⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-07 更新
Concept Based Explanations and Class Contrasting
Authors:Rudolf Herdt, Daniel Otero Baguer
Explaining deep neural networks is challenging, due to their large size and non-linearity. In this paper, we introduce a concept-based explanation method, in order to explain the prediction for an individual class, as well as contrasting any two classes, i.e. explain why the model predicts one class over the other. We test it on several openly available classification models trained on ImageNet1K, as well as on a segmentation model trained to detect tumor in stained tissue samples. We perform both qualitative and quantitative tests. For example, for a ResNet50 model from pytorch model zoo, we can use the explanation for why the model predicts a class ‘A’ to automatically select six dataset crops where the model does not predict class ‘A’. The model then predicts class ‘A’ again for the newly combined image in 71% of the cases (works for 710 out of the 1000 classes). The code including an .ipynb example is available on git: https://github.com/rherdt185/concept-based-explanations-and-class-contrasting.
解释深度神经网络是一项具有挑战性的任务,原因在于其规模庞大且非线性。在本文中,我们介绍了一种基于概念的解释方法,旨在解释针对单个类别的预测,并对比任何两个类别,即解释模型为何会预测某一类别而非其他类别。我们在公开可用的多个分类模型上进行了测试,这些模型是在ImageNet1K上训练的,以及对用于检测染色组织样本中的肿瘤的分割模型进行了测试。我们进行了定性和定量测试。例如,对于来自pytorch模型库的ResNet50模型,我们可以利用模型预测类别“A”的解释来自动选择六个数据集裁剪图像,在这些图像中,模型不会预测类别“A”。然后,对于新组合的图像,模型在71%的情况下再次预测类别“A”(在1000个类别中适用于710个类别)。包括一个.ipynb示例的代码可在git上获得:https://github.com/rherdt185/concept-based-explanations-and-class-contrasting。
论文及项目相关链接
Summary
本文介绍了一种基于概念的解释方法,用于解释深度神经网络对个别类别的预测,并对比任何两类之间的差异。作者通过该方法测试了多个公开可用的在ImageNet1K上训练的分类模型,以及一个用于检测染色组织样品中的肿瘤的分割模型。该方法既可以用于定性测试,也可以用于定量测试。例如,对于来自pytorch模型库的ResNet50模型,该方法可以解释为何模型预测某一类别“A”,并据此自动选择六个数据集中模型未预测为类别“A”的图像区域。当将这些图像重新组合成新图像后,模型在71%的情况下再次预测为类别“A”(在1000个类别中适用于710个类别)。相关代码及.ipynb示例已在git上公开。
Key Takeaways
- 引入了一种基于概念的解释方法,用于解释深度神经网络对个别类别的预测及两类之间的对比。
- 方法在多个公开可用的分类模型上进行了测试,包括在ImageNet1K上训练的模型。
- 该方法不仅可以进行定性测试,还可以进行定量测试。
- 对于特定的ResNet50模型,该方法能够解释模型预测某类别的理由,并据此自动选择数据集中的相关区域。
- 重新组合图像后,模型在大部分情况下仍能保持对原类别的预测。
- 该方法不仅适用于分类任务,也适用于分割任务,例如在检测肿瘤的应用中。
点此查看论文截图


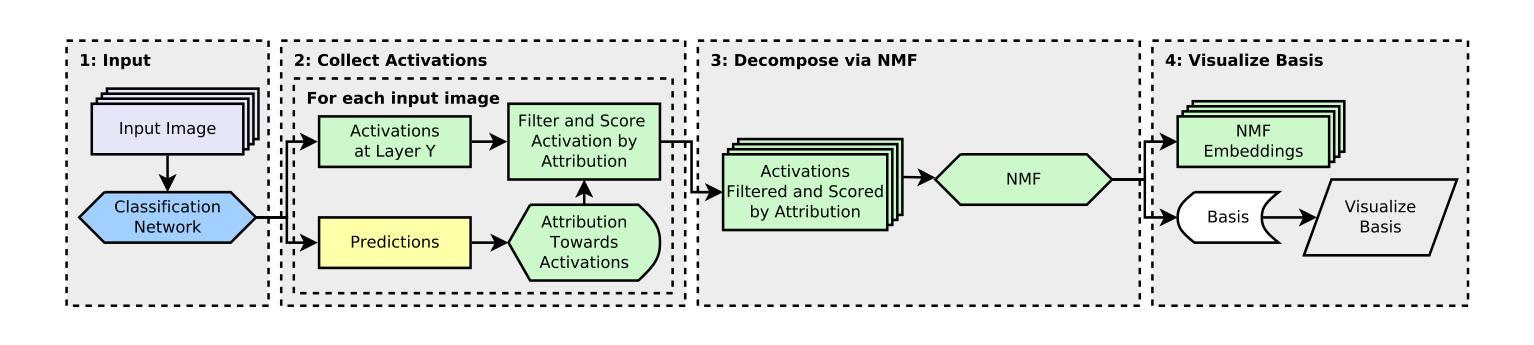
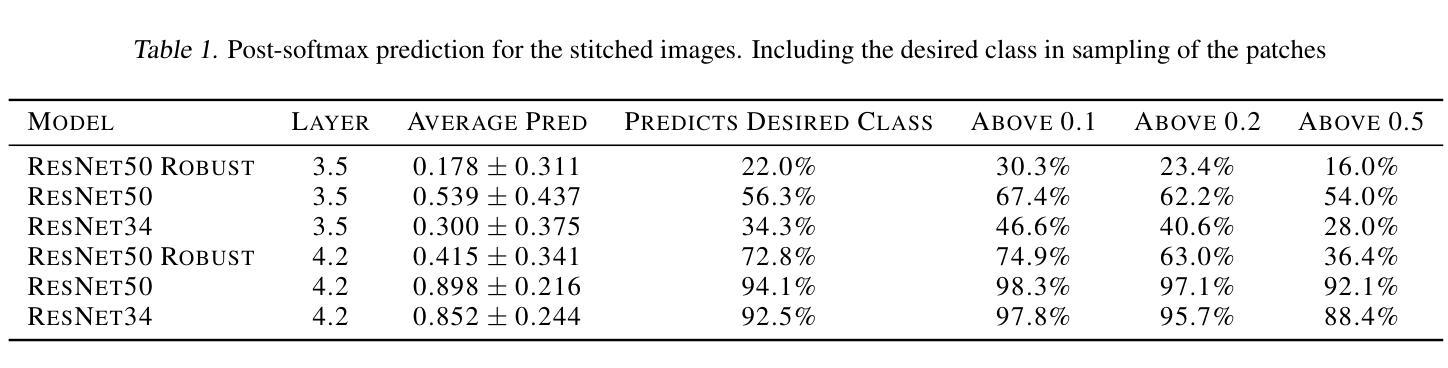
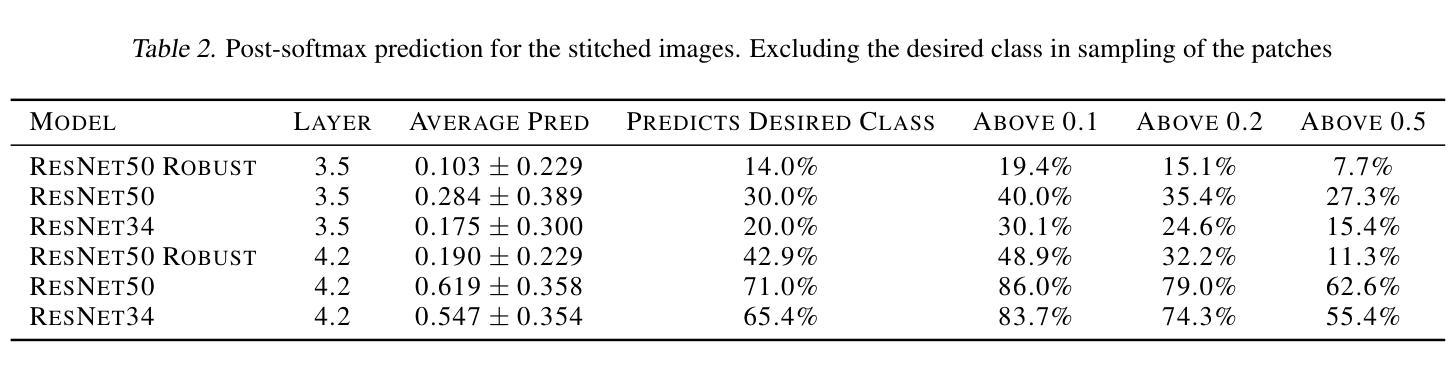
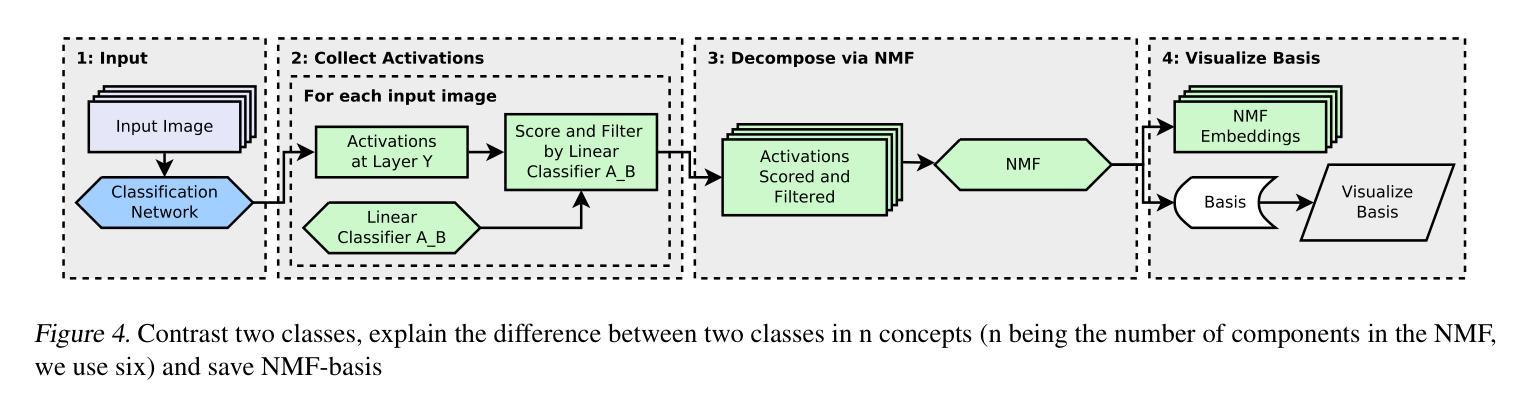
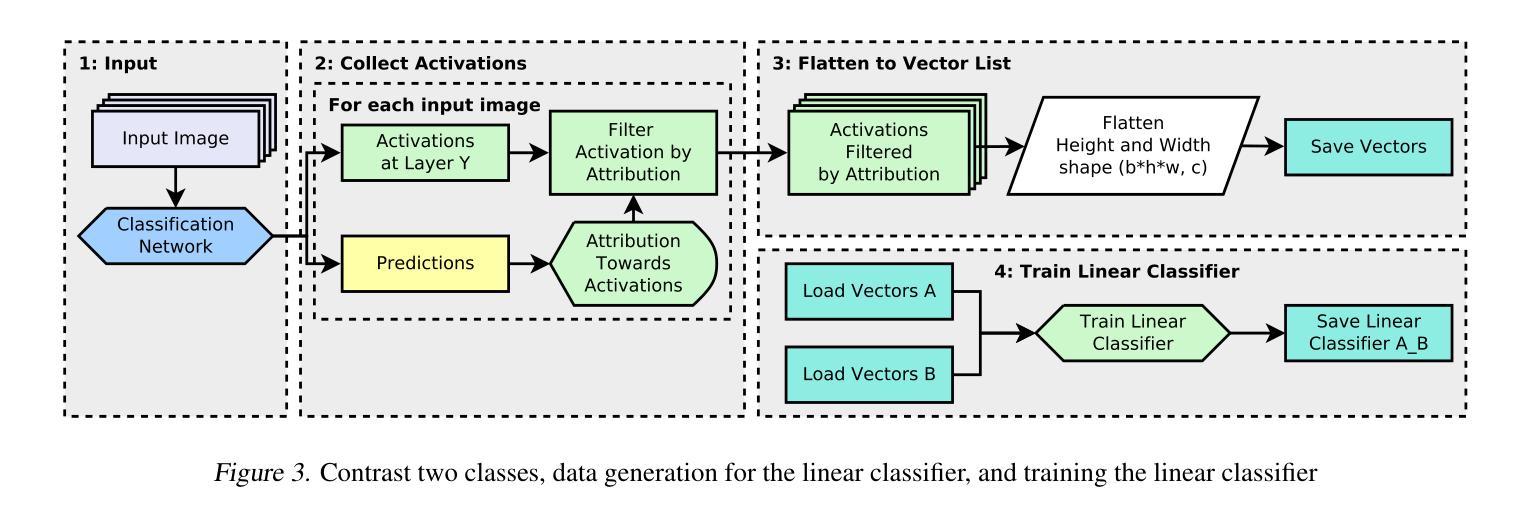

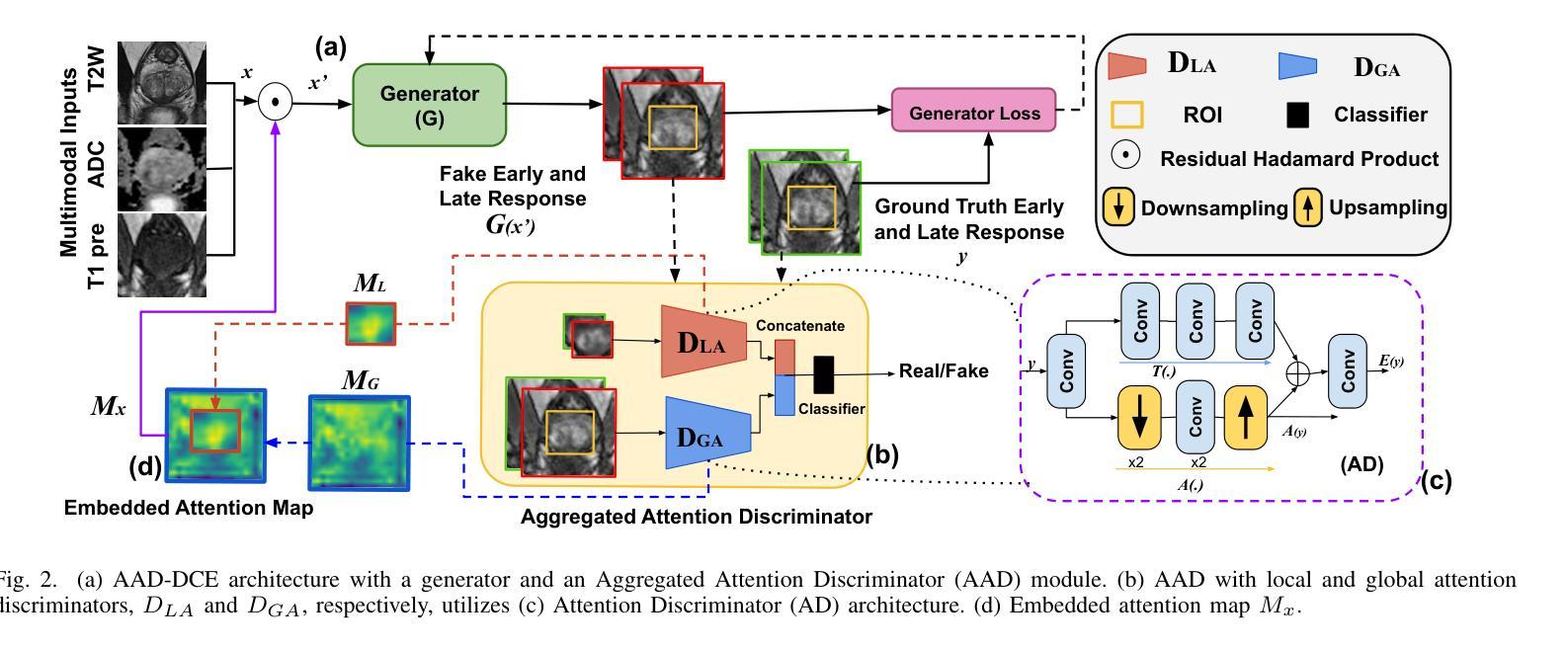
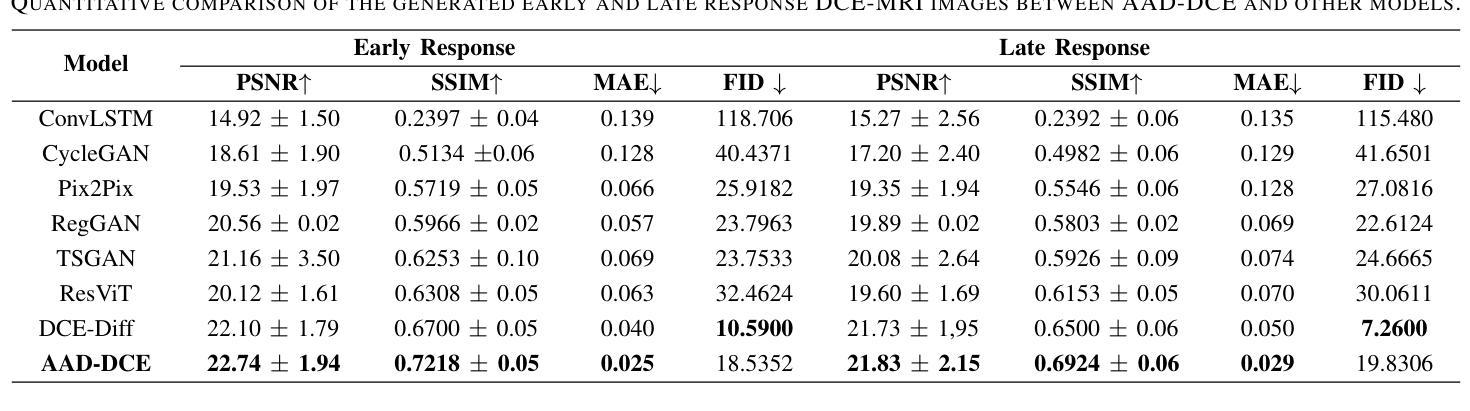
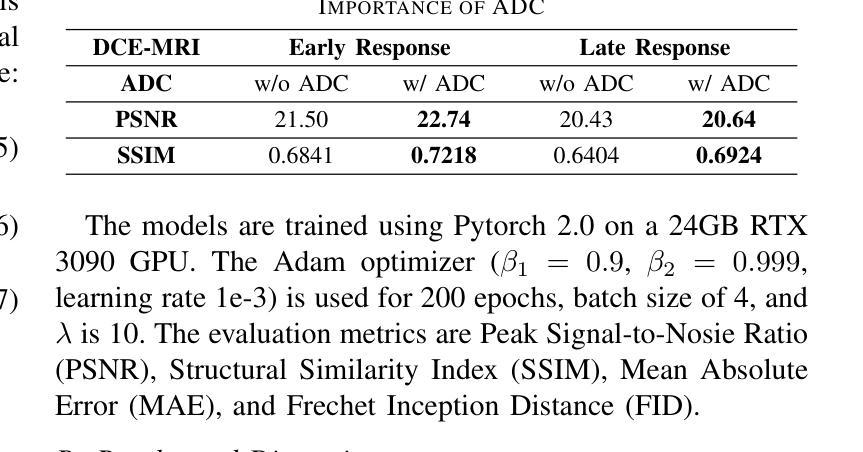
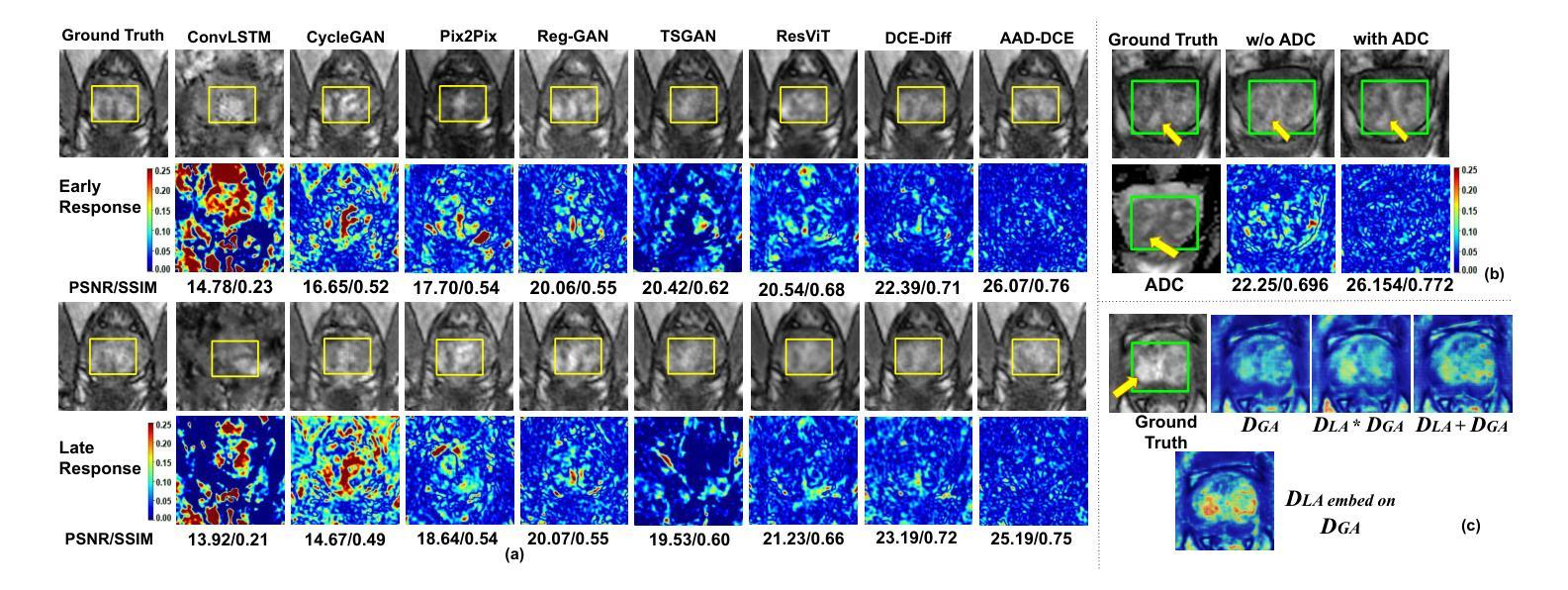
AAD-DCE: An Aggregated Multimodal Attention Mechanism for Early and Late Dynamic Contrast Enhanced Prostate MRI Synthesis
Authors:Divya Bharti, Sriprabha Ramanarayanan, Sadhana S, Kishore Kumar M, Keerthi Ram, Harsh Agarwal, Ramesh Venkatesan, Mohanasankar Sivaprakasam
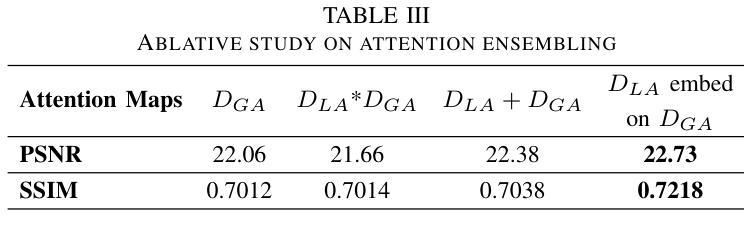
Dynamic Contrast-Enhanced Magnetic Resonance Imaging (DCE-MRI) is a medical imaging technique that plays a crucial role in the detailed visualization and identification of tissue perfusion in abnormal lesions and radiological suggestions for biopsy. However, DCE-MRI involves the administration of a Gadolinium based (Gad) contrast agent, which is associated with a risk of toxicity in the body. Previous deep learning approaches that synthesize DCE-MR images employ unimodal non-contrast or low-dose contrast MRI images lacking focus on the local perfusion information within the anatomy of interest. We propose AAD-DCE, a generative adversarial network (GAN) with an aggregated attention discriminator module consisting of global and local discriminators. The discriminators provide a spatial embedded attention map to drive the generator to synthesize early and late response DCE-MRI images. Our method employs multimodal inputs - T2 weighted (T2W), Apparent Diffusion Coefficient (ADC), and T1 pre-contrast for image synthesis. Extensive comparative and ablation studies on the ProstateX dataset show that our model (i) is agnostic to various generator benchmarks and (ii) outperforms other DCE-MRI synthesis approaches with improvement margins of +0.64 dB PSNR, +0.0518 SSIM, -0.015 MAE for early response and +0.1 dB PSNR, +0.0424 SSIM, -0.021 MAE for late response, and (ii) emphasize the importance of attention ensembling. Our code is available at https://github.com/bhartidivya/AAD-DCE.
动态对比增强磁共振成像(DCE-MRI)是一种医学成像技术,在异常病变的详细可视化和组织灌注识别方面发挥着关键作用,并为活检提供放射学建议。然而,DCE-MRI需要使用基于钆(Gad)的对比剂,这可能与体内毒性风险相关。先前合成DCE-MR图像的深度学习方法采用非对比或低剂量对比MRI图像的单模态,缺乏关注感兴趣部位的局部灌注信息。我们提出了AAD-DCE,这是一种生成对抗网络(GAN),其中包含一个聚合注意力判别器模块,由全局和局部判别器组成。判别器提供空间嵌入注意力图,以驱动生成器合成早期和晚期响应DCE-MRI图像。我们的方法采用多模态输入,包括T2加权(T2W)、表观扩散系数(ADC)和T1预对比图像进行图像合成。在ProstateX数据集上的广泛比较和消融研究表明,我们的模型(i)对各种生成器基准测试表现不敏感;(ii)在合成DCE-MRI图像方面优于其他方法,早期响应的PSNR提高0.64 dB、SSIM提高0.0518、MAE降低0.015,晚期响应的PSNR提高0.1 dB、SSIM提高0.0424、MAE降低0.021;(iii)强调了注意力集成的重要性。我们的代码位于https://github.com/bhartidivya/AAD-DCE。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary:
本文介绍了动态对比增强磁共振成像(DCE-MRI)在医学成像中的重要性及其在异常病变组织灌注的详细可视化方面的应用。然而,DCE-MRI需要使用钆(Gad)为基础的造影剂,存在体内毒性的风险。研究人员提出一种名为AAD-DCE的生成对抗网络(GAN),带有聚合注意力鉴别器模块,包括全局和局部鉴别器,旨在合成DCE-MRI的早期和晚期响应图像。该研究使用多模态输入,包括T2加权(T2W)、表观扩散系数(ADC)和T1预对比图像进行图像合成。在ProstateX数据集上的比较和消融研究表明,该方法对生成器基准测试具有不敏感性,与其他DCE-MRI合成方法相比具有卓越性能,且强调注意力集成的重要性。代码已公开。
Key Takeaways:
- DCE-MRI在医学成像中用于详细可视化组织灌注,尤其在异常病变中。
- DCE-MRI使用造影剂存在毒性风险。
- 提出一种名为AAD-DCE的GAN模型,用于合成DCE-MRI图像。
- AAD-DCE模型采用多模态输入,包括T2W、ADC和T1预对比图像。
- 研究表明,AAD-DCE模型对生成器基准测试具有不敏感性,性能卓越。
- 与其他DCE-MRI合成方法相比,AAD-DCE模型在PSNR、SSIM和MAE等评估指标上表现更优。
点此查看论文截图


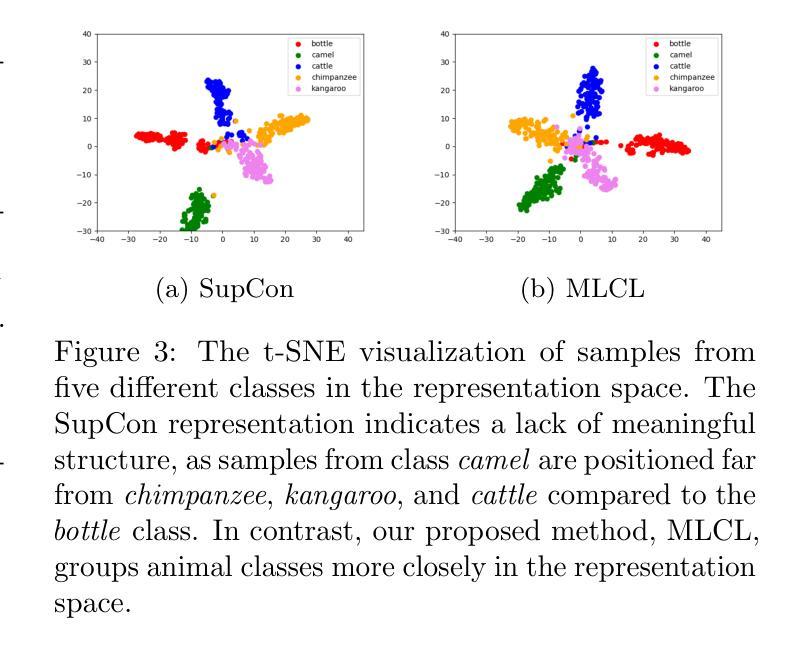
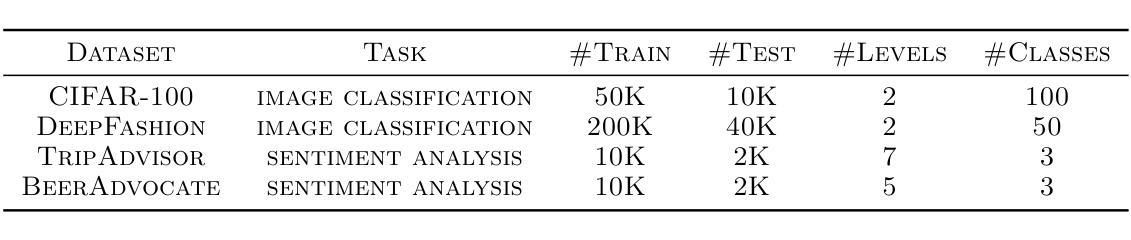
Multi-level Supervised Contrastive Learning
Authors:Naghmeh Ghanooni, Barbod Pajoum, Harshit Rawal, Sophie Fellenz, Vo Nguyen Le Duy, Marius Kloft
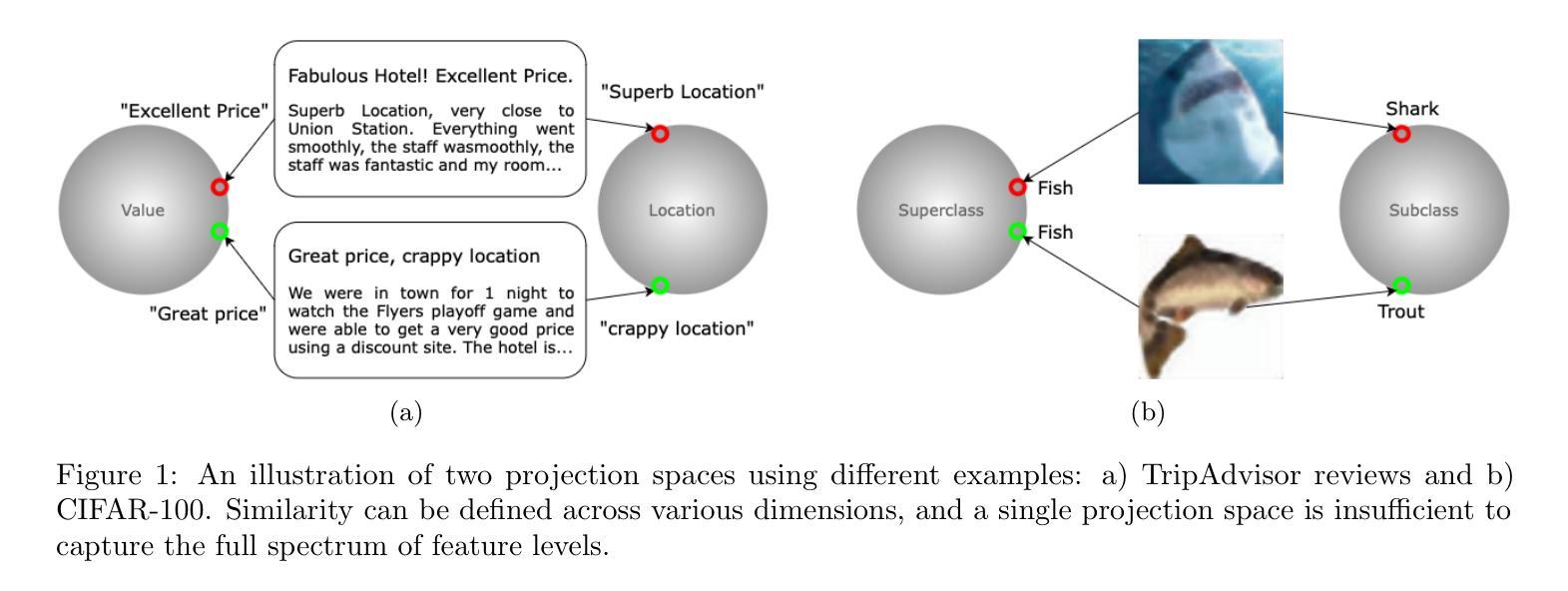
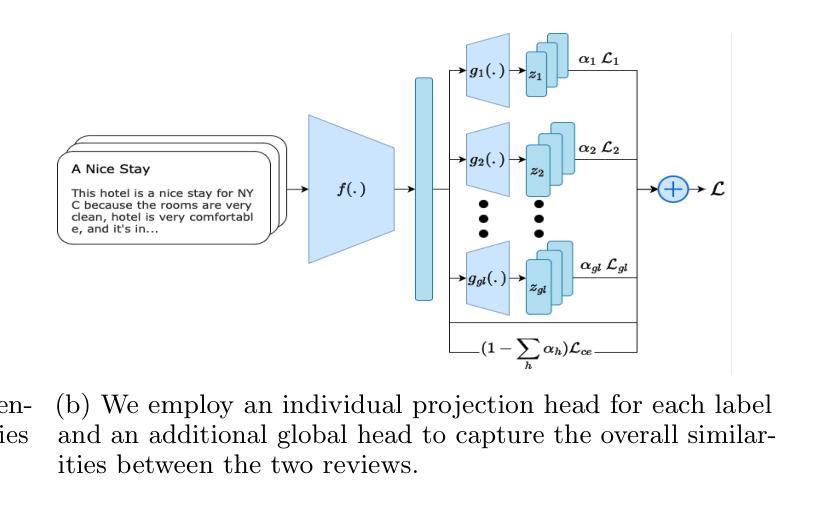
Contrastive learning is a well-established paradigm in representation learning. The standard framework of contrastive learning minimizes the distance between “similar” instances and maximizes the distance between dissimilar ones in the projection space, disregarding the various aspects of similarity that can exist between two samples. Current methods rely on a single projection head, which fails to capture the full complexity of different aspects of a sample, leading to suboptimal performance, especially in scenarios with limited training data. In this paper, we present a novel supervised contrastive learning method in a unified framework called multilevel contrastive learning (MLCL), that can be applied to both multi-label and hierarchical classification tasks. The key strength of the proposed method is the ability to capture similarities between samples across different labels and/or hierarchies using multiple projection heads. Extensive experiments on text and image datasets demonstrate that the proposed approach outperforms state-of-the-art contrastive learning methods
对比学习是表征学习中的一个成熟范式。对比学习的标准框架旨在最小化“相似”实例之间的距离,并最大化不同实例在投影空间之间的距离,同时忽略两个样本之间可能存在的各种相似性方面。当前的方法依赖于单个投影头,无法捕捉样本不同方面的全部复杂性,导致性能不佳,特别是在训练数据有限的情况下。在本文中,我们提出了一种新型的有监督对比学习方法,在一个统一框架中称为多层次对比学习(MLCL),可应用于多标签和层次分类任务。所提方法的关键优势在于能够使用多个投影头捕捉不同标签和/或层次之间的样本相似性。在文本和图像数据集上的大量实验表明,该方法优于最新的对比学习方法。
论文及项目相关链接
Summary
本文介绍了一种名为多层次对比学习(MLCL)的新型有监督对比学习方法,该方法可以在多标签和层次分类任务中表现出强大的性能。其关键优势在于能够利用多个投影头捕捉不同标签和/或层次之间的样本相似性。实验证明,该方法在文本和图像数据集上的性能优于当前最先进的对比学习方法。
Key Takeaways
- 对比学习是表示学习中的成熟范式,通过最小化“相似”实例之间的距离并最大化不同实例之间的距离来优化模型。
- 当前方法依赖于单个投影头,无法捕捉样本的各个方面复杂性,尤其在有限训练数据场景下性能较差。
- 论文提出了一种新的有监督对比学习方法——多层次对比学习(MLCL),适用于多标签和层次分类任务。
- MLCL的关键优势在于其能够利用多个投影头捕捉不同标签和/或层次之间的样本相似性。
- 实验证明,MLCL在文本和图像数据集上的性能优于其他先进的对比学习方法。
- MLCL方法可能有助于改进对比学习的性能,尤其是在处理复杂和多样化的数据集时。
点此查看论文截图

Use the 4S (Signal-Safe Speckle Subtraction): Explainable Machine Learning reveals the Giant Exoplanet AF Lep b in High-Contrast Imaging Data from 2011
Authors:Markus J. Bonse, Timothy D. Gebhard, Felix A. Dannert, Olivier Absil, Faustine Cantalloube, Valentin Christiaens, Gabriele Cugno, Emily O. Garvin, Jean Hayoz, Markus Kasper, Elisabeth Matthews, Bernhard Schölkopf, Sascha P. Quanz
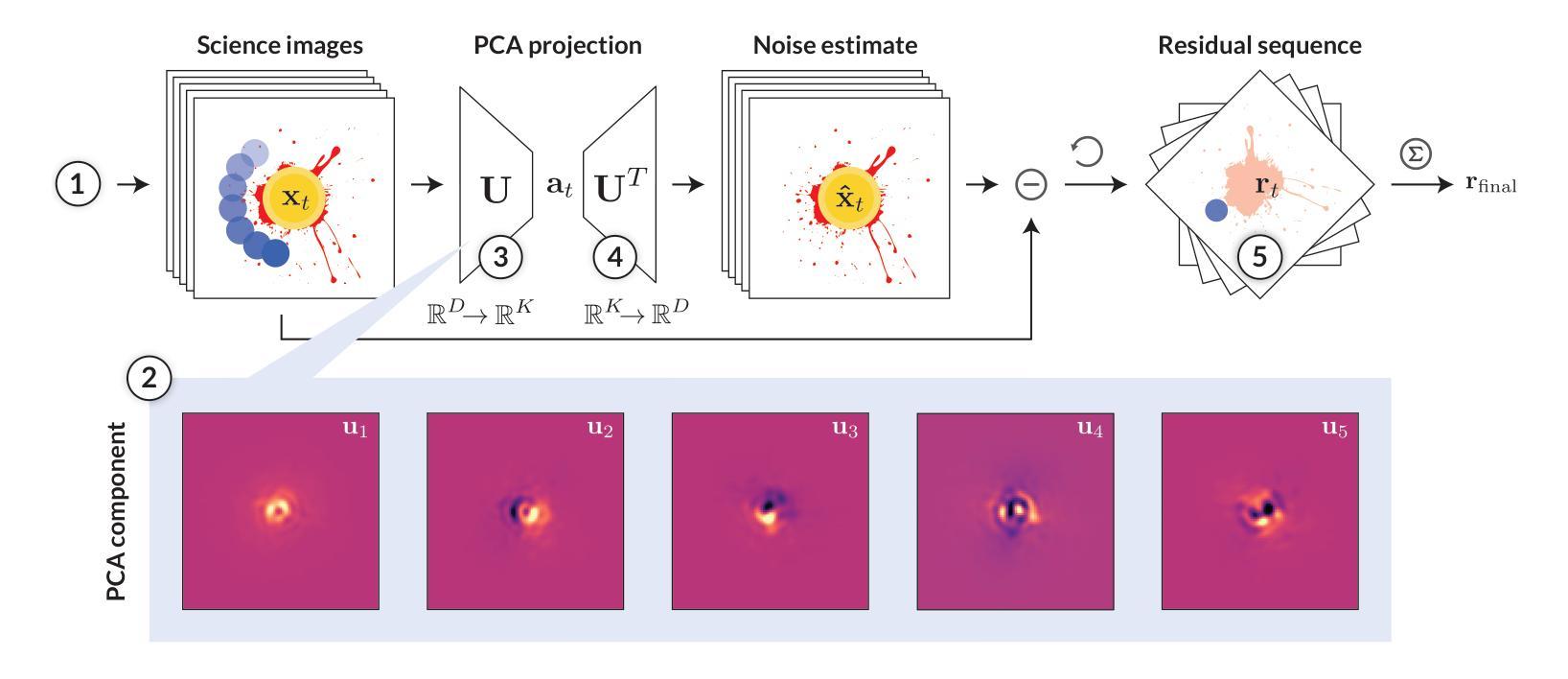
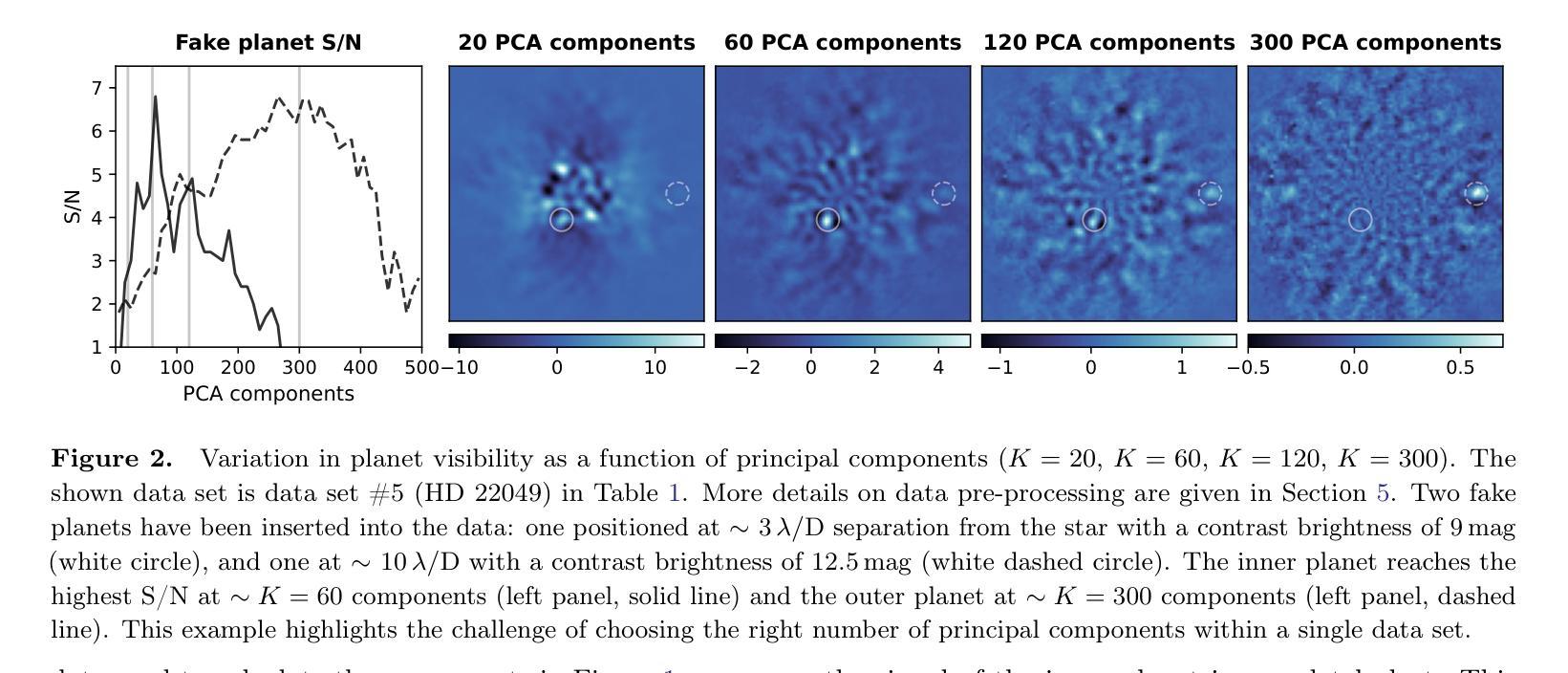
The main challenge of exoplanet high-contrast imaging (HCI) is to separate the signal of exoplanets from their host stars, which are many orders of magnitude brighter. HCI for ground-based observations is further exacerbated by speckle noise originating from perturbations in Earth’s atmosphere and imperfections in the telescope optics. Various data post-processing techniques are used to remove this speckle noise and reveal the faint planet signal. Often, however, a significant part of the planet signal is accidentally subtracted together with the noise. In the present work, we use explainable machine learning to investigate the reason for the loss of the planet signal for one of the most used post-processing methods: principal component analysis (PCA). We find that PCA learns the shape of the telescope point spread function for high numbers of PCA components. This representation of the noise captures not only the speckle noise but also the characteristic shape of the planet signal. Building on these insights, we develop a new post-processing method (4S) that constrains the noise model to minimize this signal loss. We apply our model to 11 archival HCI datasets from the VLT-NACO instrument in the L’-band and find that our model consistently outperforms PCA. The improvement is largest at close separations to the star ($\leq 4 \lambda /D$) providing up to 1.5 magnitudes deeper contrast. This enhancement enables us to detect the exoplanet AF Lep b in data from 2011, 11 years before its subsequent discovery. We present updated orbital parameters for this object.
外行星高对比度成像(HCI)的主要挑战是将外行星的信号与其宿主恒星(亮度高几个数量级)的信号区分开。基于地面观测的HCI进一步受到地球大气扰动和望远镜光学缺陷产生的斑点噪声的加剧影响。使用各种数据后处理技术来消除这种斑点噪声,并揭示微弱行星信号。然而,通常情况下,行星信号的一部分会与噪声一起意外地被减去。在本工作中,我们使用可解释的机器学习来研究最常用后处理方法之一——主成分分析(PCA)中行星信号丢失的原因。我们发现PCA学习望远镜点扩散函数(PSF)的形状对于大量PCA组件的情况。这种噪声表示不仅捕获了斑点噪声,还捕获了行星信号的典型形状。基于这些见解,我们开发了一种新型后处理方法(4S),该方法约束噪声模型以最小化信号损失。我们将模型应用于来自VLT-NACO仪器的L’-波段存档的HCI数据集,发现我们的模型在各方面均优于PCA。改善最大的是在恒星附近的近距离分离处(≤4λ/D),对比度提高了深达1.5个星等。这种增强使我们在距离很远的情况下能够检测到行星AF Lep b的数据,甚至在它被发现之前的2011年就已经检测到它。我们为此对象提供了更新的轨道参数。
论文及项目相关链接
PDF Accepted for publication in AJ, 27 pages, 18 figures. We have added a new section explaining the mathematical differences between PCA, LOCI and 4S. The data and code are now fully available and documented, see https://fours.readthedocs.io/en/latest/ Raw data: https://zenodo.org/records/11456704 Intermediate results: https://zenodo.org/records/11457071
Summary
本文利用可解释的机器学习研究高对比度成像中行星信号丢失的原因,并提出一种新的后处理方法(4S)来减少信号损失。新方法对VLT-NACO仪器存档的HCI数据集应用,表现优于主成分分析(PCA),特别是在行星与恒星近距离时效果更佳,能提升对比度达1.5个星等,并能在旧数据中预检出系外行星AF Lep b。
Key Takeaways
- 主要挑战:将系外行星信号从明亮的主星中分离出来。
- 问题现状:地面观测的高对比度成像(HCI)受到斑点噪声的影响,经常误将行星信号与噪声一起剔除。
- 研究方法:采用可解释的机器学习探究丢失行星信号的原因,特别是针对最常用的后处理方法之一——主成分分析(PCA)。
- PCA的缺陷:PCA学习了望远镜的点扩散函数形状,但这一过程也会捕捉到行星信号的特征形状。
- 新方法的发展:提出一种名为4S的新后处理方法,旨在约束噪声模型以减少信号损失。
- 实验结果:在VLT-NACO仪器的L’-波段存档的HCI数据集上应用新模型,表现优于PCA,特别是在行星与恒星近距离时效果更佳,能提升对比度达1.5个星等。
点此查看论文截图