⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-06 更新
MaintaAvatar: A Maintainable Avatar Based on Neural Radiance Fields by Continual Learning
Authors:Shengbo Gu, Yu-Kun Qiu, Yu-Ming Tang, Ancong Wu, Wei-Shi Zheng
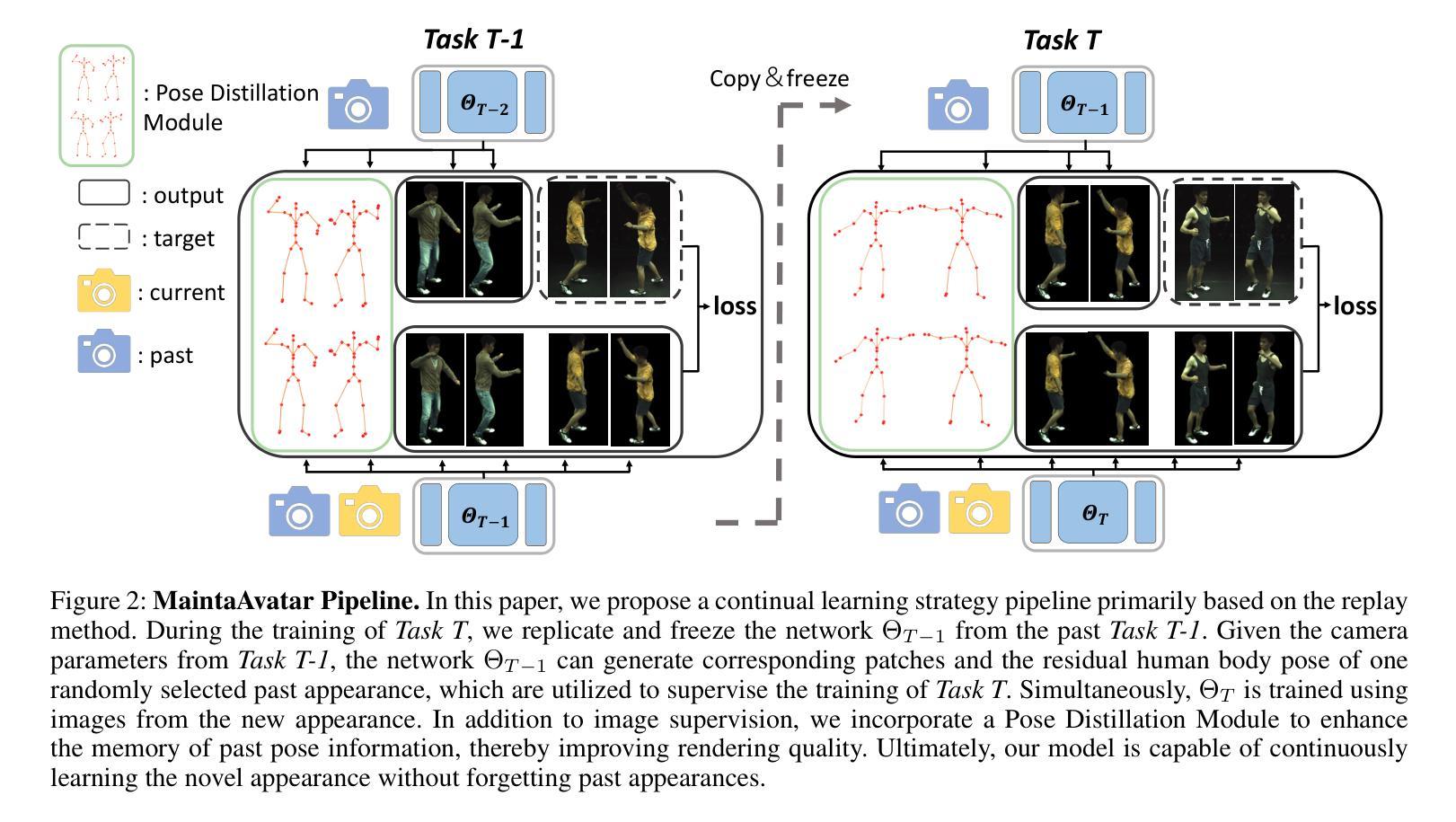
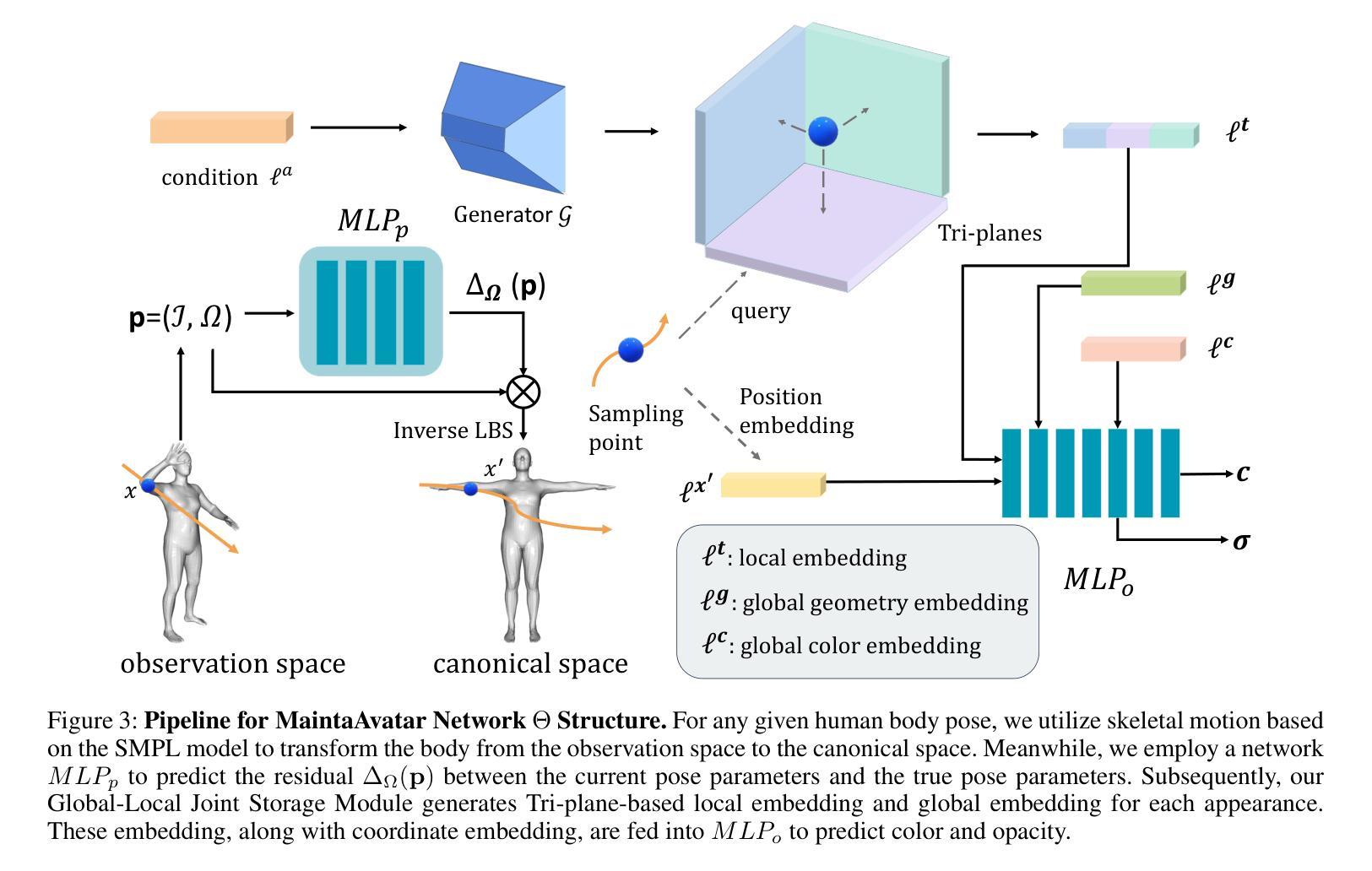
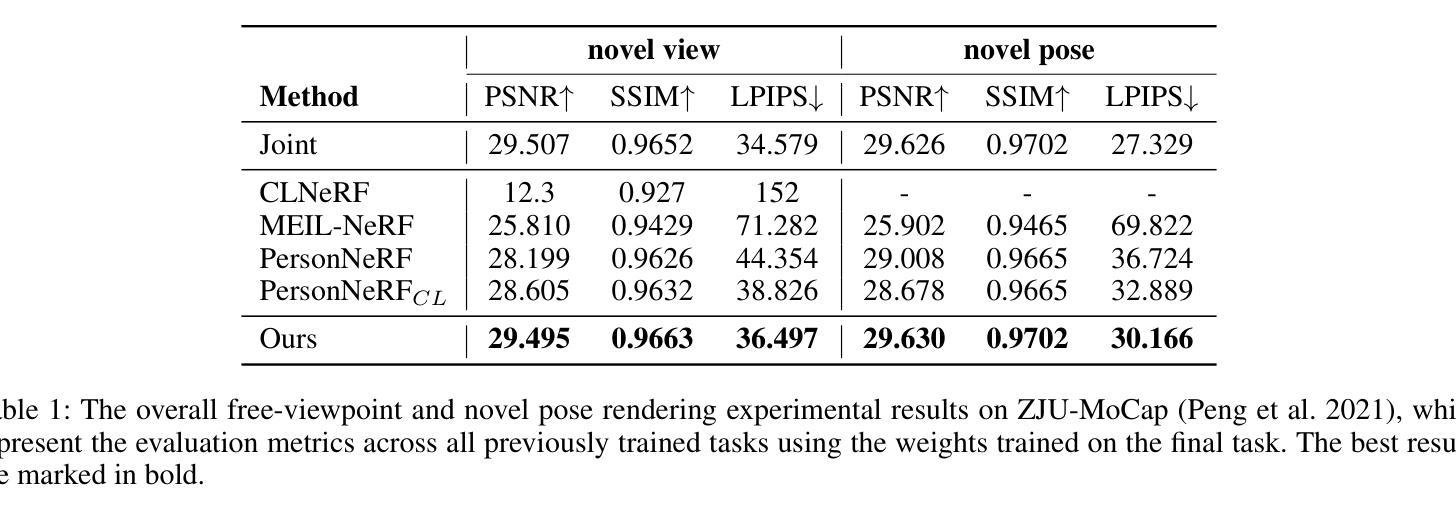
The generation of a virtual digital avatar is a crucial research topic in the field of computer vision. Many existing works utilize Neural Radiance Fields (NeRF) to address this issue and have achieved impressive results. However, previous works assume the images of the training person are available and fixed while the appearances and poses of a subject could constantly change and increase in real-world scenarios. How to update the human avatar but also maintain the ability to render the old appearance of the person is a practical challenge. One trivial solution is to combine the existing virtual avatar models based on NeRF with continual learning methods. However, there are some critical issues in this approach: learning new appearances and poses can cause the model to forget past information, which in turn leads to a degradation in the rendering quality of past appearances, especially color bleeding issues, and incorrect human body poses. In this work, we propose a maintainable avatar (MaintaAvatar) based on neural radiance fields by continual learning, which resolves the issues by utilizing a Global-Local Joint Storage Module and a Pose Distillation Module. Overall, our model requires only limited data collection to quickly fine-tune the model while avoiding catastrophic forgetting, thus achieving a maintainable virtual avatar. The experimental results validate the effectiveness of our MaintaAvatar model.
生成虚拟数字化身是计算机视觉领域的一个关键研究话题。许多现有工作利用神经辐射场(NeRF)来解决这个问题,并取得了令人印象深刻的结果。然而,以前的工作假设训练人员的图像是可用的并且是固定的,而在现实世界的场景中,主体的外观和姿势可能会不断改变并增加。如何更新虚拟化身的同时保持渲染人物旧外观的能力是一个实际挑战。一种简单的解决方案是将基于NeRF的现有虚拟化身模型与持续学习方法相结合。然而,这种方法存在一些关键问题:学习新的外观和姿势会导致模型忘记过去的信息,从而导致过去外观的渲染质量下降,特别是出现色彩溢出问题和人体姿势不正确的问题。在这项工作中,我们提出了一种基于神经辐射场的可持续化身(MaintaAvatar),它通过持续学习来解决这些问题,通过利用全局-局部联合存储模块和姿势蒸馏模块来解决这些问题。总的来说,我们的模型只需要有限的数据收集就能快速微调模型,同时避免灾难性遗忘,从而实现可持续的虚拟化身。实验结果验证了我们的MaintaAvatar模型的有效性。
论文及项目相关链接
PDF AAAI 2025. 9 pages
Summary
基于神经辐射场(NeRF)的虚拟数字分身生成是计算机视觉领域的重要研究课题。现有方法假设训练人物图像是固定可用的,但在现实场景中,人物的外貌和姿势会不断变化。如何更新虚拟分身同时保持对旧外貌的渲染能力是一大挑战。本文提出一种基于神经辐射场的可持续化身(MaintaAvatar)模型,通过持续学习解决这一问题,采用全局-局部联合存储模块和姿势蒸馏模块,只需有限的数据收集即可快速微调模型,避免灾难性遗忘,实现可持续的虚拟分身。
Key Takeaways
- 虚拟数字分身生成是计算机视觉领域的重要课题。
- 现有方法假设训练人物图像固定,但在现实中人物外貌和姿势会变化。
- 更新虚拟分身同时保持旧外貌渲染能力是现实挑战。
- 本文提出基于神经辐射场的可持续化身(MaintaAvatar)模型解决此问题。
- MaintaAvatar采用全局-局部联合存储模块和姿势蒸馏模块。
- 该模型只需有限数据收集即可快速微调,避免灾难性遗忘。
点此查看论文截图


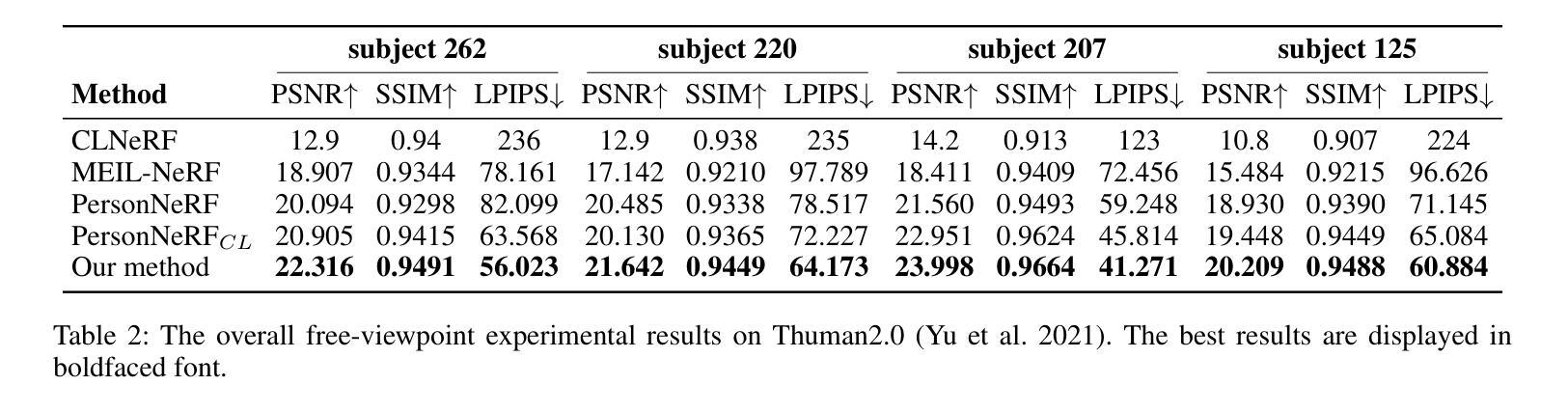
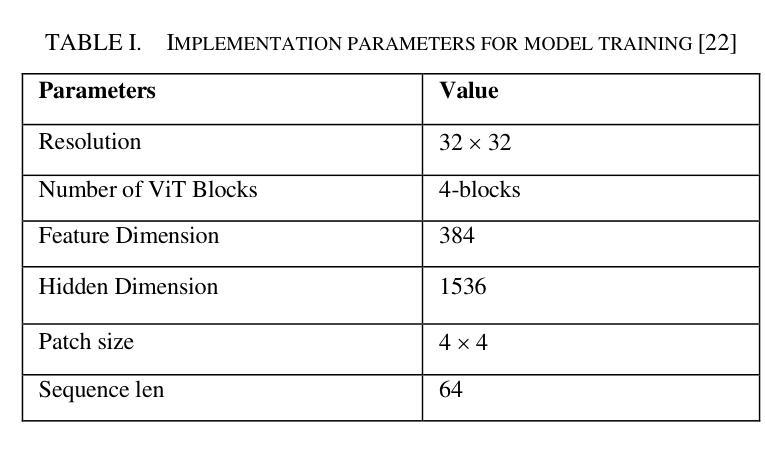
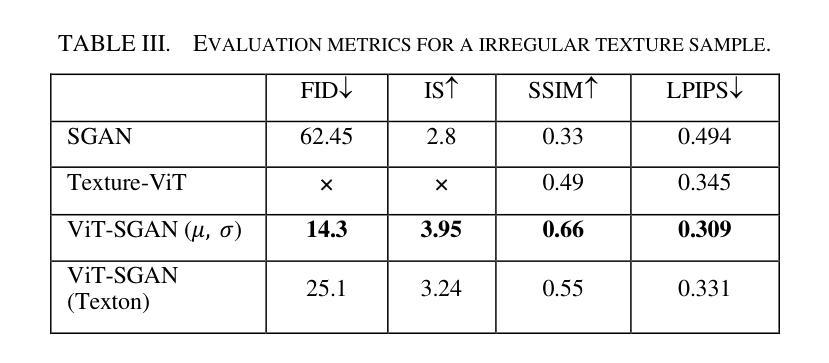
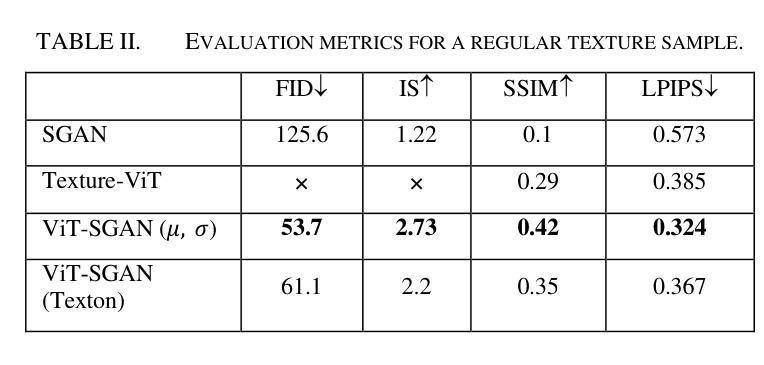
Texture Image Synthesis Using Spatial GAN Based on Vision Transformers
Authors:Elahe Salari, Zohreh Azimifar
Texture synthesis is a fundamental task in computer vision, whose goal is to generate visually realistic and structurally coherent textures for a wide range of applications, from graphics to scientific simulations. While traditional methods like tiling and patch-based techniques often struggle with complex textures, recent advancements in deep learning have transformed this field. In this paper, we propose ViT-SGAN, a new hybrid model that fuses Vision Transformers (ViTs) with a Spatial Generative Adversarial Network (SGAN) to address the limitations of previous methods. By incorporating specialized texture descriptors such as mean-variance (mu, sigma) and textons into the self-attention mechanism of ViTs, our model achieves superior texture synthesis. This approach enhances the model’s capacity to capture complex spatial dependencies, leading to improved texture quality that is superior to state-of-the-art models, especially for regular and irregular textures. Comparison experiments with metrics such as FID, IS, SSIM, and LPIPS demonstrate the substantial improvement of ViT-SGAN, which underlines its efficiency in generating diverse realistic textures.
纹理合成是计算机视觉中的一项基本任务,其目的是生成视觉真实且结构连贯的纹理,可广泛应用于图形到科学模拟的各个领域。虽然传统的平铺和基于补丁的技术通常难以处理复杂的纹理,但深度学习领域的最新进展已经改变了这一领域。本文提出了ViT-SGAN,这是一个新的混合模型,它将视觉变压器(ViTs)与空间生成对抗网络(SGAN)相结合,以解决以前方法的局限性。通过将均值方差(mu、sigma)和纹理等专用纹理描述符融入ViTs的自注意力机制中,我们的模型实现了出色的纹理合成。这种方法提高了模型捕捉复杂空间依赖关系的能力,从而产生了优于最新模型的纹理质量,尤其是规则和不规则纹理。使用FID、IS、SSIM和LPIPS等指标进行的对比实验证明了ViT-SGAN的显著改善,这突显了其在生成多样且逼真的纹理方面的效率。
论文及项目相关链接
PDF Published at the 2nd International Conference on Artificial Intelligence and Software Engineering (AI-SOFT), Shiraz University, Shiraz, Iran, 2024
摘要
本文提出了ViT-SGAN模型,该模型融合了视觉转换器(ViTs)与空间生成对抗网络(SGAN),以克服传统纹理合成方法的局限性。通过结合均值方差(mu,sigma)和纹理等纹理描述符,ViT-SGAN模型在自我关注机制中实现了出色的纹理合成。该模型提高了捕捉复杂空间依赖关系的能力,从而提高了纹理质量,尤其是针对规则和不规则纹理的生成质量超过了当前先进的模型。对比实验证明了ViT-SGAN的高效性和优势。
要点分析
- ViT-SGAN模型结合了视觉转换器(ViTs)和空间生成对抗网络(SGAN),旨在解决纹理合成领域的难题。
- 该模型通过将均值方差(mu,sigma)和纹理等纹理描述符融入ViTs的自我关注机制中,实现了卓越的性能。
- ViT-SGAN模型能够捕捉复杂的空间依赖关系,从而提高了纹理合成的质量。
- 对比实验表明,ViT-SGAN模型在生成规则和不规则纹理方面均优于当前最先进的模型。
- 该模型的性能通过FID、IS、SSIM和LPIPS等指标进行了评估,证明了其显著改进和优势。
- ViT-SGAN模型的应用范围广泛,可用于图形学、科学模拟等领域的纹理合成任务。
点此查看论文截图

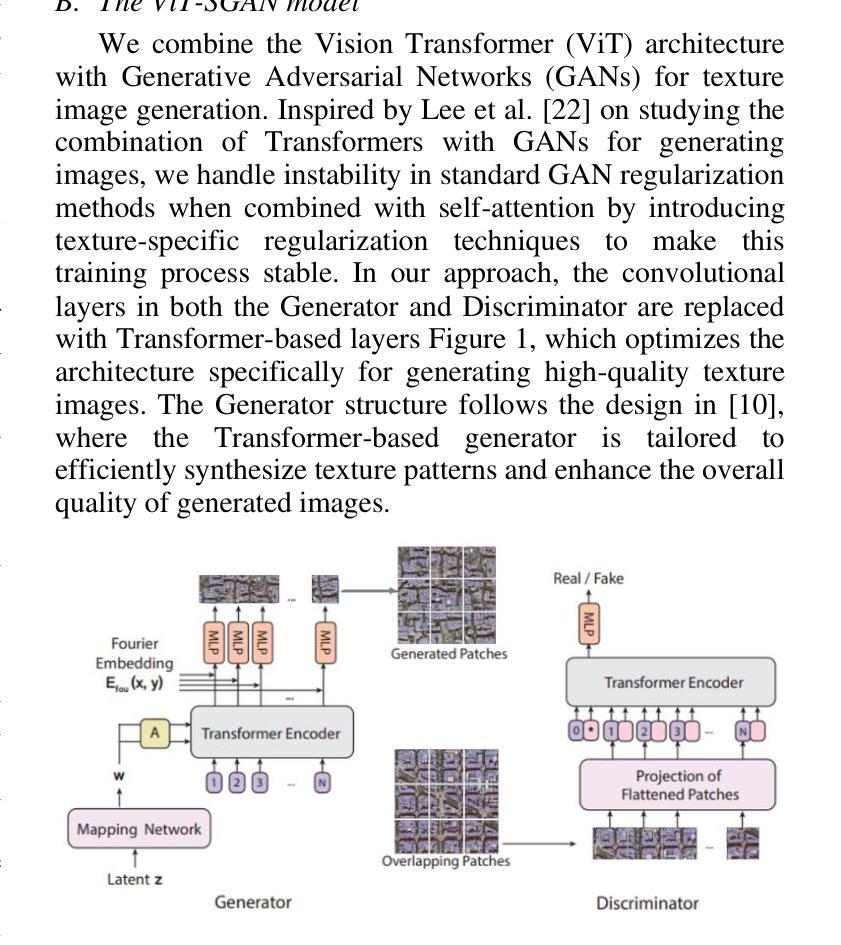
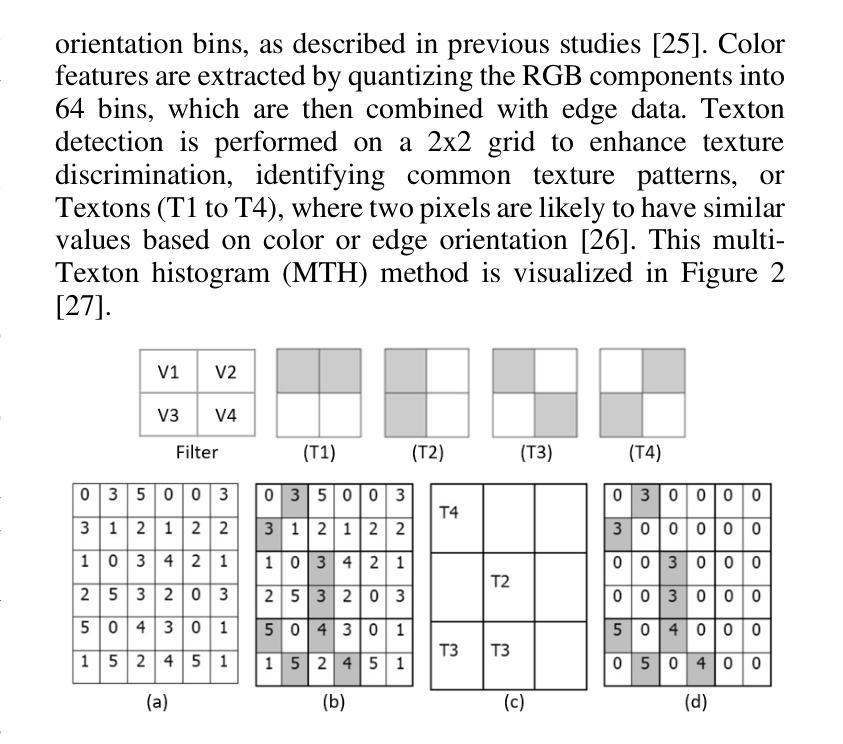
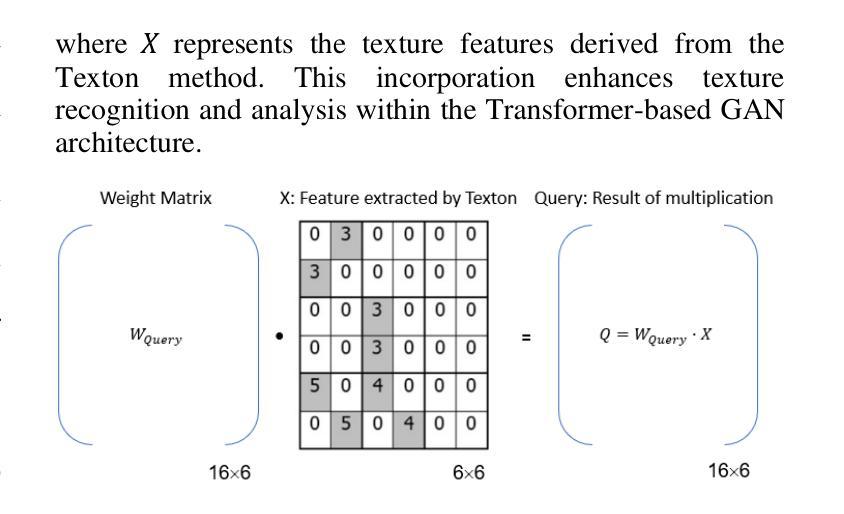

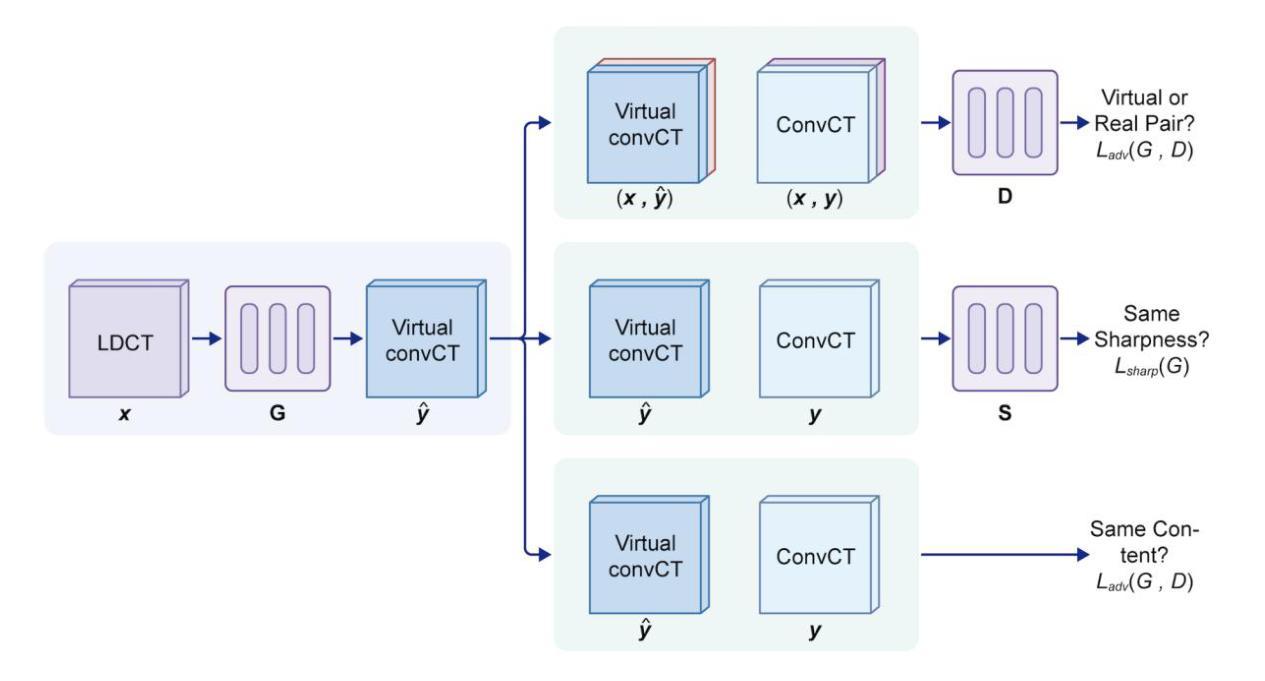
GAN-Based Architecture for Low-dose Computed Tomography Imaging Denoising
Authors:Yunuo Wang, Ningning Yang, Jialin Li
Generative Adversarial Networks (GANs) have surfaced as a revolutionary element within the domain of low-dose computed tomography (LDCT) imaging, providing an advanced resolution to the enduring issue of reconciling radiation exposure with image quality. This comprehensive review synthesizes the rapid advancements in GAN-based LDCT denoising techniques, examining the evolution from foundational architectures to state-of-the-art models incorporating advanced features such as anatomical priors, perceptual loss functions, and innovative regularization strategies. We critically analyze various GAN architectures, including conditional GANs (cGANs), CycleGANs, and Super-Resolution GANs (SRGANs), elucidating their unique strengths and limitations in the context of LDCT denoising. The evaluation provides both qualitative and quantitative results related to the improvements in performance in benchmark and clinical datasets with metrics such as PSNR, SSIM, and LPIPS. After highlighting the positive results, we discuss some of the challenges preventing a wider clinical use, including the interpretability of the images generated by GANs, synthetic artifacts, and the need for clinically relevant metrics. The review concludes by highlighting the essential significance of GAN-based methodologies in the progression of precision medicine via tailored LDCT denoising models, underlining the transformative possibilities presented by artificial intelligence within contemporary radiological practice.
生成对抗网络(GANs)在低剂量计算机断层扫描(LDCT)成像领域表现出革命性元素,为解决辐射暴露与图像质量之间的持久问题提供了高级解决方案。这篇综述综合了基于GAN的LDCT降噪技术的快速发展,从基础架构的演变到采用先进功能的最新模型,例如解剖学先验、感知损失函数和创新正则化策略。我们深入分析了各种GAN架构,包括条件GAN(cGANs)、CycleGANs和超分辨率GAN(SRGANs),阐明了它们在LDCT降噪背景下的独特优势和局限性。评估提供了与基准测试数据集和临床数据集的绩效改进相关的定性和定量结果,包括使用PSNR、SSIM和LPIPS等指标。在突出积极结果之后,我们讨论了一些阻碍更广泛临床应用的挑战,包括GAN生成图像的解读性、合成伪影以及临床相关指标的需求。最后,通过强调基于GAN的方法在通过定制LDCT降噪模型推进精准医学方面的重要作用,以及人工智能在当代放射实践中展示的变革性可能,本文得出结论。
论文及项目相关链接
Summary
GAN在低剂量计算机断层扫描(LDCT)成像领域展现出革命性作用,为解决辐射暴露与图像质量之间的平衡问题提供先进解决方案。本文综述了基于GAN的LDCT去噪技术的快速发展,从基础架构到融合解剖学先验、感知损失函数和创新正则化策略等先进特性的最新模型。通过批判性分析各种GAN架构,包括条件GAN(cGAN)、CycleGAN和超分辨率GAN(SRGAN),阐明它们在LDCT去噪中的独特优势和局限性。评估结果提供定量和定性数据,涉及性能指标如PSNR、SSIM和LPIPS。文章讨论了影响更广泛临床应用的挑战,包括GAN生成图像的解读性、合成伪影以及需要临床相关指标等。本文强调基于GAN的方法在精准医学进步中的重要性,特别是在定制LDCT去噪模型方面,突显人工智能在当代放射实践中的变革性潜力。
Key Takeaways
- GANs在LDCT成像中发挥革命性作用,解决了辐射暴露与图像质量之间的平衡问题。
- 基于GAN的LDCT去噪技术发展迅速,涵盖从基础架构到融合先进特性的最新模型。
- 不同GAN架构(如cGAN、CycleGAN、SRGAN)在LDCT去噪中有独特优势和局限性。
- 评估结果提供定量和定性数据,涉及PSNR、SSIM和LPIPS等性能指标。
- GAN生成图像的解读性、合成伪影及临床相关指标是影响更广泛临床应用的主要挑战。
- 基于GAN的方法在精准医学进步中至关重要,特别是在定制LDCT去噪模型方面。
点此查看论文截图

Generating Continual Human Motion in Diverse 3D Scenes
Authors:Aymen Mir, Xavier Puig, Angjoo Kanazawa, Gerard Pons-Moll
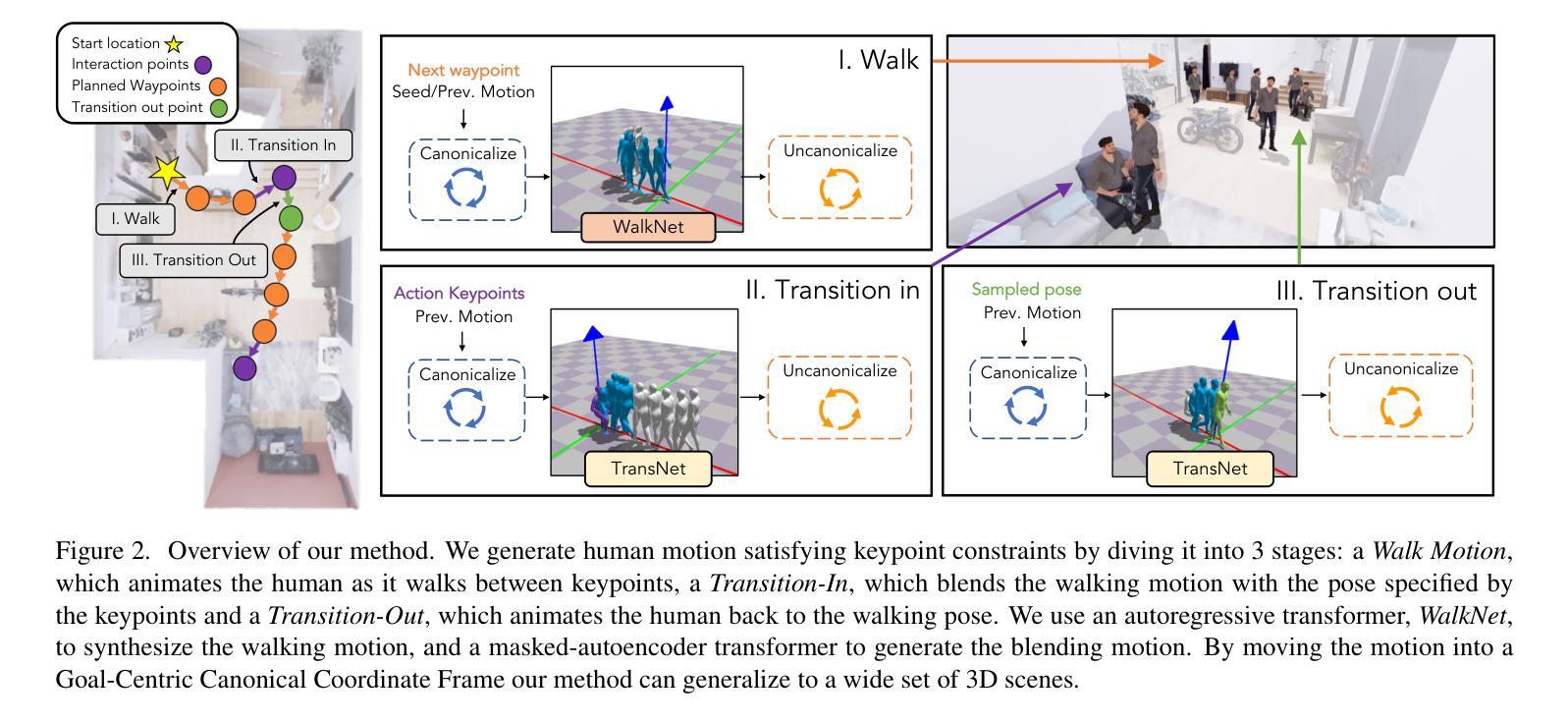
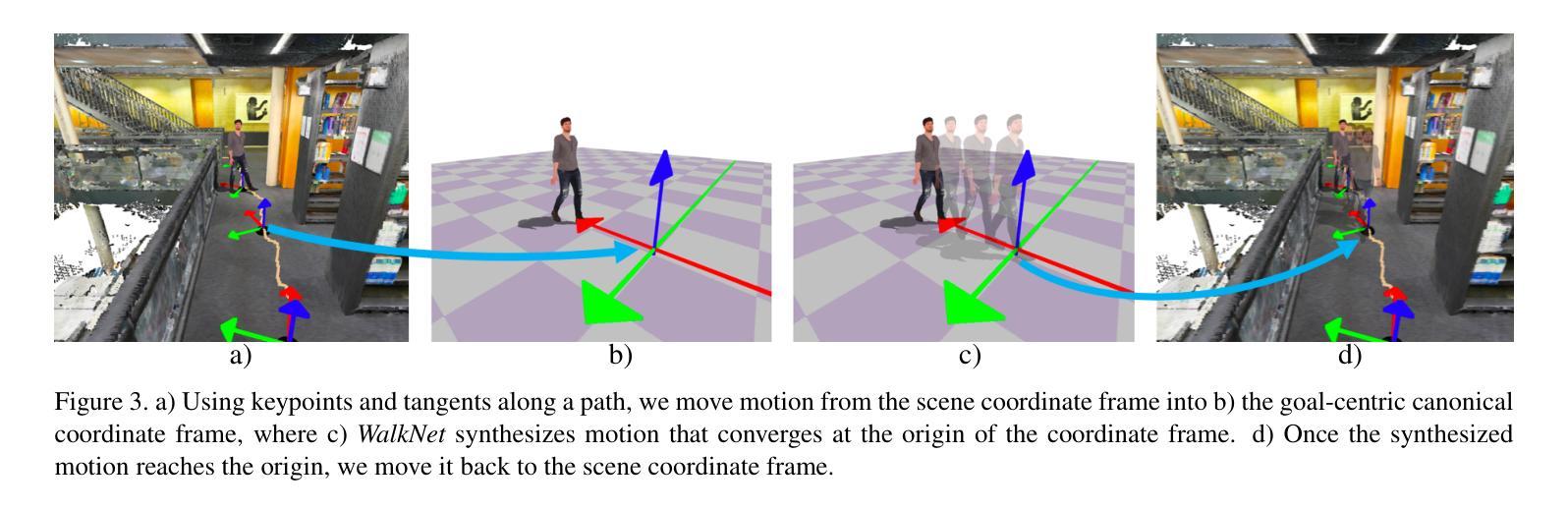
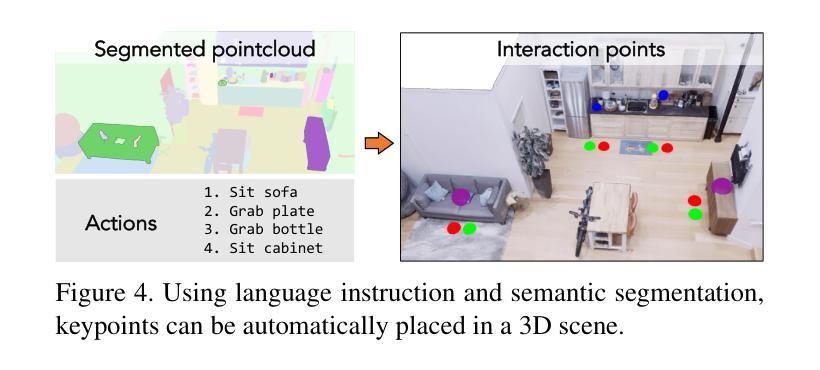
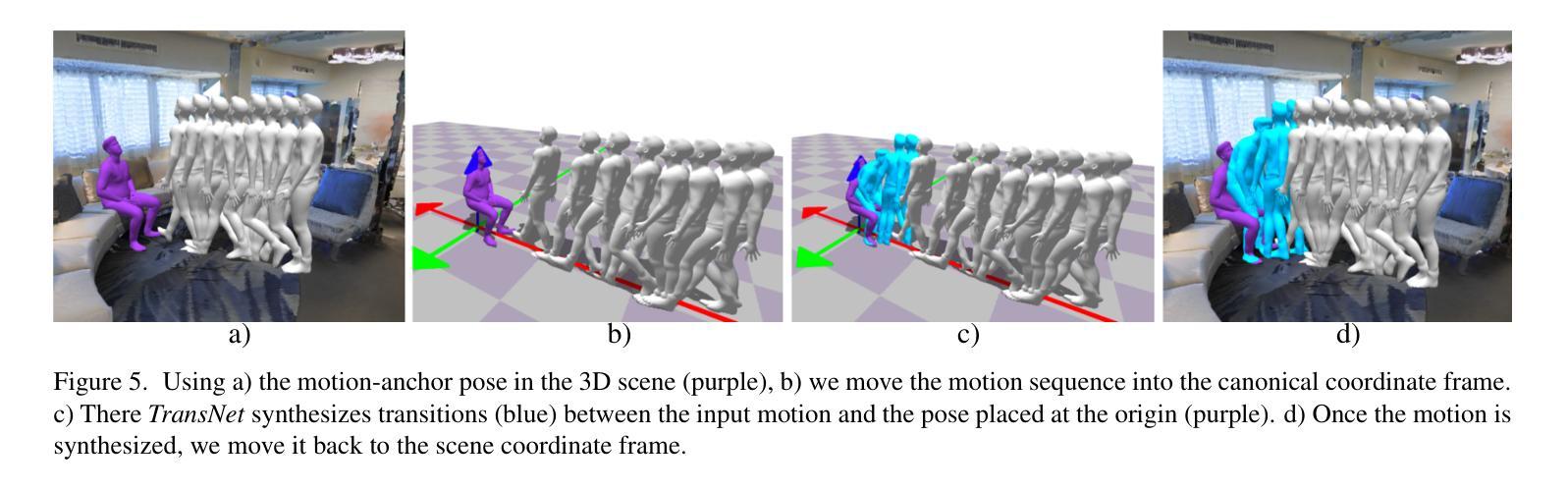
We introduce a method to synthesize animator guided human motion across 3D scenes. Given a set of sparse (3 or 4) joint locations (such as the location of a person’s hand and two feet) and a seed motion sequence in a 3D scene, our method generates a plausible motion sequence starting from the seed motion while satisfying the constraints imposed by the provided keypoints. We decompose the continual motion synthesis problem into walking along paths and transitioning in and out of the actions specified by the keypoints, which enables long generation of motions that satisfy scene constraints without explicitly incorporating scene information. Our method is trained only using scene agnostic mocap data. As a result, our approach is deployable across 3D scenes with various geometries. For achieving plausible continual motion synthesis without drift, our key contribution is to generate motion in a goal-centric canonical coordinate frame where the next immediate target is situated at the origin. Our model can generate long sequences of diverse actions such as grabbing, sitting and leaning chained together in arbitrary order, demonstrated on scenes of varying geometry: HPS, Replica, Matterport, ScanNet and scenes represented using NeRFs. Several experiments demonstrate that our method outperforms existing methods that navigate paths in 3D scenes. For more results we urge the reader to watch our supplementary video available at: https://www.youtube.com/watch?v=0wZgsdyCT4A&t=1s
我们介绍了一种在三维场景中合成动画师引导的人体运动的方法。给定一组稀疏的(3个或4个)关节位置(例如一个人的手和两个脚的位置)和三维场景中的种子运动序列,我们的方法从种子运动开始生成合理的运动序列,同时满足由提供的关键点所施加的约束。我们将连续运动合成问题分解为沿路径行走以及在关键点指定的动作中进行过渡,这使我们能够在不显式融入场景信息的情况下,生成满足场景约束的长期运动。我们的方法仅使用与场景无关的动作捕捉数据进行训练。因此,我们的方法可在具有各种几何形状的三维场景中部署。为了实现没有漂移的合理连续运动合成,我们的关键贡献是生成以目标为中心的标准坐标框架,下一个直接目标位于原点。我们的模型可以生成一连串的长时间序列动作,如抓取、坐下和倾斜等混合动作,并且可以在不同几何的场景中展示:HPS、Replica、Matterport、ScanNet以及使用NeRF表示的场景。一系列实验证明,我们的方法在三维场景中导航的路径表现优于现有方法。更多结果请观看我们在以下链接的补充视频:https://www.youtube.com/watch?v=0wZgsdyCT4A&t=1s。
论文及项目相关链接
PDF Webpage: https://virtualhumans.mpi-inf.mpg.de/origin_2/
Summary
本文介绍了一种合成动画人物在三维场景中的运动的方法。该方法能够根据稀疏的关键点(如手部和双脚的位置)和三维场景中的种子运动序列,生成合理的运动序列。该方法将连续运动合成问题分解为沿路径行走和关键点的动作过渡,从而在不明确融入场景信息的情况下,生成满足场景约束的长动作序列。该方法仅使用场景无关的mocap数据进行训练,因此可部署在各种几何形状的三维场景中。为实现无漂移的合理连续运动合成,本文的关键贡献是生成以目标为中心的标准坐标系,将下一个即时目标置于原点。该模型可生成长期、多样化的动作序列,如抓取、坐下和倾斜等动作按任意顺序组合,并在不同几何场景(如HPS、Replica、Matterport、ScanNet和使用NeRF表示的场景)中进行演示。实验表明,该方法优于现有方法在三维场景中的路径导航方法。
Key Takeaways
- 提出了一种合成动画人物在三维场景中运动的方法,基于稀疏关键点和种子运动序列生成合理的运动。
- 将连续运动合成问题分解为沿路径行走和关键动作过渡。
- 方法仅使用场景无关的mocap数据进行训练,适用于多种三维场景。
- 引入目标为中心的标准坐标系,实现无漂移的运动合成。
- 可生成包含多样化动作的长期序列,如抓取、坐下和倾斜等。
- 在不同几何场景中的演示效果良好。
点此查看论文截图