⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-07 更新
ZISVFM: Zero-Shot Object Instance Segmentation in Indoor Robotic Environments with Vision Foundation Models
Authors:Ying Zhang, Maoliang Yin, Wenfu Bi, Haibao Yan, Shaohan Bian, Cui-Hua Zhang, Changchun Hua
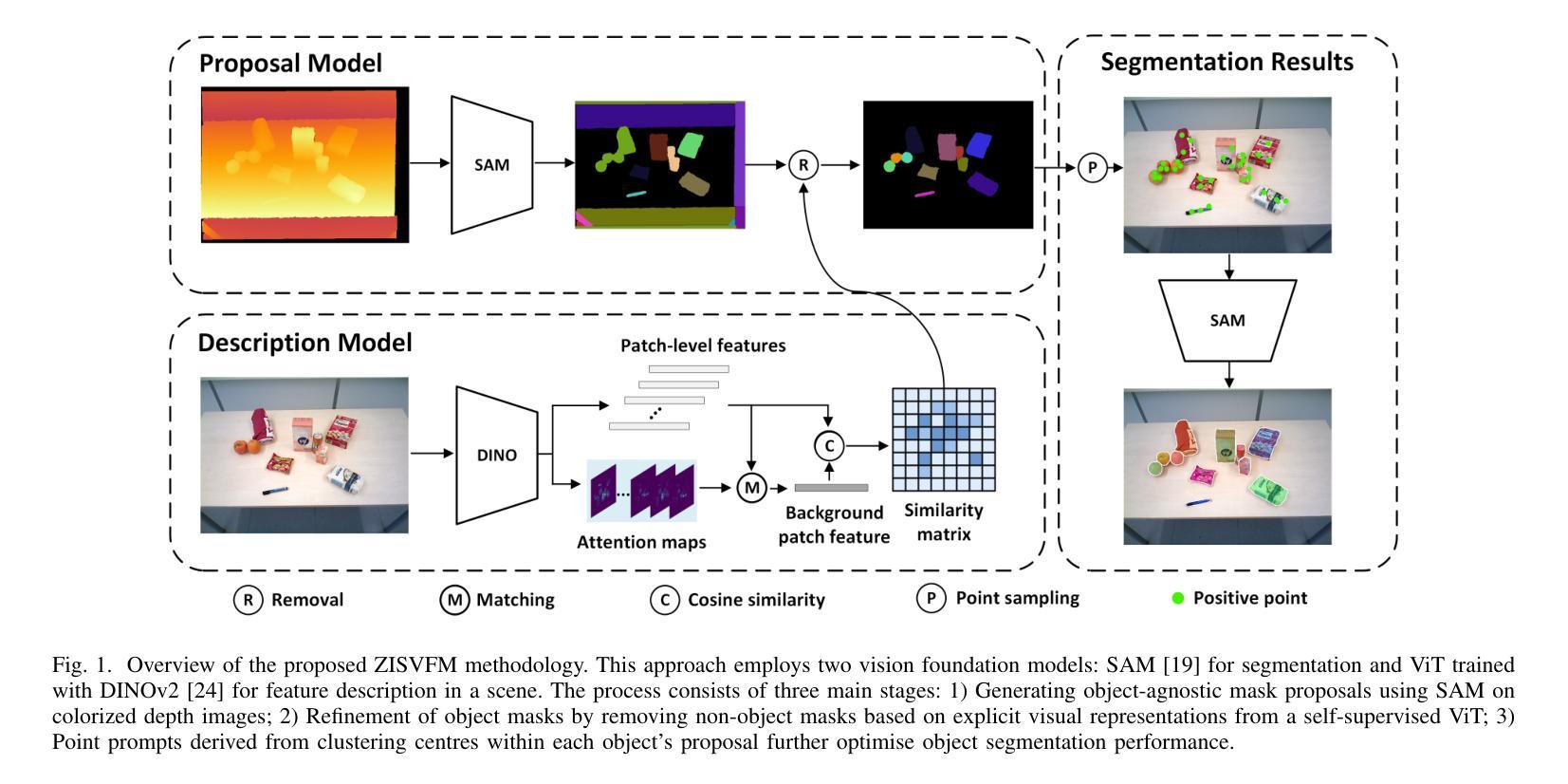
Service robots operating in unstructured environments must effectively recognize and segment unknown objects to enhance their functionality. Traditional supervised learningbased segmentation techniques require extensive annotated datasets, which are impractical for the diversity of objects encountered in real-world scenarios. Unseen Object Instance Segmentation (UOIS) methods aim to address this by training models on synthetic data to generalize to novel objects, but they often suffer from the simulation-to-reality gap. This paper proposes a novel approach (ZISVFM) for solving UOIS by leveraging the powerful zero-shot capability of the segment anything model (SAM) and explicit visual representations from a selfsupervised vision transformer (ViT). The proposed framework operates in three stages: (1) generating object-agnostic mask proposals from colorized depth images using SAM, (2) refining these proposals using attention-based features from the selfsupervised ViT to filter non-object masks, and (3) applying K-Medoids clustering to generate point prompts that guide SAM towards precise object segmentation. Experimental validation on two benchmark datasets and a self-collected dataset demonstrates the superior performance of ZISVFM in complex environments, including hierarchical settings such as cabinets, drawers, and handheld objects. Our source code is available at https://github.com/Yinmlmaoliang/zisvfm.
服务机器人在非结构化环境中运行时,必须有效地识别和分割未知物体,以提高其功能性。传统的基于监督学习的分割技术需要大量的标注数据集,这在现实场景中遇到的各种对象多样性情况下并不实用。未见对象实例分割(UOIS)方法旨在通过合成数据进行模型训练,以推广到新型对象,但它们常常受到仿真到现实的差距的影响。本文提出了一种新的解决UOIS的方法(ZISVFM),该方法利用分段任何模型(SAM)的强大零射击能力和自监督视觉变压器(ViT)的显式视觉表示。所提出的框架分为三个阶段:(1)使用SAM从彩色深度图像中生成与对象无关的掩膜提议,(2)使用自监督ViT的注意力特征对这些提议进行细化,以过滤掉非对象掩膜,(3)应用K-Medoids聚类生成点提示,引导SAM进行精确的对象分割。在两个基准数据集和自收集数据集上的实验验证表明,ZISVFM在复杂环境中具有卓越的性能,包括层次设置,如柜子、抽屉和手持物体。我们的源代码可在[https://github.com/Yinmlmaoliang/zisvfm找到。]
论文及项目相关链接
Summary
本文提出了一种基于零样本能力的分段任何模型(SAM)和自监督视觉转换器(ViT)的显式视觉表示的新方法(ZISVFM),用于解决在服务机器人中遇到的无结构环境中未见物体实例分割(UOIS)的问题。通过三个阶段,实现了基于颜色化深度图像的对象无关掩模提案生成、使用自监督ViT的注意力特征过滤非对象掩模以及使用K-Medoids聚类生成点提示来精确指导SAM进行对象分割。实验验证表明,ZISVFM在复杂环境中表现优越,包括柜子、抽屉和手持物体等层次设置。
Key Takeaways
- 服务机器人需要有效识别和分割未知物体以改善其功能,特别是在无结构环境中。
- 传统监督学习方法需要大量标注数据集,难以应对现实世界中物体的多样性。
- 未见物体实例分割(UOIS)方法旨在通过训练合成数据模型来推广到新型物体,但存在仿真与现实的差距。
- 本文提出的ZISVFM方法结合分段任何模型(SAM)和自监督视觉转换器(ViT)来解决UOIS问题。
- ZISVFM通过颜色化深度图像生成对象无关掩模提案,并使用注意力特征过滤非对象掩模。
- 利用K-Medoids聚类生成点提示,精确指导SAM进行对象分割。
点此查看论文截图