⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-13 更新
CoS: Chain-of-Shot Prompting for Long Video Understanding
Authors:Jian Hu, Zixu Cheng, Chenyang Si, Wei Li, Shaogang Gong
Multi-modal Large Language Models (MLLMs) struggle with long videos due to the need for excessive visual tokens. These tokens exceed massively the context length of MLLMs, resulting in filled by redundant task-irrelevant shots. How to select shots is an unsolved critical problem: sparse sampling risks missing key details, while exhaustive sampling overwhelms the model with irrelevant content, leading to video misunderstanding. To solve this problem, we propose Chain-of-Shot prompting (CoS). The key idea is to frame shot selection as test-time visual prompt optimisation, choosing shots adaptive to video understanding semantic task by optimising shots-task alignment. CoS has two key parts: (1) a binary video summary mechanism that performs pseudo temporal grounding, discovering a binary coding to identify task-relevant shots, and (2) a video co-reasoning module that deploys the binary coding to pair (learning to align) task-relevant positive shots with irrelevant negative shots. It embeds the optimised shot selections into the original video, facilitating a focus on relevant context to optimize long video understanding. Experiments across three baselines and five datasets demonstrate the effectiveness and adaptability of CoS. Code given in https://lwpyh.github.io/CoS.
多模态大型语言模型(MLLMs)在处理长视频时面临挑战,因为需要过多的视觉标记。这些标记大大超过了MLLM的上下文长度,导致充斥着与任务无关的镜头。如何选择镜头是一个尚未解决的关键问题:稀疏采样可能遗漏关键细节,而详尽采样则会以大量无关内容使模型感到困扰,导致视频理解出现误解。为了解决这个问题,我们提出了Chain-of-Shot提示(CoS)。关键思想是将镜头选择作为测试时的视觉提示优化,通过优化镜头与任务的对齐方式,自适应选择适合视频理解语义任务的镜头。CoS有两个关键部分:(1)二进制视频摘要机制,执行伪时间定位,发现二进制编码以识别与任务相关的镜头;(2)视频协同推理模块,部署二进制编码以配对(学习对齐)与任务相关的正面镜头与无关的负面镜头。它将优化后的镜头选择嵌入到原始视频中,促进关注相关上下文,从而优化长视频的理解。在三基线数据和五个数据集上的实验证明了CoS的有效性和适应性。相关代码可在https://lwpyh.github.io/CoS中找到。
论文及项目相关链接
PDF A training-free test-time optimisation approach for long video understanding
Summary
多模态大型语言模型在处理长视频时面临挑战,因为需要过多的视觉标记,导致模型上下文长度受限。视频剪辑的选择是关键问题,稀疏采样可能遗漏关键细节,而全面采样则使模型淹没在无关内容中,导致视频理解失误。为解决此问题,我们提出Chain-of-Shot提示法(CoS)。其核心理念是在测试时优化视觉提示,通过优化剪辑与任务的对齐方式,自适应选择适合视频理解语义任务的剪辑。CoS包括两个关键部分:一是二进制视频摘要机制,执行伪时间定位,发现二进制编码以识别任务相关剪辑;二是视频协同推理模块,利用二进制编码将任务相关的正面剪辑与无关的负面剪辑配对。它将优化后的剪辑嵌入到原始视频中,帮助专注于相关上下文,优化长视频的理解。实验证明CoS在多个基准和五个数据集上的有效性和适应性。
Key Takeaways
- 多模态大型语言模型在处理长视频时面临挑战,因为视觉标记过多导致模型上下文长度受限。
- 视频剪辑的选择是解决问题的关键,稀疏采样和全面采样都有局限性。
- Chain-of-Shot提示法(CoS)旨在通过优化剪辑与任务的对齐方式来解决这一问题。
- CoS包括二进制视频摘要机制和视频协同推理模块两个关键部分。
- 二进制视频摘要机制能够识别任务相关剪辑。
- 视频协同推理模块将任务相关的正面剪辑与无关的负面剪辑进行配对。
点此查看论文截图


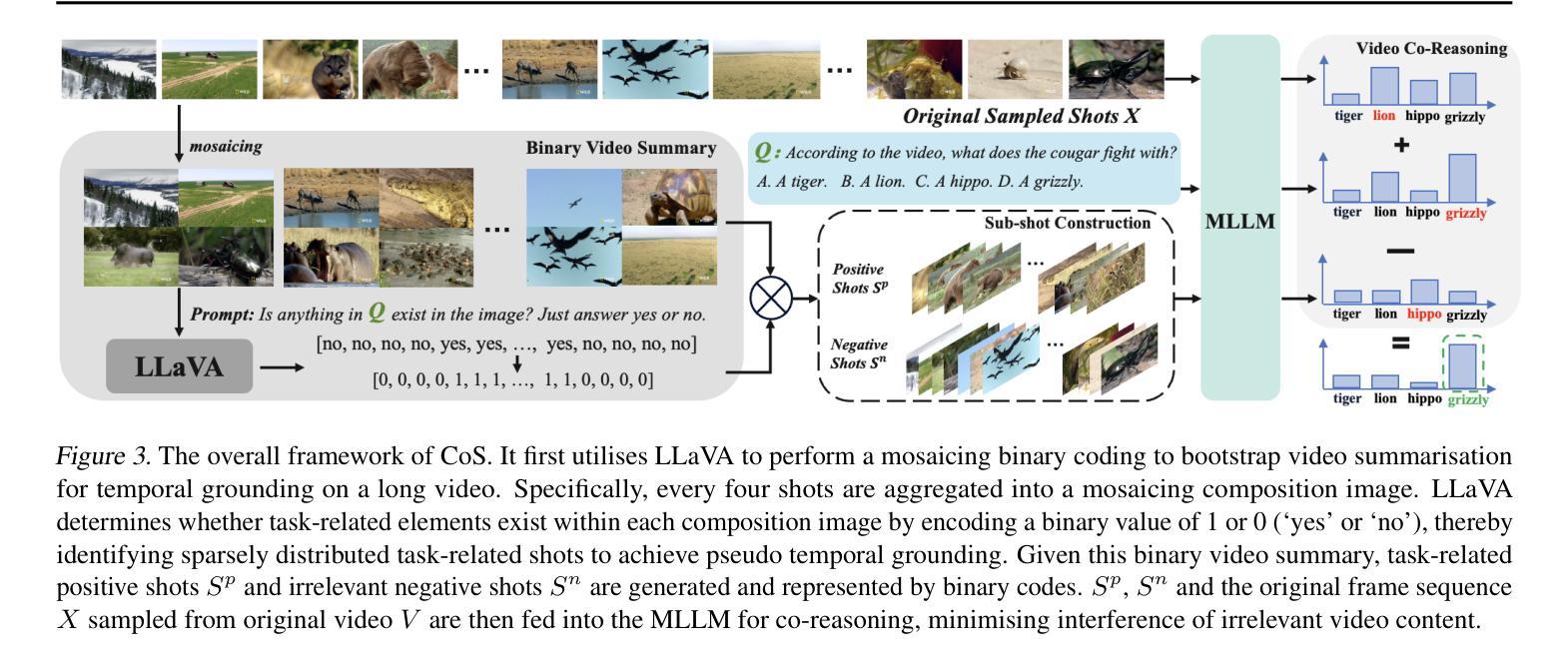
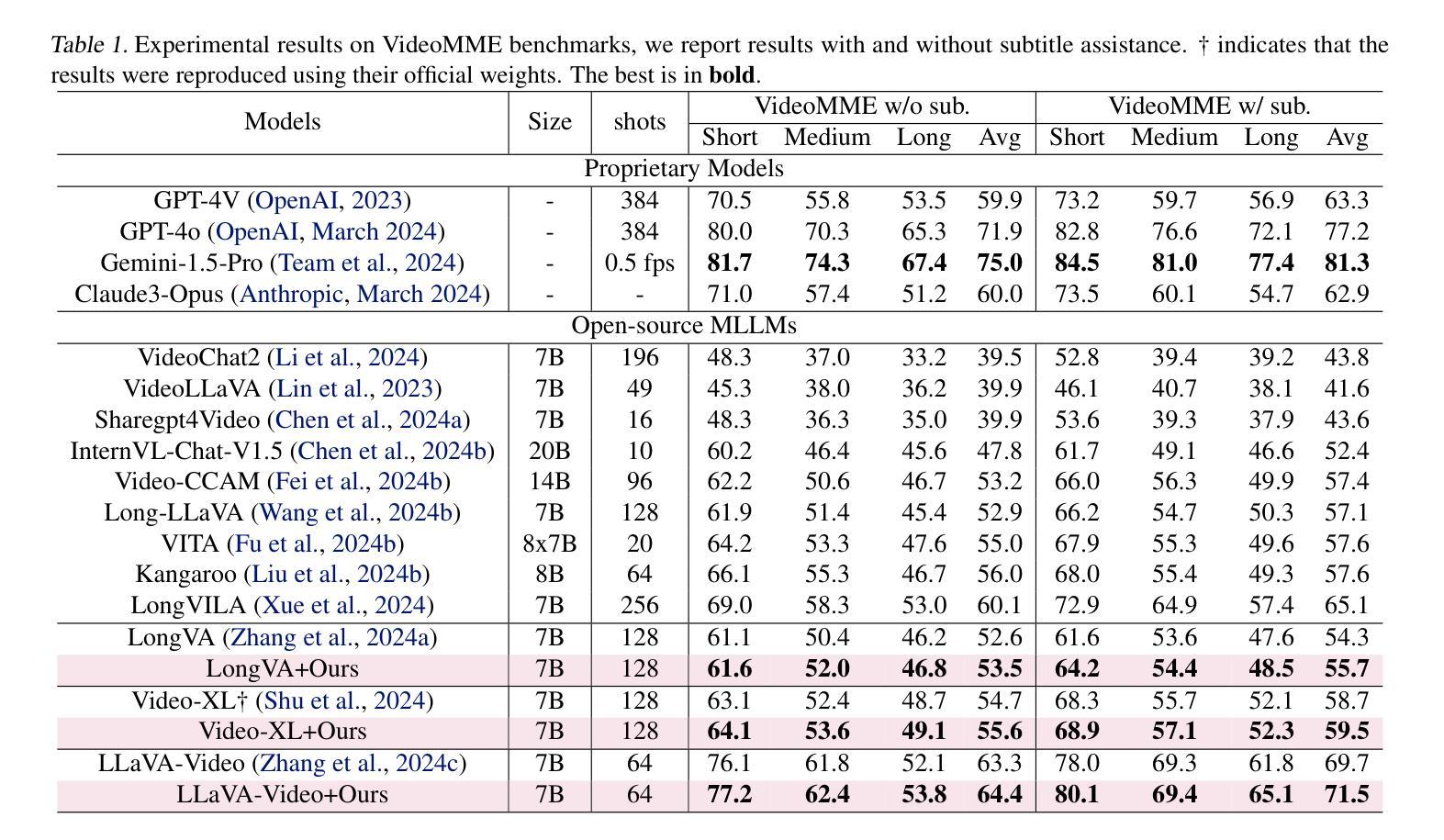
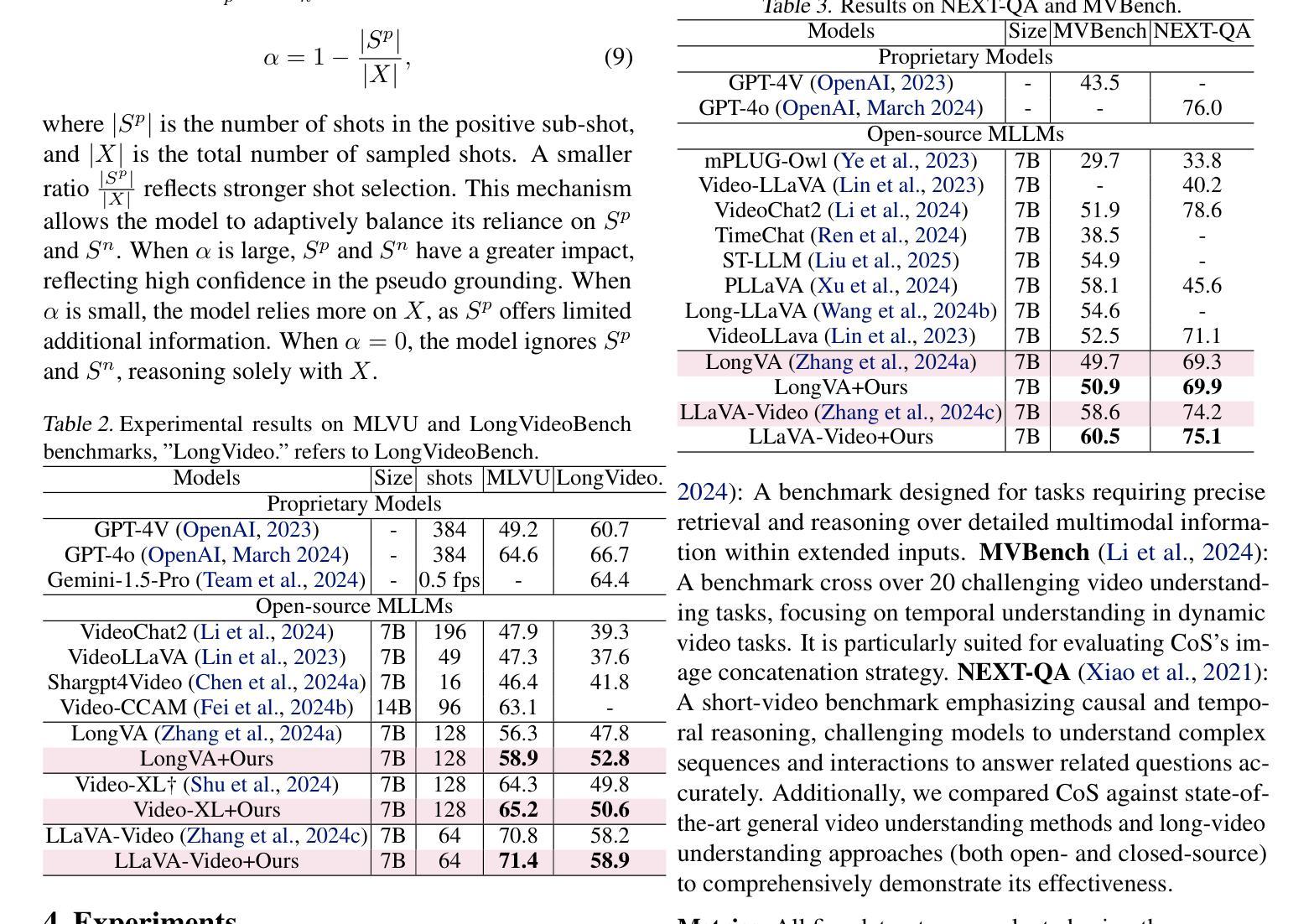
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Authors:Xiangyu Zeng, Kunchang Li, Chenting Wang, Xinhao Li, Tianxiang Jiang, Ziang Yan, Songze Li, Yansong Shi, Zhengrong Yue, Yi Wang, Yali Wang, Yu Qiao, Limin Wang
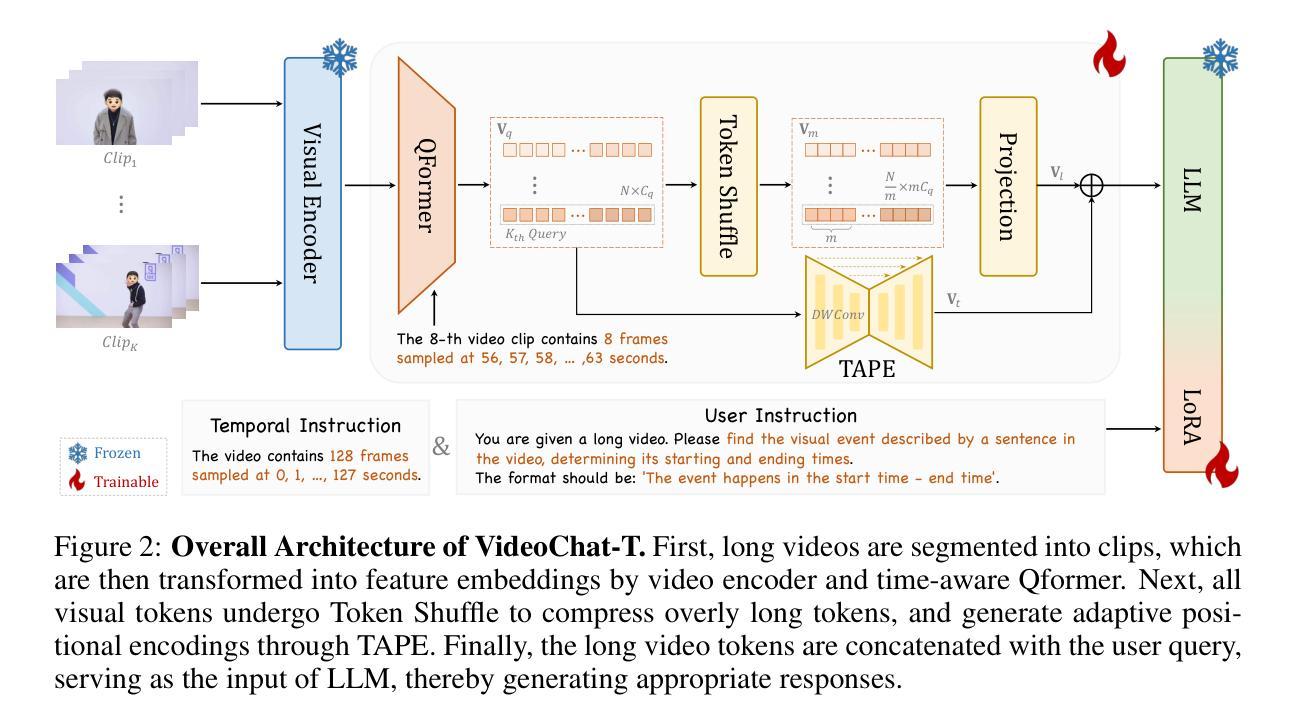
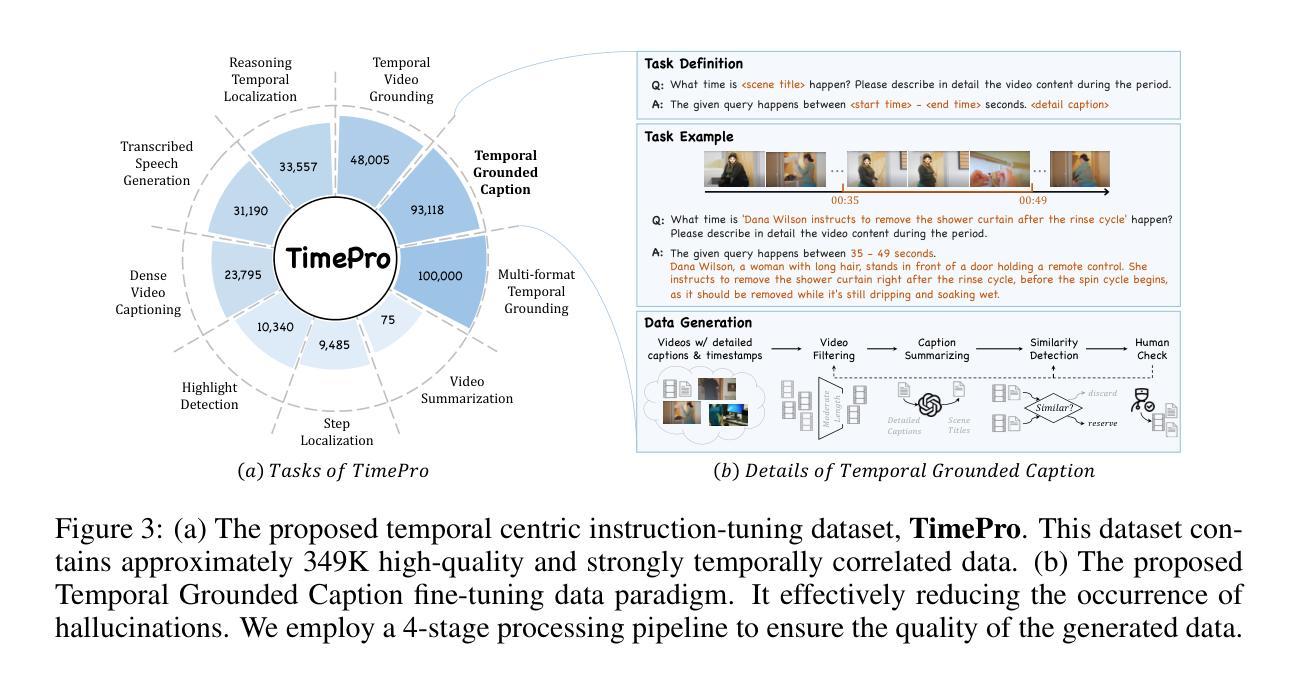
Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.
多模态大型语言模型(MLLMs)在短视频理解方面表现出令人印象深刻的性能。然而,对于MLLMs来说,理解长视频仍然是一个挑战。本文提出TimeSuite,这是一系列新设计,旨在将现有的短视频MLLMs适应于长视频理解,包括一个简单而高效的处理长视频序列的框架、一个用于MLLMs接地调整的高质量视频数据集,以及一个精心设计的指令调整任务,以明确地结合传统问答格式的接地监督。具体来说,基于VideoChat,我们通过实现令牌混洗来压缩长视频令牌并引入时间自适应位置编码(TAPE)来提高视觉表示的时间意识,从而提出我们的长视频MLLM,名为VideoChat-T。同时,我们介绍了TimePro,这是一个全面的以接地为中心的指令调整数据集,由9个任务和34.9万个高质量接地注释组成。值得注意的是,我们设计了一种新的指令调整任务类型,称为时间接地字幕,以进行详细的视频描述和相应的时间戳预测。这种明确的时间位置预测将指导MLLM在生成描述时正确关注视觉内容,从而降低LLMs产生的幻觉风险。实验结果表明,我们的TimeSuite成功地提高了短视频MLLM对长视频的理解能力,在Egoschema和VideoMME的基准测试中分别提高了5.6%和6.8%。此外,VideoChat-T表现出强大的零样本时间接地能力,显著优于现有的最先进的MLLMs。经过微调后,其性能与传统的监督专家模型相当。
论文及项目相关链接
PDF Accepted by ICLR2025
Summary
本文提出TimeSuite方案,旨在将现有的短视频多模态大型语言模型(MLLMs)适应于长视频理解。包括一个简洁高效的长视频处理框架、高质量的视频数据集用于MLLMs的地面调整,以及精心设计的一种结合传统问答格式的地面监督的指令调整任务。提出的长视频MLLM——VideoChat-T,通过实现令牌混洗来压缩长视频令牌,并引入时间自适应位置编码(TAPE)增强视觉表示的时效性。此外,还介绍了全面的以地面为中心的指令调整数据集TimePro,包括9个任务和34.9万高质量地面注释。设计了一种新的指令调整任务类型——时间地面字幕,以进行详细的视频描述和时间戳预测。整体方案增强了短MLLM对长视频的理解能力,在Egoschema和VideoMME等基准测试中分别提高了5.6%和6.8%。VideoChat-T具有强大的零镜头时间地面能力,在微调后表现与传统监督专家模型相当。
Key Takeaways
- TimeSuite方案旨在将短视频多模态大型语言模型应用于长视频理解,包括处理框架、数据集和指令调整任务的设计。
- VideoChat-T模型通过令牌混洗和引入时间自适应位置编码(TAPE)适应长视频理解。
- TimePro数据集包含多种任务和高质量注释,用于增强模型的地面能力。
- 新型指令调整任务类型——时间地面字幕,用于详细视频描述和时间戳预测。
- TimeSuite方案提高了MLLM在长视频理解方面的能力,特别是在基准测试中的表现。
- VideoChat-T模型具有强大的零镜头时间地面能力。
点此查看论文截图