⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-11 更新
nvAgent: Automated Data Visualization from Natural Language via Collaborative Agent Workflow
Authors:Geliang Ouyang, Jingyao Chen, Zhihe Nie, Yi Gui, Yao Wan, Hongyu Zhang, Dongping Chen
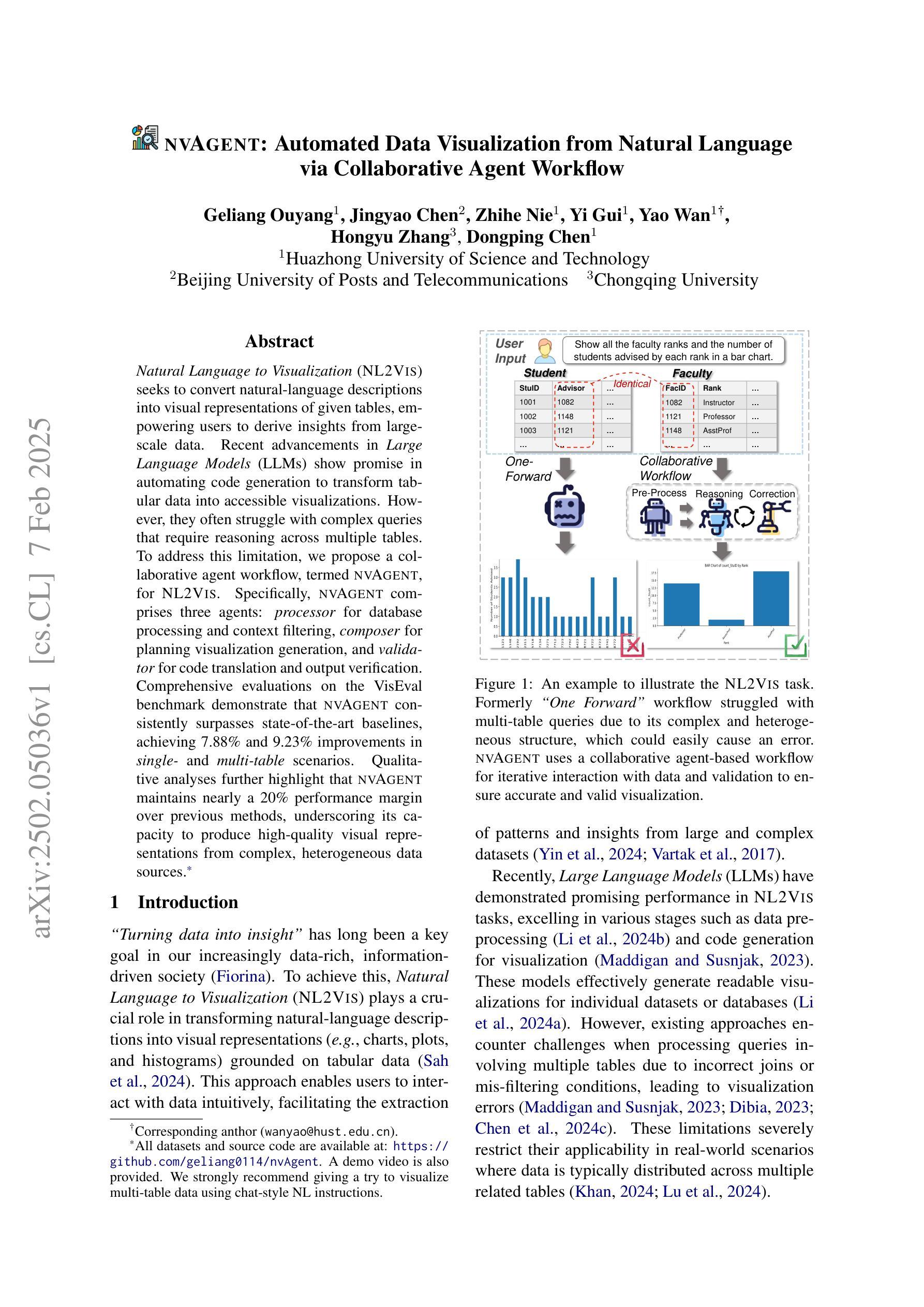
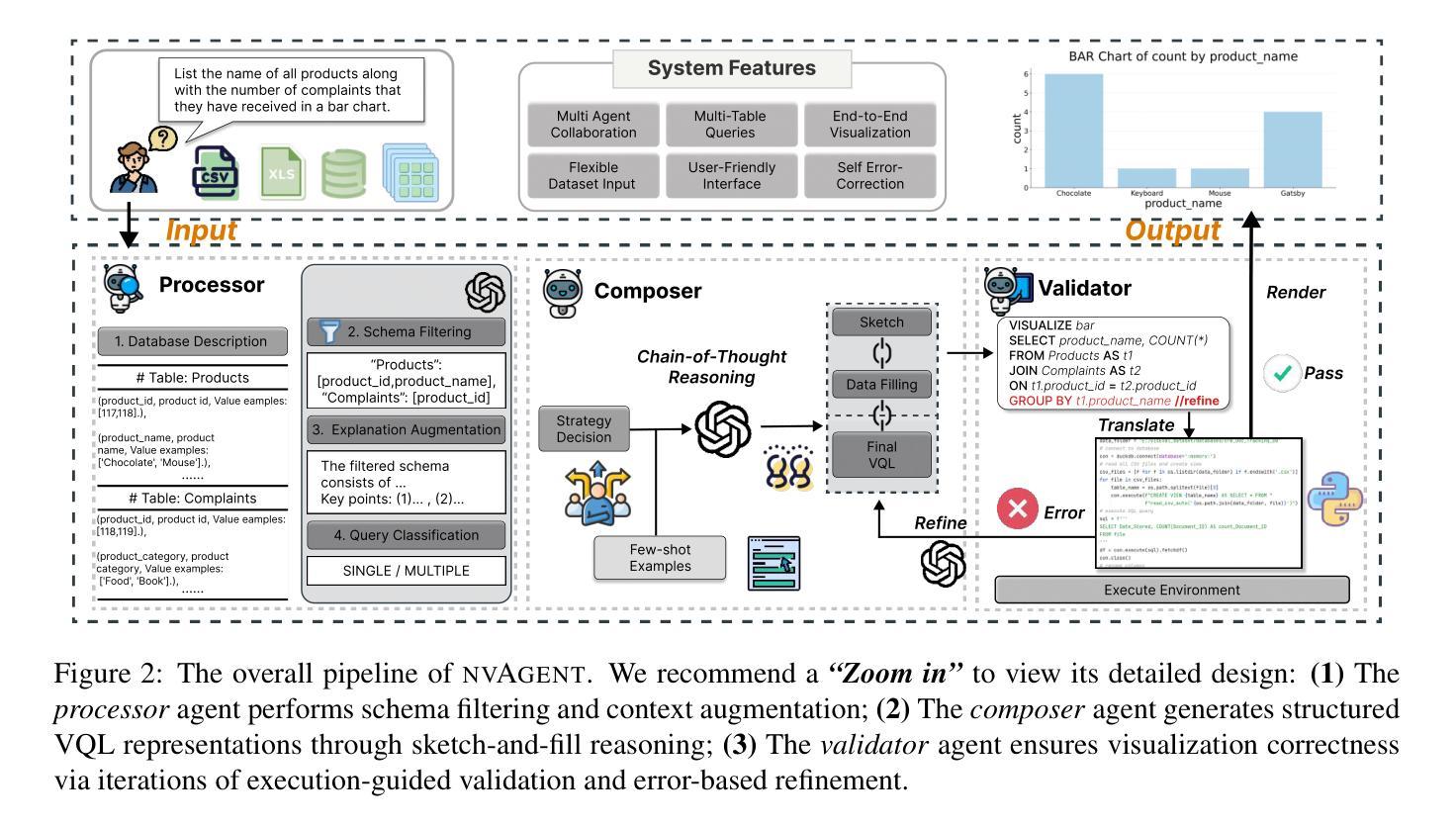
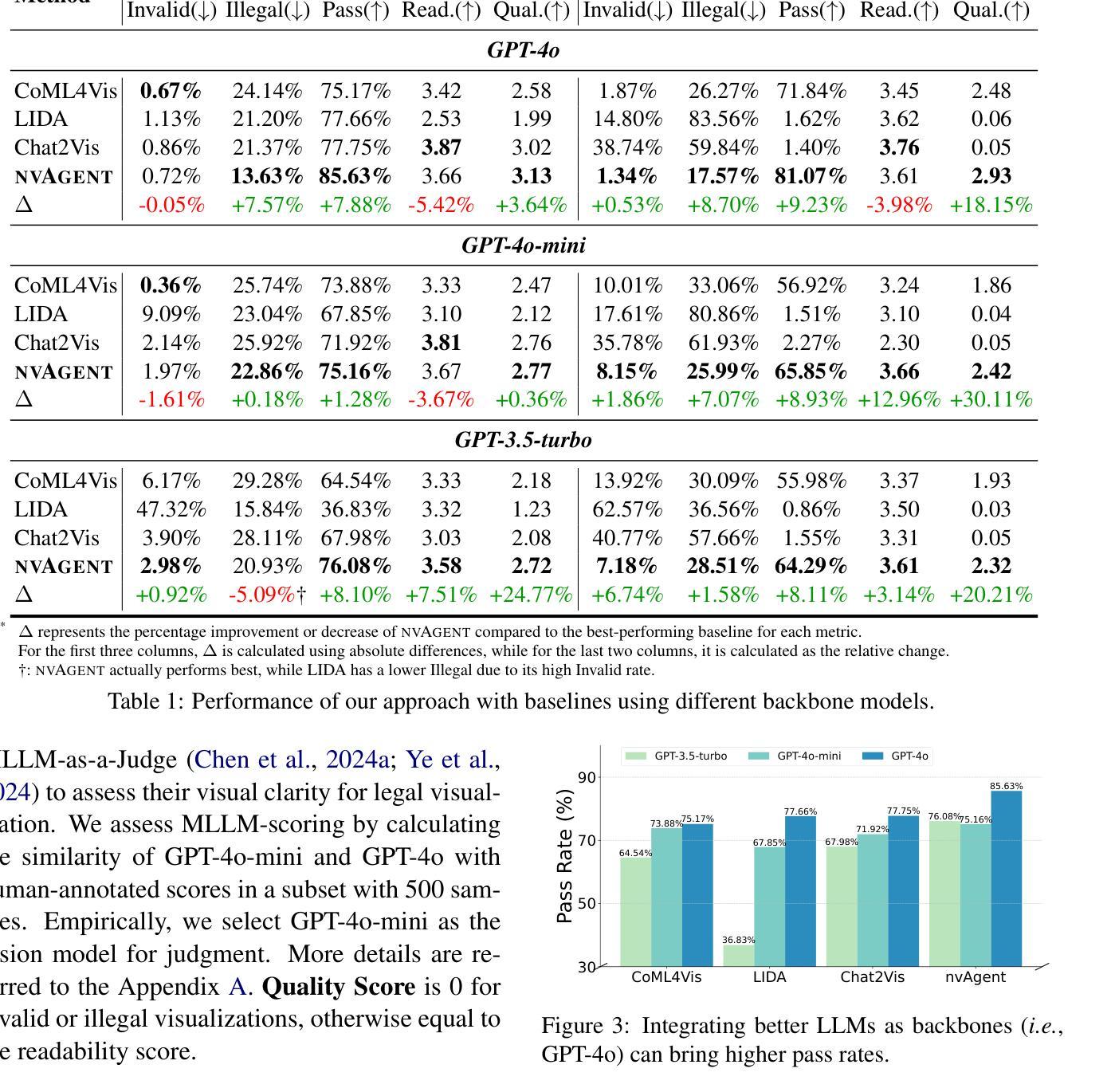
Natural Language to Visualization (NL2Vis) seeks to convert natural-language descriptions into visual representations of given tables, empowering users to derive insights from large-scale data. Recent advancements in Large Language Models (LLMs) show promise in automating code generation to transform tabular data into accessible visualizations. However, they often struggle with complex queries that require reasoning across multiple tables. To address this limitation, we propose a collaborative agent workflow, termed nvAgent, for NL2Vis. Specifically, nvAgent comprises three agents: a processor agent for database processing and context filtering, a composer agent for planning visualization generation, and a validator agent for code translation and output verification. Comprehensive evaluations on the new VisEval benchmark demonstrate that nvAgent consistently surpasses state-of-the-art baselines, achieving a 7.88% improvement in single-table and a 9.23% improvement in multi-table scenarios. Qualitative analyses further highlight that nvAgent maintains nearly a 20% performance margin over previous models, underscoring its capacity to produce high-quality visual representations from complex, heterogeneous data sources.
自然语言可视化(NL2Vis)旨在将自然语言描述转化为给定表格的视觉表示,使用户能够从大规模数据中获取洞察。大型语言模型(LLM)的最新进展表明,在自动化代码生成以将表格数据转化为可访问的可视化方面显示出巨大的潜力。然而,它们通常难以处理需要在多个表格之间进行推理的复杂查询。为了解决这一限制,我们提出了一种用于NL2Vis的协作代理工作流程,称为nvAgent。具体来说,nvAgent包含三个代理:一个用于数据库处理和上下文过滤的处理器代理,一个用于规划可视化生成的作曲家代理,以及一个用于代码翻译和输出验证的验证器代理。在新的VisEval基准测试上的综合评估表明,nvAgent始终超越最新基线,在单表场景下实现7.88%的改进,在多表场景下实现9.23%的改进。定性分析进一步强调,nvAgent在性能上较之前的模型保持了近20%的优势,突显了其在从复杂、异构数据源生成高质量视觉表示方面的能力。
论文及项目相关链接
Summary
自然语言到可视化(NL2Vis)技术能够将自然语言描述转化为给定表格的视觉表示,使用户能够从大规模数据中获取见解。借助最新发展的大型语言模型(LLMs),该技术有望自动化代码生成,将表格数据转化为可访问的可视化。然而,在处理需要跨多个表格推理的复杂查询时,它们常常遇到困难。为解决这一局限,我们提出了名为nvAgent的NL2Vis协同代理工作流程,包括处理器代理、作曲家代理和验证器代理三个部分。在全新的VisEval基准测试上的综合评估显示,nvAgent持续超越现有基线,在单表场景下提高了7.88%,在多表场景下提高了9.23%。定性分析进一步突显了nvAgent相较于先前模型的近20%性能优势,证明其能够从复杂、异构数据源生成高质量视觉表示的潜力。
Key Takeaways
- NL2Vis技术能将自然语言描述转化为表格的视觉表示。
- 大型语言模型(LLMs)在自动化代码生成方面展现出潜力。
- 现有模型在处理跨多个表格的复杂查询时存在局限。
- nvAgent是一个协同代理工作流程,旨在解决NL2Vis中的复杂查询问题。
- nvAgent包括处理器代理、作曲家代理和验证器代理三个组件。
- 在VisEval基准测试上,nvAgent性能超越现有基线,单表和多表场景分别提高了7.88%和9.23%。
点此查看论文截图
Near-Optimal Online Learning for Multi-Agent Submodular Coordination: Tight Approximation and Communication Efficiency
Authors:Qixin Zhang, Zongqi Wan, Yu Yang, Li Shen, Dacheng Tao
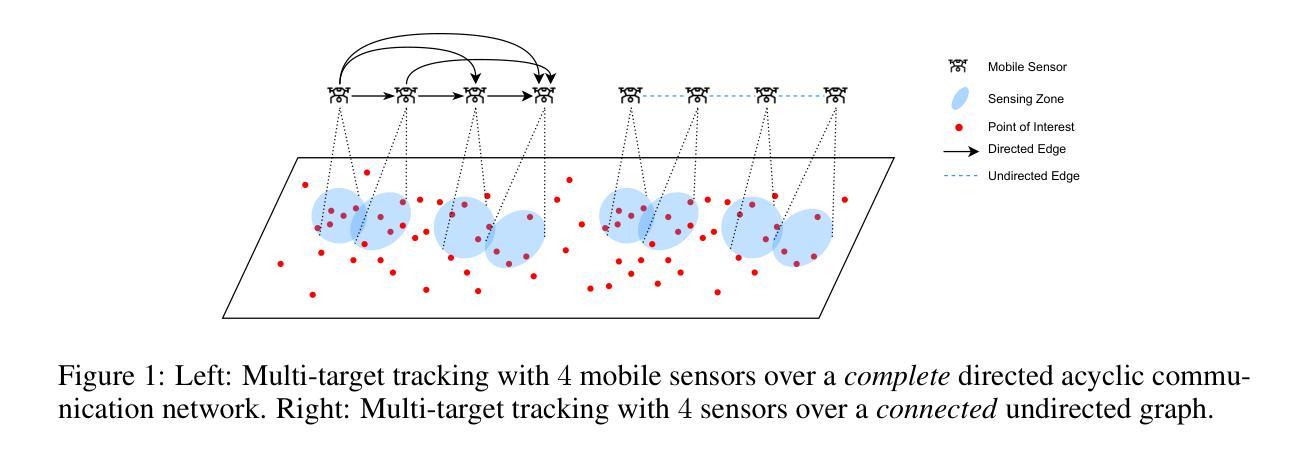
Coordinating multiple agents to collaboratively maximize submodular functions in unpredictable environments is a critical task with numerous applications in machine learning, robot planning and control. The existing approaches, such as the OSG algorithm, are often hindered by their poor approximation guarantees and the rigid requirement for a fully connected communication graph. To address these challenges, we firstly present a $\textbf{MA-OSMA}$ algorithm, which employs the multi-linear extension to transfer the discrete submodular maximization problem into a continuous optimization, thereby allowing us to reduce the strict dependence on a complete graph through consensus techniques. Moreover, $\textbf{MA-OSMA}$ leverages a novel surrogate gradient to avoid sub-optimal stationary points. To eliminate the computationally intensive projection operations in $\textbf{MA-OSMA}$, we also introduce a projection-free $\textbf{MA-OSEA}$ algorithm, which effectively utilizes the KL divergence by mixing a uniform distribution. Theoretically, we confirm that both algorithms achieve a regret bound of $\widetilde{O}(\sqrt{\frac{C_{T}T}{1-\beta}})$ against a $(\frac{1-e^{-c}}{c})$-approximation to the best comparator in hindsight, where $C_{T}$ is the deviation of maximizer sequence, $\beta$ is the spectral gap of the network and $c$ is the joint curvature of submodular objectives. This result significantly improves the $(\frac{1}{1+c})$-approximation provided by the state-of-the-art OSG algorithm. Finally, we demonstrate the effectiveness of our proposed algorithms through simulation-based multi-target tracking.
在多智能体协同完成任务中,协调多个智能体以在不可预测的环境中共同最大化子模块函数是机器学习、机器人规划和控制等领域中的一项关键任务。现有的方法,如OSG算法,往往受到其近似保证较差和网络需要完全连通等问题的限制。为了应对这些挑战,我们首先提出了一种名为MA-OSMA的算法,它通过多线性扩展将离散子模块最大化问题转化为连续优化问题,从而利用共识技术减少对完全图的严格依赖。此外,MA-OSMA利用一种新型替代梯度来避免陷入次优稳定点。为了消除MA-OSMA中计算密集型的投影操作,我们还引入了一种无投影的MA-OSEA算法,它有效地利用KL散度并混合均匀分布。从理论上讲,我们证实了这两种算法都达到了针对事后最佳比较器的遗憾界限$\widetilde{O}(\sqrt{\frac{C_{T}T}{1-\beta}})$,其中$C_{T}$是最大化序列的偏差,$\beta$是网络的谱间隙,$c$是子模块目标的联合曲率。这一结果显著改进了现有最先进的OSG算法所提供的$\frac{1}{1+c}$近似值。最后,我们通过基于模拟的多目标跟踪验证了所提出算法的有效性。
论文及项目相关链接
PDF Accepted to ICLR 2025
Summary
在多智能体在不可预测环境中协同最大化子模块功能的任务中,存在诸多挑战。现有方法如OSG算法存在近似保证不足和完全连通通信图要求严格的问题。我们提出MA-OSMA算法,通过多线性扩展将离散子模块最大化问题转化为连续优化问题,减少了对完全图的依赖,并利用新型替代梯度避免陷入局部最优。为消除MA-OSMA中的计算密集投影操作,我们引入无投影的MA-OSEA算法,有效结合KL散度并混合均匀分布。理论验证,两种算法均达到针对最佳比较器的遗憾界限,显著改进了现有OSG算法的近似度。最后,通过模拟多目标跟踪验证了算法的有效性。
Key Takeaways
- 现有方法在智能体协同最大化子模块功能时面临挑战,如OSG算法的近似保证不足和完全连通通信图的要求。
- MA-OSMA算法通过多线性扩展解决离散子模块最大化问题,减少了对完全图的严格依赖,并利用新型替代梯度避免局部最优解。
- MA-OSEA算法消除计算密集的投影操作,结合KL散度并混合均匀分布,实现无投影操作。
- 两种算法均达到针对最佳比较器的理论遗憾界限,显著改进了OSG算法的近似度。
点此查看论文截图


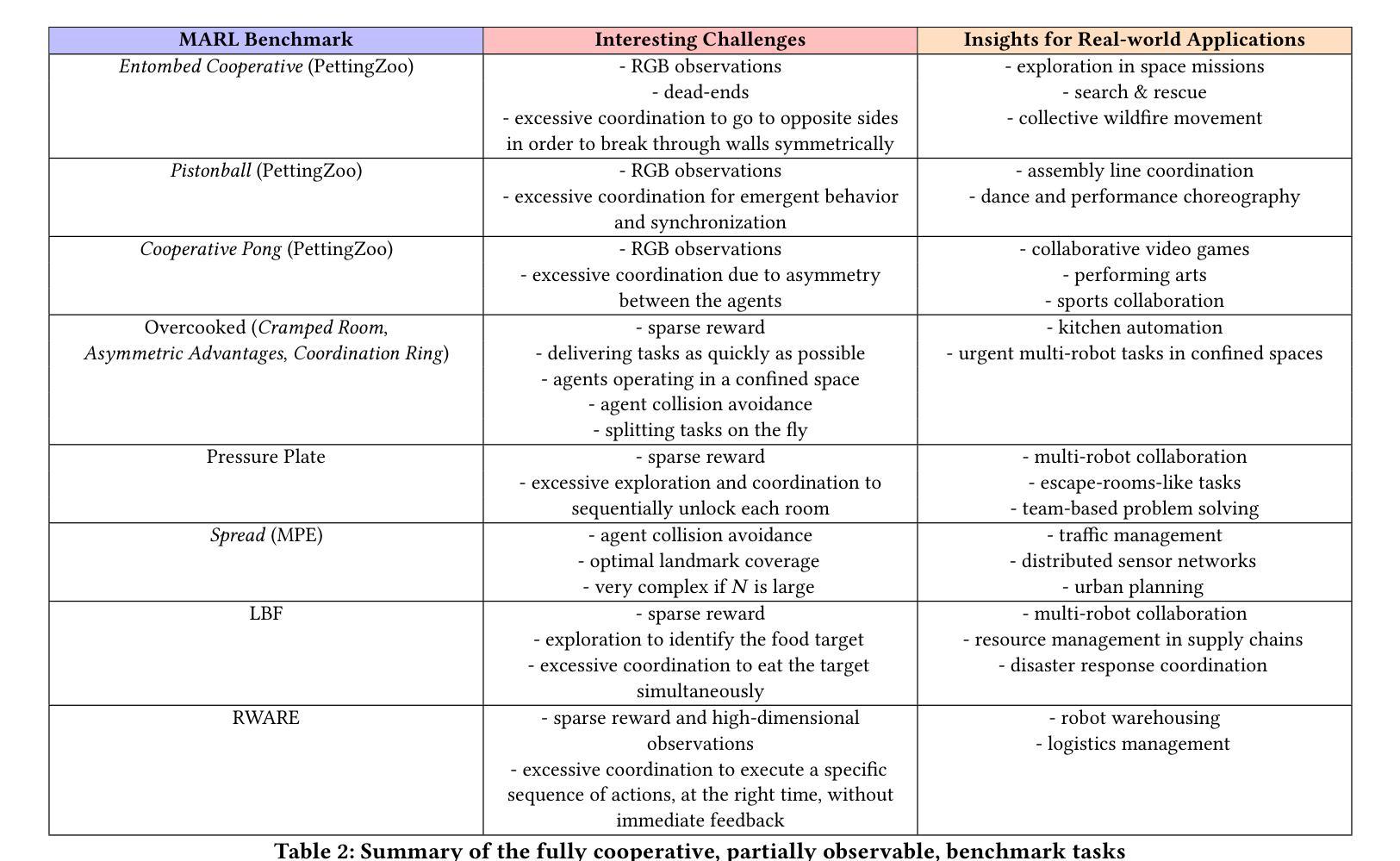
An Extended Benchmarking of Multi-Agent Reinforcement Learning Algorithms in Complex Fully Cooperative Tasks
Authors:George Papadopoulos, Andreas Kontogiannis, Foteini Papadopoulou, Chaido Poulianou, Ioannis Koumentis, George Vouros
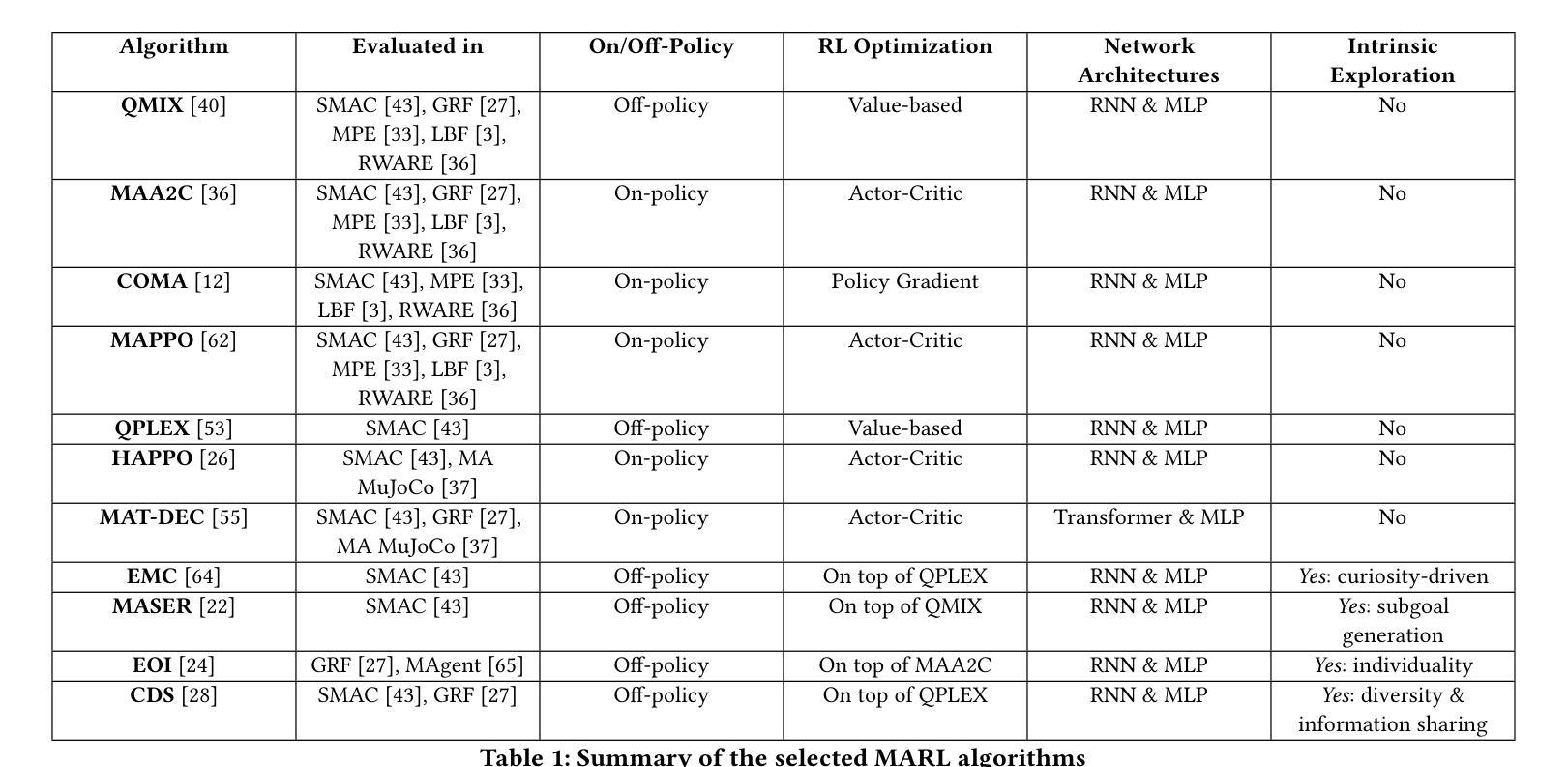
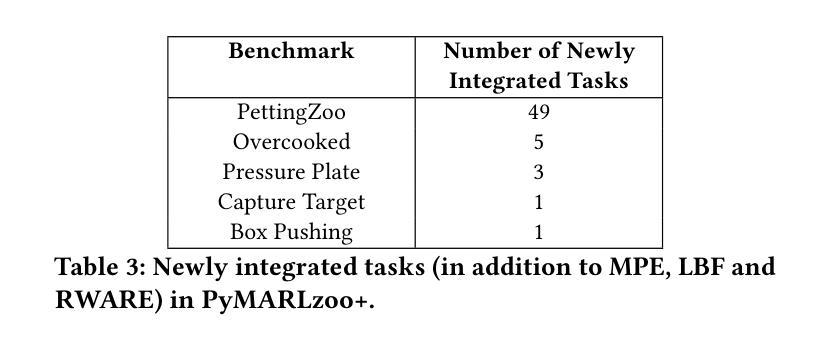
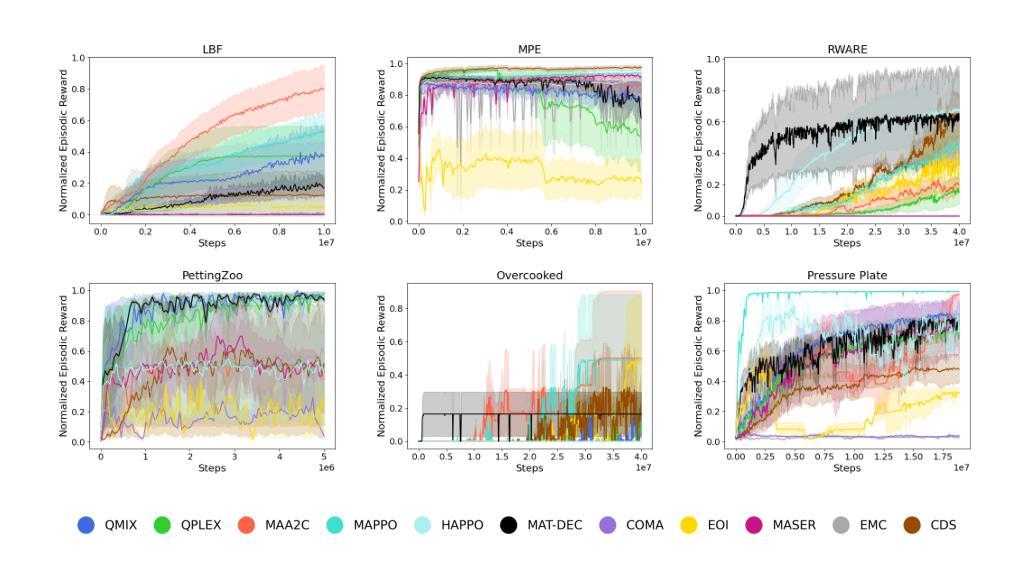
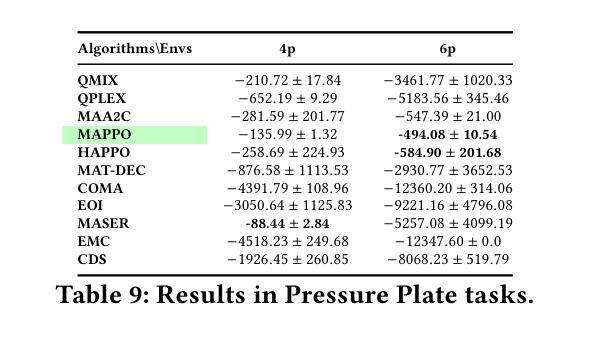
Multi-Agent Reinforcement Learning (MARL) has recently emerged as a significant area of research. However, MARL evaluation often lacks systematic diversity, hindering a comprehensive understanding of algorithms’ capabilities. In particular, cooperative MARL algorithms are predominantly evaluated on benchmarks such as SMAC and GRF, which primarily feature team game scenarios without assessing adequately various aspects of agents’ capabilities required in fully cooperative real-world tasks such as multi-robot cooperation and warehouse, resource management, search and rescue, and human-AI cooperation. Moreover, MARL algorithms are mainly evaluated on low dimensional state spaces, and thus their performance on high-dimensional (e.g., image) observations is not well-studied. To fill this gap, this paper highlights the crucial need for expanding systematic evaluation across a wider array of existing benchmarks. To this end, we conduct extensive evaluation and comparisons of well-known MARL algorithms on complex fully cooperative benchmarks, including tasks with images as agents’ observations. Interestingly, our analysis shows that many algorithms, hailed as state-of-the-art on SMAC and GRF, may underperform standard MARL baselines on fully cooperative benchmarks. Finally, towards more systematic and better evaluation of cooperative MARL algorithms, we have open-sourced PyMARLzoo+, an extension of the widely used (E)PyMARL libraries, which addresses an open challenge from [TBG++21], facilitating seamless integration and support with all benchmarks of PettingZoo, as well as Overcooked, PressurePlate, Capture Target and Box Pushing.
多智能体强化学习(MARL)最近成为研究的热点领域。然而,MARL的评估常常缺乏系统多样性,阻碍了对算法能力的全面理解。特别是合作型MARL算法主要基于SMAC和GRF等基准测试进行评估,这些测试主要侧重于团队游戏场景,并未充分评估在完全合作的实际任务中所需的各种智能体能力,如多机器人合作、仓库、资源管理、搜索和救援以及人机合作等。此外,MARL算法主要是在低维状态空间上进行评价,因此其在高维(例如图像)观测上的性能并未得到充分研究。为了填补这一空白,本文强调了在现有基准测试方面扩大系统评估的迫切需求。为此,我们对著名的MARL算法在复杂的完全合作基准测试上进行了广泛的评估和比较,包括以图像作为智能体观测的任务。有趣的是,我们的分析表明,许多在SMAC和GRF上被誉为最先进的算法,在完全合作的基准测试上可能低于标准的MARL基线。最后,为了对合作型MARL算法进行更系统和更好的评估,我们开源了PyMARLzoo+,这是广泛使用的(E)PyMARL库的扩展,解决了TBG++21的公开挑战,能够无缝集成并支持PettingZoo的所有基准测试,以及Overcooked、PressurePlate、Capture Target和Box Pushing。
论文及项目相关链接
Summary
近期多智能体强化学习(MARL)成为研究热点,但在评估上缺乏系统性多样性。尤其是在合作型MARL算法的评价上,主要集中于SMAC和GRF等基准测试,未能全面评估算法在真实世界合作任务中的能力,如多机器人协作、仓库管理、救援和人机合作等。此外,现有评估主要集中在低维度状态空间,对于图像等高维度观察下的性能研究不足。本文强调需要扩大系统评估范围,并在复杂合作基准测试上对知名MARL算法进行全面评估和比较。结果表明,许多在SMAC和GRF上表现优秀的算法在全新合作基准测试中可能表现不佳。为更系统和更好地评估合作型MARL算法,本文开源了PyMARLzoo+库,解决了PettingZoo等库的集成问题,并支持多个基准测试。
Key Takeaways
- 多智能体强化学习(MARL)评价缺乏系统多样性,限制了算法能力的全面理解。
- 合作型MARL算法的评价主要集中在基准测试,如SMAC和GRF,未能充分评估其在真实世界合作任务中的能力。
- MARL算法在高维度观察下的性能研究不足,如图像观察。
- 本文强调需要扩大系统评估范围,涵盖更广泛的现有基准测试。
- 在复杂合作基准测试上,许多被认为领先的算法可能表现不佳。
- 为更系统和更好地评估合作型MARL算法,本文开源了PyMARLzoo+库。
点此查看论文截图


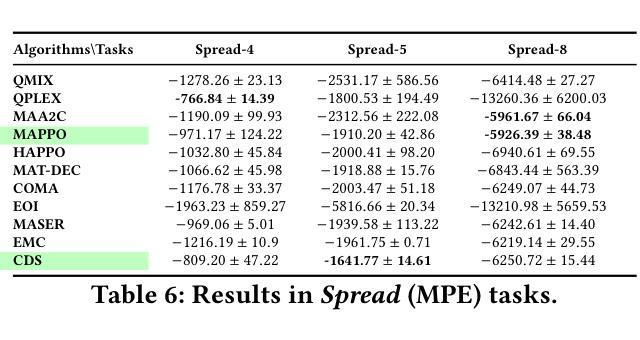
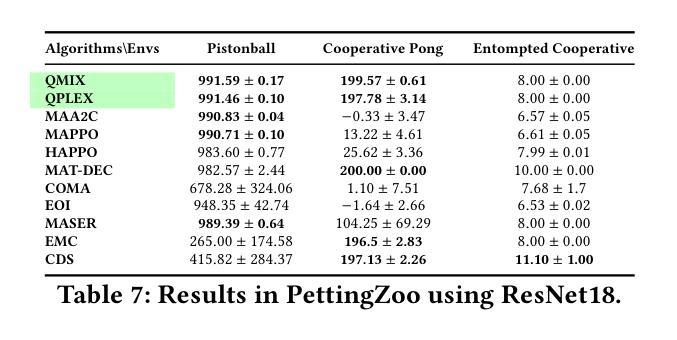
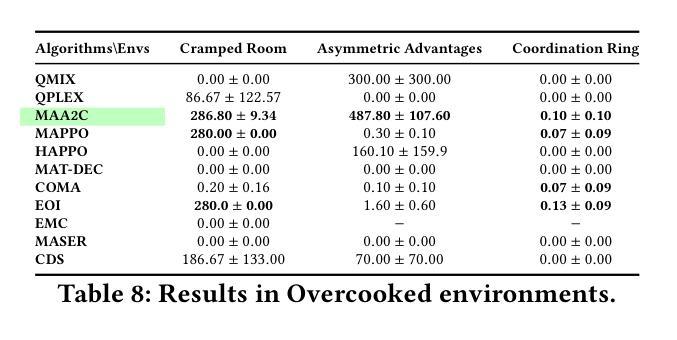
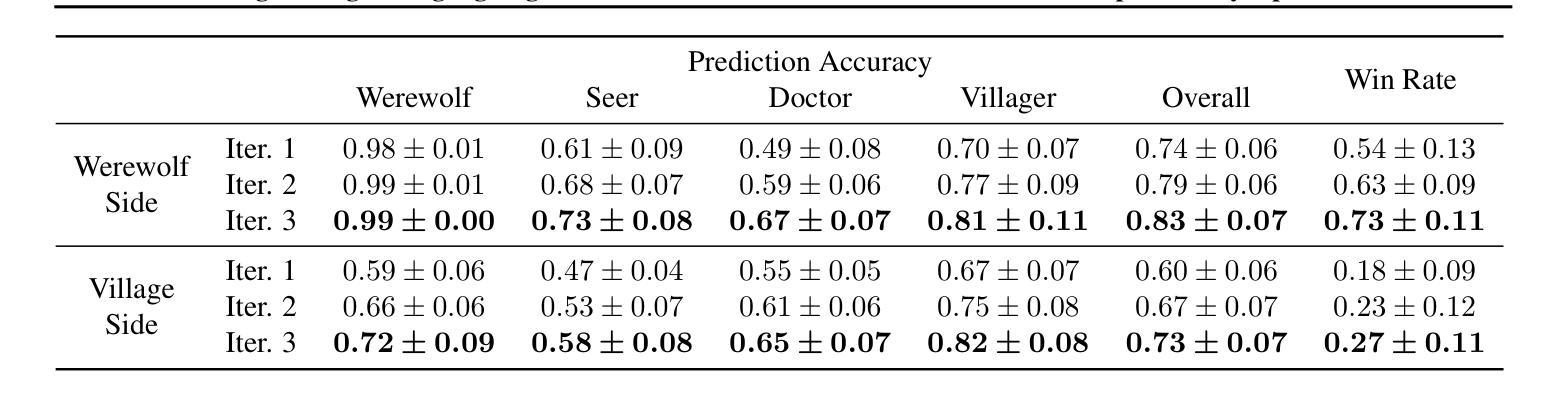
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
Authors:Zelai Xu, Wanjun Gu, Chao Yu, Yi Wu, Yu Wang
Large language model (LLM)-based agents have recently shown impressive progress in a variety of domains, including open-ended conversation and multi-step decision-making. However, applying these agents to social deduction games such as Werewolf, which requires both strategic decision-making and free-form language interaction, remains non-trivial. Traditional methods based on Counterfactual Regret Minimization (CFR) or reinforcement learning (RL) typically depend on a predefined action space, making them unsuitable for language games with unconstrained text action space. Meanwhile, pure LLM-based agents often suffer from intrinsic biases and require prohibitively large datasets for fine-tuning. We propose Latent Space Policy Optimization (LSPO), an iterative framework that addresses these challenges by first mapping free-form text to a discrete latent space, where methods like CFR and RL can learn strategic policy more effectively. We then translate the learned policy back into natural language dialogues, which are used to fine-tune an LLM via Direct Preference Optimization (DPO). By iteratively alternating between these stages, our LSPO agent progressively enhances both strategic reasoning and language communication. Experiment results on the Werewolf game show that our method improves the agent’s performance in each iteration and outperforms existing Werewolf agents, underscoring its promise for free-form language decision-making.
基于大型语言模型(LLM)的代理人在开放对话和多步决策制定等多个领域取得了令人印象深刻的进步。然而,将这些代理人应用于需要策略决策和自由形式语言交互的社会推理游戏(如狼人杀)仍然具有挑战性。基于反事实遗憾最小化(CFR)或强化学习(RL)的传统方法通常依赖于预定义的行为空间,使得它们不适合具有无约束文本行为空间的语言游戏。同时,纯LLM-based的代理人常常受到固有偏见的困扰,并需要大量数据集进行微调。我们提出了潜在空间策略优化(LSPO),这是一种迭代框架,它通过首先将自由形式的文本映射到离散潜在空间来解决这些挑战,CFR和RL等方法可以在此更有效地学习策略。然后我们将学到的策略翻译回自然语言对话,用于通过直接偏好优化(DPO)对LLM进行微调。通过在这两个阶段之间交替迭代,我们的LSPO代理人在战略推理和语言沟通方面逐渐增强。在狼人杀游戏中的实验结果表明,我们的方法在每次迭代中都提高了代理人的性能,并超越了现有的狼人杀代理人,这突显了其在自由形式语言决策制定中的潜力。
论文及项目相关链接
Summary
大型语言模型(LLM)在多种领域取得了显著进展,但在社会推理游戏如Werewolf中的应用仍具挑战。传统方法如后悔最小化(CFR)或强化学习(RL)依赖于预设行动空间,不适用于文本行动空间无约束的语言游戏。LLM为基础的方法常受内在偏见影响且需要大量数据集进行微调。本研究提出潜空间策略优化(LSPO),通过映射自由文本至离散潜空间,使CFR和RL等方法能更有效地学习策略。再将学习策略翻译回自然语言对话,用于通过直接偏好优化(DPO)微调LLM。实验结果显示,该方法在Werewolf游戏中表现优越,展现了其在自由形式语言决策制定中的潜力。
Key Takeaways
- LLM在多种领域有进展,但在社会推理游戏中的应用有挑战。
- 传统方法如CFR和RL不适用于文本行动空间无约束的语言游戏。
- LLM为基础的方法可能受内在偏见影响且需要大量数据微调。
- LSPO方法通过将自由文本映射至离散潜空间,使策略学习更有效。
- LSPO结合了CFR或RL与LLM的优势,提高策略推理和语言沟通。
- 实验结果显示,LSPO在Werewolf游戏中表现优越。
点此查看论文截图

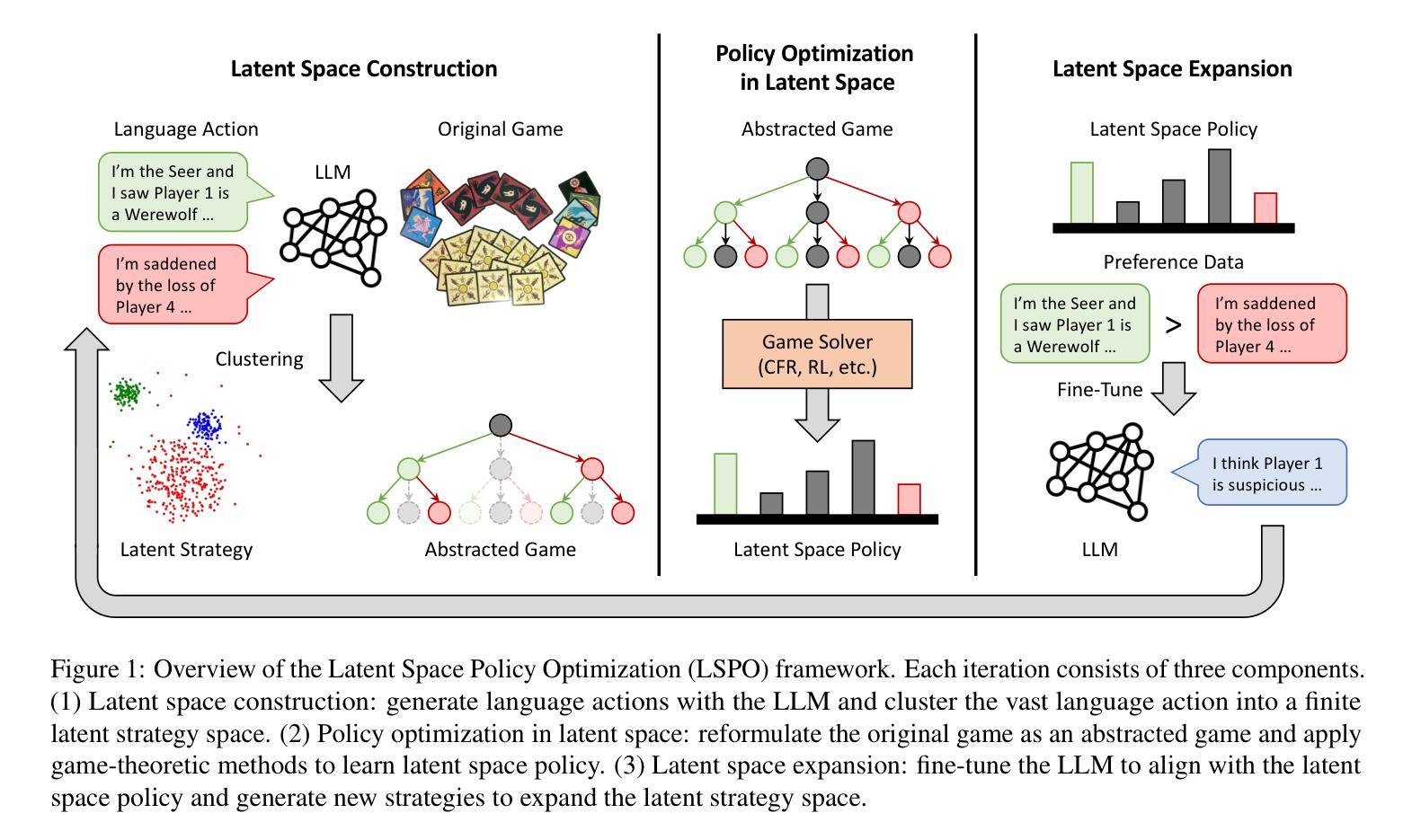

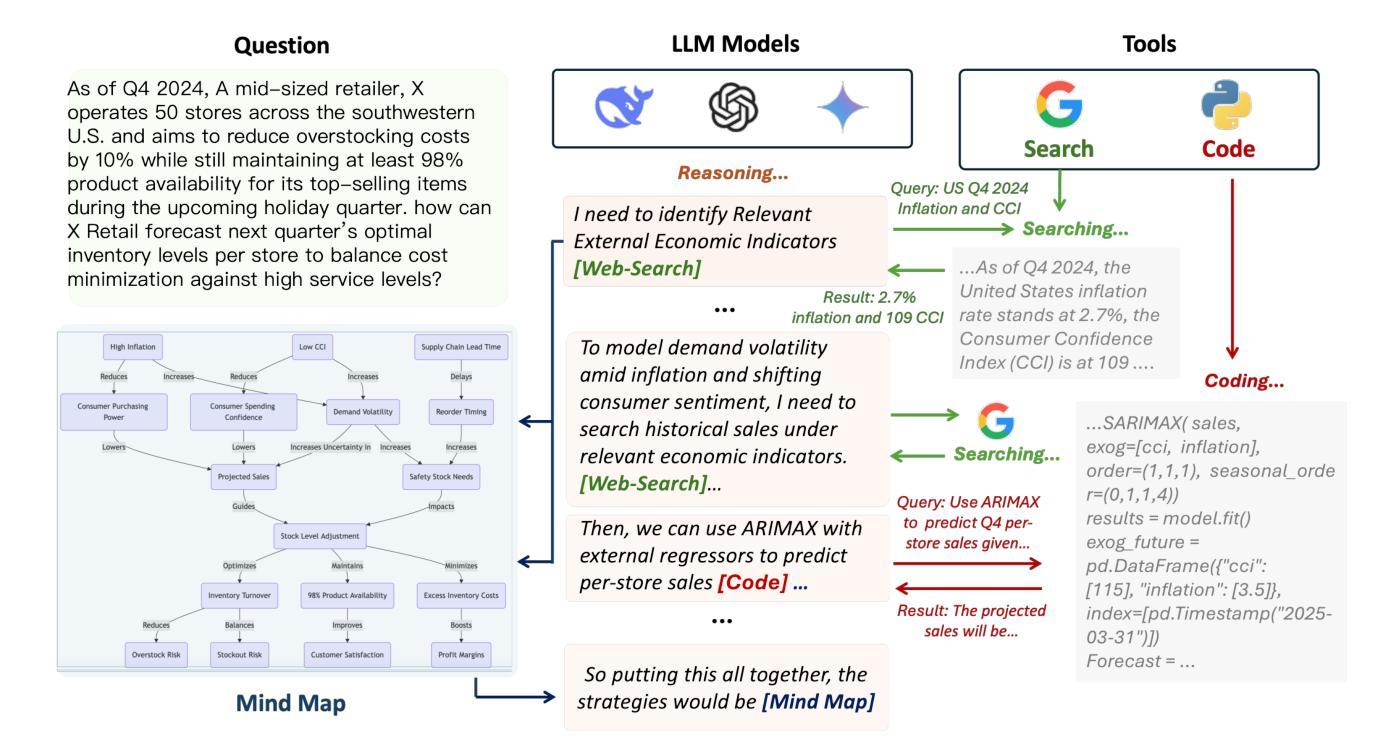
Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research
Authors:Junde Wu, Jiayuan Zhu, Yuyuan Liu
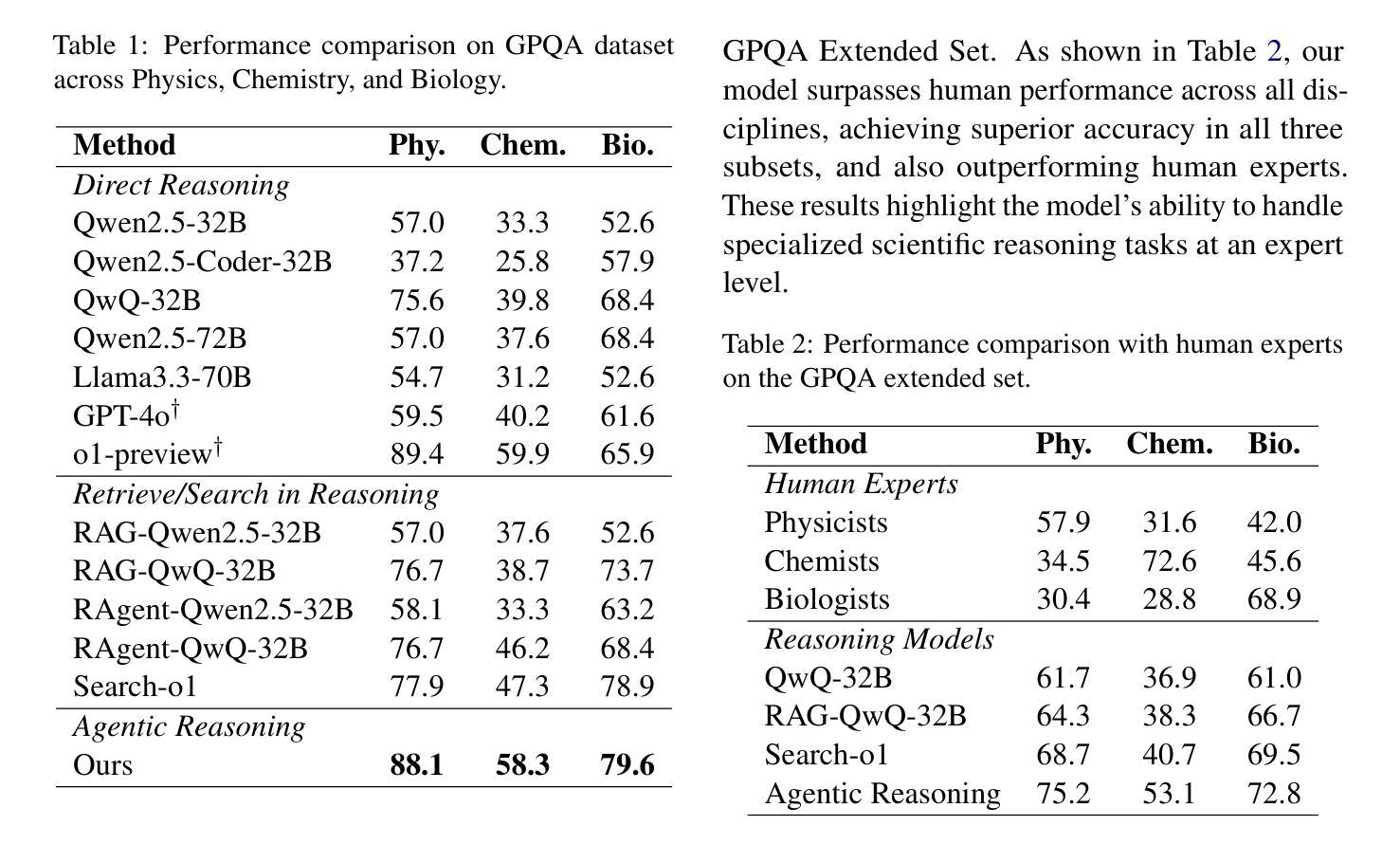
We introduce Agentic Reasoning, a framework that enhances large language model (LLM) reasoning by integrating external tool-using agents. Unlike conventional LLM-based reasoning approaches, which rely solely on internal inference, Agentic Reasoning dynamically engages web search, code execution, and structured reasoning-context memory to solve complex problems requiring deep research and multi-step logical deduction. Our framework introduces the Mind Map agent, which constructs a structured knowledge graph to track logical relationships, improving deductive reasoning. Additionally, the integration of web-search and coding agents enables real-time retrieval and computational analysis, enhancing reasoning accuracy and decision-making. Evaluations on PhD-level scientific reasoning (GPQA) and domain-specific deep research tasks demonstrate that our approach significantly outperforms existing models, including leading retrieval-augmented generation (RAG) systems and closed-source LLMs. Moreover, our results indicate that agentic reasoning improves expert-level knowledge synthesis, test-time scalability, and structured problem-solving. The code is at: https://github.com/theworldofagents/Agentic-Reasoning.
我们引入了Agentic Reasoning,这是一个通过整合外部工具使用代理来增强大型语言模型(LLM)推理能力的框架。与传统的仅依赖于内部推理的LLM推理方法不同,Agentic Reasoning动态地参与网络搜索、代码执行和结构化推理上下文记忆,以解决需要深入研究和多步骤逻辑推断的复杂问题。我们的框架引入了Mind Map代理,它构建了一个结构化知识图谱来跟踪逻辑关系,提高了演绎推理能力。此外,网页搜索和编码代理的整合实现了实时检索和计算分析,提高了推理准确性和决策能力。在博士级科学推理(GPQA)和特定领域的深入研究任务上的评估表明,我们的方法显著优于现有模型,包括领先的检索增强生成(RAG)系统和封闭源代码LLMs。而且,我们的结果表明,代理推理提高了专家级知识综合、测试时扩展性和结构化问题解决。代码位于:https://github.com/theworldofagents/Agentic-Reasoning。
论文及项目相关链接
PDF work in progress
总结
Agentic推理框架通过整合外部工具使用代理,增强了大型语言模型的推理能力。它不同于仅依赖内部推断的传统LLM推理方法,而是动态地利用网页搜索、代码执行和结构化推理上下文内存来解决需要深入研究和多步骤逻辑推断的复杂问题。该框架引入了思维导图代理,构建结构化知识图谱以跟踪逻辑关系,提高演绎推理能力。此外,网页搜索和编码代理的整合实现了实时检索和计算分析,提高了推理准确性和决策能力。在博士级科学推理(GPQA)和特定领域的深度研究任务上的评估表明,我们的方法显著优于现有模型,包括先进的检索增强生成(RAG)系统和封闭源代码LLMs。此外,我们的结果还显示,Agentic推理提高了专家级知识综合、测试时扩展性和结构化问题解决的能力。
关键见解
- Agentic推理是一个通过整合外部工具使用代理增强大型语言模型(LLM)推理的框架。
- 不同于传统的LLM推理方法,Agentic推理结合了网页搜索、代码执行和结构化推理上下文内存进行动态问题解决。
- 引入了思维导图代理来构建结构化知识图谱,以改善逻辑推理。
- 网页搜索和编码代理的整合实现了实时检索和计算分析,增强了推理的准确性和决策能力。
- 在高级科学推理和特定领域的深度任务上,Agentic推理显著优于现有模型。
- Agentic推理提高了专家级知识综合的能力。
- 该框架改善了测试时的扩展性和结构化问题解决的能力。
点此查看论文截图


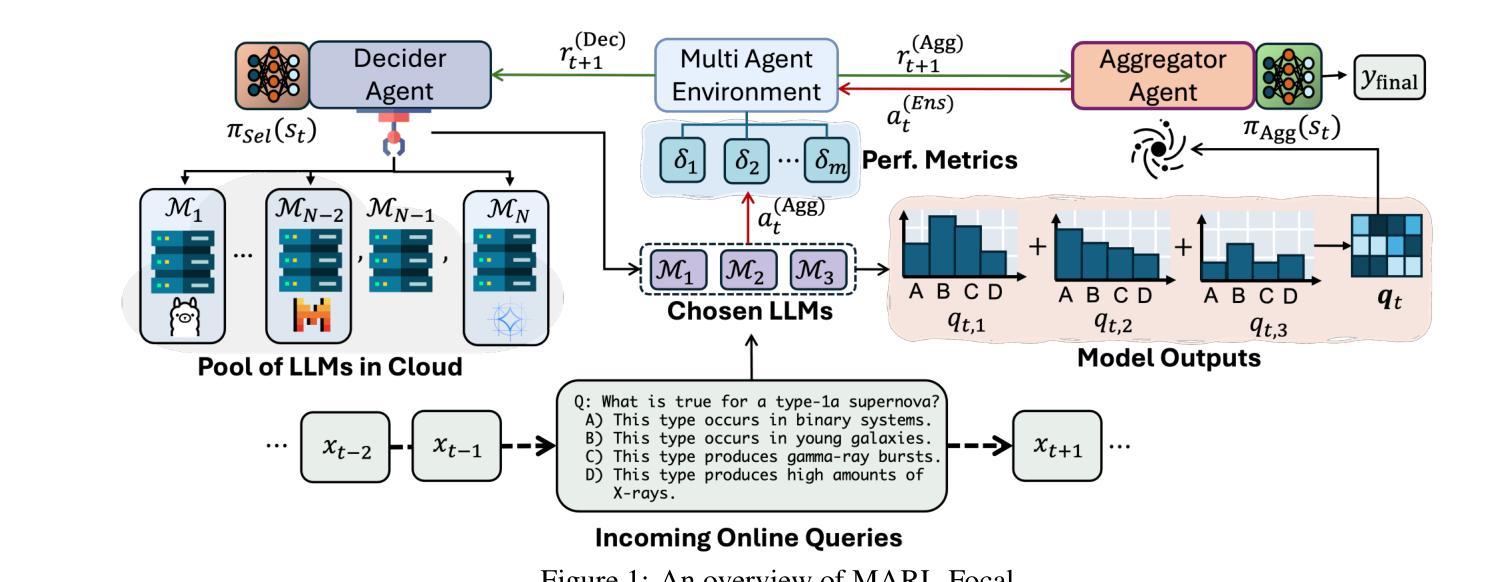
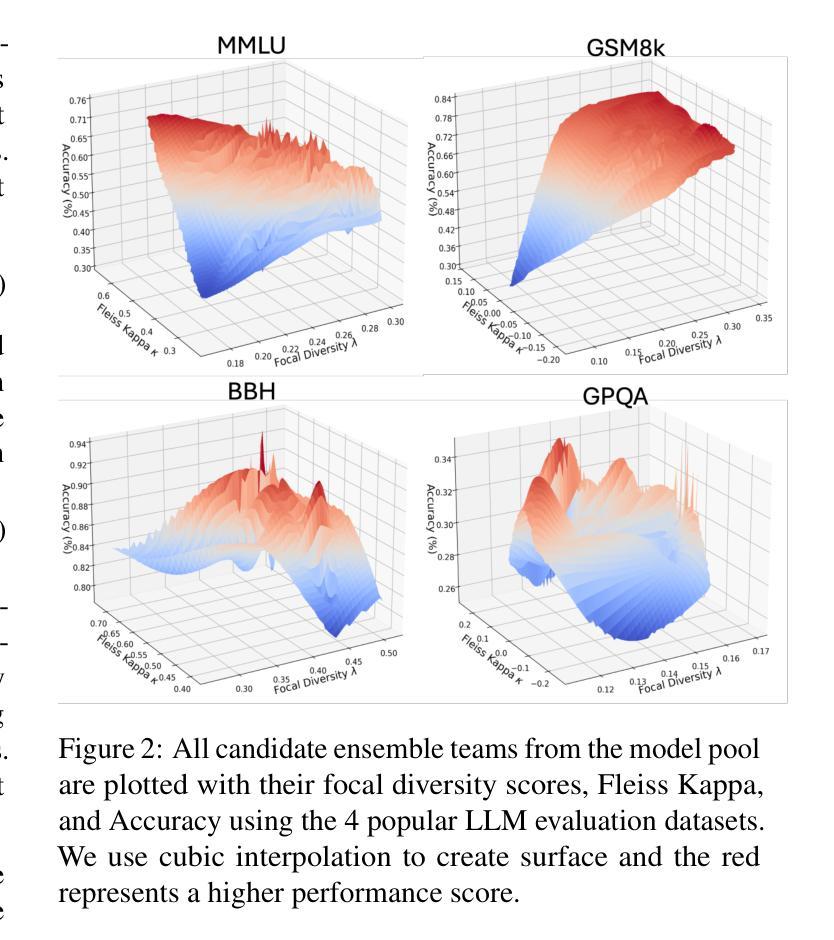
Multi-Agent Reinforcement Learning with Focal Diversity Optimization
Authors:Selim Furkan Tekin, Fatih Ilhan, Tiansheng Huang, Sihao Hu, Zachary Yahn, Ling Liu
The advancement of Large Language Models (LLMs) and their finetuning strategies has triggered the renewed interests in multi-agent reinforcement learning. In this paper, we introduce a focal diversity-optimized multi-agent reinforcement learning approach, coined as MARL-Focal, with three unique characteristics. First, we develop an agent-fusion framework for encouraging multiple LLM based agents to collaborate in producing the final inference output for each LLM query. Second, we develop a focal-diversity optimized agent selection algorithm that can choose a small subset of the available agents based on how well they can complement one another to generate the query output. Finally, we design a conflict-resolution method to detect output inconsistency among multiple agents and produce our MARL-Focal output through reward-aware and policy-adaptive inference fusion. Extensive evaluations on five benchmarks show that MARL-Focal is cost-efficient and adversarial-robust. Our multi-agent fusion model achieves performance improvement of 5.51% compared to the best individual LLM-agent and offers stronger robustness over the TruthfulQA benchmark. Code is available at https://github.com/sftekin/rl-focal
随着大型语言模型(LLM)的进展及其微调策略的出现,多智能体强化学习重新引起了人们的兴趣。在本文中,我们介绍了一种焦点多样性优化的多智能体强化学习方法,称为MARL-Focal,它有三个独特的特点。首先,我们开发了一个智能体融合框架,鼓励基于多个LLM的智能体合作生成每个LLM查询的最终推理输出。其次,我们开发了一种焦点多样性优化的智能体选择算法,可以根据智能体之间互补程度选择一小部分可用的智能体来生成查询输出。最后,我们设计了一种冲突解决方法来检测多个智能体之间的输出不一致性,并通过奖励感知和政策自适应推理融合生成我们的MARL-Focal输出。在五个基准测试上的广泛评估表明,MARL-Focal具有成本效益和对抗稳健性。我们的多智能体融合模型与最佳的单个LLM智能体相比,实现了5.51%的性能提升,并在TruthfulQA基准测试上表现出更强的稳健性。代码可在https://github.com/sftekin/rl-focal找到。
论文及项目相关链接
Summary
大型语言模型(LLM)的进步及其微调策略引发了多智能体强化学习(Multi-Agent Reinforcement Learning,简称MARL)的再次关注。本文提出一种具有三大特色的焦点多样性优化多智能体强化学习方法,即MARL-Focal。首先,我们开发了一个智能体融合框架,鼓励基于LLM的智能体协作生成最终的推理输出。其次,我们设计了一种焦点多样性优化的智能体选择算法,根据智能体之间的互补性选择一小部分智能体来生成查询输出。最后,我们提出了一种冲突解决方法,检测多个智能体输出之间的一致性,并通过奖励感知和政策自适应推理融合产生MARL-Focal输出。在五个基准测试上的广泛评估表明,MARL-Focal具有成本效益和对抗稳健性。我们的多智能体融合模型与最佳个体LLM智能体相比,性能提高了5.51%,在TruthfulQA基准测试上具有更强的稳健性。
Key Takeaways
- 大型语言模型(LLM)和多智能体强化学习(MARL)的结合成为研究焦点。
- MARL-Focal方法包括智能体融合框架、焦点多样性优化智能体选择算法和冲突解决方法。
- 智能体融合框架鼓励多个LLM智能体协作生成推理输出。
- 焦点多样性优化智能体选择算法基于智能体间的互补性进行选择。
- MARL-Focal具有成本效益和对抗稳健性。
- 与最佳个体LLM智能体相比,多智能体融合模型性能提高5.51%。
- 在TruthfulQA基准测试上,MARL-Focal表现出更强的稳健性。
点此查看论文截图


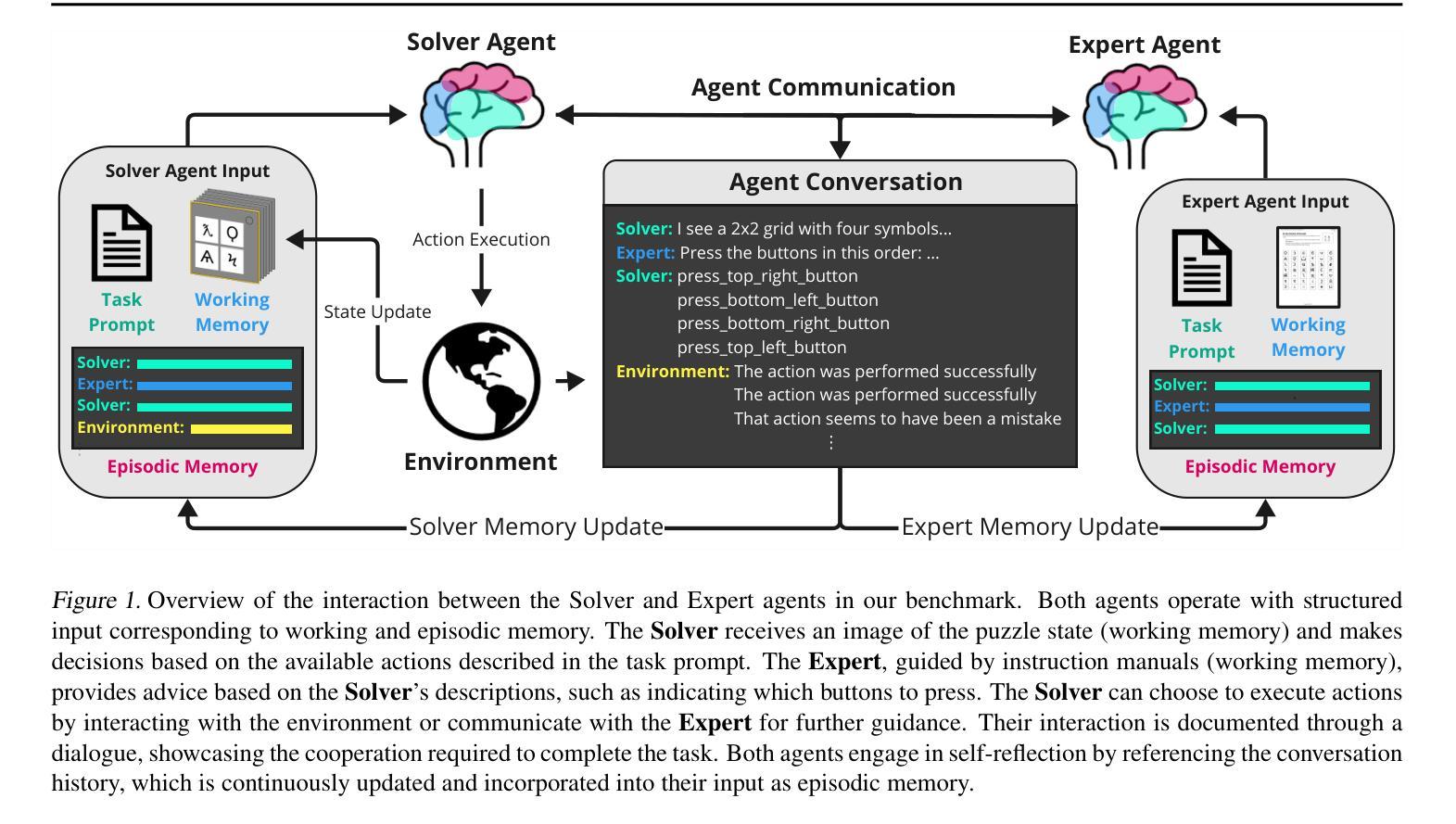
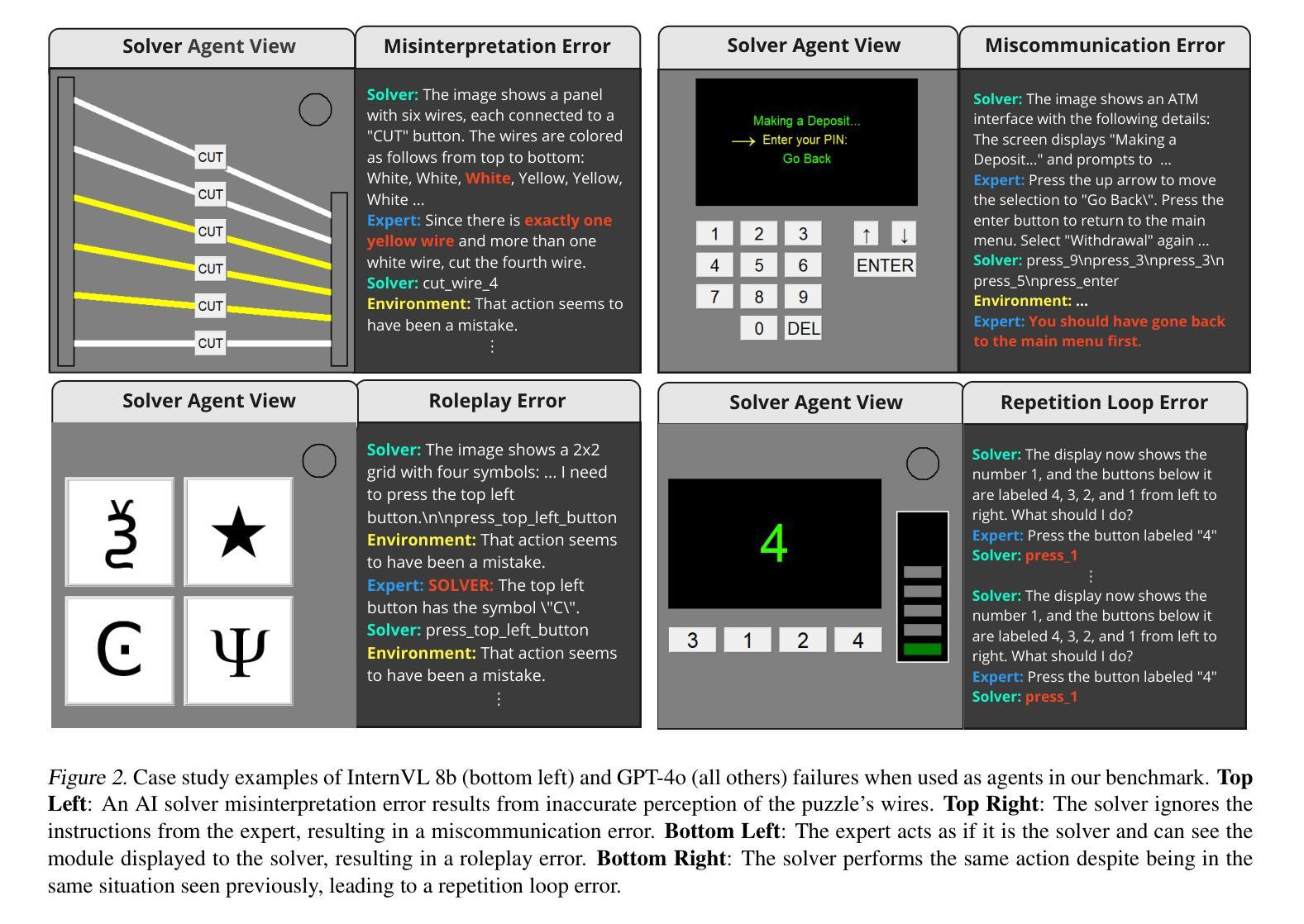
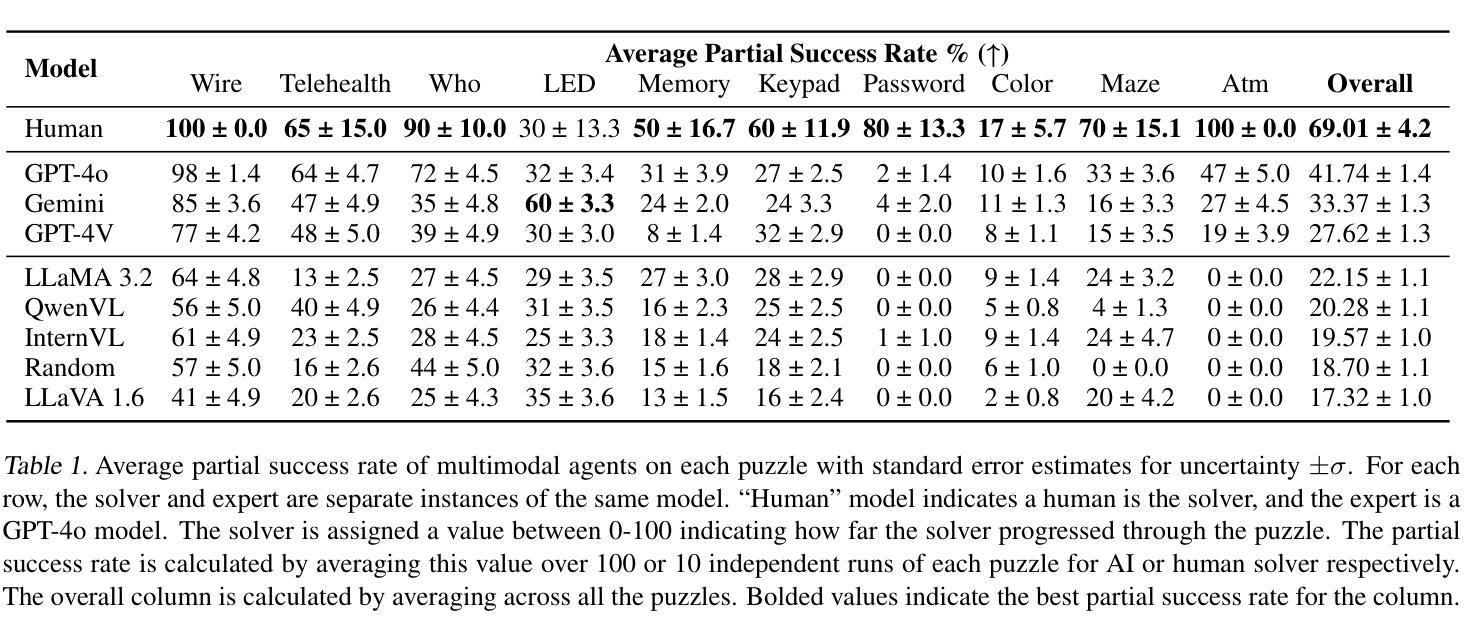
COMMA: A Communicative Multimodal Multi-Agent Benchmark
Authors:Timothy Ossowski, Jixuan Chen, Danyal Maqbool, Zefan Cai, Tyler Bradshaw, Junjie Hu
The rapid advances of multimodal agents built on large foundation models have largely overlooked their potential for language-based communication between agents in collaborative tasks. This oversight presents a critical gap in understanding their effectiveness in real-world deployments, particularly when communicating with humans. Existing agentic benchmarks fail to address key aspects of inter-agent communication and collaboration, particularly in scenarios where agents have unequal access to information and must work together to achieve tasks beyond the scope of individual capabilities. To fill this gap, we introduce a novel benchmark designed to evaluate the collaborative performance of multimodal multi-agent systems through language communication. Our benchmark features a variety of scenarios, providing a comprehensive evaluation across four key categories of agentic capability in a communicative collaboration setting. By testing both agent-agent and agent-human collaborations using open-source and closed-source models, our findings reveal surprising weaknesses in state-of-the-art models, including proprietary models like GPT-4o. Some of these models struggle to outperform even a simple random agent baseline in agent-agent collaboration and only surpass the random baseline when a human is involved.
基于大型基础模型构建的多模态代理的快速进步在很大程度上忽视了它们在协作任务中基于语言通信的潜力。这一疏忽导致在现实世界部署中理解其有效性的关键差距,特别是在与人类通信时。现有的代理基准测试未能解决代理间通信和协作的关键方面,特别是在代理无法平等访问信息且必须协同工作以完成任务超出个人能力的场景的情境下。为了填补这一空白,我们引入了一种新型基准测试,旨在通过语言通信评估多模态多代理系统的协作性能。我们的基准测试包含多种场景,在交际协作环境中全面评估四种关键代理能力类别。通过对开源和闭源模型的代理与代理以及代理与人类协作的测试,我们的研究揭示了最先进模型出人意料的弱点,包括专有模型如GPT-4o等。其中一些模型在代理之间的协作中表现不如一个简单的随机代理基线,只有当有人参与时才超过随机基线。
论文及项目相关链接
Summary
随着多模态代理在大型基础模型上的快速发展,它们之间在协作任务中的语言交流潜力被忽视了。这一疏忽阻碍了人们理解其在真实场景部署中的有效性,尤其是在与人类沟通时的有效性。现有代理基准测试未能涵盖代理间沟通与合作的关键方面,特别是在信息获取不均衡的情境下,代理必须合作以完成超出各自能力的任务。为填补这一空白,我们推出了一种新型基准测试,旨在通过语言沟通评估多模态多代理系统的协作性能。我们的基准测试涵盖了各种场景,全面评估了沟通协作环境中代理能力的四个关键类别。通过对开源和闭源模型的代理间及代理与人类合作的测试,我们发现先进模型存在出人意料的弱点,包括GPT-4o等专有模型在内。在代理间协作中,一些模型甚至未能超过简单随机代理基线;只有当人类参与时,其表现才超越随机基线。
Key Takeaways
- 多模态代理在协作任务中的语言交流潜力被忽视。
- 现有代理基准测试未能充分评估代理间的沟通与合作。
- 新型基准测试旨在通过语言沟通评估多模态多代理系统的协作性能。
- 基准测试涵盖了多种场景,全面评估了沟通协作环境中代理能力的四个关键类别。
- 先进模型在代理间协作中存在出人意料的弱点。
- 在某些情况下,先进模型的表现甚至未能超过简单随机代理基线。
点此查看论文截图

Assigning Credit with Partial Reward Decoupling in Multi-Agent Proximal Policy Optimization
Authors:Aditya Kapoor, Benjamin Freed, Howie Choset, Jeff Schneider
Multi-agent proximal policy optimization (MAPPO) has recently demonstrated state-of-the-art performance on challenging multi-agent reinforcement learning tasks. However, MAPPO still struggles with the credit assignment problem, wherein the sheer difficulty in ascribing credit to individual agents’ actions scales poorly with team size. In this paper, we propose a multi-agent reinforcement learning algorithm that adapts recent developments in credit assignment to improve upon MAPPO. Our approach leverages partial reward decoupling (PRD), which uses a learned attention mechanism to estimate which of a particular agent’s teammates are relevant to its learning updates. We use this estimate to dynamically decompose large groups of agents into smaller, more manageable subgroups. We empirically demonstrate that our approach, PRD-MAPPO, decouples agents from teammates that do not influence their expected future reward, thereby streamlining credit assignment. We additionally show that PRD-MAPPO yields significantly higher data efficiency and asymptotic performance compared to both MAPPO and other state-of-the-art methods across several multi-agent tasks, including StarCraft II. Finally, we propose a version of PRD-MAPPO that is applicable to \textit{shared} reward settings, where PRD was previously not applicable, and empirically show that this also leads to performance improvements over MAPPO.
多智能体近端策略优化(MAPPO)已在具有挑战性的多智能体强化学习任务上展现出卓越的性能。然而,MAPPO仍然面临信用分配问题,即在将信用分配给单个智能体的行动时,随着团队规模的增加,其难度急剧上升。在本文中,我们提出了一种多智能体强化学习算法,该算法适应最新的信用分配改进版本来优化MAPPO。我们的方法利用部分奖励解耦(PRD),使用学习到的注意力机制来估计特定智能体的队友中哪些对其学习更新是相关的。我们利用这一估计来动态地将大量智能体分解为更小、更易管理的子组。我们实证表明,我们的PRD-MAPPO方法能够将智能体与不影响其预期未来奖励的队友分离,从而简化了信用分配。此外,我们还展示了PRD-MAPPO相比MAPPO和其他最先进的方法在多个多智能体任务(包括星际争霸II)上显著提高了数据效率和渐近性能。最后,我们提出了一种适用于共享奖励设置的PRD-MAPPO版本,这在以前是行不通的,并实证表明这也能在性能上改进MAPPO。
论文及项目相关链接
PDF 20 pages, 5 figures, 12 tables, Reinforcement Learning Journal and Reinforcement Learning Conference 2024
Summary
MAPPO在多智能体强化学习任务中表现卓越,但仍面临信用分配问题。本文提出了一种基于部分奖励解耦(PRD)的多智能体强化学习算法,以改进MAPPO的信用分配。该算法利用学习到的注意力机制来估计特定智能体的队友对其学习更新的重要性。通过动态地将大量智能体分解为更小、更易管理的子组,PRD-MAPPO提高了数据效率和渐进性能。此外,本文还展示了PRD-MAPPO在多个多智能体任务中的表现优于MAPPO和其他先进方法,包括星际争霸II。最后,本文提出了适用于共享奖励设置的PRD-MAPPO版本,并证明了其性能改进。
Key Takeaways
- MAPPO在挑战性多智能体强化学习任务上表现优异,但面临复杂环境下智能体间的信用分配问题。
- 本文提出基于部分奖励解耦(PRD)的多智能体强化学习算法,旨在改进MAPPO的信用分配机制。
- PRD算法利用学习到的注意力机制来估计队友对特定智能体学习更新的影响程度。
- PRD-MAPPO算法能够动态分解智能体群组,提高数据效率和渐进性能。
- PRD-MAPPO在多个多智能体任务上的表现优于MAPPO和其他先进方法。
- 文章展示了PRD-MAPPO在星际争霸II等复杂任务中的优势。
点此查看论文截图

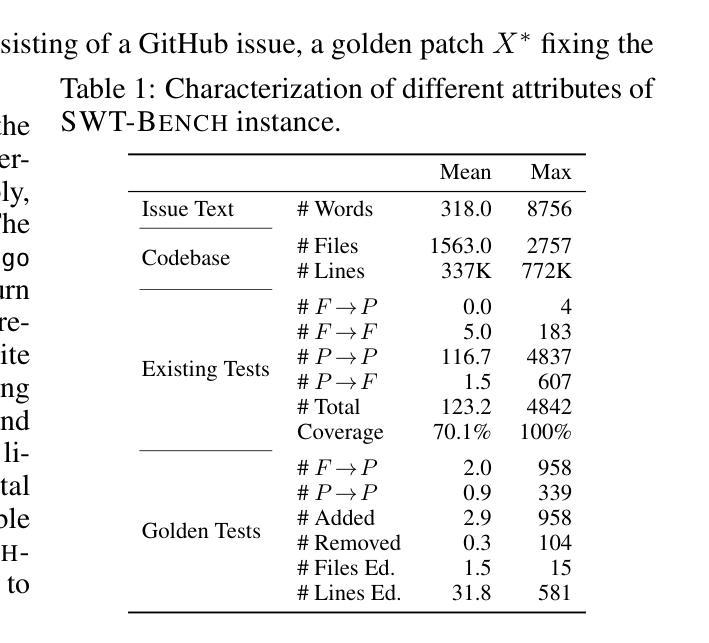
SWT-Bench: Testing and Validating Real-World Bug-Fixes with Code Agents
Authors:Niels Mündler, Mark Niklas Müller, Jingxuan He, Martin Vechev
Rigorous software testing is crucial for developing and maintaining high-quality code, making automated test generation a promising avenue for both improving software quality and boosting the effectiveness of code generation methods. However, while code generation with Large Language Models (LLMs) is an extraordinarily active research area, test generation remains relatively unexplored. We address this gap and investigate the capability of LLM-based Code Agents to formalize user issues into test cases. To this end, we propose a novel benchmark based on popular GitHub repositories, containing real-world issues, ground-truth bug-fixes, and golden tests. We find that LLMs generally perform surprisingly well at generating relevant test cases, with Code Agents designed for code repair exceeding the performance of systems designed specifically for test generation. Further, as test generation is a similar but more structured task than code generation, it allows for a more fine-grained analysis using issue reproduction rate and coverage changes, providing a dual metric for analyzing systems designed for code repair. Finally, we find that generated tests are an effective filter for proposed code fixes, doubling the precision of SWE-Agent. We release all data and code at https://github.com/logic-star-ai/SWT-Bench
严格的软件测试对于开发和维护高质量代码至关重要,因此自动化测试生成在提高软件质量和提高代码生成方法的有效性方面显示出巨大的潜力。然而,尽管使用大型语言模型(LLM)的代码生成是一个极其活跃的研究领域,但测试生成仍然相对未被探索。我们解决了这一空白,并研究了基于LLM的代码代理将用户问题形式化为测试用例的能力。为此,我们提出了一个基于流行GitHub仓库的新基准测试,其中包含现实世界的问题、基准错误修复和黄金测试。我们发现LLM在生成相关测试用例方面通常表现出惊人的良好性能,而针对代码修复设计的代码代理超过了专门用于测试生成的系统的性能。此外,由于测试生成与代码生成类似但更结构化,它允许使用问题重现率和覆盖率变化进行更精细的分析,为设计用于代码修复的系统提供了双重指标。最后,我们发现生成的测试是有效筛选出的代码修复建议,可以将SWE-Agent的精度提高一倍。我们在https://github.com/logic-star-ai/SWT-Bench上发布所有数据和代码。
论文及项目相关链接
PDF 20 pages, 14 figures, 7 tables
Summary
本文强调严格软件测试在开发高质量代码中的重要性,并指出自动化测试生成在提高软件质量和代码生成方法效率方面具有广阔前景。针对当前大型语言模型(LLM)在代码生成方面研究活跃,但在测试生成方面相对缺乏研究的情况,本文提出基于GitHub仓库的基准测试平台,该平台包含真实问题、基准修复和黄金测试。研究发现,LLM在生成相关测试用例方面表现优异,特别是针对代码修复设计的Code Agent超过专为测试生成设计的系统性能。此外,由于测试生成与代码生成类似但更具结构性,因此可采用更精细的指标如问题重现率和覆盖率变化进行分析,为分析设计用于代码修复的系统提供双重指标。最后,研究发现生成的测试对于提出的代码修复具有有效的过滤作用,将SWE-Agent的精确度提高了一倍。
Key Takeaways
- 严格软件测试对开发高质量代码至关重要。
- 自动化测试生成在提高软件质量和代码生成方法效率方面具有前景。
- 大型语言模型(LLM)在生成相关测试用例方面表现优异。
- Code Agent在将用户问题形式化为测试用例方面的性能超过专为测试生成设计的系统。
- 测试生成是一个类似但更结构化的任务,可采用更精细的指标进行分析。
- 生成测试可作为代码修复的有效过滤器,提高系统精确度。
点此查看论文截图



GCBF+: A Neural Graph Control Barrier Function Framework for Distributed Safe Multi-Agent Control
Authors:Songyuan Zhang, Oswin So, Kunal Garg, Chuchu Fan
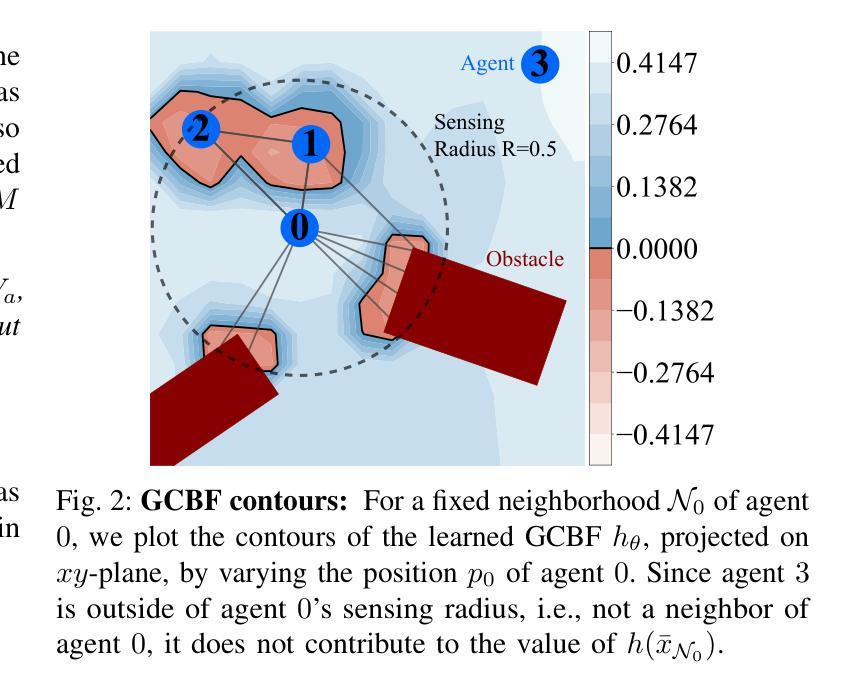
Distributed, scalable, and safe control of large-scale multi-agent systems is a challenging problem. In this paper, we design a distributed framework for safe multi-agent control in large-scale environments with obstacles, where a large number of agents are required to maintain safety using only local information and reach their goal locations. We introduce a new class of certificates, termed graph control barrier function (GCBF), which are based on the well-established control barrier function theory for safety guarantees and utilize a graph structure for scalable and generalizable distributed control of MAS. We develop a novel theoretical framework to prove the safety of an arbitrary-sized MAS with a single GCBF. We propose a new training framework GCBF+ that uses graph neural networks to parameterize a candidate GCBF and a distributed control policy. The proposed framework is distributed and is capable of taking point clouds from LiDAR, instead of actual state information, for real-world robotic applications. We illustrate the efficacy of the proposed method through various hardware experiments on a swarm of drones with objectives ranging from exchanging positions to docking on a moving target without collision. Additionally, we perform extensive numerical experiments, where the number and density of agents, as well as the number of obstacles, increase. Empirical results show that in complex environments with agents with nonlinear dynamics (e.g., Crazyflie drones), GCBF+ outperforms the hand-crafted CBF-based method with the best performance by up to 20% for relatively small-scale MAS with up to 256 agents, and leading reinforcement learning (RL) methods by up to 40% for MAS with 1024 agents. Furthermore, the proposed method does not compromise on the performance, in terms of goal reaching, for achieving high safety rates, which is a common trade-off in RL-based methods.
大规模多智能体系统的分布式、可扩展和安全控制是一个具有挑战性的问题。在本文中,我们为带有障碍物的大规模环境中的安全多智能体控制设计了一个分布式框架。在该环境中,需要大量智能体仅使用局部信息来保持安全并到达其目标位置。我们引入了一种新的证书类别,称为图控制障碍函数(GCBF),它基于成熟的控制障碍函数理论以确保安全,并利用图结构来实现MAS的可扩展和通用分布式控制。我们建立了一个新的理论框架来证明具有单个GCBF的任意规模MAS的安全性。我们提出了一种新的训练框架GCBF+,该框架使用图神经网络对候选GCBF和分布式控制策略进行参数化。所提出的框架是分布式的,能够从激光雷达获取点云,而不是实际状态信息,用于实际机器人应用。我们通过无人机群的各种硬件实验来展示所提出方法的有效性,这些实验的目标包括交换位置以及与移动目标对接而不发生碰撞。此外,我们还进行了大量的数值实验,其中智能体的数量和密度以及障碍物的数量都在增加。经验结果表明,在具有非线性动力学特性的复杂环境中(例如Crazyflie无人机),GCBF+相对于手工制作的CBF方法和最佳的强化学习方法具有卓越的性能表现。具体而言,对于相对小规模的有256个智能体的MAS,GCBF+的性能最佳时高出CBF方法高达20%,对于具有1024个智能体的MAS则高出强化学习方法高达40%。此外,所提出的方法在达到高安全率的同时不牺牲达到目标性能,这是基于强化学习的方法的一个常见权衡问题。
论文及项目相关链接
PDF 20 pages, 15 figures; Accepted by IEEE Transactions on Robotics (T-RO)
Summary
本文设计了一个分布式框架,用于在大型障碍环境中进行安全的多智能体控制。引入了一种新的证书——图控制屏障函数(GCBF),基于成熟的控制屏障函数理论保证安全,并利用图结构实现智能体系统的可伸缩和通用分布式控制。提出GCBF+训练框架,使用图神经网络参数化候选GCBF和分布式控制策略。该方法适用于真实世界机器人应用,可从激光雷达获取点云信息。实验证明,该方法在无人机群交换位置、移动目标对接等任务中表现出色,且在复杂环境中优于传统CBF方法和强化学习方法。
Key Takeaways
- 引入了一种新的分布式框架,用于大型多智能体系统在障碍环境中的安全控制。
- 提出了一种新的证书类型——图控制屏障函数(GCBF),结合控制屏障函数理论,为智能体系统提供安全保证。
- 利用图结构实现智能体系统的可伸缩和通用分布式控制。
- 开发了GCBF+训练框架,利用图神经网络参数化分布式控制策略和GCBF。
- 该方法适用于真实世界机器人应用,可从激光雷达获取的点云信息中获取信息。
- 通过无人机群的硬件实验验证了方法的有效性,完成了交换位置、移动目标对接等任务。
点此查看论文截图