⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-06 更新
FewTopNER: Integrating Few-Shot Learning with Topic Modeling and Named Entity Recognition in a Multilingual Framework
Authors:Ibrahim Bouabdallaoui, Fatima Guerouate, Samya Bouhaddour, Chaimae Saadi, Mohammed Sbihi
We introduce FewTopNER, a novel framework that integrates few-shot named entity recognition (NER) with topic-aware contextual modeling to address the challenges of cross-lingual and low-resource scenarios. FewTopNER leverages a shared multilingual encoder based on XLM-RoBERTa, augmented with language-specific calibration mechanisms, to generate robust contextual embeddings. The architecture comprises a prototype-based entity recognition branch, employing BiLSTM and Conditional Random Fields for sequence labeling, and a topic modeling branch that extracts document-level semantic features through hybrid probabilistic and neural methods. A cross-task bridge facilitates dynamic bidirectional attention and feature fusion between entity and topic representations, thereby enhancing entity disambiguation by incorporating global semantic context. Empirical evaluations on multilingual benchmarks across English, French, Spanish, German, and Italian demonstrate that FewTopNER significantly outperforms existing state-of-the-art few-shot NER models. In particular, the framework achieves improvements of 2.5-4.0 percentage points in F1 score and exhibits enhanced topic coherence, as measured by normalized pointwise mutual information. Ablation studies further confirm the critical contributions of the shared encoder and cross-task integration mechanisms to the overall performance. These results underscore the efficacy of incorporating topic-aware context into few-shot NER and highlight the potential of FewTopNER for robust cross-lingual applications in low-resource settings.
我们介绍了FewTopNER,这是一个新型框架,它将少量命名实体识别(NER)与主题感知上下文建模相结合,以解决跨语言和低资源场景的挑战。FewTopNER利用基于XLM-RoBERTa的共享多语言编码器,辅以语言特定的校准机制,生成稳健的上下文嵌入。架构包括一个基于原型的实体识别分支,采用BiLSTM和条件随机场进行序列标注,以及一个主题建模分支,通过混合概率和神经方法提取文档级语义特征。跨任务桥梁促进了实体和主题表示之间的动态双向注意力和特征融合,从而通过融入全局语义上下文增强实体消歧。在英语、法语、西班牙语、德语和意大利语的多语言基准测试上的经验评估表明,FewTopNER显著优于现有的最先进的少量命名实体识别模型。特别是,该框架在F1分数上提高了2.5-4.0个百分点,并且表现出增强的主题连贯性,如通过归一化点互信息所衡量。消融研究进一步证实了共享编码器和跨任务整合机制对整体性能的关键贡献。这些结果强调了将主题感知上下文纳入少量命名实体识别的有效性,并突出了FewTopNER在低资源设置中的稳健跨语言应用的潜力。
论文及项目相关链接
PDF Code source : https://github.com/ibrahimself/FewTopNER/
Summary
FewTopNER是一个融合少样本命名实体识别(NER)和主题感知上下文建模的新框架,旨在应对跨语言和低资源场景的挑战。它通过共享的多语言编码器生成稳健的上下文嵌入,并结合原型基础的实体识别分支和主题建模分支,实现了强大的性能。该框架在跨任务桥梁的协助下,实现了实体表示和主题表示之间的动态双向注意力和特征融合,从而通过引入全局语义上下文增强了实体消歧。在多语言基准测试上的实证评估表明,FewTopNER显著优于现有的最先进的少样本NER模型,特别是在F1分数上提高了2.5-4.0个百分点。
Key Takeaways
- FewTopNER框架融合了少样本命名实体识别(NER)和主题感知上下文建模。
- 采用共享的多语言编码器,基于XLM-RoBERTa,并增加了语言特定的校准机制,生成稳健的上下文嵌入。
- 架构包括原型基础的实体识别分支和主题建模分支。
- 通过跨任务桥梁实现实体表示和主题表示之间的动态双向注意力和特征融合。
- 在多个语言的基准测试上表现出卓越性能,显著优于其他少样本NER模型。
- 框架提高了F1分数,增强了主题连贯性。
点此查看论文截图

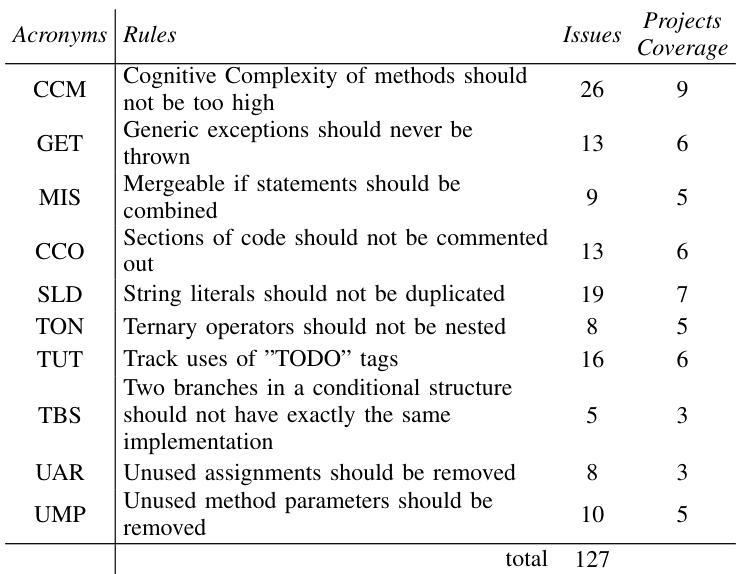
Evaluating the Effectiveness of LLMs in Fixing Maintainability Issues in Real-World Projects
Authors:Henrique Nunes, Eduardo Figueiredo, Larissa Rocha, Sarah Nadi, Fischer Ferreira, Geanderson Esteves
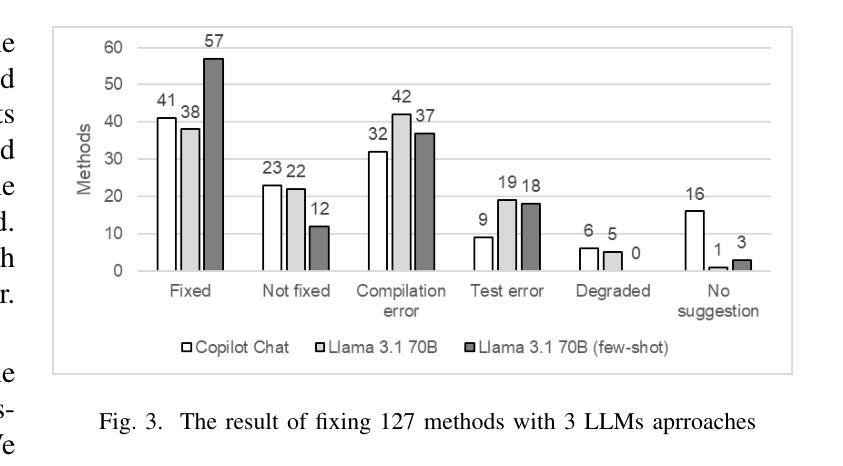
Large Language Models (LLMs) have gained attention for addressing coding problems, but their effectiveness in fixing code maintainability remains unclear. This study evaluates LLMs capability to resolve 127 maintainability issues from 10 GitHub repositories. We use zero-shot prompting for Copilot Chat and Llama 3.1, and few-shot prompting with Llama only. The LLM-generated solutions are assessed for compilation errors, test failures, and new maintainability problems. Llama with few-shot prompting successfully fixed 44.9% of the methods, while Copilot Chat and Llama zero-shot fixed 32.29% and 30%, respectively. However, most solutions introduced errors or new maintainability issues. We also conducted a human study with 45 participants to evaluate the readability of 51 LLM-generated solutions. The human study showed that 68.63% of participants observed improved readability. Overall, while LLMs show potential for fixing maintainability issues, their introduction of errors highlights their current limitations.
大型语言模型(LLM)在处理编程问题方面引起了人们的关注,但它们在解决代码可维护性方面的有效性尚不清楚。本研究旨在评估LLM解决来自GitHub上10个仓库的127个可维护性问题的能力。我们对Copilot Chat和Llama 3.1使用零样本提示,只对Llama使用小样本提示。评估LLM生成的解决方案是否存在编译错误、测试失败以及新的可维护性问题。使用小样本提示的Llama成功修复了44.9%的方法,而Copilot Chat和Llama的零样本修复分别为32.29%和30%。然而,大多数解决方案都引入了错误或新的可维护性问题。我们还进行了涉及45名参与者的研究,以评估LLM生成的51个解决方案的可读性。人类研究表明,68.63%的参与者观察到可读性有所提高。总体而言,虽然LLM在解决可维护性问题方面显示出潜力,但它们引入的错误突出了当前的局限性。
论文及项目相关链接
Summary
大型语言模型(LLMs)在解决编码问题方面备受关注,但其对代码可维护性的修复效果尚不清楚。本研究评估了LLMs解决来自GitHub仓库的127个可维护问题的能力。通过Copilot Chat的零射提示和Llama 3.1以及只有Llama的少量射击提示来评估。LLM生成的解决方案会经过编译错误测试、测试失败以及新的可维护性问题的评估。结果显示,使用少量射击提示的Llama成功修复了44.9%的方法,而Copilot Chat和Llama的零射修复了32.29%和30%。但大多数解决方案都引入了错误或新的可维护性问题。同时,本研究还进行了包含45名参与者的人类研究,以评估LLM生成的解决方案的可读性。结果显示,有68.63%的参与者认为可读性有所提高。总体而言,虽然LLMs在修复可维护性问题方面显示出潜力,但它们引入的错误也凸显了当前存在的局限性。
Key Takeaways
- 大型语言模型(LLMs)被用来解决编码问题中的可维护性问题。
- LLMs在解决GitHub仓库中的可维护性问题上的成功率达到了一定的水平。
- 使用不同的提示方法(如零射和少量射击提示)对LLMs的效果有所影响。
- LLM生成的解决方案有时会导致新的错误或可维护性问题。
- 人类研究结果表明LLM生成的解决方案在某些情况下的可读性有所提高。
- LLMs在修复可维护性问题方面具有潜力,但仍存在局限性。
点此查看论文截图



Adaptive Observation Cost Control for Variational Quantum Eigensolvers
Authors:Christopher J. Anders, Kim A. Nicoli, Bingting Wu, Naima Elosegui, Samuele Pedrielli, Lena Funcke, Karl Jansen, Stefan Kühn, Shinichi Nakajima
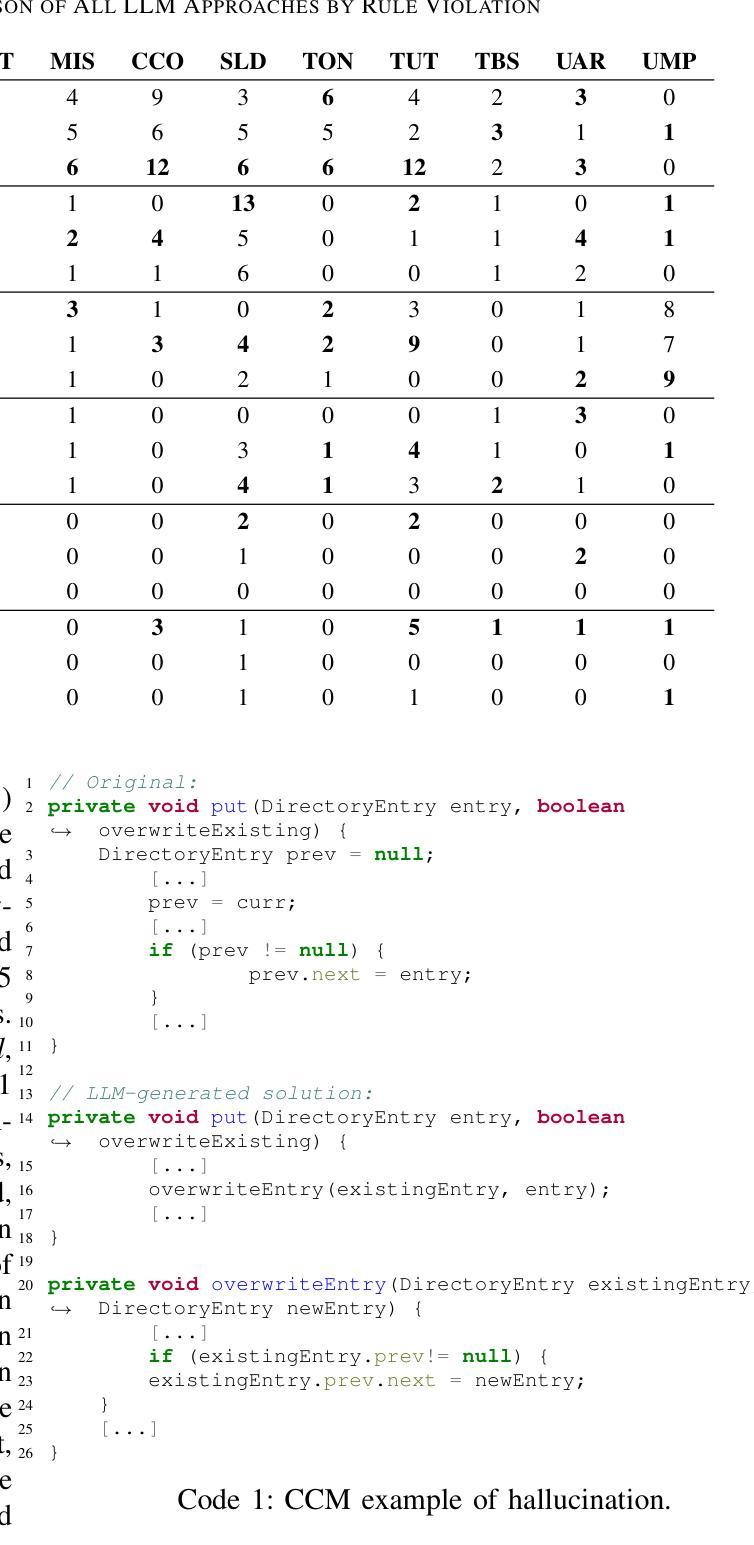
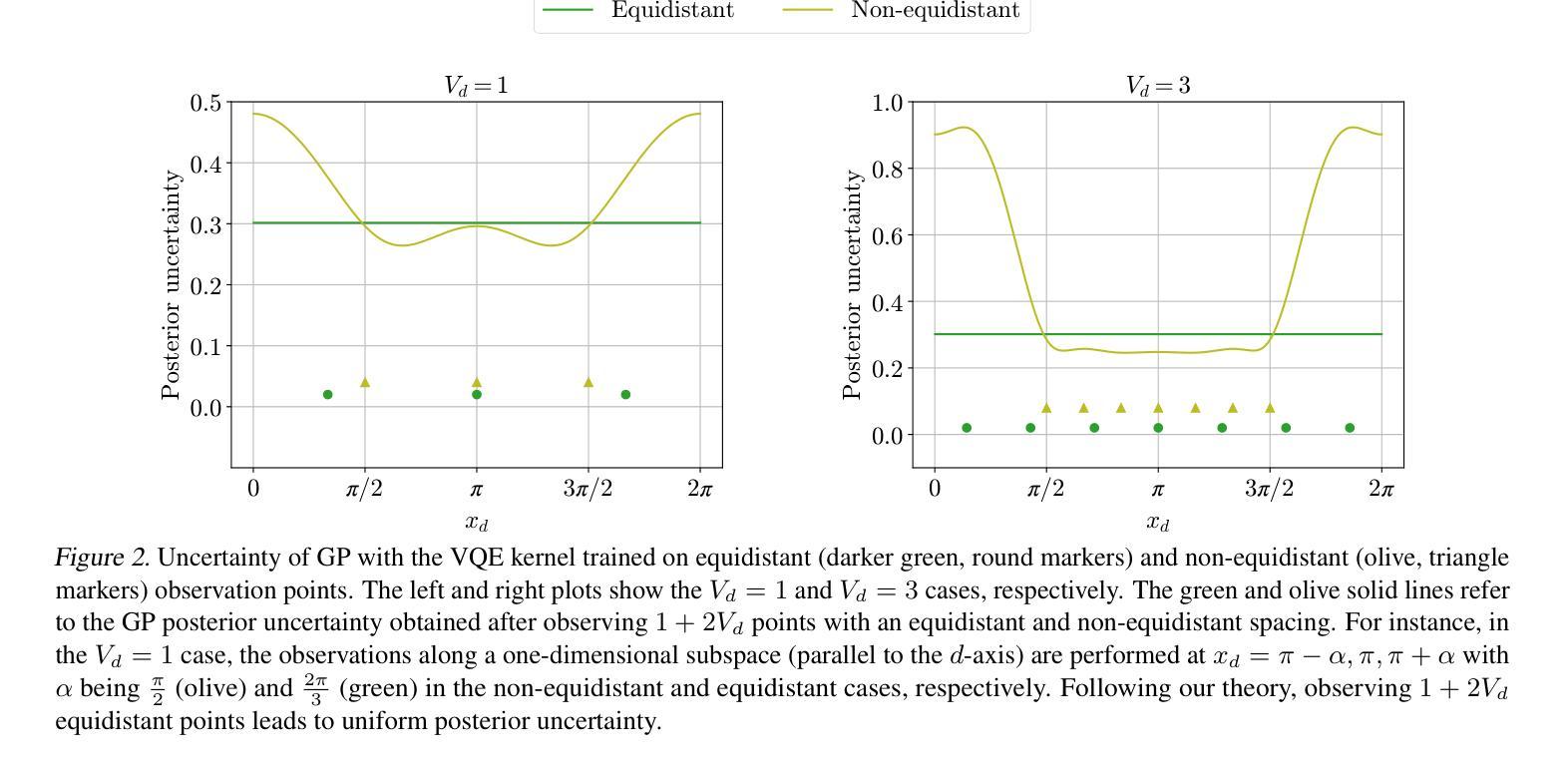
The objective to be minimized in the variational quantum eigensolver (VQE) has a restricted form, which allows a specialized sequential minimal optimization (SMO) that requires only a few observations in each iteration. However, the SMO iteration is still costly due to the observation noise – one observation at a point typically requires averaging over hundreds to thousands of repeated quantum measurement shots for achieving a reasonable noise level. In this paper, we propose an adaptive cost control method, named subspace in confident region (SubsCoRe), for SMO. SubsCoRe uses the Gaussian process (GP) surrogate, and requires it to have low uncertainty over the subspace being updated, so that optimization in each iteration is performed with guaranteed accuracy. The adaptive cost control is performed by first setting the required accuracy according to the progress of the optimization, and then choosing the minimum number of measurement shots and their distribution such that the required accuracy is satisfied. We demonstrate that SubsCoRe significantly improves the efficiency of SMO, and outperforms the state-of-the-art methods.
在变分量子本征解算器(VQE)中,要最小化的目标具有受限形式,这允许专门的顺序最小优化(SMO),每次迭代只需要几次观察。然而,由于观测噪声,SMO迭代仍然成本高昂——在一个点上的一次观测通常需要通过数百到数千次的重复量子测量来获得合理的噪声水平。在本文中,我们提出了一种用于SMO的自适应成本控制方法,名为子空间置信区域(SubsCoRe)。SubsCoRe使用高斯过程(GP)代理,要求其在更新的子空间上具有低不确定性,以确保每次迭代的优化具有保证的准确性。自适应成本控制是通过首先根据优化的进度设置所需的准确性,然后选择最小的测量次数及其分布以满足所需的准确性来实现的。我们证明了SubsCoRe可以显著提高SMO的效率并优于最新的方法。
论文及项目相关链接
PDF 9 pages, 6 figures, 41st International Conference on Machine Learning (ICML 2024)
Summary
在变分量子本征求解器(VQE)的目标函数中,有一种特殊形式允许采用只需几次观察的序列最小优化(SMO)。然而,由于观测噪声,SMO迭代仍然成本高昂——在达到合理的噪声水平时,一个观测点通常需要重复数百至数千次的量子测量。本文提出了一种名为子空间置信区域(SubsCoRe)的适应性成本控制方法,用于SMO。SubsCoRe使用高斯过程代理,要求其在更新的子空间上具有低不确定性,以确保每次迭代的优化准确性。适应性成本控制是根据优化的进度来设定所需的精度,然后选择最少的测量次数及其分布来满足所需的精度要求。我们证明SubsCoRe显著提高了SMO的效率,并优于现有先进技术。
Key Takeaways
- 变分量子本征求解器(VQE)的目标函数具有特定形式,允许序列最小优化(SMO)。
- 由于观测噪声,SMO迭代成本较高。
- 本文提出了名为子空间置信区域(SubsCoRe)的适应性成本控制方法。
- SubsCoRe使用高斯过程代理来提高优化的准确性。
- 根据优化的进度设定所需的精度。
- 通过选择最少的测量次数及其分布来满足所需的精度要求。
点此查看论文截图

BARE: Combining Base and Instruction-Tuned Language Models for Better Synthetic Data Generation
Authors:Alan Zhu, Parth Asawa, Jared Quincy Davis, Lingjiao Chen, Ion Stoica, Joseph E. Gonzalez, Matei Zaharia
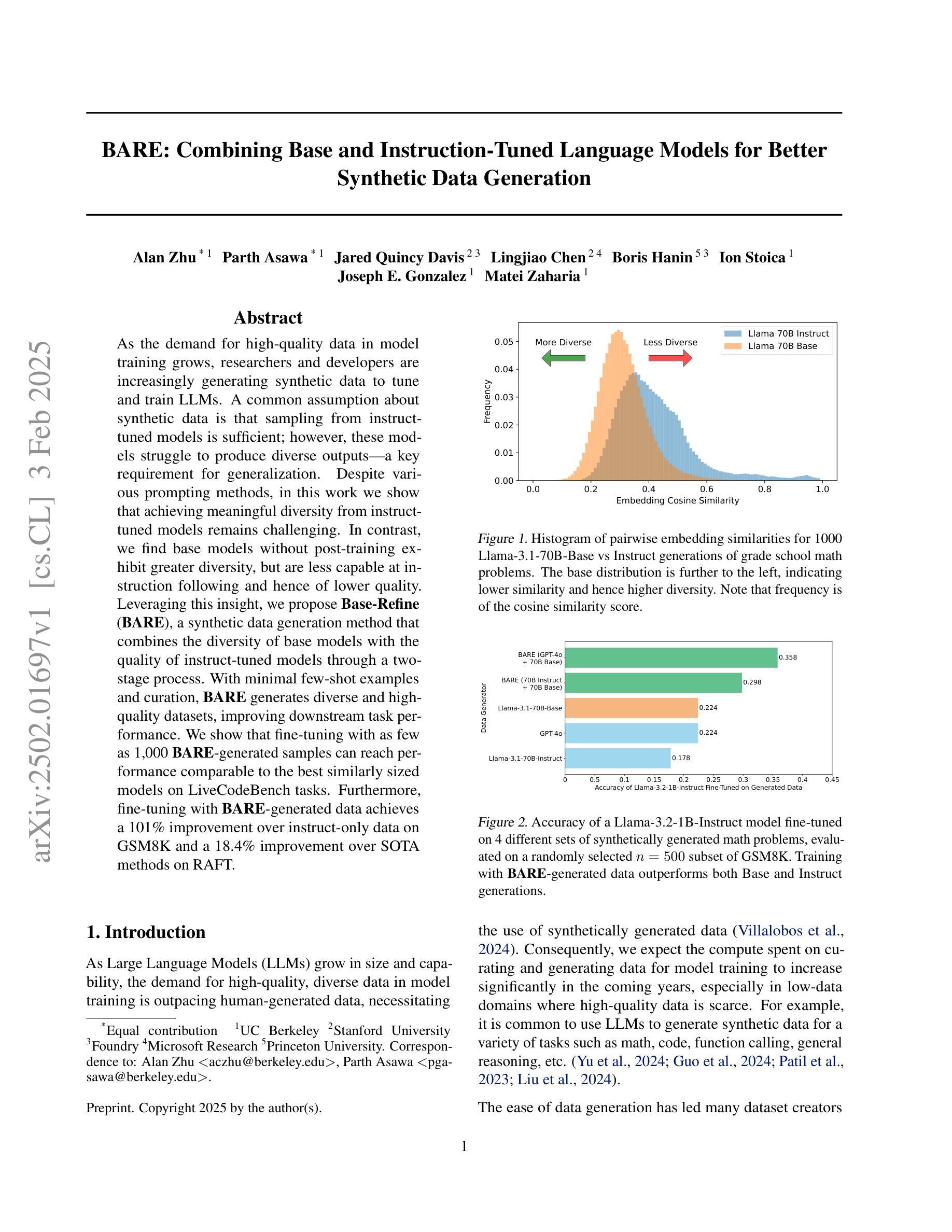
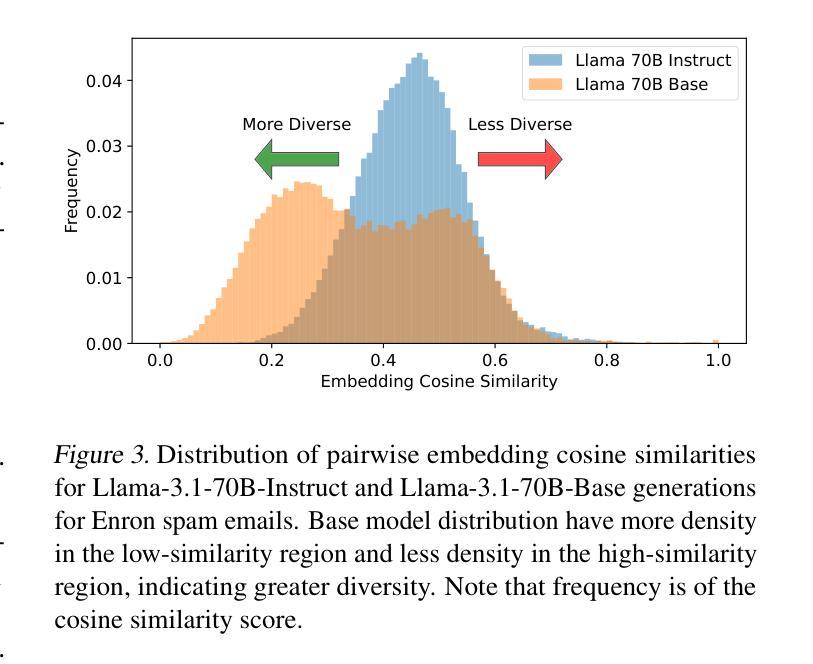
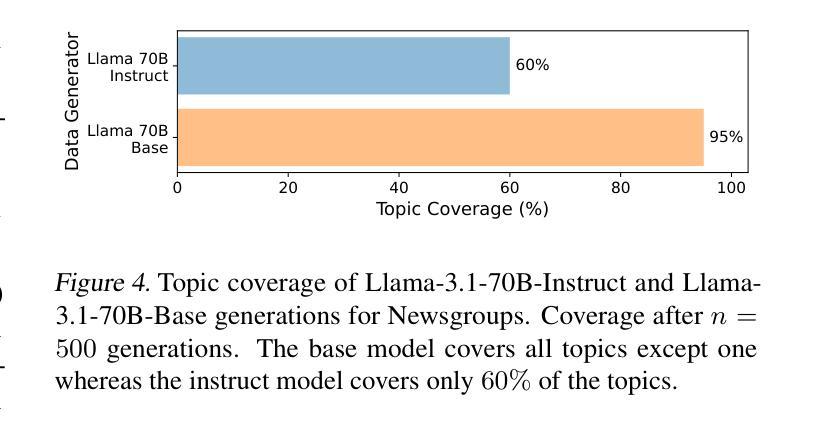
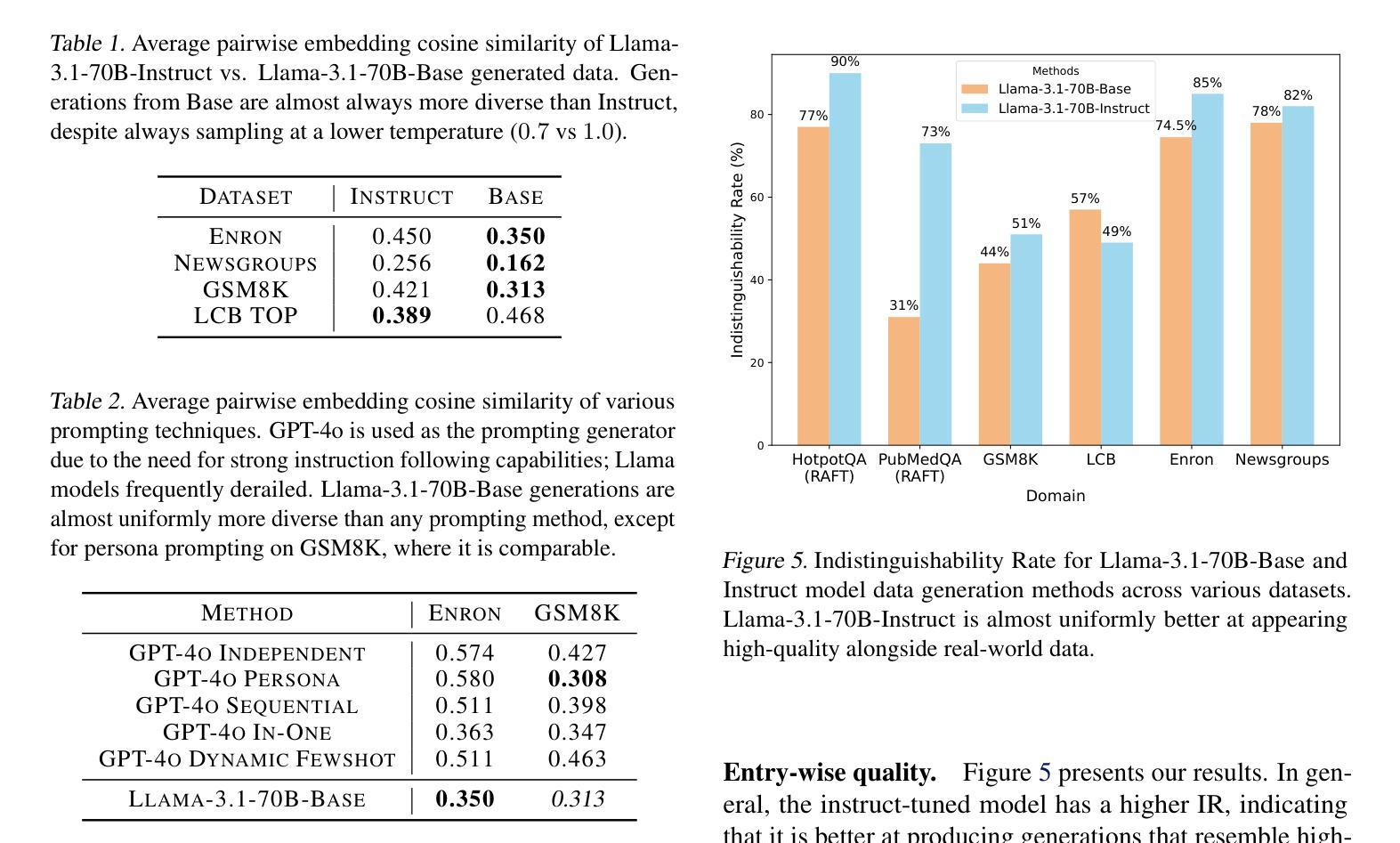
As the demand for high-quality data in model training grows, researchers and developers are increasingly generating synthetic data to tune and train LLMs. A common assumption about synthetic data is that sampling from instruct-tuned models is sufficient; however, these models struggle to produce diverse outputs-a key requirement for generalization. Despite various prompting methods, in this work we show that achieving meaningful diversity from instruct-tuned models remains challenging. In contrast, we find base models without post-training exhibit greater diversity, but are less capable at instruction following and hence of lower quality. Leveraging this insight, we propose Base-Refine (BARE), a synthetic data generation method that combines the diversity of base models with the quality of instruct-tuned models through a two-stage process. With minimal few-shot examples and curation, BARE generates diverse and high-quality datasets, improving downstream task performance. We show that fine-tuning with as few as 1,000 BARE-generated samples can reach performance comparable to the best similarly sized models on LiveCodeBench tasks. Furthermore, fine-tuning with BARE-generated data achieves a 101% improvement over instruct-only data on GSM8K and a 18.4% improvement over SOTA methods on RAFT.
随着模型训练中对于高质量数据需求的增长,研究人员和开发者正越来越多地生成合成数据来调整并训练大型语言模型。关于合成数据的一个普遍假设是,从指令调整模型中采样就足够了;然而,这些模型在产生多样化输出方面存在困难,这是泛化的一个关键要求。尽管有各种提示方法,但在这项工作中,我们表明从指令调整模型中实现有意义的多样性仍然具有挑战性。相比之下,我们发现没有经过后训练的基准模型表现出更大的多样性,但在遵循指令方面的能力较弱,因此质量较低。利用这一发现,我们提出了Base-Refine(BARE)方法,这是一种合成数据生成方法,它通过两阶段过程结合了基准模型的多样性和指令调整模型的质量。通过少量的示例和筛选,BARE可以生成多样且高质量的数据集,提高下游任务性能。我们展示使用仅1000个BARE生成样本进行微调时,其在LiveCodeBench任务上的性能可以达到与最佳相似规模模型相当的水平。此外,使用BARE生成的数据进行微调在GSM8K上实现了比仅使用指令数据提高101%的改进,并且在RAFT上相对于最先进的方法提高了18.4%。
论文及项目相关链接
Summary
研究者发现单纯依赖基于指令微调模型生成合成数据存在输出多样性不足的问题,而基础模型虽然输出多样但难以遵循指令。为此,该研究提出了一种名为Base-Refine(BARE)的合成数据生成方法,该方法结合基础模型的多样性和指令微调模型的质量,通过两阶段过程生成既多样又高质量的数据集,能提高下游任务性能。研究显示,使用BARE生成的数据集只需少量样本即可实现良好的性能。相较于只使用指令生成的数据集在GSM8K上性能提升达101%,相较于RAFT数据集上的现有最佳方法性能提升达18.4%。
Key Takeaways
- 合成数据在模型训练中的需求增长,研究者尝试通过不同方法生成合成数据以训练LLMs。
- 基于指令微调模型在生成合成数据时面临输出多样性挑战。
- 基础模型虽能产出多样输出,但难以遵循指令。
- 提出了一种名为Base-Refine(BARE)的合成数据生成方法,结合了基础模型的多样性和指令微调模型的质量。
- BARE通过两阶段过程生成既多样又高质量的数据集,能提高下游任务性能。
- 使用BARE生成的数据集只需少量样本即可实现良好的性能表现。
点此查看论文截图

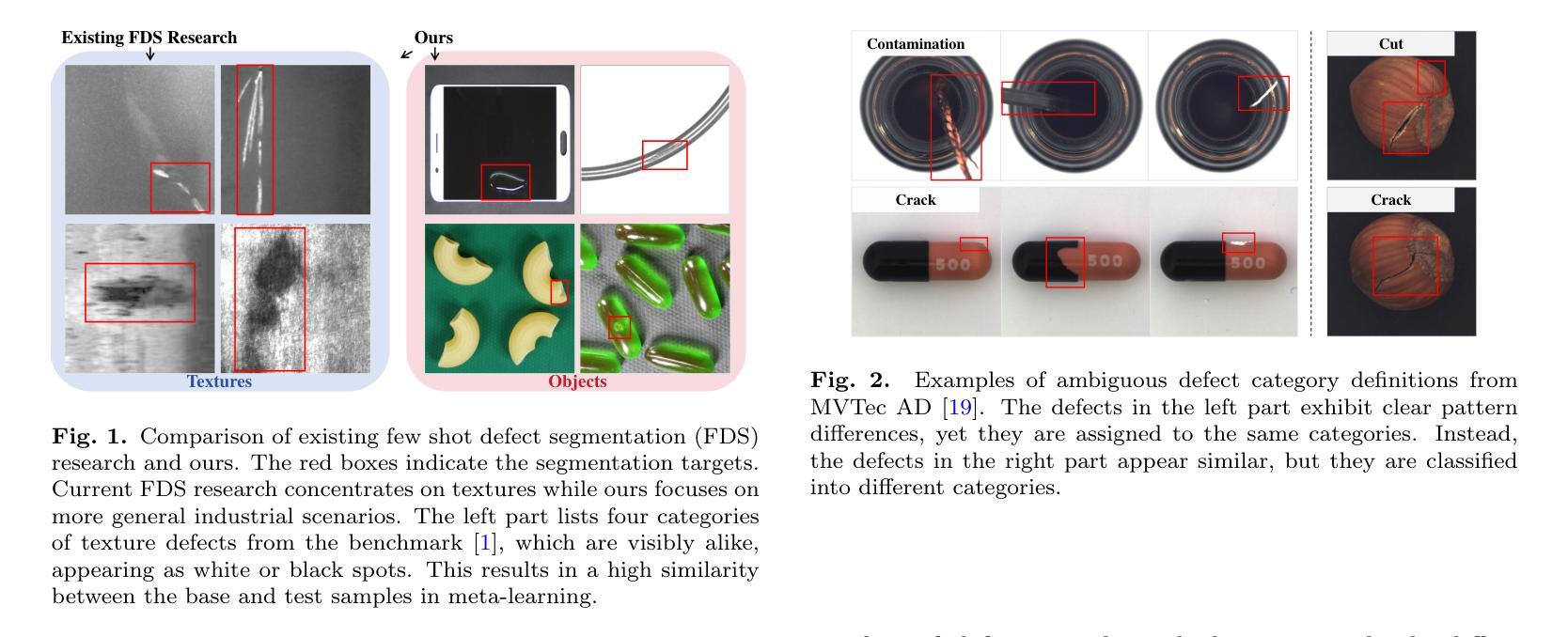
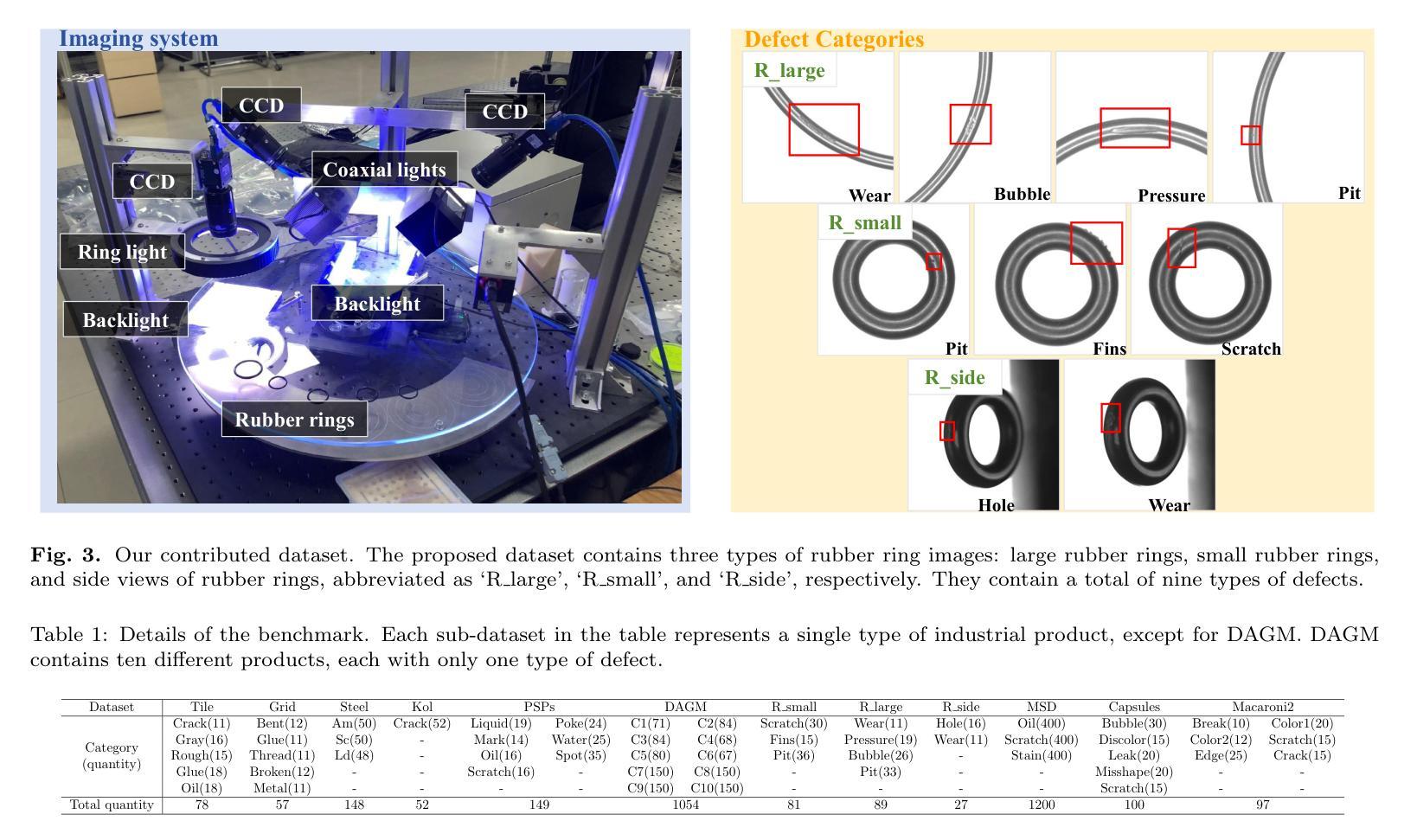
Exploring Few-Shot Defect Segmentation in General Industrial Scenarios with Metric Learning and Vision Foundation Models
Authors:Tongkun Liu, Bing Li, Xiao Jin, Yupeng Shi, Qiuying Li, Xiang Wei
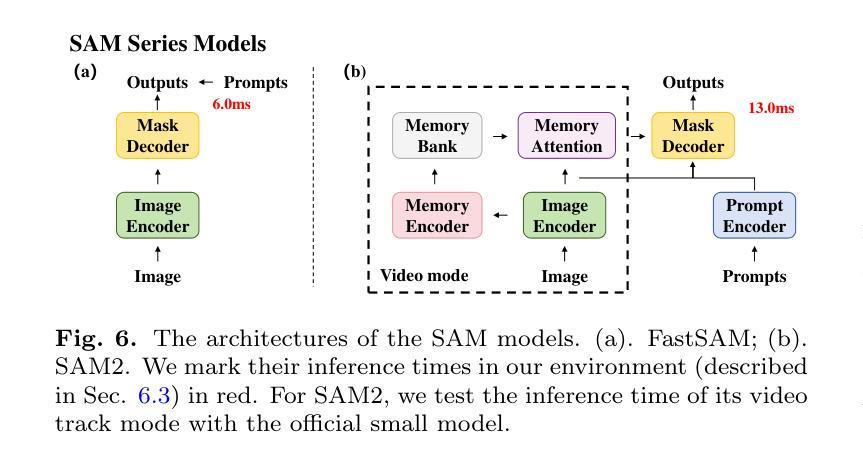
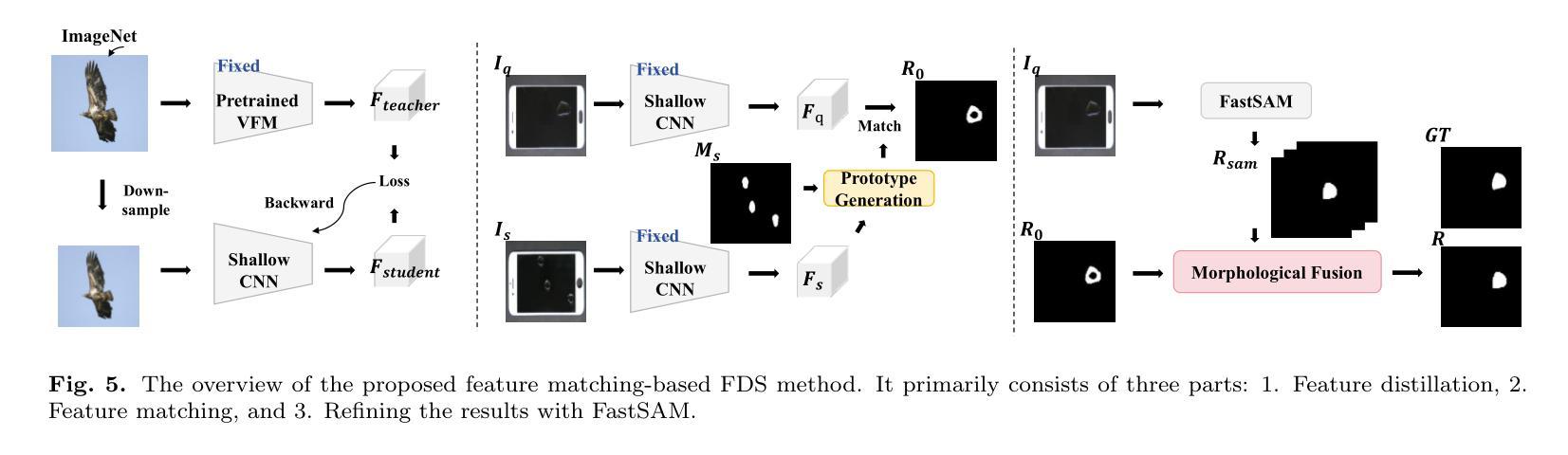
Industrial defect segmentation is critical for manufacturing quality control. Due to the scarcity of training defect samples, few-shot semantic segmentation (FSS) holds significant value in this field. However, existing studies mostly apply FSS to tackle defects on simple textures, without considering more diverse scenarios. This paper aims to address this gap by exploring FSS in broader industrial products with various defect types. To this end, we contribute a new real-world dataset and reorganize some existing datasets to build a more comprehensive few-shot defect segmentation (FDS) benchmark. On this benchmark, we thoroughly investigate metric learning-based FSS methods, including those based on meta-learning and those based on Vision Foundation Models (VFMs). We observe that existing meta-learning-based methods are generally not well-suited for this task, while VFMs hold great potential. We further systematically study the applicability of various VFMs in this task, involving two paradigms: feature matching and the use of Segment Anything (SAM) models. We propose a novel efficient FDS method based on feature matching. Meanwhile, we find that SAM2 is particularly effective for addressing FDS through its video track mode. The contributed dataset and code will be available at: https://github.com/liutongkun/GFDS.
工业缺陷分割对于制造质量控制至关重要。由于训练缺陷样本的稀缺性,小样本语义分割(FSS)在该领域具有重大意义。然而,现有的研究大多将FSS应用于简单纹理上的缺陷检测,并未考虑更多样化的场景。本文旨在通过探索FSS在更广泛的工业产品中的多种缺陷类型来解决这一差距。为此,我们贡献了一个新的真实世界数据集,并重组了一些现有数据集来建立一个更全面的少样本缺陷分割(FDS)基准测试。在这个基准测试上,我们全面研究了基于度量学习的FSS方法,包括基于元学习和基于视觉基础模型(VFMs)的方法。我们发现现有的基于元学习的方法通常不适合这项任务,而VFMs具有巨大潜力。我们进一步系统地研究了各种VFMs在此任务中的应用,涉及特征匹配和使用Segment Anything(SAM)模型两种范式。我们提出了一种基于特征匹配的新型高效FDS方法。同时,我们发现SAM2通过其视频跟踪模式在解决FDS方面特别有效。相关的数据集和代码将在https://github.com/liutongkun/GFDS上提供。
论文及项目相关链接
Summary
本文关注工业缺陷分割领域中的小样本语义分割(FSS)问题。针对现有研究主要集中在简单纹理缺陷上,而忽略更多样场景的问题,本文旨在通过探索FSS在更广泛的工业产品中的多种缺陷类型来弥补这一差距。为此,作者贡献了一个新的真实世界数据集并重新组织了现有的数据集以建立一个更全面的少样本缺陷分割(FDS)基准测试。作者深入研究了基于度量学习的FSS方法,包括基于元学习和基于视觉基础模型(VFMs)的方法。研究发现,现有的基于元学习的方法通常不适用于这项任务,而VFMs具有巨大潜力。此外,作者系统地研究了各种VFMs在此任务中的应用,并基于特征匹配提出了一种新的高效FDS方法。同时,发现SAM2模型通过视频跟踪模式在解决FDS方面特别有效。
Key Takeaways
- 工业缺陷分割中,小样语义本分割(FSS)具有重要意义,因训练缺陷样本稀缺。
- 现有研究主要关注简单纹理缺陷的FSS,缺乏多样场景考虑。
- 本文建立了一个全面的少样本缺陷分割(FDS)基准测试,包含新的真实世界数据集和重组的现有数据集。
- 基于度量学习的FSS方法被深入研究,包括基于元学习和基于视觉基础模型(VFMs)的方法。
- 现有基于元学习的方法在FDS任务上表现不佳,而VFMs展现出巨大潜力。
- 作者提出了基于特征匹配的新颖高效FDS方法,并发现SAM2模型通过视频跟踪模式特别有效。
- 贡献的数据集和代码将公开在GitHub上。
点此查看论文截图


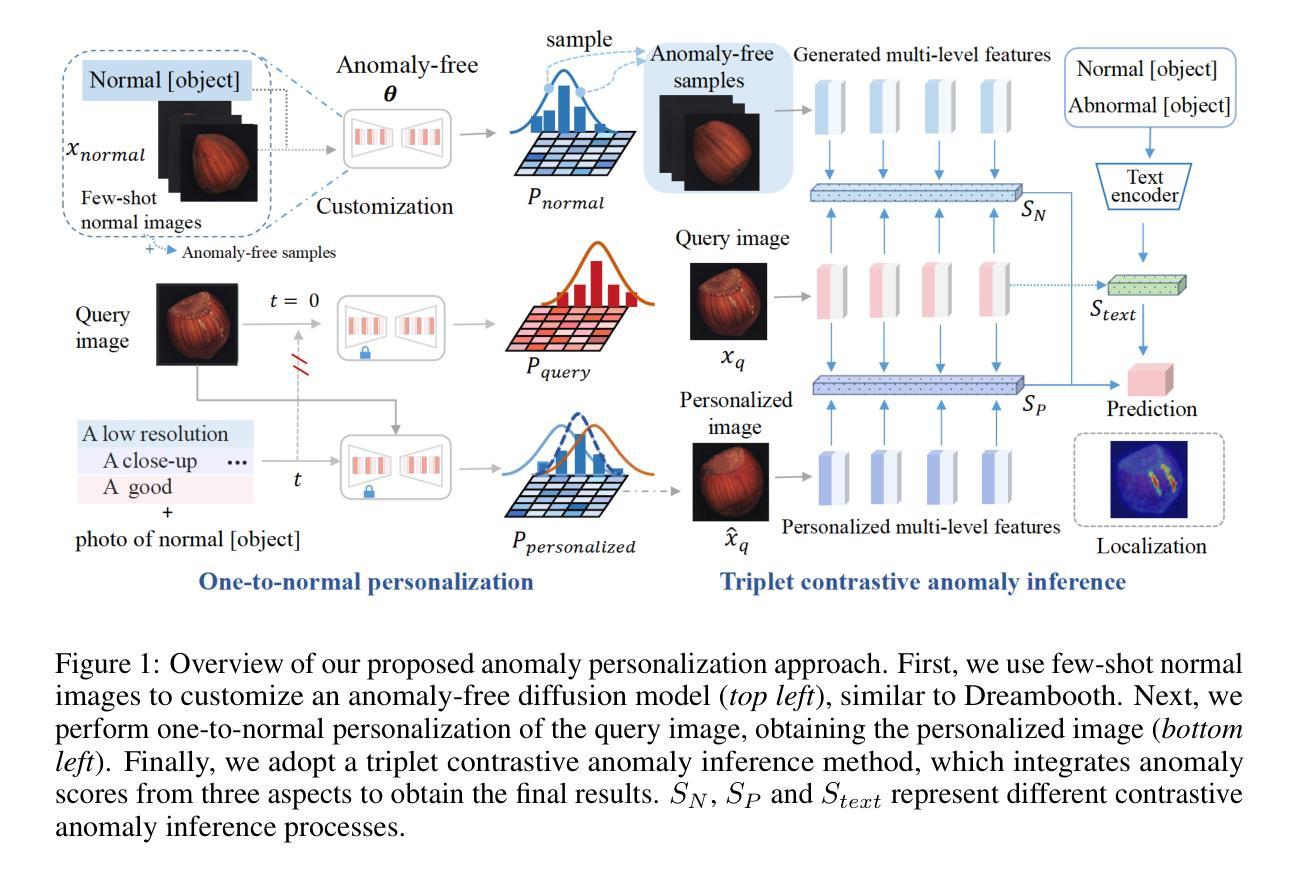
One-to-Normal: Anomaly Personalization for Few-shot Anomaly Detection
Authors:Yiyue Li, Shaoting Zhang, Kang Li, Qicheng Lao
Traditional Anomaly Detection (AD) methods have predominantly relied on unsupervised learning from extensive normal data. Recent AD methods have evolved with the advent of large pre-trained vision-language models, enhancing few-shot anomaly detection capabilities. However, these latest AD methods still exhibit limitations in accuracy improvement. One contributing factor is their direct comparison of a query image’s features with those of few-shot normal images. This direct comparison often leads to a loss of precision and complicates the extension of these techniques to more complex domains–an area that remains underexplored in a more refined and comprehensive manner. To address these limitations, we introduce the anomaly personalization method, which performs a personalized one-to-normal transformation of query images using an anomaly-free customized generation model, ensuring close alignment with the normal manifold. Moreover, to further enhance the stability and robustness of prediction results, we propose a triplet contrastive anomaly inference strategy, which incorporates a comprehensive comparison between the query and generated anomaly-free data pool and prompt information. Extensive evaluations across eleven datasets in three domains demonstrate our model’s effectiveness compared to the latest AD methods. Additionally, our method has been proven to transfer flexibly to other AD methods, with the generated image data effectively improving the performance of other AD methods.
传统异常检测(AD)方法主要依赖于从大量正常数据中进行的无监督学习。随着大型预训练视觉语言模型的出现,最近的AD方法已经发展并增强了小样本异常检测能力。然而,这些最新的AD方法在精度提高方面仍存在局限性。一个原因是它们直接将查询图像的特征与少数正常图像进行比较。这种直接比较往往会导致精度损失,并使得将这些技术扩展到更复杂领域更加复杂——这一领域仍需要以更精细和全面的方式进行探索。为了解决这些局限性,我们引入了异常个性化方法,该方法使用无异常定制生成模型对查询图像进行个性化的一对一正常转换,确保与正常流形紧密对齐。此外,为了进一步增强预测结果的稳定性和鲁棒性,我们提出了一种三元对比异常推理策略,该策略在查询和生成的异常数据池以及提示信息之间进行全面的比较。在三个领域的十一个数据集上的广泛评估证明了我们模型与最新AD方法相比的有效性。此外,我们的方法被证明可以灵活地转移到其他AD方法,生成的图像数据有效地提高了其他AD方法的性能。
论文及项目相关链接
PDF In The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS2024)
Summary
近期异常检测(AD)方法已经随着大型预训练视觉语言模型的出现而发展,提升了少样本异常检测的能力。然而,这些方法在精度提升方面仍存在局限性,主要是由于它们直接比较查询图像的特征与少量正常图像的特征。为解决这一问题,我们提出了异常个性化方法,利用无异常定制生成模型对查询图像进行个性化正常转换,同时采用三元对比异常推理策略,提高预测结果的稳定性和鲁棒性。在三个领域的十一个数据集上的广泛评估证明了我们模型的有效性。此外,该方法可灵活迁移至其他AD方法,生成的图像数据可有效提升其他AD方法的性能。
Key Takeaways
- 近期AD方法依赖预训练视觉语言模型进行少样本异常检测。
- 直接比较查询图像与少量正常图像的特征存在精度局限性。
- 引入异常个性化方法,通过无异常定制生成模型进行个性化正常转换。
- 采用三元对比异常推理策略,提高预测结果的稳定性和鲁棒性。
- 在多个数据集上的评估证明模型的有效性。
- 提出的方法可以灵活迁移至其他AD方法。
点此查看论文截图

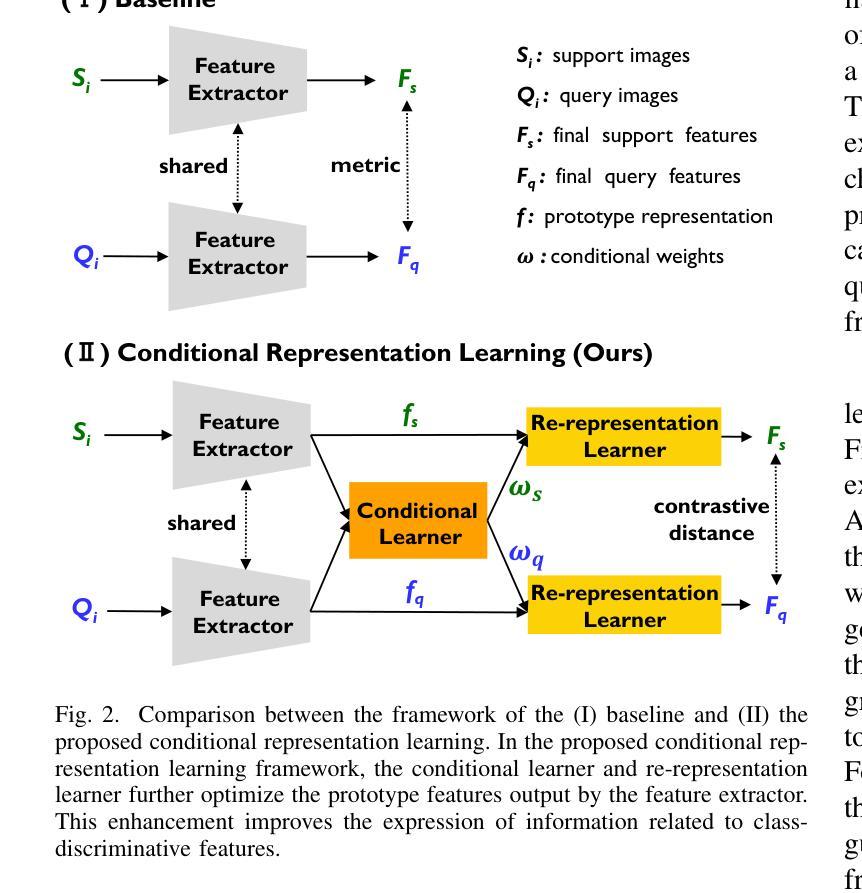
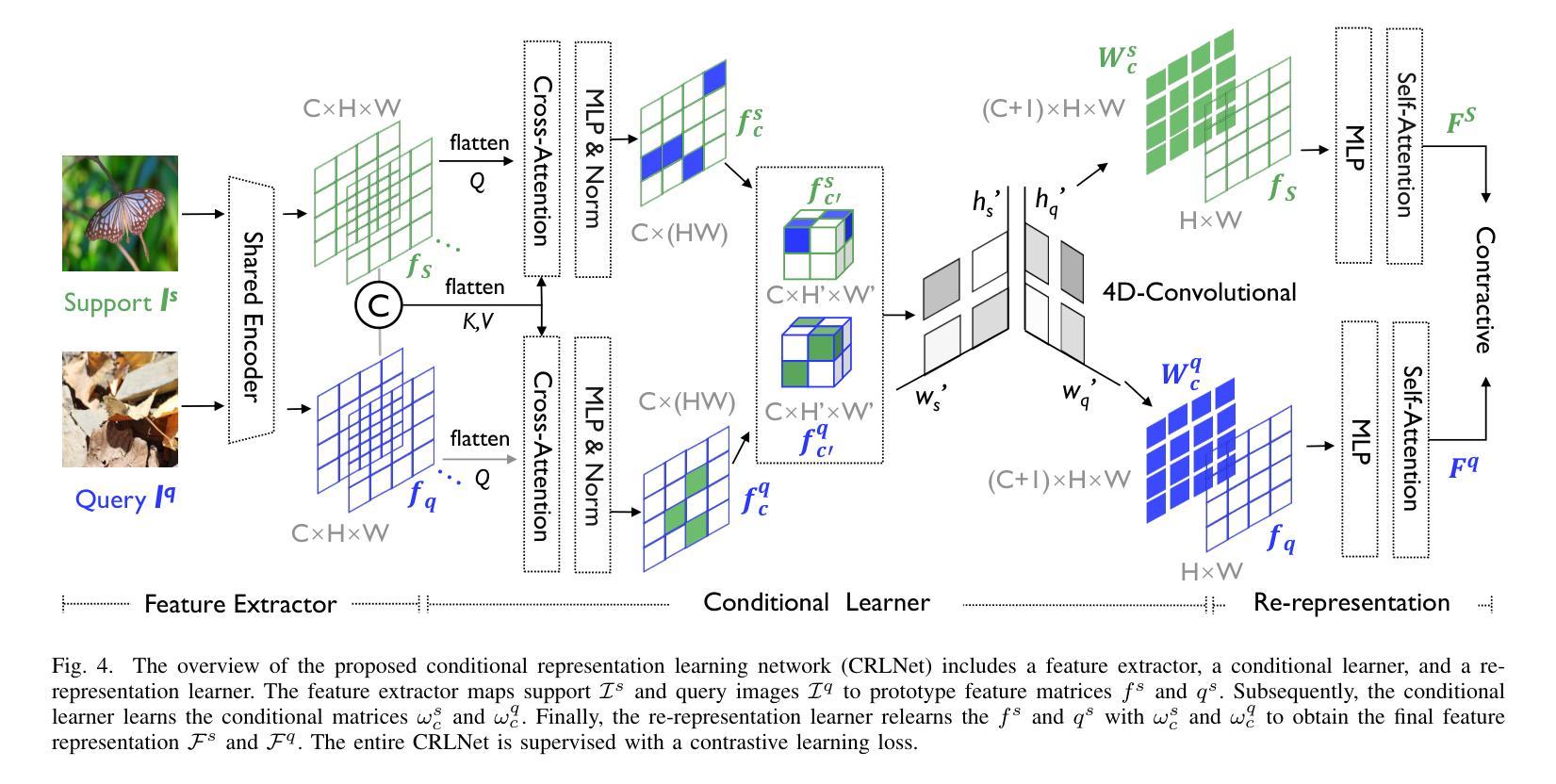
Enhancing Environmental Robustness in Few-shot Learning via Conditional Representation Learning
Authors:Qianyu Guo, Jingrong Wu, Tianxing Wu, Haofen Wang, Weifeng Ge, Wenqiang Zhang
Few-shot learning (FSL) has recently been extensively utilized to overcome the scarcity of training data in domain-specific visual recognition. In real-world scenarios, environmental factors such as complex backgrounds, varying lighting conditions, long-distance shooting, and moving targets often cause test images to exhibit numerous incomplete targets or noise disruptions. However, current research on evaluation datasets and methodologies has largely ignored the concept of “environmental robustness”, which refers to maintaining consistent performance in complex and diverse physical environments. This neglect has led to a notable decline in the performance of FSL models during practical testing compared to their training performance. To bridge this gap, we introduce a new real-world multi-domain few-shot learning (RD-FSL) benchmark, which includes four domains and six evaluation datasets. The test images in this benchmark feature various challenging elements, such as camouflaged objects, small targets, and blurriness. Our evaluation experiments reveal that existing methods struggle to utilize training images effectively to generate accurate feature representations for challenging test images. To address this problem, we propose a novel conditional representation learning network (CRLNet) that integrates the interactions between training and testing images as conditional information in their respective representation processes. The main goal is to reduce intra-class variance or enhance inter-class variance at the feature representation level. Finally, comparative experiments reveal that CRLNet surpasses the current state-of-the-art methods, achieving performance improvements ranging from 6.83% to 16.98% across diverse settings and backbones. The source code and dataset are available at https://github.com/guoqianyu-alberta/Conditional-Representation-Learning.
少量学习(FSL)最近已被广泛用应用于克服特定领域的视觉识别中训练数据的稀缺问题。在真实场景中,环境因素如复杂背景、不同照明条件、远距离拍摄和移动目标等常导致测试图像出现许多不完整的目标或噪声干扰。然而,当前的研究在评估数据集和方法论时,很大程度上忽视了“环境稳健性”的概念,即指在复杂和多样化的物理环境中保持一致性表现。这种忽视导致了FSL模型在实际测试中的性能与训练性能相比出现了显著下降。为了弥补这一差距,我们引入了一个新的真实世界多域少量学习(RD-FSL)基准测试,其中包括四个域和六个评估数据集。该基准测试中的测试图像具有各种挑战性的元素,例如隐蔽物体、小目标和模糊性等。我们的评估实验表明,现有方法难以有效地利用训练图像为具有挑战性的测试图像生成准确的特征表示。为了解决这一问题,我们提出了一种新型的条件表示学习网络(CRLNet),它将训练图像和测试图像之间的交互作为各自表示过程中的条件信息。主要目标是在特征表示层面降低类内方差或增强类间方差。最后,对比实验表明,CRLNet超越了当前最前沿的方法,在多种设置和主干网络上实现了性能提升,范围从6.8 间接翻译可能引起语义上的混淆和误解,以上翻译仅供参考。如果您有其他更具体的语境或需求,我会更乐意进一步帮助您完成翻译。
论文及项目相关链接
PDF 15 pages, 8 figures, Accepted by IEEE Transactions on Image Processing
Summary
该文本介绍了少样本学习(FSL)在现实场景中的应用挑战,如环境多样性和复杂性导致的模型性能下降。为解决这一问题,研究团队引入了新的真实世界多域少样本学习(RD-FSL)基准测试,并提出了一种新的条件表示学习网络(CRLNet)。CRLNet通过整合训练和测试图像之间的交互作为条件信息,旨在降低类内方差或增强类间方差,从而提高特征表示的准确性。实验结果显示,CRLNet在多种设置和主干网络上均超越了现有方法,实现了从6.83%到16.98%的性能提升。
Key Takeaways
- 少样本学习(FSL)在特定领域的视觉识别中,因训练数据稀缺而受到广泛应用。
- 现实场景中的环境因素影响测试图像的质量,导致现有FSL模型性能下降。
- 引入新的真实世界多域少样本学习(RD-FSL)基准测试,包含四个域和六个评估数据集。
- 测试图像具有多种挑战元素,如隐蔽物体、小目标和模糊性。
- 现有方法难以有效利用训练图像为具有挑战性的测试图像生成准确特征表示。
- 提出新的条件表示学习网络(CRLNet),通过整合训练和测试图像间的交互来提升特征表示的准确性。
- CRLNet在多种设置和主干网络上实现了显著的性能提升。
点此查看论文截图


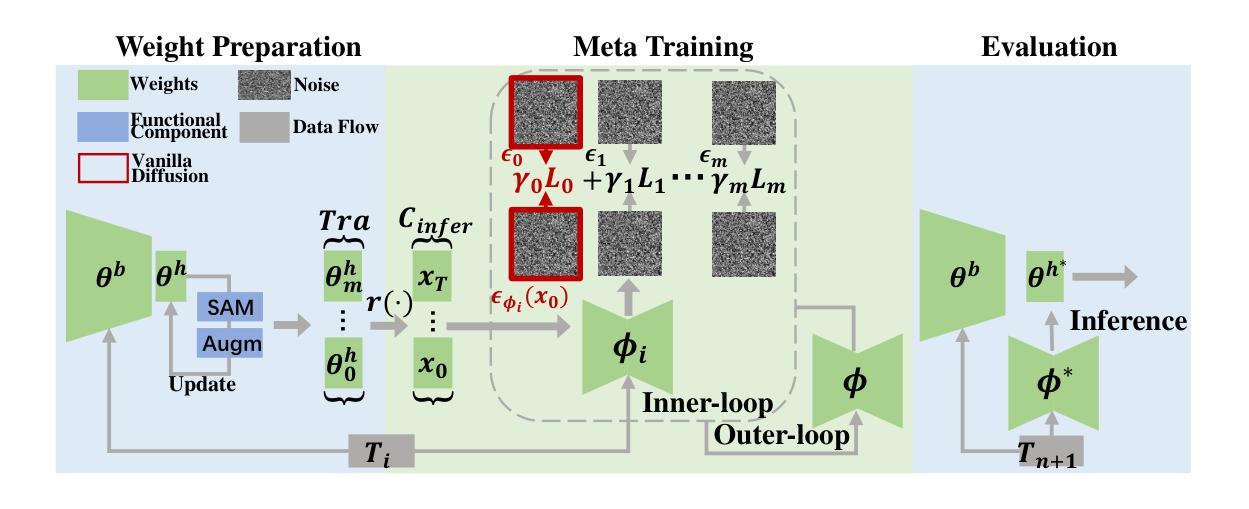
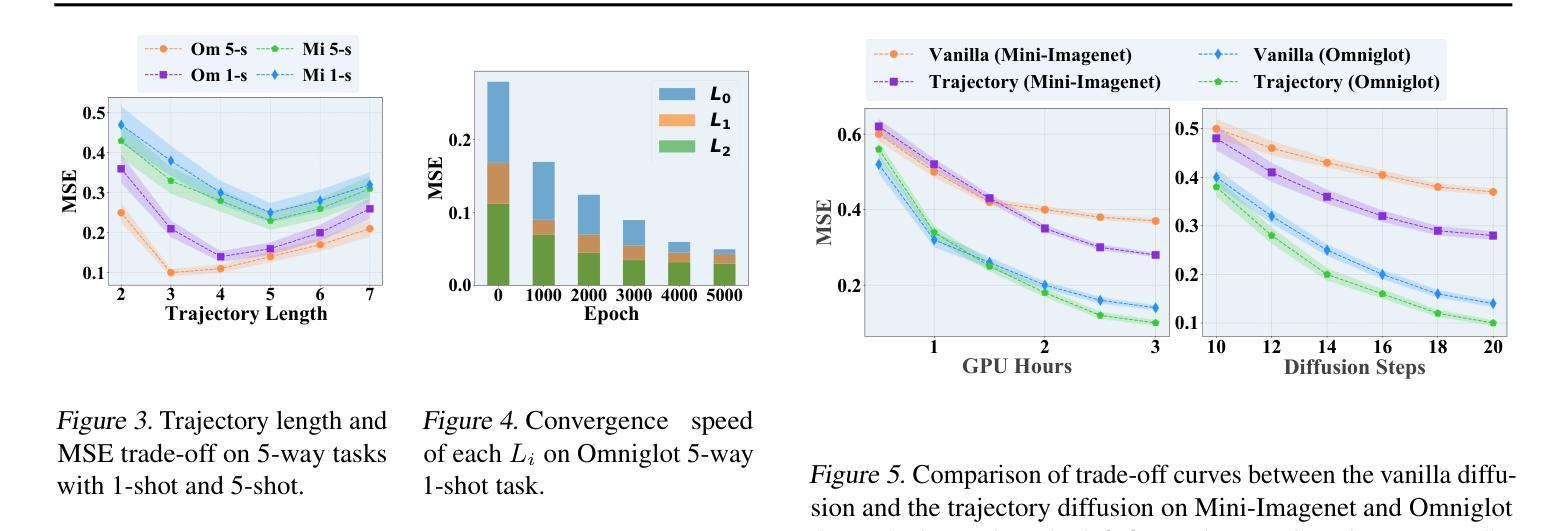
Learning to Learn Weight Generation via Trajectory Diffusion
Authors:Yunchuan Guan, Yu Liu, Ke Zhou, Zhiqi Shen, Serge Belongie, Jenq-Neng Hwang, Lei Li
Diffusion-based algorithms have emerged as promising techniques for weight generation, particularly in scenarios like multi-task learning that require frequent weight updates. However, existing solutions suffer from limited cross-task transferability. In addition, they only utilize optimal weights as training samples, ignoring the value of other weights in the optimization process. To address these issues, we propose Lt-Di, which integrates the diffusion algorithm with meta-learning to generate weights for unseen tasks. Furthermore, we extend the vanilla diffusion algorithm into a trajectory diffusion algorithm to utilize other weights along the optimization trajectory. Trajectory diffusion decomposes the entire diffusion chain into multiple shorter ones, improving training and inference efficiency. We analyze the convergence properties of the weight generation paradigm and improve convergence efficiency without additional time overhead. Our experiments demonstrate Lt-Di’s higher accuracy while reducing computational overhead across various tasks, including zero-shot and few-shot learning, multi-domain generalization, and large-scale language model fine-tuning.Our code is released at https://github.com/tuantuange/Lt-Di.
基于扩散的算法已成为权重生成的有前途的技术,特别是在需要频繁权重更新的多任务学习等场景中。然而,现有解决方案存在跨任务迁移能力有限的缺陷。此外,它们仅将最佳权重作为训练样本,忽略了优化过程中其他权重的价值。为了解决这些问题,我们提出了Lt-Di,它将扩散算法与元学习相结合,以生成未见任务的权重。此外,我们将普通的扩散算法扩展为轨迹扩散算法,以利用优化轨迹中的其他权重。轨迹扩散将整个扩散链分解为多个较短的链,提高了训练和推理效率。我们分析了权重生成范式的收敛特性,提高了收敛效率,且没有额外的时间开销。我们的实验表明,Lt-Di在各种任务中具有较高的准确性,同时减少了计算开销,包括零样本和少样本学习、多域泛化和大规模语言模型微调。我们的代码已发布在https://github.com/tuantuange/Lt-Di。
论文及项目相关链接
Summary
本文提出了一种结合扩散算法和元学习的新方法Lt-Di,用于为未见任务生成权重。该方法解决了现有解决方案中跨任务迁移能力有限的问题,并引入了轨迹扩散算法,利用优化过程中的其他权重。Lt-Di能提高训练效率和推理效率,同时改善权重生成范式的收敛性能,降低计算开销。实验表明,该方法在各种任务上具有较高的准确性和效率。
Key Takeaways
- Lt-Di结合了扩散算法和元学习,用于生成未见任务的权重。
- 现有解决方案存在跨任务迁移能力有限的问题,而Lt-Di解决了这一问题。
- Lt-Di引入了轨迹扩散算法,利用优化过程中的其他权重。
- Lt-Di通过分解整个扩散链为多个较短的链,提高了训练和推理的效率。
- Lt-Di能改善权重生成范式的收敛性能,且不会增加额外的时间开销。
- 实验表明,Lt-Di在多种任务上具有较高的准确性和效率,包括零样本和少样本学习、多域泛化和大规模语言模型微调。
点此查看论文截图

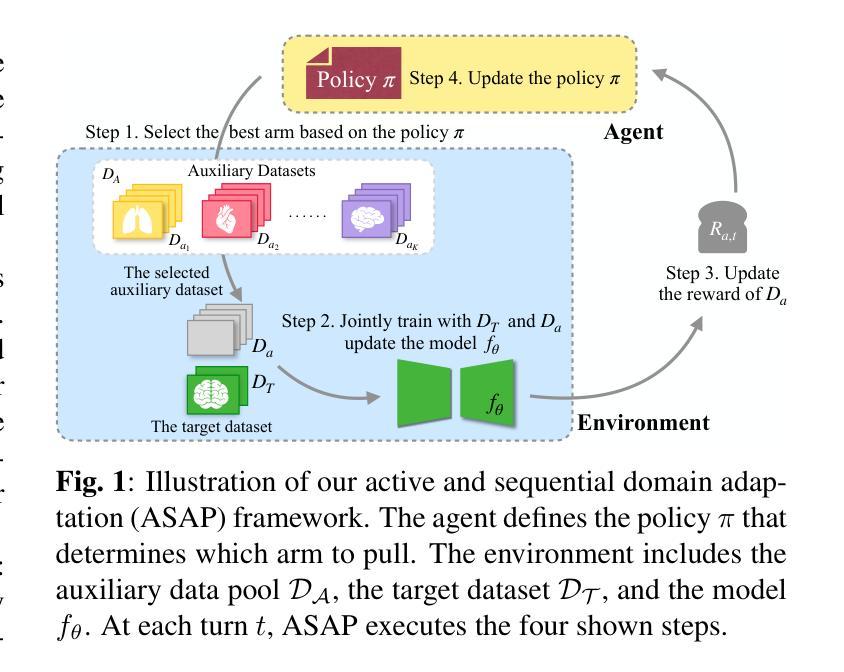
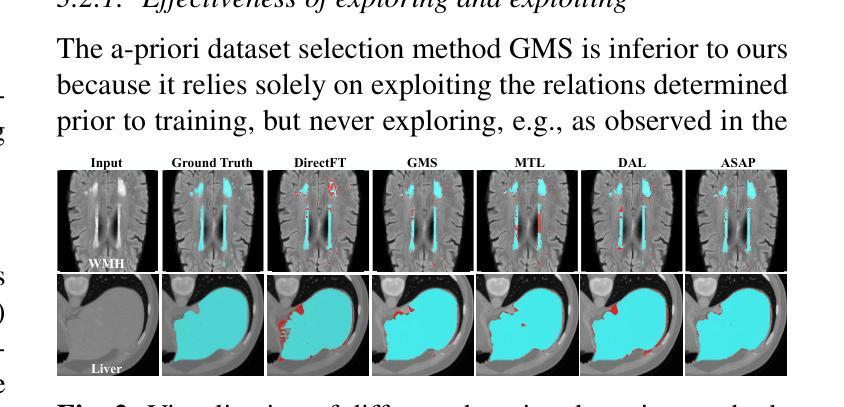
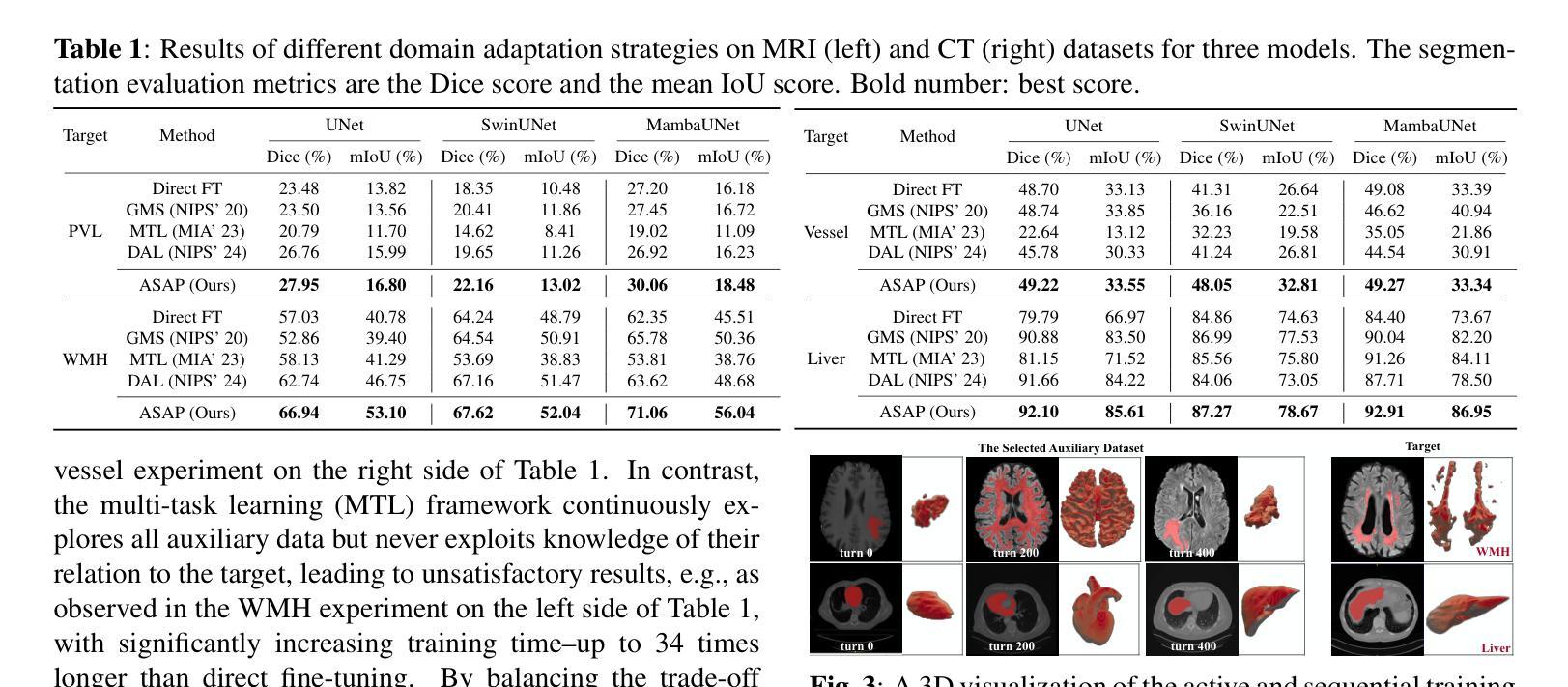
Adapting Foundation Models for Few-Shot Medical Image Segmentation: Actively and Sequentially
Authors:Jingyun Yang, Guoqing Zhang, Jingge Wang, Yang Li
Recent advances in foundation models have brought promising results in computer vision, including medical image segmentation. Fine-tuning foundation models on specific low-resource medical tasks has become a standard practice. However, ensuring reliable and robust model adaptation when the target task has a large domain gap and few annotated samples remains a challenge. Previous few-shot domain adaptation (FSDA) methods seek to bridge the distribution gap between source and target domains by utilizing auxiliary data. The selection and scheduling of auxiliaries are often based on heuristics, which can easily cause negative transfer. In this work, we propose an Active and Sequential domain AdaPtation (ASAP) framework for dynamic auxiliary dataset selection in FSDA. We formulate FSDA as a multi-armed bandit problem and derive an efficient reward function to prioritize training on auxiliary datasets that align closely with the target task, through a single-round fine-tuning. Empirical validation on diverse medical segmentation datasets demonstrates that our method achieves favorable segmentation performance, significantly outperforming the state-of-the-art FSDA methods, achieving an average gain of 27.75% on MRI and 7.52% on CT datasets in Dice score. Code is available at the git repository: https://github.com/techicoco/ASAP.
最近的进展在基础模型方面已经在计算机视觉(包括医学图像分割)中取得了令人鼓舞的结果。对特定低资源医学任务进行微调基础模型已经成为一种标准做法。然而,当目标任务具有较大的领域差距和少量的标注样本时,确保可靠和稳健的模型适应仍然是一个挑战。之前的少样本域适应(FSDA)方法试图通过利用辅助数据来缩小源域和目标域之间的分布差距。辅助数据的选择和时间安排通常基于启发式方法,这很容易导致负迁移。在这项工作中,我们提出了面向少样本域适应(FSDA)的动态辅助数据集选择的主动序贯域适应(ASAP)框架。我们将FSDA制定为多路赌博问题,并推导出一个有效的奖励函数,以优先训练与目标任务紧密对齐的辅助数据集,通过一轮微调来实现。在多样化的医学分割数据集上的经验验证表明,我们的方法实现了有利的分割性能,显著优于最新的FSDA方法,在MRI和CT数据集上的Dice得分平均提高了27.75%和7.52%。代码可在git仓库中找到:https://github.com/techicoco/ASAP。
简化
论文及项目相关链接
Summary
基于最新进展的预训练模型在医疗图像分割等计算机视觉任务上取得了显著成果。针对目标任务具有较大领域差距和少量标注样本的情况下的模型适应性问题,仍然存在挑战。本文提出了一种用于动态辅助数据集选择的主动序贯域适应(ASAP)框架。本文将few-shot领域适应问题建模为multi-armed bandit问题,并设计了高效的奖励函数以优先选择与目标任务密切相关的辅助数据集进行训练。在多样化的医学分割数据集上的实证验证表明,该方法实现了优越的分割性能,显著优于最新的few-shot领域适应方法,在MRI和CT数据集上的Dice得分平均提高了27.75%和7.52%。
Key Takeaways
- 预训练模型在医疗图像分割等任务上表现优异,尤其在fine-tuning特定低资源医疗任务方面。
- 在目标任务与源任务领域差距大、标注样本少的情况下,模型适应仍然面临挑战。
- 现有few-shot领域适应方法主要利用辅助数据缩小源域与目标域之间的差距,但辅助数据的选择和调度通常基于启发式规则,容易造成负迁移。
- 本文提出了一种新的Active and Sequential domain AdaPtation (ASAP)框架,用于动态选择辅助数据集。
- 将few-shot领域适应问题建模为multi-armed bandit问题,并设计高效的奖励函数以选择与目标任务相关的辅助数据集进行训练。
- 在多样化医学分割数据集上的实证验证显示,ASAP框架在分割性能上表现优越,显著优于现有方法。
点此查看论文截图


Predicting potentially unfair clauses in Chilean terms of services with natural language processing
Authors:Christoffer Loeffler, Andrea Martínez Freile, Tomás Rey Pizarro
This study addresses the growing concern of information asymmetry in consumer contracts, exacerbated by the proliferation of online services with complex Terms of Service that are rarely even read. Even though research on automatic analysis methods is conducted, the problem is aggravated by the general focus on English-language Machine Learning approaches and on major jurisdictions, such as the European Union. We introduce a new methodology and a substantial dataset addressing this gap. We propose a novel annotation scheme with four categories and a total of 20 classes, and apply it on 50 online Terms of Service used in Chile. Our evaluation of transformer-based models highlights how factors like language- and/or domain-specific pre-training, few-shot sample size, and model architecture affect the detection and classification of potentially abusive clauses. Results show a large variability in performance for the different tasks and models, with the highest macro-F1 scores for the detection task ranging from 79% to 89% and micro-F1 scores up to 96%, while macro-F1 scores for the classification task range from 60% to 70% and micro-F1 scores from 64% to 80%. Notably, this is the first Spanish-language multi-label classification dataset for legal clauses, applying Chilean law and offering a comprehensive evaluation of Spanish-language models in the legal domain. Our work lays the ground for future research in method development for rarely considered legal analysis and potentially leads to practical applications to support consumers in Chile and Latin America as a whole.
本研究关注消费者合同中信息不对称问题的日益严重,这一问题因在线服务的普及而加剧,这些服务具有复杂的《服务条款》,这些条款很少被阅读。尽管已经开展了关于自动分析方法的研究,但问题是由于普遍关注英语机器学习方法和主要司法管辖区(如欧洲联盟),这一问题变得更加严重。我们提出了一种新的方法和大量的数据集来解决这一差距。我们提出了一种新的标注方案,包含四个类别和总共二十个类别,并应用于智利使用的五十项在线《服务条款》。我们对基于变压器的模型进行评估,突出了语言或领域特定的预训练、少量样本大小和模型架构等因素如何影响潜在滥用条款的检测和分类。结果表明,不同任务和模型之间的性能存在很大差异,检测任务的最高宏F1分数在79%至89%之间,微F1分数高达96%,而分类任务的宏F1分数在60%至70%之间,微F1分数在64%至80%之间。值得注意的是,这是第一个用于法律条款的西班牙语多标签分类数据集,适用于智利法律,并对西班牙语模型在法律领域进行了全面评估。我们的工作为未来在法律分析方面的方法开发研究奠定了基础,并有望为智利和整个拉丁美洲的消费者提供实际支持应用。
论文及项目相关链接
PDF 37 pages, 2 figures, under review
Summary:本研究关注消费者合同中信息不对等问题的日益严重,特别是由于在线服务普及和其复杂的服务条款很少被阅读而加剧的问题。尽管已有关于自动分析方法的研究,但问题依然严峻,因为目前的研究主要集中在英语机器学习方法以及欧洲联盟等主要司法管辖区。本研究介绍了一种新方法和大规模数据集来解决这一差距。我们提出了一种新的注释方案,包括四个类别和总共20个子类别,并应用于智利使用的50项在线服务条款。我们评估了基于转换器的模型,探讨了语言、领域特定的预训练、少数样本大小和模型架构等因素对潜在滥用条款的检测和分类的影响。结果显示各项任务和模型的表现存在很大差异,检测任务的宏观F1分数最高达到89%,微观F1分数最高达到96%,而分类任务的宏观和微观F1分数分别在60%至70%和64%至80%之间。值得注意的是,这是第一个用于法律条款的西班牙语多标签分类数据集,以智利法律为依据,全面评估了西班牙语模型在法律领域的表现。本研究为未来在较少考虑的法律分析中的方法开发奠定了基础,并有望为消费者在智利乃至拉丁美洲提供支持。
Key Takeaways:
- 本研究关注在线服务合同中信息不对称的问题。
- 由于复杂的服务条款鲜少被阅读,该问题进一步加剧。
- 尽管有自动分析方法的研究,但现有研究主要集中在英语和欧洲司法管辖区。
- 提出了一种新的注释方案和数据集来解决这一差距,特别关注智利使用的在线服务条款。
- 基于转换器的模型被评估,探讨不同因素对条款检测和分类的影响。
- 检测和分类任务的表现存在很大差异,其中检测任务表现较好。
点此查看论文截图

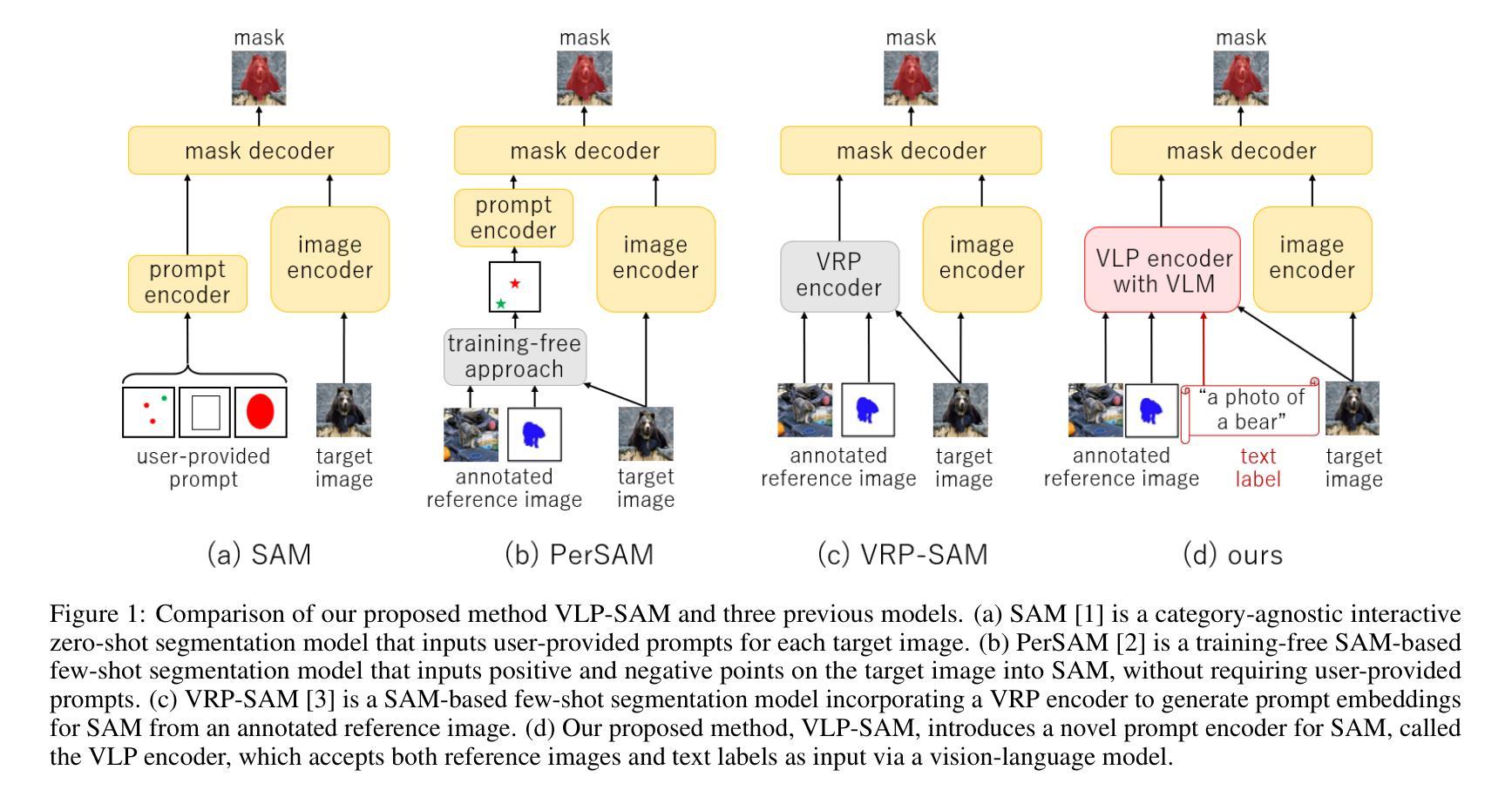
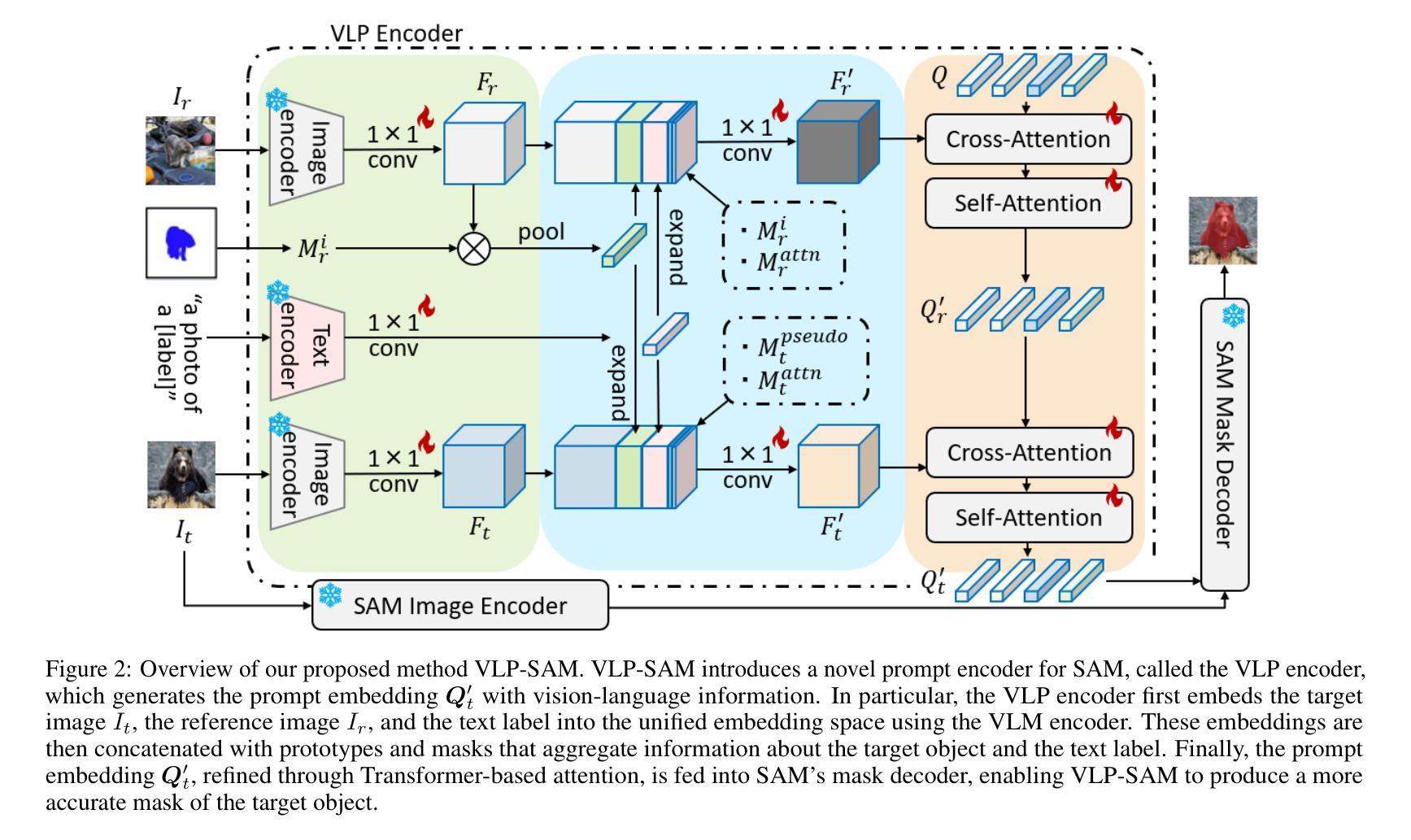
Vision and Language Reference Prompt into SAM for Few-shot Segmentation
Authors:Kosuke Sakurai, Ryotaro Shimizu, Masayuki Goto
Segment Anything Model (SAM) represents a large-scale segmentation model that enables powerful zero-shot capabilities with flexible prompts. While SAM can segment any object in zero-shot, it requires user-provided prompts for each target image and does not attach any label information to masks. Few-shot segmentation models addressed these issues by inputting annotated reference images as prompts to SAM and can segment specific objects in target images without user-provided prompts. Previous SAM-based few-shot segmentation models only use annotated reference images as prompts, resulting in limited accuracy due to a lack of reference information. In this paper, we propose a novel few-shot segmentation model, Vision and Language reference Prompt into SAM (VLP-SAM), that utilizes the visual information of the reference images and the semantic information of the text labels by inputting not only images but also language as reference information. In particular, VLP-SAM is a simple and scalable structure with minimal learnable parameters, which inputs prompt embeddings with vision-language information into SAM using a multimodal vision-language model. To demonstrate the effectiveness of VLP-SAM, we conducted experiments on the PASCAL-5i and COCO-20i datasets, and achieved high performance in the few-shot segmentation task, outperforming the previous state-of-the-art model by a large margin (6.3% and 9.5% in mIoU, respectively). Furthermore, VLP-SAM demonstrates its generality in unseen objects that are not included in the training data. Our code is available at https://github.com/kosukesakurai1/VLP-SAM.
Segment Anything Model(SAM)代表了一种大规模分割模型,它通过灵活的提示实现了强大的零样本能力。虽然SAM可以在零样本中分割任何对象,但它需要针对每个目标图像提供用户提示,并且不会在蒙版上附加任何标签信息。少样本分割模型通过输入带有标注的参考图像作为提示来解决这些问题,能够在目标图像中分割特定对象,而无需用户提供提示。之前的基于SAM的少样本分割模型仅使用带有标注的参考图像作为提示,由于缺少参考信息,导致准确性受限。在本文中,我们提出了一种新型少样本分割模型——Vision and Language reference Prompt into SAM(VLP-SAM),它利用参考图像中的视觉信息和文本标签的语义信息,不仅输入图像,还输入语言作为参考信息。特别是,VLP-SAM具有简单可扩展的结构和最小的可学习参数,使用多模态视觉语言模型将带有视觉语言信息的提示嵌入SAM中。为了证明VLP-SAM的有效性,我们在PASCAL-5i和COCO-20i数据集上进行了实验,在少样本分割任务中取得了高性能,大幅超越了之前的最新模型(分别提高了6.3%和9.5%的mIoU)。此外,VLP-SAM在未见过的对象上表现出了其普遍性,这些对象不包括在训练数据中。我们的代码可在https://github.com/kosukesakurai1/VLP-SAM上找到。
论文及项目相关链接
PDF 8 pages, 2 figures
Summary
本论文提出了一种新颖的少样本分割模型VLP-SAM,它将视觉信息与文本标签的语义信息结合,通过输入图像和文本作为参考信息来优化SAM模型的零样本能力。该模型简单、可扩展,参数可学习性低。在PASCAL-5i和COCO-20i数据集上的实验表明,其在少样本分割任务上取得了高性能,并显著优于先前的主流模型。同时,该模型对于未见对象也表现出其普遍性。
Key Takeaways
- VLP-SAM模型结合了视觉信息和文本标签的语义信息。
- 通过输入图像和文本作为参考信息,优化了SAM模型的零样本能力。
- VLP-SAM模型具有简单、可扩展的特性,且参数可学习性较低。
- 在PASCAL-5i和COCO-20i数据集上的实验验证了VLP-SAM模型在少样本分割任务上的高性能。
- VLP-SAM模型显著优于先前的主流模型,在mIoU指标上分别提升了6.3%和9.5%。
- VLP-SAM模型对于未见对象也表现出其普遍性。
点此查看论文截图

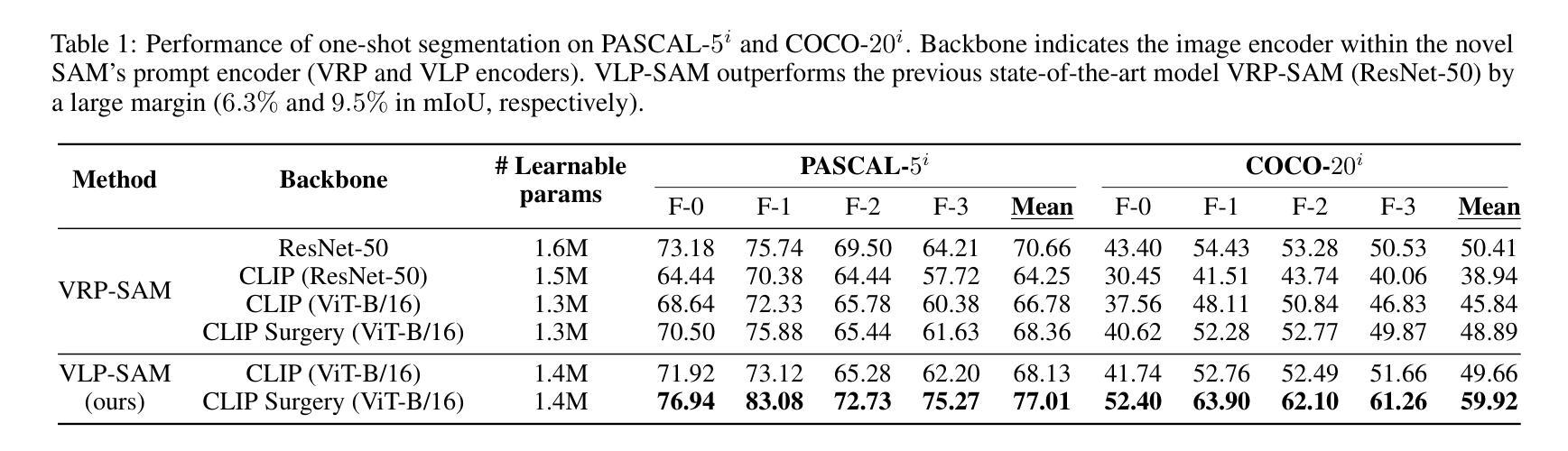
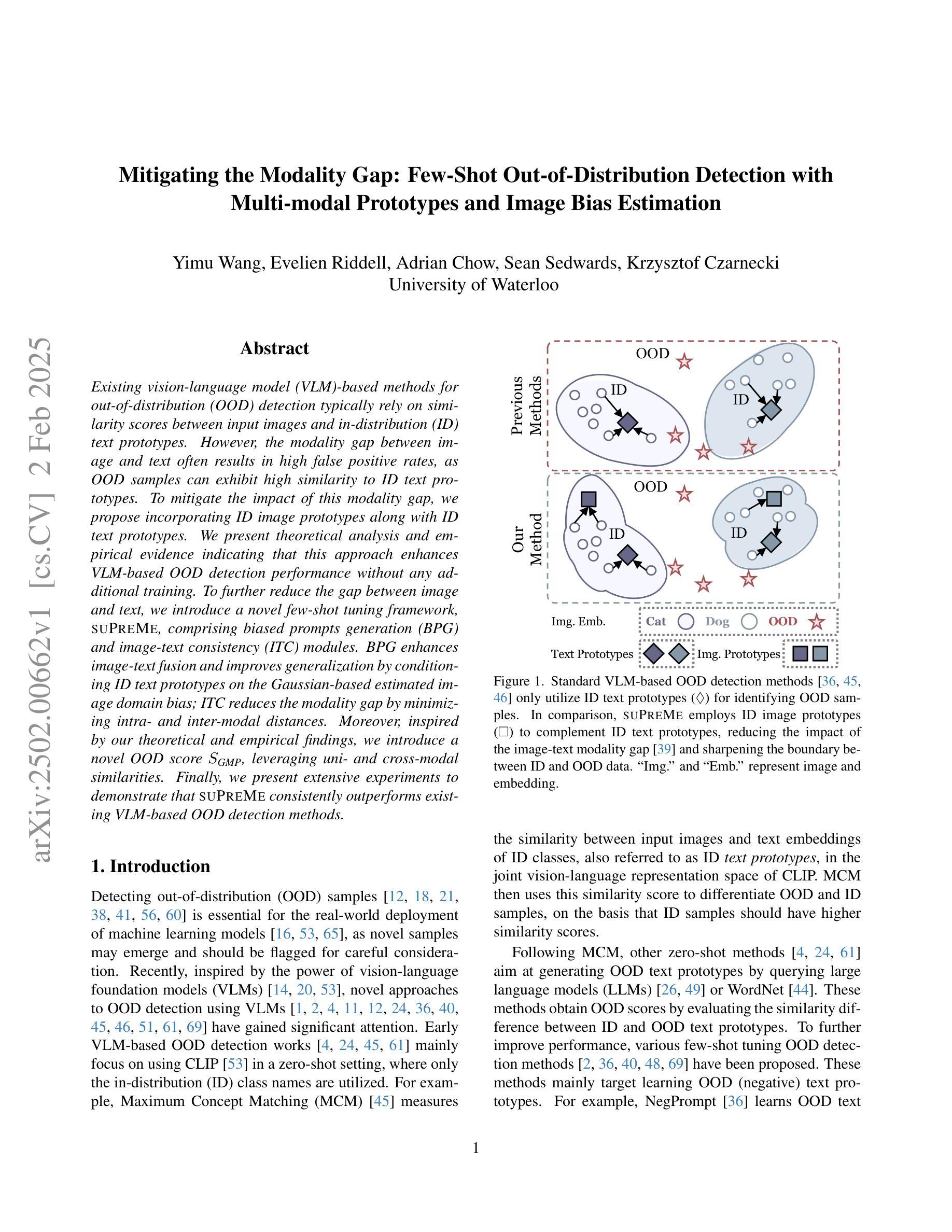
Mitigating the Modality Gap: Few-Shot Out-of-Distribution Detection with Multi-modal Prototypes and Image Bias Estimation
Authors:Yimu Wang, Evelien Riddell, Adrian Chow, Sean Sedwards, Krzysztof Czarnecki
Existing vision-language model (VLM)-based methods for out-of-distribution (OOD) detection typically rely on similarity scores between input images and in-distribution (ID) text prototypes. However, the modality gap between image and text often results in high false positive rates, as OOD samples can exhibit high similarity to ID text prototypes. To mitigate the impact of this modality gap, we propose incorporating ID image prototypes along with ID text prototypes. We present theoretical analysis and empirical evidence indicating that this approach enhances VLM-based OOD detection performance without any additional training. To further reduce the gap between image and text, we introduce a novel few-shot tuning framework, SUPREME, comprising biased prompts generation (BPG) and image-text consistency (ITC) modules. BPG enhances image-text fusion and improves generalization by conditioning ID text prototypes on the Gaussian-based estimated image domain bias; ITC reduces the modality gap by minimizing intra- and inter-modal distances. Moreover, inspired by our theoretical and empirical findings, we introduce a novel OOD score $S_{\textit{GMP}}$, leveraging uni- and cross-modal similarities. Finally, we present extensive experiments to demonstrate that SUPREME consistently outperforms existing VLM-based OOD detection methods.
现有的基于视觉语言模型(VLM)的离群值(OOD)检测通常依赖于输入图像与分布内(ID)文本原型之间的相似度得分。然而,图像和文本之间的模态差距常常导致高误报率,因为离群样本可能表现出与ID文本原型的高度相似性。为了减轻这种模态差距的影响,我们提出结合ID图像原型和ID文本原型。我们提供理论分析和实证证据表明,这种方法在不进行任何额外训练的情况下提高了基于VLM的OOD检测性能。为了进一步缩小图像和文本之间的差距,我们引入了一种新的少样本调整框架SUPREME,包括偏向提示生成(BPG)和图像文本一致性(ITC)模块。BPG通过基于高斯估计的图像域偏差对ID文本原型进行条件处理,增强图像文本的融合并提高泛化能力;ITC通过最小化跨模态距离来缩小模态差距。此外,受到理论和实证研究的启发,我们提出了一种新的OOD得分公式$S_{\text{GMP}}$,利用单模态和跨模态相似性。最后,我们通过大量实验证明,SUPREME在性能上持续超越现有基于VLM的OOD检测方法。
论文及项目相关链接
Summary
本文提出一种结合图像和文本原型的方法,通过引入少数样本微调框架SUPREME,包括偏差提示生成(BPG)和图像文本一致性(ITC)模块,缩小图像和文本之间的模态差距,提高基于视觉语言模型(VLM)的未知分布(OOD)检测性能。通过理论分析和实证研究,验证了该方法的有效性。
Key Takeaways
- 现有基于视觉语言模型(VLM)的未知分布(OOD)检测方法通常依赖于输入图像和已知分布(ID)文本原型之间的相似度得分,但存在模态差距导致高误报率。
- 提出结合ID图像原型和ID文本原型的方法,以缩小模态差距并增强VLM的OOD检测性能。
- 引入少数样本微调框架SUPREME,包括偏差提示生成(BPG)和图像文本一致性(ITC)模块,进一步提高图像和文本的融合和一致性。
- BPG通过基于高斯估计的图像域偏差对ID文本原型进行条件处理,增强了图像文本融合并提高了泛化能力。
- ITC通过最小化跨模态距离来缩小模态差距。
- 提出一种新的OOD得分公式$S_{\textit{GMP}}$,利用单模态和跨模态相似性进行更准确的OOD检测。
点此查看论文截图
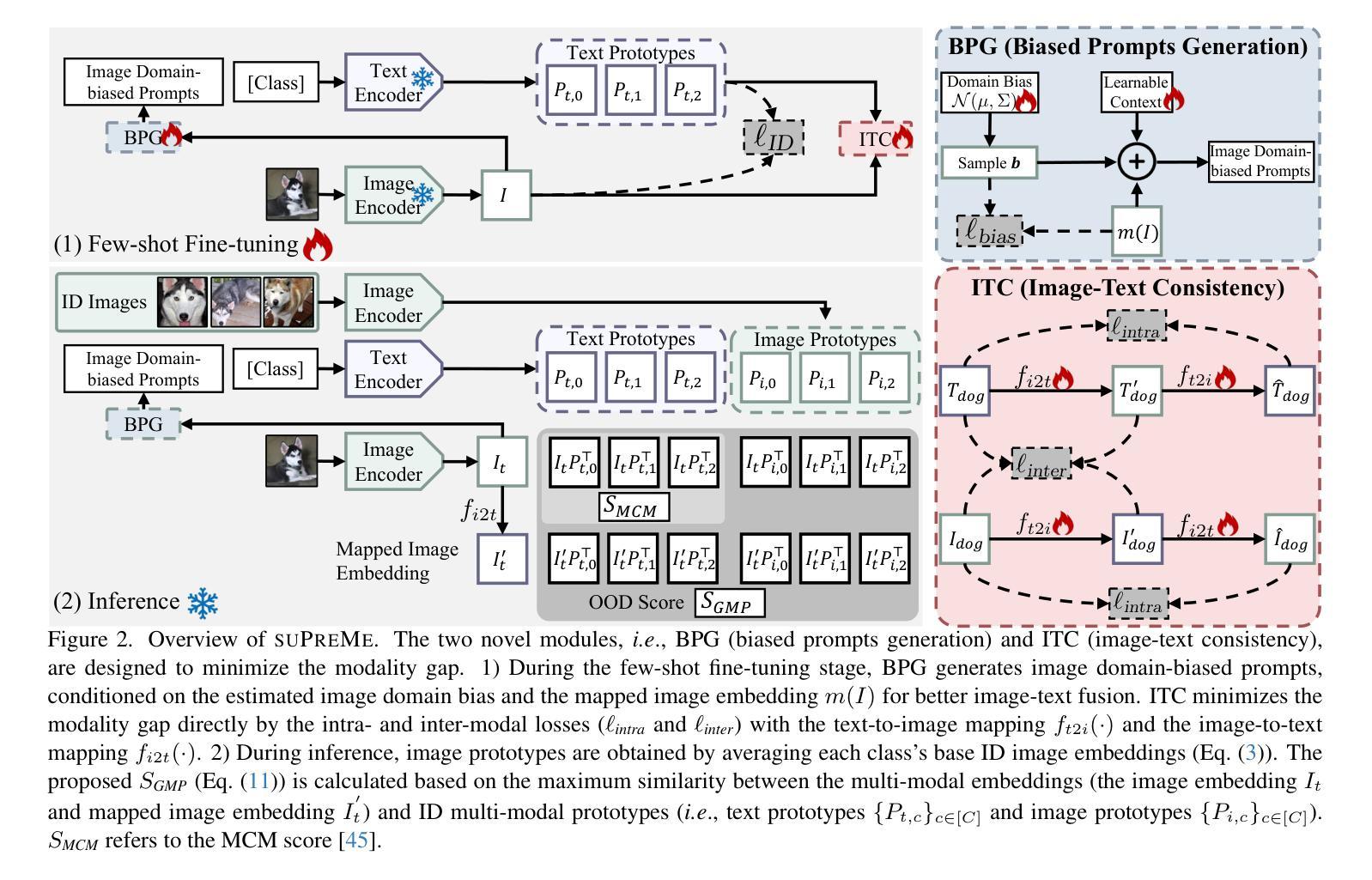
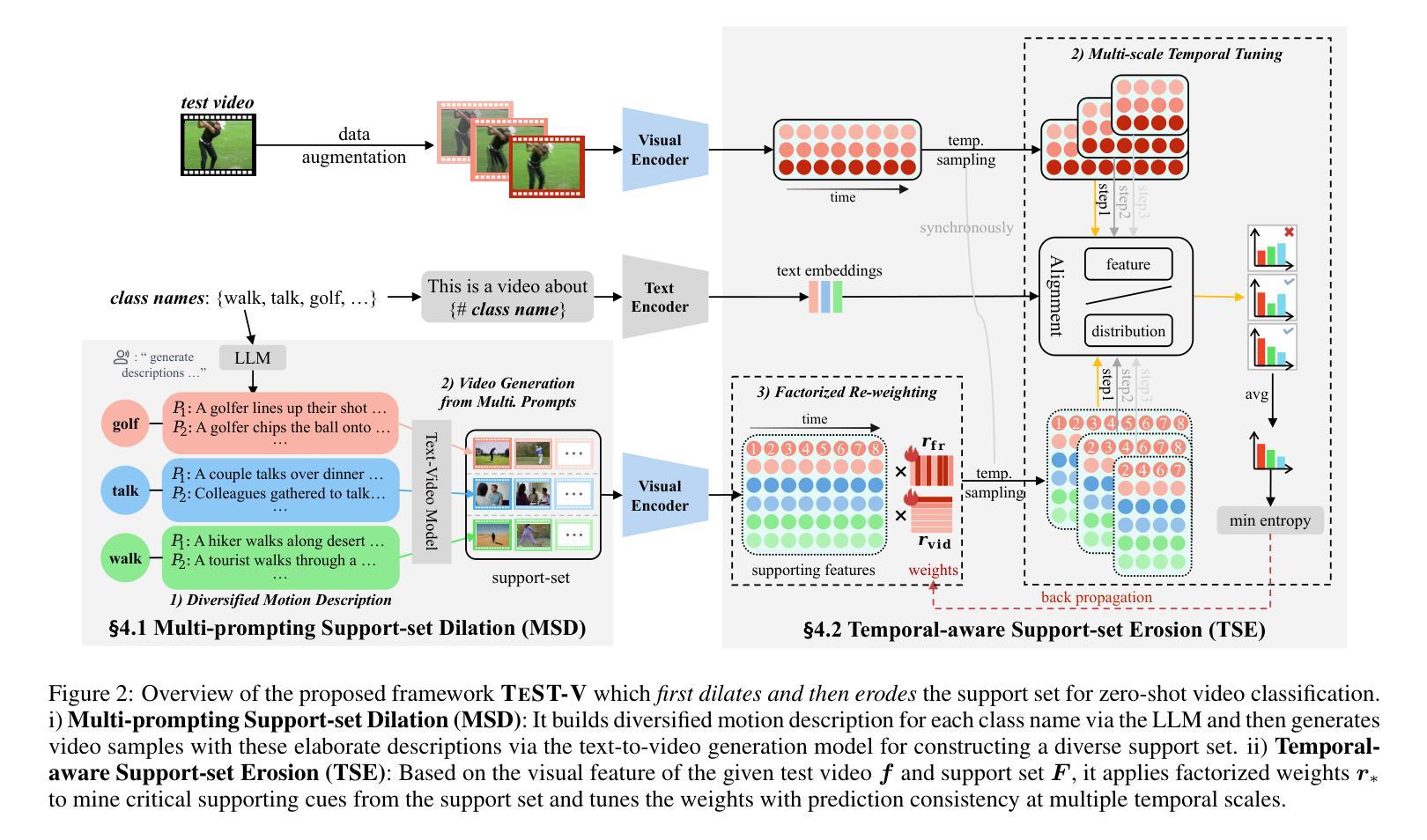
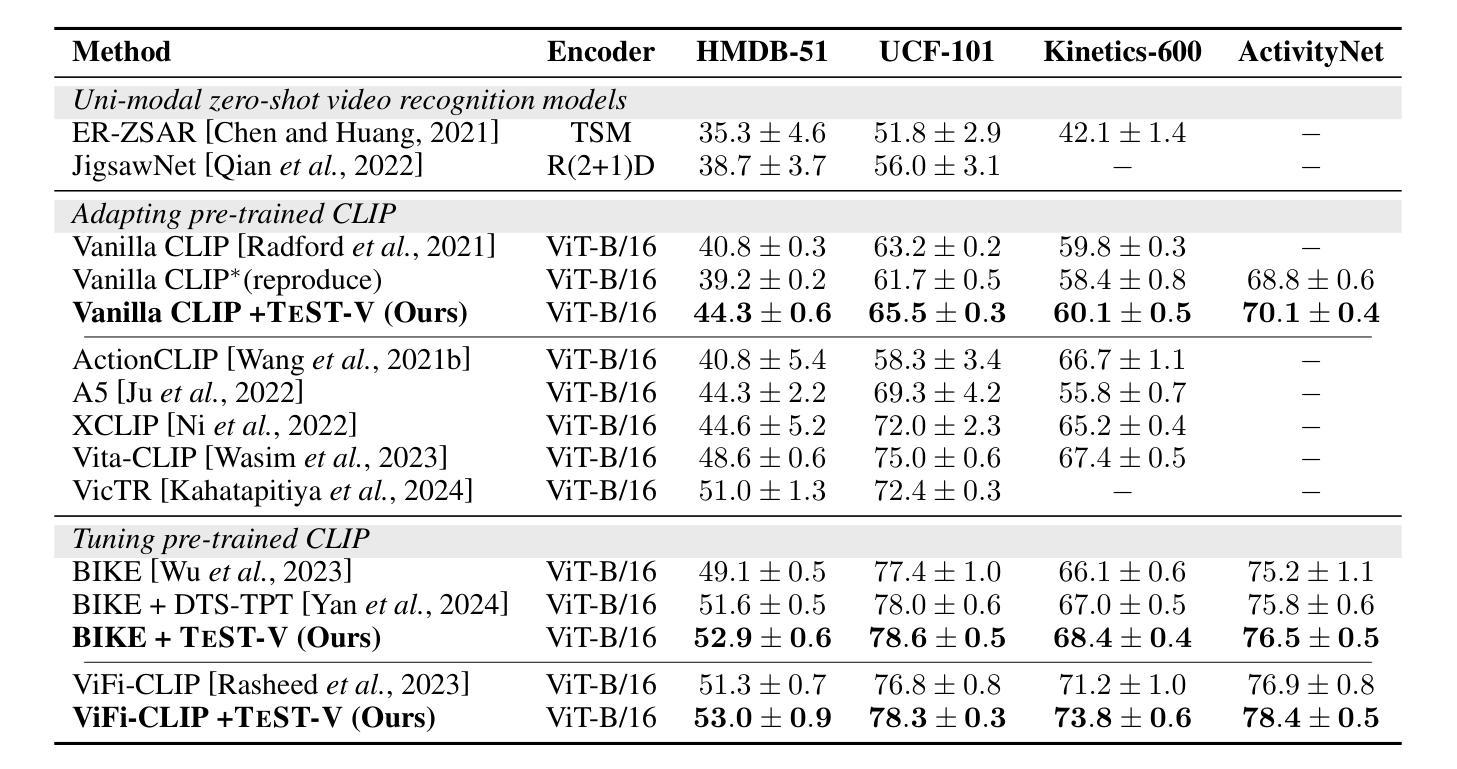
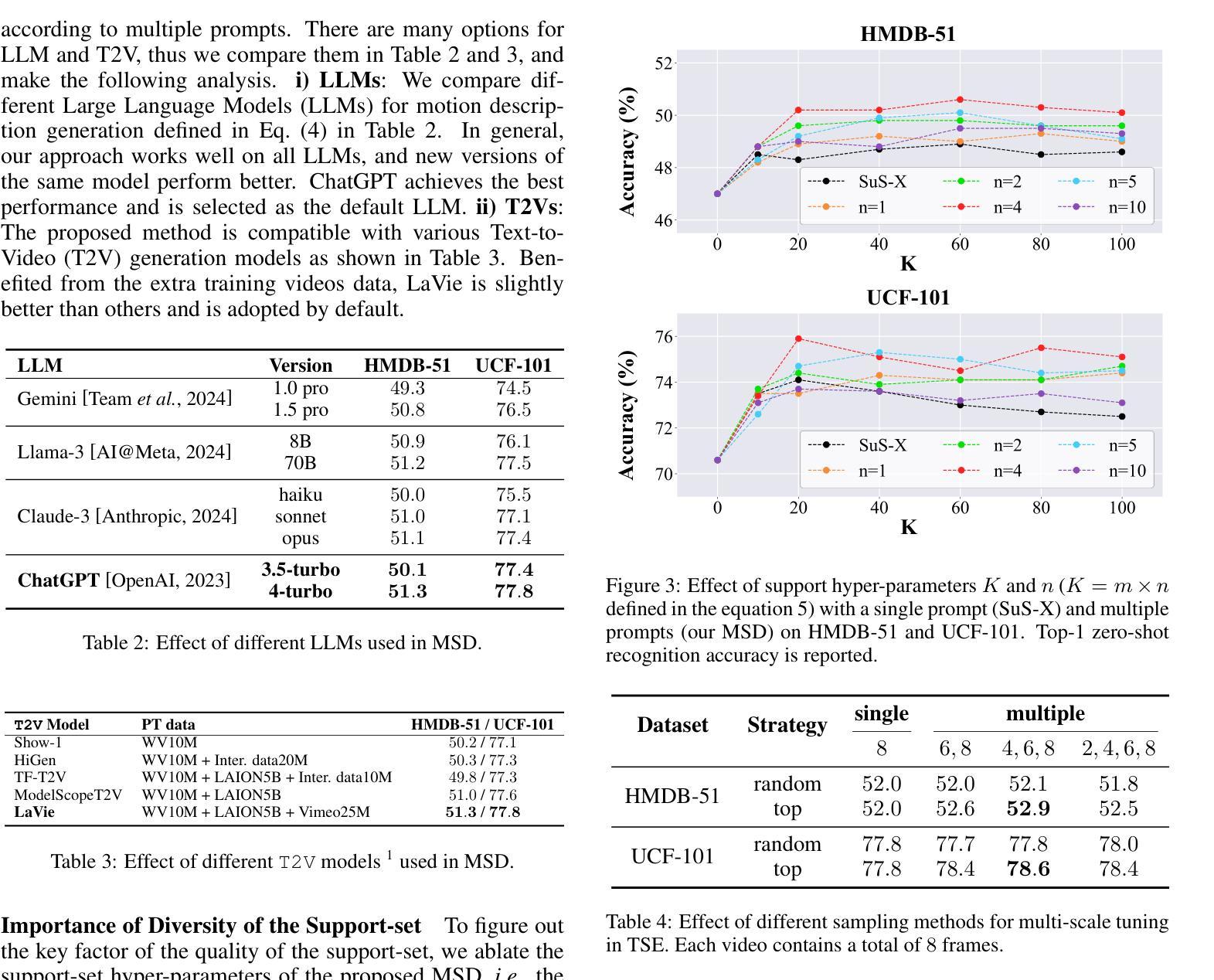
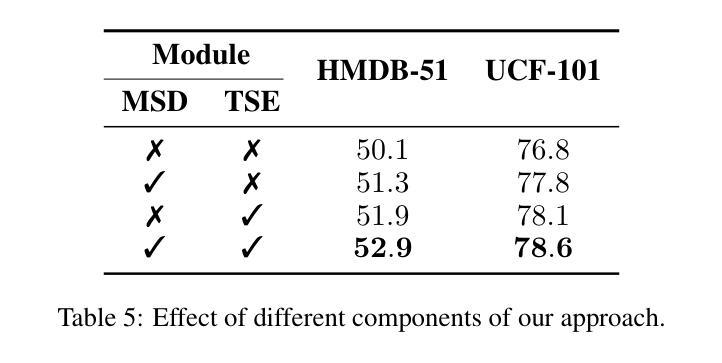
TeST-V: TEst-time Support-set Tuning for Zero-shot Video Classification
Authors:Rui Yan, Jin Wang, Hongyu Qu, Xiaoyu Du, Dong Zhang, Jinhui Tang, Tieniu Tan
Recently, adapting Vision Language Models (VLMs) to zero-shot visual classification by tuning class embedding with a few prompts (Test-time Prompt Tuning, TPT) or replacing class names with generated visual samples (support-set) has shown promising results. However, TPT cannot avoid the semantic gap between modalities while the support-set cannot be tuned. To this end, we draw on each other’s strengths and propose a novel framework namely TEst-time Support-set Tuning for zero-shot Video Classification (TEST-V). It first dilates the support-set with multiple prompts (Multi-prompting Support-set Dilation, MSD) and then erodes the support-set via learnable weights to mine key cues dynamically (Temporal-aware Support-set Erosion, TSE). Specifically, i) MSD expands the support samples for each class based on multiple prompts enquired from LLMs to enrich the diversity of the support-set. ii) TSE tunes the support-set with factorized learnable weights according to the temporal prediction consistency in a self-supervised manner to dig pivotal supporting cues for each class. $\textbf{TEST-V}$ achieves state-of-the-art results across four benchmarks and has good interpretability for the support-set dilation and erosion.
最近,通过微调类别嵌入(class embedding)使用少量提示(Test-time Prompt Tuning,TPT)或将类别名称替换为生成的视觉样本(支持集)来适应视觉语言模型(VLMs)进行零样本视觉分类,已经取得了令人鼓舞的结果。然而,TPT无法避免不同模态之间的语义鸿沟,而支持集无法调整。为此,我们取长补短,提出了一种新的框架,名为TEST-V(用于零样本视频分类的测试时支持集调整)。它首先通过多个提示(Multi-prompting Support-set Dilation,MSD)膨胀支持集,然后通过可学习权重对支持集进行侵蚀,以动态挖掘关键线索(时序感知支持集侵蚀,TSE)。具体来说,i)MSD根据从大型语言模型(LLMs)获得的多个提示扩展每个类别的支持样本,以丰富支持集的多样性。ii)TSE使用可学习权重自适应地调整支持集,以时序预测一致性为准则挖掘每个类别的关键支持线索。TEST-V在四个基准测试中实现了最新成果,并且具有良好的解释性来支持集膨胀和侵蚀的过程。
论文及项目相关链接
Summary
本文提出了一种新颖的框架TEST-V,用于零样本视频分类。该框架结合了测试时提示调整(TPT)和支持集的优势,通过多提示支持集膨胀(MSD)和时间感知支持集侵蚀(TSE)来优化支持集。MSD通过从大型语言模型(LLMs)获取多个提示来丰富支持集的多样性,而TSE则通过可学习的权重来挖掘关键线索。TEST-V在四个基准测试中实现了最先进的性能,并支持集膨胀和侵蚀具有良好的可解释性。
Key Takeaways
- TEST-V结合了测试时提示调整(TPT)和支持集的优势,用于零样本视频分类。
- 多提示支持集膨胀(MSD)通过从大型语言模型获取多个提示来丰富支持集的多样性。
- 时间感知支持集侵蚀(TSE)通过可学习的权重挖掘关键线索,根据时间预测一致性进行自我监督。
- TEST-V通过结合MSD和TSE,实现了在四个基准测试中的最佳性能。
- TEST-V具有良好的可解释性,支持集膨胀和侵蚀的过程可以清晰地理解和分析。
- TEST-V框架提高了零样本视频分类的准确性和性能。
点此查看论文截图

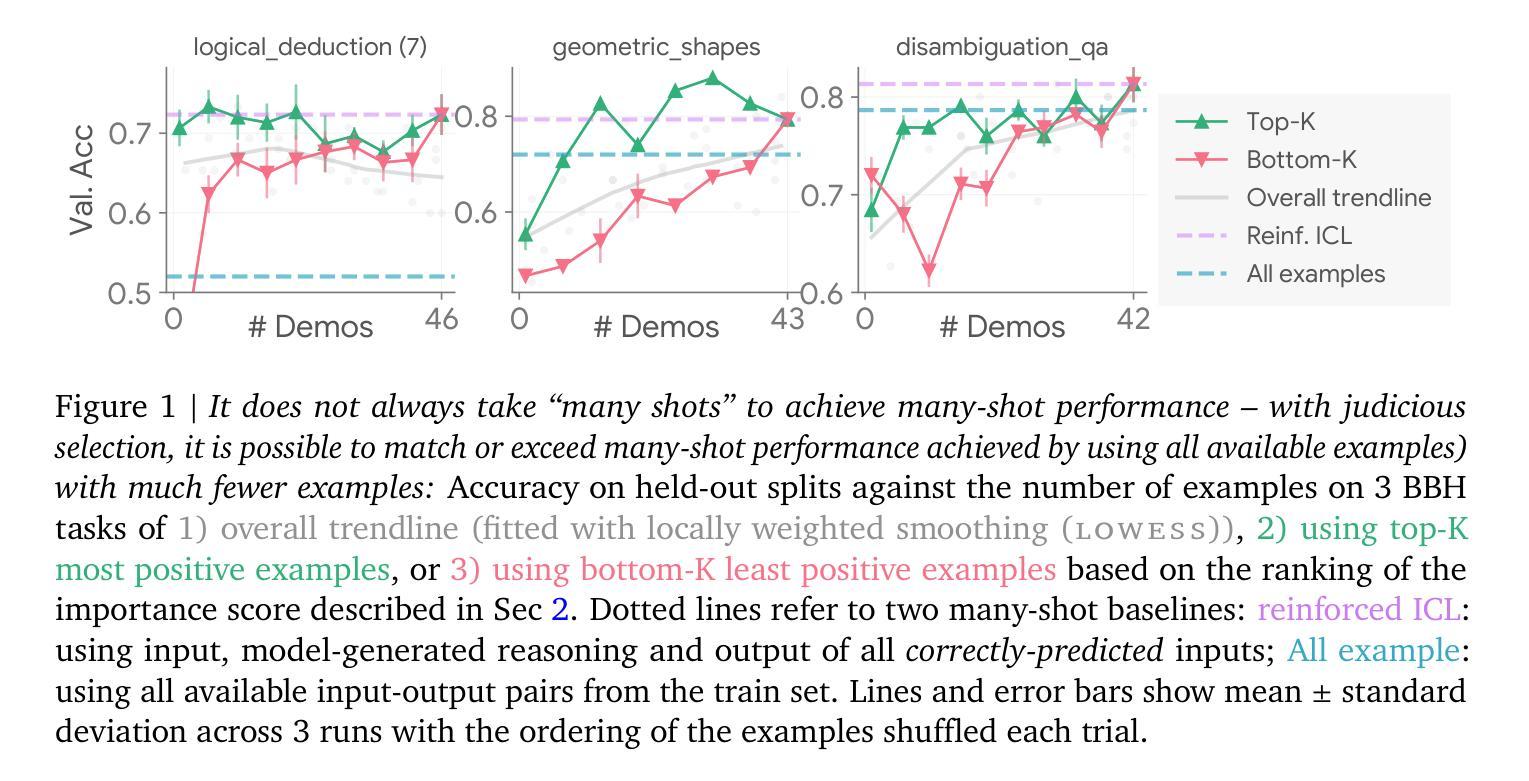
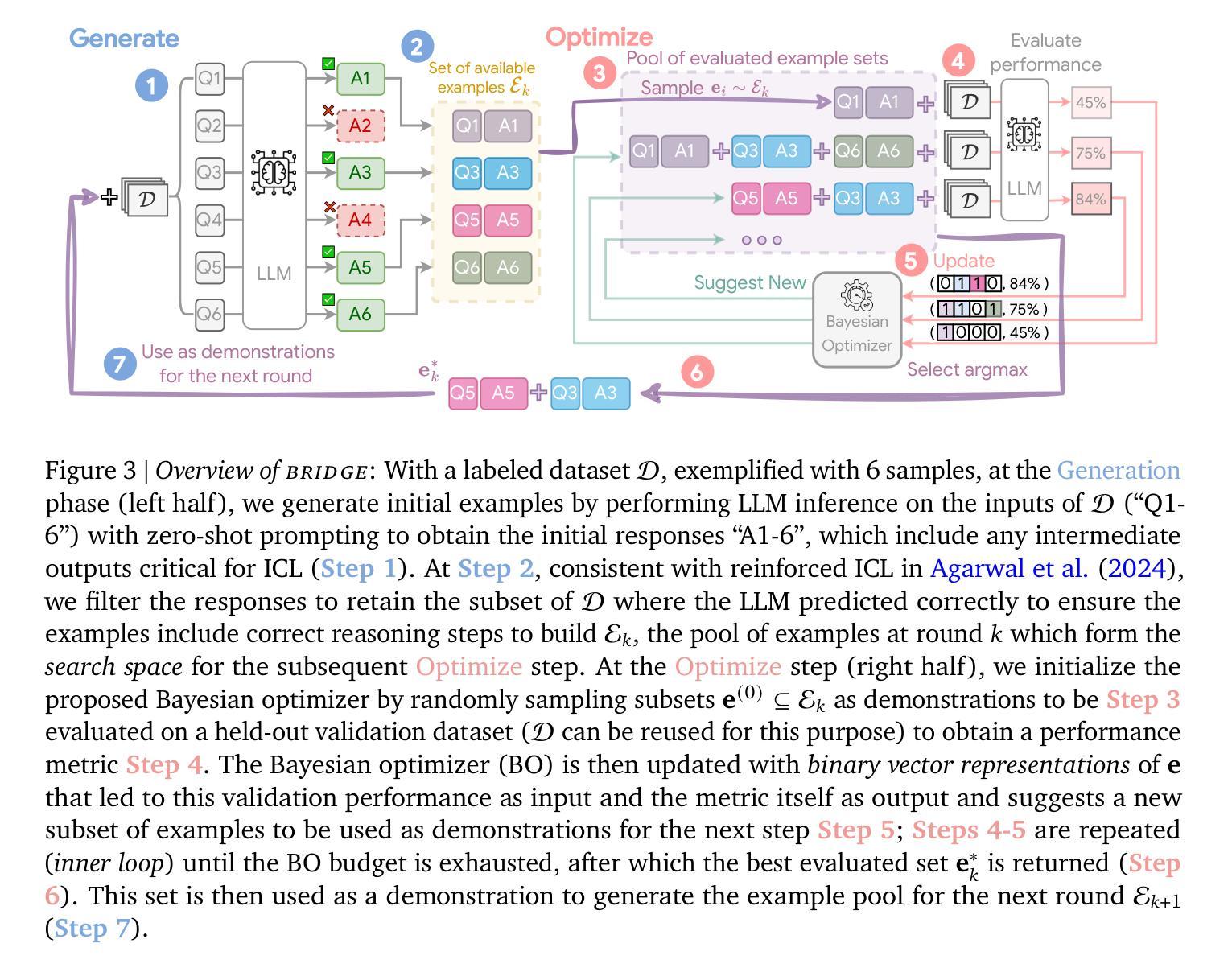
From Few to Many: Self-Improving Many-Shot Reasoners Through Iterative Optimization and Generation
Authors:Xingchen Wan, Han Zhou, Ruoxi Sun, Hootan Nakhost, Ke Jiang, Sercan Ö. Arık
Recent advances in long-context large language models (LLMs) have led to the emerging paradigm of many-shot in-context learning (ICL), where it is observed that scaling many more demonstrating examples beyond the conventional few-shot setup in the context can lead to performance benefits. However, despite its promise, it is unclear what aspects dominate the benefits and whether simply scaling to more examples is the most effective way of improving many-shot ICL. In this work, we first provide an analysis of the factors driving many-shot ICL, and we find that 1) many-shot performance can still be attributed to often a few disproportionately influential examples and 2) identifying such influential examples (“optimize”) and using them as demonstrations to regenerate new examples (“generate”) can lead to further improvements. Inspired by the findings, we propose BRIDGE, an algorithm that alternates between the optimize step with Bayesian optimization to discover the influential sets of examples and the generate step to reuse this set to expand the reasoning paths of the examples back to the many-shot regime automatically. On Gemini, Claude, and Mistral LLMs of different sizes, we show that BRIDGE to significant improvements across a diverse set of tasks, including symbolic reasoning, numerical reasoning, and code generation.
近年来,长语境大型语言模型(LLM)的最新进展催生了多示例上下文学习(ICL)的范式兴起。在该范式中,观察到在语境中扩大远超传统小样本设置的许多示例,可以带来性能上的优势。然而,尽管具有潜力,但尚不清楚哪些方面主导了这些好处,以及单纯扩大示例规模是否是改进多示例ICL的最有效方式。在这项工作中,我们首先分析了推动多示例ICL发展的因素,并发现:1)多示例性能仍然可以归功于少数不成比例地具有影响力的示例;2)识别这些有影响力的示例(“优化”),并把它们作为示范来生成新示例(“生成”),可以导致进一步的改进。受这些发现的启发,我们提出了BRIDGE算法,该算法交替进行使用贝叶斯优化来发现具有影响力的示例集(“优化”)和重用此集来自动扩展示例的推理路径到多示例范围(“生成”)。我们在Gemini、Claude和Mistral的不同规模的大型语言模型上展示了BRIDGE算法在包括符号推理、数值推理和代码生成等多样化任务上的显著改进。
论文及项目相关链接
PDF Expanded version of the ICLR 2025 paper
Summary
近期长文本大语言模型(LLM)的进步推动了多示例上下文学习(ICL)范式的兴起。研究发现,在常规少示例设置的基础上扩展更多示例上下文的规模可以带来性能上的优势。然而,尚不清楚哪些因素主导了这种优势,以及单纯扩大示例规模是否是最有效的改进方式。本文首先分析了推动多示例上下文学习发展的因素,发现:一是多示例性能的提升仍源于少数极具影响力的示例;二是通过识别这些有影响力的示例并进行优化,再利用它们生成新的示例,可以进一步改进性能。基于这些发现,本文提出了名为BRIDGE的算法,通过贝叶斯优化来发现并优化最具影响力的示例集,再利用这些示例自动扩展推理路径回到多示例状态。在不同规模的大型语言模型上进行的实验表明,该方法在不同任务上都取得了显著改进。
Key Takeaways
- 大型语言模型的性能可以通过扩大上下文中的示例数量来进一步提升。
- 性能的提升主要源于少数极具影响力的示例。
- 通过识别和优化这些有影响力的示例,可以进一步提高性能。
- BRIDGE算法结合了优化和生成步骤,通过贝叶斯优化发现最具影响力的示例集,并用于扩展推理路径。
- 在不同规模的语言模型和多种任务上,BRIDGE算法都取得了显著改进。
- 除了性能和算法层面的发现外,该研究还强调了在大规模语言模型中理解和识别关键示例的重要性。
点此查看论文截图

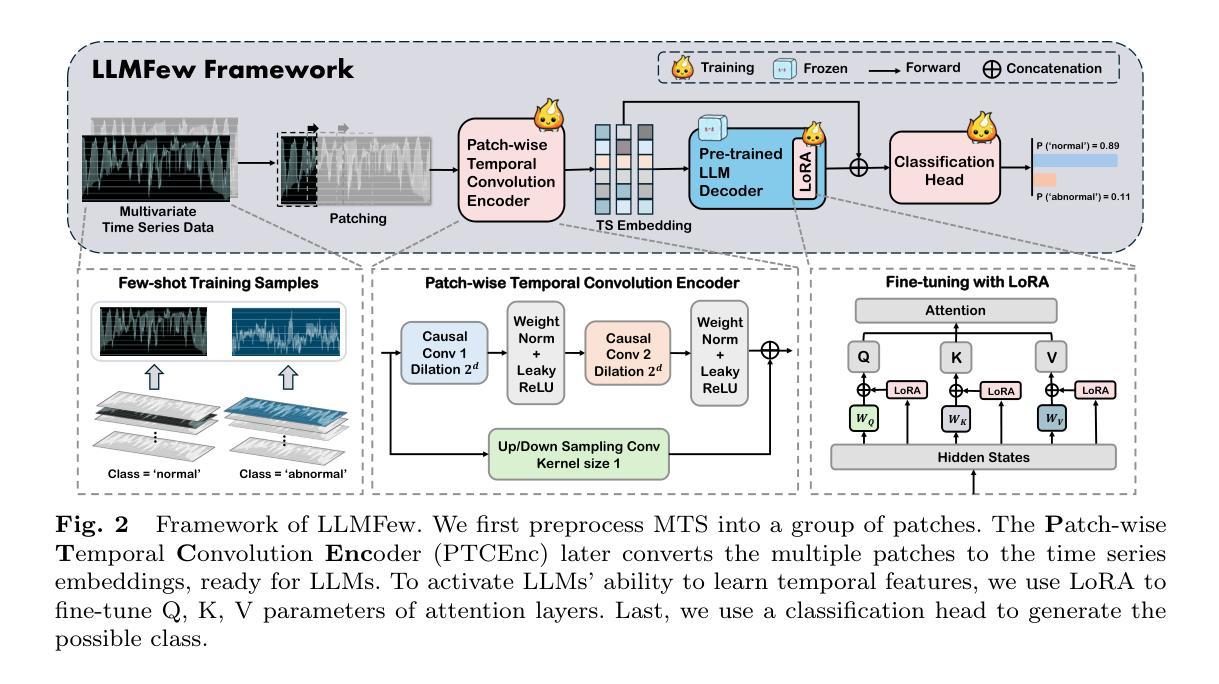
Large Language Models are Few-shot Multivariate Time Series Classifiers
Authors:Yakun Chen, Zihao Li, Chao Yang, Xianzhi Wang, Guandong Xu
Large Language Models (LLMs) have been extensively applied in time series analysis. Yet, their utility in the few-shot classification (i.e., a crucial training scenario due to the limited training data available in industrial applications) concerning multivariate time series data remains underexplored. We aim to leverage the extensive pre-trained knowledge in LLMs to overcome the data scarcity problem within multivariate time series. Specifically, we propose LLMFew, an LLM-enhanced framework to investigate the feasibility and capacity of LLMs for few-shot multivariate time series classification. This model introduces a Patch-wise Temporal Convolution Encoder (PTCEnc) to align time series data with the textual embedding input of LLMs. We further fine-tune the pre-trained LLM decoder with Low-rank Adaptations (LoRA) to enhance its feature representation learning ability in time series data. Experimental results show that our model outperformed state-of-the-art baselines by a large margin, achieving 125.2% and 50.2% improvement in classification accuracy on Handwriting and EthanolConcentration datasets, respectively. Moreover, our experimental results demonstrate that LLM-based methods perform well across a variety of datasets in few-shot MTSC, delivering reliable results compared to traditional models. This success paves the way for their deployment in industrial environments where data are limited.
大型语言模型(LLM)在时间序列分析方面得到了广泛应用。然而,关于多元时间序列数据的少样本分类(由于工业应用中可用训练数据有限,这是一个至关重要的训练场景),其在LLM中的效用尚未得到充分探索。我们的目标是利用LLM中丰富的预训练知识来解决多元时间序列中的数据稀缺问题。具体来说,我们提出了LLMFew框架,这是一个利用LLM进行少样本多元时间序列分类的增强框架。该模型引入了一个Patch-wise Temporal Convolution Encoder(PTCEnc),将时间序列数据与LLM的文本嵌入输入进行对齐。我们进一步使用Low-rank Adaptations(LoRA)对预训练的LLM解码器进行微调,以增强其在时间序列数据中的特征表示学习能力。实验结果表明,我们的模型在分类准确率上大幅度超越了最先进的基础模型,在手写和EthanolConcentration数据集上的分类准确率分别提高了125.2%和50.2%。此外,我们的实验结果表明,基于LLM的方法在少样本MTSC中表现良好,与传统模型相比提供了可靠的结果。这一成功为在工业环境中部署这些模型铺平了道路,尤其是在数据有限的情况下。
论文及项目相关链接
Summary
LLMs在多元时间序列分类方面的潜力巨大,尤其是少样本场景下。研究者提出了一种LLM增强的框架LLMFew,通过Patch-wise Temporal Convolution Encoder(PTCEnc)和Low-rank Adaptations(LoRA)技术,实现了对LLM的微调,大幅提升了分类准确度。实验证明,LLMFew模型在多个数据集上的表现均优于现有技术。这一进展为工业环境中数据有限的情况提供了新的解决方案。
Key Takeaways
- LLMs在多元时间序列分析中有广泛应用,但在少样本分类方面的潜力尚未得到充分探索。
- 研究者提出了LLMFew框架,利用LLM的预训练知识来解决多元时间序列的少样本分类问题。
- LLMFew框架通过PTCEnc技术将时间序列数据与LLM的文本嵌入输入对齐。
- 采用LoRA技术对LLM的预训练解码器进行微调,增强了其在时间序列数据中的特征表示学习能力。
- 实验结果显示,LLMFew模型在Handwriting和EthanolConcentration数据集上的分类准确度分别提高了125.2%和50.2%,显著优于现有技术。
- LLM在少样本多元时间序列分类中的表现可靠,适用于多种数据集。
点此查看论文截图

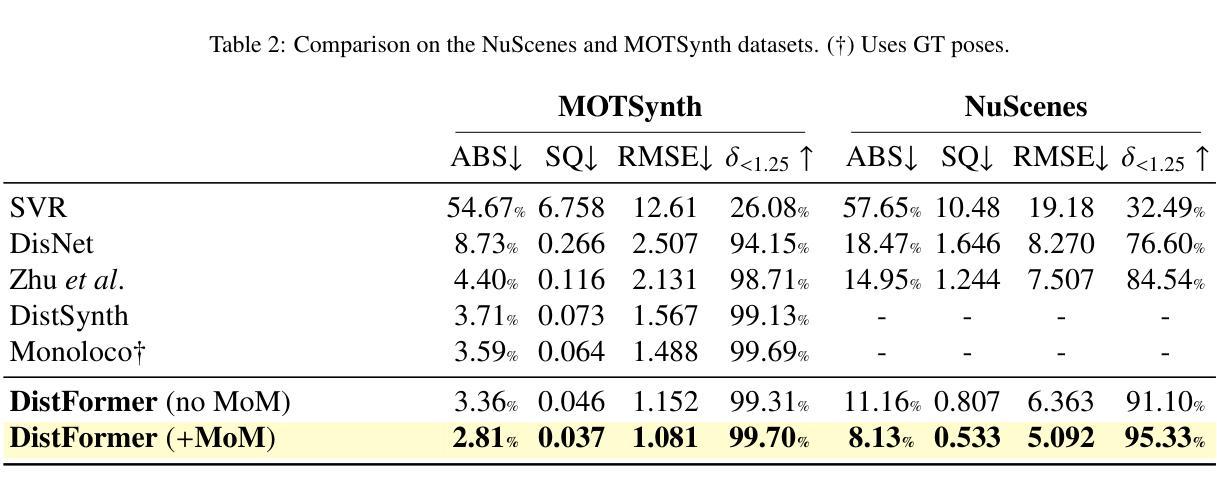
Monocular Per-Object Distance Estimation with Masked Object Modeling
Authors:Aniello Panariello, Gianluca Mancusi, Fedy Haj Ali, Angelo Porrello, Simone Calderara, Rita Cucchiara
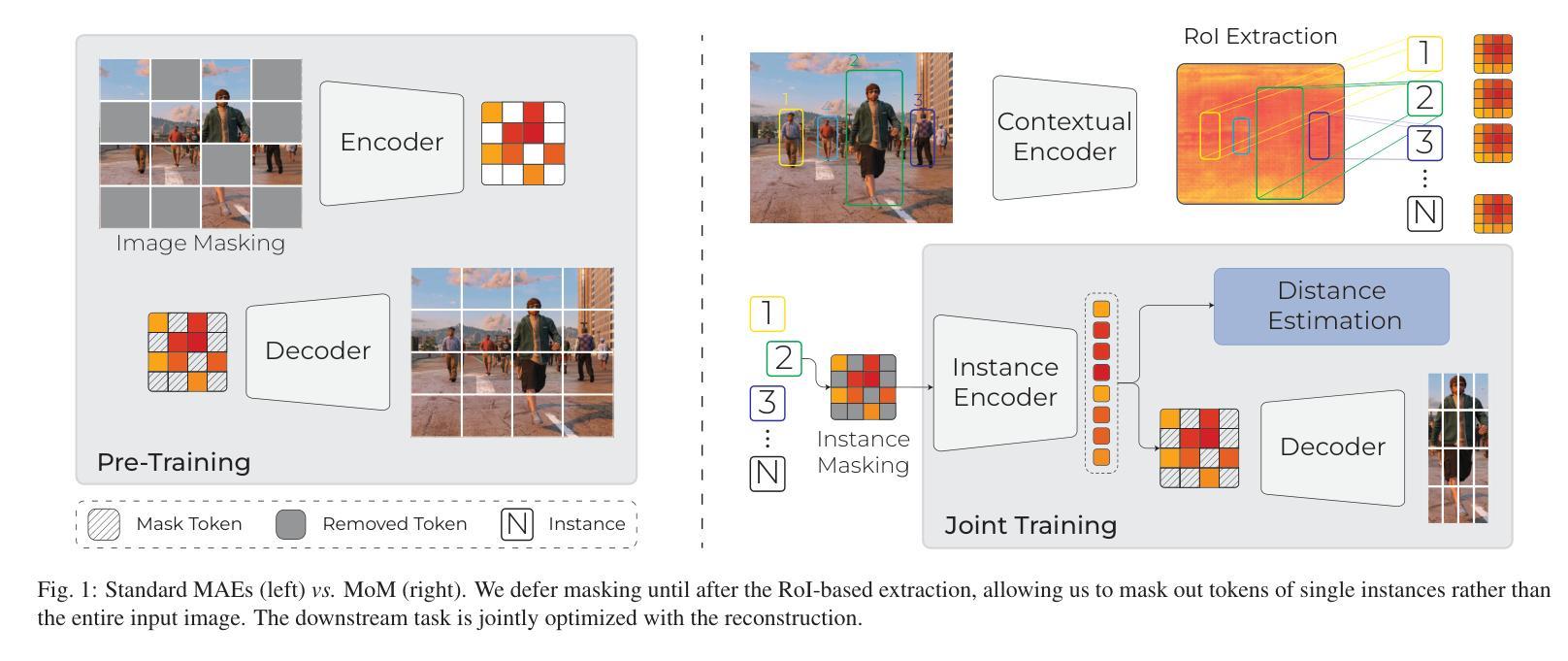
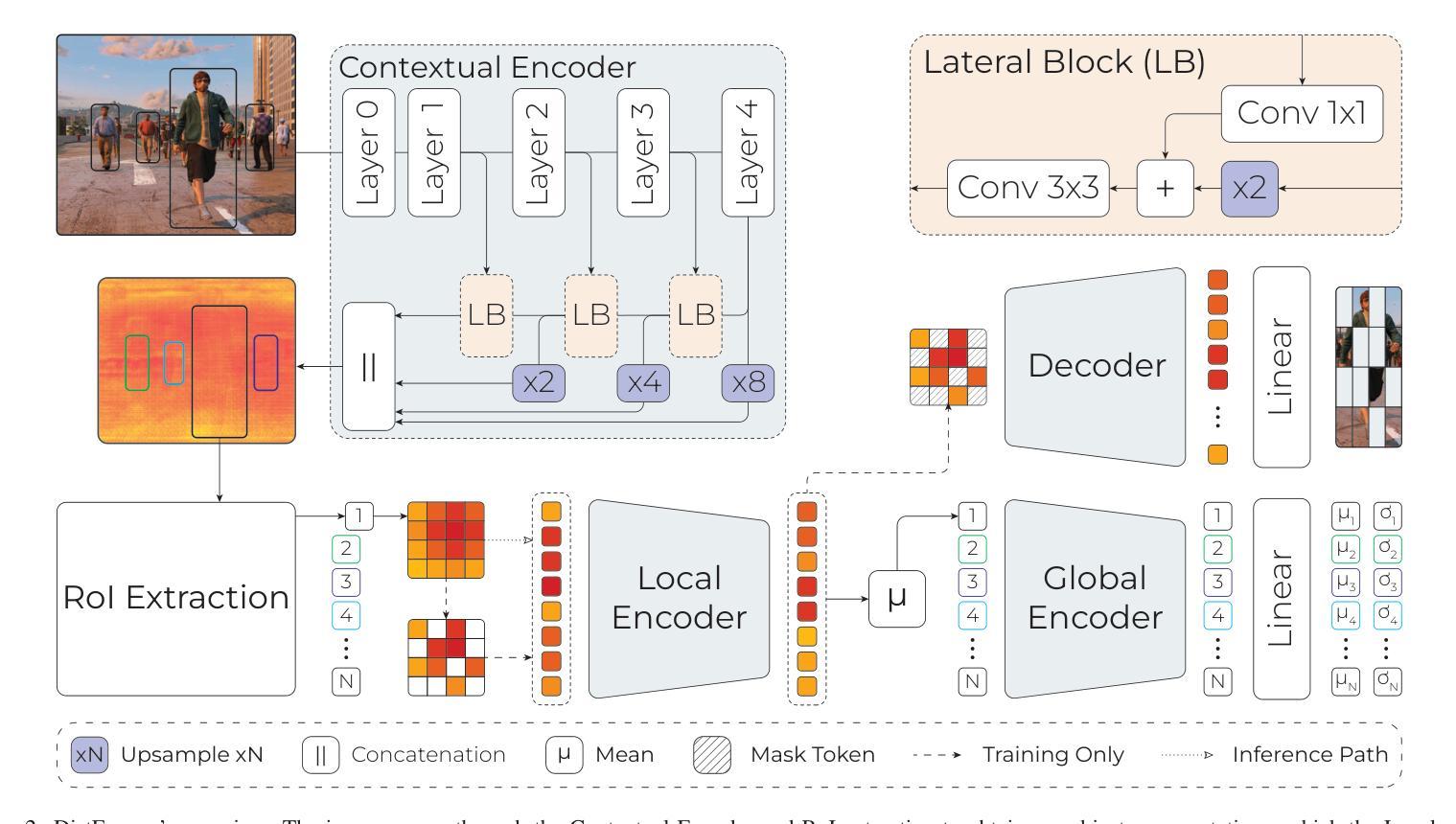
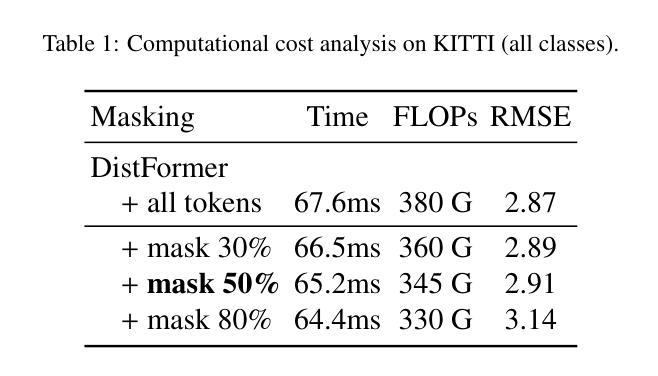
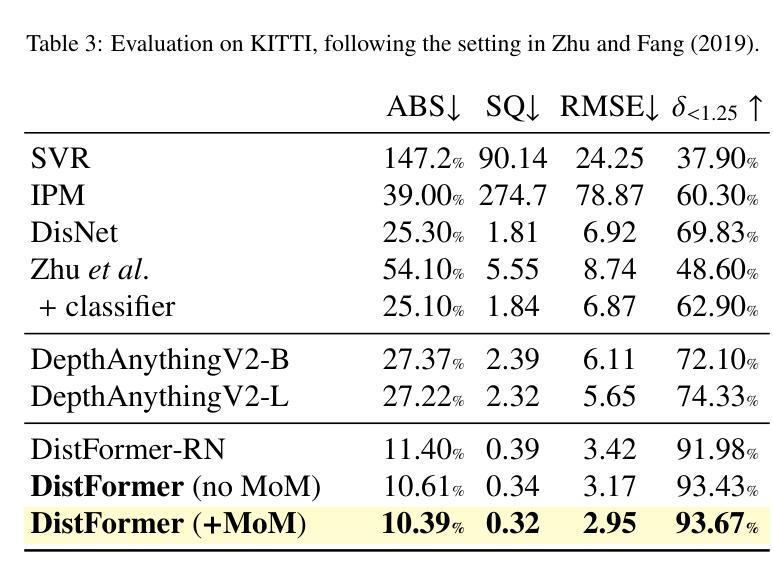
Per-object distance estimation is critical in surveillance and autonomous driving, where safety is crucial. While existing methods rely on geometric or deep supervised features, only a few attempts have been made to leverage self-supervised learning. In this respect, our paper draws inspiration from Masked Image Modeling (MiM) and extends it to multi-object tasks. While MiM focuses on extracting global image-level representations, it struggles with individual objects within the image. This is detrimental for distance estimation, as objects far away correspond to negligible portions of the image. Conversely, our strategy, termed Masked Object Modeling (MoM), enables a novel application of masking techniques. In a few words, we devise an auxiliary objective that reconstructs the portions of the image pertaining to the objects detected in the scene. The training phase is performed in a single unified stage, simultaneously optimizing the masking objective and the downstream loss (i.e., distance estimation). We evaluate the effectiveness of MoM on a novel reference architecture (DistFormer) on the standard KITTI, NuScenes, and MOTSynth datasets. Our evaluation reveals that our framework surpasses the SoTA and highlights its robust regularization properties. The MoM strategy enhances both zero-shot and few-shot capabilities, from synthetic to real domain. Finally, it furthers the robustness of the model in the presence of occluded or poorly detected objects. Code is available at https://github.com/apanariello4/DistFormer
基于每个对象的距离估计是监控和自动驾驶中的关键任务,安全至关重要。现有的方法大多依赖于几何特征或深度监督特征,只有少数尝试利用自监督学习。在这方面,我们的论文从被遮挡的图像建模(MiM)中汲取灵感,并将其扩展到多对象任务。虽然MiM侧重于提取全局图像级别的表示,但它对图像中的单个对象处理起来比较困难。这对于距离估计是有害的,因为远处的对象在图像中只占很小一部分。相反,我们的策略称为被遮挡的对象建模(MoM),实现了遮挡技术的创新应用。简而言之,我们设计了一个辅助目标来重建场景中检测到的对象的图像部分。训练阶段是在一个统一的单一阶段完成的,同时优化遮挡目标和下游损失(即距离估计)。我们在新型参考架构(DistFormer)上评估MoM的有效性,在标准的KITTI、NuScenes和MOTSynth数据集上进行了评估。我们的评估结果表明,我们的框架超越了最新技术并突出了其稳健的正则化属性。MoM策略增强了零镜头和少镜头能力,从合成到真实领域。最后,它在存在遮挡或检测不良的对象的情况下进一步提高了模型的稳健性。代码可在https://github.com/apanariello4/DistFormer找到。
论文及项目相关链接
PDF Accepted for publication in Computer Vision and Image Understanding (CVIU) 2025
Summary:本研究论文提出了一种新的技术,称为Masked Object Modeling(MoM),用于改善目标距离估算的问题。相较于先前基于全局图像级的特征提取技术,例如Masked Image Modeling(MiM),MoM可更有效地针对多目标任务进行处理。通过开发一个辅助目标来重建场景中检测到的对象的图像部分,MoM优化了训练阶段,并提高了距离估算的准确性。此外,该研究还在DistFormer架构上进行了评估,显示出其在不同数据集上的优越性能。代码已公开。
Key Takeaways:
- Masked Object Modeling (MoM)被引入以解决监控和自动驾驶中的目标距离估算问题。
- MoM技术通过重建场景中检测到的对象的图像部分来优化训练阶段。
- MoM策略结合了遮挡技术与下游任务损失(如距离估算),实现了单一统一阶段的训练。
- MoM在DistFormer架构上的表现超越了现有技术,并展示了其在不同数据集上的稳健性。
- MoM策略增强了模型的零样本和少样本能力,并具有从合成到真实域的适应性。
- MoM提高了模型对遮挡或检测不良目标的稳健性。
点此查看论文截图