⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-11 更新
SelaFD:Seamless Adaptation of Vision Transformer Fine-tuning for Radar-based Human Activity
Authors:Yijun Wang, Yong Wang, Chendong xu, Shuai Yao, Qisong Wu
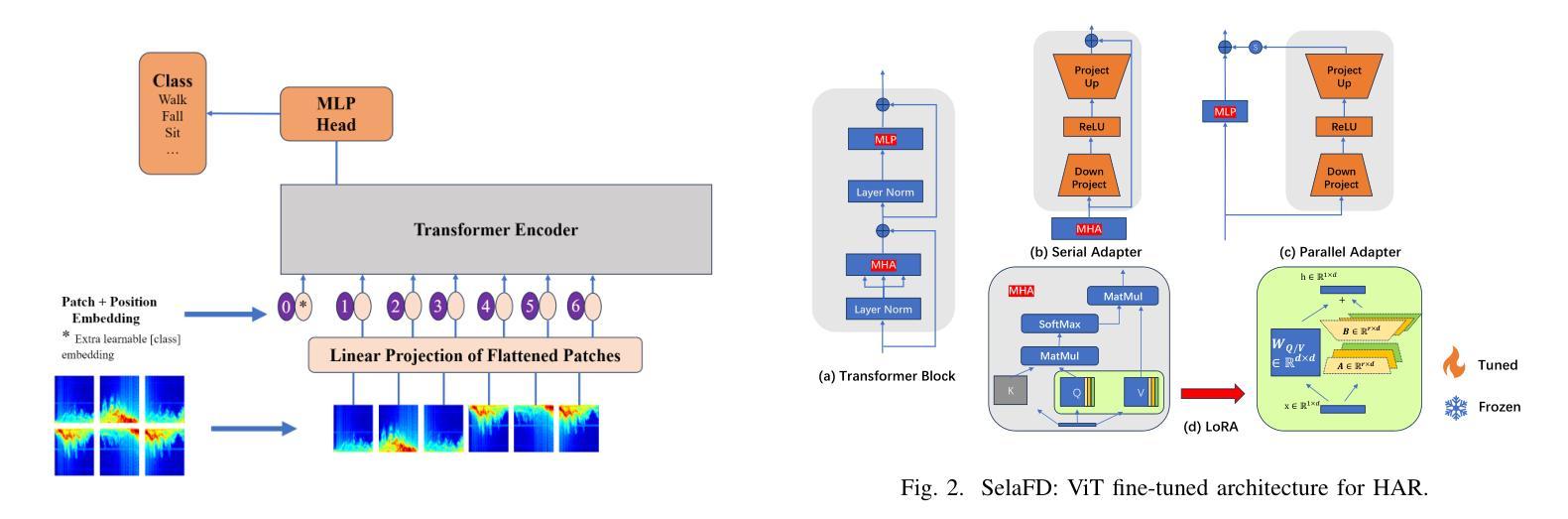
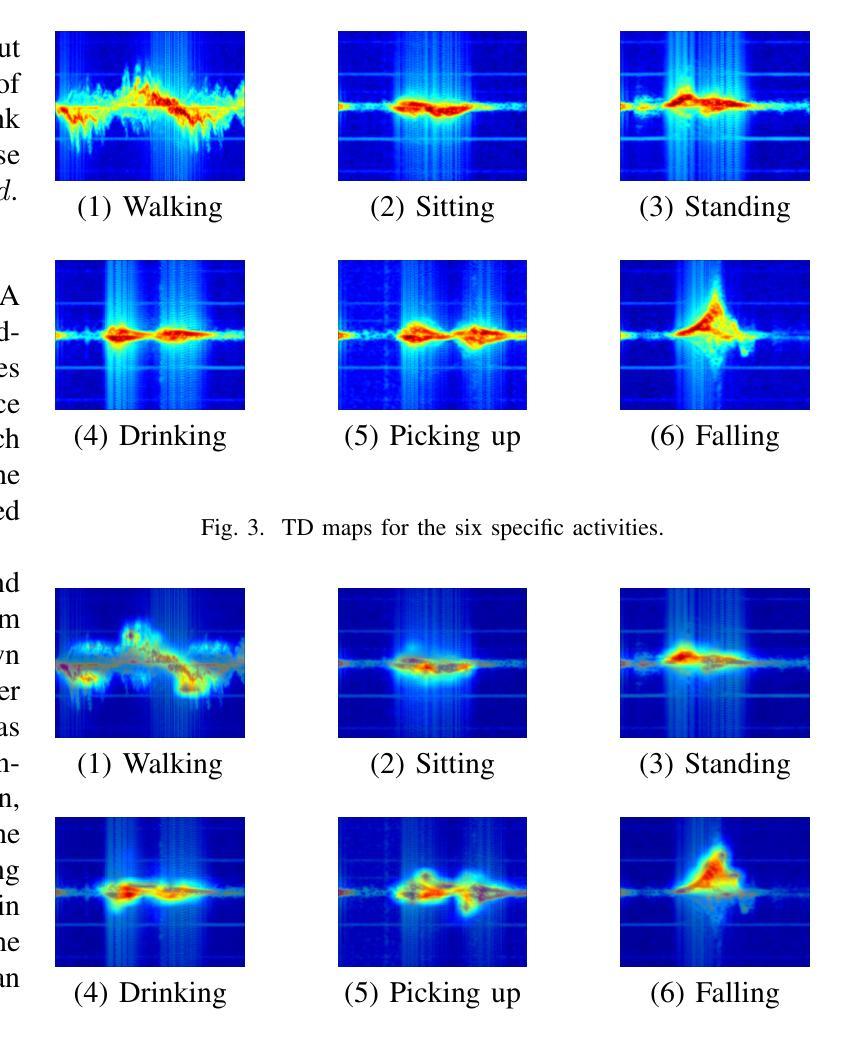
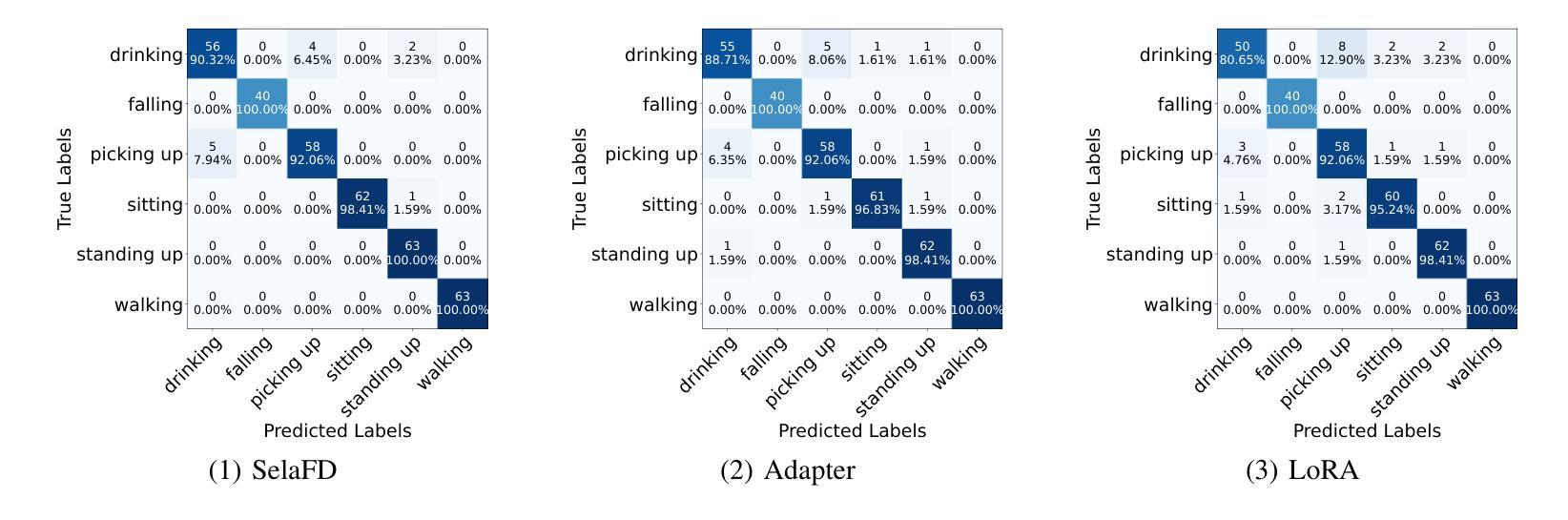
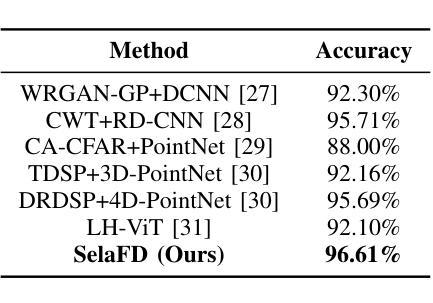
Human Activity Recognition (HAR) such as fall detection has become increasingly critical due to the aging population, necessitating effective monitoring systems to prevent serious injuries and fatalities associated with falls. This study focuses on fine-tuning the Vision Transformer (ViT) model specifically for HAR using radar-based Time-Doppler signatures. Unlike traditional image datasets, these signals present unique challenges due to their non-visual nature and the high degree of similarity among various activities. Directly fine-tuning the ViT with all parameters proves suboptimal for this application. To address this challenge, we propose a novel approach that employs Low-Rank Adaptation (LoRA) fine-tuning in the weight space to facilitate knowledge transfer from pre-trained ViT models. Additionally, to extract fine-grained features, we enhance feature representation through the integration of a serial-parallel adapter in the feature space. Our innovative joint fine-tuning method, tailored for radar-based Time-Doppler signatures, significantly improves HAR accuracy, surpassing existing state-of-the-art methodologies in this domain. Our code is released at https://github.com/wangyijunlyy/SelaFD.
人类活动识别(HAR)如跌倒检测,由于人口老龄化而变得越来越重要,需要有效的监控系统来防止与跌倒相关的严重伤害和死亡。本研究专注于使用基于雷达的Time-Doppler特征对Vision Transformer(ViT)模型进行微调,以实现HAR。与传统图像数据集不同,这些信号由于其非视觉特性和各种活动的高度相似性而具有独特的挑战。直接使用所有参数对ViT进行微调对于此应用而言证明是次优的。为了解决这一挑战,我们提出了一种采用权重空间中的低秩适配(LoRA)微调方法的新颖方法,以促进从预训练的ViT模型进行知识转移。此外,为了提取精细特征,我们通过集成特征空间中的串行并行适配器来增强特征表示。我们针对基于雷达的Time-Doppler特征量身定制的创新联合微调方法,显著提高了HAR的准确性,超越了该领域现有的最先进方法。我们的代码发布在https://github.com/wangyijunlyy/SelaFD。
论文及项目相关链接
Summary
本研究针对老龄化社会中日益重要的活动识别(如跌倒检测)问题,采用雷达Time-Doppler信号数据对Vision Transformer(ViT)模型进行微调。由于这类信号的独特性和高相似性,直接微调所有参数的ViT模型效果并不理想。因此,本研究提出了一种采用低秩适应(LoRA)的权重空间微调方法,并融合串行并行适配器以增强特征表示,显著提高了活动识别的准确性,超越了该领域的现有技术。相关代码已公开在[github链接]。
Key Takeaways
- 本研究针对雷达Time-Doppler信号数据对人类活动识别的重要性进行研究,尤其是跌倒检测。
- 直接使用传统图像数据集的方法对ViT模型进行微调并不适用于雷达Time-Doppler信号数据。
- 采用低秩适应(LoRA)的权重空间微调方法来解决上述问题,促进知识从预训练ViT模型的迁移。
- 通过在特征空间中融合串行并行适配器,增强特征表示以提取更精细的特征。
- 该方法显著提高了活动识别的准确性,并在相关领域内达到了前所未有的性能表现。
- 本研究开发了特定代码,并已公开发布以供公众访问和使用。
点此查看论文截图


AIQViT: Architecture-Informed Post-Training Quantization for Vision Transformers
Authors:Runqing Jiang, Ye Zhang, Longguang Wang, Pengpeng Yu, Yulan Guo
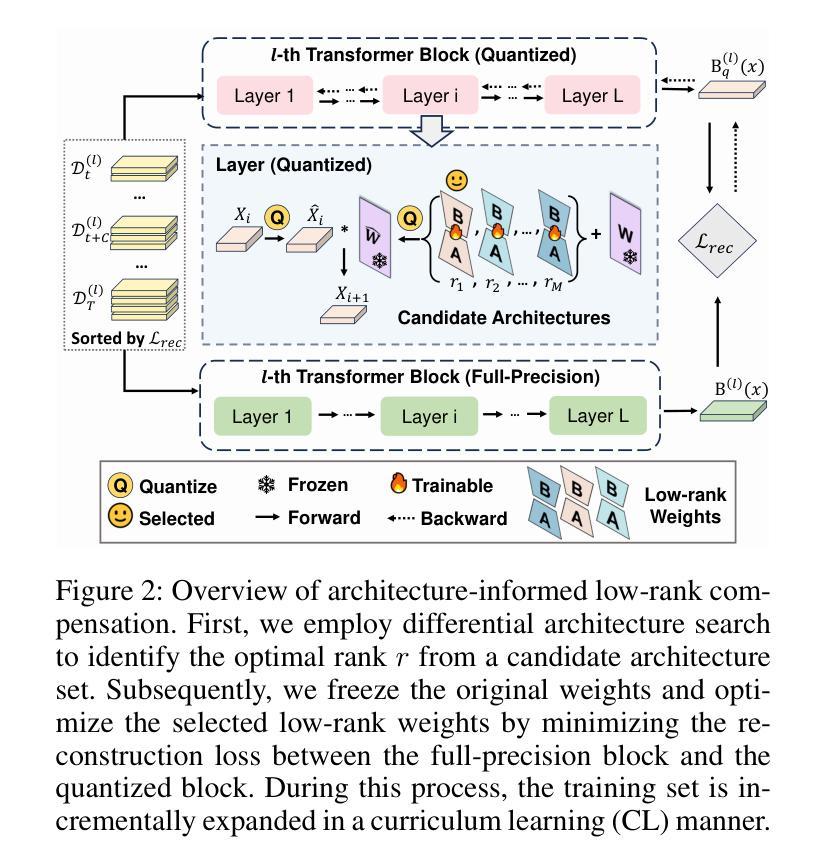
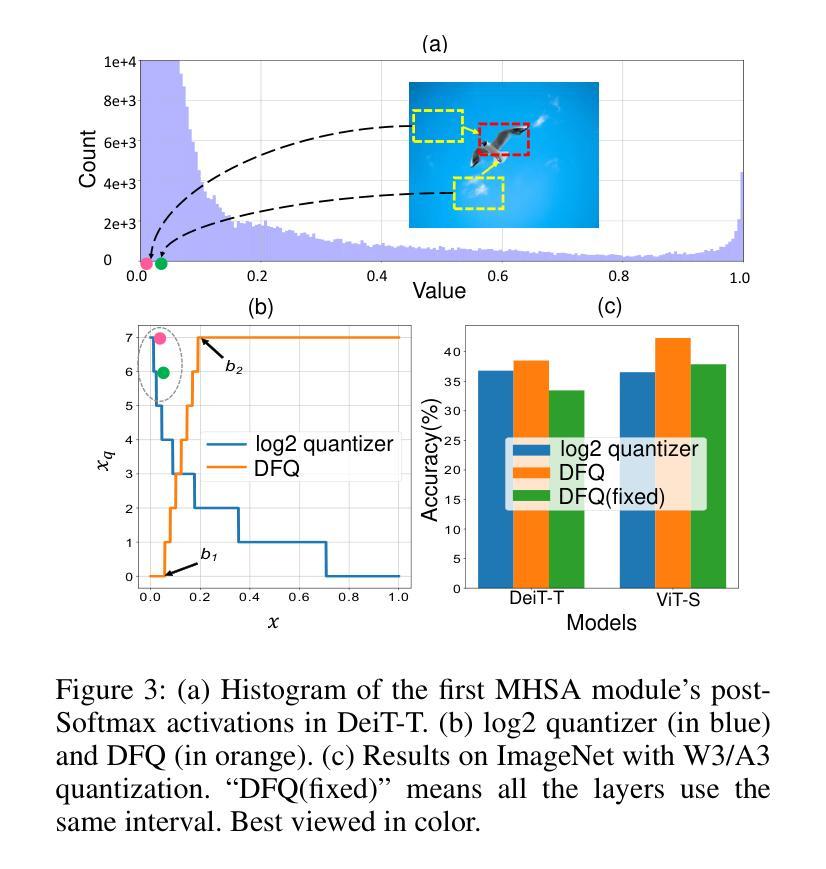
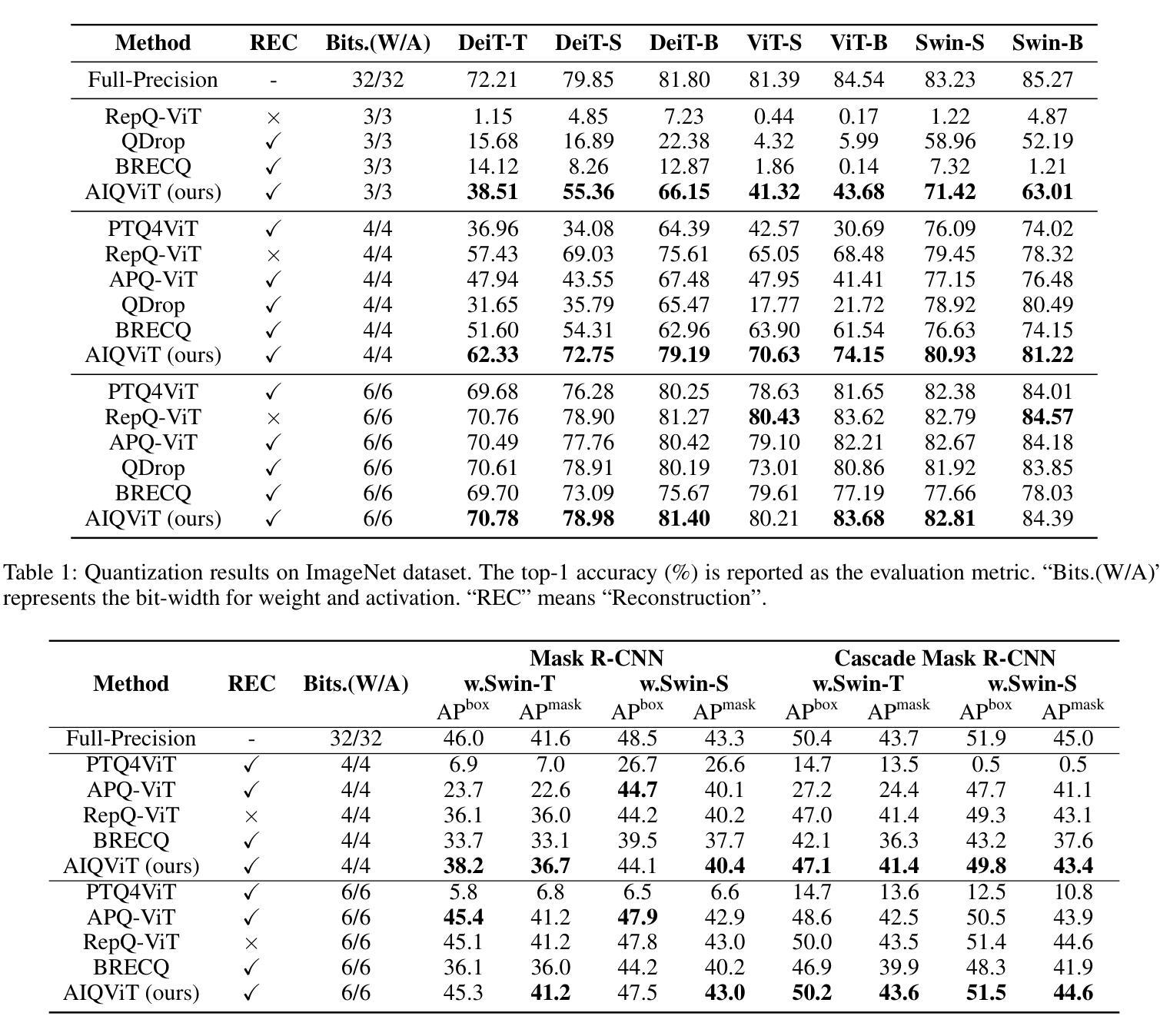
Post-training quantization (PTQ) has emerged as a promising solution for reducing the storage and computational cost of vision transformers (ViTs). Recent advances primarily target at crafting quantizers to deal with peculiar activations characterized by ViTs. However, most existing methods underestimate the information loss incurred by weight quantization, resulting in significant performance deterioration, particularly in low-bit cases. Furthermore, a common practice in quantizing post-Softmax activations of ViTs is to employ logarithmic transformations, which unfortunately prioritize less informative values around zero. This approach introduces additional redundancies, ultimately leading to suboptimal quantization efficacy. To handle these, this paper proposes an innovative PTQ method tailored for ViTs, termed AIQViT (Architecture-Informed Post-training Quantization for ViTs). First, we design an architecture-informed low rank compensation mechanism, wherein learnable low-rank weights are introduced to compensate for the degradation caused by weight quantization. Second, we design a dynamic focusing quantizer to accommodate the unbalanced distribution of post-Softmax activations, which dynamically selects the most valuable interval for higher quantization resolution. Extensive experiments on five vision tasks, including image classification, object detection, instance segmentation, point cloud classification, and point cloud part segmentation, demonstrate the superiority of AIQViT over state-of-the-art PTQ methods.
后训练量化(PTQ)已成为降低视觉变压器(ViT)的存储和计算成本的有前途的解决方案。最近的进展主要集中在制作量化器以处理由ViT特征化的特殊激活。然而,大多数现有方法低估了权重量化引起的信息损失,导致性能显著下降,特别是在低位情况下。此外,对ViT的Softmax后激活进行量化的通用做法是采用对数转换,这不幸地使接近零的无信息值优先。这种方法引入了额外的冗余,最终导致量化效率不佳。为了处理这些问题,本文提出了一种针对ViT的创新PTQ方法,称为AIQViT(用于ViT的结构感知后训练量化)。首先,我们设计了一种结构感知的低秩补偿机制,其中引入可学习的低秩权重来补偿权重量化引起的退化。其次,我们设计了一个动态聚焦量化器,以适应Softmax后激活的不平衡分布,该量化器动态选择最高量化分辨率的最有价值区间。在图像分类、目标检测、实例分割、点云分类和点云部分分割等五个视觉任务上的大量实验表明,AIQViT优于最新的PTQ方法。
论文及项目相关链接
Summary
ViT模型的PTQ方法展现出良好潜力以降低存储和计算成本。但现有方案在权重量化上忽视了信息损失,低比特场景下性能显著下降。此外,对数转换常用于量化ViT的Softmax激活值,易造成冗余。针对这些问题,本文提出量身定制的AIQViT方案,引入低秩补偿机制与动态聚焦量化器。前者通过引入可学习低秩权重补偿量化损失;后者动态选择最具价值的区间以提高量化分辨率。实验证明AIQViT在五大视觉任务上超越现有PTQ方法。
Key Takeaways
- ViT模型的PTQ方法可降低存储和计算成本。
- 现有方案在权重量化时信息损失估计不足,影响性能。
- ViT的Softmax激活值量化常采用对数转换,导致冗余。
- AIQViT通过引入低秩补偿机制与动态聚焦量化器解决上述问题。
- 低秩补偿机制通过引入可学习低秩权重补偿量化损失。
- 动态聚焦量化器能动态调整量化分辨率以提高性能。
点此查看论文截图

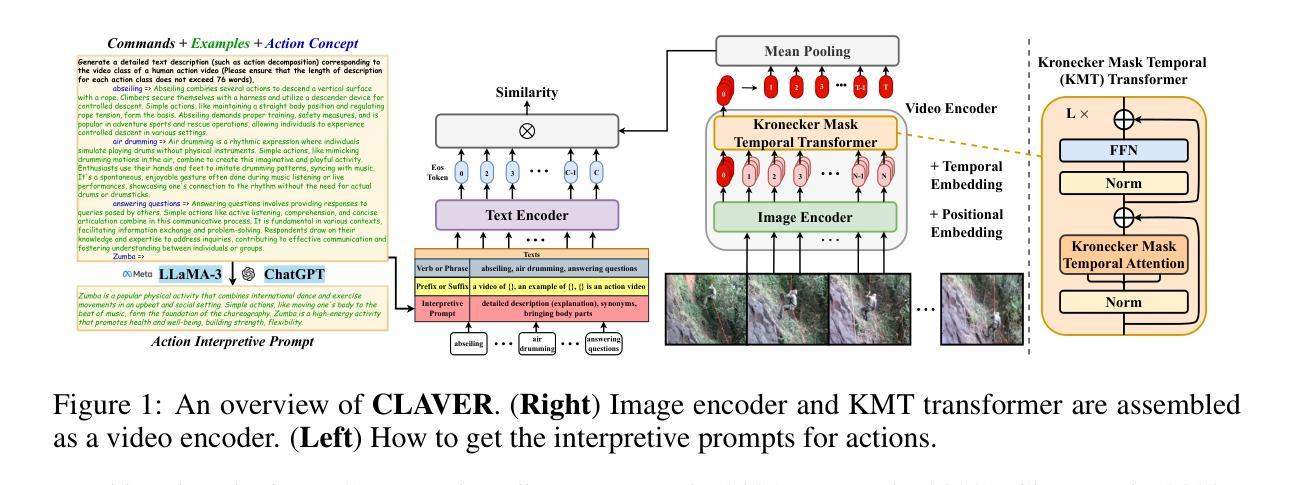
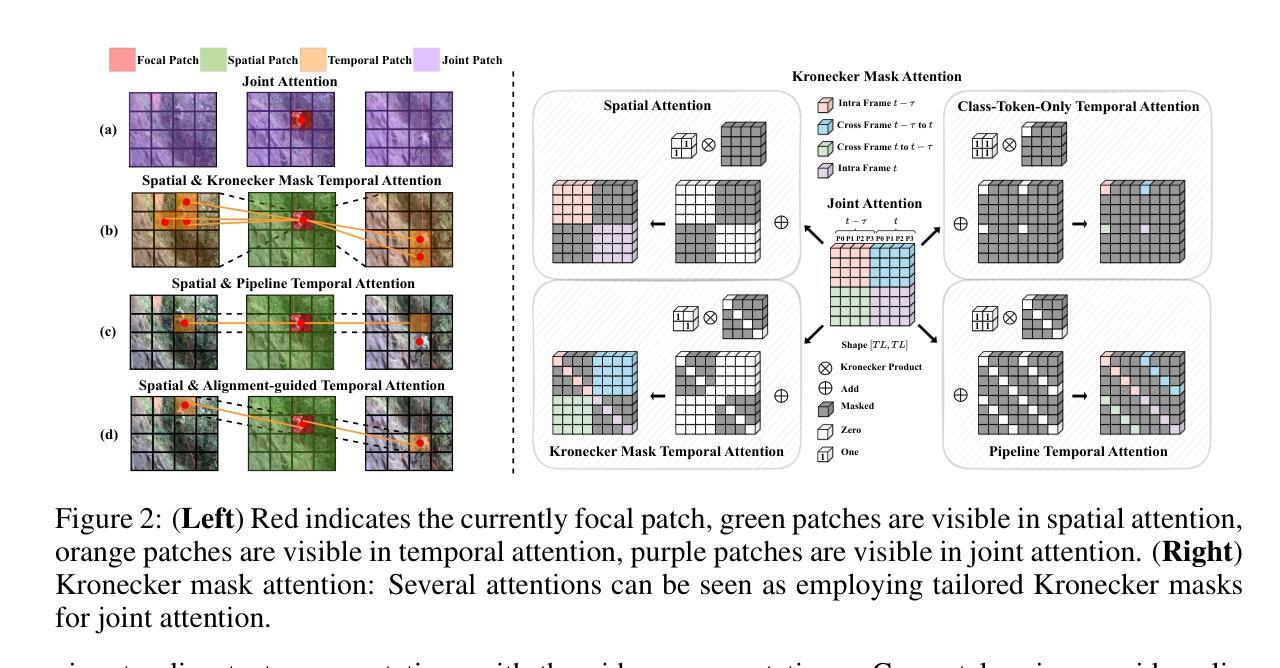
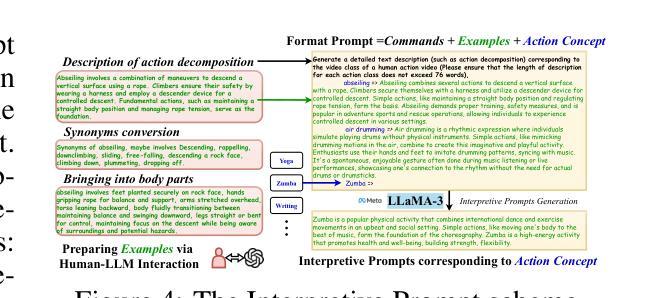
Kronecker Mask and Interpretive Prompts are Language-Action Video Learners
Authors:Jingyi Yang, Zitong Yu, Xiuming Ni, Jia He, Hui Li
Contrastive language-image pretraining (CLIP) has significantly advanced image-based vision learning. A pressing topic subsequently arises: how can we effectively adapt CLIP to the video domain? Recent studies have focused on adjusting either the textual or visual branch of CLIP for action recognition. However, we argue that adaptations of both branches are crucial. In this paper, we propose \textbf{CLAVER}: a \textbf{C}ontrastive \textbf{L}anguage-\textbf{A}ction \textbf{V}ideo Learn\textbf{er}, designed to shift CLIP’s focus from the alignment of static visual objects and concrete nouns to the alignment of dynamic action behaviors and abstract verbs. Specifically, we introduce a novel Kronecker mask attention for temporal modeling. Our tailored Kronecker mask offers three benefits 1) it expands the temporal receptive field for each token, 2) it serves as an effective spatiotemporal heterogeneity inductive bias, mitigating the issue of spatiotemporal homogenization, and 3) it can be seamlessly plugged into transformer-based models. Regarding the textual branch, we leverage large language models to generate diverse, sentence-level and semantically rich interpretive prompts of actions, which shift the model’s focus towards the verb comprehension. Extensive experiments on various benchmarks and learning scenarios demonstrate the superiority and generality of our approach. The code will be available soon.
对比语言图像预训练(CLIP)在基于图像的视觉学习方面取得了显著进展。随之而来出现了一个紧迫的问题:我们如何有效地将CLIP适应到视频领域?近期的研究主要集中在调整CLIP的文本或视觉分支来进行动作识别。然而,我们认为两个分支的适应都是至关重要的。在本文中,我们提出了CLAVER:一个对比语言-动作视频学习器(Contrastive Language-Action Video Learner),旨在将CLIP的重点从静态物体和具体名词的对齐转移到动态行为动作和抽象动词的对齐。具体来说,我们引入了一种新型克罗内克掩膜注意力来实现时序建模。我们定制的克罗内克掩膜具有三个优点:1)它扩大了每个标记的时序感受野;2)它作为有效的时空异质性归纳偏置,缓解了时空同质化的问题;3)它可以无缝地插入到基于变压器模型。关于文本分支,我们利用大型语言模型生成多样、句子级别且语义丰富的动作解释性提示,使模型关注动词的理解。在各种基准测试和学习场景的大量实验证明了我们的方法的优越性和通用性。代码很快将可用。
论文及项目相关链接
PDF Accepted to ICLR2025
Summary
CLIP技术因图像领域的视觉学习取得显著进展,如何有效将其应用于视频领域成为热门话题。本文提出CLAVER模型,通过对比语言行为视频学习器,将CLIP的重点从静态物体与具体名词的匹配转向动态行为动作与抽象动词的匹配。采用新型Kronecker Mask注意力机制进行时序建模,具有扩大时间感受野、增强时空异质性及易于集成到Transformer模型等优点。在语言分支方面,利用大型语言模型生成多样、句子级、语义丰富的动作解释性提示,使模型更注重动词理解。实验证明该方法在多种基准测试和学习场景中具有优越性和通用性。
Key Takeaways
- CLIP技术在图像视觉学习领域取得了显著进展,现在需要将重点转向视频领域的应用。
- CLAVER模型是一个对比语言行为视频学习器,强调动作和抽象动词的对齐重要性。
- 该模型采用Kronecker Mask注意力机制进行时序建模,解决了时空同质性的问题并扩大了时间感受野。
- 语言分支方面使用大型语言模型生成动作解释性提示,提高模型对动词理解的重视。
- 该模型在各种基准测试和学习场景中表现优越且通用性强。
- 该模型的代码即将公开提供。这对于后续研究和实际应用将是一大资源。
点此查看论文截图