⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-06 更新
CLIP-DQA: Blindly Evaluating Dehazed Images from Global and Local Perspectives Using CLIP
Authors:Yirui Zeng, Jun Fu, Hadi Amirpour, Huasheng Wang, Guanghui Yue, Hantao Liu, Ying Chen, Wei Zhou
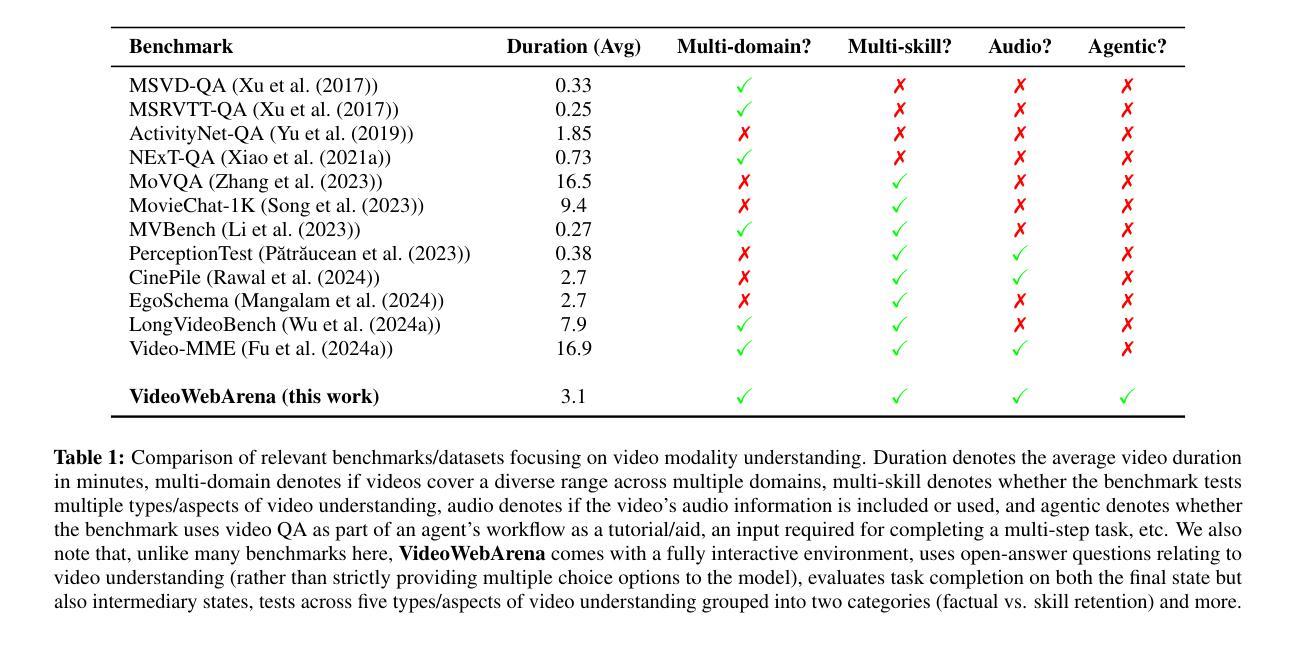
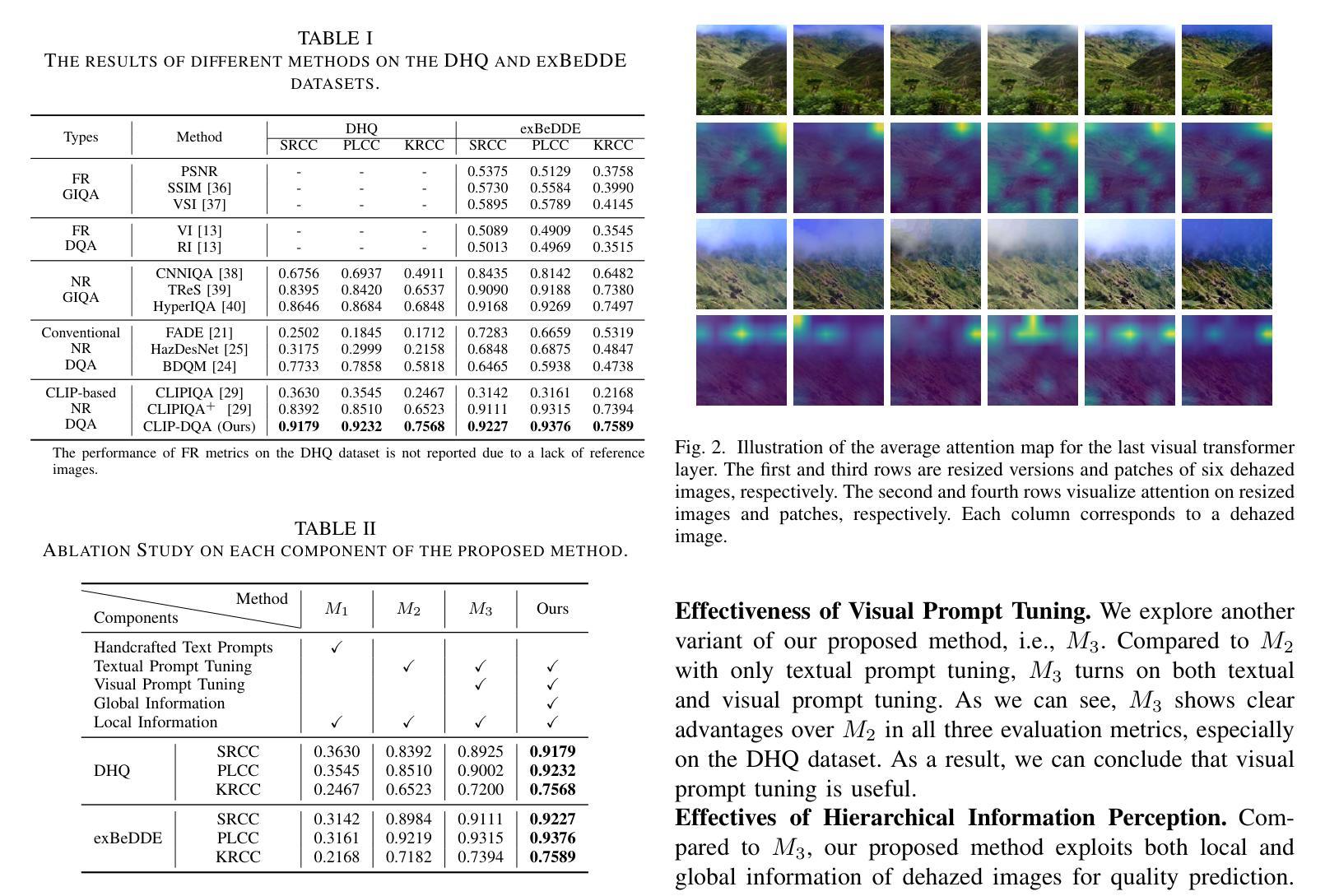
Blind dehazed image quality assessment (BDQA), which aims to accurately predict the visual quality of dehazed images without any reference information, is essential for the evaluation, comparison, and optimization of image dehazing algorithms. Existing learning-based BDQA methods have achieved remarkable success, while the small scale of DQA datasets limits their performance. To address this issue, in this paper, we propose to adapt Contrastive Language-Image Pre-Training (CLIP), pre-trained on large-scale image-text pairs, to the BDQA task. Specifically, inspired by the fact that the human visual system understands images based on hierarchical features, we take global and local information of the dehazed image as the input of CLIP. To accurately map the input hierarchical information of dehazed images into the quality score, we tune both the vision branch and language branch of CLIP with prompt learning. Experimental results on two authentic DQA datasets demonstrate that our proposed approach, named CLIP-DQA, achieves more accurate quality predictions over existing BDQA methods. The code is available at https://github.com/JunFu1995/CLIP-DQA.
盲去霾图像质量评估(BDQA)旨在无参考信息的情况下准确预测去霾图像的可视质量,对于图像去霾算法的评估、比较和优化至关重要。虽然现有的基于学习的BDQA方法已经取得了显著的成功,但DQA数据集规模较小限制了其性能。针对这一问题,本文提出适应对比语言图像预训练(CLIP)的方法,CLIP在大规模图像文本对上进行了预训练,可应用于BDQA任务。具体而言,受到人类视觉系统基于分层特征理解图像的启发,我们以去霾图像的全局和局部信息作为CLIP的输入。为了准确地将去霾图像输入的分层信息映射到质量分数上,我们采用提示学习调整CLIP的视觉分支和语言分支。在两个真实的DQA数据集上的实验结果表明,我们提出的方法——CLIP-DQA,相较于现有的BDQA方法,实现了更准确的质量预测。代码可在https://github.com/JunFu1995/CLIP-DQA上找到。
论文及项目相关链接
PDF Accepted by ISCAS 2025 (Oral)
Summary
盲去雾图像质量评估(BDQA)旨在无参考信息的情况下准确预测去雾图像的可视质量,对图像去雾算法的评估、比较和优化至关重要。现有基于学习的BDQA方法取得了显著的成功,而DQA数据集的小规模限制了其性能。本文适应对比语言图像预训练模型(CLIP),该模型在大型图像文本对上预训练,用于BDQA任务。受人类视觉系统基于层次特征理解图像的启发,我们以去雾图像的全局和局部信息作为CLIP的输入。为了准确将去雾图像的输入层次信息映射到质量得分上,我们微调了CLIP的视觉分支和语言分支,采用提示学习的方式。在真实DQA数据集上的实验结果表明,我们提出的方法CLIP-DQA相较于现有BDQA方法,质量预测更准确。代码已公开于https://github.com/JunFu1995/CLIP-DQA。
Key Takeaways
- BDQA对于图像去雾算法的评估、比较和优化非常重要。它能够预测去雾图像的可视质量且无需任何参考信息。
- 目前基于学习的BDQA方法虽取得显著成果,但受限于DQA数据集规模较小的问题。
- 本文首次尝试将对比语言图像预训练模型(CLIP)应用于BDQA任务。CLIP模型在大型图像文本对上预训练,有助于提升任务性能。
- 受人类视觉系统理解图像基于层次特征的启发,采用全局和局部信息作为CLIP模型的输入。
- 通过提示学习的方式微调CLIP模型的视觉分支和语言分支,以准确映射去雾图像的层次信息到质量得分上。
- 在真实DQA数据集上的实验表明,所提方法CLIP-DQA相较于现有BDQA方法,质量预测更准确。
点此查看论文截图

One-to-Normal: Anomaly Personalization for Few-shot Anomaly Detection
Authors:Yiyue Li, Shaoting Zhang, Kang Li, Qicheng Lao
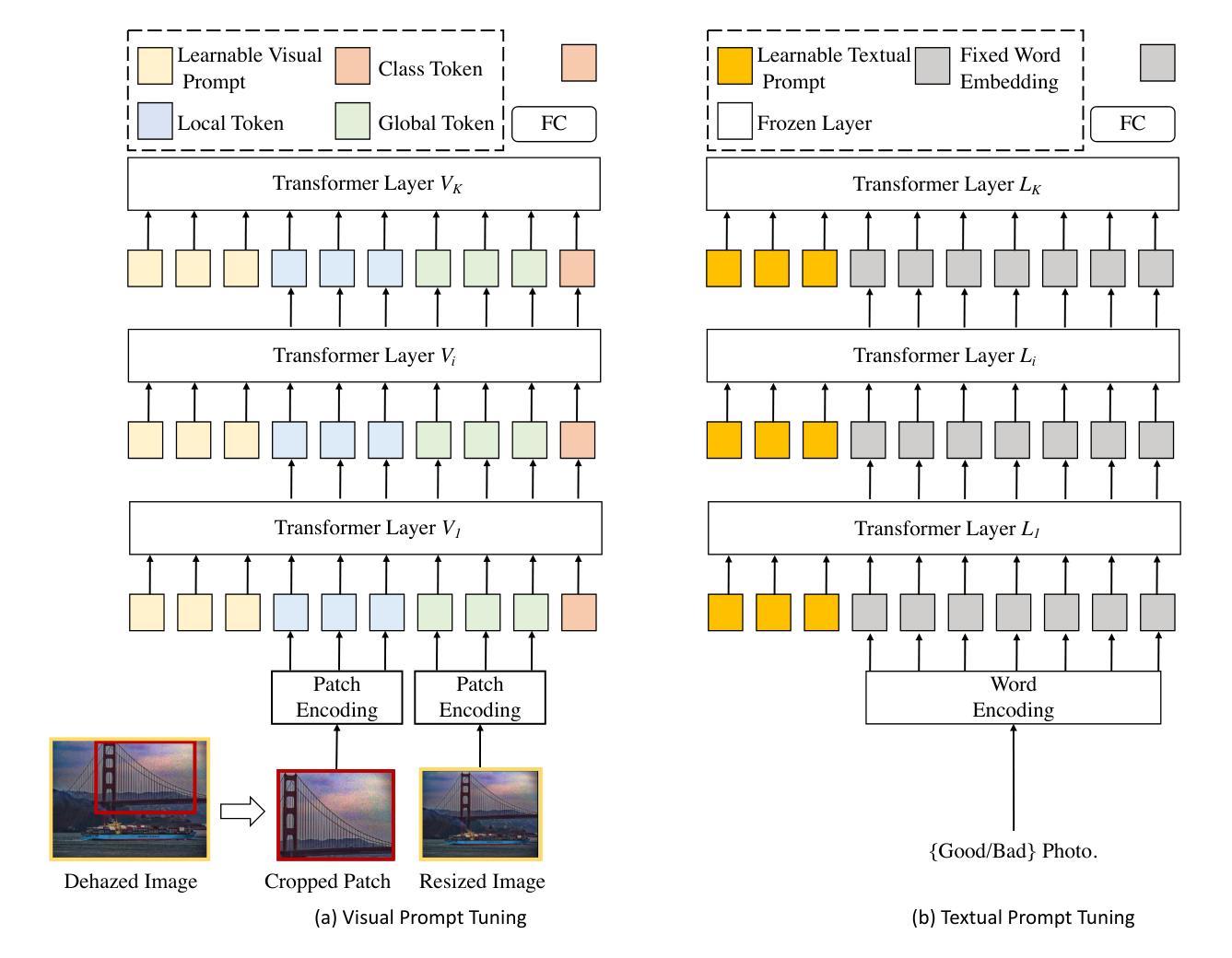
Traditional Anomaly Detection (AD) methods have predominantly relied on unsupervised learning from extensive normal data. Recent AD methods have evolved with the advent of large pre-trained vision-language models, enhancing few-shot anomaly detection capabilities. However, these latest AD methods still exhibit limitations in accuracy improvement. One contributing factor is their direct comparison of a query image’s features with those of few-shot normal images. This direct comparison often leads to a loss of precision and complicates the extension of these techniques to more complex domains–an area that remains underexplored in a more refined and comprehensive manner. To address these limitations, we introduce the anomaly personalization method, which performs a personalized one-to-normal transformation of query images using an anomaly-free customized generation model, ensuring close alignment with the normal manifold. Moreover, to further enhance the stability and robustness of prediction results, we propose a triplet contrastive anomaly inference strategy, which incorporates a comprehensive comparison between the query and generated anomaly-free data pool and prompt information. Extensive evaluations across eleven datasets in three domains demonstrate our model’s effectiveness compared to the latest AD methods. Additionally, our method has been proven to transfer flexibly to other AD methods, with the generated image data effectively improving the performance of other AD methods.
传统异常检测(AD)方法主要依赖于从大量正常数据中进行的无监督学习。随着大型预训练视觉语言模型的兴起,最近的AD方法已经发展并增强了小样本异常检测能力。然而,这些最新的AD方法在精度提升方面仍存在局限性。一个原因是它们直接将查询图像的特征与少量正常图像的特征进行比较。这种直接比较往往会导致精度损失,并使得将这些技术扩展到更复杂的领域更加复杂——这个领域在更精细和全面的方式下仍然探索不足。为了解决这些局限性,我们引入了异常个性化方法,该方法使用无异常定制化生成模型对查询图像进行个性化一对一正常转换,确保与正常流形紧密对齐。此外,为了进一步提高预测结果的稳定性和鲁棒性,我们提出了一种三元对比异常推理策略,该策略对查询和生成的异常免费数据池以及提示信息进行了全面比较。在三个领域的十一个数据集上的广泛评估表明,与最新的AD方法相比,我们的模型是有效的。另外,我们的方法已被证明可以灵活地转移到其他AD方法,生成的图像数据有效地提高了其他AD方法的性能。
论文及项目相关链接
PDF In The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS2024)
Summary
本文介绍了传统的异常检测方法主要依赖于大量正常数据的无监督学习。然而,随着大型预训练视觉语言模型的出现,最新的异常检测方法已经发展出来,提高了少样本异常检测的能力。然而,这些方法仍存在准确性提高的局限性,主要是因为它们直接比较查询图像的特征和少量正常图像的特征。为了解决这一问题,本文提出了异常个性化方法,该方法使用无异常定制生成模型对查询图像进行个性化的一对一正常转换,确保与正常流形紧密对齐。此外,为了提高预测结果的稳定性和鲁棒性,还提出了一种三元对比异常推理策略,该策略全面比较了查询和生成的异常自由数据池和提示信息。在三个领域的11个数据集上的广泛评估证明了我们模型的有效性。此外,该方法可灵活转移到其他异常检测方法中,生成的图像数据可有效提高其他异常检测方法的性能。
Key Takeaways
- 传统异常检测方法主要依赖无监督学习及大量正常数据。
- 近期方法利用大型预训练视觉语言模型提高少样本异常检测能力。
- 现有方法存在准确性提高的局限性,主要因为直接比较查询图像与正常图像特征。
- 提出异常个性化方法,利用无异常定制生成模型进行个性化转换。
- 提出三元对比异常推理策略,全面比较查询图像、生成的异常自由数据池和提示信息。
- 在多个数据集上的评估证明模型的有效性。
点此查看论文截图

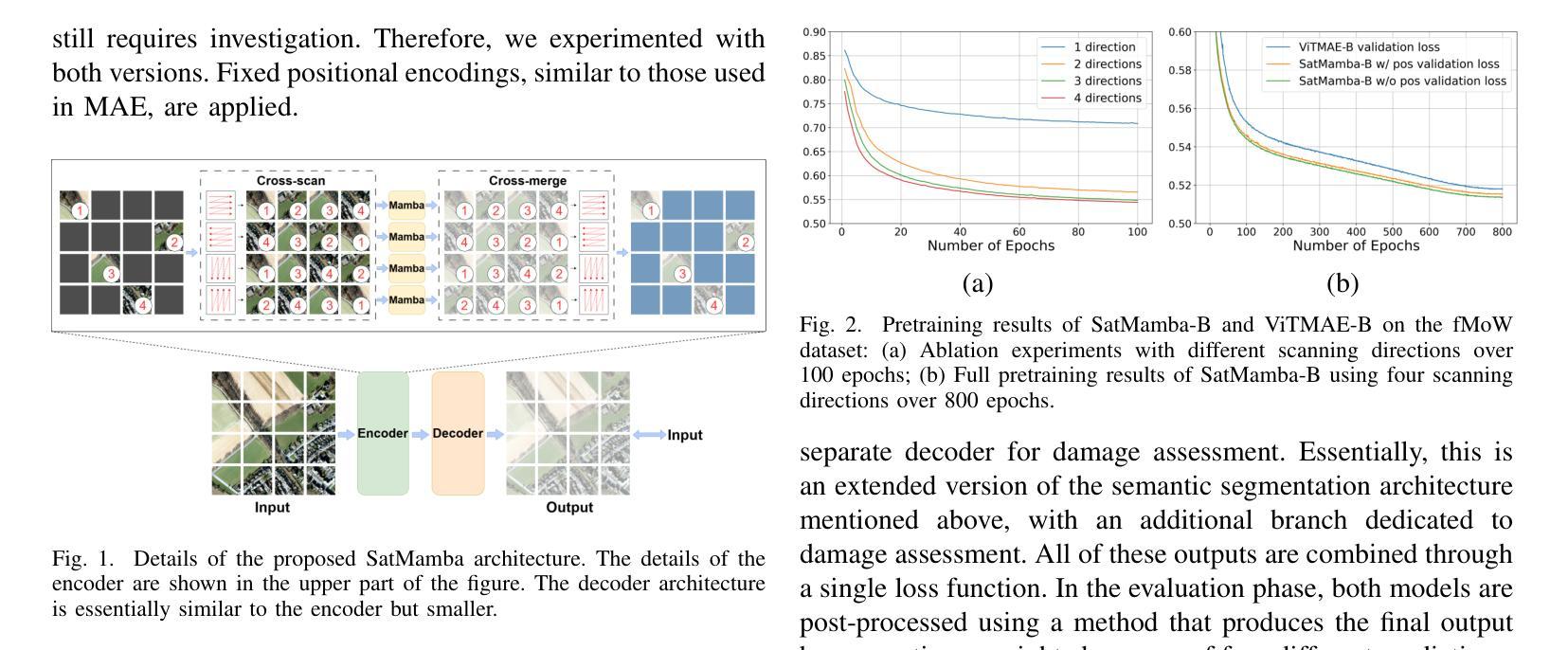
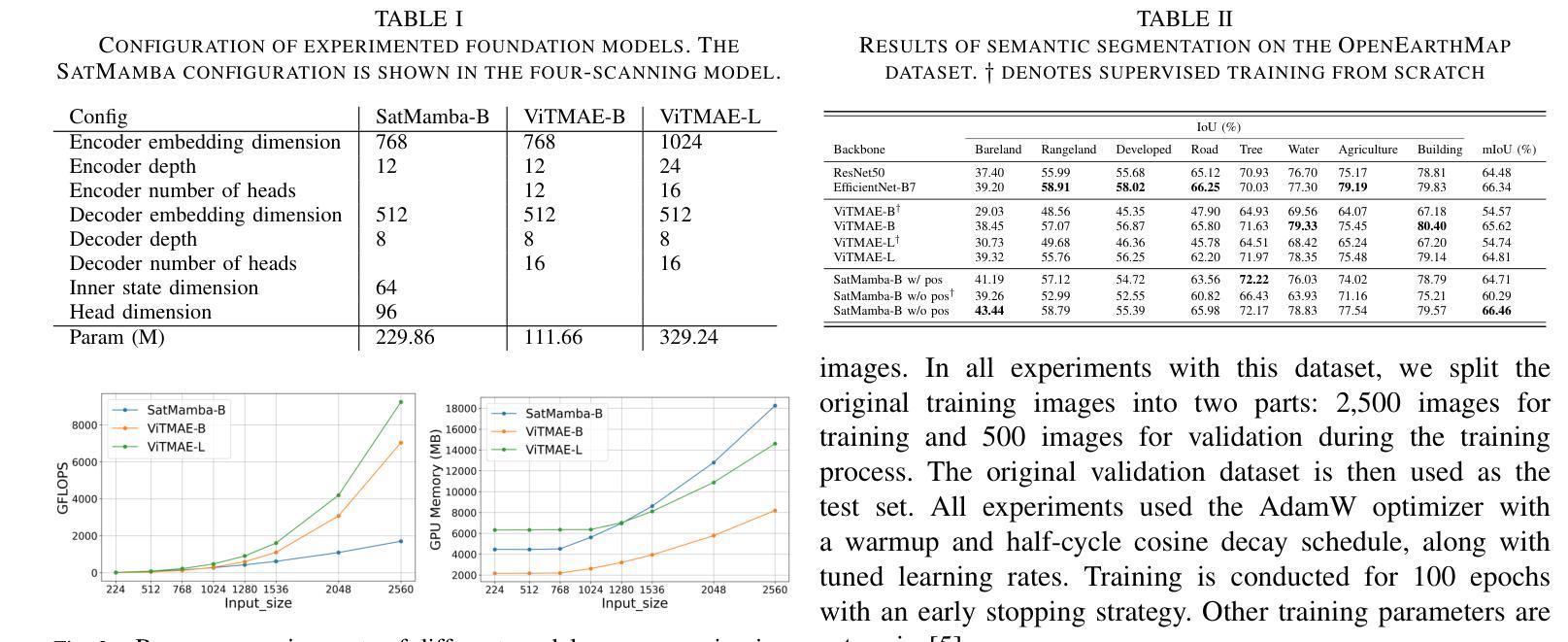
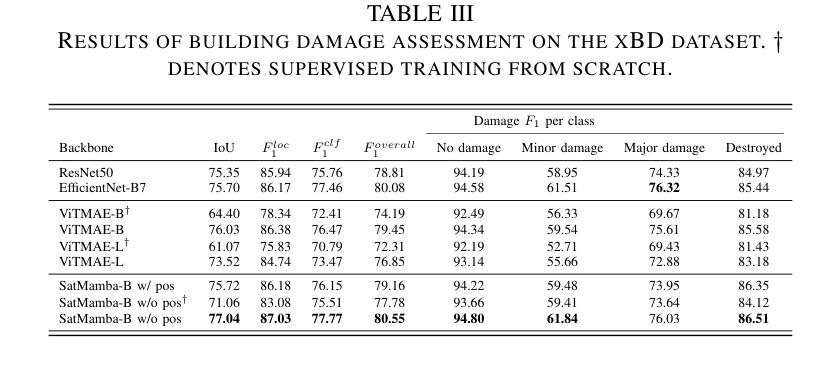
SatMamba: Development of Foundation Models for Remote Sensing Imagery Using State Space Models
Authors:Chuc Man Duc, Hiromichi Fukui
Foundation models refer to deep learning models pretrained on large unlabeled datasets through self-supervised algorithms. In the Earth science and remote sensing communities, there is growing interest in transforming the use of Earth observation data, including satellite and aerial imagery, through foundation models. Various foundation models have been developed for remote sensing, such as those for multispectral, high-resolution, and hyperspectral images, and have demonstrated superior performance on various downstream tasks compared to traditional supervised models. These models are evolving rapidly, with capabilities to handle multispectral, multitemporal, and multisensor data. Most studies use masked autoencoders in combination with Vision Transformers (ViTs) as the backbone for pretraining. While the models showed promising performance, ViTs face challenges, such as quadratic computational scaling with input length, which may limit performance on multiband and multitemporal data with long sequences. This research aims to address these challenges by proposing SatMamba, a new pretraining framework that combines masked autoencoders with State Space Model, offering linear computational scaling. Experiments on high-resolution imagery across various downstream tasks show promising results, paving the way for more efficient foundation models and unlocking the full potential of Earth observation data. The source code is available in https://github.com/mdchuc/HRSFM.
基础模型是指通过自监督算法在大规模无标签数据集上进行预训练得到的深度学习模型。在地球科学和遥感领域,人们越来越有兴趣通过基础模型来转换地球观测数据的使用方式,包括卫星和航空影像。针对遥感应用已经开发出了多种基础模型,如多光谱、高分辨率和超光谱图像模型等。与传统监督模型相比,这些模型在各种下游任务中显示出卓越的性能。这些模型正在快速发展,具备处理多光谱、多时相和多传感器数据的能力。大多数研究使用掩码自编码器与视觉转换器(ViTs)相结合作为预训练的主干。虽然这些模型表现出有希望的性能,但ViTs面临挑战,如随输入长度而呈二次方计算扩展的问题,可能会限制在长序列的多波段和多时相数据上的性能。本研究旨在通过提出SatMamba这一新的预训练框架来解决这些挑战,SatMamba结合了掩码自编码器和状态空间模型,提供线性计算扩展。在各种下游任务上的高分辨率图像实验显示出有希望的结果,为更有效率的基础模型和解锁地球观测数据的全部潜力铺平了道路。源代码可在https://github.com/mdchuc/HRSFM中找到。
论文及项目相关链接
Summary
本文介绍了在地球科学和遥感领域,使用预训练的大型深度学习模型——基础模型的应用与发展趋势。针对遥感图像的各种基础模型,如多光谱、高分辨率和超光谱图像模型,已经展现出相较于传统监督模型在下游任务上的优越性能。尽管面临计算复杂度随输入长度二次增长的挑战,尤其是针对长序列的多波段和多时序数据,本文提出了一种新的预训练框架SatMamba,结合掩码自编码器与状态空间模型,实现线性计算复杂度。实验结果表明,该框架在高分辨率图像的各种下游任务上表现出良好效果,为更高效的基础模型和地球观测数据潜力的充分发挥铺平了道路。源代码已公开。
Key Takeaways
- 基础模型在地球科学和遥感领域的应用逐渐受到关注。
- 遥感图像的基础模型如多光谱、高分辨率和超光谱图像模型表现优异。
- Vision Transformers(ViTs)面临计算复杂度随输入长度二次增长的挑战。
- SatMamba是一个新的预训练框架,结合了掩码自编码器和状态空间模型,实现线性计算复杂度。
- 实验结果表明SatMamba在高分辨率图像的下游任务上表现良好。
- 公开源代码有助于进一步的研究和模型优化。
点此查看论文截图

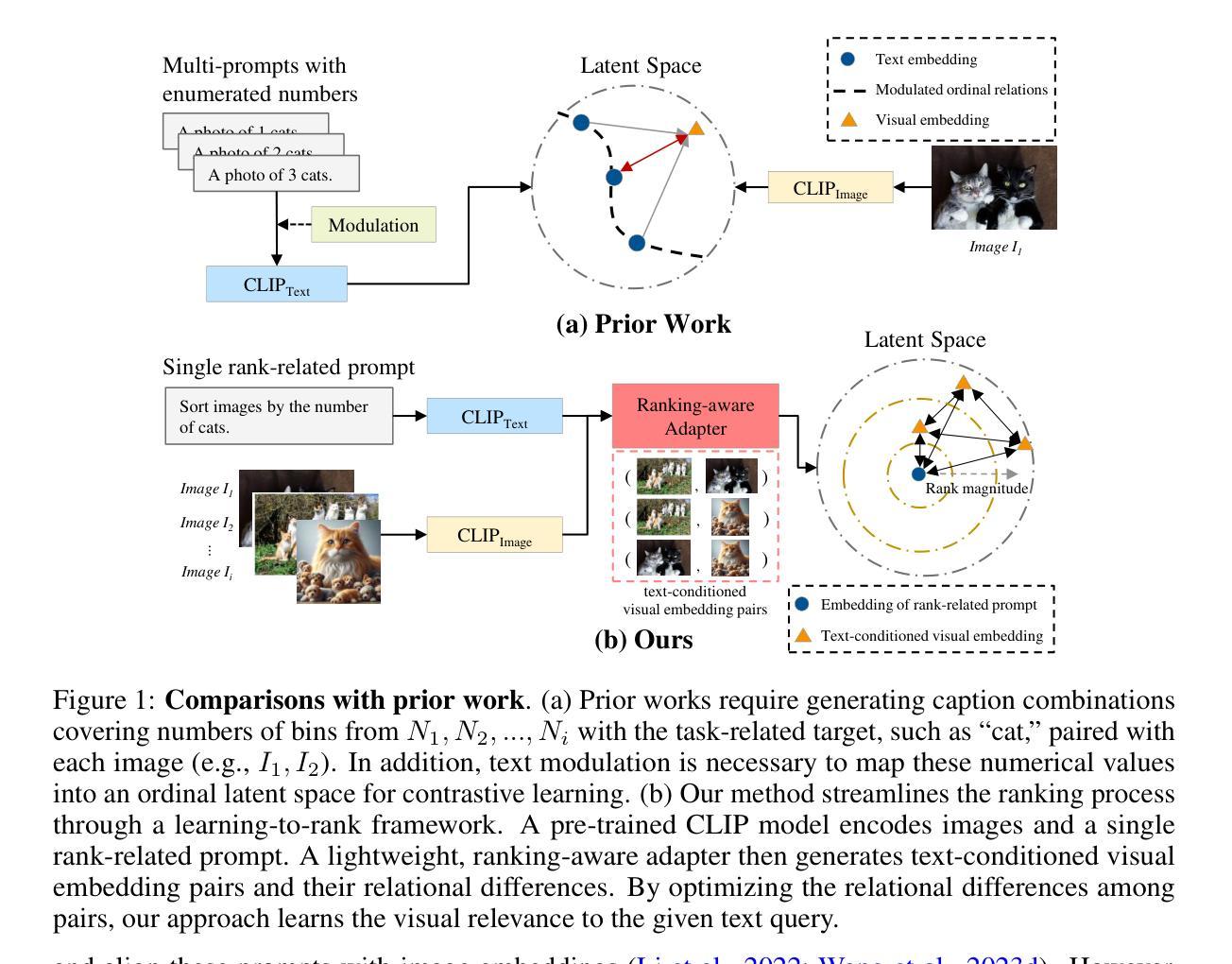
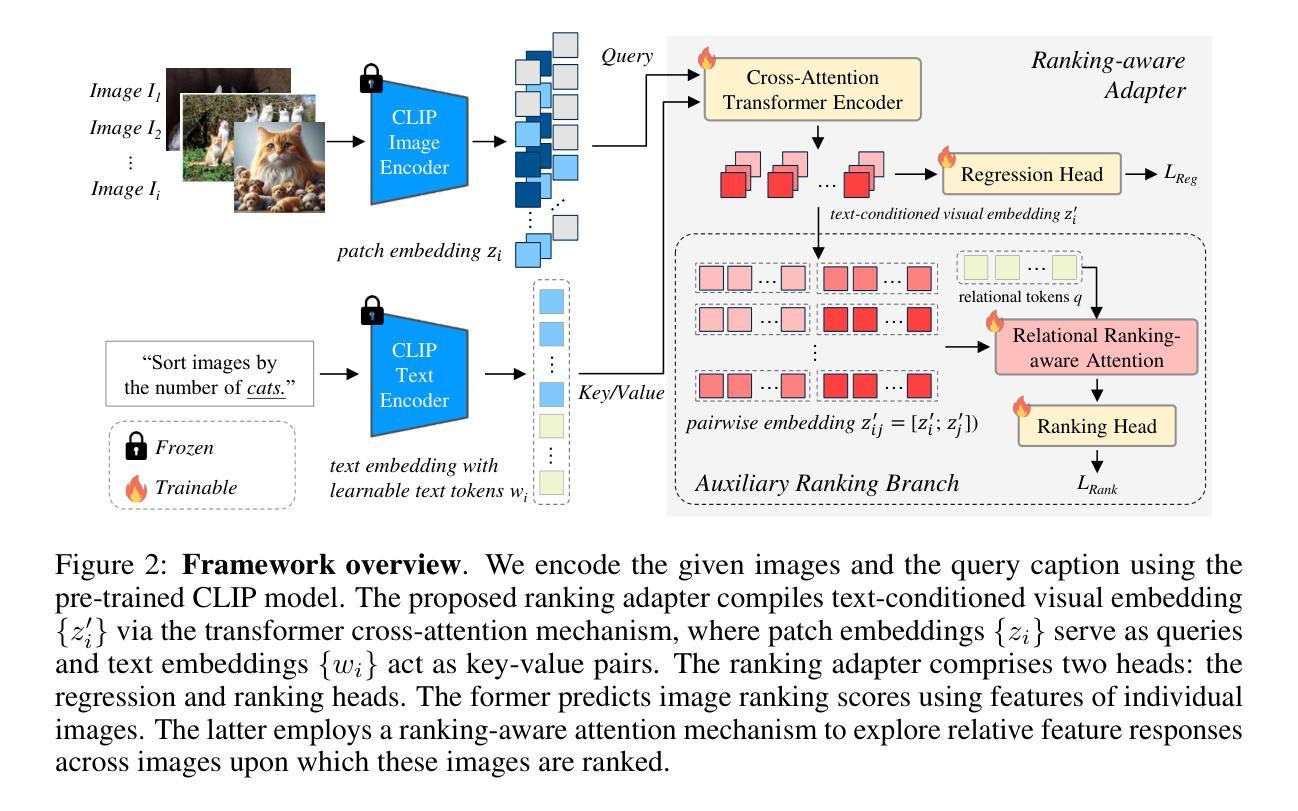
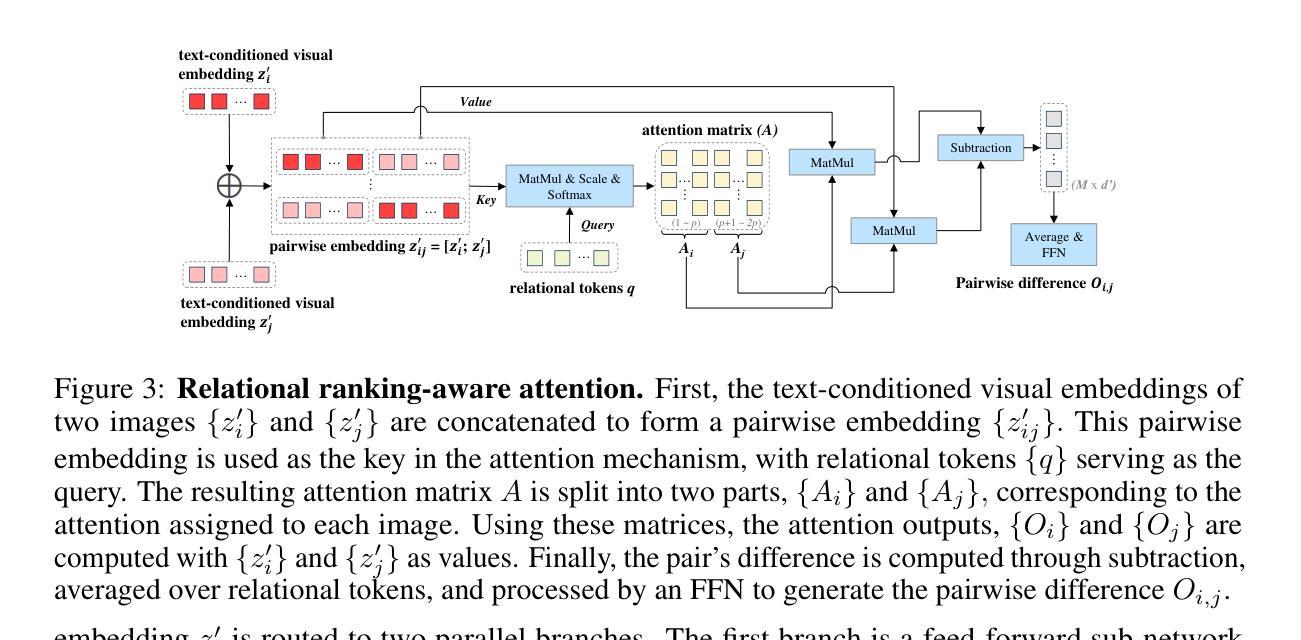
Ranking-aware adapter for text-driven image ordering with CLIP
Authors:Wei-Hsiang Yu, Yen-Yu Lin, Ming-Hsuan Yang, Yi-Hsuan Tsai
Recent advances in vision-language models (VLMs) have made significant progress in downstream tasks that require quantitative concepts such as facial age estimation and image quality assessment, enabling VLMs to explore applications like image ranking and retrieval. However, existing studies typically focus on the reasoning based on a single image and heavily depend on text prompting, limiting their ability to learn comprehensive understanding from multiple images. To address this, we propose an effective yet efficient approach that reframes the CLIP model into a learning-to-rank task and introduces a lightweight adapter to augment CLIP for text-guided image ranking. Specifically, our approach incorporates learnable prompts to adapt to new instructions for ranking purposes and an auxiliary branch with ranking-aware attention, leveraging text-conditioned visual differences for additional supervision in image ranking. Our ranking-aware adapter consistently outperforms fine-tuned CLIPs on various tasks and achieves competitive results compared to state-of-the-art models designed for specific tasks like facial age estimation and image quality assessment. Overall, our approach primarily focuses on ranking images with a single instruction, which provides a natural and generalized way of learning from visual differences across images, bypassing the need for extensive text prompts tailored to individual tasks. Code is available: github.com/uynaes/RankingAwareCLIP.
最近,视觉语言模型(VLMs)在下游任务方面取得了重大进展,这些任务需要定量概念,例如面部年龄估计和图像质量评估。这使得VLMs能够探索图像排名和检索等应用程序。然而,现有研究通常侧重于基于单张图像的推理,并严重依赖于文本提示,从而限制了它们从多张图像中学习全面理解的能力。为了解决这一问题,我们提出了一种有效而高效的方法,将CLIP模型重构为学习排名任务,并引入了一个轻量级适配器来增强CLIP进行文本引导的图像排名。具体来说,我们的方法采用可学习的提示来适应新的排名指令,并使用带有排名感知注意力的辅助分支,利用文本条件下的视觉差异进行图像排名的额外监督。我们的排名感知适配器在各种任务上始终优于微调过的CLIP,并在面部年龄估计和图像质量评估等特定任务设计的最先进模型上取得了具有竞争力的结果。总的来说,我们的方法主要侧重于使用单个指令对图像进行排名,这提供了一种从图像之间视觉差异学习的自然且通用的方式,无需针对各个任务定制大量文本提示。代码可在github.com/uynaes/RankingAwareCLIP上找到。
论文及项目相关链接
PDF github link: github.com/uynaes/RankingAwareCLIP
Summary
视觉语言模型在人脸年龄估计和图像质量评估等需要量化概念的下游任务中取得了显著进展,推动了图像排序和检索等应用的发展。然而,现有研究通常基于单图像推理,并依赖于文本提示,难以从多张图像中学习全面的理解。为此,我们提出了一种有效且高效的方法,通过改进CLIP模型以实现学习排序任务,并引入轻量级适配器来增强基于文本指导的图像排序功能。该方法通过引入可学习提示来适应新的排序指令,并利用带有排名感知注意力的辅助分支,通过文本调节的视觉差异进行额外的监督,从而实现图像排序。我们的排名感知适配器在各种任务上的表现一直优于微调后的CLIP,并在面部年龄估计和图像质量评估等特定任务上达到了具有竞争力的结果。总的来说,我们的方法主要关注于使用单一指令对图像进行排名,提供了一种自然且通用的学习图像间视觉差异的方法,无需针对个别任务定制大量的文本提示。
Key Takeaways
- 视觉语言模型在人脸年龄估计和图像质量评估等任务中取得进展。
- 现有研究主要基于单图像推理,并依赖于文本提示。
- 提出了一种改进CLIP模型的方法,以实现学习排序任务。
- 引入了可学习提示和带有排名感知注意力的辅助分支。
- 排名感知适配器在各种任务上的表现优于微调后的CLIP。
- 方法主要关注使用单一指令对图像进行排名。
点此查看论文截图