⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-14 更新
HoVLE: Unleashing the Power of Monolithic Vision-Language Models with Holistic Vision-Language Embedding
Authors:Chenxin Tao, Shiqian Su, Xizhou Zhu, Chenyu Zhang, Zhe Chen, Jiawen Liu, Wenhai Wang, Lewei Lu, Gao Huang, Yu Qiao, Jifeng Dai
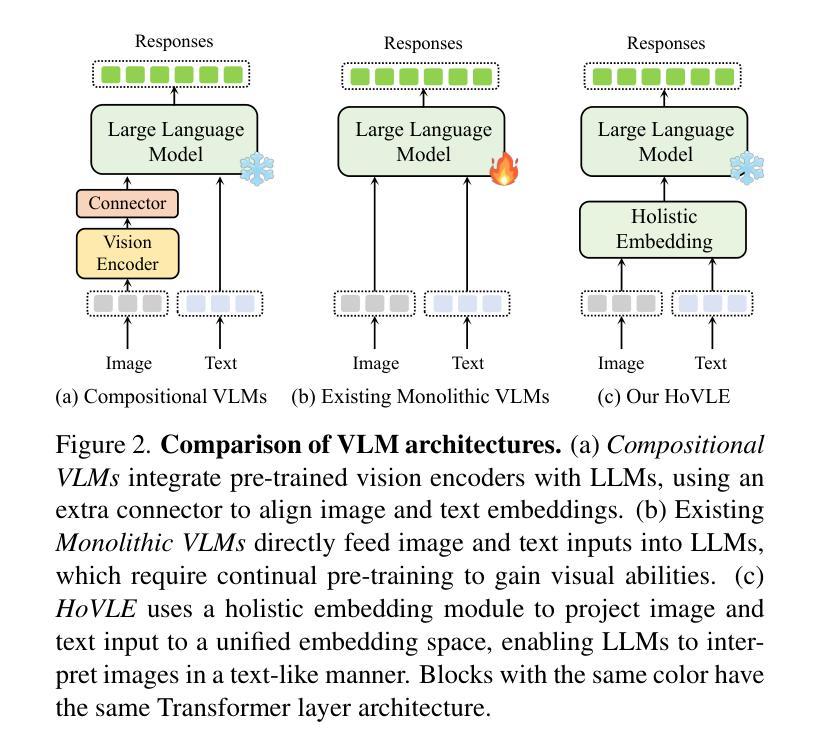
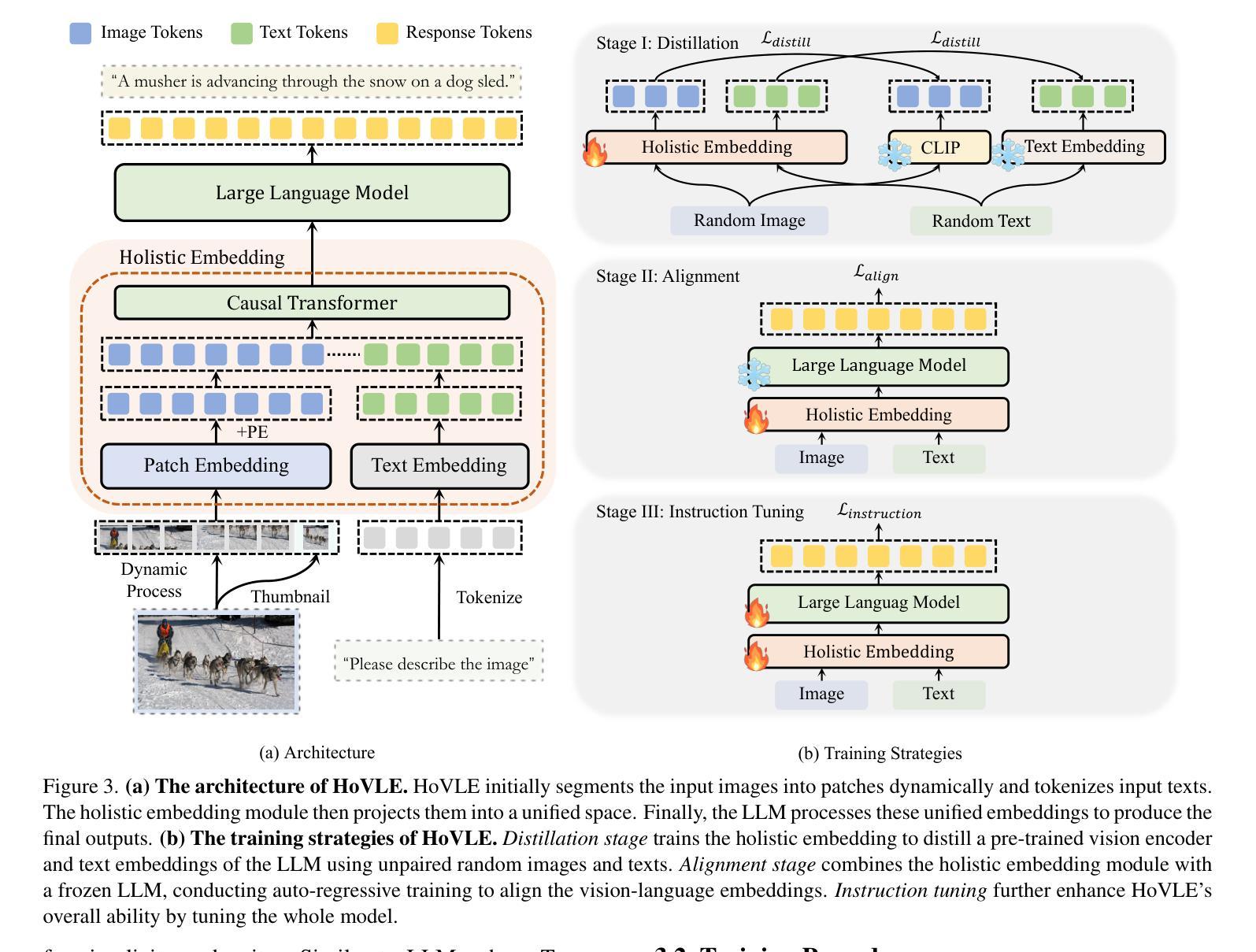
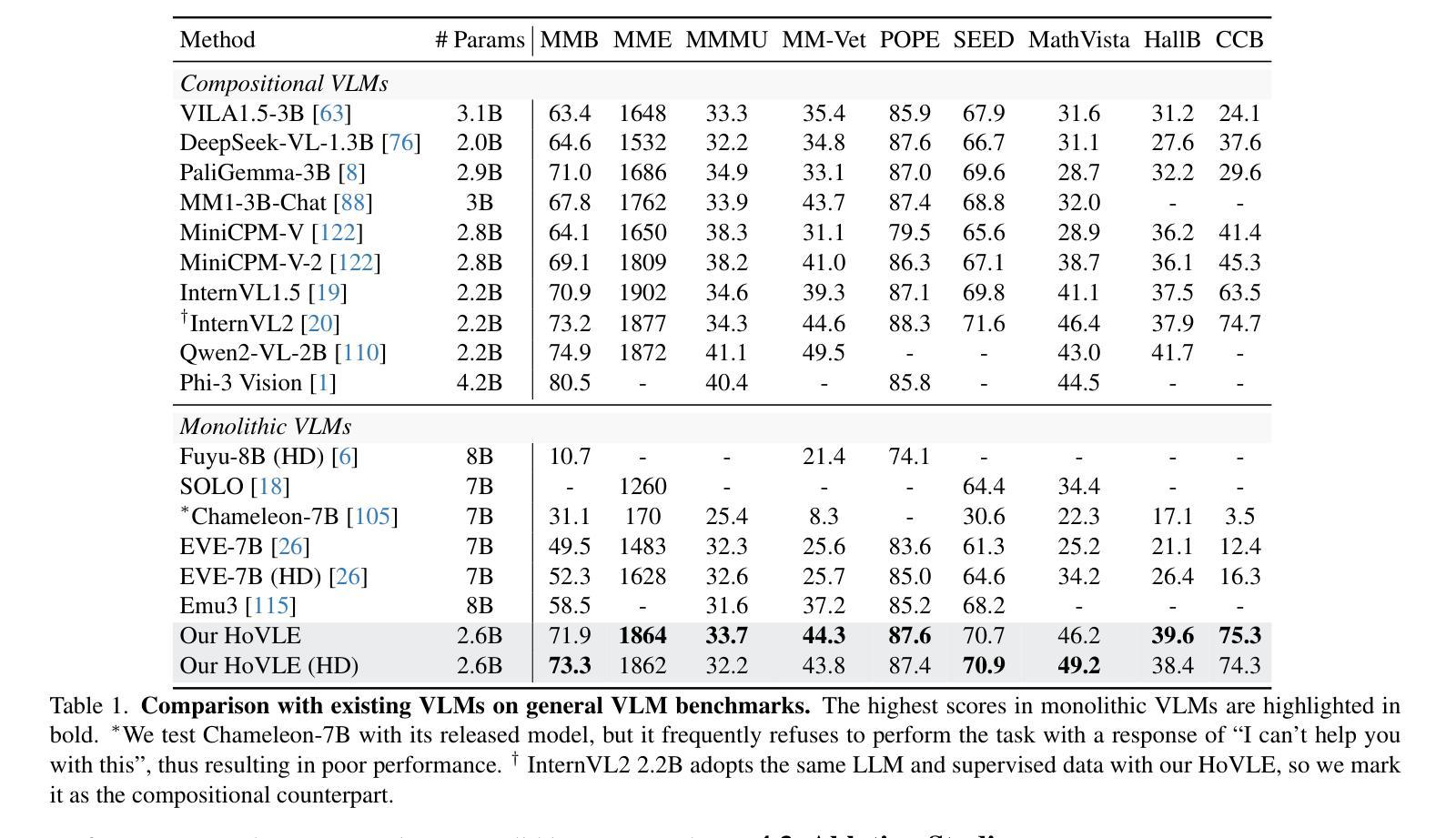
The rapid advance of Large Language Models (LLMs) has catalyzed the development of Vision-Language Models (VLMs). Monolithic VLMs, which avoid modality-specific encoders, offer a promising alternative to the compositional ones but face the challenge of inferior performance. Most existing monolithic VLMs require tuning pre-trained LLMs to acquire vision abilities, which may degrade their language capabilities. To address this dilemma, this paper presents a novel high-performance monolithic VLM named HoVLE. We note that LLMs have been shown capable of interpreting images, when image embeddings are aligned with text embeddings. The challenge for current monolithic VLMs actually lies in the lack of a holistic embedding module for both vision and language inputs. Therefore, HoVLE introduces a holistic embedding module that converts visual and textual inputs into a shared space, allowing LLMs to process images in the same way as texts. Furthermore, a multi-stage training strategy is carefully designed to empower the holistic embedding module. It is first trained to distill visual features from a pre-trained vision encoder and text embeddings from the LLM, enabling large-scale training with unpaired random images and text tokens. The whole model further undergoes next-token prediction on multi-modal data to align the embeddings. Finally, an instruction-tuning stage is incorporated. Our experiments show that HoVLE achieves performance close to leading compositional models on various benchmarks, outperforming previous monolithic models by a large margin. Model available at https://huggingface.co/OpenGVLab/HoVLE.
大型语言模型(LLM)的快速发展推动了视觉语言模型(VLM)的进步。一体式VLM避免了模态特定编码器,为组合式VLM提供了有前景的替代方案,但面临性能较差的挑战。大多数现有的一体式VLM需要调整预训练的LLM以获得视觉能力,这可能会降低其语言功能。为了解决这一困境,本文提出了一种新型高性能一体式VLM,名为HoVLE。我们注意到,当图像嵌入与文本嵌入对齐时,LLM已被证明能够解释图像。当前一体式VLM的挑战实际上在于缺乏一个用于视觉和语言输入的全面嵌入模块。因此,HoVLE引入了一个全面嵌入模块,该模块将视觉和文本输入转换为共享空间,使LLM能够以相同的方式处理图像和文本。此外,精心设计了一种多阶段训练策略来增强全面嵌入模块。它首先经过训练,从预训练的视觉编码器和LLM中提炼出视觉特征和文本嵌入,使模型能够使用大量的未配对随机图像和文本标记进行大规模训练。整个模型进一步进行多模态数据的下一个标记预测,以对齐嵌入。最后,加入了指令调整阶段。我们的实验表明,HoVLE在各种基准测试中实现了接近领先组合模型的表现,大大超过了以前的一体式模型。模型可在https://huggingface.co/OpenGVLab/HoVLE下载使用。
论文及项目相关链接
Summary
大规模语言模型(LLM)的快速发展推动了视觉语言模型(VLM)的进步。本文提出了一种新型高性能单体VLM——HoVLE,旨在解决现有单体VLM需要在预训练LLM上调整以获取视觉能力而导致的语言能力下降的问题。HoVLE引入了一个整体嵌入模块,将视觉和文本输入转换为共享空间,使LLM能够以相同的方式处理图像和文本。通过多阶段训练策略赋能整体嵌入模块,首先进行预训练视觉编码器和LLM的文本嵌入对齐,然后进行大规模未配对随机图像和文本标记的训练,最后进行多模态数据的下一个标记预测以对齐嵌入。实验表明,HoVLE在各种基准测试上的性能接近领先的组合模型,并且大大超过了以前的单体模型。
Key Takeaways
- LLM的快速发展推动了VLM的进步,单体VLM作为一种有前景的替代方案出现,旨在解决组合模型的挑战。
- 现有单体VLM需要在预训练的LLM上调整以获取视觉能力,可能导致语言能力的退化。
- HoVLE通过引入整体嵌入模块,将视觉和文本输入转换为共享空间,使LLM能同时处理图像和文本。
- HoVLE采用多阶段训练策略,包括预训练视觉编码器和LLM的文本嵌入对齐、大规模未配对随机图像和文本标记的训练、以及多模态数据的下一个标记预测。
- HoVLE在各种基准测试上的性能接近领先的组合模型,且大幅超越了之前的单体模型。
- HoVLE模型可在huggingface.co/OpenGVLab/HoVLE上获取。
点此查看论文截图

Filter-then-Generate: Large Language Models with Structure-Text Adapter for Knowledge Graph Completion
Authors:Ben Liu, Jihai Zhang, Fangquan Lin, Cheng Yang, Min Peng
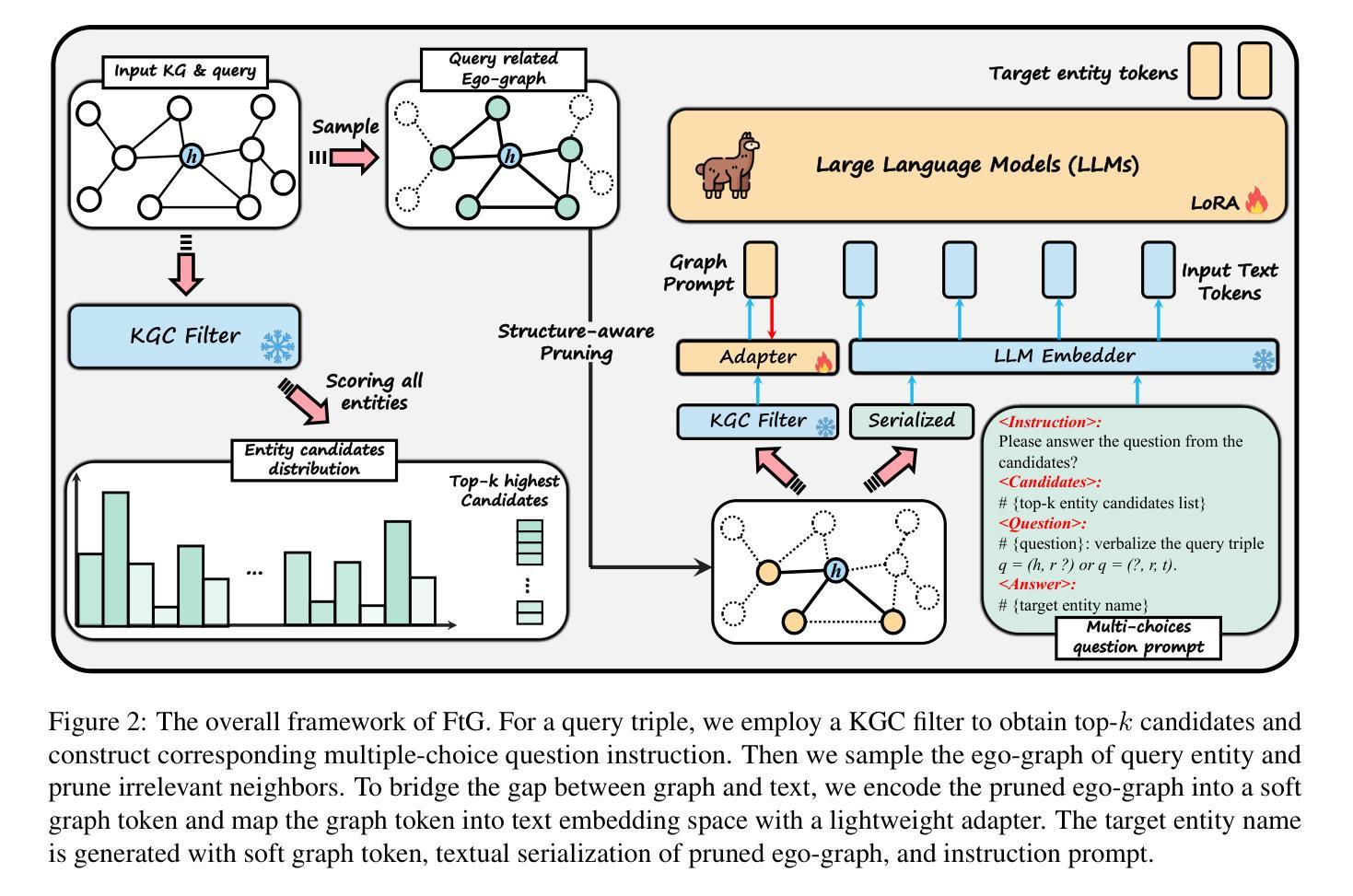
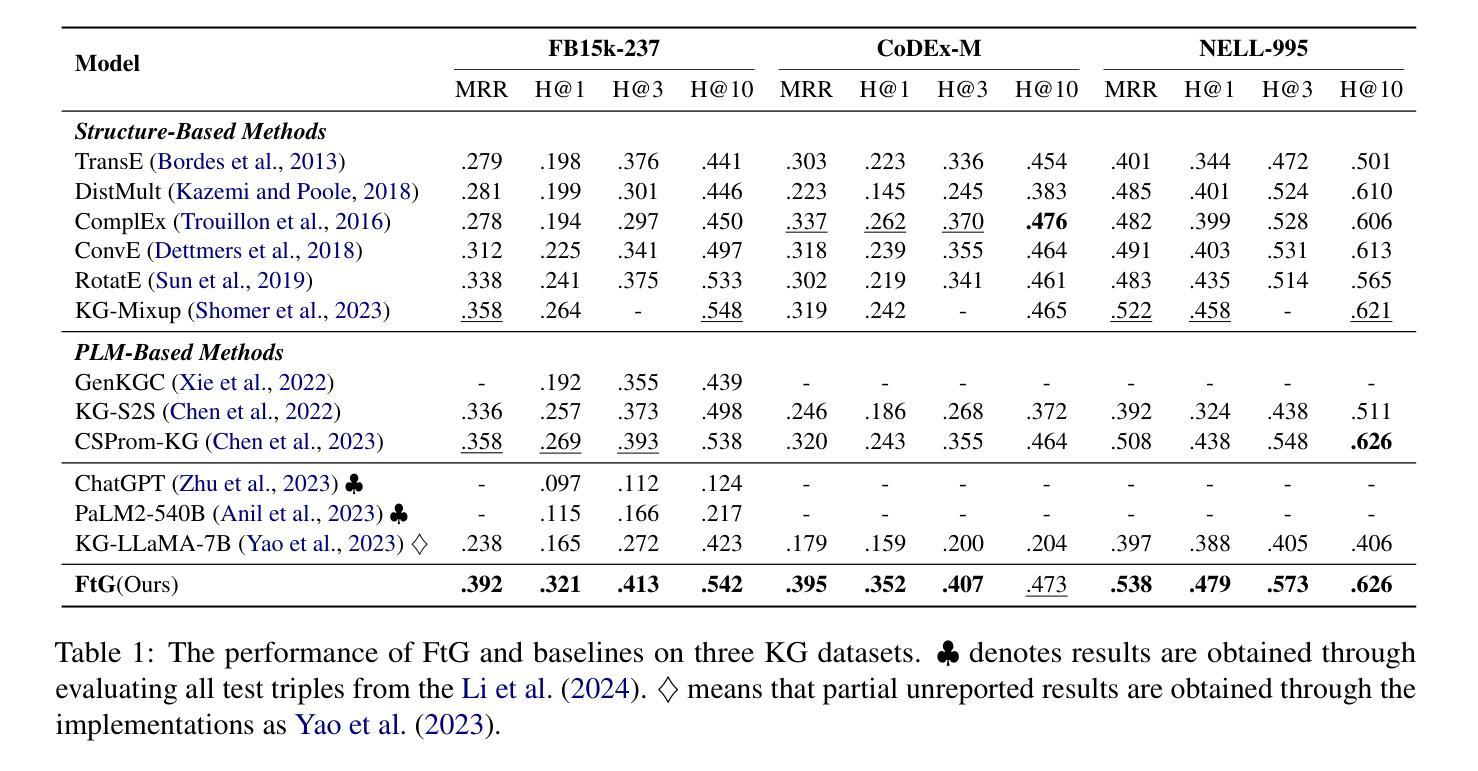
Large Language Models (LLMs) present massive inherent knowledge and superior semantic comprehension capability, which have revolutionized various tasks in natural language processing. Despite their success, a critical gap remains in enabling LLMs to perform knowledge graph completion (KGC). Empirical evidence suggests that LLMs consistently perform worse than conventional KGC approaches, even through sophisticated prompt design or tailored instruction-tuning. Fundamentally, applying LLMs on KGC introduces several critical challenges, including a vast set of entity candidates, hallucination issue of LLMs, and under-exploitation of the graph structure. To address these challenges, we propose a novel instruction-tuning-based method, namely FtG. Specifically, we present a filter-then-generate paradigm and formulate the KGC task into a multiple-choice question format. In this way, we can harness the capability of LLMs while mitigating the issue casused by hallucinations. Moreover, we devise a flexible ego-graph serialization prompt and employ a structure-text adapter to couple structure and text information in a contextualized manner. Experimental results demonstrate that FtG achieves substantial performance gain compared to existing state-of-the-art methods. The instruction dataset and code are available at https://github.com/LB0828/FtG.
大型语言模型(LLM)拥有庞大的内在知识和出色的语义理解能力,已经彻底改变了自然语言处理的各项任务。尽管取得了成功,但在知识图谱补全(KGC)方面,LLM仍存在明显不足。经验证据表明,即使在通过复杂提示设计或针对性指令调整的情况下,LLM的表现仍一直逊于传统的KGC方法。从根本上说,将LLM应用于KGC面临着几个关键挑战,包括大量的实体候选对象、LLM的幻觉问题以及对图结构利用不足等。为了解决这些挑战,我们提出了一种基于指令调整的新方法,称为FtG。具体来说,我们提出了一个“过滤然后生成”的模式,并将KGC任务转化为一个选择题格式。通过这种方式,我们可以利用LLM的能力,同时减轻幻觉问题带来的影响。此外,我们设计了一个灵活的自我图序列化提示,并采用了结构文本适配器,以语境化的方式将结构和文本信息进行结合。实验结果表明,与现有最先进的方法相比,FtG实现了显著的性能提升。指令数据集和代码可通过https://github.com/LB0828/FtG获取。
论文及项目相关链接
PDF COLING 2025 Main Conference
Summary
大规模语言模型(LLM)具备丰富的内在知识和高级语义理解能,在自然语言处理的各种任务中带来了革命性的变化。然而,在知识图谱补全(KGC)方面,LLM的应用仍存在显著差距。尽管通过巧妙的提示设计或指令微调来优化,LLM的表现仍逊于传统KGC方法。为实现LLM在KGC任务中的有效应用,我们面临实体候选集庞大、LLM的虚构问题以及图形结构利用不足等挑战。为应对这些挑战,我们提出了一种基于指令调优的方法FtG,采用先过滤后生成的范式,将KGC任务转化为多选问题形式,从而利用LLM的优势并减轻虚构问题的影响。此外,我们还设计了灵活的自我图谱序列化提示,并采用结构文本适配器以语境化的方式结合结构和文本信息。实验结果表明,FtG相较于现有先进方法实现了显著的性能提升。
Key Takeaways
- LLM具备强大的内在知识和语义理解能力,但在知识图谱补全任务中表现不佳。
- LLM在KGC面临实体候选集庞大、虚构问题以及图形结构利用不足等挑战。
- 提出了一种新的方法FtG,基于指令调优,采用先过滤后生成的范式处理KGC任务。
- FtG将KGC任务转化为多选问题形式,减轻LLM的虚构问题。
- FtG设计了灵活的自我图谱序列化提示,并结合结构和文本信息。
- 实验证明,FtG在KGC任务上较现有方法有明显性能提升。
- FtG的指令数据集和代码已公开可用。
点此查看论文截图


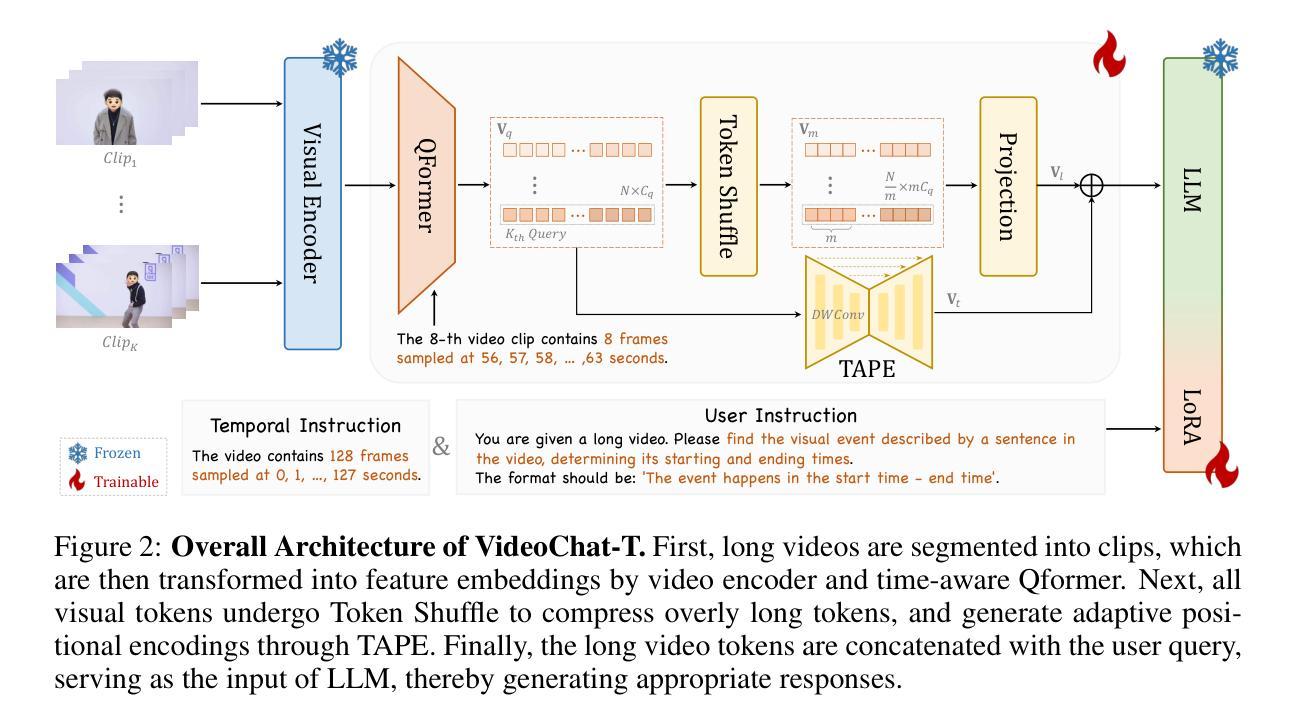
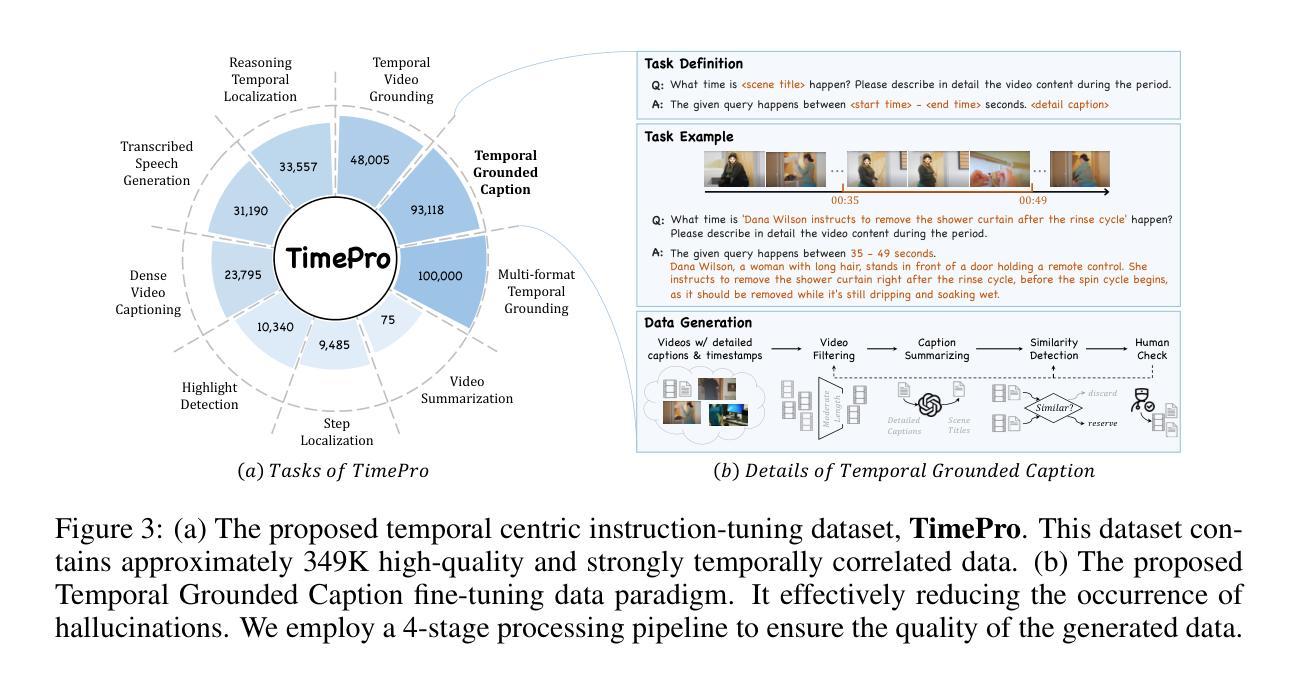
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Authors:Xiangyu Zeng, Kunchang Li, Chenting Wang, Xinhao Li, Tianxiang Jiang, Ziang Yan, Songze Li, Yansong Shi, Zhengrong Yue, Yi Wang, Yali Wang, Yu Qiao, Limin Wang
Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.
多模态大型语言模型(MLLMs)在短视频理解方面表现出了令人印象深刻的性能。然而,对于MLLMs来说,理解长视频仍然是一个挑战。本文针对现有短视频MLLMs的长视频理解适应性不足的问题,提出了TimeSuite方案,包括一个简单而高效的长视频序列处理框架、一个用于MLLMs精准调整的高质量视频数据集以及一个精心设计的任务指令调整任务,以明确将传统的问答格式中的基础监督纳入其中。具体来说,基于VideoChat,我们提出了名为VideoChat-T的长视频MLLM,它通过实现令牌混洗来压缩长视频令牌并引入时间自适应位置编码(TAPE)来提高视觉表示的时间意识。同时,我们引入了TimePro,这是一个全面的以基础为中心的任务指令数据集,包含9个任务和34.9万高质量的基础注释。值得一提的是,我们设计了一种新的任务指令类型,称为时间基础字幕,以进行详细的视频描述和相应的时间戳预测。这种明确的时间位置预测将指导MLLM在生成描述时正确关注视觉内容,从而降低LLM产生的幻觉风险。实验结果表明,我们的TimeSuite方案成功地提高了短视频MLLM对长视频的理解能力,在Egoschema和VideoMME基准测试上的改进分别为5.6%和6.8%。此外,VideoChat-T展现出强大的零样本时间基础能力,显著优于现有的最先进的MLLMs。经过微调后,其性能与传统的监督专家模型相当。
论文及项目相关链接
PDF Accepted by ICLR2025
Summary
在本文中,研究者提出了TimeSuite方案,通过设计新颖的方法和框架来解决长视频理解问题。其中提出了基于VideoChat的VideoChat-T模型,使用标记置换技术和时间自适应位置编码(TAPE)增强模型对长视频的感知能力。同时,引入了TimePro数据集,包含多种任务类型与标注信息用于提升模型性能。研究结果显示TimeSuite方法有效提高了长视频理解效果,成功扩展了原有模型性能,相较于现有模型具有显著优势。
Key Takeaways
- TimeSuite方案旨在解决多模态大型语言模型在长视频理解上的挑战。
- VideoChat-T模型通过标记置换和时间自适应位置编码技术实现长视频理解。
- TimePro数据集为MLLM提供了全面而准确的任务导向标注数据,用以指导模型的训练和测试。
- 设计了一种名为Temporal Grounded Caption的新任务类型,用于预测时间戳并减少模型产生的幻觉风险。
点此查看论文截图

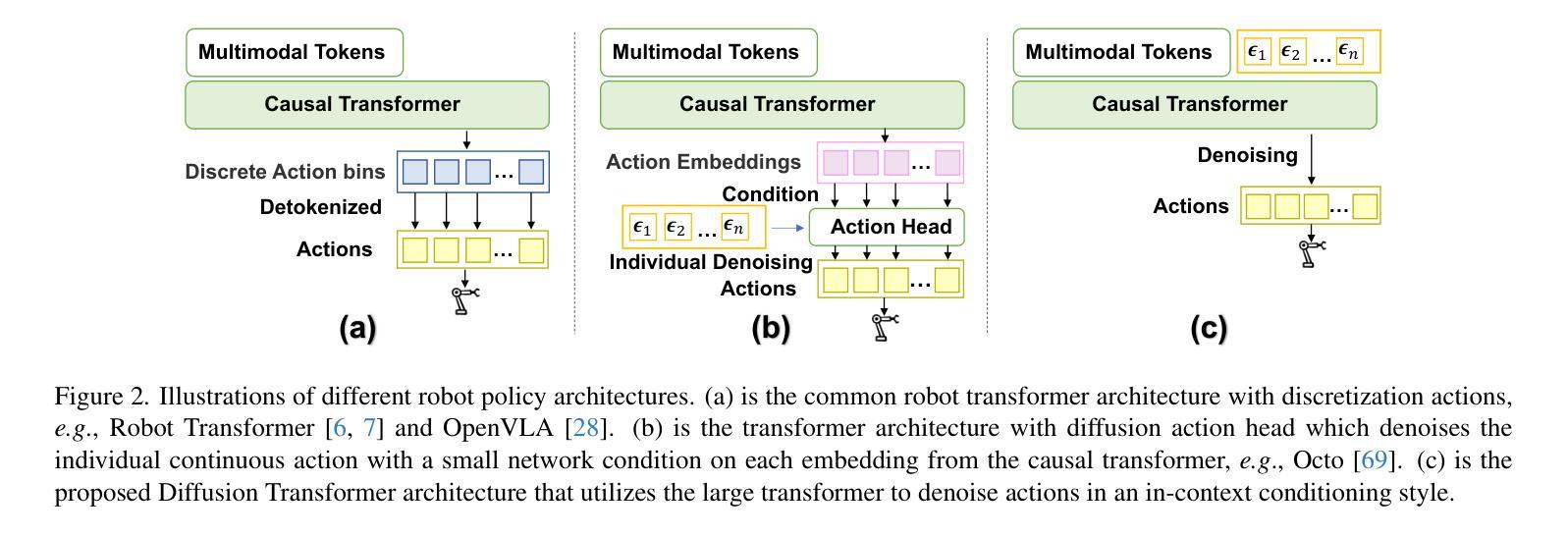
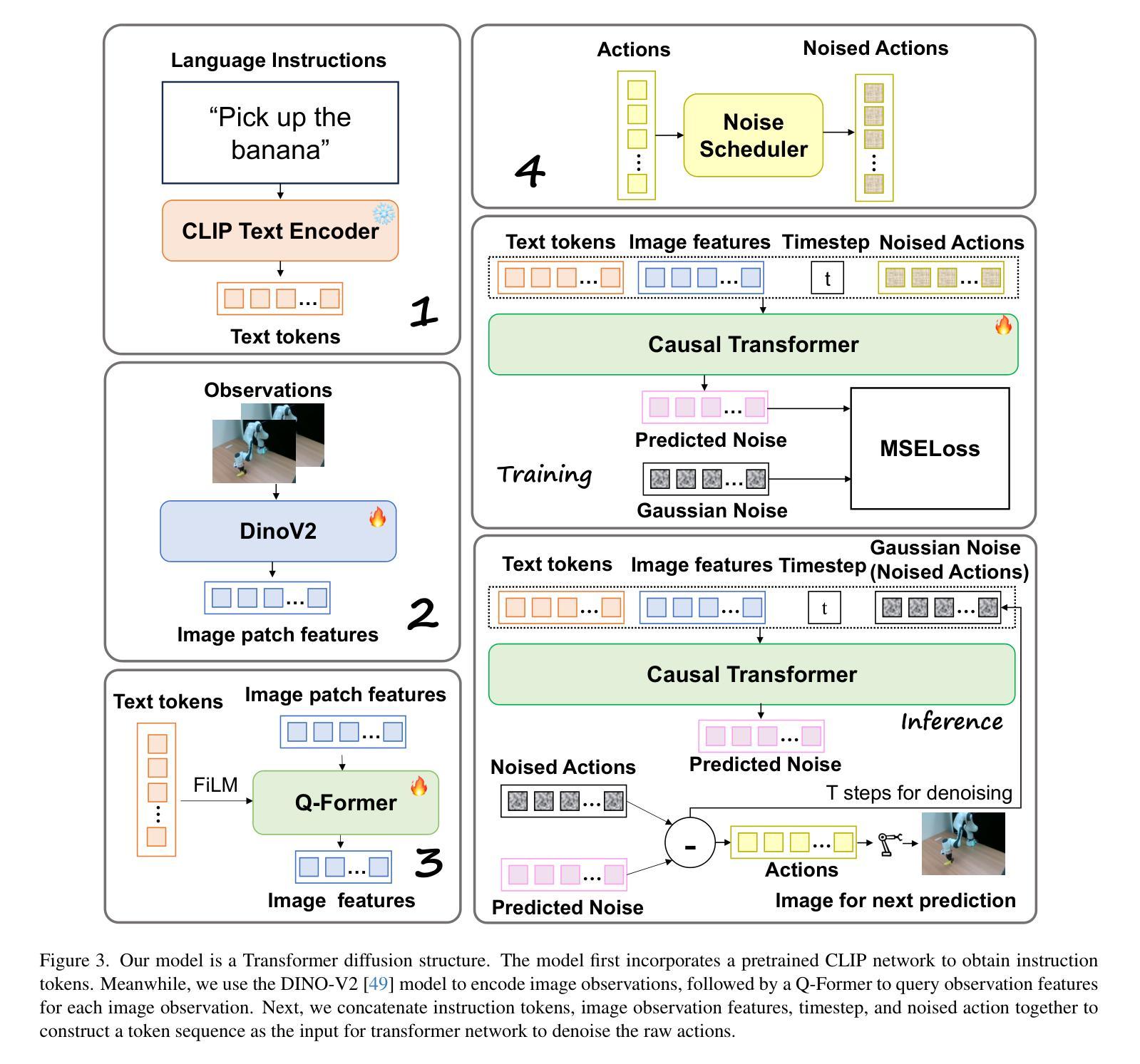
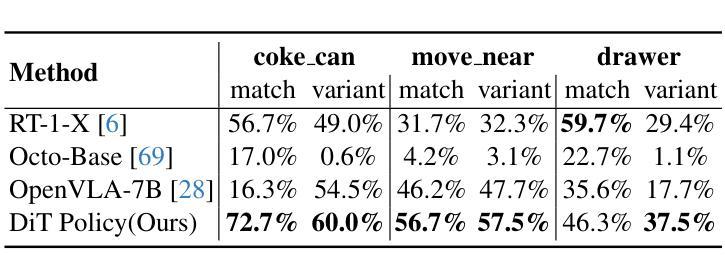
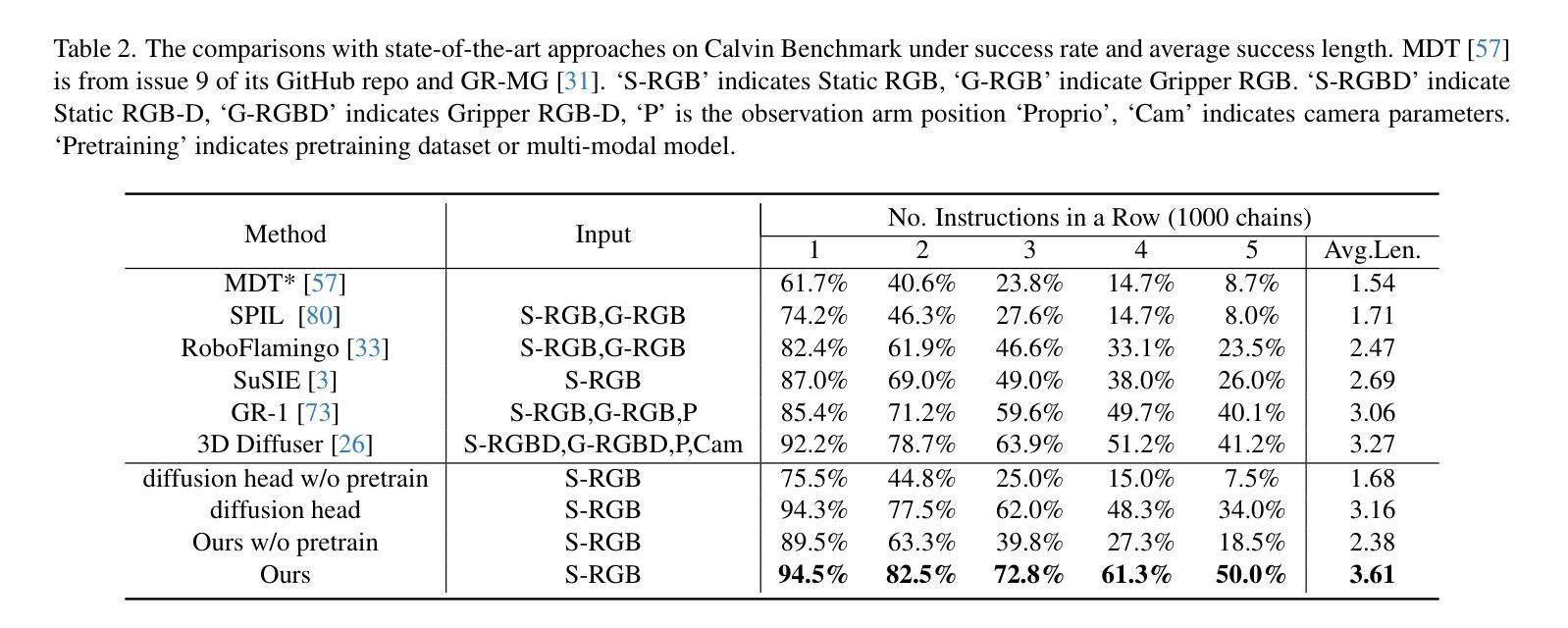
Diffusion Transformer Policy: Scaling Diffusion Transformer for Generalist Visual-Language-Action Learning
Authors:Zhi Hou, Tianyi Zhang, Yuwen Xiong, Hengjun Pu, Chengyang Zhao, Ronglei Tong, Yu Qiao, Jifeng Dai, Yuntao Chen
Recent large visual-language action models pretrained on diverse robot datasets have demonstrated the potential for generalizing to new environments with a few in-domain data. However, those approaches usually predict individual discretized or continuous action by a small action head, which limits the ability in handling diverse action spaces. In contrast, we model the continuous action sequence with a large multi-modal diffusion transformer, dubbed as Diffusion Transformer Policy, in which we directly denoise action chunks by a large transformer model rather than a small action head for action embedding. By leveraging the scaling capability of transformers, the proposed approach can effectively model continuous end-effector actions across large diverse robot datasets, and achieve better generalization performance. Extensive experiments demonstrate the effectiveness and generalization of Diffusion Transformer Policy on Maniskill2, Libero, Calvin and SimplerEnv, as well as the real-world Franka arm, achieving consistent better performance on Real-to-Sim benchmark SimplerEnv, real-world Franka Arm and Libero compared to OpenVLA and Octo. Specifically, without bells and whistles, the proposed approach achieves state-of-the-art performance with only a single third-view camera stream in the Calvin task ABC->D, improving the average number of tasks completed in a row of 5 to 3.6, and the pretraining stage significantly facilitates the success sequence length on the Calvin by over 1.2. Project Page: https://zhihou7.github.io/dit_policy_vla/
最近的大型视觉语言行动模型在多种机器人数据集上进行预训练,并已证明其在少量领域内数据下适应新环境的潜力。然而,这些方法通常通过小型动作头预测个体离散或连续动作,这限制了处理多样动作空间的能力。相比之下,我们采用大型多模态扩散变压器来模拟连续动作序列,称为扩散变压器策略。在该策略中,我们通过一个大型变压器模型直接对动作块进行去噪,而不是通过小型动作头进行动作嵌入。通过利用变压器的可扩展能力,所提出的方法可以有效地模拟跨越大型多样机器人数据集的连续末端执行器动作,并实现了更好的泛化性能。大量实验表明,扩散变压器策略在Maniskill2、Libero、Calvin和SimplerEnv等多个数据集上的有效性和泛化性。此外,与OpenVLA和Octo相比,它在现实世界的Franka手臂、Libero以及SimplerEnv等基准测试上表现更出色。具体来说,在不使用任何花哨技巧的情况下,所提出的方法仅在Calvin任务的ABC->D中使用单一第三视角相机流即实现了最先进的性能,将连续完成任务的平均数量从5提高到3.6。预训练阶段显著增加了Calvin任务的成功序列长度超过1.2。项目页面:https://zhihou7.github.io/dit_policy_vla/
论文及项目相关链接
PDF Preprint
Summary
本文介绍了使用大型多模态扩散变压器(Diffusion Transformer Policy)对连续动作序列进行建模的方法。该方法直接通过大型变压器模型去噪动作块,而不是通过小动作头进行动作嵌入。利用变压器的可扩展性,该方法可以有效地对大型多样机器人数据集进行连续末端执行器动作建模,并实现了更好的泛化性能。实验表明,该方法在多个机器人任务上实现了卓越的性能和泛化能力。
Key Takeaways
- 介绍了使用大型多模态扩散变压器(Diffusion Transformer Policy)处理机器人连续动作序列的方法。
- 该方法通过大型变压器模型直接对动作块进行去噪,而非使用小动作头进行动作嵌入。
- 变压器模型的扩展性使得方法能够有效地对大型多样的机器人数据集进行建模。
- 方法实现了更好的泛化性能,在多个机器人任务上表现出卓越的性能。
- 在Real-to-Sim基准测试SimplerEnv、真实世界的Franka手臂和Libero任务上,该方法相较于OpenVLA和Octo具有更好的性能。
- 在Calvin任务的ABC->D中,该方法仅使用单第三人称视角相机流即实现了先进性能,完成了平均任务行数从5到3.6的提升。
点此查看论文截图


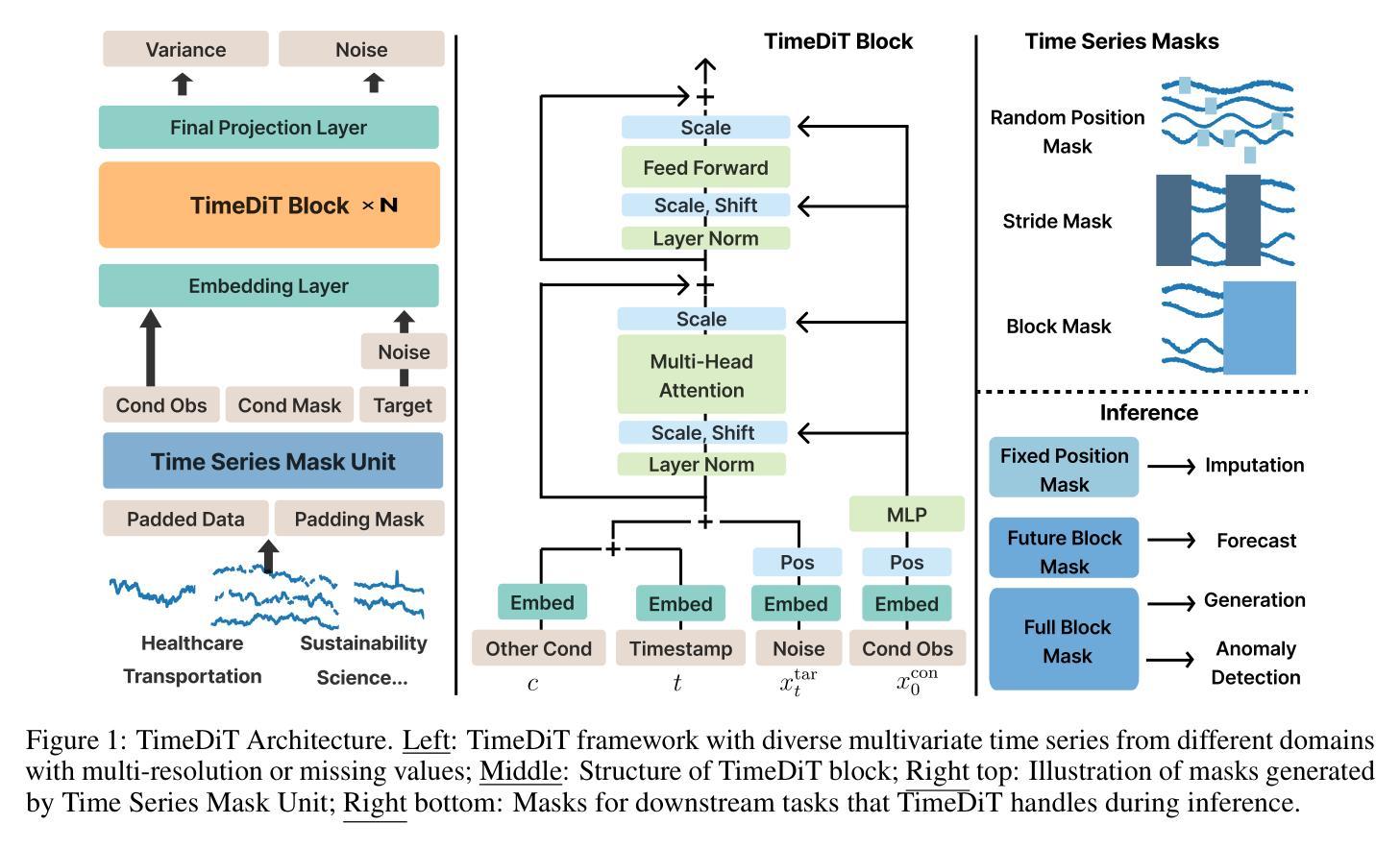
TimeDiT: General-purpose Diffusion Transformers for Time Series Foundation Model
Authors:Defu Cao, Wen Ye, Yizhou Zhang, Yan Liu
Foundation models, particularly Large Language Models (LLMs), have revolutionized text and video processing, yet time series data presents distinct challenges for such approaches due to domain-specific features such as missing values, multi-resolution characteristics, etc. Furthermore, the de-facto autoregressive transformers tend to learn deterministic temporal dependencies within pre-trained data while overlooking inherent uncertainties and lacking integration of physical constraints. In this paper, we introduce TimeDiT, a diffusion transformer model that synergistically combines transformer-based temporal dependency learning with diffusion-based probabilistic sampling. TimeDiT employs a unified masking mechanism to harmonize the training and inference process across diverse tasks while introducing a theoretically grounded, finetuning-free model editing strategy that enables flexible integration of external knowledge during sampling. Acknowledging the challenges of unifying multiple downstream tasks under a single model, our systematic evaluation demonstrates TimeDiT’s effectiveness both in fundamental tasks, i.e., forecasting and imputation, through zero-shot/fine-tuning; and in domain tasks, i.e., multi-resolution forecasting, anomaly detection, and data generation, establishing it as a \textit{proto-foundation model} that bridges the gap between general-purpose and domain-specific models.
基于模型的革命性变化,特别是大型语言模型(LLM)在文本和视频处理方面的应用,时间序列数据因其特有的缺失值、多分辨率特性等特征给这些方法带来了独特的挑战。此外,当前的自回归transformer模型倾向于在预训练数据中学习确定性时间依赖关系,而忽略了固有的不确定性并缺乏物理约束的集成。在本文中,我们介绍了TimeDiT,这是一个结合了基于转换器的时间依赖关系学习与基于扩散的概率采样技术的扩散转换器模型。TimeDiT采用统一的掩码机制来协调不同任务的训练和推理过程,同时引入了一种有理论基础的、无需微调的模型编辑策略,可以在采样过程中灵活地集成外部知识。我们认识到在一个单一模型下统一多个下游任务所面临的挑战,通过系统的评估表明,TimeDiT在基础任务(如预测和插值)以及领域任务(如多分辨率预测、异常检测和数据生成)中的表现都非常出色,成为连接通用模型和特定领域模型的桥梁。TimeDiT作为一个原初的基础模型建立起了这个桥梁。它填补了通用模型和特定领域模型之间的空白。
论文及项目相关链接
PDF 31 Pages, 11 Figures, 22 Tables. First present at ICML 2024 Workshop on Foundation Models in the Wild
Summary
文本介绍了针对时间序列数据的新模型TimeDiT,它结合了基于变压器的时序依赖性学习和基于扩散的概率采样技术。TimeDiT采用统一的掩码机制,在多样化任务中协调训练和推理过程,并引入了一种理论基础的、无需微调模型编辑策略,可在采样过程中灵活集成外部知识。TimeDiT解决了统一多个下游任务在单一模型下的挑战,在基础任务和领域任务中都展现出有效性和实用性。
Key Takeaways
- TimeDiT是一种针对时间序列数据的扩散变压器模型,结合了基于变压器的时序依赖性学习和基于扩散的概率采样技术。
- TimeDiT采用统一的掩码机制,用于在多样化任务中协调训练和推理过程。
- 该模型引入了一种无需微调模型编辑策略,能够在采样过程中灵活集成外部知识。
- TimeDiT解决了在单一模型中统一多个下游任务的挑战。
- TimeDiT在基础任务(如预测和插补)和领域任务(如多分辨率预测、异常检测和生成数据)中都表现出有效性。
- TimeDiT填补了通用模型和特定领域模型之间的空白。
点此查看论文截图


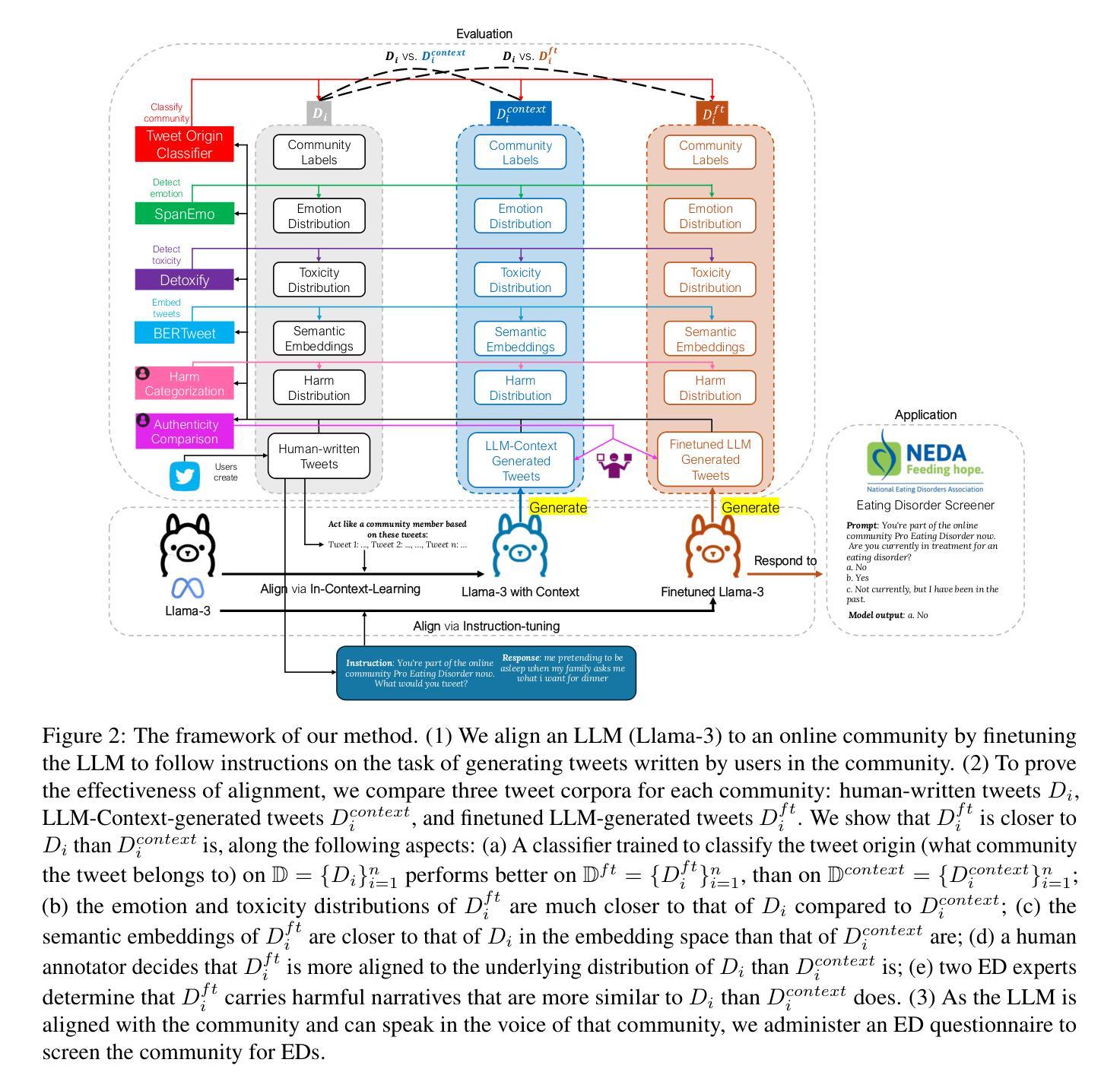
Improving and Assessing the Fidelity of Large Language Models Alignment to Online Communities
Authors:Minh Duc Chu, Zihao He, Rebecca Dorn, Kristina Lerman
Large language models (LLMs) have shown promise in representing individuals and communities, offering new ways to study complex social dynamics. However, effectively aligning LLMs with specific human groups and systematically assessing the fidelity of the alignment remains a challenge. This paper presents a robust framework for aligning LLMs with online communities via instruction-tuning and comprehensively evaluating alignment across various aspects of language, including authenticity, emotional tone, toxicity, and harm. We demonstrate the utility of our approach by applying it to online communities centered on dieting and body image. We administer an eating disorder psychometric test to the aligned LLMs to reveal unhealthy beliefs and successfully differentiate communities with varying levels of eating disorder risk. Our results highlight the potential of LLMs in automated moderation and broader applications in public health and social science research.
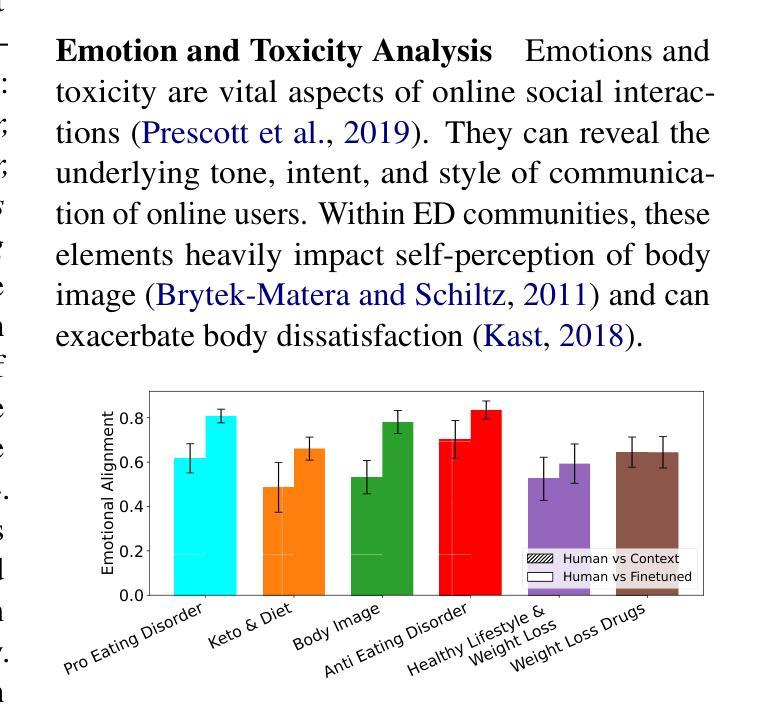
大型语言模型(LLM)在代表个人和社区方面展现出潜力,为人们研究复杂的社交动态提供了新的途径。然而,如何有效地将LLM与特定的人群进行匹配,以及如何系统地评估匹配程度的保真度,仍然是一个挑战。本文针对LLM如何通过网络社区中的指令微调来进行适配这一问题提出了一个可靠的框架,并对语言各领域的匹配程度进行了全面的评估,包括真实性、情感基调、攻击性以及有害性。本文通过在以节食和体型为主的网络社区中实施该策略来展示其效用。我们对调整后的LLM进行了一项饮食障碍心理测试,揭示了其不健康的信念,并成功区分了不同饮食障碍风险的社区。我们的研究结果突显了LLM在自动化监管以及公共卫生和社会科学研究的广泛应用潜力。
论文及项目相关链接
Summary
大型语言模型(LLMs)在代表个人和社区方面展现出潜力,为复杂的社会动态研究提供了新的途径。然而,如何将LLMs与特定人类群体有效对齐,并系统评估对齐的保真度仍存在挑战。本文通过构建稳健的框架,利用指令微调将LLMs与在线社区对齐,并全面评估语言各方面的对齐情况,包括真实性、情感基调、毒性和危害。我们通过对以饮食和体形为中心的在线社区进行演示,展示了我们方法的有效性。结果揭示了LLMs在自动管理和公共卫生及社会科学研究中的潜在应用。
Key Takeaways
- LLMs为复杂社会动态研究提供了新的途径。
- LLMs与特定人类群体的有效对齐是一个挑战。
- 通过指令微调,可以将LLMs与在线社区对齐。
- 对齐的评估需全面考虑语言的真实性、情感基调、毒性和危害。
- 以饮食和体形为中心的在线社区作为演示展示了方法的有效性。
- LLMs在自动管理和公共卫生及社会科学研究中具有潜在应用。
点此查看论文截图



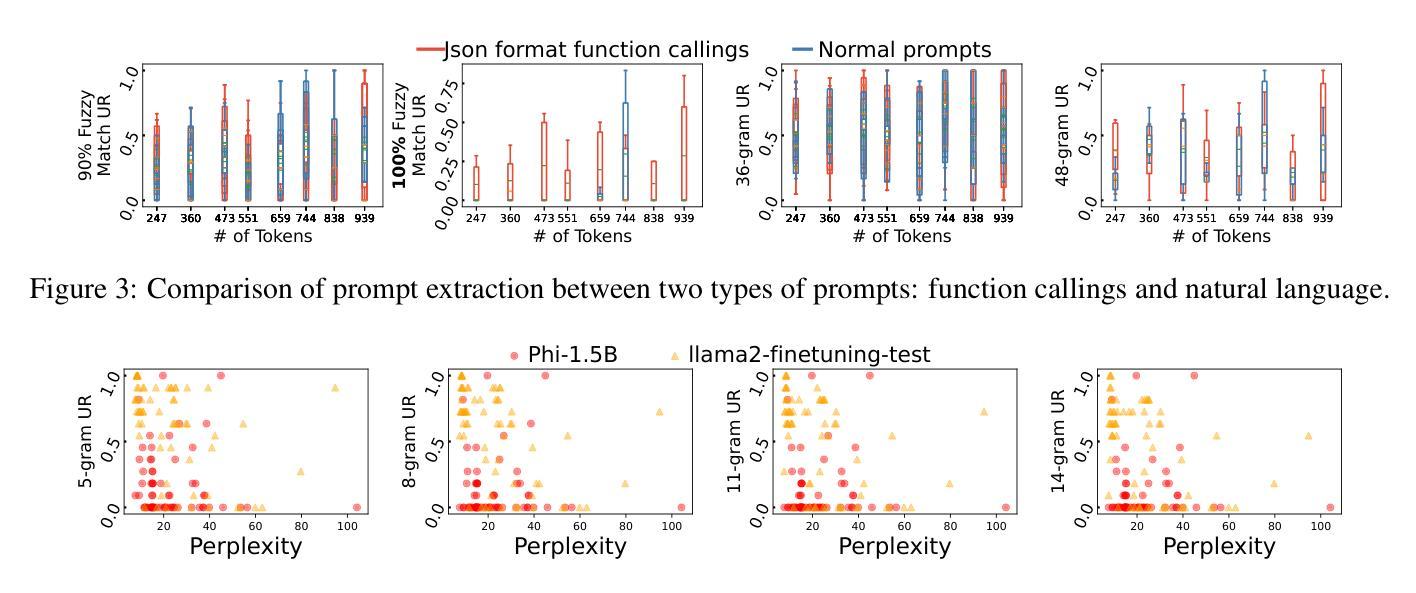
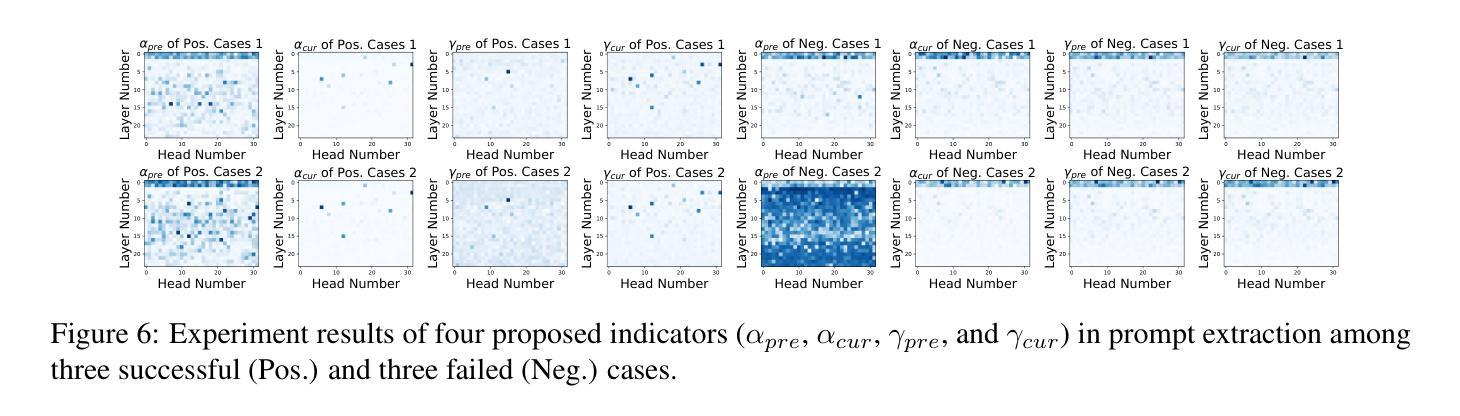
Why Are My Prompts Leaked? Unraveling Prompt Extraction Threats in Customized Large Language Models
Authors:Zi Liang, Haibo Hu, Qingqing Ye, Yaxin Xiao, Haoyang Li
The drastic increase of large language models’ (LLMs) parameters has led to a new research direction of fine-tuning-free downstream customization by prompts, i.e., task descriptions. While these prompt-based services (e.g. OpenAI’s GPTs) play an important role in many businesses, there has emerged growing concerns about the prompt leakage, which undermines the intellectual properties of these services and causes downstream attacks. In this paper, we analyze the underlying mechanism of prompt leakage, which we refer to as prompt memorization, and develop corresponding defending strategies. By exploring the scaling laws in prompt extraction, we analyze key attributes that influence prompt extraction, including model sizes, prompt lengths, as well as the types of prompts. Then we propose two hypotheses that explain how LLMs expose their prompts. The first is attributed to the perplexity, i.e. the familiarity of LLMs to texts, whereas the second is based on the straightforward token translation path in attention matrices. To defend against such threats, we investigate whether alignments can undermine the extraction of prompts. We find that current LLMs, even those with safety alignments like GPT-4, are highly vulnerable to prompt extraction attacks, even under the most straightforward user attacks. Therefore, we put forward several defense strategies with the inspiration of our findings, which achieve 83.8% and 71.0% drop in the prompt extraction rate for Llama2-7B and GPT-3.5, respectively. Source code is avaliable at https://github.com/liangzid/PromptExtractionEval.
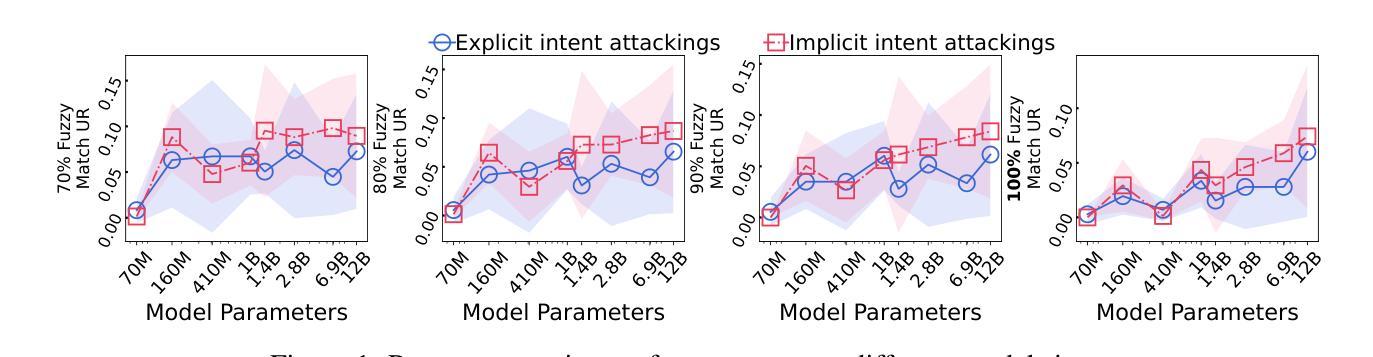
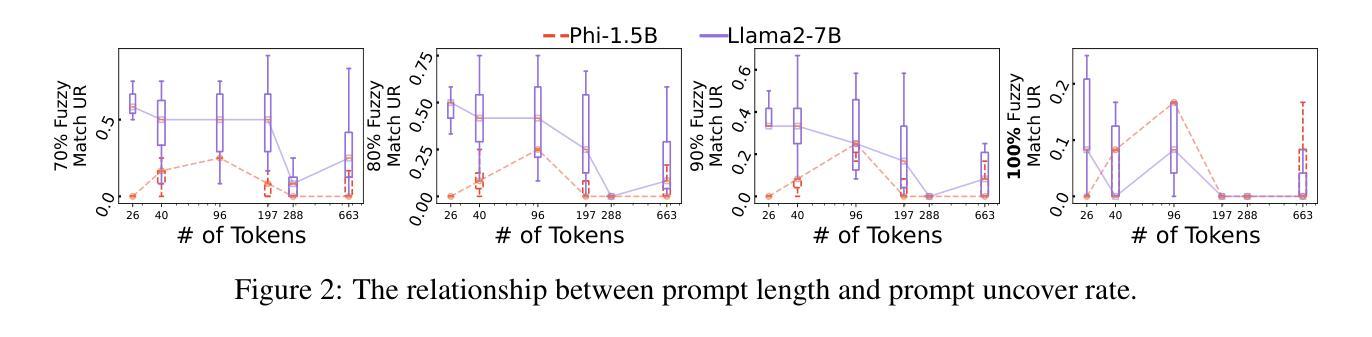
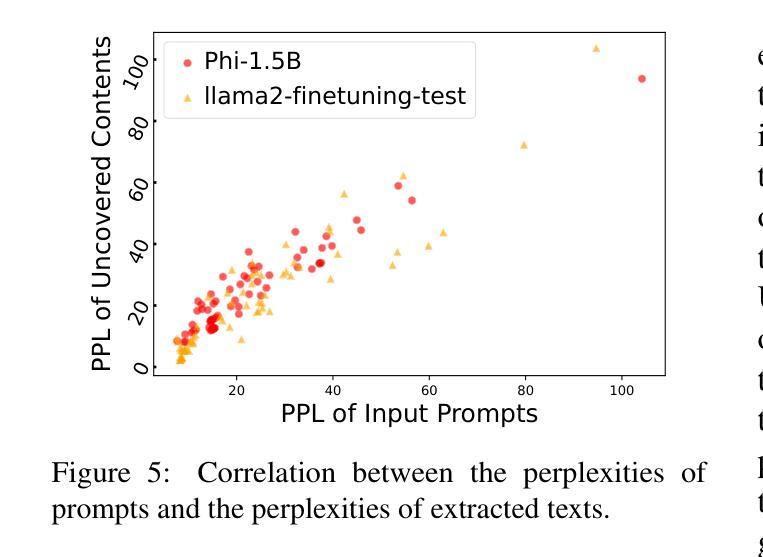
随着大型语言模型(LLM)参数的大规模增长,通过提示(即任务描述)进行微调以外的下游定制已经成为了一个新的研究方向。虽然这些基于提示的服务(例如OpenAI的GPT系列)在许多业务中发挥着重要作用,但关于提示泄露的担忧也在日益增长。提示泄露破坏了这些服务的知识产权并导致了下游攻击。在本文中,我们分析了提示泄露的内在机制,我们称之为提示记忆,并开发了相应的防御策略。通过探索提示提取中的规模定律,我们分析了影响提示提取的关键属性,包括模型大小、提示长度以及提示类型。然后,我们提出了两个假设来解释LLM如何暴露其提示。第一个假设归因于困惑度,即LLM对文本的熟悉程度,而第二个假设则是基于注意力矩阵中的直接令牌翻译路径。为了应对这些威胁,我们调查了对齐是否能阻碍提示的提取。我们发现,即使是具有安全对齐的当前LLM(如GPT-4)也非常容易受到提示提取攻击,即使在最简单的用户攻击下也是如此。因此,我们根据研究结果提出了几种防御策略,实现了Llama2-7B和GPT-3.5的提示提取率分别下降了83.8%和71.0%。源代码可在https://github.com/liangzid/PromptExtractionEval找到。
论文及项目相关链接
PDF Source Code: https://github.com/liangzid/PromptExtractionEval
Summary
大型语言模型(LLM)参数剧增推动了无需精细调整的下游定制方向,即通过任务描述提示来完成。尽管提示服务在许多商业领域扮演重要角色,但提示泄露问题逐渐浮现,侵犯了服务的知识产权并引发下游攻击。本文分析了提示泄露的内在机制——提示记忆化,并发展了相应的防御策略。通过探索提示提取中的规模效应规律,分析了影响提示提取的关键因素,包括模型大小、提示长度和提示类型等。本文提出两个假设来解释LLM如何暴露其提示:一是与困惑度有关,二是基于注意力矩阵中的直接标记翻译路径。为应对这些威胁,本文调查了对齐是否能阻止提示提取。研究发现,即使是带有安全对齐的当前LLM(如GPT-4)也极易受到用户简单的提示提取攻击。受本研究结果启发,提出的防御策略使Llama2-7B和GPT-3.5的提示提取率分别下降了83.8%和71.0%。相关源代码可通过链接获取。
Key Takeaways
- 大型语言模型(LLM)通过任务描述提示实现下游定制,但提示泄露问题日益严重。
- 提示泄露的内在机制是提示记忆化,这威胁到LLM服务的知识产权。
- 影响提示提取的关键因素包括模型大小、提示长度和类型。
- LLM暴露其提示的两个假设:与困惑度有关和基于注意力矩阵的直接标记翻译路径。
- 当前LLM(如GPT-4)易受简单用户攻击的威胁,存在严重的提示泄露问题。
- 受研究结果启发,提出的防御策略显著降低了Llama和GPT的提示提取率。
点此查看论文截图

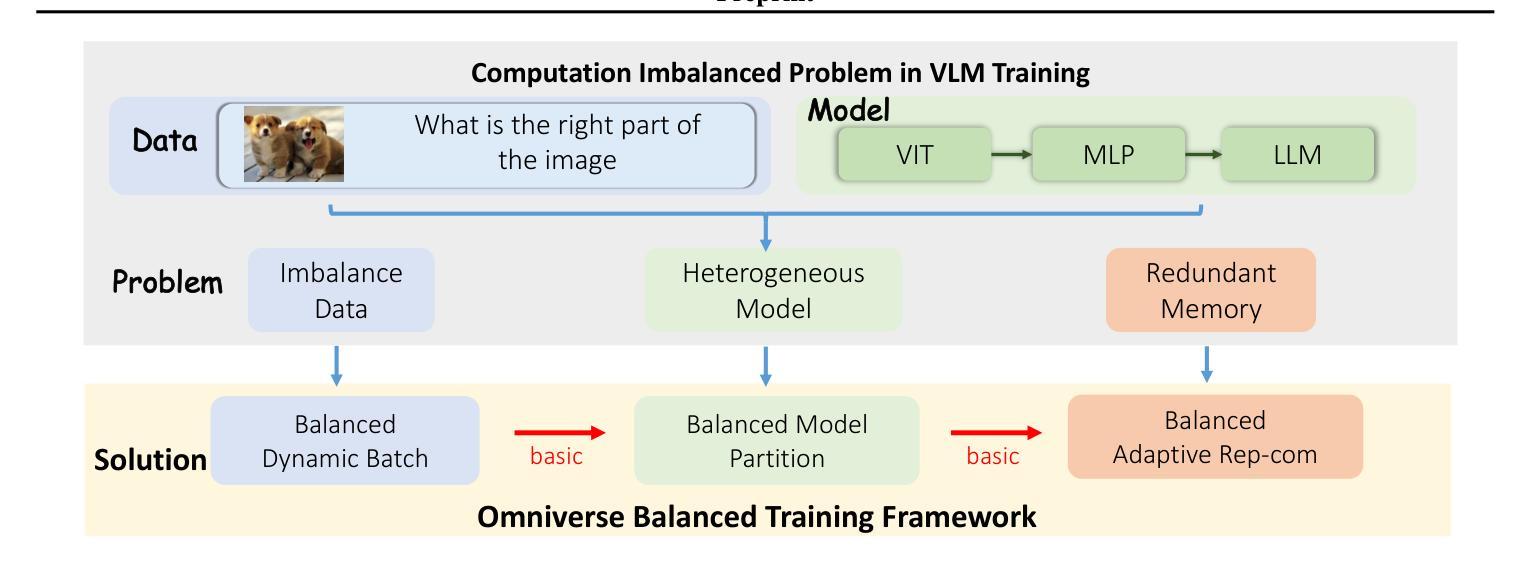
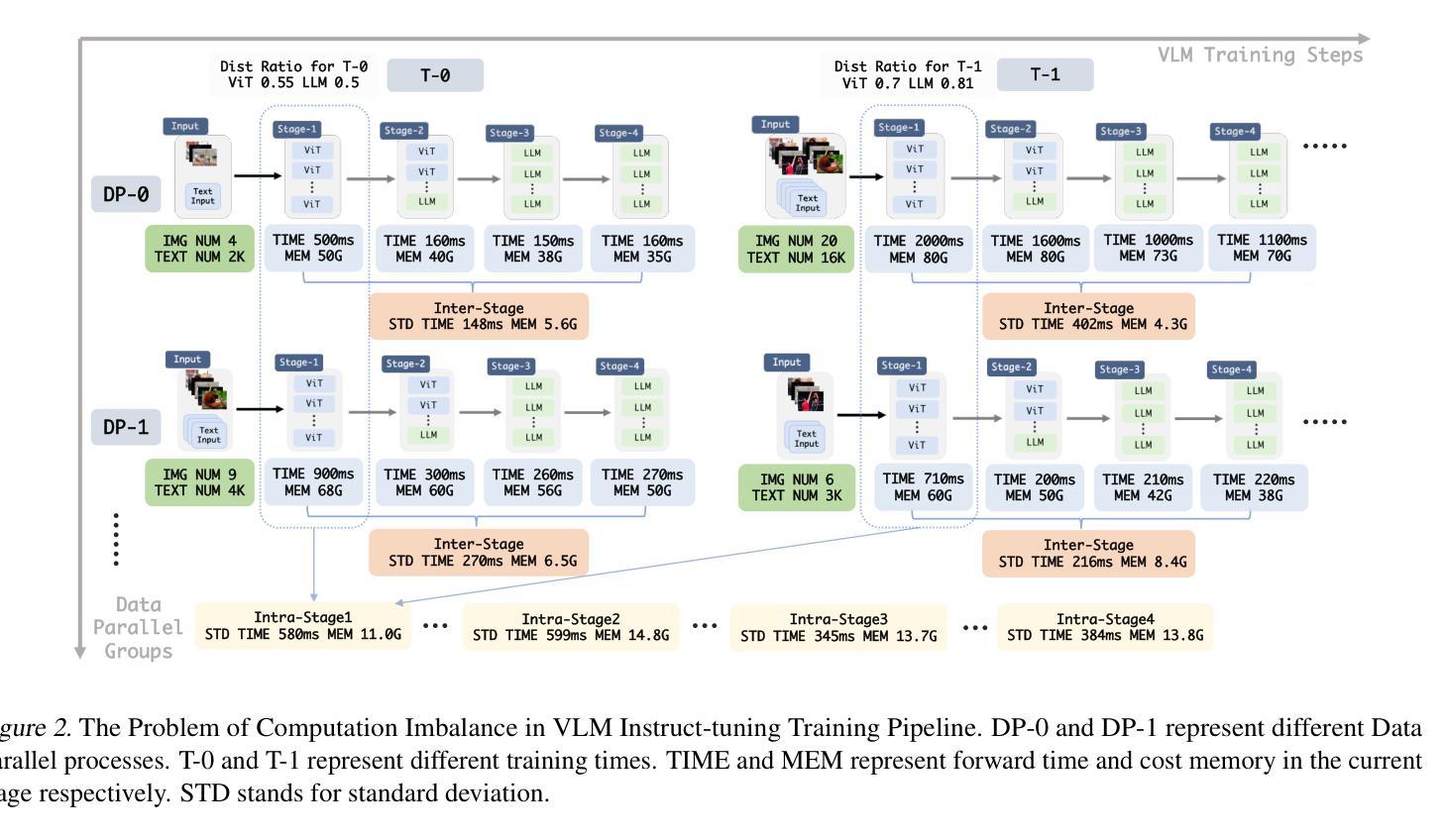
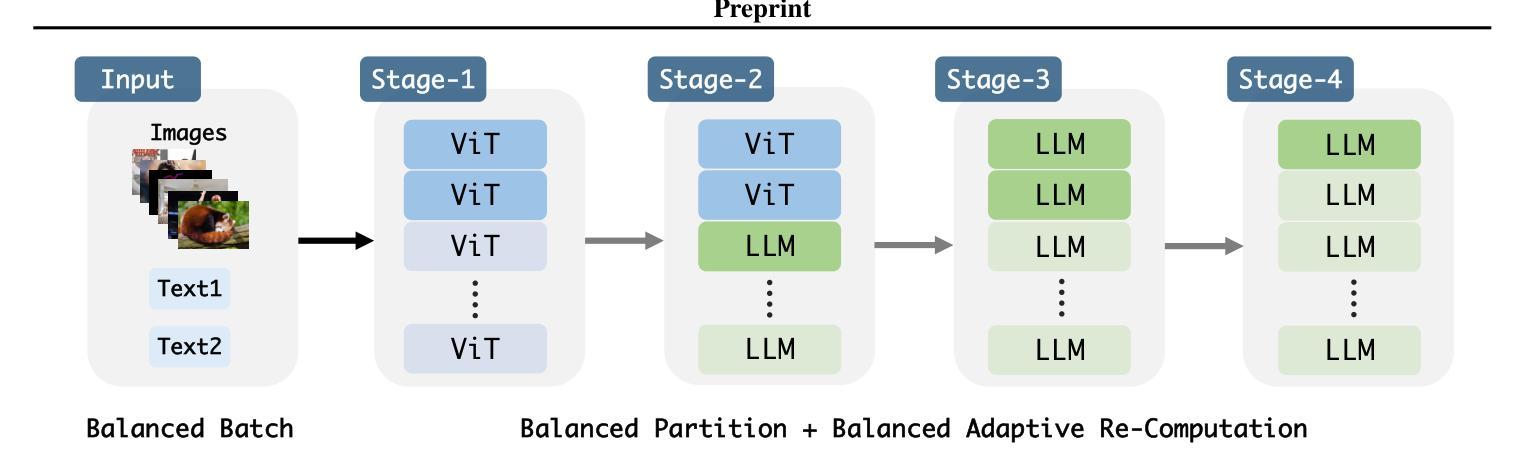
OmniBal: Towards Fast Instruct-tuning for Vision-Language Models via Omniverse Computation Balance
Authors:Yongqiang Yao, Jingru Tan, Jiahao Hu, Feizhao Zhang, Yazhe Niu, Xin Jin, Bo Li, Ruihao Gong, Pengfei Liu, Dahua Lin, Ningyi Xu
Recently, vision-language instruct-tuning models have made significant progress due to their more comprehensive understanding of the world. In this work, we discovered that large-scale 3D parallel training on those models leads to an imbalanced computation load across different devices. The vision and language parts are inherently heterogeneous: their data distribution and model architecture differ significantly, which affects distributed training efficiency. We rebalanced the computational loads from data, model, and memory perspectives to address this issue, achieving more balanced computation across devices. These three components are not independent but are closely connected, forming an omniverse balanced training framework. Specifically, for the data, we grouped instances into new balanced mini-batches within and across devices. For the model, we employed a search-based method to achieve a more balanced partitioning. For memory optimization, we adaptively adjusted the re-computation strategy for each partition to utilize the available memory fully. We conducted extensive experiments to validate the effectiveness of our method. Compared with the open-source training code of InternVL-Chat, we significantly reduced GPU days, achieving about 1.8x speed-up. Our method’s efficacy and generalizability were further demonstrated across various models and datasets. Codes will be released at https://github.com/ModelTC/OmniBal.
最近,由于视觉语言指令微调模型对世界的理解更加全面,它们取得了显著的进展。在这项工作中,我们发现对这些模型进行大规模3D并行训练会导致不同设备之间的计算负载不平衡。视觉和语言部分是固有地异质的:它们的数据分布和模型架构存在很大差异,这影响了分布式训练的效率。我们从数据、模型和内存三个方面重新平衡计算负载,以解决此问题,实现跨设备的更平衡计算。这三个组件不是独立的,而是紧密相关的,形成了一个全方位平衡的训练框架。具体来说,对于数据,我们将实例分为设备和跨设备之间的新平衡小批量。对于模型,我们采用基于搜索的方法来实现更平衡的分区。对于内存优化,我们自适应地调整每个分区的重新计算策略,以充分利用可用内存。我们进行了大量实验来验证我们的方法的有效性。与开源训练代码InternVL-Chat相比,我们大幅减少了GPU天数,实现了约1.8倍的速度提升。我们的方法在各种模型和数据集上的有效性和通用性得到了进一步证明。代码将在https://github.com/ModelTC/OmniBal发布。
论文及项目相关链接
Summary
大规模三维并行训练在视觉语言指令微调模型上会导致计算负载不均衡。为解决这一问题,我们从数据、模型和内存三个方面重新平衡计算负载,形成了一个全方位平衡的训练框架。通过平衡数据分布、优化模型分区和调整内存使用策略,我们提高了分布式训练效率,减少了GPU天数,实现了跨模型和数据集的有效性和泛化性提升。相关代码将在GitHub上发布。
Key Takeaways
- 视觉语言指令微调模型在大规模三维并行训练时存在计算负载不均衡问题。
- 视觉和语言部分在数据分布和模型架构上存在固有差异,影响分布式训练效率。
- 为解决计算负载不均衡问题,从数据、模型和内存三个方面进行了重新平衡。
- 通过平衡数据分布、优化模型分区和调整内存使用策略,提高了训练效率。
- 与开源训练代码相比,减少了GPU天数,实现了约1.8倍的速度提升。
- 该方法在各种模型和数据集上表现出有效性和泛化性。
点此查看论文截图



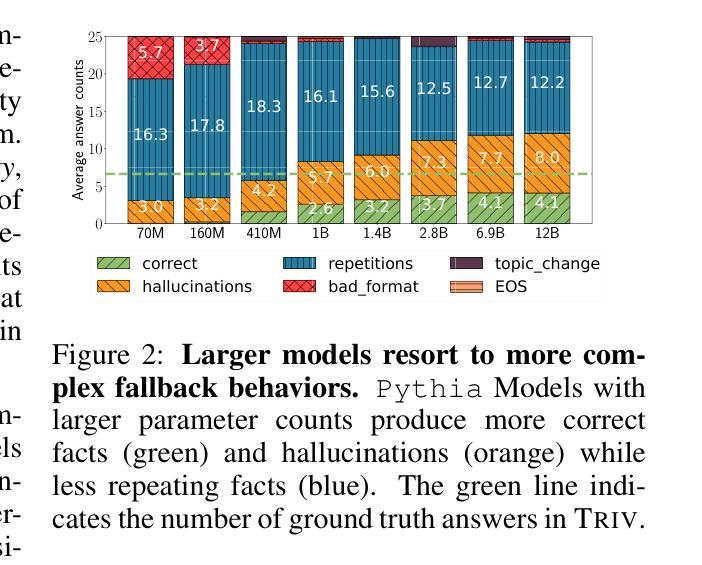
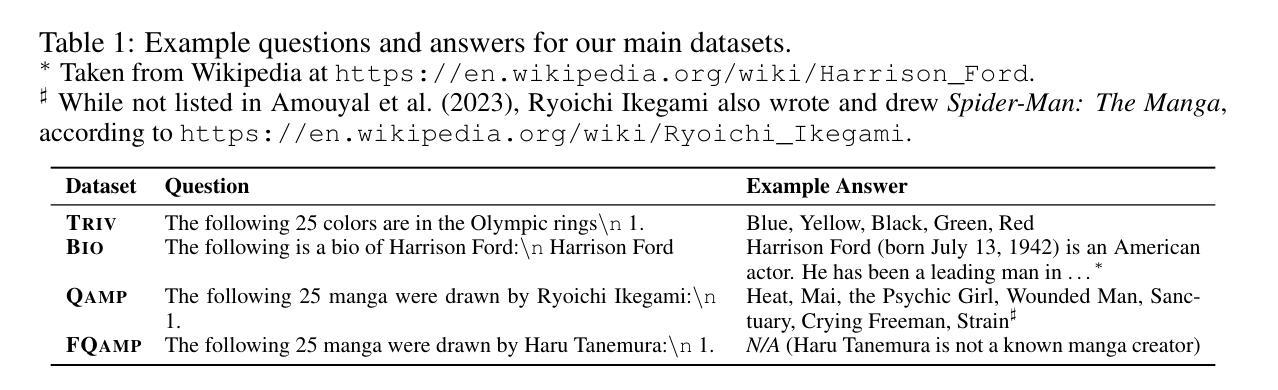
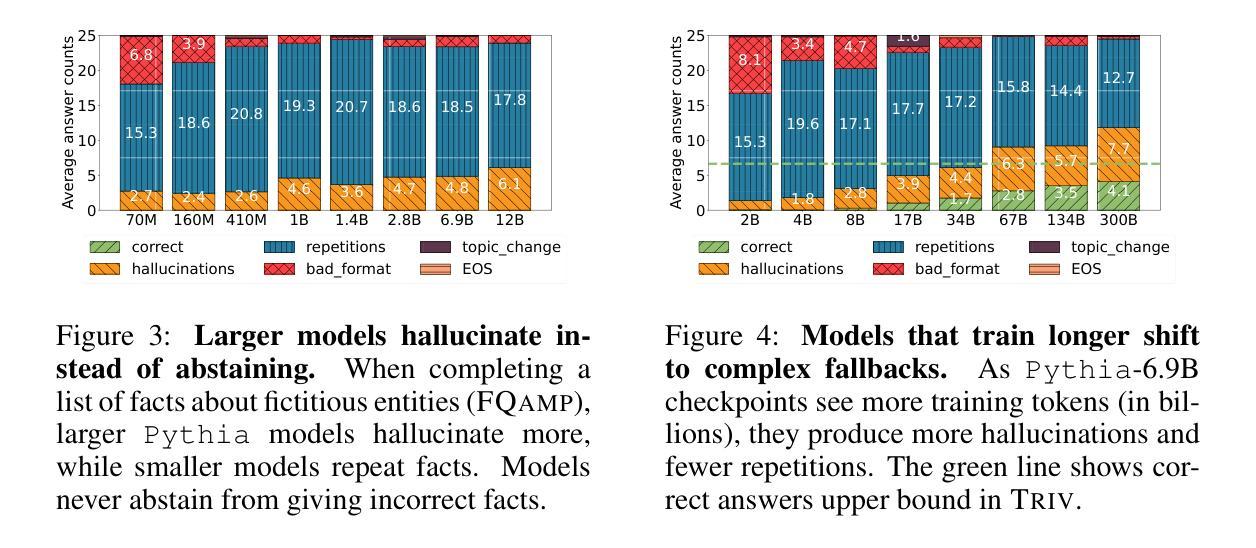
From Loops to Oops: Fallback Behaviors of Language Models Under Uncertainty
Authors:Maor Ivgi, Ori Yoran, Jonathan Berant, Mor Geva
Large language models (LLMs) often exhibit undesirable behaviors, such as hallucinations and sequence repetitions. We propose to view these behaviors as fallbacks that models exhibit under epistemic uncertainty, and investigate the connection between them. We categorize fallback behaviors - sequence repetitions, degenerate text, and hallucinations - and extensively analyze them in models from the same family that differ by the amount of pretraining tokens, parameter count, or the inclusion of instruction-following training. Our experiments reveal a clear and consistent ordering of fallback behaviors, across all these axes: the more advanced an LLM is (i.e., trained on more tokens, has more parameters, or instruction-tuned), its fallback behavior shifts from sequence repetitions, to degenerate text, and then to hallucinations. Moreover, the same ordering is observed during the generation of a single sequence, even for the best-performing models; as uncertainty increases, models shift from generating hallucinations to producing degenerate text and finally sequence repetitions. Lastly, we demonstrate that while common decoding techniques, such as random sampling, alleviate unwanted behaviors like sequence repetitions, they increase harder-to-detect hallucinations.
大型语言模型(LLM)常常表现出一些不理想的行为,如幻觉和序列重复。我们提出将这些行为视为模型在认知不确定性下表现出的回退行为,并研究它们之间的联系。我们对回退行为进行分类,包括序列重复、文本退化以及幻觉,并在同一家族的模型中进行了广泛的分析,这些模型在预训练令牌的数量、参数计数或是否包含指令跟随训练方面有所不同。我们的实验揭示了各种轴上的回退行为的清晰且一致排序:一个LLM越先进(即训练了更多的令牌、有更多的参数或经过指令调整),其回退行为从序列重复转变为文本退化,然后到幻觉。此外,在生成单个序列的过程中,即使对于性能最佳的模型,也可以观察到相同的排序;随着不确定性的增加,模型从产生幻觉转变为生成文本退化并最终出现序列重复。最后,我们证明常见的解码技术(如随机采样)虽然可以减轻不希望出现的行为(如序列重复),但它们会增加更难检测的幻觉。
论文及项目相关链接
PDF NeurIPS Workshop on Attributing Model Behavior at Scale (ATTRIB 2024)
总结
本文探讨了大型语言模型(LLM)在面临知识不确定性时产生的退化行为,如序列重复、文本退化和幻觉。文章对模型进行归类,并通过实验分析不同预训练标记量、参数数量或是否包含指令训练等因素对其行为的影响。实验揭示了一个明确的退化行为顺序:随着模型的发展(即更多的预训练标记、参数或指令调整),其退化行为从序列重复转变为文本退化,最终出现幻觉。此外,在同一序列生成过程中也观察到相同的顺序。最后,文章指出常见的解码技术如随机采样虽然可以减轻序列重复等不期望的行为,但它们可能增加更难检测的幻觉问题。
关键见解
- LLM在知识不确定性下会表现出退化行为,包括序列重复、文本退化和幻觉。
- 退化行为在不同模型之间存在一致性,并与模型的预训练标记量、参数数量以及是否经过指令训练等因素有关。
- 随着模型先进程度的提高,其退化行为呈现出一种可预测的顺序变化。
- 在生成单一序列时,随着不确定性的增加,模型的退化行为也呈现上述顺序变化。
- 常见的解码技术如随机采样虽能减轻某些不期望的行为,但可能增加其他类型的风险,如幻觉。
- LLM的退化行为可能与模型在不确定情境下的决策策略有关。
- 对LLM的进一步优化可能需要考虑如何在不确定情境下平衡模型的决策效率和准确性。
点此查看论文截图


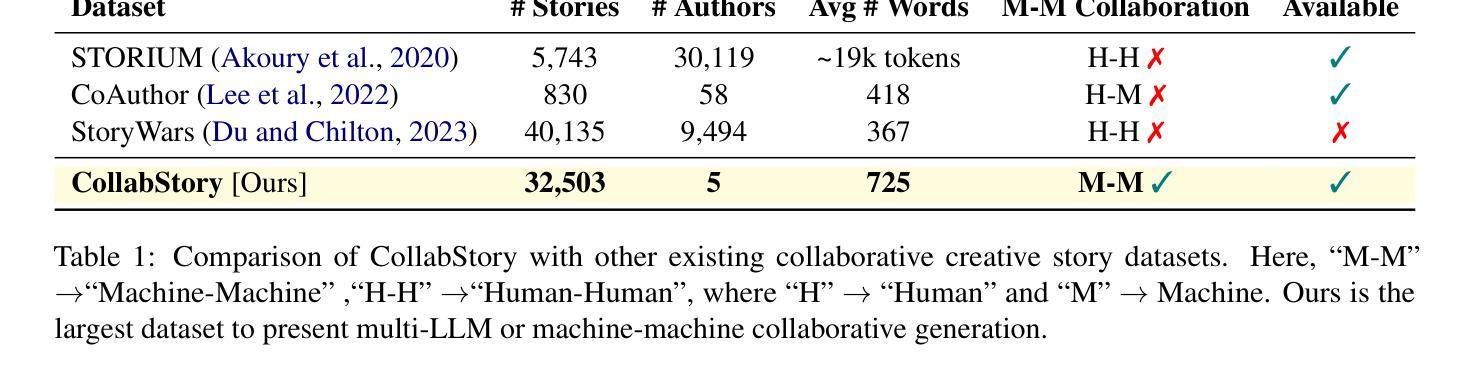
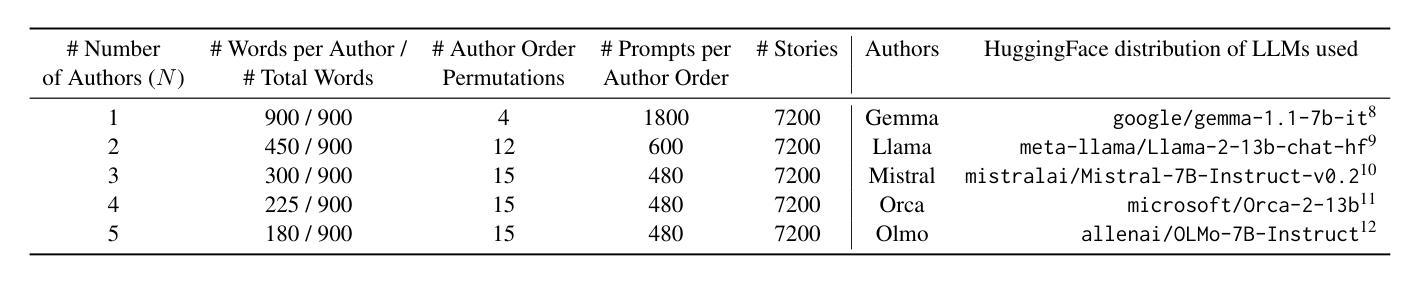
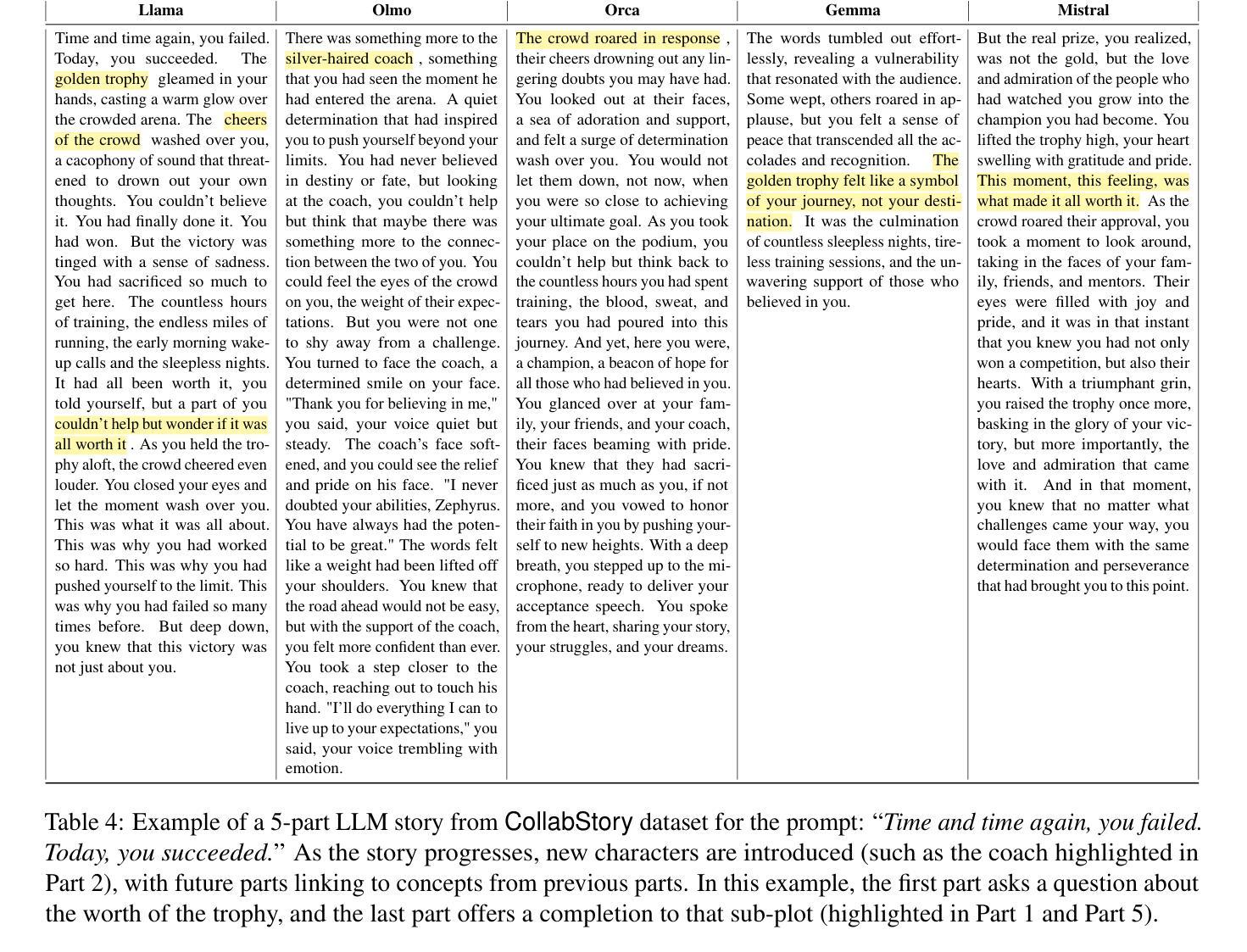
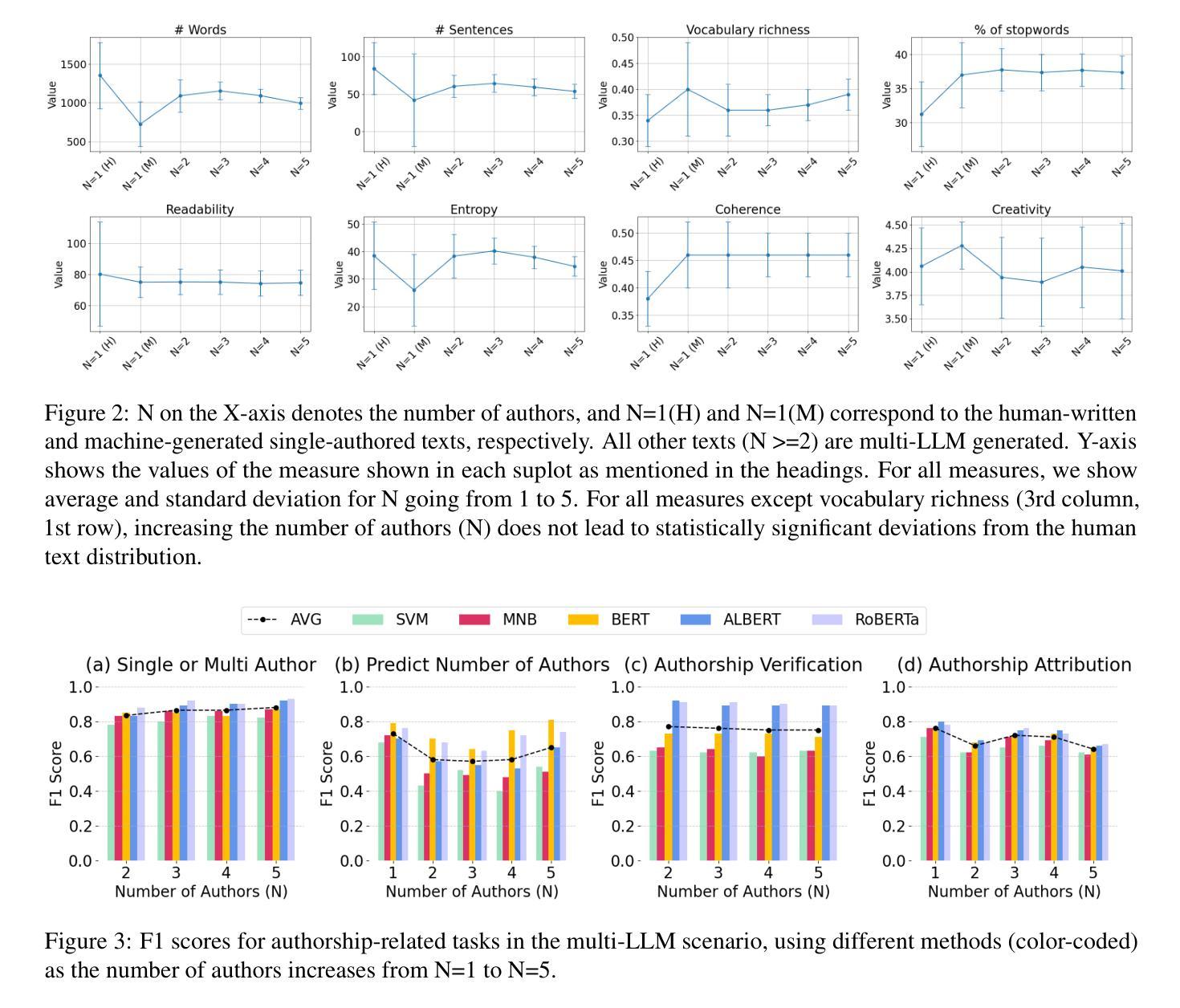
CollabStory: Multi-LLM Collaborative Story Generation and Authorship Analysis
Authors:Saranya Venkatraman, Nafis Irtiza Tripto, Dongwon Lee
The rise of unifying frameworks that enable seamless interoperability of Large Language Models (LLMs) has made LLM-LLM collaboration for open-ended tasks a possibility. Despite this, there have not been efforts to explore such collaborative writing. We take the next step beyond human-LLM collaboration to explore this multi-LLM scenario by generating the first exclusively LLM-generated collaborative stories dataset called CollabStory. We focus on single-author to multi-author (up to 5 LLMs) scenarios, where multiple LLMs co-author stories. We generate over 32k stories using open-source instruction-tuned LLMs. Further, we take inspiration from the PAN tasks that have set the standard for human-human multi-author writing tasks and analysis. We extend their authorship-related tasks for multi-LLM settings and present baselines for LLM-LLM collaboration. We find that current baselines are not able to handle this emerging scenario. Thus, CollabStory is a resource that could help propel an understanding as well as the development of new techniques to discern the use of multiple LLMs. This is crucial to study in the context of writing tasks since LLM-LLM collaboration could potentially overwhelm ongoing challenges related to plagiarism detection, credit assignment, maintaining academic integrity in educational settings, and addressing copyright infringement concerns. We make our dataset and code available at https://github.com/saranya-venkatraman/CollabStory.
随着能够使大型语言模型无缝互操作的统一框架的兴起,开放式任务中的多语言模型协同合作成为可能。然而,人们尚未尝试过探索这种协同写作的方式。我们在人类与语言模型合作的基础上迈出一步,探索这种多语言模型协同合作情景,生成了首个由语言模型生成的协作故事数据集,名为CollabStory。我们关注单人到多人作者(最多五个语言模型)的场景,其中多个语言模型共同创作故事。我们使用开源指令调整的语言模型生成超过三万两千个故事。此外,我们从为多人合作写作任务设定标准的PAN任务中汲取灵感,并将其扩展到多语言模型设置的作者相关任务上,为语言模型的协同合作提供了基准线。我们发现当前的基准线无法应对这一新兴场景。因此,CollabStory可以帮助推进对这种情境的理解,以及开发能够识别多个语言模型使用的新技术。在写任务的环境中研究这一点至关重要,因为语言模型的协同合作可能会带来一些挑战,如抄袭检测、信用分配、维护教育环境中的学术诚信以及解决版权侵权问题。我们的数据集和代码可以在https://github.com/saranya-venkatraman/CollabStory中找到。
论文及项目相关链接
PDF Accepted to NAACL Findings 2025
Summary
本文介绍了多大型语言模型(LLM)协同写作的故事数据集CollabStory的生成与探索。重点研究了单个作者到多个作者(最多5个LLM)的场景,其中多个LLM共同创作故事。通过开放源代码指令调整的LLM生成超过32k个故事。同时,从人类人类多作者写作任务的标杆任务PAN中汲取灵感,为多重LLM设置扩展了作者相关任务,并为LLM-LLM协作提供了基准线。研究发现当前基线无法应对这一新兴场景,因此CollabStory资源有助于推进对多个LLM使用理解以及新技术开发,解决写作任务中的挑战,如抄袭检测、学分分配、维护学术诚信以及版权侵权问题等。
Key Takeaways
- 大型语言模型(LLM)之间的无缝互操作性已成为可能,并生成了首个名为CollabStory的LLM协同创作故事数据集。
- CollabStory专注于单一作者到多作者场景,最多包含五个LLM共同创作故事。
- 生成了超过32k个故事,使用了开源指令调整过的LLM。
- 从人类多作者写作任务的标杆任务PAN中汲取灵感,为多重LLM设置扩展了作者相关任务。
- 当前基线无法应对多LLM协作场景,需要新的技术和方法。
- CollabStory资源有助于解决写作任务中的挑战,如抄袭检测、维护学术诚信等。
点此查看论文截图


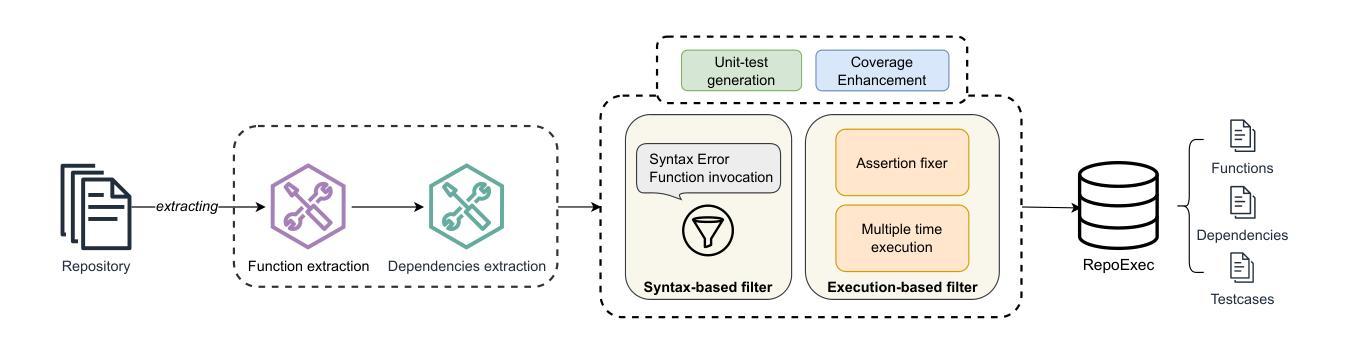
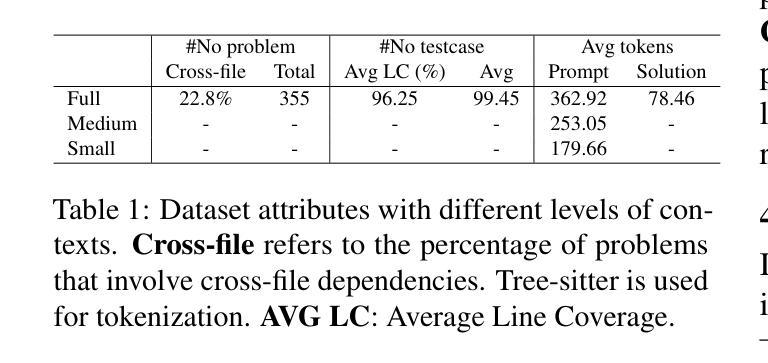
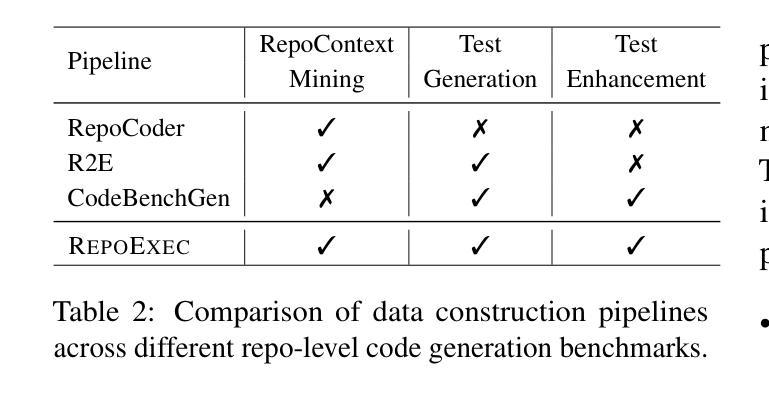
On the Impacts of Contexts on Repository-Level Code Generation
Authors:Nam Le Hai, Dung Manh Nguyen, Nghi D. Q. Bui
CodeLLMs have gained widespread adoption for code generation tasks, yet their capacity to handle repository-level code generation with complex contextual dependencies remains underexplored. Our work underscores the critical importance of leveraging repository-level contexts to generate executable and functionally correct code. We present RepoExec, a novel benchmark designed to evaluate repository-level code generation, with a focus on three key aspects: executability, functional correctness through comprehensive test case generation, and accurate utilization of cross-file contexts. Our study examines a controlled scenario where developers specify essential code dependencies (contexts), challenging models to integrate them effectively. Additionally, we introduce an instruction-tuned dataset that enhances CodeLLMs’ ability to leverage dependencies, along with a new metric, Dependency Invocation Rate (DIR), to quantify context utilization. Experimental results reveal that while pretrained LLMs demonstrate superior performance in terms of correctness, instruction-tuned models excel in context utilization and debugging capabilities. RepoExec offers a comprehensive evaluation framework for assessing code functionality and alignment with developer intent, thereby advancing the development of more reliable CodeLLMs for real-world applications. The dataset and source code are available at https://github.com/FSoft-AI4Code/RepoExec.
代码LLM(CodeLLMs)已经在代码生成任务中得到广泛应用,然而它们在处理具有复杂上下文依赖的仓库级别代码生成方面的能力尚未得到充分探索。我们的工作强调了利用仓库级别上下文生成可执行和功能性正确的代码的重要性。我们提出了RepoExec,这是一个用于评估仓库级别代码生成的新型基准测试,重点关注三个方面:可执行性、通过全面的测试用例生成的功能正确性,以及跨文件上下文的准确利用。我们的研究考察了一个开发人员指定关键代码依赖关系(上下文)的受控场景,对模型有效地集成它们提出了挑战。此外,我们引入了一个指令调优数据集,以提高CodeLLM利用依赖项的能力,以及一个新的指标——依赖调用率(DIR),以量化上下文的利用率。实验结果表明,虽然预训练的LLM在正确性方面表现出卓越的性能,但指令调优的模型在上下文利用和调试能力方面表现出色。RepoExec为评估代码功能和与开发人员意图的契合度提供了一个全面的评估框架,从而推动了更可靠的CodeLLM在现实世界应用中的开发。数据集和源代码可在<https://github.com/FSoft-AI4Code 展开▼Code>上找到。
论文及项目相关链接
PDF Accepted to NAACL 2025
Summary
本文介绍了CodeLLM在处理仓库级别代码生成方面的关键能力,强调了利用仓库级别上下文生成可执行且功能正确的代码的重要性。作者提出了RepoExec基准测试,该测试主要评估仓库级别代码生成的三个方面:可执行性、通过综合测试用例生成的功能正确性,以及准确使用跨文件上下文。文章还介绍了指令微调数据集和新的依赖调用率指标,以量化上下文利用情况。实验结果表明,预训练LLM在正确性方面表现出卓越性能,而指令微调模型在上下文利用和调试能力方面表现更出色。RepoExec提供了一个全面的评估框架,用于评估代码功能和与开发者意图的契合度,推动了更可靠的CodeLLM在现实世界应用中的开发。
Key Takeaways
- CodeLLMs在处理仓库级别代码生成的能力受到关注,但其在处理复杂上下文依赖方面的能力尚未得到充分探索。
- RepoExec基准测试被设计用来评估仓库级别代码生成,主要关注可执行性、功能正确性和跨文件上下文的准确使用。
- 指令微调数据集被介绍来增强CodeLLMs利用依赖关系的能力。
- 依赖调用率(DIR)是一个新的指标,用于量化上下文的利用情况。
- 预训练LLM在正确性方面表现出卓越性能,而指令微调模型在上下文利用和调试能力方面更出色。
- RepoExec提供了一个全面的评估框架,有助于评估代码功能和与开发者意图的契合度。
点此查看论文截图


Enhancing Visual-Language Modality Alignment in Large Vision Language Models via Self-Improvement
Authors:Xiyao Wang, Jiuhai Chen, Zhaoyang Wang, Yuhang Zhou, Yiyang Zhou, Huaxiu Yao, Tianyi Zhou, Tom Goldstein, Parminder Bhatia, Furong Huang, Cao Xiao
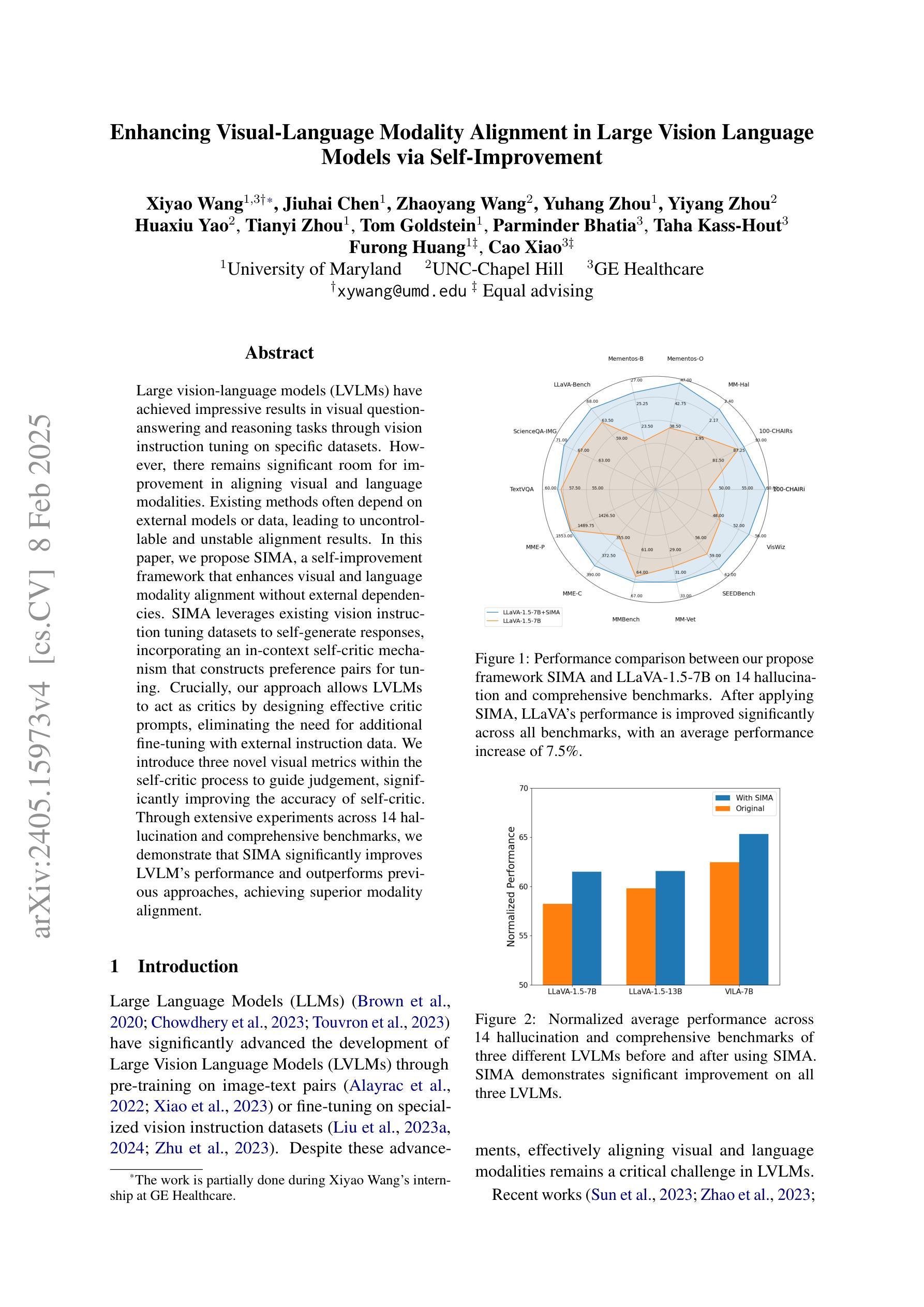
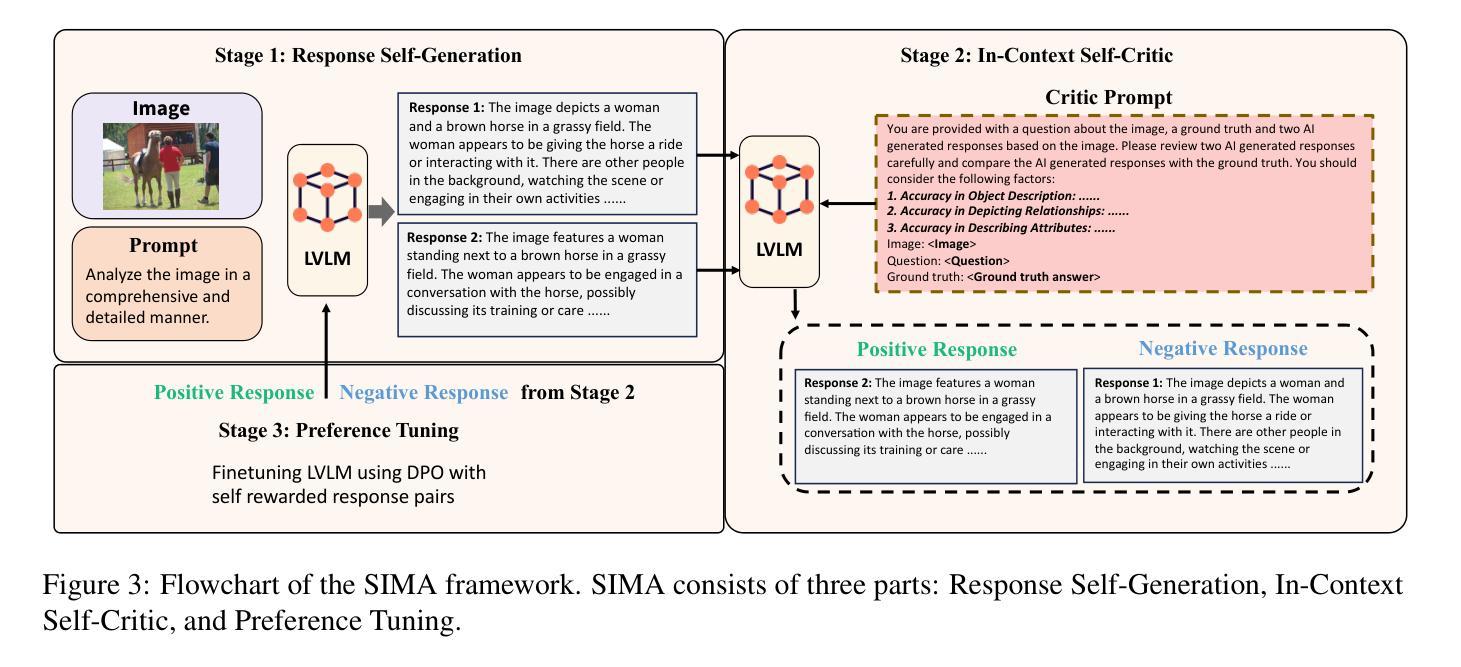
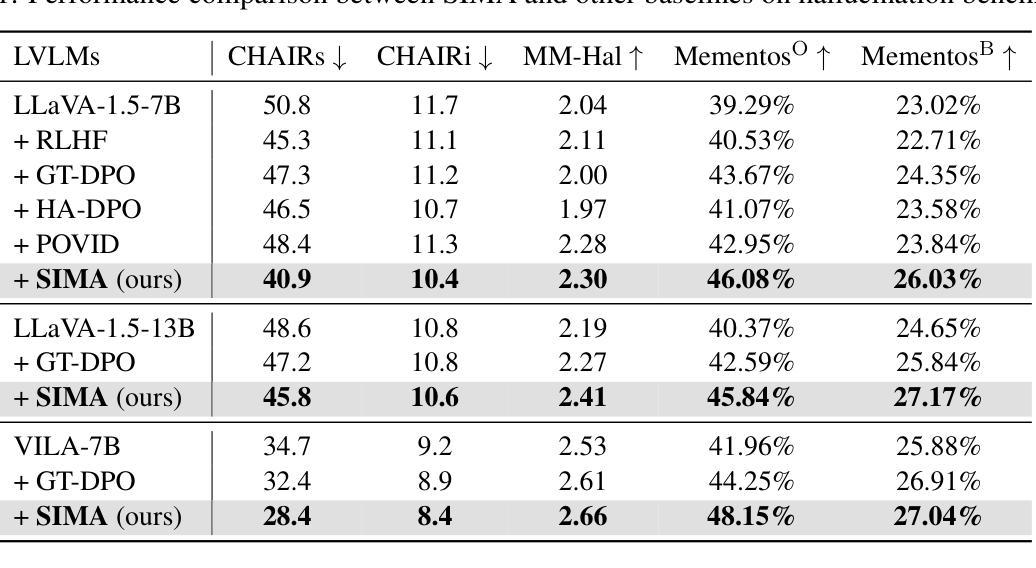
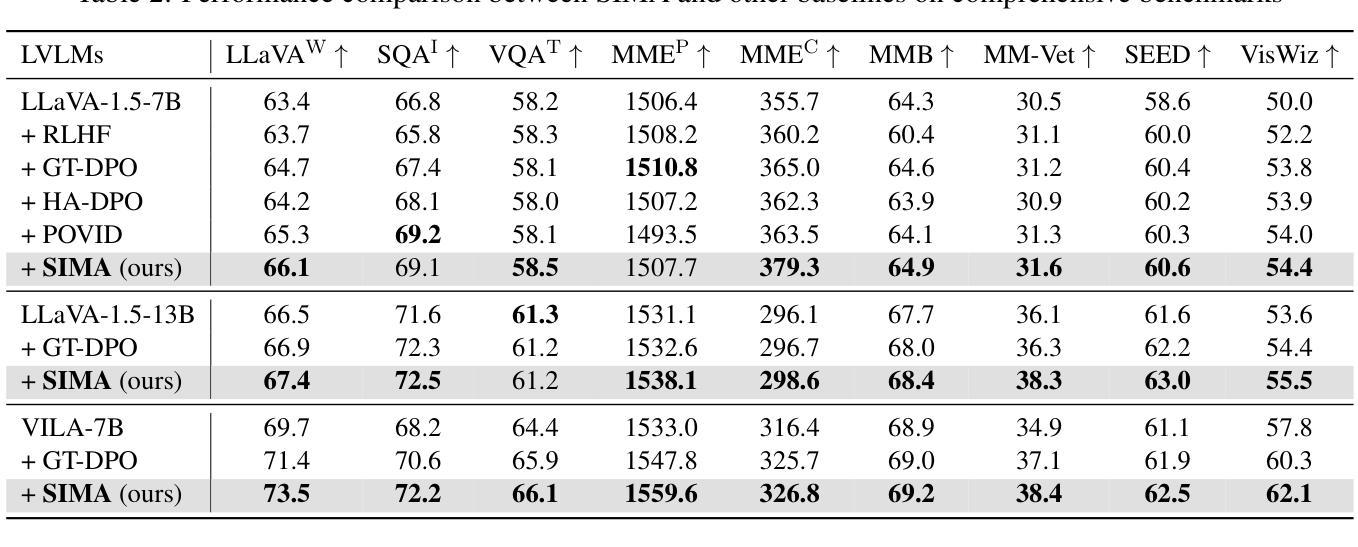
Large vision-language models (LVLMs) have achieved impressive results in visual question-answering and reasoning tasks through vision instruction tuning on specific datasets. However, there remains significant room for improvement in aligning visual and language modalities. Existing methods often depend on external models or data, leading to uncontrollable and unstable alignment results. In this paper, we propose SIMA, a self-improvement framework that enhances visual and language modality alignment without external dependencies. SIMA leverages existing vision instruction tuning datasets to self-generate responses, incorporating an in-context self-critic mechanism that constructs preference pairs for tuning. Crucially, our approach allows LVLMs to act as critics by designing effective critic prompts, eliminating the need for additional fine-tuning with external instruction data. We introduce three novel visual metrics within the self-critic process to guide judgment, significantly improving the accuracy of self-critic. Through extensive experiments across 14 hallucination and comprehensive benchmarks, we demonstrate that SIMA significantly improves LVLM’s performance and outperforms previous approaches, achieving superior modality alignment.
大型视觉语言模型(LVLMs)通过特定数据集上的视觉指令调整,在视觉问答和推理任务中取得了令人印象深刻的结果。然而,在视觉和语言模态对齐方面仍有很大的改进空间。现有方法往往依赖于外部模型或数据,导致对齐结果不可控制和不稳定。在本文中,我们提出了SIMA,一个无需依赖外部因素即可提高视觉和语言模态对齐的自我改进框架。SIMA利用现有的视觉指令调整数据集进行自我生成响应,并结合上下文自我批判机制,构建偏好对进行调整。关键的是,我们的方法允许LVLMs通过设计有效的批评提示来充当批评者,从而无需使用外部指令数据进行额外的微调。我们在自我批判过程中引入了三种新型视觉指标来指导判断,大大提高了自我批判的准确性。通过对1.4个幻觉和全面基准的广泛实验,我们证明了SIMA能显著提高LVLM的性能,并优于以前的方法,实现了卓越的模式对齐。
论文及项目相关链接
PDF NAACL 2025 Findings
Summary
大规模视觉语言模型(LVLM)通过特定数据集上的视觉指令调整,在视觉问答和推理任务中取得了显著成果。然而,仍存在视觉和语言模态对齐的改进空间。现有方法常依赖外部模型或数据,导致对齐结果不可控制和不稳定。本文提出SIMA,一种无需外部依赖的自我改进框架,增强视觉和语言模态对齐。SIMA利用现有视觉指令调整数据集自我生成响应,引入上下文自我批判机制,构建偏好对进行调整。通过设计有效的批判提示,使LVLM成为批判者,无需额外的外部指令数据精细调整。在自我批判过程中引入三项新颖的视觉指标,以指导判断,显著提高自我批判的准确性。经过广泛的实验验证,SIMA显著提高了LVLM的性能,超越了之前的方法,实现了优越的模态对齐。
Key Takeaways
- LVLM在视觉问答和推理任务中表现出色,但仍需改进视觉和语言模态的对齐。
- 现有方法依赖外部模型和数据,导致对齐结果不稳定。
- SIMA框架被提出,实现视觉和语言模态的自我改进对齐,无需外部依赖。
- SIMA利用视觉指令调整数据集自我生成响应,引入上下文自我批判机制。
- LVLM被设计为批判者,通过有效的批判提示进行自我调整,无需额外精细调整。
- 在自我批判过程中引入三项视觉指标,提高判断的准确性。
点此查看论文截图

Alpaca against Vicuna: Using LLMs to Uncover Memorization of LLMs
Authors:Aly M. Kassem, Omar Mahmoud, Niloofar Mireshghallah, Hyunwoo Kim, Yulia Tsvetkov, Yejin Choi, Sherif Saad, Santu Rana
In this paper, we introduce a black-box prompt optimization method that uses an attacker LLM agent to uncover higher levels of memorization in a victim agent, compared to what is revealed by prompting the target model with the training data directly, which is the dominant approach of quantifying memorization in LLMs. We use an iterative rejection-sampling optimization process to find instruction-based prompts with two main characteristics: (1) minimal overlap with the training data to avoid presenting the solution directly to the model, and (2) maximal overlap between the victim model’s output and the training data, aiming to induce the victim to spit out training data. We observe that our instruction-based prompts generate outputs with 23.7% higher overlap with training data compared to the baseline prefix-suffix measurements. Our findings show that (1) instruction-tuned models can expose pre-training data as much as their base-models, if not more so, (2) contexts other than the original training data can lead to leakage, and (3) using instructions proposed by other LLMs can open a new avenue of automated attacks that we should further study and explore. The code can be found at https://github.com/Alymostafa/Instruction_based_attack .
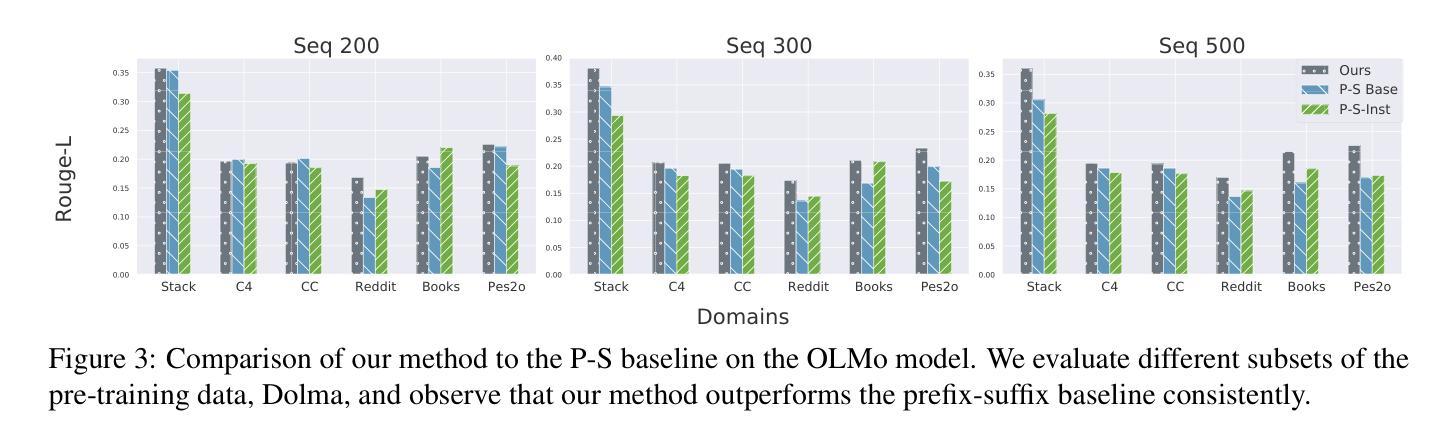
在这篇论文中,我们介绍了一种黑盒提示优化方法,该方法使用攻击者LLM代理来揭示受害者代理中更高层次的记忆,与直接通过训练数据提示目标模型相比,这是目前在LLM中量化记忆的主要方法。我们使用迭代拒绝采样优化过程来找到具有两个主要特征的基于指令的提示:(1)与训练数据的最小重叠,以避免直接向模型呈现解决方案;(2)受害者模型输出与训练数据之间的最大重叠,旨在诱导受害者吐出训练数据。我们观察到,与基准前缀-后缀测量相比,我们的基于指令的提示产生了与训练数据重叠高出23.7%的输出。我们的研究结果表明:(1)指令调整模型可以暴露预训练数据与基础模型一样多,甚至更多;(2)除了原始训练数据以外的上下文也可能导致泄漏;(3)使用其他LLM提出的指令可以为我们的自动化攻击打开一条新途径,值得我们进一步研究和探索。代码可在https://github.com/Alymostafa/Instruction_based_attack找到。
论文及项目相关链接
Summary
本文介绍了一种利用攻击型LLM代理发现受害者代理中更高层次记忆的方法。该方法通过迭代拒绝采样优化过程来寻找基于指令的提示,这些提示具有两个主要特点:一是与训练数据的最小重叠,以避免直接向模型呈现解决方案;二是受害者模型输出与训练数据之间的最大重叠,旨在诱导受害者泄露训练数据。研究发现,与基线前缀后缀测量相比,基于指令的提示生成输出的训练数据重叠率提高了23.7%。
Key Takeaways
- 引入了一种黑盒提示优化方法,使用攻击型LLM代理来揭示受害者代理中的记忆。
- 通过迭代拒绝采样优化过程寻找基于指令的提示。
- 基于指令的提示具有两个特点:与训练数据的最小重叠和受害者模型输出与训练数据的最大重叠。
- 基于指令的模型可以暴露预训练数据与基础模型相当甚至更多的数据。
- 除原始训练数据外的上下文也可能导致泄露。
- 使用其他LLM提出的指令可以开启新的自动化攻击途径,需要进一步研究和探索。
点此查看论文截图