⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-07 更新
Metis: A Foundation Speech Generation Model with Masked Generative Pre-training
Authors:Yuancheng Wang, Jiachen Zheng, Junan Zhang, Xueyao Zhang, Huan Liao, Zhizheng Wu
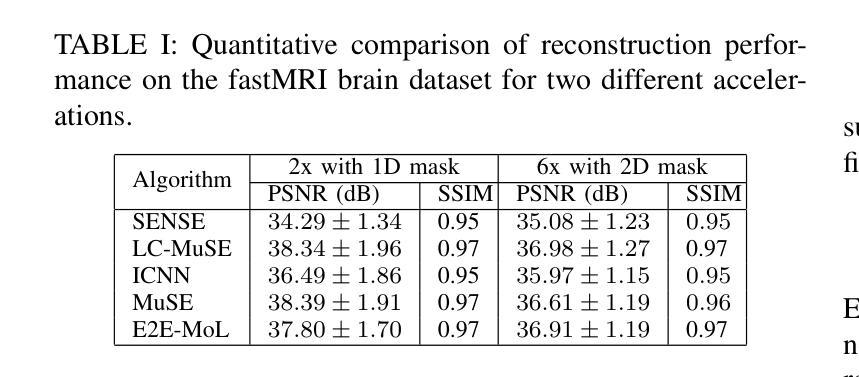
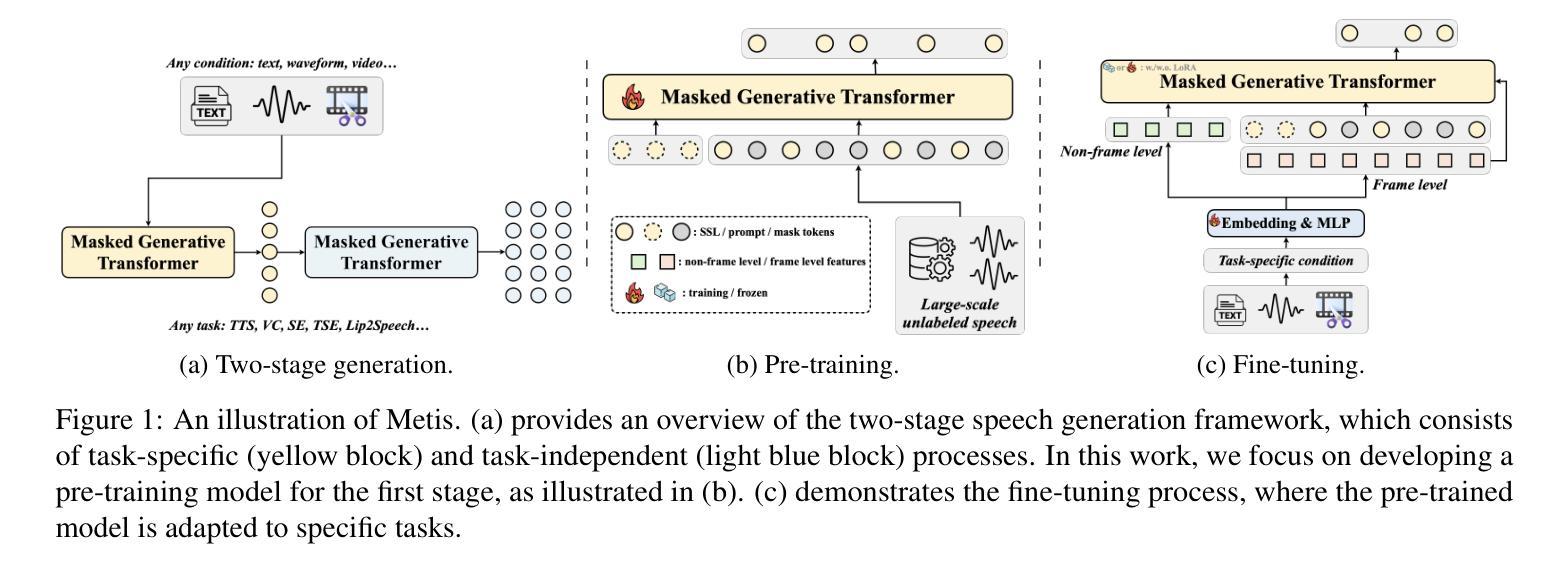
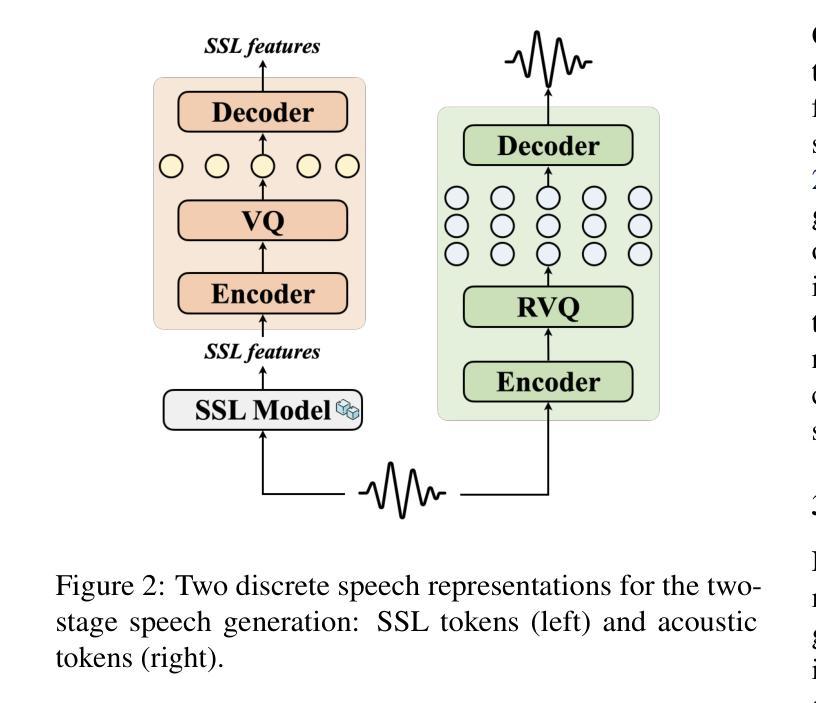
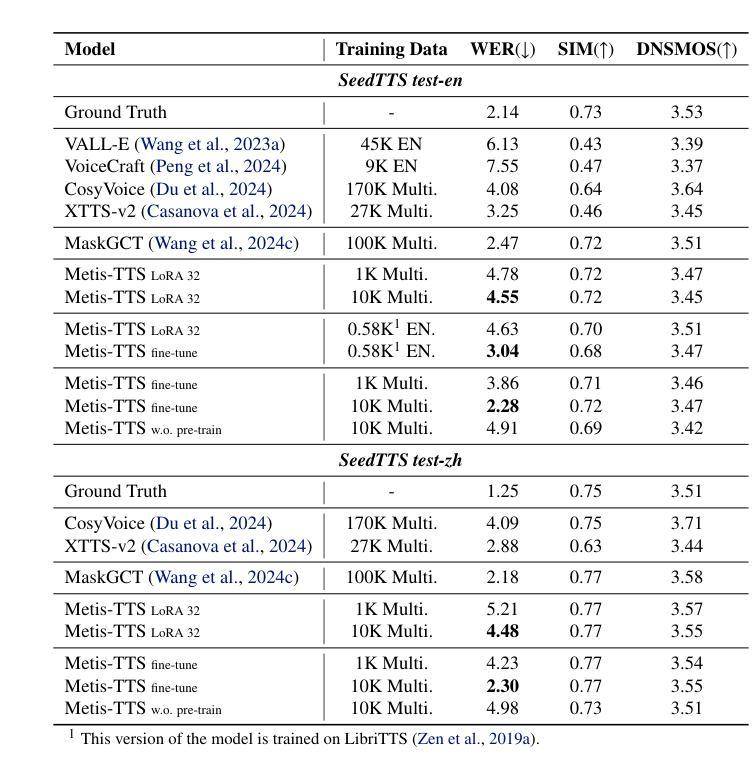
We introduce Metis, a foundation model for unified speech generation. Unlike previous task-specific or multi-task models, Metis follows a pre-training and fine-tuning paradigm. It is pre-trained on large-scale unlabeled speech data using masked generative modeling and then fine-tuned to adapt to diverse speech generation tasks. Specifically, 1) Metis utilizes two discrete speech representations: SSL tokens derived from speech self-supervised learning (SSL) features, and acoustic tokens directly quantized from waveforms. 2) Metis performs masked generative pre-training on SSL tokens, utilizing 300K hours of diverse speech data, without any additional condition. 3) Through fine-tuning with task-specific conditions, Metis achieves efficient adaptation to various speech generation tasks while supporting multimodal input, even when using limited data and trainable parameters. Experiments demonstrate that Metis can serve as a foundation model for unified speech generation: Metis outperforms state-of-the-art task-specific or multi-task systems across five speech generation tasks, including zero-shot text-to-speech, voice conversion, target speaker extraction, speech enhancement, and lip-to-speech, even with fewer than 20M trainable parameters or 300 times less training data. Audio samples are are available at https://metis-demo.github.io/.
我们介绍了Metis,这是一个统一的语音生成基础模型。与之前的任务特定或多任务模型不同,Metis遵循预训练和微调的模式。它使用遮罩生成建模在大规模无标签语音数据上进行预训练,然后针对各种语音生成任务进行微调以适应。具体来说,1)Metis利用两种离散语音表示:来自语音自监督学习(SSL)特征的SSL令牌和直接从波形量化的声学令牌。2)Metis在SSL令牌上进行遮罩生成预训练,利用30万小时的多样语音数据,无需任何额外条件。3)通过特定任务的微调,Metis能够高效适应各种语音生成任务,同时支持多模态输入,即使使用有限的数据和可训练参数也是如此。实验表明,Metis可以作为统一的语音生成基础模型:即使在少于20M的可训练参数或300倍的训练数据下,Metis在五个语音生成任务上的表现也优于最新的任务特定或多任务系统,包括零样本文本到语音、语音转换、目标说话人提取、语音增强和唇到语音。音频样本可在https://metis-demo.github.io/找到。
论文及项目相关链接
Summary
本文介绍了Metis——一个统一的语音生成基础模型。Metis采用预训练与微调的模式,使用大规模无标签语音数据进行预训练,并通过微调适应各种语音生成任务。它利用两种离散语音表示:SSL令牌和量化声波得到的声学令牌。实验表明,Metis在五个语音生成任务上的表现优于最先进的任务特定或多任务系统,包括零样本文本到语音、语音转换、目标说话人提取、语音增强和唇语同步。即使是参数更少或者训练数据量大幅减少的情况下,其表现仍然超越先前模型。详情可访问相关演示网站了解音频样本。
Key Takeaways
- Metis是一个统一的语音生成基础模型,采用预训练与微调的模式。
- Metis使用大规模无标签语音数据进行预训练,并采用了两种离散语音表示方法。
- Metis能够高效适应多种语音生成任务,并支持多模态输入。
- 在五个不同的语音生成任务上,Metis的表现优于其他先进的任务特定或多任务系统。
- Metis在参数数量和训练数据量较少的情况下仍能保持出色的性能。
- 音频样本可通过相关演示网站访问。
点此查看论文截图

Differentially-Private Multi-Tier Federated Learning: A Formal Analysis and Evaluation
Authors:Evan Chen, Frank Po-Chen Lin, Dong-Jun Han, Christopher G. Brinton
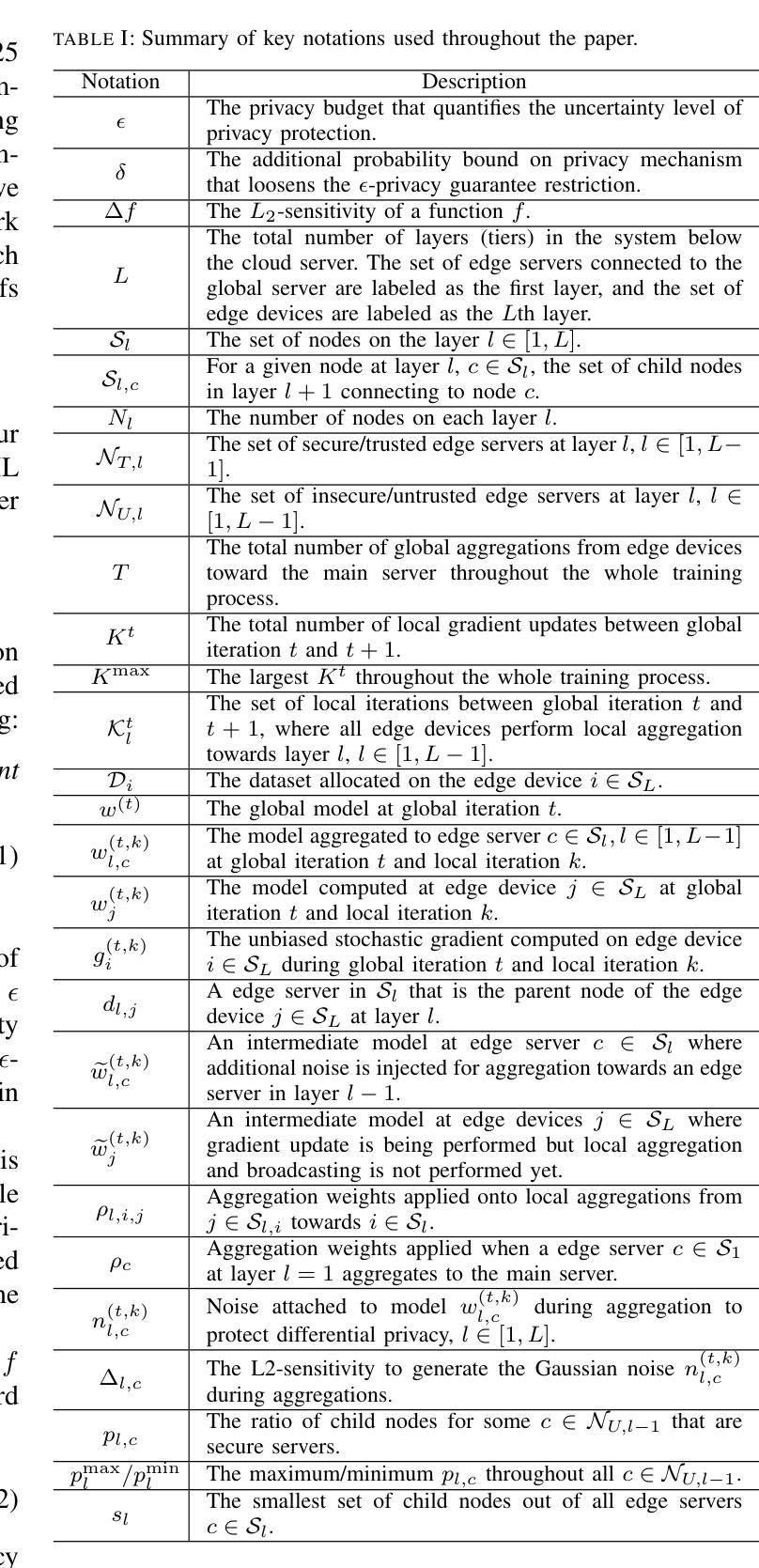
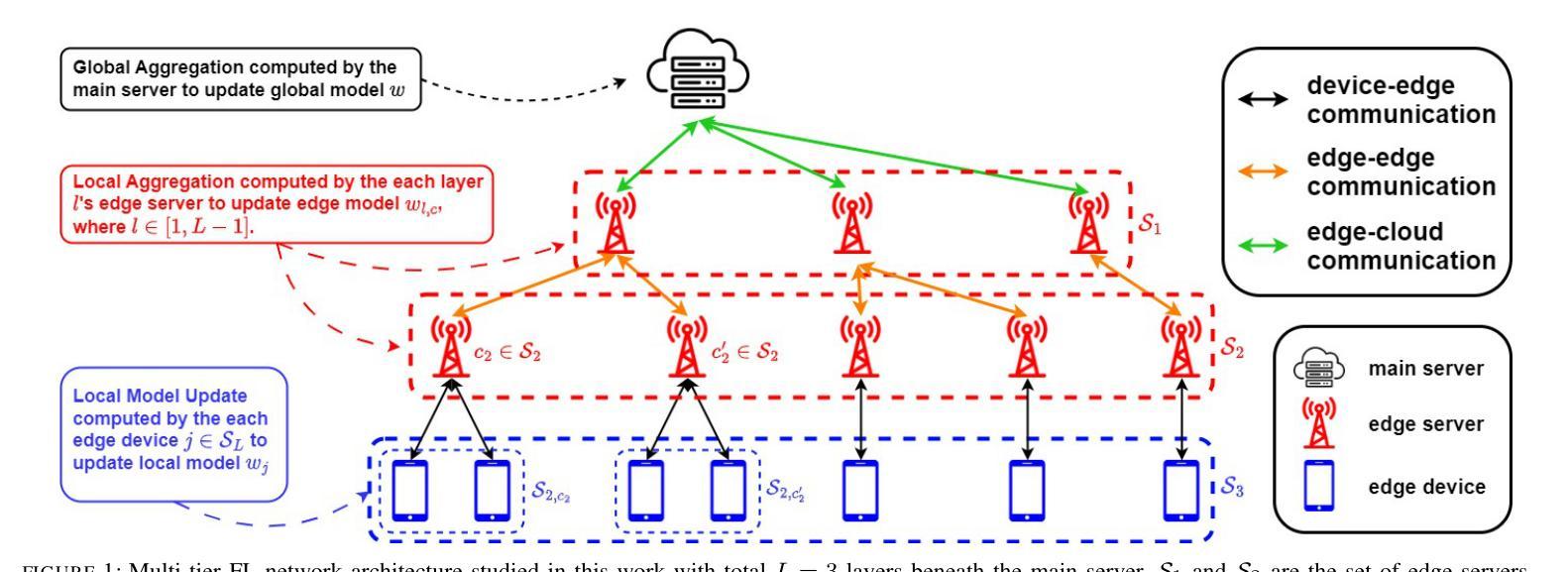
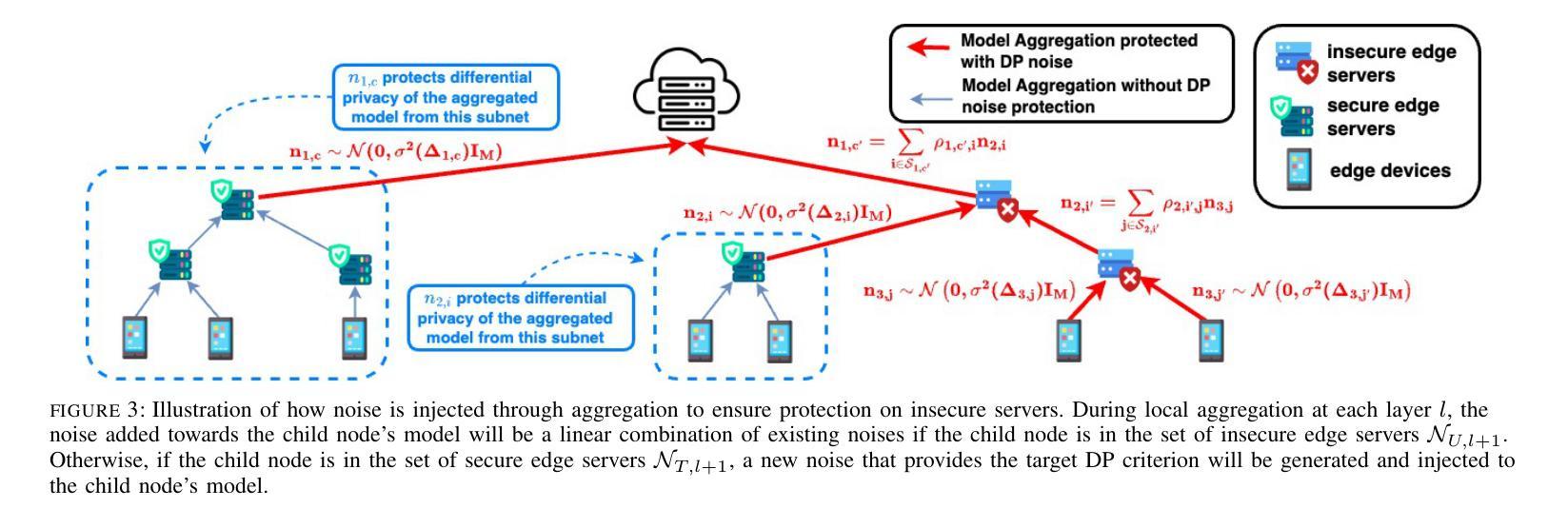
While federated learning (FL) eliminates the transmission of raw data over a network, it is still vulnerable to privacy breaches from the communicated model parameters. Differential privacy (DP) is often employed to address such issues. However, the impact of DP on FL in multi-tier networks – where hierarchical aggregations couple noise injection decisions at different tiers, and trust models are heterogeneous across subnetworks – is not well understood. To fill this gap, we develop \underline{M}ulti-Tier \underline{F}ederated Learning with \underline{M}ulti-Tier \underline{D}ifferential \underline{P}rivacy ({\tt M$^2$FDP}), a DP-enhanced FL methodology for jointly optimizing privacy and performance over such networks. One of the key principles of {\tt M$^2$FDP} is to adapt DP noise injection across the established edge/fog computing hierarchy (e.g., edge devices, intermediate nodes, and other tiers up to cloud servers) according to the trust models in different subnetworks. We conduct a comprehensive analysis of the convergence behavior of {\tt M$^2$FDP} under non-convex problem settings, revealing conditions on parameter tuning under which the training process converges sublinearly to a finite stationarity gap that depends on the network hierarchy, trust model, and target privacy level. We show how these relationships can be employed to develop an adaptive control algorithm for {\tt M$^2$FDP} that tunes properties of local model training to minimize energy, latency, and the stationarity gap while meeting desired convergence and privacy criterion. Subsequent numerical evaluations demonstrate that {\tt M$^2$FDP} obtains substantial improvements in these metrics over baselines for different privacy budgets and system configurations.
虽然联邦学习(FL)消除了通过网络传输原始数据的需求,但它仍然容易受到通信模型参数泄露导致的隐私侵犯。为了解决这些问题,通常采用差分隐私(DP)。然而,在多层网络中,差分隐私对联邦学习的影响尚未得到充分理解——其中分层聚合在不同层级上结合了噪声注入决策,并且子网络之间的信任模型是异构的。为了填补这一空白,我们开发了多层联邦学习与多层差分隐私(M$^2$FDP),这是一种增强的差分隐私联邦学习方法,用于在这种网络上联合优化隐私和性能。M$^2$FDP的关键原则之一是根据不同子网络中的信任模型,在建立的边缘/雾计算层次结构(例如边缘设备、中间节点和云服务器等其他层级)中适应差分隐私噪声注入。我们对M$^2$FDP在非凸问题设置下的收敛行为进行了综合分析,揭示了参数调整的条件下,训练过程以次线性的方式收敛到一个有限的稳定性差距,这取决于网络层次结构、信任模型和目标隐私级别。我们展示了如何运用这些关系来开发M$^2$FDP的自适应控制算法,该算法可以调整本地模型训练的特性,以最小化能量、延迟和稳定性差距,同时满足所需的收敛性和隐私标准。随后的数值评估表明,对于不同的隐私预算和系统配置,M$^2$FDP在这些指标上取得了显著的改进。
论文及项目相关链接
PDF This paper is under review in IEEE/ACM Transactions on Networking Special Issue on AI and Networking
摘要
在联邦学习(FL)中,虽然不需要通过网络传输原始数据,但仍然存在通过通信模型参数泄露隐私的风险。为解决这一问题,常采用差分隐私(DP)技术。然而,在多层级网络中,差分隐私技术对联邦学习的影响并未得到充分理解,其中涉及不同层级间的噪声注入决策和子网络间的异构信任模型。为解决此空白,我们提出了多层级联邦学习与多层级差分隐私融合的方法(M$^2$FDP),这是一种增强DP的FL方法,旨在优化此类网络中的隐私和性能。M$^2$FDP的关键原则之一是根据各子网络中的信任模型,在边缘计算/雾计算层级(如边缘设备、中间节点和云服务器等)自适应调整DP噪声注入。我们对M$^2$FDP在非凸问题设置下的收敛行为进行了综合分析,揭示了参数调整的条件,训练过程可以次线性收敛到一个有限的稳定性差距,这取决于网络层次结构、信任模型和目标隐私级别。我们还展示了如何利用这些关系来为M$^2$FDP开发自适应控制算法,该算法可调整本地模型训练的特性,以最小化能量、延迟和稳定性差距,同时满足所需的收敛性和隐私标准。数值评估表明,对于不同的隐私预算和系统配置,M$^2$FDP在这些指标上取得了显著改进。
关键见解
- M$^2$FDP方法结合了联邦学习和差分隐私,旨在优化多层级网络中的隐私和性能。
- M$^2$FDP根据子网络中的信任模型自适应调整差分隐私的噪声注入。
- 在非凸问题设置下,M$^2$FDP的收敛行为取决于网络层次结构、信任模型和隐私目标级别。
- 提出了一个自适应控制算法,可以根据网络条件和隐私需求调整模型训练参数。
- M$^2$FDP在能量、延迟、收敛性和隐私等方面相比基准方法有明显改进。
- 数值评估证明了M$^2$FDP在不同隐私预算和系统配置下的有效性。
点此查看论文截图