⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-11 更新
Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment
Authors:Minh-Quan Le, Gaurav Mittal, Tianjian Meng, A S M Iftekhar, Vishwas Suryanarayanan, Barun Patra, Dimitris Samaras, Mei Chen
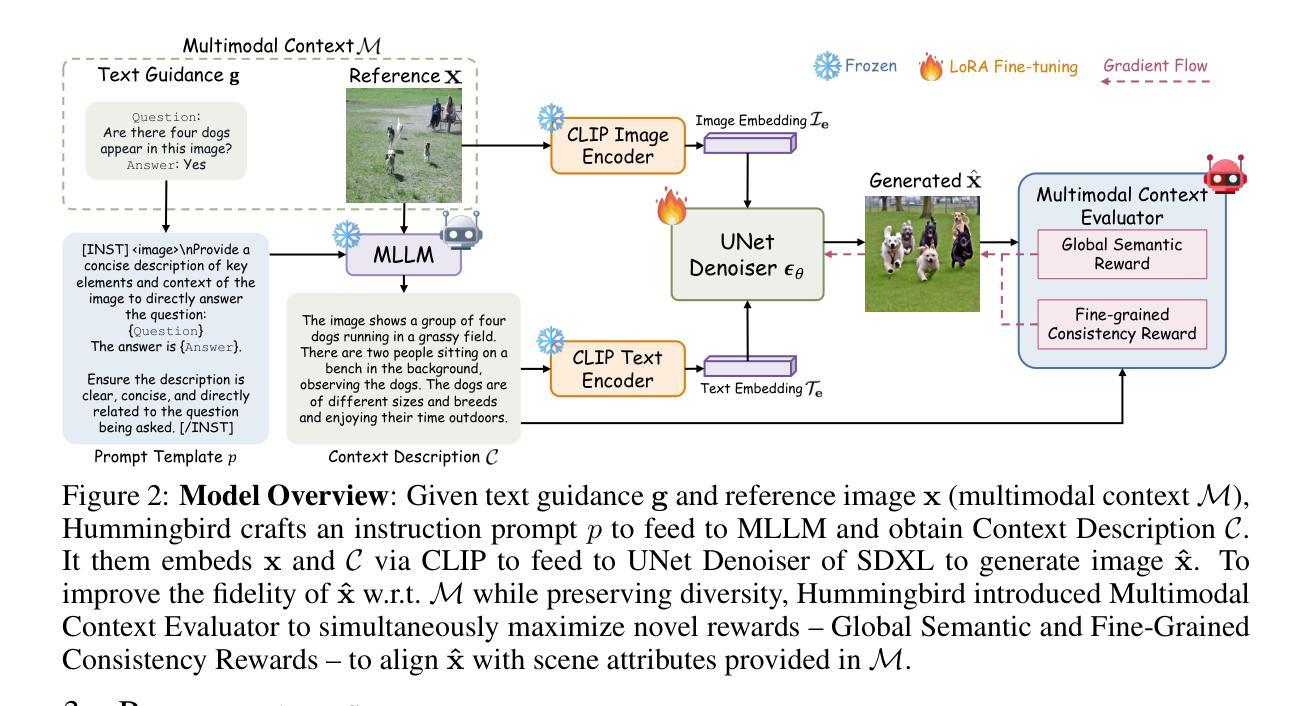
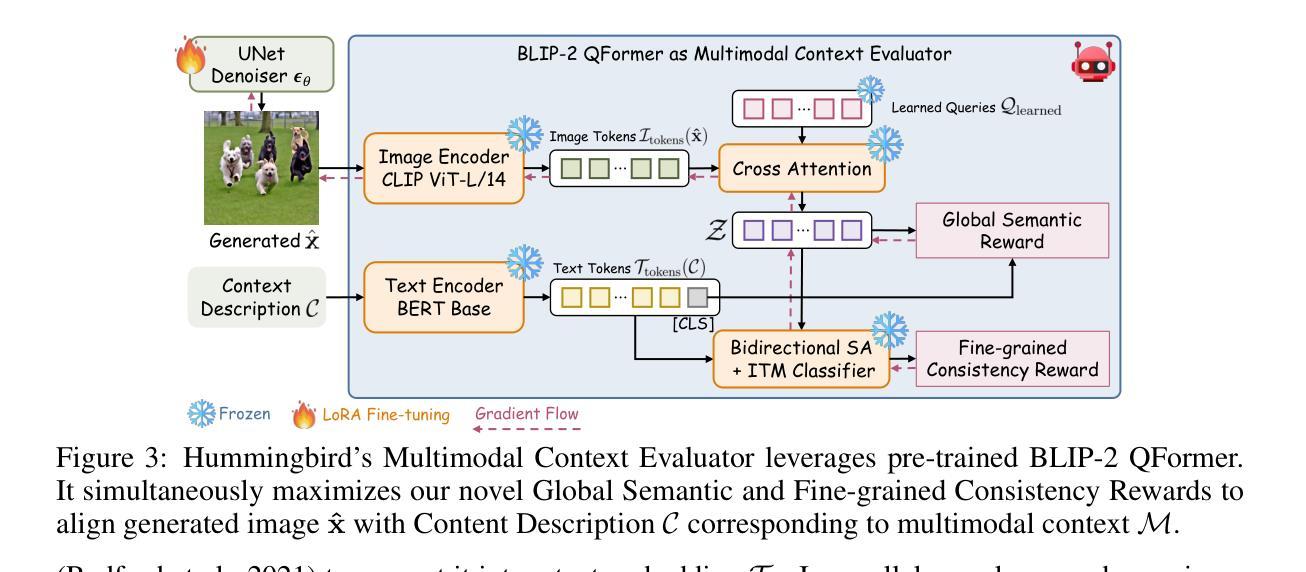
While diffusion models are powerful in generating high-quality, diverse synthetic data for object-centric tasks, existing methods struggle with scene-aware tasks such as Visual Question Answering (VQA) and Human-Object Interaction (HOI) Reasoning, where it is critical to preserve scene attributes in generated images consistent with a multimodal context, i.e. a reference image with accompanying text guidance query. To address this, we introduce Hummingbird, the first diffusion-based image generator which, given a multimodal context, generates highly diverse images w.r.t. the reference image while ensuring high fidelity by accurately preserving scene attributes, such as object interactions and spatial relationships from the text guidance. Hummingbird employs a novel Multimodal Context Evaluator that simultaneously optimizes our formulated Global Semantic and Fine-grained Consistency Rewards to ensure generated images preserve the scene attributes of reference images in relation to the text guidance while maintaining diversity. As the first model to address the task of maintaining both diversity and fidelity given a multimodal context, we introduce a new benchmark formulation incorporating MME Perception and Bongard HOI datasets. Benchmark experiments show Hummingbird outperforms all existing methods by achieving superior fidelity while maintaining diversity, validating Hummingbird’s potential as a robust multimodal context-aligned image generator in complex visual tasks.
虽然扩散模型在生成对象中心任务的高质量、多样化的合成数据方面表现出强大的能力,但现有方法在场景感知任务(如视觉问答(VQA)和人机交互(HOI)推理)方面遇到了困难。在这些任务中,保持生成图像的场景属性与多模态上下文(即带有文本指导查询的参考图像)的一致性至关重要。为了解决这个问题,我们引入了蜂鸟(Hummingbird),这是第一个基于扩散的图像生成器。给定多模态上下文,蜂鸟能够生成与参考图像高度相关的多样化图像,同时确保高保真度,准确保留场景属性,如对象交互和文本指导中的空间关系。蜂鸟采用了一种新型的多模态上下文评估器,同时优化我们制定的全局语义和精细粒度一致性奖励,以确保生成的图像在保持与文本指导相关的场景属性的同时,保持多样性。作为第一个解决在给定多模态上下文中同时保持多样性和保真度的任务模型,我们引入了一个新的基准测试制定,结合了MME感知和Bongard HOI数据集。基准测试显示,蜂鸟在所有现有方法中表现出最佳性能,在保持多样性的同时实现了高保真度,验证了蜂鸟在复杂视觉任务中作为稳健的多模态上下文对齐图像生成器的潜力。
论文及项目相关链接
PDF Accepted to ICLR 2025. Project page: https://roar-ai.github.io/hummingbird
Summary
扩散模型在生成对象中心任务的高质量和多样化合成数据方面表现出强大的能力,但在场景感知任务(如视觉问答和人类对象交互推理)中,现有方法存在困难。针对这些问题,我们推出了Hummingbird——首款基于扩散的图像生成器。它可以根据多模态上下文生成高度多样化的图像,同时确保高度保真,准确保留场景属性,如对象交互和文本指导的空间关系。Hummingbird采用新型多模态上下文评估器,同时优化我们制定的全局语义和精细一致性奖励,以确保生成的图像在保持多样性的同时,根据文本指导保留参考图像的场景属性。作为首个解决在复杂视觉任务中保持多样性和保真度的模型,我们引入了结合MME感知和Bongard HOI数据集的新基准测试。基准测试显示,Hummingbird在保持多样性的同时实现了卓越的保真度,验证了其在复杂视觉任务中作为稳健的多模态上下文对齐图像生成器的潜力。
Key Takeaways
- 扩散模型在生成对象中心任务的高质量和多样化合成数据方面具有优势。
- 在场景感知任务(如视觉问答和人类对象交互推理)中,现有扩散模型存在挑战。
- Hummingbird是首款基于扩散的图像生成器,能够根据多模态上下文生成高度多样化的图像。
- Hummingbird能准确保留场景属性,如对象交互和文本指导的空间关系。
- Hummingbird采用多模态上下文评估器,同时优化全局语义和精细一致性奖励。
- 基准测试显示Hummingbird在保持多样性的同时实现了卓越的性能。
点此查看论文截图


Beautiful Images, Toxic Words: Understanding and Addressing Offensive Text in Generated Images
Authors:Aditya Kumar, Tom Blanchard, Adam Dziedzic, Franziska Boenisch
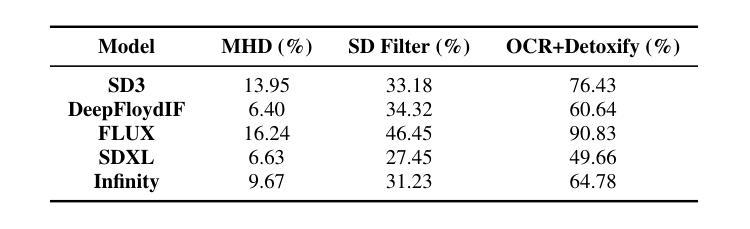
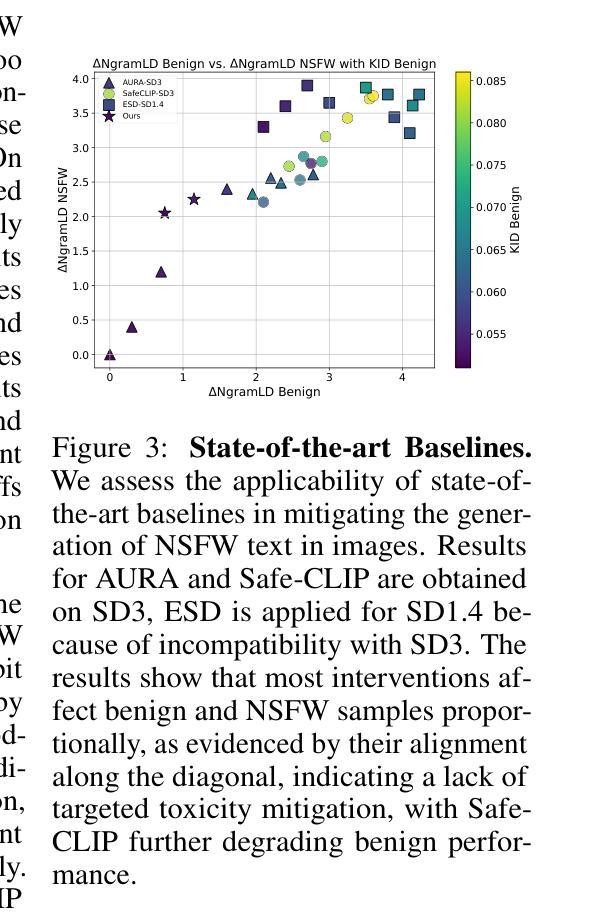
State-of-the-art visual generation models, such as Diffusion Models (DMs) and Vision Auto-Regressive Models (VARs), produce highly realistic images. While prior work has successfully mitigated Not Safe For Work (NSFW) content in the visual domain, we identify a novel threat: the generation of NSFW text embedded within images. This includes offensive language, such as insults, racial slurs, and sexually explicit terms, posing significant risks to users. We show that all state-of-the-art DMs (e.g., SD3, Flux, DeepFloyd IF) and VARs (e.g., Infinity) are vulnerable to this issue. Through extensive experiments, we demonstrate that existing mitigation techniques, effective for visual content, fail to prevent harmful text generation while substantially degrading benign text generation. As an initial step toward addressing this threat, we explore safety fine-tuning of the text encoder underlying major DM architectures using a customized dataset. Thereby, we suppress NSFW generation while preserving overall image and text generation quality. Finally, to advance research in this area, we introduce ToxicBench, an open-source benchmark for evaluating NSFW text generation in images. ToxicBench provides a curated dataset of harmful prompts, new metrics, and an evaluation pipeline assessing both NSFW-ness and generation quality. Our benchmark aims to guide future efforts in mitigating NSFW text generation in text-to-image models and is available at https://github.com/sprintml/ToxicBench
先进的视觉生成模型,如扩散模型(DMs)和视觉自回归模型(VARs),能够生成高度逼真的图像。尽管先前的工作成功地在视觉领域缓解了不宜工作场所(NSFW)的内容问题,但我们发现了一种新的威胁:在图像中嵌入NSFW文本的生成。这包括攻击性语言,如侮辱、种族歧视和性明确术语,对用户构成重大风险。我们证明所有先进的DMs(例如SD3、Flux、DeepFloyd IF)和VARs(例如Infinity)都面临这个问题的威胁。通过大量实验,我们证明现有的缓解技术,对于视觉内容是有效的,但无法防止有害文本生成,同时还会显著降低良性文本生成。作为解决这一威胁的初步步骤,我们探索了主要DM架构底层文本编码器的安全微调技术,使用自定义数据集。因此,我们在保持整体图像和文本生成质量的同时,抑制了NSFW的生成。最后,为了推动该领域的研究,我们推出了ToxicBench,这是一个用于评估图像中NSFW文本生成的开源基准测试。ToxicBench提供了一个有害提示的精选数据集、新指标和评估流程,评估NSFW程度和生成质量。我们的基准测试旨在指导未来在文本到图像模型中缓解NSFW文本生成的工作,可在https://github.com/sprintml/ToxicBench访问。
论文及项目相关链接
摘要
最新视觉生成模型,如扩散模型(DMs)和视觉自回归模型(VARs),能生成高度逼真的图像。我们发现一种新型威胁:图像中嵌入的成人文本内容生成,包括侮辱、种族歧视和性明确术语等冒犯性语言,对用户构成重大风险。现有的缓解技术无法阻止有害文本生成,反而可能对良性文本生成造成显著影响。作为解决此威胁的初步尝试,我们探索了对主要扩散模型文本编码器进行安全微调的方法,使用自定义数据集来抑制成人内容生成并保持整体图像和文本生成质量。最后,为了推进该领域的研究,我们推出了ToxicBench开放基准测试,用于评估图像中的成人文本生成。我们的基准测试旨在指导未来在文本到图像模型中抑制成人文本生成的工作,并可通过链接访问:[链接地址]。
关键见解
- 视觉生成模型(如DMs和VARs)面临新型威胁:图像中嵌入的成人文本内容生成。
- 现有缓解技术无法有效防止有害文本生成,同时对良性文本造成影响。
- 对主要扩散模型的文本编码器进行安全微调,可抑制成人内容生成并保持图像和文本生成质量。
- 引入了ToxicBench开放基准测试,用于评估图像中的成人文本生成,包含有害提示的精选数据集、新指标和评估管道。
- 该基准测试旨在指导未来在文本到图像模型中抑制成人文本生成的研究工作。
- 安全微调方法和基准测试为应对成人文本生成问题提供了初步解决方案和评估工具。
点此查看论文截图



C2GM: Cascading Conditional Generation of Multi-scale Maps from Remote Sensing Images Constrained by Geographic Features
Authors:Chenxing Sun, Yongyang Xu, Xuwei Xu, Xixi Fan, Jing Bai, Xiechun Lu, Zhanlong Chen
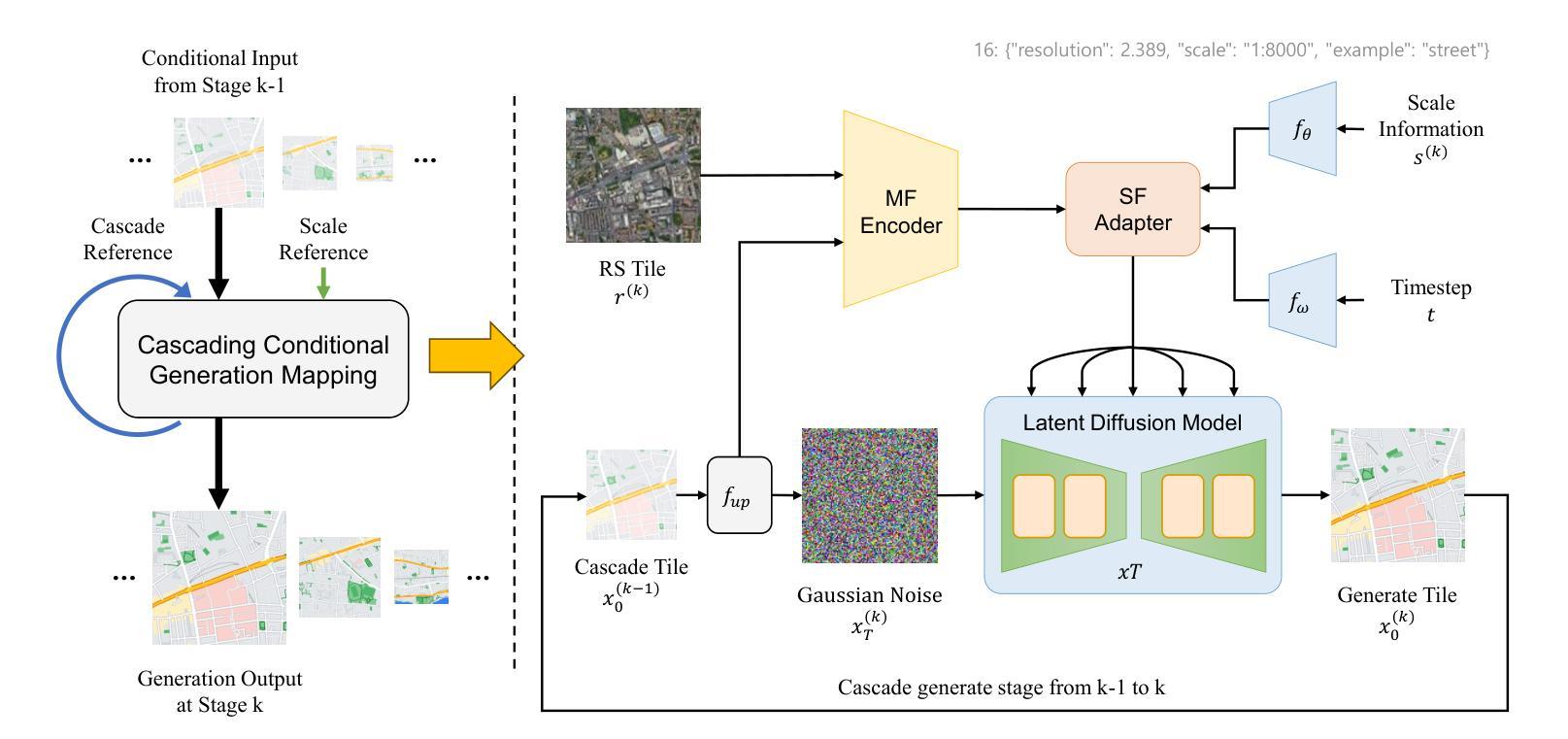
Multi-scale maps are essential representations of surveying and cartographic results, serving as fundamental components of geographic services. Current image generation networks can quickly produce map tiles from remote-sensing images. However, generative models designed for natural images often focus on texture features, neglecting the unique characteristics of remote-sensing features and the scale attributes of tile maps. This limitation in generative models impairs the accurate representation of geographic information, and the quality of tile map generation still needs improvement. Diffusion models have demonstrated remarkable success in various image generation tasks, highlighting their potential to address this challenge. This paper presents C2GM, a novel framework for generating multi-scale tile maps through conditional guided diffusion and multi-scale cascade generation. Specifically, we implement a conditional feature fusion encoder to extract object priors from remote sensing images and cascade reference double branch input, ensuring an accurate representation of complex features. Low-level generated tiles act as constraints for high-level map generation, enhancing visual continuity. Moreover, we incorporate map scale modality information using CLIP to simulate the relationship between map scale and cartographic generalization in tile maps. Extensive experimental evaluations demonstrate that C2GM consistently achieves the state-of-the-art (SOTA) performance on all metrics, facilitating the rapid and effective generation of multi-scale large-format maps for emergency response and remote mapping applications.
多尺度地图是测绘和地图学结果的必要表现形式,也是地理服务的基本组成部分。当前的图像生成网络可以快速从遥感图像中生成地图瓦片。然而,针对自然图像设计的生成模型往往侧重于纹理特征,忽略了遥感特征的独特性和瓦片地图的尺度属性。生成模型的这一局限性影响了地理信息的准确表示,瓦片地图生成的质量仍有待提高。扩散模型在各种图像生成任务中表现出了显著的成功,突显了它们解决这一挑战的潜力。本文提出了C2GM,这是一种通过条件引导扩散和多尺度级联生成生成多尺度瓦片地图的新型框架。具体来说,我们实现了条件特征融合编码器,以从遥感图像中提取对象先验知识,并级联参考双重分支输入,以确保复杂特征的准确表示。低级生成的瓦片作为高级地图生成的约束,增强了视觉连续性。此外,我们结合CLIP融入地图尺度模态信息,模拟瓦片地图中地图尺度和地图概括之间的关系。大量的实验评估表明,C2GM在所有指标上始终达到最新技术水平,为应急响应和远程映射应用快速有效地生成多尺度大幅面地图提供了便利。
论文及项目相关链接
Summary
基于扩散模型的多尺度地图生成技术研究。当前图像生成网络能够从遥感图像快速生成地图瓦片,但传统生成模型关注纹理特征,忽略了遥感特征的独特性和地图瓦片的尺度属性。本文提出C2GM框架,通过条件引导扩散和多尺度级联生成,实现多尺度地图瓦片的生成。引入条件特征融合编码器和级联参考双重分支输入,确保复杂特征的准确表示。此外,结合地图尺度模态信息,模拟地图尺度与制图概括之间的关系。实验评估表明,C2GM在各项指标上均达到最新水平,为应急响应和远程测绘应用提供了快速有效的多尺度大比例尺地图生成方法。
Key Takeaways
- 多尺度地图在地理服务中扮演着基础组件的角色,当前图像生成网络能快速生成地图瓦片,但质量有待提升。
- 传统生成模型主要关注纹理特征,忽略了遥感特征的独特性和地图瓦片的尺度属性。
- 扩散模型在图像生成任务中表现出显著成功,具有解决这一挑战潜力。
- C2GM框架通过条件引导扩散和多尺度级联生成,实现多尺度地图瓦片的生成。
- C2GM引入条件特征融合编码器和级联参考双重分支输入,确保复杂特征的准确表示。
- C2GM结合地图尺度模态信息,模拟地图尺度与制图概括之间的关系。
点此查看论文截图

Augmented Conditioning Is Enough For Effective Training Image Generation
Authors:Jiahui Chen, Amy Zhang, Adriana Romero-Soriano
Image generation abilities of text-to-image diffusion models have significantly advanced, yielding highly photo-realistic images from descriptive text and increasing the viability of leveraging synthetic images to train computer vision models. To serve as effective training data, generated images must be highly realistic while also sufficiently diverse within the support of the target data distribution. Yet, state-of-the-art conditional image generation models have been primarily optimized for creative applications, prioritizing image realism and prompt adherence over conditional diversity. In this paper, we investigate how to improve the diversity of generated images with the goal of increasing their effectiveness to train downstream image classification models, without fine-tuning the image generation model. We find that conditioning the generation process on an augmented real image and text prompt produces generations that serve as effective synthetic datasets for downstream training. Conditioning on real training images contextualizes the generation process to produce images that are in-domain with the real image distribution, while data augmentations introduce visual diversity that improves the performance of the downstream classifier. We validate augmentation-conditioning on a total of five established long-tail and few-shot image classification benchmarks and show that leveraging augmentations to condition the generation process results in consistent improvements over the state-of-the-art on the long-tailed benchmark and remarkable gains in extreme few-shot regimes of the remaining four benchmarks. These results constitute an important step towards effectively leveraging synthetic data for downstream training.
文本生成图像扩散模型的图像生成能力已经取得了重大进展,能够从描述性的文本中产生高度逼真的图像,提高了利用合成图像训练计算机视觉模型的可行性。为了作为有效的训练数据,生成的图像必须在目标数据分布的支持下足够逼真且多样化。然而,最先进的条件图像生成模型主要经过优化用于创意应用,优先考虑图像的真实性和对提示的遵循,而非条件多样性。在本文中,我们研究了如何改进生成图像的多样性,旨在提高其作为训练下游图像分类模型的有效性,而无需微调图像生成模型。我们发现,通过在生成过程中以增强的真实图像和文本提示作为条件,可以产生有效的合成数据集用于下游训练。以真实训练图像作为条件使生成过程语境化,产生与真实图像分布同域的图像,而数据增强引入了视觉多样性,提高了下游分类器的性能。我们在五个公认的长尾和少样本图像分类基准测试集上验证了增强条件下的表现,并展示了在利用增强条件来引导生成过程时,对长尾基准测试集表现稳定优于现有技术,并且在其余四个基准测试集的极端少样本情况下取得了显著的成绩。这些结果有效地利用合成数据进行下游训练的重要一步。
论文及项目相关链接
Summary
本文探讨了如何改进生成图像多样性以提高其作为下游图像分类模型训练数据的效率。研究发现,通过对生成过程进行真实图像和文本提示的条件化,可以产生有效的合成数据集用于下游训练。条件化真实训练图像使生成图像具有与真实图像分布相同的领域性,而数据增强则引入视觉多样性,提高了下游分类器的性能。在五个长期尾部和短期图像分类基准测试中验证了增强条件化方法的有效性,该方法在长尾基准测试中表现优于最新技术,并在其余四个基准测试中实现了显著的极端短期收益。这些结果有效利用了合成数据对下游训练的重要性。
Key Takeaways
- 文本到图像的扩散模型已经能够生成高度逼真的图像。
- 生成图像必须既真实又多样,才能作为有效的训练数据。
- 现有条件图像生成模型主要优化创意应用,注重图像真实性和提示遵循性,但忽略了条件多样性。
- 通过将生成过程条件化在真实图像和文本提示上,可以产生与真实图像分布相同领域的合成图像。
- 条件化真实训练图像结合数据增强有助于提高下游分类器的性能。
- 在多个图像分类基准测试中验证了增强条件化方法的有效性。
点此查看论文截图




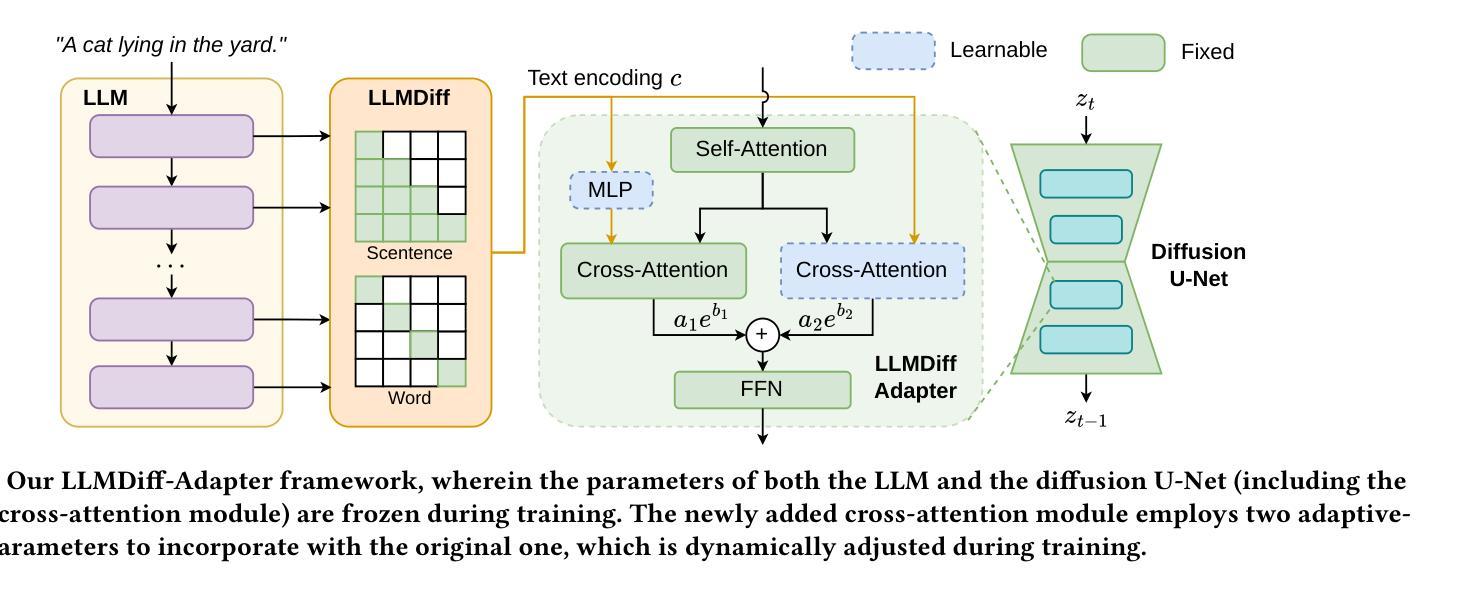
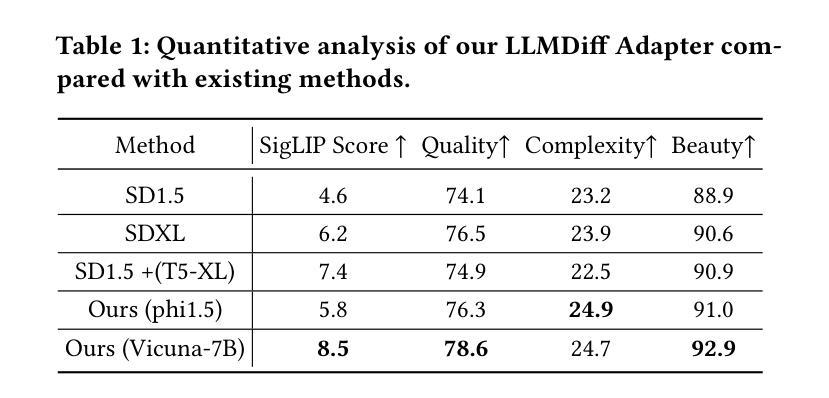
Decoder-Only LLMs are Better Controllers for Diffusion Models
Authors:Ziyi Dong, Yao Xiao, Pengxu Wei, Liang Lin
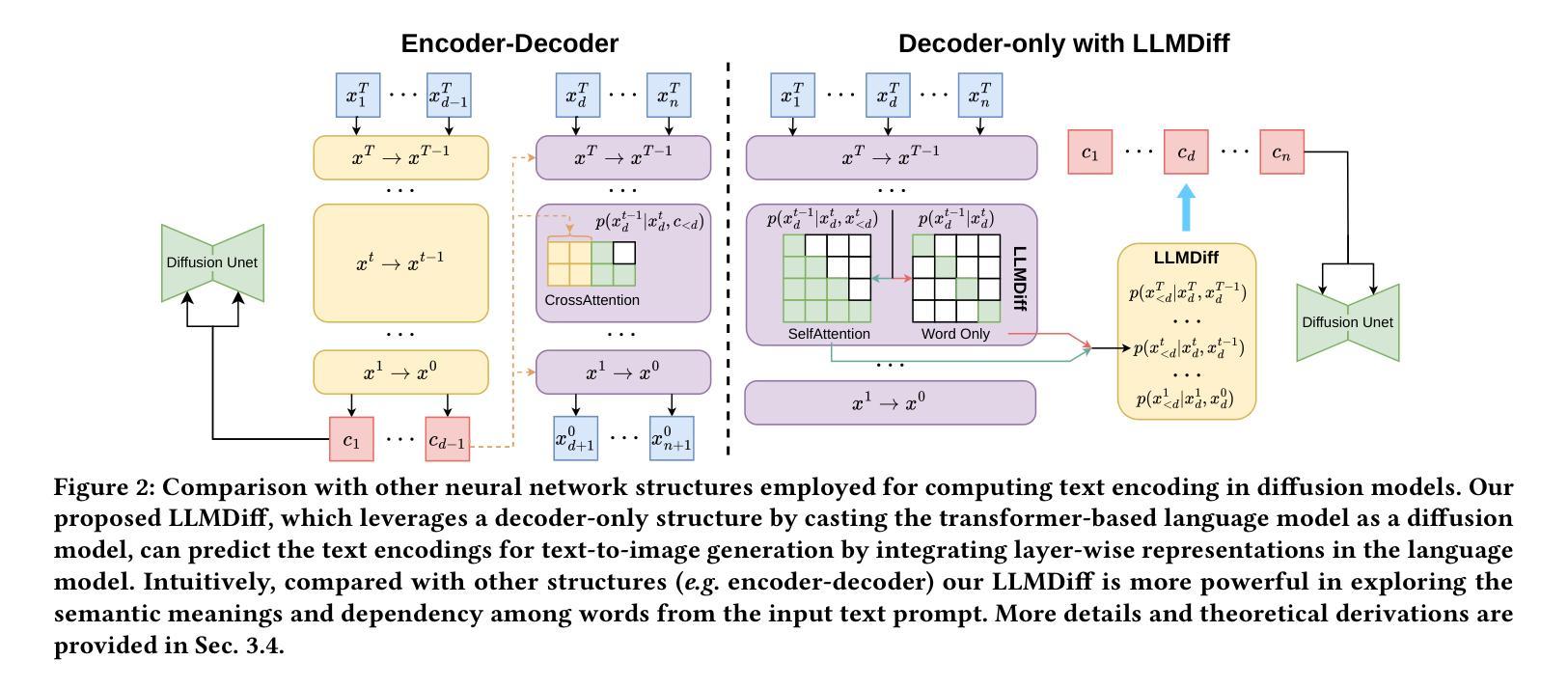
Groundbreaking advancements in text-to-image generation have recently been achieved with the emergence of diffusion models. These models exhibit a remarkable ability to generate highly artistic and intricately detailed images based on textual prompts. However, obtaining desired generation outcomes often necessitates repetitive trials of manipulating text prompts just like casting spells on a magic mirror, and the reason behind that is the limited capability of semantic understanding inherent in current image generation models. Specifically, existing diffusion models encode the text prompt input with a pre-trained encoder structure, which is usually trained on a limited number of image-caption pairs. The state-of-the-art large language models (LLMs) based on the decoder-only structure have shown a powerful semantic understanding capability as their architectures are more suitable for training on very large-scale unlabeled data. In this work, we propose to enhance text-to-image diffusion models by borrowing the strength of semantic understanding from large language models, and devise a simple yet effective adapter to allow the diffusion models to be compatible with the decoder-only structure. Meanwhile, we also provide a supporting theoretical analysis with various architectures (e.g., encoder-only, encoder-decoder, and decoder-only), and conduct extensive empirical evaluations to verify its effectiveness. The experimental results show that the enhanced models with our adapter module are superior to the stat-of-the-art models in terms of text-to-image generation quality and reliability.
最近,随着扩散模型的兴起,文本到图像生成领域取得了突破性的进展。这些模型表现出根据文本提示生成高度艺术和精细细节图像的能力。然而,要获得想要的生成结果通常需要重复操作文本提示,就像在魔镜上施展咒语一样,背后的原因是当前图像生成模型固有的有限语义理解能力。具体来说,现有的扩散模型使用预训练的编码器结构对文本提示进行编码,通常只在有限的图像-字幕对上进行训练。基于仅解码器结构的最先进的大型语言模型已经显示出强大的语义理解能力,因为它们的架构更适合在非常大的未标记数据上进行训练。在这项工作中,我们提出通过借鉴大型语言模型的语义理解能力来增强文本到图像的扩散模型,并设计了一个简单有效的适配器,使扩散模型与仅解码器结构兼容。同时,我们还通过不同的架构(如仅编码器、编码器-解码器和仅解码器)进行了理论上的支持分析,并通过广泛的实证评估验证了其有效性。实验结果表明,采用我们适配器模块的增强型模型在文本到图像生成的质量和可靠性方面均优于现有先进技术模型。
论文及项目相关链接
Summary
文本到图像生成领域的突破进展得益于扩散模型的出现。这些模型能够根据文本提示生成高度艺术和精细的图像。然而,为了获得理想的生成结果,通常需要像对魔镜施魔法一样重复操作文本提示。现有扩散模型使用预训练编码器结构对文本提示进行编码,这限制了其语义理解能力。本研究借鉴大型语言模型的语义理解优势,提出增强文本到图像扩散模型的方案,并设计简单有效的适配器,使扩散模型与解码器结构兼容。实验结果表明,使用适配器模块的增强模型在文本到图像生成质量和可靠性方面优于现有模型。
Key Takeaways
- 扩散模型在文本到图像生成领域取得重大进展,可基于文本提示生成高度艺术和精细图像。
- 获得理想生成结果通常需要重复操作文本提示,这反映了当前图像生成模型在语义理解方面的局限性。
- 现有扩散模型使用预训练编码器结构进行文本提示编码。
- 大型语言模型展现出强大的语义理解能力,其架构更适合在大量未标注数据上进行训练。
- 本研究提出通过借鉴大型语言模型的语义理解优势来增强文本到图像扩散模型。
- 设计了一个简单有效的适配器,使扩散模型与解码器结构兼容。
点此查看论文截图

DiMSUM: Diffusion Mamba – A Scalable and Unified Spatial-Frequency Method for Image Generation
Authors:Hao Phung, Quan Dao, Trung Dao, Hoang Phan, Dimitris Metaxas, Anh Tran
We introduce a novel state-space architecture for diffusion models, effectively harnessing spatial and frequency information to enhance the inductive bias towards local features in input images for image generation tasks. While state-space networks, including Mamba, a revolutionary advancement in recurrent neural networks, typically scan input sequences from left to right, they face difficulties in designing effective scanning strategies, especially in the processing of image data. Our method demonstrates that integrating wavelet transformation into Mamba enhances the local structure awareness of visual inputs and better captures long-range relations of frequencies by disentangling them into wavelet subbands, representing both low- and high-frequency components. These wavelet-based outputs are then processed and seamlessly fused with the original Mamba outputs through a cross-attention fusion layer, combining both spatial and frequency information to optimize the order awareness of state-space models which is essential for the details and overall quality of image generation. Besides, we introduce a globally-shared transformer to supercharge the performance of Mamba, harnessing its exceptional power to capture global relationships. Through extensive experiments on standard benchmarks, our method demonstrates superior results compared to DiT and DIFFUSSM, achieving faster training convergence and delivering high-quality outputs. The codes and pretrained models are released at https://github.com/VinAIResearch/DiMSUM.git.
我们引入了一种新颖的扩散模型的状态空间架构,有效利用空间和频率信息,增强对输入图像局部特征的归纳偏见,用于图像生成任务。状态空间网络(包括革命性的循环神经网络Mamba)通常从左到右扫描输入序列,但在设计有效的扫描策略时面临困难,尤其是在处理图像数据时。我们的方法证明,将小波变换整合到Mamba中,可以增强对视觉输入的局部结构意识,并通过将频率分解为小波子带更好地捕获长期频率关系,这些基于小波的输出代表低频和高频成分。这些基于小波的输出经过处理,并通过跨注意力融合层无缝融合到原始的Mamba输出中,结合空间和频率信息优化状态空间模型的顺序意识,这对于图像生成的细节和整体质量至关重要。此外,我们引入了一个全局共享变压器来增强Mamba的性能,利用其捕捉全局关系的卓越能力。在标准基准测试上的大量实验表明,我们的方法与DiT和DIFFUSSM相比具有优越的结果,实现更快的训练收敛速度并提供高质量的输出。代码和预训练模型发布在https://github.com/VinAIResearch/DiMSUM.git。
论文及项目相关链接
PDF Accepted to NeurIPS 2024. Project page: https://vinairesearch.github.io/DiMSUM/
Summary
本文介绍了一种新型状态空间架构的扩散模型,该模型通过利用小波变换强化局部特征意识,并结合全局共享变压器来增强Mamba模型的性能。新模型能在图像生成任务中有效结合空间与频率信息,提升模型对细节和整体质量的把控力,并在标准基准测试中表现出卓越结果。相关代码和预训练模型已发布在GitHub上。
Key Takeaways
- 引入新型状态空间架构扩散模型,融合空间与频率信息以提升图像生成任务的局部特征感知能力。
- 采用小波变换技术集成至Mamba模型,有助于优化模型对视觉输入局部结构的认知,并通过解耦频率成分来提升长期关系捕捉能力。
- 通过交叉注意力融合层,将基于小波的输出生成与原始Mamba输出相结合,优化状态空间模型的顺序感知能力。
- 引入全局共享变压器以进一步提升Mamba性能,利用其捕捉全局关系的能力。
- 在标准基准测试中进行广泛实验验证,展示新模型在图像生成任务上的优越性。
- 新模型相较于DiT和DIFFUSSM展现出更快的训练收敛速度和高质量输出。
点此查看论文截图