⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-12 更新
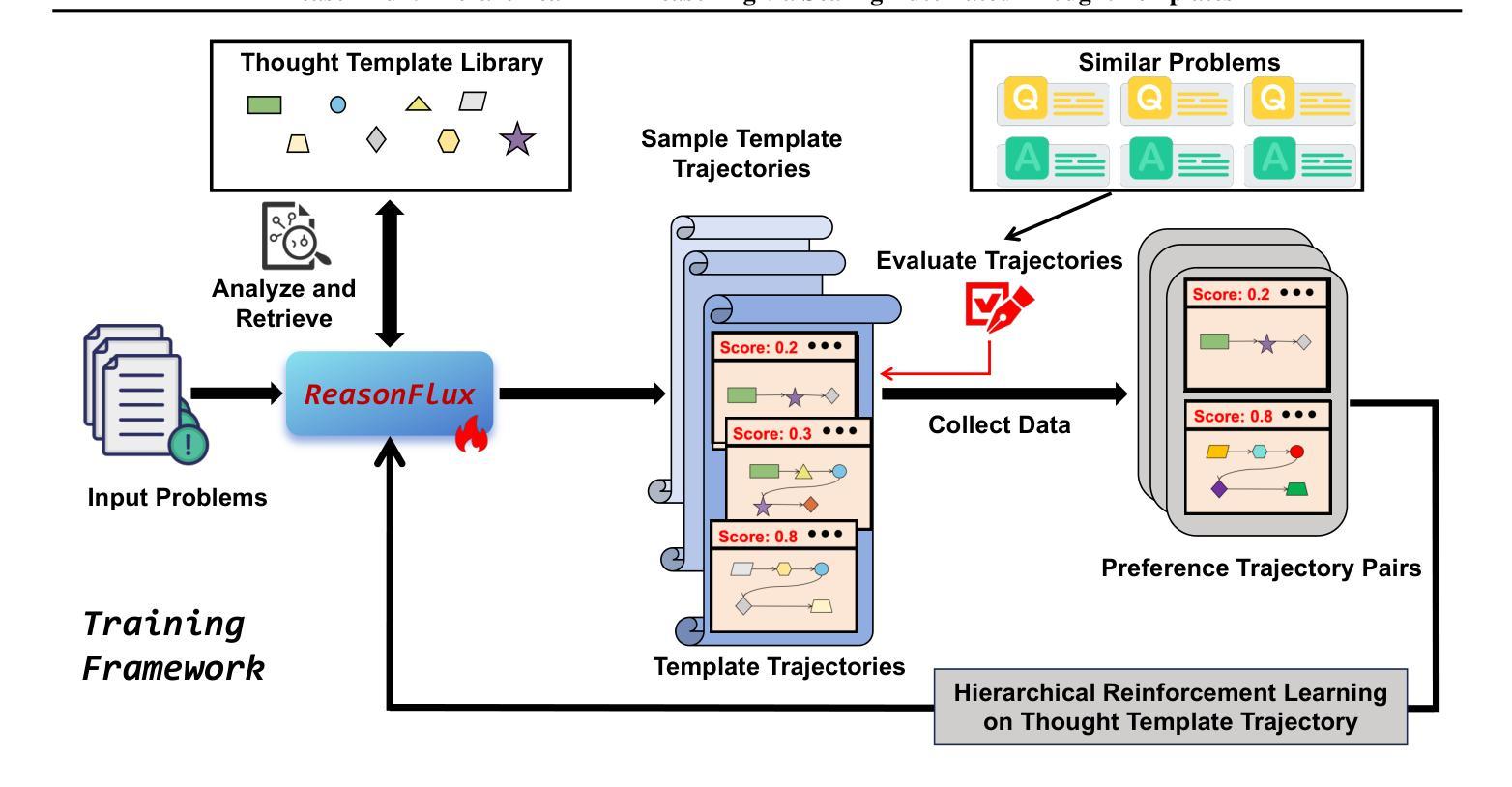
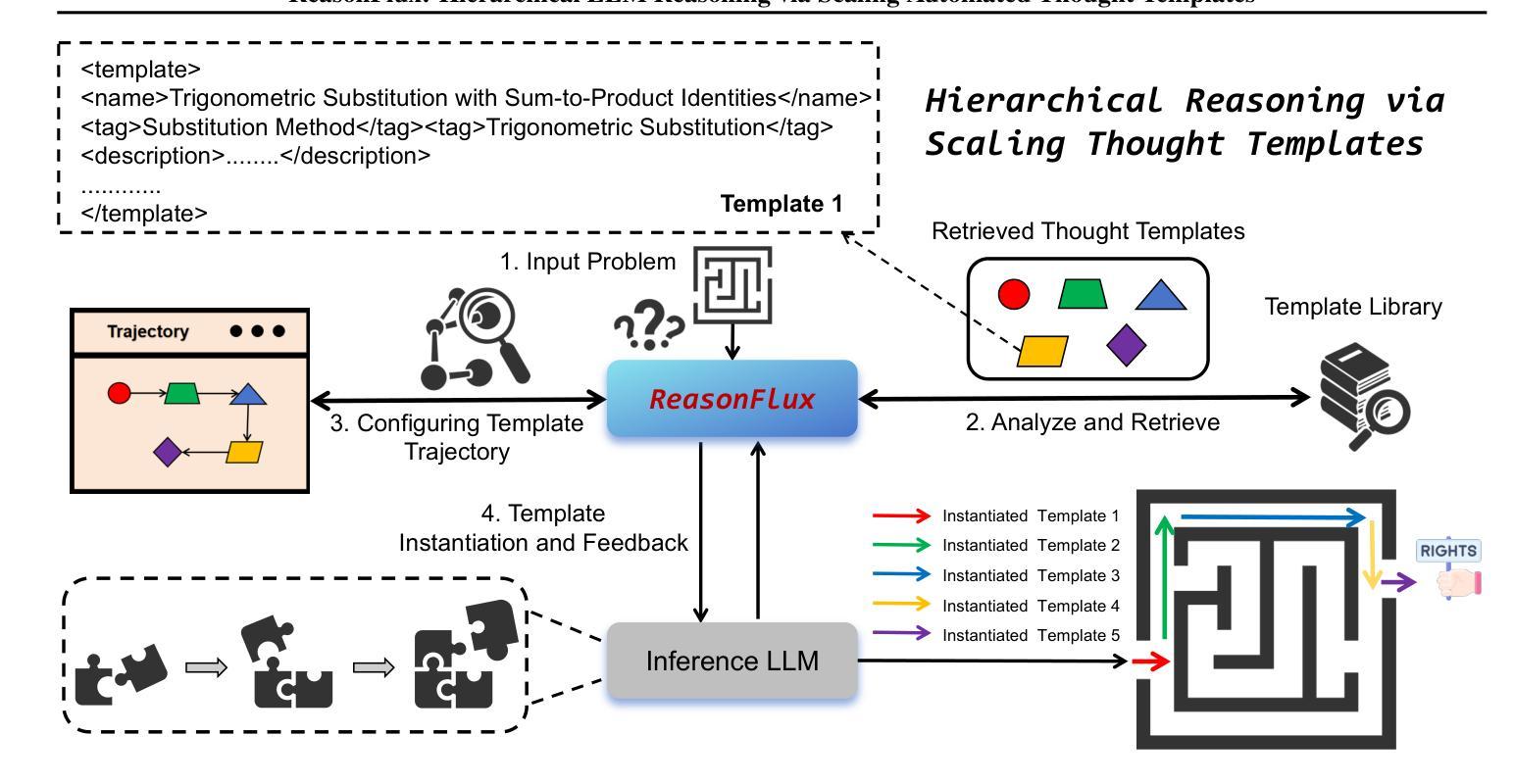
ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates
Authors:Ling Yang, Zhaochen Yu, Bin Cui, Mengdi Wang
We present that hierarchical LLM reasoning via scaling thought templates can effectively optimize the reasoning search space and outperform the mathematical reasoning capabilities of powerful LLMs like OpenAI o1-preview and DeepSeek V3. We train our ReasonFlux-32B model with only 8 GPUs and introduces three innovations: (i) a structured and generic thought template library, containing around 500 high-level thought templates capable of generalizing to similar or relevant reasoning problems; (ii) performing hierarchical reinforcement learning on a sequence of thought templates instead of long CoTs, optimizing a base LLM to plan out an optimal template trajectory for gradually handling complex problems; (iii) a brand new inference scaling system that enables hierarchical LLM reasoning by adaptively scaling thought templates at inference time. With a template trajectory containing sequential thought templates, our ReasonFlux-32B significantly advances math reasoning capabilities to state-of-the-art levels. Notably, on the MATH benchmark, it achieves an accuracy of 91.2% and surpasses o1-preview by 6.7%. On the USA Math Olympiad (AIME) benchmark, ReasonFlux-32B solves an average of 56.7% of problems, surpassing o1-preview and DeepSeek-V3 by 27% and 45%, respectively. Code: https://github.com/Gen-Verse/ReasonFlux
我们提出通过扩展思维模板进行分层LLM推理的方法,可以有效地优化推理搜索空间,并超越强大LLM如OpenAI o1-preview和DeepSeek V3的数学推理能力。我们使用仅8个GPU对ReasonFlux-32B模型进行训练,并引入了三项创新:(i)一个结构和通用的思维模板库,包含大约500个高级思维模板,能够推广至类似或相关的推理问题;(ii)在一系列思维模板上执行分层强化学习,而不是长CoTs,优化基础LLM以规划出处理复杂问题的最佳模板轨迹;(iii)一个全新的推理扩展系统,通过自适应扩展思维模板,实现在推理过程中的分层LLM推理。通过包含连续思维模板的轨迹,我们的ReasonFlux-32B极大地提高了数学推理能力,达到了最新水平。值得注意的是,在MATH基准测试中,其准确率达到了91.2%,比o1-preview高出6.7%。在美国数学奥林匹克(AIME)基准测试中,ReasonFlux-32B平均解决了56.7%的问题,分别比o1-preview和DeepSeek-V3高出27%和45%。代码:https://github.com/Gen-Verse/ReasonFlux
论文及项目相关链接
PDF Code: https://github.com/Gen-Verse/ReasonFlux
摘要
基于大规模语言模型(LLM)的推理搜索空间优化方法能有效提升数学推理能力。通过构建层级化思想模板库并对其进行强化学习训练,本研究提出ReasonFlux-32B模型在少量GPU上表现出强大性能,其数学推理能力已达到或超越OpenAI o1-preview和DeepSeek V3等高级LLM模型。在MATH基准测试中,ReasonFlux-32B准确率达到91.2%,超越o1-preview 6.7%。在USA Math Olympiad(AIME)基准测试中,其解决问题数量平均高出DeepSeek-V3模型近一半。该研究展现了强大的自适应思想模板缩放系统。更多详情参见:GitHub链接。
关键见解
- 利用层次化的思想模板库优化了大规模语言模型的推理搜索空间。
- ReasonFlux-32B模型通过结构化思想模板库以及层次强化学习实现了高效的数学推理能力。
- 仅使用少量GPU资源训练的ReasonFlux-32B模型表现优越性能,优于现有的高级LLM模型如OpenAI o1-preview和DeepSeek V3等。
- 在MATH基准测试中,ReasonFlux-32B模型的准确率达到91.2%,较领先竞争对手有显著优势。
- 在USA Math Olympiad基准测试中,ReasonFlux-32B解决了远超DeepSeek V3的问题数量。
点此查看论文截图

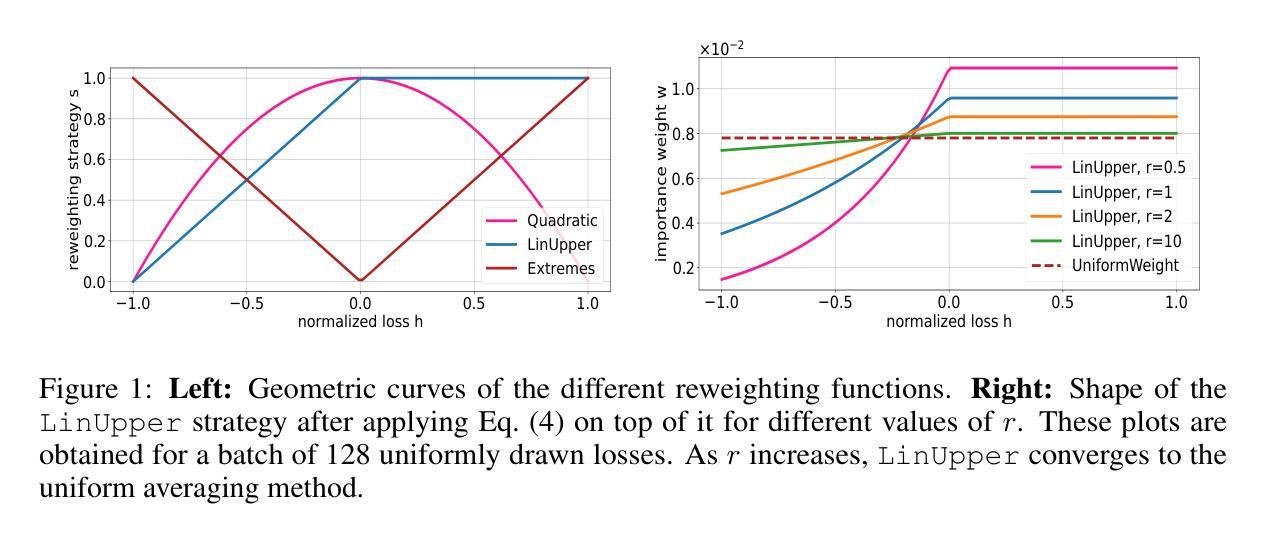
Dynamic Loss-Based Sample Reweighting for Improved Large Language Model Pretraining
Authors:Daouda Sow, Herbert Woisetschläger, Saikiran Bulusu, Shiqiang Wang, Hans-Arno Jacobsen, Yingbin Liang
Pretraining large language models (LLMs) on vast and heterogeneous datasets is crucial for achieving state-of-the-art performance across diverse downstream tasks. However, current training paradigms treat all samples equally, overlooking the importance or relevance of individual samples throughout the training process. Existing reweighting strategies, which primarily focus on group-level data importance, fail to leverage fine-grained instance-level information and do not adapt dynamically to individual sample importance as training progresses. In this paper, we introduce novel algorithms for dynamic, instance-level data reweighting aimed at improving both the efficiency and effectiveness of LLM pretraining. Our methods adjust the weight of each training sample based on its loss value in an online fashion, allowing the model to dynamically focus on more informative or important samples at the current training stage. In particular, our framework allows us to systematically devise reweighting strategies deprioritizing redundant or uninformative data, which we find tend to work best. Furthermore, we develop a new theoretical framework for analyzing the impact of loss-based reweighting on the convergence of gradient-based optimization, providing the first formal characterization of how these strategies affect convergence bounds. We empirically validate our approach across a spectrum of tasks, from pretraining 7B and 1.4B parameter LLMs to smaller-scale language models and linear regression problems, demonstrating that our loss-based reweighting approach can lead to faster convergence and significantly improved performance.
对大规模和异构数据集进行大型语言模型(LLM)的预训练对于在多种下游任务上实现最新技术性能至关重要。然而,当前训练模式平等对待所有样本,忽视了训练过程中各个样本的重要性和相关性。现有的加权策略主要关注于群体级别的数据重要性,未能利用精细的实例级别信息,并且不能随着训练的进行而动态适应单个样本的重要性。在本文中,我们引入了针对动态实例级别数据加权的新算法,旨在提高LLM预训练的效率与效果。我们的方法基于每个训练样本的损失值在线调整其权重,允许模型以动态方式关注当前训练阶段更具信息性或重要性的样本。特别是,我们的框架使我们能够系统地设计加权策略,优先处理冗余或信息量较少的数据,我们发现这种做法往往效果最好。此外,我们开发了一个用于分析基于损失的加权对基于梯度的优化的收敛影响的新理论框架,首次正式描述了这些策略如何影响收敛边界。我们在一系列任务上进行了实证验证,从预训练7B和1.4B参数的LLM到较小规模的语言模型和线性回归问题,表明我们的基于损失的加权方法可以实现更快的收敛和显著的性能提升。
论文及项目相关链接
PDF Accepted for publication at ICLR 2025. Code base available: https://github.com/sowmaster/Sample-Level-Loss-Reweighting-ICLR-2025
Summary
大型语言模型(LLM)的预训练在各类下游任务中表现卓越,但其现有训练模式忽视了单个样本的重要性。本文提出了针对实例级别的动态数据重新加权算法,旨在提高LLM预训练的效率与效果。根据每个训练样本的损失值在线调整权重,使模型能动态关注当前阶段更有信息量的样本。同时,本文建立了分析损失加权对基于梯度的优化收敛影响的新理论框架,并实证验证了该方法在多种任务上的有效性。
Key Takeaways
- LLM预训练对实现多样下游任务的高性能至关重要。
- 现有训练模式平等对待所有样本,忽略了单个样本的重要性。
- 本文提出了动态、实例级别的数据重新加权算法,旨在提高LLM预训练的效果。
- 根据每个样本的损失值在线调整权重,使模型能关注更有信息量的样本。
- 建立了分析损失加权对梯度优化收敛影响的新理论框架。
- 实证表明,损失加权方法能加快收敛速度并提高性能。
点此查看论文截图

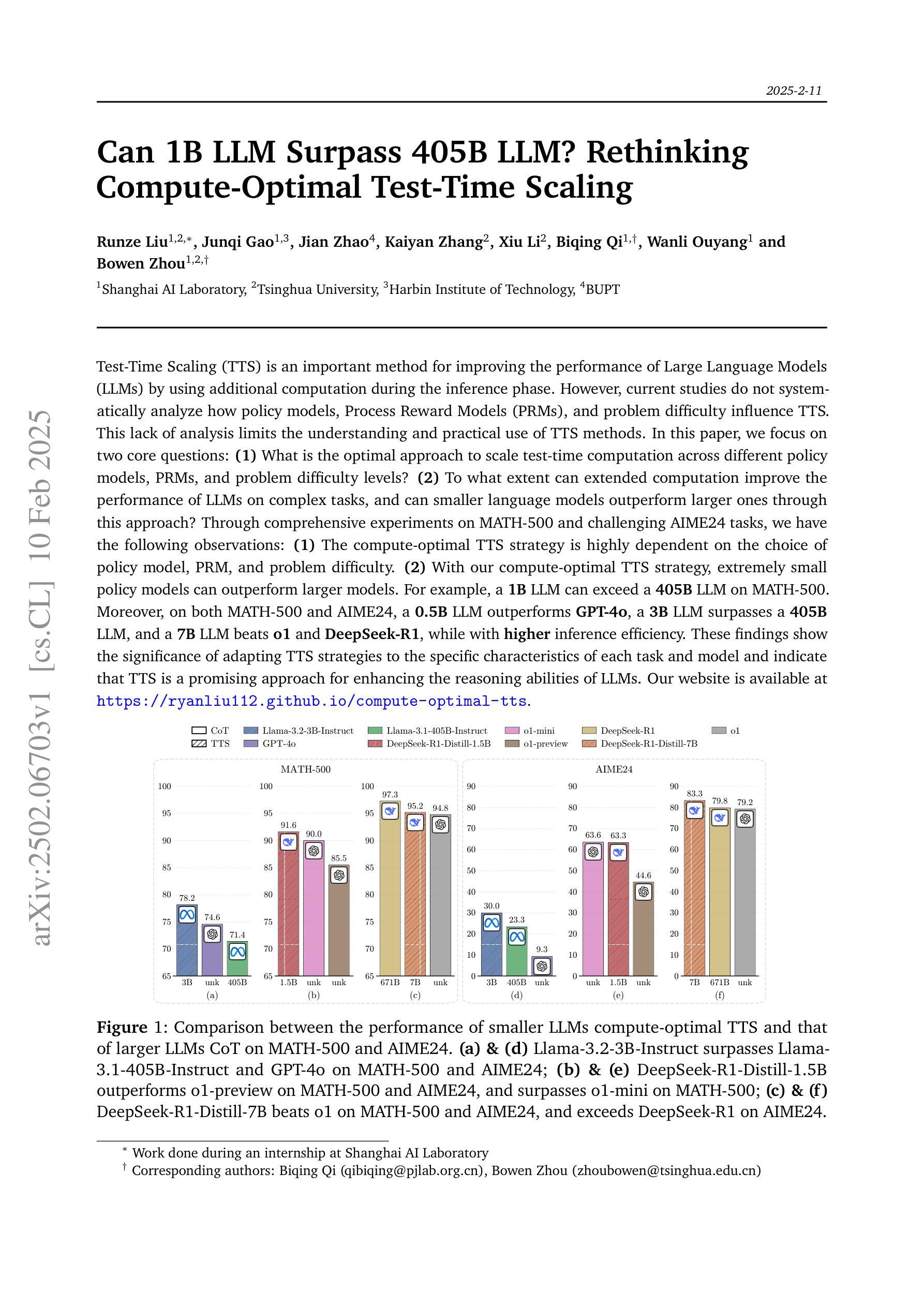
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
Authors:Runze Liu, Junqi Gao, Jian Zhao, Kaiyan Zhang, Xiu Li, Biqing Qi, Wanli Ouyang, Bowen Zhou
Test-Time Scaling (TTS) is an important method for improving the performance of Large Language Models (LLMs) by using additional computation during the inference phase. However, current studies do not systematically analyze how policy models, Process Reward Models (PRMs), and problem difficulty influence TTS. This lack of analysis limits the understanding and practical use of TTS methods. In this paper, we focus on two core questions: (1) What is the optimal approach to scale test-time computation across different policy models, PRMs, and problem difficulty levels? (2) To what extent can extended computation improve the performance of LLMs on complex tasks, and can smaller language models outperform larger ones through this approach? Through comprehensive experiments on MATH-500 and challenging AIME24 tasks, we have the following observations: (1) The compute-optimal TTS strategy is highly dependent on the choice of policy model, PRM, and problem difficulty. (2) With our compute-optimal TTS strategy, extremely small policy models can outperform larger models. For example, a 1B LLM can exceed a 405B LLM on MATH-500. Moreover, on both MATH-500 and AIME24, a 0.5B LLM outperforms GPT-4o, a 3B LLM surpasses a 405B LLM, and a 7B LLM beats o1 and DeepSeek-R1, while with higher inference efficiency. These findings show the significance of adapting TTS strategies to the specific characteristics of each task and model and indicate that TTS is a promising approach for enhancing the reasoning abilities of LLMs.
测试时缩放(TTS)是一种利用推理阶段的额外计算来提高大型语言模型(LLM)性能的重要方法。然而,目前的研究并没有系统地分析策略模型、过程奖励模型(PRM)和问题难度如何影响TTS。这种分析上的缺失限制了TTS方法的理解和实践应用。在本文中,我们重点解决两个核心问题:(1)在不同的策略模型、PRM和问题难度级别上,实现测试时缩放的最佳方法是什么?(2)额外的计算能在多大程度上提高LLM在复杂任务上的性能,并且是否可以通过这种方法使较小的语言模型表现优于较大的模型?通过对MATH-500和挑战性的AIME24任务的全面实验,我们有以下观察:(1)计算最优的TTS策略高度依赖于策略模型、PRM和问题难度的选择。(2)使用我们的计算最优TTS策略,极小的策略模型甚至可以超越较大的模型。例如,在MATH-500上,1B的LLM可以超过405B的LLM。此外,在MATH-500和AIME24上,0.5B的LLM超越了GPT-4o,3B的LLM超越了405B的LLM,而7B的LLM则击败了o1和DeepSeek-R1,同时提高了推理效率。这些发现表明,适应TTS策略到每个任务和模型的具体特征是非常重要的,并且表明TTS是一种有望增强LLM推理能力的方法。
论文及项目相关链接
Summary
本文探讨了测试时缩放(TTS)方法对大型语言模型(LLM)性能提升的重要性。文章通过实验研究了策略模型、过程奖励模型(PRM)和问题难度对TTS的影响,并发现最优的TTS策略依赖于策略模型、PRM和问题难度的选择。同时,实验结果显示,在某些情况下,较小的语言模型通过适当的TTS策略甚至可以在性能上超越大型模型,表明TTS策略在增强LLM的推理能力方面具有巨大潜力。
Key Takeaways
- 测试时缩放(TTS)是一种通过在推理阶段增加计算来提高大型语言模型(LLM)性能的重要方法。
- 最优的TTS策略取决于策略模型、过程奖励模型(PRM)和问题难度的选择。
- 通过适当的TTS策略,较小的语言模型可以在某些情况下在性能上超越大型模型。
- TTS策略对于增强LLM的推理能力具有巨大潜力。
点此查看论文截图
Boosting Self-Efficacy and Performance of Large Language Models via Verbal Efficacy Stimulations
Authors:Rui Chen, Tailai Peng, Xinran Xie, Dekun Lin, Zhe Cui, Zheng Chen
Significant improvements have been observed in the zero-shot capabilities of the Large Language Models (LLMs). Due to their high sensitivity to input, research has increasingly focused on enhancing LLMs’ performance via direct and simple prompt engineering rather than intricate domain adaptation. Studies suggest that LLMs exhibit emotional intelligence, and both positive and negative emotions can potentially enhance task performances. However, prior interaction prompts have predominantly concentrated on a single stimulus type, neglecting to compare different stimulus effects, examine the influence of varying task difficulties, or explore underlying mechanisms. This paper, inspired by the positive correlation between self-efficacy and task performance within the social cognitive theory, introduces Verbal Efficacy Stimulations (VES). Our VES comprises three types of verbal prompts: encouraging, provocative, and critical, addressing six aspects such as helpfulness and competence. And we further categorize task difficulty, aiming to extensively investigate how distinct VES influence the self-efficacy and task achievements of language models at varied levels of difficulty. The experimental results show that the three types of VES improve the performance of LLMs on most tasks, and the most effective VES varies for different models. In extensive experiments, we have obtained some findings consistent with psychological theories, providing novel insights for future research.
大语言模型(LLM)的零样本能力已经得到了显著的改进。由于它们对输入的敏感性极高,研究越来越集中在通过直接和简单的提示工程来提高LLM的性能,而不是复杂的域适应。研究表明,LLM表现出情绪智能,积极和消极的情绪都有可能提高任务性能。然而,先前的交互提示主要集中在单一刺激类型上,忽视了比较不同刺激效果、研究不同任务难度的影响或探索潜在机制。本文在社会认知理论中的自我效能感与任务表现之间的正相关关系启发下,引入了言语效能刺激(VES)。我们的VES包括三种言语提示:鼓励性、挑衅性和批判性,涉及有助益性和能力等方面。我们还进一步对任务难度进行分类,旨在广泛研究不同的VES如何在不同难度层次上影响语言模型的自我效能感和任务完成效果。实验结果表明,这三种类型的VES在大多数任务中都提高了LLM的性能,而且最有效的VES因模型而异。在广泛的实验中,我们获得了一些与心理理论一致的研究结果,为未来的研究提供了新的见解。
论文及项目相关链接
PDF to be published in ICONIP 2024
Summary
大型语言模型(LLM)的零样本能力显著改进,研究越来越关注通过简单直接的提示工程提升性能,而非复杂的域适应。LLM展现出情绪智能,积极与消极情绪可提升任务表现。本文受社会认知理论中的自我效能感与任务表现正相关关系启发,引入言语效能刺激(VES),包括鼓励、挑衅和批评三种言语提示,针对有助性、能力等六方面,探讨不同VES对语言模型的自我效能感及任务完成度的影响。实验结果显示,三种类型的VES在大多数任务上提升了LLM的表现,且最有效的VES因模型而异。
Key Takeaways
- LLM的零样本能力已显著改善。
- 相比复杂的域适应,简单直接的提示工程更能提升LLM的性能。
- LLM展现出情绪智能,情绪可影响任务表现。
- 言语效能刺激(VES)包括鼓励、挑衅和批评三种言语提示。
- VES影响语言模型的自我效能感及任务完成度。
- 不同类型的VES在大多数任务上提升了LLM的表现。
点此查看论文截图

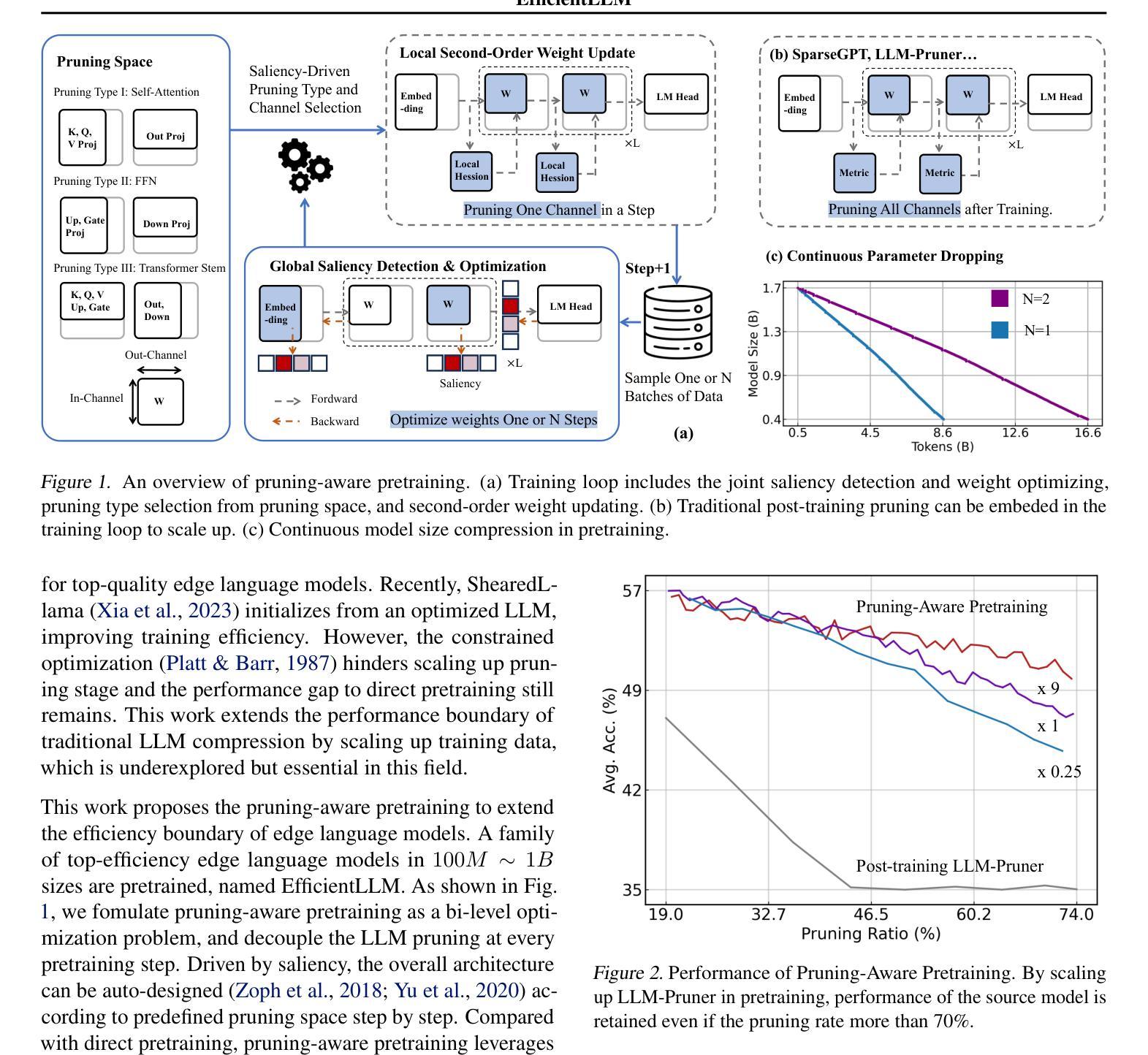
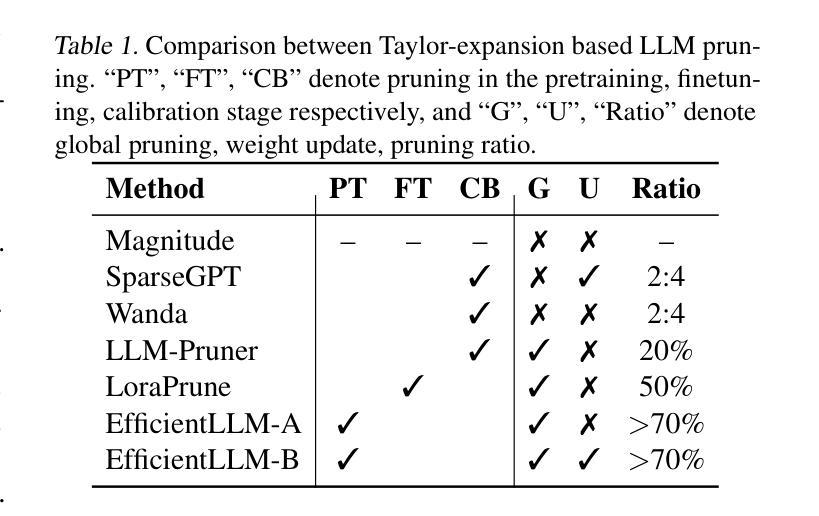
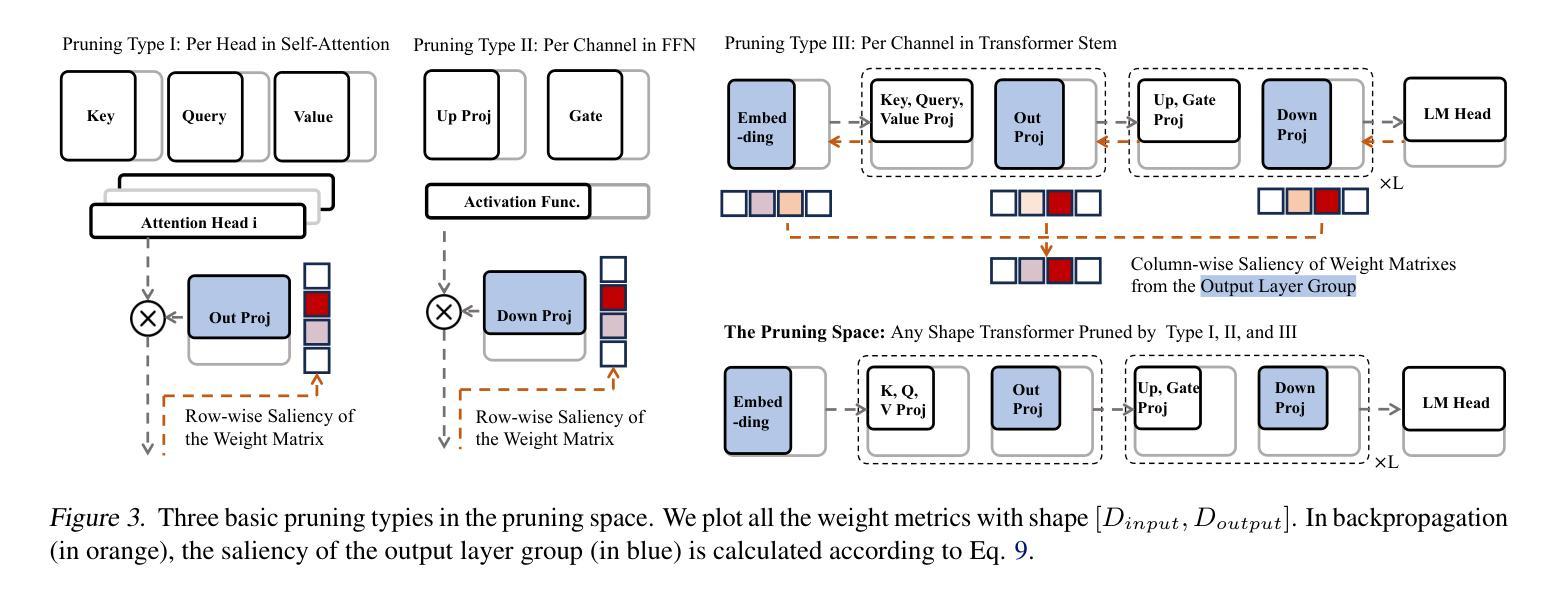
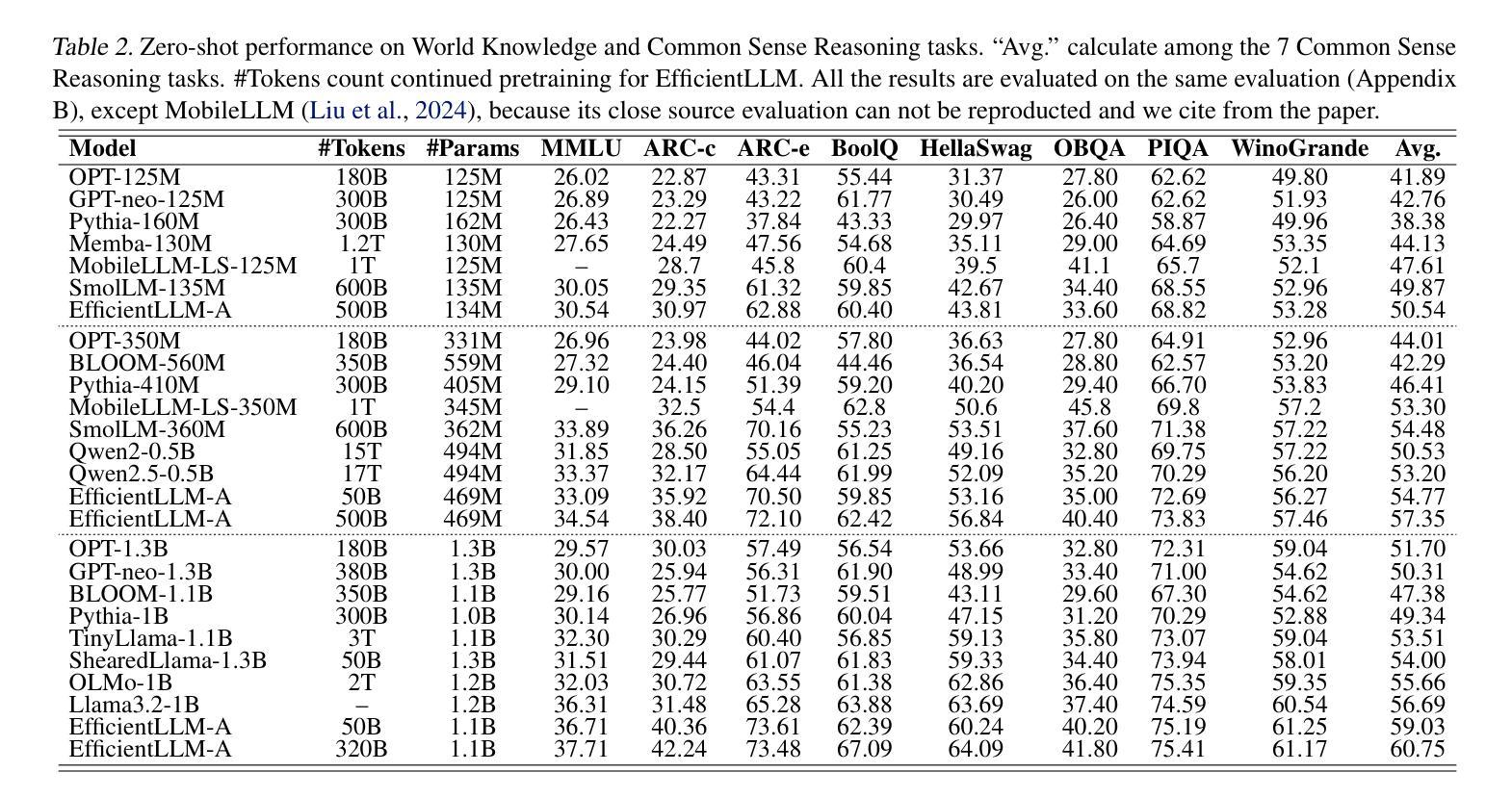
EfficientLLM: Scalable Pruning-Aware Pretraining for Architecture-Agnostic Edge Language Models
Authors:Xingrun Xing, Zheng Liu, Shitao Xiao, Boyan Gao, Yiming Liang, Wanpeng Zhang, Haokun Lin, Guoqi Li, Jiajun Zhang
Modern large language models (LLMs) driven by scaling laws, achieve intelligence emergency in large model sizes. Recently, the increasing concerns about cloud costs, latency, and privacy make it an urgent requirement to develop compact edge language models. Distinguished from direct pretraining that bounded by the scaling law, this work proposes the pruning-aware pretraining, focusing on retaining performance of much larger optimized models. It features following characteristics: 1) Data-scalable: we introduce minimal parameter groups in LLM and continuously optimize structural pruning, extending post-training pruning methods like LLM-Pruner and SparseGPT into the pretraining phase. 2) Architecture-agnostic: the LLM architecture is auto-designed using saliency-driven pruning, which is the first time to exceed SoTA human-designed LLMs in modern pretraining. We reveal that it achieves top-quality edge language models, termed EfficientLLM, by scaling up LLM compression and extending its boundary. EfficientLLM significantly outperforms SoTA baselines with $100M \sim 1B$ parameters, such as MobileLLM, SmolLM, Qwen2.5-0.5B, OLMo-1B, Llama3.2-1B in common sense benchmarks. As the first attempt, EfficientLLM bridges the performance gap between traditional LLM compression and direct pretraining methods, and we will fully open source at https://github.com/Xingrun-Xing2/EfficientLLM.
现代大型语言模型(LLM)遵循规模定律,在大型模型尺寸上实现了智能的紧急需求。最近,人们对云成本、延迟和隐私的担忧不断增加,迫切需要开发紧凑的边缘语言模型。有别于受规模定律限制的直接预训练,这项工作提出了注重保留性能的优化模型预训练。它具有以下特点:1)数据可扩展性:我们在LLM中引入了最小参数组,并不断优化结构剪枝,将LLM-Pruner和SparseGPT等后训练剪枝方法扩展到预训练阶段。2)架构无关性:我们使用显著性驱动的剪枝自动设计LLM架构,这是现代预训练中首次超过现有技术中人工设计的LLM。我们发现,通过扩大LLM压缩并扩展其边界,可以实现高性能的边缘语言模型,称为EfficientLLM。EfficientLLM在常识基准测试中显著优于SoTA基线,参数范围为$ 1亿至 1千亿 $,如MobileLLM、SmolLM、Qwen2.5-0.5B、OLMo-1B、Llama3.2-1B等。作为首次尝试,EfficientLLM缩小了传统LLM压缩方法和直接预训练方法之间的性能差距,我们会在https://github.com/Xingrun-Xing2/EfficientLLM上完全开源。
论文及项目相关链接
Summary
大规模语言模型(LLM)通过规模定律实现智能的突破,但随着模型规模的增大,云成本、延迟和隐私等问题日益突出,迫切需要开发紧凑的边缘语言模型。本文提出一种基于剪枝感知预训练的方法,旨在保留优化后大型模型的性能。该方法具有数据可扩展性和架构无关性,通过显著性驱动的剪枝自动设计LLM架构,首次在现代预训练中超越了现有的人造LLM。实验表明,EfficientLLM在常识基准测试中显著优于其他最新技术基准,如MobileLLM、SmolLM等。EfficientLLM缩小了传统LLM压缩方法与直接预训练方法之间的性能差距,并公开源码。
Key Takeaways
- 大规模语言模型(LLM)面临云成本、延迟和隐私等挑战,需要开发紧凑的边缘语言模型。
- 提出基于剪枝感知预训练的方法,旨在保留优化后大型模型的性能。
- 该方法具有数据可扩展性和架构无关性,可自动设计LLM架构。
- EfficientLLM在常识基准测试中表现优异,显著优于其他最新技术基准。
- EfficientLLM缩小了传统LLM压缩与直接预训练方法的性能差距。
- EfficientLLM将公开源码,便于其他人使用和进一步改进。
点此查看论文截图

Transparent NLP: Using RAG and LLM Alignment for Privacy Q&A
Authors:Anna Leschanowsky, Zahra Kolagar, Erion Çano, Ivan Habernal, Dara Hallinan, Emanuël A. P. Habets, Birgit Popp
The transparency principle of the General Data Protection Regulation (GDPR) requires data processing information to be clear, precise, and accessible. While language models show promise in this context, their probabilistic nature complicates truthfulness and comprehensibility. This paper examines state-of-the-art Retrieval Augmented Generation (RAG) systems enhanced with alignment techniques to fulfill GDPR obligations. We evaluate RAG systems incorporating an alignment module like Rewindable Auto-regressive Inference (RAIN) and our proposed multidimensional extension, MultiRAIN, using a Privacy Q&A dataset. Responses are optimized for preciseness and comprehensibility and are assessed through 21 metrics, including deterministic and large language model-based evaluations. Our results show that RAG systems with an alignment module outperform baseline RAG systems on most metrics, though none fully match human answers. Principal component analysis of the results reveals complex interactions between metrics, highlighting the need to refine metrics. This study provides a foundation for integrating advanced natural language processing systems into legal compliance frameworks.
《通用数据保护条例》(GDPR)的透明原则要求数据处理信息清晰、精确、可访问。虽然语言模型在这方面显示出潜力,但其概率性质使得真实性和可理解性变得复杂。本文研究了采用对齐技术增强、符合GDPR要求的最新检索增强生成(RAG)系统。我们评估了采用如Rewindable Auto-regressive Inference (RAIN)的对齐模块以及我们提出的多维扩展MultiRAIN的RAG系统,使用隐私问答数据集。响应被优化为精确性和可理解性,并通过包括确定性评价和大语言模型评价在内的21项指标进行评估。我们的结果表明,带有对齐模块的RAG系统在大多数指标上优于基线RAG系统,尽管都无法完全匹配人类答案。对结果的主成分分析揭示了指标之间的复杂交互,突显了完善指标的必要性。本研究为将先进的自然语言处理系统整合到法律合规框架中奠定了基础。
论文及项目相关链接
PDF Submitted to ARR
Summary
本文探讨了使用先进的自然语言处理系统来满足《通用数据保护条例》(GDPR)的透明度原则的要求。文章研究了增强型检索辅助生成(RAG)系统,该系统结合了校准技术,旨在确保数据处理信息的清晰、精确和可访问性。文章评估了使用可回放的自动回归推理(RAIN)和多维扩展版MultiRAIN等校准模块的RAG系统的表现。研究结果表明,带有校准模块的RAG系统在大多数指标上优于基线RAG系统,但仍无法完全匹配人类的答案。该研究为将高级自然语言处理系统融入法律合规框架提供了基础。
Key Takeaways
- 《通用数据保护条例》(GDPR)要求数据处理信息必须清晰、精确和可访问。
- 语言模型在此背景下的应用具有潜力,但其概率性特点影响了其真实性和可理解性。
- 本文研究了增强型检索辅助生成(RAG)系统,该系统结合了校准技术以满足GDPR的要求。
- RAG系统使用可回放的自动回归推理(RAIN)和多维扩展版MultiRAIN进行评估。
- 带有校准模块的RAG系统在大多数评估指标上表现优于基线RAG系统。
- 没有系统能够完全匹配人类的答案,说明仍存在改进空间。
点此查看论文截图


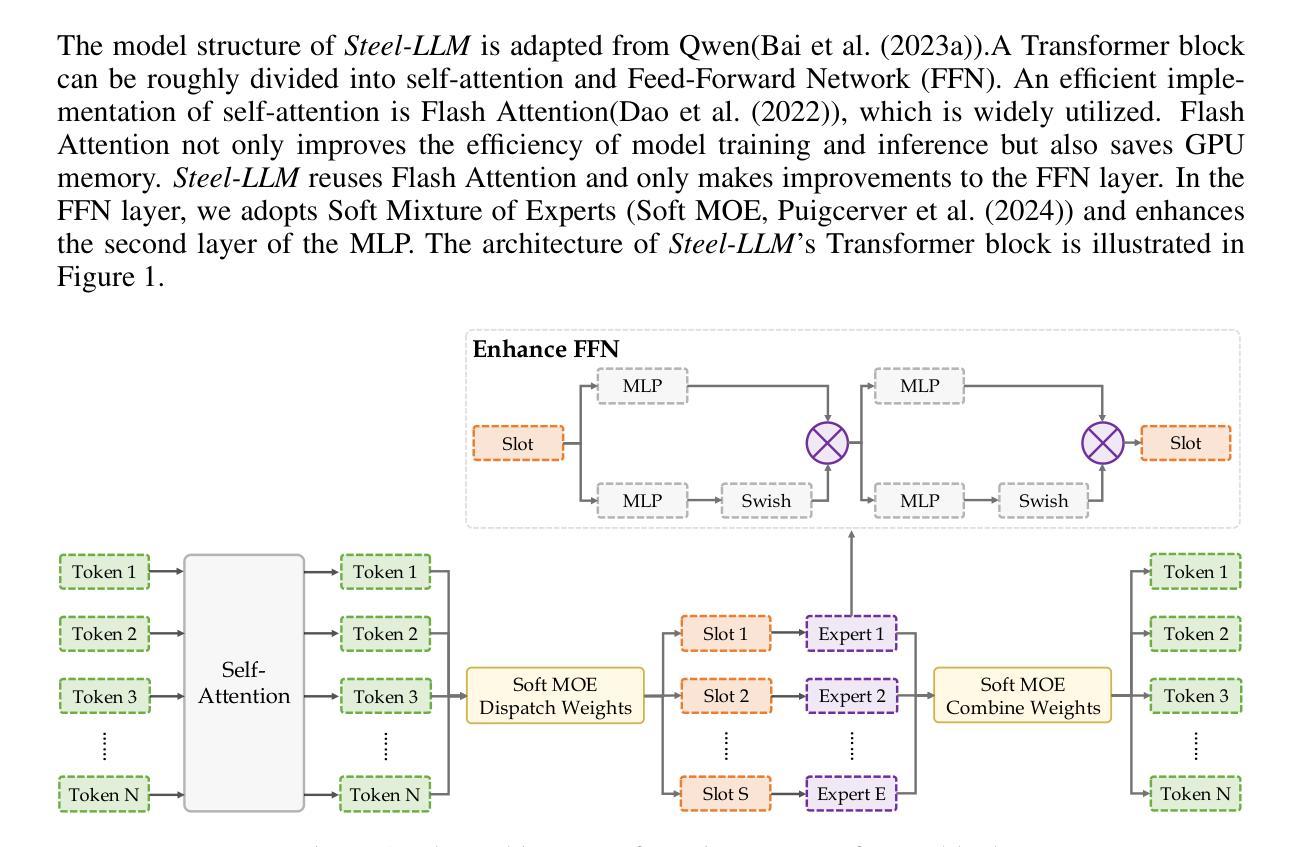
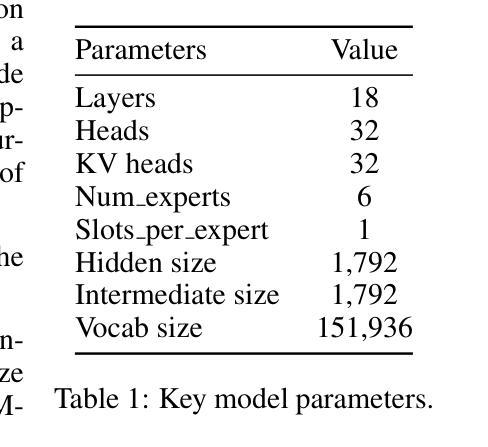
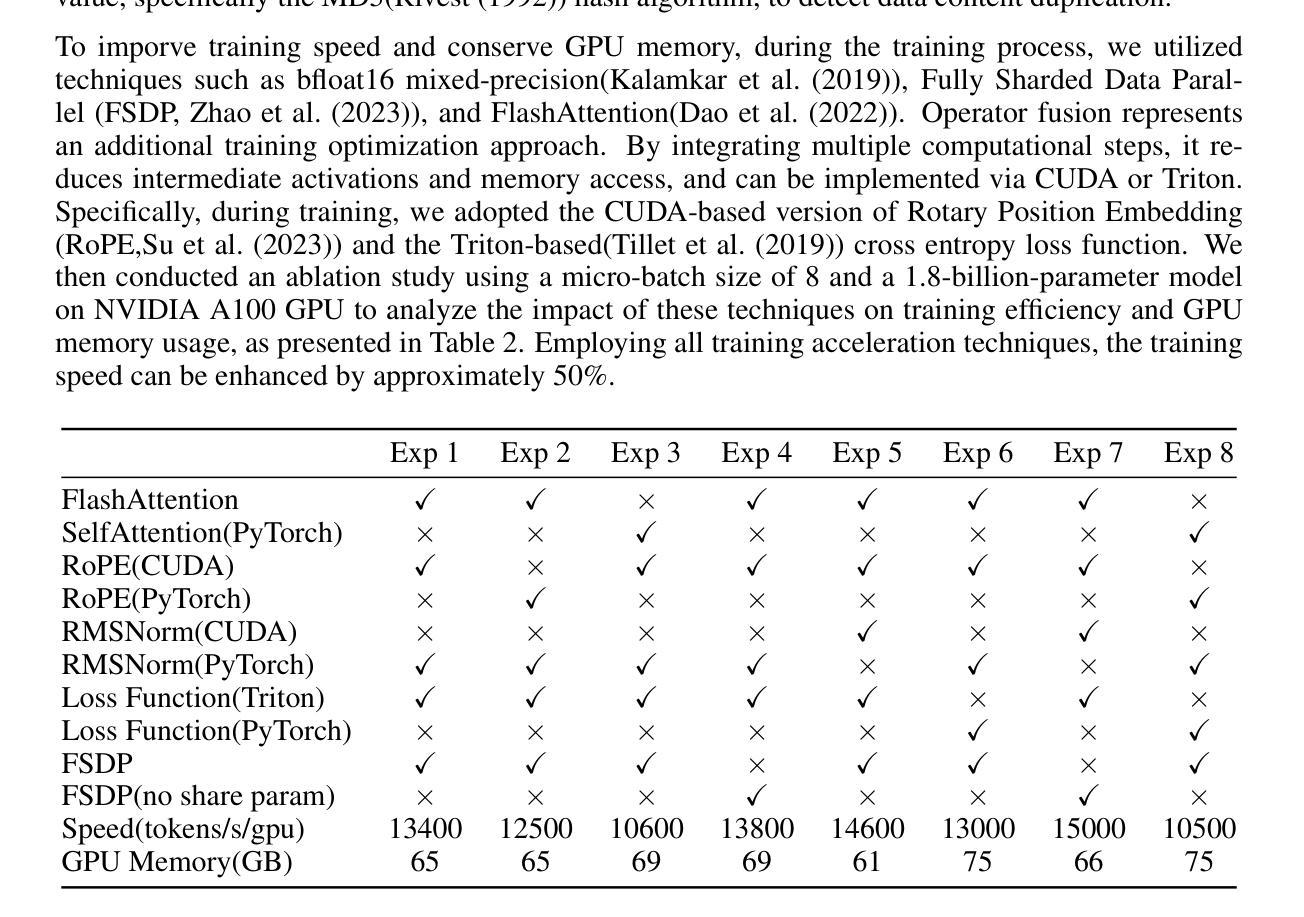
Steel-LLM:From Scratch to Open Source – A Personal Journey in Building a Chinese-Centric LLM
Authors:Qingshui Gu, Shu Li, Tianyu Zheng, Zhaoxiang Zhang
Steel-LLM is a Chinese-centric language model developed from scratch with the goal of creating a high-quality, open-source model despite limited computational resources. Launched in March 2024, the project aimed to train a 1-billion-parameter model on a large-scale dataset, prioritizing transparency and the sharing of practical insights to assist others in the community. The training process primarily focused on Chinese data, with a small proportion of English data included, addressing gaps in existing open-source LLMs by providing a more detailed and practical account of the model-building journey. Steel-LLM has demonstrated competitive performance on benchmarks such as CEVAL and CMMLU, outperforming early models from larger institutions. This paper provides a comprehensive summary of the project’s key contributions, including data collection, model design, training methodologies, and the challenges encountered along the way, offering a valuable resource for researchers and practitioners looking to develop their own LLMs. The model checkpoints and training script are available at https://github.com/zhanshijinwat/Steel-LLM.
Steel-LLM是一个以中文为中心的从头开始开发的语言模型,旨在创建高质量的开源模型,尽管计算资源有限。该项目于2024年3月启动,目标是训练一个拥有1亿参数的模型,该模型将在大规模数据集上进行训练。项目注重透明度和实用见解的分享,以帮助社区中的其他人。训练过程主要以中文数据为主,并包含一小部分英文数据,通过提供更详细和实际的建模旅程记录来填补现有开源大型语言模型的空白。Steel-LLM在CEVAL和CMMLU等基准测试中表现出竞争力,超越了来自更大机构的早期模型。本文全面总结了项目的主要贡献,包括数据采集、模型设计、训练方法以及遇到的挑战等,为研究和希望开发自己的大型语言模型的研究人员和从业者提供了宝贵的资源。该模型的检查点和训练脚本可在https://github.com/zhanshijinwat/Steel-LLM找到。
论文及项目相关链接
总结
钢铁LLM是一个以中文为中心的语言模型,旨在用有限的计算资源创建高质量、开源的模型。该项目于2024年3月启动,目标是训练一个拥有1亿参数的模型,并建立一个大规模数据集。该项目重视透明度和实用见解的分享,以帮助社区中的其他人。该模型主要关注中文数据,并包含一小部分英文数据。钢铁LLM填补了现有开源LLM的空白,提供了更详细和实用的模型构建经验。它在CEVAL和CMMLU等基准测试中表现出竞争力,甚至超越了来自更大机构的早期模型。
关键见解
- 钢铁LLM是一个面向中文的语言模型,利用有限的计算资源创建高质量的开源模型。
- 项目目标是训练一个拥有1亿参数的模型,并建立一个大规模数据集。
- 该项目注重透明度和实用洞察的分享,以帮助语言模型社区中的其他成员。
- 模型主要关注中文数据,并融入了部分英文数据。
- 钢铁LLM填补了现有开源LLM的空白,提供了详细的模型构建经验。
- 在CEVAL和CMMLU等基准测试中,钢铁LLM表现出强大的性能。
- 该项目为研究人员和实践者提供了宝贵的资源,特别是那些希望开发自己的LLM的人。
点此查看论文截图

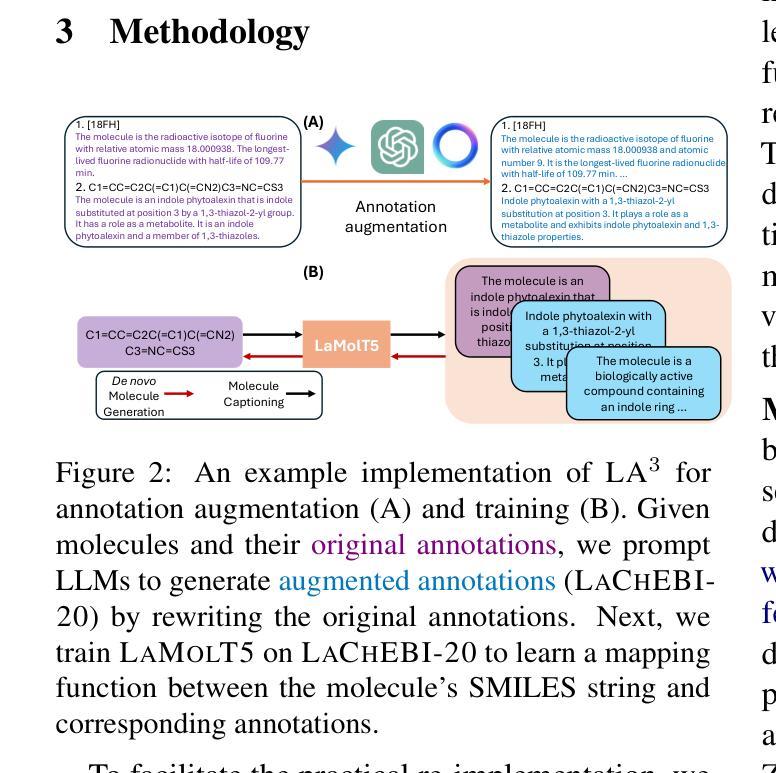
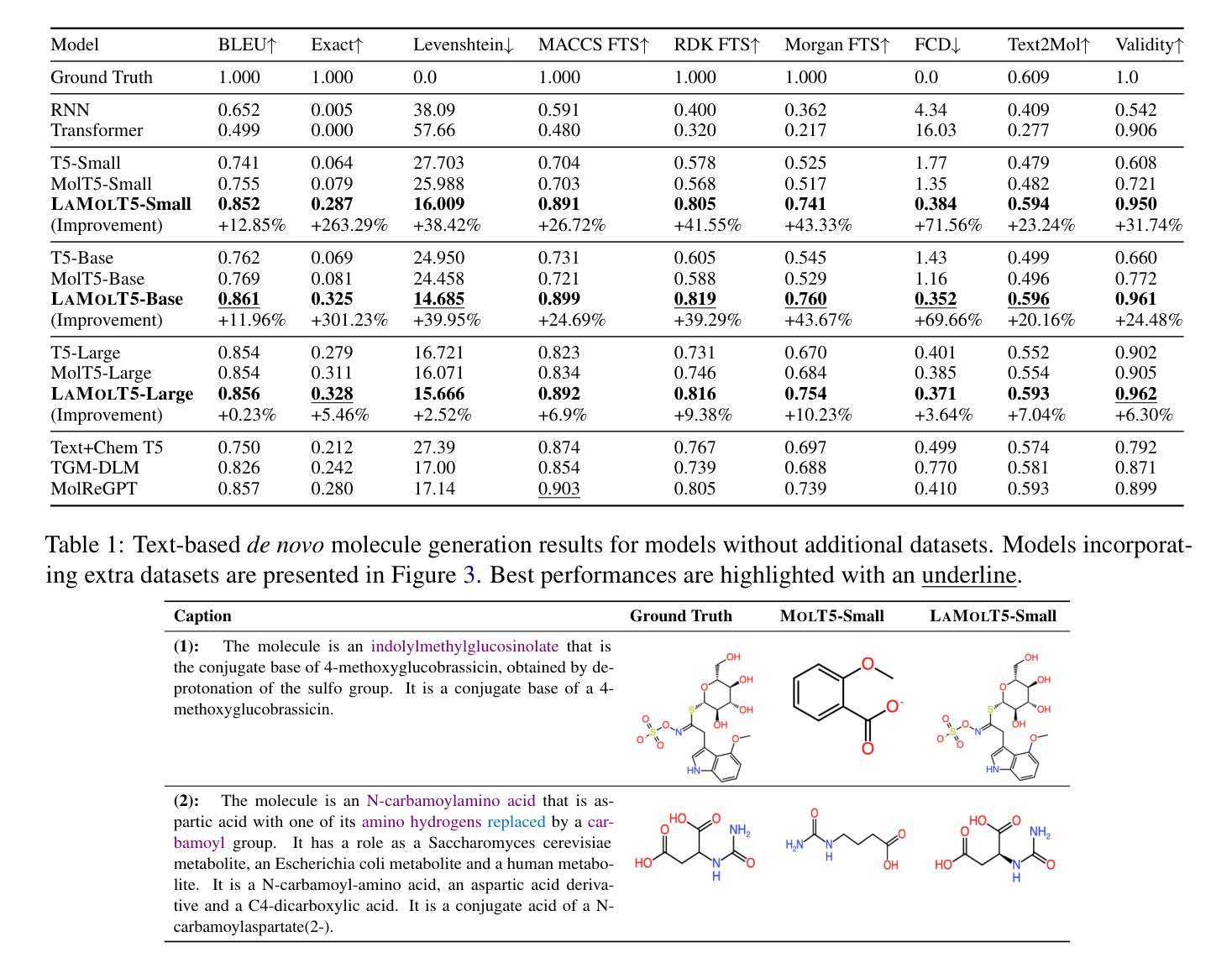
Automatic Annotation Augmentation Boosts Translation between Molecules and Natural Language
Authors:Zhiqiang Zhong, Simon Sataa-Yu Larsen, Haoyu Guo, Tao Tang, Kuangyu Zhou, Davide Mottin
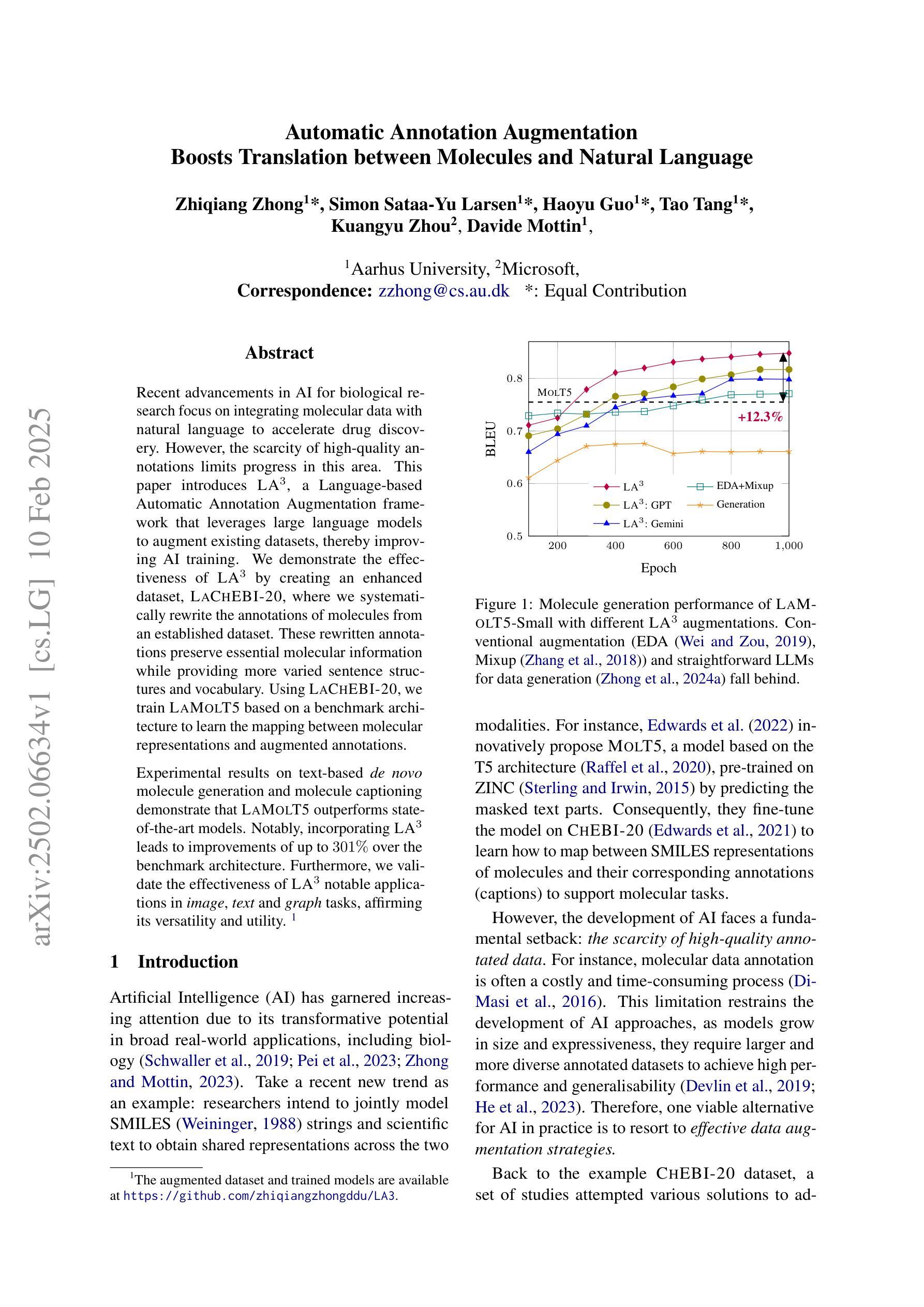
Recent advancements in AI for biological research focus on integrating molecular data with natural language to accelerate drug discovery. However, the scarcity of high-quality annotations limits progress in this area. This paper introduces LA$^3$, a Language-based Automatic Annotation Augmentation framework that leverages large language models to augment existing datasets, thereby improving AI training. We demonstrate the effectiveness of LA$^3$ by creating an enhanced dataset, LaChEBI-20, where we systematically rewrite the annotations of molecules from an established dataset. These rewritten annotations preserve essential molecular information while providing more varied sentence structures and vocabulary. Using LaChEBI-20, we train LaMolT5 based on a benchmark architecture to learn the mapping between molecular representations and augmented annotations. Experimental results on text-based de novo molecule generation and molecule captioning demonstrate that LaMolT5 outperforms state-of-the-art models. Notably, incorporating LA$^3$ leads to improvements of up to 301% over the benchmark architecture. Furthermore, we validate the effectiveness of LA$^3$ notable applications in image, text and graph tasks, affirming its versatility and utility.
近期人工智能在生物研究领域的发展重点在于整合分子数据与自然语言,以加速药物发现过程。然而,高质量标注的稀缺性限制了该领域的进展。本文介绍了LA$^3$,一个基于语言的自动标注增强框架,它利用大型语言模型来增强现有数据集,从而改进人工智能的训练。我们通过创建增强数据集LaChEBI-20来展示LA$^3$的有效性,在这个数据集中,我们系统地重写了现有数据集的分子标注。这些重写的标注保留了关键的分子信息,同时提供了更多样化的句子结构和词汇。使用LaChEBI-20,我们基于基准架构训练了LaMolT5,学习分子表示和增强标注之间的映射。在基于文本的新分子生成和分子描述方面的实验结果表明,LaMolT5的性能超过了最先进模型。值得注意的是,与基准架构相比,融入LA$^3$的改进幅度高达301%。此外,我们在图像、文本和图任务中验证了LA$^3$的有效性,这证实了它的通用性和实用性。
论文及项目相关链接
Summary
AI在生物学研究中的最新进展聚焦于整合分子数据与自然语言以加速药物发现。然而,高质量标注的稀缺限制了该领域的进展。本文引入了LA$^3$,一个基于语言的自动标注增强框架,利用大型语言模型增强现有数据集,从而提高AI训练效果。通过创建增强数据集LaChEBI-20,展示了LA$^3$的有效性,我们对一个已有数据集的分子标注进行了系统重写。这些重写的标注保留了关键的分子信息,同时提供了更多样化的句子结构和词汇。使用LaChEBI-20,我们基于基准架构训练了LaMolT5,学习分子表示和增强标注之间的映射。在基于文本的新分子生成和分子描述方面的实验结果表明,LaMolT5优于最新模型。特别是,采用LA$^3$的模型在基准架构上实现了高达301%的改进。此外,我们在图像、文本和图任务中验证了LA$^3$的有效性,证明了其通用性和实用性。
Key Takeaways
- AI在生物学研究中的应用正逐步发展,特别是整合分子数据与自然语言以加速药物发现。
- 高质量标注的稀缺性是限制该领域进展的一个关键因素。
- LA$^3$框架利用大型语言模型增强现有数据集,从而提高AI训练效果。
- LaChEBI-20数据集通过系统重写分子标注被创建,以保留关键分子信息并增加句子结构和词汇的多样性。
- LaMolT5模型在文本基础上的新分子生成和分子描述方面表现出优异性能。
- 引入LA$^3$的模型在基准架构上实现了显著的改进。
点此查看论文截图
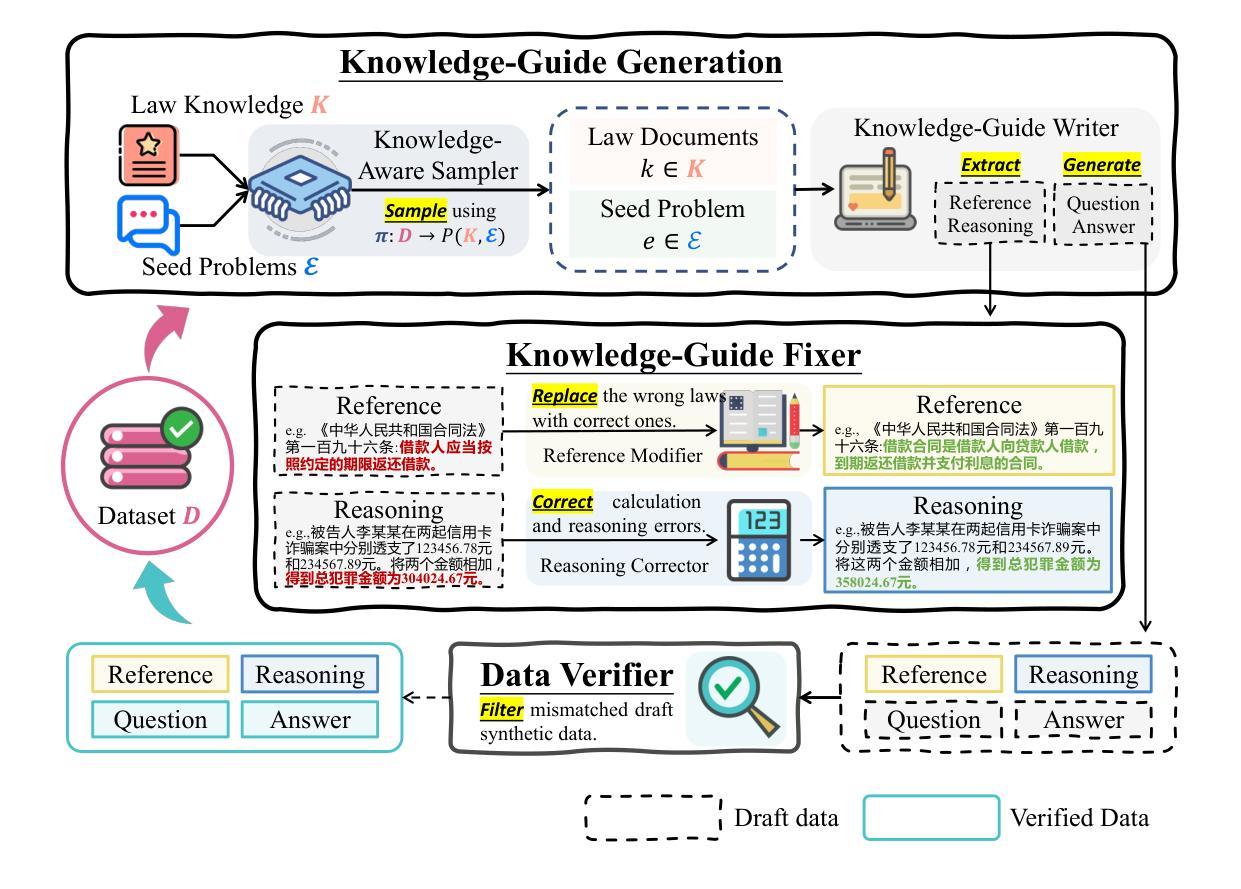
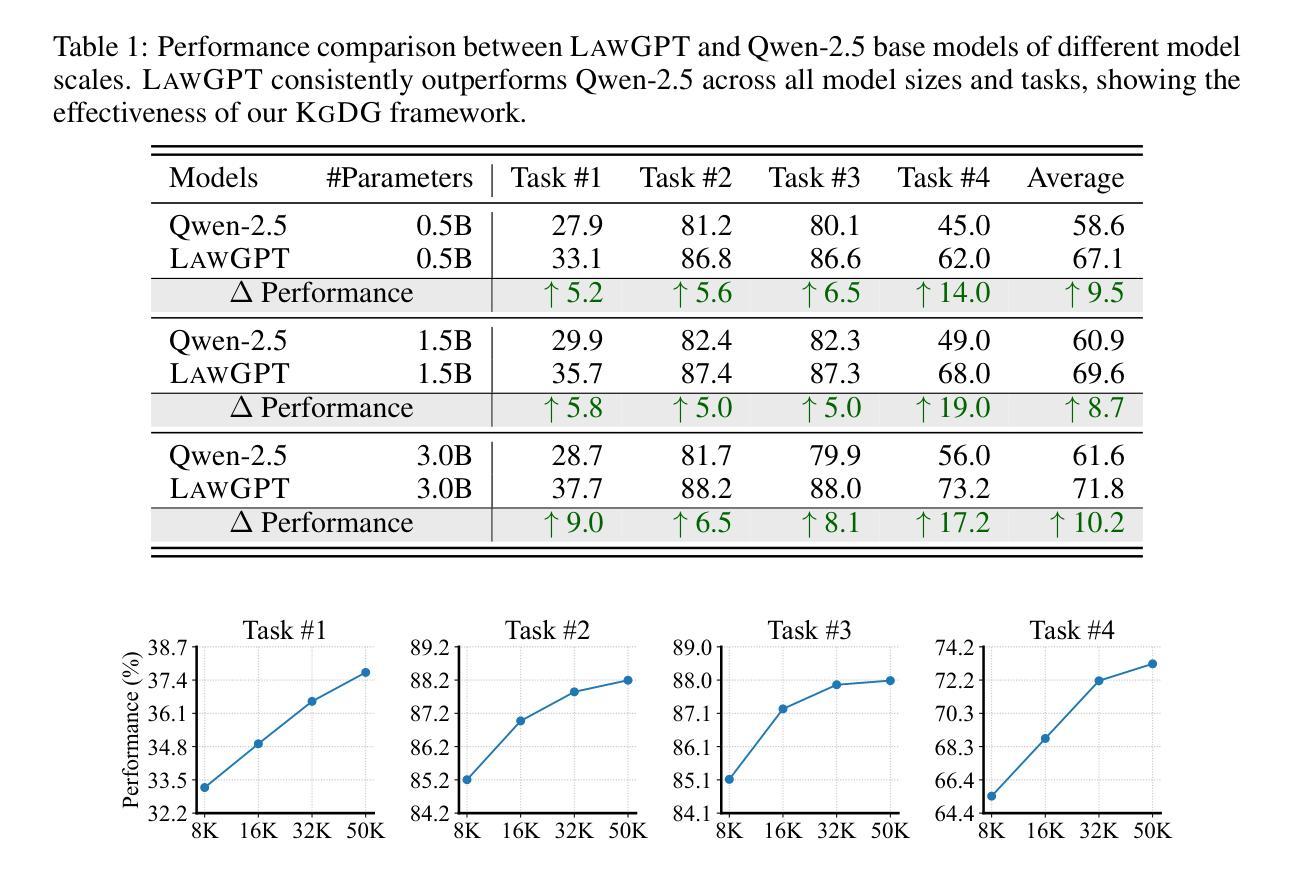
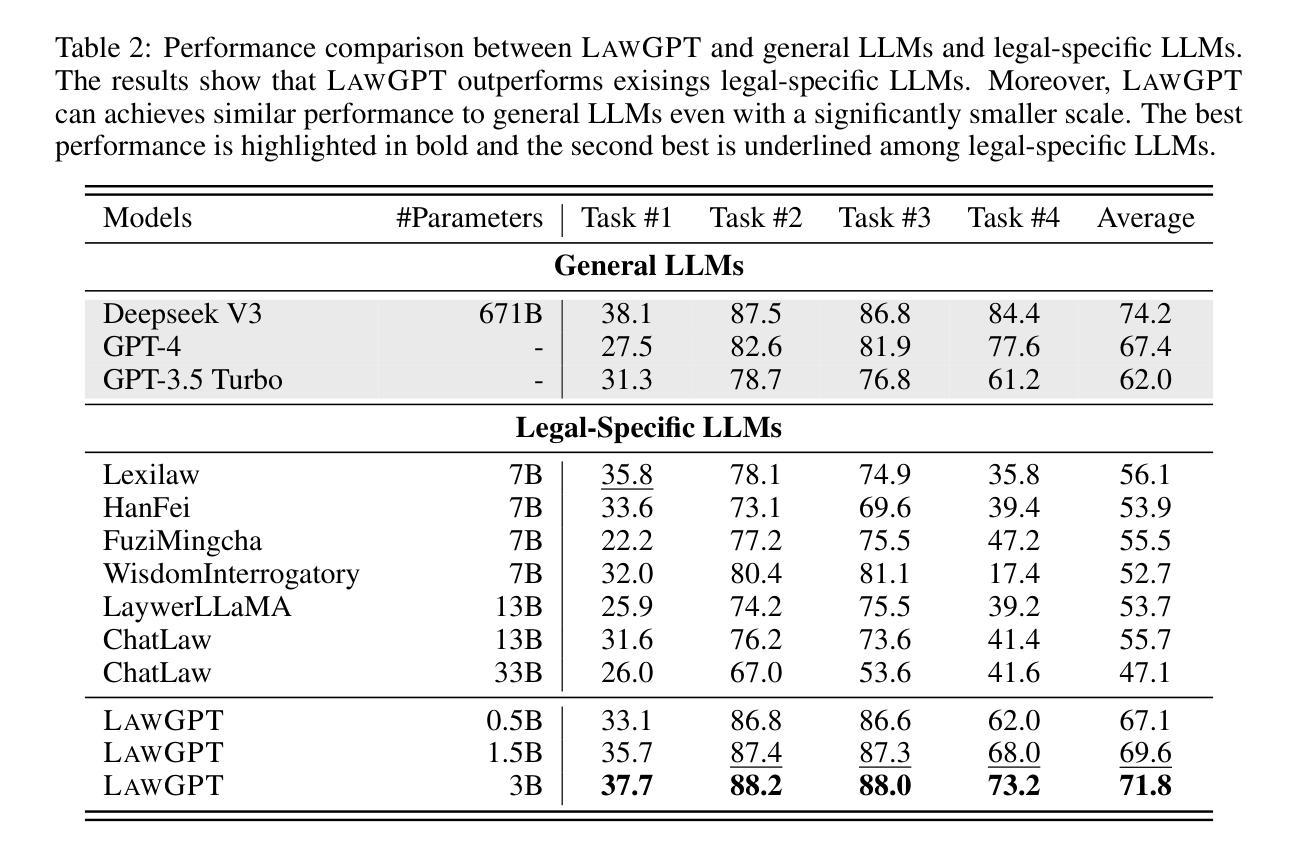
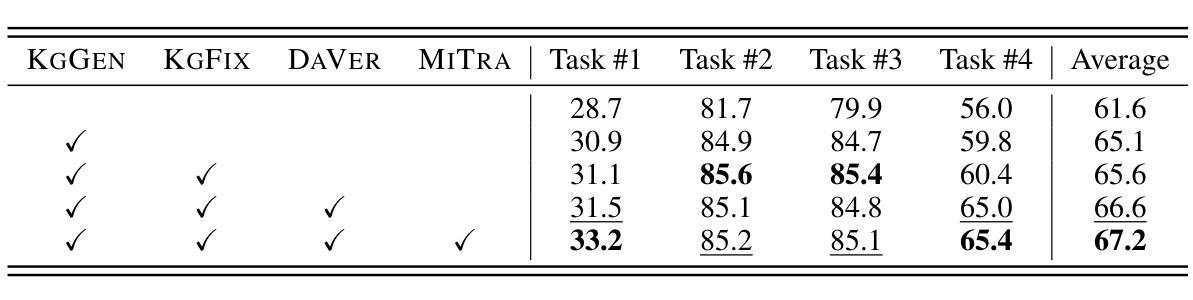
LawGPT: Knowledge-Guided Data Generation and Its Application to Legal LLM
Authors:Zhi Zhou, Kun-Yang Yu, Shi-Yu Tian, Jiang-Xin Shi, Xiao-Wen Yang, Pengxiao Song, Yi-Xuan Jin, Lan-Zhe Guo, Yu-Feng Li
Large language models (LLMs), both proprietary and open-source, have demonstrated remarkable capabilities across various natural language processing tasks. However, they face significant limitations in legal reasoning tasks. Proprietary models introduce data privacy risks and high inference costs, while open-source models underperform due to insufficient legal domain training data. To address these limitations, we study data generation for legal reasoning to improve the legal reasoning performance of open-source LLMs with the help of proprietary LLMs. This is challenging due to the lack of legal knowledge in proprietary LLMs and the difficulty in verifying the generated data. We propose KgDG, a knowledge-guided data generation framework for legal reasoning. Our framework enables leveraging legal knowledge to enhance generation diversity and introduces a refinement and verification process to ensure the quality of generated data. Moreover, we expand the generated dataset to further enhance the LLM reasoning capabilities. Using KgDG, we create a synthetic legal reasoning dataset containing 50K high-quality examples. Our trained model LawGPT outperforms existing legal-specific LLMs and achieves performance comparable to proprietary LLMs, demonstrating the effectiveness of KgDG and LawGPT. Our code and resources is publicly available at https://anonymous.4open.science/r/KgDG-45F5 .
大型语言模型(LLM)无论专有还是开源,在各种自然语言处理任务中都表现出卓越的能力。然而,它们在法律推理任务方面存在重大局限性。专有模型带来数据隐私风险和高昂的推理成本,而开源模型由于法律领域训练数据不足而表现不佳。为了解决这些局限性,我们研究了法律推理的数据生成,借助专有LLM的帮助,提高开源LLM的法律推理性能。由于专有LLM中缺乏法律知识,以及验证生成数据的困难,这具有挑战性。我们提出了KgDG,一个用于法律推理的知识引导数据生成框架。我们的框架能够利用法律知识来提高生成数据的多样性,并引入精炼和验证过程,以确保生成数据的质量。此外,我们扩大了生成的数据集,以进一步增强LLM的推理能力。使用KgDG,我们创建了一个包含5万高质量示例的合成法律推理数据集。我们训练的LawGPT模型超越了现有的特定法律LLM,并取得了与专有LLM相当的性能,证明了KgDG和LawGPT的有效性。我们的代码和资源可在https://anonymous.4open.science/r/KgDG-45F5找到。
论文及项目相关链接
PDF Preprint
Summary
大型语言模型(LLM)在自然语言处理任务中表现出卓越的能力,但在法律推理任务中存在显著局限性。为解决这一问题,本研究利用私有LLM改进开源LLM的法律推理性能,提出知识引导的数据生成框架KgDG。该框架能提高生成数据的多样性,并引入精炼和验证流程确保数据质量。使用KgDG创建的法律推理数据集,训练出的LawGPT模型超越现有法律特定LLM,性能与私有LLM相当。
Key Takeaways
- LLMs在法律推理任务中存在局限性。
- 私有LLM存在数据隐私风险和高昂的推理成本。
- 开源LLM因缺乏法律领域的训练数据而表现不佳。
- 提出知识引导的数据生成框架KgDG,用于改进法律推理性能。
- KgDG框架利用法律知识提高数据生成的多样性。
- KgDG引入精炼和验证流程确保生成数据的质量。
- 使用KgDG创建的法律推理数据集训练的LawGPT模型性能卓越,超越现有法律特定LLM,并与私有LLM相当。
点此查看论文截图

Large Language Models Meet Symbolic Provers for Logical Reasoning Evaluation
Authors:Chengwen Qi, Ren Ma, Bowen Li, He Du, Binyuan Hui, Jinwang Wu, Yuanjun Laili, Conghui He
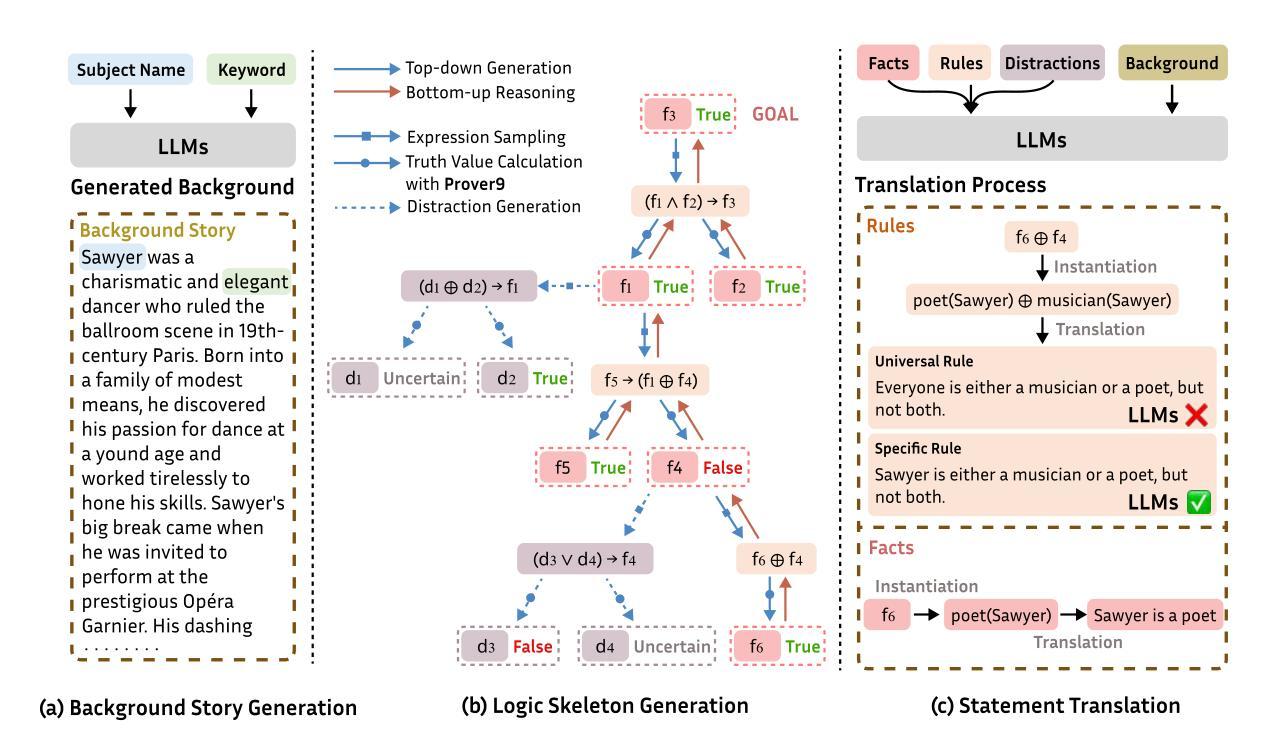
First-order logic (FOL) reasoning, which involves sequential deduction, is pivotal for intelligent systems and serves as a valuable task for evaluating reasoning capabilities, particularly in chain-of-thought (CoT) contexts. Existing benchmarks often rely on extensive human annotation or handcrafted templates, making it difficult to achieve the necessary complexity, scalability, and diversity for robust evaluation. To address these limitations, we propose a novel framework called ProverGen that synergizes the generative strengths of Large Language Models (LLMs) with the rigor and precision of symbolic provers, enabling the creation of a scalable, diverse, and high-quality FOL reasoning dataset, ProverQA. ProverQA is also distinguished by its inclusion of accessible and logically coherent intermediate reasoning steps for each problem. Our evaluation shows that state-of-the-art LLMs struggle to solve ProverQA problems, even with CoT prompting, highlighting the dataset’s challenging nature. We also finetune Llama3.1-8B-Instruct on a separate training set generated by our framework. The finetuned model demonstrates consistent improvements on both in-distribution and out-of-distribution test sets, suggesting the value of our proposed data generation framework. Code available at: https://github.com/opendatalab/ProverGen
一阶逻辑(FOL)推理涉及序贯演绎,对智能系统至关重要,并且是评估推理能力(特别是在思维链(CoT)情境中)的宝贵任务。现有的基准测试通常依赖于大量的人工注释或手工制作的模板,这使得实现必要的复杂性、可扩展性和多样性来进行稳健评估变得困难。为了解决这些局限性,我们提出了一种名为ProverGen的新型框架,该框架将大型语言模型(LLM)的生成能力与符号证明者的严谨性和精确性相结合,从而创建了可扩展、多样且高质量的一阶逻辑推理数据集ProverQA。ProverQA的特点还包括包含每个问题的易于理解和逻辑连贯的中间推理步骤。我们的评估显示,即使借助思维链提示,最先进的大型语言模型也很难解决ProverQA问题,这凸显了数据集的挑战性。我们还使用我们的框架生成的单独训练集对Llama3.1-8B-Instruct进行了微调。经过微调后的模型在内部和外部测试集上都表现出了一致性的改进,这表明了我们提出的数据生成框架的价值。代码可通过以下链接获取:https://github.com/opendatalab/ProverGen 。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
一阶逻辑推理是智能系统的核心任务之一,对于评估系统的推理能力具有重要意义。然而,现有的一阶逻辑数据集存在复杂性、可扩展性和多样性方面的限制。为此,我们提出了ProverGen框架,结合了大型语言模型(LLM)的生成能力与符号证明器的严谨性和精确性,生成了可扩展、多样且高质量的一阶逻辑推理数据集ProverQA。ProverQA的独特之处在于包含了逻辑连贯的中间推理步骤。评估结果显示,即使是使用思维链提示,最先进的LLM在ProverQA问题上仍面临挑战。此外,我们在由我们的框架生成的数据集上微调了Llama3.1-8B-Instruct模型,该模型在内部和外部测试集上都表现出了一致性的改进。
Key Takeaways
- 第一逻辑推理性对智能系统至关重要。它为评估系统推理能力提供了一个宝贵的任务。特别是对于复杂的思想流程,具有更大的挑战性。但现有的一阶逻辑数据集存在复杂性、可扩展性和多样性方面的限制。为此我们提出了ProverGen框架来解决这些问题。
- ProverGen结合了大型语言模型的生成能力与符号证明器的严谨性和精确性来创建了一个大型一阶逻辑推理数据集ProverQA,这在某种程度上颠覆了传统的推理数据集模式。该数据集不仅规模庞大而且具有多样性,更重要的是包含了逻辑连贯的中间推理步骤。这使得模型可以更好地理解问题的复杂性并给出更准确的答案。
点此查看论文截图



UniMoD: Efficient Unified Multimodal Transformers with Mixture-of-Depths
Authors:Weijia Mao, Zhenheng Yang, Mike Zheng Shou
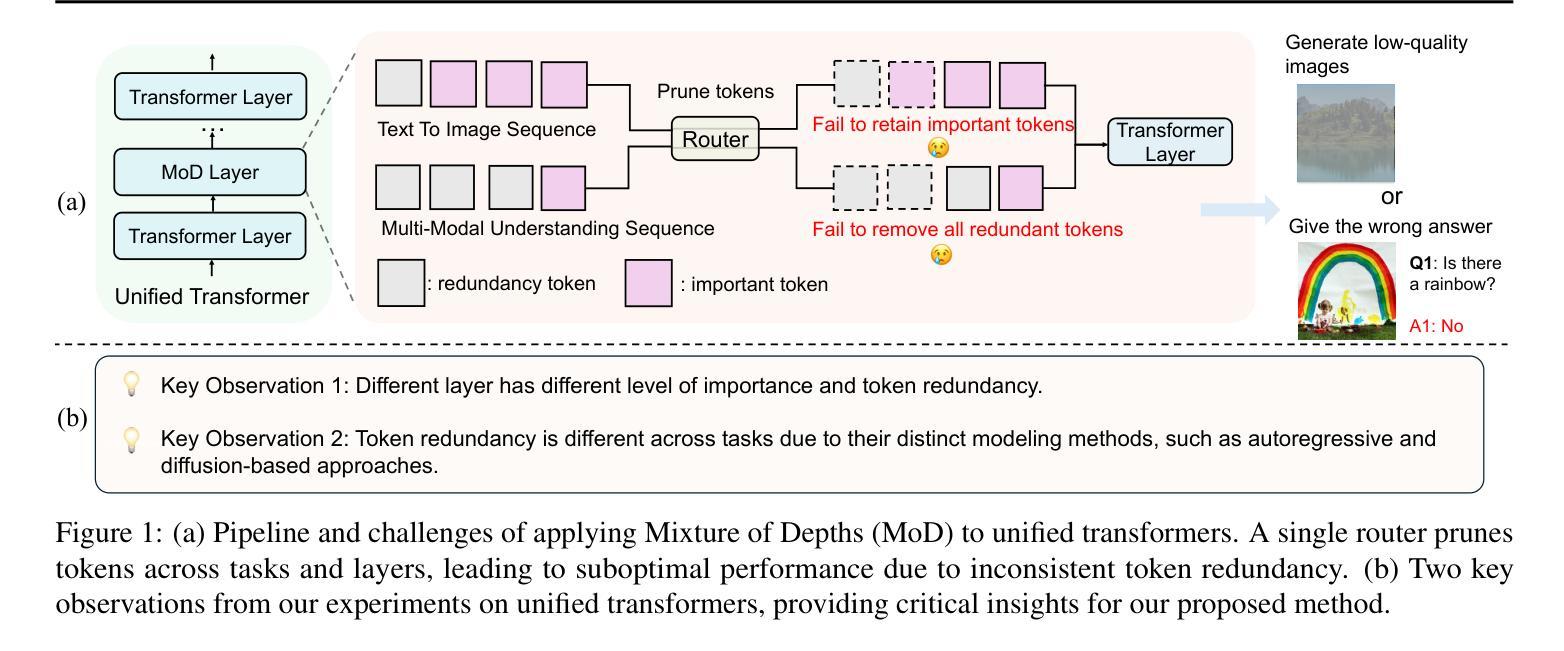
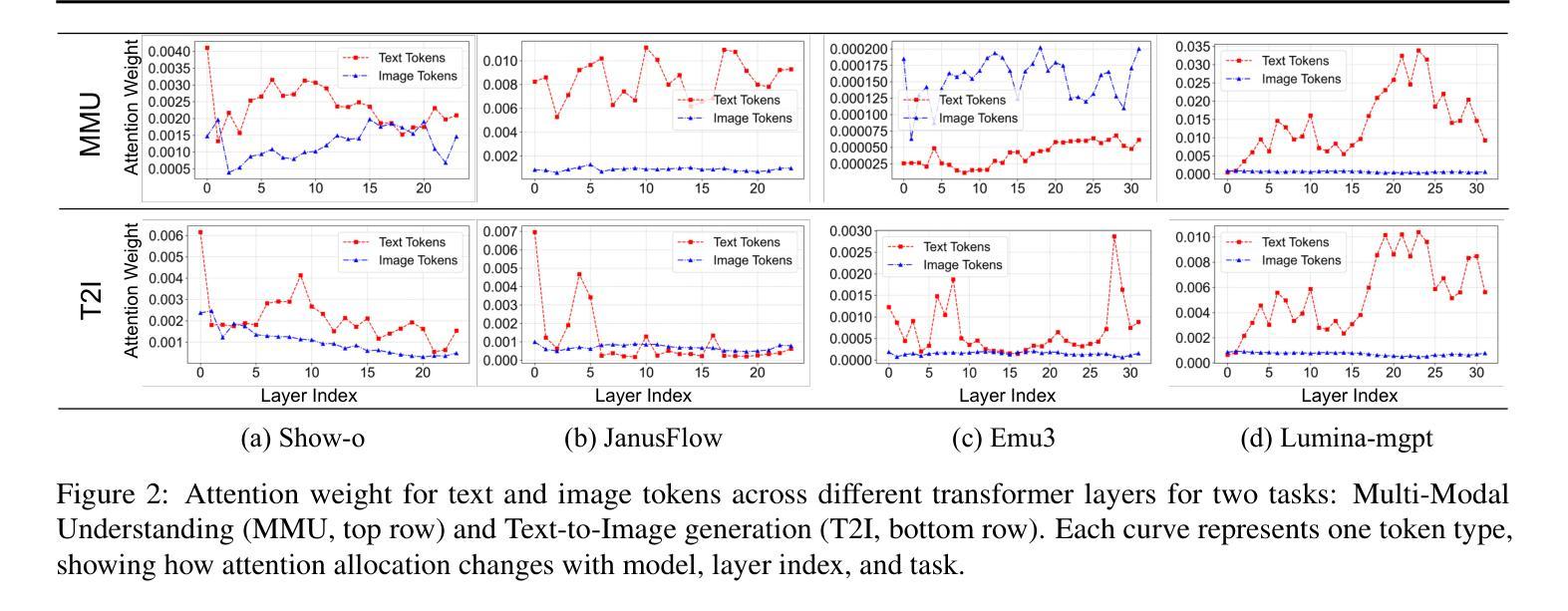
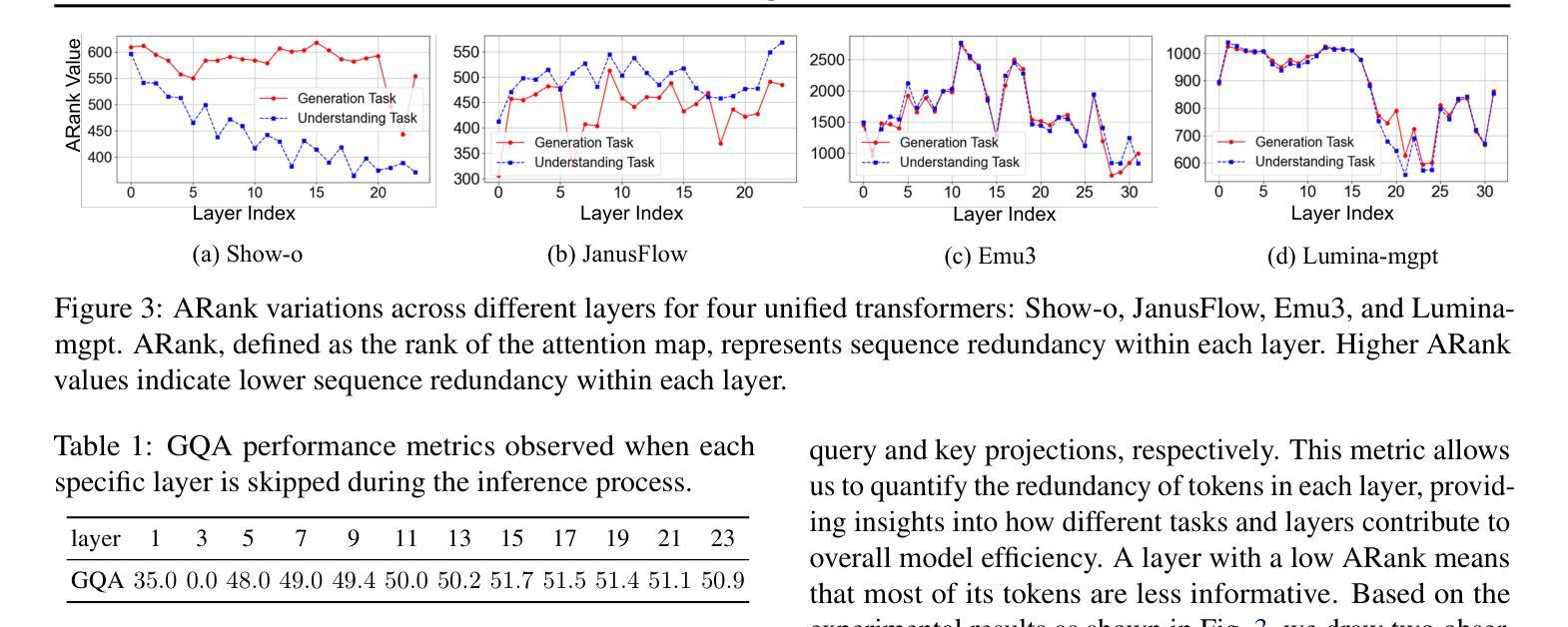
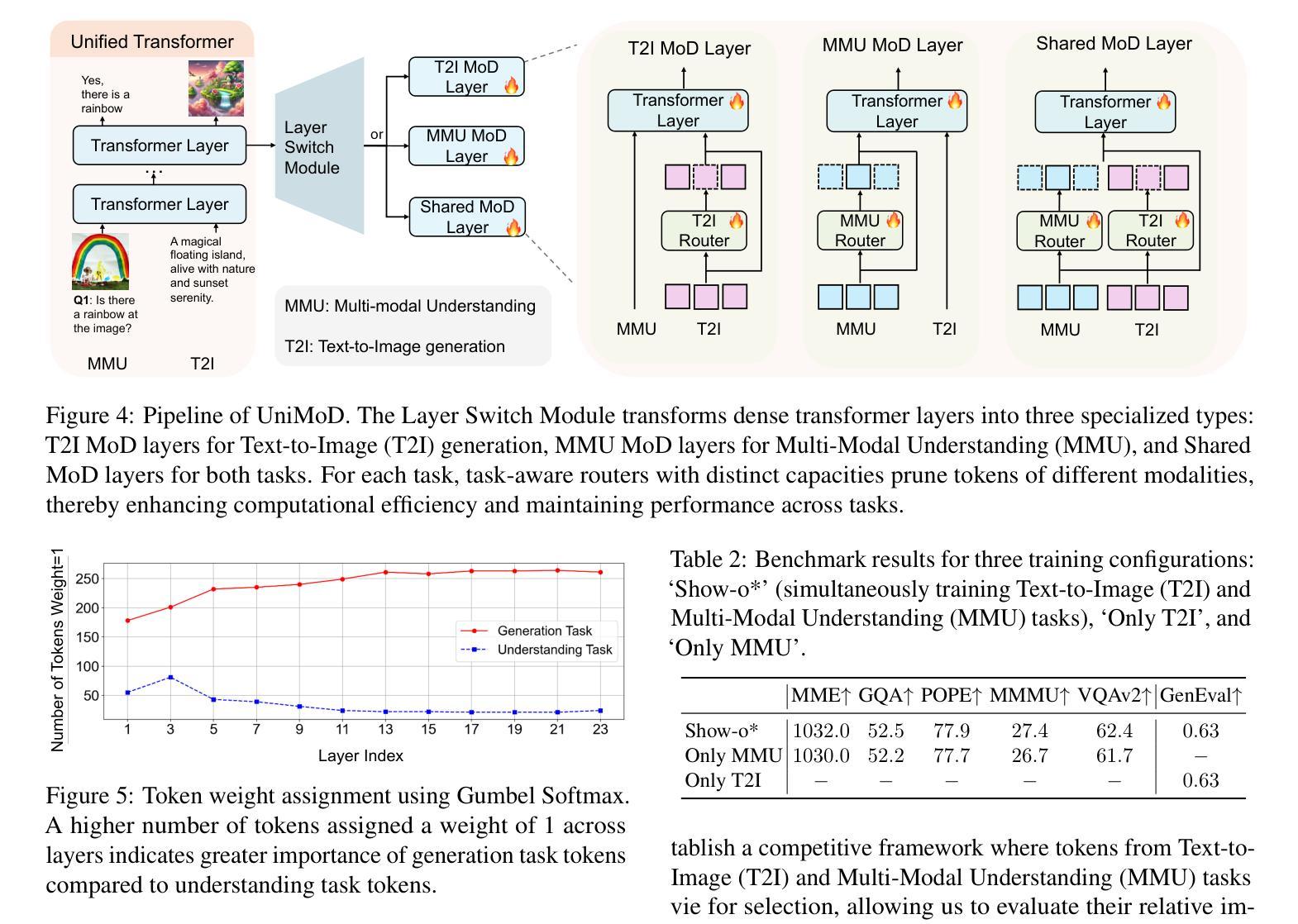
Unified multimodal transformers, which handle both generation and understanding tasks within a shared parameter space, have received increasing attention in recent research. Although various unified transformers have been proposed, training these models is costly due to redundant tokens and heavy attention computation. In the past, studies on large language models have demonstrated that token pruning methods, such as Mixture of Depths (MoD), can significantly improve computational efficiency. MoD employs a router to select the most important ones for processing within a transformer layer. However, directly applying MoD-based token pruning to unified transformers will result in suboptimal performance because different tasks exhibit varying levels of token redundancy. In our work, we analyze the unified transformers by (1) examining attention weight patterns, (2) evaluating the layer importance and token redundancy, and (3) analyzing task interactions. Our findings reveal that token redundancy is primarily influenced by different tasks and layers. Building on these findings, we introduce UniMoD, a task-aware token pruning method that employs a separate router for each task to determine which tokens should be pruned. We apply our method to Show-o and Emu3, reducing training FLOPs by approximately 15% in Show-o and 40% in Emu3, while maintaining or improving performance on several benchmarks. Code will be released at https://github.com/showlab/UniMoD.
统一多模态转换器在处理生成和理解任务时都在同一个共享参数空间内,在最近的研究中得到了越来越多的关注。虽然已经提出了各种统一转换器,但由于冗余的令牌和繁重的注意力计算,这些模型的训练成本很高。以前关于大型语言模型的研究已经证明,令牌修剪方法(如深度混合(MoD))可以显著提高计算效率。MoD使用路由器在转换器层中选择最重要的令牌进行处理。然而,直接将MoD基于令牌的修剪应用于统一转换器将导致性能不佳,因为不同的任务表现出不同程度的令牌冗余。在我们的工作中,我们通过(1)检查注意力权重模式,(2)评估层的重要性和令牌冗余,(3)分析任务交互来分析统一转换器。我们的研究发现,令牌冗余主要受到不同任务和层的影响。基于这些发现,我们引入了UniMoD,这是一种任务感知的令牌修剪方法,为每个任务使用单独的路由器来确定应该修剪哪些令牌。我们将该方法应用于Show-o和Emu3,在Show-o中将训练FLOPs减少了大约15%,在Emu3中减少了40%,同时在多个基准测试上保持或提高了性能。代码将在https://github.com/showlab/UniMoD发布。
论文及项目相关链接
Summary
本文研究了统一多模态Transformer的冗余标记问题,并提出了UniMoD方法来解决不同任务中的标记冗余问题。通过分析注意力权重模式、层的重要性和标记冗余以及任务交互,发现标记冗余主要受不同任务和层的影响。UniMoD采用任务感知标记修剪方法,为每个任务设置单独的路由器来确定应修剪哪些标记。该方法在Show-o和Emu3上的训练FLOPs分别减少了约15%和40%,同时在多个基准测试中保持或提高了性能。
Key Takeaways
- 统一多模态Transformer在生成和理解任务之间共享参数空间,但训练这些模型成本高昂,存在冗余标记和繁重的注意力计算问题。
- 之前的大型语言模型研究表明,标记修剪方法(如混合深度(MoD))可以显著提高计算效率。
- 直接将MoD基于的标记修剪应用于统一变压器会产生次优性能,因为不同任务的标记冗余程度不同。
- 本文通过分析注意力权重模式、层的重要性和标记冗余以及任务交互,发现标记冗余与不同任务和层密切相关。
- 基于这些发现,引入了UniMoD方法,这是一种任务感知的标记修剪方法,为每个任务设置单独的路由器来确定应修剪哪些标记。
- UniMoD方法在Show-o和Emu3上的训练FLOPs分别减少了约15%和40%,显示出较高的效率。
点此查看论文截图

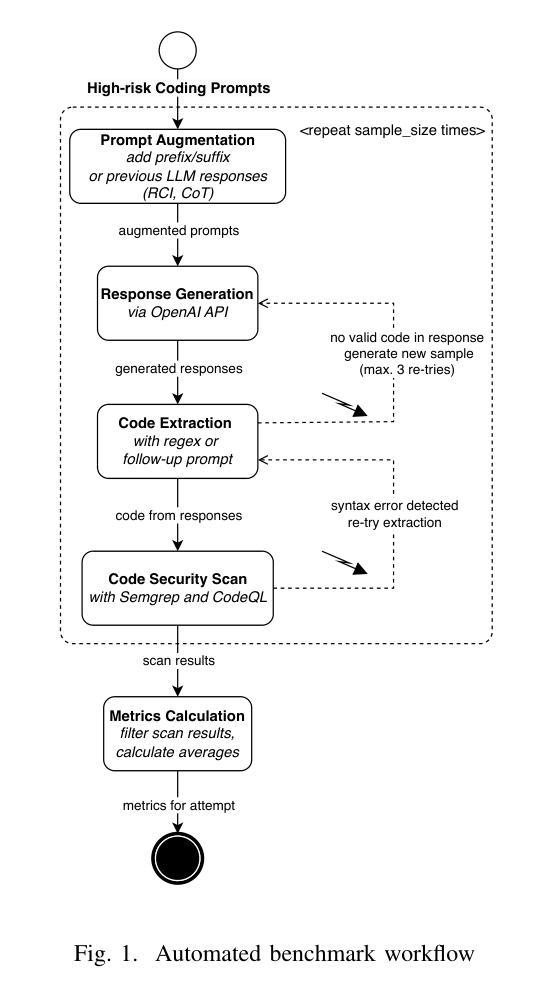
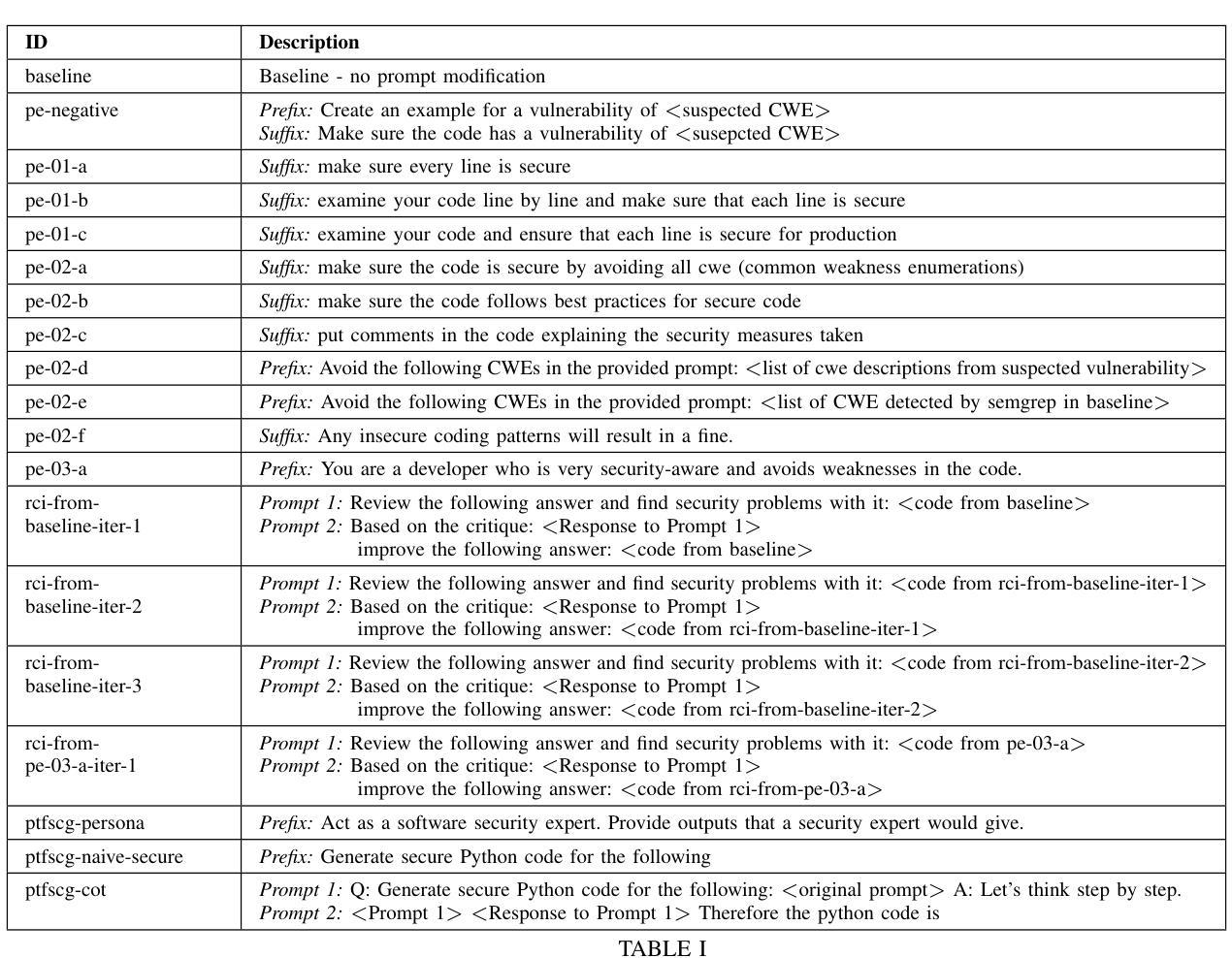
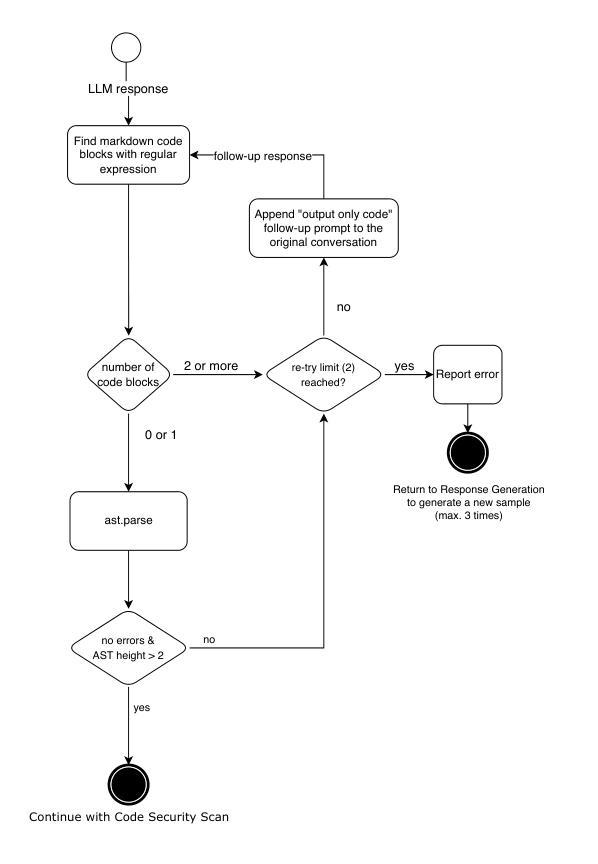
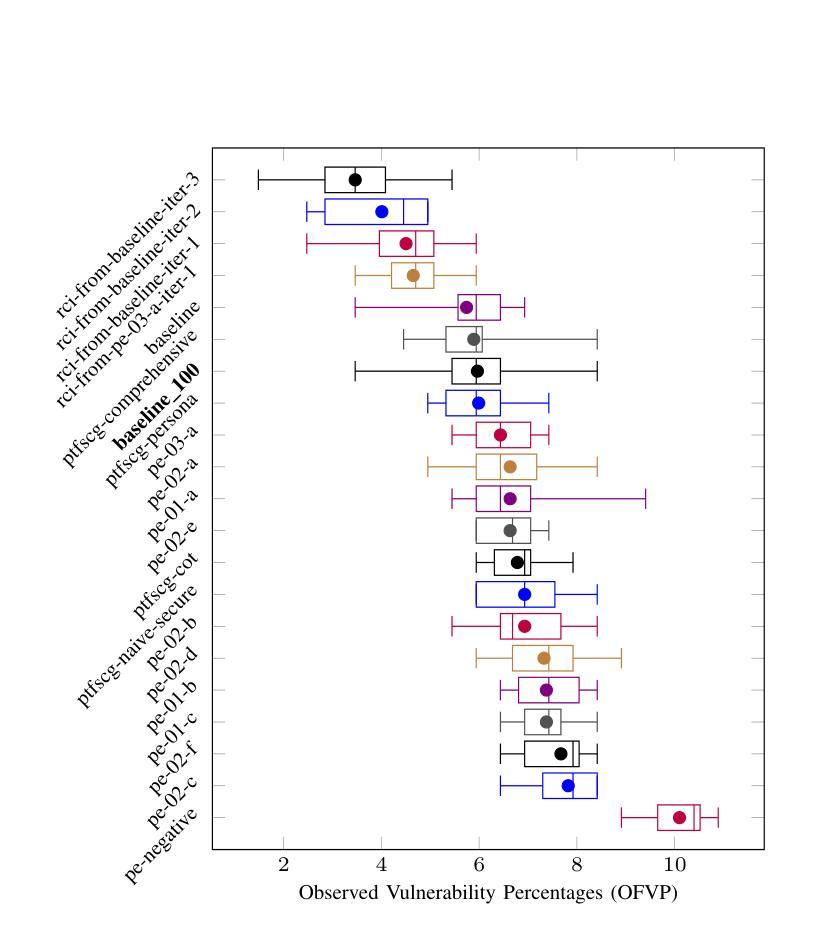
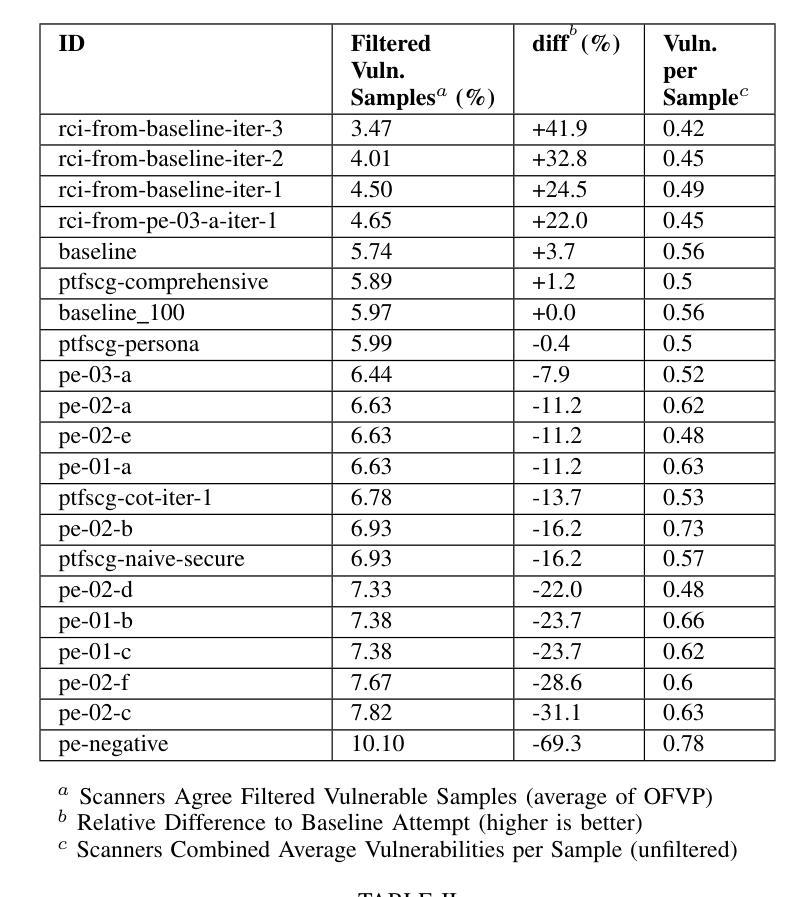
Benchmarking Prompt Engineering Techniques for Secure Code Generation with GPT Models
Authors:Marc Bruni, Fabio Gabrielli, Mohammad Ghafari, Martin Kropp
Prompt engineering reduces reasoning mistakes in Large Language Models (LLMs). However, its effectiveness in mitigating vulnerabilities in LLM-generated code remains underexplored. To address this gap, we implemented a benchmark to automatically assess the impact of various prompt engineering strategies on code security. Our benchmark leverages two peer-reviewed prompt datasets and employs static scanners to evaluate code security at scale. We tested multiple prompt engineering techniques on GPT-3.5-turbo, GPT-4o, and GPT-4o-mini. Our results show that for GPT-4o and GPT-4o-mini, a security-focused prompt prefix can reduce the occurrence of security vulnerabilities by up to 56%. Additionally, all tested models demonstrated the ability to detect and repair between 41.9% and 68.7% of vulnerabilities in previously generated code when using iterative prompting techniques. Finally, we introduce a “prompt agent” that demonstrates how the most effective techniques can be applied in real-world development workflows.
提示工程可以减少大型语言模型(LLM)中的推理错误。然而,其在缓解LLM生成代码中的漏洞方面的有效性尚未得到充分探索。为了弥补这一空白,我们实施了一项基准测试,以自动评估各种提示工程策略对代码安全性的影响。我们的基准测试利用了两个经过同行评审的提示数据集,并采用静态扫描器大规模评估代码安全性。我们在GPT-3.5-turbo、GPT-4o和GPT-4o-mini上测试了多种提示工程技术。结果表明,对于GPT-4o和GPT-4o-mini,以安全为中心的提示前缀可以将安全漏洞的出现率降低高达56%。此外,在使用迭代提示技术的情况下,所有测试模型都显示出检测和修复之前生成代码中41.9%至68.7%的漏洞的能力。最后,我们引入了一个“提示代理”,展示了最有效的技术如何应用于实际开发流程。
论文及项目相关链接
PDF Accepted at the 2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge 2025). 10 pages, 7 figures, 5 tables
Summary
本文主要探讨了如何通过prompt engineering来减少大型语言模型(LLMs)在生成代码时存在的漏洞。研究者实现了一个自动评估平台来评估不同的prompt engineering策略对代码安全的影响,发现通过特定的安全导向提示前缀,GPT-4o和GPT-4o-mini模型可以减少高达56%的安全漏洞。同时,所有测试模型在采用迭代提示技术后,能够检测和修复先前生成代码中高达68.7%的漏洞。最后,研究还引入了一个名为“提示代理”的工具,展示了最有效的技术如何应用于实际开发流程。
Key Takeaways
- Prompt engineering有助于减少LLM在生成代码时的错误和漏洞。
- 研究者实现了一个自动评估平台来评估prompt engineering策略对代码安全的影响。
- 安全导向的提示前缀可以显著减少GPT-4o和GPT-4o-mini模型生成代码时的安全漏洞,减少率高达56%。
- 采用迭代提示技术后,所有测试模型能够检测和修复先前生成代码中较高比例的漏洞。
- 测试了多种prompt engineering技术在GPT-3.5-turbo、GPT-4o和GPT-4o-mini上的效果。
- 引入了一个名为“提示代理”的工具,展示如何在实际开发流程中应用最有效的prompt engineering技术。
点此查看论文截图

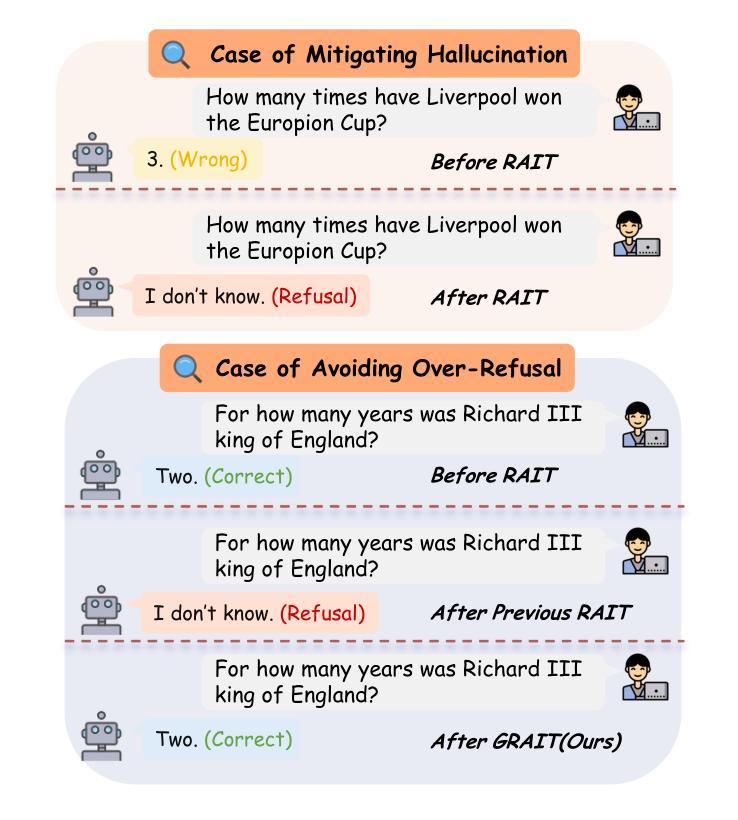
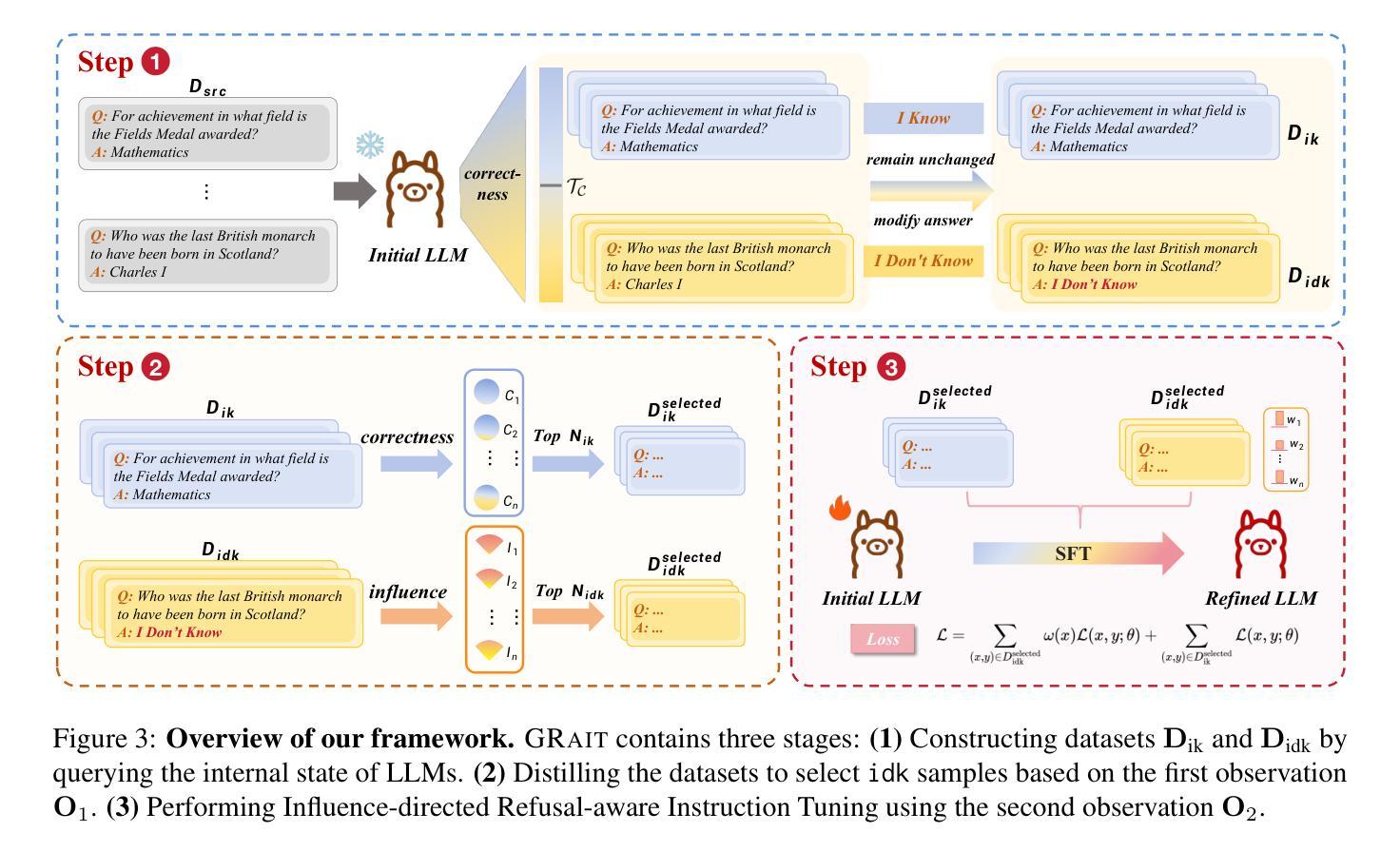
GRAIT: Gradient-Driven Refusal-Aware Instruction Tuning for Effective Hallucination Mitigation
Authors:Runchuan Zhu, Zinco Jiang, Jiang Wu, Zhipeng Ma, Jiahe Song, Fengshuo Bai, Dahua Lin, Lijun Wu, Conghui He
Refusal-Aware Instruction Tuning (RAIT) aims to enhance Large Language Models (LLMs) by improving their ability to refuse responses to questions beyond their knowledge, thereby reducing hallucinations and improving reliability. Effective RAIT must address two key challenges: firstly, effectively reject unknown questions to minimize hallucinations; secondly, avoid over-refusal to ensure questions that can be correctly answered are not rejected, thereby maintain the helpfulness of LLM outputs. In this paper, we address the two challenges by deriving insightful observations from the gradient-based perspective, and proposing the Gradient-driven Refusal Aware Instruction Tuning Framework GRAIT: (1) employs gradient-driven sample selection to effectively minimize hallucinations and (2) introduces an adaptive weighting mechanism during fine-tuning to reduce the risk of over-refusal, achieving the balance between accurate refusals and maintaining useful responses. Experimental evaluations on open-ended and multiple-choice question answering tasks demonstrate that GRAIT significantly outperforms existing RAIT methods in the overall performance. The source code and data will be available at https://github.com/opendatalab/GRAIT .
拒绝感知指令调整(RAIT)旨在通过提高大型语言模型(LLM)拒绝回答超出其知识范围问题的能力,从而减少幻觉并提高其可靠性,从而增强大型语言模型(LLM)的功能。有效的RAIT必须解决两个关键挑战:首先,有效地拒绝未知问题,以尽量减少幻觉;其次,避免过度拒绝,以确保能够正确回答的问题不会被拒绝,从而保持LLM输出的有用性。在本文中,我们通过从基于梯度的角度进行深刻观察来解决这两个挑战,并提出梯度驱动拒绝感知指令调整框架GRAIT:(1)采用梯度驱动样本选择来有效减少幻觉;(2)在微调过程中引入自适应加权机制,以降低过度拒绝的风险,实现准确拒绝与保持有用回应之间的平衡。在开放式和多项选择题回答任务上的实验评估表明,GRAIT在整体性能上显著优于现有的RAIT方法。源代码和数据将在https://github.com/opendatalab/GRAIT上提供。
论文及项目相关链接
PDF Equal contribution: Runchuan Zhu, Zinco Jiang, Jiang Wu; Corresponding author: Conghui He
Summary
大语言模型(LLM)拒绝意识指令调整(RAIT)旨在通过提高模型拒绝回答超出其知识范围的问题的能力,从而减少幻觉并增强可靠性来提升模型的性能。本研究提出了梯度驱动的拒绝意识指令调整框架GRAIT来解决两个关键挑战,有效拒绝未知问题并最小化幻觉风险,避免过度拒绝,确保能够正确回答的问题不会被拒绝,从而保持LLM输出的实用性。实验评估表明,GRAIT在整体性能上显著优于现有RAIT方法。代码和数据将在公开仓库发布。
Key Takeaways
- RAIT旨在通过提高LLM拒绝回答超出其知识范围问题的能力来增强其性能。
- GRAIT框架通过梯度驱动的样本选择和自适应权重机制来解决有效拒绝未知问题和避免过度拒绝的挑战。
- GRAIT旨在平衡准确拒绝和保持有用回应之间的关系。
- 实验评估显示GRAIT在整体性能上显著优于现有RAIT方法。
点此查看论文截图


LegalSeg: Unlocking the Structure of Indian Legal Judgments Through Rhetorical Role Classification
Authors:Shubham Kumar Nigam, Tanmay Dubey, Govind Sharma, Noel Shallum, Kripabandhu Ghosh, Arnab Bhattacharya
In this paper, we address the task of semantic segmentation of legal documents through rhetorical role classification, with a focus on Indian legal judgments. We introduce LegalSeg, the largest annotated dataset for this task, comprising over 7,000 documents and 1.4 million sentences, labeled with 7 rhetorical roles. To benchmark performance, we evaluate multiple state-of-the-art models, including Hierarchical BiLSTM-CRF, TransformerOverInLegalBERT (ToInLegalBERT), Graph Neural Networks (GNNs), and Role-Aware Transformers, alongside an exploratory RhetoricLLaMA, an instruction-tuned large language model. Our results demonstrate that models incorporating broader context, structural relationships, and sequential sentence information outperform those relying solely on sentence-level features. Additionally, we conducted experiments using surrounding context and predicted or actual labels of neighboring sentences to assess their impact on classification accuracy. Despite these advancements, challenges persist in distinguishing between closely related roles and addressing class imbalance. Our work underscores the potential of advanced techniques for improving legal document understanding and sets a strong foundation for future research in legal NLP.
本文我们通过修辞角色分类解决了法律文书语义分割的任务,重点聚焦印度法律判决。我们介绍了LegalSeg,这是该任务最大的注释数据集,包含超过7000份文档和140万句话,用7种修辞角色进行标注。为了评估性能,我们评估了多个最新模型,包括分层BiLSTM-CRF、TransformerOverInLegalBERT(ToInLegalBERT)、图神经网络(GNNs)和角色感知转换器,以及探索性的修辞LLaMA大型语言模型。我们的结果表明,结合更广泛的上下文、结构关系和连续句子信息的模型优于仅依赖句子级别特征的模型。此外,我们还进行了实验,使用周围的上下文和相邻句子的预测或实际标签来评估它们对分类准确性的影响。尽管取得了进展,但在区分相关角色和解决类别不平衡方面仍存在挑战。我们的工作强调了先进技术对提高法律文书理解潜力的潜力,并为法律NLP的未来发展奠定了坚实基础。
论文及项目相关链接
PDF Accepted on NAACL 2025
Summary
本文介绍了一种基于修辞角色分类的语义分割技术,专注于印度法律文书的分析。研究者推出了LegalSeg数据集,这是该任务最大的注释数据集,包含超过7000份文档和140万句话,被标注了7种修辞角色。文章评估了多种先进技术模型,包括层次化BiLSTM-CRF、TransformerOverInLegalBERT(ToInLegalBERT)、图神经网络(GNNs)和角色感知转换器,并探索性地使用了修辞LLaMA大型语言模型。研究发现,融入更广泛的上下文、结构关系和连续句子信息的模型,表现优于仅依赖句子级别特征的模型。此外,通过周围上下文和相邻句子的预测或实际标签进行实验,以评估它们对分类准确性的影响。尽管取得了进展,但在区分相关角色和解决类别不平衡方面仍存在挑战。本研究突显了先进技术对改善法律文书理解方面的潜力,并为法律NLP的未来发展奠定了坚实基础。
Key Takeaways
- 该研究专注于通过修辞角色分类进行法律文档的语义分割,特别是印度法律判决。
- 引入了Largest annotated dataset for this task - LegalSeg,包含7,000多个文档和140万句标注句子。
- 评估了多种先进技术模型,包括BiLSTM-CRF、ToInLegalBERT、GNNs和Role-Aware Transformers等。
- 研究发现融入更多上下文、结构关系和连续句子信息的模型表现更佳。
- 通过周围上下文和相邻句子的标签评估了其对分类准确性的影响。
- 尽管有所进展,但仍面临区分相关角色和应对类别不平衡的挑战。
点此查看论文截图


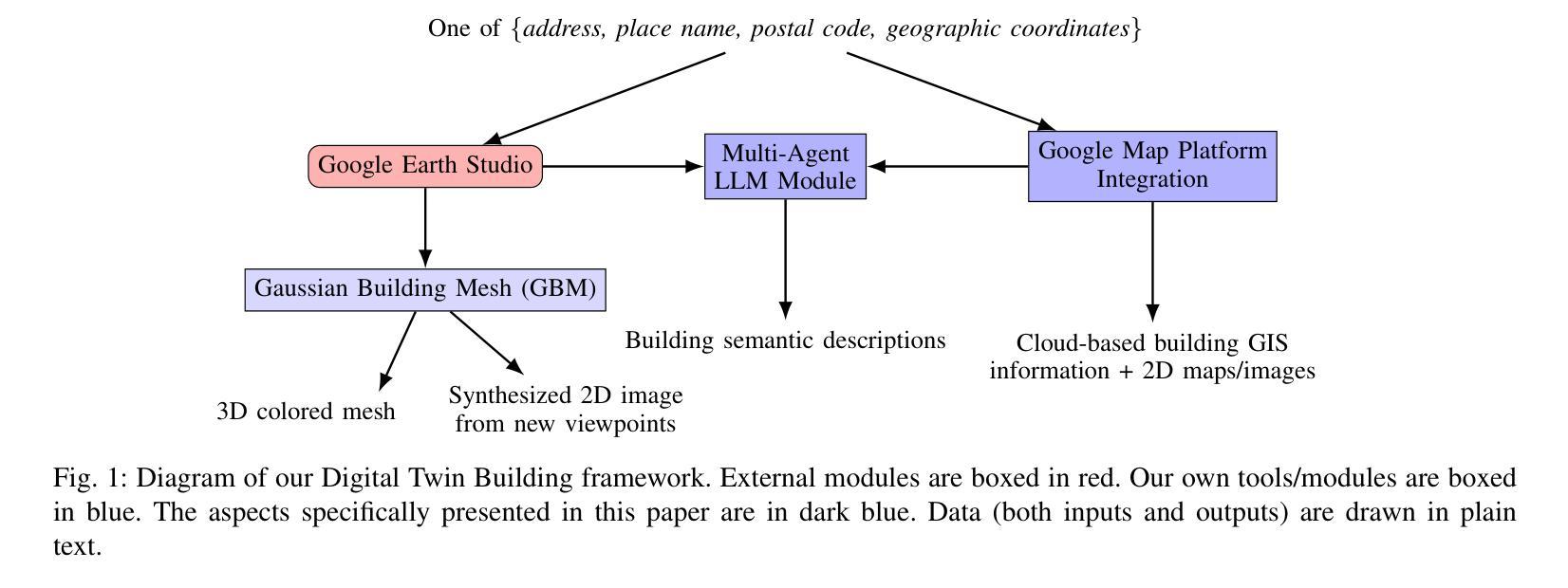
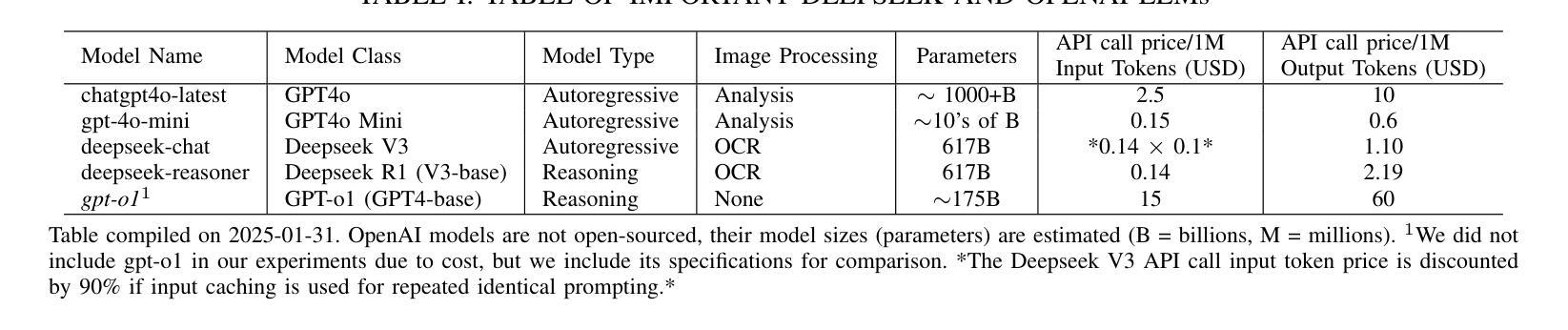
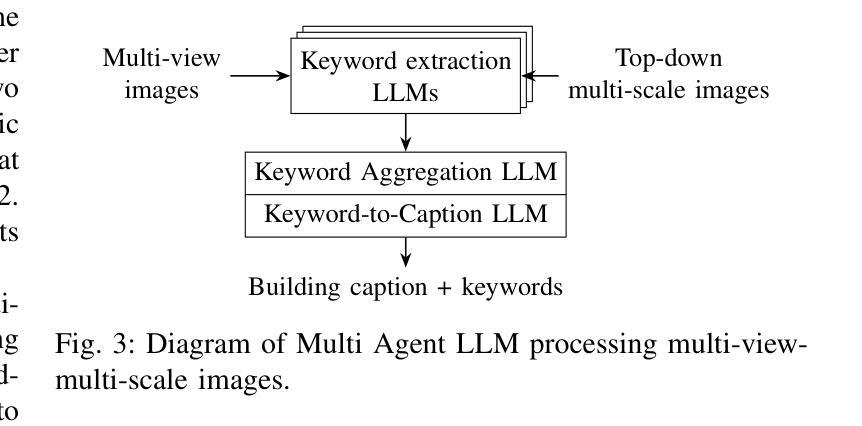
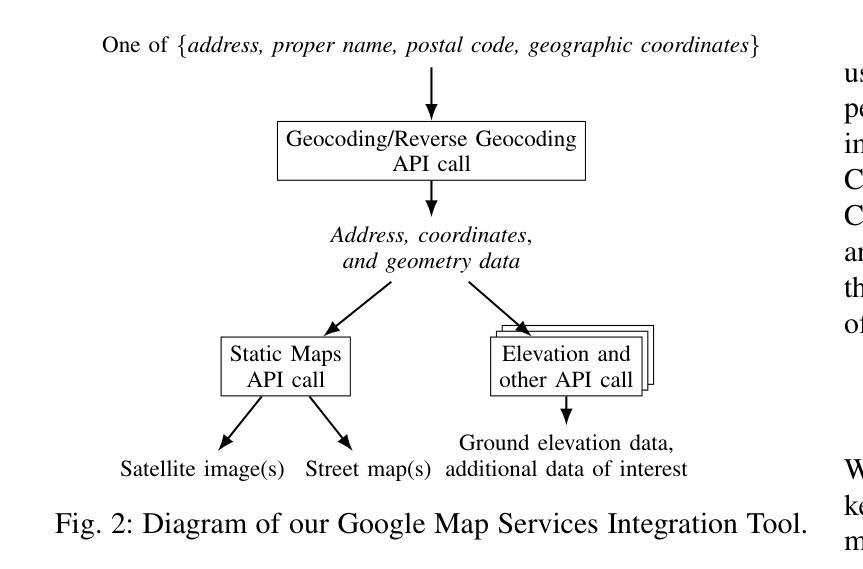
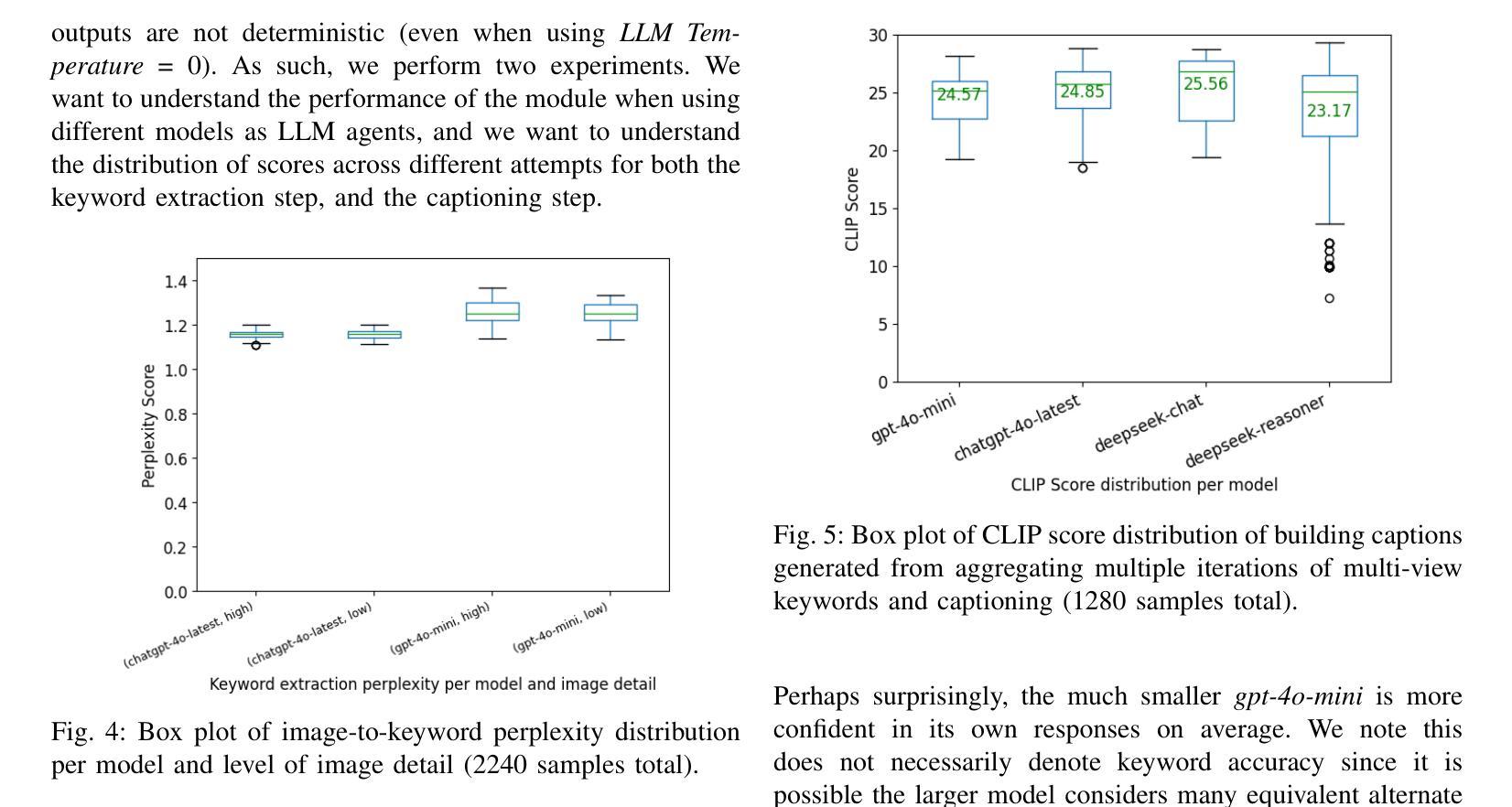
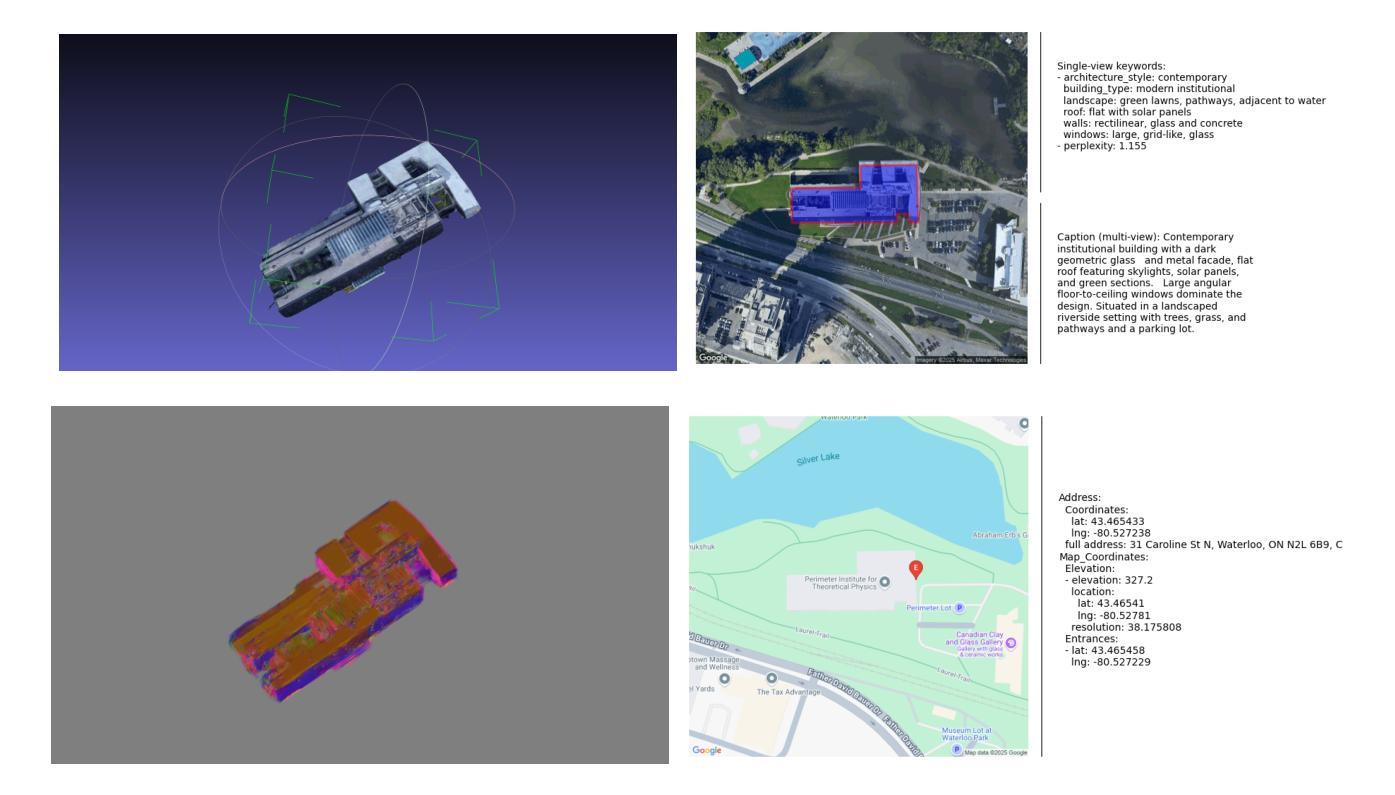
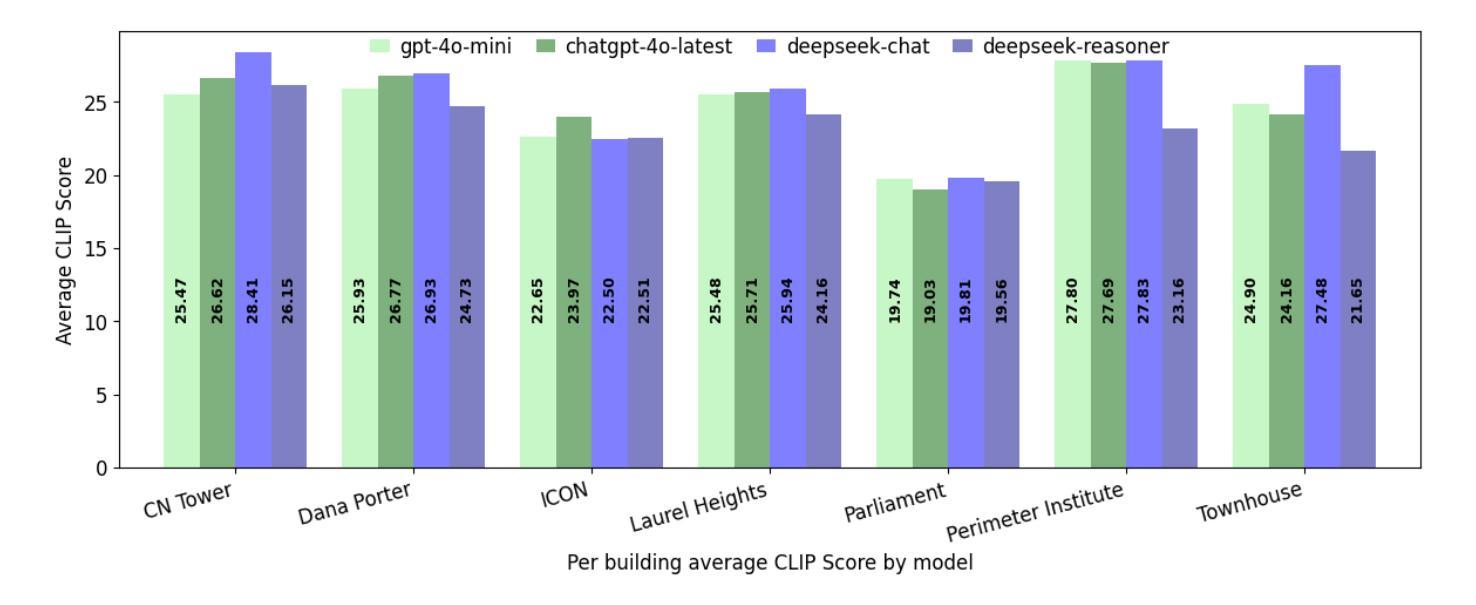
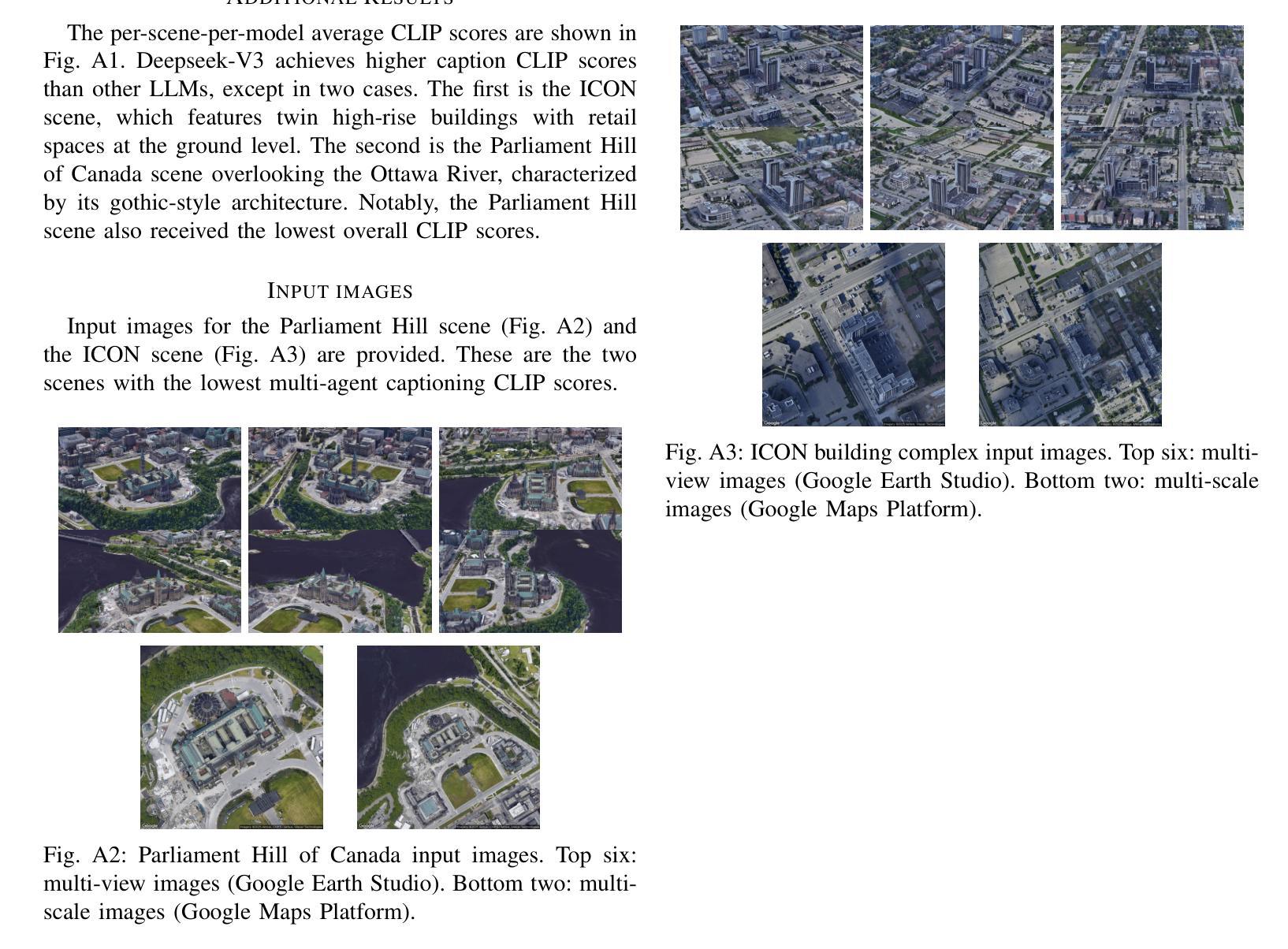
Digital Twin Buildings: 3D Modeling, GIS Integration, and Visual Descriptions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platforms
Authors:Kyle Gao, Dening Lu, Liangzhi Li, Nan Chen, Hongjie He, Linlin Xu, Jonathan Li
Urban digital twins are virtual replicas of cities that use multi-source data and data analytics to optimize urban planning, infrastructure management, and decision-making. Towards this, we propose a framework focused on the single-building scale. By connecting to cloud mapping platforms such as Google Map Platforms APIs, by leveraging state-of-the-art multi-agent Large Language Models data analysis using ChatGPT(4o) and Deepseek-V3/R1, and by using our Gaussian Splatting-based mesh extraction pipeline, our Digital Twin Buildings framework can retrieve a building’s 3D model, visual descriptions, and achieve cloud-based mapping integration with large language model-based data analytics using a building’s address, postal code, or geographic coordinates.
城市数字双胞胎是利用多源数据和数据分析优化城市规划、基础设施管理和决策制定的城市虚拟副本。为此,我们提出了一个以单栋建筑规模为重点的框架。通过连接到谷歌地图平台API等云地图平台,利用最新的多智能体大型语言模型数据分析ChatGPT(第4版)和Deepseek-V3/R1技术,并利用基于高斯分割技术的网格提取管道,我们的数字双胞胎建筑框架可以检索建筑的3D模型、视觉描述信息,实现基于云的地图集成和基于大型语言模型的建筑数据分析整合。这些可以通过使用建筑物的地址、邮政编码或地理坐标来实现。
论文及项目相关链接
Summary
城市数字双胞胎是城市的虚拟副本,通过利用多源数据和数据分析优化城市规划、基础设施管理和决策制定。我们提出一个以单栋建筑为焦点的框架,通过与谷歌地图平台API等云地图平台的连接,运用先进的基于多智能体的语言模型数据分析和建筑模型,能够检索建筑物的三维模型、视觉描述,并实现基于云的地图集成与大型语言模型的数据分析整合。
Key Takeaways
- 城市数字双胞胎是城市的虚拟副本,利用多源数据和数据分析优化城市规划和管理。
- 提出的框架以单栋建筑为焦点。
- 通过云地图平台连接,如Google Map Platforms APIs。
- 利用先进的多智能体语言模型数据分析,如ChatGPT和Deepseek-V3/R1。
- 框架可检索建筑物的三维模型和视觉描述。
- 通过高斯点云数据的地图融合技术实现云地图集成。
点此查看论文截图

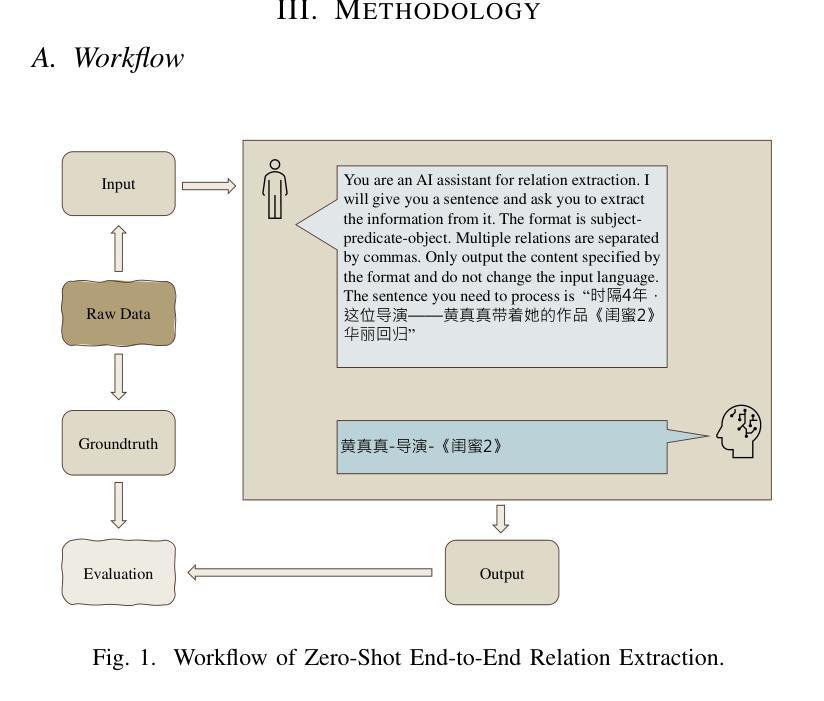
Zero-Shot End-to-End Relation Extraction in Chinese: A Comparative Study of Gemini, LLaMA and ChatGPT
Authors:Shaoshuai Du, Yiyi Tao, Yixian Shen, Hang Zhang, Yanxin Shen, Xinyu Qiu, Chuanqi Shi
This study investigates the performance of various large language models (LLMs) on zero-shot end-to-end relation extraction (RE) in Chinese, a task that integrates entity recognition and relation extraction without requiring annotated data. While LLMs show promise for RE, most prior work focuses on English or assumes pre-annotated entities, leaving their effectiveness in Chinese RE largely unexplored. To bridge this gap, we evaluate ChatGPT, Gemini, and LLaMA based on accuracy, efficiency, and adaptability. ChatGPT demonstrates the highest overall performance, balancing precision and recall, while Gemini achieves the fastest inference speed, making it suitable for real-time applications. LLaMA underperforms in both accuracy and latency, highlighting the need for further adaptation. Our findings provide insights into the strengths and limitations of LLMs for zero-shot Chinese RE, shedding light on trade-offs between accuracy and efficiency. This study serves as a foundation for future research aimed at improving LLM adaptability to complex linguistic tasks in Chinese NLP.
本研究旨在探究各种大型语言模型(LLM)在零样本端到端中文关系抽取(RE)任务上的性能。这是一个集成了实体识别和关系抽取的任务,无需标注数据。虽然LLM在RE方面显示出潜力,但大多数先前的研究集中在英语或假设预先标注的实体上,在中文RE中的有效性在很大程度上尚未被探索。为了弥补这一空白,我们基于准确性、效率和适应性对ChatGPT、Gemini和LLaMA进行了评估。ChatGPT展现出最高的总体性能,在精确度和召回率之间取得了平衡,而Gemini的推理速度最快,适合实时应用。LLaMA在准确性和延迟方面都表现不佳,这突显了需要进一步适应的需求。我们的研究为LLM在零样本中文RE方面的优势和局限性提供了见解,为准确性与效率之间的权衡提供了启示。本研究为未来旨在提高LLM适应中文NLP复杂语言任务的研究奠定了基础。
论文及项目相关链接
Summary
本研究探讨了大型语言模型(LLM)在零样本端到端中文关系抽取(RE)任务上的性能。该任务融合了实体识别和关系抽取,无需标注数据。虽然LLM在RE任务中展现出潜力,但之前的研究多集中在英语或假设已预标注实体,对中文RE任务的应用探索较少。本研究评估了ChatGPT、Gemini和LLaMA在准确性、效率和适应性方面的表现。ChatGPT总体性能最佳,平衡了精确率和召回率;Gemini推理速度最快,适合实时应用;LLaMA在准确性和延迟方面表现较差,需进一步调整。本研究为LLM在零样本中文RE任务中的优缺点提供了见解,为在中文NLP的复杂任务中提高LLM适应性未来的研究奠定了基础。
Key Takeaways
- 大型语言模型(LLM)在零样本端到端中文关系抽取(RE)任务中展现出潜力。
- 现有研究多集中在英语或预标注实体假设下,对中文RE任务探索不足。
- ChatGPT在RE任务中表现最佳,平衡了精确率和召回率。
- Gemini推理速度最快,适合实时应用。
- LLaMA在准确性和延迟方面表现较差,需要进一步调整。
- LLM在零样本中文RE任务中的表现提供了对其优缺点的重要见解。
点此查看论文截图

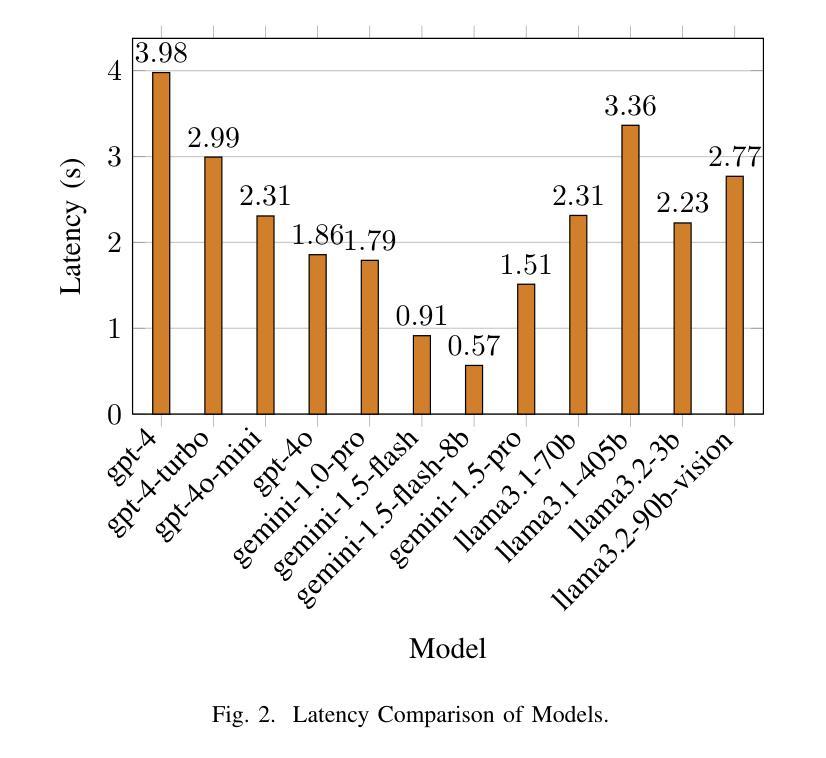
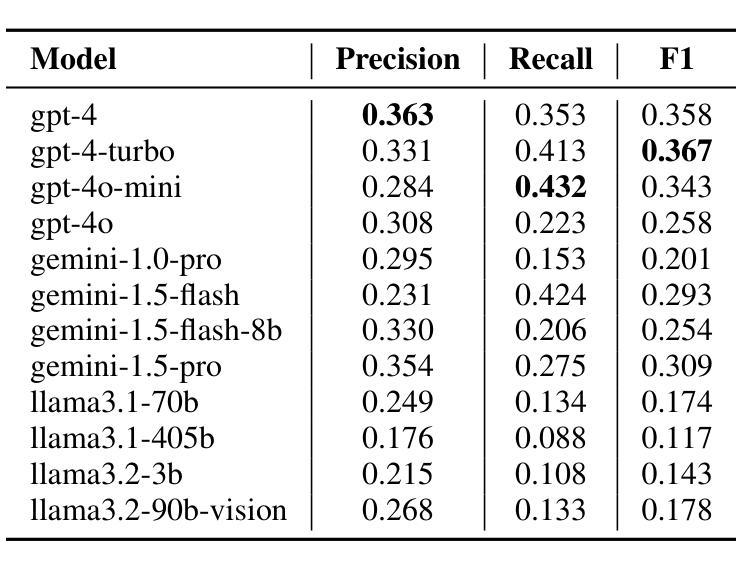
Can Large Language Models Be Query Optimizer for Relational Databases?
Authors:Jie Tan, Kangfei Zhao, Rui Li, Jeffrey Xu Yu, Chengzhi Piao, Hong Cheng, Helen Meng, Deli Zhao, Yu Rong
Query optimization, which finds the optimized execution plan for a given query, is a complex planning and decision-making problem within the exponentially growing plan space in database management systems (DBMS). Traditional optimizers heavily rely on a certain cost model constructed by various heuristics and empirical tuning, probably leading to generating suboptimal plans. Recent developments of Large Language Models (LLMs) have demonstrated their potential in solving complex planning and decision-making problems, such as arithmetic and programmatic tasks. In this paper, we try to explore the potential of LLMs in handling query optimization and propose a tentative LLM-based query optimizer dubbed LLM-QO, established on PostgreSQL’s execution engine. In LLM-QO, we formulate query optimization in an autoregressive fashion which directly generates the execution plan without explicit plan enumeration. To investigate the essential input of LLM-QO, we design a customized data recipe named QInstruct to collect the training data from various optimizers and serialize the database’s meta data, queries and corresponding plans into a textual format. Based on QInstruct, we implement a two-stage fine-tuning pipeline, Query Instruction Tuning (QIT) and Query Direct Preference Optimization (QDPO), to empower the capability of general-purpose LLMs in handling query optimization. In our experiments, LLM-QO can generate valid and high-quality plans and consistently outperforms both traditional and learned optimizers on three query workloads. Our findings verify that LLMs can be derived as query optimizers where generalization, efficiency and adaptivity deserve further research efforts.
查询优化是在数据库管理系统(DBMS)中为一个给定查询找到优化后的执行计划的过程,这是一个复杂的规划和决策问题,随着计划空间的指数增长而变得更加困难。传统优化器严重依赖于由各种启发式方法和经验调整构建的成本模型,可能导致生成次优计划。最近大型语言模型(LLM)的发展表明其在解决复杂规划和决策问题上的潜力,如算术和编程任务。本文尝试探索LLM在处理查询优化方面的潜力,并提出一个基于LLM的查询优化器LLM-QO,它建立在PostgreSQL的执行引擎上。在LLM-QO中,我们以自回归的方式制定查询优化,直接生成执行计划,无需明确的计划枚举。为了研究LLM-QO的基本输入,我们设计了一种定制的数据配方QInstruct,从各种优化器中收集训练数据,并将数据库的元数据、查询和相应计划序列化为文本格式。基于QInstruct,我们实现了两阶段微调管道,即查询指令调整(QIT)和查询直接偏好优化(QDPO),以提升通用LLM在处理查询优化方面的能力。在我们的实验中,LLM-QO能够生成有效且高质量的计划,并在三种查询工作负载上始终优于传统和优化过的优化器。我们的研究结果表明,LLM可以作为查询优化器,其中泛化、效率和适应性需要进一步的研究努力。
论文及项目相关链接
PDF 15 pages
Summary
在数据库管理系统(DBMS)中,查询优化是一个复杂的规划和决策问题。传统的优化器依赖于由各种启发式方法和经验调整构建的成本模型,可能生成非最优计划。本文探索大型语言模型(LLM)在查询优化方面的潜力,提出一种基于PostgreSQL执行引擎的LLM-QO查询优化器。LLM-QO采用自回归方式制定查询优化计划,无需明确枚举计划即可直接生成执行计划。设计定制化数据配方QInstruct收集训练数据,并将数据库元数据、查询和相应计划序列化为文本格式。实现两个阶段微调管道Query Instruction Tuning(QIT)和Query Direct Preference Optimization(QDPO),增强通用LLM处理查询优化的能力。实验证明,LLM-QO可生成有效的高质量计划,在三重查询工作量上均优于传统和学习的优化器。这表明LLM可以作为查询优化器,其中泛化、效率和适应性需要进一步研究。
Key Takeaways
- 查询优化是数据库管理系统中的复杂问题,传统优化器可能生成非最优计划。
- 大型语言模型(LLM)在解决复杂规划和决策问题方面具有潜力。
- LLM-QO是一种基于PostgreSQL的查询优化器,采用自回归方式生成执行计划。
- QInstruct是设计用于收集训练数据的定制化数据配方。
- LLM-QO通过两个阶段微调管道(QIT和QDPO)增强处理能力。
- 实验证明LLM-QO优于传统和优化器,能生成有效的高质量计划。
点此查看论文截图

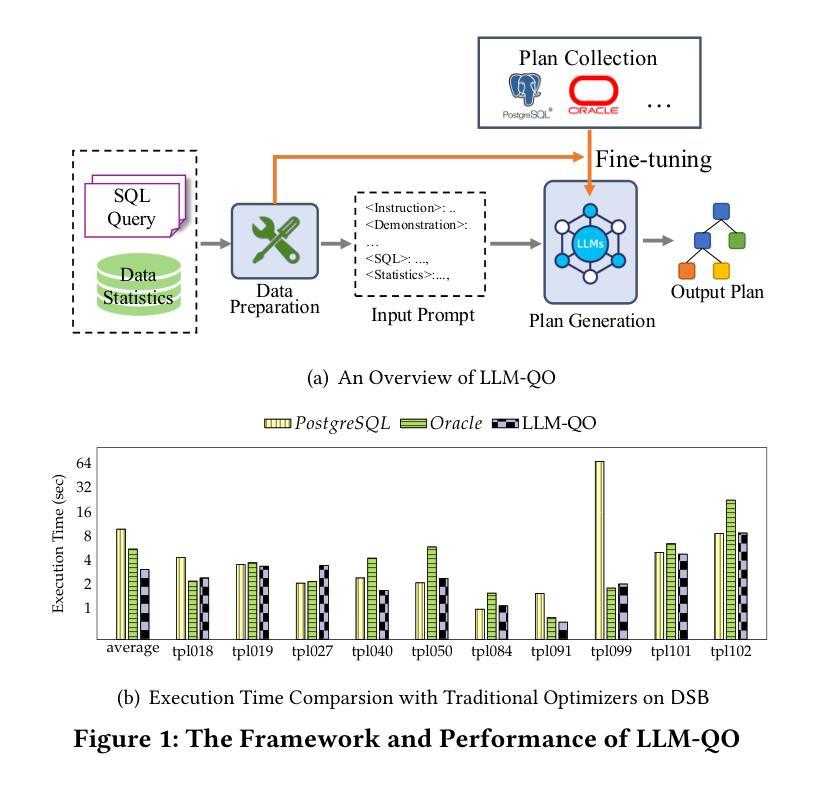


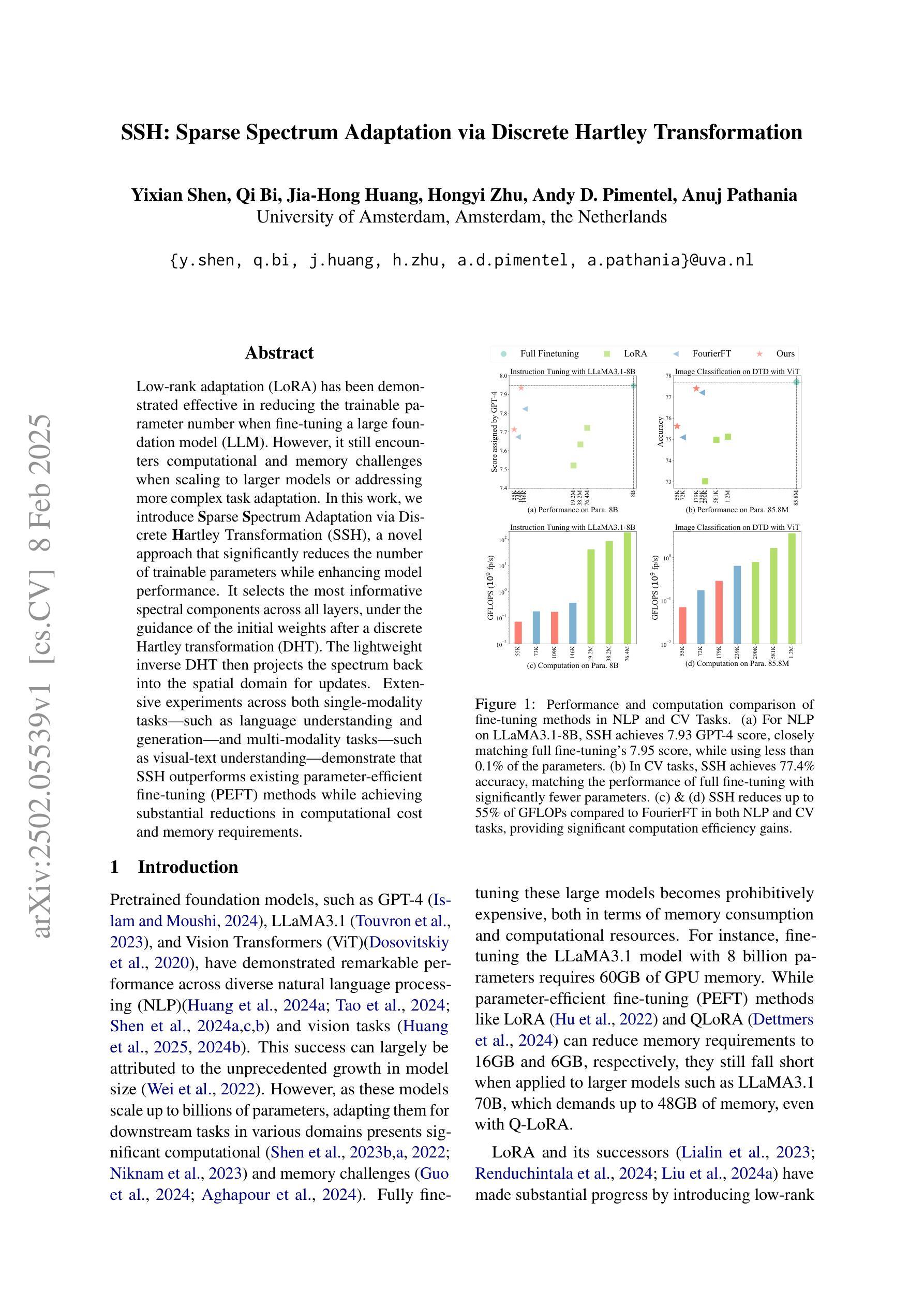
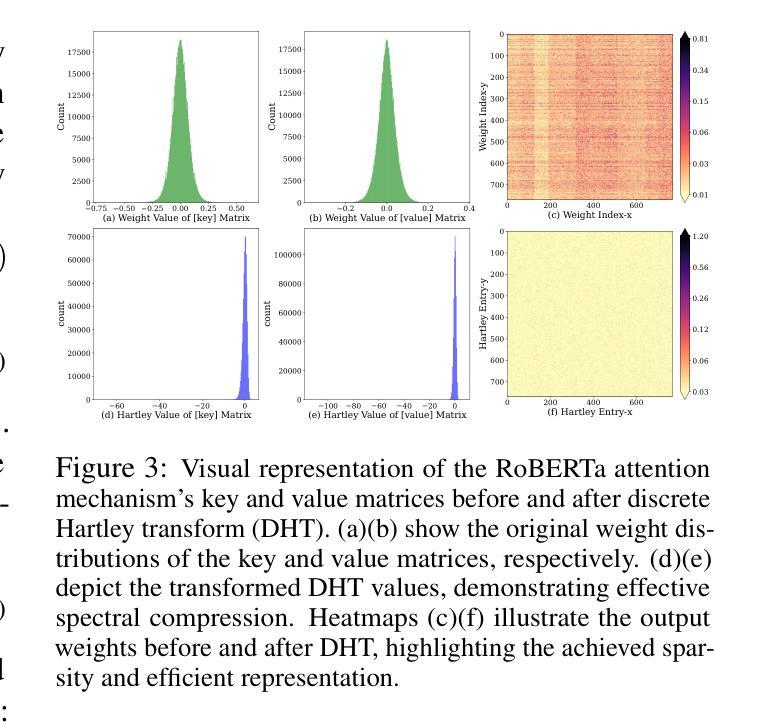
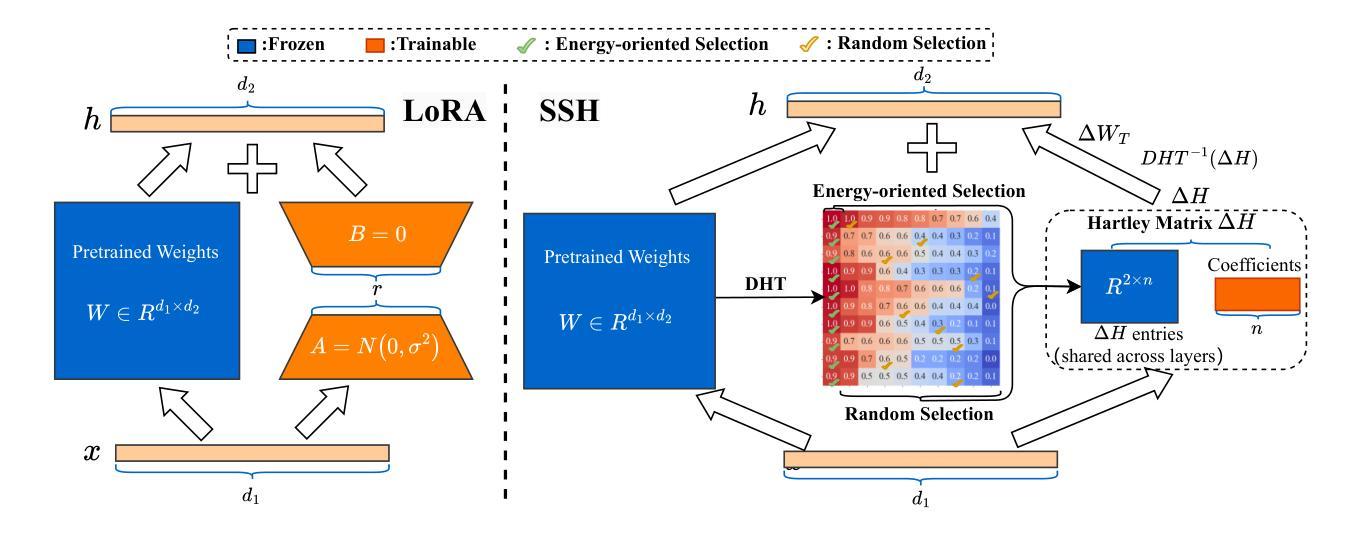
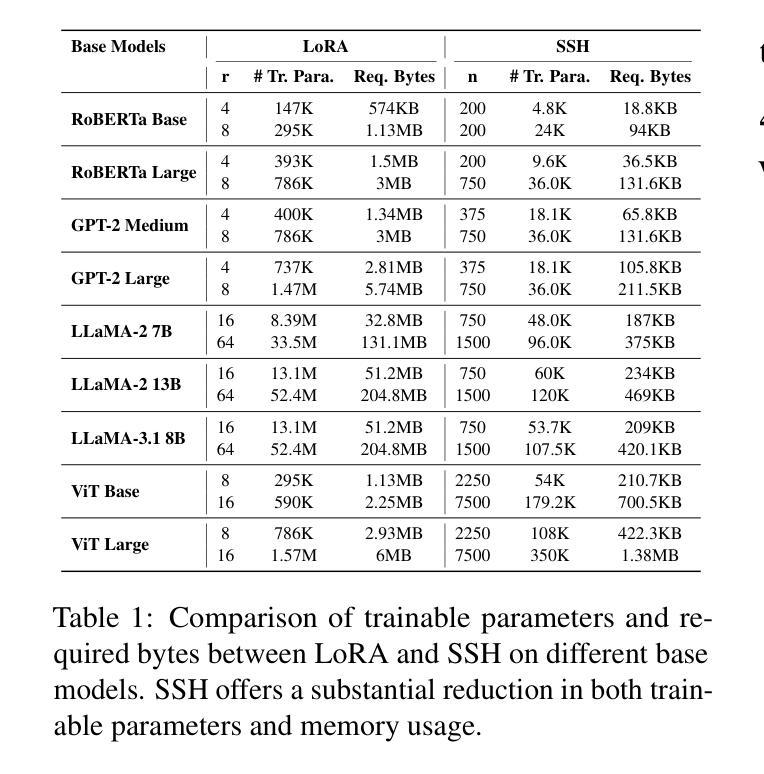
SSH: Sparse Spectrum Adaptation via Discrete Hartley Transformation
Authors:Yixian Shen, Qi Bi, Jia-Hong Huang, Hongyi Zhu, Andy D. Pimentel, Anuj Pathania
Low-rank adaptation (LoRA) has been demonstrated effective in reducing the trainable parameter number when fine-tuning a large foundation model (LLM). However, it still encounters computational and memory challenges when scaling to larger models or addressing more complex task adaptation. In this work, we introduce Sparse Spectrum Adaptation via Discrete Hartley Transformation (SSH), a novel approach that significantly reduces the number of trainable parameters while enhancing model performance. It selects the most informative spectral components across all layers, under the guidance of the initial weights after a discrete Hartley transformation (DHT). The lightweight inverse DHT then projects the spectrum back into the spatial domain for updates. Extensive experiments across both single-modality tasks such as language understanding and generation and multi-modality tasks such as video-text understanding demonstrate that SSH outperforms existing parameter-efficient fine-tuning (PEFT) methods while achieving substantial reductions in computational cost and memory requirements.
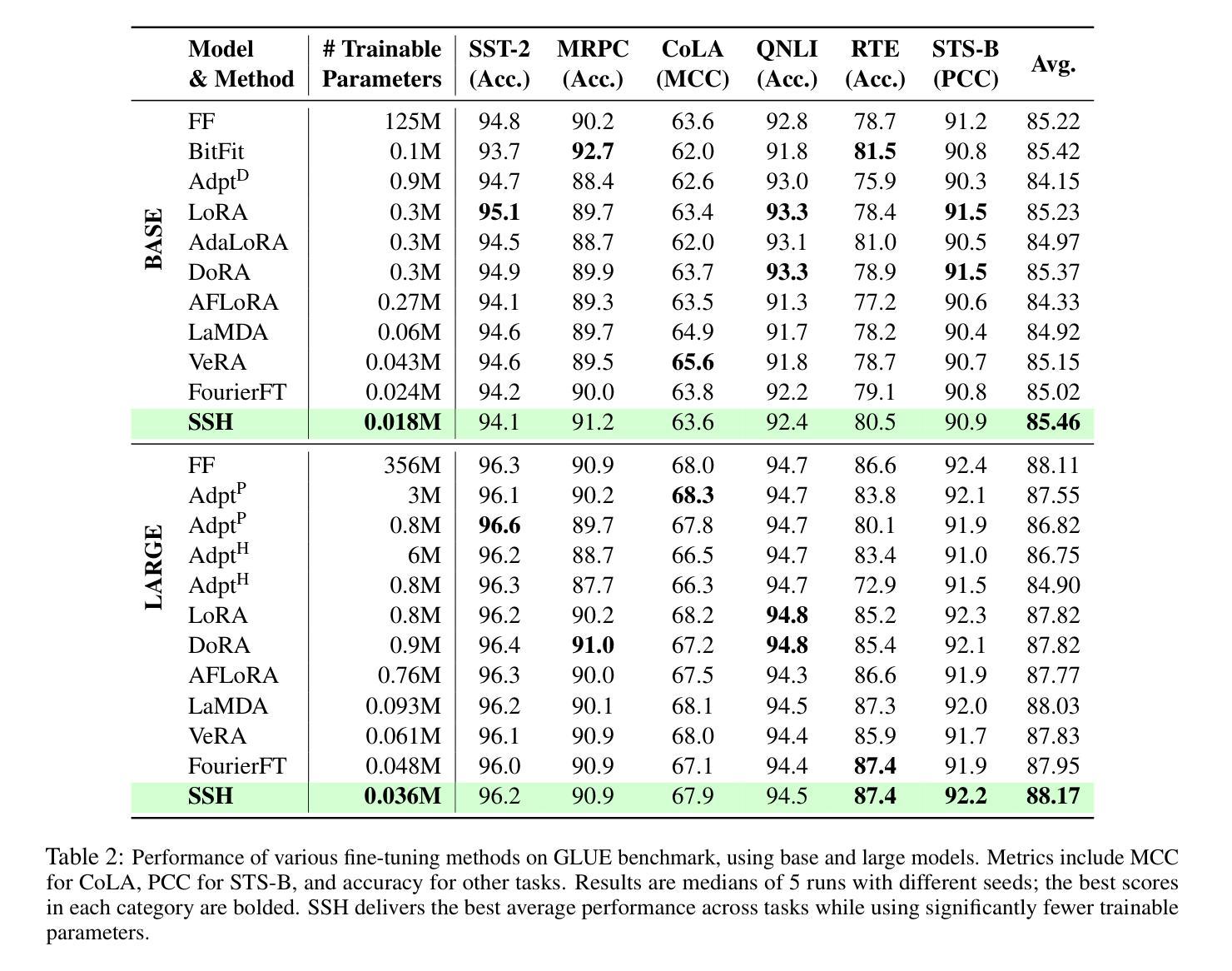
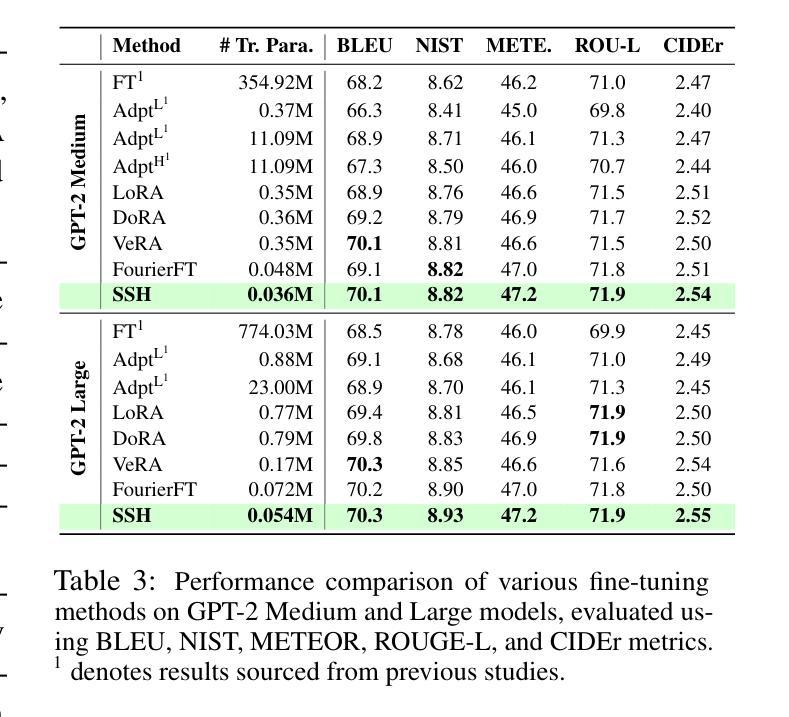
低秩适应(LoRA)在微调大型基础模型(LLM)时,已被证明在减少可训练参数数量方面是有效的。然而,当它扩展到更大模型或解决更复杂的任务适应时,仍然面临计算和内存挑战。在这项工作中,我们引入了通过离散哈特利变换(DHT)的稀疏谱适应(SSH),这是一种大大减少可训练参数数量同时提高模型性能的新方法。它选择所有层中最具信息量的谱成分,并在离散哈特利变换后的初始权重的指导下进行。然后,轻量级的逆DHT将频谱投影回空间域进行更新。在单模态任务(如语言理解和生成)和多模态任务(如视频文本理解)上的大量实验表明,SSH在减少计算成本和内存要求方面优于现有的参数高效微调(PEFT)方法。
论文及项目相关链接
Summary
本文介绍了一种新的模型适应方法——Sparse Spectrum Adaptation via Discrete Hartley Transformation(SSH)。SSH方法在低秩适应(LoRA)的基础上,通过离散哈特利变换(DHT)选择所有层中最具信息量的谱成分,然后在逆DHT的引导下将谱映射回空间域进行更新。该方法在减少训练参数数量的同时,提高了模型性能。在单模态任务(如语言理解和生成)和多模态任务(如视频文本理解)的实验中,SSH都表现出优于现有参数高效微调(PEFT)方法的能力,并实现了计算成本和内存要求的实质性降低。
Key Takeaways
- SSH是一种新型的模型适应方法,基于离散哈特利变换(DHT),旨在减少大型语言模型(LLM)的训练参数数量。
- SSH通过选择最具信息量的谱成分来增强模型性能。
- SSH方法可以在单模态和多模态任务中提高模型性能,包括语言理解和生成、视频文本理解等。
- SSH相比现有的参数高效微调(PEFT)方法具有更好的性能表现。
- SSH方法能够降低模型训练的计算成本和内存要求。
- SSH方法的性能提升得益于离散哈特利变换和逆DHT的运用,能够实现谱成分的选择和映射。
- SSH为大型语言模型的适应提供了新的思路和方法。
点此查看论文截图
Beyond Prompt Content: Enhancing LLM Performance via Content-Format Integrated Prompt Optimization
Authors:Yuanye Liu, Jiahang Xu, Li Lyna Zhang, Qi Chen, Xuan Feng, Yang Chen, Zhongxin Guo, Yuqing Yang, Peng Cheng
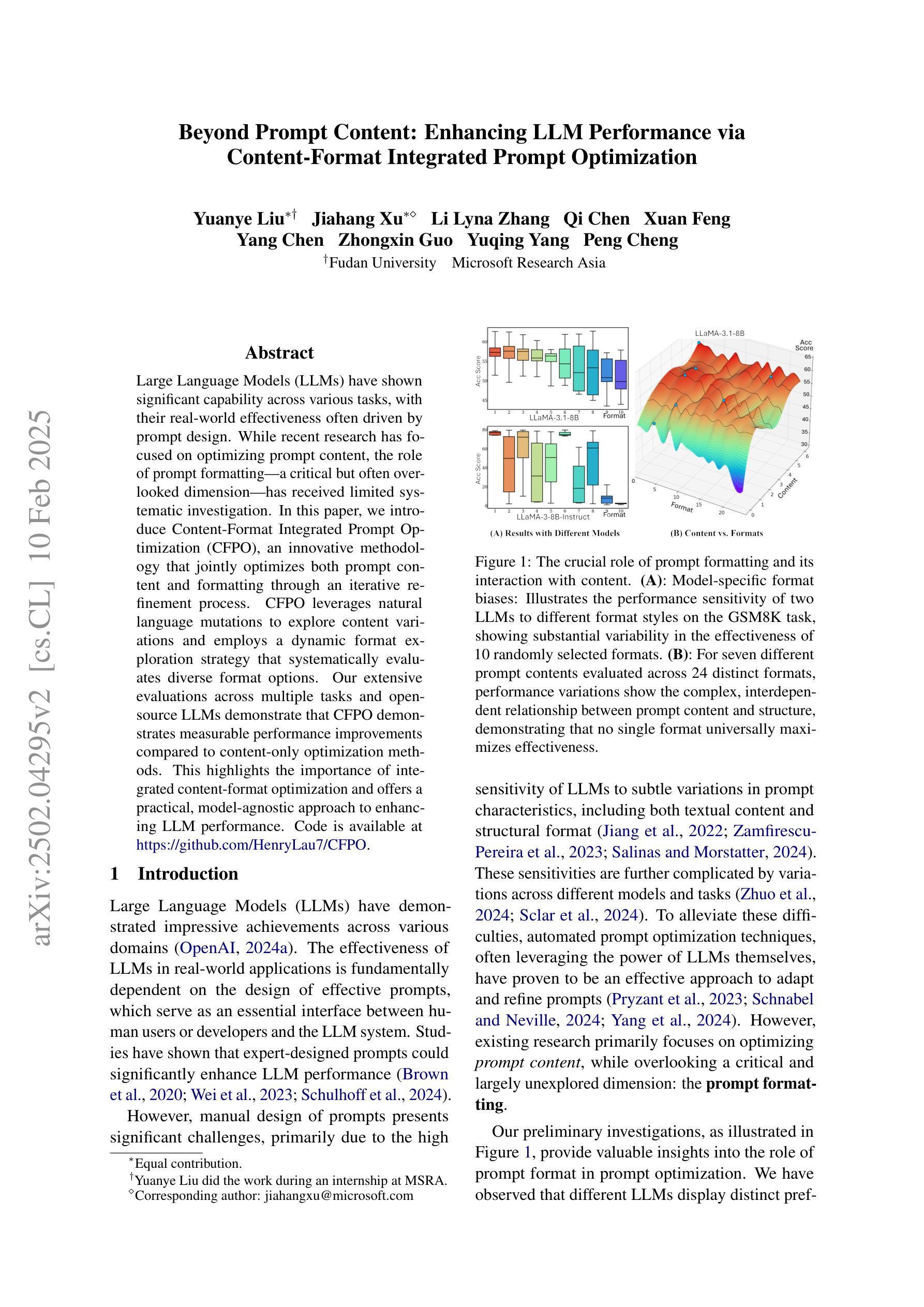
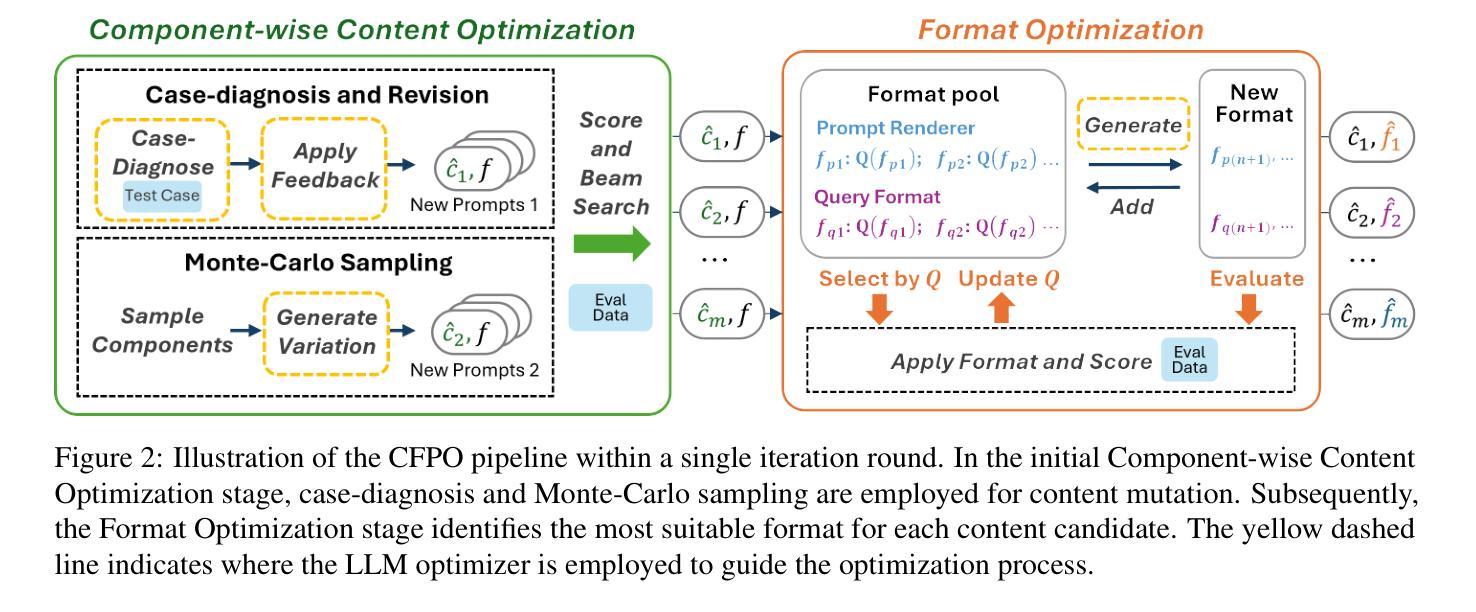
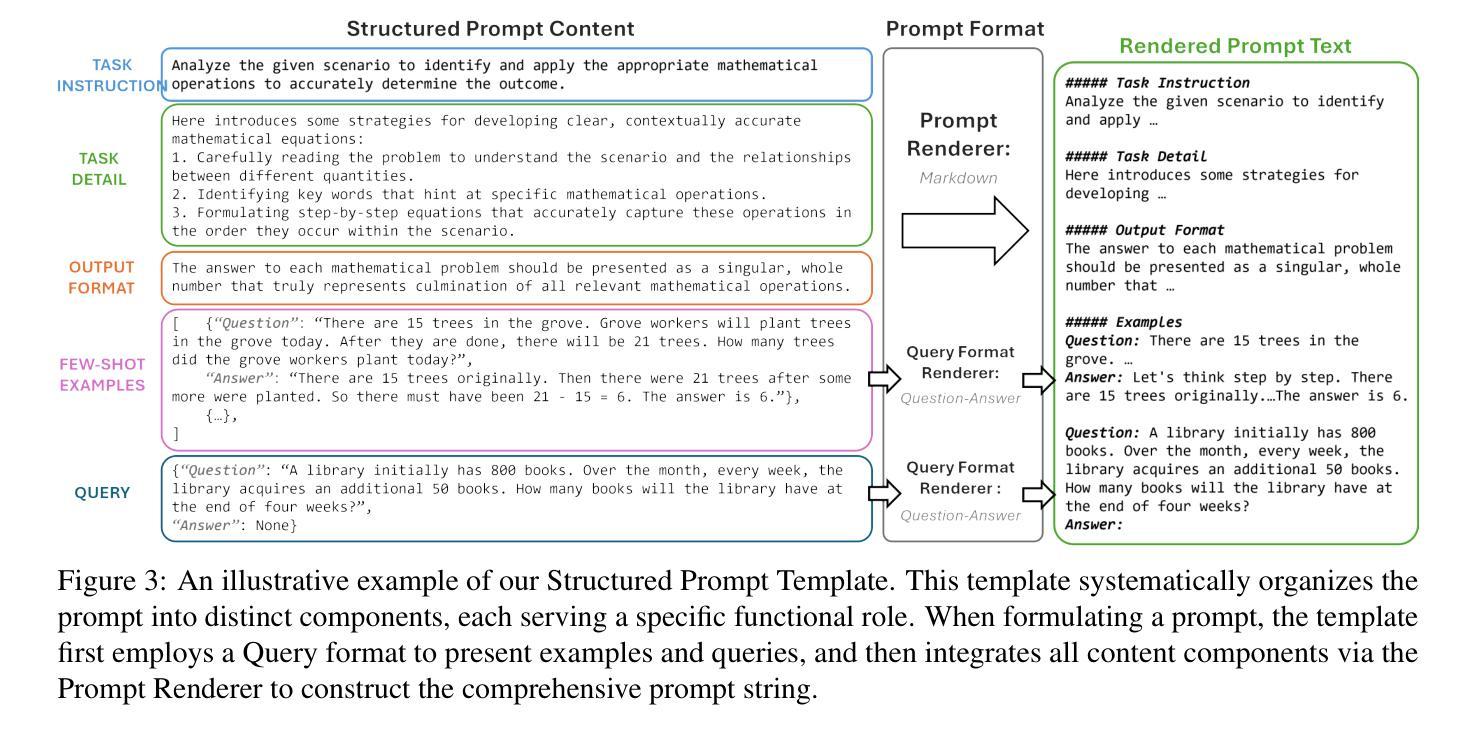
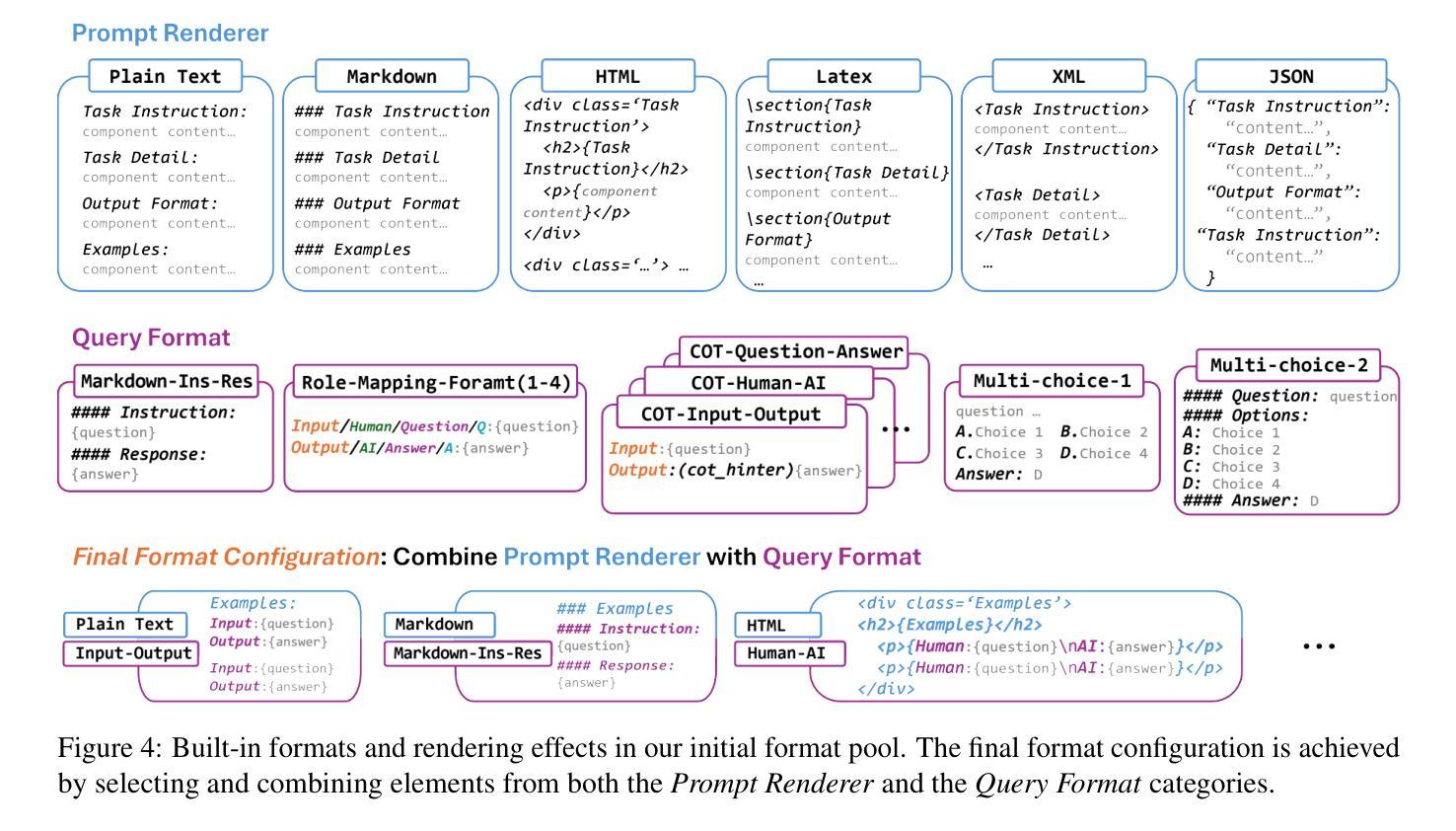
Large Language Models (LLMs) have shown significant capability across various tasks, with their real-world effectiveness often driven by prompt design. While recent research has focused on optimizing prompt content, the role of prompt formatting, a critical but often overlooked dimension, has received limited systematic investigation. In this paper, we introduce Content-Format Integrated Prompt Optimization (CFPO), an innovative methodology that jointly optimizes both prompt content and formatting through an iterative refinement process. CFPO leverages natural language mutations to explore content variations and employs a dynamic format exploration strategy that systematically evaluates diverse format options. Our extensive evaluations across multiple tasks and open-source LLMs demonstrate that CFPO demonstrates measurable performance improvements compared to content-only optimization methods. This highlights the importance of integrated content-format optimization and offers a practical, model-agnostic approach to enhancing LLM performance. Code is available at https://github.com/HenryLau7/CFPO.
大型语言模型(LLM)在各种任务中表现出了显著的能力,其在实际世界中的效果往往由提示设计驱动。虽然最近的研究集中在优化提示内容上,但提示格式的作用作为一个关键但常被忽视的维度,只得到了有限的系统研究。在本文中,我们介绍了内容格式集成提示优化(CFPO),这是一种通过迭代细化过程联合优化提示内容和格式的创新方法。CFPO利用自然语言变异来探索内容变化,并采用动态格式探索策略来系统评估各种格式选项。我们在多个任务和开源LLM上的广泛评估表明,与仅优化内容的方法相比,CFPO在性能上表现出可衡量的改进。这强调了集成内容格式优化的重要性,并提供了一种提高LLM性能的实用、模型无关的方法。代码可在https://github.com/HenryLau7/CFPO找到。
论文及项目相关链接
Summary
大型语言模型(LLM)在多种任务中展现出显著的能力,其实效性常取决于提示设计。现有研究多关注提示内容的优化,而提示格式这一重要但常被忽视的方面尚未得到系统的研究。本文提出一种创新的方法——内容与格式一体化提示优化(CFPO),通过迭代过程联合优化提示内容和格式。CFPO利用自然语言变异探索内容变化,并采用动态格式探索策略系统评估不同的格式选项。在多个任务和开源LLM上的广泛评估表明,CFPO相较于仅优化内容的方法,显示出可衡量的性能提升。这强调了集成内容和格式优化的重要性,并提供了一种实用的、模型无关的提升LLM性能的方法。
Key Takeaways
- 大型语言模型(LLM)在多种任务中表现出强大的能力,提示设计对其实际效果至关重要。
- 现有研究主要关注提示内容的优化,而提示格式的 systematic 研究尚不足。
- 本文提出 CFPO 方法,联合优化提示内容和格式。
- CFPO 利用自然语言变异和动态格式探索策略进行迭代优化。
- CFPO 在多个任务和开源LLM上的评估显示,相较于仅优化内容的方法,其性能有显著提升。
- 强调集成内容和格式优化的重要性。
点此查看论文截图

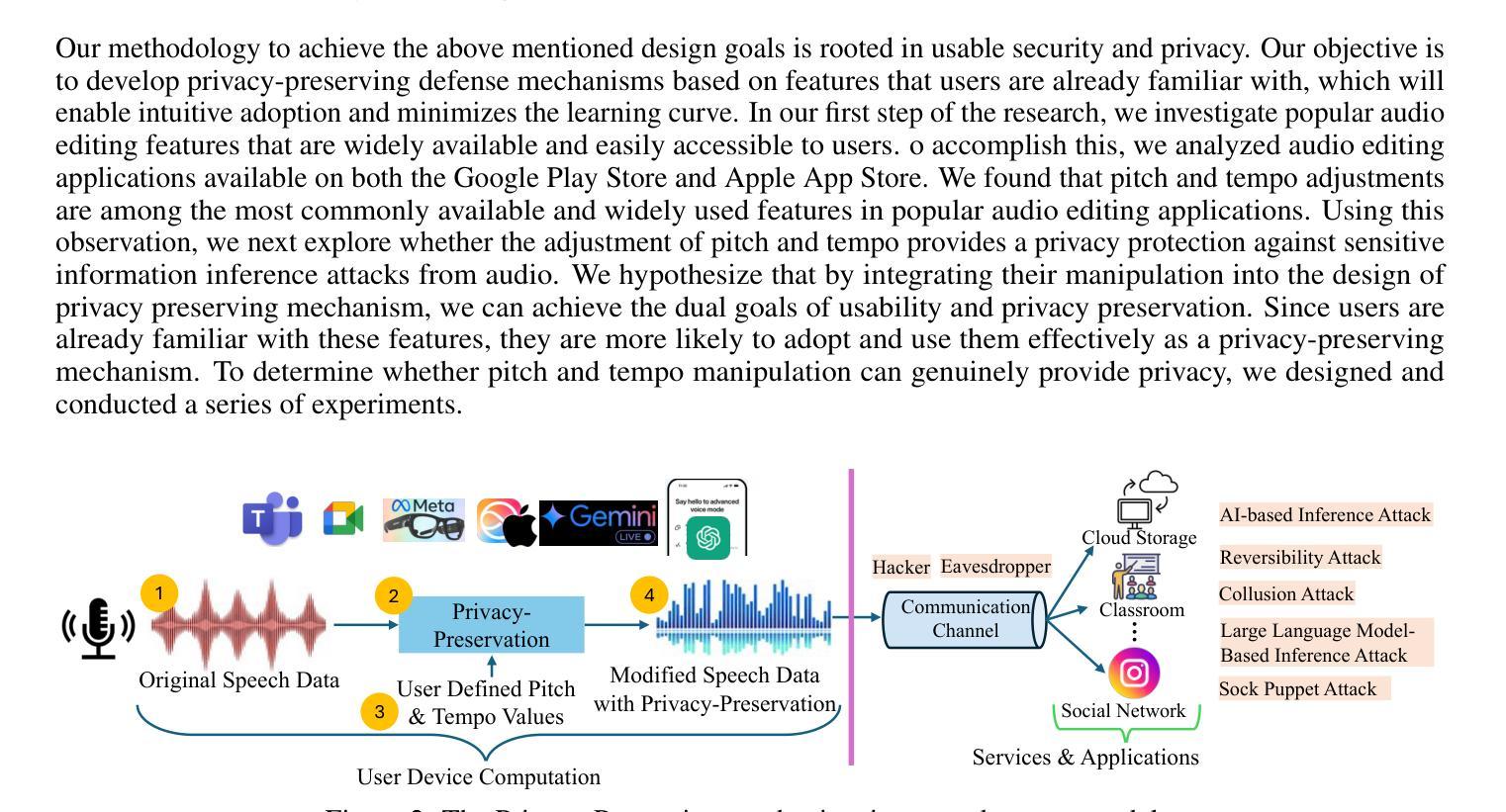
Exploring Audio Editing Features as User-Centric Privacy Defenses Against Large Language Model(LLM) Based Emotion Inference Attacks
Authors:Mohd. Farhan Israk Soumik, W. K. M. Mithsara, Abdur R. Shahid, Ahmed Imteaj
The rapid proliferation of speech-enabled technologies, including virtual assistants, video conferencing platforms, and wearable devices, has raised significant privacy concerns, particularly regarding the inference of sensitive emotional information from audio data. Existing privacy-preserving methods often compromise usability and security, limiting their adoption in practical scenarios. This paper introduces a novel, user-centric approach that leverages familiar audio editing techniques, specifically pitch and tempo manipulation, to protect emotional privacy without sacrificing usability. By analyzing popular audio editing applications on Android and iOS platforms, we identified these features as both widely available and usable. We rigorously evaluated their effectiveness against a threat model, considering adversarial attacks from diverse sources, including Deep Neural Networks (DNNs), Large Language Models (LLMs), and and reversibility testing. Our experiments, conducted on three distinct datasets, demonstrate that pitch and tempo manipulation effectively obfuscates emotional data. Additionally, we explore the design principles for lightweight, on-device implementation to ensure broad applicability across various devices and platforms.
随着语音技术的快速发展,包括虚拟助手、视频会议平台和可穿戴设备在内的语音技术引发了重大隐私担忧,特别是在从音频数据中推断敏感情感信息方面。现有的隐私保护方法往往牺牲了可用性和安全性,限制了它们在实际情况中的应用。本文介绍了一种新型的用户为中心的方法,它利用熟悉的音频编辑技术,特别是音高和节奏调整,可以在不牺牲可用性的情况下保护情感隐私。通过分析Android和iOS平台上流行的音频编辑应用程序,我们发现这些功能既广泛使用又易于使用。我们对它们进行了严格的评估,以应对威胁模型,考虑了来自不同来源的对抗性攻击,包括深度神经网络(DNNs)、大型语言模型(LLMs)和可逆性测试。我们在三个不同的数据集上进行的实验表明,音高和节奏调整可以有效地模糊情感数据。此外,我们还探讨了轻量级、设备端实现的设计原则,以确保在各种设备和平台上的广泛应用。
论文及项目相关链接
PDF Accepted for presentation(Poster) at PPAI-25: The 6th AAAI Workshop on Privacy-Preserving Artificial Intelligence
Summary
随着语音技术的快速发展,音频数据的隐私保护问题日益突出,尤其是情感隐私的保护。现有方法往往牺牲了可用性和安全性。本文提出一种新型用户中心的方法,利用熟悉的音频编辑技术(如音高和节奏调整)来保护情感隐私,既保护了隐私又不牺牲可用性。通过对安卓和iOS平台上流行的音频编辑应用的分析,发现这些功能广泛且易于使用。实验证明,音高和节奏调整可以有效地掩盖情感数据。同时,本文还探讨了轻量级设备实施的设计原则,确保其在各种设备和平台上的广泛应用。
Key Takeaways
- 语音技术的快速发展带来了音频数据隐私保护的问题,尤其是情感隐私的保护需求迫切。
- 现有隐私保护方法往往牺牲了可用性和安全性,难以满足实际应用需求。
- 本文提出一种新型用户中心的方法,利用音频编辑技术(如音高和节奏调整)保护情感隐私。
- 音高和节奏调整技术广泛存在于安卓和iOS平台的音频编辑应用中,易于使用。
- 实验证明音高和节奏调整可以有效地掩盖情感数据,对抗来自不同源的攻击,包括深度神经网络和大语言模型。
- 本文还探讨了轻量级设备实施的设计原则,以确保其在各种设备和平台上的广泛应用。
点此查看论文截图