⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-07 更新
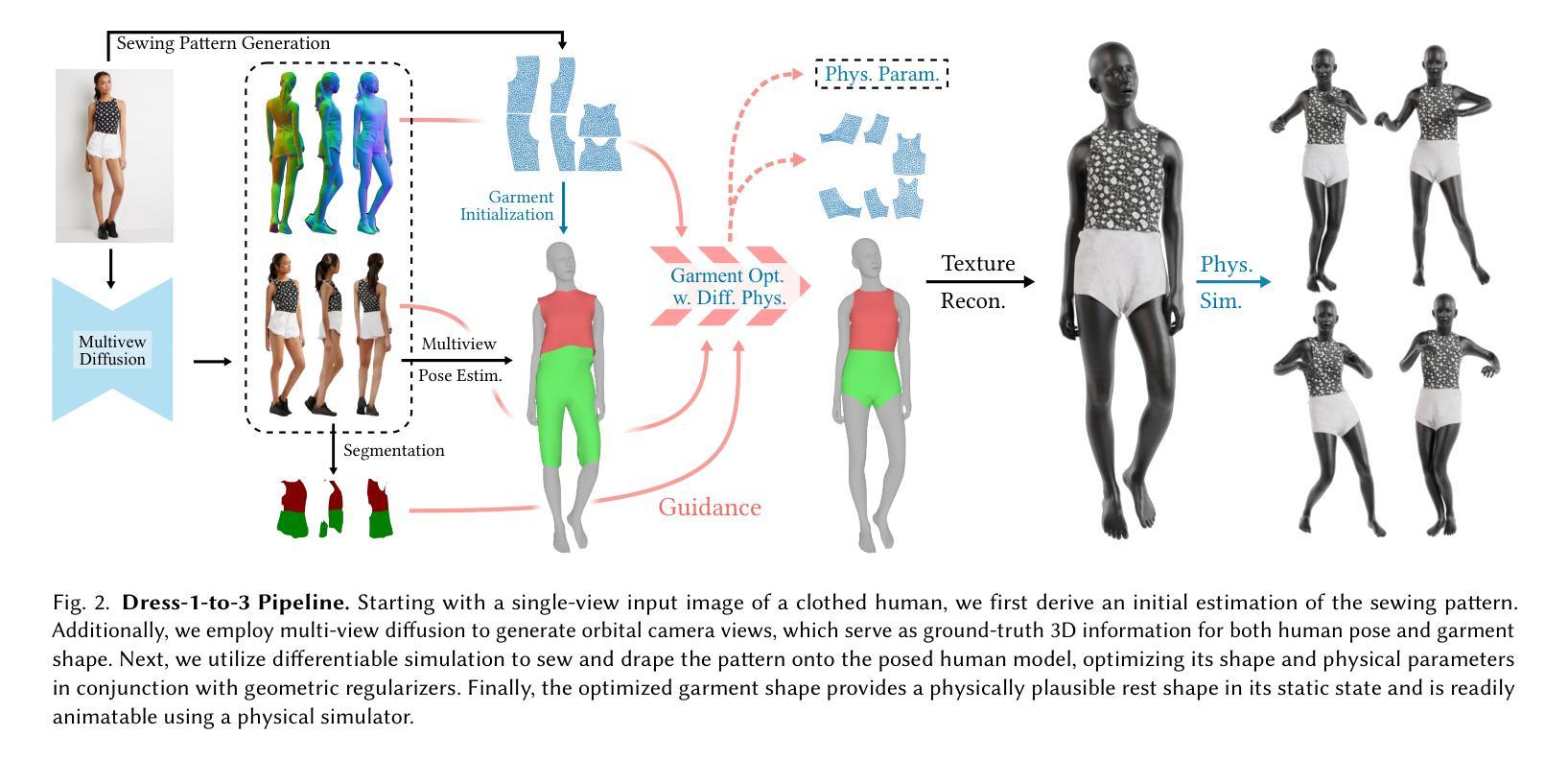
Dress-1-to-3: Single Image to Simulation-Ready 3D Outfit with Diffusion Prior and Differentiable Physics
Authors:Xuan Li, Chang Yu, Wenxin Du, Ying Jiang, Tianyi Xie, Yunuo Chen, Yin Yang, Chenfanfu Jiang
Recent advances in large models have significantly advanced image-to-3D reconstruction. However, the generated models are often fused into a single piece, limiting their applicability in downstream tasks. This paper focuses on 3D garment generation, a key area for applications like virtual try-on with dynamic garment animations, which require garments to be separable and simulation-ready. We introduce Dress-1-to-3, a novel pipeline that reconstructs physics-plausible, simulation-ready separated garments with sewing patterns and humans from an in-the-wild image. Starting with the image, our approach combines a pre-trained image-to-sewing pattern generation model for creating coarse sewing patterns with a pre-trained multi-view diffusion model to produce multi-view images. The sewing pattern is further refined using a differentiable garment simulator based on the generated multi-view images. Versatile experiments demonstrate that our optimization approach substantially enhances the geometric alignment of the reconstructed 3D garments and humans with the input image. Furthermore, by integrating a texture generation module and a human motion generation module, we produce customized physics-plausible and realistic dynamic garment demonstrations. Project page: https://dress-1-to-3.github.io/
近期大型模型的进展极大地推动了图像到3D重建的技术。然而,生成的模型通常被融合成单个部分,这在下游任务中的应用受到了限制。本文重点关注3D服装生成,这是虚拟试穿等应用的关键领域,要求服装可分离且适合模拟。我们介绍了Dress-1-to-3,这是一个新颖的管道,它可以从野生图像中重建物理可行的、适合模拟的分离服装,包括缝纫图案和人类。从图像开始,我们的方法结合了预训练的图像到缝纫图案生成模型,以创建粗糙的缝纫图案,以及与预训练的多视图扩散模型相结合,生成多视图图像。缝纫图案进一步使用基于生成的多视图图像的可微分服装模拟器进行细化。多种实验表明,我们的优化方法极大地提高了重建的3D服装和人体与输入图像的几何对齐。此外,通过集成纹理生成模块和人类运动生成模块,我们生成了定制的、物理可行的逼真动态服装演示。项目页面:https://dress-1-to-3.github.io/
论文及项目相关链接
PDF Project page: https://dress-1-to-3.github.io/
Summary
本文介绍了Dress-1-to-3项目,该项目提出了一种从单张图像重建物理可行性高、模拟就绪的分离衣物的新方法。通过结合预训练的图像到缝纫模式生成模型和预训练的多视角扩散模型,该项目能够生成多视角图像并优化缝纫模式。此外,通过可微分的服装模拟器,该项目能够生成逼真的动态服装演示。
Key Takeaways
- Dress-1-to-3项目能够从单张图像重建物理可行性高的分离衣物。
- 该项目使用了预训练的图像到缝纫模式生成模型和预训练的多视角扩散模型。
- 通过结合多视角图像生成和缝纫模式优化,提高了重建衣物的几何对齐度。
- 项目采用了可微分的服装模拟器来优化缝纫模式。
- 该项目能够生成逼真的动态服装演示。
- Dress-1-to-3项目在虚拟试穿等应用上具有潜在的应用价值。
点此查看论文截图

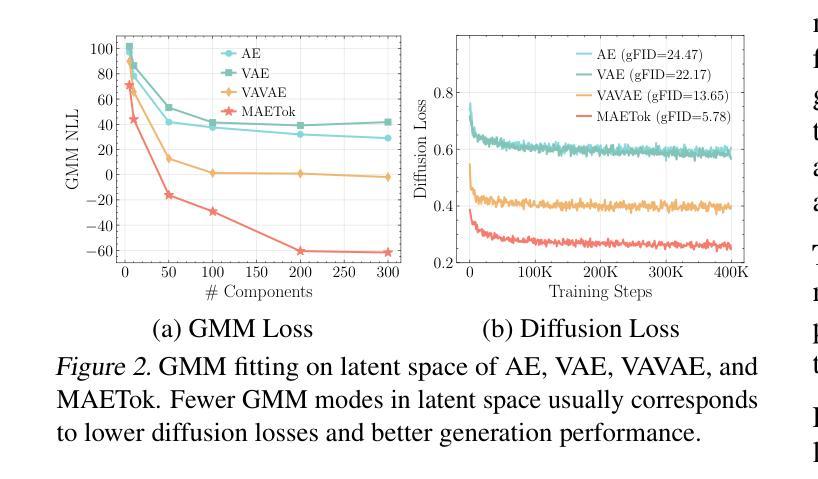
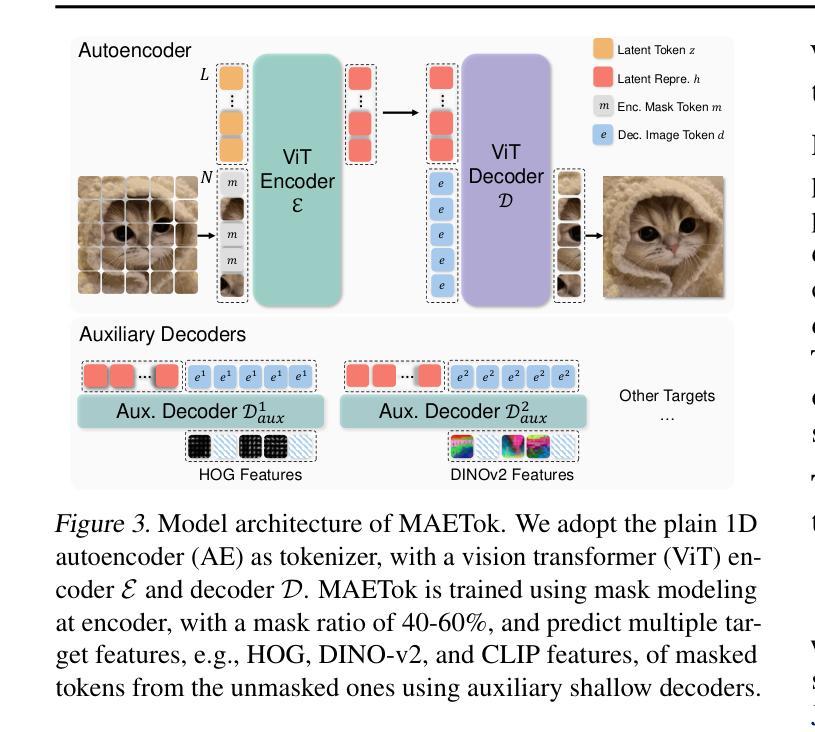
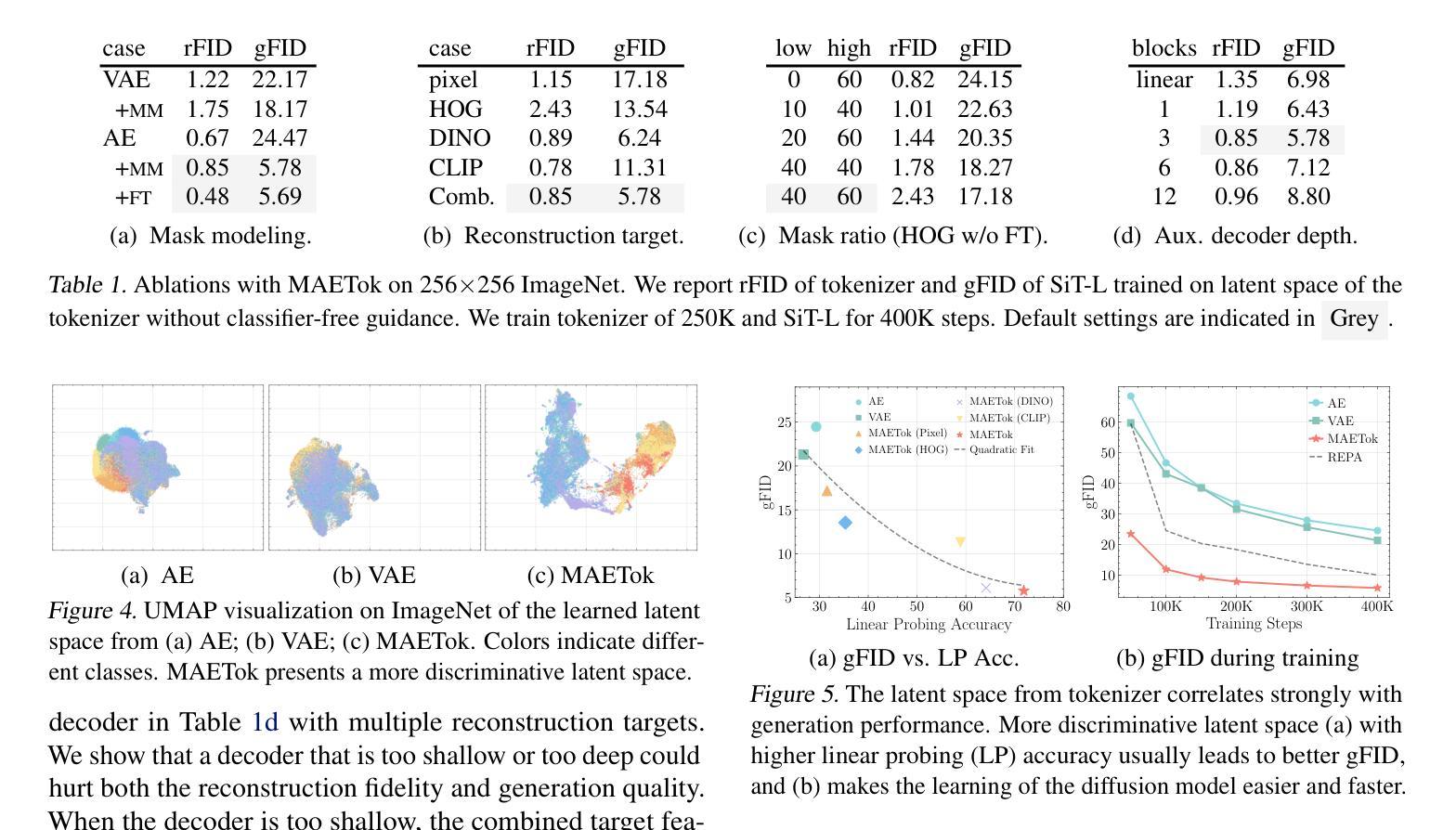
Masked Autoencoders Are Effective Tokenizers for Diffusion Models
Authors:Hao Chen, Yujin Han, Fangyi Chen, Xiang Li, Yidong Wang, Jindong Wang, Ze Wang, Zicheng Liu, Difan Zou, Bhiksha Raj
Recent advances in latent diffusion models have demonstrated their effectiveness for high-resolution image synthesis. However, the properties of the latent space from tokenizer for better learning and generation of diffusion models remain under-explored. Theoretically and empirically, we find that improved generation quality is closely tied to the latent distributions with better structure, such as the ones with fewer Gaussian Mixture modes and more discriminative features. Motivated by these insights, we propose MAETok, an autoencoder (AE) leveraging mask modeling to learn semantically rich latent space while maintaining reconstruction fidelity. Extensive experiments validate our analysis, demonstrating that the variational form of autoencoders is not necessary, and a discriminative latent space from AE alone enables state-of-the-art performance on ImageNet generation using only 128 tokens. MAETok achieves significant practical improvements, enabling a gFID of 1.69 with 76x faster training and 31x higher inference throughput for 512x512 generation. Our findings show that the structure of the latent space, rather than variational constraints, is crucial for effective diffusion models. Code and trained models are released.
最近,潜在扩散模型的进步证明了其在高分辨率图像合成中的有效性。然而,为了更好地学习和生成扩散模型,来自tokenizer的潜在空间属性仍然有待探索。在理论和实践上,我们发现生成质量的提高与具有更好结构的潜在分布密切相关,例如具有更少的高斯混合模式和更具区分性的特征。受这些见解的启发,我们提出了MAETok,这是一个利用掩膜建模的自编码器(AE),以学习语义丰富的潜在空间,同时保持重建保真度。大量实验验证了我们分析的有效性,证明了变分自编码器形式并非必需,仅使用AE的判别性潜在空间就能在ImageNet生成任务上实现最先进的性能,仅使用128个令牌。MAETok实现了重大实际改进,在512x512生成任务中实现了1.69的gFID,训练速度提高了76倍,推理速度提高了31倍。我们的研究结果表明,对于有效的扩散模型来说,潜在空间的结构比变分约束更为重要。代码和训练模型已发布。
论文及项目相关链接
Summary
近期潜扩散模型的进步已证明其在高分辨率图像合成中的有效性。然而,关于如何利用tokenizer的潜在空间以更好地学习和生成扩散模型,仍存在许多待探索之处。研究发现,更好的生成质量与具有更好结构的潜在分布密切相关,如具有更少的高斯混合模式和更具区分性的特征。受此启发,我们提出了MAETok,这是一种利用掩模建模的自编码器(AE),用于学习语义丰富的潜在空间,同时保持重建保真度。实验验证我们的分析,证明变分自编码器形式并非必需,仅使用AE的判别性潜在空间即可在ImageNet生成上实现卓越性能,使用仅128个令牌。MAETok实现了实际改进,在512x512生成的情况下,gFID达到1.69,训练速度提高76倍,推理速度提高31倍。我们的研究结果表明,潜在空间的结构对于有效的扩散模型至关重要,而不是变分约束。
Key Takeaways
- 潜扩散模型的最新进展已证明其在高分辨率图像合成中的有效性。
- 潜在空间的结构对于扩散模型的性能至关重要。
- 使用tokenizer的潜在空间进行更好的学习和生成待探索。
- 更好的生成质量与具有更好结构的潜在分布密切相关。
- MAETok是一种利用掩模建模的自编码器(AE),旨在学习语义丰富的潜在空间并保持重建保真度。
- MAETok实现了显著的实际改进,提高了生成质量和效率。
点此查看论文截图


A Mixture-Based Framework for Guiding Diffusion Models
Authors:Yazid Janati, Badr Moufad, Mehdi Abou El Qassime, Alain Durmus, Eric Moulines, Jimmy Olsson
Denoising diffusion models have driven significant progress in the field of Bayesian inverse problems. Recent approaches use pre-trained diffusion models as priors to solve a wide range of such problems, only leveraging inference-time compute and thereby eliminating the need to retrain task-specific models on the same dataset. To approximate the posterior of a Bayesian inverse problem, a diffusion model samples from a sequence of intermediate posterior distributions, each with an intractable likelihood function. This work proposes a novel mixture approximation of these intermediate distributions. Since direct gradient-based sampling of these mixtures is infeasible due to intractable terms, we propose a practical method based on Gibbs sampling. We validate our approach through extensive experiments on image inverse problems, utilizing both pixel- and latent-space diffusion priors, as well as on source separation with an audio diffusion model. The code is available at https://www.github.com/badr-moufad/mgdm
降噪扩散模型在贝叶斯反问题领域取得了显著进展。最近的方法使用预训练的扩散模型作为先验来解决一系列问题,仅利用推理时间计算,从而无需在同一数据集上对特定任务模型进行重新训练。为了近似贝叶斯反问题的后验概率,扩散模型从一系列中间后验分布中进行采样,每个分布都有一个难以处理的可能性函数。这项工作提出了这些中间分布的一种新型混合近似方法。由于这些混合的直接基于梯度的采样由于难以处理的项目而不可行,我们提出了一种基于吉布斯采样的实用方法。我们通过图像反问题的大量实验验证了我们的方法,这些方法利用了像素和潜在空间扩散先验,以及使用音频扩散模型的源分离。代码可在https://www.github.com/badr-moufad/mgdm上找到。
论文及项目相关链接
Summary
去噪扩散模型在贝叶斯反问题领域取得了显著进展。最新方法利用预训练的扩散模型作为先验来解决各种问题,仅利用推理时间的计算,从而无需在相同数据集上针对特定任务重新训练模型。本文提出了一种中间分布的新型混合近似方法,用于近似贝叶斯反问题的后验分布。由于这些混合物的直接基于梯度的采样是不切实际的,因此我们提出了一种基于吉布斯采样的实用方法。我们通过图像反问题实验验证了我们的方法,这些实验利用了像素和潜在空间的扩散先验,以及音频扩散模型的源分离。
Key Takeaways
- 去噪扩散模型在贝叶斯反问题领域有重要应用。
- 预训练的扩散模型被用作解决各种问题的先验,无需针对特定任务重新训练模型。
- 提出了一种新型混合近似方法,用于近似贝叶斯反问题的后验分布。
- 直接基于梯度的采样由于具有不可知的可能性而不切实际。
- 采用吉布斯采样方法作为实用替代方案。
- 在图像反问题和音频扩散模型的源分离上进行了广泛的实验验证。
点此查看论文截图




When are Diffusion Priors Helpful in Sparse Reconstruction? A Study with Sparse-view CT
Authors:Matt Y. Cheung, Sophia Zorek, Tucker J. Netherton, Laurence E. Court, Sadeer Al-Kindi, Ashok Veeraraghavan, Guha Balakrishnan
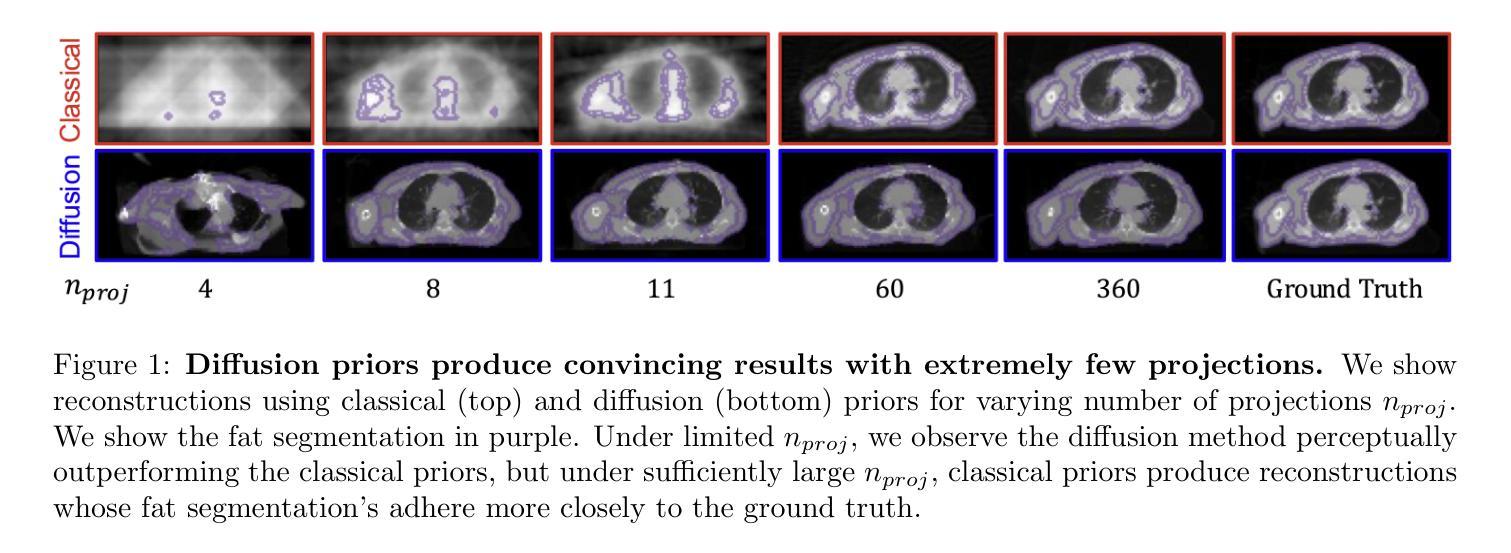
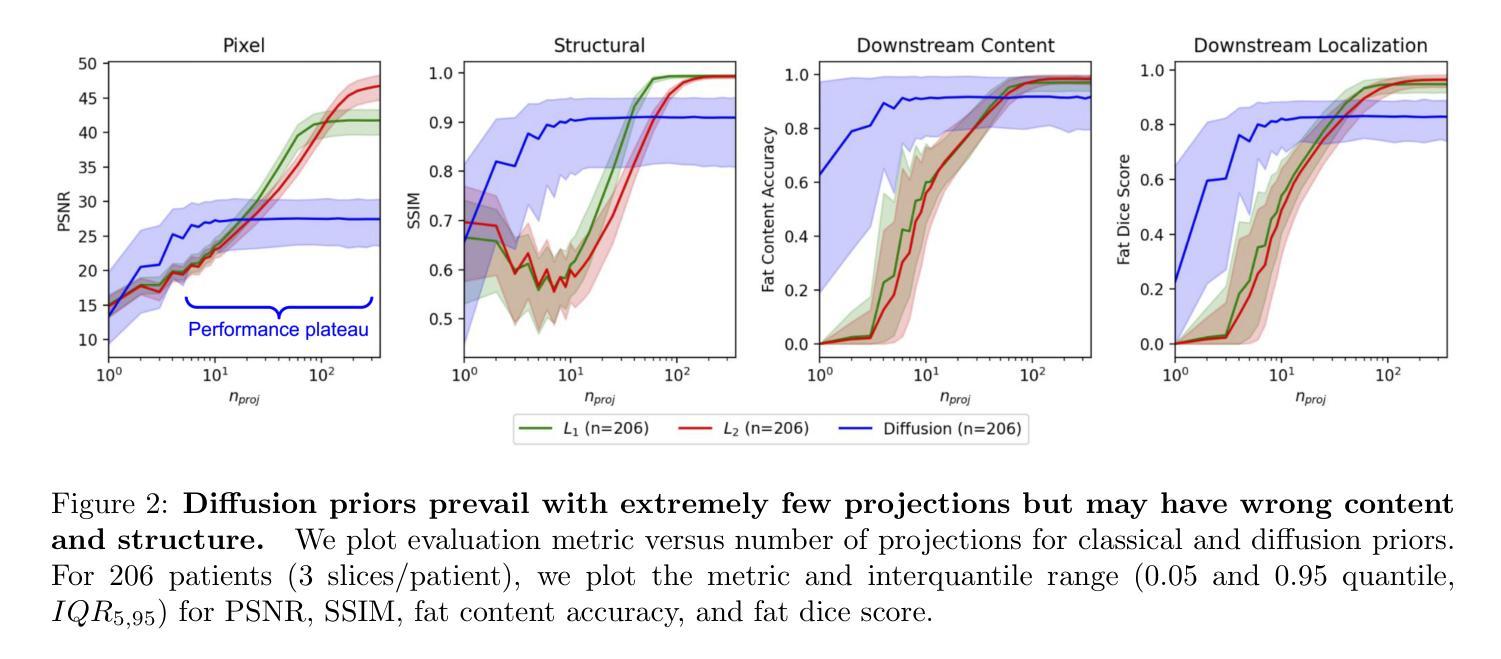
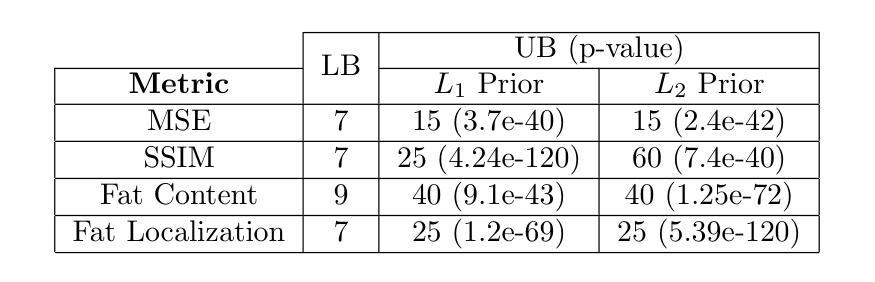
Diffusion models demonstrate state-of-the-art performance on image generation, and are gaining traction for sparse medical image reconstruction tasks. However, compared to classical reconstruction algorithms relying on simple analytical priors, diffusion models have the dangerous property of producing realistic looking results \emph{even when incorrect}, particularly with few observations. We investigate the utility of diffusion models as priors for image reconstruction by varying the number of observations and comparing their performance to classical priors (sparse and Tikhonov regularization) using pixel-based, structural, and downstream metrics. We make comparisons on low-dose chest wall computed tomography (CT) for fat mass quantification. First, we find that classical priors are superior to diffusion priors when the number of projections is ``sufficient’’. Second, we find that diffusion priors can capture a large amount of detail with very few observations, significantly outperforming classical priors. However, they fall short of capturing all details, even with many observations. Finally, we find that the performance of diffusion priors plateau after extremely few ($\approx$10-15) projections. Ultimately, our work highlights potential issues with diffusion-based sparse reconstruction and underscores the importance of further investigation, particularly in high-stakes clinical settings.
扩散模型在图像生成方面表现出了最先进的性能,并且在稀疏医学图像重建任务中获得了牵引。然而,与依赖于简单分析先验知识的传统重建算法相比,扩散模型具有产生逼真结果的风险,即使结果是错误的,特别是在观测数量较少的情况下。我们通过改变观测数量,使用像素、结构和下游指标来比较扩散模型作为图像重建先验的实用性,并与稀疏先验和Tikhonov正则化等传统先验进行比较。我们在低剂量胸腔壁计算机断层扫描(CT)的脂肪质量定量评估中进行了比较。首先,我们发现当投影数量“足够”时,经典先验优于扩散先验。其次,我们发现扩散先验可以在非常少的观测值中捕捉到大量细节,显著优于传统先验。然而,即使在很多观测值的情况下,它们也无法捕捉到所有细节。最后,我们发现扩散先验在极少的投影(约10-15个)之后性能达到稳定。最终,我们的工作突出了扩散模型在稀疏重建中的潜在问题,并强调了进一步调查的重要性,特别是在高风险的临床环境中。
论文及项目相关链接
PDF Accepted at IEEE ISBI 2025, 5 pages, 2 figures, 1 table
Summary
本文探讨了扩散模型作为图像重建先验的实用性,与经典先验方法进行比较。研究发现,在观测数量足够时,经典先验表现优于扩散先验;但在观测数量较少时,扩散先验能够捕捉大量细节,显著优于经典先验。然而,即使观测数量增多,扩散先验也无法完全捕捉所有细节。最终,本文强调了扩散模型在稀疏重建中的潜在问题,并强调了对高风险的医疗临床环境进行进一步研究的重要性。
Key Takeaways
- 扩散模型在图像生成方面表现出卓越性能,并开始用于稀疏医学图像重建任务。
- 与依赖简单分析先验的经典重建算法相比,扩散模型能够产生逼真的结果,即使结果不正确。
- 在观测数量充足时,经典先验表现优于扩散先验。
- 在观测数量较少时,扩散先验能够捕捉大量细节,显著优于经典先验。
- 扩散先验无法完全捕捉所有细节,即使在观测数量较多的情况下。
- 扩散基于的稀疏重建性能在极少数投影后达到稳定状态。
点此查看论文截图

Fast Direct: Query-Efficient Online Black-box Guidance for Diffusion-model Target Generation
Authors:Kim Yong Tan, Yueming Lyu, Ivor Tsang, Yew-Soon Ong
Guided diffusion-model generation is a promising direction for customizing the generation process of a pre-trained diffusion-model to address the specific downstream tasks. Existing guided diffusion models either rely on training of the guidance model with pre-collected datasets or require the objective functions to be differentiable. However, for most real-world tasks, the offline datasets are often unavailable, and their objective functions are often not differentiable, such as image generation with human preferences, molecular generation for drug discovery, and material design. Thus, we need an \textbf{online} algorithm capable of collecting data during runtime and supporting a \textbf{black-box} objective function. Moreover, the \textbf{query efficiency} of the algorithm is also critical because the objective evaluation of the query is often expensive in the real-world scenarios. In this work, we propose a novel and simple algorithm, \textbf{Fast Direct}, for query-efficient online black-box target generation. Our Fast Direct builds a pseudo-target on the data manifold to update the noise sequence of the diffusion model with a universal direction, which is promising to perform query-efficient guided generation. Extensive experiments on twelve high-resolution ($\small {1024 \times 1024}$) image target generation tasks and six 3D-molecule target generation tasks show $\textbf{6}\times$ up to $\textbf{10}\times$ query efficiency improvement and $\textbf{11}\times$ up to $\textbf{44}\times$ query efficiency improvement, respectively. Our implementation is publicly available at: https://github.com/kimyong95/guide-stable-diffusion/tree/fast-direct
引导式扩散模型生成方向对于定制预训练的扩散模型的生成过程以解决特定的下游任务具有广阔前景。现有的引导式扩散模型要么依赖于使用预先收集的数据集对引导模型进行训练,要么需要目标函数可微。然而,对于大多数现实世界任务而言,离线数据集通常不可用,且其目标函数通常不可微分,例如根据人类偏好进行图像生成、为药物发现生成分子以及材料设计。因此,我们需要一种能够在运行时收集数据并支持黑箱目标函数的在线算法。此外,算法的查询效率也至关重要,因为在现实场景中,目标查询评估往往成本高昂。在这项工作中,我们提出了一种新颖而简单的算法——Fast Direct,用于高效查询在线黑箱目标生成。我们的Fast Direct在数据流形上构建伪目标,以通用方向更新扩散模型的噪声序列,这有望实现高效的查询引导生成。在十二个高分辨率($\small {1024 \times 1024}$)图像目标生成任务和六个3D分子目标生成任务上的广泛实验显示,查询效率提高了$\textbf{6}\times$到$\textbf{10}\times$,以及分别提高了$\textbf{11}\times$到$\textbf{44}\times$。我们的实现可在以下网址公开访问:https://github.com/kimyong95/guide-stable-diffusion/tree/fast-direct。
论文及项目相关链接
Summary
本文介绍了扩散模型的新方向——在线数据指导下的扩散模型生成。现有的模型大多依赖离线数据集和可微的目标函数进行训练和指导。但实际应用中,许多任务无法使用离线数据集或目标函数不可微,如图像生成、药物发现的分子生成和材料设计。因此,需要一种在线算法,能在运行时收集数据并支持黑箱目标函数。本文提出了一种简单而高效的算法——Fast Direct,用于在线黑箱目标生成。该算法在图像和分子生成任务上均表现出优秀的查询效率和生成效果。
Key Takeaways
- 扩散模型生成正在朝着定制化方向发展,以应对特定的下游任务。
- 现有模型依赖于离线数据集和可微的目标函数进行训练和指导,但实际应用中存在局限性。
- Fast Direct算法通过在线数据指导扩散模型的生成过程,支持黑箱目标函数,并具有较高的查询效率。
- Fast Direct算法在图像和分子生成任务上表现出优秀的性能。
- 该算法通过构建伪目标在数据流形上进行更新,以通用方向引导噪声序列的扩散模型。
- 该算法在多个高清晰度图像生成任务和分子生成任务上进行了广泛实验验证,证明了其有效性。
点此查看论文截图



One-Prompt-One-Story: Free-Lunch Consistent Text-to-Image Generation Using a Single Prompt
Authors:Tao Liu, Kai Wang, Senmao Li, Joost van de Weijer, Fahad Shahbaz Khan, Shiqi Yang, Yaxing Wang, Jian Yang, Ming-Ming Cheng
Text-to-image generation models can create high-quality images from input prompts. However, they struggle to support the consistent generation of identity-preserving requirements for storytelling. Existing approaches to this problem typically require extensive training in large datasets or additional modifications to the original model architectures. This limits their applicability across different domains and diverse diffusion model configurations. In this paper, we first observe the inherent capability of language models, coined context consistency, to comprehend identity through context with a single prompt. Drawing inspiration from the inherent context consistency, we propose a novel training-free method for consistent text-to-image (T2I) generation, termed “One-Prompt-One-Story” (1Prompt1Story). Our approach 1Prompt1Story concatenates all prompts into a single input for T2I diffusion models, initially preserving character identities. We then refine the generation process using two novel techniques: Singular-Value Reweighting and Identity-Preserving Cross-Attention, ensuring better alignment with the input description for each frame. In our experiments, we compare our method against various existing consistent T2I generation approaches to demonstrate its effectiveness through quantitative metrics and qualitative assessments. Code is available at https://github.com/byliutao/1Prompt1Story.
文本转图像生成模型可以从输入提示中创建高质量的图像。然而,它们在支持故事叙述中的身份一致性生成方面存在困难。针对这个问题的现有方法通常需要在大型数据集上进行大量训练或对原始模型架构进行额外修改。这限制了它们在不同领域和多样化扩散模型配置中的应用性。在本文中,我们首先观察到语言模型的固有能力,称为上下文一致性,通过单个提示理解身份。从固有的上下文一致性中汲取灵感,我们提出了一种新颖的无需训练的一致文本转图像(T2I)生成方法,称为“One-Prompt-One-Story”(1Prompt1Story)。我们的1Prompt1Story方法将所有提示合并为一个输入,用于T2I扩散模型,初步保留角色身份。然后我们使用两种新技术完善生成过程:奇异值再权值和身份保持交叉注意力,确保与每个帧的输入描述更好对齐。我们的实验将我们的方法与各种现有的一致T2I生成方法进行比较,通过定量指标和定性评估来证明其有效性。代码可在https://github.com/byliutao/1Prompt1Story找到。
论文及项目相关链接
PDF 28 pages, 22 figures, ICLR2025 conference
Summary
文本到图像生成模型能够从输入提示创建高质量图像。然而,它们在支持身份保持的故事叙述的连续生成方面存在挑战。现有解决此问题的方法通常需要在大型数据集上进行大量训练或对原始模型架构进行额外修改,这限制了它们在不同领域和多样化扩散模型配置中的应用性。本文首先观察到语言模型的内在能力,称之为上下文一致性,能够通过单个提示理解身份。受内在上下文一致性的启发,我们提出了一种新颖的无需训练的一致文本到图像(T2I)生成方法,称为“One-Prompt-One-Story”(1Prompt1Story)。我们的方法将多个提示合并为一个单独的输入,用于T2I扩散模型,最初保留角色身份。然后,我们使用两种新技术完善生成过程:奇异值重加权和身份保持交叉注意力,确保与每个帧的输入描述更好地对齐。通过定量指标和定性评估,我们验证了该方法的有效性。代码可在 https://github.com/byliutao/1Prompt1Story 找到。
Key Takeaways
- 文本到图像生成模型能够生成高质量图像,但在支持身份保持的故事叙述的连续生成上遇到困难。
- 现有方法解决此问题通常需要大量训练和模型架构修改,限制了其在不同领域的应用。
- 本文提出利用语言模型的内在上下文一致性来解决这一问题。
- 提出了一种新颖的无需训练的一致文本到图像生成方法——“One-Prompt-One-Story”(1Prompt1Story)。
- 1Prompt1Story方法通过将多个提示合并为一个输入,用于T2I扩散模型,从而保留角色身份。
- 通过对生成过程进行技术完善,如奇异值重加权和身份保持交叉注意力,提高了与输入描述的对齐程度。
点此查看论文截图



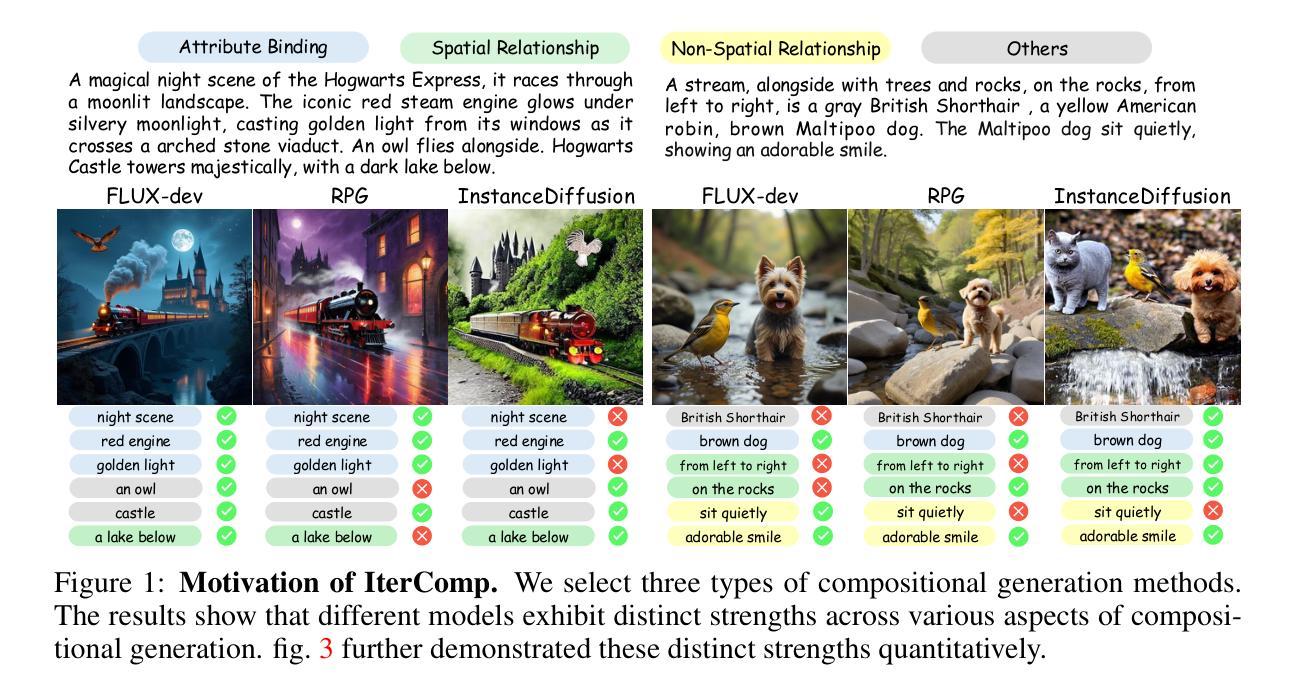
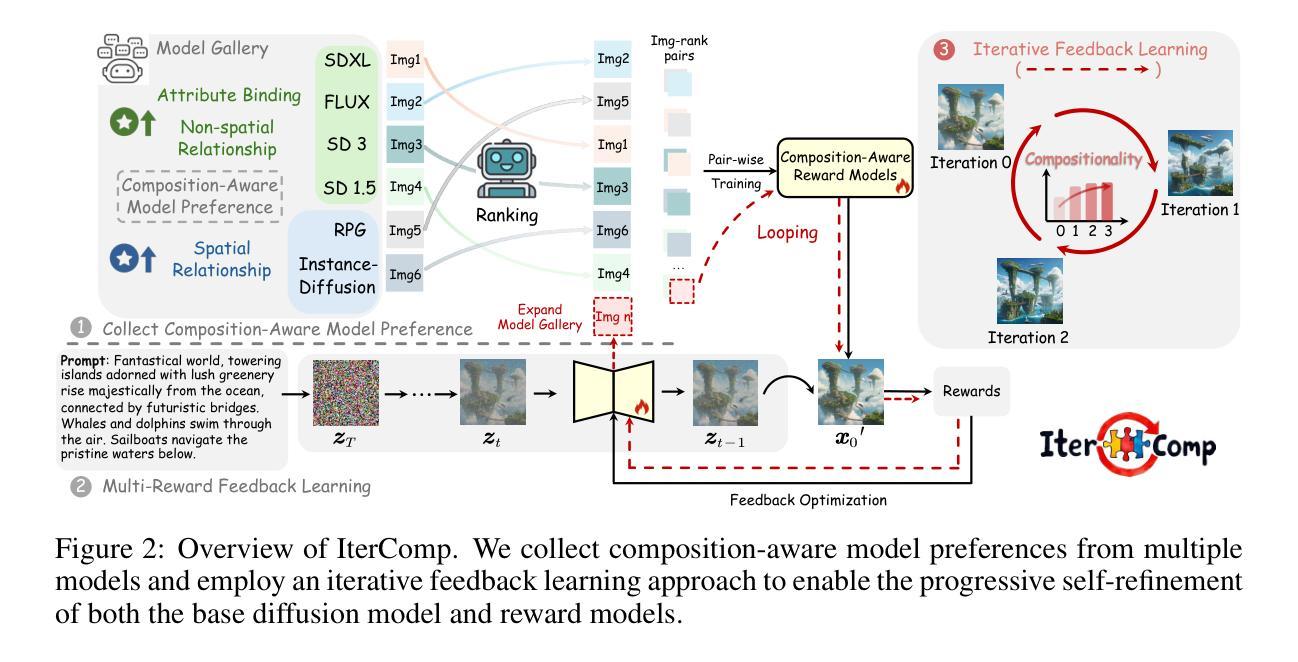
IterComp: Iterative Composition-Aware Feedback Learning from Model Gallery for Text-to-Image Generation
Authors:Xinchen Zhang, Ling Yang, Guohao Li, Yaqi Cai, Jiake Xie, Yong Tang, Yujiu Yang, Mengdi Wang, Bin Cui
Advanced diffusion models like RPG, Stable Diffusion 3 and FLUX have made notable strides in compositional text-to-image generation. However, these methods typically exhibit distinct strengths for compositional generation, with some excelling in handling attribute binding and others in spatial relationships. This disparity highlights the need for an approach that can leverage the complementary strengths of various models to comprehensively improve the composition capability. To this end, we introduce IterComp, a novel framework that aggregates composition-aware model preferences from multiple models and employs an iterative feedback learning approach to enhance compositional generation. Specifically, we curate a gallery of six powerful open-source diffusion models and evaluate their three key compositional metrics: attribute binding, spatial relationships, and non-spatial relationships. Based on these metrics, we develop a composition-aware model preference dataset comprising numerous image-rank pairs to train composition-aware reward models. Then, we propose an iterative feedback learning method to enhance compositionality in a closed-loop manner, enabling the progressive self-refinement of both the base diffusion model and reward models over multiple iterations. Theoretical proof demonstrates the effectiveness and extensive experiments show our significant superiority over previous SOTA methods (e.g., Omost and FLUX), particularly in multi-category object composition and complex semantic alignment. IterComp opens new research avenues in reward feedback learning for diffusion models and compositional generation. Code: https://github.com/YangLing0818/IterComp
先进的扩散模型,如RPG、Stable Diffusion 3和FLUX,在组合文本到图像生成方面取得了显著的进步。然而,这些方法通常在组合生成方面表现出各自独特的优势,一些模型在属性绑定方面表现出色,而其他模型则在空间关系方面表现优异。这种差异突显了需要一种能够利用各种模型的互补优势来全面改进组合能力的方法。为此,我们引入了IterComp,这是一个新的框架,它从多个模型中聚合组合感知模型偏好,并采用迭代反馈学习方法来提高组合生成能力。具体来说,我们精选了六个强大的开源扩散模型,并评估了它们的三个关键组合指标:属性绑定、空间关系和非空间关系。基于这些指标,我们开发了一个包含众多图像排名对的组合感知模型偏好数据集,以训练组合感知奖励模型。然后,我们提出了一种迭代反馈学习方法,以闭环方式提高组合性,使基础扩散模型和奖励模型能够在多次迭代中不断进步和自我完善。理论证明我们的方法有效,大量实验表明,与之前的最佳方法(如Omost和FLUX)相比,我们在多类别对象组合和复杂语义对齐方面表现出显著的优势。IterComp为扩散模型的奖励反馈学习和组合生成研究开辟了新的途径。代码地址:https://github.com/YangLing0818/IterComp
论文及项目相关链接
PDF ICLR 2025. Project: https://github.com/YangLing0818/IterComp
Summary
本文介绍了针对扩散模型在文本到图像生成中的不足,提出了一种新型框架IterComp。该框架能够汇聚多个模型的组合感知模型偏好,并通过迭代反馈学习方法增强组合生成能力。通过构建包含图像排序对的组合感知模型偏好数据集,并引入迭代反馈学习方法,实现基础扩散模型和奖励模型的闭环优化和自我精进。相较于其他先进方法,IterComp在多类别对象组合和复杂语义对齐方面表现出显著优势,为扩散模型的奖励反馈学习和组合生成研究开启了新的方向。
Key Takeaways
- 扩散模型如RPG、Stable Diffusion 3和FLUX在文本到图像生成方面取得了显著进展,但在组合生成方面仍存在互补性。
- IterComp框架汇聚多个模型的组合感知模型偏好,提高全面改进组合能力。
- 构建包含图像排序对的组合感知模型偏好数据集以训练奖励模型。
- 引入迭代反馈学习方法实现基础扩散模型和奖励模型的闭环优化和自我精进。
- IterComp在多类别对象组合和复杂语义对齐方面表现显著优于其他方法。
- IterComp为扩散模型的奖励反馈学习和组合生成研究提供了新的方向。
点此查看论文截图


PixelShuffler: A Simple Image Translation Through Pixel Rearrangement
Authors:Omar Zamzam
Image-to-image translation is a topic in computer vision that has a vast range of use cases ranging from medical image translation, such as converting MRI scans to CT scans or to other MRI contrasts, to image colorization, super-resolution, domain adaptation, and generating photorealistic images from sketches or semantic maps. Image style transfer is also a widely researched application of image-to-image translation, where the goal is to synthesize an image that combines the content of one image with the style of another. Existing state-of-the-art methods often rely on complex neural networks, including diffusion models and language models, to achieve high-quality style transfer, but these methods can be computationally expensive and intricate to implement. In this paper, we propose a novel pixel shuffle method that addresses the image-to-image translation problem generally with a specific demonstrative application in style transfer. The proposed method approaches style transfer by shuffling the pixels of the style image such that the mutual information between the shuffled image and the content image is maximized. This approach inherently preserves the colors of the style image while ensuring that the structural details of the content image are retained in the stylized output. We demonstrate that this simple and straightforward method produces results that are comparable to state-of-the-art techniques, as measured by the Learned Perceptual Image Patch Similarity (LPIPS) loss for content preservation and the Fr'echet Inception Distance (FID) score for style similarity. Our experiments validate that the proposed pixel shuffle method achieves competitive performance with significantly reduced complexity, offering a promising alternative for efficient image style transfer, as well as a promise in usability of the method in general image-to-image translation tasks.
图像到图像的翻译是计算机视觉中的一个主题,具有广泛的应用场景,从医学图像翻译(例如将MRI扫描转换为CT扫描或其他MRI对比剂)到图像上色、超分辨率、域适应以及从草图或语义地图生成逼真的图像等。图像风格迁移也是图像到图像翻译的一个广泛应用,目标是将一张图像的内容与另一张的风格合成在一起。现有的先进方法通常依赖于复杂的神经网络,包括扩散模型和语言模型,以实现高质量的风格迁移,但这些方法计算成本高昂且实施复杂。在本文中,我们提出了一种新颖的像素重排方法,该方法一般性地解决了图像到图像的翻译问题,并以风格迁移作为具体演示应用。所提出的方法通过重排风格图像的像素来接近风格迁移,使得重排图像和内容图像之间的互信息最大化。这种方法本质上保留了风格图像的颜色,同时确保内容图像的结构细节保留在风格化的输出中。我们证明,这种简单直接的方法产生的结果与先进技术产生的结果相当,通过保留内容的感知图像块相似性(LPIPS)损失和风格相似度的Fréchet Inception距离(FID)分数来衡量。我们的实验证实,所提出的像素重排方法在显著降低复杂性的同时实现了有竞争力的性能,为高效的图像风格迁移提供了有前景的替代方案,同时也为一般图像到图像翻译任务中该方法的使用提供了前景。
论文及项目相关链接
摘要
本文提出一种针对图像到图像翻译问题的新型像素重排方法,特别是在风格转移中的应用。该方法通过重排风格图像的像素,最大化重排图像与内容图像之间的互信息,从而在保留风格图像颜色的同时,确保内容图像的结构细节在风格化输出中得到保留。实验证明,该方法的结果与先进技术相当,并在内容保留和风格相似性方面表现出竞争力。
关键见解
- 图像到图像翻译在计算机视觉中是一个广泛研究的主题,涵盖了多种应用场景,包括医学图像翻译、图像色彩化、超分辨率、域适应以及从草图或语义地图生成真实感图像。
- 风格转移是图像到图像翻译的一个应用,旨在合成一个结合了一张图像的内容和另一张图像的风格的图像。
- 当前先进技术常依赖复杂的神经网络,包括扩散模型和语言模型,来实现高质量的风格转移,但这些方法计算成本高昂且实施复杂。
- 本文提出了一种新型的像素重排方法,通过最大化重排风格图像与内容图像之间的互信息来解决图像到图像翻译问题。
- 该方法能够在保留风格图像颜色的同时,确保内容图像的结构细节在风格化输出中得到保留。
- 实验证明,该方法的结果与先进技术相当,并在内容保留和风格相似性方面表现出竞争力,且实现复杂度显著降低。
点此查看论文截图


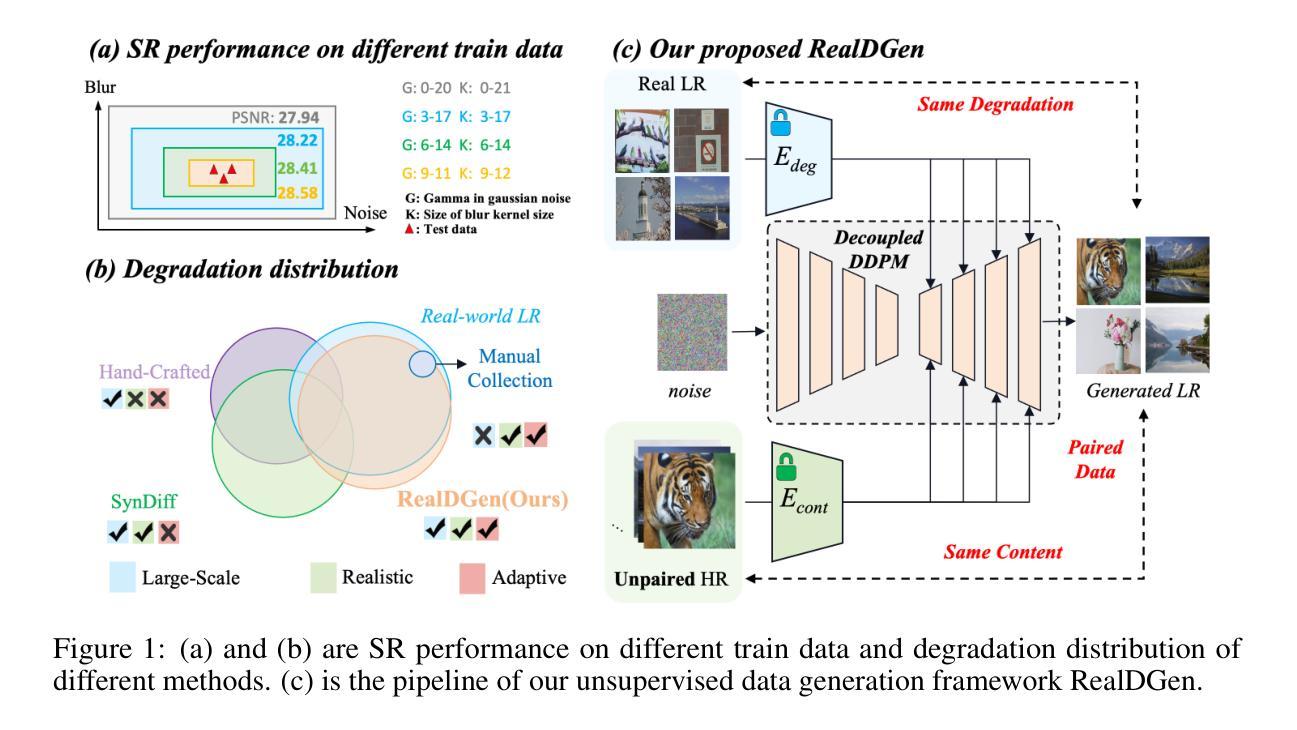
Towards Realistic Data Generation for Real-World Super-Resolution
Authors:Long Peng, Wenbo Li, Renjing Pei, Jingjing Ren, Jiaqi Xu, Yang Wang, Yang Cao, Zheng-Jun Zha
Existing image super-resolution (SR) techniques often fail to generalize effectively in complex real-world settings due to the significant divergence between training data and practical scenarios. To address this challenge, previous efforts have either manually simulated intricate physical-based degradations or utilized learning-based techniques, yet these approaches remain inadequate for producing large-scale, realistic, and diverse data simultaneously. In this paper, we introduce a novel Realistic Decoupled Data Generator (RealDGen), an unsupervised learning data generation framework designed for real-world super-resolution. We meticulously develop content and degradation extraction strategies, which are integrated into a novel content-degradation decoupled diffusion model to create realistic low-resolution images from unpaired real LR and HR images. Extensive experiments demonstrate that RealDGen excels in generating large-scale, high-quality paired data that mirrors real-world degradations, significantly advancing the performance of popular SR models on various real-world benchmarks.
现有的图像超分辨率(SR)技术由于在训练数据和实际场景之间存在巨大差异,往往不能在复杂的真实世界环境中有效地推广。为了应对这一挑战,之前的研究要么手动模拟复杂的基于物理的退化,要么利用基于学习的技术,但这些方法仍然不足以同时生成大规模、现实和多样化的数据。在本文中,我们介绍了一种新型的Realistic Decoupled Data Generator(RealDGen)方法,这是一种针对现实世界超分辨率设计的无监督学习数据生成框架。我们精心制定了内容和退化提取策略,并将其集成到一种新型的内容与退化解耦扩散模型中,以从未配对的真实低分辨率和高分辨率图像中创建逼真的低分辨率图像。大量实验表明,RealDGen在生成大规模、高质量配对数据方面表现出色,这些数据反映了现实世界中的退化情况,并在各种真实世界基准测试中显著提高了流行SR模型的性能。
论文及项目相关链接
PDF accepted by ICLR 2025
Summary
本文提出一种新型的现实解耦数据生成器(RealDGen),这是一种针对现实世界的超分辨率问题的无监督学习数据生成框架。它采用内容和降解提取策略,结合内容降解解耦扩散模型,从非配对的低分辨率和高分辨率图像中生成逼真的低分辨率图像。实验证明,RealDGen能够生成大规模、高质量、符合现实退化情况的数据,显著提高了在各种现实基准测试中的超分辨率模型性能。
Key Takeaways
- 现有图像超分辨率技术在复杂现实场景中泛化效果不佳。
- 此前的方法包括手动模拟物理降解和使用学习技术,但无法同时产生大规模、现实和多样化的数据。
- 引入了一种新型的现实解耦数据生成器(RealDGen),这是一种无监督学习框架,专为现实世界的超分辨率问题设计。
- RealDGen采用内容和降解提取策略,结合内容降解解耦扩散模型。
- 该方法能够从非配对的低分辨率和高分辨率图像中生成逼真的低分辨率图像。
- 实验证明,RealDGen能生成大规模、高质量、反映现实退化情况的数据。
点此查看论文截图


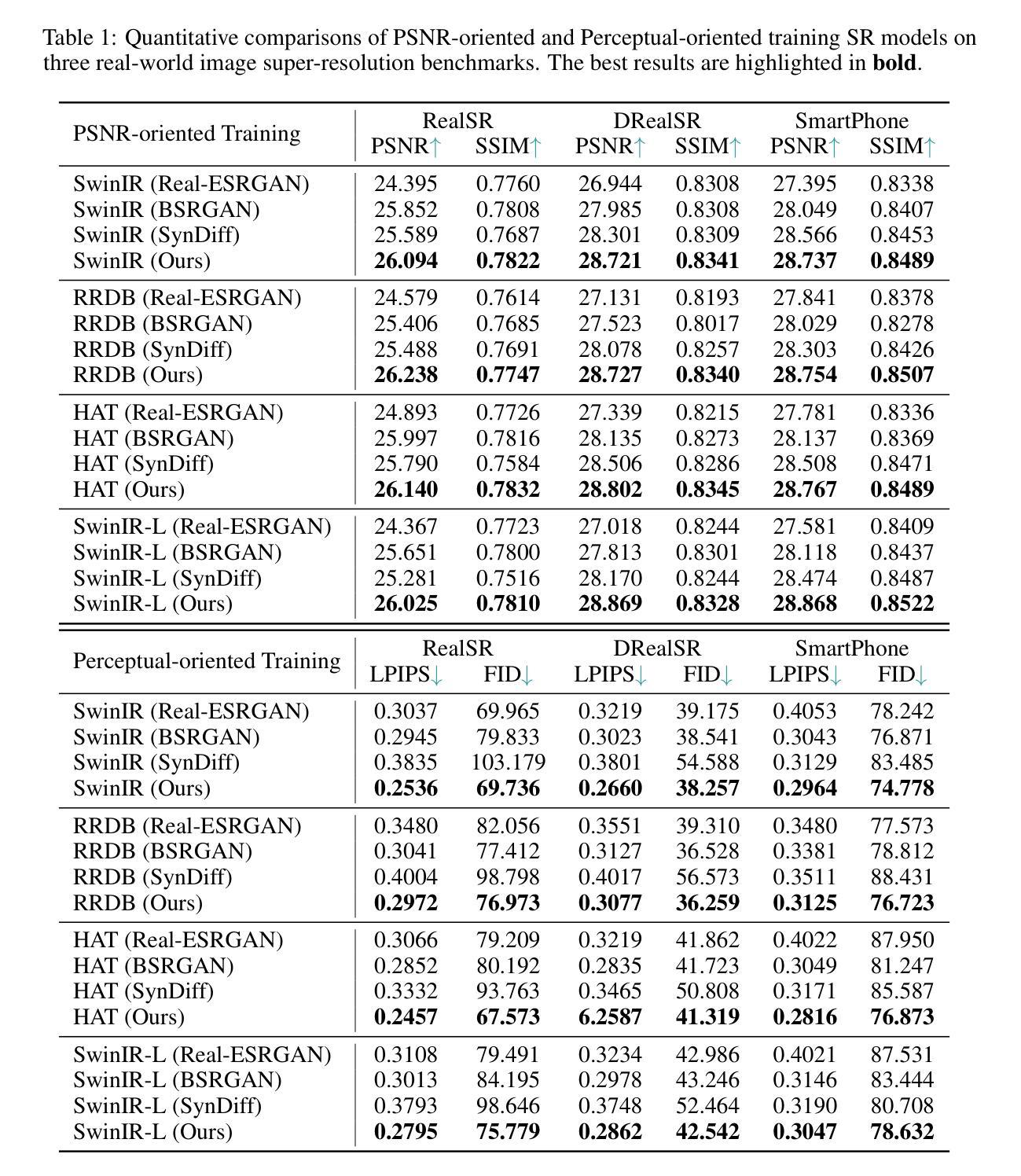
Diffusion Bridge Implicit Models
Authors:Kaiwen Zheng, Guande He, Jianfei Chen, Fan Bao, Jun Zhu
Denoising diffusion bridge models (DDBMs) are a powerful variant of diffusion models for interpolating between two arbitrary paired distributions given as endpoints. Despite their promising performance in tasks like image translation, DDBMs require a computationally intensive sampling process that involves the simulation of a (stochastic) differential equation through hundreds of network evaluations. In this work, we take the first step in fast sampling of DDBMs without extra training, motivated by the well-established recipes in diffusion models. We generalize DDBMs via a class of non-Markovian diffusion bridges defined on the discretized timesteps concerning sampling, which share the same marginal distributions and training objectives, give rise to generative processes ranging from stochastic to deterministic, and result in diffusion bridge implicit models (DBIMs). DBIMs are not only up to 25$\times$ faster than the vanilla sampler of DDBMs but also induce a novel, simple, and insightful form of ordinary differential equation (ODE) which inspires high-order numerical solvers. Moreover, DBIMs maintain the generation diversity in a distinguished way, by using a booting noise in the initial sampling step, which enables faithful encoding, reconstruction, and semantic interpolation in image translation tasks. Code is available at https://github.com/thu-ml/DiffusionBridge.
去噪扩散桥模型(DDBMs)是在给定的两个任意配对分布端点之间进行插值的扩散模型的一种强大变体。尽管它们在图像翻译等任务中表现出有前途的性能,但DDBMs需要计算密集采样过程,这涉及通过数百次网络评估模拟(随机)微分方程。在这项工作中,我们采取了加快DDBMs采样的第一步,无需额外训练,受到扩散模型的成熟食谱的启发。我们通过定义离散时间步长上的非马尔可夫扩散桥对DDBMs进行概括,这些桥与采样相关,具有相同的边缘分布和训练目标,产生从随机到确定性的生成过程,并形成扩散桥隐模型(DBIMs)。DBIMs不仅比普通DDBMs采样器快25倍,而且引入了一种新的、简单且富有洞察力的常微分方程(ODE),激发了高阶数值求解器的灵感。此外,DBIMs以独特的方式保持了生成的多样性,通过在初始采样步骤中使用引导噪声,这使其在图像翻译任务中实现了忠实的编码、重建和语义插值。代码可在https://github.com/thu-ml/DiffusionBridge找到。
论文及项目相关链接
PDF Accepted at ICLR 2025
Summary
DDBMs(去噪扩散桥梁模型)是用于在两个任意配对分布之间进行插值的强大扩散模型变体。为加快DDBMs的采样过程,本研究通过非马尔可夫扩散桥梁对DDBMs进行推广,形成扩散桥梁隐模型(DBIMs)。DBIMs不仅速度高达原DDBMs的25倍,还启发使用高阶数值求解器。此外,DBIMs通过初始采样步骤中的引导噪声保持了生成多样性,使编码、重建和图像翻译任务中的语义插值更加准确。相关代码已公开。
Key Takeaways
- Denoising Diffusion Bridge Models (DDBMs) 允许在两个任意配对分布间进行插值。
- 采样过程计算密集,涉及模拟随机微分方程和数百次网络评估。
- 本研究推广了DDBMs,形成扩散桥梁隐模型(DBIMs),以加快采样速度。
- DBIMs通过非马尔可夫扩散桥梁定义,具有相同的边际分布和培训目标。
- DBIMs不仅使采样速度提高了高达25倍,还启发了高阶数值求解器的使用。
- DBIMs通过初始采样步骤中的引导噪声保持生成多样性。
点此查看论文截图



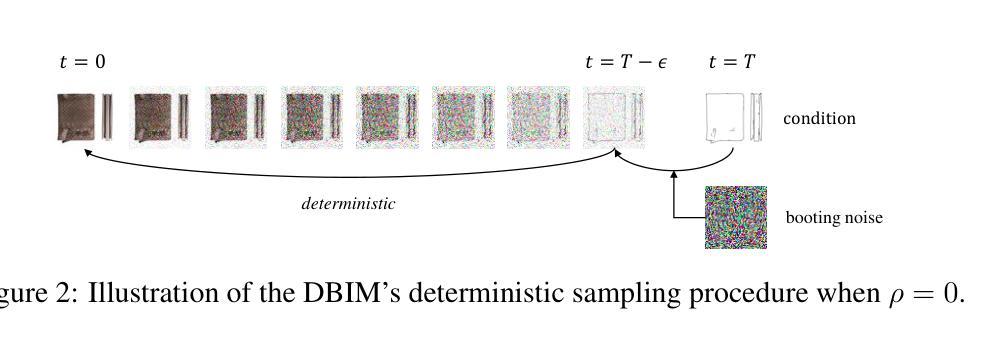
Images that Sound: Composing Images and Sounds on a Single Canvas
Authors:Ziyang Chen, Daniel Geng, Andrew Owens
Spectrograms are 2D representations of sound that look very different from the images found in our visual world. And natural images, when played as spectrograms, make unnatural sounds. In this paper, we show that it is possible to synthesize spectrograms that simultaneously look like natural images and sound like natural audio. We call these visual spectrograms images that sound. Our approach is simple and zero-shot, and it leverages pre-trained text-to-image and text-to-spectrogram diffusion models that operate in a shared latent space. During the reverse process, we denoise noisy latents with both the audio and image diffusion models in parallel, resulting in a sample that is likely under both models. Through quantitative evaluations and perceptual studies, we find that our method successfully generates spectrograms that align with a desired audio prompt while also taking the visual appearance of a desired image prompt. Please see our project page for video results: https://ificl.github.io/images-that-sound/
光谱图(Spectrograms)是声音的一种二维表现形式,它们与我们视觉世界中的图像截然不同。当自然图像被用作光谱图时,会产生不自然的声音。在本文中,我们展示了可以合成同时看起来像自然图像并听起来像自然音频的光谱图。我们称这些光谱图为“图像声音”。我们的方法简单且零启动,它利用在共享潜在空间中运行的预训练文本到图像和文本到光谱图扩散模型。在反向过程中,我们并行使用音频和图像扩散模型对噪声潜在数据进行去噪处理,从而得到一个可能在两个模型下都存在的样本。通过定量评估和感知研究,我们发现我们的方法成功地生成了与期望的音频提示对齐的光谱图,同时采用了期望的图像提示的视觉外观。视频结果请参见我们的项目页面:https://ificl.github.io/images-that-sound/
论文及项目相关链接
PDF Accepted to NeurIPS 2024. Project site: https://ificl.github.io/images-that-sound/
摘要
该论文展示了如何将频谱图(sound的二维表示)与自然图像和音频相结合,合成出既像自然图像又发出自然音频的频谱图。研究团队利用预训练的文本到图像和文本到频谱图的扩散模型,通过反向过程在共享潜在空间中生成同时符合音频和图像提示的样本。该研究为合成视听内容开辟了新的方向。
要点提炼
- 论文展示了一种能够合成兼具自然图像外观和自然音频效果的频谱图的技术。
- 研究使用了预训练的文本到图像和文本到频谱图的扩散模型,在共享潜在空间中进行操作。
- 通过反向过程,研究团队使用音频和图像扩散模型并行去噪潜在噪声,生成同时符合两个模型的样本。
- 该方法成功生成与音频提示对齐的频谱图,同时保留视觉提示的外观。
- 研究通过定量评估和感知研究验证了方法的有效性。
- 该技术为视听内容的合成开辟了新的方向,具有广泛的应用前景。
点此查看论文截图


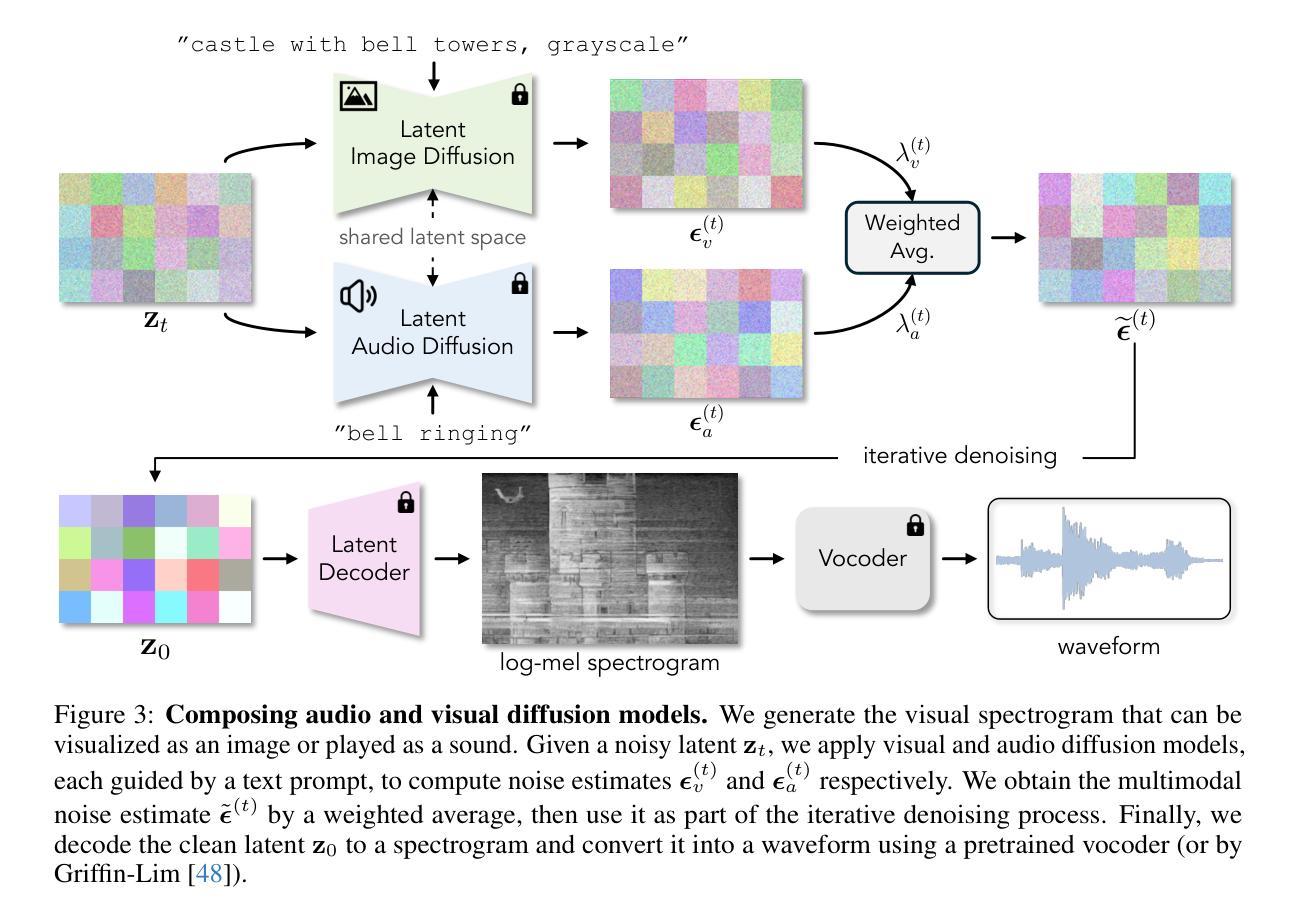
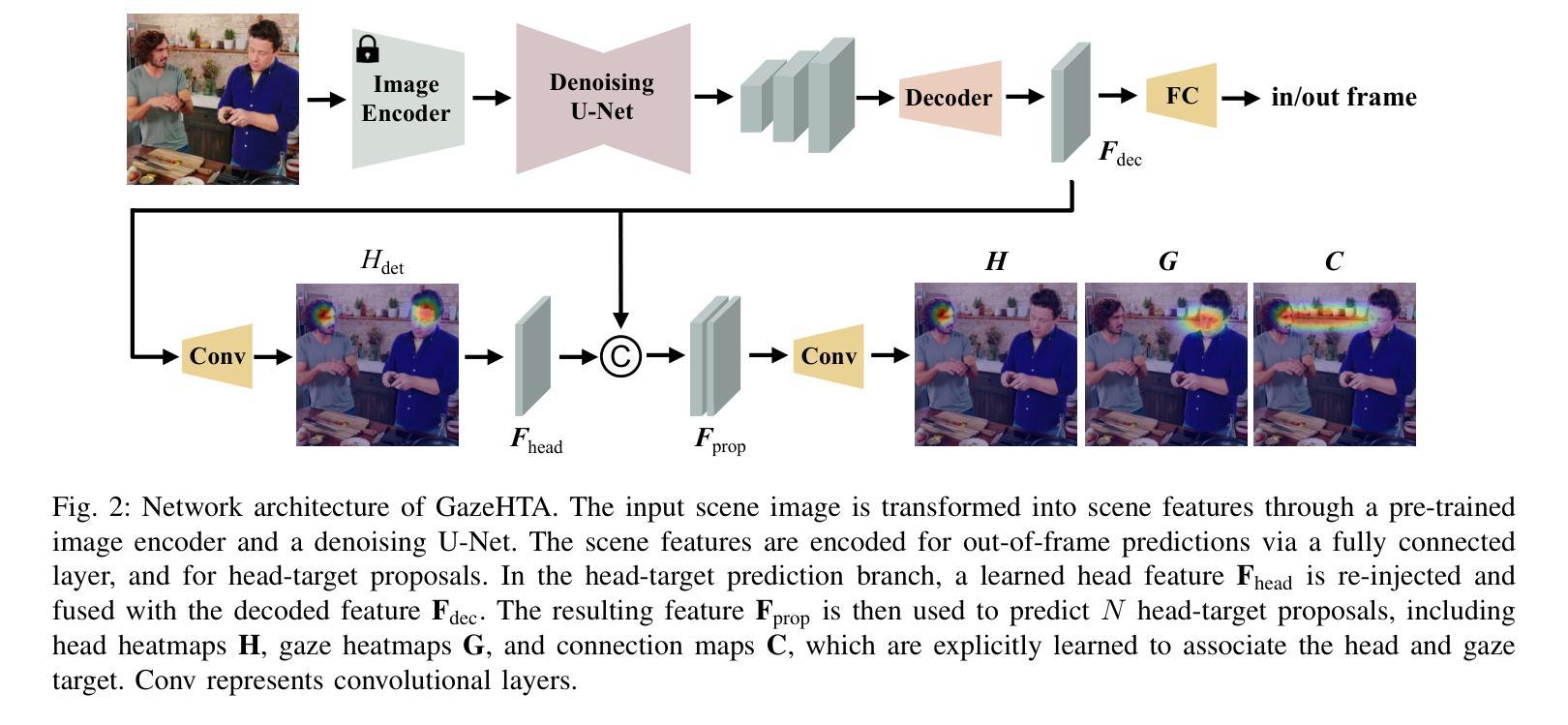
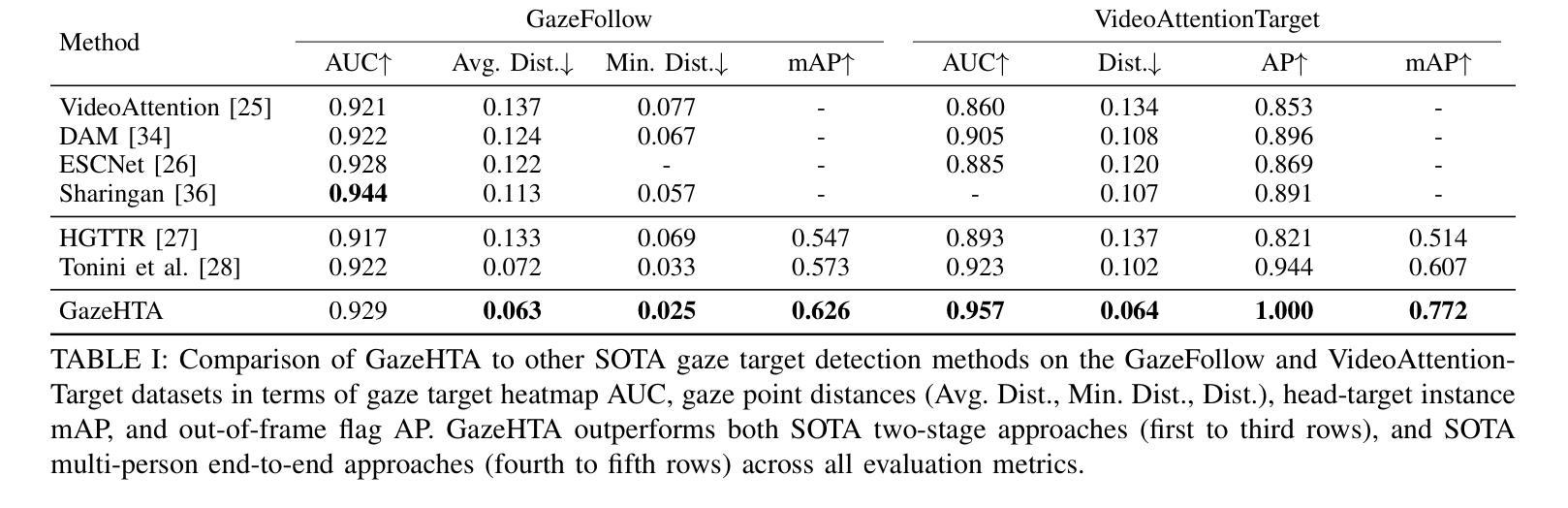
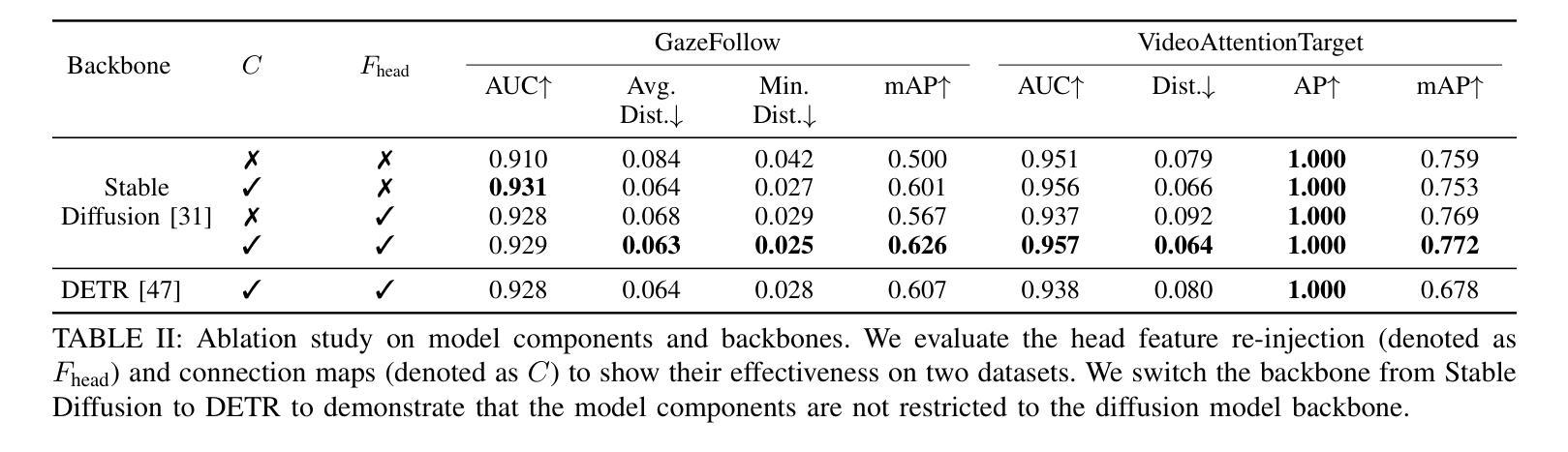
GazeHTA: End-to-end Gaze Target Detection with Head-Target Association
Authors:Zhi-Yi Lin, Jouh Yeong Chew, Jan van Gemert, Xucong Zhang
Precisely detecting which object a person is paying attention to is critical for human-robot interaction since it provides important cues for the next action from the human user. We propose an end-to-end approach for gaze target detection: predicting a head-target connection between individuals and the target image regions they are looking at. Most of the existing methods use independent components such as off-the-shelf head detectors or have problems in establishing associations between heads and gaze targets. In contrast, we investigate an end-to-end multi-person Gaze target detection framework with Heads and Targets Association (GazeHTA), which predicts multiple head-target instances based solely on input scene image. GazeHTA addresses challenges in gaze target detection by (1) leveraging a pre-trained diffusion model to extract scene features for rich semantic understanding, (2) re-injecting a head feature to enhance the head priors for improved head understanding, and (3) learning a connection map as the explicit visual associations between heads and gaze targets. Our extensive experimental results demonstrate that GazeHTA outperforms state-of-the-art gaze target detection methods and two adapted diffusion-based baselines on two standard datasets.
精确检测人们正在关注的对象对于人机交互至关重要,因为它为来自人类用户的下一个动作提供了重要线索。我们提出了一种端到端的注视目标检测方法来预测个体与他们所关注的图像区域之间的头目标关联。现有的大多数方法使用独立组件,如现成的头部检测器,或者在建立头部和注视目标之间关联时存在问题。相比之下,我们研究了具有头部和目标关联(GazeHTA)的端到端多人注视目标检测框架。该框架仅基于输入场景图像预测多个头部目标实例。GazeHTA通过以下方式解决注视目标检测中的挑战:(1)利用预训练的扩散模型提取场景特征以进行丰富的语义理解;(2)重新注入头部特征以增强头部先验知识,提高头部理解;(3)学习连接图作为头部和注视目标之间的明确视觉关联。我们的大量实验结果表明,GazeHTA在两项标准数据集上的表现优于最新的注视目标检测方法以及两项经过适应的扩散基线方法。
论文及项目相关链接
Summary
一种新型端到端多人注视目标检测框架GazeHTA被提出,它能够预测个体与注视目标图像区域之间的头目标连接。它借助预训练的扩散模型提取场景特征进行丰富的语义理解,增强头部特征以改善头部理解,并学习连接图作为头部和注视目标之间的明确视觉关联。在两项标准数据集上的实验结果表明,GazeHTA在注视目标检测方面的性能优于现有方法以及两个基于扩散的基线方法。
Key Takeaways
- GazeHTA是一个端到端的多人注视目标检测框架,能够预测个体与注视目标之间的连接。
- 该框架利用预训练的扩散模型提取场景特征,实现丰富的语义理解。
- GazeHTA通过增强头部特征来改善对头部的理解。
- 学习连接图作为头部和注视目标之间的明确视觉关联是GazeHTA的关键特点。
- GazeHTA在标准数据集上的实验性能优于现有方法及基于扩散的基线方法。
- 现有方法存在的问题包括使用独立组件、头检测器的问题以及建立头与注视目标之间关联的挑战。
点此查看论文截图