⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-08 更新
Transformers Boost the Performance of Decision Trees on Tabular Data across Sample Sizes
Authors:Mayuka Jayawardhana, Renbo, Samuel Dooley, Valeriia Cherepanova, Andrew Gordon Wilson, Frank Hutter, Colin White, Tom Goldstein, Micah Goldblum
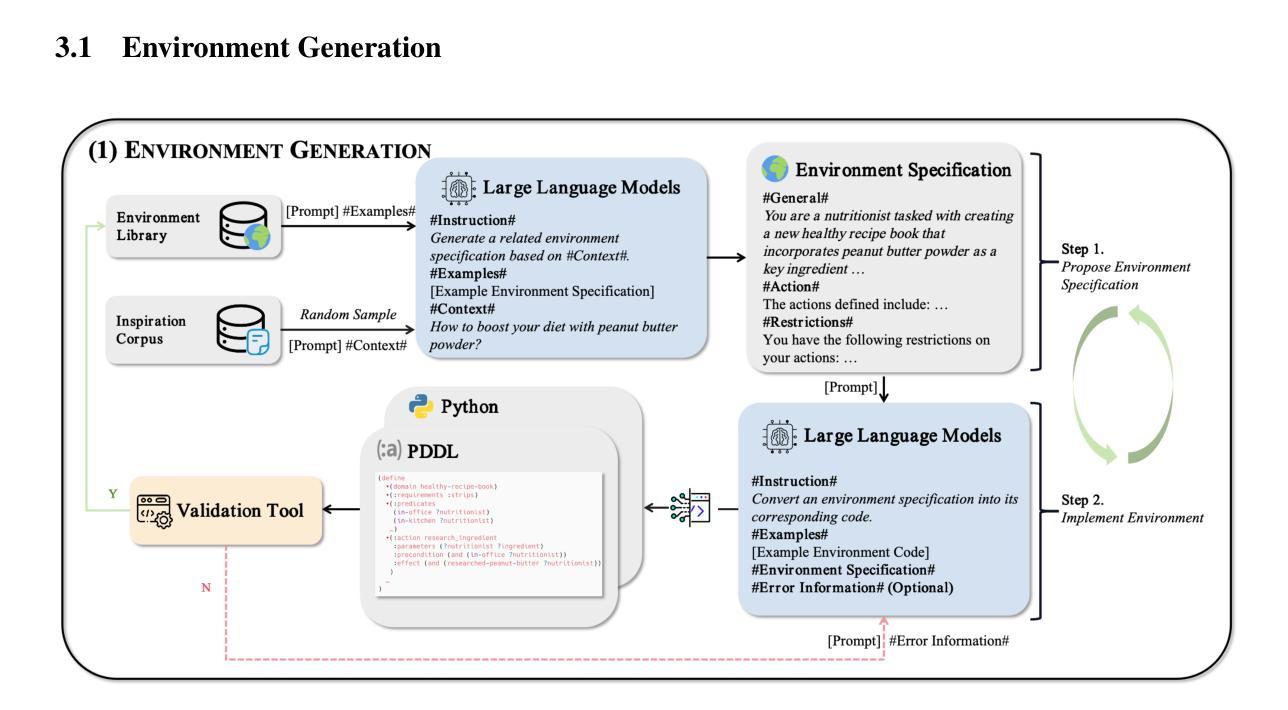
Large language models (LLMs) perform remarkably well on tabular datasets in zero- and few-shot settings, since they can extract meaning from natural language column headers that describe features and labels. Similarly, TabPFN, a recent non-LLM transformer pretrained on numerous tables for in-context learning, has demonstrated excellent performance for dataset sizes up to a thousand samples. In contrast, gradient-boosted decision trees (GBDTs) are typically trained from scratch on each dataset without benefiting from pretraining data and must learn the relationships between columns from their entries alone since they lack natural language understanding. LLMs and TabPFN excel on small tabular datasets where a strong prior is essential, yet they are not competitive with GBDTs on medium or large datasets, since their context lengths are limited. In this paper, we propose a simple and lightweight approach for fusing large language models and TabPFN with gradient-boosted decision trees, which allows scalable GBDTs to benefit from the natural language capabilities and pretraining of transformers. We name our fusion methods LLM-Boost and PFN-Boost, respectively. While matching or surpassing the performance of the transformer at sufficiently small dataset sizes and GBDTs at sufficiently large sizes, LLM-Boost and PFN-Boost outperform both standalone components on a wide range of dataset sizes in between. We demonstrate state-of-the-art performance against numerous baselines and ensembling algorithms. We find that PFN-Boost achieves the best average performance among all methods we test for all but very small dataset sizes. We release our code at http://github.com/MayukaJ/LLM-Boost .
大型语言模型(LLM)在零样本和少样本设置下的表格数据集上表现非常出色,因为它们可以从描述特征和标签的自然语言列标题中提取意义。类似地,TabPFN作为一个最近非LLM的转换器,经过大量表格的预训练用于上下文学习,在数据集大小高达一千个样本时表现出了卓越的性能。相比之下,梯度提升决策树(GBDT)通常针对每个数据集从头开始训练,无法从预训练数据中获益,并且它们只能从条目本身中学习列之间的关系,因为缺乏自然语言理解。LLM和TabPFN在小型表格数据集中表现出色,其中强先验知识至关重要,但在中型或大型数据集方面却不与GBDT竞争,因为它们的上下文长度有限。在本文中,我们提出了一种简单而轻量级的方法,将大型语言模型和TabPFN与梯度提升决策树融合,允许可扩展的GBDT受益于转换器的自然语言能力和预训练。我们将我们的融合方法分别命名为LLM-Boost和PFN-Boost。尽管在足够小的数据集大小方面匹配或超过了转换器的性能,并在足够大的尺寸方面匹配了GBDT的性能,但LLM-Boost和PFN-Boost在一系列中间数据集大小上的表现均优于两个独立组件。我们对许多基准线和集成算法表现出了最先进的性能。我们发现,除了非常小的数据集大小外,PFN-Boost在所有方法中取得了最佳的平均性能。我们在http://github.com/MayukaJ/LLM-Boost上发布了我们的代码。
论文及项目相关链接
PDF 12 pages, 6 figures
Summary
大型语言模型(LLMs)在零样本和少样本的表格数据集上表现优异,因为它们可以从描述特征和标签的自然语言列标题中提取意义。而预训练在多个表格上的非LLM转换器TabPFN在小型数据集上展示了出色的性能。相比之下,梯度提升决策树(GBDTs)通常需要从头开始训练,不依赖于预训练数据,它们依赖于数据条目的关系学习而非自然语言理解。本文提出了一种简单而轻量级的方法,将大型语言模型和TabPFN与梯度提升决策树相融合,我们称之为LLM-Boost和PFN-Boost。这两种融合方法在小数据集上匹配或超过转换器的性能,在大数据集上匹配或超过GBDT的性能,并在中间范围的数据集上超越了两者。代码已发布在链接。
Key Takeaways
- 大型语言模型(LLMs)能从自然语言的列标题中提取表格数据集的特征和标签意义,在零样本和少样本设置下表现优秀。
- TabPFN预训练模型在小型表格数据集上展示了出色的性能。
- 梯度提升决策树(GBDTs)通常需要从数据条目中学习关系,缺乏自然语言理解能力。
- 提出了LLM-Boost和PFN-Boost方法,融合了大型语言模型与TabPFN与GBDTs,提升了在各种数据集大小上的性能。
- LLM-Boost和PFN-Boost在不同数据集大小上均表现出超越单一组件的性能。
- 在除了非常小的数据集以外的所有数据集大小中,PFN-Boost取得了最佳的平均性能。
点此查看论文截图

VICON: A Foundation Model for Multi-Physics Fluid Dynamics via Vision In-Context Operator Networks
Authors:Yadi Cao, Yuxuan Liu, Liu Yang, Rose Yu, Hayden Schaeffer, Stanley Osher
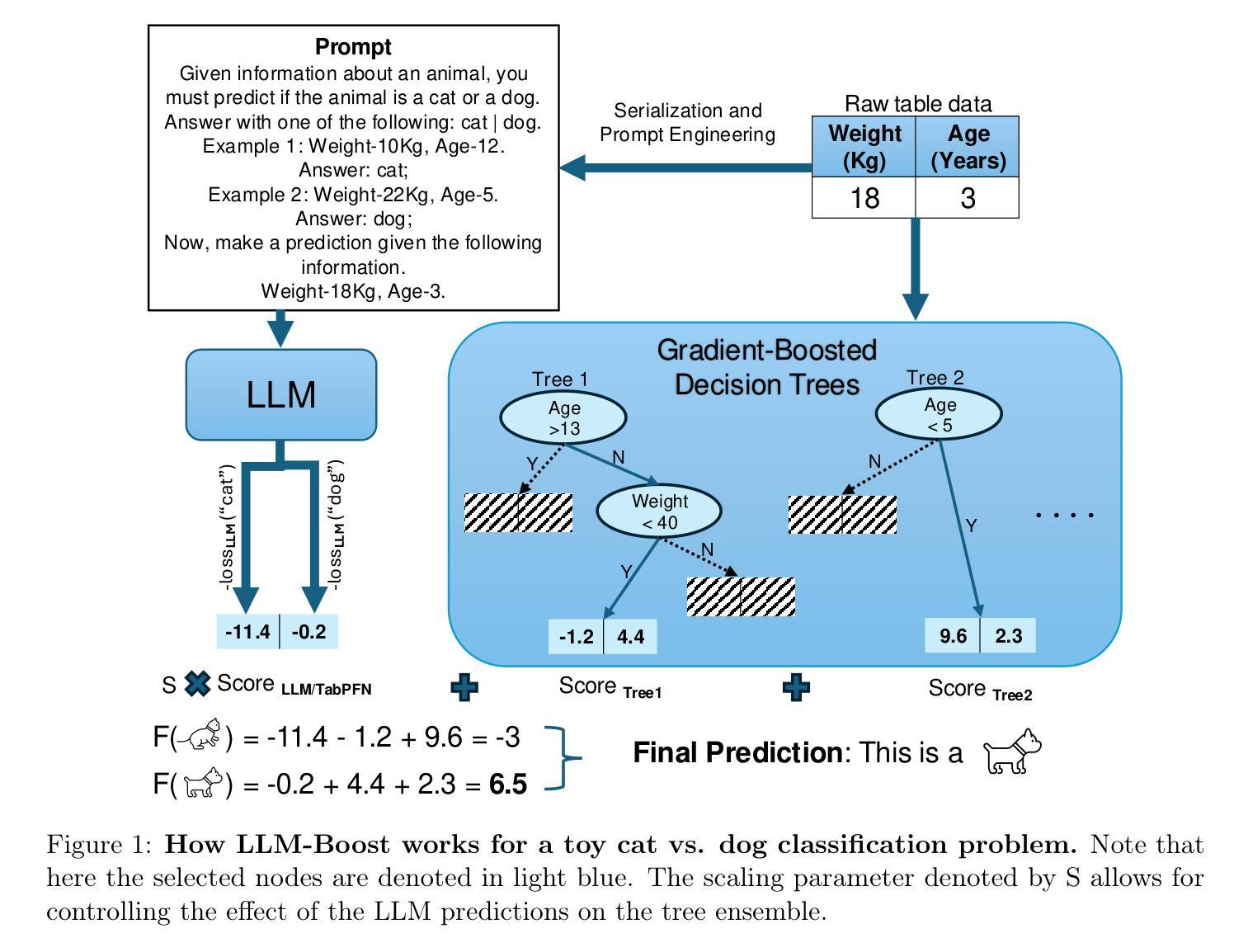
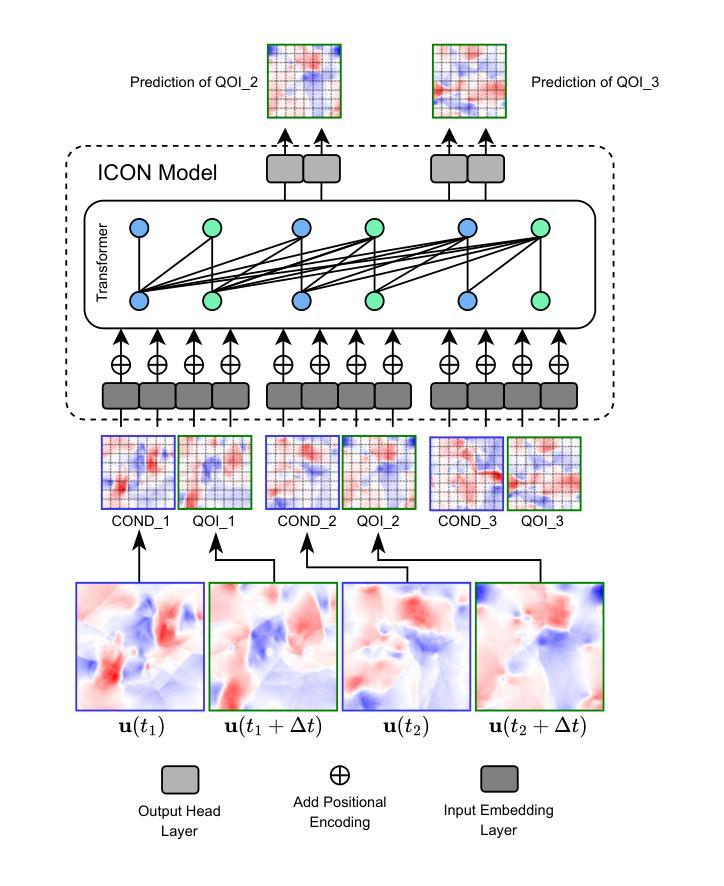
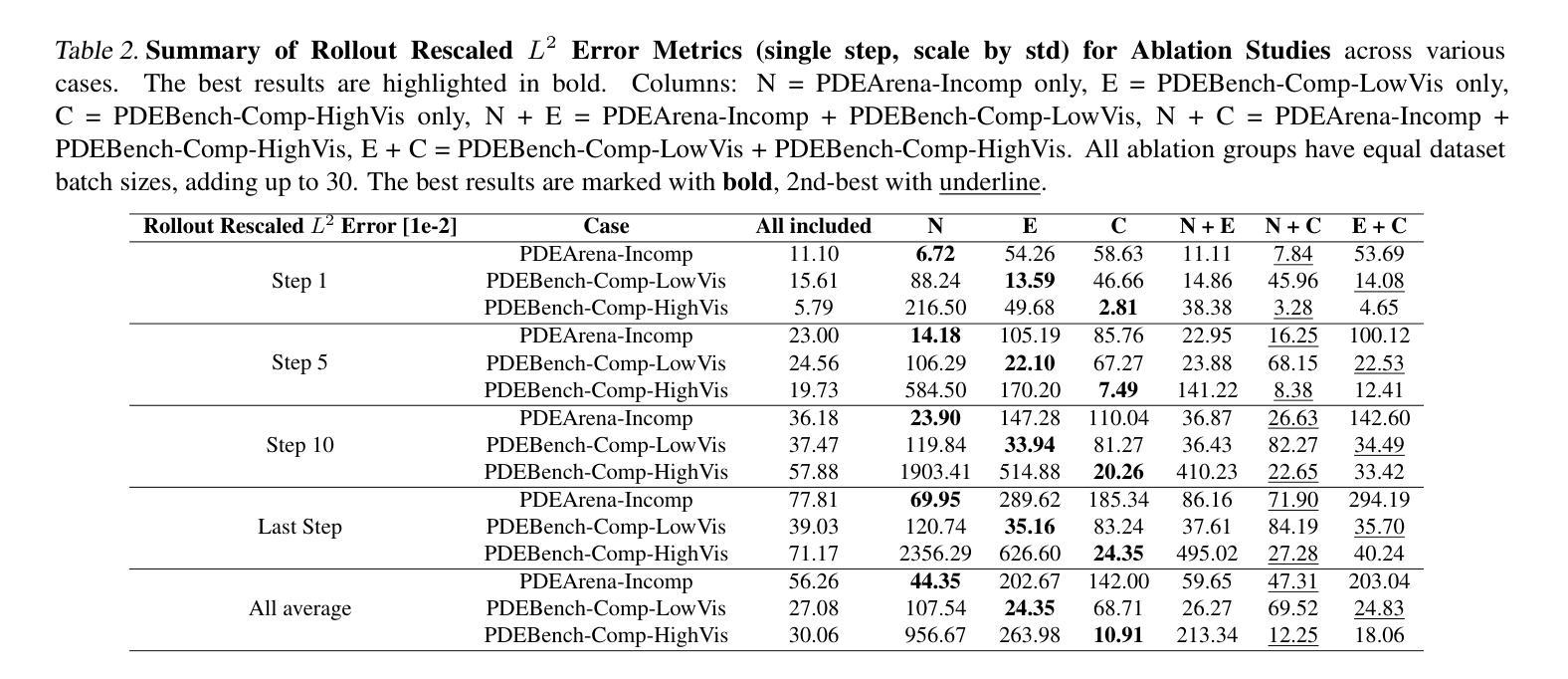
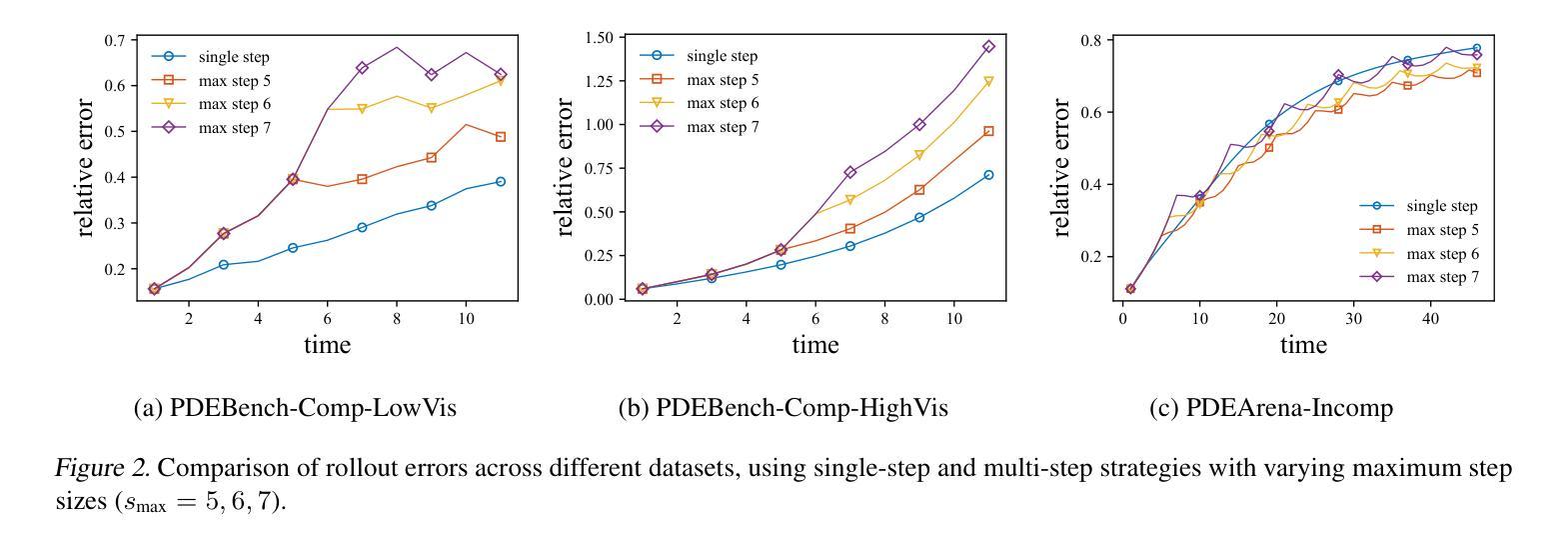
In-Context Operator Networks (ICONs) are models that learn operators across different types of PDEs using a few-shot, in-context approach. Although they show successful generalization to various PDEs, existing methods treat each data point as a single token, and suffer from computational inefficiency when processing dense data, limiting their application in higher spatial dimensions. In this work, we propose \textit{Vision In-Context Operator Networks} (VICON), incorporating a vision transformer architecture that efficiently processes 2D functions through patch-wise operations. We evaluated our method on three fluid dynamics datasets, demonstrating both superior performance (reducing the rescaled $L^2$ error by $40%$ and $61.6%$ for two benchmark datasets for compressible flows, respectively) and computational efficiency (requiring only one-third of the inference time per frame) in long-term rollout predictions compared to the current state-of-the-art sequence-to-sequence model with fixed timestep prediction: Multiple Physics Pretraining (MPP). Compared to MPP, our method preserves the benefits of in-context operator learning, enabling flexible context formation when dealing with insufficient frame counts or varying timestep values.
上下文操作网络(ICONs)是一类模型,它们采用少量样本上下文学习方法,学习不同类型偏微分方程(PDEs)之间的操作符。尽管它们成功推广到各种偏微分方程,但现有方法将每个数据点视为单个标记,在处理密集数据时计算效率低下,限制了它们在更高空间维度中的应用。在这项工作中,我们提出了“视觉上下文操作网络”(VICON),它结合了视觉变压器架构,通过块操作有效处理二维函数。我们在三个流体动力学数据集上评估了我们的方法,展示了在长期滚动预测中优于当前先进序列到序列模型的表现,并伴随着更高的计算效率(减少了重置后的平均绝对误差的一半左右和两个基准数据集压缩流动的重建效果的$ L ^ 2 $误差减少为原来的百分之四十和百分之六十一,并且每帧推理时间只需三分之一)。与MPP相比,我们的方法保留了上下文操作学习的优点,在处理不足帧数或不同时间步长值时能够形成灵活的上下文。
论文及项目相关链接
PDF update 2 more experiments compared to original submission; minor writing adjustments
Summary
本文介绍了In-Context Operator Networks(ICONs)在处理不同类型PDEs时的应用,但现有方法在处理密集数据时存在计算效率低下的问题。为此,本文提出了Vision In-Context Operator Networks(VICON),结合视觉转换器架构,通过补丁操作高效地处理二维函数。在三个流体动力学数据集上的实验表明,与当前最先进的序列到序列模型相比,VICON在长期滚动预测中表现出优越的性能和计算效率,能够在不足帧计数或不同时间步长值时灵活形成上下文。
Key Takeaways
- In-Context Operator Networks (ICONs) 能够学习不同类型的PDEs中的操作符,并采用少样本上下文方法实现泛化。
- 现有方法在处理密集数据时存在计算效率低下的问题,限制了其在高空间维度中的应用。
- Vision In-Context Operator Networks (VICON) 引入视觉转换器架构,通过补丁操作高效处理二维函数。
- VICON在流体动力学数据集上的实验表现出优越的性能,减少了错误率,并提高了计算效率。
- VICON能够在长期滚动预测中灵活形成上下文,处理不足帧计数或不同时间步长值的情况。
点此查看论文截图


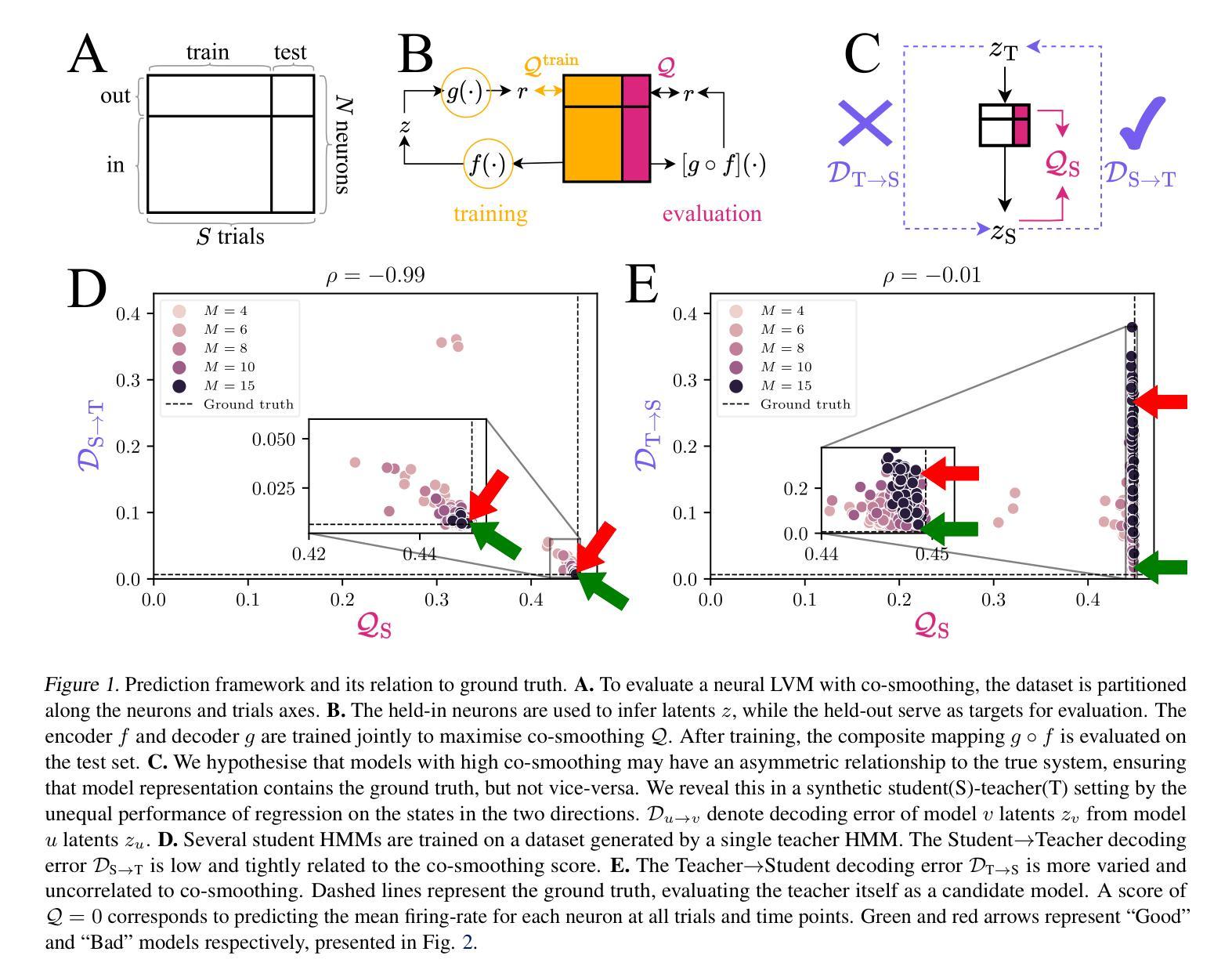
When predict can also explain: few-shot prediction to select better neural latents
Authors:Kabir Dabholkar, Omri Barak
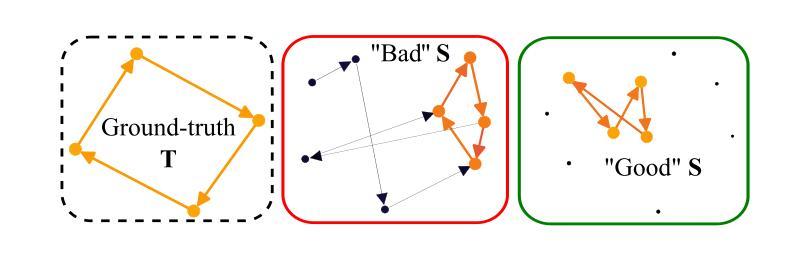
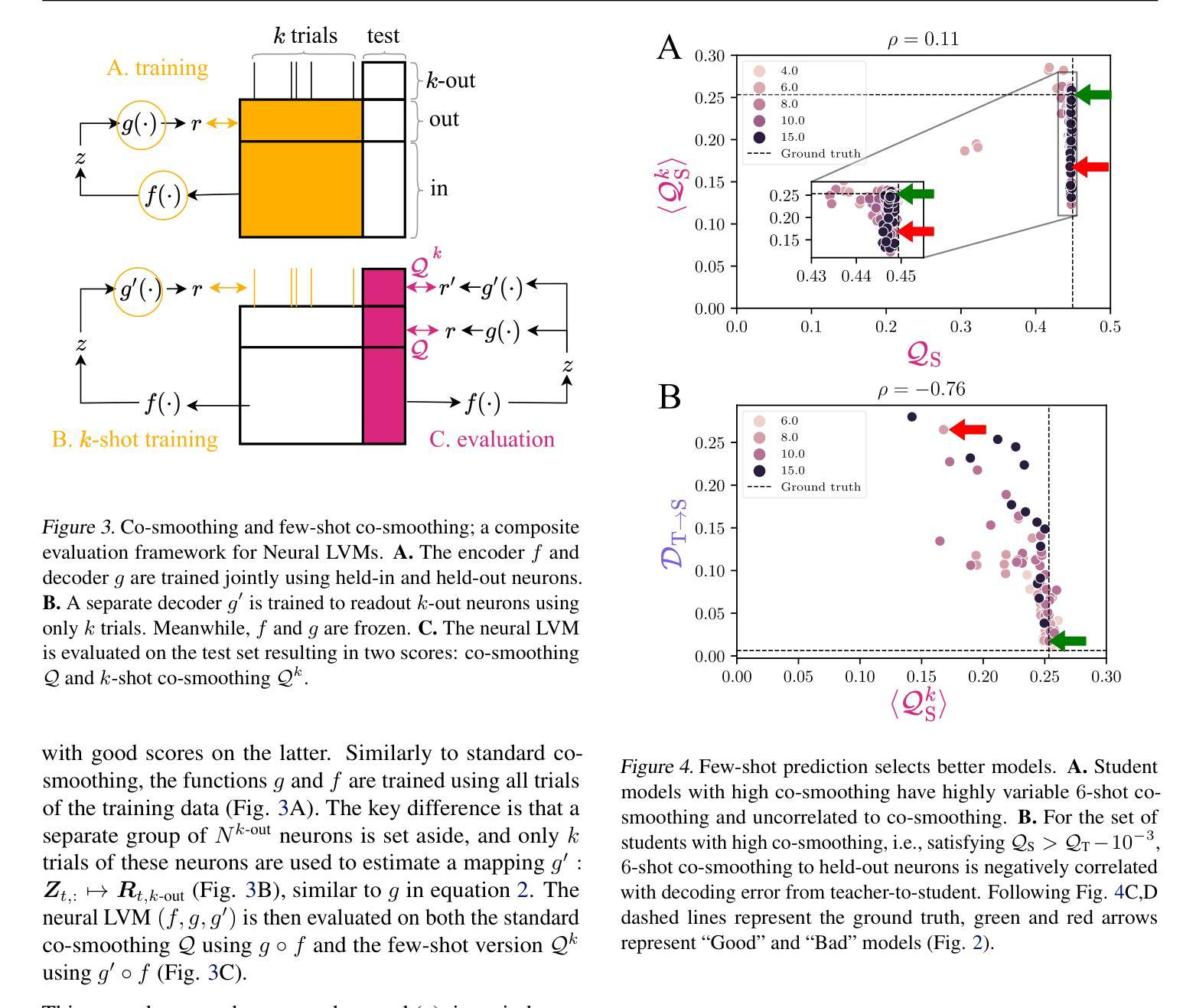
Latent variable models serve as powerful tools to infer underlying dynamics from observed neural activity. Ideally, the inferred dynamics should align with true ones. However, due to the absence of ground truth data, prediction benchmarks are often employed as proxies. One widely-used method, co-smoothing, involves jointly estimating latent variables and predicting observations along held-out channels to assess model performance. In this study, we reveal the limitations of the co-smoothing prediction framework and propose a remedy. In a student-teacher setup with Hidden Markov Models, we demonstrate that the high co-smoothing model space encompasses models with arbitrary extraneous dynamics in their latent representations. To address this, we introduce a secondary metric – few-shot co-smoothing, performing regression from the latent variables to held-out channels in the data using fewer trials. Our results indicate that among models with near-optimal co-smoothing, those with extraneous dynamics underperform in the few-shot co-smoothing compared to ‘minimal’ models that are devoid of such dynamics. We provide analytical insights into the origin of this phenomenon and further validate our findings on real neural data using two state-of-the-art methods: LFADS and STNDT. In the absence of ground truth, we suggest a novel measure to validate our approach. By cross-decoding the latent variables of all model pairs with high co-smoothing, we identify models with minimal extraneous dynamics. We find a correlation between few-shot co-smoothing performance and this new measure. In summary, we present a novel prediction metric designed to yield latent variables that more accurately reflect the ground truth, offering a significant improvement for latent dynamics inference.
潜在变量模型是推断观察到的神经活动背后动力学的重要工具。理想情况下,推断出的动力学应该与真实情况一致。然而,由于缺乏真实数据,通常使用预测基准作为代理。一种广泛使用的方法,即协同平滑法,涉及共同估计潜在变量并预测未观察到的通道以评估模型性能。在这项研究中,我们揭示了协同平滑预测框架的局限性并提出了补救措施。在隐藏马尔可夫模型的师生设置中,我们证明了高协同平滑模型空间包含了具有任意额外动力学的模型作为其潜在表示。为了解决这一问题,我们引入了次要指标——少镜头协同平滑法,使用较少的试验次数从潜在变量回归数据中未观察到的通道。我们的结果表明,在近最优协同平滑的模型中,具有额外动力学的模型在少镜头协同平滑方面的表现不如没有这种动力学的“最小”模型。我们对这种现象的起源进行了深入分析,并通过两种方法——LFADS和STNDT,在真实神经数据上进一步验证了我们的发现。在缺乏真实数据的情况下,我们提出了一种新的方法来验证我们的方法。通过对所有高协同平滑模型对的潜在变量进行交叉解码,我们确定了具有最小额外动力学的模型。我们发现少镜头协同平滑性能与这个新指标之间存在相关性。总之,我们提出了一种新的预测指标,旨在产生更能准确反映真实情况的潜在变量,为潜在动力学推断提供了重大改进。
论文及项目相关链接
Summary
此文本探讨了潜在变量模型在推断神经活动动力学方面的局限性,并提出了一种新的预测指标——少样本协同平滑。研究发现,高协同平滑模型空间中包含具有任意额外动力学的模型。为解决这一问题,作者引入了少样本协同平滑作为次要指标,在数据中使用较少的试验次数进行回归预测。研究表明,在近最优协同平滑模型中,具有额外动力学的模型在少样本协同平滑方面的表现不如“最小”模型。作者还提供了对此现象的分析见解,并在真实神经数据上验证了这一发现。为验证其方法的有效性,作者提出了一种新的度量方式——通过交叉解码所有高协同平滑模型的潜在变量来识别具有最小额外动力学的模型。总体而言,该研究提出了一种新的预测指标,旨在更准确地反映实际情况的潜在变量,为潜在动力学推断提供了重大改进。
Key Takeaways
- 潜在变量模型用于从观察到的神经活动中推断底层动力学,但由于缺乏真实数据,通常采用预测基准作为代理来衡量模型性能。
- 现有的协同平滑方法存在局限性,可能会包含具有任意额外动力学的模型。
- 引入少样本协同平滑作为次要指标,通过较少的试验次数进行回归预测,以评估模型性能。
- 在近最优协同平滑模型中,具有额外动力学的模型在少样本协同平滑方面的表现较差。
- 通过交叉解码所有高协同平滑模型的潜在变量来识别具有最小额外动力学的模型,提出了一种新的度量方式。
- 新的预测指标能更准确地反映实际情况的潜在变量,为潜在动力学推断提供了改进。
点此查看论文截图