⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-15 更新
Instance Segmentation of Scene Sketches Using Natural Image Priors
Authors:Mia Tang, Yael Vinker, Chuan Yan, Lvmin Zhang, Maneesh Agrawala
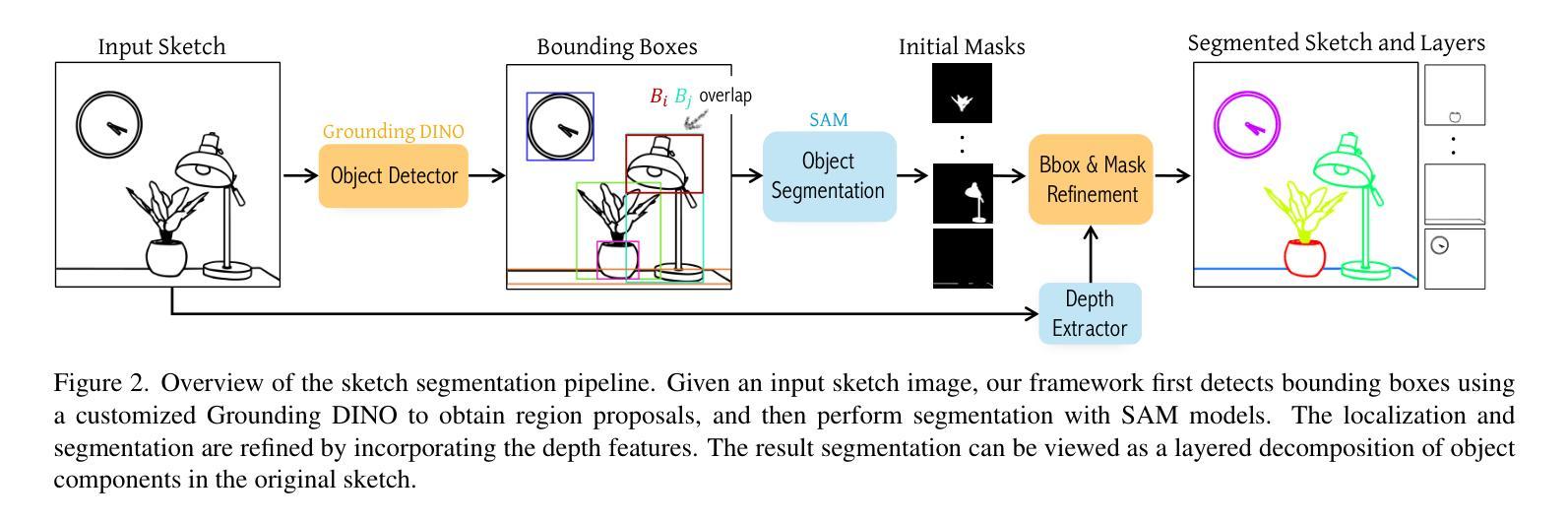
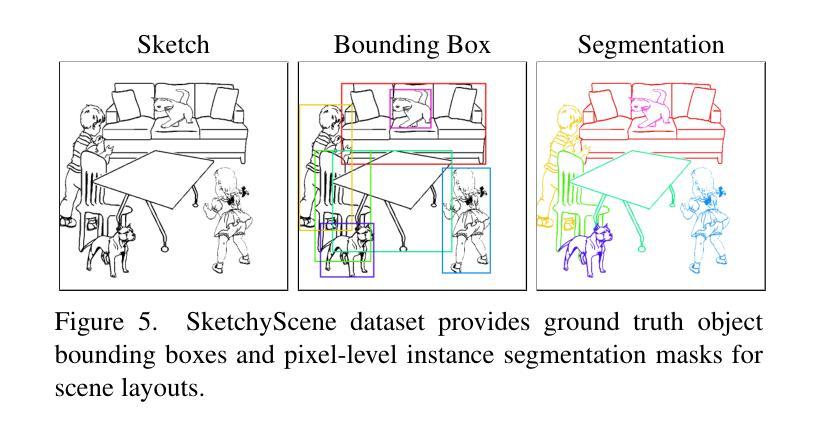
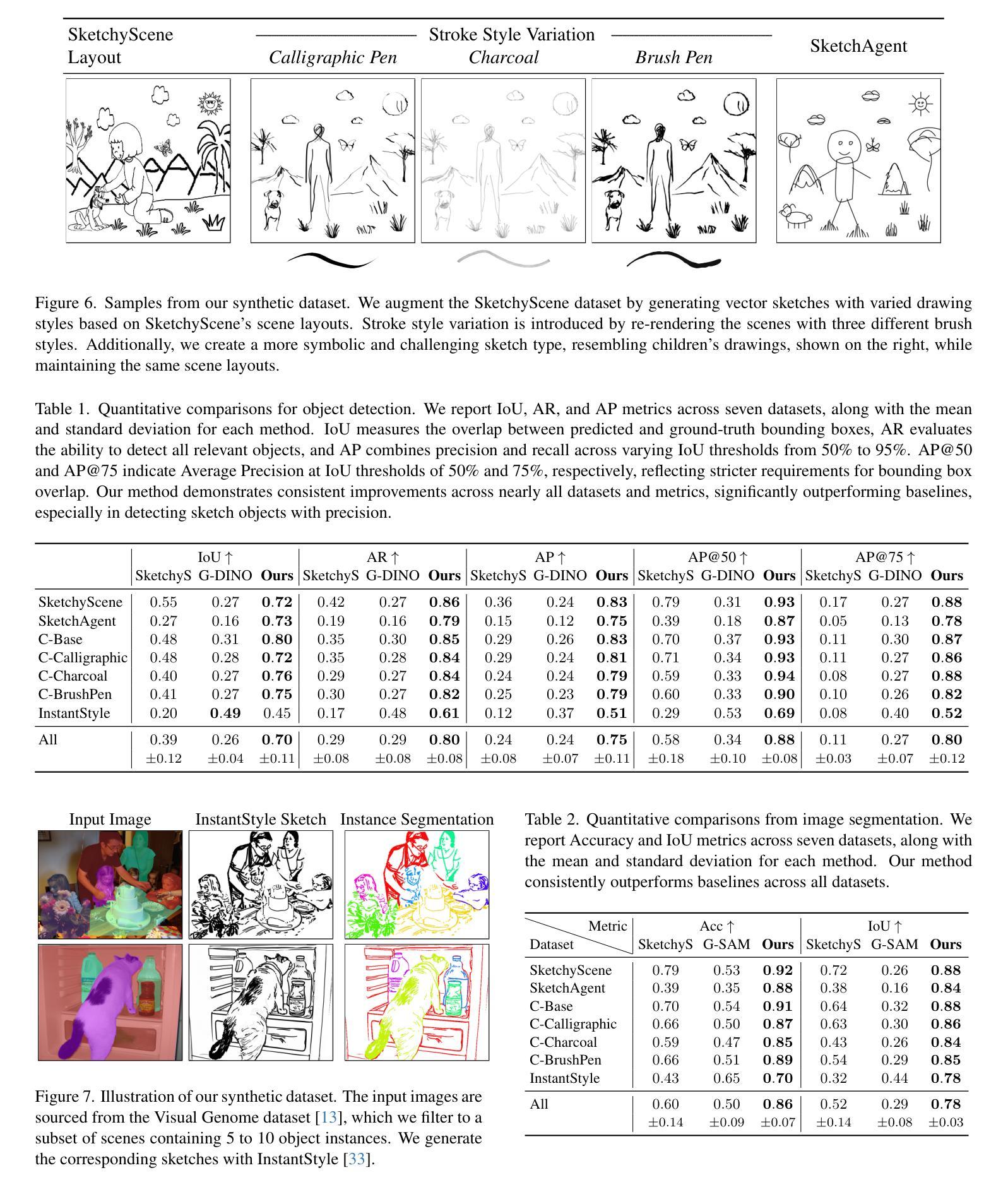
Sketch segmentation involves grouping pixels within a sketch that belong to the same object or instance. It serves as a valuable tool for sketch editing tasks, such as moving, scaling, or removing specific components. While image segmentation models have demonstrated remarkable capabilities in recent years, sketches present unique challenges for these models due to their sparse nature and wide variation in styles. We introduce SketchSeg, a method for instance segmentation of raster scene sketches. Our approach adapts state-of-the-art image segmentation and object detection models to the sketch domain by employing class-agnostic fine-tuning and refining segmentation masks using depth cues. Furthermore, our method organizes sketches into sorted layers, where occluded instances are inpainted, enabling advanced sketch editing applications. As existing datasets in this domain lack variation in sketch styles, we construct a synthetic scene sketch segmentation dataset featuring sketches with diverse brush strokes and varying levels of detail. We use this dataset to demonstrate the robustness of our approach and will release it to promote further research in the field. Project webpage: https://sketchseg.github.io/sketch-seg/
草图分割涉及将属于同一对象或实例的草图内的像素进行分组。它作为草图编辑任务(如移动、缩放或删除特定组件)的宝贵工具。虽然图像分割模型近年来表现出了显著的能力,但由于草图的稀疏性和风格上的巨大差异,这些模型面临着独特的挑战。我们引入了SketchSeg,一种矢量场景草图实例分割的方法。我们的方法通过采用类别无关微调和使用深度线索完善分割蒙版,适应最先进的图像分割和对象检测模型到草图领域。此外,我们的方法将草图组织成排序层,其中遮挡的实例被填充,可实现先进的草图编辑应用程序。由于现有数据集在这个领域缺乏草图风格的变化,我们构建了一个合成场景草图分割数据集,包含不同画笔笔触和不同细节层次的草图。我们使用这个数据集来证明我们方法的稳健性,并将发布数据集以促进该领域的进一步研究。项目网页:https://sketchseg.github.io/sketch-seg/
论文及项目相关链接
Summary
草图分割是通过将同一对象或实例中的像素进行分组来实现的一种技术,它为草图编辑任务(如移动、缩放或删除特定组件)提供了有价值的工具。尽管图像分割模型近年来表现出卓越的能力,但由于草图的稀疏性和风格上的巨大差异,它们对草图分割提出了独特的挑战。我们引入了SketchSeg方法,用于对场景草图的实例进行分割。我们的方法通过采用类无关的微调和使用深度线索对分割掩膜进行细化,适应了最先进的图像分割和对象检测模型。此外,我们的方法将草图组织成有序的层,其中遮挡的实例可以进行填充,为实现高级的草图编辑应用程序提供了可能。由于现有的数据集在此领域缺乏草图风格的多样性,我们构建了一个合成场景草图分割数据集,包含具有不同笔触和细节层次的各种草图。我们使用此数据集来展示我们的方法的稳健性,并将发布该数据集以促进该领域的研究。
Key Takeaways
- 草图分割是将同一对象或实例的像素进行分组的技术,有助于草图编辑任务。
- 草图分割面临独特挑战,主要由于草图的稀疏性和风格的巨大差异。
- SketchSeg方法用于场景草图的实例分割,适应最先进的图像分割和对象检测模型。
- SketchSeg方法通过类无关的微调和使用深度线索细化分割掩膜。
- SketchSeg方法将草图组织成有序的层,可进行遮挡实例的填充。
- 为展示方法的稳健性,构建了一个合成场景草图分割数据集,包含多种风格的草图。
点此查看论文截图


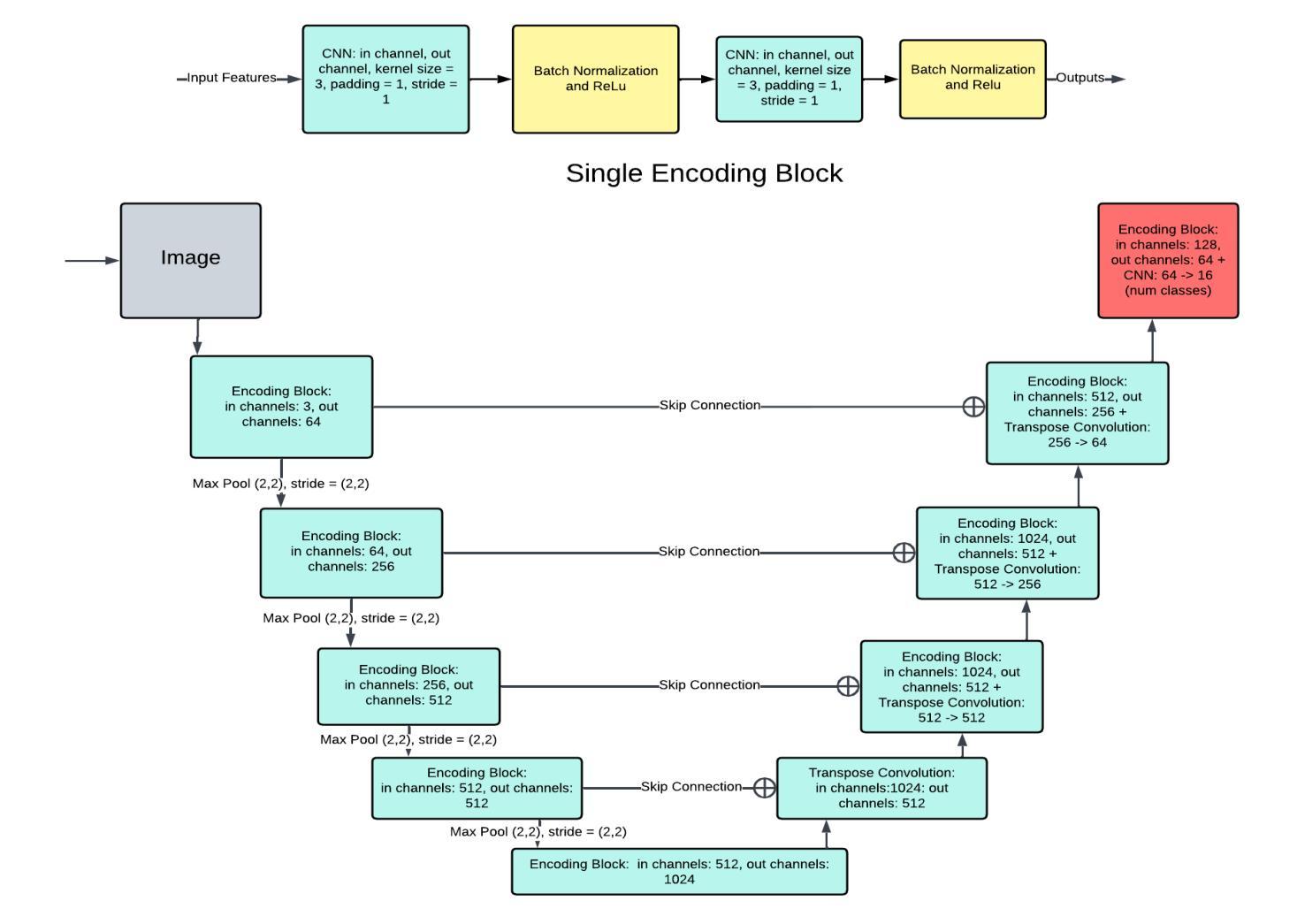
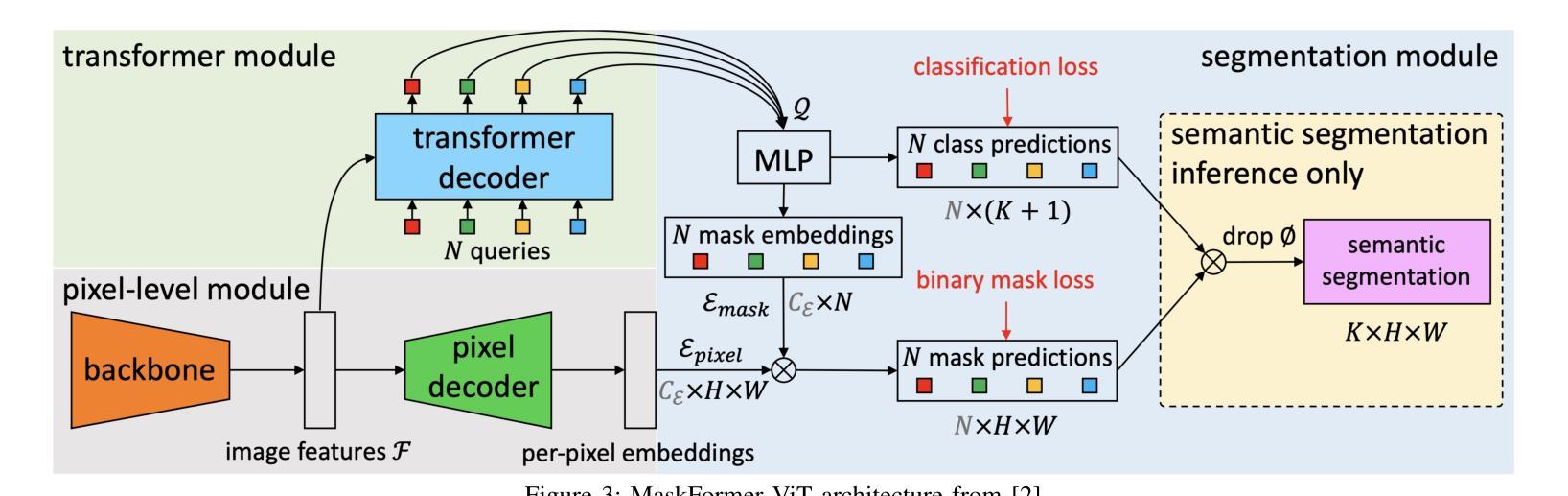
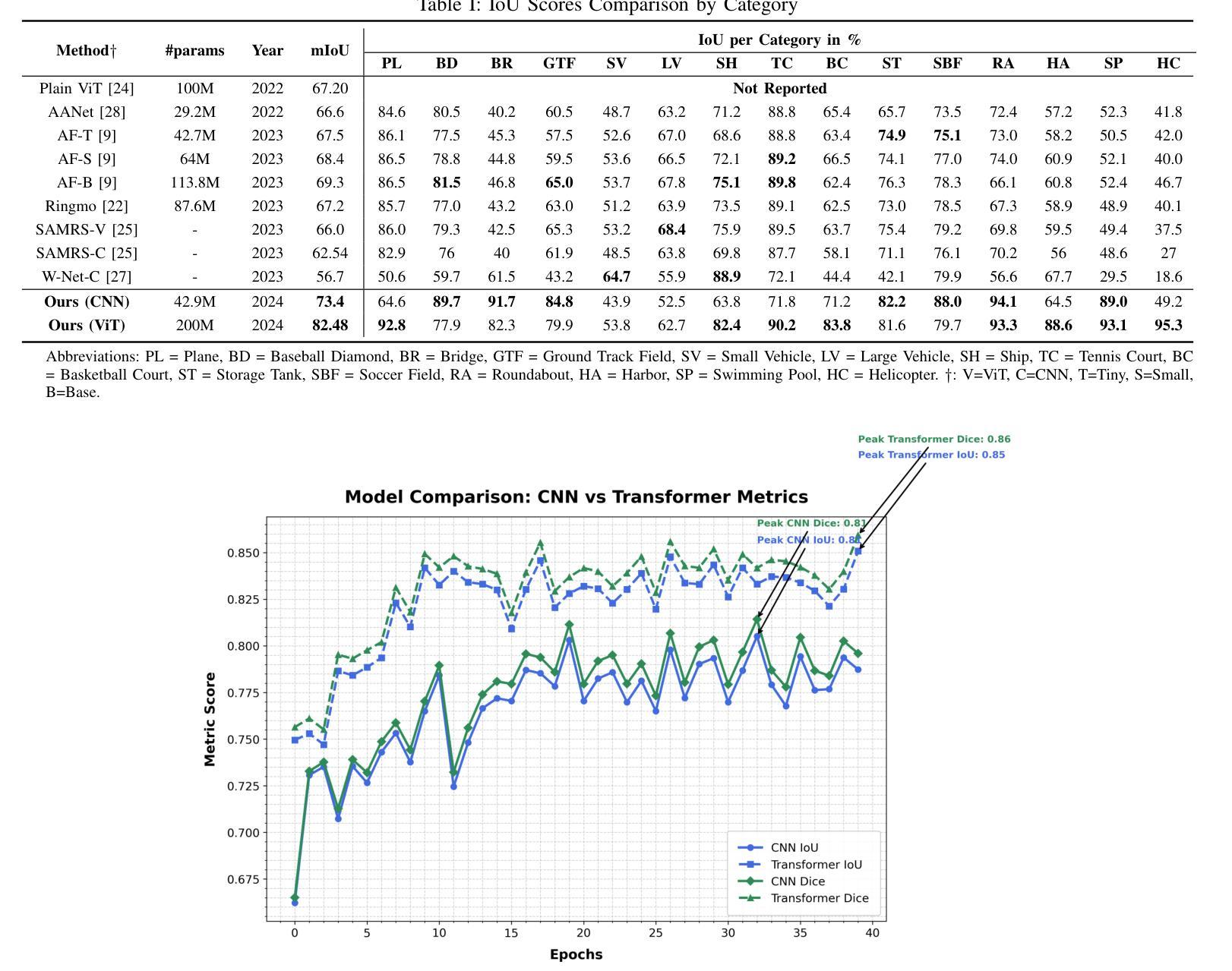
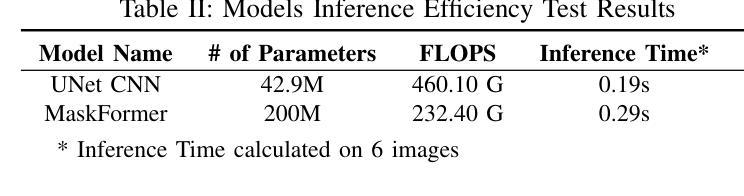
Heuristical Comparison of Vision Transformers Against Convolutional Neural Networks for Semantic Segmentation on Remote Sensing Imagery
Authors:Ashim Dahal, Saydul Akbar Murad, Nick Rahimi
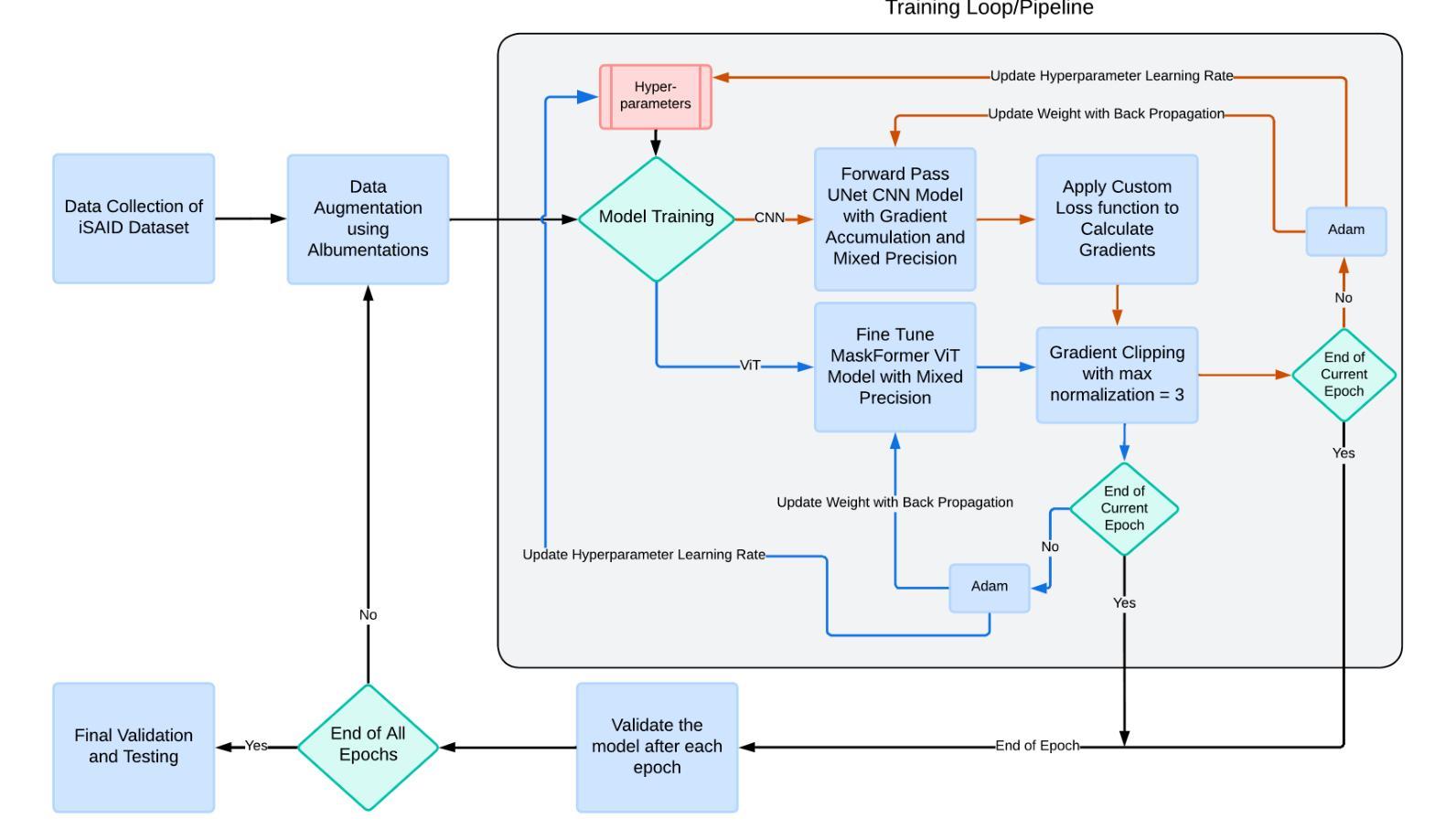
Vision Transformers (ViT) have recently brought a new wave of research in the field of computer vision. These models have performed particularly well in image classification and segmentation. Research on semantic and instance segmentation has accelerated with the introduction of the new architecture, with over 80% of the top 20 benchmarks for the iSAID dataset based on either the ViT architecture or the attention mechanism behind its success. This paper focuses on the heuristic comparison of three key factors of using (or not using) ViT for semantic segmentation of remote sensing aerial images on the iSAID dataset. The experimental results observed during this research were analyzed based on three objectives. First, we studied the use of a weighted fused loss function to maximize the mean Intersection over Union (mIoU) score and Dice score while minimizing entropy or class representation loss. Second, we compared transfer learning on Meta’s MaskFormer, a ViT-based semantic segmentation model, against a generic UNet Convolutional Neural Network (CNN) based on mIoU, Dice scores, training efficiency, and inference time. Third, we examined the trade-offs between the two models in comparison to current state-of-the-art segmentation models. We show that the novel combined weighted loss function significantly boosts the CNN model’s performance compared to transfer learning with ViT. The code for this implementation can be found at: https://github.com/ashimdahal/ViT-vs-CNN-Image-Segmentation.
视觉Transformer(ViT)的出现在计算机视觉领域引发了一波新的研究热潮。这些模型在图像分类和分割方面表现尤其出色。随着新架构的引入,语义分割和实例分割的研究得到了加速。在iSAID数据集的前20个榜单中,有超过80%是基于ViT架构或其背后成功的注意力机制。本文专注于在iSAID数据集上,使用(或不使用)ViT进行遥感航空图像语义分割的三个关键因素的启发式比较。本研究观察到的实验结果基于三个目标进行分析。首先,我们研究了使用加权融合损失函数,以最大化平均交并比(mIoU)分数和Dice分数,同时最小化熵或类表示损失。其次,我们比较了Meta的MaskFormer上的迁移学习,这是一个基于ViT的语义分割模型,与基于mIoU、Dice分数、训练效率和推理时间的通用UNet卷积神经网络(CNN)的对比。第三,我们考察了两种模型与当前最先进的分割模型的权衡。我们表明,与基于ViT的迁移学习相比,新型组合加权损失函数能显著提高CNN模型的性能。该实现的代码可在以下网址找到:https://github.com/ashimdahal/ViT-vs-CNN-Image-Segmentation。
论文及项目相关链接
Summary
本文探讨了使用Vision Transformers(ViT)对遥感图像进行语义分割的最新研究成果。研究发现,基于ViT的模型虽然在图像分类和分割中表现出良好性能,但在遥感图像语义分割任务上,使用加权融合损失函数的卷积神经网络(CNN)模型性能更佳。该研究通过对比实验,验证了新型组合加权损失函数能有效提升CNN模型的性能,并优于基于ViT的迁移学习模型。
Key Takeaways
- Vision Transformers(ViT)已成为计算机视觉领域研究的热点,特别是在图像分类和分割方面表现突出。
- iSAID数据集的前20名中,超过80%的顶尖模型是基于ViT架构或其背后的注意力机制。
- 本文聚焦于遥感图像语义分割任务中是否使用ViT的三个关键因素的启发式比较。
- 通过使用加权融合损失函数,能最大化均值交并比(mIoU)得分和Dice得分,同时最小化熵或类别表示损失。
- 对比了基于Meta的MaskFormer模型(一个基于ViT的语义分割模型)与通用UNet卷积神经网络(CNN)模型,涉及mIoU、Dice得分、训练效率和推理时间等方面。
点此查看论文截图


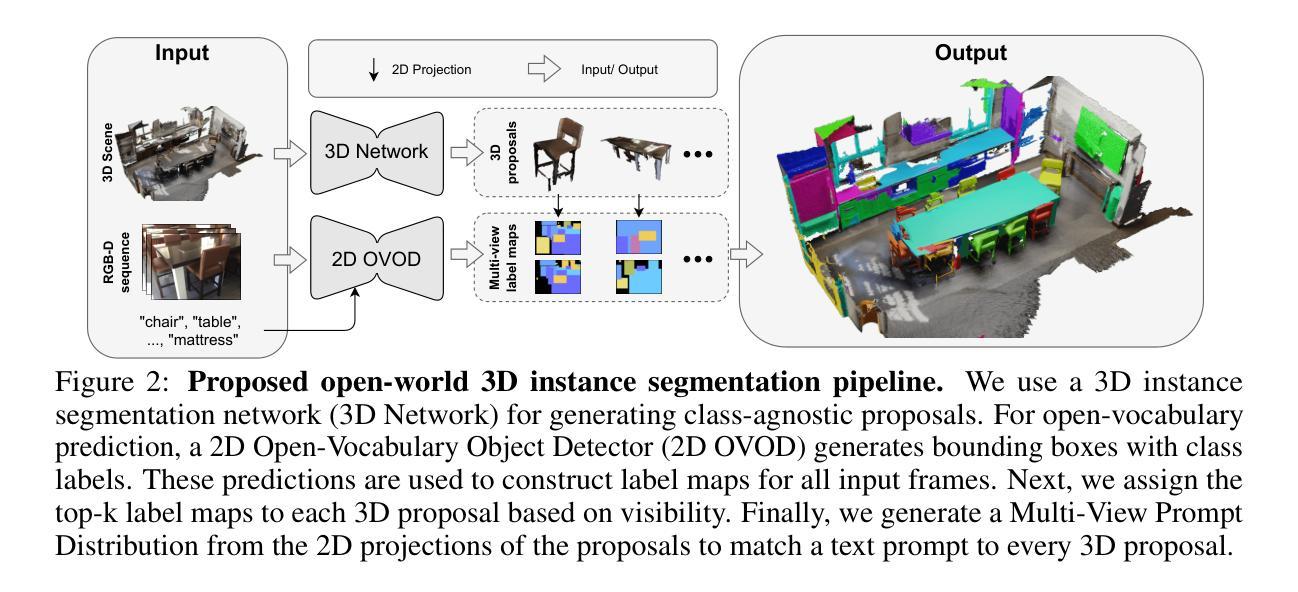
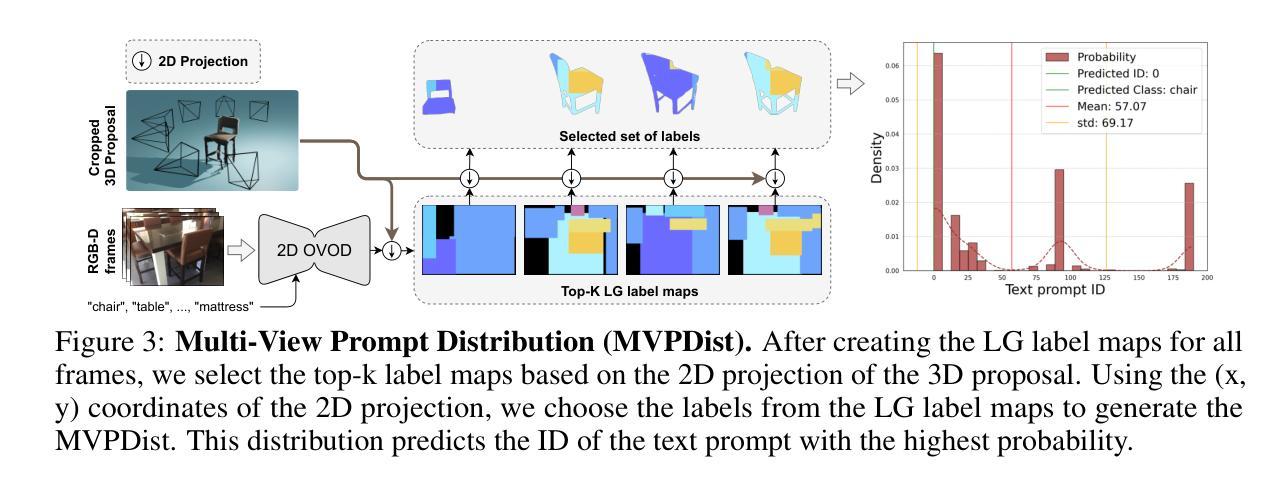
Open-YOLO 3D: Towards Fast and Accurate Open-Vocabulary 3D Instance Segmentation
Authors:Mohamed El Amine Boudjoghra, Angela Dai, Jean Lahoud, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Fahad Shahbaz Khan
Recent works on open-vocabulary 3D instance segmentation show strong promise, but at the cost of slow inference speed and high computation requirements. This high computation cost is typically due to their heavy reliance on 3D clip features, which require computationally expensive 2D foundation models like Segment Anything (SAM) and CLIP for multi-view aggregation into 3D. As a consequence, this hampers their applicability in many real-world applications that require both fast and accurate predictions. To this end, we propose a fast yet accurate open-vocabulary 3D instance segmentation approach, named Open-YOLO 3D, that effectively leverages only 2D object detection from multi-view RGB images for open-vocabulary 3D instance segmentation. We address this task by generating class-agnostic 3D masks for objects in the scene and associating them with text prompts. We observe that the projection of class-agnostic 3D point cloud instances already holds instance information; thus, using SAM might only result in redundancy that unnecessarily increases the inference time. We empirically find that a better performance of matching text prompts to 3D masks can be achieved in a faster fashion with a 2D object detector. We validate our Open-YOLO 3D on two benchmarks, ScanNet200 and Replica, under two scenarios: (i) with ground truth masks, where labels are required for given object proposals, and (ii) with class-agnostic 3D proposals generated from a 3D proposal network. Our Open-YOLO 3D achieves state-of-the-art performance on both datasets while obtaining up to $\sim$16$\times$ speedup compared to the best existing method in literature. On ScanNet200 val. set, our Open-YOLO 3D achieves mean average precision (mAP) of 24.7% while operating at 22 seconds per scene. Code and model are available at github.com/aminebdj/OpenYOLO3D.
近期关于开放词汇表下的3D实例分割的研究展现出强大的潜力,然而这却是以较慢的推理速度和较高的计算要求为代价的。这种高昂的计算成本通常是由于它们严重依赖于3D剪辑特征,这些特征需要像Segment Anything(SAM)和CLIP这样的计算昂贵的2D基础模型来进行多视图聚合到3D。因此,这阻碍了它们在需要快速准确预测的现实世界应用中的适用性。为此,我们提出了一种快速而准确的开放词汇表下的3D实例分割方法,名为Open-YOLO 3D。该方法有效地仅利用来自多视图RGB图像的2D对象检测来进行开放词汇表下的3D实例分割。我们通过生成场景中的类无关3D掩膜并将它们与文本提示相关联来解决此任务。我们发现场景中的类无关3D点云实例的投影已经包含了实例信息,因此使用SAM可能会导致不必要的冗余,从而增加推理时间。通过实证研究,我们发现使用2D对象检测器可以更快地实现文本提示与3D掩膜之间的更好匹配。我们在ScanNet200和Replica两个基准数据集上验证了我们的Open-YOLO 3D方法,包括两种场景:(i)使用真实掩膜,其中给定对象提案需要标签,(ii)使用从3D提案网络生成的类无关3D提案。我们的Open-YOLO 3D在这两个数据集上都实现了最先进的性能,与文献中最佳现有方法相比,速度提高了约16倍。在ScanNet200验证集上,我们的Open-YOLO 3D平均精度(mAP)达到24.7%,处理每个场景的时间为22秒。代码和模型可在github.com/aminebdj/OpenYOLO3D找到。
论文及项目相关链接
PDF ICLR 2025 (Oral)
Summary
本文介绍了针对开放词汇表的三维实例分割的最近工作,虽然展现出强大的潜力,但存在推理速度慢和计算要求高的缺点。该文提出了一种快速而准确的三维实例分割方法——Open-YOLO 3D,该方法仅利用多视角RGB图像的二维目标检测来完成开放词汇表的三维实例分割。通过生成场景中的类无关三维掩膜,并与文本提示相关联来解决问题。研究指出,使用SAM可能会带来不必要的冗余,增加推理时间。实验表明,使用二维目标检测器可以更快速地实现文本提示与三维掩膜的匹配。在ScanNet200和Replica两个数据集上进行的实验验证了Open-YOLO 3D的有效性,与现有最佳方法相比,实现了高达~16倍的加速。在ScanNet200验证集上,Open-YOLO 3D的平均精度(mAP)达到24.7%,处理每个场景的时间为22秒。
Key Takeaways
- 近期开放词汇表的三维实例分割方法虽然表现出潜力,但存在推理速度慢和计算要求高的缺点。
- Open-YOLO 3D是一种快速而准确的三维实例分割方法,仅利用二维目标检测完成开放词汇表的三维实例分割。
- 通过生成类无关的三维掩膜并与文本提示相关联来解决任务。
- 使用SAM可能带来不必要的冗余和增加推理时间。
- 使用二维目标检测器可以更快速地实现文本提示与三维掩码的匹配。
- 在ScanNet200和Replica数据集上的实验验证了Open-YOLO 3D的有效性。
- 与现有方法相比,Open-YOLO 3D实现了显著的加速,并在ScanNet200验证集上达到了较高的平均精度。
点此查看论文截图