⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-07 更新
ZISVFM: Zero-Shot Object Instance Segmentation in Indoor Robotic Environments with Vision Foundation Models
Authors:Ying Zhang, Maoliang Yin, Wenfu Bi, Haibao Yan, Shaohan Bian, Cui-Hua Zhang, Changchun Hua
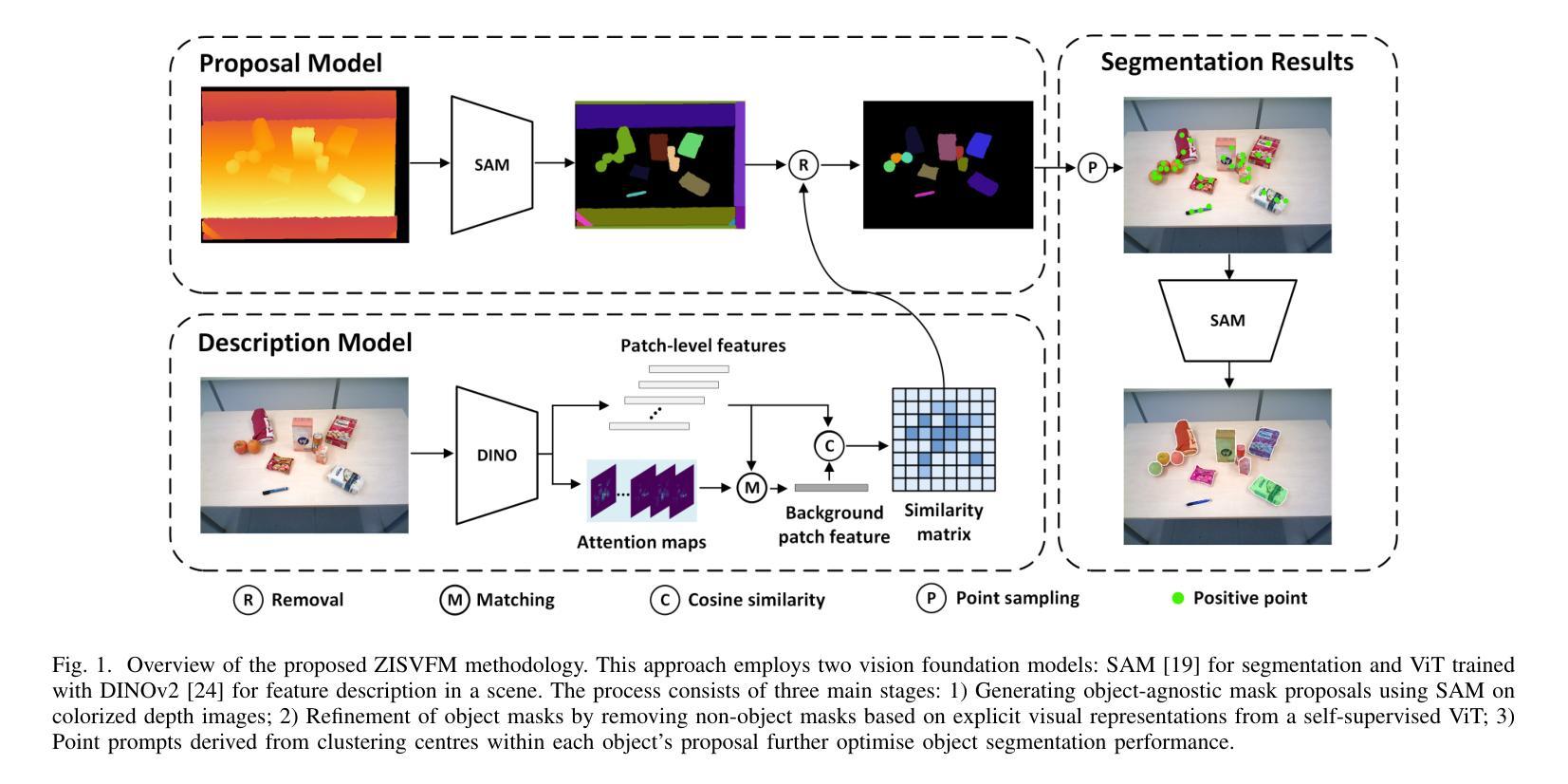
Service robots operating in unstructured environments must effectively recognize and segment unknown objects to enhance their functionality. Traditional supervised learningbased segmentation techniques require extensive annotated datasets, which are impractical for the diversity of objects encountered in real-world scenarios. Unseen Object Instance Segmentation (UOIS) methods aim to address this by training models on synthetic data to generalize to novel objects, but they often suffer from the simulation-to-reality gap. This paper proposes a novel approach (ZISVFM) for solving UOIS by leveraging the powerful zero-shot capability of the segment anything model (SAM) and explicit visual representations from a selfsupervised vision transformer (ViT). The proposed framework operates in three stages: (1) generating object-agnostic mask proposals from colorized depth images using SAM, (2) refining these proposals using attention-based features from the selfsupervised ViT to filter non-object masks, and (3) applying K-Medoids clustering to generate point prompts that guide SAM towards precise object segmentation. Experimental validation on two benchmark datasets and a self-collected dataset demonstrates the superior performance of ZISVFM in complex environments, including hierarchical settings such as cabinets, drawers, and handheld objects. Our source code is available at https://github.com/Yinmlmaoliang/zisvfm.
在服务机器人操作的无结构环境中,必须有效地识别和分割未知物体以增强其功能。传统的基于监督学习的分割技术需要大量的注释数据集,这在现实场景中遇到的各种对象多样性中是不切实际的。未见对象实例分割(UOIS)方法旨在通过合成数据进行模型训练,以推广到新型对象来解决这一问题,但它们常常受到仿真到现实的差距的影响。本文提出了一种解决UOIS的新方法(ZISVFM),它利用分段任何模型(SAM)的强大零射击能力和自监督视觉变压器(ViT)的显式视觉表示。所提出的框架分为三个阶段:(1)使用SAM从彩色深度图像生成对象无关掩膜提案;(2)使用自监督ViT的注意力特征对这些提案进行过滤非对象掩膜;(3)应用K-Medoids聚类生成点提示,引导SAM进行精确的对象分割。在两个基准数据集和自收集数据集上的实验验证表明,ZISVFM在复杂环境中表现出卓越的性能,包括层次设置,如柜子、抽屉和手持物体。我们的源代码可在https://github.com/Yinmlmaoliang/zisvfm找到。
论文及项目相关链接
Summary
本文提出一种基于零样本能力的分割任何事情模型(SAM)和自监督视觉转换器(ViT)的显式视觉表示的新方法(ZISVFM),用于解决在未知对象实例分割(UOIS)中遇到的仿真到现实差距问题。该方法通过颜色化深度图像生成对象无关掩膜提案,使用自监督ViT的注意力特征过滤非对象掩膜,并应用K-Medoids聚类生成点提示,引导SAM进行精确对象分割。在复杂环境中,包括柜子、抽屉和手持物体等分层设置下的性能表现优异。
Key Takeaways
- 服务机器人在非结构化环境中需要有效识别和分割未知物体以增强其功能。
- 传统基于监督学习的分割技术需要大量标注数据集,对于现实世界中遇到的多种对象而言不太实用。
- 未见对象实例分割(UOIS)方法旨在通过合成数据进行模型训练以推广到新型对象,但面临仿真到现实的差距问题。
- 本文提出一种新颖方法ZISVFM,结合分割任何事情模型(SAM)和自监督视觉转换器(ViT)来解决UOIS问题。
- ZISVFM方法包括三个阶段:从颜色化深度图像生成对象无关掩膜提案,使用自监督ViT过滤非对象掩膜,以及应用K-Medoids聚类进行精确对象分割。
- 实验验证表明,ZISVFM在复杂环境中表现优异,特别是在柜子、抽屉和手持物体等分层设置下。
- 源代码已公开可用。
点此查看论文截图



Enhancing Quantum-ready QUBO-based Suppression for Object Detection with Appearance and Confidence Features
Authors:Keiichiro Yamamura, Toru Mitsutake, Hiroki Ishikura, Daiki Kusuhara, Akihiro Yoshida, Katsuki Fujisawa
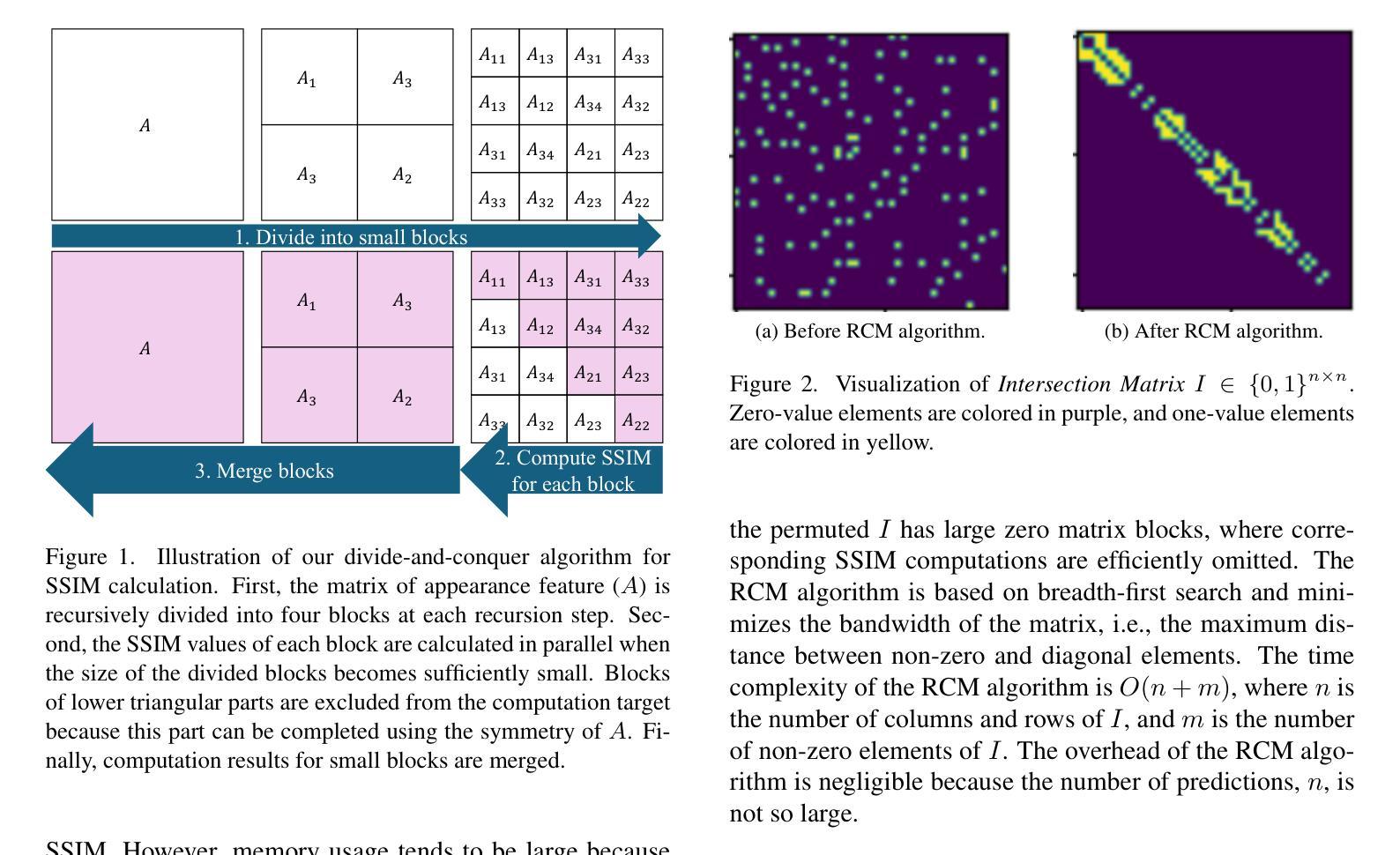
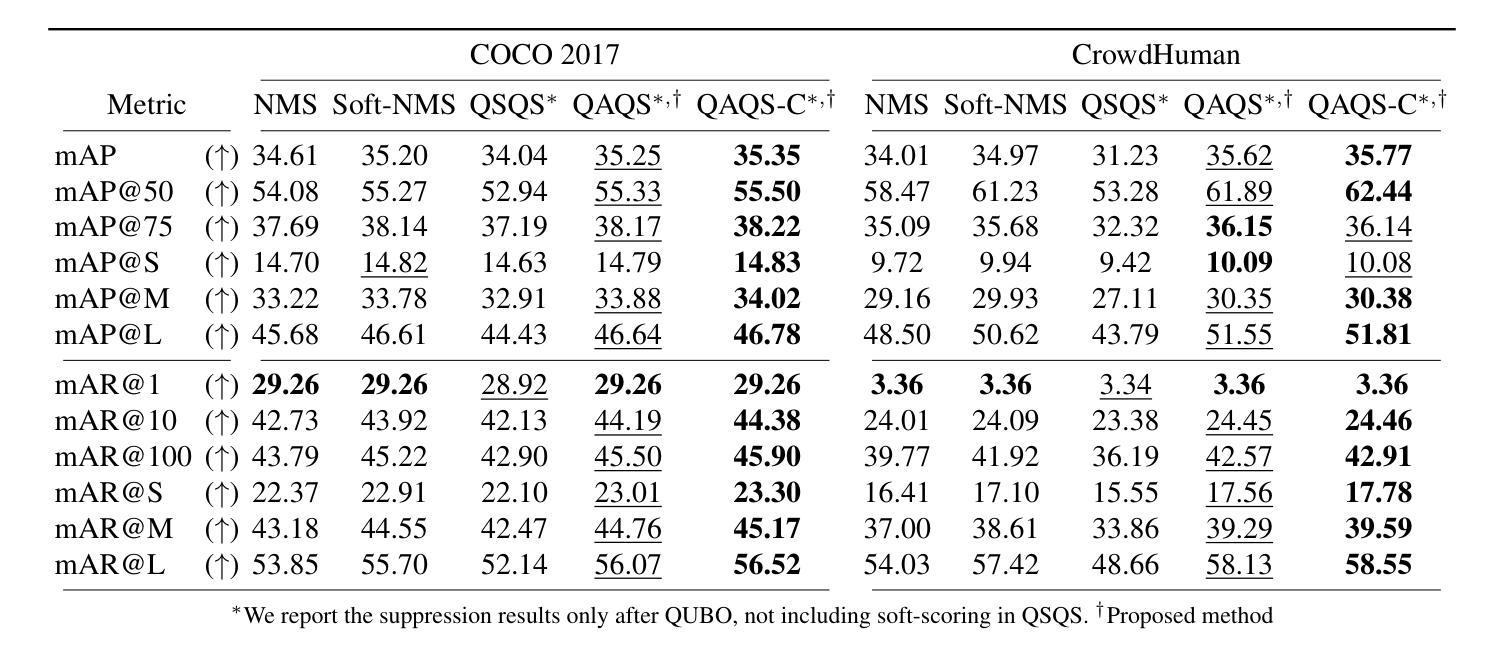
Quadratic Unconstrained Binary Optimization (QUBO)-based suppression in object detection is known to have superiority to conventional Non-Maximum Suppression (NMS), especially for crowded scenes where NMS possibly suppresses the (partially-) occluded true positives with low confidence scores. Whereas existing QUBO formulations are less likely to miss occluded objects than NMS, there is room for improvement because existing QUBO formulations naively consider confidence scores and pairwise scores based on spatial overlap between predictions. This study proposes new QUBO formulations that aim to distinguish whether the overlap between predictions is due to the occlusion of objects or due to redundancy in prediction, i.e., multiple predictions for a single object. The proposed QUBO formulation integrates two features into the pairwise score of the existing QUBO formulation: i) the appearance feature calculated by the image similarity metric and ii) the product of confidence scores. These features are derived from the hypothesis that redundant predictions share a similar appearance feature and (partially-) occluded objects have low confidence scores, respectively. The proposed methods demonstrate significant advancement over state-of-the-art QUBO-based suppression without a notable increase in runtime, achieving up to 4.54 points improvement in mAP and 9.89 points gain in mAR.
基于二次无约束二元优化(QUBO)的对象检测中的抑制方法被证明优于传统的非极大值抑制(NMS),特别是在拥挤场景中,NMS可能会抑制低置信度的(部分)遮挡真阳性。虽然现有的QUBO公式不太可能遗漏被遮挡的物体,相对于NMS仍有一定的改进空间。现有QUBO公式仅基于置信度和预测之间的空间重叠的配对分数。本研究提出了新型的QUBO公式,旨在区分预测之间的重叠是由于物体遮挡还是由于预测冗余,即单个物体的多个预测。所提出的QUBO公式将两个特征集成到现有QUBO公式的配对分数中:(i)通过图像相似度度量计算的外貌特征;(ii)置信度分数的乘积。这些特征源于一个假设,即冗余预测具有相似的外貌特征,而(部分)遮挡的物体具有较低的置信度分数。所提出的方法在最新QUBO抑制技术的基础上取得了显著进展,且运行时没有显著增加,平均精度(mAP)提高了4.54点,平均召回率(mAR)提高了9.89点。
论文及项目相关链接
PDF 8 pages for main contents, 3 pages for appendix, 3 pages for reference
Summary
基于二次无约束二进制优化(QUBO)的目标检测抑制方法相较于传统的非极大值抑制(NMS)在拥挤场景中表现更优,特别是在处理遮挡的真实阳性且置信度较低的情景时更为出色。本研究提出新的QUBO公式,旨在区分预测之间的重叠是由于物体遮挡还是冗余预测造成的。新方法将现有QUBO的配对分数融入两个新特性:i)通过图像相似度度量的外观特征,以及ii)置信度分数的乘积。实验表明,相较于最新的QUBO抑制方法,新方法在运行时没有明显增加,且在mAP上最多提高了4.54点,在mAR上提高了9.89点。
Key Takeaways
- QUBO抑制方法在拥挤场景中的表现优于传统NMS。
- 现有QUBO公式能够减少遮挡物体的误判。
- 本研究提出了新的QUBO公式,旨在区分预测重叠的原因。
- 新方法融入了两个新特性:基于图像相似度度量的外观特征和置信度分数的乘积。
- 新方法在不增加显著运行时间的情况下,实现了显著的性能提升。
- 在mAP和mAR指标上,新方法较最新的QUBO抑制方法有明显的性能提升。
点此查看论文截图


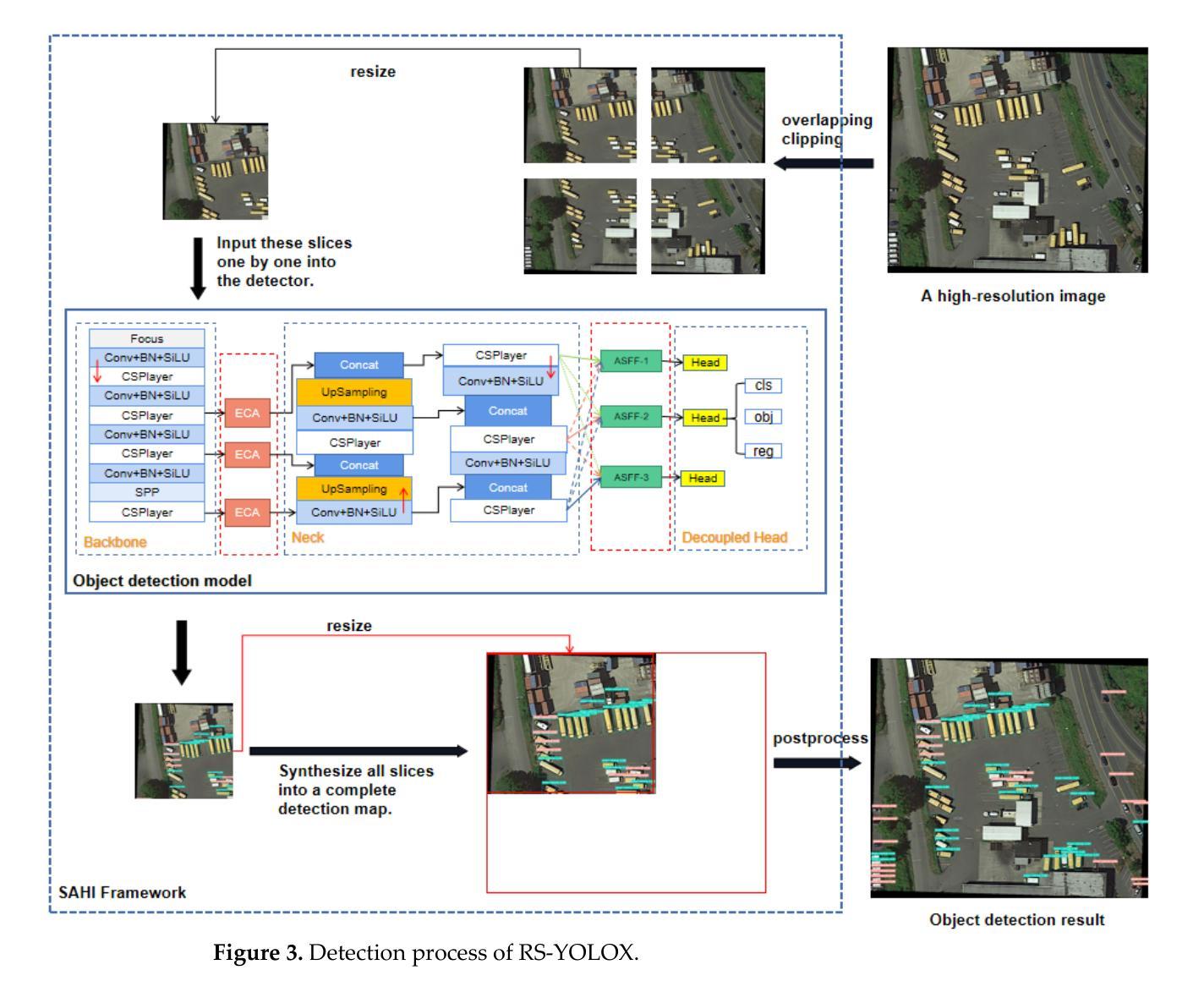
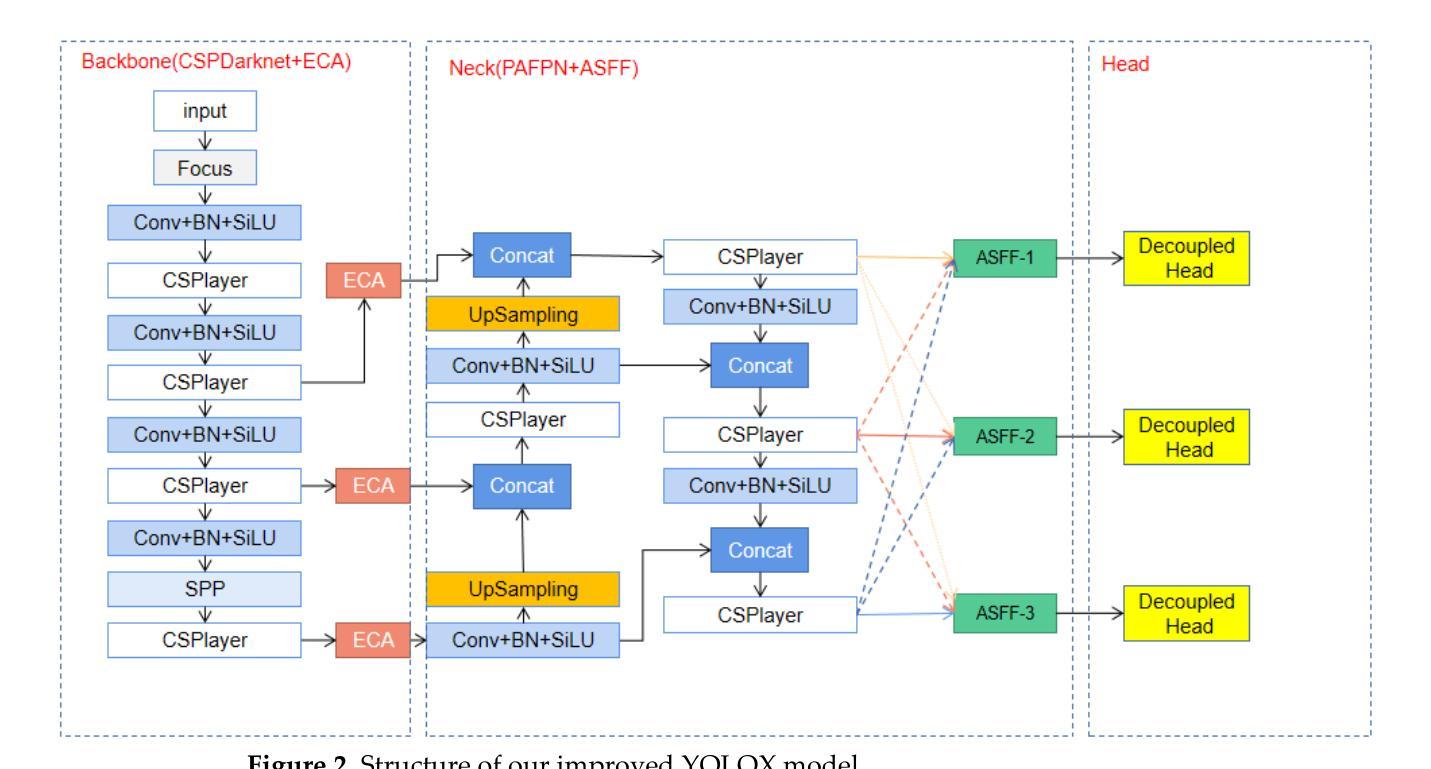
RS-YOLOX: A High Precision Detector for Object Detection in Satellite Remote Sensing Images
Authors:Lei Yang, Guowu Yuan, Hao Zhou, Hongyu Liu, Jian Chen, Hao Wu
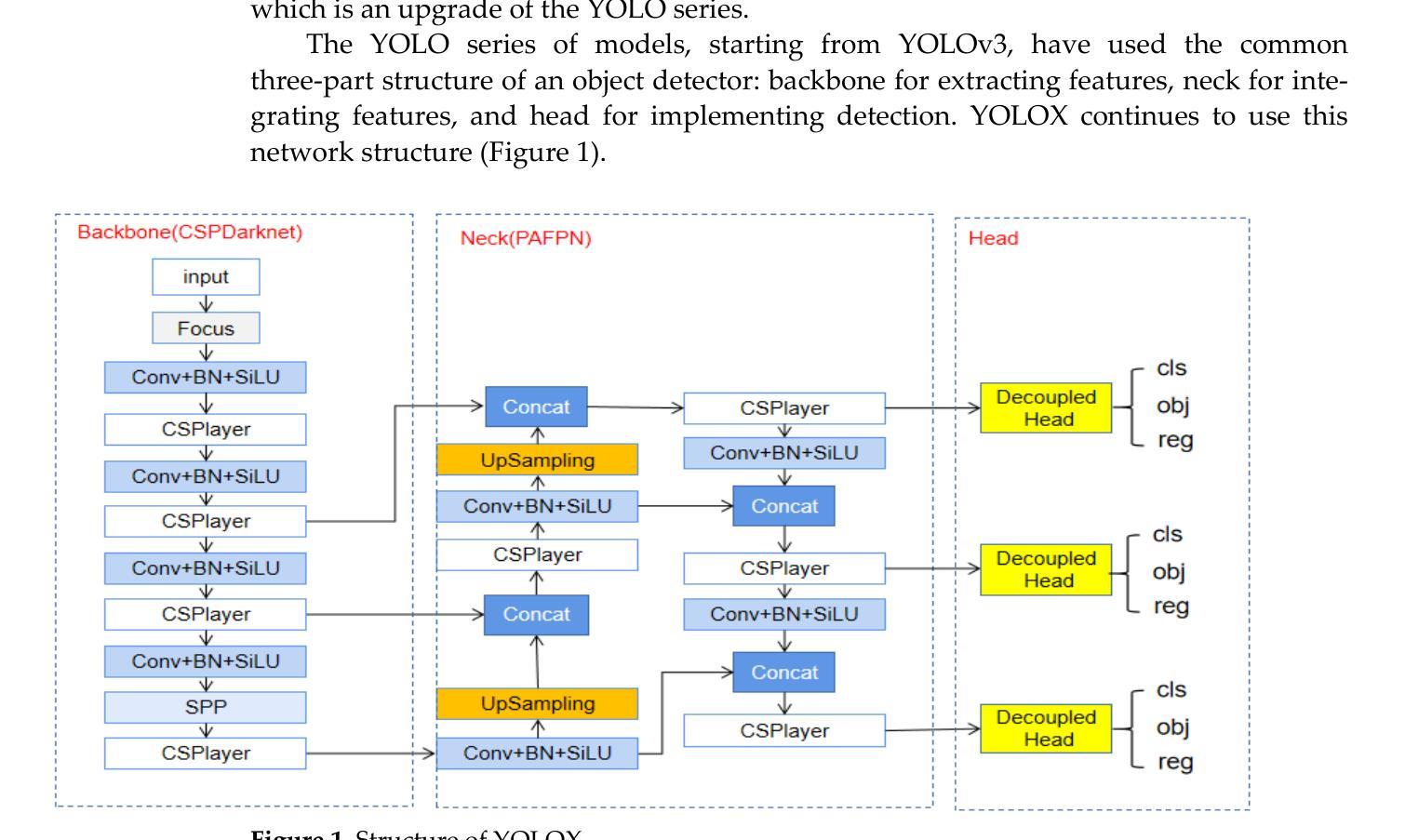
Automatic object detection by satellite remote sensing images is of great significance for resource exploration and natural disaster assessment. To solve existing problems in remote sensing image detection, this article proposes an improved YOLOX model for satellite remote sensing image automatic detection. This model is named RS-YOLOX. To strengthen the feature learning ability of the network, we used Efficient Channel Attention (ECA) in the backbone network of YOLOX and combined the Adaptively Spatial Feature Fusion (ASFF) with the neck network of YOLOX. To balance the numbers of positive and negative samples in training, we used the Varifocal Loss function. Finally, to obtain a high-performance remote sensing object detector, we combined the trained model with an open-source framework called Slicing Aided Hyper Inference (SAHI). This work evaluated models on three aerial remote sensing datasets (DOTA-v1.5, TGRS-HRRSD, and RSOD). Our comparative experiments demonstrate that our model has the highest accuracy in detecting objects in remote sensing image datasets.
卫星遥感图像自动目标检测对资源勘探和灾害评估具有重要意义。为了解决遥感图像检测中存在的问题,本文提出了一种改进的用于卫星遥感图像自动检测的YOLOX模型,名为RS-YOLOX。为增强网络的特征学习能力,我们在YOLOX的骨干网中使用了有效的通道注意力(ECA),并将自适应空间特征融合(ASFF)与YOLOX的颈部网络相结合。为了平衡训练中的正负样本数量,我们使用了Varifocal Loss函数。最后,为了获得高性能的遥感目标检测器,我们将训练好的模型与名为切片辅助超推理(SAHI)的开源框架相结合。本工作在三个航空遥感数据集(DOTA-v1.5、TGRS-HRRSD和RSOD)上评估了模型性能。对比实验表明,我们的模型在遥感图像数据集上的目标检测精度最高。
论文及项目相关链接
Summary
卫星遥感图像自动目标检测对资源勘探和自然灾害评估具有重要意义。针对遥感图像检测存在的问题,本文提出一种改进的YOLOX模型,用于卫星遥感图像自动检测,命名为RS-YOLOX。该模型通过引入Efficient Channel Attention(ECA)强化网络特征学习能力,并结合Adaptively Spatial Feature Fusion(ASFF)优化YOLOX的颈部网络。为解决训练中正负样本数量不平衡问题,采用Varifocal Loss函数。最后,通过与开源框架Slicing Aided Hyper Inference(SAHI)结合,获得高性能遥感目标检测器。在三个航空遥感数据集(DOTA-v1.5、TGRS-HRRSD和RSOD)上进行的对比实验表明,该模型在遥感图像数据集上的目标检测精度最高。
Key Takeaways
- 卫星遥感图像自动目标检测对资源勘探和灾害评估有重要意义。
- 本文提出改进YOLOX模型的RS-YOLOX用于卫星遥感图像自动检测。
- 通过引入ECA强化网络特征学习能力。
- 结合ASFF优化YOLOX颈部网络。
- 采用Varifocal Loss函数解决正负样本数量不平衡问题。
- 与开源框架SAHI结合,获得高性能遥感目标检测器。
点此查看论文截图

On the Inherent Robustness of One-Stage Object Detection against Out-of-Distribution Data
Authors:Aitor Martinez-Seras, Javier Del Ser, Aitzol Olivares-Rad, Alain Andres, Pablo Garcia-Bringas
Robustness is a fundamental aspect for developing safe and trustworthy models, particularly when they are deployed in the open world. In this work we analyze the inherent capability of one-stage object detectors to robustly operate in the presence of out-of-distribution (OoD) data. Specifically, we propose a novel detection algorithm for detecting unknown objects in image data, which leverages the features extracted by the model from each sample. Differently from other recent approaches in the literature, our proposal does not require retraining the object detector, thereby allowing for the use of pretrained models. Our proposed OoD detector exploits the application of supervised dimensionality reduction techniques to mitigate the effects of the curse of dimensionality on the features extracted by the model. Furthermore, it utilizes high-resolution feature maps to identify potential unknown objects in an unsupervised fashion. Our experiments analyze the Pareto trade-off between the performance detecting known and unknown objects resulting from different algorithmic configurations and inference confidence thresholds. We also compare the performance of our proposed algorithm to that of logits-based post-hoc OoD methods, as well as possible fusion strategies. Finally, we discuss on the competitiveness of all tested methods against state-of-the-art OoD approaches for object detection models over the recently published Unknown Object Detection benchmark. The obtained results verify that the performance of avant-garde post-hoc OoD detectors can be further improved when combined with our proposed algorithm.
鲁棒性是开发安全可信模型的一个基本方面,特别是在将它们部署在开放世界中时。在这项工作中,我们分析了一阶段目标检测器在存在离群分布(Out-of-Distribution,OoD)数据时稳健运行的能力。具体来说,我们提出了一种用于检测图像数据中未知对象的新检测算法,该算法利用模型从每个样本中提取的特征。与文献中的其他最新方法不同,我们的提议不需要重新训练目标检测器,从而可以使用预训练模型。我们提出的离群分布检测器利用监督降维技术的应用来减轻模型提取特征时维度诅咒的影响。此外,它利用高分辨率特征图以无监督的方式识别潜在的未知对象。我们的实验分析了不同算法配置和推理置信度阈值之间在检测已知和未知对象方面的帕累托权衡。我们还比较了我们提出的算法与基于logits的后验离群分布方法的性能,以及可能的融合策略。最后,我们讨论了所有测试方法与最近发布的未知对象检测基准测试中的最新离群目标检测模型的竞争力。所得结果证实,将我们的算法与最先进的后验离群分布检测器相结合可以进一步提高性能。
论文及项目相关链接
PDF 13 figures, 4 tables, under review
Summary
本文分析了一阶段目标检测器在开放世界环境下对未知对象检测的鲁棒性。提出了一种无需重新训练目标检测器的新检测算法,利用模型从每个样本中提取的特征进行未知对象检测。该算法采用监督降维技术减轻维度灾难对特征的影响,并利用高分辨率特征图进行无监督的潜在未知对象识别。实验结果分析显示,不同算法配置和推理置信度阈值之间的性能权衡,并与基于日志的后验未知对象检测方法以及可能的融合策略进行了比较。最终讨论了在最新未知对象检测基准测试上,所提出算法与其他先进未知对象检测方法的竞争力。结果显示,结合所提算法可进一步提高前沿后验未知对象检测器的性能。
Key Takeaways
- 分析了目标检测器在开放世界环境下的鲁棒性挑战。
- 提出了一种新型未知对象检测算法,无需重新训练目标检测器。
- 利用模型提取的特征进行检测,并采用了监督降维技术来减轻维度灾难的影响。
- 利用高分辨率特征图进行无监督潜在未知对象识别。
- 通过实验分析了不同算法配置和推理置信度阈值之间的性能权衡。
- 与基于日志的后验未知对象检测方法以及可能的融合策略进行了比较。
点此查看论文截图

