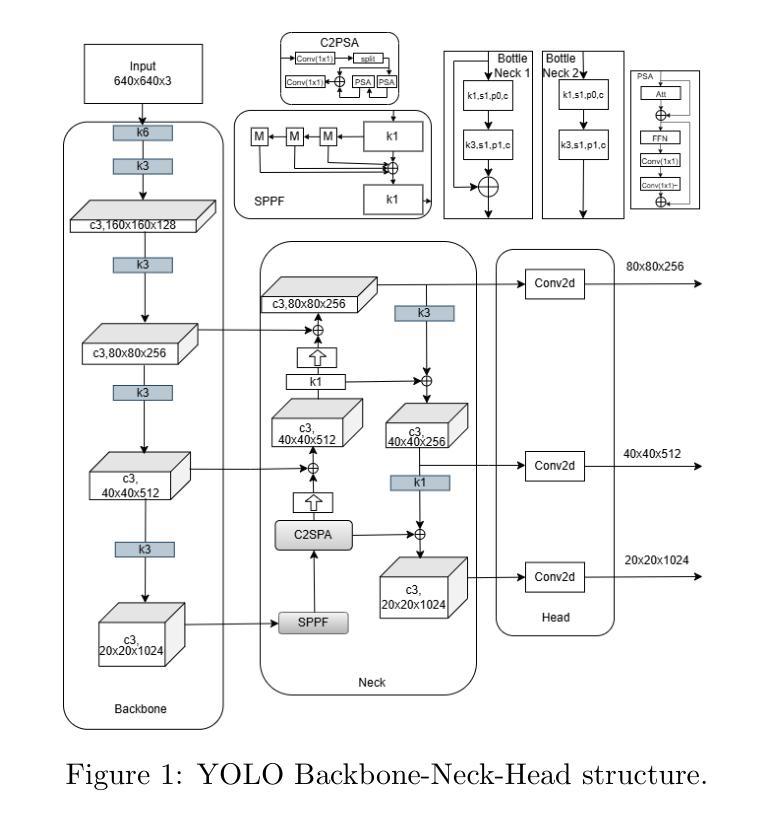
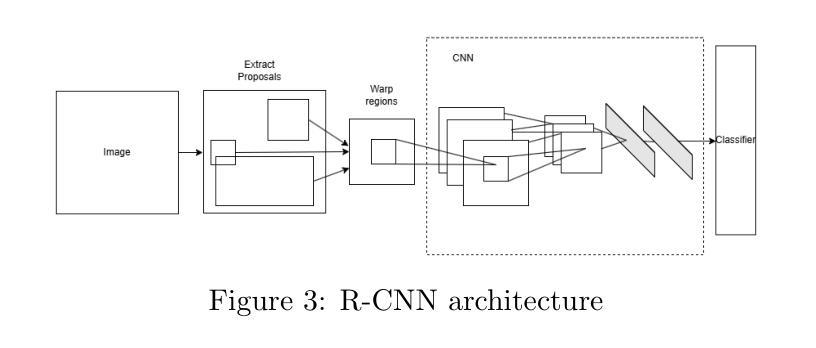
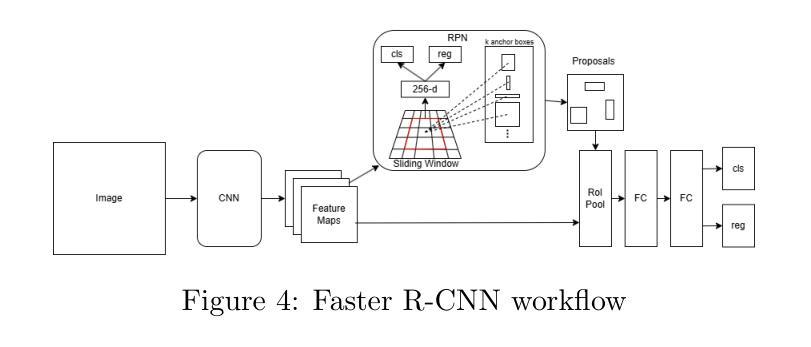
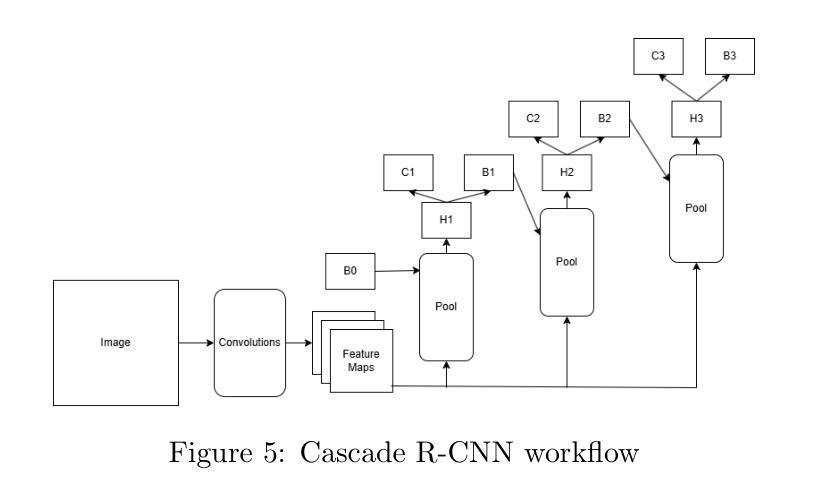
⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-08 更新
Point2RBox-v2: Rethinking Point-supervised Oriented Object Detection with Spatial Layout Among Instances
Authors:Yi Yu, Botao Ren, Peiyuan Zhang, Mingxin Liu, Junwei Luo, Shaofeng Zhang, Feipeng Da, Junchi Yan, Xue Yang
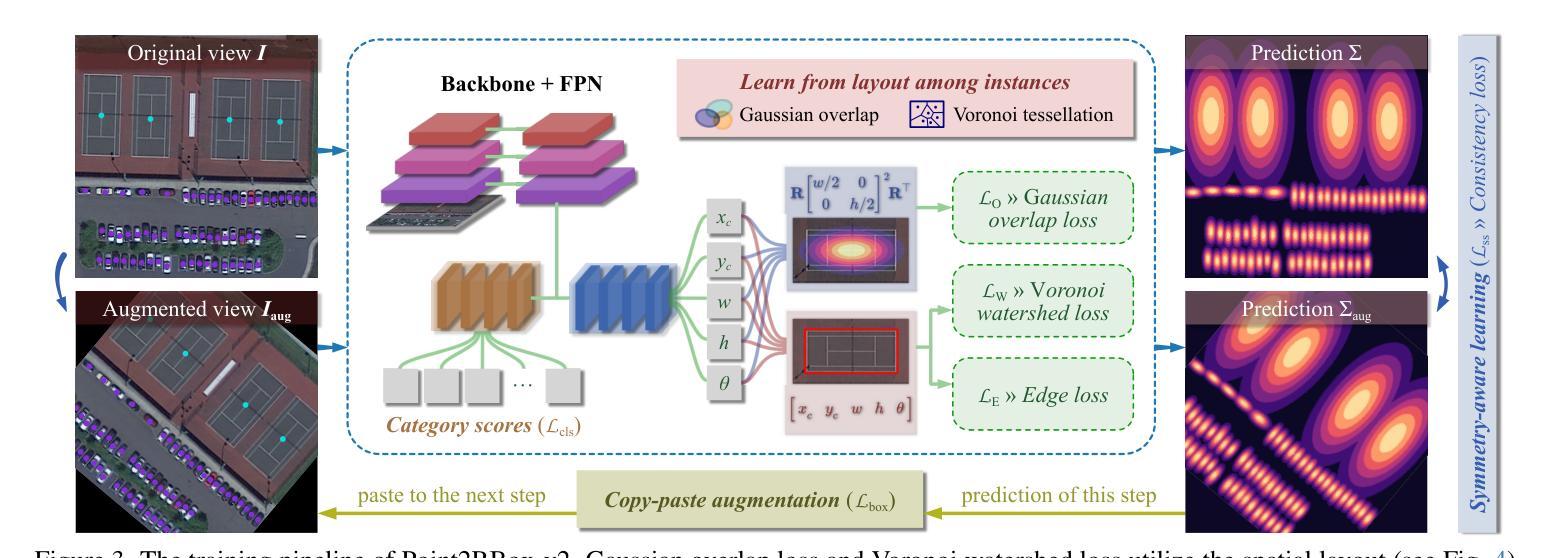
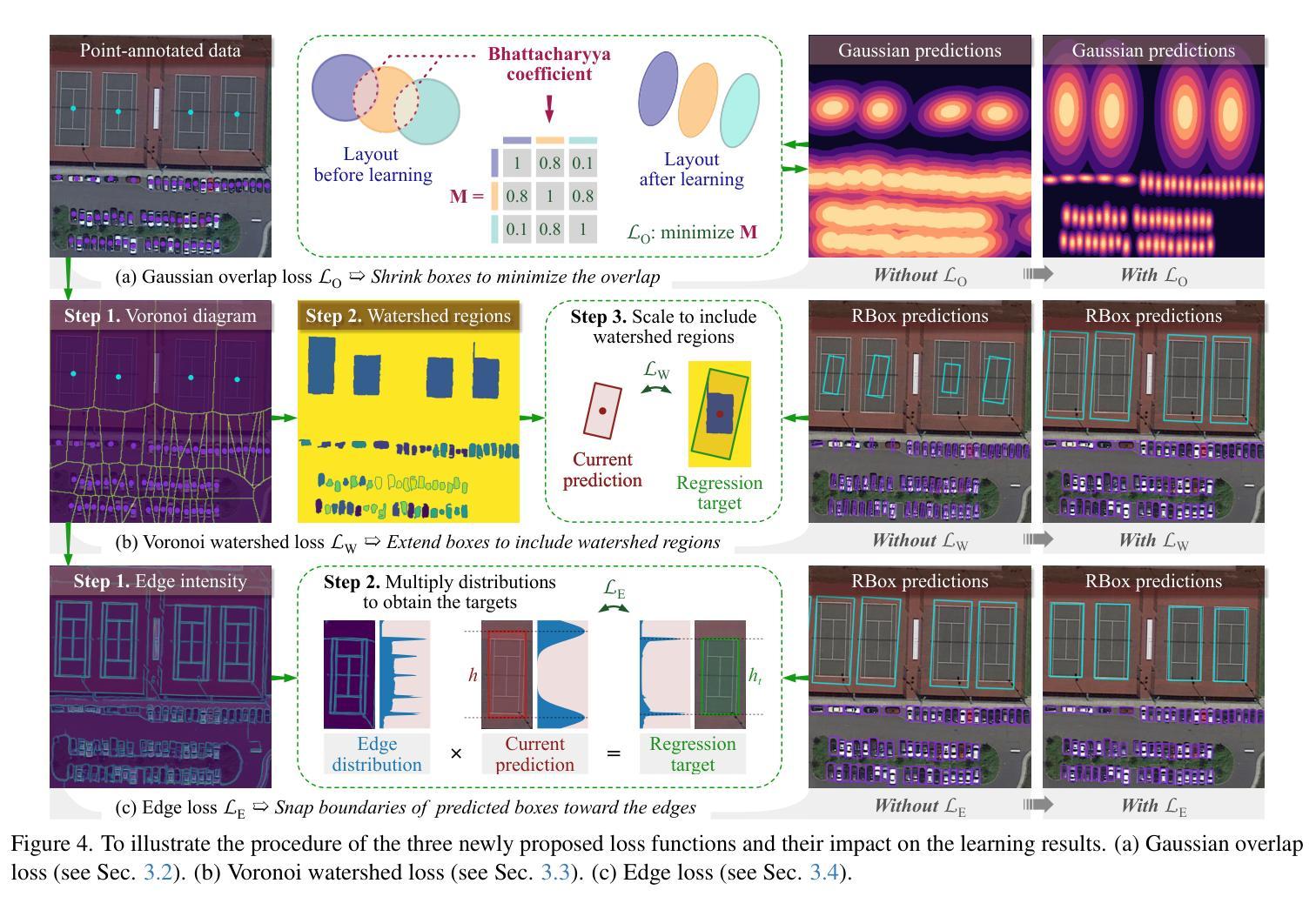
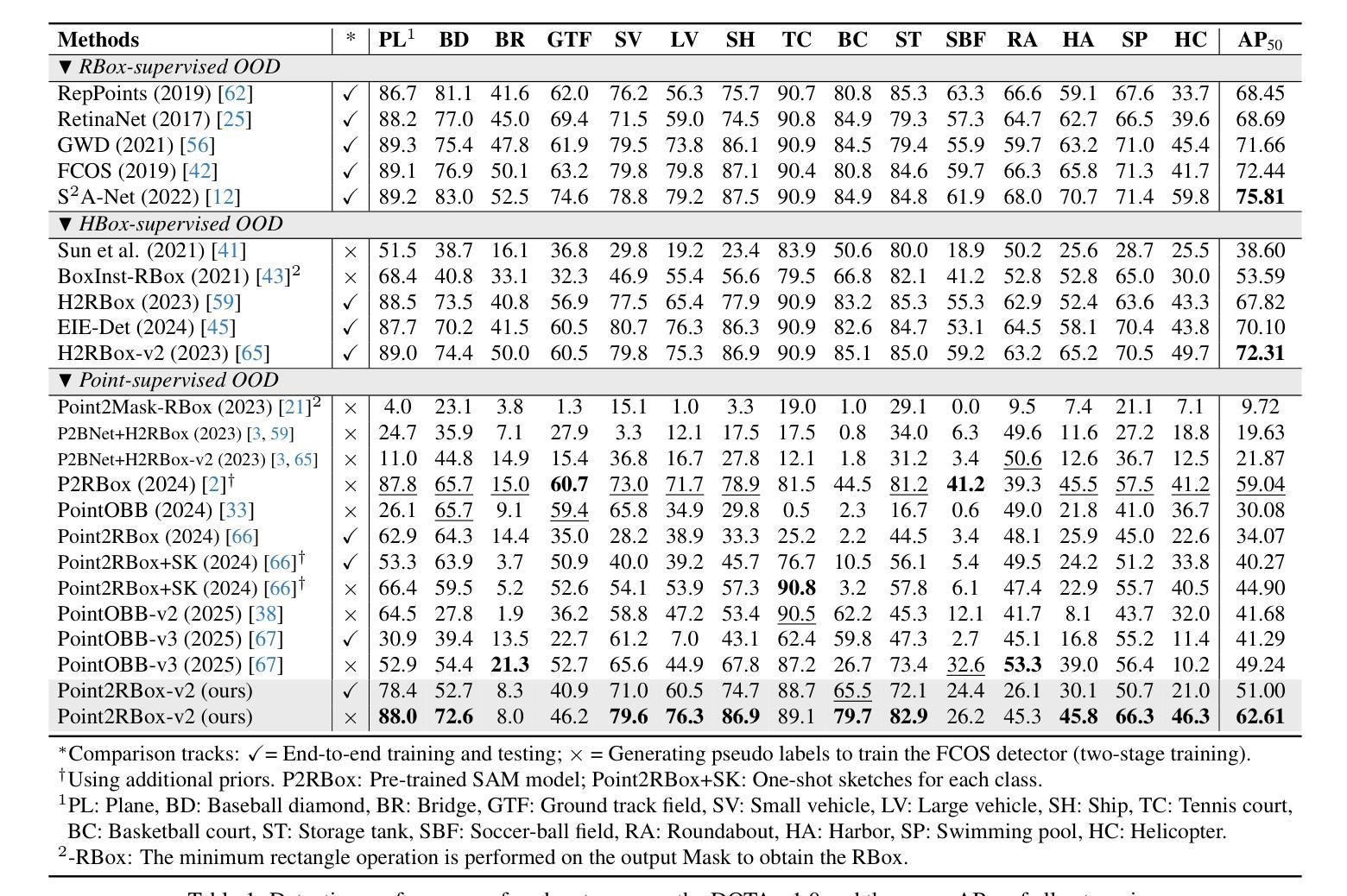
With the rapidly increasing demand for oriented object detection (OOD), recent research involving weakly-supervised detectors for learning OOD from point annotations has gained great attention. In this paper, we rethink this challenging task setting with the layout among instances and present Point2RBox-v2. At the core are three principles: 1) Gaussian overlap loss. It learns an upper bound for each instance by treating objects as 2D Gaussian distributions and minimizing their overlap. 2) Voronoi watershed loss. It learns a lower bound for each instance through watershed on Voronoi tessellation. 3) Consistency loss. It learns the size/rotation variation between two output sets with respect to an input image and its augmented view. Supplemented by a few devised techniques, e.g. edge loss and copy-paste, the detector is further enhanced.To our best knowledge, Point2RBox-v2 is the first approach to explore the spatial layout among instances for learning point-supervised OOD. Our solution is elegant and lightweight, yet it is expected to give a competitive performance especially in densely packed scenes: 62.61%/86.15%/34.71% on DOTA/HRSC/FAIR1M. Code is available at https://github.com/VisionXLab/point2rbox-v2.
随着定向目标检测(OOD)需求的快速增长,最近关于利用弱监督检测器从点注释中学习OOD的研究引起了极大的关注。在本文中,我们重新思考了这一具有挑战性的任务设置与实例之间的布局,并推出了Point2RBox-v2。其核心包含三个原则:1)高斯重叠损失。它将对象视为二维高斯分布,通过最小化其重叠来学习每个实例的上界。2)Voronoi分水岭损失。它通过Voronoi剖分上的分水岭来学习每个实例的下界。3)一致性损失。它学习输入图像及其增强视图对应的两个输出集之间的大小/旋转变化。通过补充一些设计的技术,如边缘损失和复制粘贴,进一步增强了检测器。据我们所知,Point2RBox-v2是第一个探索实例之间空间布局以进行点监督OOD学习的研究。我们的解决方案既优雅又轻便,预计尤其在密集场景中能表现出竞争力:在DOTA/HRSC/FAIR1M上的性能分别为62.61%/86.15%/34.71%。代码可在https://github.com/VisionXLab/point2rbox-v2中找到。
论文及项目相关链接
PDF 11 pages, 5 figures, 10 tables
Summary:
本文提出了Point2RBox-v2方法,旨在解决从点注释中学习定向目标检测的问题。核心思想包括三个原则:高斯重叠损失、Voronoi水域损失和一致性损失。该方法能够学习实例之间的空间布局,预计在高密度场景中表现优异,在DOTA、HRSC和FAIR1M上的性能分别为62.61%、86.15%、34.71%。代码已开源。
Key Takeaways:
- Point2RBox-v2方法利用三个核心原则:高斯重叠损失、Voronoi水域损失和一致性损失来学习实例间的空间布局。
- 该方法能够从点注释中学习定向目标检测(OOD)。
- 该方法具有优越性,能够在高密度场景中实现出色的性能。
- 在DOTA、HRSC和FAIR1M数据集上的性能分别达到62.61%、86.15%、34.71%。
- 该解决方案是优雅且轻量级的。
点此查看论文截图


Optimized Unet with Attention Mechanism for Multi-Scale Semantic Segmentation
Authors:Xuan Li, Quanchao Lu, Yankaiqi Li, Muqing Li, Yijiashun Qi
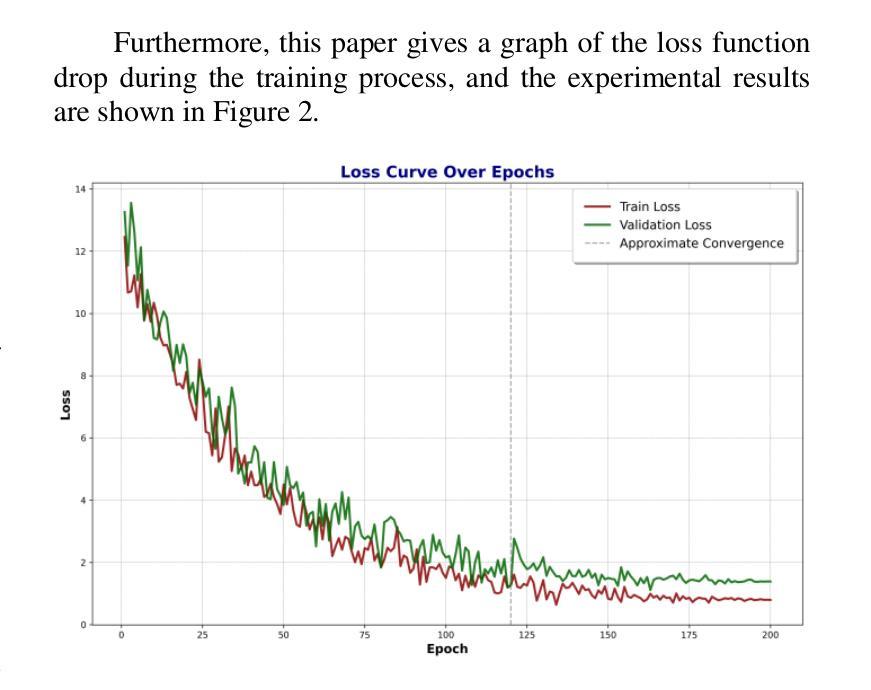
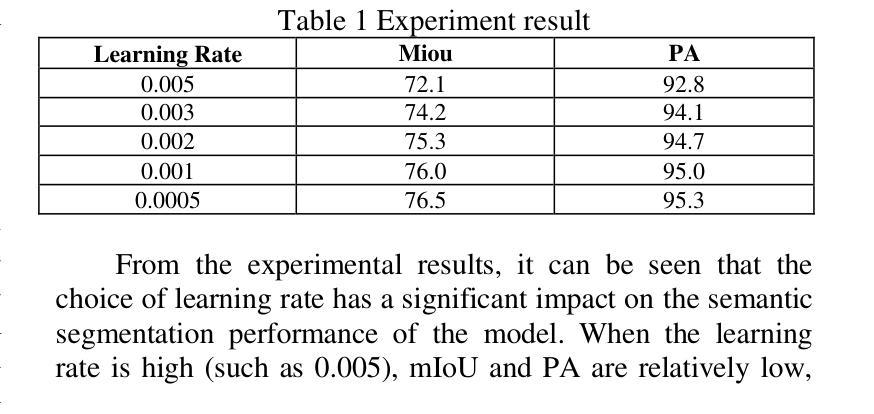
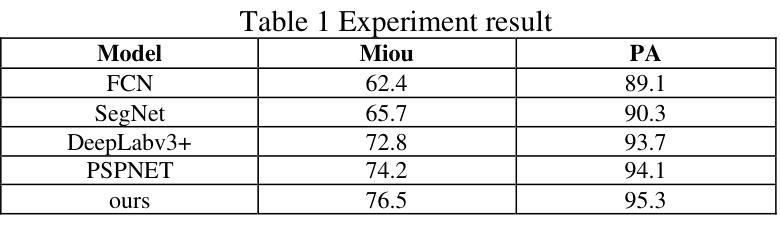
Semantic segmentation is one of the core tasks in the field of computer vision, and its goal is to accurately classify each pixel in an image. The traditional Unet model achieves efficient feature extraction and fusion through an encoder-decoder structure, but it still has certain limitations when dealing with complex backgrounds, long-distance dependencies, and multi-scale targets. To this end, this paper proposes an improved Unet model combined with an attention mechanism, introduces channel attention and spatial attention modules, enhances the model’s ability to focus on important features, and optimizes skip connections through a multi-scale feature fusion strategy, thereby improving the combination of global semantic information and fine-grained features. The experiment is based on the Cityscapes dataset and compared with classic models such as FCN, SegNet, DeepLabv3+, and PSPNet. The improved model performs well in terms of mIoU and pixel accuracy (PA), reaching 76.5% and 95.3% respectively. The experimental results verify the superiority of this method in dealing with complex scenes and blurred target boundaries. In addition, this paper discusses the potential of the improved model in practical applications and future expansion directions, indicating that it has broad application value in fields such as autonomous driving, remote sensing image analysis, and medical image processing.
语义分割是计算机视觉领域的核心任务之一,其目标是对图像中的每个像素进行准确分类。传统的Unet模型通过编码器-解码器结构实现有效的特征提取和融合,但在处理复杂背景、长距离依赖关系和多尺度目标时仍存在一定的局限性。为此,本文提出了一种结合注意力机制的改进型Unet模型,引入了通道注意力和空间注意力模块,增强了模型对重要特征的聚焦能力,并通过多尺度特征融合策略优化了跳过连接,从而提高了全局语义信息和细粒度特征的组合。实验基于Cityscapes数据集,与FCN、SegNet、DeepLabv3+和PSPNet等经典模型进行了比较。改进后的模型在mIoU和像素精度(PA)方面表现良好,分别达到了76.5%和95.3%。实验结果验证了该方法在处理复杂场景和模糊目标边界方面的优越性。此外,本文还讨论了改进模型在实际应用中的潜力和未来扩展方向,表明它在自动驾驶、遥感图像分析和医疗图像处理等领域具有广泛的应用价值。
论文及项目相关链接
Summary
本文改进了Unet模型,结合注意力机制,引入通道注意力模块和空间注意力模块,提高了模型对重要特征的聚焦能力。通过多尺度特征融合策略优化跳跃连接,提高了全局语义信息和精细特征的结合效果。在Cityscapes数据集上进行实验,与经典模型相比,改进模型在mIoU和像素精度上表现优异,分别达到了76.5%和95.3%。验证了该方法在处理复杂场景和模糊目标边界方面的优越性,具有广泛的应用价值。
Key Takeaways
- 语义分割是计算机视觉领域的核心任务之一,旨在准确地对图像中的每个像素进行分类。
- 传统Unet模型通过编码器-解码器结构实现有效的特征提取和融合,但在处理复杂背景、长距离依赖关系和跨尺度目标时存在局限性。
- 改进后的Unet模型结合了注意力机制,提高了对重要特征的聚焦能力。
- 引入通道注意力模块和空间注意力模块,优化模型性能。
- 通过多尺度特征融合策略优化跳跃连接,促进全局语义信息和精细特征的结合。
- 在Cityscapes数据集上进行的实验表明,改进模型在mIoU和像素精度方面表现优异,分别达到76.5%和95.3%。
点此查看论文截图


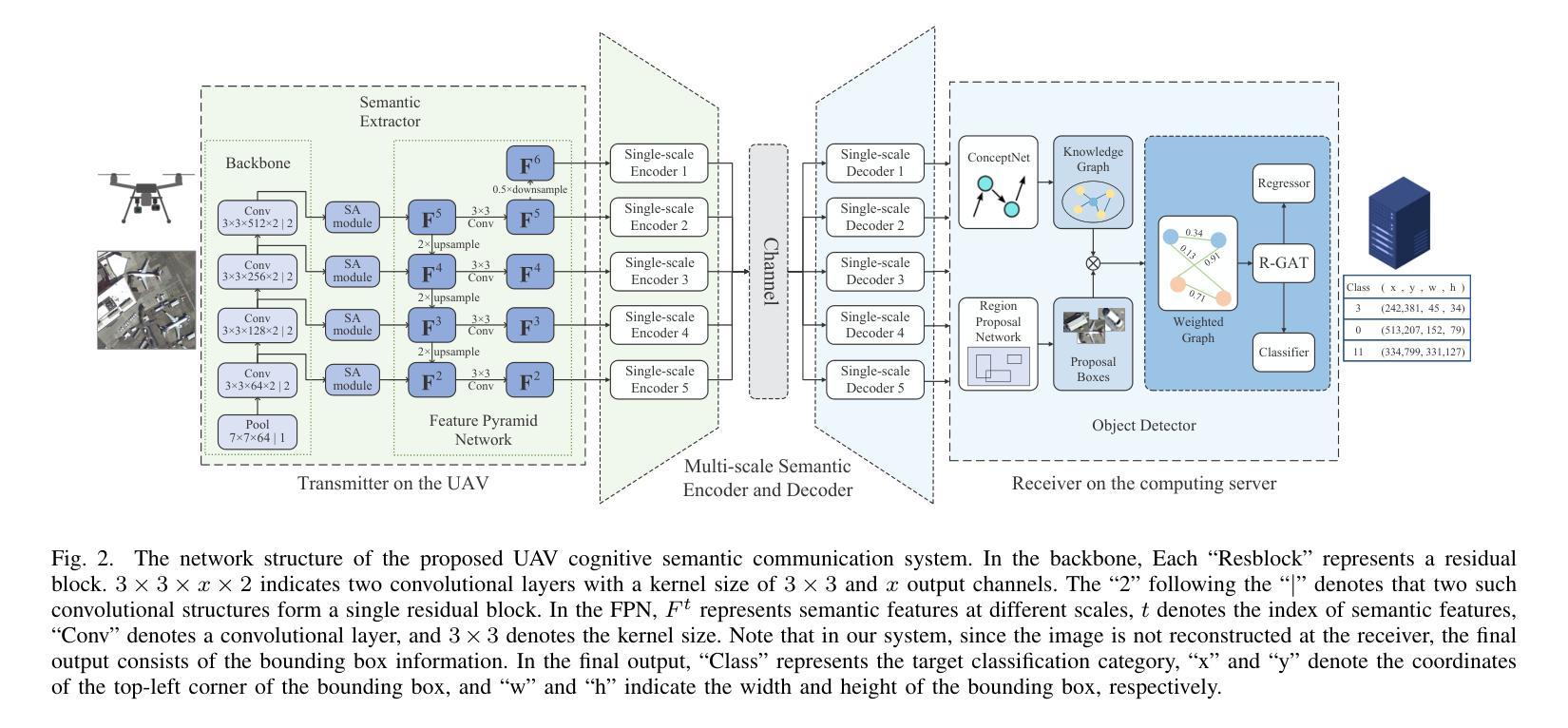
UAV Cognitive Semantic Communications Enabled by Knowledge Graph for Robust Object Detection
Authors:Xi Song, Fuhui Zhou, Rui Ding, Zhibo Qu, Yihao Li, Qihui Wu, Naofal Al-Dhahir
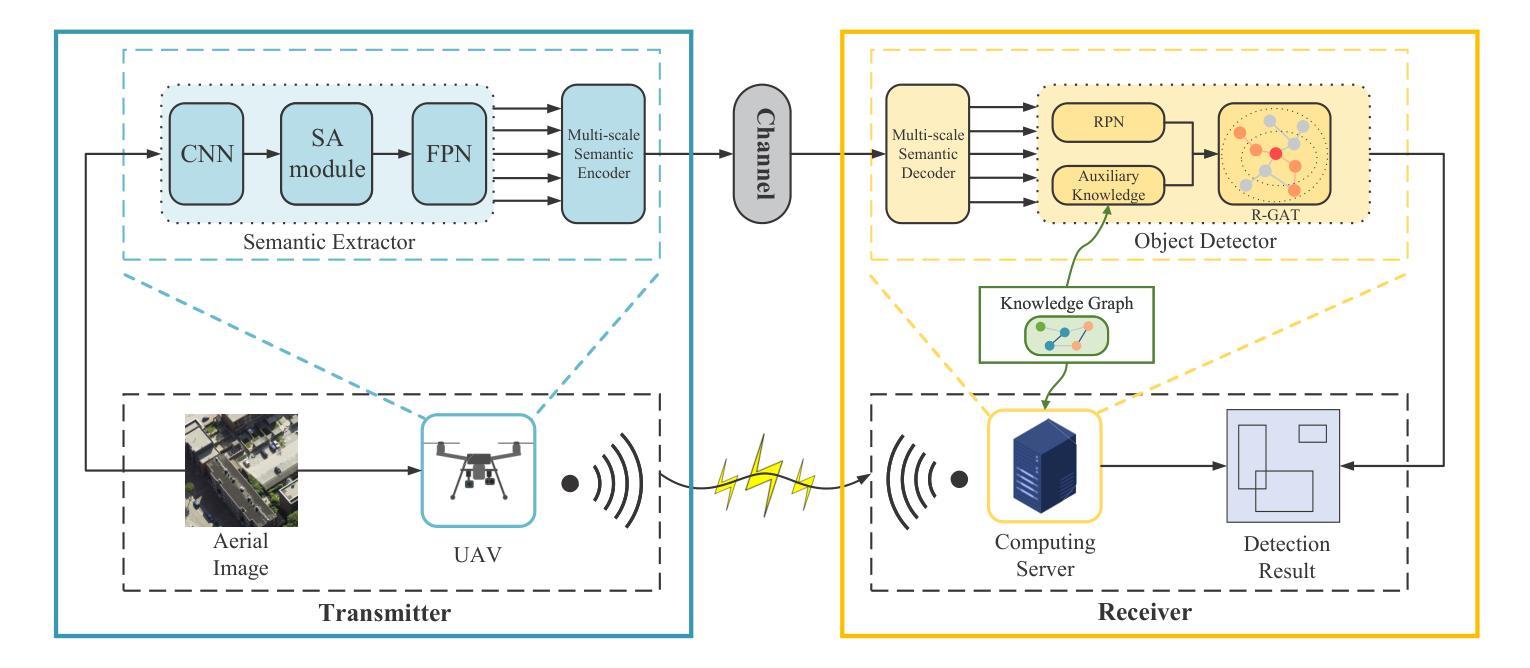
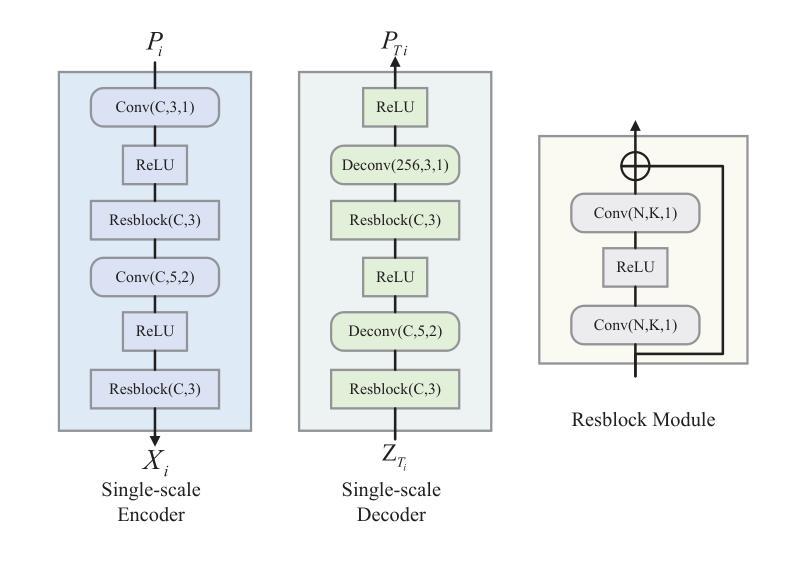
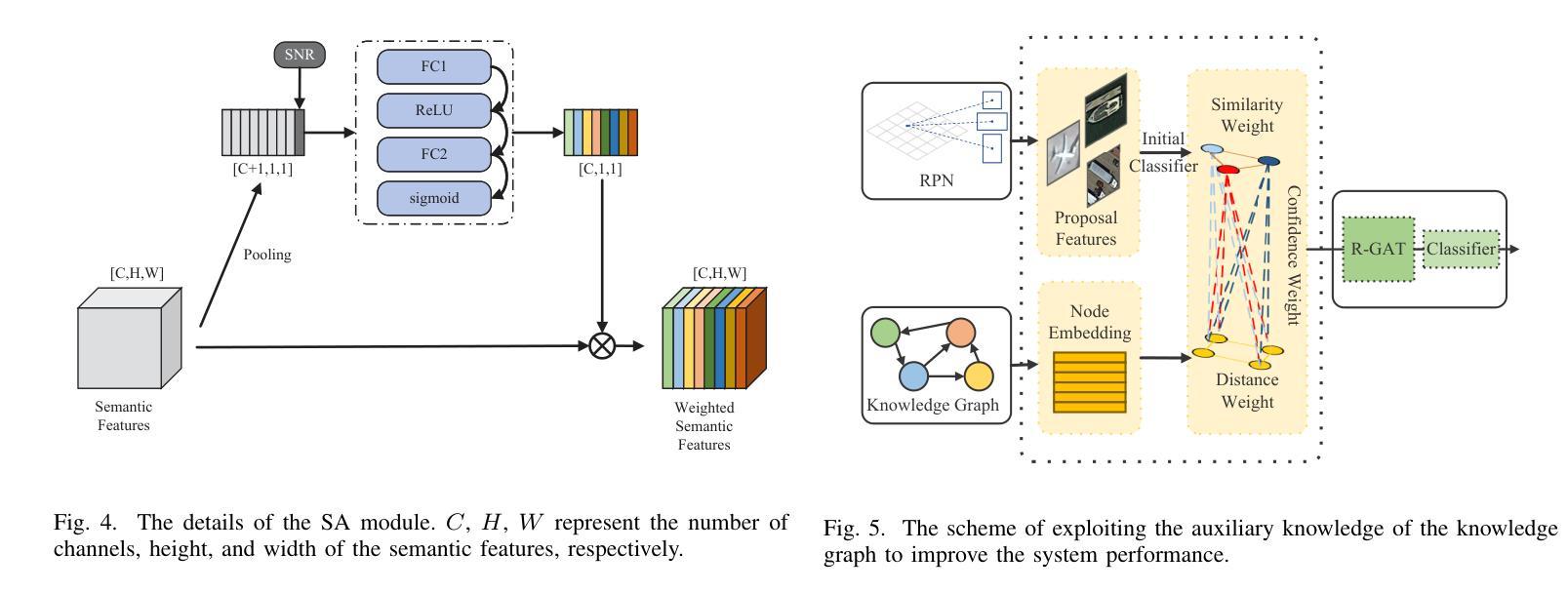
Unmanned aerial vehicles (UAVs) are widely used for object detection. However, the existing UAV-based object detection systems are subject to severe challenges, namely, their limited computation, energy and communication resources, which limits the achievable detection performance. To overcome these challenges, a UAV cognitive semantic communication system is proposed by exploiting a knowledge graph. Moreover, we design a multi-scale codec for semantic compression to reduce data transmission volume while guaranteeing detection performance. Considering the complexity and dynamicity of UAV communication scenarios, a signal-to-noise ratio (SNR) adaptive module with robust channel adaptation capability is introduced. Furthermore, an object detection scheme is proposed by exploiting the knowledge graph to overcome channel noise interference and compression distortion. Simulation results conducted on the practical aerial image dataset demonstrate that our proposed semantic communication system outperforms benchmark systems in terms of detection accuracy, communication robustness, and computation efficiency, especially in dealing with low bandwidth compression ratios and low SNR regimes.
无人机(UAV)广泛用于目标检测。然而,现有的基于无人机的目标检测系统面临着严峻的挑战,即它们的计算、能源和通信资源有限,这限制了检测性能的实现。为了克服这些挑战,提出了一种利用知识图的无人机认知语义通信系统。此外,我们设计了一种多尺度语义压缩编码器,以减少数据传输量,同时保证检测性能。考虑到无人机通信场景的复杂性和动态性,引入了一个具有鲁棒性信道自适应能力的信噪比(SNR)自适应模块。此外,还提出了一种利用知识图的目标检测方案,以克服信道噪声干扰和压缩失真。在实际航空图像数据集上进行的仿真结果表明,我们提出的语义通信系统在检测精度、通信鲁棒性和计算效率方面优于基准系统,特别是在处理低带宽压缩比和低信噪比情况下表现更为出色。
论文及项目相关链接
Summary
无人机在目标检测领域应用广泛,但现有系统面临计算、能源和通信资源的限制,影响了检测性能。为此,本文提出一种基于知识图谱的无人机认知语义通信系统,设计多尺度语义压缩编码,以减少数据传输量并保证检测性能。同时,引入信噪比自适应模块,提高信道适应性。通过利用知识图谱,克服信道噪声干扰和压缩失真,提高目标检测效果。仿真实验证明,该系统在检测准确率、通信稳健性和计算效率方面均优于基准系统,尤其在处理低带宽压缩比和低信噪比情况下表现更出色。
Key Takeaways
- 无人机在目标检测中广泛应用,但面临计算、能源和通信资源的限制。
- 引入知识图谱的无人机认知语义通信系统以解决现有挑战。
- 设计多尺度语义压缩编码,减少数据传输量并保证检测性能。
- 引入信噪比自适应模块,提高信道适应性。
- 利用知识图谱克服信道噪声干扰和压缩失真。
- 仿真实验证明该系统在检测准确率、通信稳健性和计算效率方面优于基准系统。
点此查看论文截图

An Empirical Study of Methods for Small Object Detection from Satellite Imagery
Authors:Xiaohui Yuan, Aniv Chakravarty, Lichuan Gu, Zhenchun Wei, Elinor Lichtenberg, Tian Chen
This paper reviews object detection methods for finding small objects from remote sensing imagery and provides an empirical evaluation of four state-of-the-art methods to gain insights into method performance and technical challenges. In particular, we use car detection from urban satellite images and bee box detection from satellite images of agricultural lands as application scenarios. Drawing from the existing surveys and literature, we identify several top-performing methods for the empirical study. Public, high-resolution satellite image datasets are used in our experiments.
本文回顾了从遥感图像中寻找小物体的目标检测方法,并对四种最新方法进行了经验评估,以深入了解其性能和技术挑战。特别是以城市卫星图像的车辆检测和农业卫星图像的蜂箱检测为应用场景进行分析。基于现有的调查和文献,我们确定了针对实证研究的几种表现最好的方法。实验采用了公共高分辨率卫星图像数据集。
论文及项目相关链接
Summary:
本文综述了从遥感影像中检测小物体的对象检测方法,并对四种最新方法进行了实证评估,以了解其在不同场景下的性能和技术挑战。该研究特别关注城市卫星图像中的汽车检测和农业用地卫星图像中的蜂箱检测场景。通过现有调查和文献,确定了实证研究中表现最好的几种方法。本研究使用了公共高分辨率卫星图像数据集进行实验。
Key Takeaways:
- 本文综述了从遥感影像中进行小物体检测的对象检测方法。
- 实证评估了四种最新方法,关注其在不同场景下的性能。
- 研究涉及城市卫星图像中的汽车检测和农业用地卫星图像中的蜂箱检测场景。
- 基于现有调查和文献,确定了表现最好的几种检测方法。
- 研究使用了公共高分辨率卫星图像数据集进行实验。
- 通过实证评估,获得了关于方法性能和技术挑战的重要见解。
点此查看论文截图