⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-08 更新
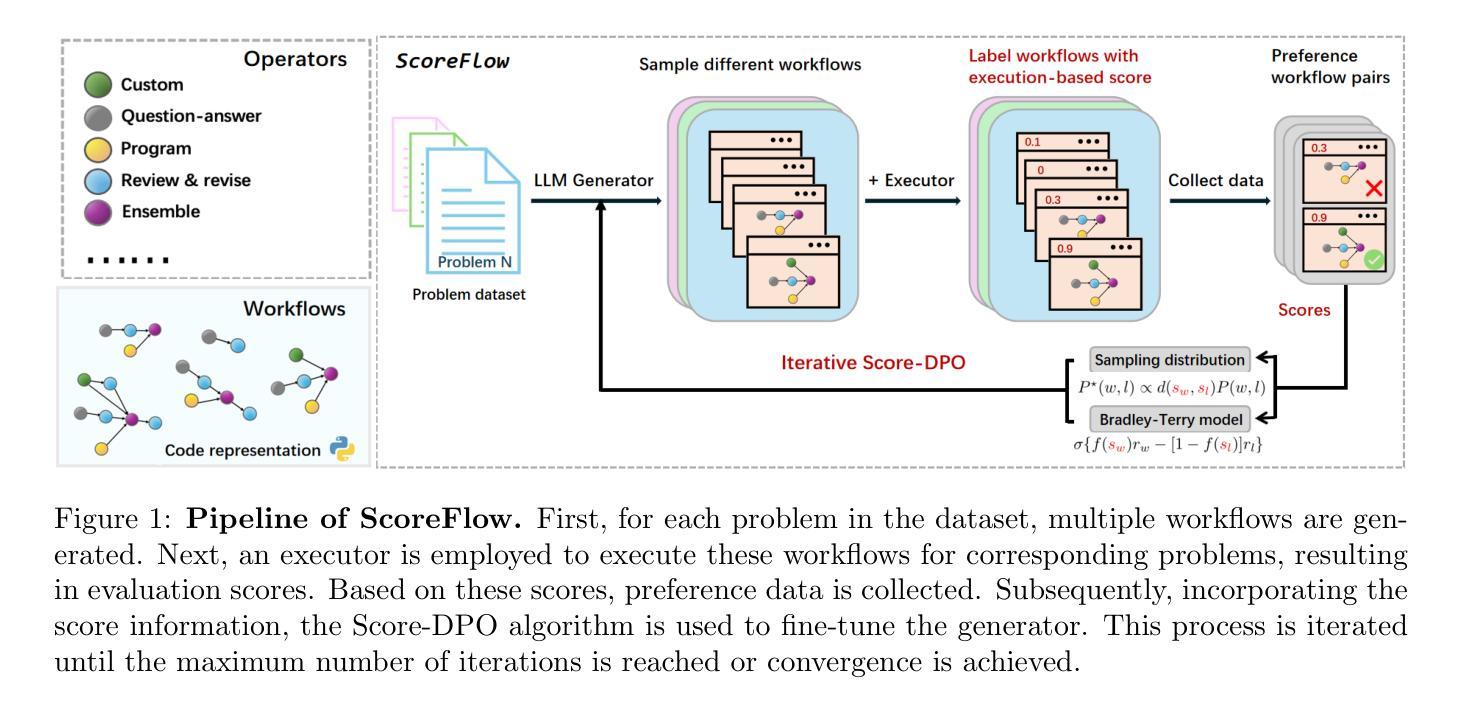
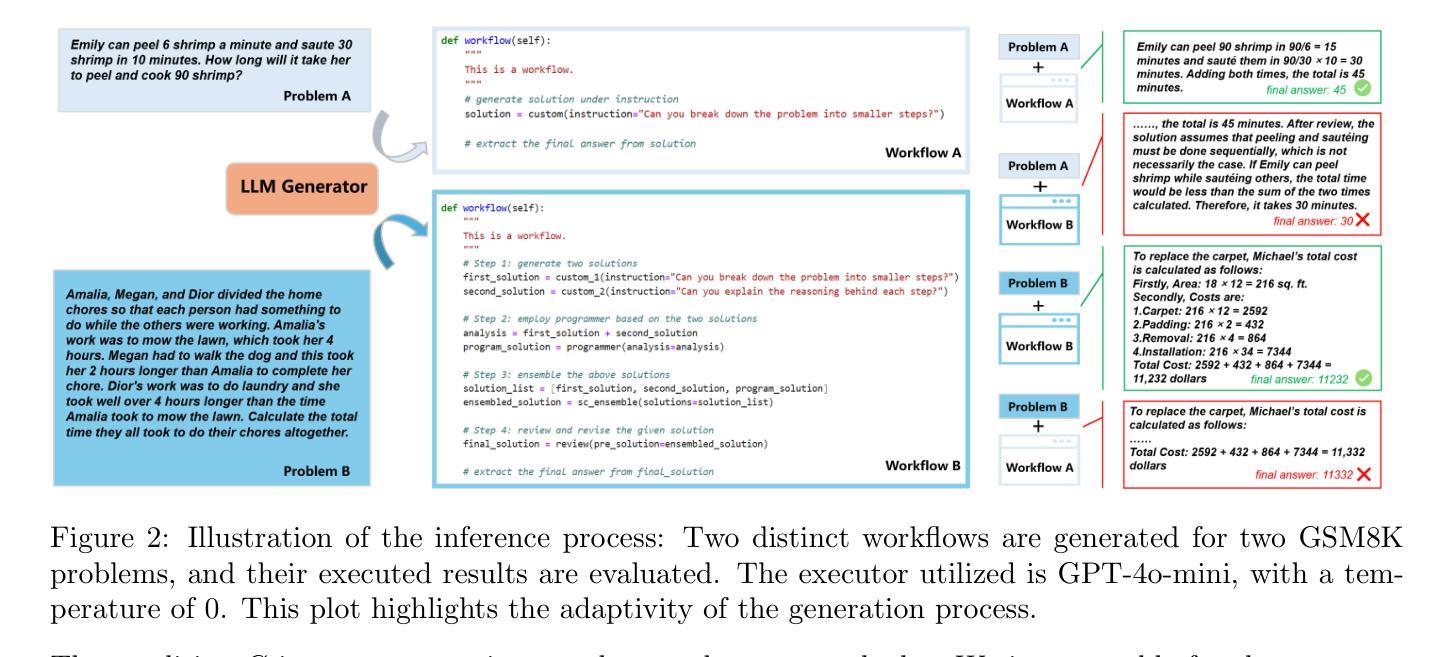
ScoreFlow: Mastering LLM Agent Workflows via Score-based Preference Optimization
Authors:Yinjie Wang, Ling Yang, Guohao Li, Mengdi Wang, Bryon Aragam
Recent research has leveraged large language model multi-agent systems for complex problem-solving while trying to reduce the manual effort required to build them, driving the development of automated agent workflow optimization methods. However, existing methods remain inflexible due to representational limitations, a lack of adaptability, and poor scalability when relying on discrete optimization techniques. We address these challenges with ScoreFlow, a simple yet high-performance framework that leverages efficient gradient-based optimization in a continuous space. ScoreFlow incorporates Score-DPO, a novel variant of the direct preference optimization method that accounts for quantitative feedback. Across six benchmarks spanning question answering, coding, and mathematical reasoning, ScoreFlow achieves an 8.2% improvement over existing baselines. Moreover, it empowers smaller models to outperform larger ones with lower inference costs. Project: https://github.com/Gen-Verse/ScoreFlow
最近的研究利用大型语言模型多智能体系统进行复杂问题解决,同时尝试减少构建所需的人工努力,推动自动智能体工作流程优化方法的发展。然而,由于表示限制、缺乏适应性和在依赖离散优化技术时的糟糕可扩展性,现有方法仍然不够灵活。我们针对这些挑战,提出了ScoreFlow框架,它利用连续空间中的高效基于梯度的优化。ScoreFlow结合了Score-DPO,这是一种考虑定量反馈的直接偏好优化方法的新颖变体。在涵盖问答、编码和数学推理的六个基准测试中,ScoreFlow相较于现有基准测试实现了8.2%的改进。此外,它使小型模型能够以较低推理成本超越大型模型。项目地址:https://github.com/Gen-Verse/ScoreFlow
论文及项目相关链接
PDF Project: https://github.com/Gen-Verse/ScoreFlow
Summary
近期研究利用大型语言模型多智能体系统解决复杂问题,旨在减少建模所需的人工努力,推动智能体工作流程优化方法的开发。然而,现有方法存在灵活性不足的问题,如在表示方面的局限性、缺乏适应性和在依赖离散优化技术时的可伸缩性差。我们借助ScoreFlow框架解决这些问题,该框架采用高效的基于梯度的优化方法,在连续空间内实现性能优化。ScoreFlow结合了Score-DPO这一新型直接偏好优化方法,考虑了定量反馈。在涵盖问答、编码和数学推理的六个基准测试中,ScoreFlow较现有基线提高了8.2%。此外,它还能使小型模型以较低推理成本超越大型模型。项目地址:GitHub链接。
Key Takeaways
- 大型语言模型多智能体系统用于复杂问题求解,旨在减少建模的人工干预。
- 现有智能体工作流程优化方法存在灵活性问题,如表示局限、缺乏适应性和可伸缩性差。
- ScoreFlow框架通过高效的基于梯度的优化方法在连续空间内实现性能优化。
- ScoreFlow结合了Score-DPO这一新型直接偏好优化方法,考虑了定量反馈。
- 在多个基准测试中,ScoreFlow较现有方法性能有所提升。
- ScoreFlow使小型模型能在较低推理成本下表现出超越大型模型的性能。
点此查看论文截图

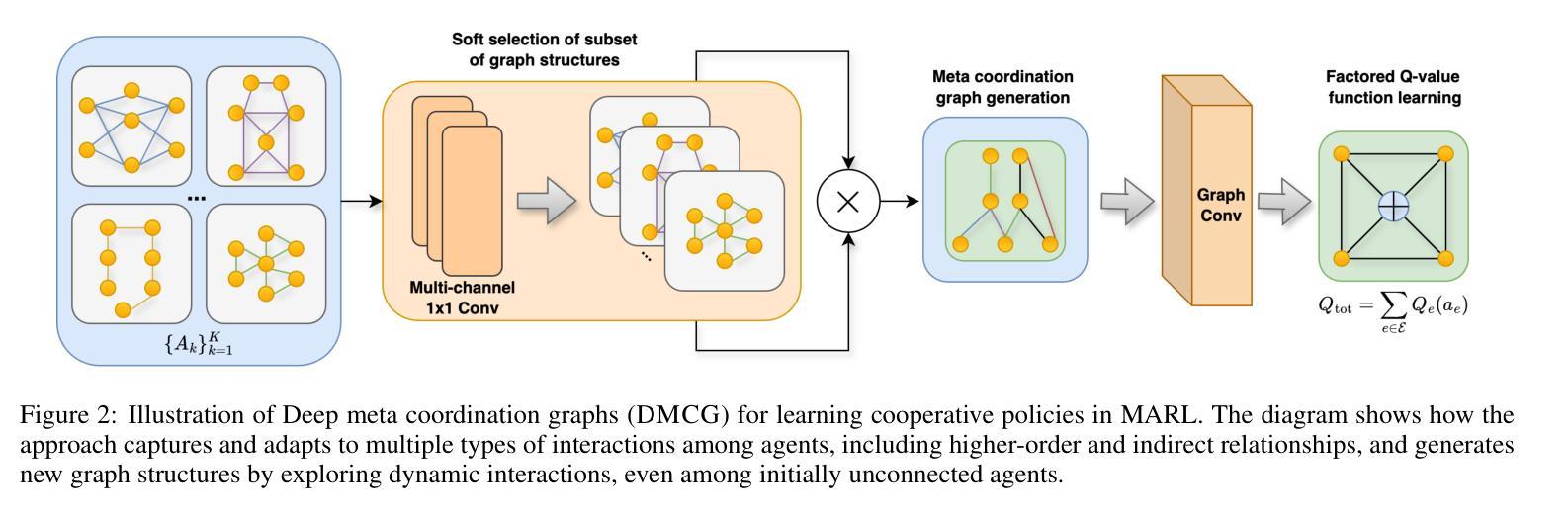
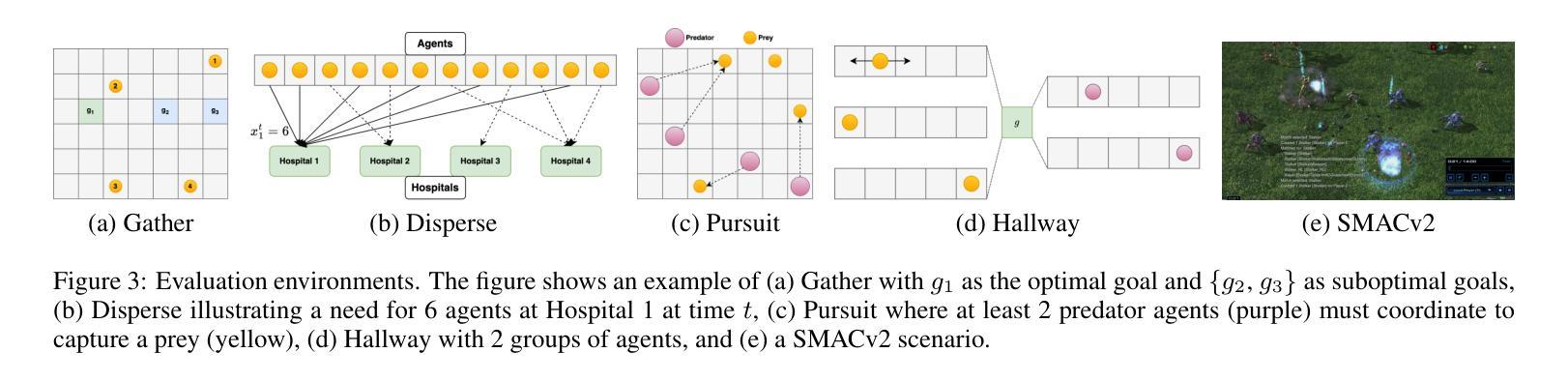
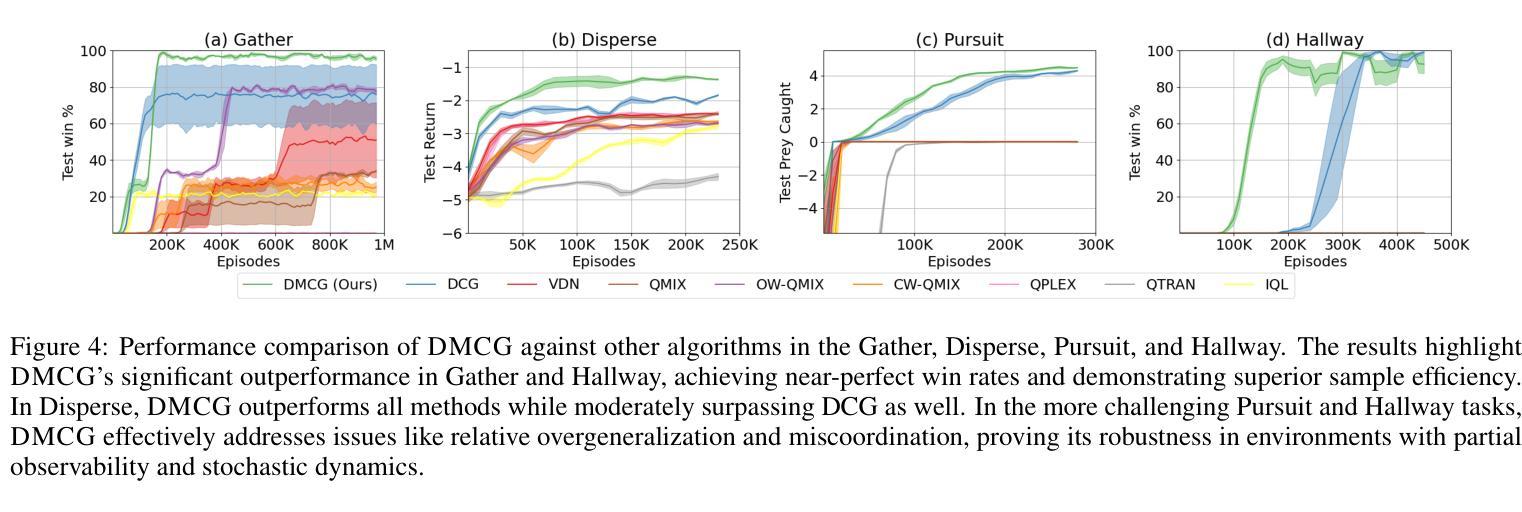
Deep Meta Coordination Graphs for Multi-agent Reinforcement Learning
Authors:Nikunj Gupta, James Zachary Hare, Rajgopal Kannan, Viktor Prasanna
This paper presents deep meta coordination graphs (DMCG) for learning cooperative policies in multi-agent reinforcement learning (MARL). Coordination graph formulations encode local interactions and accordingly factorize the joint value function of all agents to improve efficiency in MARL. However, existing approaches rely solely on pairwise relations between agents, which potentially oversimplifies complex multi-agent interactions. DMCG goes beyond these simple direct interactions by also capturing useful higher-order and indirect relationships among agents. It generates novel graph structures accommodating multiple types of interactions and arbitrary lengths of multi-hop connections in coordination graphs to model such interactions. It then employs a graph convolutional network module to learn powerful representations in an end-to-end manner. We demonstrate its effectiveness in multiple coordination problems in MARL where other state-of-the-art methods can suffer from sample inefficiency or fail entirely. All codes can be found here: https://github.com/Nikunj-Gupta/dmcg-marl.
本文提出了深度元协调图(DMCG),用于学习多智能体强化学习(MARL)中的合作策略。协调图公式编码局部交互,并相应地分解所有智能体的联合值函数,以提高MARL中的效率。然而,现有方法仅依赖于智能体之间的配对关系,这可能会过于简化复杂的多智能体交互。DMCG超越了这些简单的直接交互,通过捕获智能体之间有用的高阶和间接关系。它生成了适应多种交互类型和协调图中任意长度的多跳连接的新型图形结构,以模拟这些交互。然后,它采用图卷积网络模块以端到端的方式学习强大的表示。我们在MARL中的多个协调问题上证明了其有效性,而其他最新方法可能会遭受样本效率低下或完全失败的问题。所有代码可在https://github.com/Nikunj-Gupta/dmcg-marl 找到。
论文及项目相关链接
Summary
本文介绍了深度元协调图(DMCG)在多智能体强化学习(MARL)中学习合作策略的应用。协调图公式能够编码局部交互,并据此对所有智能体的联合值函数进行因子分解,以提高MARL的效率。然而,现有方法仅依赖于智能体之间的两两关系,这可能会简化复杂的多智能体交互。DMCG通过捕获智能体之间的高阶和间接关系,超越了这些简单的直接交互。它生成了容纳多种类型交互和任意长度的多跳连接的新型图形结构,并采用图卷积网络模块以端到端的方式学习强大的表示。在多个协调问题的多智能体强化学习中,我们证明了其有效性,而其他最新方法可能会遭受样本效率低下或完全失败的问题。
Key Takeaways
- DMCG用于多智能体强化学习中的合作策略学习。
- 协调图公式可编码局部交互并联合因子分解智能体的值函数。
- 现有方法主要基于智能体间的两两关系,可能简化复杂交互。
- DMCG捕获智能体之间的高阶和间接关系。
- DMCG生成新型图形结构以容纳多种类型交互和多跳连接。
- 采用图卷积网络模块进行强大的表示学习。
点此查看论文截图

Speaking the Language of Teamwork: LLM-Guided Credit Assignment in Multi-Agent Reinforcement Learning
Authors:Muhan Lin, Shuyang Shi, Yue Guo, Vaishnav Tadiparthi, Behdad Chalaki, Ehsan Moradi Pari, Simon Stepputtis, Woojun Kim, Joseph Campbell, Katia Sycara
Credit assignment, the process of attributing credit or blame to individual agents for their contributions to a team’s success or failure, remains a fundamental challenge in multi-agent reinforcement learning (MARL), particularly in environments with sparse rewards. Commonly-used approaches such as value decomposition often lead to suboptimal policies in these settings, and designing dense reward functions that align with human intuition can be complex and labor-intensive. In this work, we propose a novel framework where a large language model (LLM) generates dense, agent-specific rewards based on a natural language description of the task and the overall team goal. By learning a potential-based reward function over multiple queries, our method reduces the impact of ranking errors while allowing the LLM to evaluate each agent’s contribution to the overall task. Through extensive experiments, we demonstrate that our approach achieves faster convergence and higher policy returns compared to state-of-the-art MARL baselines.
在多智能体强化学习(MARL)中,特别是在奖励稀疏的环境中,对智能体的贡献进行信用分配,即对其在团队成功或失败中的贡献给予正面或负面的评价,仍然是一个基本挑战。常用的方法如价值分解在这些场景中往往导致次优策略,而设计符合人类直觉的密集奖励函数可能既复杂又耗时。在这项工作中,我们提出了一种新型框架,该框架使用一个大型语言模型(LLM)基于任务的自然语言描述和总体团队目标生成密集的、针对特定智能体的奖励。通过在多个查询上学习基于潜力的奖励函数,我们的方法降低了排名错误的影响,同时允许LLM评估每个智能体对整体任务的贡献。通过广泛的实验,我们证明了我们的方法与最先进的MARL基线相比,实现了更快的收敛和更高的策略回报。
论文及项目相关链接
PDF 11 pages, 6 figures
Summary:在多智能体强化学习(MARL)中,信用分配是一个基本挑战,特别是在奖励稀疏的环境中。常见的方法如价值分解在这些环境中往往导致次优策略,而设计符合人类直觉的密集奖励函数可能复杂且耗时。本研究提出了一种新型框架,利用大型语言模型(LLM)基于任务的自然语言描述和整体团队目标生成密集、特定于智能体的奖励。通过基于多个查询学习基于潜力的奖励函数,我们的方法减少了排名错误的影响,并允许LLM评估每个智能体对整体任务的贡献。实验表明,我们的方法相较于最先进的MARL基准方法,实现了更快的收敛和更高的策略回报。
Key Takeaways:
- 信用分配在多智能体强化学习(MARL)中是一个挑战,尤其在奖励稀疏的环境中。
- 常见方法如价值分解在奖励稀疏的环境中可能导致次优策略。
- 设计符合人类直觉的密集奖励函数可能很复杂并且耗时。
- 提出了一种新型框架,利用大型语言模型(LLM)生成特定于智能体的密集奖励。
- 该框架通过基于多个查询学习基于潜力的奖励函数,减少排名错误的影响。
- LLM能评估每个智能体对整体任务的贡献。
点此查看论文截图


Discrete GCBF Proximal Policy Optimization for Multi-agent Safe Optimal Control
Authors:Songyuan Zhang, Oswin So, Mitchell Black, Chuchu Fan
Control policies that can achieve high task performance and satisfy safety constraints are desirable for any system, including multi-agent systems (MAS). One promising technique for ensuring the safety of MAS is distributed control barrier functions (CBF). However, it is difficult to design distributed CBF-based policies for MAS that can tackle unknown discrete-time dynamics, partial observability, changing neighborhoods, and input constraints, especially when a distributed high-performance nominal policy that can achieve the task is unavailable. To tackle these challenges, we propose DGPPO, a new framework that simultaneously learns both a discrete graph CBF which handles neighborhood changes and input constraints, and a distributed high-performance safe policy for MAS with unknown discrete-time dynamics. We empirically validate our claims on a suite of multi-agent tasks spanning three different simulation engines. The results suggest that, compared with existing methods, our DGPPO framework obtains policies that achieve high task performance (matching baselines that ignore the safety constraints), and high safety rates (matching the most conservative baselines), with a constant set of hyperparameters across all environments.
对于任何系统(包括多智能体系统,MAS)来说,能够实现高任务性能并满足安全约束的控制策略都是理想的。确保MAS安全的一种有前途的技术是分布式控制屏障函数(CBF)。然而,为MAS设计基于分布式CBF的策略以处理未知离散时间动态、部分可观察性、变化的邻域和输入约束是困难的,尤其是在不存在能够实现任务的高性能名义策略的情况下。为了应对这些挑战,我们提出了DGPPO,这是一个新的框架,可以同时学习处理邻域变化和输入约束的离散图CBF,以及针对具有未知离散时间动态的多智能体系统的分布式高性能安全策略。我们在跨越三个不同仿真引擎的多智能体任务套件上对我们的主张进行了实证验证。结果表明,与现有方法相比,我们的DGPPO框架获得的策略在实现高任务性能(匹配忽略安全约束的基线)和高安全率(匹配最保守的基线)方面表现出色,且所有环境下的超参数都是恒定的。
论文及项目相关链接
PDF 31 pages, 15 figures, accepted by the thirteenth International Conference on Learning Representations (ICLR 2025)
Summary
在面临高任务性能和安全约束的系统需求时,分布式控制屏障函数(CBF)是一个有效的技术。然而,对于具有未知离散时间动力学特性、部分可观察性、变化邻域和输入约束的多智能体系统(MAS),设计基于分布式CBF的策略是一大挑战。为了应对这些挑战,我们提出了DGPPO这一新框架,它能同时学习处理邻域变化和输入约束的离散图CBF,以及针对未知离散时间动力学特性的分布式高性能安全策略。经验验证显示,我们的框架在多项多智能体任务中表现优异,既实现了高任务性能(与忽略安全约束的基线相匹配),又保证了高安全率(与最保守的基线相匹配),且在所有环境中使用的超参数都是恒定的。
Key Takeaways
- 分布式控制屏障函数(CBF)在确保多智能体系统(MAS)的安全性方面表现出巨大潜力。
- 设计针对未知离散时间动力学、部分可观察性、变化邻域和输入约束的分布式CBF策略是一大挑战。
- DGPPO框架能同时学习处理邻域变化和输入约束的离散图CBF及高性能安全策略。
- DGPPO框架在多个多智能体任务中实现了高任务性能和高安全率。
- DGPPO框架在仿真验证中展现了优越性,且其性能在不同环境中具有一致性。
- 与现有方法相比,DGPPO框架能够在满足安全约束的同时实现接近最佳的任务性能。
点此查看论文截图

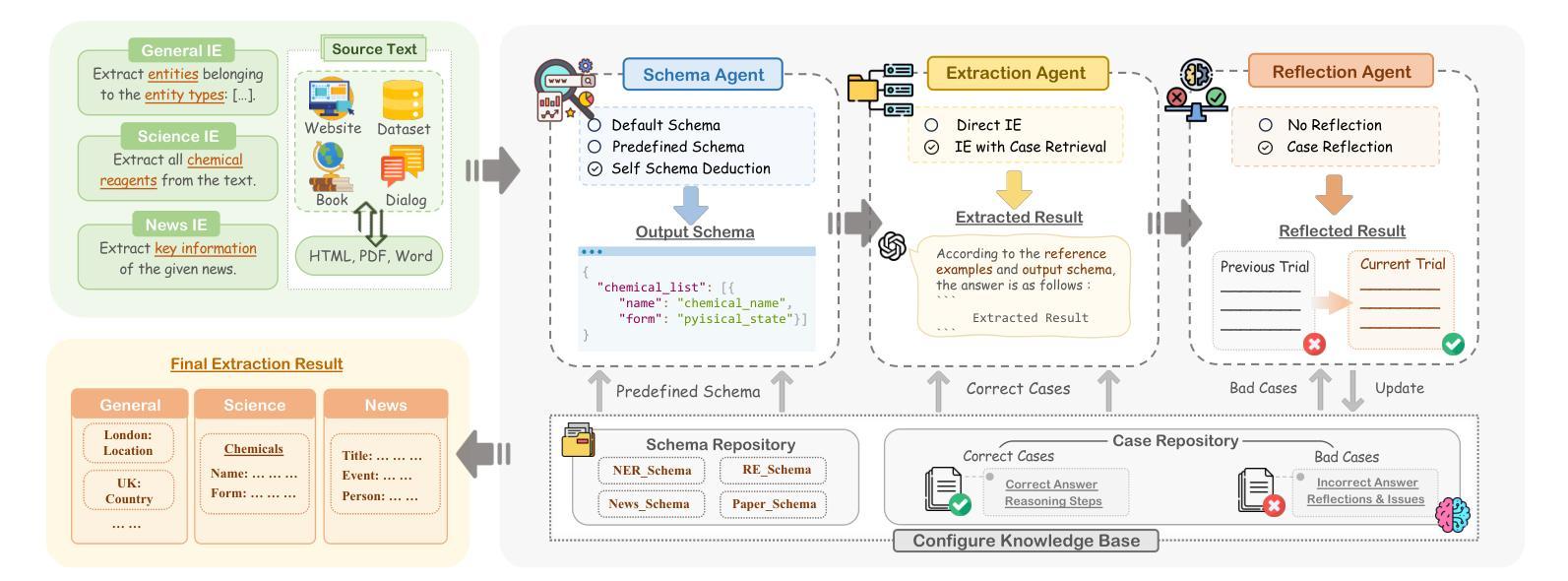
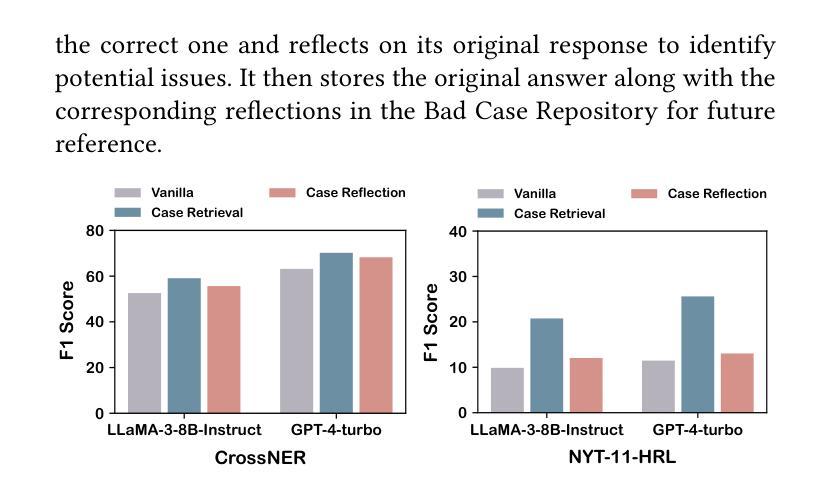
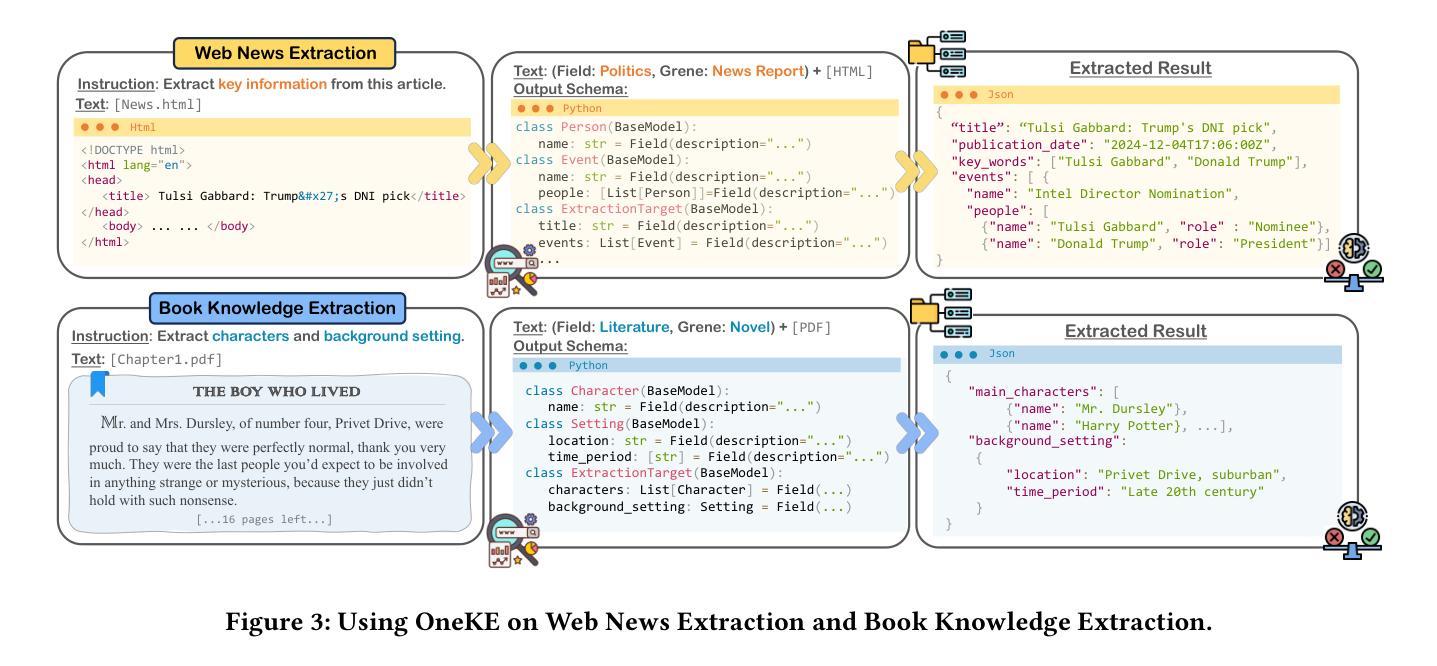
OneKE: A Dockerized Schema-Guided LLM Agent-based Knowledge Extraction System
Authors:Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Ningyu Zhang, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, Da Zheng, Haofen Wang, Huajun Chen
We introduce OneKE, a dockerized schema-guided knowledge extraction system, which can extract knowledge from the Web and raw PDF Books, and support various domains (science, news, etc.). Specifically, we design OneKE with multiple agents and a configure knowledge base. Different agents perform their respective roles, enabling support for various extraction scenarios. The configure knowledge base facilitates schema configuration, error case debugging and correction, further improving the performance. Empirical evaluations on benchmark datasets demonstrate OneKE’s efficacy, while case studies further elucidate its adaptability to diverse tasks across multiple domains, highlighting its potential for broad applications. We have open-sourced the Code at https://github.com/zjunlp/OneKE and released a Video at http://oneke.openkg.cn/demo.mp4.
我们介绍了OneKE,这是一个Docker化的模式引导知识提取系统,可以从网页和原始PDF书籍中提取知识,并支持多个领域(科学、新闻等)。具体来说,我们设计OneKE时采用了多个代理和一个配置知识库。不同的代理执行各自的角色,支持各种提取场景。配置知识库便于模式配置、错误情况调试和修正,进一步提高性能。在基准数据集上的经验评估证明了OneKE的有效性,而案例研究进一步说明了其在多个领域的不同任务的适应性,突出了其广泛的应用潜力。我们已经将代码开源在https://github.com/zjunlp/OneKE,并发布了一个视频在http://oneke.openkg.cn/demo.mp4。
论文及项目相关链接
PDF WWW 2025 Demonstration
Summary:
我们推出了一款名为OneKE的Docker化架构指导知识提取系统,可从网页和PDF书籍中提取知识,并适用于多个领域(如科学、新闻等)。OneKE设计有多个代理和一个配置知识库,不同代理执行各自的任务,支持各种提取场景。配置知识库便于架构配置、错误调试和修正,提高了系统性能。在基准数据集上的实证评估证明了OneKE的有效性,案例研究进一步说明了其在多个领域不同任务的适应性,展现了其广泛的应用潜力。我们已在https://github.com/zjunlp/OneKE开源了代码,并在http://oneke.openkg.cn/demo.mp4发布了视频。
Key Takeaways:
- OneKE是一个Docker化的知识提取系统,可以从网页和PDF书籍中提取知识。
- OneKE支持多个领域,如科学和新闻。
- OneKE设计有多个代理,每个代理执行特定的任务,以适应不同的提取场景。
- 配置知识库有助于提高系统性能,方便架构配置、错误调试和修正。
- 实证评估和案例研究证明了OneKE的有效性和适应性。
- OneKE已开源,并提供了视频演示。
点此查看论文截图

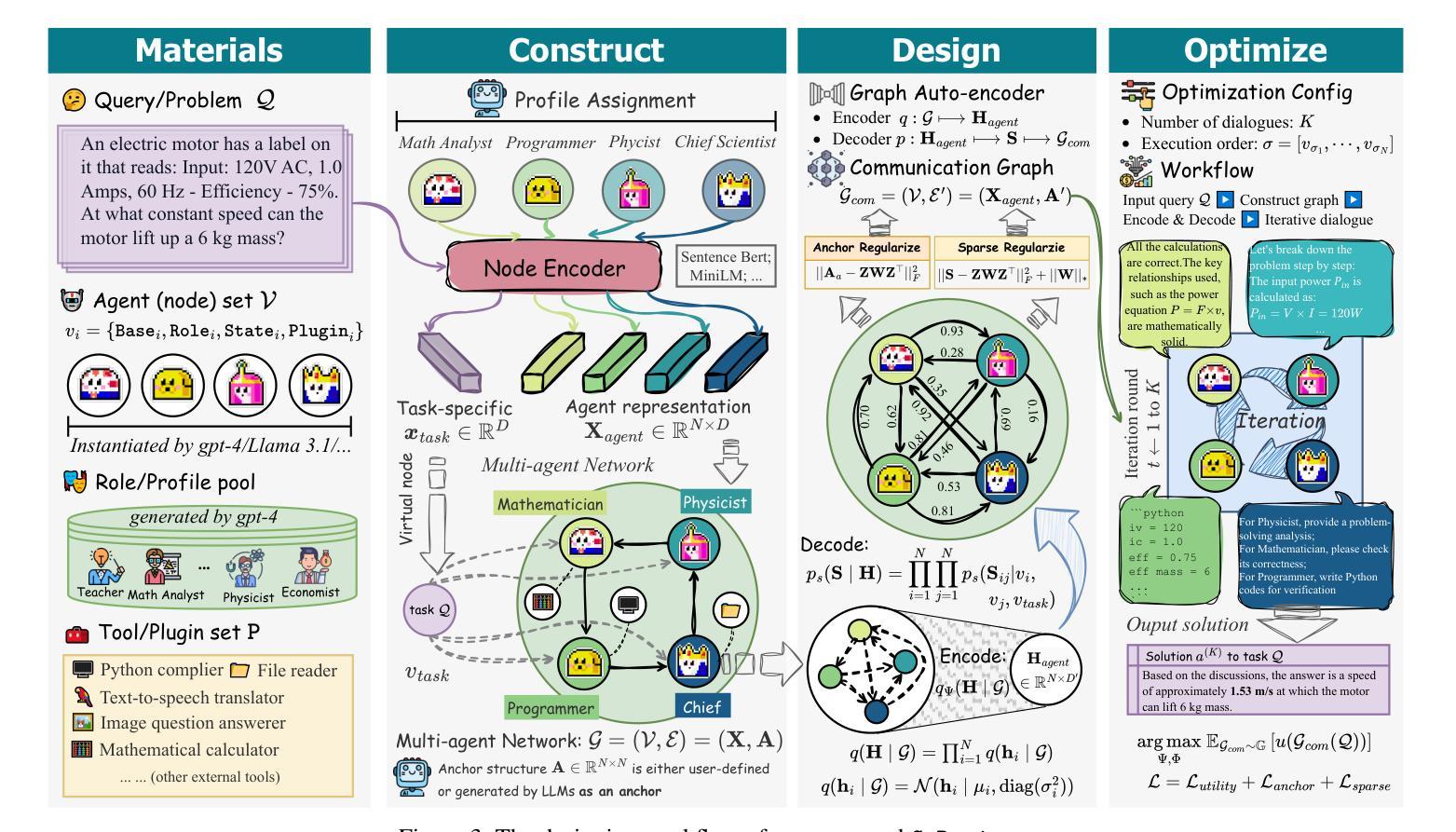
G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks
Authors:Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, Dawei Cheng
Recent advancements in large language model (LLM)-based agents have demonstrated that collective intelligence can significantly surpass the capabilities of individual agents, primarily due to well-crafted inter-agent communication topologies. Despite the diverse and high-performing designs available, practitioners often face confusion when selecting the most effective pipeline for their specific task: \textit{Which topology is the best choice for my task, avoiding unnecessary communication token overhead while ensuring high-quality solution?} In response to this dilemma, we introduce G-Designer, an adaptive, efficient, and robust solution for multi-agent deployment, which dynamically designs task-aware, customized communication topologies. Specifically, G-Designer models the multi-agent system as a multi-agent network, leveraging a variational graph auto-encoder to encode both the nodes (agents) and a task-specific virtual node, and decodes a task-adaptive and high-performing communication topology. Extensive experiments on six benchmarks showcase that G-Designer is: \textbf{(1) high-performing}, achieving superior results on MMLU with accuracy at $84.50%$ and on HumanEval with pass@1 at $89.90%$; \textbf{(2) task-adaptive}, architecting communication protocols tailored to task difficulty, reducing token consumption by up to $95.33%$ on HumanEval; and \textbf{(3) adversarially robust}, defending against agent adversarial attacks with merely $0.3%$ accuracy drop.
最近,基于大型语言模型(LLM)的代理人的进步表明,集体智能可以显著超过单个代理人的能力,这主要是因为精心设计的代理人之间的通信拓扑。尽管存在各种高性能的设计方案,但从业者在选择最有效的特定任务流水线时经常感到困惑:对于我的任务,哪种拓扑是最佳选择,同时避免不必要的通信令牌开销并确保高质量的解决方案?针对这一困境,我们引入了G-Designer,这是一种用于多代理部署的自适应、高效且稳健的解决方案,可动态设计任务感知的定制通信拓扑。具体来说,G-Designer将多代理系统建模为多个代理网络,利用变分图自动编码器对节点(代理)和特定任务的虚拟节点进行编码,并解码出任务自适应且高性能的通信拓扑。在六个基准测试上的大量实验表明,G-Designer具有以下特点:(1)高性能:在MMLU上的准确度达到84.50%,在HumanEval上的pass@1达到89.90%;(2)任务自适应:根据任务难度定制通信协议,在HumanEval上最多减少高达95.33%的令牌消耗;(3)对抗性稳健:能够抵御代理人对抗性攻击,仅导致准确率下降0.3%。
论文及项目相关链接
Summary
大型语言模型(LLM)为基础代理人的最新进展表明,集体智能可以显著超越个体代理人的能力,这主要得益于精心设计的跨代理通信拓扑。针对多代理部署问题,我们推出了G-Designer,这是一个自适应、高效且稳健的解决方案,能够动态设计任务感知的定制通信拓扑。实验表明,G-Designer在多个基准测试上表现出卓越性能,包括高准确性、任务适应性和对抗稳健性。
Key Takeaways
- 大型语言模型为基础代理人的集体智能显著超越个体代理人能力。
- 跨代理通信拓扑设计是集体智能表现的关键。
- G-Designer是一个自适应、高效且稳健的多代理部署解决方案。
- G-Designer能动态设计任务感知的定制通信拓扑。
- G-Designer在多个基准测试中表现出高准确性、任务适应性和对抗稳健性。
- G-Designer通过建模多代理系统为多代理网络并利用变异图自编码器编码节点和任务特定虚拟节点,实现高效通信拓扑解码。
点此查看论文截图


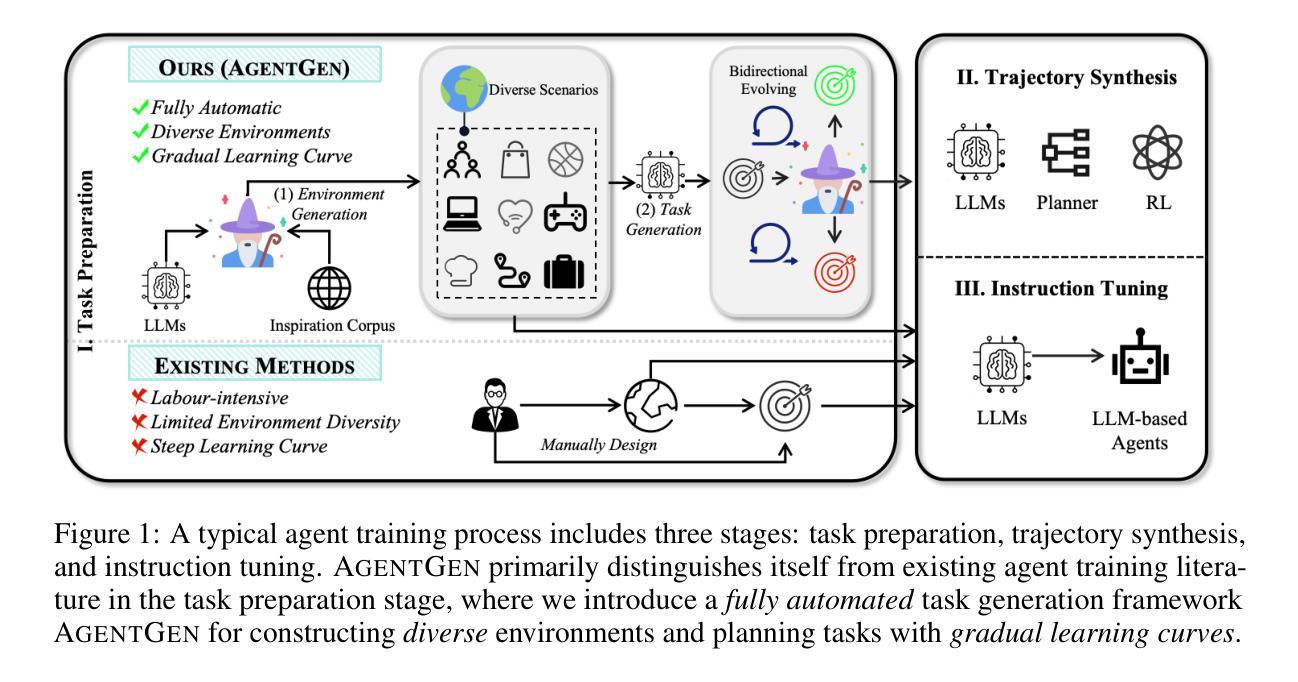
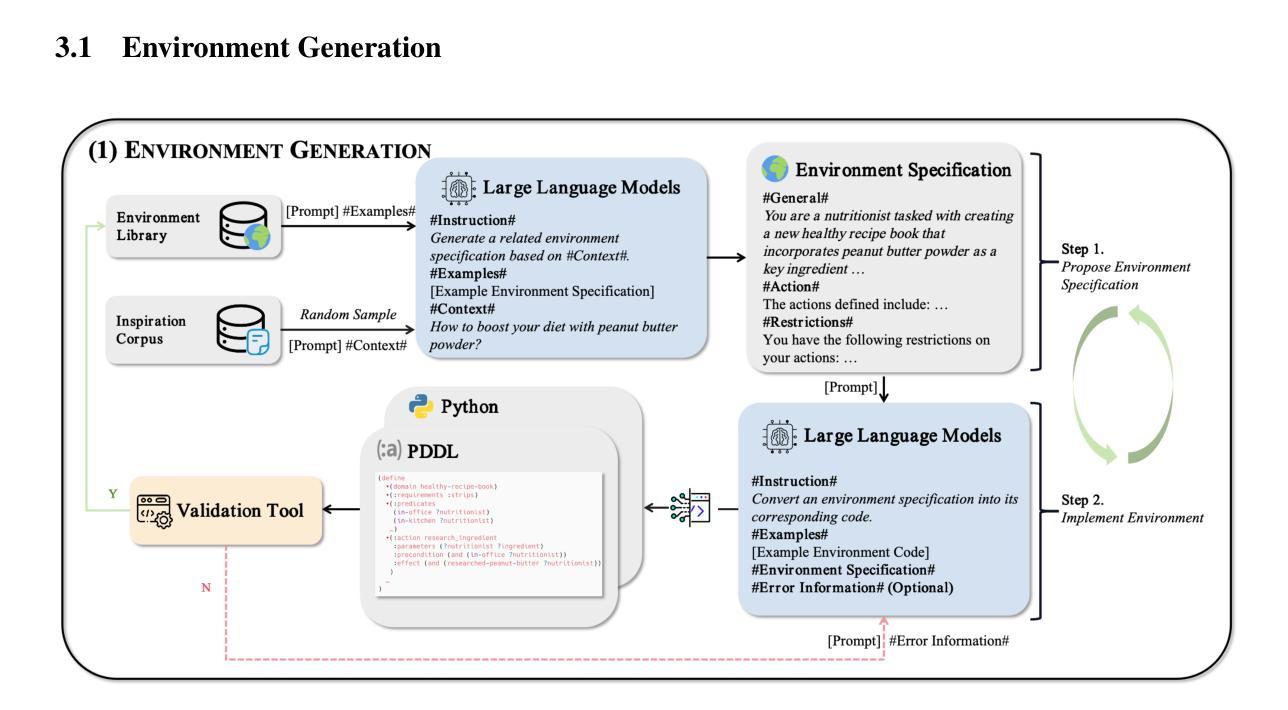
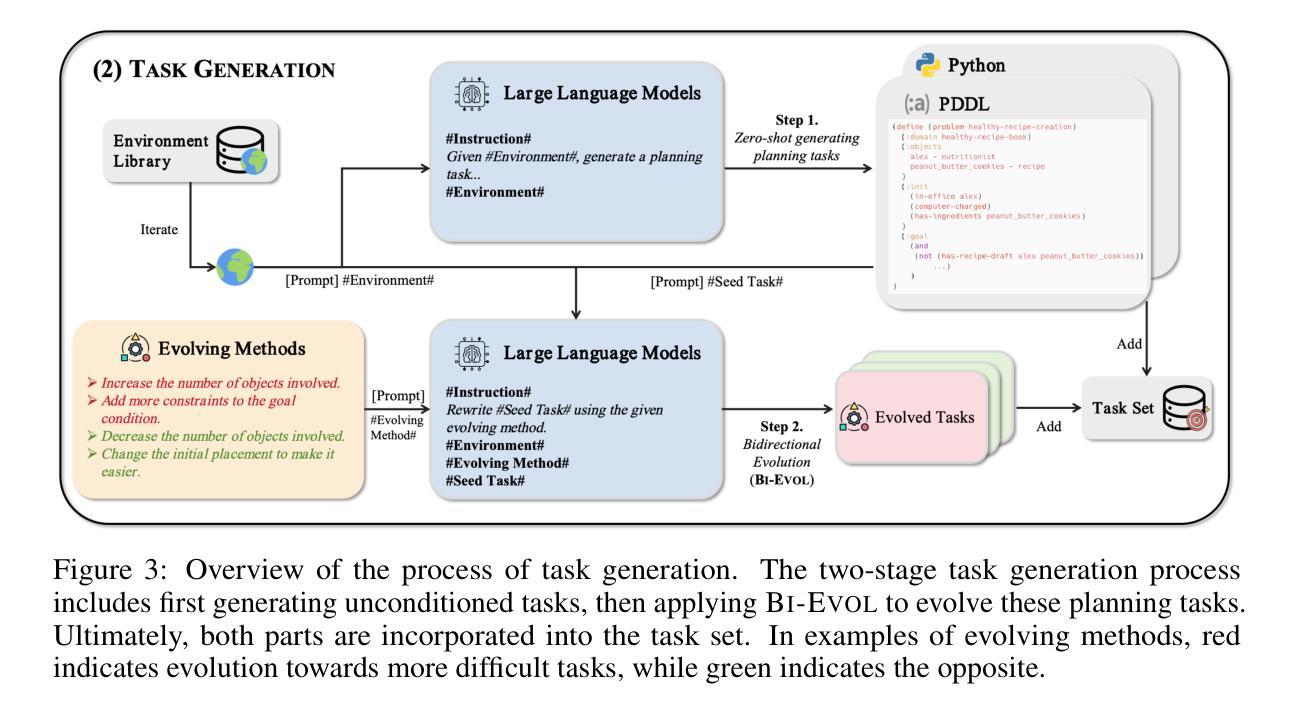
AgentGen: Enhancing Planning Abilities for Large Language Model based Agent via Environment and Task Generation
Authors:Mengkang Hu, Pu Zhao, Can Xu, Qingfeng Sun, Jianguang Lou, Qingwei Lin, Ping Luo, Saravan Rajmohan
Large Language Model-based agents have garnered significant attention and are becoming increasingly popular. Furthermore, planning ability is a crucial component of an LLM-based agent, which generally entails achieving a desired goal from an initial state. This paper investigates enhancing the planning abilities of LLMs through instruction tuning, referred to as agent training. Recent studies have demonstrated that utilizing expert-level trajectory for instruction-tuning LLMs effectively enhances their planning capabilities. However, existing work primarily focuses on synthesizing trajectories from manually designed planning tasks and environments. The labor-intensive nature of creating these environments and tasks impedes the generation of sufficiently varied and extensive trajectories. To address this limitation, this paper explores the automated synthesis of diverse environments and a gradual range of planning tasks, from easy to difficult. We introduce a framework, AgentGen, that leverages LLMs first to generate environments and subsequently generate planning tasks conditioned on these environments. Specifically, to improve environmental diversity, we propose using an inspiration corpus composed of various domain-specific text segments as the context for synthesizing environments. Moreover, to increase the difficulty diversity of generated planning tasks, we propose a bidirectional evolution method, Bi-Evol, that evolves planning tasks from easier and harder directions to synthesize a task set with a smoother difficulty curve. The evaluation results derived from AgentBoard show that AgentGen greatly improves LLMs’ planning ability, e.g., the AgentGen instruction-tuned Llama-3.1-8B surpasses GPT-3.5 in overall performance. Moreover, the AgentGen-tuned Llama-3.1-70B model achieves state-of-the-art results in planning tasks. Project page: https://agent-gen.github.io/.
基于大型语言模型的智能体已经引起了广泛的关注并且越来越受欢迎。此外,规划能力是基于大型语言模型(LLM)的智能体的关键组成部分,通常涉及从初始状态实现预期目标。本文旨在通过指令微调(也称为智能体训练)来提高大型语言模型的规划能力。最近的研究表明,利用专家级轨迹对大型语言模型进行指令微调可以有效地提高其规划能力。然而,现有的工作主要集中在从手动设计的规划任务和环境中合成轨迹。创建这些环境和任务需要大量的人工劳动,阻碍了足够多样化和广泛的轨迹生成。为了解决这个问题,本文探讨了自动化合成多样环境和一系列从简单到复杂的规划任务。我们引入了一个名为AgentGen的框架,它首先利用大型语言模型生成环境,然后根据这些环境生成规划任务。具体来说,为了提高环境多样性,我们建议使用由各种领域特定文本片段组成的灵感语料库作为合成环境的上下文。此外,为了提高生成规划任务的难度多样性,我们提出了一种双向进化方法Bi-Evol,该方法可以从简单和困难的方向进化规划任务,以合成难度曲线更平滑的任务集。来自AgentBoard的评估结果表明,AgentGen大大提高了大型语言模型的规划能力。例如,经过AgentGen指令微调的Llama-3.1-8B在整体性能上超越了GPT-3.5。此外,经过AgentGen训练的Llama-3.1-70B模型在规划任务上达到了最新水平。项目页面:https://agent-gen.github.io/。
论文及项目相关链接
PDF Accepted by KDD 2025 (Research Track). Project page: https://agent-gen.github.io/
摘要
大型语言模型为基础的智能代理得到了广泛关注并越来越受欢迎。规划能力是LLM基础代理的关键组成部分,包括从初始状态实现目标。本研究旨在通过指令微调增强LLM的规划能力,称为代理训练。现有研究证明利用专家级轨迹进行指令微调LLM能有效提升其规划能力。然而,现有的工作主要集中在从手动设计的规划任务和环境中合成轨迹,创建这些环境和任务需要大量劳动力,阻碍了足够多样和广泛的轨迹生成。本研究探索了环境和规划任务的自动化合成,从简单到复杂。引入AgentGen框架,利用LLM首先生成环境,然后根据这些环境生成规划任务。为提高环境多样性,我们提出使用包含各种领域特定文本片段的灵感语料库作为合成环境的上下文。为提高生成规划任务的难度多样性,我们提出了双向进化方法Bi-Evol,该方法从容易和困难的方向进化规划任务,合成难度曲线更平滑的任务集。通过AgentBoard进行的评估结果表明,AgentGen极大地提高了LLM的规划能力,例如,通过AgentGen指令微调的Llama-3.1-8B在总体性能上超越了GPT-3.5。此外,使用AgentGen调教的Llama-3.1-70B模型在规划任务上达到了最新水平。项目页面:https://agent-gen.github.io/。
要点摘要
- 大型语言模型为基础的智能代理受到关注,规划能力是关键。
- 现有研究通过指令微调增强LLM的规划能力。
- 手动创建环境和任务阻碍轨迹生成,需要自动化合成方法。
- 引入AgentGen框架,利用LLM生成环境和规划任务。
- 使用灵感语料库提高环境多样性,提出双向进化方法增加任务难度多样性。
- AgentGen显著提高了LLM的规划能力,某些模型性能超越现有技术。
点此查看论文截图

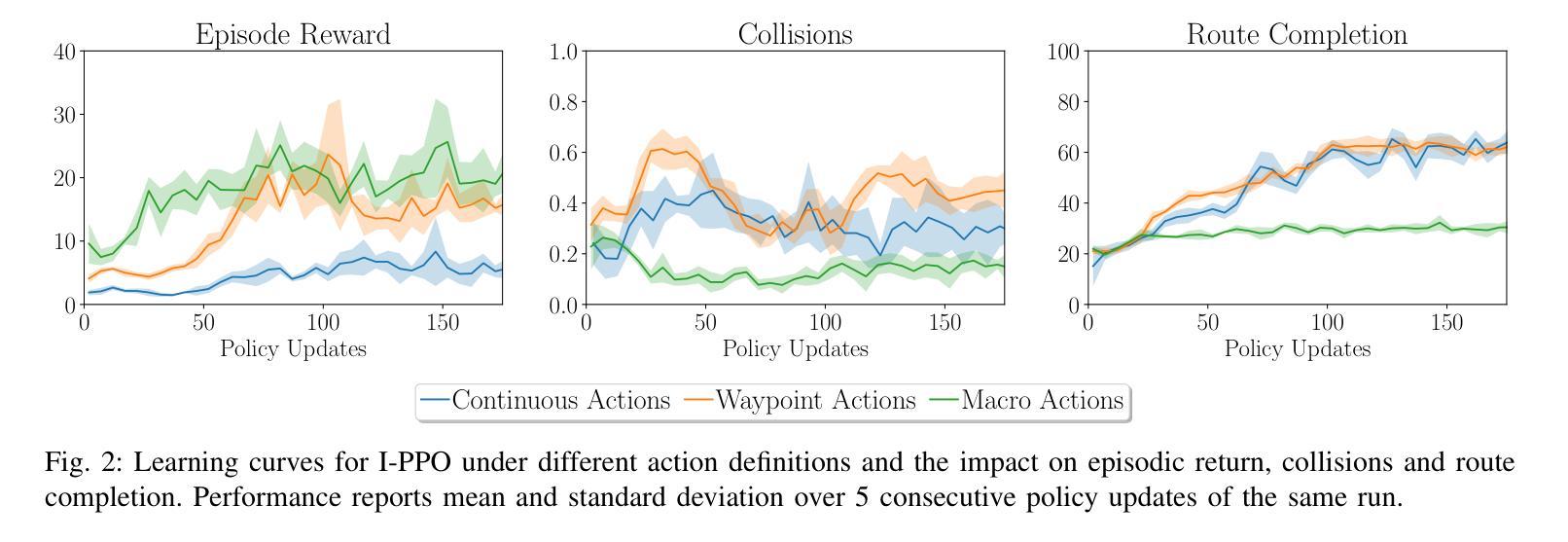
Scenario-Based Curriculum Generation for Multi-Agent Autonomous Driving
Authors:Axel Brunnbauer, Luigi Berducci, Peter Priller, Dejan Nickovic, Radu Grosu
The automated generation of diverse and complex training scenarios has been an important ingredient in many complex learning tasks. Especially in real-world application domains, such as autonomous driving, auto-curriculum generation is considered vital for obtaining robust and general policies. However, crafting traffic scenarios with multiple, heterogeneous agents is typically considered as a tedious and time-consuming task, especially in more complex simulation environments. In our work, we introduce MATS-Gym, a Multi-Agent Traffic Scenario framework to train agents in CARLA, a high-fidelity driving simulator. MATS-Gym is a multi-agent training framework for autonomous driving that uses partial scenario specifications to generate traffic scenarios with variable numbers of agents. This paper unifies various existing approaches to traffic scenario description into a single training framework and demonstrates how it can be integrated with techniques from unsupervised environment design to automate the generation of adaptive auto-curricula. The code is available at https://github.com/AutonomousDrivingExaminer/mats-gym.
自动化生成多样且复杂的训练场景已成为许多复杂学习任务的重要组成部分。特别是在现实世界的应用领域,如自动驾驶,自动课程生成对于获得稳健和通用的策略被认为是至关重要的。然而,在更复杂的模拟环境中,制作具有多个异质代理的交通场景通常被认为是一项乏味且耗时的任务。在我们的工作中,我们介绍了MATS-Gym,这是一个用于在CARLA(高保真驾驶模拟器)中训练代理的多代理交通场景框架。MATS-Gym是一个用于自动驾驶的多代理训练框架,它使用部分场景规范来生成具有可变代理数量的交通场景。本文统一了现有的各种交通场景描述方法,将其纳入一个单一的训练框架,并展示了如何将其与无监督环境设计技术相结合,以自动生成自适应的自动课程。代码可在https://github.com/AutonomousDrivingExaminer/mats-gym获取。
论文及项目相关链接
PDF Accepted for publication at the International Conference on Robotics and Automation (ICRA) 2025
Summary
自动化生成多样且复杂的训练场景在许多复杂学习任务中扮演着重要角色。特别是在自动驾驶等实际应用领域,自动课程生成对于获得稳健和通用的策略至关重要。然而,在更复杂的仿真环境中,构建具有多个异质代理的交通场景通常被视为一项繁琐且耗时的任务。我们的工作引入了MATS-Gym,这是一个在CARLA驾驶模拟器中训练代理的多代理交通场景框架。MATS-Gym是一个用于自动驾驶的多代理训练框架,它使用部分场景规范来生成具有可变代理数量的交通场景。本文统一了现有的各种交通场景描述方法,并将其纳入一个单一的训练框架中,并展示了如何将其与无监督环境设计技术相结合,以自动生成自适应的自动课程。
Key Takeaways
- 自动化生成复杂和多样的训练场景在许多学习任务是重要的。
- 在自动驾驶等实际应用中,自动课程生成对获得稳健和通用策略至关重要。
- 构建具有多个异质代理的交通场景是一项繁琐且耗时的任务。
- MATS-Gym是一个多代理训练框架,用于在CARLA驾驶模拟器中训练代理。
- MATS-Gym使用部分场景规范生成具有可变代理数量的交通场景。
- 该框架统一了多种现有的交通场景描述方法。
点此查看论文截图



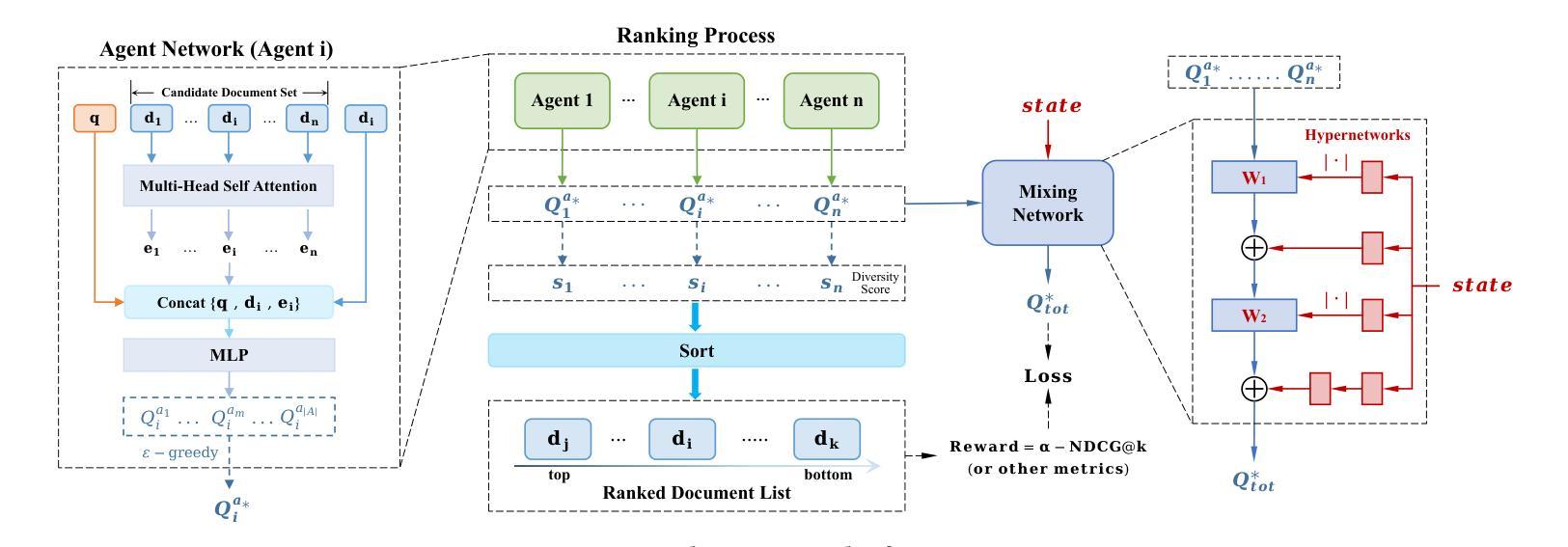
MA4DIV: Multi-Agent Reinforcement Learning for Search Result Diversification
Authors:Yiqun Chen, Jiaxin Mao, Yi Zhang, Dehong Ma, Long Xia, Jun Fan, Daiting Shi, Zhicong Cheng, Simiu Gu, Dawei Yin
Search result diversification (SRD), which aims to ensure that documents in a ranking list cover a broad range of subtopics, is a significant and widely studied problem in Information Retrieval and Web Search. Existing methods primarily utilize a paradigm of “greedy selection”, i.e., selecting one document with the highest diversity score at a time or optimize an approximation of the objective function. These approaches tend to be inefficient and are easily trapped in a suboptimal state. To address these challenges, we introduce Multi-Agent reinforcement learning (MARL) for search result DIVersity, which called MA4DIV. In this approach, each document is an agent and the search result diversification is modeled as a cooperative task among multiple agents. By modeling the SRD ranking problem as a cooperative MARL problem, this approach allows for directly optimizing the diversity metrics, such as $\alpha$-NDCG, while achieving high training efficiency. We conducted experiments on public TREC datasets and a larger scale dataset in the industrial setting. The experiemnts show that MA4DIV achieves substantial improvements in both effectiveness and efficiency than existing baselines, especially on the industrial dataset. The code of MA4DIV can be seen on https://github.com/chenyiqun/MA4DIV.
搜索结果多样化(SRD)旨在确保排名列表中的文档涵盖广泛的子主题,是信息检索和网页搜索中一个重大且被广泛研究的问题。现有方法主要采用“贪婪选择”范式,即一次选择一个具有最高多样性得分的文档或优化目标函数的近似值。这些方法往往效率低下,且容易陷入次优状态。为了解决这些挑战,我们引入了用于搜索结果多样性的多智能体强化学习(MARL),称为MA4DIV。在此方法中,每个文档都是一个智能体,搜索结果多样化被建模为多个智能体之间的合作任务。通过将SRD排名问题建模为合作型MARL问题,此方法能够直接优化多样性指标(例如α-NDCG),同时实现高训练效率。我们在公共TREC数据集和工业设置的更大规模数据集上进行了实验。实验表明,MA4DIV在有效性和效率方面均实现了对现有基准的重大改进,尤其是在工业数据集上。MA4DIV的代码可见于https://github.com/chenyiqun/MA4DIV。
论文及项目相关链接
Summary
该文本介绍了搜索结果多样化(SRD)在信息检索和网页搜索中的重要性及其现有方法面临的挑战。为解决这些问题,引入基于多智能体的强化学习(MARL)来进行搜索结果多样化,即MA4DIV方法。此方法将文档视为智能体,将搜索结果多样化建模为多个智能体之间的合作任务。实验表明,MA4DIV相较于现有基线方法在有效性和效率上都有显著提高,特别是在工业数据集上。
Key Takeaways
- 搜索结果多样化(SRD)在信息检索和网页搜索中是一个重要且被广泛研究的问题。
- 现有方法主要使用“贪婪选择”范式,但这种方法往往效率低下,容易陷入次优状态。
- 为解决这些挑战,引入了基于多智能体的强化学习(MARL)的MA4DIV方法。
- 在MA4DIV方法中,每个文档都被视为一个智能体,搜索结果多样化被建模为多个智能体之间的合作任务。
- MA4DIV方法能够直接优化多样性指标(如α-NDCG),同时实现高训练效率。
- 实验结果表明,MA4DIV在有效性和效率上都优于现有基线方法,特别是在工业数据集上。
点此查看论文截图