⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-07 更新
Do Large Language Model Benchmarks Test Reliability?
Authors:Joshua Vendrow, Edward Vendrow, Sara Beery, Aleksander Madry
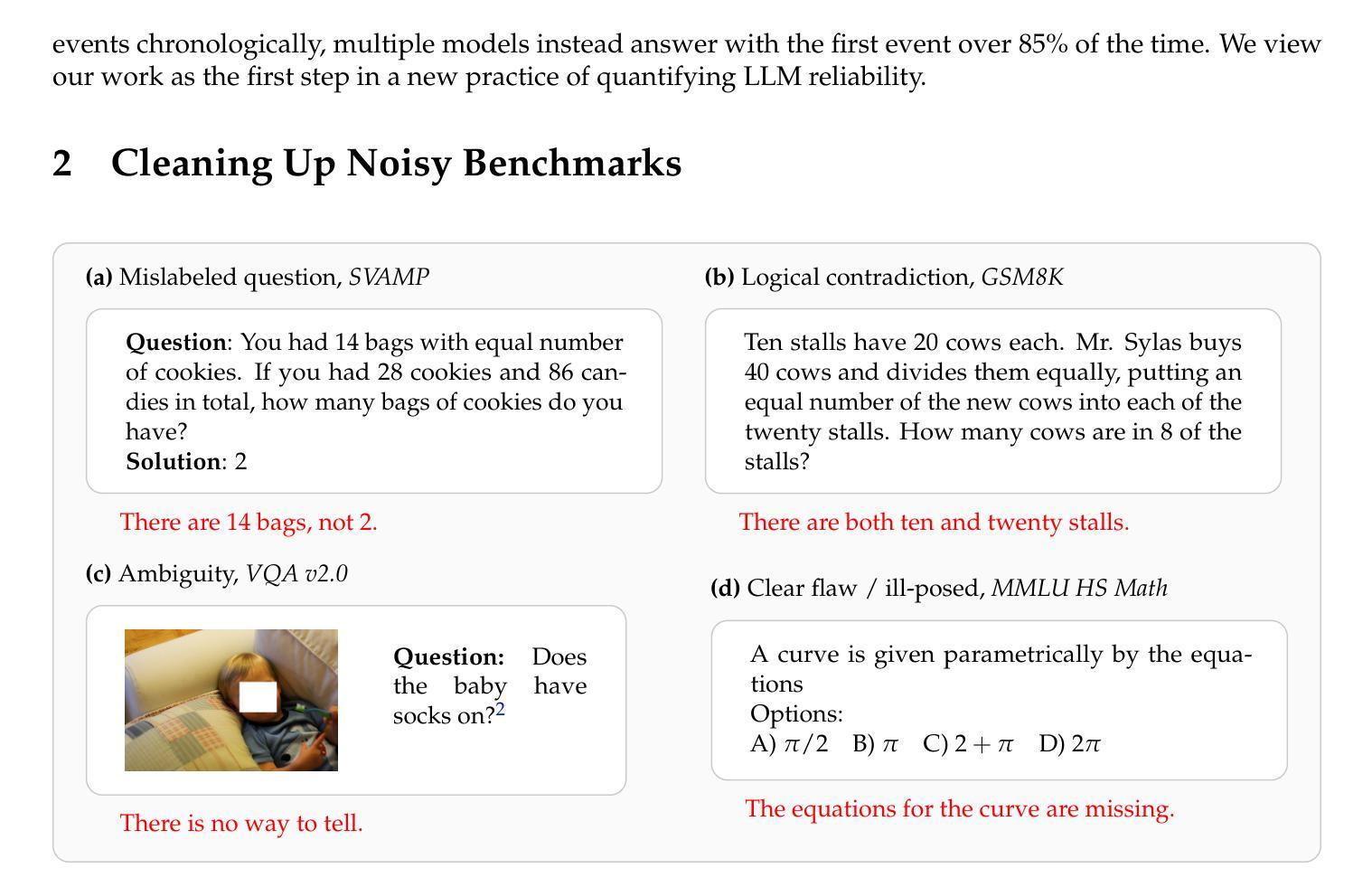
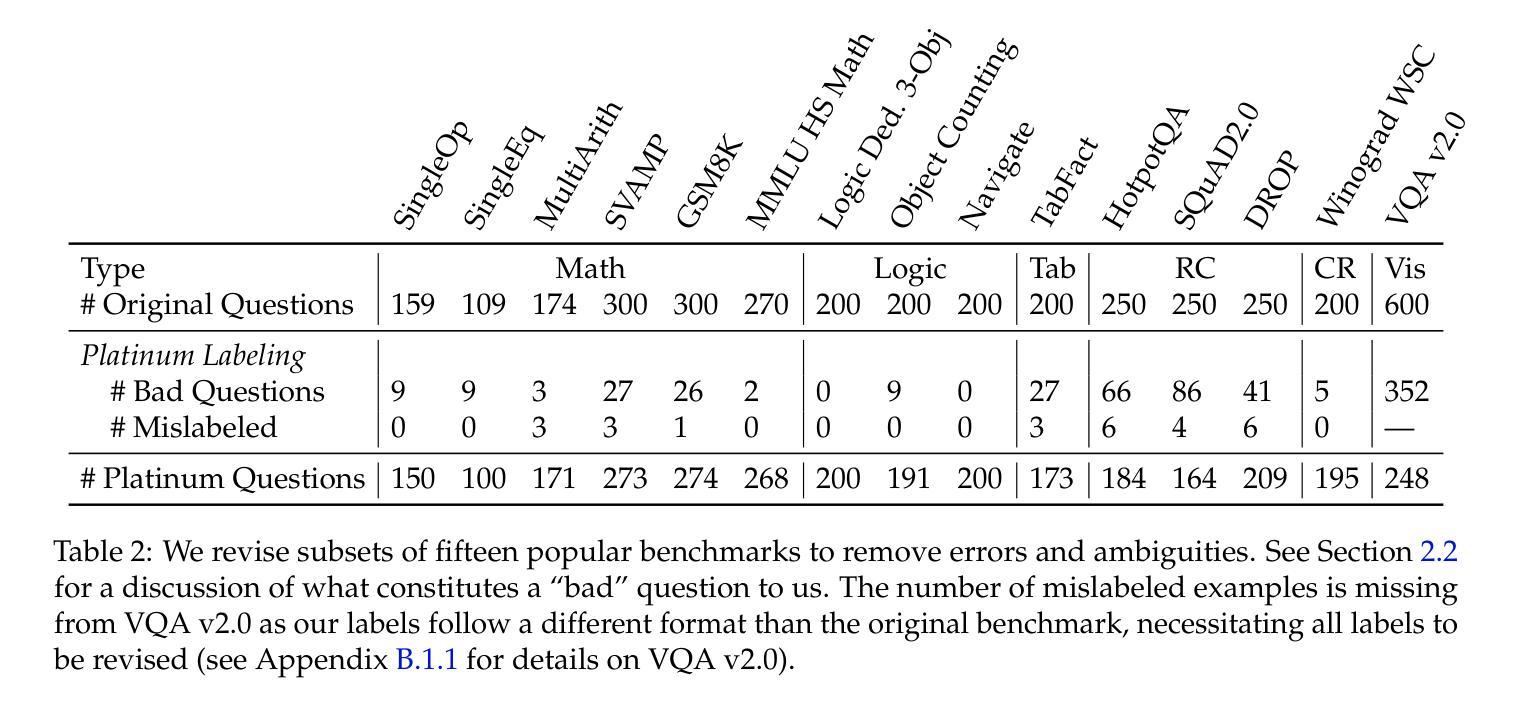
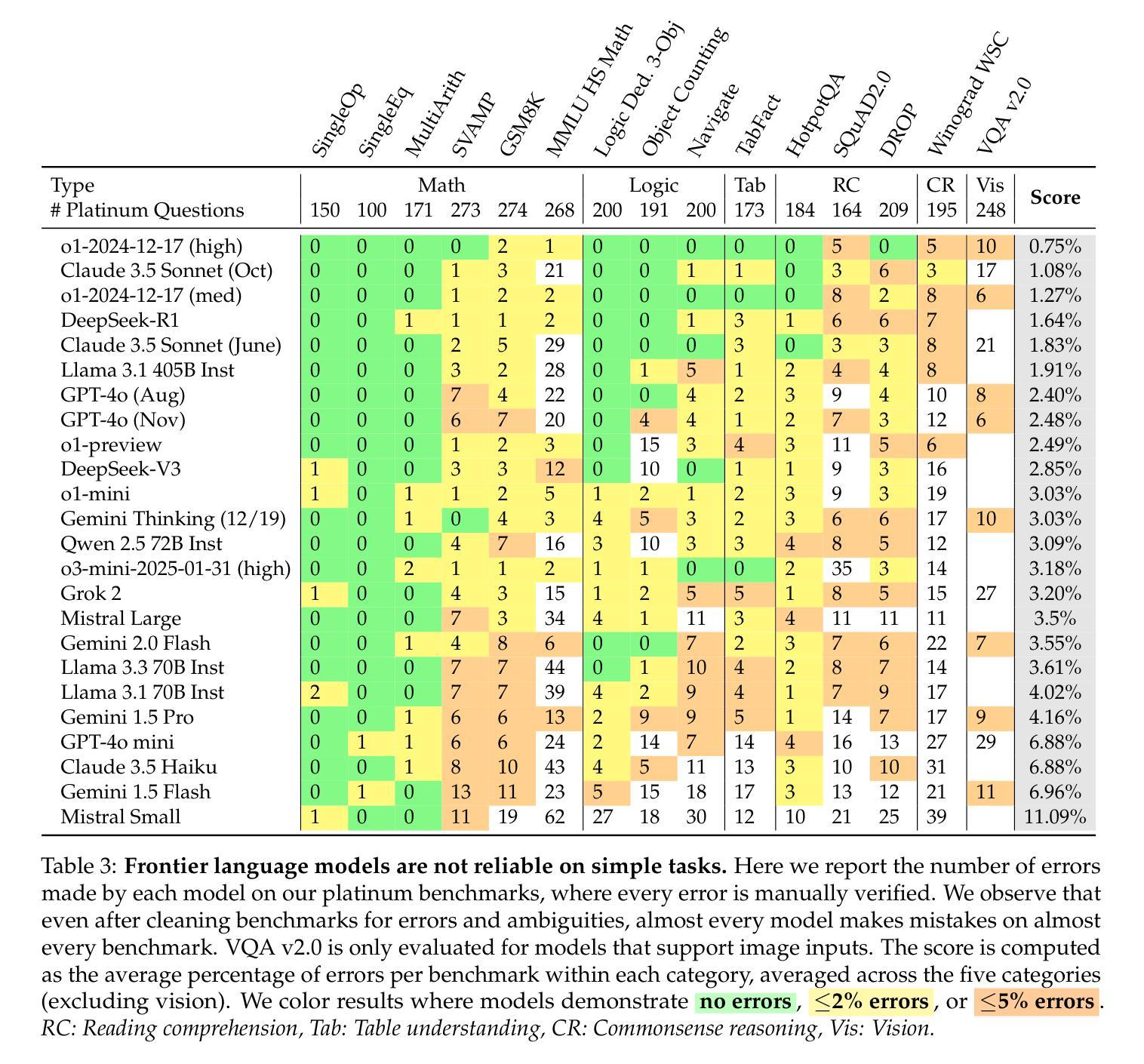
When deploying large language models (LLMs), it is important to ensure that these models are not only capable, but also reliable. Many benchmarks have been created to track LLMs’ growing capabilities, however there has been no similar focus on measuring their reliability. To understand the potential ramifications of this gap, we investigate how well current benchmarks quantify model reliability. We find that pervasive label errors can compromise these evaluations, obscuring lingering model failures and hiding unreliable behavior. Motivated by this gap in the evaluation of reliability, we then propose the concept of so-called platinum benchmarks, i.e., benchmarks carefully curated to minimize label errors and ambiguity. As a first attempt at constructing such benchmarks, we revise examples from fifteen existing popular benchmarks. We evaluate a wide range of models on these platinum benchmarks and find that, indeed, frontier LLMs still exhibit failures on simple tasks such as elementary-level math word problems. Analyzing these failures further reveals previously unidentified patterns of problems on which frontier models consistently struggle. We provide code at https://github.com/MadryLab/platinum-benchmarks
在部署大型语言模型(LLM)时,确保这些模型不仅具备能力,而且可靠是非常重要的。虽然已经创建了许多基准测试来跟踪LLM不断增长的能力,但对于衡量它们的可靠性并没有类似的关注。为了了解这一差距的潜在影响,我们调查了当前基准测试对模型可靠性量化的程度。我们发现普遍存在的标签错误可能会损害这些评估结果,掩盖模型持久的失败和不可靠的行为。受这种可靠性评估差距的驱动,我们随后提出了所谓的铂金基准测试的概念,即精心策划的基准测试,以尽量减少标签错误和模糊性。作为构建此类基准测试的初步尝试,我们修订了来自十五个现有流行基准测试的示例。我们在这些铂金基准测试上评估了广泛的模型,并发现前沿的LLM确实在简单的任务(如小学水平的数学应用题)上表现出失败。进一步分析这些失败揭示了之前未发现的模式问题,前沿模型在这些问题上一直表现困难。我们在https://github.com/MadryLab/platinum-benchmarks上提供了代码。
论文及项目相关链接
Summary
大型语言模型(LLM)的部署需兼顾能力和可靠性。当前主要关注模型的能力评估,而缺乏对其可靠性的衡量。研究发现,普遍存在的标签错误会影响模型评估,掩盖模型失败和不可靠行为。为此,提出“白金基准测试”概念,精心编制以最小化标签错误和模糊性。修订现有15个流行基准测试中的例子,发现前沿LLM在简单任务上仍有失败,如小学数学题。分析这些失败揭示之前未识别的问题模式。
Key Takeaways
- LLM部署需同时关注能力和可靠性。
- 当前主要关注模型的能力评估基准测试,缺乏对其可靠性的衡量。
- 标签错误会影响模型评估,掩盖模型失败和不可靠行为。
- 提出“白金基准测试”概念,以最小化标签错误和模糊性。
- 修订现有基准测试例子,发现前沿LLM在简单任务上的失败。
- 这些失败揭示之前未识别的问题模式。
点此查看论文截图

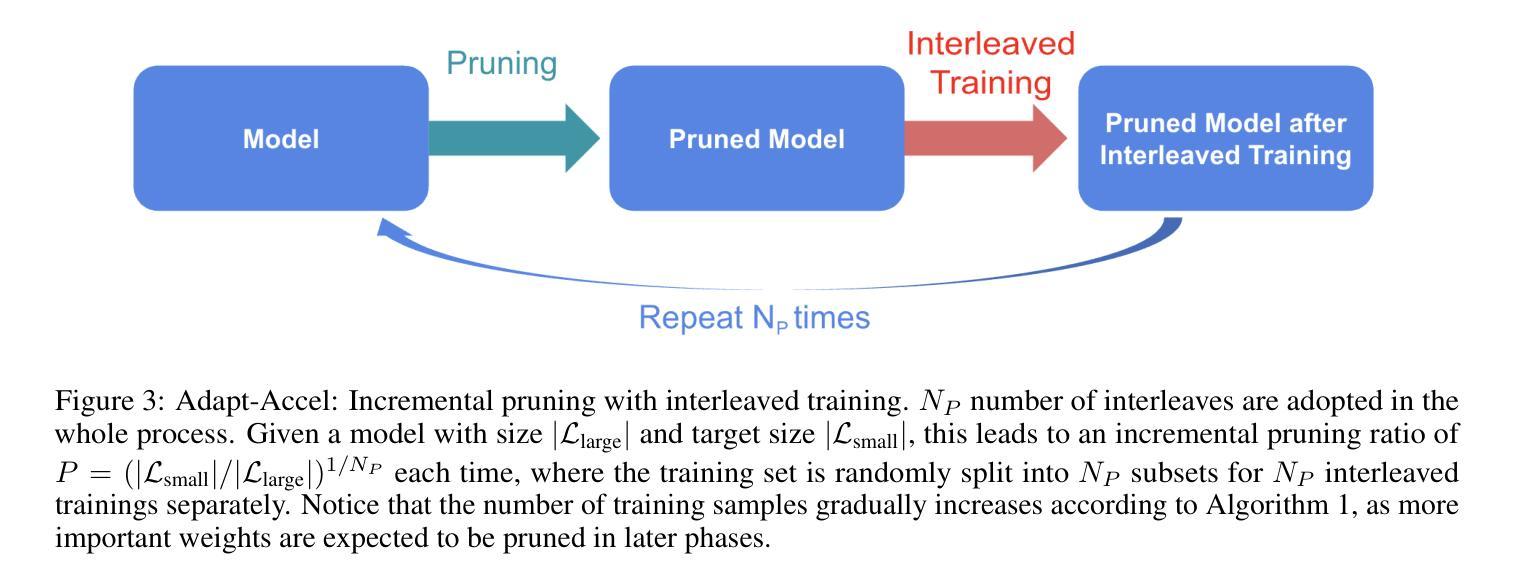
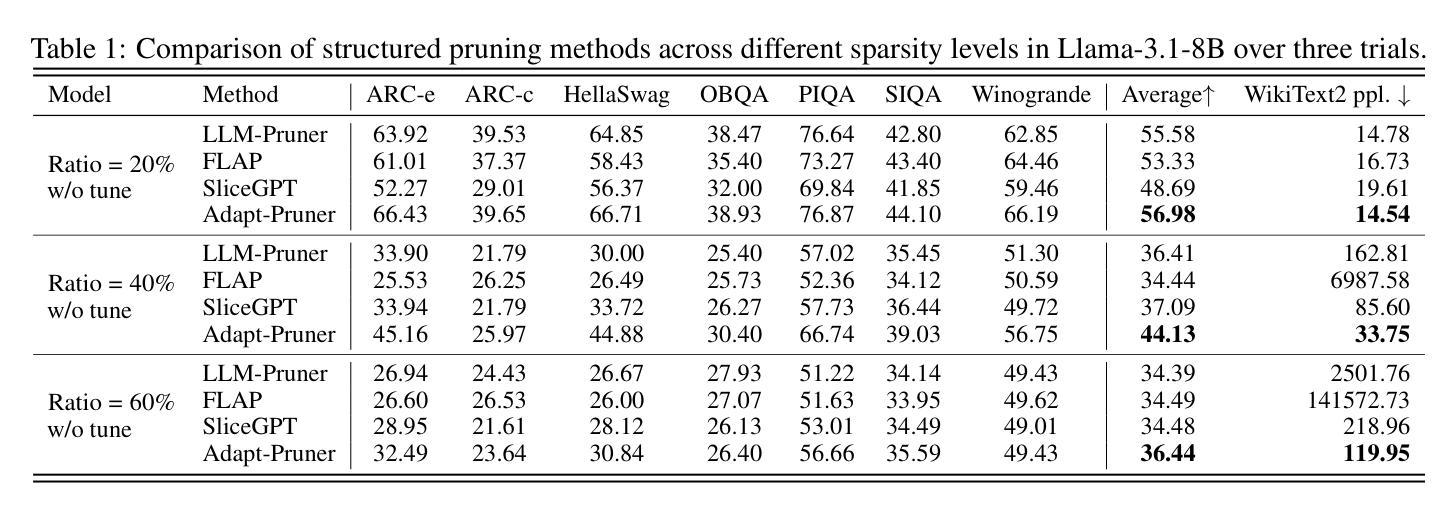
Adapt-Pruner: Adaptive Structural Pruning for Efficient Small Language Model Training
Authors:Boyao Wang, Rui Pan, Shizhe Diao, Xingyuan Pan, Jipeng Zhang, Renjie Pi, Tong Zhang
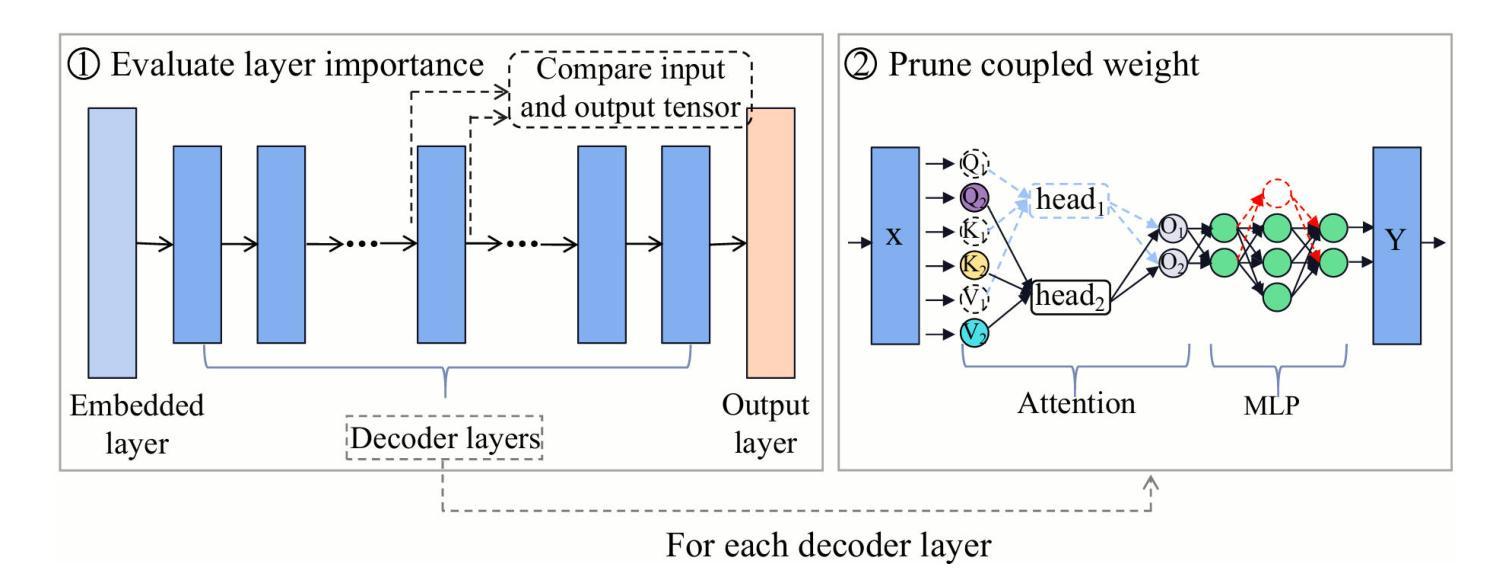
Small language models (SLMs) have attracted considerable attention from both academia and industry due to their broad range of applications in edge devices. To obtain SLMs with strong performance, conventional approaches either pre-train the models from scratch, which incurs substantial computational costs, or compress/prune existing large language models (LLMs), which results in performance drops and falls short in comparison to pre-training. In this paper, we investigate the family of acceleration methods that involve both structured pruning and model training. We found 1) layer-wise adaptive pruning (Adapt-Pruner) is extremely effective in LLMs and yields significant improvements over existing pruning techniques, 2) adaptive pruning equipped with further training leads to models comparable to those pre-training from scratch, 3) incremental pruning brings non-trivial performance gain by interleaving pruning with training and only removing a small portion of neurons ($\sim$5%) at a time. Experimental results on LLaMA-3.1-8B demonstrate that Adapt-Pruner outperforms conventional pruning methods, such as LLM-Pruner, FLAP, and SliceGPT, by an average of 1%-7% in accuracy on commonsense benchmarks. Additionally, Adapt-Pruner restores the performance of MobileLLM-125M to 600M on the MMLU benchmark with 200$\times$ fewer tokens via pruning from its larger counterparts, and discovers a new 1B model that surpasses LLaMA-3.2-1B in multiple benchmarks.
小型语言模型(SLM)因其边缘设备应用的广泛性而引起了学术界和工业界的广泛关注。为了获得性能强大的SLM,传统的方法要么从头开始预训练模型,这会产生巨大的计算成本,要么压缩或修剪现有的大型语言模型(LLM),但这会导致性能下降,且无法与预训练相抗衡。在本文中,我们研究了涉及结构化修剪和模型训练相结合的加速方法。我们发现:1)逐层自适应修剪(Adapt-Pruner)在LLM中极为有效,对现有修剪技术产生了重大改进;2)配备进一步训练的自适应修剪产生的模型与从头开始预训练的模型相当;3)增量修剪通过交替进行修剪和培训,每次只移除一小部分神经元(~5%),带来了不小的性能提升。在LLaMA-3.1-8B上的实验结果表明,Adapt-Pruner在常识基准测试上的准确率平均优于传统的修剪方法(如LLM-Pruner、FLAP和SliceGPT)1%-7%。此外,Adapt-Pruner通过修剪更大的模型,将MobileLLM-125M的性能恢复到600M的级别(MMLU基准测试),并发现了一个新的1B模型,该模型在多个基准测试中超越了LLaMA-3.2-1B。
论文及项目相关链接
摘要
本文探讨了涉及结构剪枝和模型训练的加速方法,研究了小型语言模型(SLM)的强大性能。发现层适应剪枝(Adapt-Pruner)在大语言模型(LLM)中极为有效,对现有剪枝技术有显著改善。结合进一步训练的适应剪枝可生成与从头开始预训练的模型相当的性能。增量剪枝通过交替进行剪枝和训练,每次仅移除一小部分神经元(约5%),带来了不俗的性能提升。在LLaMA-3.1-8B上的实验结果表明,Adapt-Pruner在常识基准测试上的准确度平均高出传统剪枝方法(如LLM-Pruner、FLAP和SliceGPT)1%-7%。此外,Adapt-Pruner通过从大模型中剪枝,将MobileLLM-125M的性能恢复到MMLU基准测试的600M水平,并发现一个新的小型模型(仅1B),在多个基准测试中超过了LLaMA-3.2-1B。总体而言,该研究展示了剪枝技术在小型语言模型中的潜力与优势。
关键见解
- 层适应剪枝(Adapt-Pruner)在大型语言模型(LLM)中表现卓越,显著改进了现有剪枝技术。
- 结合进一步训练的适应剪枝能够生成与从头开始预训练的模型相当的性能。
- 增量剪枝通过交替进行剪枝和训练,可提升模型性能。
- Adapt-Pruner在常识基准测试上的准确度平均高出其他传统剪枝方法。
- 通过从大模型中剪枝,Adapt-Pruner可将小型语言模型的性能提升至更高水平。
- 研究发现了一个新的小型语言模型,性能在多个基准测试中超过了现有模型。
点此查看论文截图



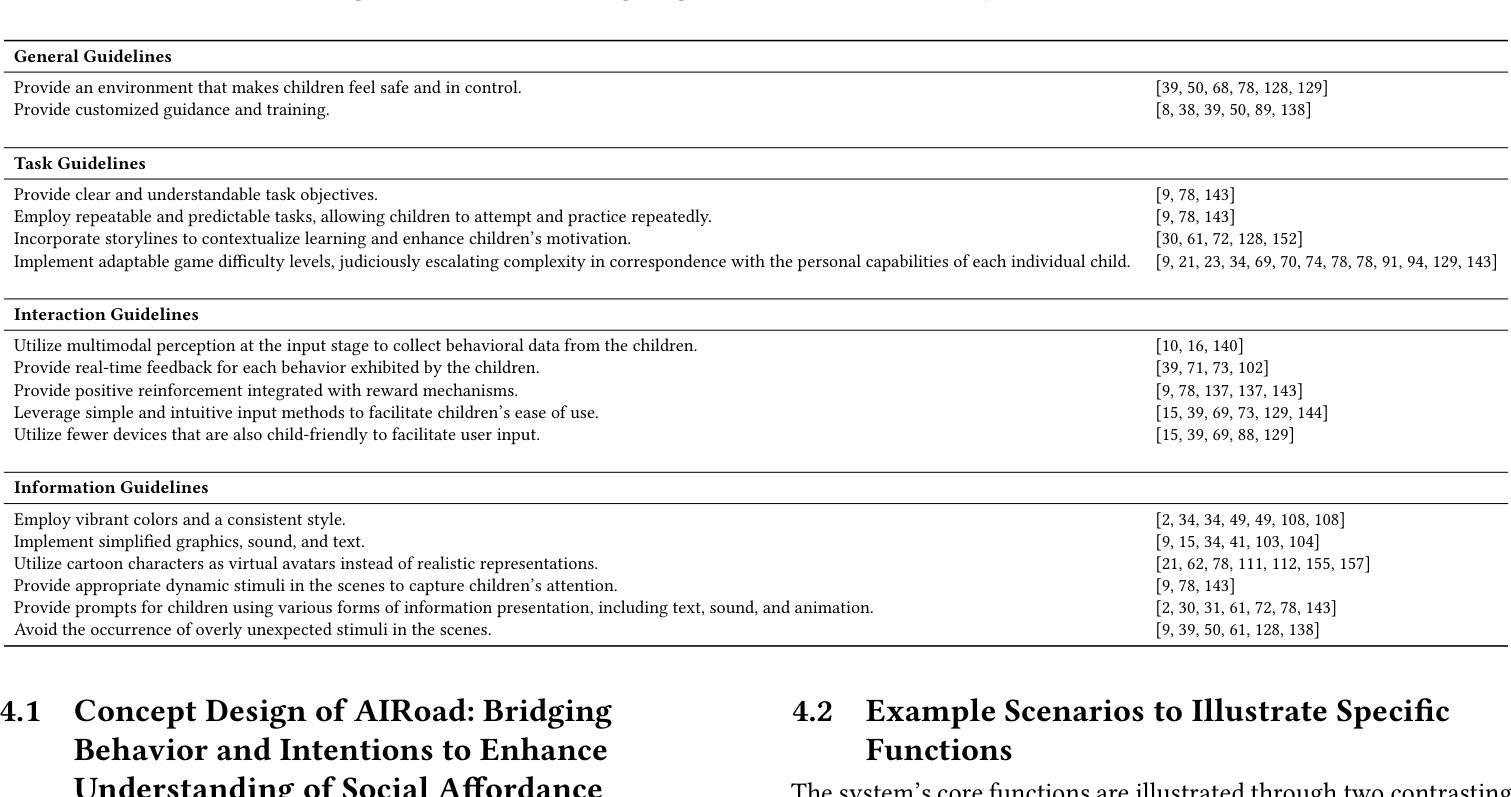
Designing LLM-simulated Immersive Spaces to Enhance Autistic Children’s Social Affordances Understanding
Authors:Yancheng Cao, Yangyang HE, Yonglin Chen, Menghan Chen, Shanhe You, Yulin Qiu, Min Liu, Chuan Luo, Chen Zheng, Xin Tong, Jing Liang, Jiangtao Gong
One of the key challenges faced by autistic children is understanding social affordances in complex environments, which further impacts their ability to respond appropriately to social signals. In traffic scenarios, this impairment can even lead to safety concerns. In this paper, we introduce an LLM-simulated immersive projection environment designed to improve this ability in autistic children while ensuring their safety. We first propose 17 design considerations across four major categories, derived from a comprehensive review of previous research. Next, we developed a system called AIroad, which leverages LLMs to simulate drivers with varying social intents, expressed through explicit multimodal social signals. AIroad helps autistic children bridge the gap in recognizing the intentions behind behaviors and learning appropriate responses through various stimuli. A user study involving 14 participants demonstrated that this technology effectively engages autistic children and leads to significant improvements in their comprehension of social affordances in traffic scenarios. Additionally, parents reported high perceived usability of the system. These findings highlight the potential of combining LLM technology with immersive environments for the functional rehabilitation of autistic children in the future.
自闭症儿童面临的关键挑战之一是理解复杂环境中的社会规范,这进一步影响了他们对社会信号的适当反应能力。在交通场景中,这种障碍甚至会导致安全问题。在本文中,我们介绍了一种由大型语言模型模拟的沉浸式投影环境,旨在提高自闭症儿童在这一方面的能力,同时确保他们的安全。我们首先提出四个主要类别的17个设计考量,这些考量是基于对先前研究的全面回顾而得出的。接下来,我们开发了一个名为AIroad的系统,它利用大型语言模型模拟具有不同社会意图的驾驶员,这些意图通过明确的多模式社会信号来表达。AIroad帮助自闭症儿童弥识别人类行为背后的意图差距,并通过各种刺激学习适当的反应。一项涉及14名参与者的用户研究表明,这种技术有效地吸引了自闭症儿童的参与,并在他们对交通场景中的社会规范的理解方面取得了显著的进步。此外,父母报告了系统的高可用性感知。这些发现强调了将大型语言模型技术与沉浸式环境相结合在未来对自闭症儿童进行功能康复的潜力。
论文及项目相关链接
PDF iui2025
Summary
基于自闭症患者难以理解复杂环境中的社交规则和惯例的挑战,本文设计了一种利用大型语言模型(LLM)模拟沉浸式投影环境以提高自闭症儿童理解能力的技术系统AIroad。AIroad借助LLM技术模拟驾驶者的社交意图,并通过多模态社交信号表达这些意图。通过用户研究,证明AIroad能够帮助自闭症儿童识别行为背后的意图并学习适当反应。父母报告称系统的高可用性,显示该技术具有潜力为自闭症儿童的功能康复提供帮助。
Key Takeaways
- 自闭症儿童面临理解复杂环境中社交规则的挑战,导致他们难以对社会信号做出适当反应。
- 针对自闭症儿童的理解能力问题,提出了一个利用LLM技术的沉浸式投影环境设计,旨在提高他们的社交理解能力。
- 系统AIroad模拟不同驾驶者的社交意图,通过多模态社交信号帮助自闭症儿童识别和理解这些意图。
- 通过用户研究验证了AIroad的有效性,参与者表现出对社交规则的更好理解。
- 父母对AIroad系统的可用性给予了高度评价。
- AIroad技术为自闭症儿童的功能康复提供了潜在的帮助。
点此查看论文截图

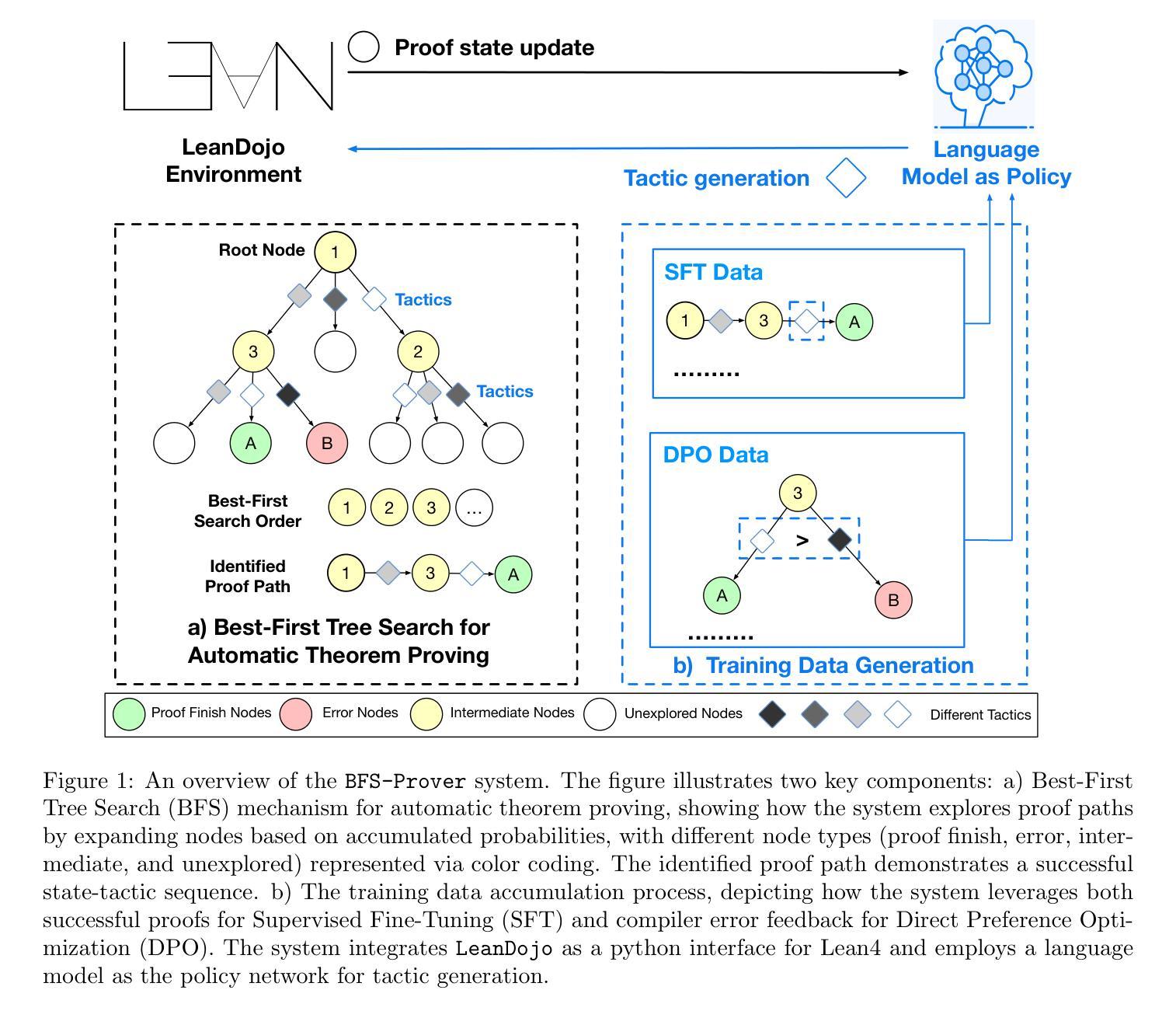
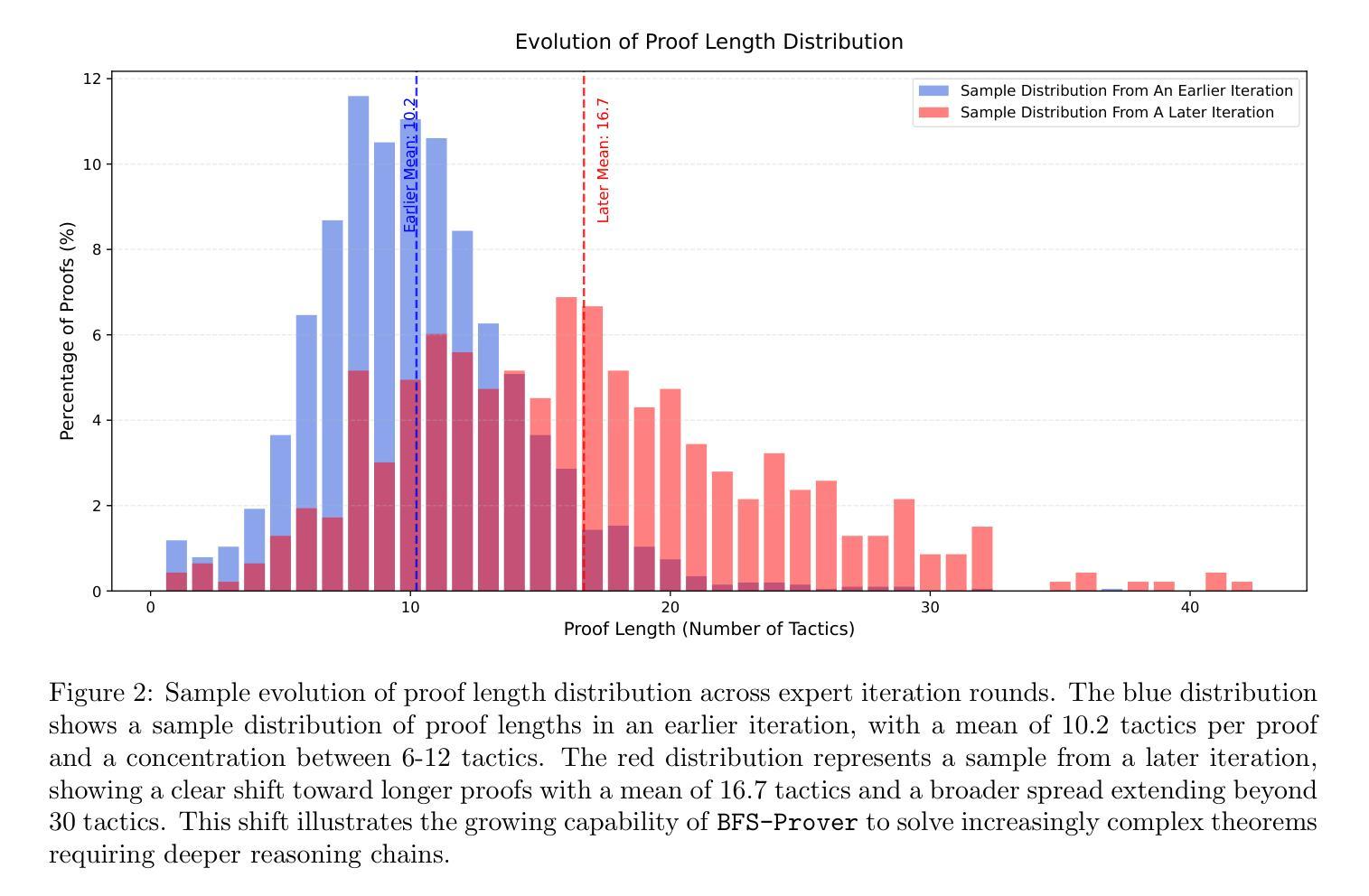
BFS-Prover: Scalable Best-First Tree Search for LLM-based Automatic Theorem Proving
Authors:Ran Xin, Chenguang Xi, Jie Yang, Feng Chen, Hang Wu, Xia Xiao, Yifan Sun, Shen Zheng, Kai Shen
Recent advancements in large language models (LLMs) have spurred growing interest in automatic theorem proving using Lean4, where effective tree search methods are crucial for navigating proof search spaces. While the existing approaches primarily rely on value functions and Monte Carlo Tree Search (MCTS), the potential of simpler methods like Best-First Search (BFS) remains underexplored. This paper investigates whether BFS can achieve competitive performance in large-scale theorem proving tasks. We present \texttt{BFS-Prover}, a scalable expert iteration framework, featuring three key innovations. First, we implement strategic data filtering at each expert iteration round, excluding problems solvable via beam search node expansion to focus on harder cases. Second, we improve the sample efficiency of BFS through Direct Preference Optimization (DPO) applied to state-tactic pairs automatically annotated with compiler error feedback, refining the LLM’s policy to prioritize productive expansions. Third, we employ length normalization in BFS to encourage exploration of deeper proof paths. \texttt{BFS-Prover} achieves a score of $71.31$ on the MiniF2F test set and therefore challenges the perceived necessity of complex tree search methods, demonstrating that BFS can achieve competitive performance when properly scaled.
近期大型语言模型(LLM)的进步激发了使用Lean4进行自动定理证明的兴趣,其中有效的树搜索方法在证明搜索空间中导航至关重要。虽然现有方法主要依赖于值函数和蒙特卡洛树搜索(MCTS),但更简单方法如最佳优先搜索(BFS)的潜力尚未得到充分探索。本文旨在研究BFS在大规模定理证明任务中是否能够实现具有竞争力的性能。我们提出了可扩展的专家迭代框架
BFS-Prover',它具有三个关键创新点。首先,我们在每个专家迭代轮次实现战略数据过滤,排除可通过光束搜索节点扩展解决的问题,专注于更复杂的案例。其次,我们通过应用于状态战术对的直接偏好优化(DPO)改进了BFS的样本效率,状态战术对会自动注释编译器错误反馈,以优化LLM的策略,使其优先进行有生产价值的扩展。最后,我们在BFS中采用长度归一化,以鼓励更深入的证明路径的探索。BFS-Prover’在MiniF2F测试集上取得了71.31的分数,从而质疑了复杂树搜索方法的必要性,证明当适当扩展时,BFS可以实现具有竞争力的性能。
论文及项目相关链接
摘要
大型语言模型(LLM)的最新进展激发了使用Lean4进行自动定理证明的兴趣,其中有效的树搜索方法在证明搜索空间中至关重要。虽然现有方法主要依赖于值函数和蒙特卡洛树搜索(MCTS),但更简单的方法如最佳优先搜索(BFS)的潜力尚未得到充分探索。本文研究BFS在大规模定理证明任务中是否具有竞争力。我们提出了可扩展的专家迭代框架BFS-Prover,具有三个关键创新点。首先,我们在每个专家迭代轮次中实现战略数据过滤,排除可以通过束搜索节点扩展解决的问题,专注于更复杂的情况。其次,通过应用于状态战术对自动注释的编译器错误反馈的直接偏好优化(DPO),提高了BFS的样本效率,优化了LLM的策略以优先考虑有效的扩展。最后,我们在BFS中采用长度归一化,以鼓励更深入的证明路径的探索。BFS-Prover在MiniF2F测试集上取得了71.31的评分,从而挑战了复杂树搜索方法的必要性,表明适当扩展的BFS可以实现有竞争力的性能。
关键见解
- 大型语言模型(LLM)在自动定理证明领域的应用正受到越来越多的关注,其中有效的树搜索方法至关重要。
- 虽然蒙特卡洛树搜索(MCTS)是当前主要方法,但最佳优先搜索(BFS)的潜力尚未得到充分探索。
- 本文提出的BFS-Prover专家迭代框架具有三个关键创新点,包括战略数据过滤、直接偏好优化(DPO)和长度归一化。
- 通过战略数据过滤,BFS-Prover能够专注于更复杂的证明问题。
- DPO提高了BFS的样本效率,通过优化LLM的策略以优先考虑有效的扩展。
- 长度归一化鼓励BFS探索更深入的证明路径。
点此查看论文截图

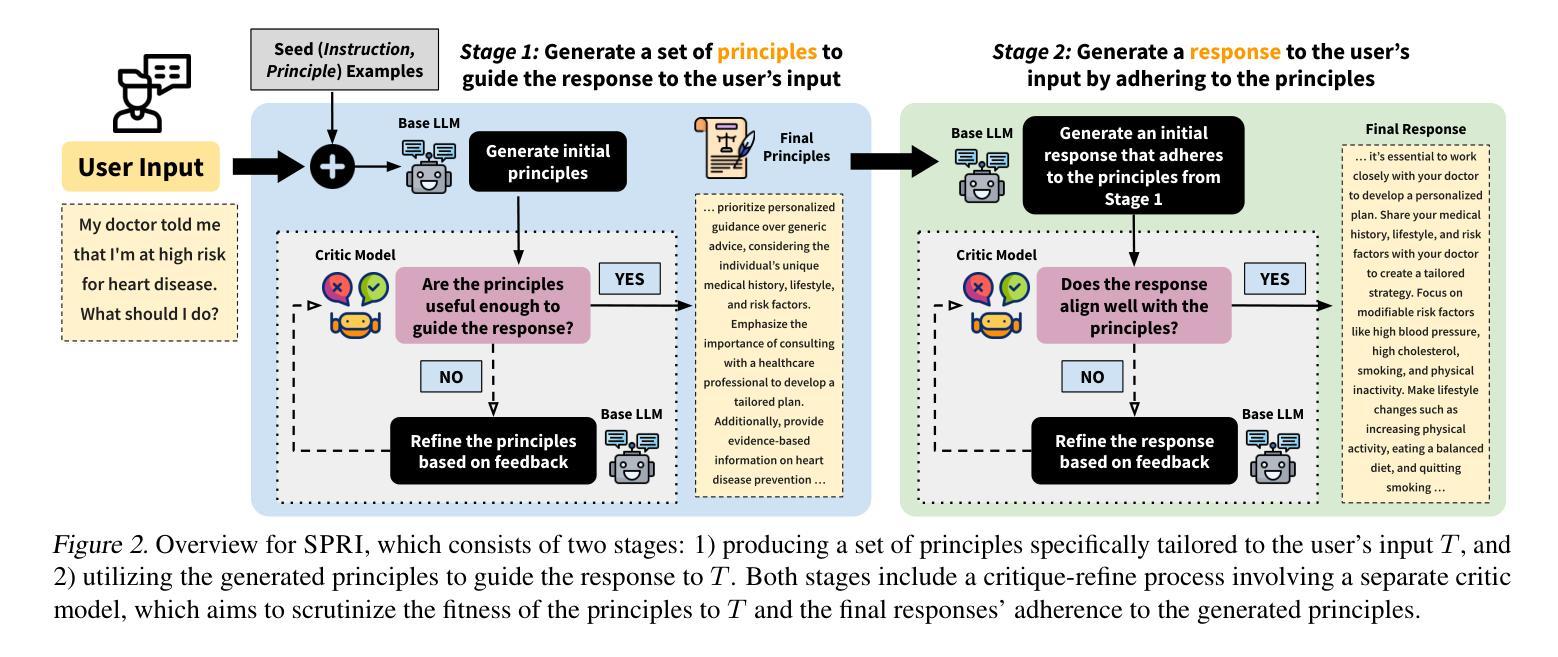
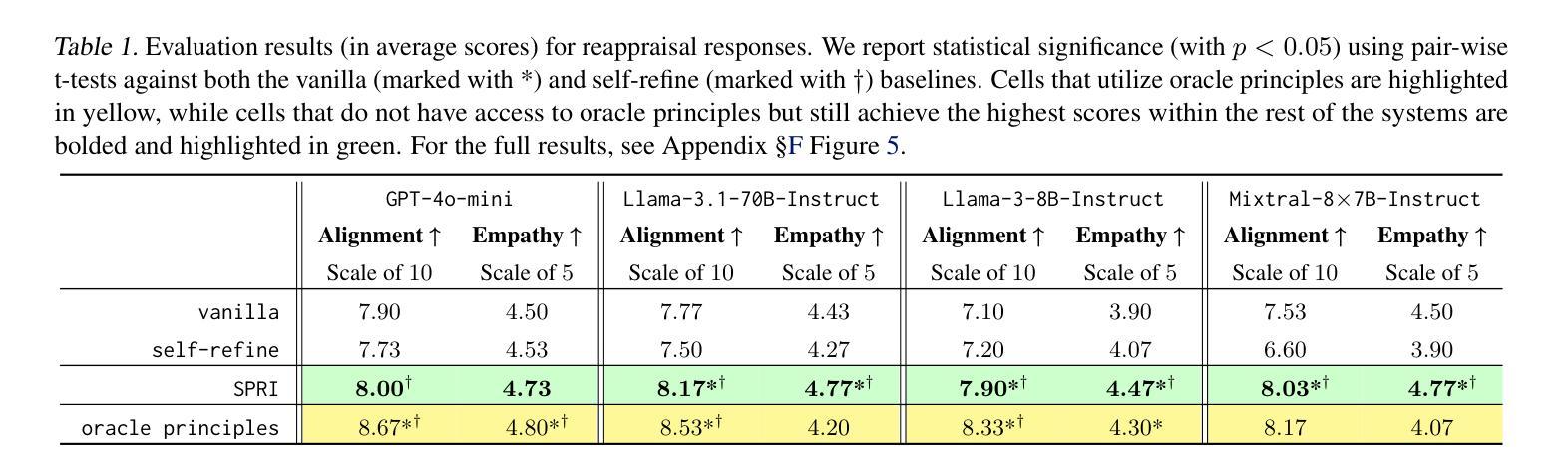
SPRI: Aligning Large Language Models with Context-Situated Principles
Authors:Hongli Zhan, Muneeza Azmat, Raya Horesh, Junyi Jessy Li, Mikhail Yurochkin
Aligning Large Language Models to integrate and reflect human values, especially for tasks that demand intricate human oversight, is arduous since it is resource-intensive and time-consuming to depend on human expertise for context-specific guidance. Prior work has utilized predefined sets of rules or principles to steer the behavior of models (Bai et al., 2022; Sun et al., 2023). However, these principles tend to be generic, making it challenging to adapt them to each individual input query or context. In this work, we present Situated-PRInciples (SPRI), a framework requiring minimal or no human effort that is designed to automatically generate guiding principles in real-time for each input query and utilize them to align each response. We evaluate SPRI on three tasks, and show that 1) SPRI can derive principles in a complex domain-specific task that leads to on-par performance as expert-crafted ones; 2) SPRI-generated principles lead to instance-specific rubrics that outperform prior LLM-as-a-judge frameworks; 3) using SPRI to generate synthetic SFT data leads to substantial improvement on truthfulness. We release our code and model generations at https://github.com/honglizhan/SPRI-public.
将大型语言模型与人类价值观相结合并反映出来,特别是在需要精细人类监督的任务中,是一项艰巨的任务,因为依赖人类专家提供特定情境的指导是资源密集型和耗时的。早期的工作已经利用预先定义的一组规则或原则来引导模型的行为(Bai等人,2022年;Sun等人,2023年)。然而,这些原则往往是通用的,难以适应每个单独的输入查询或上下文。在本研究中,我们提出了情境化原则(SPRI),这是一个需要最小或无需人工参与的框架,旨在实时为每个输入查询自动生成指导原则,并利用它们来对齐每个响应。我们在三项任务上评估了SPRI,并证明:1)SPRI可以在复杂的特定领域任务中推导出原则,其性能与专家制定的原则相当;2)SPRI生成的原则导致实例特定的规则,优于先前的LLM作为法官的框架;3)使用SPRI生成合成SFT数据导致真实性显著提高。我们在https://github.com/honglizhan/SPRI-public上发布了我们的代码和模型生成的数据。
论文及项目相关链接
Summary
基于大型语言模型集成和反映人类价值观的挑战性,本研究提出了一种名为Situated-PRInciples(SPRI)的框架,该框架能够实时为每一个输入查询自动生成指导原则,并利用这些原则对齐每一个响应,无需或只需极少的人工参与。实验表明,SPRI能在复杂领域任务中推导出与专家制定的原则相当的原则,且在实例特定的评判标准上优于先前的LLM判断框架。此外,使用SPRI生成合成数据可显著提高真实性。
Key Takeaways
- 大型语言模型集成和反映人类价值观是一个具有挑战性的问题。
- SPRI框架可以实时为每一个输入查询自动生成指导原则,实现模型的自动对齐。
- SPRI框架可以减少对人工经验的依赖。
- SPRI在复杂领域任务中推导出的原则与专家制定的原则相当。
- SPRI在实例特定的评判标准上优于先前的LLM判断框架。
- 使用SPRI生成合成数据可以显著提高真实性。
点此查看论文截图

LIMO: Less is More for Reasoning
Authors:Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, Pengfei Liu
We present a fundamental discovery that challenges our understanding of how complex reasoning emerges in large language models. While conventional wisdom suggests that sophisticated reasoning tasks demand extensive training data (>100,000 examples), we demonstrate that complex mathematical reasoning abilities can be effectively elicited with surprisingly few examples. Through comprehensive experiments, our proposed model LIMO demonstrates unprecedented performance in mathematical reasoning. With merely 817 curated training samples, LIMO achieves 57.1% accuracy on AIME and 94.8% on MATH, improving from previous SFT-based models’ 6.5% and 59.2% respectively, while only using 1% of the training data required by previous approaches. LIMO demonstrates exceptional out-of-distribution generalization, achieving 40.5% absolute improvement across 10 diverse benchmarks, outperforming models trained on 100x more data, challenging the notion that SFT leads to memorization rather than generalization. Based on these results, we propose the Less-Is-More Reasoning Hypothesis (LIMO Hypothesis): In foundation models where domain knowledge has been comprehensively encoded during pre-training, sophisticated reasoning capabilities can emerge through minimal but precisely orchestrated demonstrations of cognitive processes. This hypothesis posits that the elicitation threshold for complex reasoning is determined by two key factors: (1) the completeness of the model’s encoded knowledge foundation during pre-training, and (2) the effectiveness of post-training examples as “cognitive templates” that show the model how to utilize its knowledge base to solve complex reasoning tasks. To facilitate reproducibility and future research in data-efficient reasoning, we release LIMO as a comprehensive open-source suite at https://github.com/GAIR-NLP/LIMO.
我们提出了一项具有挑战性的新发现,这项发现对我们理解大型语言模型中复杂推理如何产生提出了新的挑战。虽然传统智慧表明,复杂的推理任务需要大量的训练数据(>100,000个样本),但我们证明,使用出人意料的少量样本可以有效地激发复杂的数学推理能力。通过全面的实验,我们提出的LIMO模型在数学推理方面表现出了前所未有的性能。仅使用817个精选的训练样本,LIMO在AIME上达到了57.1%的准确率,在MATH上达到了94.8%的准确率,相较于之前的基于SFT的模型分别提高了6.5%和59.2%,同时仅使用了之前方法所需训练数据的1%。LIMO展现出卓越的非分布泛化能力,在10个不同的基准测试中实现了40.5%的绝对改进,超越了使用100倍数据的模型,这挑战了SFT导致记忆而非泛化的观念。基于这些结果,我们提出了“少即是多”的推理假设(LIMO假设):在已全面编码领域知识的基石模型中,通过少量但精心编排的认知过程演示,可以产生复杂的推理能力。该假设认为,复杂推理的激发阈值由两个关键因素决定:(1)预训练期间模型中编码的知识基础的完整性,(2)作为“认知模板”的后期训练样本的有效性,这些模板向模型展示如何利用其知识库来解决复杂的推理任务。为了促进数据高效推理的再现性和未来研究,我们在https://github.com/GAIR-NLP/LIMO上发布了LIMO作为一个全面的开源套件。
论文及项目相关链接
PDF 17 pages
Summary
该研究发现挑战了我们对大型语言模型中复杂推理能力如何出现的理解。传统观点认为复杂的推理任务需要大量的训练数据(> 10万个例子),但本研究显示,使用少数意外惊人的例子可以有效激发复杂的数学推理能力。通过全面的实验,所提出的LIMO模型在数学推理方面展现出前所未有的性能。仅使用817个精选的训练样本,LIMO在AIME上达到57.1%的准确率,在MATH上达到94.8%,相较于之前的基于SFT的模型分别提高了6.5%和35.6%。LIMO展现出卓越的非分布泛化能力,在10个不同的基准测试中实现了40.5%的绝对改进,甚至超越了使用100倍数据的模型,质疑了SFT可能导致记忆而非泛化的观点。研究结果引出了一种新的假设——少即是多推理假设(LIMO假设):在预训练阶段全面编码领域知识的模型,可以通过最少的、精心组织后的认知过程演示来激发复杂的推理能力。假设的关键在于预训练期间模型知识基础的完整性以及后训练示例作为“认知模板”的有效性。为了促进数据高效推理的再现性和未来研究,LIMO作为一个全面的开源套件已经发布。
Key Takeaways
- 复杂的数学推理能力可以通过使用少量精选的训练样本进行有效激发。
- 新的模型LIMO仅使用很少的训练样本就能在数学推理任务上取得优异性能。
- LIMO展现出卓越的非分布泛化能力,质疑了SFT可能导致记忆而非泛化的观点。
- LIMO假设提出,复杂推理能力的出现取决于模型预训练知识基础的完整性和后训练示例的有效性。
- 传统观点关于大量训练数据的需要受到挑战。
- 通过少量精准的训练示例演示可以引导模型解决复杂的推理任务。
点此查看论文截图

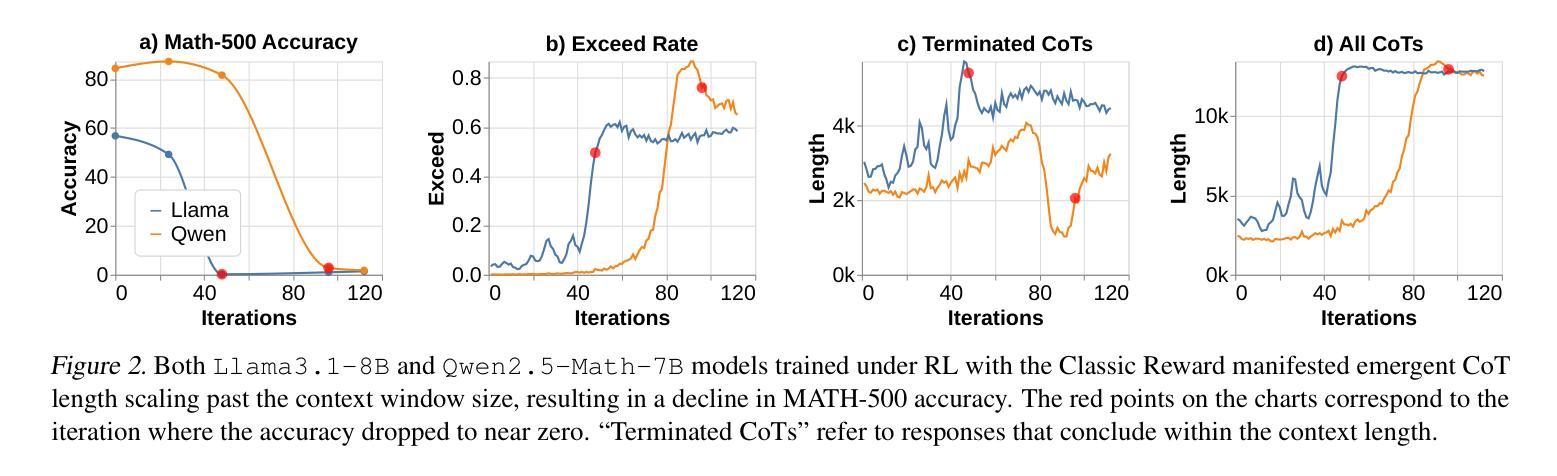
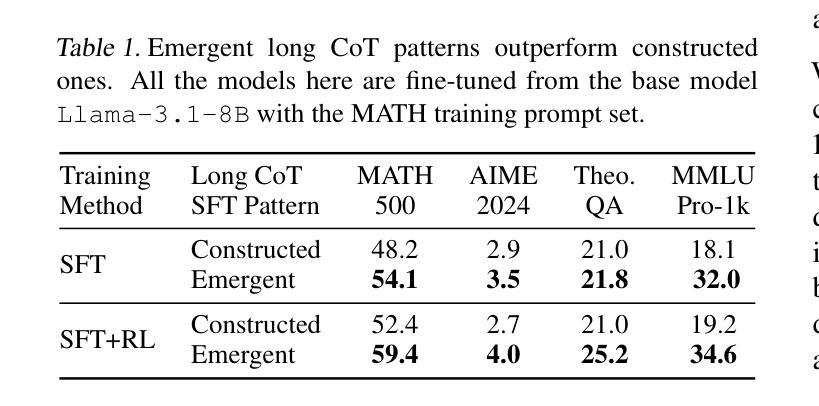
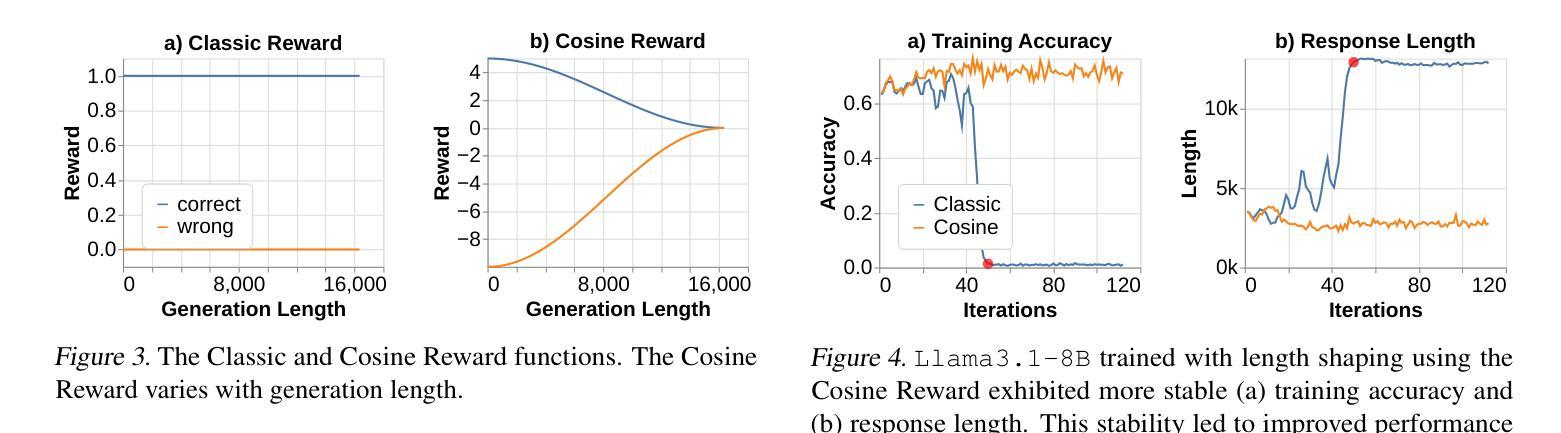
Demystifying Long Chain-of-Thought Reasoning in LLMs
Authors:Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, Xiang Yue
Scaling inference compute enhances reasoning in large language models (LLMs), with long chains-of-thought (CoTs) enabling strategies like backtracking and error correction. Reinforcement learning (RL) has emerged as a crucial method for developing these capabilities, yet the conditions under which long CoTs emerge remain unclear, and RL training requires careful design choices. In this study, we systematically investigate the mechanics of long CoT reasoning, identifying the key factors that enable models to generate long CoT trajectories. Through extensive supervised fine-tuning (SFT) and RL experiments, we present four main findings: (1) While SFT is not strictly necessary, it simplifies training and improves efficiency; (2) Reasoning capabilities tend to emerge with increased training compute, but their development is not guaranteed, making reward shaping crucial for stabilizing CoT length growth; (3) Scaling verifiable reward signals is critical for RL. We find that leveraging noisy, web-extracted solutions with filtering mechanisms shows strong potential, particularly for out-of-distribution (OOD) tasks such as STEM reasoning; and (4) Core abilities like error correction are inherently present in base models, but incentivizing these skills effectively for complex tasks via RL demands significant compute, and measuring their emergence requires a nuanced approach. These insights provide practical guidance for optimizing training strategies to enhance long CoT reasoning in LLMs. Our code is available at: https://github.com/eddycmu/demystify-long-cot.
扩展推理计算增强了大型语言模型(LLM)的推理能力,长期的思维链(CoT)使回溯和错误修正等策略得以实施。强化学习(RL)已经成为发展这些能力的重要方法,然而长期CoT出现的条件仍不清楚,而且RL训练需要仔细的设计选择。在这项研究中,我们系统地研究了长期CoT推理的机制,确定了使模型生成长期CoT轨迹的关键因素。通过广泛的监督微调(SFT)和RL实验,我们提出了四个主要发现:
(1)虽然SFT并不是绝对必要的,但它简化了训练并提高了效率;
(2)推理能力往往随着训练计算的增加而涌现,但其发展并非必然,这使得奖励塑造对于稳定CoT长度增长至关重要;
(3)扩大可验证的奖励信号对RL至关重要。我们发现,利用带有过滤机制的嘈杂的网页提取解决方案具有很强的潜力,特别是对于像STEM推理之类的离分布任务;
(4)基础模型本身就具有错误修正等核心能力,但要通过RL有效地激励这些技能来完成复杂任务需要大量的计算,而且衡量它们的出现需要一种细致的方法。这些见解为优化训练策略以增强LLM中的长期CoT推理提供了实际指导。我们的代码可在此处找到:https://github.com/eddycmu/demystify-long-cot。
论文及项目相关链接
PDF Preprint, under review
Summary
大语言模型(LLM)通过推理计算扩展来提升推理能力,其中长思考链(CoTs)策略如回溯和错误校正尤为重要。强化学习(RL)是开发这些能力的重要方法,但长思考链出现的条件尚不清楚,且RL训练需要谨慎设计选择。本研究通过系统的调查长思考链推理的机制,确定了促进模型生成长思考链轨迹的关键因素。通过广泛的监督微调(SFT)和RL实验,我们提出四点主要发现:SFT并非必需,但简化训练并提高效率;推理能力往往随着训练计算的增加而发展,但其发展并非必然,奖励塑形对稳定思考长度增长至关重要;验证奖励信号的扩展对RL至关重要;基于过滤机制的嘈杂的网页提取解决方案对于出分布任务(如STEM推理)具有巨大潜力;基础模型本身就具备纠错等核心能力,但通过RL激励这些技能进行复杂任务需要大量的计算,并且衡量它们的出现需要细致的方法。这些见解为优化训练策略以提高LLM的长思考链推理能力提供了实际指导。
Key Takeaways
- 监督微调(SFT)虽然不是必需的,但它可以简化训练并提高效率。
- 推理能力会随着训练计算的增加而发展,但这一过程并不稳定,奖励塑形是关键。
- 扩展验证奖励信号对强化学习至关重要。
- 利用带有过滤机制的嘈杂网页提取解决方案对于处理出分布任务具有潜力。
- 基础模型已经具备一些核心能力如错误校正,但要通过强化学习有效激励这些技能需要大量计算。
- 测量这些能力的出现需要细致的方法。
点此查看论文截图



Simplifying Formal Proof-Generating Models with ChatGPT and Basic Searching Techniques
Authors:Sangjun Han, Taeil Hur, Youngmi Hur, Kathy Sangkyung Lee, Myungyoon Lee, Hyojae Lim
The challenge of formal proof generation has a rich history, but with modern techniques, we may finally be at the stage of making actual progress in real-life mathematical problems. This paper explores the integration of ChatGPT and basic searching techniques to simplify generating formal proofs, with a particular focus on the miniF2F dataset. We demonstrate how combining a large language model like ChatGPT with a formal language such as Lean, which has the added advantage of being verifiable, enhances the efficiency and accessibility of formal proof generation. Despite its simplicity, our best-performing Lean-based model surpasses all known benchmarks with a 31.15% pass rate. We extend our experiments to include other datasets and employ alternative language models, showcasing our models’ comparable performance in diverse settings and allowing for a more nuanced analysis of our results. Our findings offer insights into AI-assisted formal proof generation, suggesting a promising direction for future research in formal mathematical proof.
形式化证明生成这一挑战有着悠久的历史背景,但随着现代技术的发展,我们可能终于处于在实际数学问题上取得真正进展的阶段。本文探讨了将ChatGPT和基本搜索技术相结合,以简化形式化证明生成的过程,特别是侧重于miniF2F数据集的应用。我们展示了如何将ChatGPT等大型语言模型与Lean等可验证的形式化语言相结合,以提高形式化证明的效率和可及性。尽管我们的基于Lean的最佳模型非常简单,但其通过率达到了31.15%,超过了所有已知基准测试。我们进一步扩展实验,包括使用其他数据集和替代语言模型,展示了我们的模型在不同环境中的可比性能,并允许对结果进行更微妙的分析。我们的研究为人工智能辅助形式化证明生成提供了见解,并为未来形式化数学证明的研究指明了有前景的方向。
论文及项目相关链接
Summary
现代技术可能使我们在实际的数学问题上取得进展。本文探讨了将ChatGPT和基本搜索技术相结合,以简化生成形式证明的过程,特别关注miniF2F数据集。通过与形式语言(如Lean)相结合,这种技术可以提高形式证明生成的效率和可及性。最佳性能的Lean模型超越了所有已知基准测试,达到31.15%的通过率。实验还扩展到其他数据集并使用其他语言模型,展示了在各种环境中的性能可比性,并为结果提供了更微妙的分析。这为人工智能辅助形式证明生成提供了见解,并为未来形式数学证明的研究提供了有希望的方向。
Key Takeaways
- 现代技术有助于在实际数学问题上的形式证明生成取得进展。
- ChatGPT与基本搜索技术的结合简化了形式证明生成过程。
- 与形式语言Lean的结合提高了形式证明生成的效率和可及性。
- 最佳性能的Lean模型在miniF2F数据集上的通过率达到31.15%,超越现有基准。
- 实验扩展到其他数据集和语言模型,展示了模型的广泛适用性。
- 不同环境下的实验结果为分析提供了更微妙的视角。
点此查看论文截图

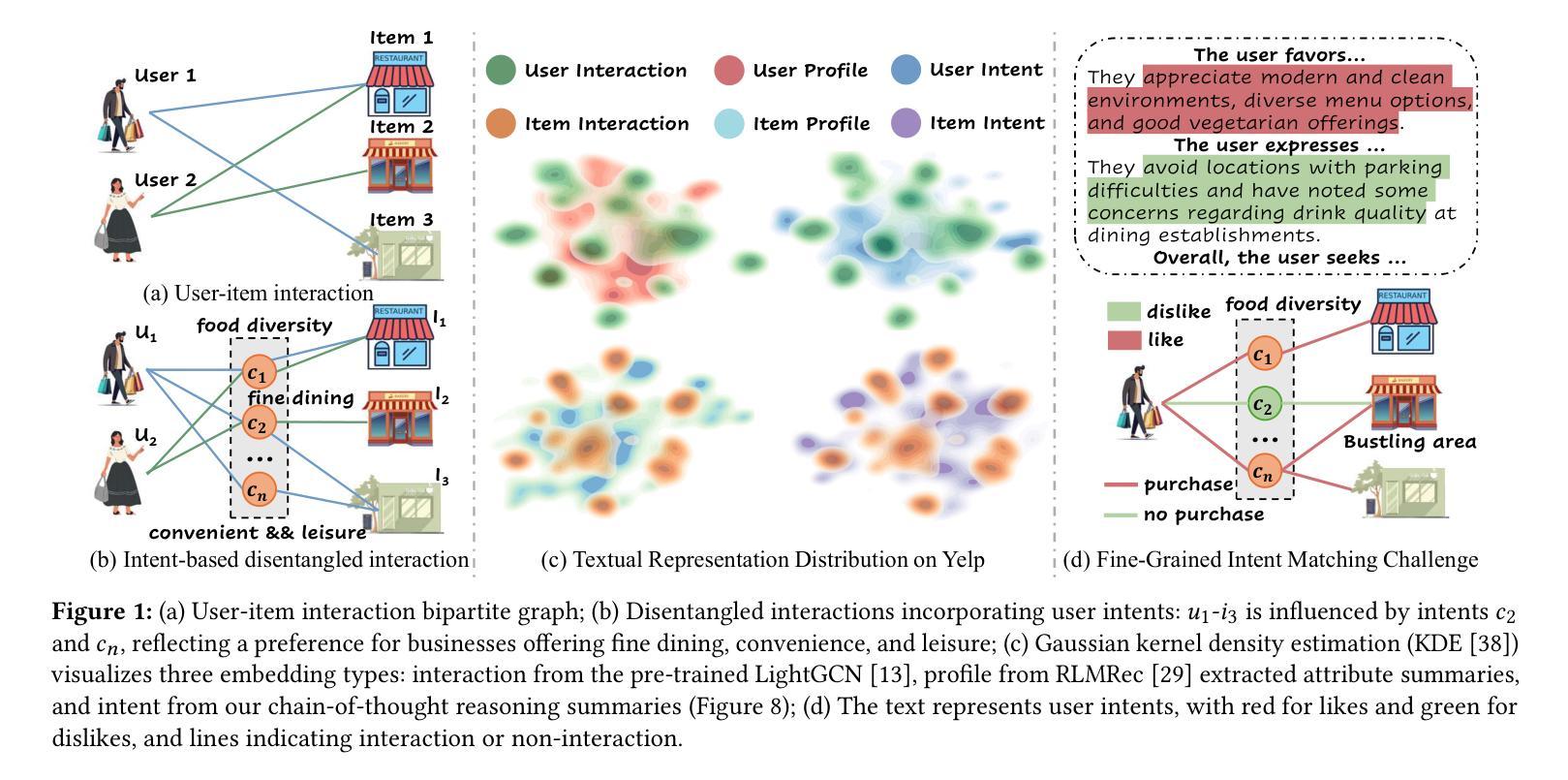
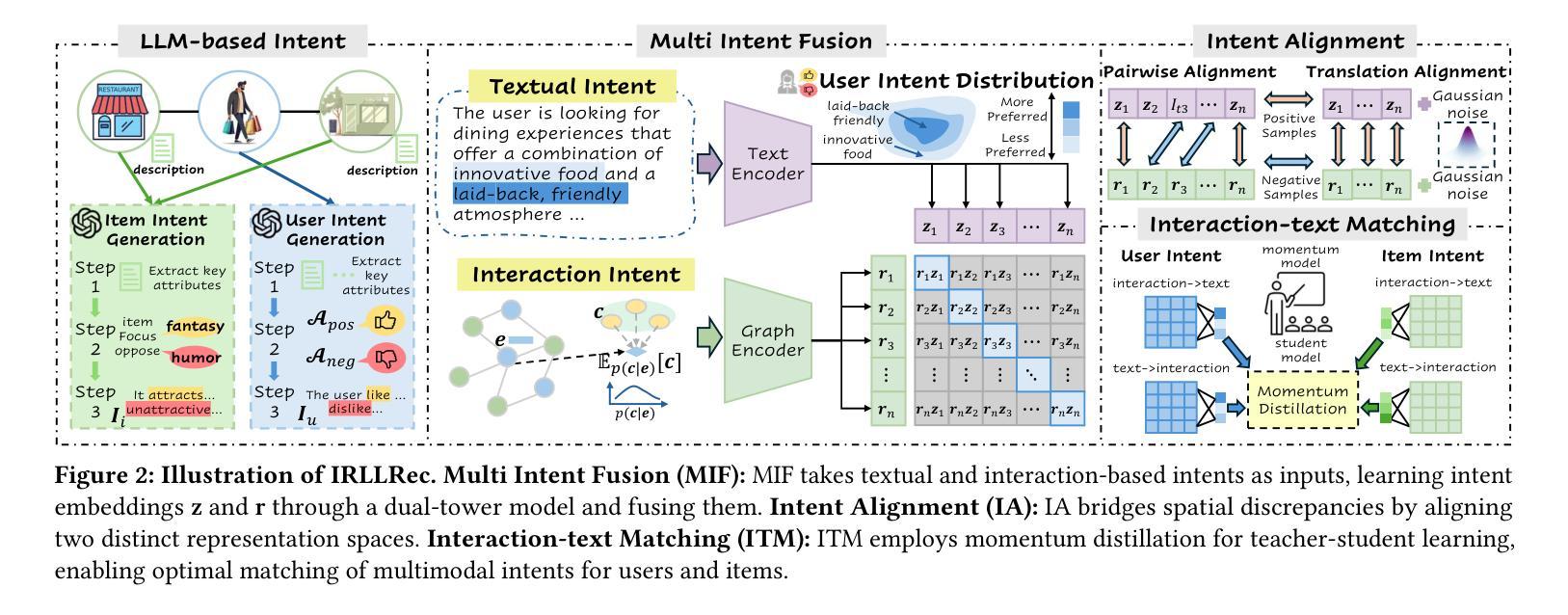
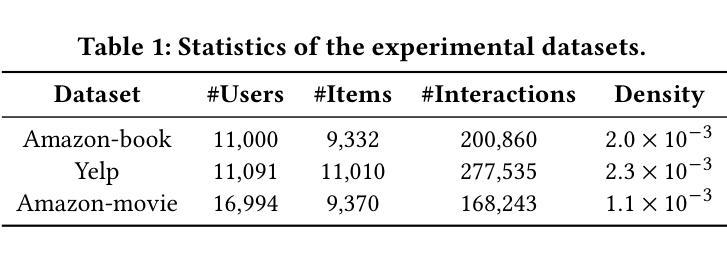
Intent Representation Learning with Large Language Model for Recommendation
Authors:Yu Wang, Lei Sang, Yi Zhang, Yiwen Zhang
Intent-based recommender systems have garnered significant attention for uncovering latent fine-grained preferences. Intents, as underlying factors of interactions, are crucial for improving recommendation interpretability. Most methods define intents as learnable parameters updated alongside interactions. However, existing frameworks often overlook textual information (e.g., user reviews, item descriptions), which is crucial for alleviating the sparsity of interaction intents. Exploring these multimodal intents, especially the inherent differences in representation spaces, poses two key challenges: i) How to align multimodal intents and effectively mitigate noise issues; ii) How to extract and match latent key intents across modalities. To tackle these challenges, we propose a model-agnostic framework, Intent Representation Learning with Large Language Model (IRLLRec), which leverages large language models (LLMs) to construct multimodal intents and enhance recommendations. Specifically, IRLLRec employs a dual-tower architecture to learn multimodal intent representations. Next, we propose pairwise and translation alignment to eliminate inter-modal differences and enhance robustness against noisy input features. Finally, to better match textual and interaction-based intents, we employ momentum distillation to perform teacher-student learning on fused intent representations. Empirical evaluations on three datasets show that our IRLLRec framework outperforms baselines. The implementation is available at https://github.com/wangyu0627/IRLLRec.
基于意图的推荐系统已经引起了人们的广泛关注,因为它能够揭示潜在的精细偏好。作为交互的基础因素,意图对于提高推荐的可解释性至关重要。大多数方法将意图定义为可学习的参数,并随着交互进行更新。然而,现有框架往往忽视了文本信息(如用户评论、商品描述),这对于缓解交互意图的稀疏性至关重要。探索这些多模式意图,尤其是表示空间中的内在差异,提出了两个关键挑战:一是如何对齐多模式意图并有效地缓解噪声问题;二是如何跨模态提取和匹配潜在的关键意图。为了应对这些挑战,我们提出了一个模型无关框架——基于大语言模型的意图表示学习(IRLLRec),它利用大型语言模型构建多模式意图并提高推荐效果。具体来说,IRLLRec采用双塔架构来学习多模式意图表示。接下来,我们提出配对和翻译对齐来消除模态之间的差异,并提高对抗噪声输入特征的稳健性。最后,为了更好地匹配文本和基于交互的意图,我们在融合的意图表示上采用动量蒸馏法进行师徒学习。在三套数据集上的实证评估表明,我们的IRLLRec框架优于基准线。相关实现可访问 https://github.com/wangyu0627/IRLLRec 了解。
论文及项目相关链接
PDF 11 pages, 8 figures
Summary:
意图感知推荐系统通过挖掘潜在精细偏好引起了广泛关注。意图作为交互的基本因素,对于提高推荐的可解释性至关重要。大多数方法将意图定义为可学习的参数,与交互一起更新。然而,现有框架往往忽略了文本信息(如用户评论、商品描述),这对于缓解交互意图的稀疏性至关重要。为了应对如何对齐多模式意图并有效缓解噪声问题以及如何在不同模式下提取和匹配潜在关键意图这两个挑战,我们提出了一个模型无关的框架,名为“基于大语言模型的意图表示学习”(IRLLRec)。IRLLRec利用大型语言模型构建多模式意图并增强推荐。具体而言,IRLLRec采用双塔架构来学习多模式意图表示。然后,我们提出配对和翻译对齐来消除跨模式的差异并提高对不同输入特征的稳健性。最后,为了更好地匹配文本和基于交互的意图,我们采用动量蒸馏法对融合的意图表示进行师徒学习。在三个数据集上的实证评估表明,我们的IRLLRec框架优于基线方法。具体实现请参考https://github.com/wangyu0627/IRLLRec。
Key Takeaways:
- 意图感知推荐系统挖掘用户潜在精细偏好,以提高推荐的可解释性。
- 现有推荐系统方法多忽略文本信息,如用户评论和商品描述,这影响了交互意图的丰富性。
- 处理多模式意图面临两大挑战:对齐不同模式的意图并消除噪声,以及在不同模式下提取和匹配关键潜在意图。
- IRLLRec框架利用大型语言模型构建多模式意图表示,采用双塔架构来学习这些表示。
- IRLLRec通过配对和翻译对齐来增强对不同输入特征的稳健性,并消除跨模式的差异。
- 动量蒸馏法用于匹配文本和基于交互的意图,对融合的意图表示进行师徒学习。
点此查看论文截图

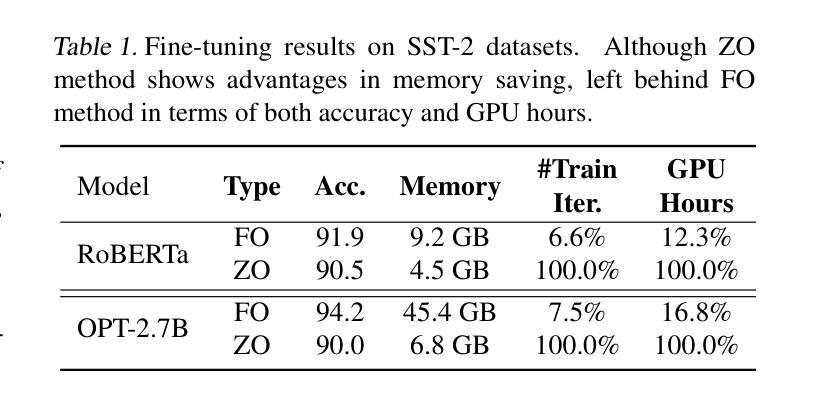
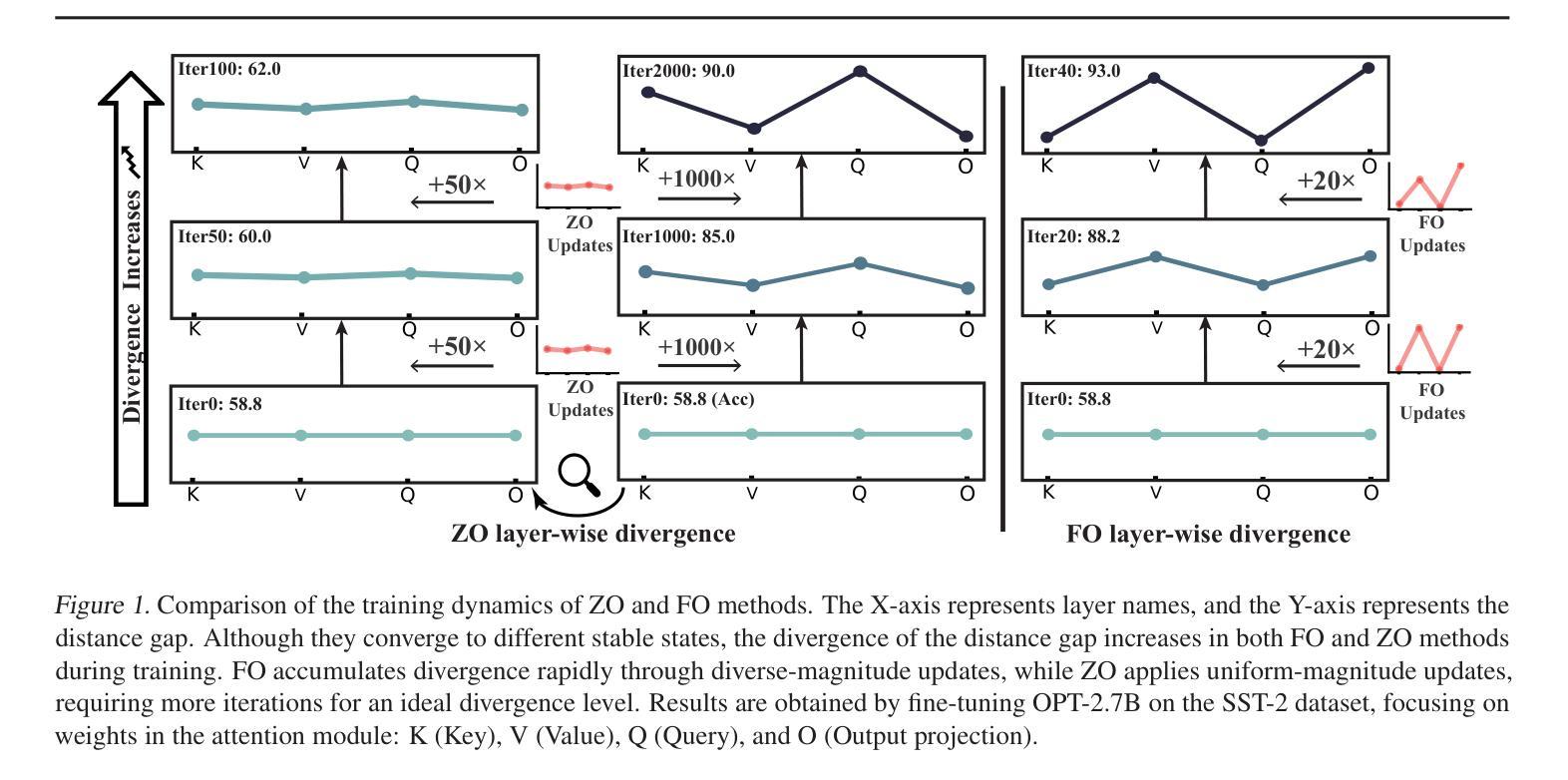
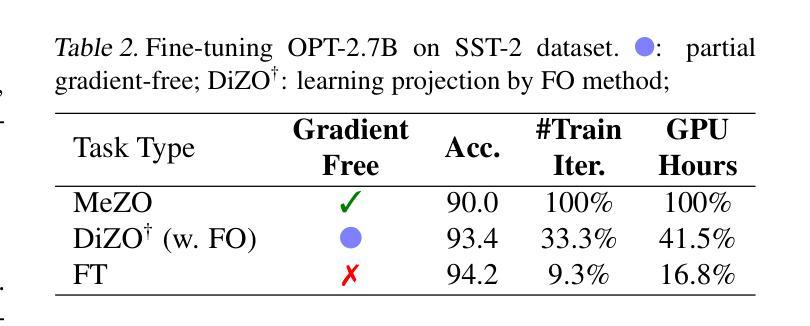
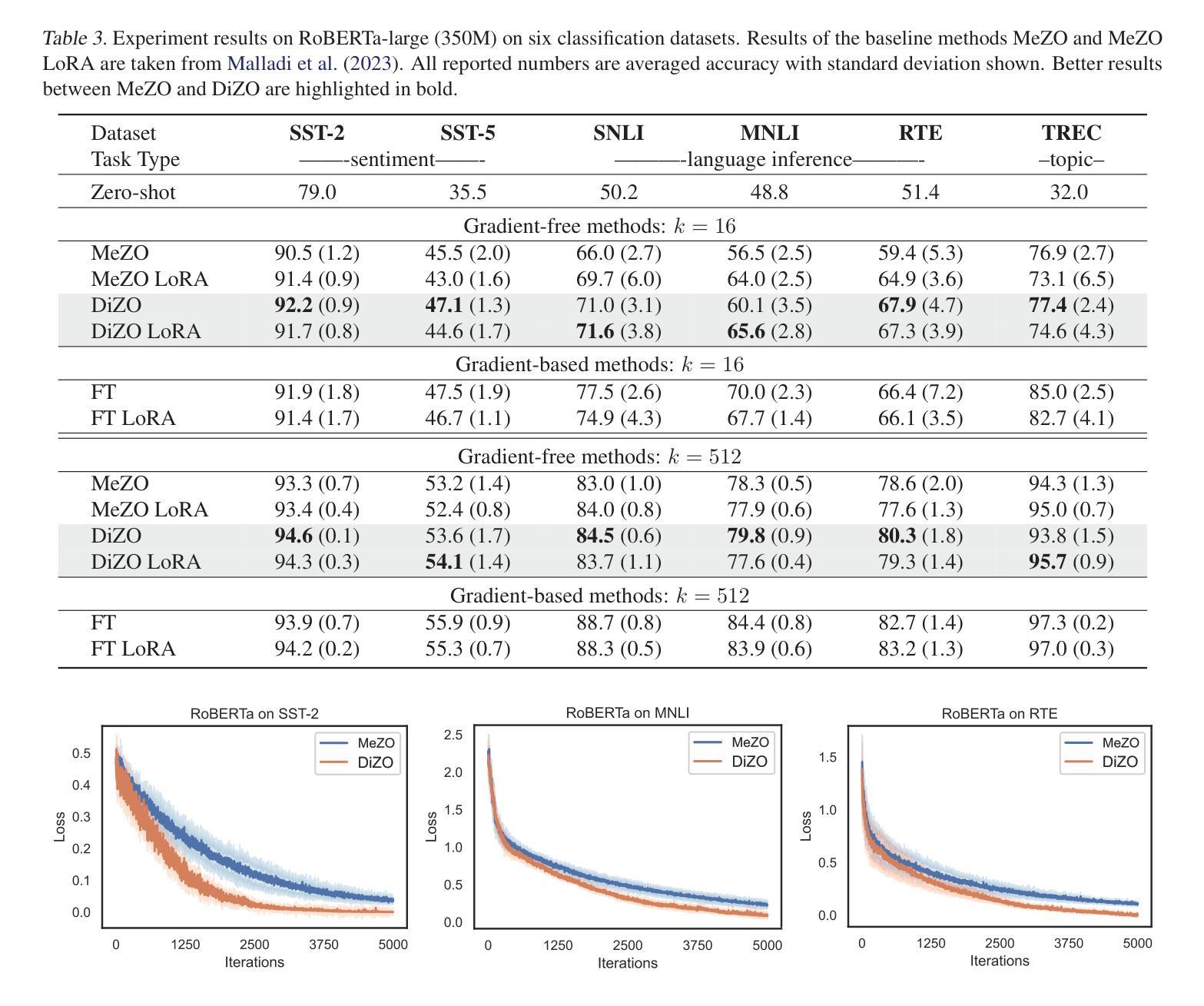
Harmony in Divergence: Towards Fast, Accurate, and Memory-efficient Zeroth-order LLM Fine-tuning
Authors:Qitao Tan, Jun Liu, Zheng Zhan, Caiwei Ding, Yanzhi Wang, Jin Lu, Geng Yuan
Large language models (LLMs) excel across various tasks, but standard first-order (FO) fine-tuning demands considerable memory, significantly limiting real-world deployment. Recently, zeroth-order (ZO) optimization stood out as a promising memory-efficient training paradigm, avoiding backward passes and relying solely on forward passes for gradient estimation, making it attractive for resource-constrained scenarios. However, ZO method lags far behind FO method in both convergence speed and accuracy. To bridge the gap, we introduce a novel layer-wise divergence analysis that uncovers the distinct update pattern of FO and ZO optimization. Aiming to resemble the learning capacity of FO method from the findings, we propose \textbf{Di}vergence-driven \textbf{Z}eroth-\textbf{O}rder (\textbf{DiZO}) optimization. DiZO conducts divergence-driven layer adaptation by incorporating projections to ZO updates, generating diverse-magnitude updates precisely scaled to layer-wise individual optimization needs. Our results demonstrate that DiZO significantly reduces the needed iterations for convergence without sacrificing throughput, cutting training GPU hours by up to 48% on various datasets. Moreover, DiZO consistently outperforms the representative ZO baselines in fine-tuning RoBERTa-large, OPT-series, and Llama-series on downstream tasks and, in some cases, even surpasses memory-intensive FO fine-tuning.
大型语言模型(LLM)在各种任务中表现出色,但标准的一阶(FO)微调需要大量的内存,这极大地限制了其在现实世界中的应用。最近,零阶(ZO)优化作为一种具有前景的内存高效训练范式脱颖而出,它避免了反向传递并只依赖正向传递进行梯度估计,因此对于资源受限的场景具有很强的吸引力。然而,ZO方法在收敛速度和准确性方面都远远落后于FO方法。为了弥补这一差距,我们引入了一种新型逐层发散分析,揭示了FO和ZO优化的不同更新模式。基于我们的发现,我们旨在模仿FO方法的学习能力,并提出了DiZO(发散驱动零阶优化)。DiZO通过结合投影到ZO更新来进行发散驱动的层适应,生成精确缩放至每层个别优化需求的更新幅度。我们的结果表明,DiZO在无需牺牲吞吐量的情况下显著减少了所需的收敛迭代次数,在各种数据集上将训练GPU小时数减少了高达48%。此外,DiZO在微调RoBERTa大型模型、OPT系列和Llama系列时,在下游任务上始终优于代表性的ZO基线,并且在某些情况下甚至超过了内存密集型的FO微调。
论文及项目相关链接
Summary
大型语言模型(LLM)在各种任务中表现出色,但标准一阶微调需要大量内存,限制了其在现实世界的部署。零阶优化作为一种内存效率高的训练范式备受关注,它避免了反向传播并只依赖正向传播进行梯度估计,适用于资源受限的场景。然而,零阶方法在收敛速度和准确性方面远远落后于一阶方法。为了缩小差距,本文进行了逐层发散分析,揭示了一阶和零阶优化的不同更新模式。基于这些发现,提出了发散驱动零阶优化(DiZO)。DiZO通过结合投影到零阶更新来进行发散驱动层适配,生成精确缩放、幅度各异的更新,以满足各层的个别优化需求。结果证明,DiZO在不影响吞吐量的情况下显著减少了收敛所需的迭代次数,在多种数据集上将GPU训练时间减少了高达48%。此外,DiZO在微调RoBERTa-large、OPT系列和Llama系列时,在下游任务上的表现均优于代表性的零阶基线,甚至有些情况下超过了内存密集的一阶微调。
Key Takeaways
- 大型语言模型(LLM)在各种任务中表现出色,但标准一阶微调需要大量内存。
- 零阶优化是一种内存效率高的训练范式,但其在收敛速度和准确性方面存在不足。
- 通过逐层发散分析,发现一阶和零阶优化的不同更新模式。
- 提出了发散驱动零阶优化(DiZO),通过结合投影到零阶更新来进行层适配。
- DiZO显著减少了收敛所需的迭代次数,并提高了训练效率。
- DiZO在多种数据集上将GPU训练时间减少了高达48%。
点此查看论文截图

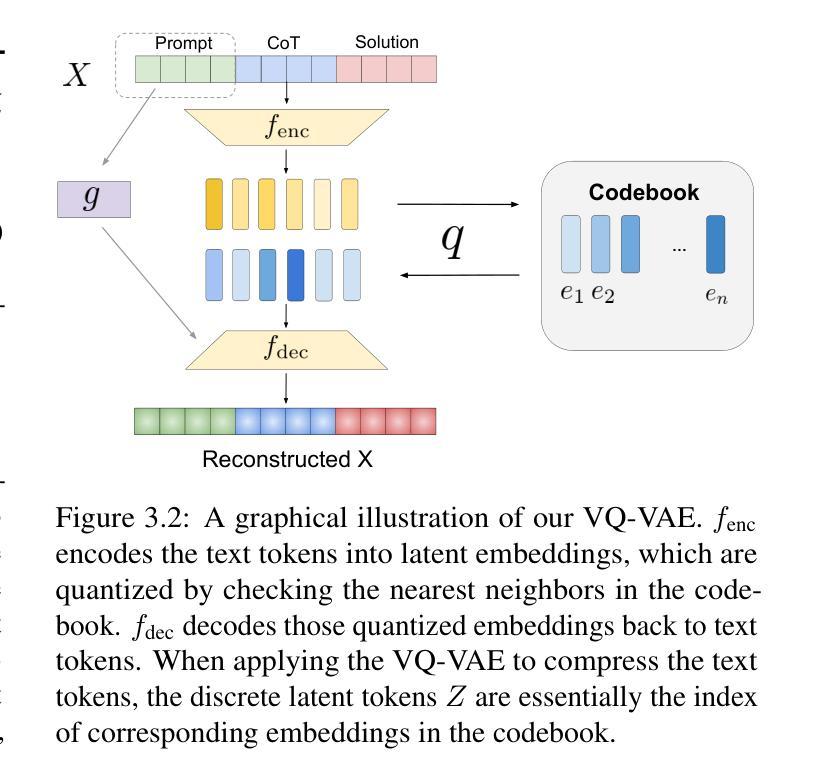
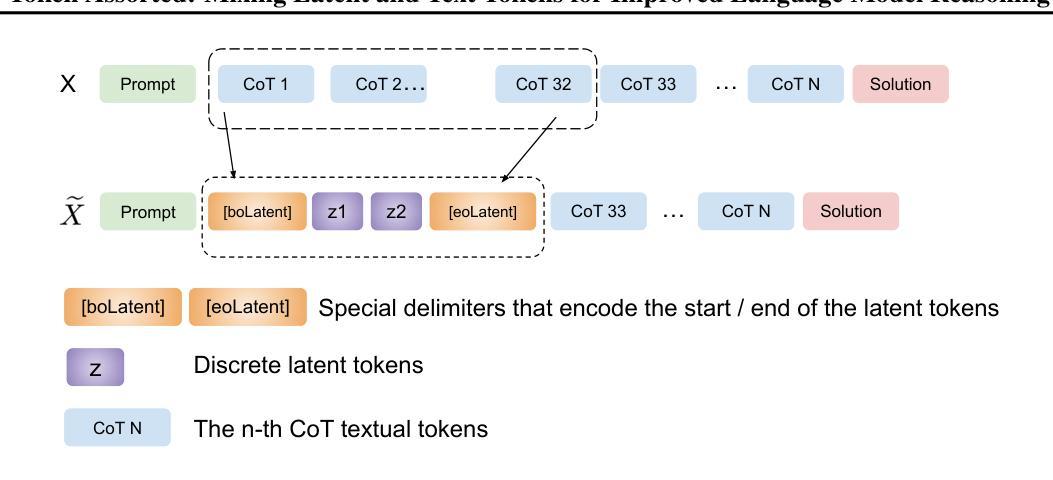
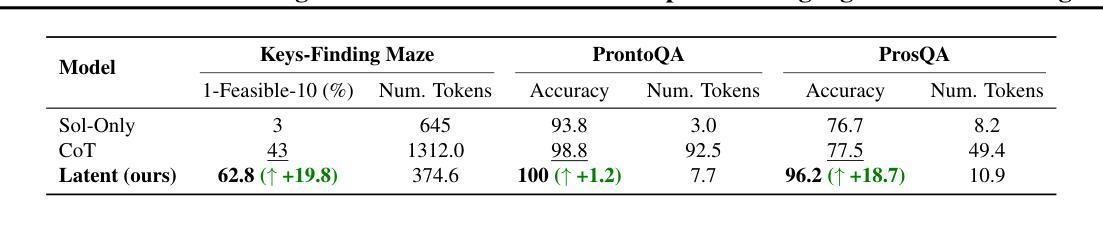
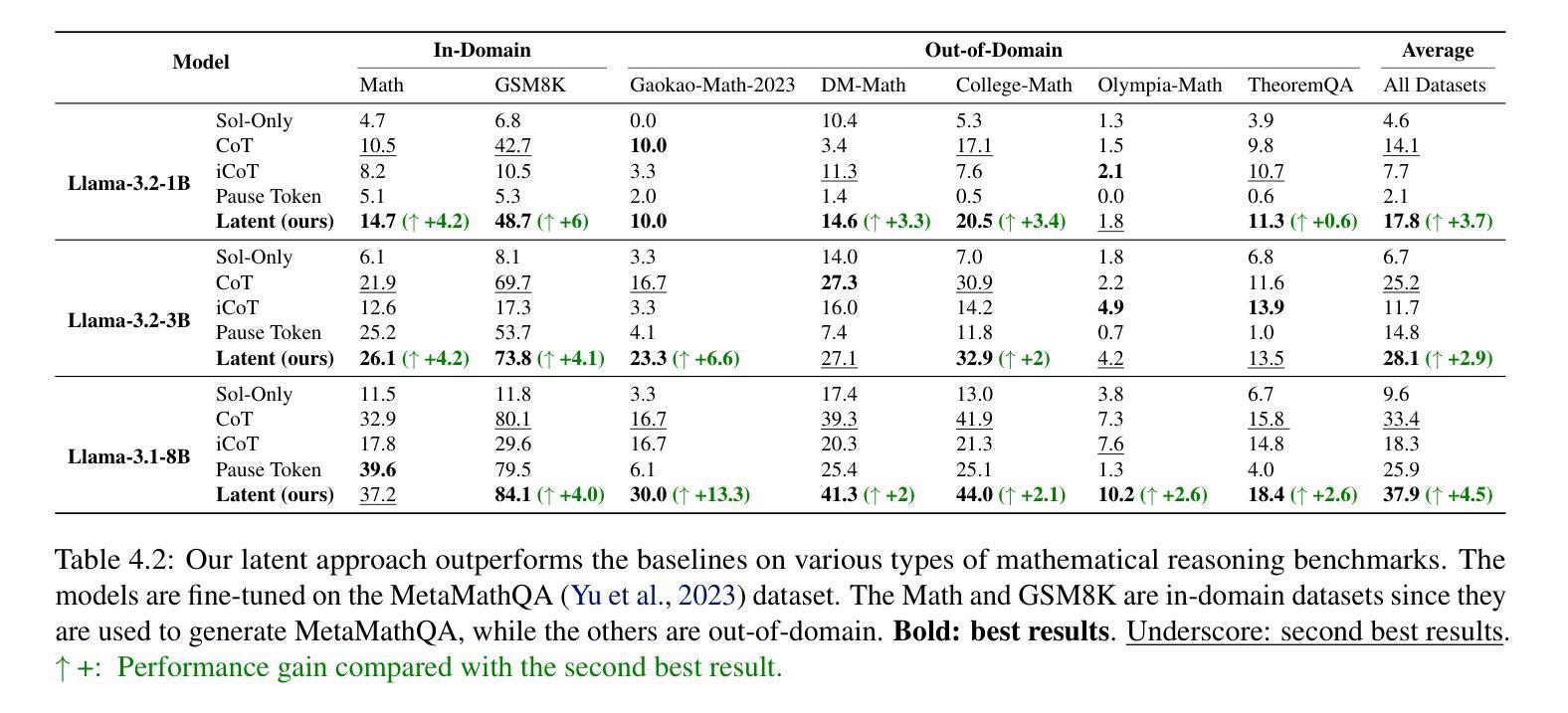
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
Authors:DiJia Su, Hanlin Zhu, Yingchen Xu, Jiantao Jiao, Yuandong Tian, Qinqing Zheng
Large Language Models (LLMs) excel at reasoning and planning when trained on chainof-thought (CoT) data, where the step-by-step thought process is explicitly outlined by text tokens. However, this results in lengthy inputs where many words support textual coherence rather than core reasoning information, and processing these inputs consumes substantial computation resources. In this work, we propose a hybrid representation of the reasoning process, where we partially abstract away the initial reasoning steps using latent discrete tokens generated by VQ-VAE, significantly reducing the length of reasoning traces. We explore the use of latent trace abstractions in two scenarios: 1) training the model from scratch for the Keys-Finding Maze problem, 2) fine-tuning LLMs on this hybrid data with an extended vocabulary including unseen latent tokens, for both logical and mathematical reasoning problems. To facilitate effective learning, we introduce a simple training procedure that randomly mixes latent and text tokens, which enables fast adaptation to new latent tokens. Our approach consistently outperforms the baselines methods in various benchmarks.
大型语言模型(LLM)在基于思维链(CoT)数据训练时,擅长推理和规划。在这种数据中,文本标记会明确概述逐步的思维方式。然而,这会导致冗长的输入,其中许多词语支持文本连贯性而非核心推理信息,处理这些输入会消耗大量的计算资源。在这项工作中,我们提出了推理过程的混合表示方法,该方法使用VQ-VAE生成的潜在离散标记来部分抽象最初的推理步骤,从而显著减少推理痕迹的长度。我们探索了潜在痕迹抽象在两种场景中的应用:1)从头开始训练模型以解决找钥匙迷宫问题;2)在此混合数据上微调LLM,扩展词汇表,包括未见过的潜在标记,用于逻辑和数学推理问题。为了促进有效学习,我们引入了一种简单的训练程序,该程序随机混合潜在标记和文本标记,这可以实现对新潜在标记的快速适应。我们的方法在各种基准测试中始终优于基线方法。
论文及项目相关链接
Summary
大型语言模型(LLMs)在链状思维(CoT)数据训练时擅长推理和规划,但这种方式导致输入文本冗长,许多词汇是为了保持文本连贯性而非核心推理信息。本研究提出了一种混合的推理过程表示方法,通过VQ-VAE生成的潜在离散令牌部分抽象最初的推理步骤,显著减少推理轨迹的长度。本研究探讨了潜在轨迹抽象在两种场景中的应用:一是在迷宫寻钥问题中从头训练模型;二是在逻辑和数学推理问题上对LLM进行微调,扩展词汇表包含未见过的潜在令牌。为有效学习,研究引入了一种简单的训练程序,可随机混合潜在令牌和文本令牌,使模型快速适应新令牌。该方法在各种基准测试中始终优于基线方法。
Key Takeaways
- LLMs在链状思维(CoT)数据训练方面表现出强大的推理和规划能力。
- 现有方法中输入文本冗长,包含大量非核心推理信息的词汇。
- 研究提出了一种混合表示方法,通过潜在离散令牌部分抽象最初的推理步骤。
- 潜在轨迹抽象应用于两种场景:从头训练模型和微调LLM。
- 扩展的词汇表包含未见过的潜在令牌,用于逻辑和数学推理问题。
- 引入了一种简单的训练程序,随机混合潜在和文本令牌,促进模型对新令牌的快速适应。
- 该方法在各种基准测试中表现优于基线方法。
点此查看论文截图

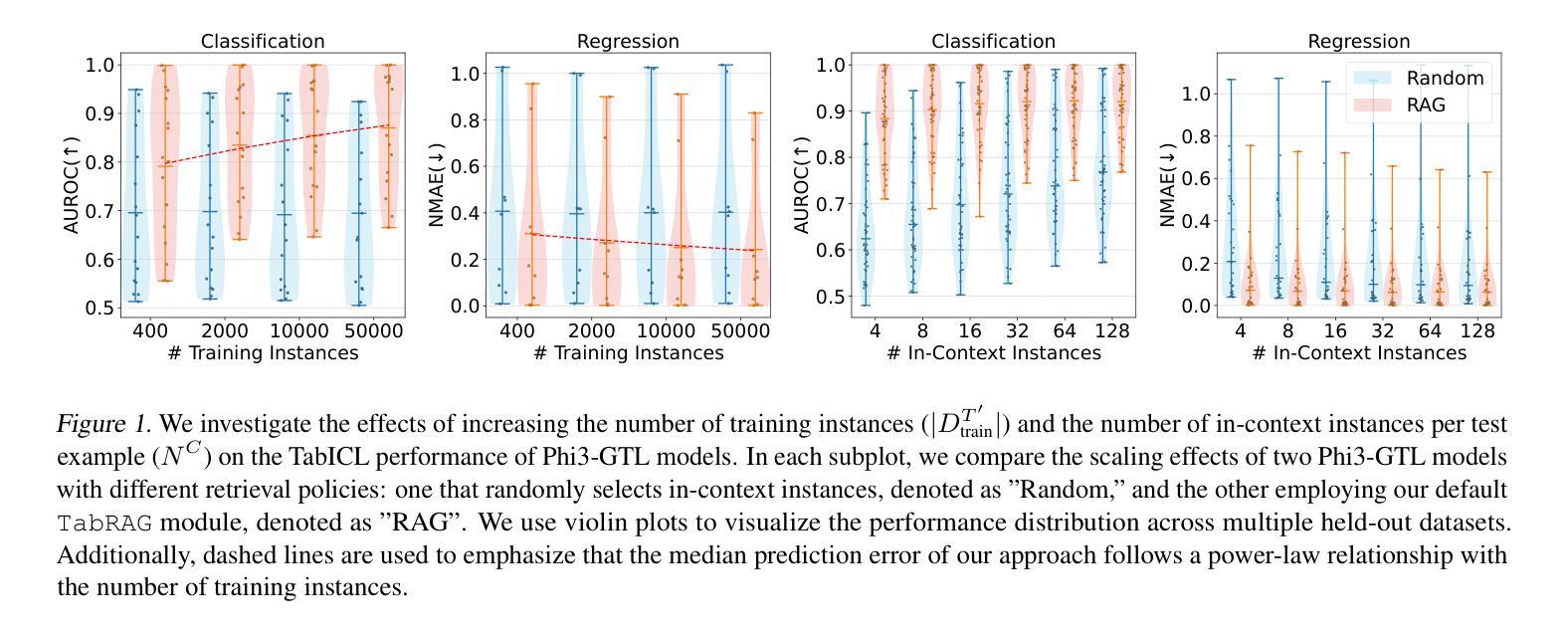
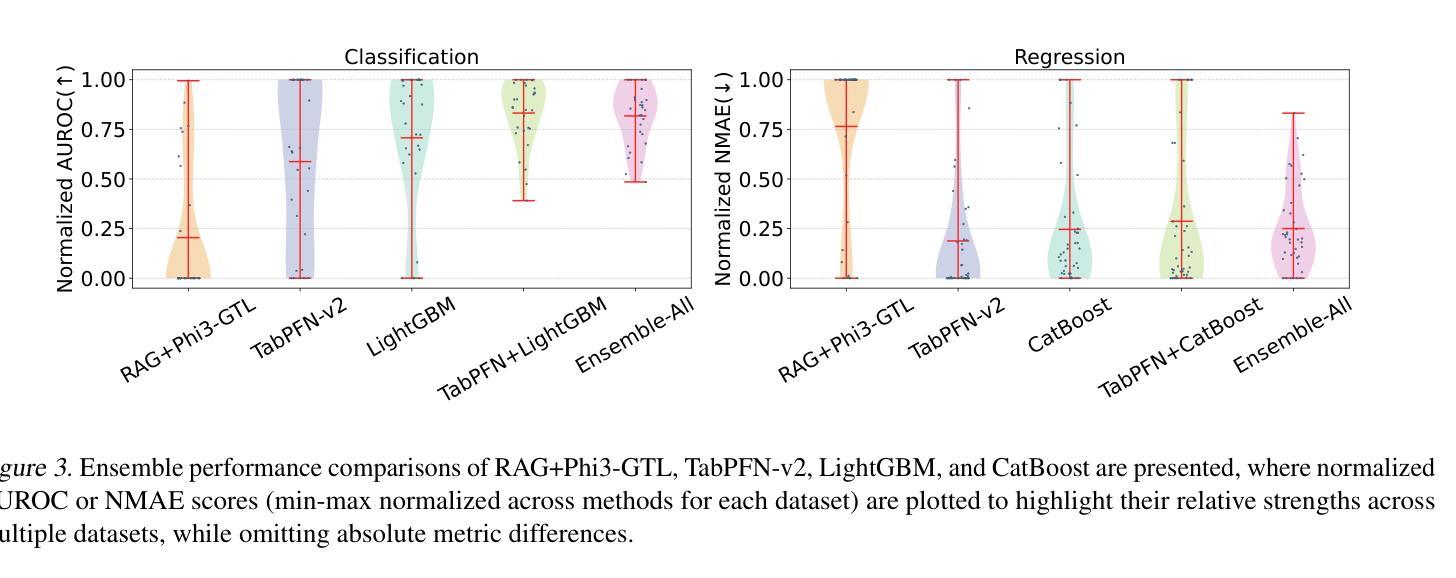
Scalable In-Context Learning on Tabular Data via Retrieval-Augmented Large Language Models
Authors:Xumeng Wen, Shun Zheng, Zhen Xu, Yiming Sun, Jiang Bian
Recent studies have shown that large language models (LLMs), when customized with post-training on tabular data, can acquire general tabular in-context learning (TabICL) capabilities. These models are able to transfer effectively across diverse data schemas and different task domains. However, existing LLM-based TabICL approaches are constrained to few-shot scenarios due to the sequence length limitations of LLMs, as tabular instances represented in plain text consume substantial tokens. To address this limitation and enable scalable TabICL for any data size, we propose retrieval-augmented LLMs tailored to tabular data. Our approach incorporates a customized retrieval module, combined with retrieval-guided instruction-tuning for LLMs. This enables LLMs to effectively leverage larger datasets, achieving significantly improved performance across 69 widely recognized datasets and demonstrating promising scaling behavior. Extensive comparisons with state-of-the-art tabular models reveal that, while LLM-based TabICL still lags behind well-tuned numeric models in overall performance, it uncovers powerful algorithms under limited contexts, enhances ensemble diversity, and excels on specific datasets. These unique properties underscore the potential of language as a universal and accessible interface for scalable tabular data learning.
最近的研究表明,大型语言模型(LLM)在针对表格数据进行后训练定制后,可以获得通用的上下文表格学习(TabICL)能力。这些模型能够在不同的数据模式和任务领域中实现有效的迁移。然而,由于LLM的序列长度限制,现有的基于LLM的TabICL方法仅限于小样本场景,以纯文本形式表示的表格实例会消耗大量令牌。为了解决这一限制,实现任何数据规模的可扩展TabICL,我们提出了针对表格数据增强的检索辅助LLM。我们的方法结合了一个定制的检索模块,以及与检索引导的LLM指令调整相结合。这使得LLM能够有效利用更大的数据集,在69个广泛认可的数据集上实现了显著的性能提升,并表现出了有前景的可扩展行为。与最先进表格模型的广泛比较表明,虽然基于LLM的TabICL在总体性能上仍落后于经过良好调整的数值模型,但它在有限环境下发现了强大的算法,增强了组合多样性,并在特定数据集上表现出卓越性能。这些独特特性突显了语言作为通用和可访问接口在可扩展表格数据学习中的潜力。
论文及项目相关链接
PDF Preprint
Summary
大型语言模型(LLM)通过针对表格数据进行后训练,可以获取通用的表格上下文学习能力(TabICL)。然而,由于表格实例以纯文本形式表示会消耗大量令牌,现有LLM的序列长度限制使其仅限于小样例场景。为解决此限制并实现任何数据大小的可扩展TabICL,我们提出了针对表格数据的检索增强型LLM。该方法结合了定制化的检索模块和检索指导的LLM指令微调技术,使LLM能够有效地利用更大的数据集,在69个广泛认可的数据集上实现了显著的性能提升,并展现出有前景的扩展性。尽管LLM的TabICL在总体性能上仍落后于经过良好调整的数值模型,但它能在有限上下文中揭示强大的算法,提高集成多样性,并在特定数据集上表现出色。这凸显了语言作为可扩展表格数据学习的通用和可访问接口的巨大潜力。
Key Takeaways
- LLM具备通过后天训练学习TabICL的能力,能够跨不同数据模式和任务域进行有效迁移。
- LLM在表格数据处理上受限于序列长度,主要适用于小样例场景。
- 检索增强型LLM通过结合检索模块和指令微调技术解决了序列长度限制问题,实现了可扩展的TabICL。
- 检索增强型LLM在多个数据集上表现出显著性能提升。
- LLM-based TabICL在总体性能上虽不及数值模型,但在特定情境下揭示强大算法,提高集成多样性。
- 语言作为表格数据学习的接口具有通用性和可访问性。
点此查看论文截图


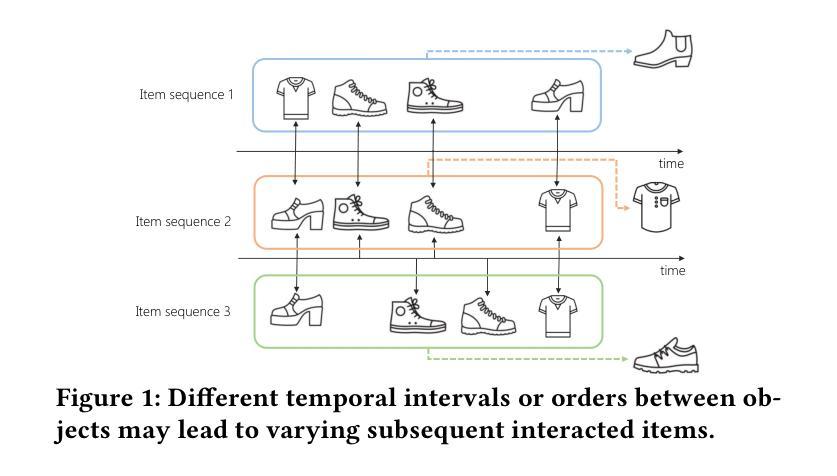
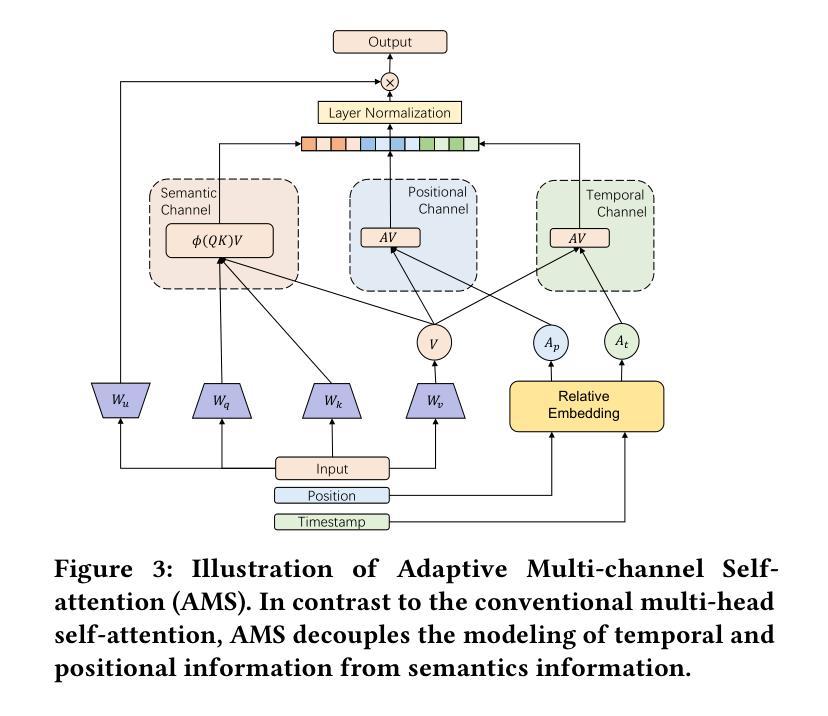
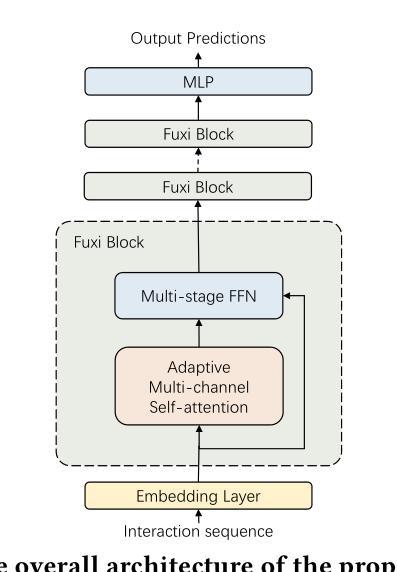
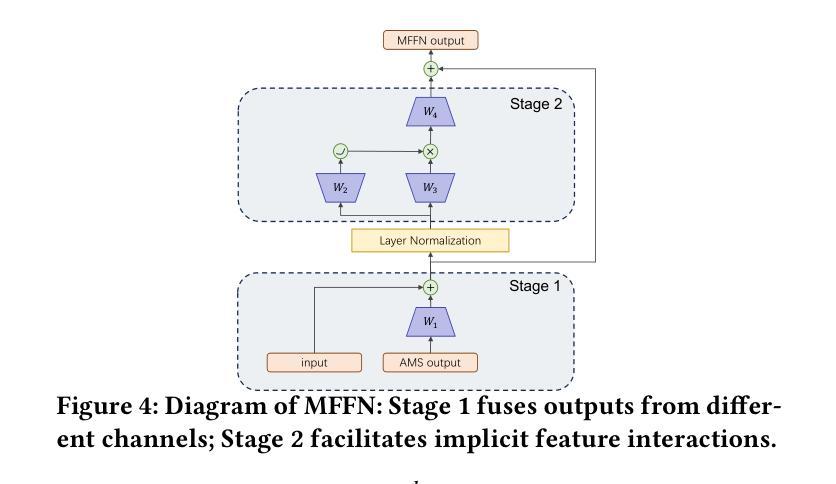
FuXi-$α$: Scaling Recommendation Model with Feature Interaction Enhanced Transformer
Authors:Yufei Ye, Wei Guo, Jin Yao Chin, Hao Wang, Hong Zhu, Xi Lin, Yuyang Ye, Yong Liu, Ruiming Tang, Defu Lian, Enhong Chen
Inspired by scaling laws and large language models, research on large-scale recommendation models has gained significant attention. Recent advancements have shown that expanding sequential recommendation models to large-scale recommendation models can be an effective strategy. Current state-of-the-art sequential recommendation models primarily use self-attention mechanisms for explicit feature interactions among items, while implicit interactions are managed through Feed-Forward Networks (FFNs). However, these models often inadequately integrate temporal and positional information, either by adding them to attention weights or by blending them with latent representations, which limits their expressive power. A recent model, HSTU, further reduces the focus on implicit feature interactions, constraining its performance. We propose a new model called FuXi-$\alpha$ to address these issues. This model introduces an Adaptive Multi-channel Self-attention mechanism that distinctly models temporal, positional, and semantic features, along with a Multi-stage FFN to enhance implicit feature interactions. Our offline experiments demonstrate that our model outperforms existing models, with its performance continuously improving as the model size increases. Additionally, we conducted an online A/B test within the Huawei Music app, which showed a $4.76%$ increase in the average number of songs played per user and a $5.10%$ increase in the average listening duration per user. Our code has been released at https://github.com/USTC-StarTeam/FuXi-alpha.
受缩放定律和大语言模型的启发,对大规模推荐模型的研究已引起广泛关注。最近的进展表明,将序列推荐模型扩展到大规模推荐模型可以是一种有效的策略。当前最先进的序列推荐模型主要使用自注意力机制进行项目之间的显式特征交互,而隐式交互则通过前馈网络(FFN)进行管理。然而,这些模型往往不能充分地整合时间和位置信息,无论是通过将它们添加到注意力权重中,还是将它们与潜在表示混合,这都限制了它们的表达能力。最近的一个模型HSTU进一步减少了隐式特征交互的关注度,制约了其性能。为了解决这些问题,我们提出了一种新的模型——FuXi-$\alpha$。该模型引入了一种自适应多通道自注意力机制,能够独特地建模时间、位置和语义特征,以及一个多阶段FFN,以增强隐式特征交互。我们的离线实验表明,我们的模型优于现有模型,并且随着模型规模的增加,其性能不断提高。此外,我们在华为音乐应用程序中进行了在线A/B测试,平均每用户播放歌曲数量增加了4.76%,平均每用户收听时长增加了5.10%。我们的代码已发布在https://github.com/USTC-StarTeam/FuXi-alpha。
论文及项目相关链接
PDF Accepted by WWW2025
Summary
受尺度定律和大语言模型的启发,大规模推荐模型研究备受关注。新的模型FuXi-$\alpha$通过引入自适应多通道自注意力机制和分阶段前馈网络解决了现有模型的不足,包括建模时间、位置和语义特征的分离以及强化隐性特征交互的问题。该模型在不同规模的实验中表现出超越现有模型性能的优势,并在华为音乐应用的在线A/B测试中实现了平均每用户播放歌曲数和平均收听时间的增长。代码已发布在GitHub上。
Key Takeaways
- 大规模推荐模型研究因尺度定律和大语言模型的启发而备受关注。
- 当前先进的顺序推荐模型主要利用自注意力机制进行项目间的显式特征交互,而隐性交互则通过前馈网络(FFNs)管理。
- 现有模型在集成时间和位置信息方面存在不足,这限制了它们的表达能力。
- FuXi-$\alpha$模型通过引入自适应多通道自注意力机制来分别建模时间、位置和语义特征。
- FuXi-$\alpha$模型采用分阶段前馈网络以增强隐性特征交互。
- 线下实验表明,FuXi-$\alpha$模型优于现有模型,且性能随着模型规模的增加而不断提升。
点此查看论文截图

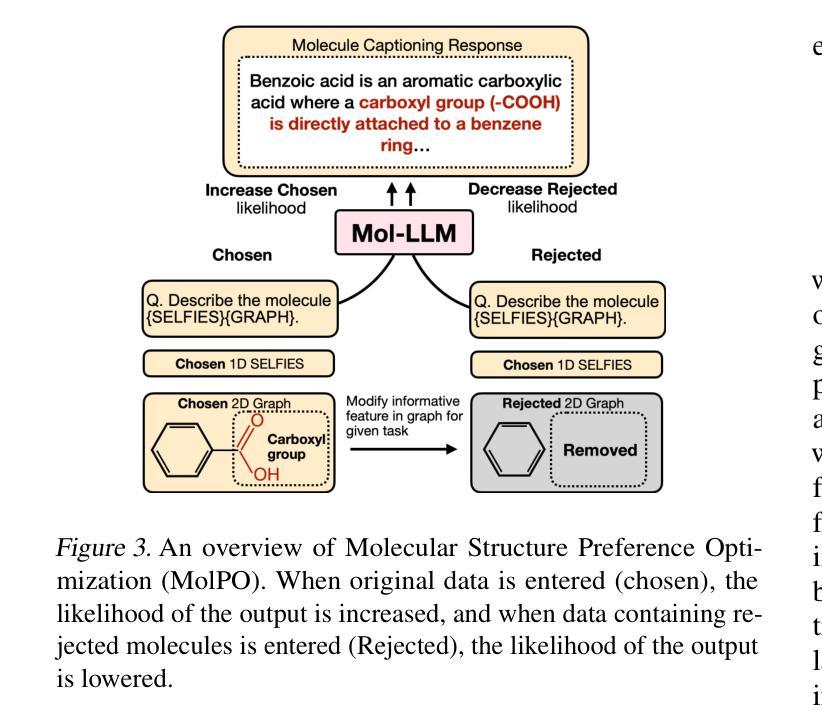
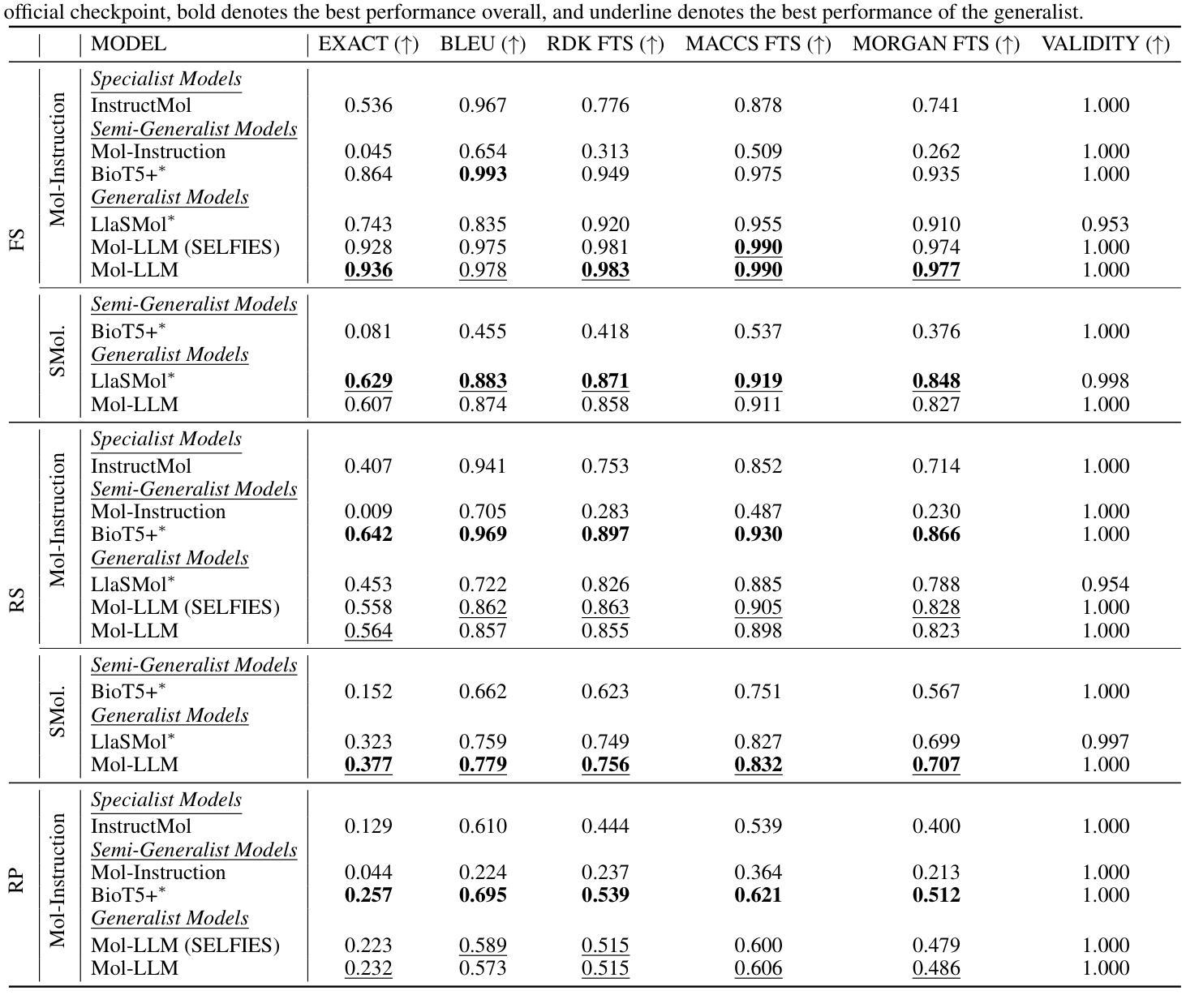
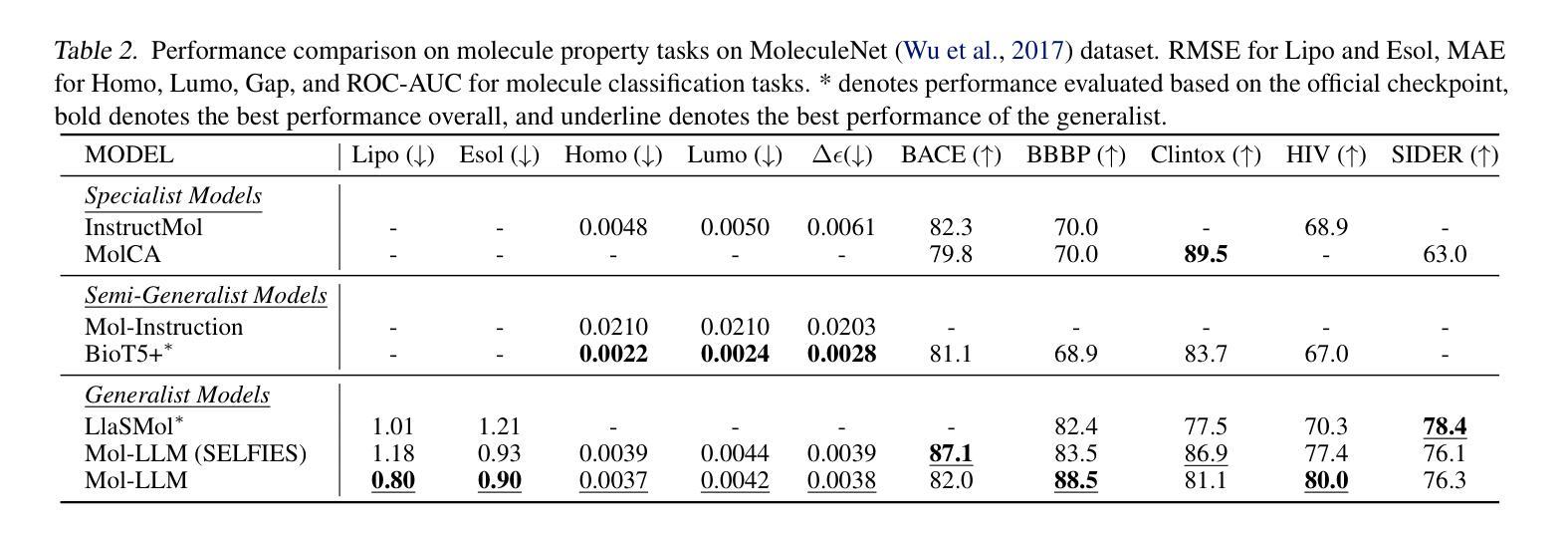
Mol-LLM: Generalist Molecular LLM with Improved Graph Utilization
Authors:Chanhui Lee, Yuheon Song, YongJun Jeong, Hanbum Ko, Rodrigo Hormazabal, Sehui Han, Kyunghoon Bae, Sungbin Lim, Sungwoong Kim
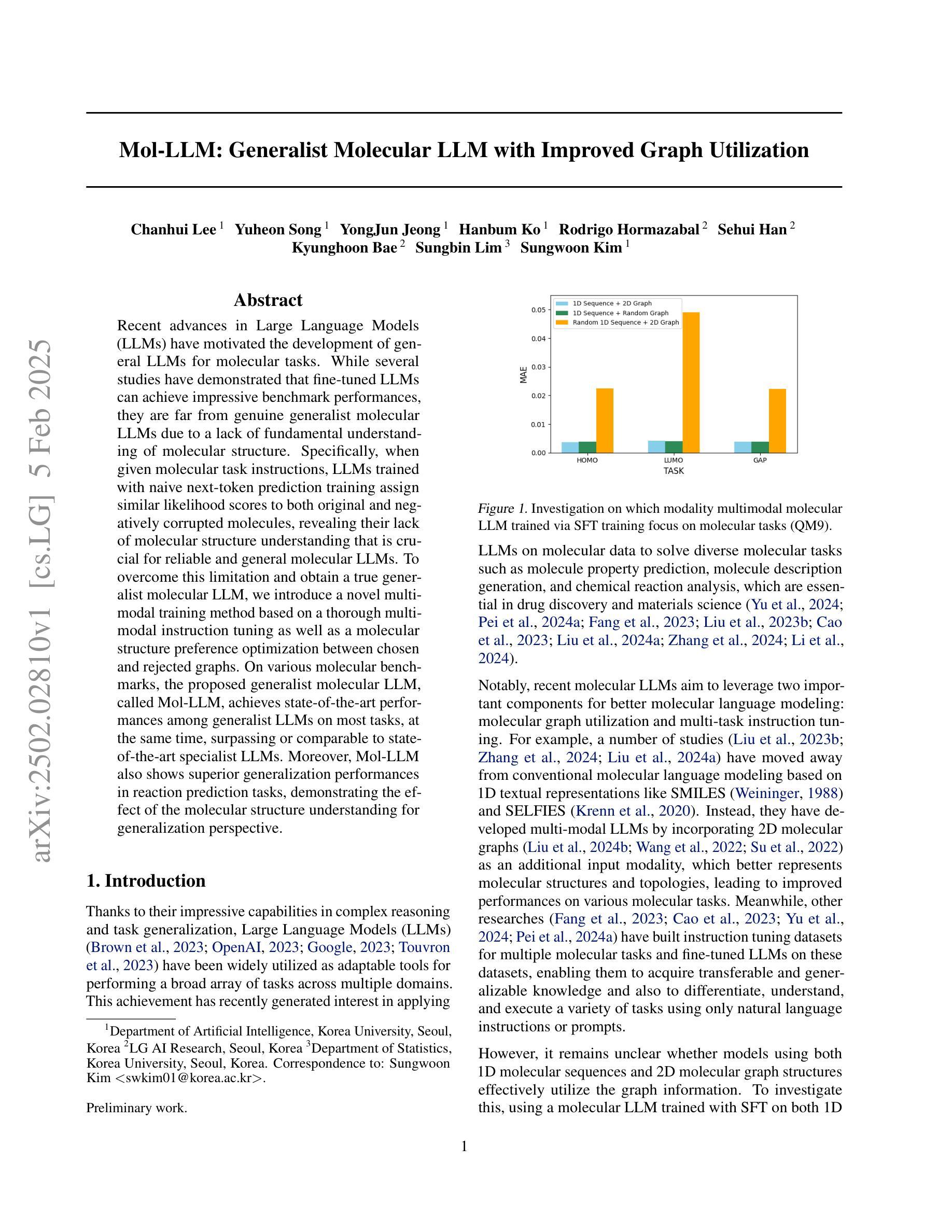
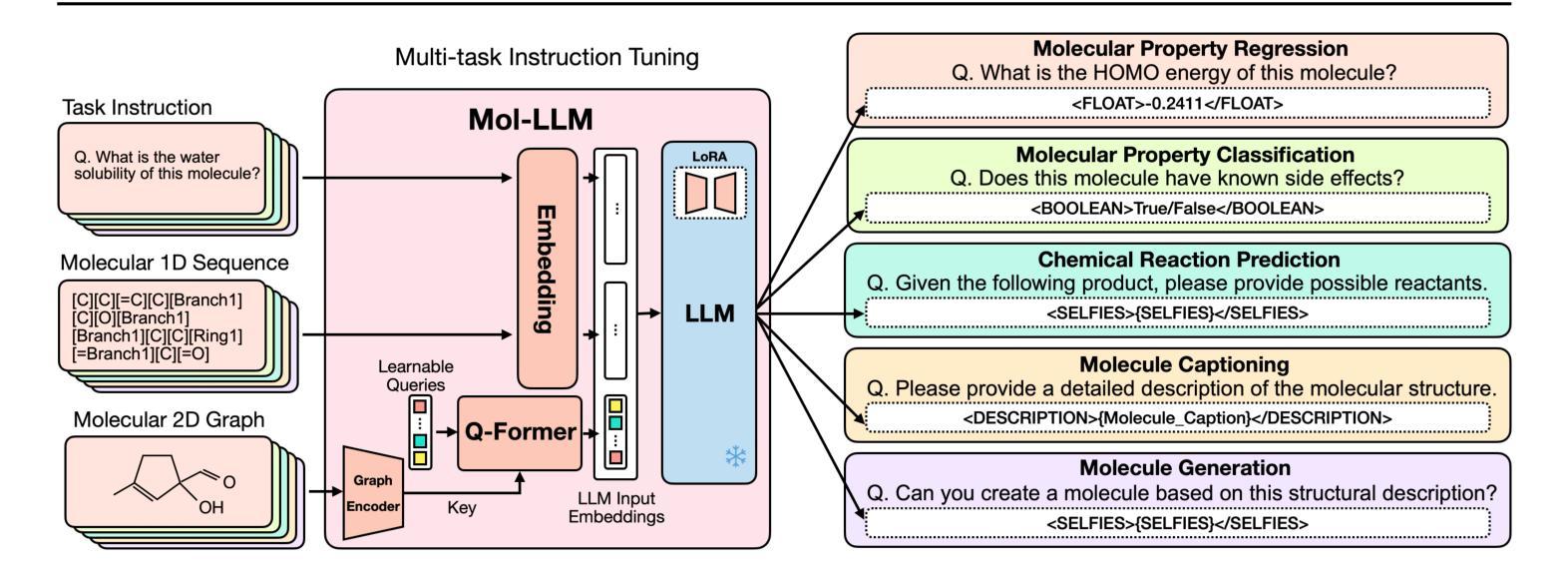
Recent advances in Large Language Models (LLMs) have motivated the development of general LLMs for molecular tasks. While several studies have demonstrated that fine-tuned LLMs can achieve impressive benchmark performances, they are far from genuine generalist molecular LLMs due to a lack of fundamental understanding of molecular structure. Specifically, when given molecular task instructions, LLMs trained with naive next-token prediction training assign similar likelihood scores to both original and negatively corrupted molecules, revealing their lack of molecular structure understanding that is crucial for reliable and general molecular LLMs. To overcome this limitation and obtain a true generalist molecular LLM, we introduce a novel multi-modal training method based on a thorough multi-modal instruction tuning as well as a molecular structure preference optimization between chosen and rejected graphs. On various molecular benchmarks, the proposed generalist molecular LLM, called Mol-LLM, achieves state-of-the-art performances among generalist LLMs on most tasks, at the same time, surpassing or comparable to state-of-the-art specialist LLMs. Moreover, Mol-LLM also shows superior generalization performances in reaction prediction tasks, demonstrating the effect of the molecular structure understanding for generalization perspective.
最近大型语言模型(LLM)的进展推动了通用LLM在分子任务领域的发展。虽然已有研究表明,经过微调的LLM可以在基准测试中实现令人印象深刻的性能,但由于缺乏对分子结构的基本理解,它们距离真正的通用分子LLM还很远。具体来说,当接受分子任务指令时,用简单的下一个令牌预测训练而获得的LLM会对原始分子和负面干扰分子分配相似的可能性分数,这揭示了它们缺乏对于分子结构的理解,这对于可靠和通用的分子LLM至关重要。为了克服这一局限性并获得真正的通用分子LLM,我们引入了一种基于全面多模式指令调整以及所选和拒绝图形之间分子结构偏好优化的新型多模式训练方法。在各种分子基准测试中,我们提出的通用分子LLM(称为Mol-LLM)在大多数任务上实现了最先进的性能,同时超越或相当于最新专业LLM。此外,Mol-LLM在反应预测任务中也表现出优异的泛化性能,证明了从泛化角度理解分子结构的效果。
论文及项目相关链接
Summary
大型语言模型(LLM)的最新进展促进了通用LLM在分子任务中的应用。尽管已有研究表明经过微调的大型语言模型可以在基准测试中取得令人印象深刻的性能,但由于缺乏对分子结构的基本理解,它们距离真正的通用分子LLM还很远。针对这一问题,我们引入了一种基于全面多模式指令调整以及所选和拒绝图形之间的分子结构偏好优化的新型多模式训练方法。在各种分子基准测试中,我们提出的名为Mol-LLM的通用分子LLM在大多数任务上实现了最新技术性能,同时在某些任务上超越了或相当于最新技术水平的专家LLM。此外,Mol-LLM在反应预测任务中显示出卓越泛化性能,证明了理解分子结构对泛化性能的影响。
Key Takeaways
- 大型语言模型(LLM)正被应用于分子任务,但仍缺乏真正的通用分子理解。
- 当前LLM在分子任务上的表现受限于对分子结构的基本理解缺失。
- 针对这一缺陷,提出了名为Mol-LLM的新型多模式训练方法。
- Mol-LLM在多种分子基准测试中表现优秀,部分任务上达到或超越了专家LLM的性能。
- Mol-LLM在反应预测任务中展现出良好的泛化能力。
- 理解和掌握分子结构对于提高LLM在分子任务中的性能至关重要。
点此查看论文截图
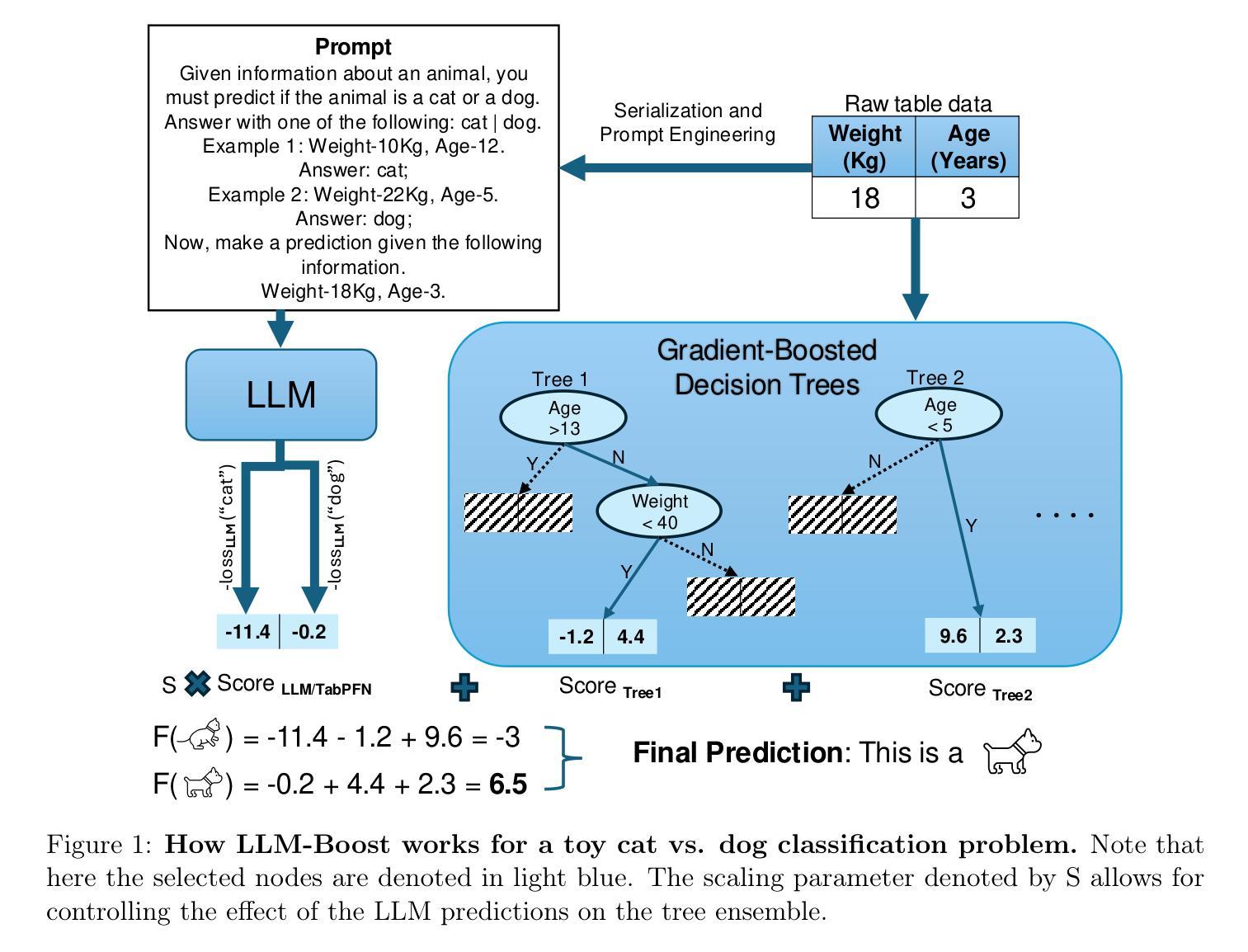
Transformers Boost the Performance of Decision Trees on Tabular Data across Sample Sizes
Authors:Mayuka Jayawardhana, Renbo Tu, Samuel Dooley, Valeriia Cherepanova, Andrew Gordon Wilson, Frank Hutter, Colin White, Tom Goldstein, Micah Goldblum
Large language models (LLMs) perform remarkably well on tabular datasets in zero- and few-shot settings, since they can extract meaning from natural language column headers that describe features and labels. Similarly, TabPFN, a recent non-LLM transformer pretrained on numerous tables for in-context learning, has demonstrated excellent performance for dataset sizes up to a thousand samples. In contrast, gradient-boosted decision trees (GBDTs) are typically trained from scratch on each dataset without benefiting from pretraining data and must learn the relationships between columns from their entries alone since they lack natural language understanding. LLMs and TabPFN excel on small tabular datasets where a strong prior is essential, yet they are not competitive with GBDTs on medium or large datasets, since their context lengths are limited. In this paper, we propose a simple and lightweight approach for fusing large language models and TabPFN with gradient-boosted decision trees, which allows scalable GBDTs to benefit from the natural language capabilities and pretraining of transformers. We name our fusion methods LLM-Boost and PFN-Boost, respectively. While matching or surpassing the performance of the transformer at sufficiently small dataset sizes and GBDTs at sufficiently large sizes, LLM-Boost and PFN-Boost outperform both standalone components on a wide range of dataset sizes in between. We demonstrate state-of-the-art performance against numerous baselines and ensembling algorithms. We find that PFN-Boost achieves the best average performance among all methods we test for all but very small dataset sizes. We release our code at http://github.com/MayukaJ/LLM-Boost .
大型语言模型(LLMs)在零样本和少样本设置下的表格数据集上表现非常出色,因为它们可以从描述特征和标签的自然语言列标题中提取意义。与此类似,TabPFN是一个最近的非LLM转换器,它在众多表格上进行预训练,用于上下文学习,并已显示出在最多达一千个样本的数据集上的出色性能。相比之下,梯度提升决策树(GBDTs)通常会在每个数据集上从头开始训练,无法从预训练数据中获益,并且由于它们缺乏自然语言理解,必须仅从条目本身学习列之间的关系。LLMs和TabPFN在小型表格数据集上表现出色,其中强烈的先验知识至关重要,但在中等或大型数据集上,它们与GBDTs不具有竞争力,因为它们的上下文长度有限。在本文中,我们提出了一种简单而轻量级的融合大型语言模型和TabPFN与梯度提升决策树的方法,这允许可扩展的GBDT受益于转换器的自然语言能力和预训练。我们将我们的融合方法分别命名为LLM-Boost和PFN-Boost。尽管它们在足够小的数据集大小上可以与转换器的性能相匹配或超越,并且在足够大的尺寸上可以与GBDTs的性能相匹配,但LLM-Boost和PFN-Boost在中间范围的多种数据集大小上都表现出优于两个独立组件的性能。我们与众多基准线和集成算法相比,展现了最佳性能。我们发现,除非常小的数据集大小外,PFN-Boost在所有方法中获得了最佳的平均性能。我们在http://github.com/MayukaJ/LLM-Boost上发布了我们的代码。
论文及项目相关链接
PDF 12 pages, 6 figures
Summary
大型语言模型(LLMs)在零样本和少样本的表格数据集上表现优异,能从自然语言描述的列标题中提取特征和标签的意义。而预训练在大量表格上的非LLM模型TabPFN,对于千样本规模以下的数据集也展现了出色的性能。相较之下,梯度提升决策树(GBDTs)通常从数据集中直接训练,缺乏自然语言理解的能力。在小规模表格数据集中,LLMs和TabPFN凭借强大的先验知识表现出色,但在中大规模数据集上则不如GBDTs。本文提出了一种简单轻量级的融合大型语言模型和TabPFN与梯度提升决策树的方法,我们称之为LLM-Boost和PFN-Boost。这两种融合方法能在不同数据集大小之间实现优于单一组件的性能,特别是在中等规模数据集上表现尤为突出。
Key Takeaways
- LLMs和TabPFN能从自然语言描述的列标题中提取特征和标签意义,在零样本和少样本的表格数据集上表现优异。
- GBDTs通常从数据集中直接训练,缺乏自然语言理解能力,在中大规模数据集上表现较好。
- LLM-Boost和PFN-Boost融合大型语言模型和TabPFN与梯度提升决策树的方法能在不同数据集大小之间实现优异性能。
- LLM-Boost和PFN-Boost相较于单一组件和基线算法,展现出更优越的性能。
- PFN-Boost在除极小规模数据集外的所有数据集大小上都取得了最佳平均性能。
- 融合方法结合了LLMs和GBDTs的优势,能够在不同数据集大小上实现均衡的性能表现。
点此查看论文截图

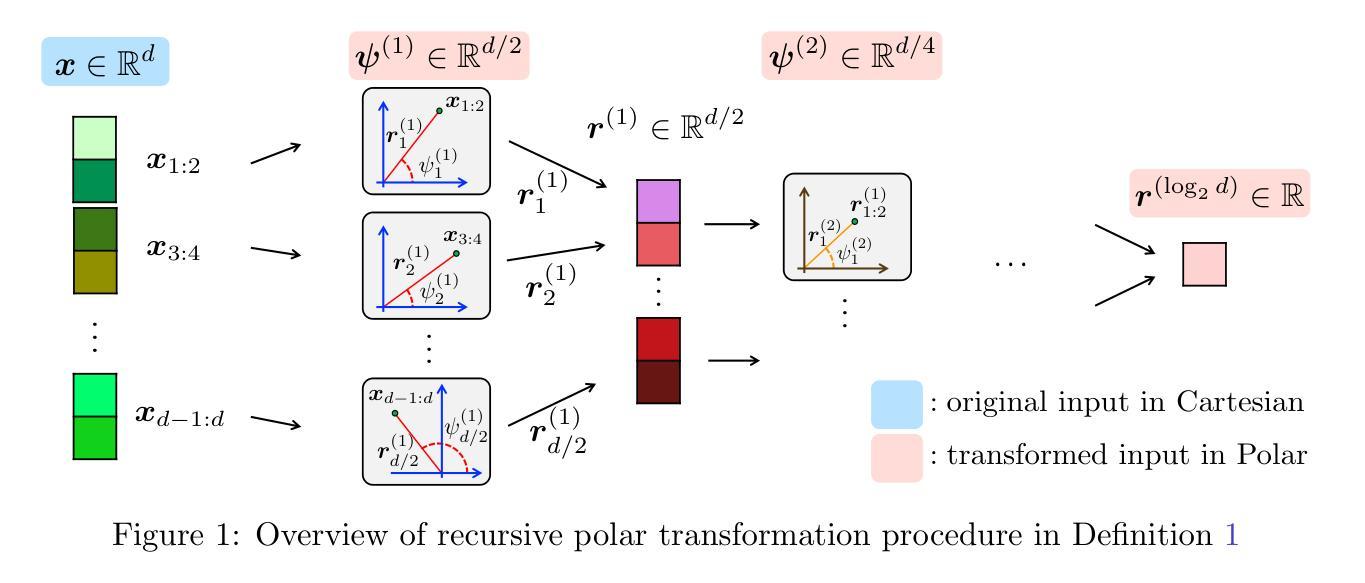
PolarQuant: Quantizing KV Caches with Polar Transformation
Authors:Insu Han, Praneeth Kacham, Amin Karbasi, Vahab Mirrokni, Amir Zandieh
Large language models (LLMs) require significant memory to store Key-Value (KV) embeddings in their KV cache, especially when handling long-range contexts. Quantization of these KV embeddings is a common technique to reduce memory consumption. This work introduces PolarQuant, a novel quantization method employing random preconditioning and polar transformation. Our method transforms the KV embeddings into polar coordinates using an efficient recursive algorithm and then quantizes resulting angles. Our key insight is that, after random preconditioning, the angles in the polar representation exhibit a tightly bounded and highly concentrated distribution with an analytically computable form. This nice distribution eliminates the need for explicit normalization, a step required by traditional quantization methods which introduces significant memory overhead because quantization parameters (e.g., zero point and scale) must be stored in full precision per each data block. PolarQuant bypasses this normalization step, enabling substantial memory savings. The long-context evaluation demonstrates that PolarQuant compresses the KV cache by over x4.2 while achieving the best quality scores compared to the state-of-the-art methods.
大型语言模型(LLM)需要在其KV缓存中存储大量的键值(KV)嵌入,特别是在处理长范围上下文时。为了减少内存消耗,量化这些KV嵌入是一种常见的做法。这项工作引入了PolarQuant,这是一种采用随机预处理和极坐标变换的新型量化方法。我们的方法使用高效的递归算法将KV嵌入转换为极坐标,然后对所得的角进行量化。我们的关键见解是,经过随机预处理后,极坐标表示中的角度呈现出紧密且高度集中的分布,具有可分析计算的形式。这种美观的分布不需要额外的标准化步骤,这是传统量化方法所要求的,而这些量化方法中的每个数据块都必须以全精度存储量化参数(例如零点和尺度),这会引入额外的内存开销。PolarQuant通过绕过标准化步骤实现了显著的内存节省。长上下文评估结果表明,PolarQuant压缩了KV缓存超过x4.2倍,同时取得了最好的质量分数与最新技术相比有所超越。
论文及项目相关链接
Summary
大型语言模型(LLM)的键值(KV)嵌入需要占用大量内存来存储,处理长范围上下文时尤其如此。为减少内存消耗,本文提出一种名为PolarQuant的新型量化方法,采用随机预处理和极坐标变换。该方法通过高效的递归算法将KV嵌入转换为极坐标,然后量化结果角度。关键见解是,随机预处理后,极坐标中的角度呈现出界限紧密、高度集中的分布,具有可分析的计算形式。这种分布无需执行传统量化方法所需的归一化步骤,从而避免了因存储量化参数(例如零点和比例)而产生的内存开销。PolarQuant通过绕过此归一化步骤,实现了可观的内存节省。长上下文评估表明,PolarQuant将KV缓存压缩了超过4.2倍,同时达到了相比最新技术最佳的质量评分。
Key Takeaways
- LLM的KV嵌入需要大内存来存储。
- 极坐标量化方法PolarQuant被引入,用于减少内存消耗。
- PolarQuant使用随机预处理和极坐标转换。
- 随机预处理后的角度分布紧密且集中,无需归一化步骤。
- 传统量化方法需要存储量化参数,增加了内存开销。
- PolarQuant显著减少了内存使用,压缩了KV缓存超过4.2倍。
点此查看论文截图

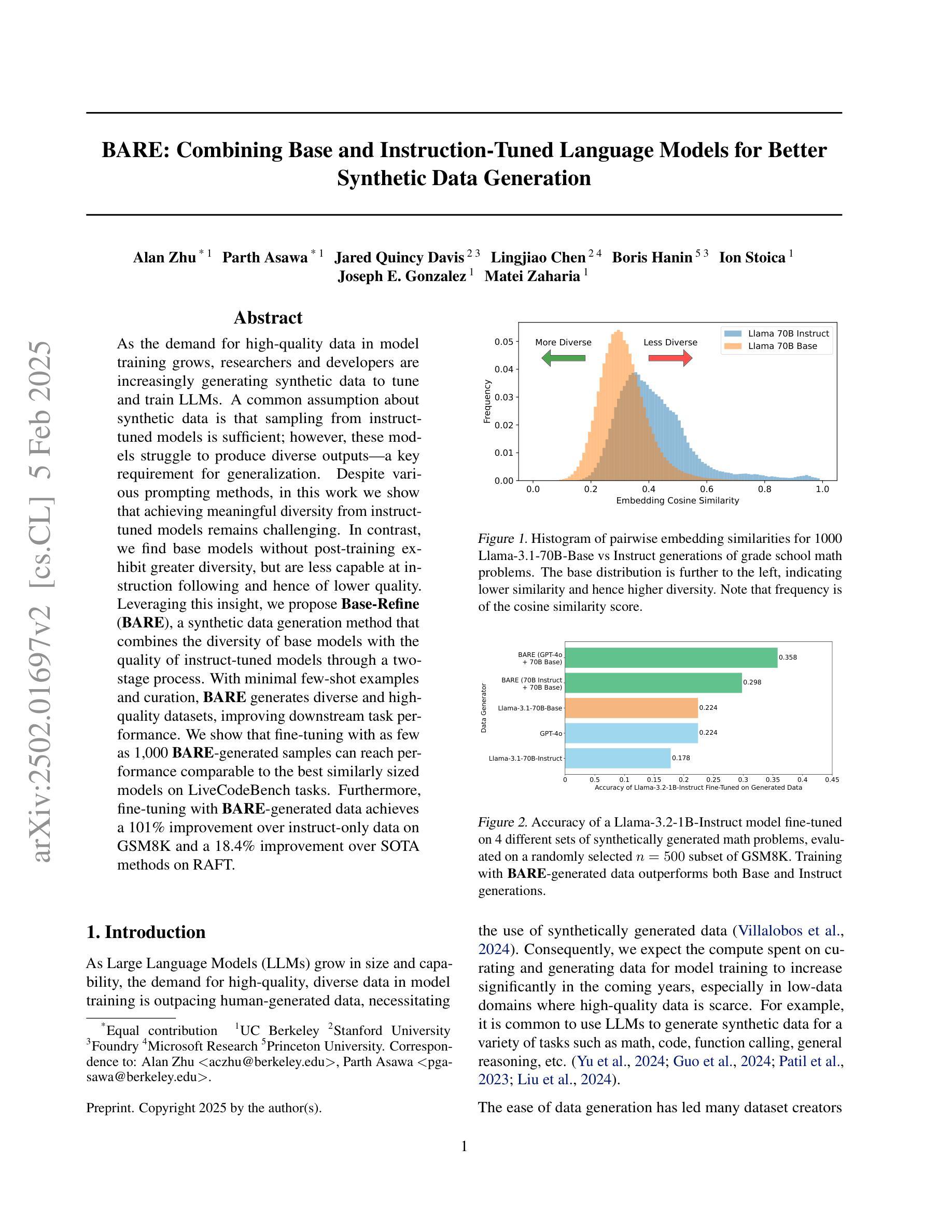
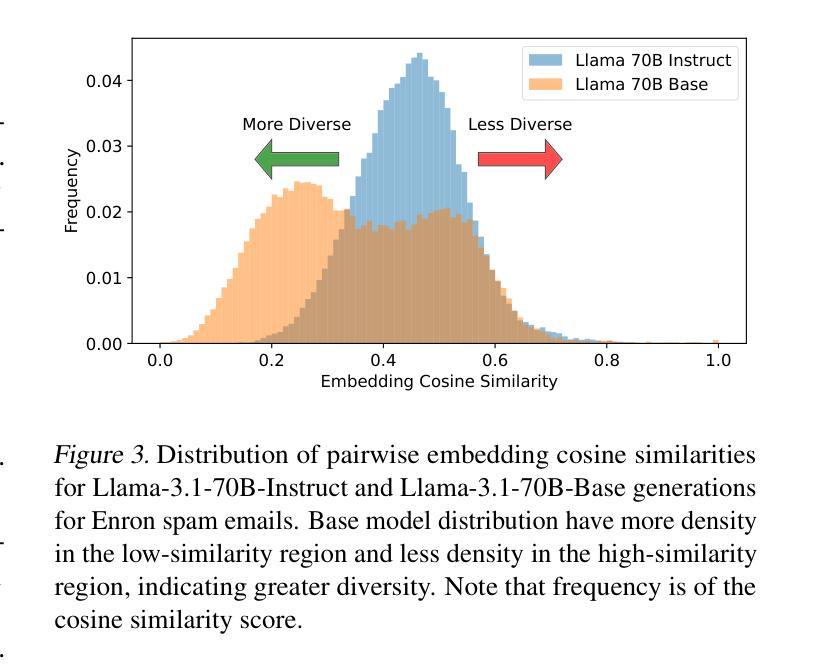
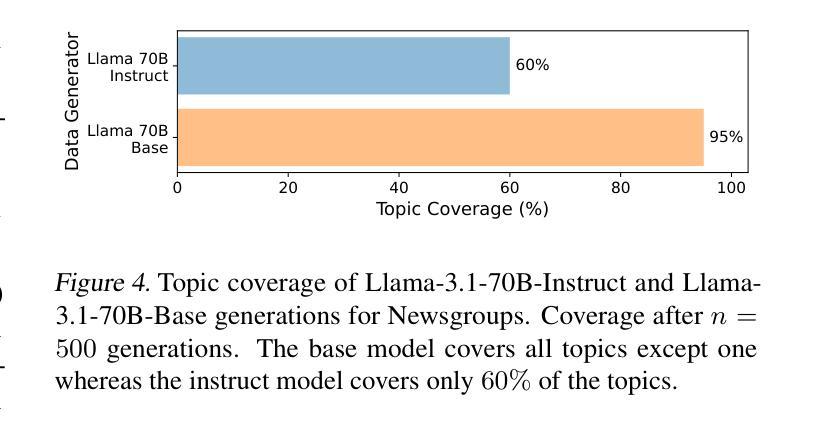
BARE: Combining Base and Instruction-Tuned Language Models for Better Synthetic Data Generation
Authors:Alan Zhu, Parth Asawa, Jared Quincy Davis, Lingjiao Chen, Boris Hanin, Ion Stoica, Joseph E. Gonzalez, Matei Zaharia
As the demand for high-quality data in model training grows, researchers and developers are increasingly generating synthetic data to tune and train LLMs. A common assumption about synthetic data is that sampling from instruct-tuned models is sufficient; however, these models struggle to produce diverse outputs-a key requirement for generalization. Despite various prompting methods, in this work we show that achieving meaningful diversity from instruct-tuned models remains challenging. In contrast, we find base models without post-training exhibit greater diversity, but are less capable at instruction following and hence of lower quality. Leveraging this insight, we propose Base-Refine (BARE), a synthetic data generation method that combines the diversity of base models with the quality of instruct-tuned models through a two-stage process. With minimal few-shot examples and curation, BARE generates diverse and high-quality datasets, improving downstream task performance. We show that fine-tuning with as few as 1,000 BARE-generated samples can reach performance comparable to the best similarly sized models on LiveCodeBench tasks. Furthermore, fine-tuning with BARE-generated data achieves a 101% improvement over instruct-only data on GSM8K and a 18.4% improvement over SOTA methods on RAFT.
随着模型训练中对高质量数据的需求不断增长,研究人员和开发人员正在越来越多地生成合成数据来调整和训练大型语言模型。关于合成数据的常见假设是,从指令调整过的模型中采样就足够了;然而,这些模型在产生多样化输出方面存在困难,这是泛化的一个关键要求。尽管有各种提示方法,但在这项工作中,我们表明从指令调整过的模型中实现有意义的多样性仍然具有挑战性。相比之下,我们发现没有经过后训练的基准模型表现出更大的多样性,但在遵循指令方面的能力较弱,因此质量较低。基于这一发现,我们提出了Base-Refine(BARE)方法,这是一种合成数据生成技术,它通过两阶段过程结合基准模型的多样性和指令调整过的模型的质量。通过少量的示例和筛选,BARE生成了多样且高质量的数据集,提高了下游任务性能。我们表明,使用BARE生成样本仅1000个进行微调即可在LiveCodeBench任务上达到与最佳相似规模模型相当的性能。此外,使用BARE生成的数据进行微调在GSM8K上实现了比仅使用指令数据提高101%,在RAFT上比现有最佳方法提高了18.4%。
论文及项目相关链接
Summary
基于生成高质量模型训练数据需求的提升,研究者利用合成数据优化与训练大型语言模型(LLM)。虽然对合成数据的常规假设是通过指令微调模型采样足够的数据即可,但这些模型难以生成多样化输出,这对于模型的泛化能力至关重要。尽管有各种提示方法,但在这项工作中发现从指令微调模型实现有意义多样性仍然具有挑战性。相反,研究发现未经训练的基准模型展现出更大的输出多样性,但在遵循指令方面的能力较低。利用这一见解,研究提出了结合基准模型的多样性和指令微调模型的质量的合成数据生成方法——Base-Refine(BARE)。通过少量的示例和精心筛选的两阶段过程,BARE能生成多样且高质量的数据集,提高了下游任务性能。研究结果表明,仅使用1,000个BARE生成样本进行微调即可在LiveCodeBench任务上达到与最佳相似规模模型相当的性能。此外,使用BARE生成数据进行微调在GSM8K上实现了对指令仅数据的改进提升了101%,并且在RAFT上相对于现有方法提高了18.4%。
Key Takeaways
- 研究人员正在利用合成数据优化和训练大型语言模型(LLM)。
- 虽然指令微调模型能够生成数据,但它们难以生成多样化输出。
- 未经训练的基准模型展现出更大的输出多样性,但在遵循指令方面的能力较低。
- 提出的Base-Refine(BARE)方法结合了基准模型的多样性和指令微调模型的质量。
- BARE通过两阶段过程生成多样且高质量的数据集,提高了下游任务性能。
- 使用少量BARE生成的样本进行微调即可达到良好的性能。
点此查看论文截图
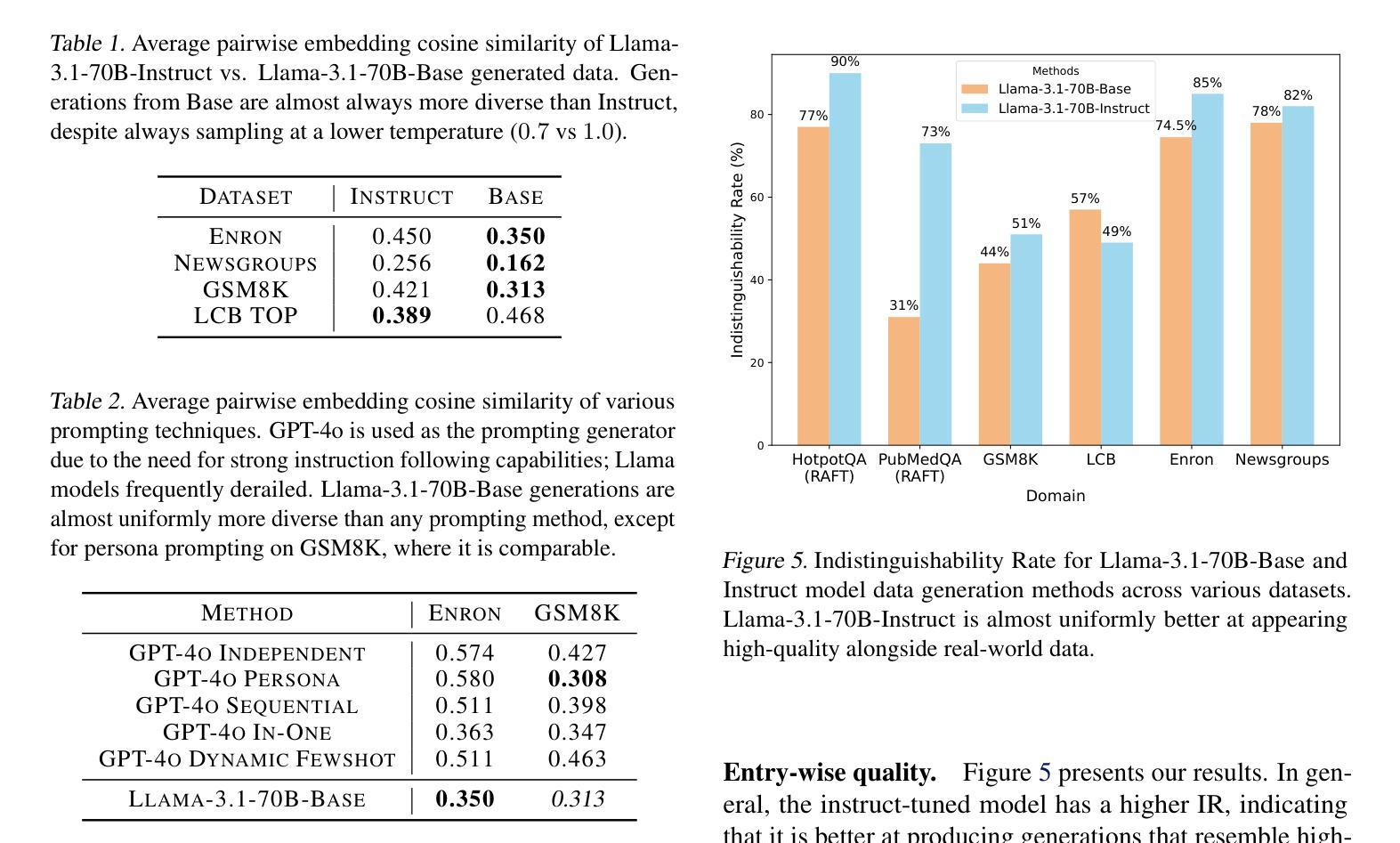

Efficient Prompt Compression with Evaluator Heads for Long-Context Transformer Inference
Authors:Weizhi Fei, Xueyan Niu, Guoqing Xie, Yingqing Liu, Bo Bai, Wei Han
Although applications involving long-context inputs are crucial for the effective utilization of large language models (LLMs), they also result in increased computational costs and reduced performance. To address this challenge, we propose an efficient, training-free prompt compression method that retains key information within compressed prompts. We identify specific attention heads in transformer-based LLMs, which we designate as evaluator heads, that are capable of selecting tokens in long inputs that are most significant for inference. Building on this discovery, we develop EHPC, an Evaluator Head-based Prompt Compression method, which enables LLMs to rapidly “skim through” input prompts by leveraging only the first few layers with evaluator heads during the pre-filling stage, subsequently passing only the important tokens to the model for inference. EHPC achieves state-of-the-art results across two mainstream benchmarks: prompt compression and long-context inference acceleration. Consequently, it effectively reduces the complexity and costs associated with commercial API calls. We further demonstrate that EHPC attains competitive results compared to key-value cache-based acceleration methods, thereby highlighting its potential to enhance the efficiency of LLMs for long-context tasks.
虽然涉及长上下文输入的应用对于有效利用大型语言模型(LLM)至关重要,但它们也会导致计算成本增加和性能下降。为了应对这一挑战,我们提出了一种高效、无需训练提示压缩方法,该方法能够在压缩提示中保留关键信息。我们确定了基于transformer的LLM中的特定注意力头,将其指定为评估头,这些评估头能够选择长输入中最有利于推理的标记。基于这一发现,我们开发了EHPC,一种基于评估头的提示压缩方法,它使LLM能够借助预填充阶段仅利用前几层中的评估头快速“浏览”输入提示,随后只将重要标记传递给模型进行推理。EHPC在两个主流基准测试:提示压缩和长上下文推理加速方面取得了最新结果。因此,它有效地降低了商业API调用的复杂性和成本。我们还证明,EHPC与基于键值缓存的加速方法相比取得了具有竞争力的结果,从而突显了其在提高LLM长上下文任务效率方面的潜力。
论文及项目相关链接
Summary
大型语言模型(LLM)在处理长上下文输入时面临计算成本增加和性能下降的挑战。为此,我们提出了一种高效的训练免费提示压缩方法,该方法能够在压缩提示的同时保留关键信息。我们确定了基于转换器的LLM中的特定注意力头,称为评估头,这些头能够选择长输入中对推理最重要的标记。基于此发现,我们开发了EHPC(基于评估头的提示压缩方法),使LLM能够迅速浏览输入提示,仅在预填充阶段使用前几层带有评估头,然后仅将重要标记传递给模型进行推理。EHPC在两个主流基准测试中达到了最新水平的结果,即提示压缩和长上下文推理加速。这有效降低了商业API调用的复杂性和成本,并与基于键值缓存的加速方法取得了有竞争力的结果。这显示了EHPC在提高LLM在长上下文任务中的效率方面的潜力。
Key Takeaways
- 大型语言模型(LLM)在处理长上下文输入时面临计算成本增加和性能下降的挑战。
- 提出了一种训练免费的提示压缩方法,能够压缩提示并保留关键信息。
- 通过确定特定的注意力头——评估头,能够在LLM中筛选出对推理最重要的标记。
- 开发了EHPC方法,通过利用评估头在前几层中进行预填充,加速了长上下文推理。
- EHPC在提示压缩和长上下文推理加速方面达到了最新水平的结果。
- EHPC有效降低了商业API调用的复杂性及成本。
点此查看论文截图



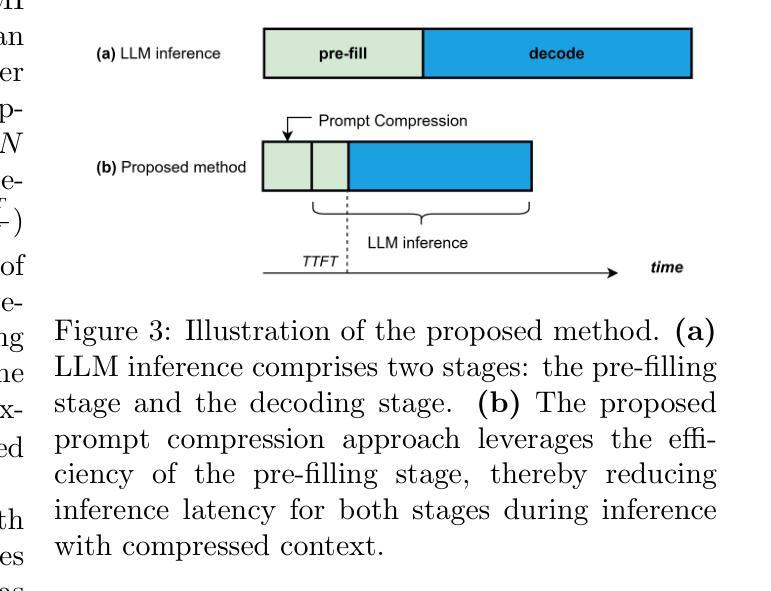
How Developers Interact with AI: A Taxonomy of Human-AI Collaboration in Software Engineering
Authors:Christoph Treude, Marco A. Gerosa
Artificial intelligence (AI), including large language models and generative AI, is emerging as a significant force in software development, offering developers powerful tools that span the entire development lifecycle. Although software engineering research has extensively studied AI tools in software development, the specific types of interactions between developers and these AI-powered tools have only recently begun to receive attention. Understanding and improving these interactions has the potential to enhance productivity, trust, and efficiency in AI-driven workflows. In this paper, we propose a taxonomy of interaction types between developers and AI tools, identifying eleven distinct interaction types, such as auto-complete code suggestions, command-driven actions, and conversational assistance. Building on this taxonomy, we outline a research agenda focused on optimizing AI interactions, improving developer control, and addressing trust and usability challenges in AI-assisted development. By establishing a structured foundation for studying developer-AI interactions, this paper aims to stimulate research on creating more effective, adaptive AI tools for software development.
人工智能(AI),包括大型语言模型和生成式AI,正在软件开发领域崭露头角,为开发者提供贯穿整个开发生命周期的强大工具。尽管软件工程研究已经对软件开发中的AI工具进行了广泛的研究,但开发者与这些AI工具之间的特定交互类型最近才开始受到关注。理解和改进这些交互有可能提高AI驱动工作流程中的生产力、信任和效率。在本文中,我们提出了开发者与AI工具之间交互类型的分类,识别了十一种不同的交互类型,如自动完成代码建议、命令驱动操作和对话辅助。基于这种分类,我们概述了一项以优化AI交互、改善开发者控制和解决AI辅助开发中的信任和可用性挑战为重点的研究议程。通过为研究开发者与AI之间的交互建立结构化的基础,本文旨在刺激关于创建更有效、自适应的AI工具用于软件开发的进一步研究。
论文及项目相关链接
PDF Accepted at 2nd ACM International Conference on AI Foundation Models and Software Engineering (FORGE 2025)
Summary:人工智能(AI),包括大型语言模型和生成式AI,正在软件开发领域崭露头角,为开发者提供贯穿整个开发生命周期的强大工具。尽管软件工程研究已对AI工具在软件开发中的应用进行了广泛研究,但开发者与这些AI工具之间的特定交互类型最近才开始受到关注。理解和改进这些交互有望提高AI驱动工作流程中的生产力、信任和效率。本文提出了开发者与AI工具之间交互类型的分类,确定了包括自动完成代码建议、命令驱动操作和对话辅助等十一种不同的交互类型。在此基础上,我们提出了以优化AI交互、改善开发者控制和解决AI辅助开发中的信任和可用性挑战为重点的研究议程。本文旨在通过为开发者与AI之间的交互建立结构化基础,刺激关于创建更有效、适应性更强的AI工具的研究。
Key Takeaways:
- AI在软件开发中扮演重要角色,提供贯穿整个开发生命周期的强大工具。
- 开发者与AI工具的交互类型开始受到关注,这对提高AI工作流程的生产力、信任和效率有重要意义。
- 本文提出了一个开发者与AI工具之间交互类型的分类,包括十一种不同的交互类型,如自动完成代码建议、命令驱动操作和对话辅助等。
- 需要优化AI交互,改善开发者对AI工具的控制。
- 解决AI辅助开发中的信任和可用性挑战是研究的重点。
- 本文旨在建立研究开发者与AI之间交互的结构化基础。
点此查看论文截图

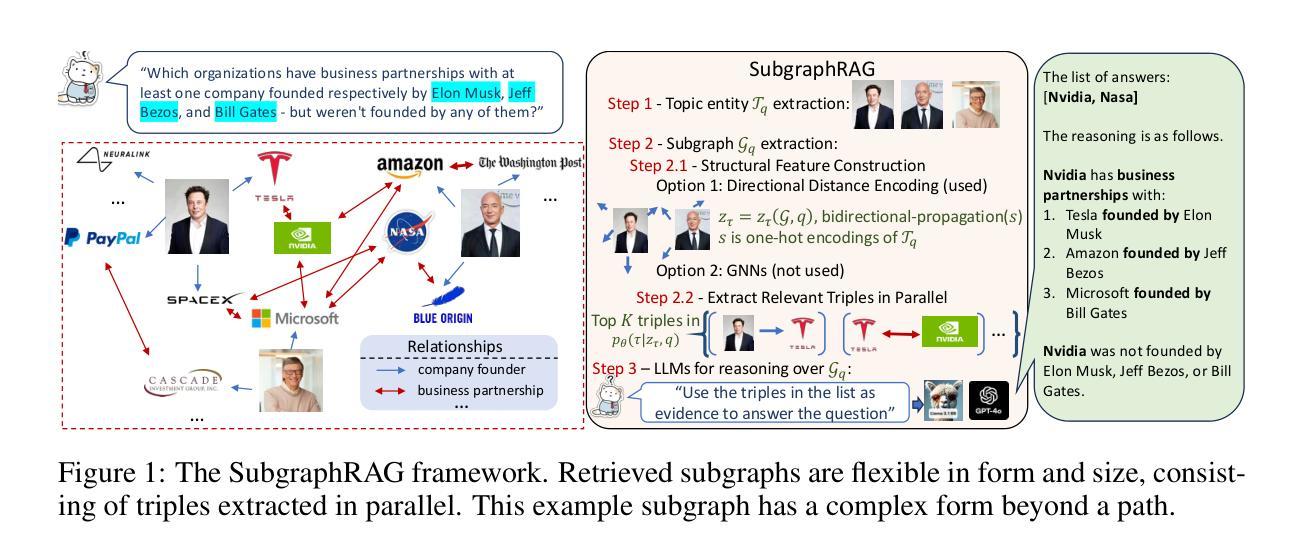
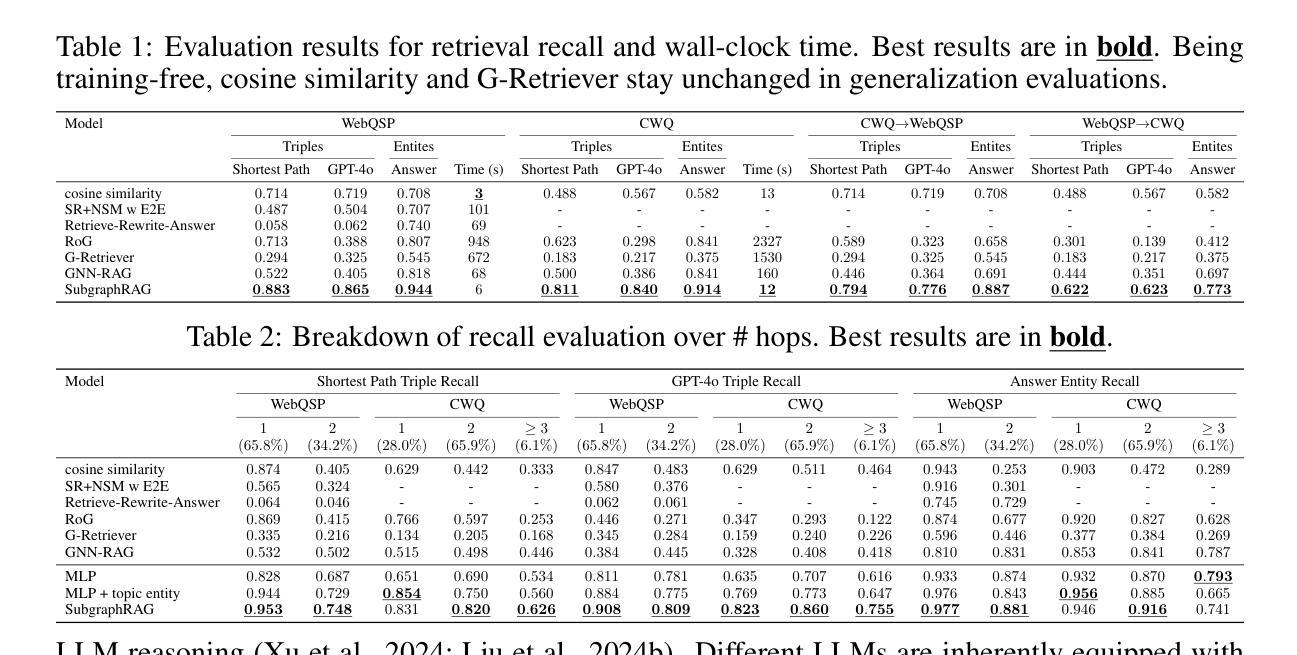
Simple Is Effective: The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation
Authors:Mufei Li, Siqi Miao, Pan Li
Large Language Models (LLMs) demonstrate strong reasoning abilities but face limitations such as hallucinations and outdated knowledge. Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) addresses these issues by grounding LLM outputs in structured external knowledge from KGs. However, current KG-based RAG frameworks still struggle to optimize the trade-off between retrieval effectiveness and efficiency in identifying a suitable amount of relevant graph information for the LLM to digest. We introduce SubgraphRAG, extending the KG-based RAG framework that retrieves subgraphs and leverages LLMs for reasoning and answer prediction. Our approach innovatively integrates a lightweight multilayer perceptron with a parallel triple-scoring mechanism for efficient and flexible subgraph retrieval while encoding directional structural distances to enhance retrieval effectiveness. The size of retrieved subgraphs can be flexibly adjusted to match the query’s need and the downstream LLM’s capabilities. This design strikes a balance between model complexity and reasoning power, enabling scalable and generalizable retrieval processes. Notably, based on our retrieved subgraphs, smaller LLMs like Llama3.1-8B-Instruct deliver competitive results with explainable reasoning, while larger models like GPT-4o achieve state-of-the-art accuracy compared with previous baselines – all without fine-tuning. Extensive evaluations on the WebQSP and CWQ benchmarks highlight SubgraphRAG’s strengths in efficiency, accuracy, and reliability by reducing hallucinations and improving response grounding.
大型语言模型(LLM)虽然展现出强大的推理能力,但仍存在诸如幻觉和知识储备过时等局限性。基于知识图谱(KG)的检索增强生成(RAG)通过将LLM输出根植于知识图谱中的结构化外部知识来解决这些问题。然而,现有的基于知识图谱的RAG框架在优化检索有效性与效率之间的权衡时,仍然难以确定适合LLM消化的大量相关图信息。我们引入了子图RAG,扩展了基于知识图谱的RAG框架,该框架检索子图并利用LLM进行推理和答案预测。我们的方法创新地整合了轻量级多层感知器和并行三元评分机制,以实现高效且灵活的子图检索,同时编码方向结构距离以提高检索效率。检索到的子图大小可以根据查询的需要和下游LLM的能力进行灵活调整。这种设计在模型复杂度和推理能力之间达到了平衡,实现了可扩展且通用的检索过程。值得注意的是,基于我们检索到的子图,较小的LLM(如Llama3.1-8B-Instruct)能够展现出具有解释性的推理结果,而较大的模型(如GPT-4o)则达到了前所未有的准确性——所有这一切都不需要进行微调。在WebQSP和CWQ基准测试上的广泛评估,突显了子图RAG在效率、准确性和可靠性方面的优势,它减少了幻觉并改善了响应依据。
论文及项目相关链接
PDF Accepted by ICLR 2025; Code available at https://github.com/Graph-COM/SubgraphRAG
Summary
大型语言模型(LLM)具备强大的推理能力,但存在幻象和知识过时等问题。基于知识图谱(KG)的检索增强生成(RAG)方法通过结合外部结构化知识来解决这些问题。然而,现有KG-based RAG框架在优化检索有效性与效率之间仍存在挑战。我们提出SubgraphRAG,扩展了KG-based RAG框架,通过检索子图并利用LLM进行推理和答案预测。该方法通过轻量级多层感知机和并行三元组评分机制实现高效灵活的子图检索,同时编码方向结构距离以增强检索效果。子图大小可根据查询需求和下游LLM能力灵活调整。这一设计在模型复杂度和推理能力之间达到了平衡,实现了可伸缩和通用的检索过程。在WebQSP和CWQ基准测试上的广泛评估表明,SubgraphRAG在效率、准确性和可靠性方面表现出色,减少了幻象,提高了响应的接地性。
Key Takeaways
- LLM具备强大的推理能力,但存在幻象和知识过时问题。
- KG-based RAG方法通过结合外部结构化知识解决这些问题。
- 现有KG-based RAG框架在优化检索有效性与效率方面存在挑战。
- SubgraphRAG通过检索子图并利用LLM进行推理和答案预测来扩展KG-based RAG框架。
- SubgraphRAG实现了高效灵活的子图检索,通过轻量级多层感知机和并行三元组评分机制。
- SubgraphRAG通过编码方向结构距离以增强检索效果。
点此查看论文截图