⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-15 更新
Optimizing GPT for Video Understanding: Zero-Shot Performance and Prompt Engineering
Authors:Mark Beliaev, Victor Yang, Madhura Raju, Jiachen Sun, Xinghai Hu
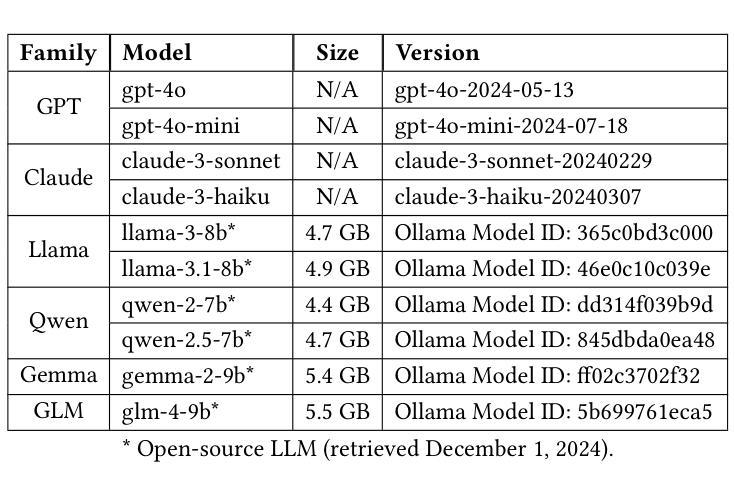
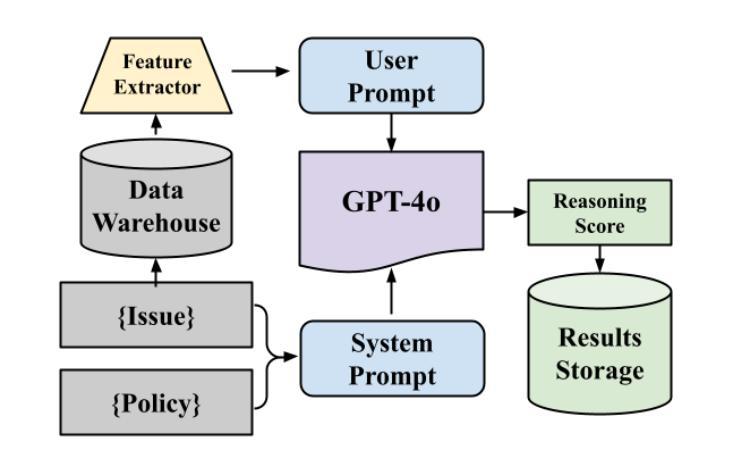
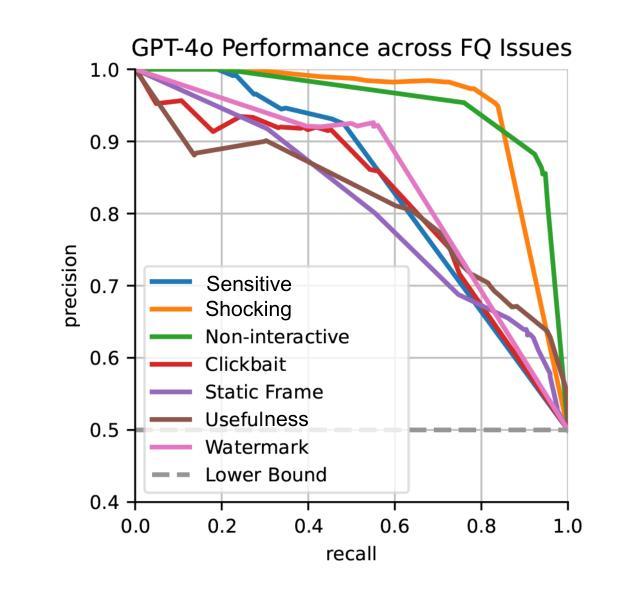
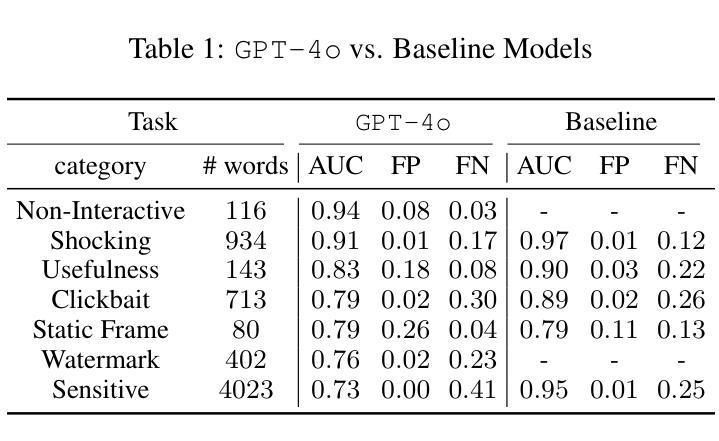
In this study, we tackle industry challenges in video content classification by exploring and optimizing GPT-based models for zero-shot classification across seven critical categories of video quality. We contribute a novel approach to improving GPT’s performance through prompt optimization and policy refinement, demonstrating that simplifying complex policies significantly reduces false negatives. Additionally, we introduce a new decomposition-aggregation-based prompt engineering technique, which outperforms traditional single-prompt methods. These experiments, conducted on real industry problems, show that thoughtful prompt design can substantially enhance GPT’s performance without additional finetuning, offering an effective and scalable solution for improving video classification systems across various domains in industry.
在这项研究中,我们通过探索和优化基于GPT的模型,针对七个关键的视频质量类别进行零样本分类,以解决视频内容分类行业的挑战。我们提出了一种改进GPT性能的新方法,通过提示优化和政策细化,证明简化复杂政策可以显著降低假阴性结果。此外,我们引入了一种基于分解聚合的提示工程技术,它优于传统的单提示方法。这些针对真实行业问题进行的实验表明,有策略性的提示设计可以显著提高GPT的性能,无需额外的微调,为改善各行业视频分类系统提供了有效且可扩展的解决方案。
论文及项目相关链接
Summary:
本研究针对视频内容分类行业的挑战,通过探索和优化基于GPT的模型,实现了零样本分类在七个关键视频质量类别中的应用。研究通过优化提示和细化策略,提高了GPT的性能,并引入了一种基于分解聚合的提示工程技术,该方法优于传统单提示方法。在真实行业问题上的实验表明,有策略的提示设计可以在不额外微调的情况下显著提高GPT的性能,为改进各行业中的视频分类系统提供了有效且可扩展的解决方案。
Key Takeaways:
- 研究探索了基于GPT的视频内容分类模型在七个关键视频质量类别中的零样本分类应用。
- 通过优化提示和策略细化,提高了GPT模型的性能。
- 引入了一种新的基于分解聚合的提示工程技术,该技术在实验上优于传统单提示方法。
- 简化复杂策略能显著降低误报。
- 提示设计对提高GPT性能至关重要,而无需额外的微调。
- 该研究为视频分类系统提供了有效且可扩展的解决方案。
点此查看论文截图

Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Authors:Haobo Yuan, Xiangtai Li, Tao Zhang, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, Ming-Hsuan Yang
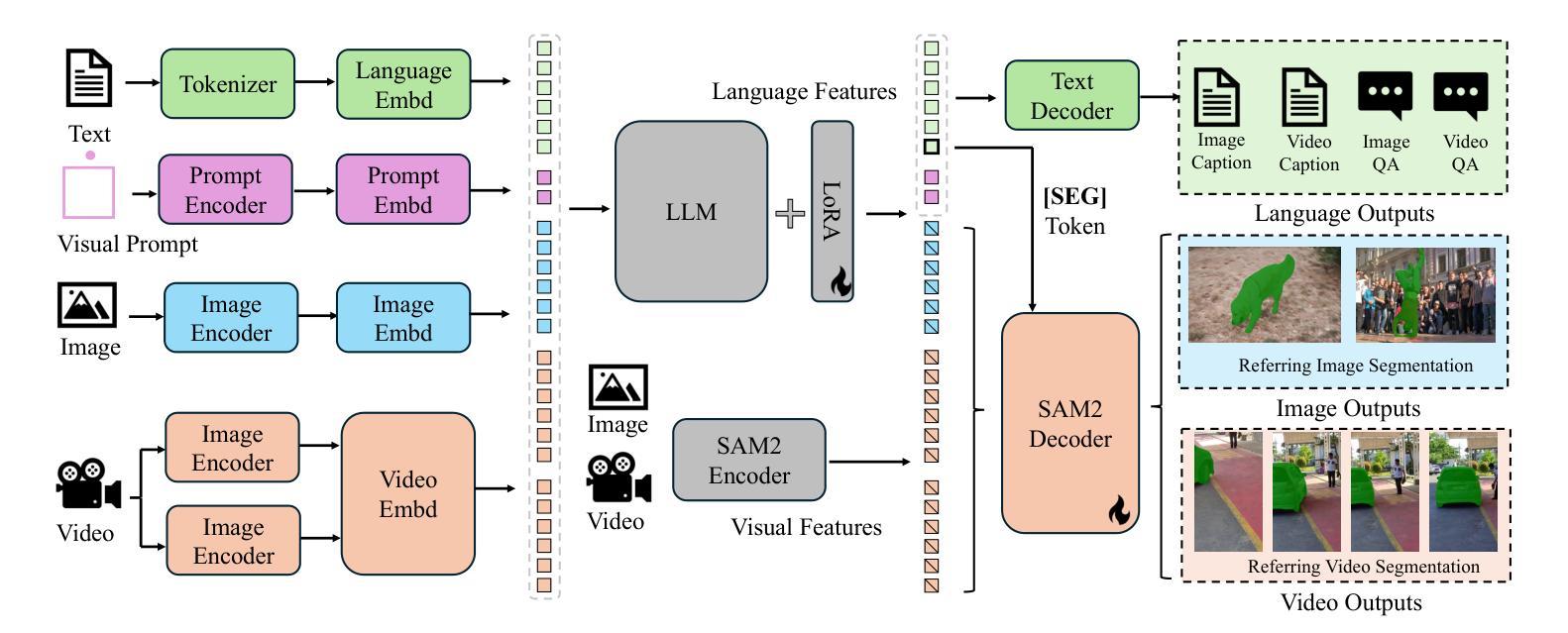
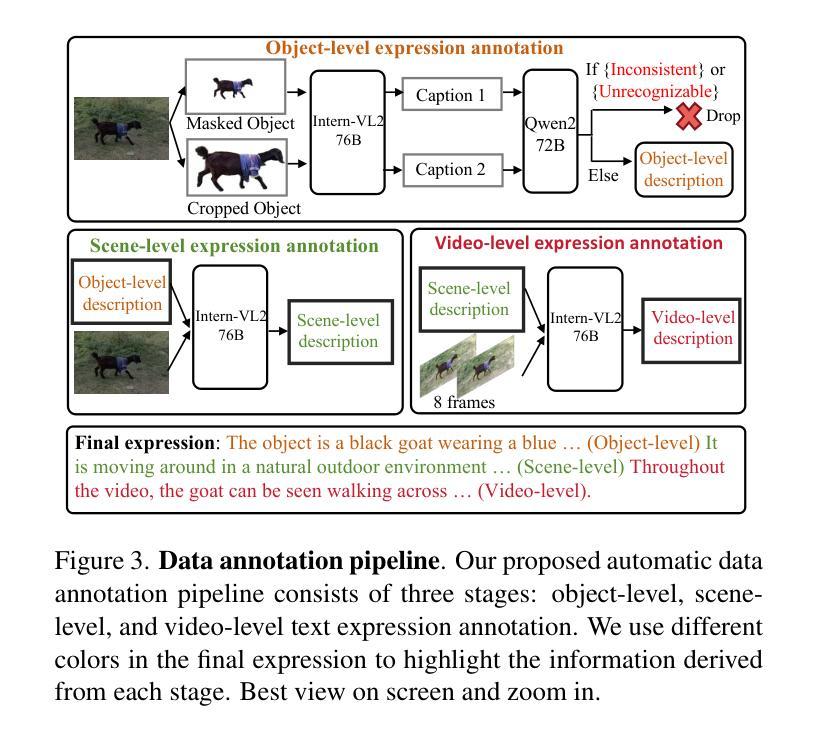
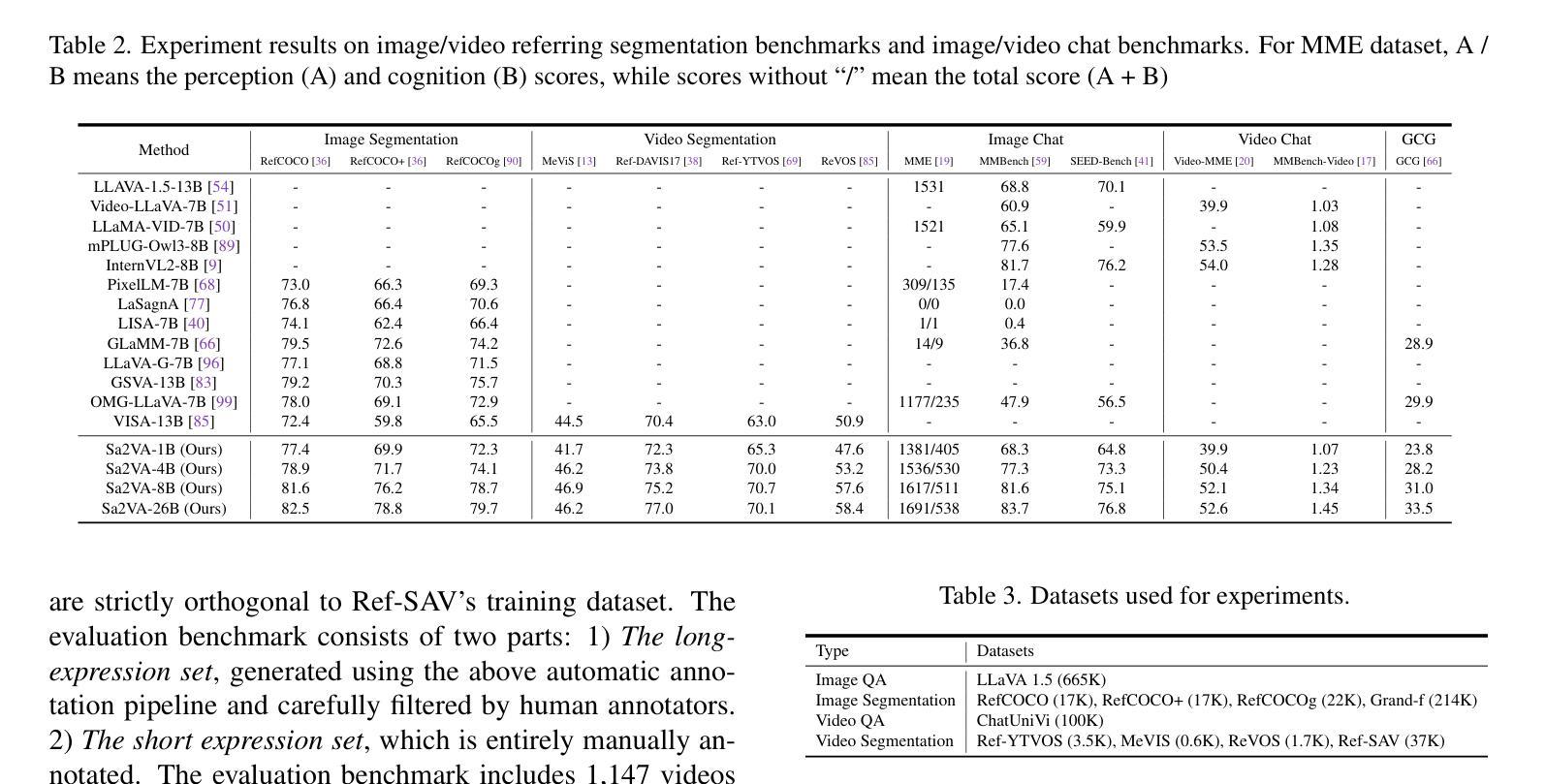
This work presents Sa2VA, the first unified model for dense grounded understanding of both images and videos. Unlike existing multi-modal large language models, which are often limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including referring segmentation and conversation, with minimal one-shot instruction tuning. Sa2VA combines SAM-2, a foundation video segmentation model, with LLaVA, an advanced vision-language model, and unifies text, image, and video into a shared LLM token space. Using the LLM, Sa2VA generates instruction tokens that guide SAM-2 in producing precise masks, enabling a grounded, multi-modal understanding of both static and dynamic visual content. Additionally, we introduce Ref-SAV, an auto-labeled dataset containing over 72k object expressions in complex video scenes, designed to boost model performance. We also manually validate 2k video objects in the Ref-SAV datasets to benchmark referring video object segmentation in complex environments. Experiments show that Sa2VA achieves state-of-the-art across multiple tasks, particularly in referring video object segmentation, highlighting its potential for complex real-world applications.
本文介绍了Sa2VA,这是首个统一模型,用于密集地对图像和视频进行理解。不同于现有的多模态大型语言模型,这些模型通常仅限于特定的模态和任务,而Sa2VA支持广泛的图像和视频任务,包括指代分割和对话,并通过一次简单的指令调整即可实现。Sa2VA结合了SAM-2(基础视频分割模型)和LLaVA(先进的视觉语言模型),并将文本、图像和视频统一到共享的LLM标记空间中。通过LLM,Sa2VA生成指令令牌,引导SAM-2生成精确蒙版,实现对静态和动态视觉内容的基于地面的多模态理解。此外,我们引入了Ref-SAV数据集,该数据集包含超过7万多个复杂视频场景中的对象表达式,旨在提高模型性能。我们还手动验证了Ref-SAV数据集中的2千个视频对象,为指代视频对象分割在复杂环境中的基准测试提供了依据。实验表明,Sa2VA在多个任务上均达到了最新水平,特别是在指代视频对象分割方面表现出色,突显其在复杂现实世界应用中的潜力。
论文及项目相关链接
PDF Project page: https://lxtgh.github.io/project/sa2va
Summary
本文主要介绍了Sa2VA模型,该模型是集图像和视频深度理解的首个统一模型。它结合了SAM-2视频分割模型和LLaVA先进的视觉语言模型,将文本、图像和视频统一到共享的LLM令牌空间。通过LLM生成指令令牌,指导SAM-2生成精确掩膜,实现对静态和动态视觉内容的深度、多模态理解。同时引入Ref-SAV数据集,提升模型在复杂视频场景中的表现。实验证明,Sa2VA在多任务上均达到领先水平,尤其在指代视频对象分割方面展现出其在复杂现实应用中的潜力。
Key Takeaways
- Sa2VA是首个集图像和视频深度理解的统一模型。
- Sa2VA支持多种图像和视频任务,包括指代分割和对话。
- Sa2VA结合SAM-2视频分割模型和LLaVA视觉语言模型,将文本、图像和视频统一到共享的LLM令牌空间。
- LLM生成指令令牌,指导SAM-2生成精确掩膜,实现多模态理解。
- 引入Ref-SAV数据集,用于提升模型在复杂视频场景中的表现。
- 手动验证的Ref-SAV数据集为视频对象分割提供了基准测试。
点此查看论文截图