⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-08 更新
GS-LiDAR: Generating Realistic LiDAR Point Clouds with Panoramic Gaussian Splatting
Authors:Junzhe Jiang, Chun Gu, Yurui Chen, Li Zhang
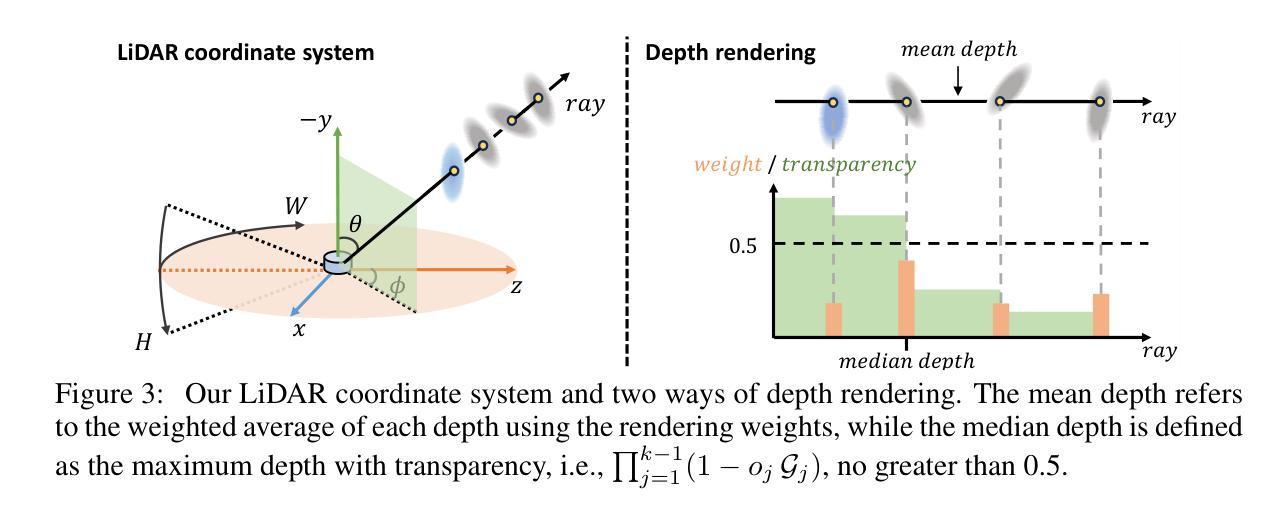
LiDAR novel view synthesis (NVS) has emerged as a novel task within LiDAR simulation, offering valuable simulated point cloud data from novel viewpoints to aid in autonomous driving systems. However, existing LiDAR NVS methods typically rely on neural radiance fields (NeRF) as their 3D representation, which incurs significant computational costs in both training and rendering. Moreover, NeRF and its variants are designed for symmetrical scenes, making them ill-suited for driving scenarios. To address these challenges, we propose GS-LiDAR, a novel framework for generating realistic LiDAR point clouds with panoramic Gaussian splatting. Our approach employs 2D Gaussian primitives with periodic vibration properties, allowing for precise geometric reconstruction of both static and dynamic elements in driving scenarios. We further introduce a novel panoramic rendering technique with explicit ray-splat intersection, guided by panoramic LiDAR supervision. By incorporating intensity and ray-drop spherical harmonic (SH) coefficients into the Gaussian primitives, we enhance the realism of the rendered point clouds. Extensive experiments on KITTI-360 and nuScenes demonstrate the superiority of our method in terms of quantitative metrics, visual quality, as well as training and rendering efficiency.
激光雷达新型视图合成(NVS)作为激光雷达仿真中的一项新型任务而出现,它从新型视角提供有价值的模拟点云数据,以辅助自动驾驶系统。然而,现有的激光雷达NVS方法通常依赖于神经辐射场(NeRF)作为其3D表示,这在训练和渲染方面都带来了显著的计算成本。此外,NeRF及其变体是为对称场景设计的,使得它们不适合驾驶场景。为了解决这些挑战,我们提出了GS-激光雷达,这是一个用全景高斯涂抹生成现实激光雷达点云数据的新框架。我们的方法采用具有周期性振动特性的2D高斯基元,可以精确重建驾驶场景中静态和动态元素的几何形状。我们进一步引入了一种新型的全景渲染技术,具有明确的射线-涂抹交集,由全景激光雷达监督指导。通过将强度和射线下降球谐(SH)系数纳入高斯基元,我们提高了渲染点云的真实性。在KITTI-360和nuScenes上的大量实验表明,我们的方法在定量指标、视觉质量以及训练和渲染效率方面都表现出优越性。
论文及项目相关链接
Summary
LiDAR新颖视图合成(NVS)是LiDAR模拟中的一项新任务,可从新颖视角生成模拟的点云数据,以辅助自动驾驶系统。现有LiDAR NVS方法通常依赖于神经辐射场(NeRF)作为3D表示,但其在训练和渲染方面都存在较大的计算成本。为此,提出GS-LiDAR框架,采用全景高斯涂抹方法生成真实的LiDAR点云,结合强度与球面谐波系数提升点云真实感。在KITTI-360和nuScenes数据集上的实验证明,该方法在定量指标、视觉质量以及训练和渲染效率上表现卓越。
Key Takeaways
- LiDAR新颖视图合成(NVS)是LiDAR模拟中的新任务,生成模拟点云数据用于辅助自动驾驶系统。
- 现有LiDAR NVS方法主要依赖神经辐射场(NeRF),存在计算成本高的缺点。
- GS-LiDAR框架使用全景高斯涂抹方法生成真实的LiDAR点云数据,解决了现有方法的计算成本高问题。
- GS-LiDAR能精确重建驾驶场景中的静态和动态元素。
- 该方法通过引入新的全景渲染技术和球面谐波系数增强点云的真实性。
- 在KITTI-360和nuScenes数据集上的实验证明了GS-LiDAR在定量指标、视觉质量上的优越性。
点此查看论文截图


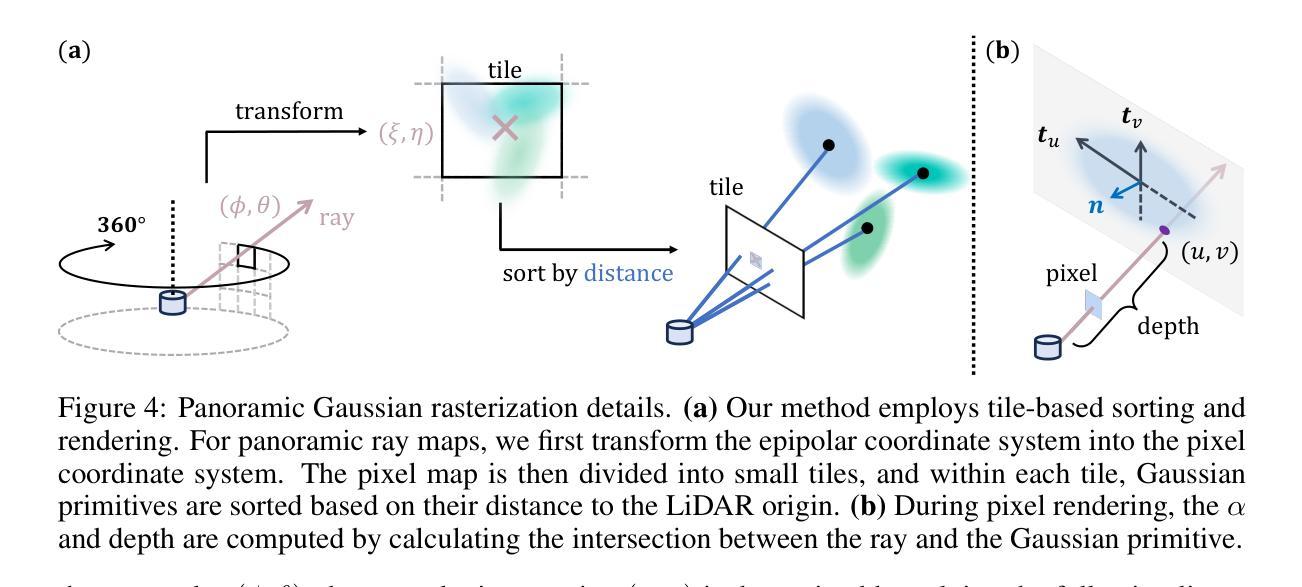
GS-CPR: Efficient Camera Pose Refinement via 3D Gaussian Splatting
Authors:Changkun Liu, Shuai Chen, Yash Bhalgat, Siyan Hu, Ming Cheng, Zirui Wang, Victor Adrian Prisacariu, Tristan Braud
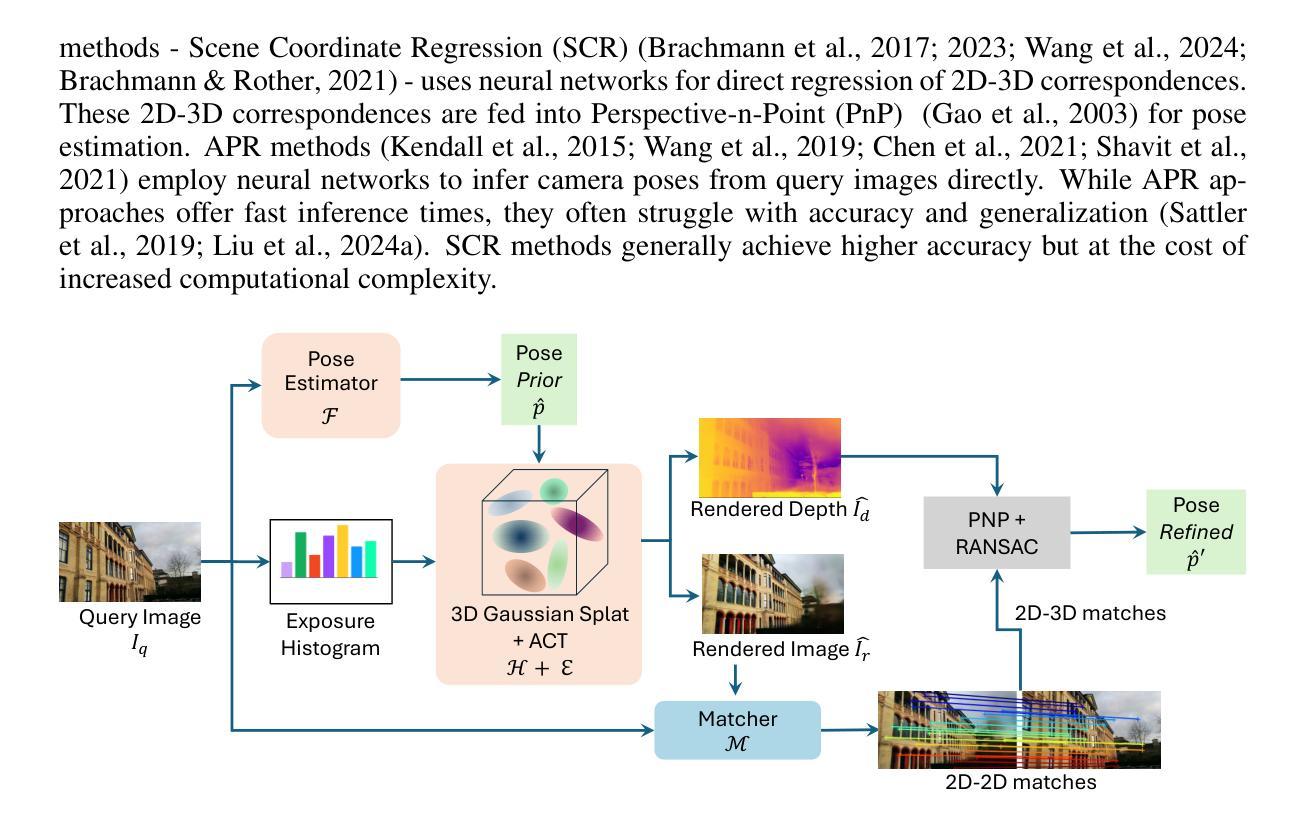
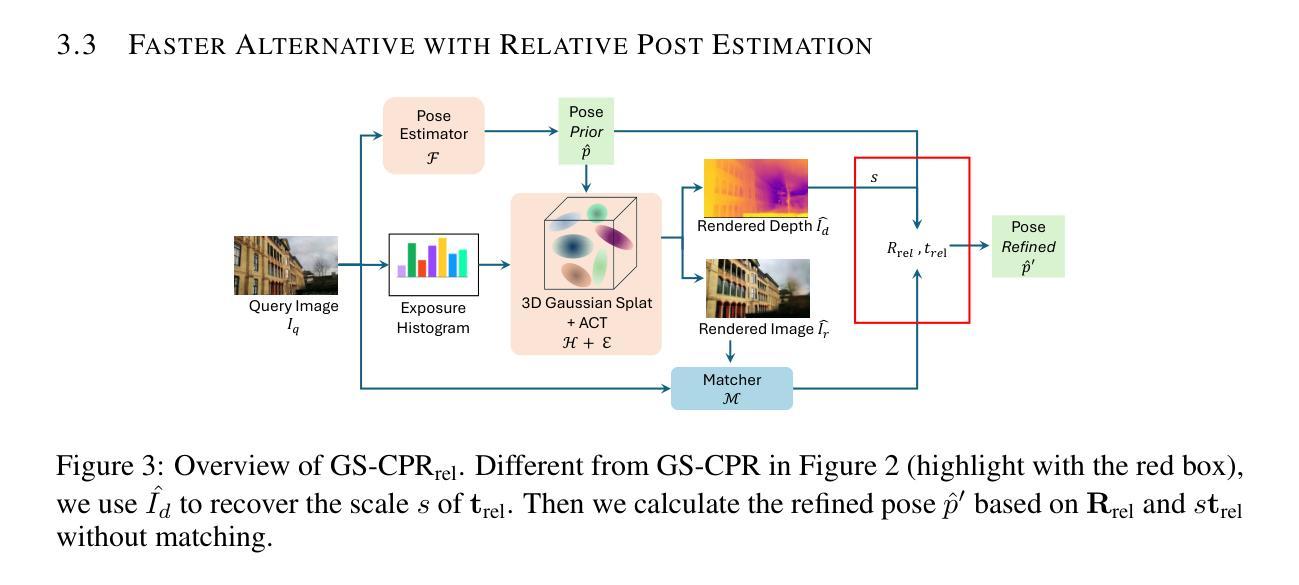
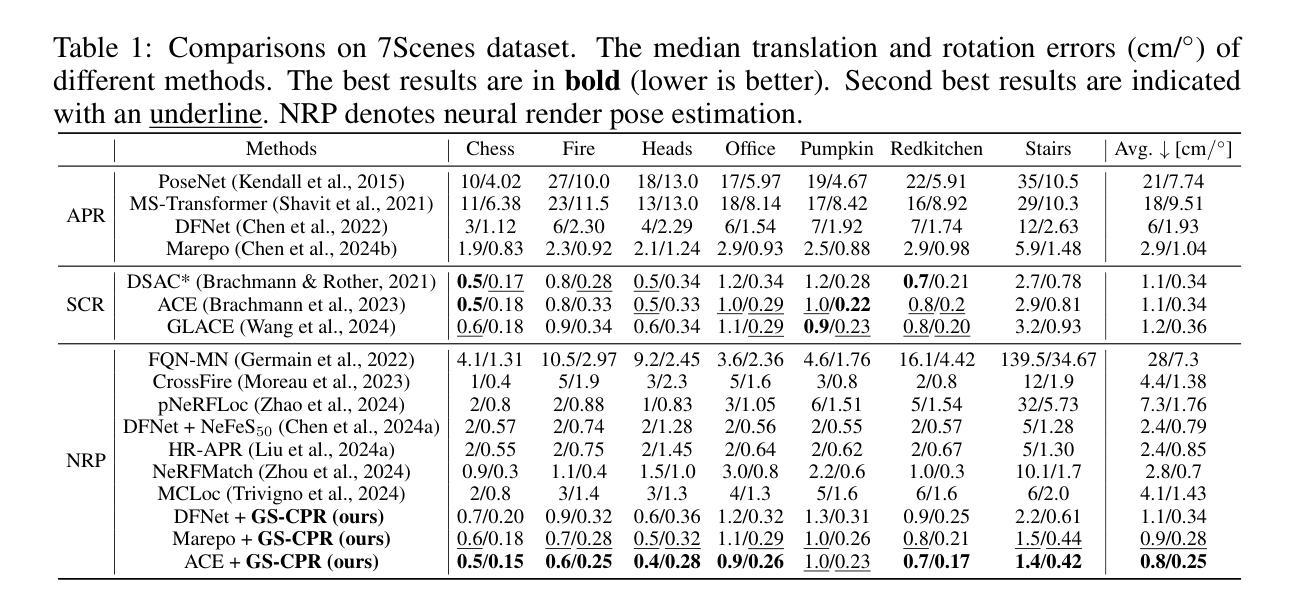
We leverage 3D Gaussian Splatting (3DGS) as a scene representation and propose a novel test-time camera pose refinement (CPR) framework, GS-CPR. This framework enhances the localization accuracy of state-of-the-art absolute pose regression and scene coordinate regression methods. The 3DGS model renders high-quality synthetic images and depth maps to facilitate the establishment of 2D-3D correspondences. GS-CPR obviates the need for training feature extractors or descriptors by operating directly on RGB images, utilizing the 3D foundation model, MASt3R, for precise 2D matching. To improve the robustness of our model in challenging outdoor environments, we incorporate an exposure-adaptive module within the 3DGS framework. Consequently, GS-CPR enables efficient one-shot pose refinement given a single RGB query and a coarse initial pose estimation. Our proposed approach surpasses leading NeRF-based optimization methods in both accuracy and runtime across indoor and outdoor visual localization benchmarks, achieving new state-of-the-art accuracy on two indoor datasets. The project page is available at https://gsloc.active.vision.
我们利用三维高斯拼贴(3DGS)作为场景表示,并提出了一种新型测试时相机姿态优化(CPR)框架,GS-CPR。此框架提高了最先进的绝对姿态回归和场景坐标回归方法的定位精度。3DGS模型渲染高质量合成图像和深度图,有助于建立2D-3D对应关系。GS-CPR直接在RGB图像上操作,而无需训练特征提取器或描述符,利用三维基础模型MASt3R进行精确2D匹配。为了提高我们的模型在具有挑战性的室外环境中的稳健性,我们在3DGS框架中引入了一个曝光自适应模块。因此,给定一个单一的RGB查询和一个粗略的初始姿态估计,GS-CPR能够实现高效的一次性姿态优化。我们的方法在室内和室外视觉定位基准测试中都超越了领先的基于NeRF的优化方法,在两项室内数据集上达到了新的最先进的精度。项目页面可通过https://gsloc.active.vision访问。
论文及项目相关链接
PDF Accepted to ICLR2025. During the ICLR review process, we changed the name of our framework from GSLoc to GS-CPR (Camera Pose Refinement) according to the comments of reviewers. The project page is available at https://gsloc.active.vision
Summary
该文本介绍了基于3D高斯点云技术(3DGS)的场景表示方法,并提出了一种新型的测试时相机姿态优化(CPR)框架GS-CPR。该技术能提高当前主流绝对姿态回归和场景坐标回归方法的定位精度。GS-CPR通过利用高质量的合成图像和深度图建立二维到三维的对应关系,简化了训练特征提取器或描述符的需求,并可直接在RGB图像上操作。此外,该框架还融入了曝光自适应模块,提高了模型在复杂户外环境中的稳健性。GS-CPR能实现高效的一次姿态优化,只需一个RGB查询图像和粗略的初始姿态估计即可。该方法在室内和室外视觉定位基准测试中超越了领先的NeRF优化方法,在两项室内数据集上达到了新的最先进的精度。
Key Takeaways
- 利用3D高斯点云技术(3DGS)作为场景表示方法。
- 提出了一种新型的测试时相机姿态优化(CPR)框架GS-CPR,增强了定位精度。
- GS-CPR通过高质量合成图像和深度图建立二维到三维的对应关系。
- GS-CPR简化了训练特征提取器或描述符的需求,可直接在RGB图像上操作。
- 融入曝光自适应模块,提高了模型在复杂户外环境的稳健性。
- GS-CPR实现了一次姿态优化,只需一个RGB查询图像和粗略的初始姿态估计。
点此查看论文截图

Segment Any 3D Gaussians
Authors:Jiazhong Cen, Jiemin Fang, Chen Yang, Lingxi Xie, Xiaopeng Zhang, Wei Shen, Qi Tian
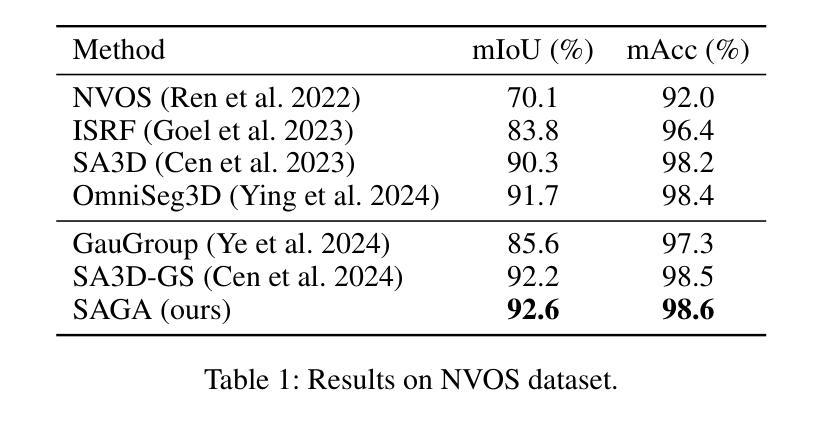
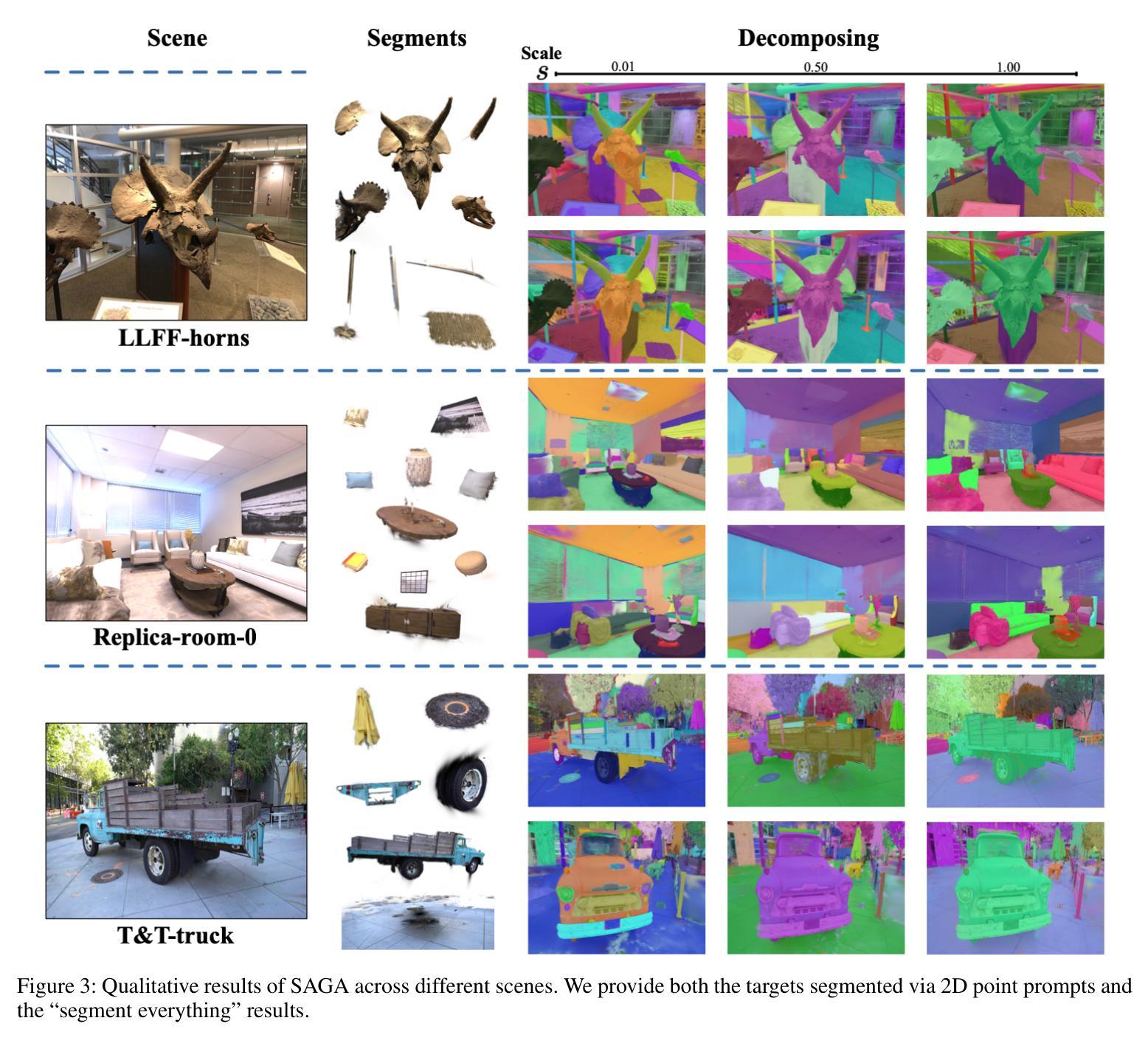
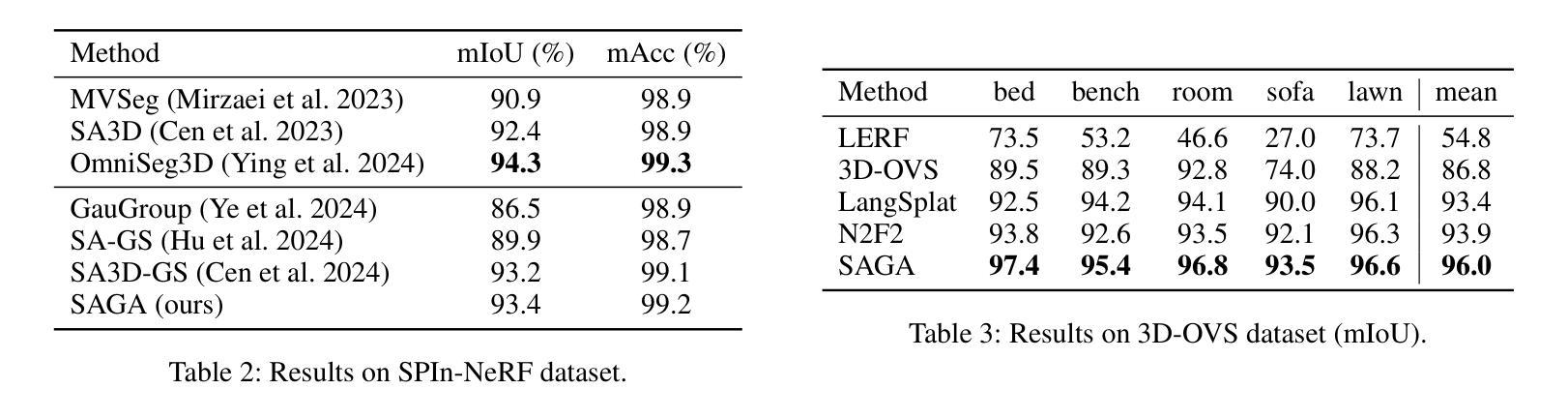
This paper presents SAGA (Segment Any 3D GAussians), a highly efficient 3D promptable segmentation method based on 3D Gaussian Splatting (3D-GS). Given 2D visual prompts as input, SAGA can segment the corresponding 3D target represented by 3D Gaussians within 4 ms. This is achieved by attaching an scale-gated affinity feature to each 3D Gaussian to endow it a new property towards multi-granularity segmentation. Specifically, a scale-aware contrastive training strategy is proposed for the scale-gated affinity feature learning. It 1) distills the segmentation capability of the Segment Anything Model (SAM) from 2D masks into the affinity features and 2) employs a soft scale gate mechanism to deal with multi-granularity ambiguity in 3D segmentation through adjusting the magnitude of each feature channel according to a specified 3D physical scale. Evaluations demonstrate that SAGA achieves real-time multi-granularity segmentation with quality comparable to state-of-the-art methods. As one of the first methods addressing promptable segmentation in 3D-GS, the simplicity and effectiveness of SAGA pave the way for future advancements in this field. Our code will be released.
本文介绍了SAGA(Segment Any 3D Gaussians),这是一种基于3D高斯摊展(3D-GS)的高效可提示的3D分割方法。给定二维视觉提示作为输入,SAGA可以在4毫秒内分割由三维高斯表示的相应三维目标。这是通过将尺度门控亲和特征附加到每个三维高斯上,赋予其面向多粒度分割的新属性来实现的。具体来说,提出了一种尺度感知对比训练策略来进行尺度门控亲和特征学习。它1)从二维蒙版中提取分段任何模型(SAM)的分割能力到亲和特征中,2)采用软尺度门控机制,通过根据指定的三维物理尺度调整每个特征通道的幅度来处理三维分割中的多粒度模糊。评估结果表明,SAGA实现了实时多粒度分割,其质量可与最新方法相媲美。作为解决3D-GS中可提示分割的首批方法之一,SAGA的简单性和有效性为这一领域的未来发展铺平了道路。我们的代码将会发布。
论文及项目相关链接
PDF AAAI-25. Project page: https://jumpat.github.io/SAGA
Summary
本文介绍了基于三维高斯散斑(3D-GS)的高度有效的三维提示分割方法——SAGA(分段任何三维高斯)。给定二维视觉提示作为输入,SAGA可以在4毫秒内分割由三维高斯表示的三维目标。它通过为每个三维高斯附加一个尺度门控亲和特征来实现这一点,赋予其面向多粒度分割的新属性。具体地说,提出了一种尺度感知对比训练策略来进行尺度门控亲和特征学习。评估结果表明,SAGA实现了实时多粒度分割,其质量可与最先进的方法相媲美。作为解决三维高斯散斑中可提示分割的首批方法之一,SAGA的简单性和有效性为这一领域的未来发展铺平了道路。我们的代码将公开发布。
Key Takeaways
- SAGA是一种基于三维高斯散斑(3D-GS)的三维提示分割方法。
- SAGA能够在短时间内(4毫秒内)完成三维目标的分割。
- 通过为每个三维高斯附加尺度门控亲和特征,实现多粒度分割。
- 采用了尺度感知对比训练策略进行尺度门控亲和特征学习。
- SAGA的分割质量与现有最先进的方法相当,且能实现实时多粒度分割。
- 作为解决三维GS中可提示分割问题的首批方法之一,SAGA具有简单有效的特点。
点此查看论文截图