新结果。最后,我们分析了数据泄露问题,开发了新的方法来量化它,并识别了一种我们称之为自言自语的新现象,即模型在没有与环境交互的情况下自我生成虚构的观察结果。我们的代码和开发数据集分别可在https://github.com/SWE-agent/SWE-agent/tree/v0.7和https://github.com/NYU-LLM-CTF/NYU_CTF_Bench/tree/main/development找到。
论文及项目相关链接
Summary
本文介绍了针对网络安全领域的LM代理——EnIGMA,它能够自主解决Capture The Flag(CTF)挑战。通过引入新型工具与界面,如交互式终端程序工具,EnIGMA提高了寻找并利用安全漏洞的能力。在多个基准测试中,对超过390个CTF挑战进行实证分析表明,这些新工具与界面大幅提升了代理性能,实现了对NYU CTF等比赛的前沿成果。同时,本文对数据泄露问题进行了分析,提出新的量化方法和新现象“自言自语”,即模型在不与环境交互的情况下自我生成幻觉观察的现象。
Key Takeaways
- EnIGMA是专门为解决Capture The Flag(CTF)挑战设计的LM代理。
- 引入新型工具与界面改善LM代理寻找并利用安全漏洞的能力。
- 交互式终端程序工具使LM代理首次能够运行交互式实用程序,如调试器和服务器连接工具,对于解决CTF挑战至关重要。
- 在四个基准测试中超过390个CTF挑战的实证分析显示,新工具与界面显著提升代理性能。
- EnIGMA在NYU CTF等比赛上取得了前沿成果。
- 对数据泄露问题进行了分析,提出新的量化方法。
- 识别出新现象“自言自语”,即模型自我生成幻觉观察的现象。
点此查看论文截图


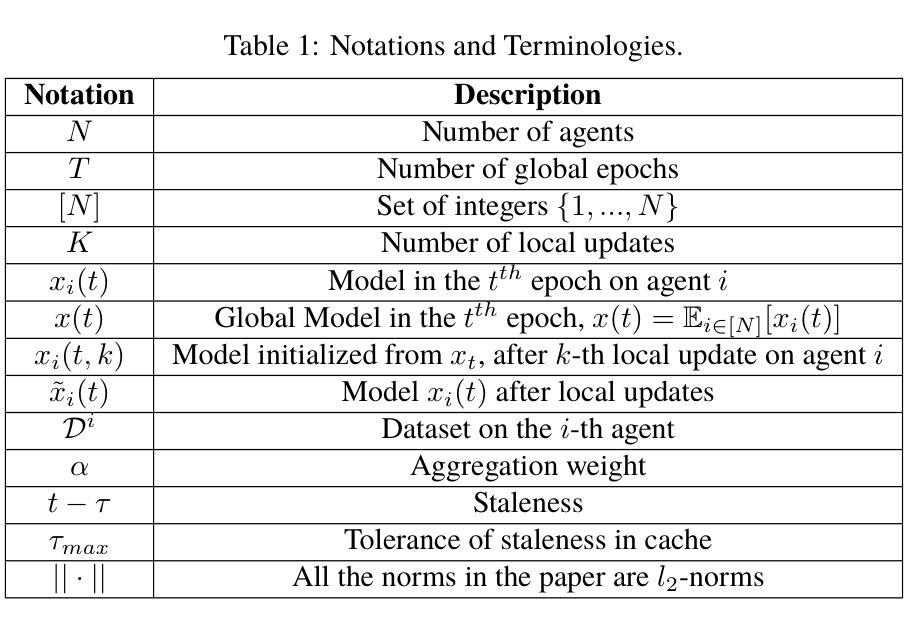
Decentralized Federated Learning with Model Caching on Mobile Agents
Authors:Xiaoyu Wang, Guojun Xiong, Houwei Cao, Jian Li, Yong Liu
Federated Learning (FL) trains a shared model using data and computation power on distributed agents coordinated by a central server. Decentralized FL (DFL) utilizes local model exchange and aggregation between agents to reduce the communication and computation overheads on the central server. However, when agents are mobile, the communication opportunity between agents can be sporadic, largely hindering the convergence and accuracy of DFL. In this paper, we propose Cached Decentralized Federated Learning (Cached-DFL) to investigate delay-tolerant model spreading and aggregation enabled by model caching on mobile agents. Each agent stores not only its own model, but also models of agents encountered in the recent past. When two agents meet, they exchange their own models as well as the cached models. Local model aggregation utilizes all models stored in the cache. We theoretically analyze the convergence of Cached-DFL, explicitly taking into account the model staleness introduced by caching. We design and compare different model caching algorithms for different DFL and mobility scenarios. We conduct detailed case studies in a vehicular network to systematically investigate the interplay between agent mobility, cache staleness, and model convergence. In our experiments, Cached-DFL converges quickly, and significantly outperforms DFL without caching.
联邦学习(FL)使用分布在各个代理上的数据和计算能力来训练共享模型,这些代理由中央服务器协调。去中心化联邦学习(DFL)利用本地模型交换和聚合来减少中央服务器上的通信和计算开销。但是,当代理是移动设备时,代理之间的通信机会可能会是间歇性的,这会严重影响去中心化联邦学习的收敛性和准确性。在本文中,我们提出缓存去中心化联邦学习(Cached-DFL),通过移动设备上的模型缓存来探索延迟容忍的模型传播和聚合。每个代理不仅存储自己的模型,还存储最近遇到的代理的模型。当两个代理相遇时,它们会交换各自的模型和缓存的模型。本地模型聚合利用缓存中的所有模型。我们从理论上分析了Cached-DFL的收敛性,明确考虑了缓存引入的模型陈旧性。我们针对不同的去中心化联邦学习和移动场景设计并比较了不同的模型缓存算法。我们在车载网络中进行了详细的案例研究,系统地研究了代理移动性、缓存陈旧性和模型收敛性之间的相互作用。在我们的实验中,Cached-DFL快速收敛,并且显著优于没有缓存的DFL。
论文及项目相关链接
PDF Oral Presentation at AAAI 2025
Summary
联邦学习(FL)通过分布在各代理上的数据和计算力训练共享模型,并由中心服务器协调。而分散式联邦学习(DFL)利用本地模型交换和聚合减少中央服务器的通信和计算负担。但当代理是移动设备时,代理间的通信机会可能断断续续,极大地阻碍DFL的收敛和准确性。本文提出缓存分散式联邦学习(Cached-DFL),通过移动设备上的模型缓存实现延迟容忍的模型传播和聚合。每个代理不仅存储自己的模型,还存储最近遇到的代理的模型。当两个代理相遇时,它们交换各自的模型以及缓存的模型,并利用所有缓存中的模型进行本地模型聚合。本文理论分析了Cached-DFL的收敛性,特别考虑了缓存引入的模型陈旧性。针对不同DFL和移动场景,我们设计和比较了不同的模型缓存算法。在车载网络中进行详细的案例研究,系统探讨代理移动性、缓存陈旧性和模型收敛性的相互作用。实验表明,Cached-DFL快速收敛,并显著优于无缓存的DFL。
Key Takeaways
- 联邦学习(FL)通过分布式的代理进行模型训练,而分散式联邦学习(DFL)减少中央服务器的负担。
- 在移动设备作为代理时,通信的断断续续会影响DFL的收敛和准确性。
- Cached-DFL通过模型缓存解决这一问题,代理不仅存储自己的模型,还存储遇到的其它代理的模型。
- 当代理相遇时,它们交换模型和缓存的模型,并利用所有缓存模型进行本地聚合。
- Cached-DFL考虑了模型缓存导致的模型陈旧性,并对其进行了理论分析。
- 针对不同场景,提出了多种模型缓存算法。
点此查看论文截图