⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-08 更新
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Authors:Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu Jin, Zheqi DAI, Hongzhan Lin, Jianyi Chen, Xingjian Du, Liumeng Xue, Yunlin Chen, Zhifei Li, Lei Xie, Qiuqiang Kong, Yike Guo, Wei Xue
Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time compute. However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing. This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama. Our experiments reveal that scaling train-time compute for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns. Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy. In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.
最近,基于文本的 大型语言模型(LLM),特别是GPT系列和O1模型,在训练和推理时间的计算扩展方面取得了显著成效。然而,当前最先进的利用LLM的TTS系统通常是多阶段的,需要单独的模型(例如LLM之后的扩散模型),这使得在训练或测试期间扩展特定模型变得复杂。本文有以下贡献:首先,我们探索了语音合成中的训练时间和推理时间计算扩展。其次,我们提出了一个用于语音合成的简单框架Llasa,它采用单层向量量化(VQ)编解码器和单一的Transformer架构,与Llama等标准LLM完全对齐。我们的实验表明,扩展Llasa的训练时间计算可以持续提高合成语音的自然度,并生成更复杂和准确的语言韵律模式。此外,从扩展推理时间计算的角度来看,我们在搜索过程中采用了语音理解模型作为验证器,发现扩展推理时间计算可以使采样模式转向特定验证器的偏好,从而提高情感表达、音色一致性和内容准确性。另外,我们公开发布了TTS模型(1B、3B、8B)和编解码器模型的检查点和训练代码。
论文及项目相关链接
Summary
本文探讨了基于文本的大型语言模型(LLMs)在训练和推理时间计算方面的扩展性对语音合成的影响。提出了一种名为Llasa的简洁语音合成框架,采用单层向量量化编解码器和与标准LLMs(如Llama)兼容的单Transformer架构。实验表明,扩展训练时间计算可提高合成语音的自然度,并生成更复杂且准确的语调模式。从扩展推理时间计算的角度来看,使用语音理解模型作为验证器进行搜索,可使采样模式更符合特定验证器的偏好,从而提高情感表达、音色一致性和内容准确性。此外,公开了TTS模型(1B、3B、8B)和编解码器模型的检查点和训练代码。
Key Takeaways
- 近期基于文本的大型语言模型(LLMs)在语音合成中表现出训练时间和推理时间计算扩展的有效性。
- 当前的先进TTS系统通常利用多阶段和多个模型,使得在训练或测试时难以决定如何扩展特定模型。
- Llasa框架使用单层向量量化编解码器和与LLMs兼容的单Transformer架构,简化了语音合成过程。
- 扩展训练时间计算可提高合成语音的自然度和生成更复杂、准确的语调模式。
- 扩展推理时间计算可以通过使采样模式更符合特定验证器的偏好,提高情感表达、音色一致性和内容准确性。
- Llasa框架的TTS模型和编解码器模型的检查点和训练代码已公开。
点此查看论文截图

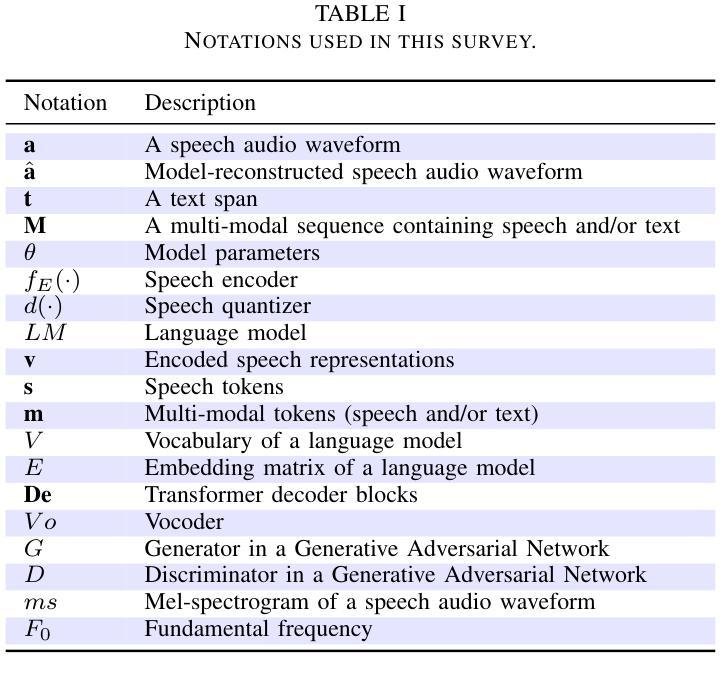
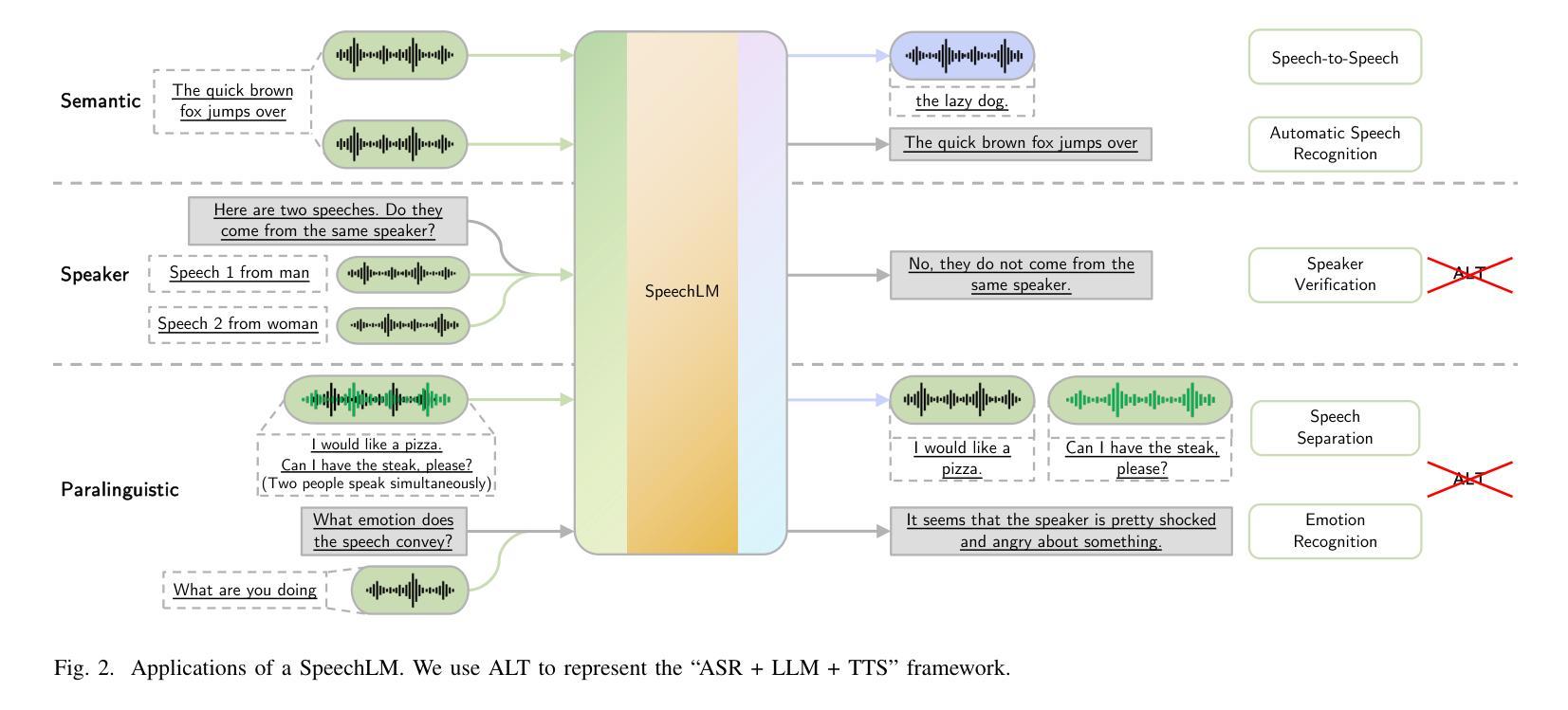
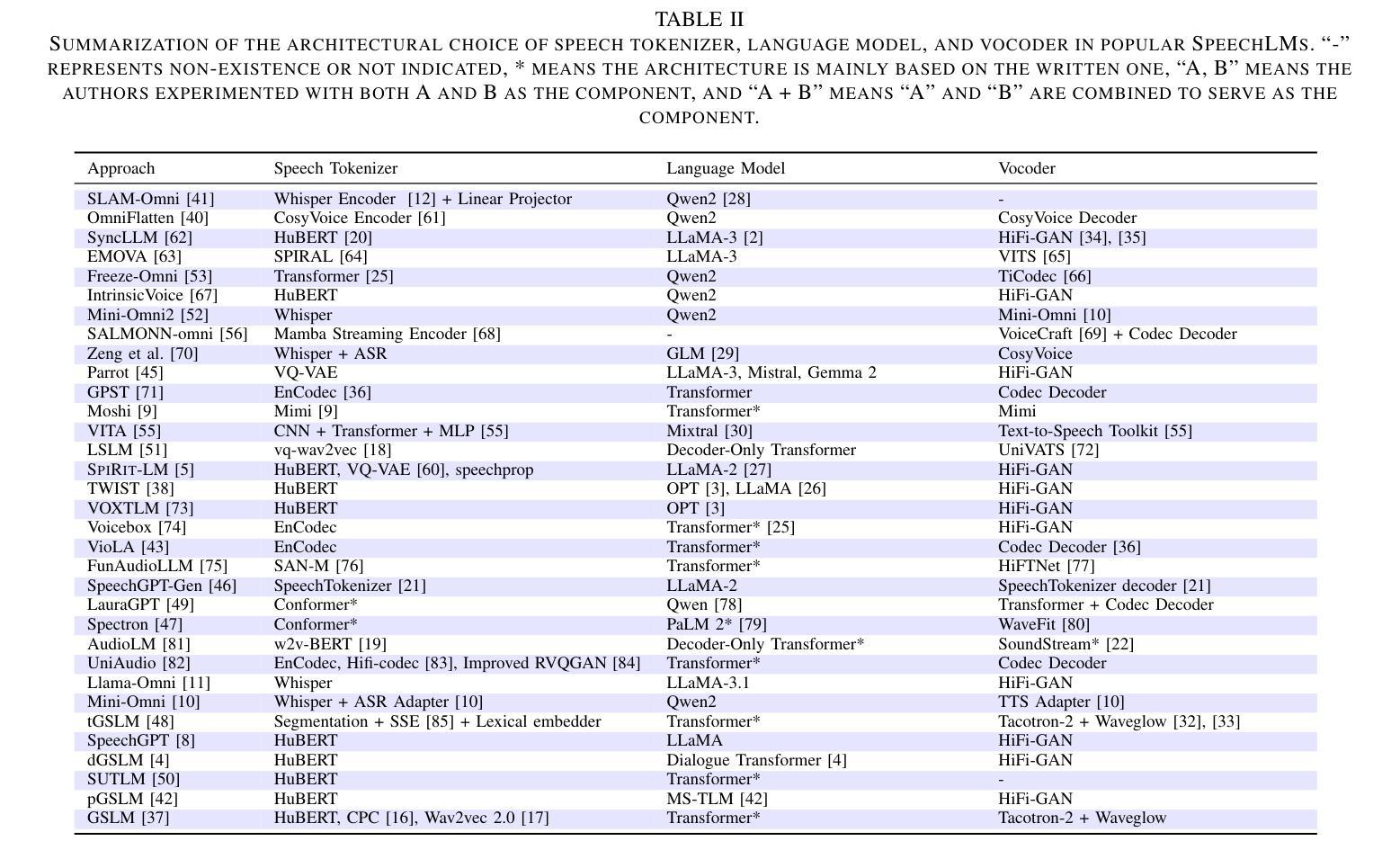
Recent Advances in Speech Language Models: A Survey
Authors:Wenqian Cui, Dianzhi Yu, Xiaoqi Jiao, Ziqiao Meng, Guangyan Zhang, Qichao Wang, Yiwen Guo, Irwin King
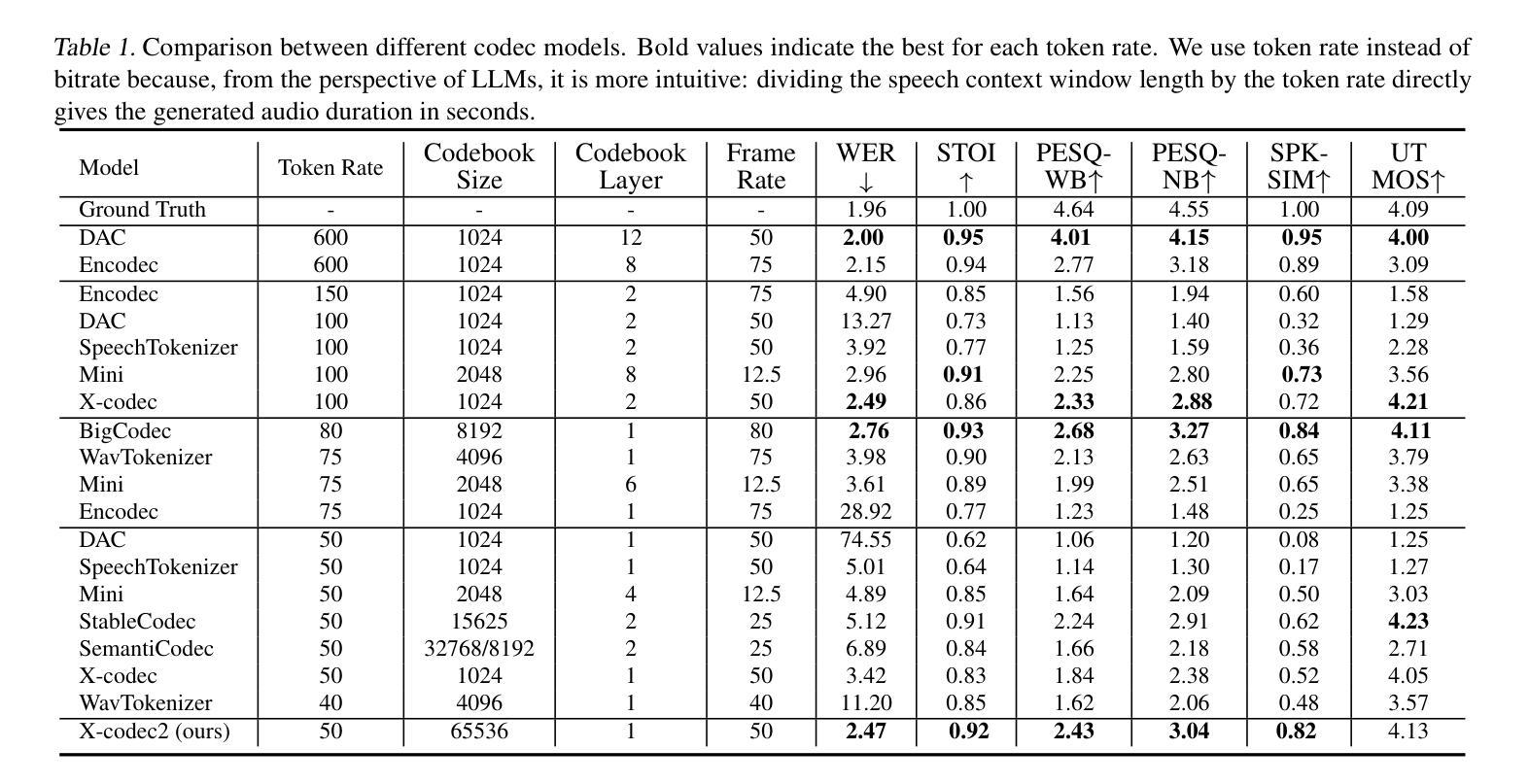
Large Language Models (LLMs) have recently garnered significant attention, primarily for their capabilities in text-based interactions. However, natural human interaction often relies on speech, necessitating a shift towards voice-based models. A straightforward approach to achieve this involves a pipeline of ``Automatic Speech Recognition (ASR) + LLM + Text-to-Speech (TTS)”, where input speech is transcribed to text, processed by an LLM, and then converted back to speech. Despite being straightforward, this method suffers from inherent limitations, such as information loss during modality conversion, significant latency due to the complex pipeline, and error accumulation across the three stages. To address these issues, Speech Language Models (SpeechLMs) – end-to-end models that generate speech without converting from text – have emerged as a promising alternative. This survey paper provides the first comprehensive overview of recent methodologies for constructing SpeechLMs, detailing the key components of their architecture and the various training recipes integral to their development. Additionally, we systematically survey the various capabilities of SpeechLMs, categorize their evaluation metrics, and discuss the challenges and future research directions in this rapidly evolving field. The GitHub repository is available at https://github.com/dreamtheater123/Awesome-SpeechLM-Survey
最近,大型语言模型(LLMs)因其文本交互能力而备受关注。然而,人类的自然交互通常依赖于语音,因此需要向语音模型转变。实现这一目标的一种直接方法是采用“自动语音识别(ASR)+ LLM +文本到语音(TTS)”的管道,其中输入语音被转录为文本,由LLM处理,然后再转回语音。尽管这种方法很直接,但它存在固有的局限性,例如模式转换过程中的信息丢失、因复杂管道而产生的显著延迟以及三个阶段的误差累积。为了解决这个问题,语音语言模型(SpeechLMs)——一种无需从文本转换即可生成语音的端到端模型——作为一种有前途的替代方案而出现。这篇综述论文提供了构建SpeechLM的最新方法的首次全面概述,详细描述了其架构的关键组件以及对其开发至关重要的各种训练配方。此外,我们还系统地调查了SpeechLMs的各种功能,对其评估指标进行了分类,并讨论了这一快速演变领域面临的挑战和未来研究方向。GitHub仓库可在https://github.com/dreamtheater123/Awesome-SpeechLM-Survey找到。
论文及项目相关链接
PDF Work in progress
Summary
大语言模型在文本交互领域备受瞩目,但人类自然交互更多依赖于语音。为实现语音交互,通常采用“语音识别(ASR)+大语言模型+语音合成(TTS)”的流程,但存在信息损失、延迟和误差累积等问题。为解决这些问题,出现了语音语言模型(SpeechLMs)——无需文本转换即可生成语音的端到端模型。本文首次全面概述了SpeechLMs的近期构建方法,详细阐述了其架构的关键组件和开发所需的各种训练方案。同时,系统调查了SpeechLMs的各项功能、评价标准和挑战,并探讨了该领域的未来研究方向。
Key Takeaways
- 大语言模型在文本交互领域备受关注,但人类自然交互更多依赖语音。
- 传统ASR+LLM+TTS的方法存在信息损失、延迟和误差累积的问题。
- 语音语言模型(SpeechLMs)作为无需文本转换即可生成语音的端到端模型,正在成为新的研究热点。
- 本文首次全面概述了SpeechLMs的近期构建方法及其架构的关键组件。
- SpeechLMs具备多种功能,包括语音识别、语音合成等。
- 文章系统调查了SpeechLMs的评价标准和挑战。
点此查看论文截图



Blade: A package for block-triangular form improved Feynman integrals decomposition
Authors:Xin Guan, Xiao Liu, Yan-Qing Ma, Wen-Hao Wu
In this article, we present the package {\tt Blade} as the first implementation of the block-triangular form improved Feynman integral reduction method. The block-triangular form has orders of magnitude fewer equations compared to the plain integration-by-parts system, allowing for strictly block-by-block solutions. This results in faster evaluations and reduced resource consumption. We elucidate the algorithms involved in obtaining the block-triangular form along with their implementations. Additionally, we introduce novel algorithms for finding the canonical form and symmetry relations of Feynman integrals, as well as for performing spanning-sector reduction. Our benchmarks for various state-of-the-art problems demonstrate that {\tt Blade} is remarkably competitive among existing reduction tools. Furthermore, the {\tt Blade} package offers several distinctive features, including support for complex kinematic variables or masses, user-defined Feynman prescriptions for each propagator, and general integrands.
本文中,我们展示了包(Blade)作为块三角形式改进的费曼积分缩减方法的第一个实现。块三角形式与纯分部积分系统相比,方程的数量减少了很多个数量级,可以进行严格的逐块求解。这导致更快的评估和减少资源消耗。我们详细说明了获得块三角形式的算法及其实现。此外,我们还介绍了寻找费曼积分的标准形式和对称关系的全新算法,以及进行跨度扇形缩减的方法。我们对各种最新问题的基准测试表明,Blade在现有缩减工具中表现非常具有竞争力。此外,Blade软件包提供了几个独特的功能,包括支持复杂的运动学变量或质量、针对每个传播器的用户定义的费曼处方和一般被积函数。
论文及项目相关链接
PDF Version to be published in Computer Physics Communications
Summary
文章介绍了首个实现块三角形式的改进型费曼积分约简方法的软件包Blade。块三角形式相比传统的积分式方法大大减少了方程数量,能够实现分块解,提高评估速度和降低资源消耗。文章详细阐述了获得块三角形式的算法及其实现,并介绍了寻找费曼积分的规范形式和对称关系的全新算法以及执行跨度扇形约简的算法。针对当前最先进的问题的基准测试表明,Blade在现有约简工具中表现非常具有竞争力。此外,Blade软件包提供了一些独特的功能,包括支持复杂的运动学变量或质量、用户定义的每个传播者的费曼规定和一般积分变量。
Key Takeaways
- Blade是首个实现块三角形式的费曼积分约简方法的软件包。
- 块三角形式相比传统的积分式方法能显著减少方程数量。
- 块三角形式允许分块解,提高了评估速度并降低了资源消耗。
- Blade包含用于获得块三角形式的算法及其实现。
- Blade引入了寻找费曼积分的规范形式和对称关系的新算法。
- Blade能够进行跨度扇形约简。
点此查看论文截图