⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-07 更新
Distilling Implicit Multimodal Knowledge into Large Language Models for Zero-Resource Dialogue Generation
Authors:Bo Zhang, Hui Ma, Jian Ding, Jian Wang, Bo Xu, Hongfei Lin
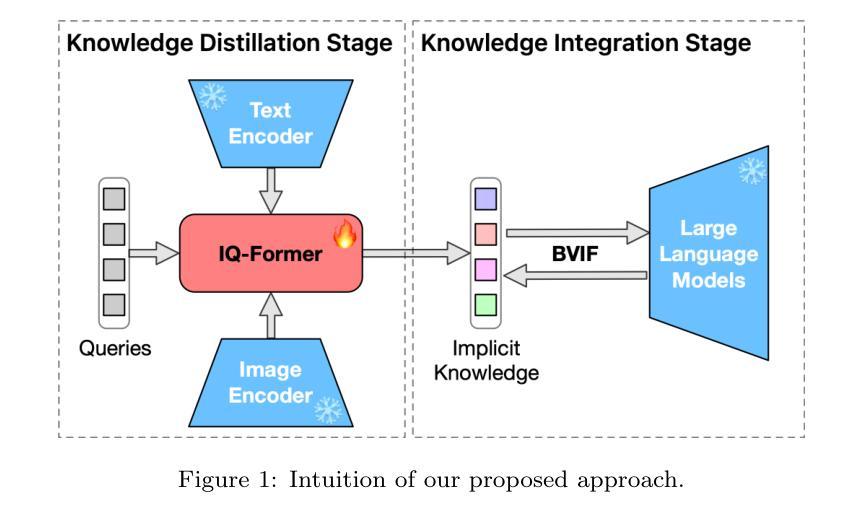
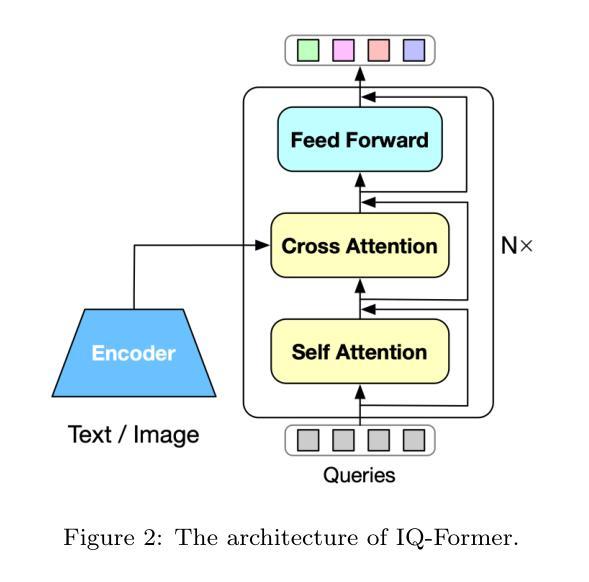
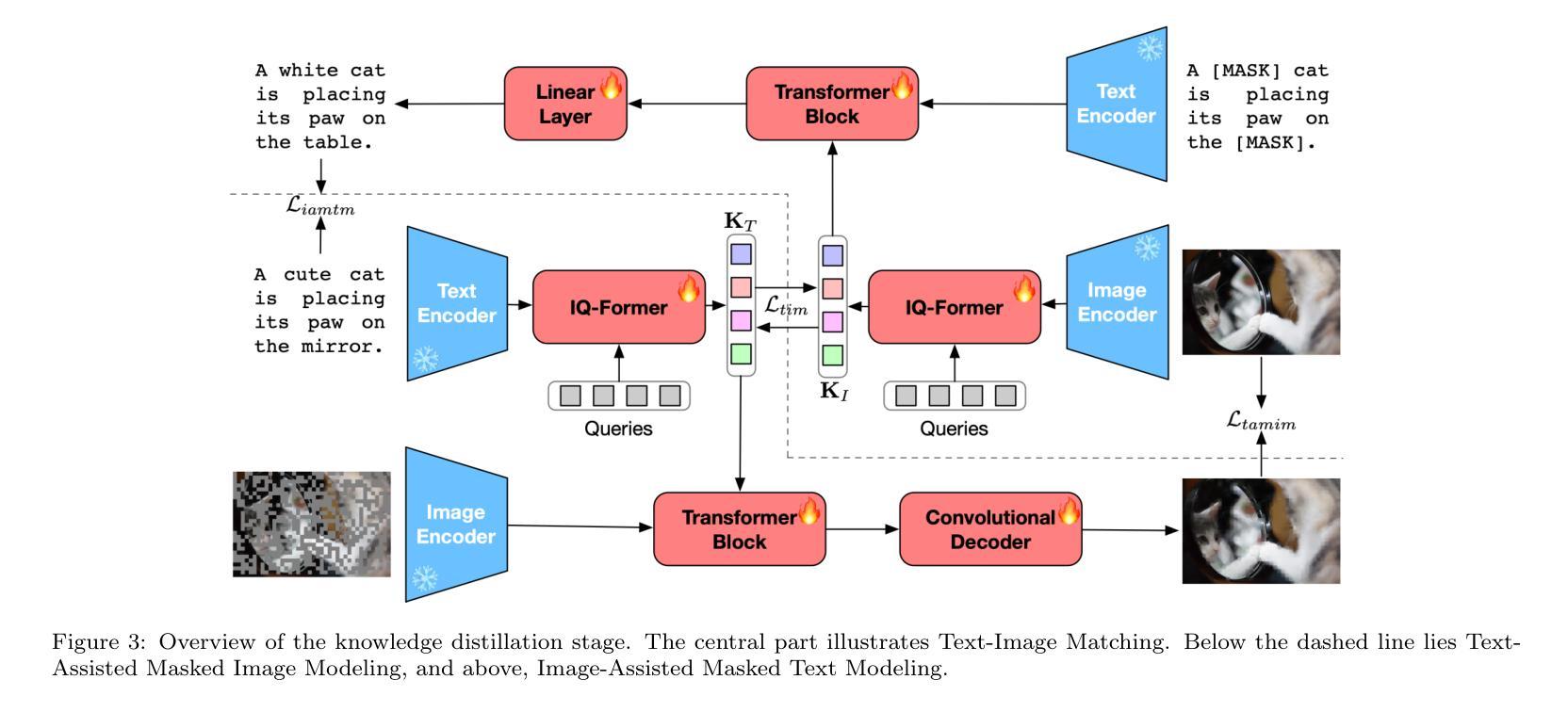
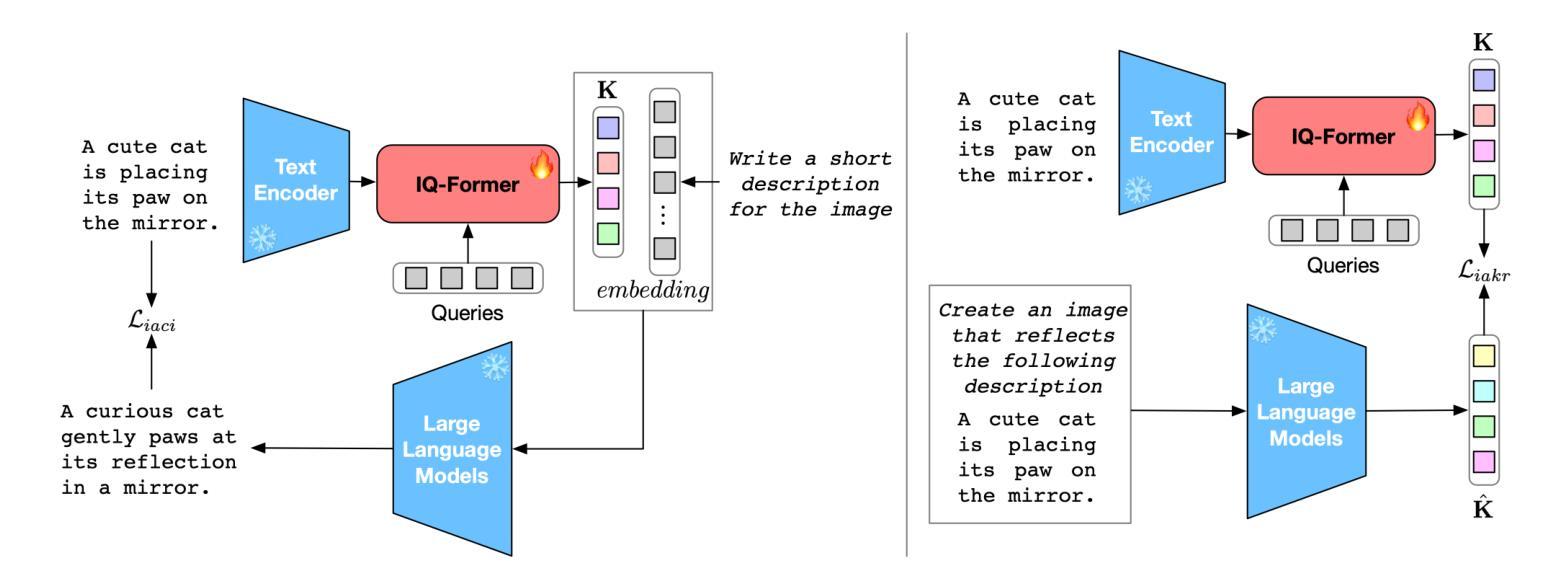
Integrating multimodal knowledge into large language models (LLMs) represents a significant advancement in dialogue generation capabilities. However, the effective incorporation of such knowledge in zero-resource scenarios remains a substantial challenge due to the scarcity of diverse, high-quality dialogue datasets. To address this, we propose the Visual Implicit Knowledge Distillation Framework (VIKDF), an innovative approach aimed at enhancing LLMs for enriched dialogue generation in zero-resource contexts by leveraging implicit multimodal knowledge. VIKDF comprises two main stages: knowledge distillation, using an Implicit Query Transformer to extract and encode visual implicit knowledge from image-text pairs into knowledge vectors; and knowledge integration, employing a novel Bidirectional Variational Information Fusion technique to seamlessly integrate these distilled vectors into LLMs. This enables the LLMs to generate dialogues that are not only coherent and engaging but also exhibit a deep understanding of the context through implicit multimodal cues, effectively overcoming the limitations of zero-resource scenarios. Our extensive experimentation across two dialogue datasets shows that VIKDF outperforms existing state-of-the-art models in generating high-quality dialogues. The code is available at https://github.com/zhangbo-nlp/VIKDF.
将多模态知识集成到大型语言模型(LLM)中,是对对话生成能力的一次重大突破。然而,在零资源场景中有效地结合这种知识仍然是一个巨大的挑战,因为缺乏多样化、高质量的对话数据集。为了解决这一问题,我们提出了视觉隐知识蒸馏框架(VIKDF),这是一种旨在利用隐多模态知识增强LLM在零资源环境下的丰富对话生成能力的新方法。VIKDF主要包括两个阶段:知识蒸馏,使用隐查询转换器从图像文本对中提取和编码隐知识到知识向量;知识集成,采用新型双向变分信息融合技术,无缝地将这些蒸馏向量集成到LLM中。这使得LLM不仅能够生成连贯且引人入胜的对话,而且能够通过隐多模态线索深刻地理解上下文,有效克服零资源场景的局限性。我们在两个对话数据集上的大量实验表明,VIKDF在生成高质量对话方面优于现有的最先进的模型。代码可在https://github.com/zhangbo-nlp/VIKDF找到。
论文及项目相关链接
PDF Accepted by Information Fusion. The code is available at https://github.com/zhangbo-nlp/VIKDF
Summary
多模态知识融入大型语言模型(LLM)是提升对话生成能力的重要进展。但在零资源场景下有效融入这种知识是一大挑战,因为缺乏多样、高质量对话数据集。为此,我们提出视觉隐性知识蒸馏框架(VIKDF),旨在借助隐性多模态知识,在零资源情境下增强LLM的对话生成能力。VIKDF包括两个阶段:知识蒸馏和知识的整合。通过隐性查询转换器从图像文本对中提取编码视觉隐性知识为知识向量;并采用新型双向变分信息融合技术,无缝整合这些蒸馏后的向量到LLM中。这使LLM不仅生成连贯、引人入胜的对话,而且通过隐性多模态线索展现深度理解上下文的能力,有效克服零资源场景的局限性。
Key Takeaways
- 多模态知识融入大型语言模型(LLM)能提升对话生成能力。
- 在零资源场景下有效融入多模态知识是挑战,因缺乏多样、高质量对话数据集。
- 视觉隐性知识蒸馏框架(VIKDF)通过利用隐性多模态知识增强LLM在零资源情境下的对话生成能力。
- VIKDF包括两个阶段:知识蒸馏和知识的整合。
- 通过隐性查询转换器提取编码视觉隐性知识为知识向量。
- 采用双向变分信息融合技术无缝整合蒸馏后的向量到LLM中。
点此查看论文截图