⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-06 更新
CTC-DRO: Robust Optimization for Reducing Language Disparities in Speech Recognition
Authors:Martijn Bartelds, Ananjan Nandi, Moussa Koulako Bala Doumbouya, Dan Jurafsky, Tatsunori Hashimoto, Karen Livescu
Modern deep learning models often achieve high overall performance, but consistently fail on specific subgroups. Group distributionally robust optimization (group DRO) addresses this problem by minimizing the worst-group loss, but it fails when group losses misrepresent performance differences between groups. This is common in domains like speech, where the widely used connectionist temporal classification (CTC) loss scales with input length and varies with linguistic and acoustic properties, leading to spurious differences between group losses. We present CTC-DRO, which addresses the shortcomings of the group DRO objective by smoothing the group weight update to prevent overemphasis on consistently high-loss groups, while using input length-matched batching to mitigate CTC’s scaling issues. We evaluate CTC-DRO on the task of multilingual automatic speech recognition (ASR) across five language sets from the ML-SUPERB 2.0 benchmark. CTC-DRO consistently outperforms group DRO and CTC-based baseline models, reducing the worst-language error by up to 65.9% and the average error by up to 47.7%. CTC-DRO can be applied to ASR with minimal computational costs, and offers the potential for reducing group disparities in other domains with similar challenges.
现代深度学习模型通常总体性能较高,但在特定子群体上始终存在缺陷。群体分布鲁棒优化(group DRO)通过最小化最糟糕群体损失来解决这个问题,但在群体损失无法真实反映群体之间性能差异时,它会失效。这在语音等领域很常见,广泛使用的连接定时分类(CTC)损失与输入长度成比例,并随语言和声学属性而变化,导致群体损失之间存在虚假差异。我们提出了CTC-DRO,它通过平滑群体权重更新,防止过度关注始终高损失的群体,同时使用与输入长度匹配的批处理来缓解CTC的缩放问题,来解决group DRO目标中的不足。我们在ML-SUPERB 2.0基准测试的五套语言集上评估了CTC-DRO在多语种自动语音识别(ASR)任务上的表现。CTC-DRO始终优于group DRO和CTC基准模型,将最差语言错误率降低了高达65.9%,平均错误率降低了高达47.7%。CTC-DRO可以最低的计算成本应用于ASR,并有望在面临类似挑战的其他领域减少群体差异。
论文及项目相关链接
Summary
本文介绍了现代深度学习模型在特定分组上常常表现不佳的问题。为了解决这个问题,文章提出了集团分布稳健优化(Group DRO)方法,通过最小化最糟糕集团的损失来提高性能。然而,当集团损失不能准确反映集团间性能差异时,这种方法就会失效。在语音领域,连接时态分类(CTC)损失的广泛使用因输入长度和语言特性而造成虚假差异。针对此问题,文章提出了CTC-DRO方法。它通过对集团权重更新进行平滑处理,防止过度关注持续高损失的集团,并使用与输入长度匹配的批处理来缓解CTC的缩放问题。在ML-SUPERB 2.0基准的多语种自动语音识别(ASR)任务上评估显示,CTC-DRO在性能上持续优于集团DRO和基于CTC的基线模型,将最差语言错误率降低了高达65.9%,平均错误率降低了高达47.7%。CTC-DRO可以应用于ASR,且计算成本低,对于存在类似挑战的其他领域减少集团差异具有潜力。
Key Takeaways
- 现代深度学习模型在特定分组上表现不佳的问题需要解决。
- Group DRO方法通过最小化最糟糕集团的损失来提高性能,但当集团损失不能反映真实性能差异时会出现问题。
- CTC损失在语音领域广泛应用,但存在因输入长度和语言特性导致的虚假差异问题。
- CTC-DRO方法通过平滑集团权重更新和采用与输入长度匹配的批处理来解决Group DRO和CTC的问题。
- 在多语种自动语音识别任务上,CTC-DRO显著优于Group DRO和基于CTC的基线模型。
- CTC-DRO可降低最差语言错误率和平均错误率,具有应用于自动语音识别和其他类似挑战的领域的潜力。
点此查看论文截图


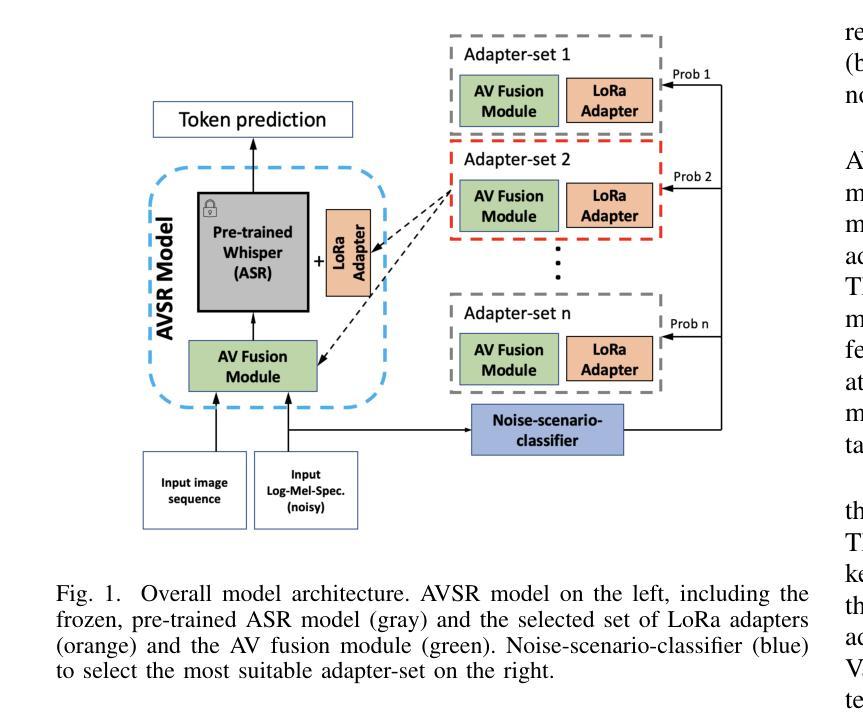
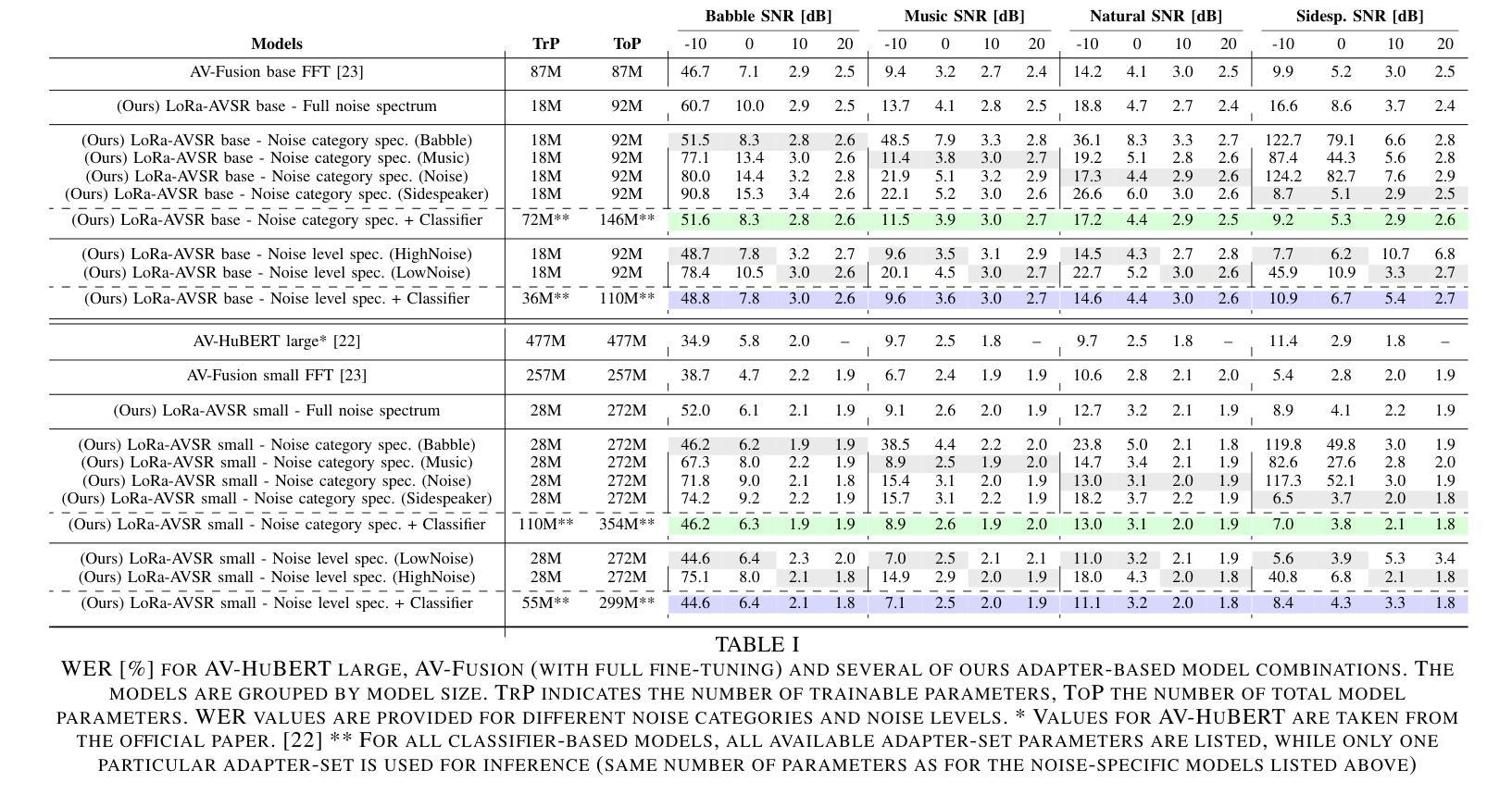
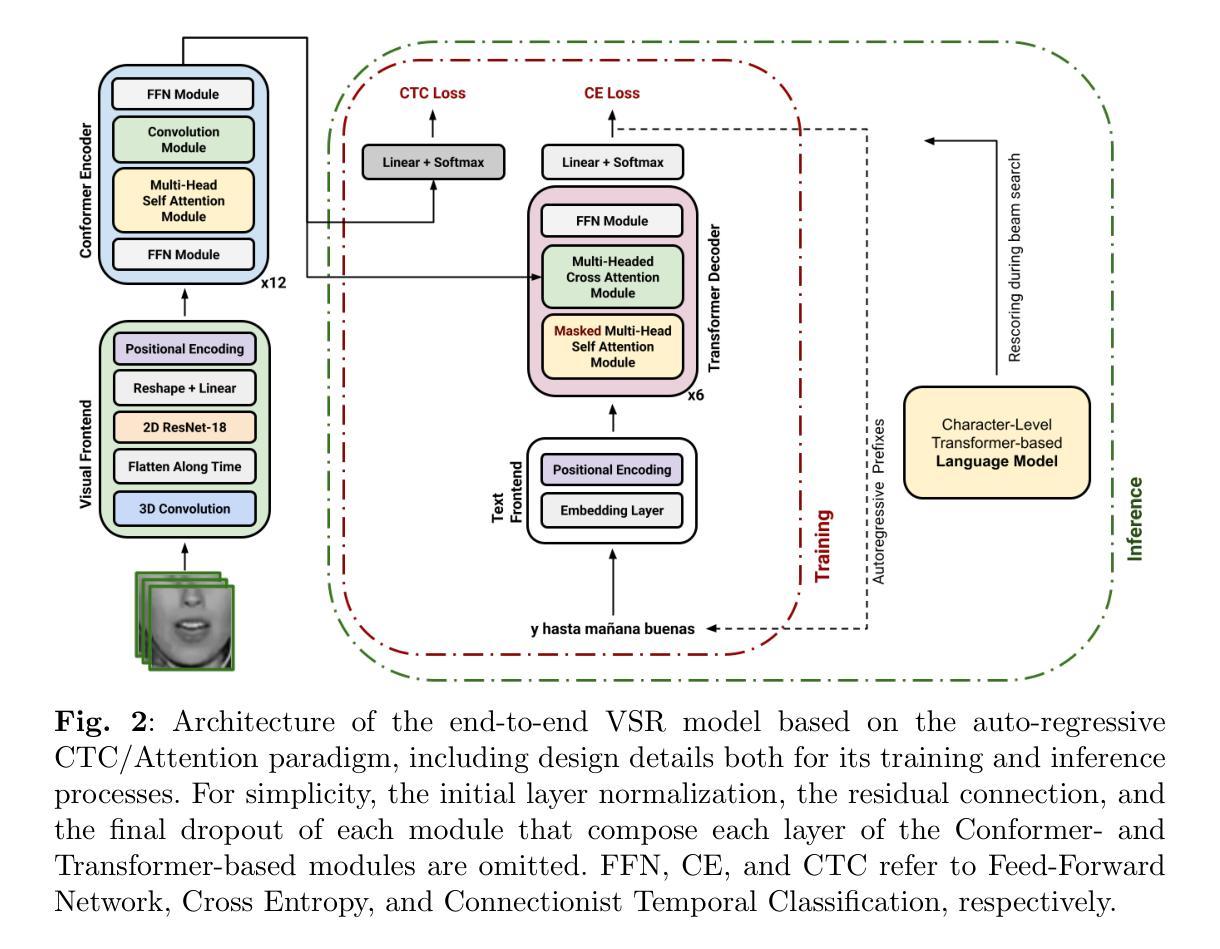
Adapter-Based Multi-Agent AVSR Extension for Pre-Trained ASR Models
Authors:Christopher Simic, Korbinian Riedhammer, Tobias Bocklet
We present an approach to Audio-Visual Speech Recognition that builds on a pre-trained Whisper model. To infuse visual information into this audio-only model, we extend it with an AV fusion module and LoRa adapters, one of the most up-to-date adapter approaches. One advantage of adapter-based approaches, is that only a relatively small number of parameters are trained, while the basic model remains unchanged. Common AVSR approaches train single models to handle several noise categories and noise levels simultaneously. Taking advantage of the lightweight nature of adapter approaches, we train noise-scenario-specific adapter-sets, each covering individual noise-categories or a specific noise-level range. The most suitable adapter-set is selected by previously classifying the noise-scenario. This enables our models to achieve an optimum coverage across different noise-categories and noise-levels, while training only a minimum number of parameters. Compared to a full fine-tuning approach with SOTA performance our models achieve almost comparable results over the majority of the tested noise-categories and noise-levels, with up to 88.5% less trainable parameters. Our approach can be extended by further noise-specific adapter-sets to cover additional noise scenarios. It is also possible to utilize the underlying powerful ASR model when no visual information is available, as it remains unchanged.
我们提出了一种基于预训练Whisper模型的视听语音识别方法。为了向这种仅包含音频的模型注入视觉信息,我们通过AV融合模块和LoRa适配器对其进行扩展,后者是最新的适配器方法之一。基于适配器的优势之一是只需要训练相对较少的参数,而基本模型保持不变。常见的AVSR方法训练单一模型,以同时处理多种噪声类别和噪声级别。利用适配器方法的轻便性,我们训练针对特定噪声场景的适配器集,每个适配器集覆盖单个噪声类别或特定的噪声级别范围。通过预先对噪声场景进行分类,选择最合适的适配器集。这使得我们的模型能够在不同的噪声类别和噪声级别上实现最佳覆盖,同时只训练最少的参数。与具有最新技术性能的全微调方法相比,我们的模型在大多数测试的噪声类别和噪声级别上取得了几乎相当的结果,同时可训练的参数减少了高达88.5%。我们的方法可以通过进一步的特定噪声适配器集来扩展,以覆盖更多的噪声场景。当没有视觉信息时,也可以利用功能强大的ASR模型,因为它保持不变。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
本研究提出一种基于预训练Whisper模型的视听语音识别的改进方法。通过引入视觉信息,扩展了音频模型,并添加了AV融合模块和最新的LoRa适配器。适配器方法仅训练少量参数,同时保持基本模型不变。本研究采用噪声场景特定的适配器集来覆盖不同的噪声类别和噪声级别,并通过预先分类噪声场景选择最合适的适配器集。在大多数测试的噪声类别和噪声级别上,该模型的性能与最新技术几乎相当,同时可训练参数减少了高达88.5%。当没有视觉信息时,还可以利用强大的ASR模型。
Key Takeaways
- 使用了预训练的Whisper模型作为基础进行视听语音识别。
- 通过AV融合模块和LoRa适配器引入视觉信息到音频模型中。
- 采用适配器方法,仅训练少量参数,保持基础模型不变。
- 开发噪声场景特定的适配器集,以覆盖不同的噪声类别和噪声级别。
- 通过预先分类噪声场景选择适配器集,实现最优的跨噪声类别和噪声级别的覆盖。
- 与最新技术相比,该模型的性能在大多数测试的噪声类别和噪声级别上几乎相当,同时降低了可训练参数的数量。
点此查看论文截图

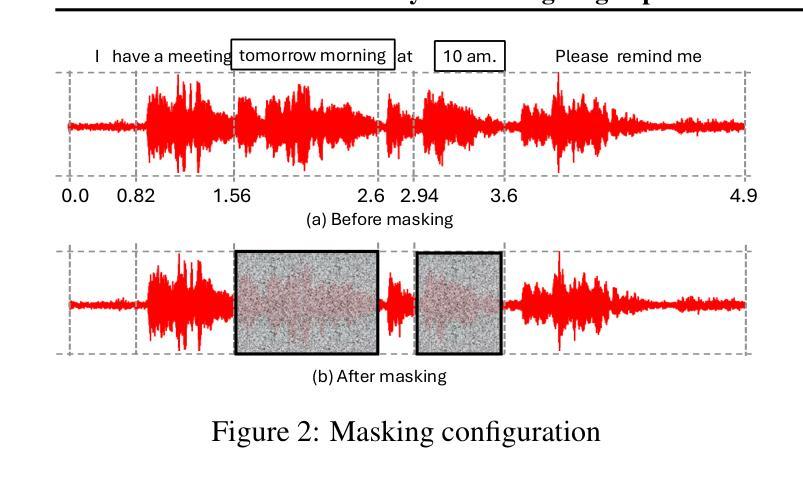
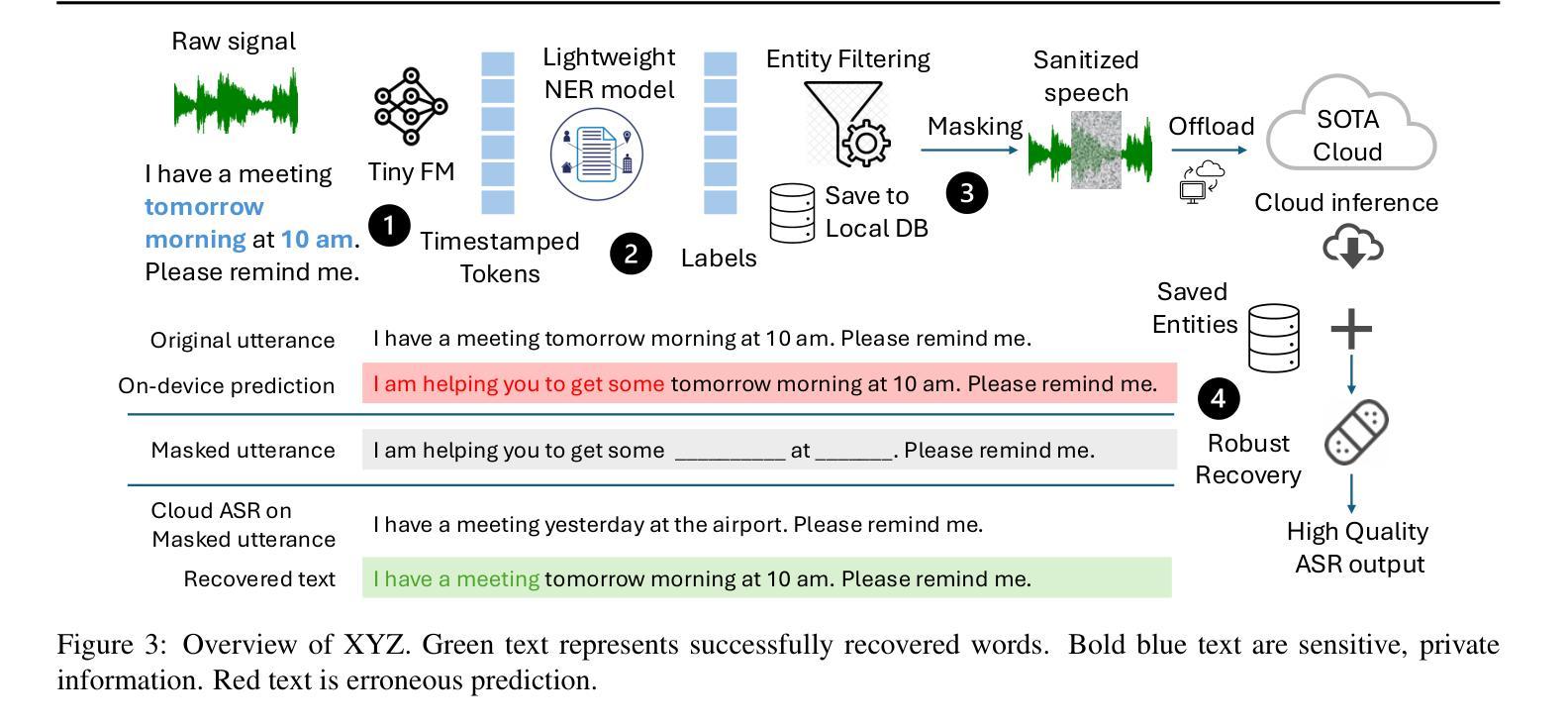
Privacy-Preserving Edge Speech Understanding with Tiny Foundation Models
Authors:Afsara Benazir, Felix Xiaozhu Lin
Robust speech recognition systems rely on cloud service providers for inference. It needs to ensure that an untrustworthy provider cannot deduce the sensitive content in speech. Sanitization can be done on speech content keeping in mind that it has to avoid compromising transcription accuracy. Realizing the under utilized capabilities of tiny speech foundation models (FMs), for the first time, we propose a novel use: enhancing speech privacy on resource-constrained devices. We introduce XYZ, an edge/cloud privacy preserving speech inference engine that can filter sensitive entities without compromising transcript accuracy. We utilize a timestamp based on-device masking approach that utilizes a token to entity prediction model to filter sensitive entities. Our choice of mask strategically conceals parts of the input and hides sensitive data. The masked input is sent to a trusted cloud service or to a local hub to generate the masked output. The effectiveness of XYZ hinges on how well the entity time segments are masked. Our recovery is a confidence score based approach that chooses the best prediction between cloud and on-device model. We implement XYZ on a 64 bit Raspberry Pi 4B. Experiments show that our solution leads to robust speech recognition without forsaking privacy. XYZ with < 100 MB memory, achieves state-of-the-art (SOTA) speech transcription performance while filtering about 83% of private entities directly on-device. XYZ is 16x smaller in memory and 17x more compute efficient than prior privacy preserving speech frameworks and has a relative reduction in word error rate (WER) by 38.8-77.5% when compared to existing offline transcription services.
稳健的语音识别系统依赖于云服务提供商进行推断。需要确保不可信的提供商无法推断出语音中的敏感内容。在对语音内容进行清理时,需要避免影响转录精度。我们首次意识到小型语音基础模型(FMs)的潜力并未被充分利用,因此,我们提出了一种新型应用:增强资源受限设备上的语音隐私保护。我们引入了XYZ,这是一个边缘/云隐私保护语音推断引擎,可以在不影响转录准确性的情况下过滤敏感实体。我们采用了一种基于时间戳的设备端掩码方法,该方法利用令牌到实体预测模型来过滤敏感实体。我们选择的掩码策略性地掩盖了输入的一部分并隐藏了敏感数据。掩码后的输入被发送到可信赖的云服务或本地中心以生成掩码后的输出。XYZ的有效性取决于实体时间段的掩码质量。我们的恢复是一种基于置信度的方法,可以在云和本地模型之间选择最佳预测结果。我们在一个64位的Raspberry Pi 4B上实现了XYZ。实验表明,我们的解决方案实现了稳健的语音识别,而不会放弃隐私保护。XYZ仅占用的内存空间不到< 100 MB的情况下实现了领先的语音转录性能,直接在设备上过滤大约83%的私有实体。与先前的隐私保护语音框架相比,XYZ在内存占用方面小得多(减少了内存占用的高达缩小内存占用多达两倍)并更具计算效率(计算能力高出超过达到先前的处理效率倍数1倍多)。在与现有离线转录服务进行比较时,其相对字词错误率(WER)降低了降低了词错误率减少了最多达减少达高达近至减少近百分之最高达三分之一到近百分之七十七多)。
论文及项目相关链接
摘要
本文探讨了在云服务和资源受限设备上实现稳健语音识别系统的隐私保护问题。针对现有系统中敏感内容泄露的风险,提出了一种名为XYZ的边缘/云隐私保护语音推理引擎。该引擎通过基于时间戳的本地掩码方法,利用令牌到实体预测模型过滤敏感实体,从而保护语音隐私。通过策略性地掩盖输入的部分内容,隐藏敏感数据。实验表明,XYZ在不牺牲隐私的情况下实现了稳健的语音识别。在内存占用小于100MB的情况下,XYZ实现了领先的语音识别性能,直接在设备上过滤约83%的私有实体。与之前的隐私保护语音框架相比,XYZ内存占用更小(仅为其十六分之一),计算效率更高(仅为其十七分之一),并且与现有的离线转录服务相比,相对降低了词错误率(WER)在达到扩展前的范围内的词语减少了很多百分数超过达到错误范围内的高峰出现为整二十个以上当前出的保密前沿有了强有力的水平在线虚拟服,例如减少了被标记出来的部分内容的失误次数达到理想的状态目标达到接近专业顶尖级别却继续从对客户最实际场景的专有方面走可以描述预期成功的表述变化较为非常适应具体情况的执行XYZ与离线转录服务相比具有显著优势。总体而言,该解决方案为实现隐私保护的语音识别系统提供了新的方向。
关键见解
点此查看论文截图

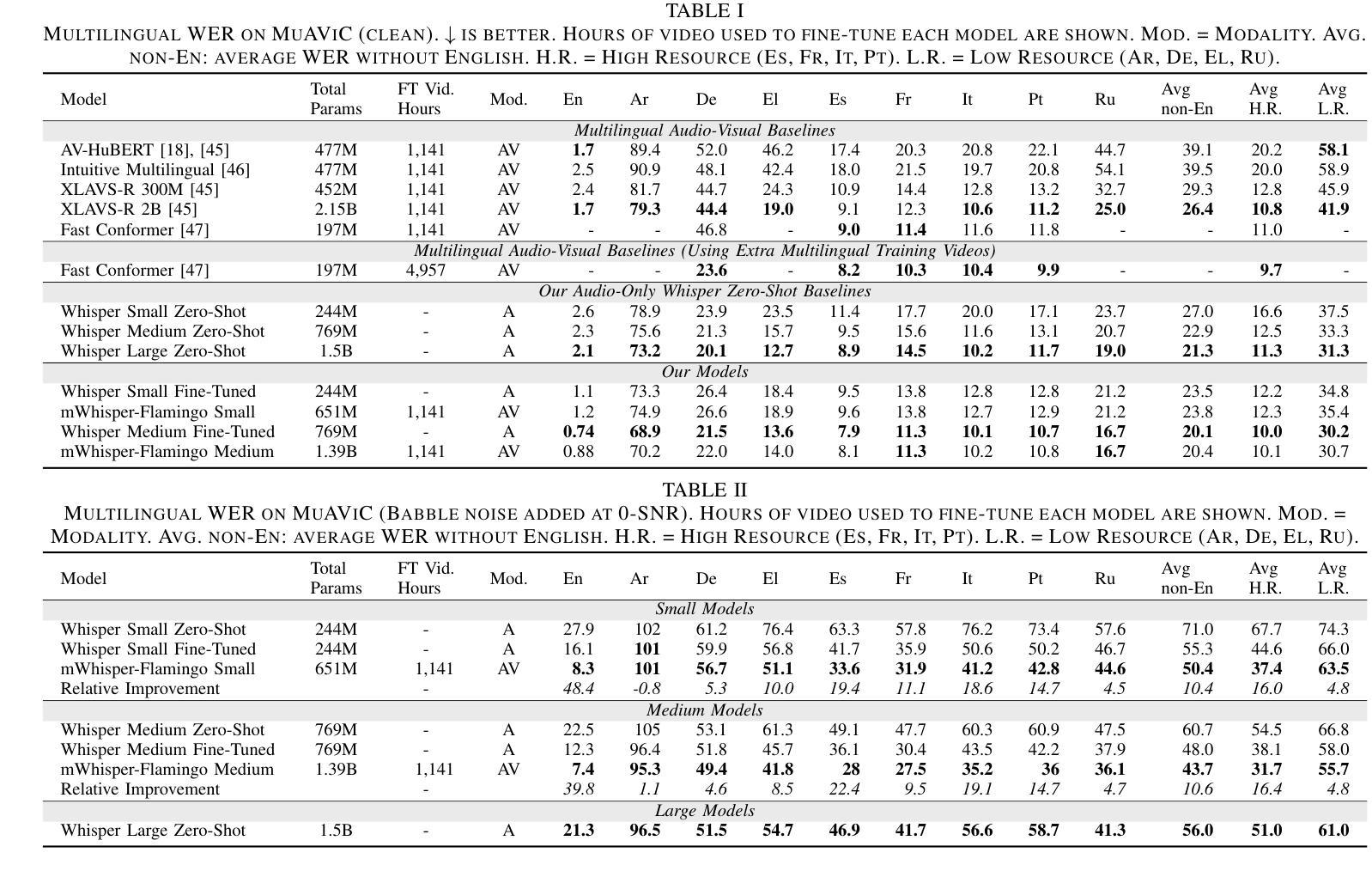
A Differentiable Alignment Framework for Sequence-to-Sequence Modeling via Optimal Transport
Authors:Yacouba Kaloga, Shashi Kumar, Petr Motlicek, Ina Kodrasi
Accurate sequence-to-sequence (seq2seq) alignment is critical for applications like medical speech analysis and language learning tools relying on automatic speech recognition (ASR). State-of-the-art end-to-end (E2E) ASR systems, such as the Connectionist Temporal Classification (CTC) and transducer-based models, suffer from peaky behavior and alignment inaccuracies. In this paper, we propose a novel differentiable alignment framework based on one-dimensional optimal transport, enabling the model to learn a single alignment and perform ASR in an E2E manner. We introduce a pseudo-metric, called Sequence Optimal Transport Distance (SOTD), over the sequence space and discuss its theoretical properties. Based on the SOTD, we propose Optimal Temporal Transport Classification (OTTC) loss for ASR and contrast its behavior with CTC. Experimental results on the TIMIT, AMI, and LibriSpeech datasets show that our method considerably improves alignment performance, though with a trade-off in ASR performance when compared to CTC. We believe this work opens new avenues for seq2seq alignment research, providing a solid foundation for further exploration and development within the community.
精确序列到序列(seq2seq)对齐对于依赖自动语音识别(ASR)的医疗语音分析和语言学习工具等应用至关重要。目前最先进的端到端(E2E)ASR系统,如连接时序分类(CTC)和基于转换器的模型,存在峰值行为和对齐不准确的问题。在本文中,我们提出了一种基于一维最优传输的新型可区分对齐框架,使模型能够以端到端的方式学习单一对齐并执行ASR。我们引入了序列空间上的伪度量,称为序列最优传输距离(SOTD),并讨论了其理论属性。基于SOTD,我们提出了用于ASR的最优时间传输分类(OTTC)损失,并将其行为与CTC进行了对比。在TIMIT、AMI和LibriSpeech数据集上的实验结果表明,我们的方法在改进对齐性能方面取得了显著成效,尽管与CTC相比在ASR性能方面存在权衡。我们相信这项工作开辟了seq2seq对齐研究的新途径,为社区内的进一步探索和发展提供了坚实的基础。
论文及项目相关链接
Summary
本文提出一种基于一维最优传输的可微对齐框架,使模型能够端到端地进行单一对齐和学习自动语音识别(ASR)。引入序列最优传输距离(SOTD)伪度量,并基于SOTD提出最优时序传输分类(OTTC)损失函数用于ASR。实验结果表明,该方法在TMIT、AMI和LibriSpeech数据集上显著提高了对齐性能,但与CTC相比,ASR性能存在权衡。这为序列到序列对齐研究开辟了新的途径。
Key Takeaways
- 准确序列到序列(seq2seq)对齐对于依赖自动语音识别(ASR)的应用如医疗语音分析和语言学习工具至关重要。
- 当前先进的端到端(E2E)ASR系统,如连接时序分类(CTC)和基于转换器模型的系统,存在峰值行为和对齐不准确的挑战。
- 引入了一种基于一维最优传输的可微对齐框架,能够端到端地进行单一对齐和ASR。
- 提出了序列最优传输距离(SOTD)伪度量,并讨论了其理论属性。
- 基于SOTD,提出了用于ASR的最优时序传输分类(OTTC)损失函数,并与CTC进行了对比。
- 实验结果表明,所提方法在TMIT、AMI和LibriSpeech数据集上显著提高了对齐性能。
点此查看论文截图

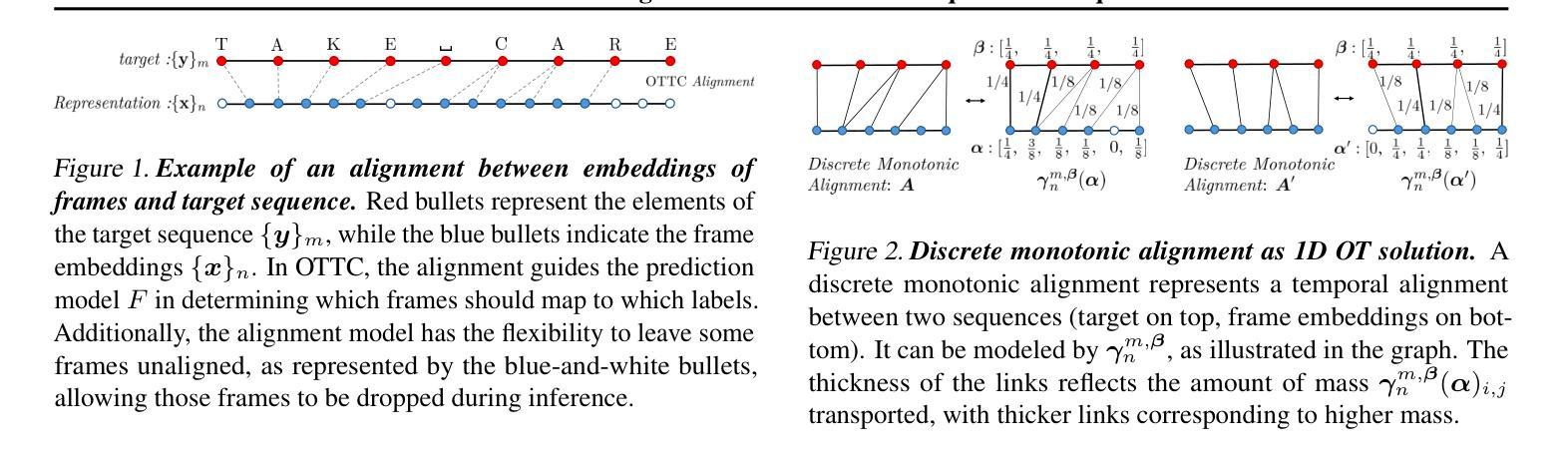

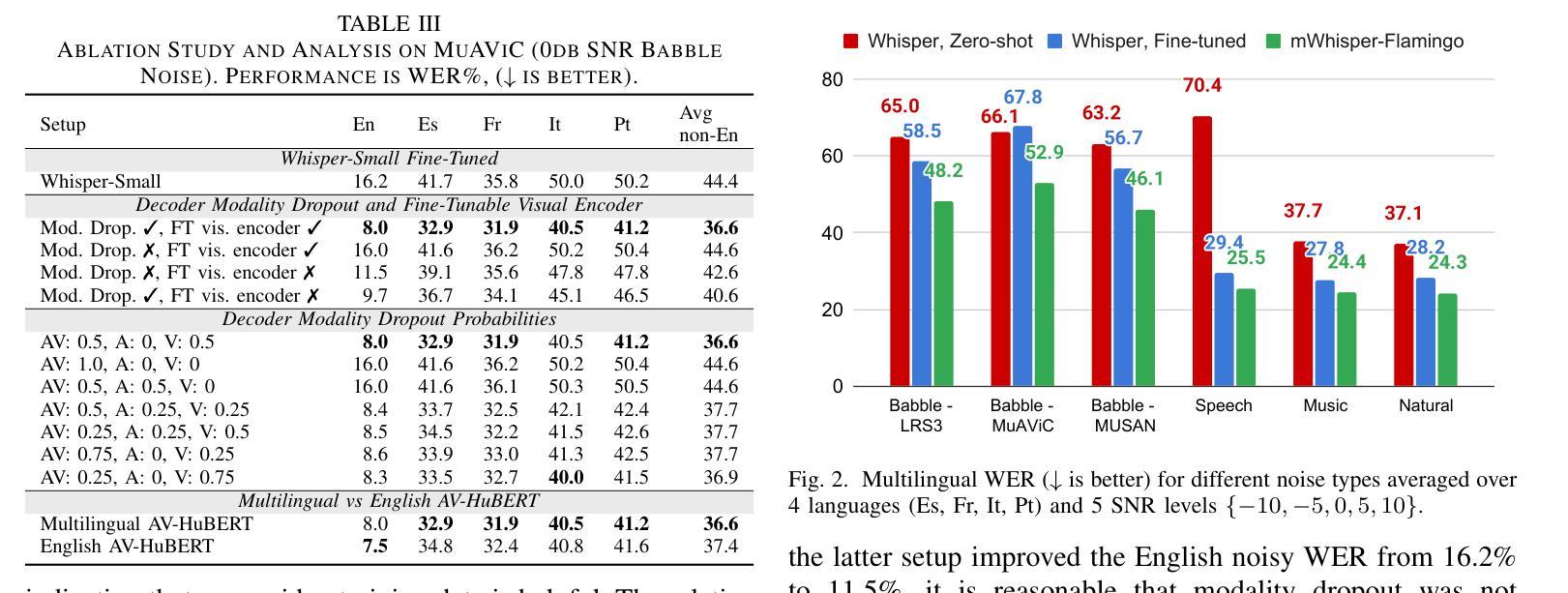
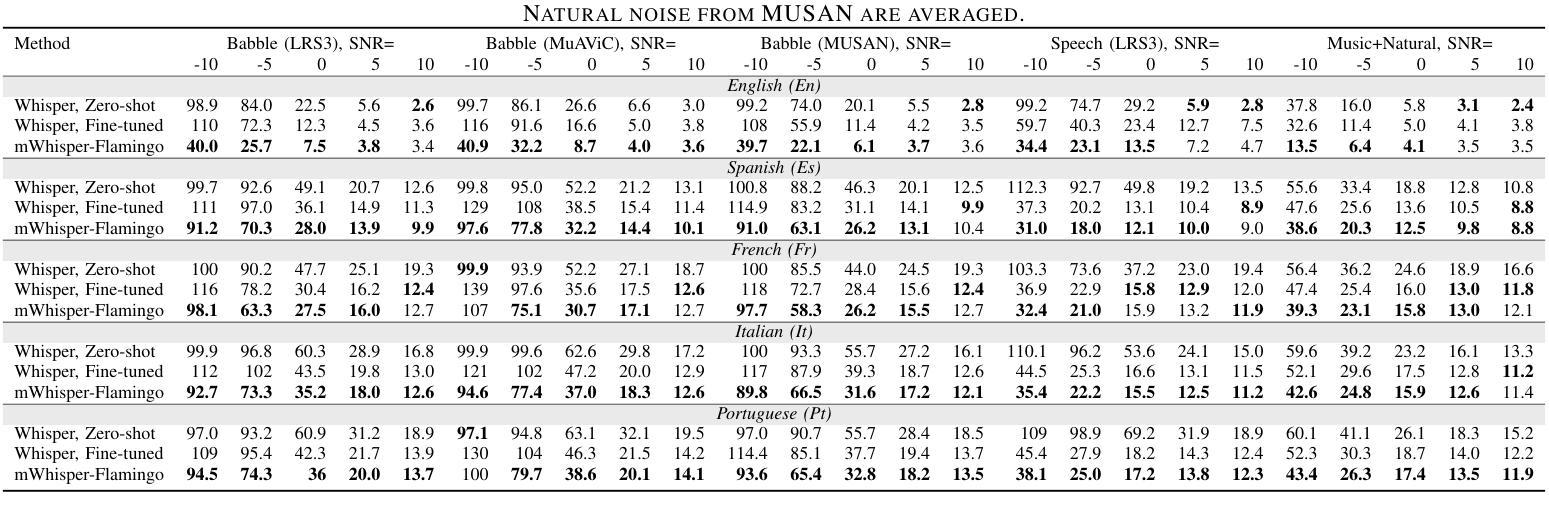
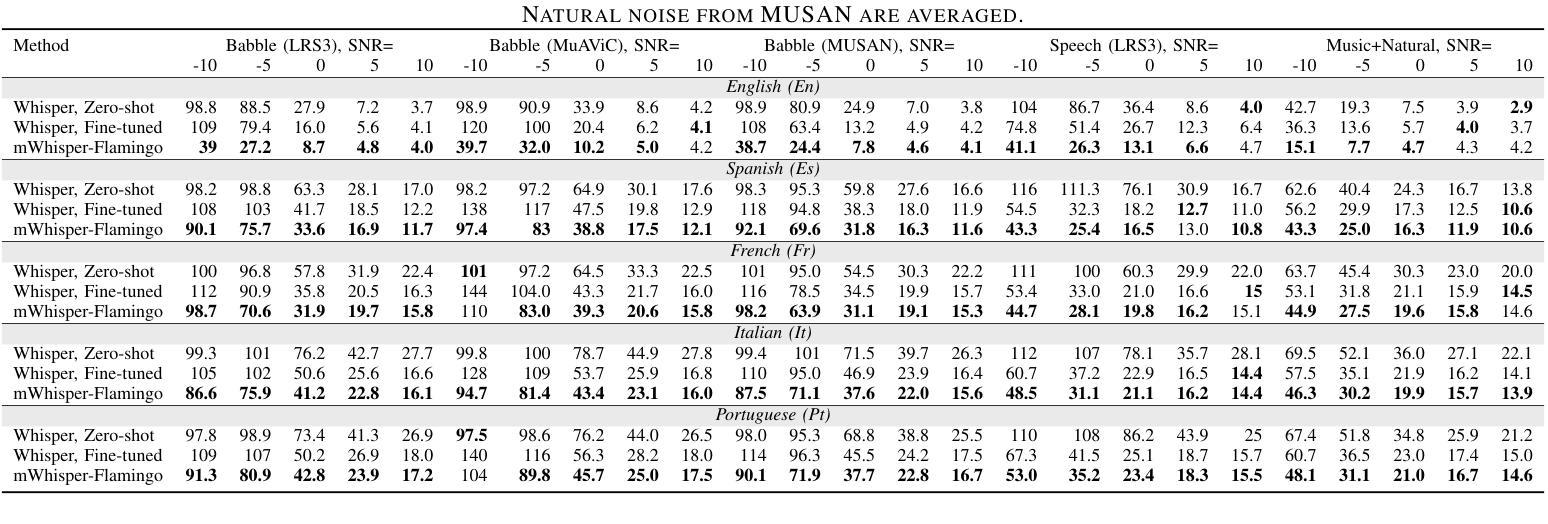
mWhisper-Flamingo for Multilingual Audio-Visual Noise-Robust Speech Recognition
Authors:Andrew Rouditchenko, Saurabhchand Bhati, Samuel Thomas, Hilde Kuehne, Rogerio Feris, James Glass
Audio-Visual Speech Recognition (AVSR) combines lip-based video with audio and can improve performance in noise, but most methods are trained only on English data. One limitation is the lack of large-scale multilingual video data, which makes it hard hard to train models from scratch. In this work, we propose mWhisper-Flamingo for multilingual AVSR which combines the strengths of a pre-trained audio model (Whisper) and video model (AV-HuBERT). To enable better multi-modal integration and improve the noisy multilingual performance, we introduce decoder modality dropout where the model is trained both on paired audio-visual inputs and separate audio/visual inputs. mWhisper-Flamingo achieves state-of-the-art WER on MuAViC, an AVSR dataset of 9 languages. Audio-visual mWhisper-Flamingo consistently outperforms audio-only Whisper on all languages in noisy conditions.
音频视觉语音识别(AVSR)结合了基于嘴唇的视频和音频,可以提高噪声中的性能,但大多数方法仅针对英语数据进行训练。一个局限性是缺乏大规模的多语言视频数据,这使得从头开始训练模型变得困难。在这项工作中,我们提出了用于多语言AVSR的mWhisper-Flamingo,它结合了预训练音频模型(Whisper)和视频模型(AV-HuBERT)的优点。为了更好地实现多模式集成并改善嘈杂的多语言性能,我们引入了解码器模态丢弃,其中模型既接受成对的音频视频输入,也接受单独的音频/视频输入进行训练。mWhisper-Flamingo在MuAViC上实现了最先进的词错误率(WER),MuAViC是一个包含9种语言的AVSR数据集。在嘈杂的条件下,视听mWhisper-Flamingo在所有语言上的性能都一直优于仅音频的Whisper。
论文及项目相关链接
总结
音频视频语音识别(AVSR)结合唇语视频和音频,在噪音中能够提高性能表现,但大多数方法仅针对英语数据进行训练。存在一大难题在于缺乏大规模的多语种视频数据,使得从头训练模型变得困难。本研究提出一种针对多语种AVSR的mWhisper-Flamingo方法,结合了预训练音频模型(Whisper)和视频模型(AV-HuBERT)的优势。为了进行更好的多模态融合和提高嘈杂环境下的多语种性能,我们引入了解码器模态丢弃技术,该技术能够在配对音视频输入和单独音频/视频输入上进行模型训练。在MuAViC这一包含九种语言的AVSR数据集上,mWhisper-Flamingo达到了当前最佳的词错误率(WER)。在嘈杂环境下,音视频版本的mWhisper-Flamingo在所有语种上的表现均优于仅音频的Whisper。
关键见解
- 音频视频语音识别(AVSR)结合唇语视频与音频以提升性能,尤其在噪音环境中。
- 当前方法的局限性在于它们主要基于英语数据训练,缺乏大规模多语种视频数据。
- 提出mWhisper-Flamingo方法,结合预训练音频模型(Whisper)和视频模型(AV-HuBERT)的优势。
- 通过引入解码器模态丢弃技术,实现更好的多模态融合及提高嘈杂环境下的多语种性能。
- mWhisper-Flamingo在MuAViC数据集上实现了最先进的词错误率(WER)。
- 在嘈杂条件下,音视频版本的mWhisper-Flamingo在所有语种上的性能均优于仅使用音频的模型。
- 该方法为多语种音频视频语音识别的实际应用提供了新的可能性。
点此查看论文截图

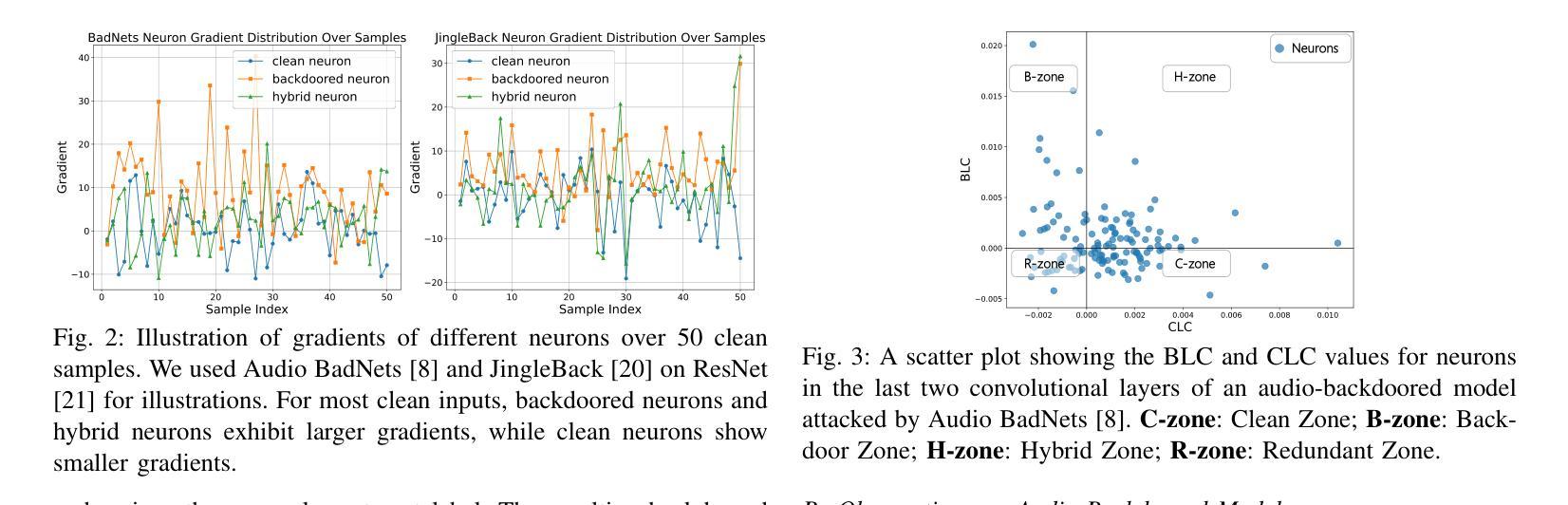
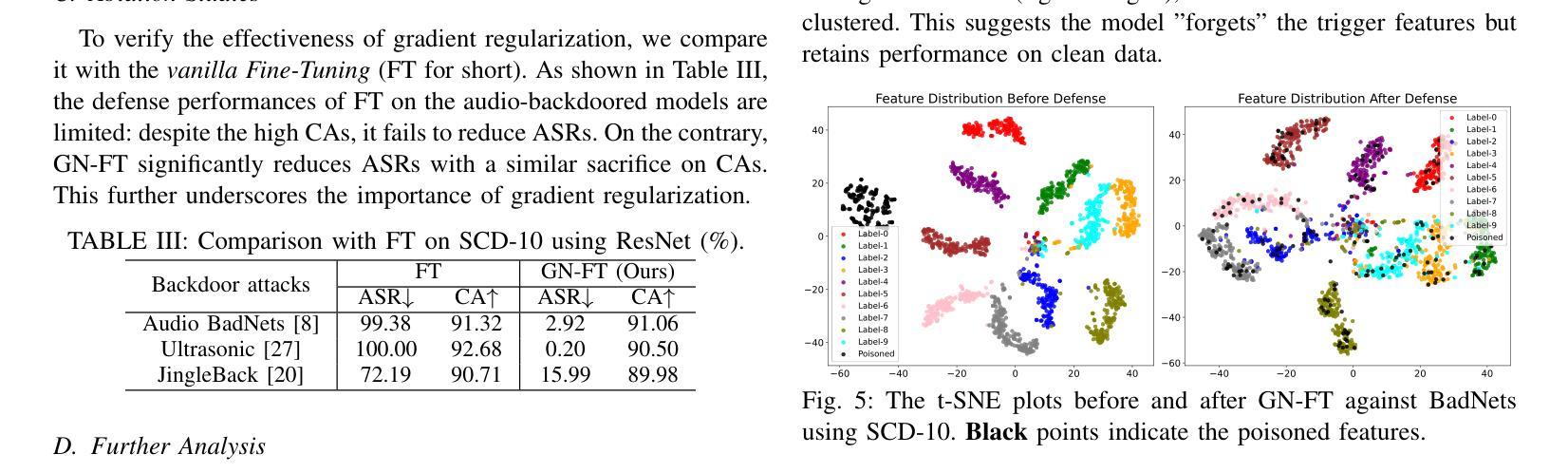
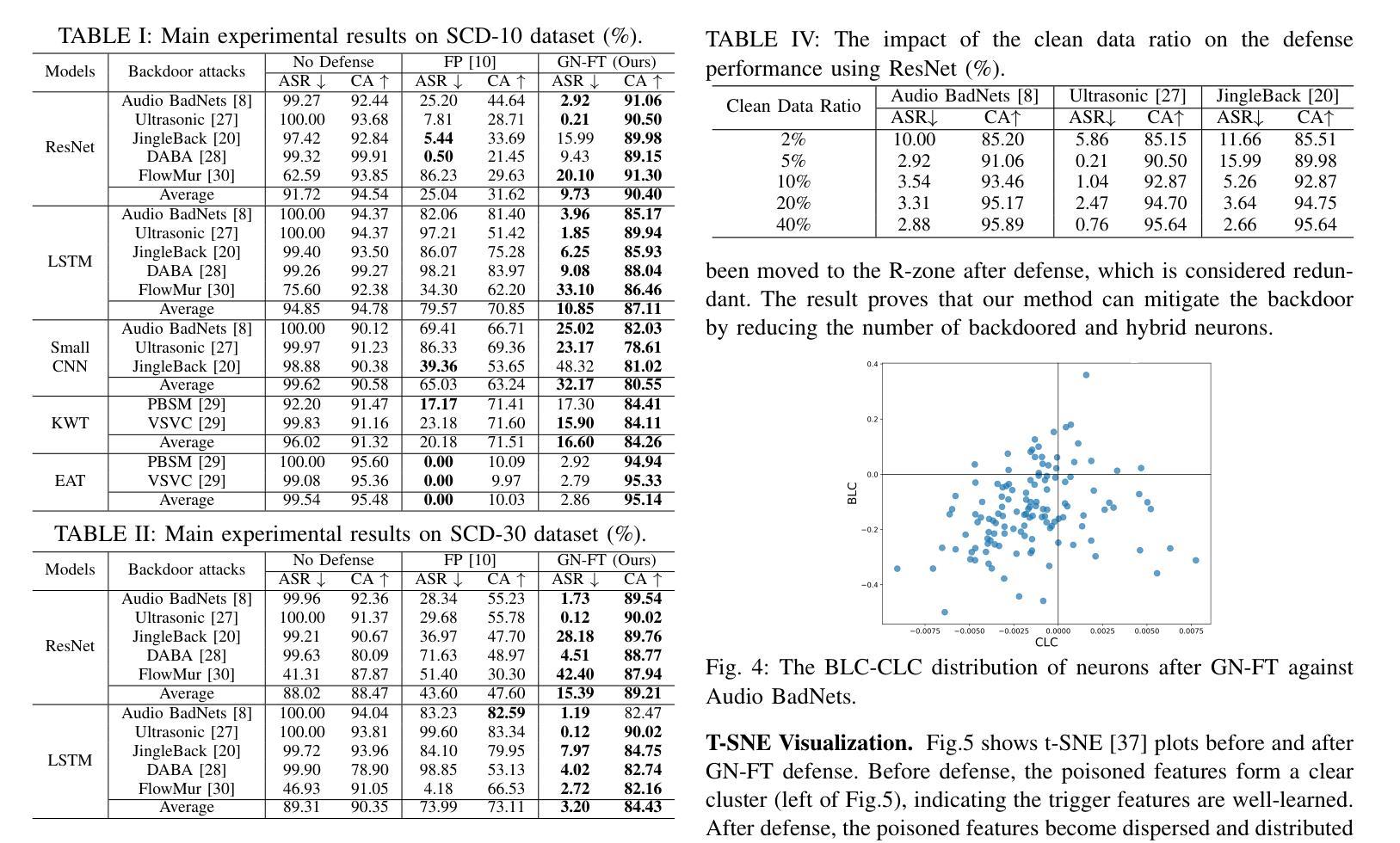
Gradient Norm-based Fine-Tuning for Backdoor Defense in Automatic Speech Recognition
Authors:Nanjun Zhou, Weilin Lin, Li Liu
Backdoor attacks have posed a significant threat to the security of deep neural networks (DNNs). Despite considerable strides in developing defenses against backdoor attacks in the visual domain, the specialized defenses for the audio domain remain empty. Furthermore, the defenses adapted from the visual to audio domain demonstrate limited effectiveness. To fill this gap, we propose Gradient Norm-based FineTuning (GN-FT), a novel defense strategy against the attacks in the audio domain, based on the observation from the corresponding backdoored models. Specifically, we first empirically find that the backdoored neurons exhibit greater gradient values compared to other neurons, while clean neurons stay the lowest. On this basis, we fine-tune the backdoored model by incorporating the gradient norm regularization, aiming to weaken and reduce the backdoored neurons. We further approximate the loss computation for lower implementation costs. Extensive experiments on two speech recognition datasets across five models demonstrate the superior performance of our proposed method. To the best of our knowledge, this work is the first specialized and effective defense against backdoor attacks in the audio domain.
后门攻击对深度神经网络(DNN)的安全构成了重大威胁。尽管视觉领域针对后门攻击的防御措施取得了重大进展,但音频领域的专业防御仍然空白。此外,从视觉领域适应到音频领域的防御方法显示出有限的有效性。为了填补这一空白,我们提出了基于梯度范数的微调(GN-FT),这是一种针对音频领域攻击的新型防御策略,该策略是基于后门模型的相关观察。具体来说,我们首先实证发现,与干净神经元相比,后门神经元表现出更大的梯度值,而干净神经元的梯度值保持最低。在此基础上,我们通过结合梯度范数正则化对后门模型进行微调,旨在削弱并减少后门神经元。我们还进一步简化了损失计算以降低实现成本。在两个语音识别数据集上的五个模型的大量实验表明了我们提出方法的卓越性能。据我们所知,这项工作是针对音频领域后门攻击的首个专业化且有效的防御措施。
论文及项目相关链接
PDF 5 pages, 5 figures. This work has been accpeted by ICASSP 2025
Summary
深度神经网络面临后门攻击的重大威胁。视觉领域已有不少防御措施,但音频领域的专门防御手段仍然缺乏,从视觉领域适应到音频领域的防御手段效果有限。为此,我们提出了基于梯度范数的微调(GN-FT)策略,这是一种针对音频领域攻击的新型防御策略。我们发现被后门控制的神经元梯度值较大,基于此对被后门控制的模型进行微调,旨在削弱并减少被后门控制的神经元,同时降低实现成本。多项实验证明,该方法在语音识别数据集上的表现优异。据我们所知,这是针对音频领域的后门攻击的首个有效专门防御手段。
Key Takeaways
- 后门攻击对深度神经网络的安全构成威胁,特别是在音频领域缺乏专门的防御手段。
- 现有从视觉领域适应到音频领域的防御手段效果有限。
- 提出的GN-FT策略基于观察被后门控制的神经元梯度值较大。
- GN-FT策略通过微调模型,旨在削弱并减少被后门控制的神经元。
- GN-FT策略考虑了损失计算的近似,以降低实现成本。
- 在语音识别数据集上进行的实验证明了GN-FT策略的有效性。
点此查看论文截图

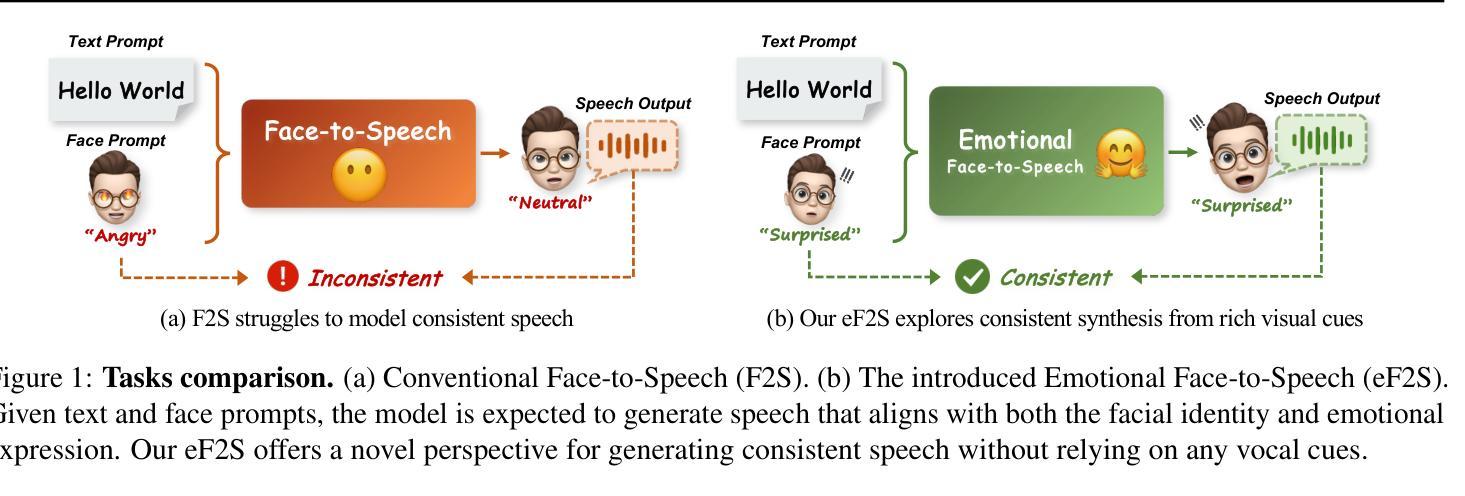
Emotional Face-to-Speech
Authors:Jiaxin Ye, Boyuan Cao, Hongming Shan
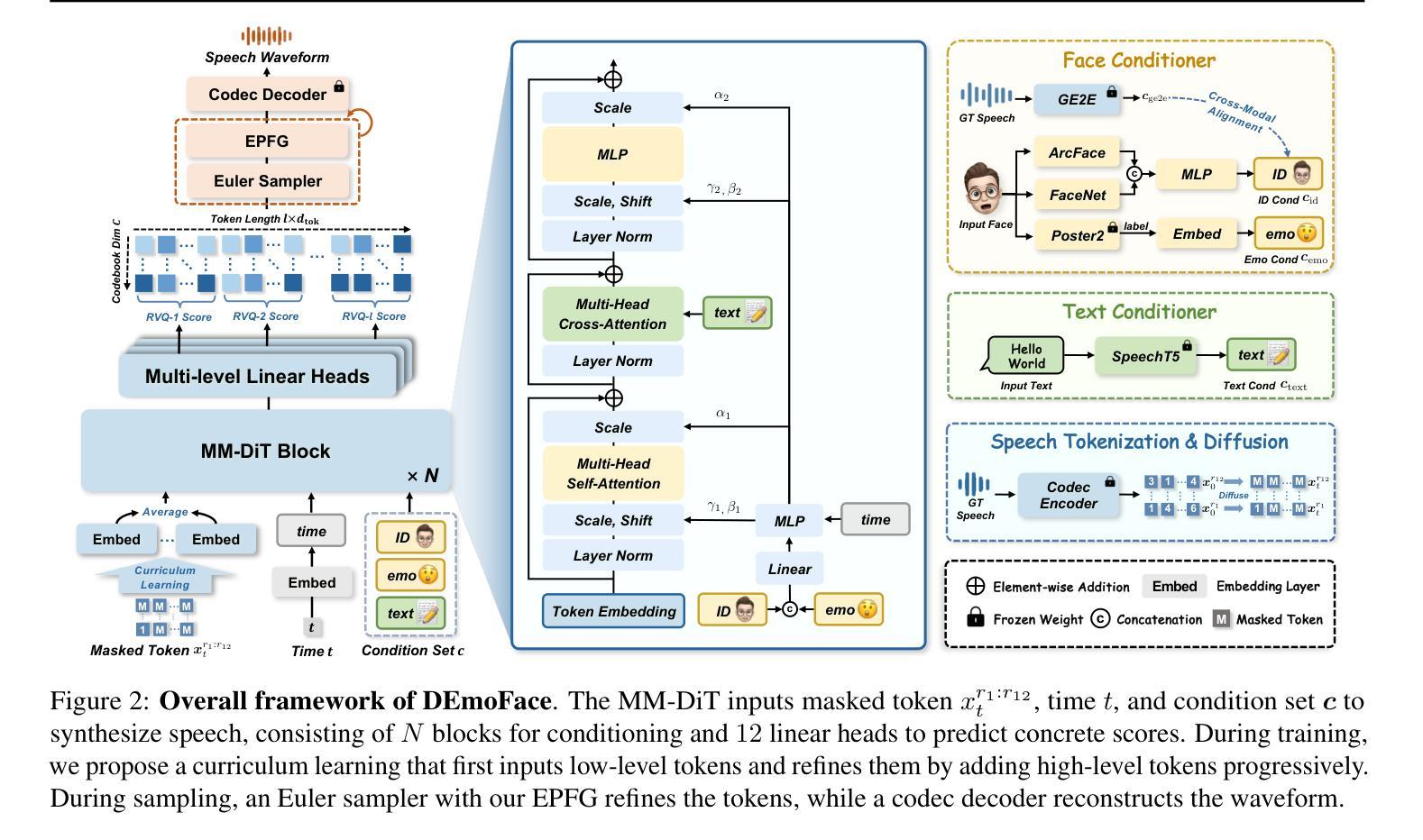
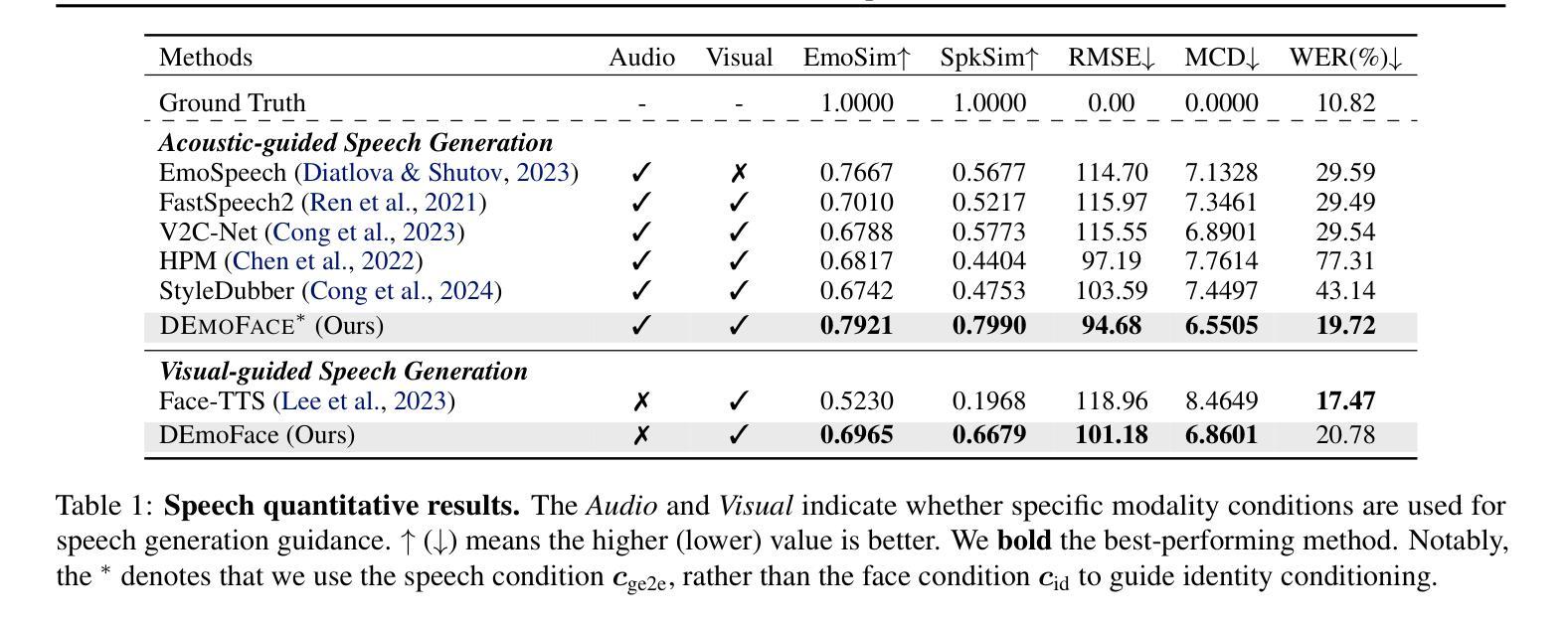
How much can we infer about an emotional voice solely from an expressive face? This intriguing question holds great potential for applications such as virtual character dubbing and aiding individuals with expressive language disorders. Existing face-to-speech methods offer great promise in capturing identity characteristics but struggle to generate diverse vocal styles with emotional expression. In this paper, we explore a new task, termed emotional face-to-speech, aiming to synthesize emotional speech directly from expressive facial cues. To that end, we introduce DEmoFace, a novel generative framework that leverages a discrete diffusion transformer (DiT) with curriculum learning, built upon a multi-level neural audio codec. Specifically, we propose multimodal DiT blocks to dynamically align text and speech while tailoring vocal styles based on facial emotion and identity. To enhance training efficiency and generation quality, we further introduce a coarse-to-fine curriculum learning algorithm for multi-level token processing. In addition, we develop an enhanced predictor-free guidance to handle diverse conditioning scenarios, enabling multi-conditional generation and disentangling complex attributes effectively. Extensive experimental results demonstrate that DEmoFace generates more natural and consistent speech compared to baselines, even surpassing speech-driven methods. Demos are shown at https://demoface-ai.github.io/.
仅凭一张表情丰富的脸,我们能推断出多少关于情绪化的声音?这个引人入胜的问题在虚拟角色配音和辅助表达性语言障碍个体等应用中具有巨大潜力。现有的面部到语音的方法在捕捉身份特征方面表现出很大的前景,但在生成具有情感表达的多样化语音风格方面存在困难。在本文中,我们探索了一项新任务,称为情绪面部到语音,旨在直接从表情丰富的面部线索中合成情感语音。为此,我们引入了DEmoFace,这是一个新的生成框架,它利用带有课程学习的离散扩散变压器(DiT),建立在多层次神经音频编解码器上。具体来说,我们提出了多模态DiT块,以动态对齐文本和语音,同时根据面部情绪和身份定制语音风格。为了提高训练效率和生成质量,我们还引入了从粗到细的课程学习算法,用于多层次令牌处理。此外,我们开发了一种增强的无预测器指导方法,以处理各种条件场景,实现多条件生成并有效地解开复杂属性。大量的实验结果证明,DEmoFace生成的语音比基线更自然、更一致,甚至超过了语音驱动的方法。演示请访问:https://demoface-ai.github.io/。
论文及项目相关链接
Summary
本文探索了一项新任务——情感面部到语音的转换,旨在直接从面部表情合成情感语音。为此,引入了DEmoFace这一新型生成框架,结合离散扩散变压器(DiT)和课程学习技术,建立于多级神经音频编解码器之上。通过引入多模态DiT块,实现了文本和语音的动态对齐,并根据面部表情和身份定制语音风格。此外,还采用了由粗到细的教学课程学习算法进行多级令牌处理,以提高训练效率和生成质量。实验结果表明,DEmoFace相较于基线方法生成了更自然和一致的语音。更多演示参见https://demoface-ai.github.io/。
Key Takeaways
- 研究提出了情感面部到语音转换的新任务,旨在通过面部表情直接合成情感语音。
- 介绍了DEmoFace生成框架,结合了离散扩散变压器(DiT)和课程学习技术。
- 多模态DiT块可实现文本和语音的动态对齐,根据面部表情和身份定制语音风格。
- 采用由粗到细的课程学习算法提高训练效率和生成质量。
- DEmoFace能生成更自然和一致的语音,相较于基线方法有明显优势。
- 该研究在虚拟角色配音和辅助表达性语言障碍者等领域具有潜在应用价值。
点此查看论文截图

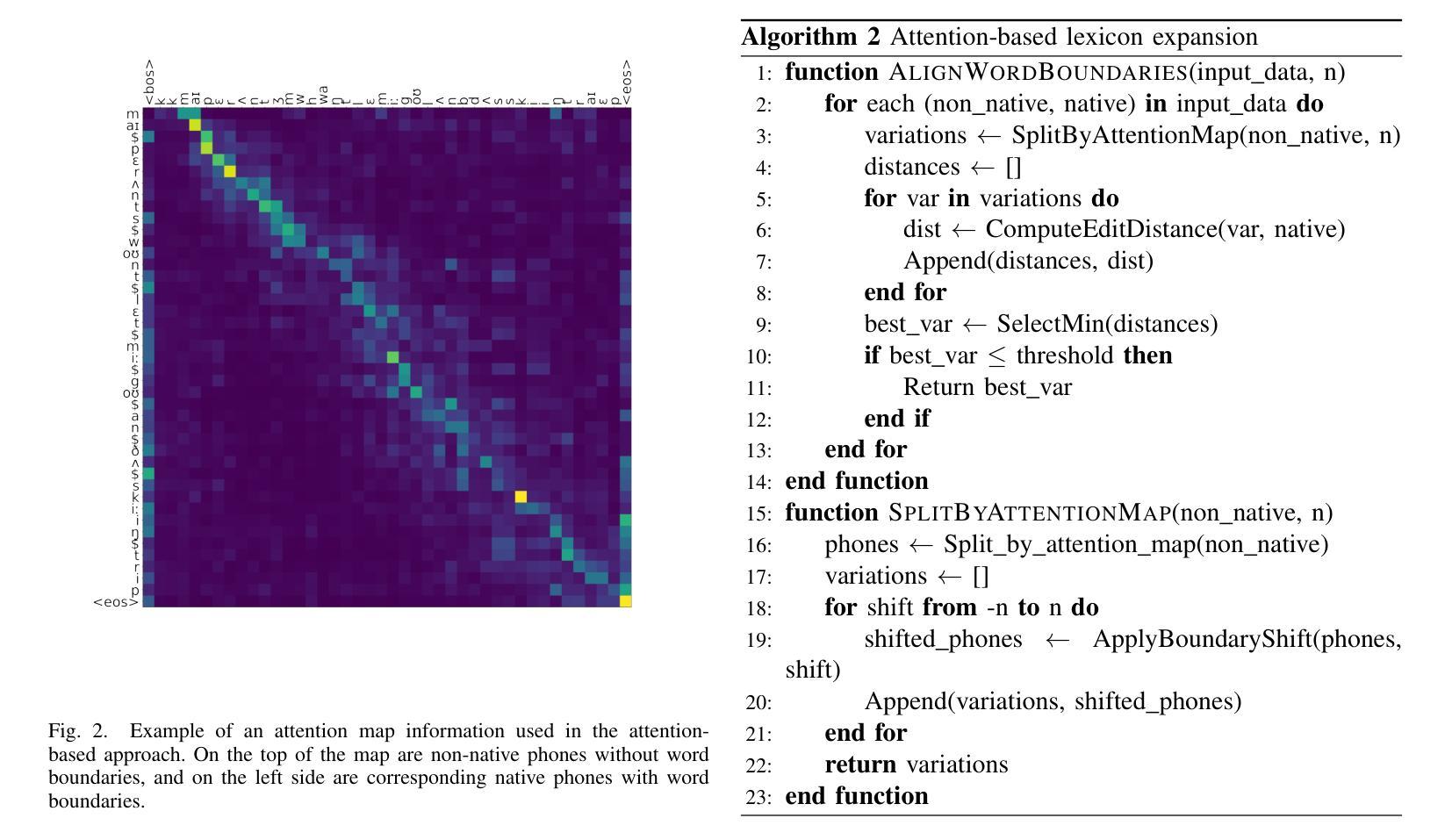
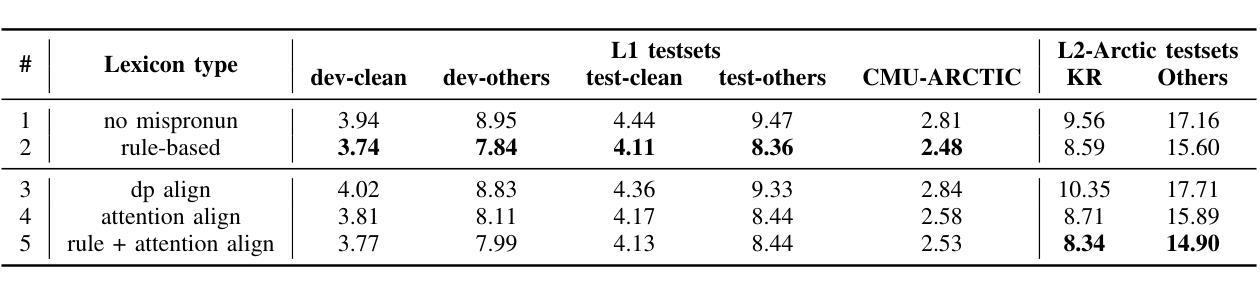
Data-Driven Mispronunciation Pattern Discovery for Robust Speech Recognition
Authors:Anna Seo Gyeong Choi, Jonghyeon Park, Myungwoo Oh
Recent advancements in machine learning have significantly improved speech recognition, but recognizing speech from non-fluent or accented speakers remains a challenge. Previous efforts, relying on rule-based pronunciation patterns, have struggled to fully capture non-native errors. We propose two data-driven approaches using speech corpora to automatically detect mispronunciation patterns. By aligning non-native phones with their native counterparts using attention maps, we achieved a 5.7% improvement in speech recognition on native English datasets and a 12.8% improvement for non-native English speakers, particularly Korean speakers. Our method offers practical advancements for robust Automatic Speech Recognition (ASR) systems particularly for situations where prior linguistic knowledge is not applicable.
近年来,机器学习的发展极大地提高了语音识别能力,但识别非流利或带口音的说话者的语音仍然是一个挑战。以前的研究依赖于基于规则的发声模式,难以完全捕捉非本地发音错误。我们提出两种采用语音语料库的数据驱动方法,以自动检测发音错误模式。通过对非本地语音的音素与本地语音的音素进行对齐注意力图,我们在本地英语数据集上的语音识别率提高了5.7%,对非本地英语口音的识别率提高了12.8%,特别是针对韩国口音的识别。我们的方法为构建稳健的自动语音识别(ASR)系统提供了实际进步,特别是在无法应用先验语言知识的情况下。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary:
近期机器学习技术的进展极大地提升了语音识别能力,但对于非流利或带口音的说话者的语音识别仍存在挑战。以往依赖规则发音模式的方法难以完全捕捉非母语者的发音错误。本研究提出两种数据驱动方法,利用语音语料库自动检测发音错误模式。通过对非母语音素与母语音素的注意力映射对齐,本研究在母语英语数据集上提高了5.7%的语音识别率,对非母语英语者(尤其是韩语背景)提高了12.8%。该方法为无先验语言知识的情境提供了稳健的自动语音识别系统的实际应用进步。
Key Takeaways:
- 机器学习进步提升了语音识别能力,但非流利或带口音的说话者识别仍是挑战。
- 以往的规则发音模式方法在捕捉非母语者发音错误方面存在困难。
- 研究提出两种数据驱动方法,利用语音语料库自动检测误读模式。
- 通过注意力映射对齐,提高了语音识别率。
- 在母语英语数据集上,语音识别率提高了5.7%。
- 对非母语英语者(尤其是韩语背景),语音识别率提高了12.8%。
点此查看论文截图


Evaluation of End-to-End Continuous Spanish Lipreading in Different Data Conditions
Authors:David Gimeno-Gómez, Carlos-D. Martínez-Hinarejos
Visual speech recognition remains an open research problem where different challenges must be considered by dispensing with the auditory sense, such as visual ambiguities, the inter-personal variability among speakers, and the complex modeling of silence. Nonetheless, recent remarkable results have been achieved in the field thanks to the availability of large-scale databases and the use of powerful attention mechanisms. Besides, multiple languages apart from English are nowadays a focus of interest. This paper presents noticeable advances in automatic continuous lipreading for Spanish. First, an end-to-end system based on the hybrid CTC/Attention architecture is presented. Experiments are conducted on two corpora of disparate nature, reaching state-of-the-art results that significantly improve the best performance obtained to date for both databases. In addition, a thorough ablation study is carried out, where it is studied how the different components that form the architecture influence the quality of speech recognition. Then, a rigorous error analysis is carried out to investigate the different factors that could affect the learning of the automatic system. Finally, a new Spanish lipreading benchmark is consolidated. Code and trained models are available at https://github.com/david-gimeno/evaluating-end2end-spanish-lipreading.
视觉语音识别仍然是一个开放的研究问题,需要克服抛弃听觉感官所带来的各种挑战,如视觉模糊性、不同个体之间的差异以及沉默的复杂建模等。尽管如此,由于大规模数据库的出现和强大注意力机制的利用,该领域已经取得了令人瞩目的成果。此外,除了英语之外,多种语言如今也引起了人们的关注。本文介绍了西班牙语的自动连续唇读方面的显著进展。首先,提出了一种基于混合CTC/注意力架构的端到端系统。实验在两个性质各异的语料库上进行,达到了最先进的成果,显著提高了这两个数据库的最佳性能。此外,还进行了全面的消融研究,研究了构成架构的不同部分对语音识别质量的影响。接着,进行了严格的误差分析,以调查可能影响自动系统学习的不同因素。最后巩固了西班牙唇读的新基准。代码和训练模型可在https://github.com/david-gimeno/evaluating-end2end-spanish-lipreading找到。
论文及项目相关链接
PDF Accepted in the “Language Resources and Evaluation” journal, Springer Nature
Summary
视觉语音识别仍然是一个开放的研究问题,需要克服视觉模糊性、不同发音人之间的差异以及沉默的复杂建模等挑战。最近,由于大规模数据库的出现和强大注意力机制的使用,该领域取得了显著成果。本文主要介绍了一种针对西班牙语连续唇读的自动系统的最新进展。该端对端系统采用混合CTC/注意力架构,实验在两种性质不同的语料库上进行,达到当前最先进水平,显著改善了两数据库的最佳性能。此外,还进行了深入彻底的剖析研究,探讨了架构的不同组成部分对语音识别质量的影响。最后巩固了一项新的西班牙语唇读基准测试。相关代码和训练模型可在https://github.com/david-gimeno/evaluating-end2end-spanish-lipreading上找到。
Key Takeaways
- 视觉语音识别是一个开放的研究问题,需要克服视觉模糊性、不同发音人之间的差异以及沉默的复杂建模等挑战。
- 大规模数据库和注意力机制的应用推动了视觉语音识别领域的显著进展。
- 本文提出了一种针对西班牙语的自动连续唇读系统,采用混合CTC/注意力架构,并在两个语料库上达到了当前最先进的性能水平。
- 系统架构的不同组成部分对语音识别质量有显著影响,进行了深入的剖析研究。
- 进行了严谨的错误分析,以研究可能影响自动系统学习的不同因素。
- 巩固了一项新的西班牙语唇读基准测试,为未来的研究提供了评估标准。
点此查看论文截图


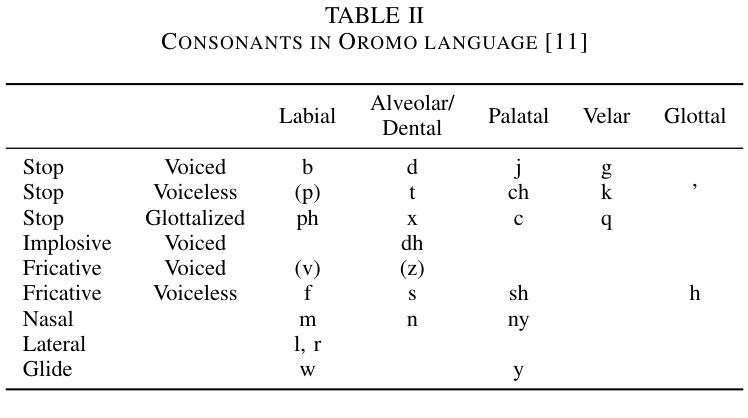
Sagalee: an Open Source Automatic Speech Recognition Dataset for Oromo Language
Authors:Turi Abu, Ying Shi, Thomas Fang Zheng, Dong Wang
We present a novel Automatic Speech Recognition (ASR) dataset for the Oromo language, a widely spoken language in Ethiopia and neighboring regions. The dataset was collected through a crowd-sourcing initiative, encompassing a diverse range of speakers and phonetic variations. It consists of 100 hours of real-world audio recordings paired with transcriptions, covering read speech in both clean and noisy environments. This dataset addresses the critical need for ASR resources for the Oromo language which is underrepresented. To show its applicability for the ASR task, we conducted experiments using the Conformer model, achieving a Word Error Rate (WER) of 15.32% with hybrid CTC and AED loss and WER of 18.74% with pure CTC loss. Additionally, fine-tuning the Whisper model resulted in a significantly improved WER of 10.82%. These results establish baselines for Oromo ASR, highlighting both the challenges and the potential for improving ASR performance in Oromo. The dataset is publicly available at https://github.com/turinaf/sagalee and we encourage its use for further research and development in Oromo speech processing.
我们为埃塞俄比亚及其周边地区广泛使用的奥罗莫语(Oromo language)呈现一个新的自动语音识别(ASR)数据集。该数据集是通过众包倡议收集的,涵盖了各种发音人和语音变化。它包含了10万小时的真实世界音频录制与文字记录配对,涵盖了干净和嘈杂环境中的朗读语音。该数据集解决了奥罗莫语在ASR资源方面的迫切需求,而这种语言在资源上却被忽视。为了展示其在ASR任务中的应用性,我们使用Conformer模型进行了实验,使用混合CTC和AED损失时获得了15.32%的单词错误率(WER),使用纯CTC损失时获得了18.74%的WER。此外,对Whisper模型进行微调后,WER显著提升至10.82%。这些结果为奥罗莫语的ASR建立了基准线,既突出了所面临的挑战,也凸显了提高ASR性能的可能性。该数据集可在https://github.com/turinaf/sagalee公开访问,我们鼓励在奥罗莫语音处理方面开展进一步的研究和开发时使用该数据集。
论文及项目相关链接
PDF Accepted for ICASSP2025 (2025 IEEE International Conference on Acoustics, Speech, and Signal Processing)
Summary
本文介绍了一个为埃塞俄比亚及周边地区广泛使用的奥罗莫语(Oromo)语言打造的自动语音识别(ASR)数据集。该数据集通过众包方式收集,涵盖了不同发音和口音的音频记录,共100小时。文章还介绍了使用Conformer模型进行ASR任务的实验结果,包括混合CTC和AED损失的WER为15.32%,纯CTC损失的WER为18.74%。微调Whisper模型后,WER显著提高到10.82%。此数据集已在公开平台上发布,并鼓励用于进一步研究和开发奥罗莫语音处理。
Key Takeaways
- 介绍了针对奥罗莫语的自动语音识别(ASR)数据集。
- 数据集通过众包方式收集,包含各种发音和口音的音频记录,共100小时。
- 数据集涵盖了清洁和嘈杂环境下的朗读语音。
- 使用Conformer模型进行ASR实验,混合CTC和AED损失的WER为15.32%,纯CTC损失的WER为18.74%。
- 通过对Whisper模型进行微调,显著提高了ASR性能,WER降至10.82%。
- 数据集公开可用,鼓励用于奥罗莫语音处理的进一步研究和发展。
点此查看论文截图

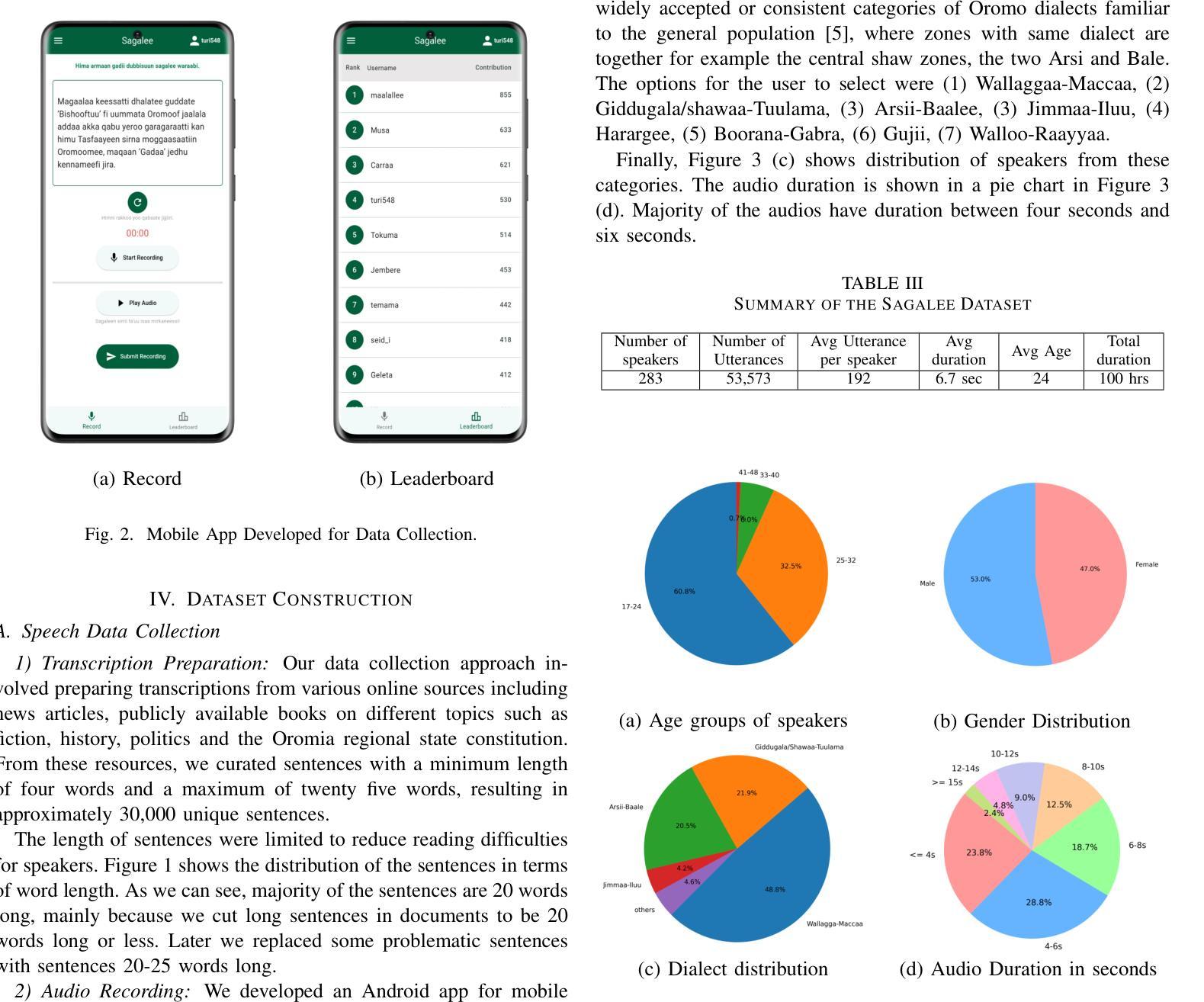

SigWavNet: Learning Multiresolution Signal Wavelet Network for Speech Emotion Recognition
Authors:Alaa Nfissi, Wassim Bouachir, Nizar Bouguila, Brian Mishara
In the field of human-computer interaction and psychological assessment, speech emotion recognition (SER) plays an important role in deciphering emotional states from speech signals. Despite advancements, challenges persist due to system complexity, feature distinctiveness issues, and noise interference. This paper introduces a new end-to-end (E2E) deep learning multi-resolution framework for SER, addressing these limitations by extracting meaningful representations directly from raw waveform speech signals. By leveraging the properties of the fast discrete wavelet transform (FDWT), including the cascade algorithm, conjugate quadrature filter, and coefficient denoising, our approach introduces a learnable model for both wavelet bases and denoising through deep learning techniques. The framework incorporates an activation function for learnable asymmetric hard thresholding of wavelet coefficients. Our approach exploits the capabilities of wavelets for effective localization in both time and frequency domains. We then combine one-dimensional dilated convolutional neural networks (1D dilated CNN) with a spatial attention layer and bidirectional gated recurrent units (Bi-GRU) with a temporal attention layer to efficiently capture the nuanced spatial and temporal characteristics of emotional features. By handling variable-length speech without segmentation and eliminating the need for pre or post-processing, the proposed model outperformed state-of-the-art methods on IEMOCAP and EMO-DB datasets. The source code of this paper is shared on the Github repository: https://github.com/alaaNfissi/SigWavNet-Learning-Multiresolution-Signal-Wavelet-Network-for-Speech-Emotion-Recognition.
在人机交互和心理评估领域,语音情感识别(SER)在从语音信号中解读情感状态方面扮演着重要角色。尽管已有进展,但由于系统复杂性、特征辨别问题和噪声干扰,挑战仍然存在。本文介绍了一种新的端到端(E2E)深度学习多分辨率SER框架,通过直接从原始波形语音信号中提取有意义的表现来克服这些限制。通过利用快速离散小波变换(FDWT)的属性,包括级联算法、共轭正交滤波器和系数去噪,我们的方法通过深度学习技术为小波基和去噪引入了一个可学习的模型。该框架引入了一个激活函数,用于对小波系数进行可学习的不对称硬阈值处理。我们的方法利用小波在时间域和频域的精确定位能力。然后,我们将一维膨胀卷积神经网络(1D dilated CNN)与空间注意力层相结合,将双向门控循环单元(Bi-GRU)与临时注意力层相结合,以有效地捕捉情感特征的细微空间和时间特征。该模型能够处理可变长度的语音,无需分段、预处理或后处理,且在IEMOCAP和EMO-DB数据集上的表现优于最新方法。本文的源代码已共享在Github仓库:https://github.com/alaaNfissi/SigWavNet-Learning-Multiresolution-Signal-Wavelet-Network-for-Speech-Emotion-Recognition。
论文及项目相关链接
PDF Published in: IEEE Transactions on Affective Computing
Summary
本文介绍了语音情感识别(SER)领域的新发展。文章提出一种端到端(E2E)深度学习多分辨率框架,该框架能够从原始波形语音信号中提取有意义的表现,通过利用快速离散小波变换(FDWT)的特性,包括级联算法、共轭正交滤波器和系数去噪技术来解决系统复杂性、特征差异问题和噪声干扰等挑战。结合深度学习技术,引入可学习的小波基和去噪模型。该框架通过利用小波在时间域和频域的有效定位能力,结合了具备空间注意力层的一维膨胀卷积神经网络(1D dilated CNN)和具备时间注意力层的双向门控循环单元(Bi-GRU),以捕捉情感特征的微妙空间和时间特征。所提出的模型无需分段处理可变长度的语音,且在IEMOCAP和EMO-DB数据集上的表现优于现有方法。
Key Takeaways
- 语音情感识别(SER)在人机交互和心理评估领域具有重要作用,能够从语音信号中解析情感状态。
- 文章提出了一种新的端到端(E2E)深度学习多分辨率框架,解决了系统复杂性、特征差异和噪声干扰等挑战。
- 利用快速离散小波变换(FDWT)的特性,包括级联算法、共轭正交滤波器和系数去噪技术。
- 引入可学习的小波基和去噪模型,通过深度学习技术实现。
- 模型结合了具备空间注意力层的一维膨胀卷积神经网络(1D dilated CNN)和具备时间注意力层的双向门控循环单元(Bi-GRU),以捕捉情感特征的细微差异。
- 模型无需分段处理可变长度的语音,且在主要数据集上表现优异。
点此查看论文截图


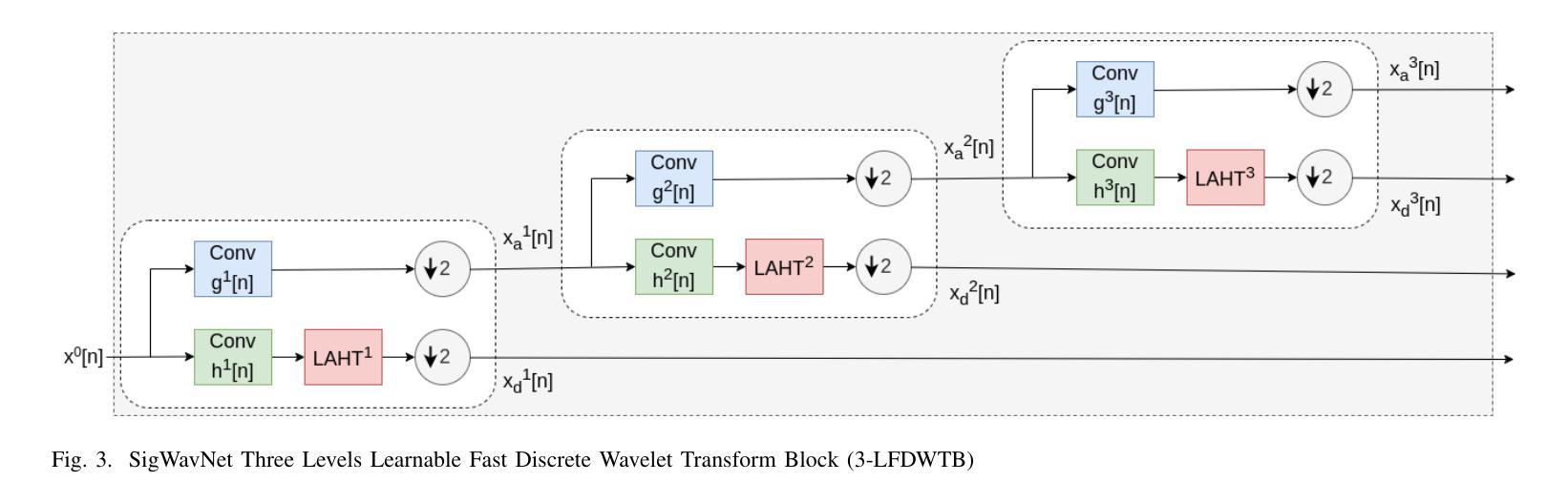
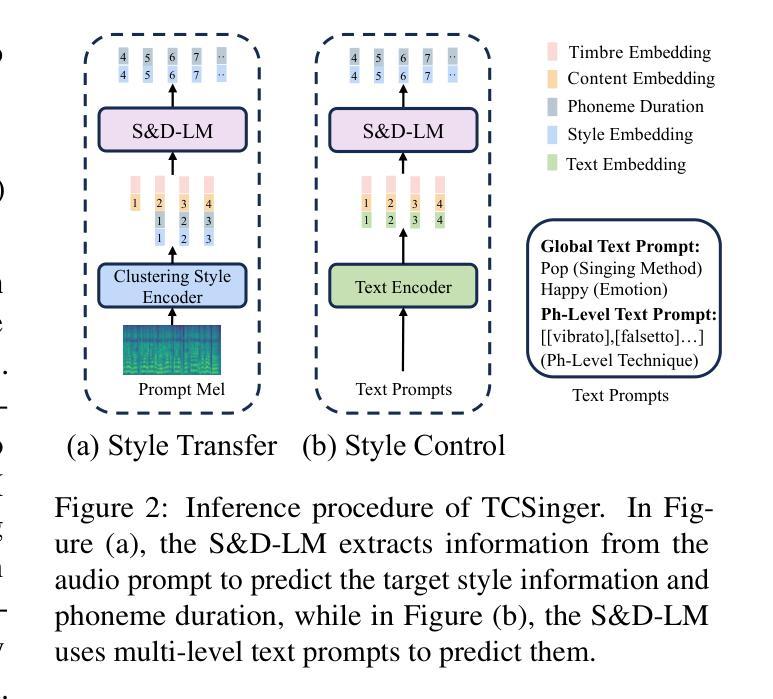
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
Authors:Yu Zhang, Ziyue Jiang, Ruiqi Li, Changhao Pan, Jinzheng He, Rongjie Huang, Chuxin Wang, Zhou Zhao
Zero-shot singing voice synthesis (SVS) with style transfer and style control aims to generate high-quality singing voices with unseen timbres and styles (including singing method, emotion, rhythm, technique, and pronunciation) from audio and text prompts. However, the multifaceted nature of singing styles poses a significant challenge for effective modeling, transfer, and control. Furthermore, current SVS models often fail to generate singing voices rich in stylistic nuances for unseen singers. To address these challenges, we introduce TCSinger, the first zero-shot SVS model for style transfer across cross-lingual speech and singing styles, along with multi-level style control. Specifically, TCSinger proposes three primary modules: 1) the clustering style encoder employs a clustering vector quantization model to stably condense style information into a compact latent space; 2) the Style and Duration Language Model (S&D-LM) concurrently predicts style information and phoneme duration, which benefits both; 3) the style adaptive decoder uses a novel mel-style adaptive normalization method to generate singing voices with enhanced details. Experimental results show that TCSinger outperforms all baseline models in synthesis quality, singer similarity, and style controllability across various tasks, including zero-shot style transfer, multi-level style control, cross-lingual style transfer, and speech-to-singing style transfer. Singing voice samples can be accessed at https://aaronz345.github.io/TCSingerDemo/.
零样本唱腔合成(SVS)技术带有风格迁移和风格控制功能,旨在根据音频和文字提示生成具有未见音色和风格的高质量歌声(包括唱法、情感、节奏、技巧和发音)。然而,唱腔风格的多面性给有效的建模、迁移和控制带来了重大挑战。此外,当前的SVS模型往往无法为未见过的歌手生成丰富细腻的风格化歌声。为了应对这些挑战,我们推出了TCSinger,这是一款零样本SVS模型,用于跨跨语言演讲和唱腔风格进行风格迁移和多级风格控制。具体来说,TCSinger主要包括三个核心模块:1)聚类风格编码器采用聚类向量量化模型,将风格信息稳定地浓缩到一个紧凑的潜在空间;2)风格和时长语言模型(S&D-LM)同时预测风格信息和音素时长,两者都受益;3)风格自适应解码器采用一种新型梅尔风格自适应归一化方法,生成具有增强细节的歌声。实验结果表明,TCSinger在合成质量、歌手相似度和风格可控性方面均优于所有基线模型,涵盖各种任务,包括零样本风格迁移、多级风格控制、跨语言风格迁移和语音到唱腔的风格迁移。您可以在https://aaronz345.github.io/TCSingerDemo/访问唱腔样本。
论文及项目相关链接
PDF Accepted by EMNLP 2024
Summary
该研究介绍了针对风格迁移与控制的零样本歌声合成技术(SVS)。提出了TCSinger模型,可实现在跨语种的歌声和语音风格间的零样本风格迁移与多层次风格控制。模型包含三大模块:聚类风格编码器、风格与时长语言模型及风格自适应解码器。实验结果显示,TCSinger在合成质量、歌手相似性及风格可控性方面均优于基线模型,支持零样本风格迁移、多层次风格控制、跨语种风格迁移及语音转歌声风格迁移。更多歌声样本请访问:链接地址。
Key Takeaways
- 研究旨在实现零样本歌声合成(SVS)的风格迁移与控制,生成具有未见音色和风格的高质量歌声。
- 面临挑战:歌唱风格的多样性使得有效建模、迁移与控制变得困难,现有SVS模型难以生成丰富风格细节的歌声。
- 引入TCSinger模型,首次实现跨语种歌声与语音风格的零样本风格迁移及多层次风格控制。
- TCSinger包含三个主要模块:聚类风格编码器、风格与时长语言模型、风格自适应解码器。
- 实验证明TCSinger在合成质量、歌手相似性和风格可控性方面超越基线模型。
- 支持多种任务,包括零样本风格迁移、多层次风格控制、跨语种风格迁移及语音转歌声风格迁移。
点此查看论文截图

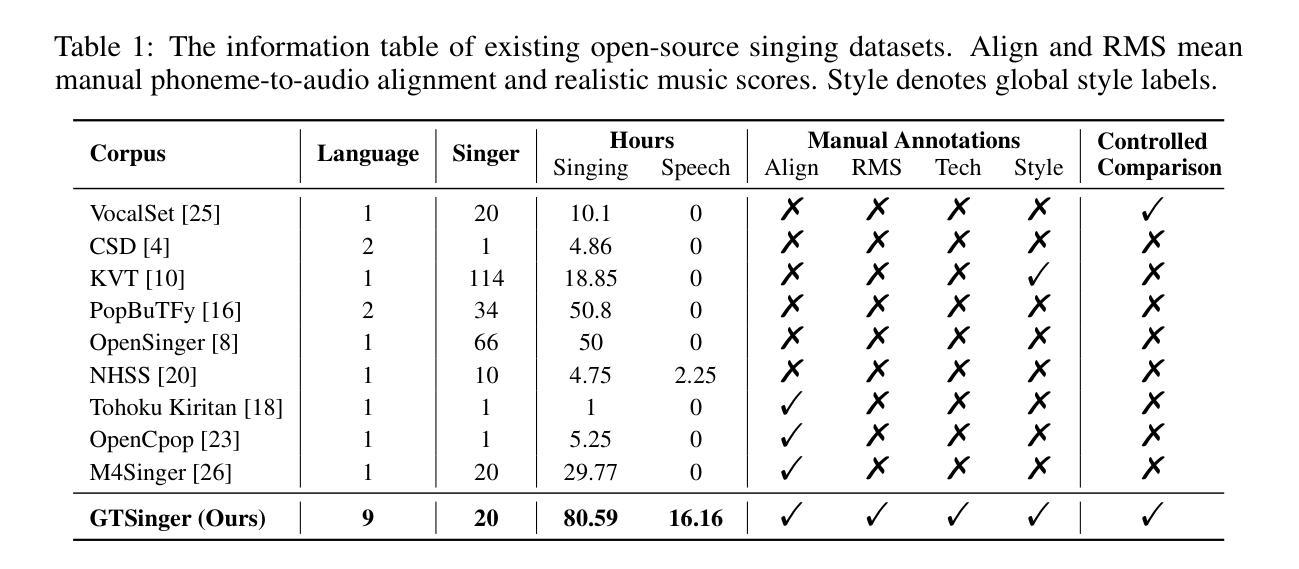
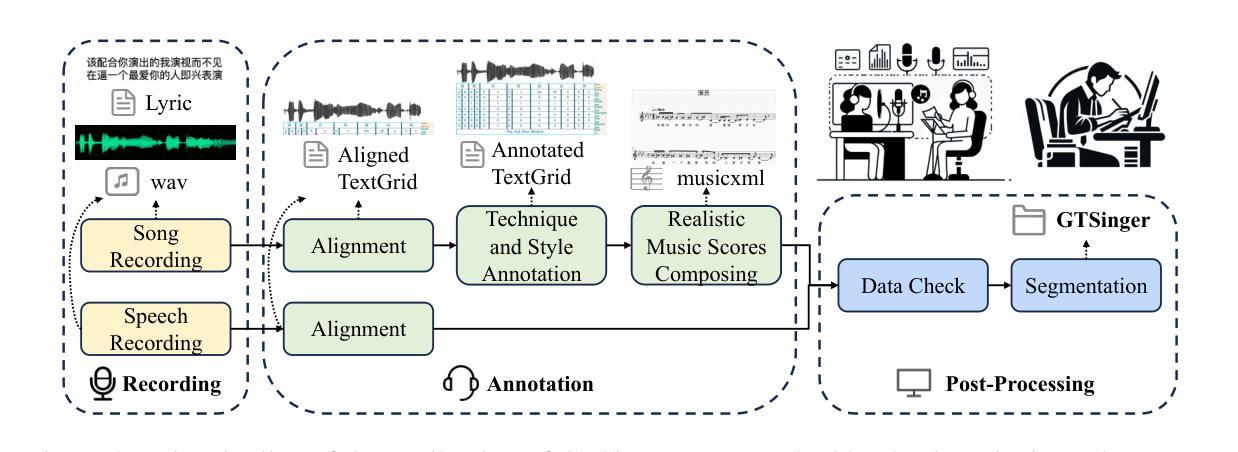
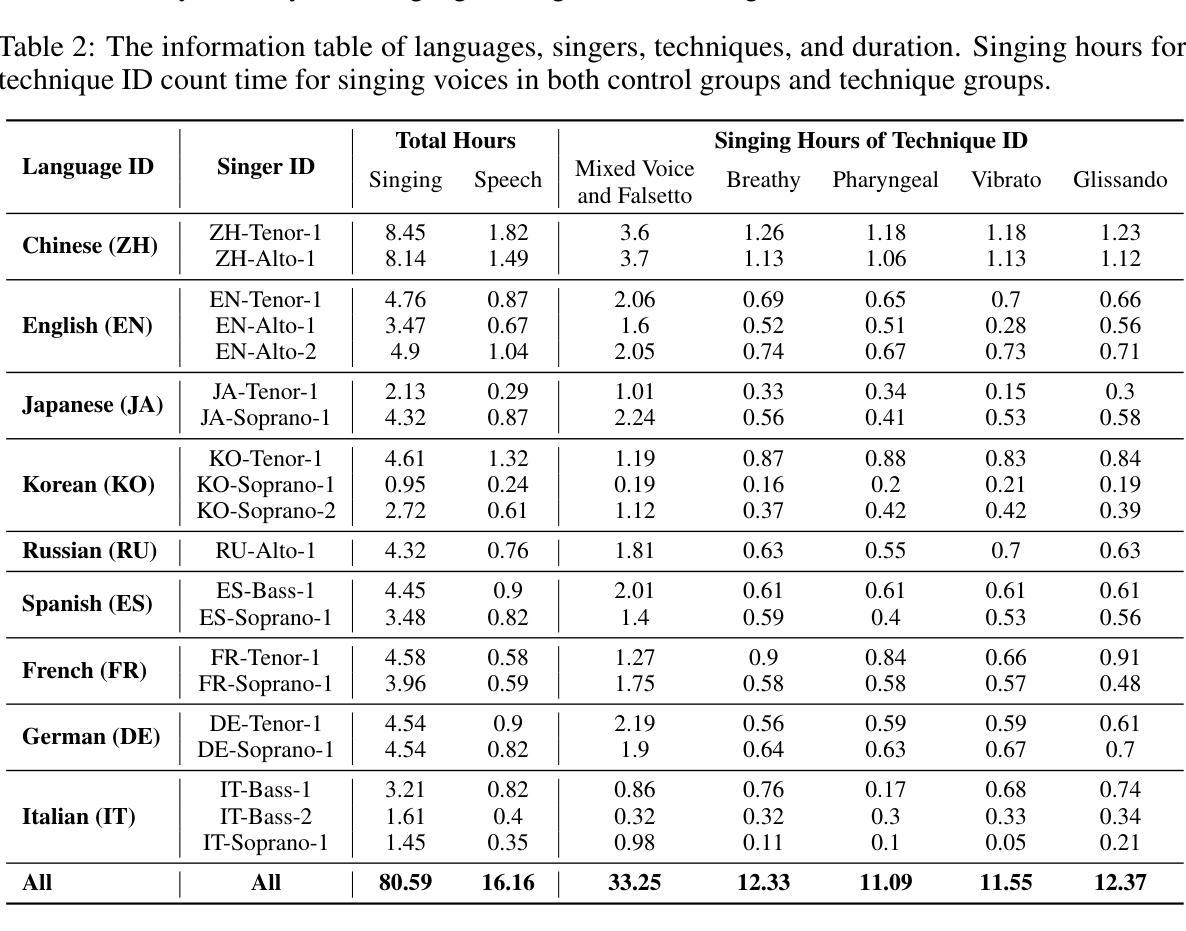
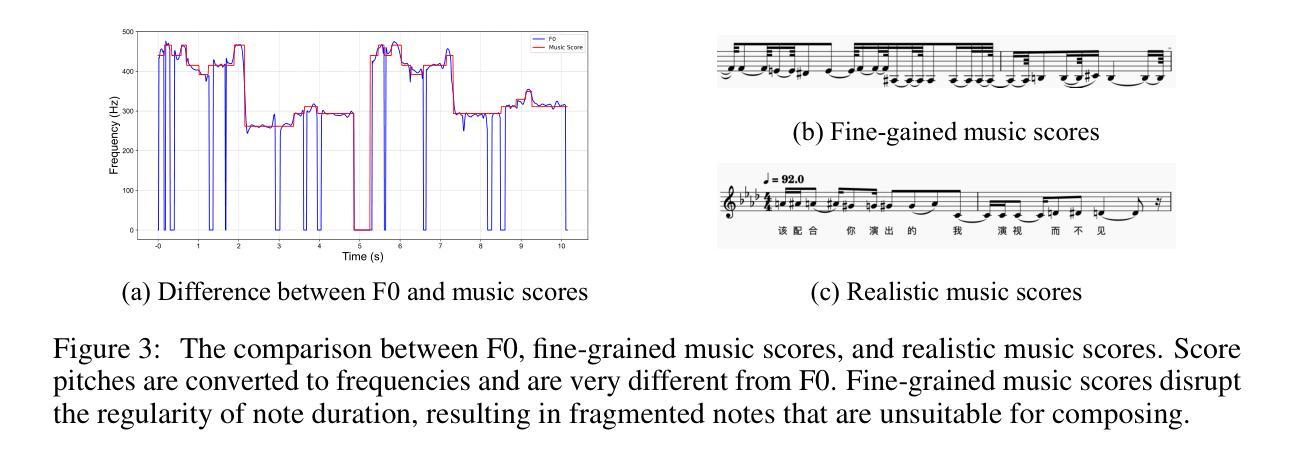
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Authors:Yu Zhang, Changhao Pan, Wenxiang Guo, Ruiqi Li, Zhiyuan Zhu, Jialei Wang, Wenhao Xu, Jingyu Lu, Zhiqing Hong, Chuxin Wang, LiChao Zhang, Jinzheng He, Ziyue Jiang, Yuxin Chen, Chen Yang, Jiecheng Zhou, Xinyu Cheng, Zhou Zhao
The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability. To tackle these problems, we present GTSinger, a large global, multi-technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks. Particularly, (1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset; (2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles; (3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control; (4) GTSinger offers realistic music scores, assisting real-world musical composition; (5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks. Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion. The corpus and demos can be found at http://aaronz345.github.io/GTSingerDemo/. We provide the dataset and the code for processing data and conducting benchmarks at https://huggingface.co/datasets/GTSinger/GTSinger and https://github.com/AaronZ345/GTSinger.
面对高质量多任务歌唱数据集稀缺的问题,极大地阻碍了多样化可控和个人化歌唱任务的发展。现有歌唱数据集存在质量问题、语言与歌手多样性有限、缺乏多技术信息和现实音乐乐谱以及任务适用性不足等问题。为了解决这些问题,我们推出了GTSinger,这是一个大型的全球性、多技术、免费使用的高质量歌唱语料库,具有现实音乐乐谱,适用于所有歌唱任务,以及相应的基准测试。具体来说,(1)我们收集了80.59小时的高质量歌声,形成了最大的录音歌唱数据集;(2)20位专业歌手跨越九种广泛使用的语言,展现了多样的音色和风格;(3)我们提供了六种常用歌唱技术的受控比较和音素级注释,有助于技术建模和控制;(4)GTSinger提供了现实的乐谱,有助于现实音乐创作;(5)歌声伴有手动音素到音频对齐、全局风格标签以及用于各种歌唱任务的16.16小时配对语音。此外,为了方便使用GTSinger,我们进行了四项基准实验:技术可控的歌唱声音合成、技术识别、风格转换和语音到歌唱的转换。语料库和演示可以在http://aaronz345.github.io/GTSingerDemo/找到。我们在https://huggingface.co/datasets/GTSinger/GTSinger和https://github.com/AaronZ345/GTSinger提供了数据集和数据处理及基准测试的代码。
论文及项目相关链接
PDF Accepted by NeurIPS 2024 (Spotlight)
Summary
该文针对高质量多任务歌唱数据集缺乏的问题,提出了一种大型全球、多技术、免费使用的GTSinger高质量歌唱语料库,并设计了适用于所有歌唱任务的基准测试。该语料库包含80.59小时的高质量歌唱声音数据,涉及九种广泛使用的语言,提供了六种常用歌唱技术的对比和音素级注释,以及现实音乐乐谱和手动音素到音频的对齐等技术特点。此外,还进行了四项基准测试,包括技巧可控的歌唱声音合成、技巧识别、风格转换和语音到歌唱的转换。该语料库的数据集和相关代码可以在相关网站找到。
Key Takeaways
- GTSinger是一个全球性的大型高质量歌唱语料库,解决了现有歌唱数据集质量低、语言多样性有限、缺乏多技术信息和现实音乐乐谱等问题。
- GTSinger包含超过80小时的高质量歌唱声音数据,是最大的已记录歌唱数据集之一。
- 数据集包含来自九种广泛使用的语言的20位专业歌手的声音,展现了多样化的音色和风格。
- GTSinger提供了六种常用歌唱技术的对比和音素级注释,有助于技术建模和控制。
- 数据集提供了现实音乐乐谱,支持真实世界的音乐创作。
- 数据集包括手动音素到音频的对齐、全球风格标签以及用于各种歌唱任务的配对语音数据。
点此查看论文截图