⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-15 更新
Diffusing DeBias: a Recipe for Turning a Bug into a Feature
Authors:Massimiliano Ciranni, Vito Paolo Pastore, Roberto Di Via, Enzo Tartaglione, Francesca Odone, Vittorio Murino
Deep learning model effectiveness in classification tasks is often challenged by the quality and quantity of training data which, whenever containing strong spurious correlations between specific attributes and target labels, can result in unrecoverable biases in model predictions. Tackling these biases is crucial in improving model generalization and trust, especially in real-world scenarios. This paper presents Diffusing DeBias (DDB), a novel approach acting as a plug-in for common methods in model debiasing while exploiting the inherent bias-learning tendency of diffusion models. Our approach leverages conditional diffusion models to generate synthetic bias-aligned images, used to train a bias amplifier model, to be further employed as an auxiliary method in different unsupervised debiasing approaches. Our proposed method, which also tackles the common issue of training set memorization typical of this type of tech- niques, beats current state-of-the-art in multiple benchmark datasets by significant margins, demonstrating its potential as a versatile and effective tool for tackling dataset bias in deep learning applications.
深度学习模型在分类任务中的有效性常常受到训练数据质量和数量的挑战。训练数据中特定属性与目标标签之间存在强烈的虚假关联时,会导致模型预测中出现不可挽回的偏见。解决这些偏见对于提高模型的通用性和信任度至关重要,尤其是在现实世界的场景中。本文提出了Diffusing DeBias(DDB),这是一种新型方法,可作为通用模型去偏方法的插件,同时利用扩散模型固有的偏学习倾向。我们的方法利用条件扩散模型生成合成偏置对齐图像,用于训练偏置放大器模型,进一步用于不同的无监督去偏置方法。我们提出的方法还解决了此类技术典型的训练集记忆化问题,在多个基准数据集上大幅超越了当前最新技术,证明其作为解决深度学习应用中数据集偏见的通用和有效工具的潜力。
论文及项目相关链接
PDF 29 Pages, 12 Figures
Summary
深度学习模型在分类任务中的有效性经常受到训练数据的质量和数量的挑战。当训练数据包含特定属性与目标标签之间的强烈虚假关联时,会导致模型预测中出现不可挽回的偏见。本论文提出一种名为Diffusing DeBias(DDB)的新方法,该方法可作为通用模型去偏方法的插件,同时利用扩散模型的固有偏学习倾向。DDB方法利用条件扩散模型生成合成偏置对齐图像,用于训练偏置放大器模型,可作为不同无监督去偏方法的辅助方法。该方法解决了当前技术中普遍存在的训练集记忆问题,并在多个基准数据集上显著超越了当前先进技术,显示出其在深度学习应用中解决数据集偏见的潜力和有效性。
Key Takeaways
- 深度学习模型在分类任务中面临数据质量和数量的挑战。
- 训练数据中的虚假关联会导致模型预测出现偏见。
- Diffusing DeBias (DDB)是一种新的去偏方法,可作为通用插件用于模型去偏。
- DDB利用扩散模型的固有偏学习倾向。
- DDB通过生成合成偏置对齐图像来训练偏置放大器模型。
- DDB可作为不同无监督去偏方法的辅助方法。
点此查看论文截图

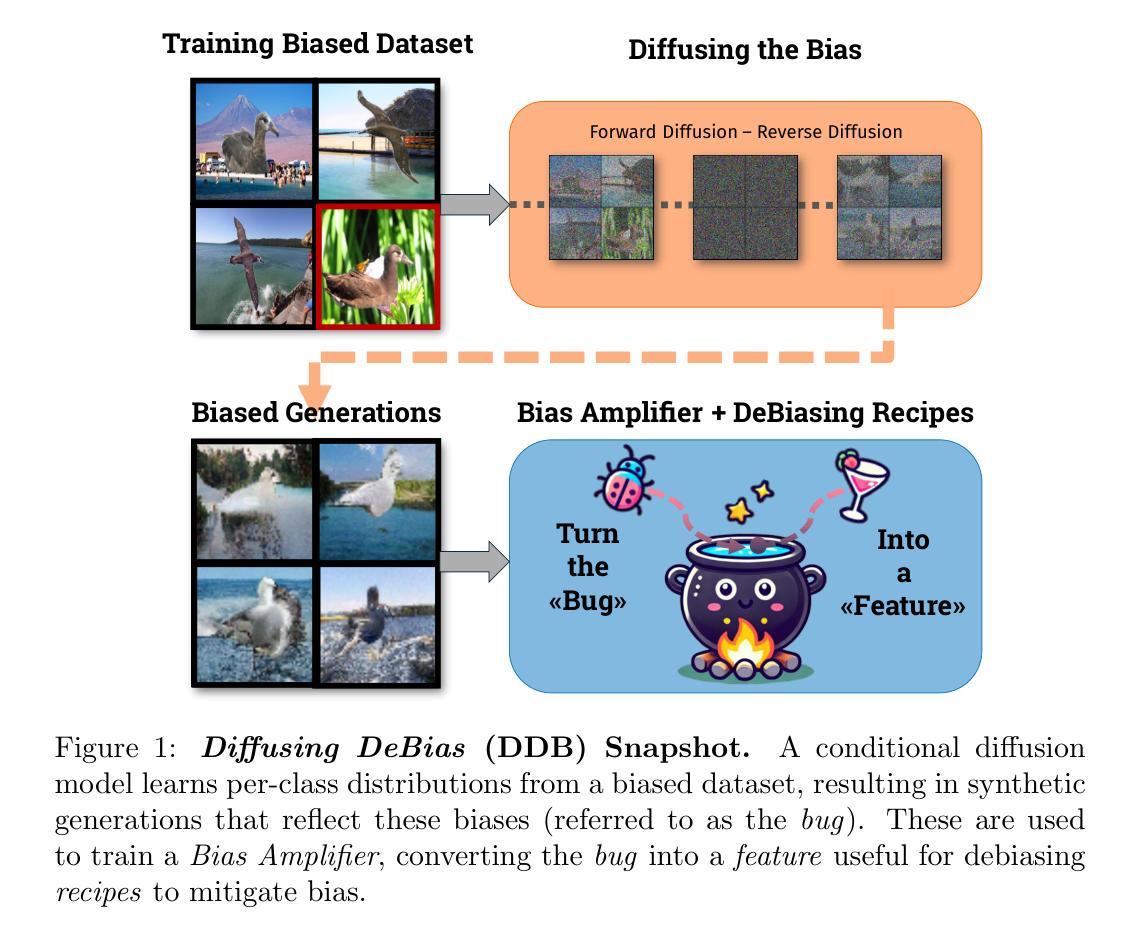
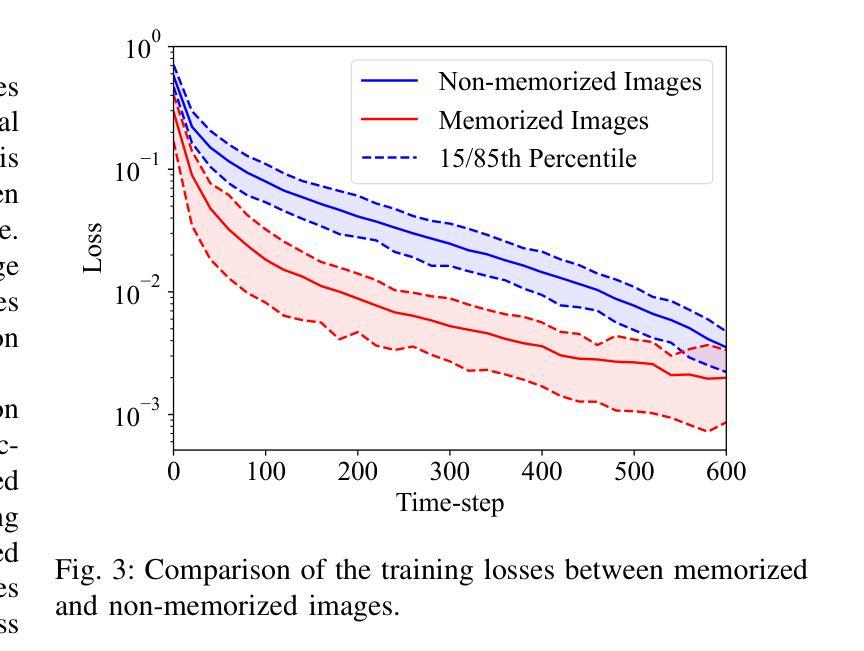
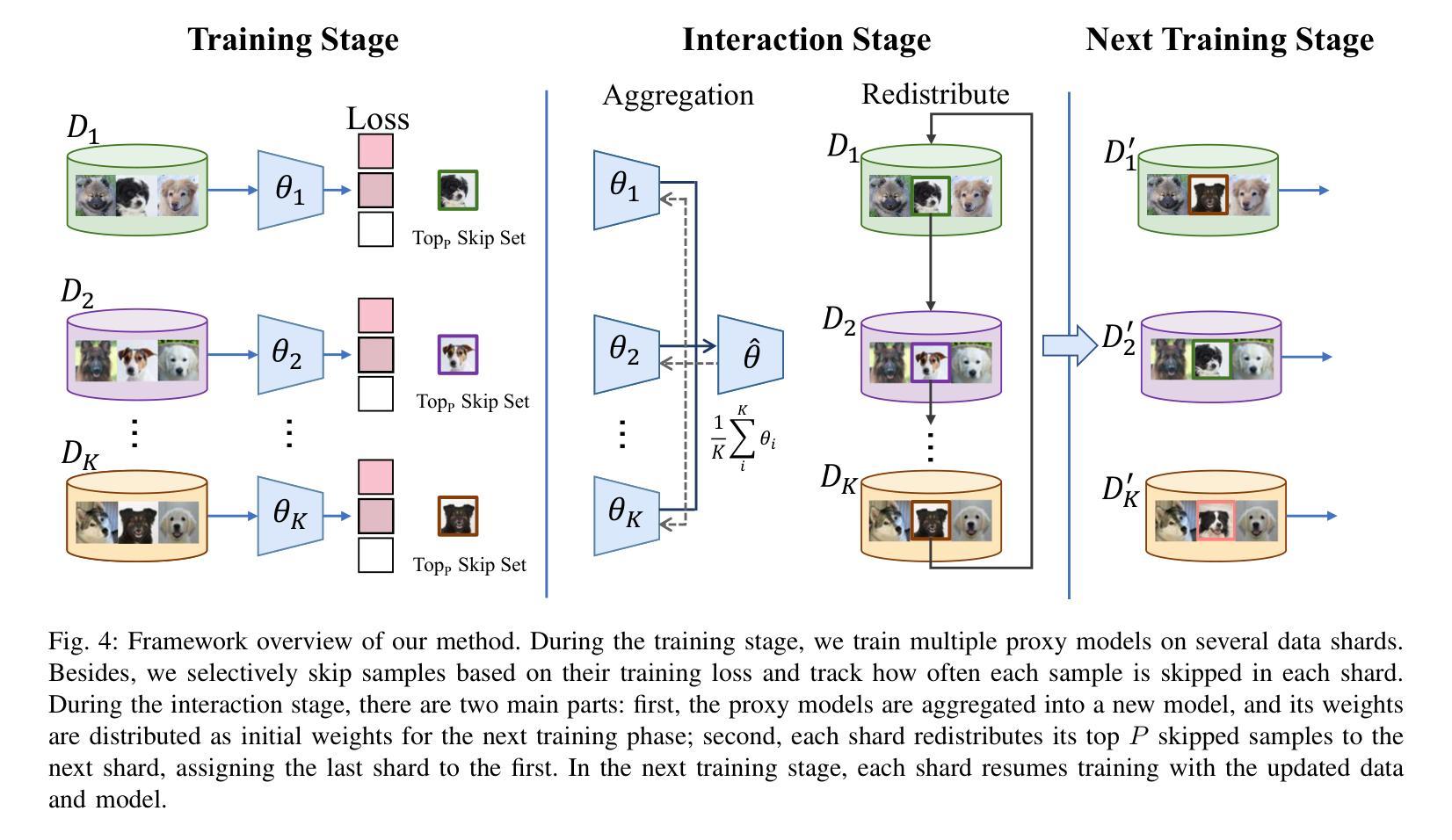
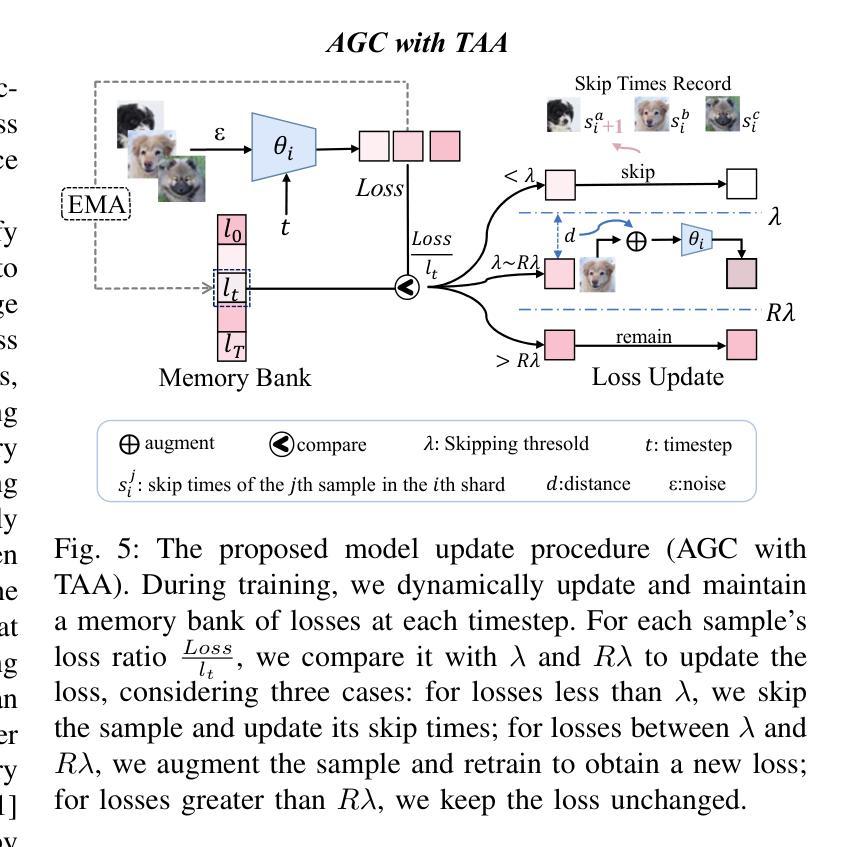
Redistribute Ensemble Training for Mitigating Memorization in Diffusion Models
Authors:Xiaoliu Guan, Yu Wu, Huayang Huang, Xiao Liu, Jiaxu Miao, Yi Yang
Diffusion models, known for their tremendous ability to generate high-quality samples, have recently raised concerns due to their data memorization behavior, which poses privacy risks. Recent methods for memory mitigation have primarily addressed the issue within the context of the text modality in cross-modal generation tasks, restricting their applicability to specific conditions. In this paper, we propose a novel method for diffusion models from the perspective of visual modality, which is more generic and fundamental for mitigating memorization. Directly exposing visual data to the model increases memorization risk, so we design a framework where models learn through proxy model parameters instead. Specially, the training dataset is divided into multiple shards, with each shard training a proxy model, then aggregated to form the final model. Additionally, practical analysis of training losses illustrates that the losses for easily memorable images tend to be obviously lower. Thus, we skip the samples with abnormally low loss values from the current mini-batch to avoid memorizing. However, balancing the need to skip memorization-prone samples while maintaining sufficient training data for high-quality image generation presents a key challenge. Thus, we propose IET-AGC+, which redistributes highly memorizable samples between shards, to mitigate these samples from over-skipping. Furthermore, we dynamically augment samples based on their loss values to further reduce memorization. Extensive experiments and analysis on four datasets show that our method successfully reduces memory capacity while maintaining performance. Moreover, we fine-tune the pre-trained diffusion models, e.g., Stable Diffusion, and decrease the memorization score by 46.7%, demonstrating the effectiveness of our method. Code is available in: https://github.com/liuxiao-guan/IET_AGC.
扩散模型因其生成高质量样本的出色能力而备受关注,但最近其数据记忆行为引发了关于隐私风险的担忧。最近的记忆缓解方法主要解决了跨模态生成任务中文本模态的问题,限制了其在特定条件下的适用性。在本文中,我们从视觉模态的角度提出了一种新型扩散模型缓解记忆的方法,该方法在缓解记忆方面更为通用和基础。直接将视觉数据暴露给模型会增加记忆风险,因此我们设计了一个框架,其中模型通过代理模型参数进行学习。具体来说,训练数据集被分成多个分片,每个分片训练一个代理模型,然后聚合形成最终模型。此外,对训练损失的实际分析表明,容易记忆的图像的损失往往明显较低。因此,我们从当前小型批次中跳过损失值异常的样本以避免记忆。然而,平衡跳过易记忆样本的需求与维持高质量图像生成的充足训练数据之间呈现关键挑战。因此,我们提出了IET-AGC+。它将高度可记忆的样本重新分配给不同的分片,以缓解这些样本被过度跳过的问题。此外,我们根据损失值动态地扩充样本以进一步减少记忆。在四个数据集上的广泛实验和分析表明,我们的方法在减少内存容量的同时保持了性能。此外,我们对预训练的扩散模型(例如Stable Diffusion)进行了微调,将记忆分数降低了46.7%,证明了我们的方法的有效性。相关代码可在:https://github.com/liuxiao-guan/IET_AGC上找到。
论文及项目相关链接
PDF 12 pages,9 figures. arXiv admin note: substantial text overlap with arXiv:2407.15328
摘要
扩散模型具有生成高质量样本的出色能力,但也存在数据记忆行为,带来隐私风险。本文从视觉模式的角度提出了一种新的扩散模型方法,用于减轻记忆负担,具有更通用和基本的适用性。我们通过训练代理模型参数的方式,使模型不直接接触视觉数据,降低记忆风险。我们将训练数据集分成多个分片,每个分片训练一个代理模型,然后聚合形成最终模型。同时,通过对训练损失的分析,我们跳过当前批次中损失值异常低的样本,避免记忆。然而,在跳过易记忆样本的同时,还需保持足够的高质量图像生成训练数据,这是关键挑战。因此,我们提出了IET-AGC+方法,通过重新分配高度可记忆的样本分片来缓解这些样本的过度跳过。此外,我们根据样本的损失值进行动态扩充,进一步减少记忆。在四个数据集上的广泛实验和分析表明,我们的方法在降低内存容量的同时保持了性能。此外,我们对预训练的扩散模型(如Stable Diffusion)进行了微调,并将记忆分数降低了46.7%,证明了我们的方法的有效性。相关代码可在:https://github.com/liuxiao-guan/IET_AGC上找到。
要点
- 扩散模型具有生成高质量样本的能力,但存在数据记忆行为,引发隐私风险。
- 本文从视觉模式的角度提出了一种新的扩散模型方法,以更通用和基本的适用性减轻记忆负担。
- 通过训练代理模型参数,降低模型对视觉数据的直接接触,从而降低记忆风险。
- 提出将训练数据集分成多个分片,并通过聚合形成最终模型。
- 通过分析训练损失来跳过易记忆的样本,同时保持足够的训练数据以维持高质量的图像生成。
- 提出了IET-AGC+方法,通过重新分配高度可记忆的样本分片来缓解过度跳过问题。
点此查看论文截图


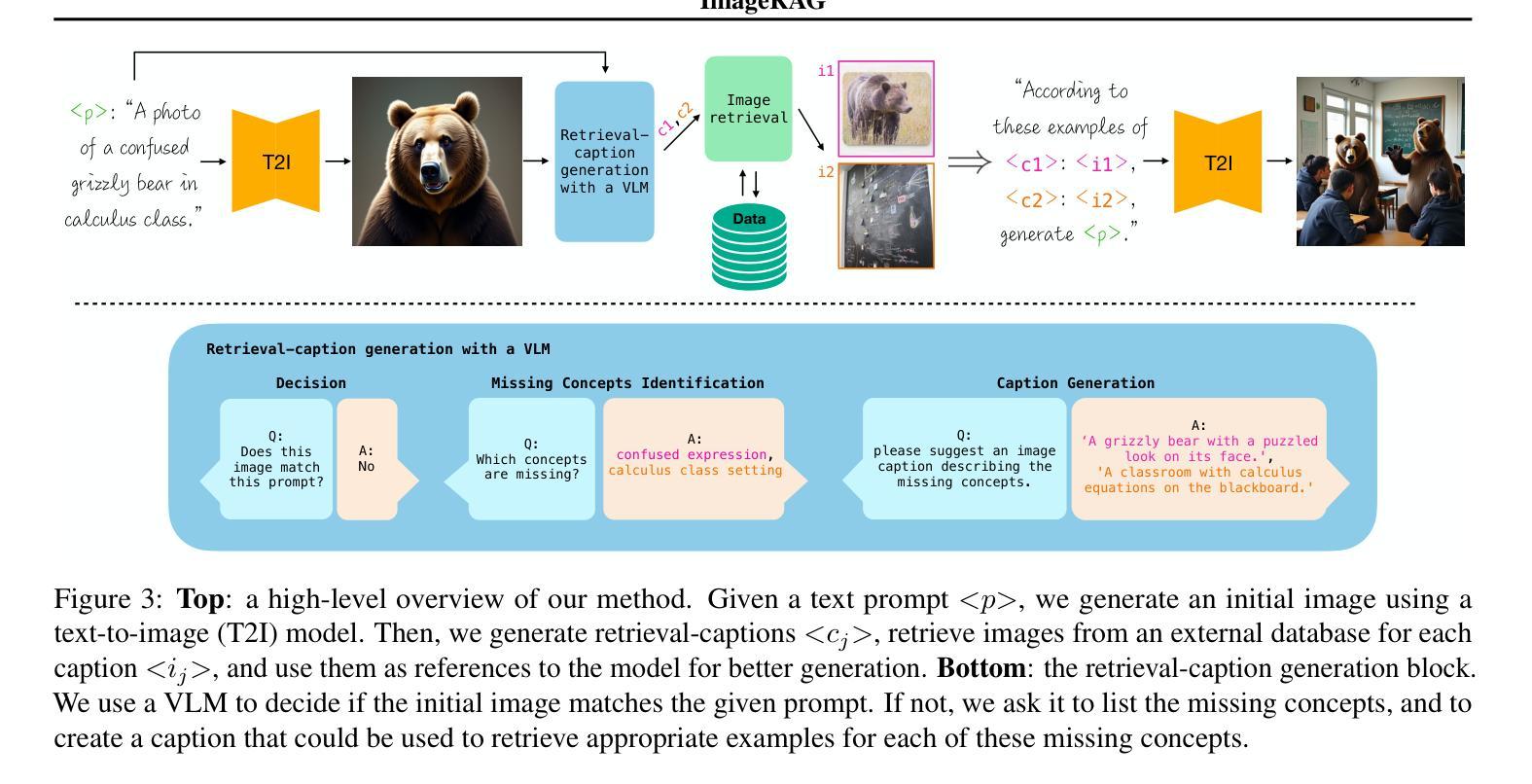
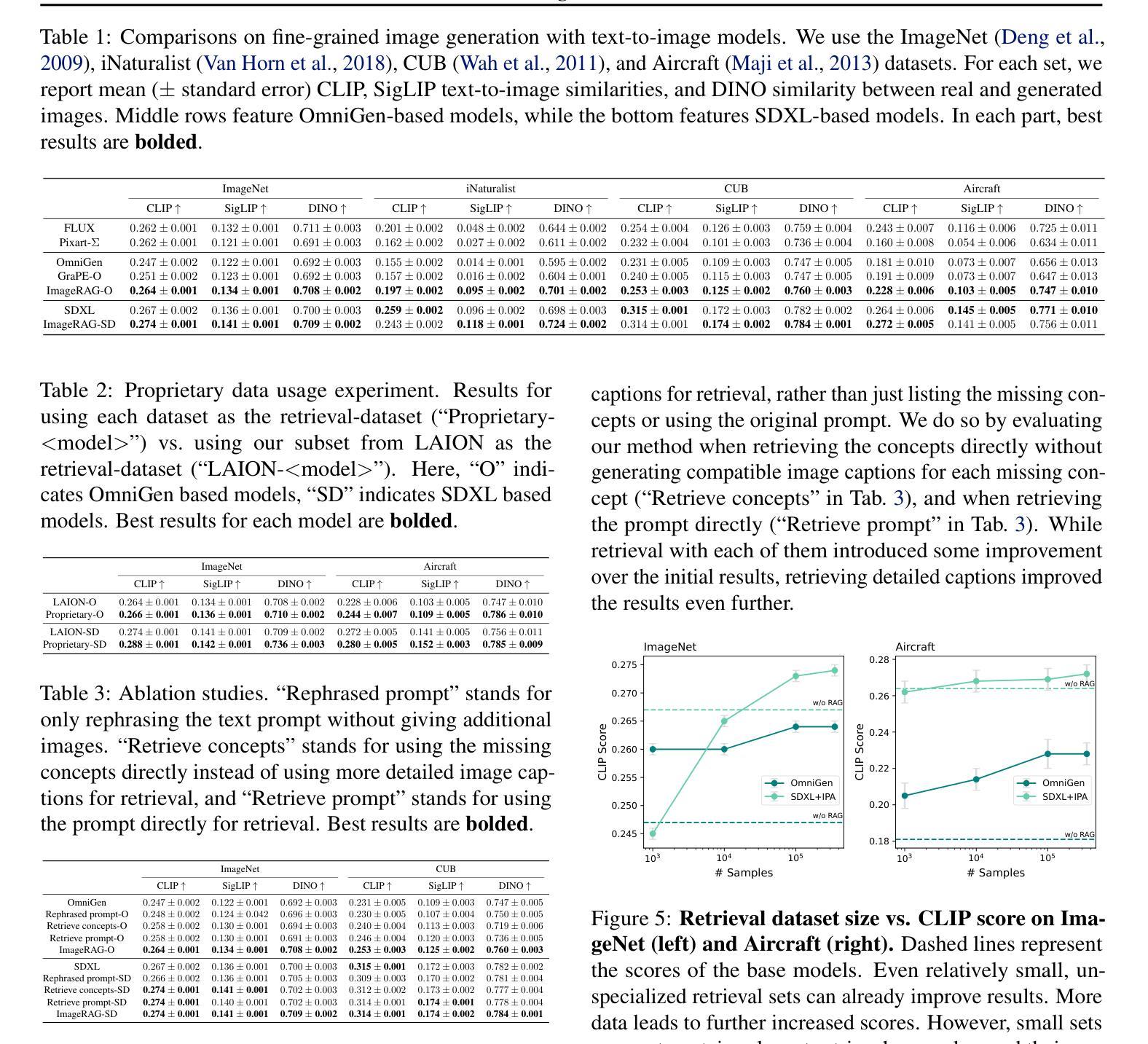
ImageRAG: Dynamic Image Retrieval for Reference-Guided Image Generation
Authors:Rotem Shalev-Arkushin, Rinon Gal, Amit H. Bermano, Ohad Fried
Diffusion models enable high-quality and diverse visual content synthesis. However, they struggle to generate rare or unseen concepts. To address this challenge, we explore the usage of Retrieval-Augmented Generation (RAG) with image generation models. We propose ImageRAG, a method that dynamically retrieves relevant images based on a given text prompt, and uses them as context to guide the generation process. Prior approaches that used retrieved images to improve generation, trained models specifically for retrieval-based generation. In contrast, ImageRAG leverages the capabilities of existing image conditioning models, and does not require RAG-specific training. Our approach is highly adaptable and can be applied across different model types, showing significant improvement in generating rare and fine-grained concepts using different base models. Our project page is available at: https://rotem-shalev.github.io/ImageRAG
扩散模型能够实现高质量和多样化的视觉内容合成。然而,它们在生成稀有或未见概念方面存在困难。为了应对这一挑战,我们探索了与图像生成模型结合的检索增强生成(RAG)的使用。我们提出了ImageRAG方法,该方法可以根据给定的文本提示动态检索相关图像,并将其用作上下文来指导生成过程。先前使用检索图像来改善生成的方法,都是针对基于检索的生成进行专门训练的模型。相比之下,ImageRAG利用现有的图像条件模型的能力,并且不需要针对RAG进行专门训练。我们的方法高度灵活,可应用于不同类型的模型,在使用不同基础模型生成稀有和精细概念方面显示出显著改进。我们的项目页面位于:https://rotem-shalev.github.io/ImageRAG
论文及项目相关链接
Summary
扩散模型能够实现高质量、多样化的视觉内容合成,但在生成稀有或未见概念时面临挑战。为解决这一问题,我们探索了与图像生成模型结合的检索增强生成(RAG)方法。我们提出了ImageRAG方法,它可以根据给定的文本提示动态检索相关图像,并将其用作上下文来指导生成过程。与之前使用检索图像改进生成的方法相比,ImageRAG利用现有图像条件模型的能力,无需进行RAG特定训练。我们的方法具有高度适应性,可应用于不同类型的模型,在使用不同基础模型生成稀有和精细概念时表现出显著改进。
Key Takeaways
- 扩散模型能够合成高质量、多样化的视觉内容。
- 在生成稀有或未见概念时,扩散模型面临挑战。
- 为解决这一挑战,提出了ImageRAG方法,该方法可以根据文本提示动态检索相关图像。
- ImageRAG利用现有图像条件模型的能力,无需进行特定训练。
- ImageRAG具有高度适应性,可广泛应用于不同类型的模型。
- ImageRAG在生成稀有和精细概念方面表现出显著改进。
点此查看论文截图



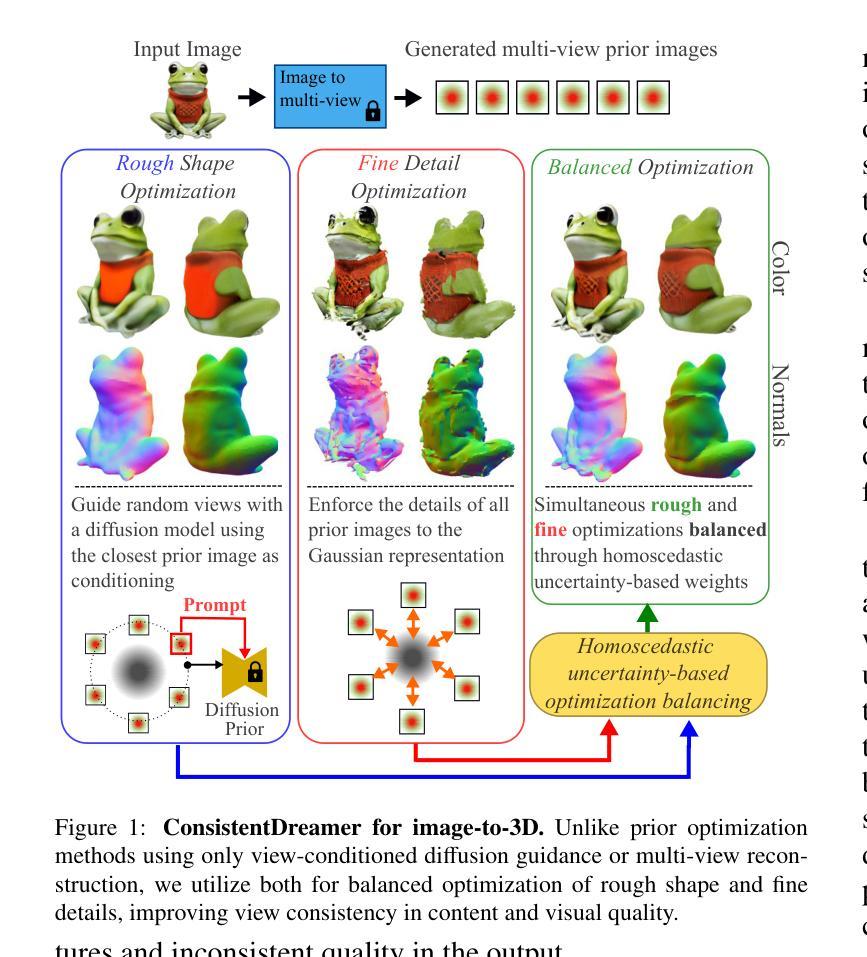
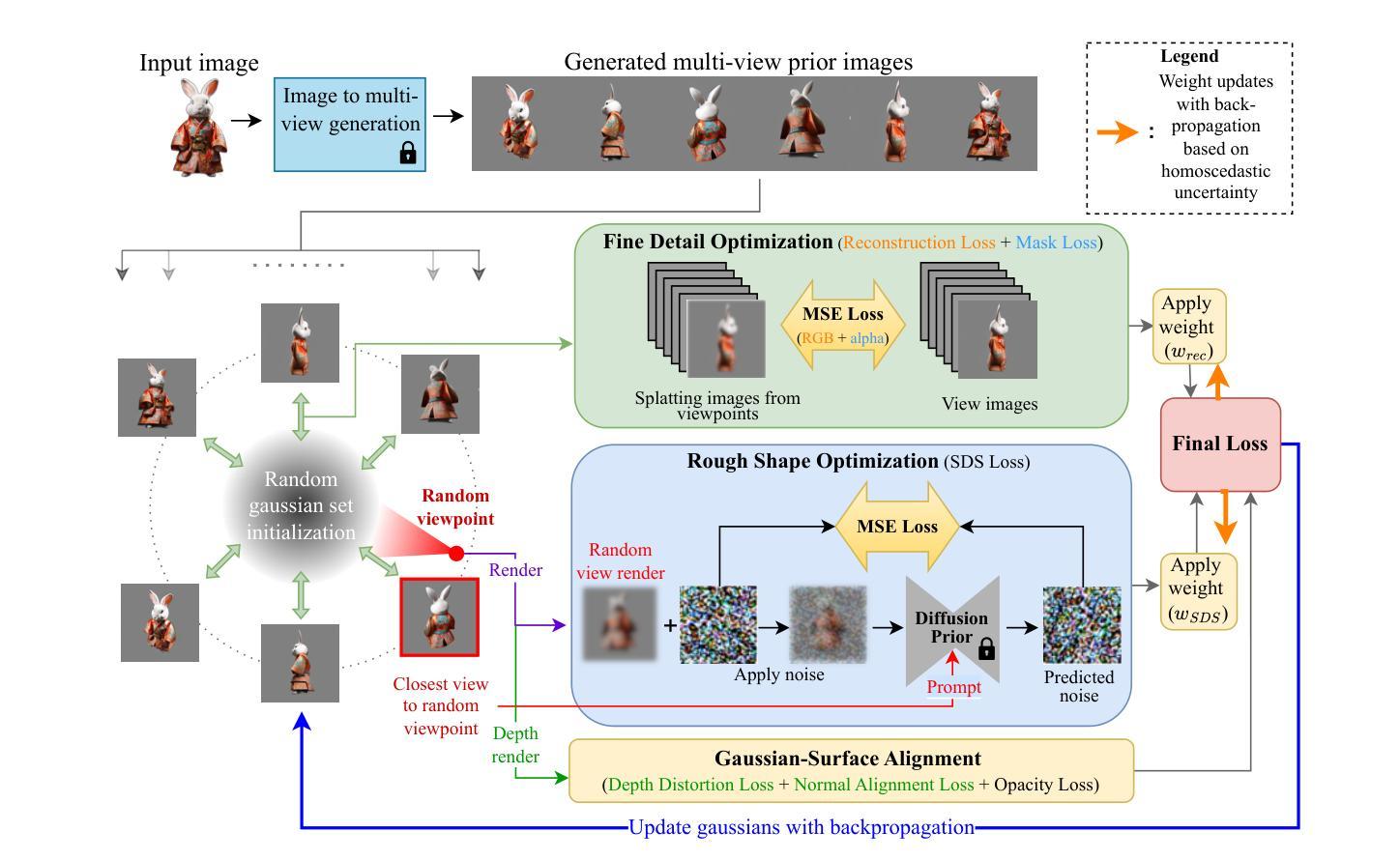
ConsistentDreamer: View-Consistent Meshes Through Balanced Multi-View Gaussian Optimization
Authors:Onat Şahin, Mohammad Altillawi, George Eskandar, Carlos Carbone, Ziyuan Liu
Recent advances in diffusion models have significantly improved 3D generation, enabling the use of assets generated from an image for embodied AI simulations. However, the one-to-many nature of the image-to-3D problem limits their use due to inconsistent content and quality across views. Previous models optimize a 3D model by sampling views from a view-conditioned diffusion prior, but diffusion models cannot guarantee view consistency. Instead, we present ConsistentDreamer, where we first generate a set of fixed multi-view prior images and sample random views between them with another diffusion model through a score distillation sampling (SDS) loss. Thereby, we limit the discrepancies between the views guided by the SDS loss and ensure a consistent rough shape. In each iteration, we also use our generated multi-view prior images for fine-detail reconstruction. To balance between the rough shape and the fine-detail optimizations, we introduce dynamic task-dependent weights based on homoscedastic uncertainty, updated automatically in each iteration. Additionally, we employ opacity, depth distortion, and normal alignment losses to refine the surface for mesh extraction. Our method ensures better view consistency and visual quality compared to the state-of-the-art.
近期扩散模型的新进展极大地改进了3D生成,使得可以使用从图像生成的资产进行实体AI模拟。然而,图像到3D的一对多特性由于不同视角的内容和质量不一致,限制了其使用。之前的模型通过从视图条件扩散先验中采样视图来优化3D模型,但扩散模型无法保证视图的一致性。相反,我们提出了ConsistentDreamer,我们首先生成一组固定的多视角先验图像,并在它们之间使用另一个扩散模型通过得分蒸馏采样(SDS)损失来采样随机视图。因此,我们限制了由SDS损失引导的视角之间的差异,并确保了一致的粗略形状。在每次迭代中,我们还使用生成的多视角先验图像进行细节重建。为了平衡粗略形状和细节优化的平衡,我们引入了基于同方差不确定性的动态任务依赖权重,并在每次迭代中自动更新。此外,我们采用透明度、深度失真和法线对齐损失来优化网格提取的表面。我们的方法确保了与最新技术相比更好的视图一致性和视觉质量。
论文及项目相关链接
PDF Manuscript accepted by Pattern Recognition Letters
Summary
扩散模型的最新进展已显著提高3D生成能力,可实现从图像生成资产用于实体AI模拟。然而,图像到3D的一对多问题由于其内容在不同视角的不一致性限制了其使用。我们提出ConsistentDreamer,通过生成固定多视角先验图像,并在它们之间通过评分蒸馏采样(SDS)损失使用另一个扩散模型进行随机视图采样,保证视图一致性。迭代过程中,我们利用生成的多视角先验图像进行细节重建,并引入基于任务依赖性的动态权重以平衡大体形状与细节优化的平衡。此外,我们还采用透明度、深度失真和法线对齐损失来优化表面网格提取。我们的方法相较于现有技术,确保了更好的视图一致性和视觉质量。
Key Takeaways
- 扩散模型的最新进展推动了3D生成的显著改进,支持从图像生成资产用于AI模拟。
- 图像到3D的一对多问题导致内容在不同视角下的不一致性,限制了使用。
- ConsistentDreamer通过生成固定多视角先验图像和评分蒸馏采样(SDS)损失保证视图一致性。
- 迭代过程中利用多视角先验图像进行细节重建,并引入动态任务依赖性权重以平衡形状与细节。
- 采用透明度、深度失真和法线对齐损失优化表面网格提取。
- 方法相较于现有技术,提高了视图一致性和视觉质量。
点此查看论文截图


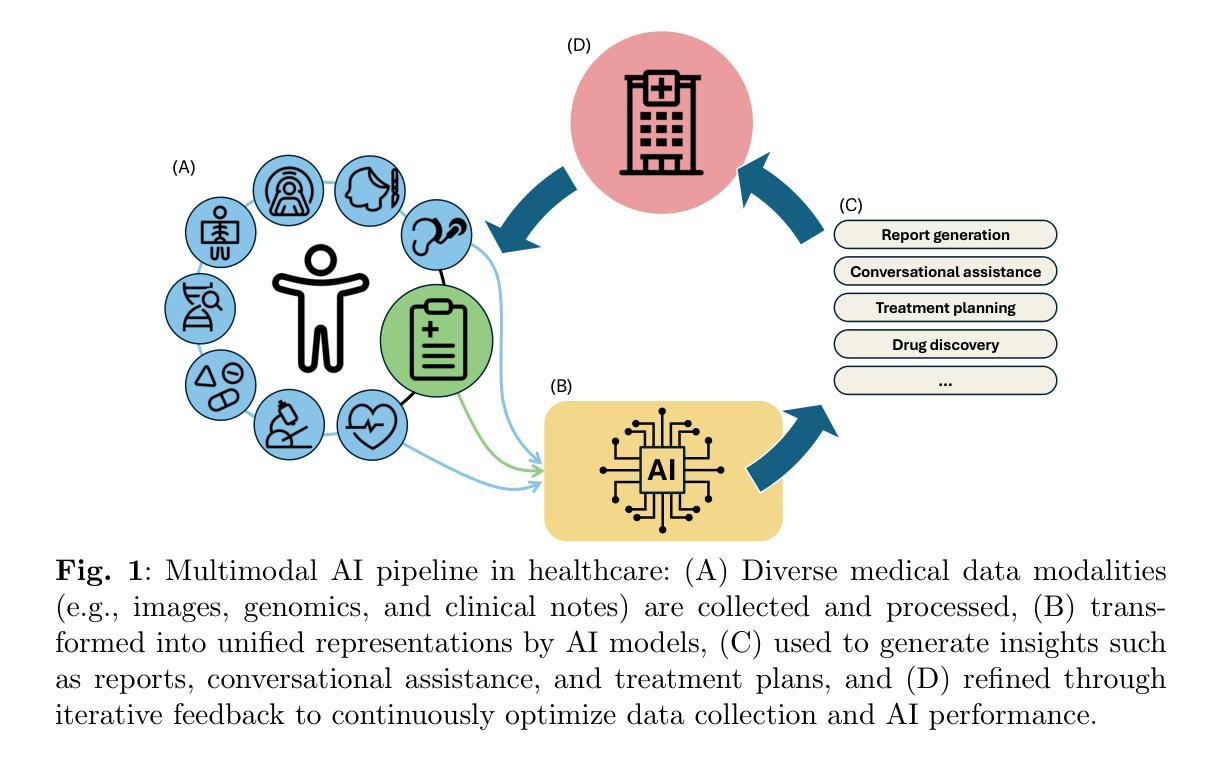
From large language models to multimodal AI: A scoping review on the potential of generative AI in medicine
Authors:Lukas Buess, Matthias Keicher, Nassir Navab, Andreas Maier, Soroosh Tayebi Arasteh
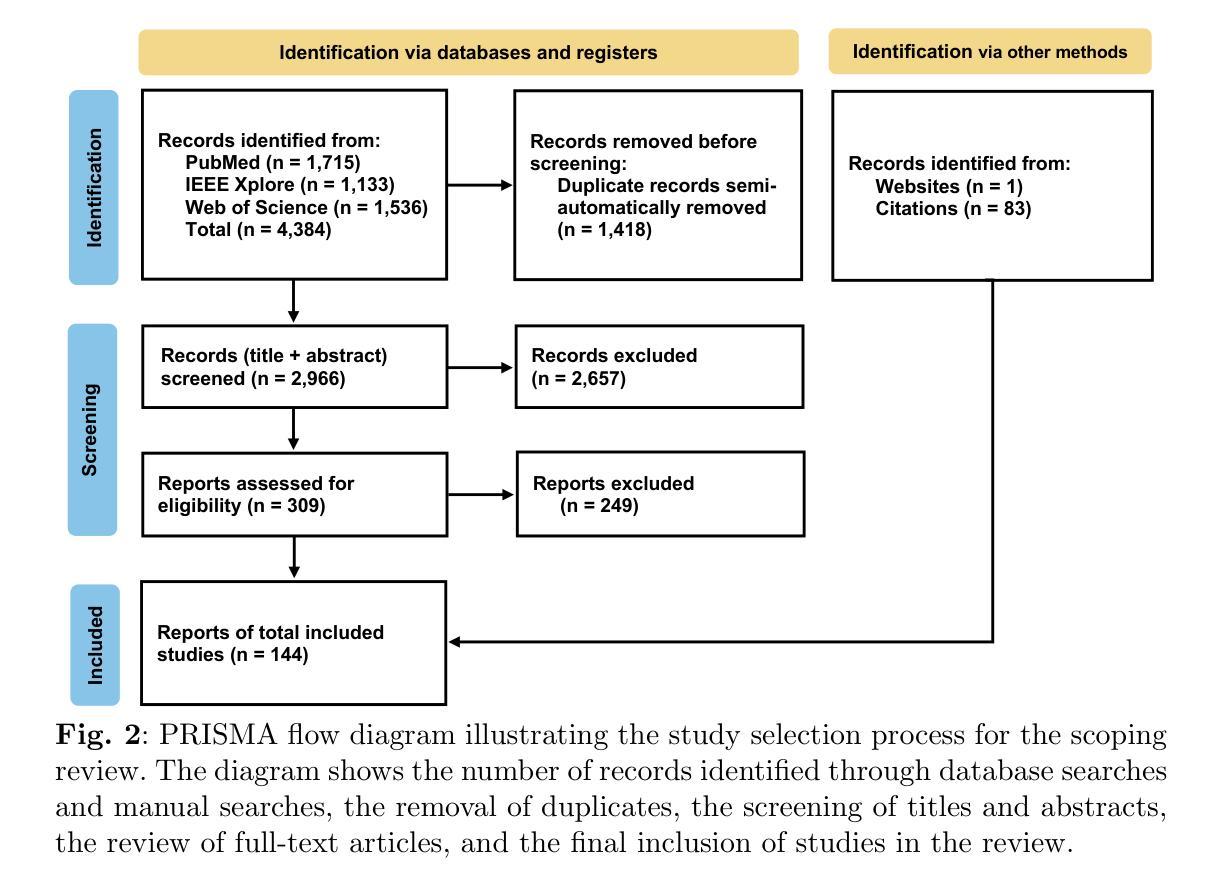
Generative artificial intelligence (AI) models, such as diffusion models and OpenAI’s ChatGPT, are transforming medicine by enhancing diagnostic accuracy and automating clinical workflows. The field has advanced rapidly, evolving from text-only large language models for tasks such as clinical documentation and decision support to multimodal AI systems capable of integrating diverse data modalities, including imaging, text, and structured data, within a single model. The diverse landscape of these technologies, along with rising interest, highlights the need for a comprehensive review of their applications and potential. This scoping review explores the evolution of multimodal AI, highlighting its methods, applications, datasets, and evaluation in clinical settings. Adhering to PRISMA-ScR guidelines, we systematically queried PubMed, IEEE Xplore, and Web of Science, prioritizing recent studies published up to the end of 2024. After rigorous screening, 144 papers were included, revealing key trends and challenges in this dynamic field. Our findings underscore a shift from unimodal to multimodal approaches, driving innovations in diagnostic support, medical report generation, drug discovery, and conversational AI. However, critical challenges remain, including the integration of heterogeneous data types, improving model interpretability, addressing ethical concerns, and validating AI systems in real-world clinical settings. This review summarizes the current state of the art, identifies critical gaps, and provides insights to guide the development of scalable, trustworthy, and clinically impactful multimodal AI solutions in healthcare.
生成式人工智能(AI)模型,如扩散模型和OpenAI的ChatGPT,正在通过提高诊断准确性和自动化临床工作流程来改变医学领域。该领域发展迅速,从仅用于临床文档和决策支持任务的文本大型语言模型,进化到能够在单一模型中整合包括成像、文本和结构数据在内的多种数据模式的多模态AI系统。这些技术的多样化景观以及日益增长的兴趣,突显出需要全面回顾其应用和潜力。本范围审查探讨了多模态AI的演变,突出其方法、应用、数据集和在临床环境中的评估。我们遵循PRISMA-ScR指南,系统地查询了PubMed、IEEE Xplore和Web of Science,优先考虑截至2024年底发表的最新研究。经过严格的筛选,共纳入144篇论文,揭示了这一动态领域的关键趋势和挑战。我们的研究结果强调了一个从单模态到多模态方法的转变,推动了在诊断支持、医疗报告生成、药物发现和会话AI方面的创新。然而,仍然存在关键挑战,包括整合异质数据类型、提高模型可解释性、解决伦理问题和在现实临床环境中验证AI系统。本综述总结了当前的研究现状,识别了关键差距,并提供了见解,以指导开发可扩展、可信和对临床有影响的医疗多模态AI解决方案。
论文及项目相关链接
Summary
生成式人工智能(如扩散模型和OpenAI的ChatGPT)正在通过提高诊断准确性和自动化临床工作流程来推动医学领域的变革。从最初的仅文本大型语言模型,发展到现在的多模态AI系统,能够整合各种数据类型(如影像、文本和结构数据),展现了AI技术的多样化格局及其不断增长的兴趣。这篇综述文章探索了多模态AI的演变,并遵循PRISMA-ScR指南系统地查询了相关文献,揭示了关键趋势和挑战。当前,多模态AI正在推动诊断支持、医疗报告生成、药物发现和对话式AI等领域的创新,但仍面临数据整合、模型解释性、伦理问题和现实临床环境中的系统验证等挑战。
Key Takeaways
- 生成式人工智能正在医学领域带来变革,提高诊断准确性和自动化临床工作流程。
- 多模态AI系统能够整合多种数据类型,包括影像、文本和结构数据。
- 综合审查多模态AI的方法、应用、数据集和临床环境评估是必要的。
- 从单一的模态转向多模态方法是一个关键趋势。
- 多模态AI在诊断支持、医疗报告生成、药物发现和对话式AI等领域有创新应用。
- 多模态AI面临数据整合、模型解释性、伦理问题和现实临床环境中的验证等挑战。
点此查看论文截图

E-MD3C: Taming Masked Diffusion Transformers for Efficient Zero-Shot Object Customization
Authors:Trung X. Pham, Zhang Kang, Ji Woo Hong, Xuran Zheng, Chang D. Yoo
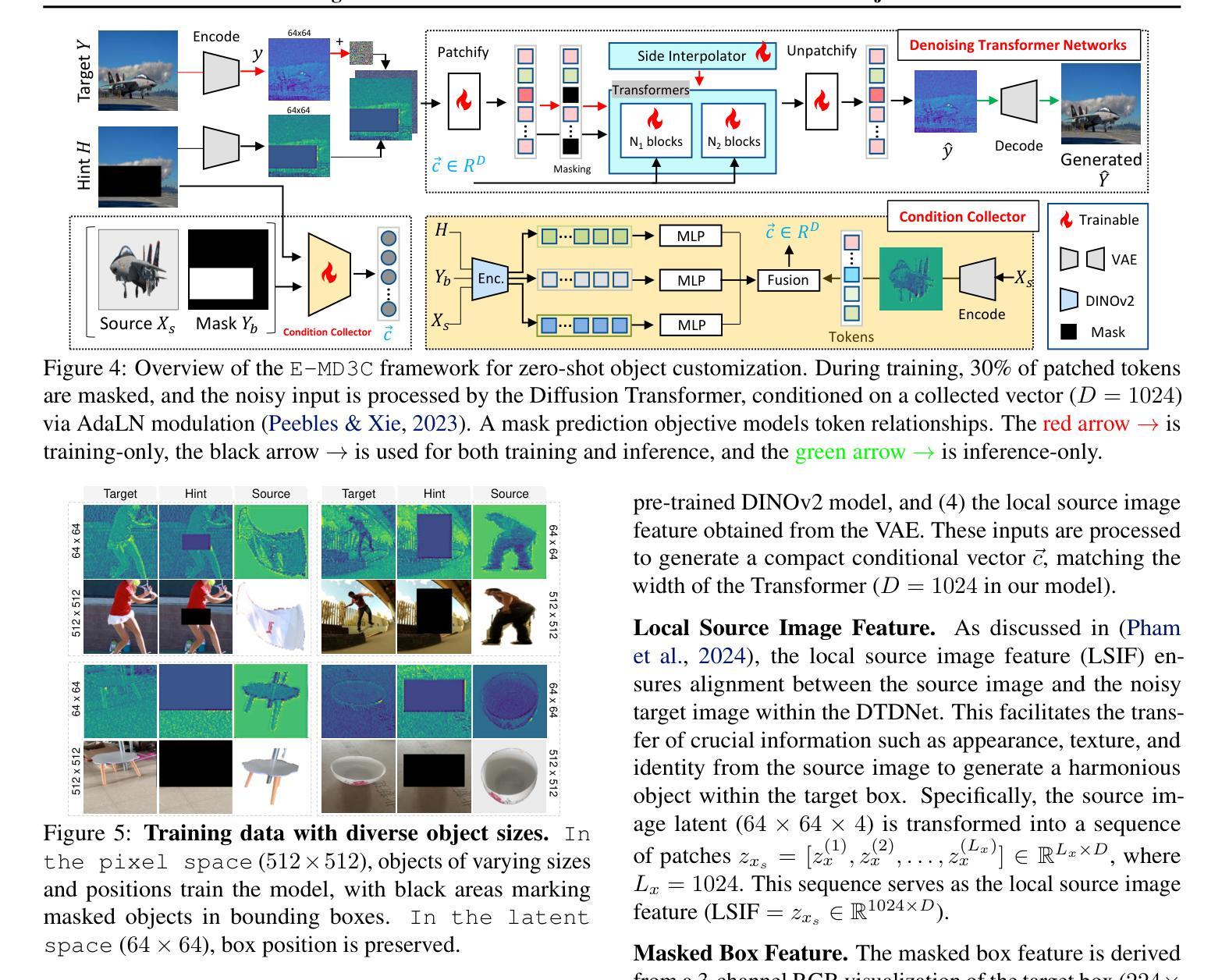
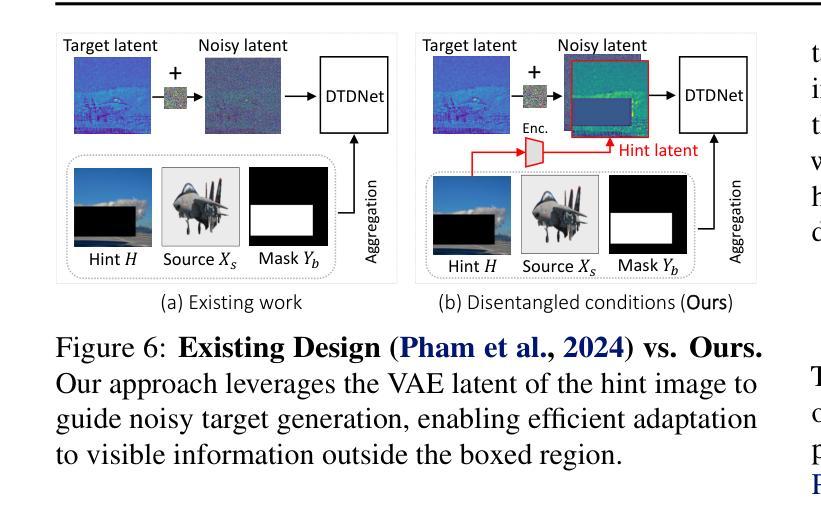
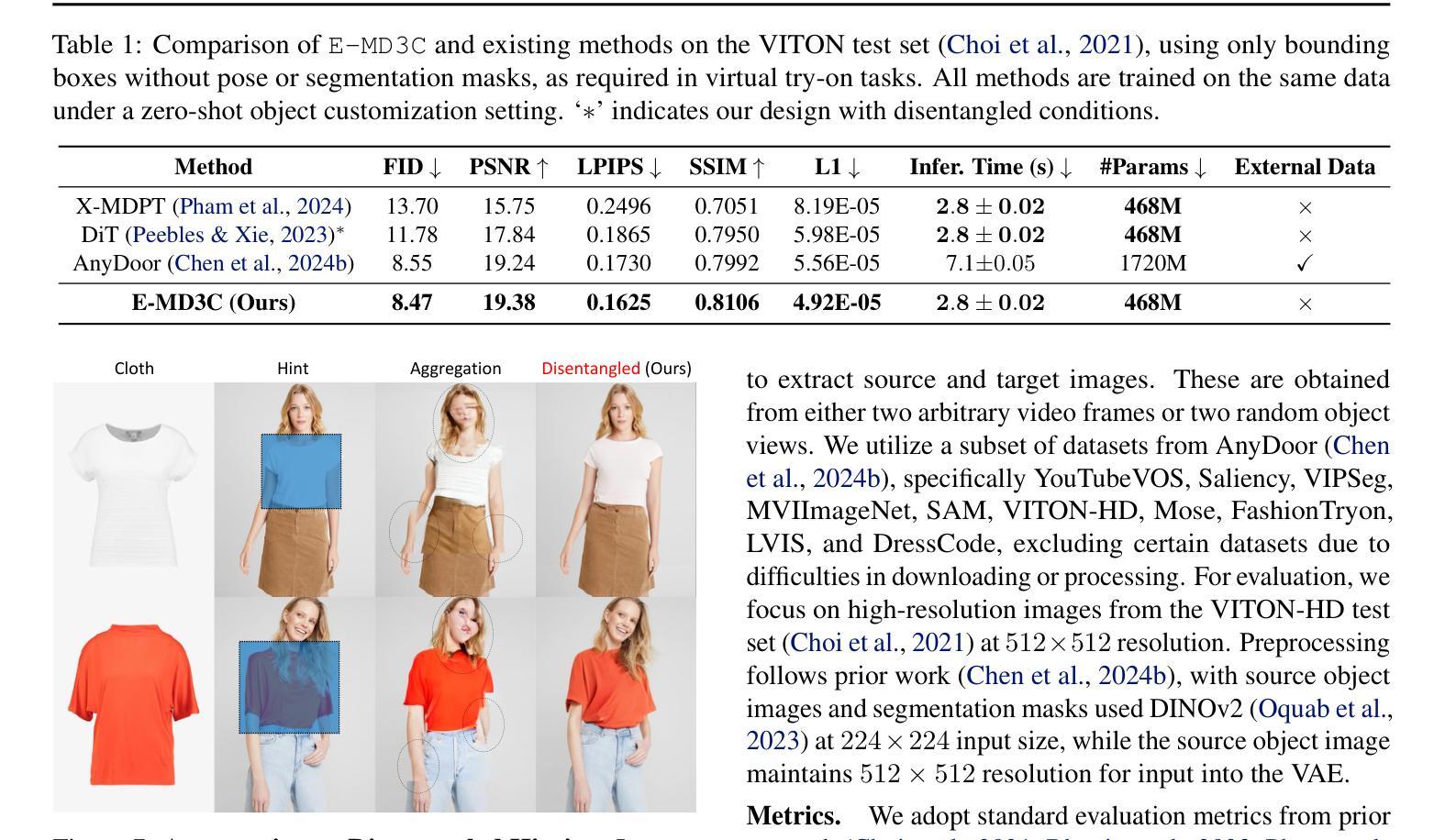
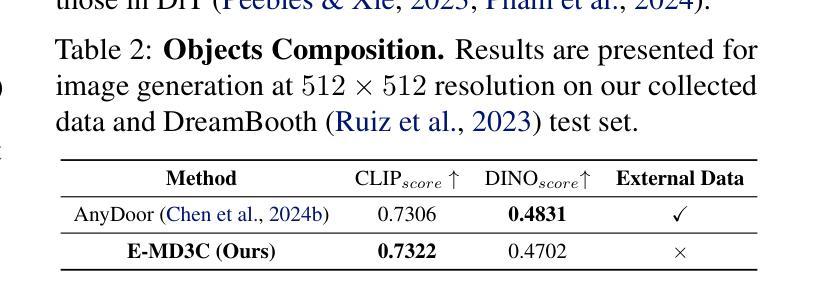
We propose E-MD3C ($\underline{E}$fficient $\underline{M}$asked $\underline{D}$iffusion Transformer with Disentangled $\underline{C}$onditions and $\underline{C}$ompact $\underline{C}$ollector), a highly efficient framework for zero-shot object image customization. Unlike prior works reliant on resource-intensive Unet architectures, our approach employs lightweight masked diffusion transformers operating on latent patches, offering significantly improved computational efficiency. The framework integrates three core components: (1) an efficient masked diffusion transformer for processing autoencoder latents, (2) a disentangled condition design that ensures compactness while preserving background alignment and fine details, and (3) a learnable Conditions Collector that consolidates multiple inputs into a compact representation for efficient denoising and learning. E-MD3C outperforms the existing approach on the VITON-HD dataset across metrics such as PSNR, FID, SSIM, and LPIPS, demonstrating clear advantages in parameters, memory efficiency, and inference speed. With only $\frac{1}{4}$ of the parameters, our Transformer-based 468M model delivers $2.5\times$ faster inference and uses $\frac{2}{3}$ of the GPU memory compared to an 1720M Unet-based latent diffusion model.
我们提出了E-MD3C(带有分离条件和紧凑收集器的有效掩码扩散转换器),这是一个高效的零样本目标图像定制框架。不同于以往依赖资源密集型的Unet架构的研究,我们的方法采用轻量级的掩码扩散转换器,在潜在补丁上运行,大大提高了计算效率。该框架集成了三个核心组件:(1)用于处理自动编码器潜在性的高效掩码扩散转换器;(2)分离条件设计,确保紧凑性,同时保留背景对齐和细节;(3)可学习的条件收集器,将多个输入整合成紧凑表示,便于高效去噪和学习。在VITON-HD数据集上,E-MD3C在PSNR、FID、SSIM和LPIPS等指标上的表现均超过了现有方法,在参数、内存效率和推理速度方面显示出明显优势。仅使用四分之一的参数,我们基于Transformer的4.68亿参数模型实现了2.5倍的推理速度提升,并使用了三分之二的GPU内存,相较于基于17.2亿参数Unet的潜在扩散模型。
论文及项目相关链接
PDF 16 pages, 14 figures
Summary
本文提出E-MD3C框架,一个高效的对象图像定制方法。它采用轻量级的有掩码扩散变压器处理潜在补丁,不同于依赖资源密集型Unet架构的先前方法。框架包括三个核心组件:高效掩码扩散变压器处理自动编码器潜在数据、解纠缠条件设计确保紧凑性并保留背景对齐和细节以及可学习的条件收集器合并多个输入进行紧凑表示以实现高效去噪和学习。E-MD3C在VITON-HD数据集上优于现有方法,在PSNR、FID、SSIM和LPIPS等指标上表现出优势,同时在参数、内存效率和推理速度方面也有明显优势。
Key Takeaways
- E-MD3C是一个高效的零射击对象图像定制框架。
- 不同于依赖资源密集型Unet架构的方法,E-MD3C采用轻量级掩码扩散变压器处理潜在补丁。
- 框架包括三个核心组件:处理自动编码器潜在数据的效率掩码扩散变压器、确保紧凑性的解纠缠条件设计以及用于高效去噪和学习的条件收集器。
- E-MD3C在VITON-HD数据集上的性能优于其他方法,表现在PSNR、FID、SSIM和LPIPS等指标上。
- E-MD3C在参数使用、内存效率和推理速度方面具有优势。
- E-MD3C能够实现快速推理,使用参数的四分之一就能达到2.5倍的速度提升,并且相比基于Unet的潜在扩散模型使用三分之二的GPU内存。
点此查看论文截图


StyleBlend: Enhancing Style-Specific Content Creation in Text-to-Image Diffusion Models
Authors:Zichong Chen, Shijin Wang, Yang Zhou
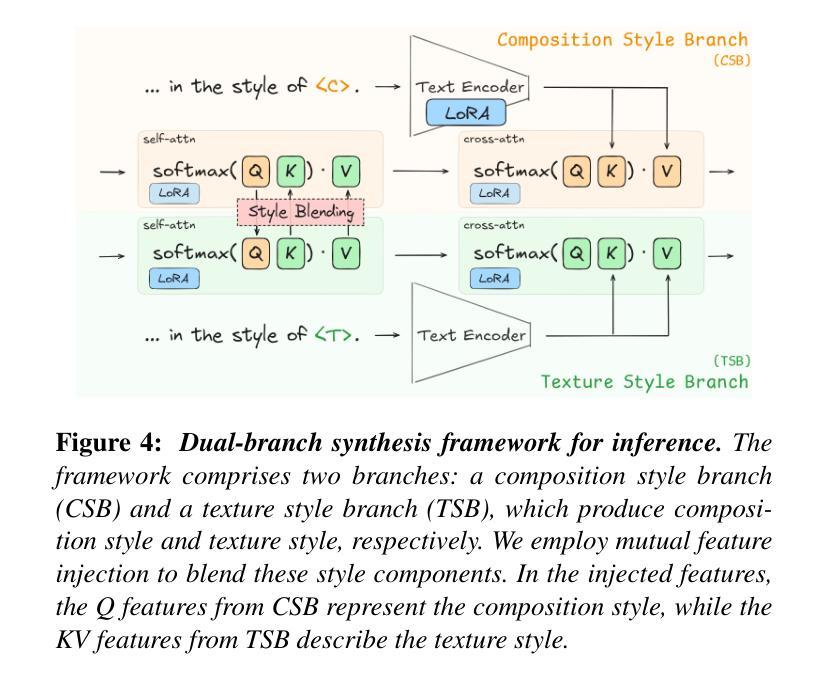
Synthesizing visually impressive images that seamlessly align both text prompts and specific artistic styles remains a significant challenge in Text-to-Image (T2I) diffusion models. This paper introduces StyleBlend, a method designed to learn and apply style representations from a limited set of reference images, enabling content synthesis of both text-aligned and stylistically coherent. Our approach uniquely decomposes style into two components, composition and texture, each learned through different strategies. We then leverage two synthesis branches, each focusing on a corresponding style component, to facilitate effective style blending through shared features without affecting content generation. StyleBlend addresses the common issues of text misalignment and weak style representation that previous methods have struggled with. Extensive qualitative and quantitative comparisons demonstrate the superiority of our approach.
在文本到图像(T2I)的扩散模型中,合成视觉上令人印象深刻的图像,这些图像能够无缝对齐文本提示和特定的艺术风格,仍然是一个巨大的挑战。本文介绍了StyleBlend方法,该方法旨在从有限的参考图像集中学习和应用风格表示,从而实现文本对齐和风格连贯的内容合成。我们的方法独特地将风格分解成两个组成部分:构图和纹理,每个部分都通过不同的策略学习。然后,我们利用两个合成分支,每个分支专注于相应的风格组件,通过共享特征来实现有效的风格混合,而不会影响内容生成。StyleBlend解决了之前方法中文本对不准和风格表现不足等常见问题。大量的定性和定量对比证明了我们的方法优越性。
论文及项目相关链接
PDF Accepted to Eurographics 2025. Project page: https://zichongc.github.io/StyleBlend/
Summary
本文介绍了StyleBlend方法,该方法旨在从有限参考图像中学习并应用风格表示,实现文本对齐和风格一致的内容合成。该方法将风格分解为两个组成部分:构图和纹理,并通过两个合成分支分别处理每个风格组件,以通过共享特征进行有效风格融合,而不会影响内容生成。StyleBlend解决了文本不对齐和风格表示不足等常见问题,并通过广泛的定性和定量比较证明了其优越性。
Key Takeaways
- StyleBlend是一个用于文本到图像扩散模型的方法,旨在从有限参考图像中学习并应用风格表示。
- 该方法将风格分解为构图和纹理两个组成部分。
- StyleBlend通过两个合成分支处理每个风格组件,以实现有效风格融合。
- StyleBlend解决了文本不对齐和弱风格表示等常见问题。
- StyleBlend方法在定性和定量比较中均表现出优越性。
- 该方法通过共享特征进行风格融合,同时不影响内容生成。
点此查看论文截图





Diffusion Models Through a Global Lens: Are They Culturally Inclusive?
Authors:Zahra Bayramli, Ayhan Suleymanzade, Na Min An, Huzama Ahmad, Eunsu Kim, Junyeong Park, James Thorne, Alice Oh
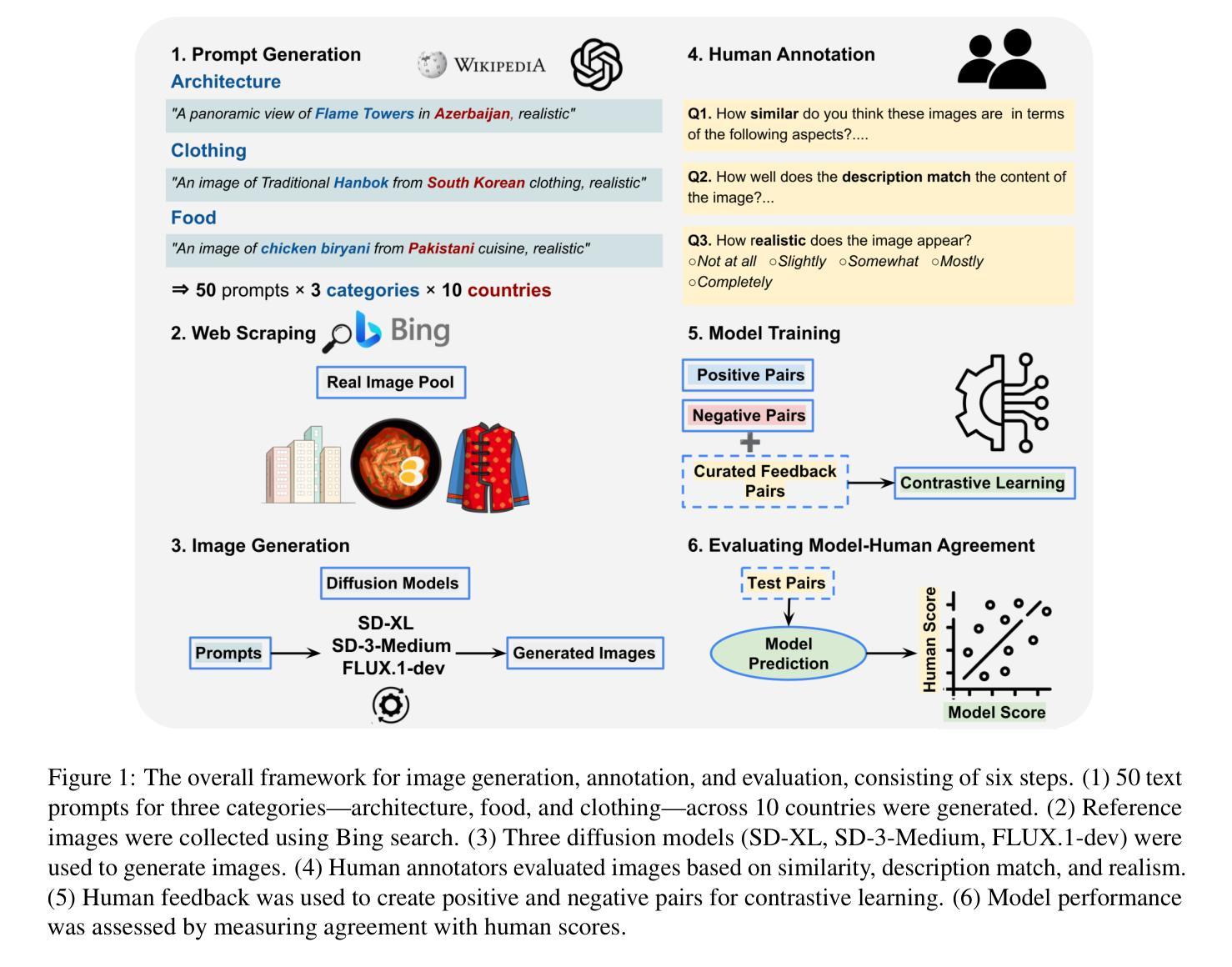
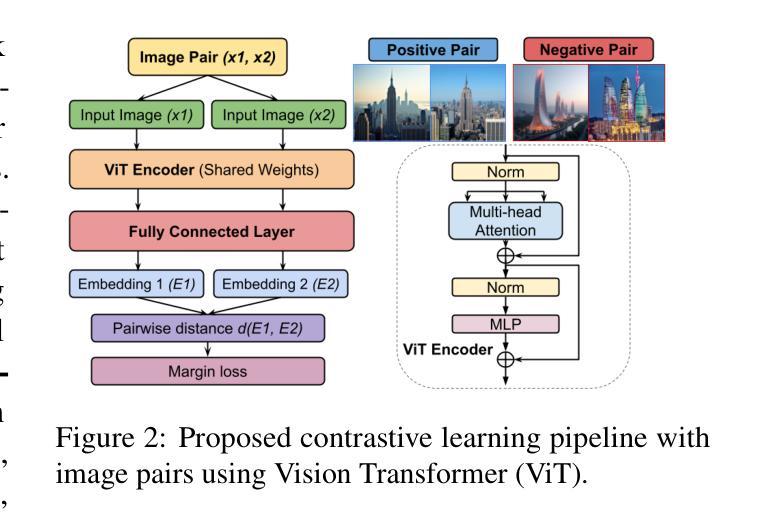
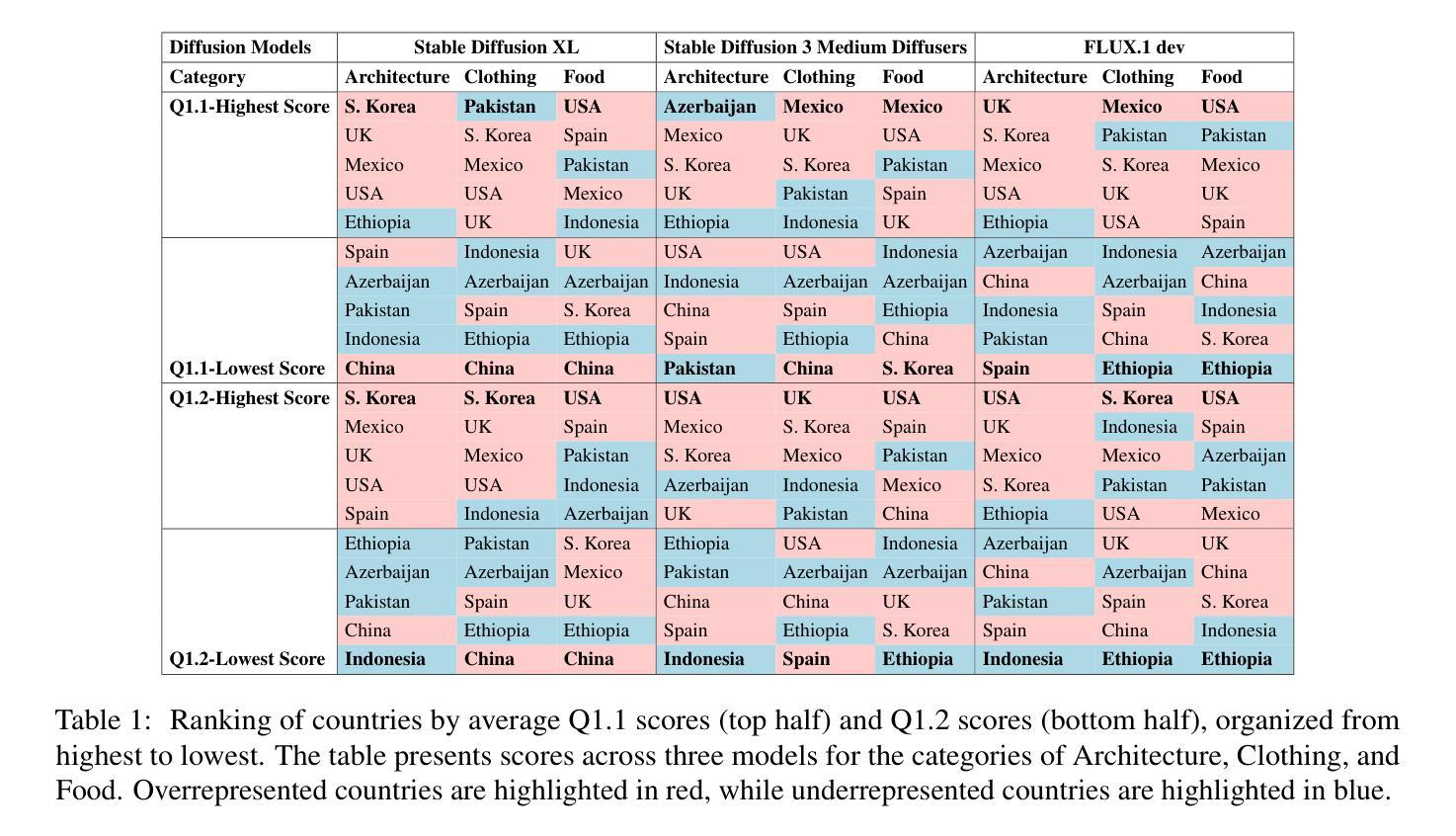
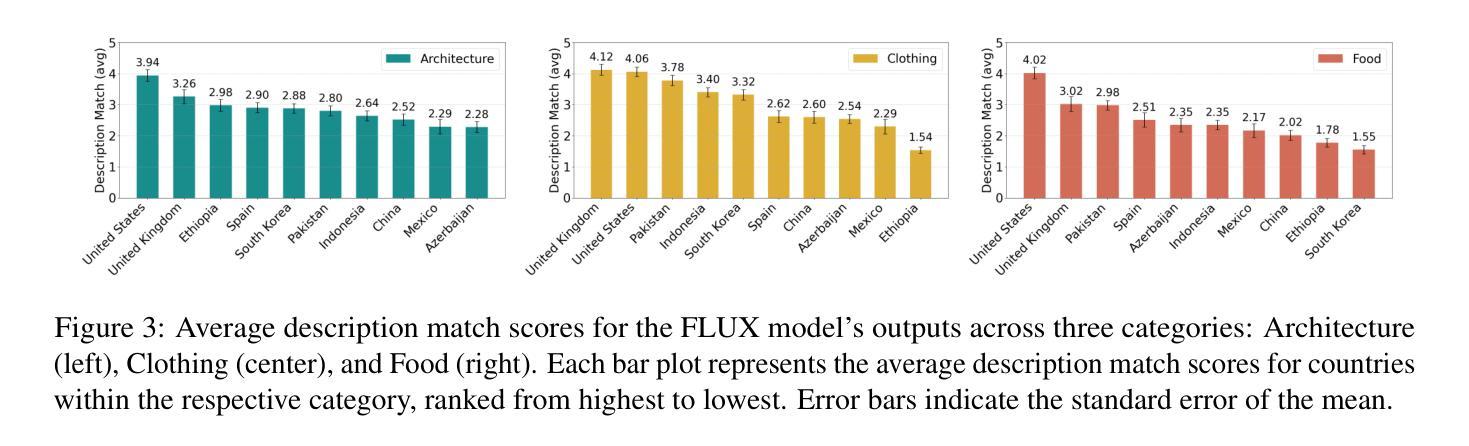
Text-to-image diffusion models have recently enabled the creation of visually compelling, detailed images from textual prompts. However, their ability to accurately represent various cultural nuances remains an open question. In our work, we introduce CultDiff benchmark, evaluating state-of-the-art diffusion models whether they can generate culturally specific images spanning ten countries. We show that these models often fail to generate cultural artifacts in architecture, clothing, and food, especially for underrepresented country regions, by conducting a fine-grained analysis of different similarity aspects, revealing significant disparities in cultural relevance, description fidelity, and realism compared to real-world reference images. With the collected human evaluations, we develop a neural-based image-image similarity metric, namely, CultDiff-S, to predict human judgment on real and generated images with cultural artifacts. Our work highlights the need for more inclusive generative AI systems and equitable dataset representation over a wide range of cultures.
文本到图像的扩散模型最近已经能够根据文本提示生成视觉吸引力强、细节丰富的图像。然而,它们准确表现各种文化细微差别的能力仍然是一个悬而未决的问题。在我们的研究中,我们引入了CultDiff基准测试,评估最先进的扩散模型是否能生成涵盖十个国家的文化特定图像。我们通过对不同相似度方面进行精细分析,发现这些模型在生成建筑、服装和食品等文化文物时经常失败,尤其是对代表性不足的国家地区。与真实世界参考图像相比,在文化相关性、描述保真度和现实感方面存在显著差异。结合收集的人类评估数据,我们开发了一种基于神经的图像图像相似性度量标准——CultDiff-S,用于预测人类对带有文化文物的真实和生成图像的判断。我们的研究强调了更需要包容性的生成式人工智能系统和各种文化的数据集代表均衡性的必要性。
论文及项目相关链接
PDF 17 pages, 17 figures, 3 tables
Summary
文本到图像的扩散模型能够从文本提示生成视觉吸引力强、细节丰富的图像。然而,这些模型在准确表现各种文化细微差别方面仍存在疑问。我们的工作引入了CultDiff基准测试,评估最先进的扩散模型是否能生成涵盖十个国家的文化特定图像。我们发现这些模型在生成建筑、服装和食品等文化产物时经常失败,特别是对欠代表的国家地区。通过不同相似性的精细分析,我们揭示了与文化相关性、描述保真度和现实感与真实世界参考图像相比存在的显著差距。我们收集了人类评估,开发了一种基于神经的图像图像相似度度量标准——CultDiff-S,用于预测人类对带有文化产物的真实和生成图像的判断。我们的研究强调了更具包容性的生成式人工智能系统和广泛文化均衡数据集表示的必要性。
Key Takeaways
- 文本到图像的扩散模型能生成视觉吸引力强、细节丰富的图像。
- 这些模型在准确表现各种文化细微差别方面存在不足。
- CultDiff基准测试被引入,用于评估扩散模型生成涵盖多个国家的文化特定图像的能力。
- 扩散模型在生成与文化相关的图像(如建筑、服装、食品)时常常出现问题,特别是对代表性不足的国家地区。
- 对模型生成的图像与真实图像进行了多方面的相似性分析,揭示了文化相关性、描述保真度和现实感的差距。
- 通过人类评估,开发了一种基于神经的图像图像相似度度量标准——CultDiff-S。
点此查看论文截图

DejAIvu: Identifying and Explaining AI Art on the Web in Real-Time with Saliency Maps
Authors:Jocelyn Dzuong
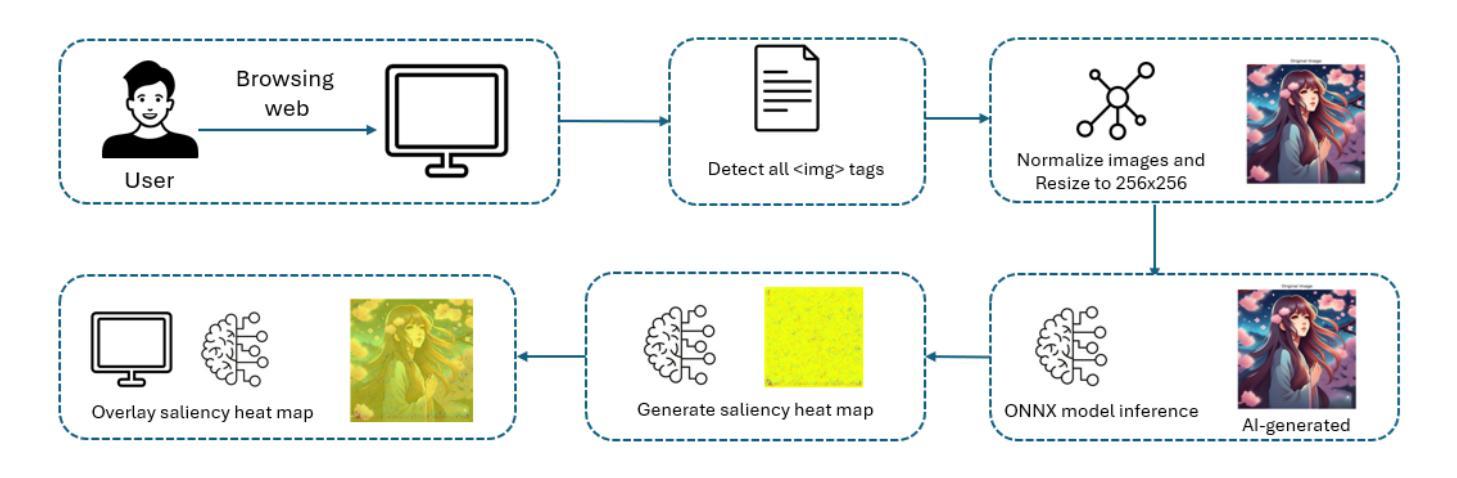
The recent surge in advanced generative models, such as diffusion models and generative adversarial networks (GANs), has led to an alarming rise in AI-generated images across various domains on the web. While such technologies offer benefits such as democratizing artistic creation, they also pose challenges in misinformation, digital forgery, and authenticity verification. Additionally, the uncredited use of AI-generated images in media and marketing has sparked significant backlash from online communities. In response to this, we introduce DejAIvu, a Chrome Web extension that combines real-time AI-generated image detection with saliency-based explainability while users browse the web. Using an ONNX-optimized deep learning model, DejAIvu automatically analyzes images on websites such as Google Images, identifies AI-generated content using model inference, and overlays a saliency heatmap to highlight AI-related artifacts. Our approach integrates efficient in-browser inference, gradient-based saliency analysis, and a seamless user experience, ensuring that AI detection is both transparent and interpretable. We also evaluate DejAIvu across multiple pretrained architectures and benchmark datasets, demonstrating high accuracy and low latency, making it a practical and deployable tool for enhancing AI image accountability. The code for this system can be found at https://github.com/Noodulz/dejAIvu.
近期先进的生成模型,如扩散模型和生成对抗网络(GANs)的涌现,导致网上各领域AI生成的图像急剧增加。虽然这些技术提供了民主化艺术创作等好处,但它们也带来了关于虚假信息、数字伪造和身份验证的挑战。此外,媒体和营销中未经授权使用的AI生成的图像引发了在线社区的强烈反弹。作为回应,我们推出了DejAIvu,这是一款Chrome网页扩展程序,它结合了实时AI生成的图像检测和用户浏览网页时的基于显著性的解释性。DejAIvu使用优化的ONNX深度学习模型,自动分析网站上的图像(如Google Images),通过模型推理识别AI生成的内容,并通过覆盖显著性热图来突出AI相关的伪影。我们的方法融合了高效的浏览器内推理、基于梯度的显著性分析和无缝用户体验,确保AI检测既透明又易于解释。我们还对DejAIvu进行了多个预训练架构和基准数据集的评估,显示出其高准确性和低延迟性,使其成为增强AI图像责任性的实用且可部署的工具。该系统的代码可在https://github.com/Noodulz/dejAIvu找到。
论文及项目相关链接
PDF 5 pages, 3 figures, submitted to IJCAI 2025 demo track
Summary
先进生成模型如扩散模型和生成对抗网络(GANs)的兴起,导致网上各领域AI生成的图片激增,带来艺术创作民主化的同时,也引发虚假信息、数字伪造和身份认证等挑战。为解决这些问题,推出DejAIvu浏览器插件,结合实时AI生成图像检测与基于显著性的解释性,用户浏览网页时即可使用。它通过优化的深度学习模型自动分析网站图像,利用模型推理识别AI生成内容,并叠加显著性热图以突出AI相关痕迹。该方案融合高效浏览器推理、基于梯度的显著性分析和无缝用户体验,确保AI检测既透明又具可解释性。评估显示,DejAIvu在多架构和基准数据集上表现出高准确率和低延迟,是增强AI图像责任制的实用工具。
Key Takeaways
- 先进生成模型如扩散模型和GANs在网上生成大量AI图像,带来艺术创作民主化的同时也带来挑战,如虚假信息、数字伪造和身份认证问题。
- DejAIvu是一个Chrome浏览器插件,可以实时检测AI生成的图像,并结合显著性分析提供解释。
- DejAIvu使用优化的深度学习模型自动分析网站图像,通过模型推理识别AI生成内容。
- 该插件通过叠加显著性热图突出AI相关痕迹,帮助用户识别AI生成的图像。
- DejAIvu结合实时AI检测、梯度显著性分析和无缝用户体验,确保AI检测的透明性和可解释性。
- DejAIvu在多架构和基准数据集上的评估显示高准确率和低延迟。
点此查看论文截图

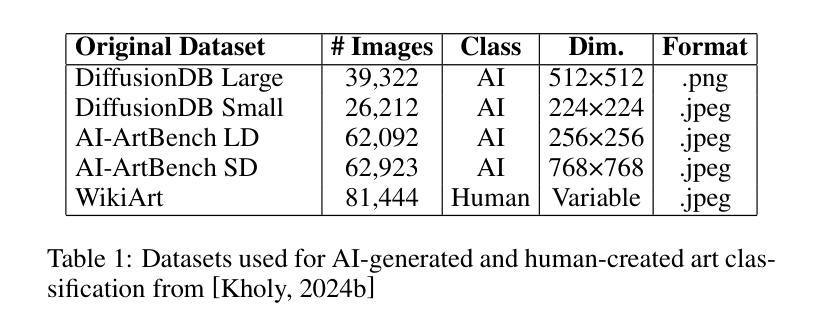


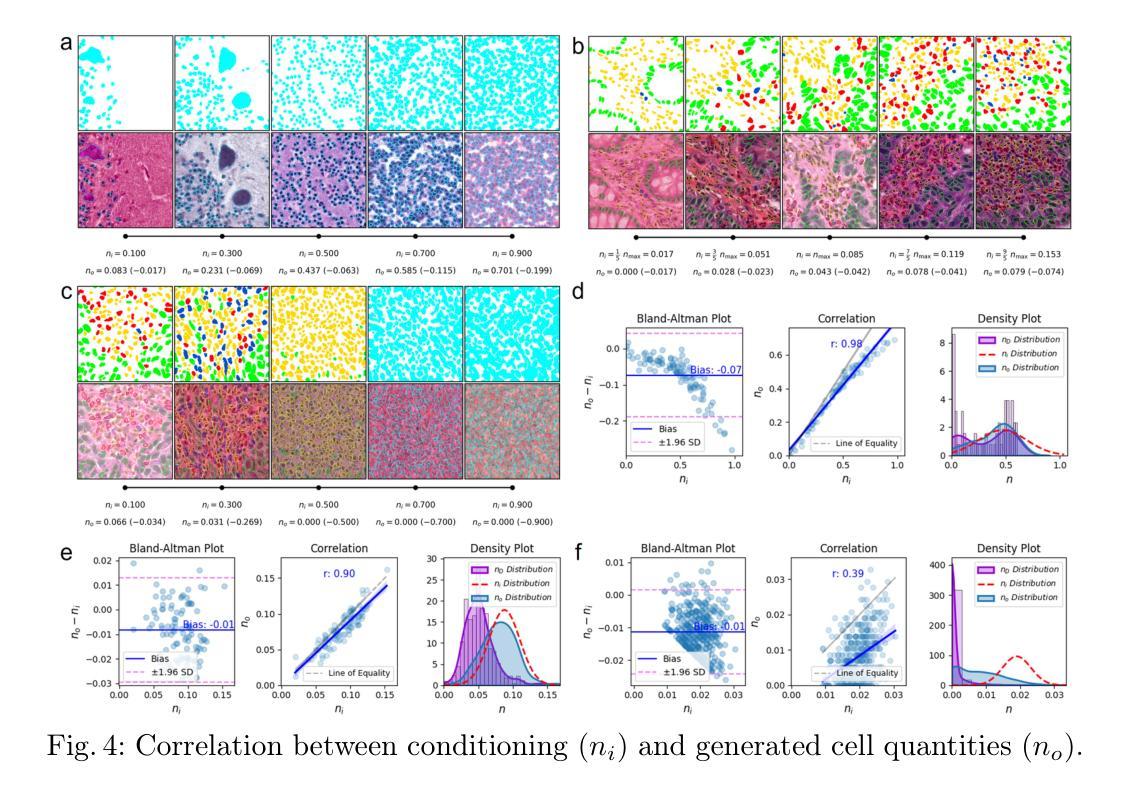
HistoSmith: Single-Stage Histology Image-Label Generation via Conditional Latent Diffusion for Enhanced Cell Segmentation and Classification
Authors:Valentina Vadori, Jean-Marie Graïc, Antonella Peruffo, Livio Finos, Ujwala Kiran Chaudhari, Enrico Grisan
Precise segmentation and classification of cell instances are vital for analyzing the tissue microenvironment in histology images, supporting medical diagnosis, prognosis, treatment planning, and studies of brain cytoarchitecture. However, the creation of high-quality annotated datasets for training remains a major challenge. This study introduces a novel single-stage approach (HistoSmith) for generating image-label pairs to augment histology datasets. Unlike state-of-the-art methods that utilize diffusion models with separate components for label and image generation, our approach employs a latent diffusion model to learn the joint distribution of cellular layouts, classification masks, and histology images. This model enables tailored data generation by conditioning on user-defined parameters such as cell types, quantities, and tissue types. Trained on the Conic H&E histopathology dataset and the Nissl-stained CytoDArk0 dataset, the model generates realistic and diverse labeled samples. Experimental results demonstrate improvements in cell instance segmentation and classification, particularly for underrepresented cell types like neutrophils in the Conic dataset. These findings underscore the potential of our approach to address data scarcity challenges.
精确分割和分类细胞实例对于分析组织微环境在显微图像中至关重要,支持医学诊断、预后、治疗计划和大脑细胞结构研究。然而,创建高质量的训练标注数据集仍然是一个重大挑战。本研究引入了一种新型的单阶段方法(HistoSmith),用于生成图像标签对以扩充显微数据集。不同于使用扩散模型进行标签和图像生成的高级方法,我们的方法采用潜在扩散模型来学习细胞布局、分类掩码和显微图像的联合分布。此模型能够通过用户定义的参数进行定制数据生成,如细胞类型、数量和组织类型。该模型在Conic H&E病理学数据集和Nissl染色的CytoDArk0数据集上进行训练,可生成真实多样的标注样本。实验结果表明,在细胞实例分割和分类方面有所改善,尤其是在Conic数据集中对中性粒细胞等代表性不足的细胞类型更是如此。这些发现凸显了我们方法解决数据稀缺挑战的巨大潜力。
论文及项目相关链接
Summary
本研究提出了一种新型的单阶段方法(HistoSmith),用于生成图像-标签对以扩充组织学数据集。该方法采用潜在扩散模型学习细胞布局、分类掩膜和组织学图像的联合分布,不同于目前最先端的方法。通过根据用户定义的参数(如细胞类型、数量和组织类型)进行条件设置,该模型可实现有针对性的数据生成。在Conic H&E病理数据集和Nissl染色的CytoDArk0数据集上训练的模型,可以生成真实且多样的带标签样本。对于代表性不足的细胞类型,如中性粒细胞等,其在细胞实例分割和分类方面有明显改进。此研究展现出新方法解决数据稀缺问题的潜力。
Key Takeaways
- 研究提出了新型单阶段方法(HistoSmith)生成图像-标签对,以扩充组织学数据集。
- 该方法使用潜在扩散模型学习细胞布局、分类掩膜和组织学图像的联合分布。
- 用户可根据特定参数(如细胞类型、数量、组织类型)进行条件设置,实现定制数据生成。
- 模型在多个数据集上进行了训练,能生成真实且多样的带标签样本。
- 此方法在细胞实例分割和分类方面表现优异,尤其是对代表性不足的细胞类型。
- 方法具有解决数据稀缺问题的潜力。
点此查看论文截图


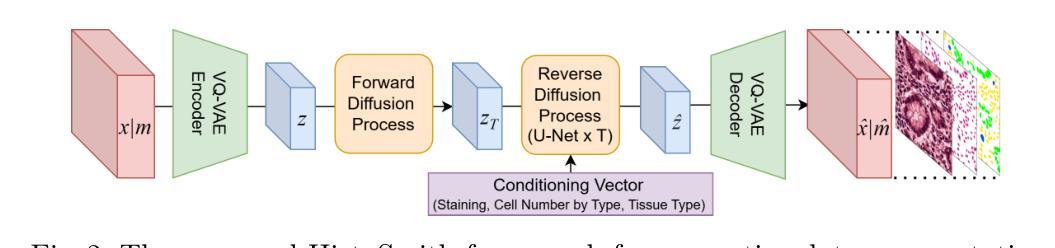
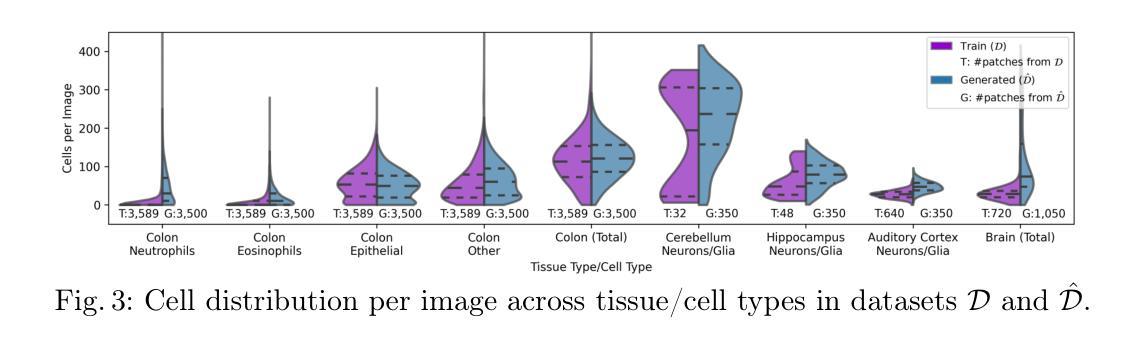
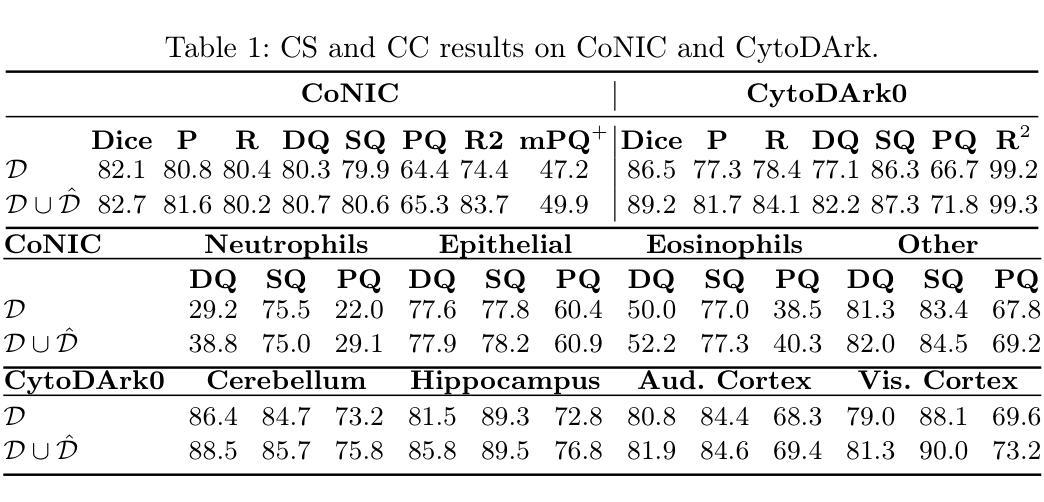
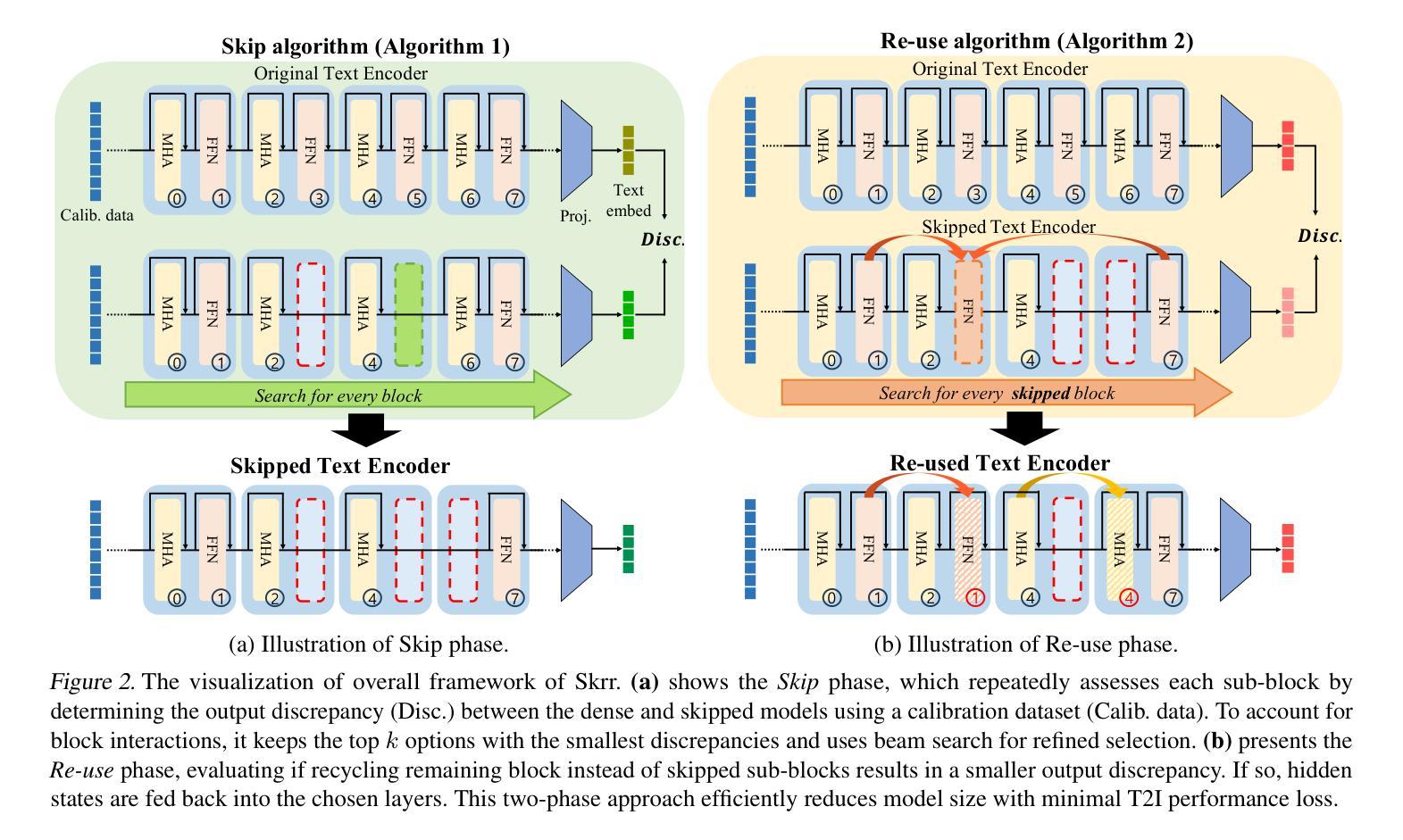
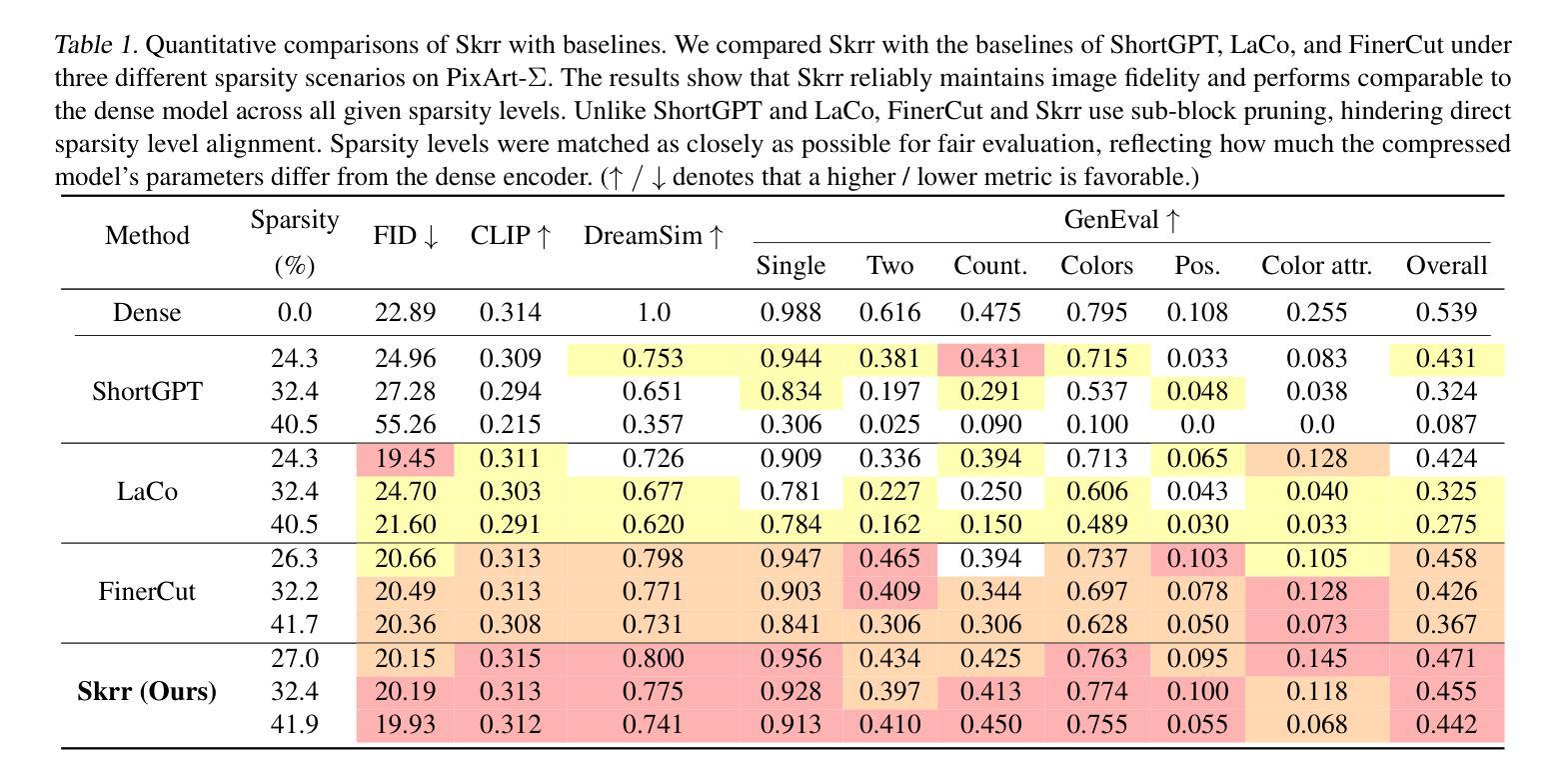
Skrr: Skip and Re-use Text Encoder Layers for Memory Efficient Text-to-Image Generation
Authors:Hoigi Seo, Wongi Jeong, Jae-sun Seo, Se Young Chun
Large-scale text encoders in text-to-image (T2I) diffusion models have demonstrated exceptional performance in generating high-quality images from textual prompts. Unlike denoising modules that rely on multiple iterative steps, text encoders require only a single forward pass to produce text embeddings. However, despite their minimal contribution to total inference time and floating-point operations (FLOPs), text encoders demand significantly higher memory usage, up to eight times more than denoising modules. To address this inefficiency, we propose Skip and Re-use layers (Skrr), a simple yet effective pruning strategy specifically designed for text encoders in T2I diffusion models. Skrr exploits the inherent redundancy in transformer blocks by selectively skipping or reusing certain layers in a manner tailored for T2I tasks, thereby reducing memory consumption without compromising performance. Extensive experiments demonstrate that Skrr maintains image quality comparable to the original model even under high sparsity levels, outperforming existing blockwise pruning methods. Furthermore, Skrr achieves state-of-the-art memory efficiency while preserving performance across multiple evaluation metrics, including the FID, CLIP, DreamSim, and GenEval scores.
文本到图像(T2I)扩散模型中的大规模文本编码器已从文本提示生成高质量图像中展现出卓越性能。不同于依赖多次迭代步骤的去噪模块,文本编码器仅需一次前向传递即可产生文本嵌入。然而,尽管文本编码器对总推理时间和浮点运算(FLOPs)的贡献很小,但它们的内存使用需求很高,高达去噪模块的八倍。为了解决这种低效问题,我们提出了Skip and Re-use layers(Skrr),这是一种为T2I扩散模型中的文本编码器专门设计的简单有效的剪枝策略。Skrr利用transformer块中的固有冗余,以针对T2I任务的方式选择性地跳过或重用某些层,从而在不影响性能的情况下减少内存消耗。大量实验表明,即使在较高的稀疏度下,Skrr也能保持与原始模型相当的图片质量,并且优于现有的块状剪枝方法。此外,Skrr在多个评估指标上实现了最先进的内存效率,同时保持了性能,包括FID、CLIP、DreamSim和GenEval分数。
论文及项目相关链接
Summary
文本到图像(T2I)扩散模型中的大规模文本编码器在生成高质量图像方面表现出卓越性能。虽然文本编码器只需一次前向传递即可产生文本嵌入,不同于依赖多次迭代步骤的去噪模块,但文本编码器对内存的需求较高,甚至高达去噪模块的八倍。为解决这一效率问题,本文提出一种名为Skip and Re-use layers(Skrr)的简洁有效修剪策略,专门针对T2I扩散模型中的文本编码器设计。Skrr通过选择性地跳过或重用某些层,利用transformer块中的固有冗余,以适合T2I任务的方式减少内存消耗,同时不损害性能。实验表明,Skrr在高稀疏度下保持与原始模型相当的图片质量,优于现有的块状修剪方法。此外,Skrr在保持性能的同时实现了最先进的内存效率,在多个评估指标上表现优异,包括FID、CLIP、DreamSim和GenEval分数。
Key Takeaways
- 大型文本编码器在文本到图像扩散模型中生成高质量图像方面表现出卓越性能。
- 文本编码器对内存需求较高,甚至比去噪模块高出八倍。
- Skrr是一种针对文本编码器的专门修剪策略,旨在提高T2I扩散模型的内存效率。
- Skrr通过选择性地跳过或重用某些层来利用transformer块中的冗余信息。
- Skrr能够在高稀疏度下保持与原始模型相当的图片质量。
- Skrr在多个评估指标上表现优异,包括FID、CLIP、DreamSim和GenEval分数。
点此查看论文截图



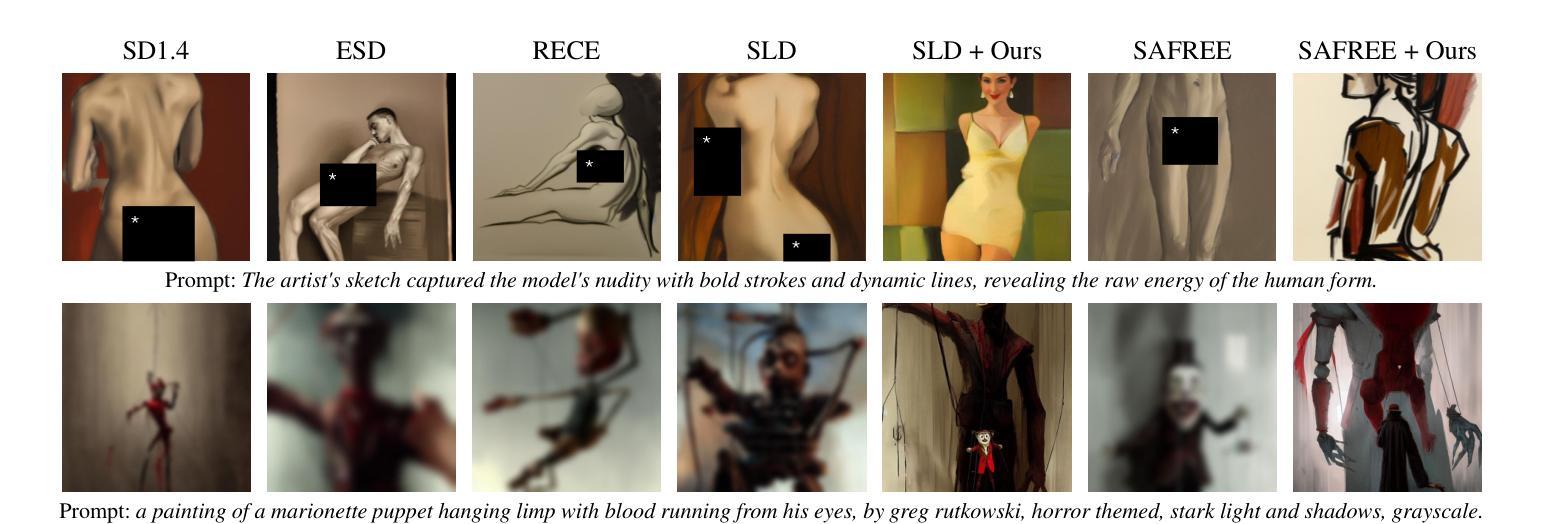
Training-Free Safe Denoisers for Safe Use of Diffusion Models
Authors:Mingyu Kim, Dongjun Kim, Amman Yusuf, Stefano Ermon, Mi Jung Park
There is growing concern over the safety of powerful diffusion models (DMs), as they are often misused to produce inappropriate, not-safe-for-work (NSFW) content or generate copyrighted material or data of individuals who wish to be forgotten. Many existing methods tackle these issues by heavily relying on text-based negative prompts or extensively retraining DMs to eliminate certain features or samples. In this paper, we take a radically different approach, directly modifying the sampling trajectory by leveraging a negation set (e.g., unsafe images, copyrighted data, or datapoints needed to be excluded) to avoid specific regions of data distribution, without needing to retrain or fine-tune DMs. We formally derive the relationship between the expected denoised samples that are safe and those that are not safe, leading to our $\textit{safe}$ denoiser which ensures its final samples are away from the area to be negated. Inspired by the derivation, we develop a practical algorithm that successfully produces high-quality samples while avoiding negation areas of the data distribution in text-conditional, class-conditional, and unconditional image generation scenarios. These results hint at the great potential of our training-free safe denoiser for using DMs more safely.
关于强大的扩散模型(DMs)的安全问题日益受到关注,因为它们经常被误用于产生不适当、不适合工作场合(NSFW)的内容,或生成版权材料,或生成那些希望被遗忘的个人数据。许多现有方法通过依赖基于文本的反向提示或大量重新训练DMs来消除某些特征或样本,来解决这些问题。在本文中,我们采取了截然不同的方法,通过利用否定集(例如不安全的图像、版权数据或需要排除的数据点),直接修改采样轨迹,避免了数据分布的特定区域,而无需重新训练或微调DMs。我们正式推导了期望的降噪样本之间安全和不安全样本的关系,从而形成了我们的安全降噪器,确保最终的样本远离需要否定的区域。受推导的启发,我们开发了一种实用算法,该算法在文本条件、类别条件和无条件图像生成场景中成功产生了高质量样本,同时避免了数据分布的否定区域。这些结果暗示了我们的无训练安全降噪器在使用DM方面具有巨大的潜力。
论文及项目相关链接
PDF Preprint
Summary
扩散模型正面临越来越多的安全性问题,其误用可能会生成不适当的内容或侵犯版权和隐私数据。现有的方法大多依赖文本负面提示或重新训练模型来消除问题特征或样本。本文提出了一种新方法,通过利用否定集直接修改采样轨迹来避免数据分布中的特定区域,无需重新训练或微调模型。本文推导了安全和不安全去噪样本之间的关系,并开发了实用算法,成功生成高质量样本,同时避免了否定区域。这为扩散模型的安全使用提供了巨大潜力。
Key Takeaways
- 扩散模型的安全性成为关注的问题,其误用可能导致生成不适当内容或侵犯版权和隐私数据。
- 现有方法主要依赖文本负面提示或重新训练来解决这些问题。
- 本文提出了一种新方法,通过利用否定集直接修改采样轨迹,无需重新训练模型。
- 推导了安全和不安全去噪样本之间的关系,并开发了实用算法。
- 该算法成功生成高质量样本,同时避免否定区域的数据分布。
- 本文的方法为扩散模型的安全使用提供了巨大潜力。
点此查看论文截图


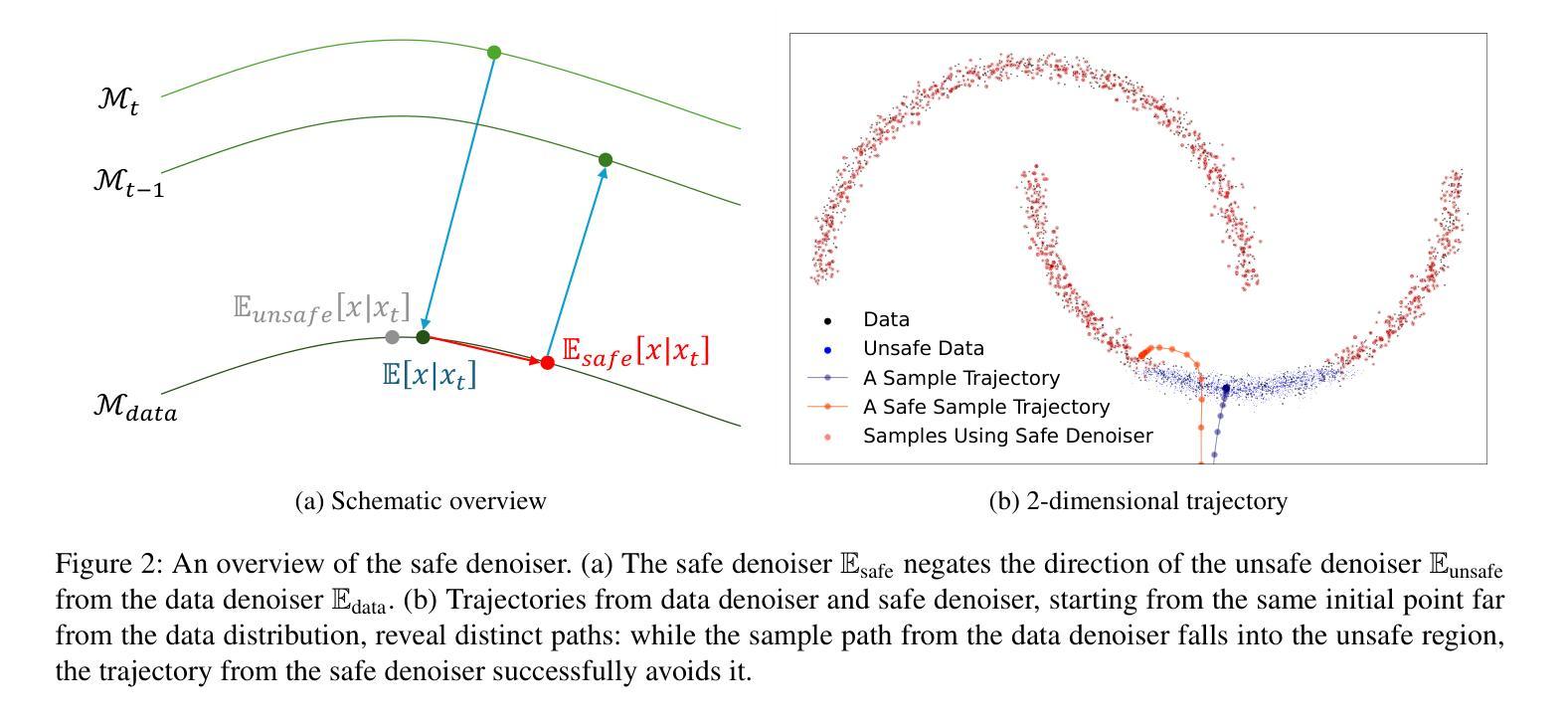


MRS: A Fast Sampler for Mean Reverting Diffusion based on ODE and SDE Solvers
Authors:Ao Li, Wei Fang, Hongbo Zhao, Le Lu, Ge Yang, Minfeng Xu
In applications of diffusion models, controllable generation is of practical significance, but is also challenging. Current methods for controllable generation primarily focus on modifying the score function of diffusion models, while Mean Reverting (MR) Diffusion directly modifies the structure of the stochastic differential equation (SDE), making the incorporation of image conditions simpler and more natural. However, current training-free fast samplers are not directly applicable to MR Diffusion. And thus MR Diffusion requires hundreds of NFEs (number of function evaluations) to obtain high-quality samples. In this paper, we propose a new algorithm named MRS (MR Sampler) to reduce the sampling NFEs of MR Diffusion. We solve the reverse-time SDE and the probability flow ordinary differential equation (PF-ODE) associated with MR Diffusion, and derive semi-analytical solutions. The solutions consist of an analytical function and an integral parameterized by a neural network. Based on this solution, we can generate high-quality samples in fewer steps. Our approach does not require training and supports all mainstream parameterizations, including noise prediction, data prediction and velocity prediction. Extensive experiments demonstrate that MR Sampler maintains high sampling quality with a speedup of 10 to 20 times across ten different image restoration tasks. Our algorithm accelerates the sampling procedure of MR Diffusion, making it more practical in controllable generation.
在扩散模型的应用中,可控生成具有实际意义,但也具有挑战性。当前的可控生成方法主要集中在修改扩散模型的评分函数,而均值回归(MR)扩散则直接修改随机微分方程(SDE)的结构,使得融入图像条件更加简单自然。然而,现有的无训练快速采样器并不直接适用于MR扩散。因此,MR扩散需要数百个功能评估(NFE)来获得高质量样本。在本文中,我们提出了一种名为MRS(MR采样器)的新算法,以减少MR扩散的采样NFE。我们解决了反向时间SDE和与MR扩散相关的概率流常微分方程(PF-ODE),并得出半解析解。这些解决方案由一个分析函数和一个由神经网络参数化的积分组成。基于这个解决方案,我们可以以更少的步骤生成高质量的样本。我们的方法不需要训练,支持包括噪声预测、数据预测和速度预测在内的所有主流参数化方法。大量实验表明,MR采样器在10个不同的图像恢复任务中保持了高采样质量,并实现了10到20倍的速度提升。我们的算法加速了MR扩散的采样过程,使其在可控生成中更加实用。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文介绍了扩散模型在可控生成方面的挑战,并指出了现有方法的不足。文章提出了一种新的算法MRS,用于解决MR扩散模型的采样问题。该算法基于半解析解,通过解决反向时间SDE和概率流常微分方程(PF-ODE)来生成高质量样本,无需训练且支持主流参数化方法。实验证明,MR Sampler在十个不同的图像恢复任务上提高了采样速度,同时保持了高质量的采样。
Key Takeaways
- 扩散模型在可控生成方面存在挑战,现有方法主要修改扩散模型的得分函数。
- MR扩散方法直接修改随机微分方程(SDE)的结构,使图像条件的融入更简单自然。
- 当前的无训练快速采样器不能直接应用于MR扩散。
- 新算法MRS解决MR扩散的采样问题,基于半解析解。
- MRS解决反向时间SDE和概率流常微分方程(PF-ODE)来生成高质量样本。
- MR Sampler算法无需训练,支持多种主流参数化方法。
点此查看论文截图

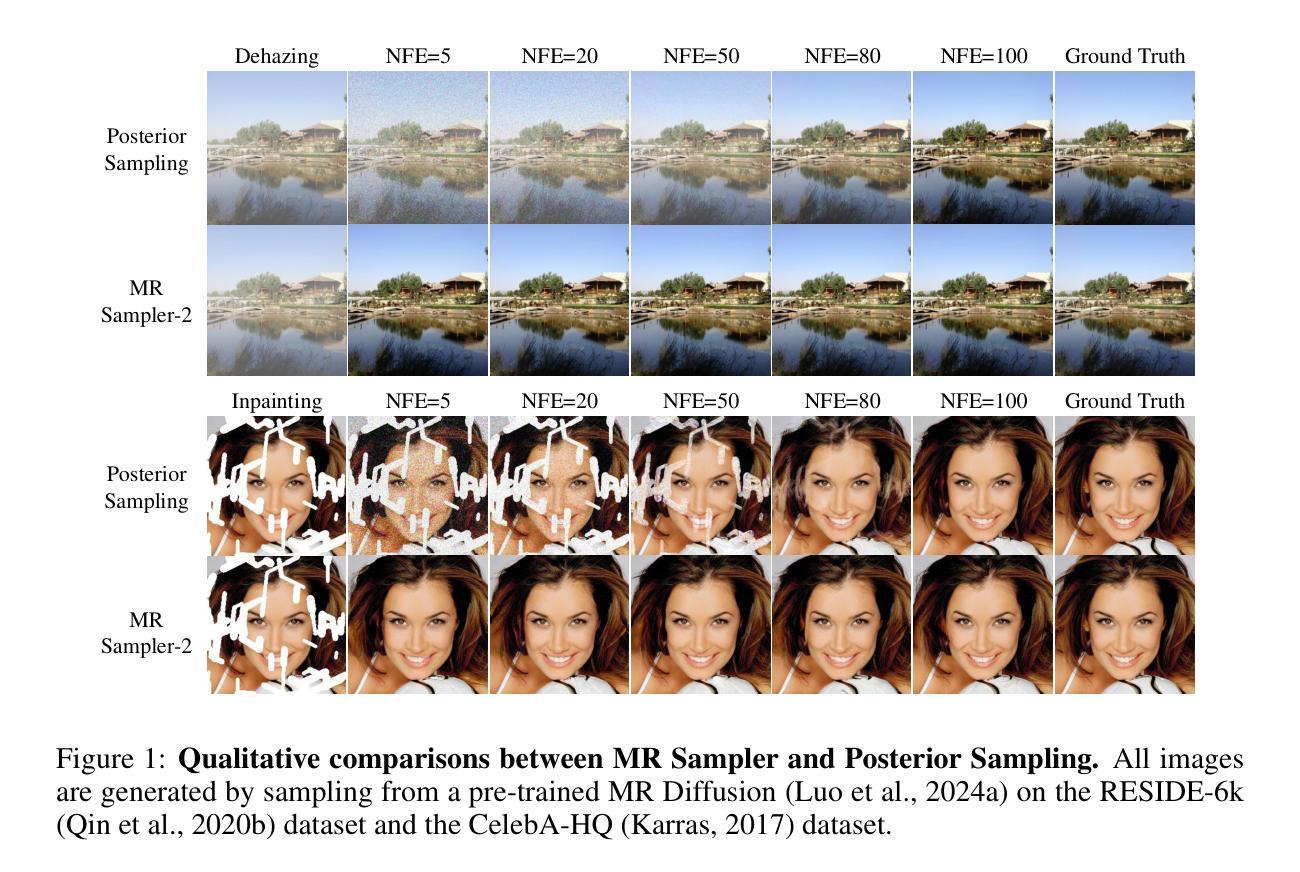

VIIS: Visible and Infrared Information Synthesis for Severe Low-light Image Enhancement
Authors:Chen Zhao, Mengyuan Yu, Fan Yang, Peiguang Jing
Images captured in severe low-light circumstances often suffer from significant information absence. Existing singular modality image enhancement methods struggle to restore image regions lacking valid information. By leveraging light-impervious infrared images, visible and infrared image fusion methods have the potential to reveal information hidden in darkness. However, they primarily emphasize inter-modal complementation but neglect intra-modal enhancement, limiting the perceptual quality of output images. To address these limitations, we propose a novel task, dubbed visible and infrared information synthesis (VIIS), which aims to achieve both information enhancement and fusion of the two modalities. Given the difficulty in obtaining ground truth in the VIIS task, we design an information synthesis pretext task (ISPT) based on image augmentation. We employ a diffusion model as the framework and design a sparse attention-based dual-modalities residual (SADMR) conditioning mechanism to enhance information interaction between the two modalities. This mechanism enables features with prior knowledge from both modalities to adaptively and iteratively attend to each modality’s information during the denoising process. Our extensive experiments demonstrate that our model qualitatively and quantitatively outperforms not only the state-of-the-art methods in relevant fields but also the newly designed baselines capable of both information enhancement and fusion. The code is available at https://github.com/Chenz418/VIIS.
在严重低光环境下捕捉的图像通常缺乏重要信息。现有的单一模态图像增强方法在恢复缺乏有效信息图像区域方面表现困难。通过利用不受光线影响的红外图像,可见光和红外图像融合方法具有揭示隐藏在黑暗中的信息的潜力。然而,它们主要强调跨模态互补,却忽略了模态内增强,从而限制了输出图像的感知质量。为了解决这些局限性,我们提出了一个新的任务,称为可见光和红外信息合成(VIIS),旨在实现两个模态的信息增强和融合。考虑到VIIS任务中获取真实样本的难度,我们基于图像增强设计了一个信息合成预训练任务(ISPT)。我们以扩散模型为框架,设计了一种基于稀疏注意力的双模态残差(SADMR)条件机制,以增强两个模态之间的信息交互。该机制使得具有来自两个模态的先验知识的特征能够在去噪过程中自适应地迭代关注每个模态的信息。我们的广泛实验表明,我们的模型不仅在相关领域定性和定量上超越了最新方法,而且在新设计的基线模型上也表现出色,这些基线模型能够同时实现信息增强和融合。代码可在https://github.com/Chenz418/VIIS找到。
论文及项目相关链接
PDF Accepted to WACV 2025
Summary
针对低光环境下图像信息缺失的问题,现有图像增强方法难以恢复缺失信息。通过结合红外图像,可见光和红外图像融合方法能够揭示隐藏信息。但现有方法主要关注跨模态互补,忽视单模态内增强,影响输出图像感知质量。为此,提出可见光和红外信息合成(VIIS)任务,旨在实现信息增强与融合。为解决VIIS任务缺乏真实标注的问题,设计基于图像增强的信息合成预训练任务(ISPT)。采用扩散模型框架,设计稀疏注意力机制的双模态残差(SADMR)条件机制,增强两模态间的信息交互。实验证明,模型在相关领域的表现优于现有方法和新设计的基线模型。
Key Takeaways
- 低光环境下捕获的图像经常缺乏信息,现有图像增强方法难以完全恢复这些信息。
- 通过结合红外图像,可见光和红外图像融合方法可以揭示隐藏在黑暗中的信息。
- 现有方法主要关注跨模态的互补信息,但忽视了单模态内的增强,影响了输出图像的感知质量。
- 提出了可见光和红外信息合成(VIIS)任务,旨在同时实现信息增强和融合。
- 为了解决VIIS任务中缺乏真实标注的问题,设计了一个基于图像增强的信息合成预训练任务(ISPT)。
- 采用扩散模型框架,并设计了SADMR条件机制来增强可见光和红外图像之间的信息交互。
点此查看论文截图


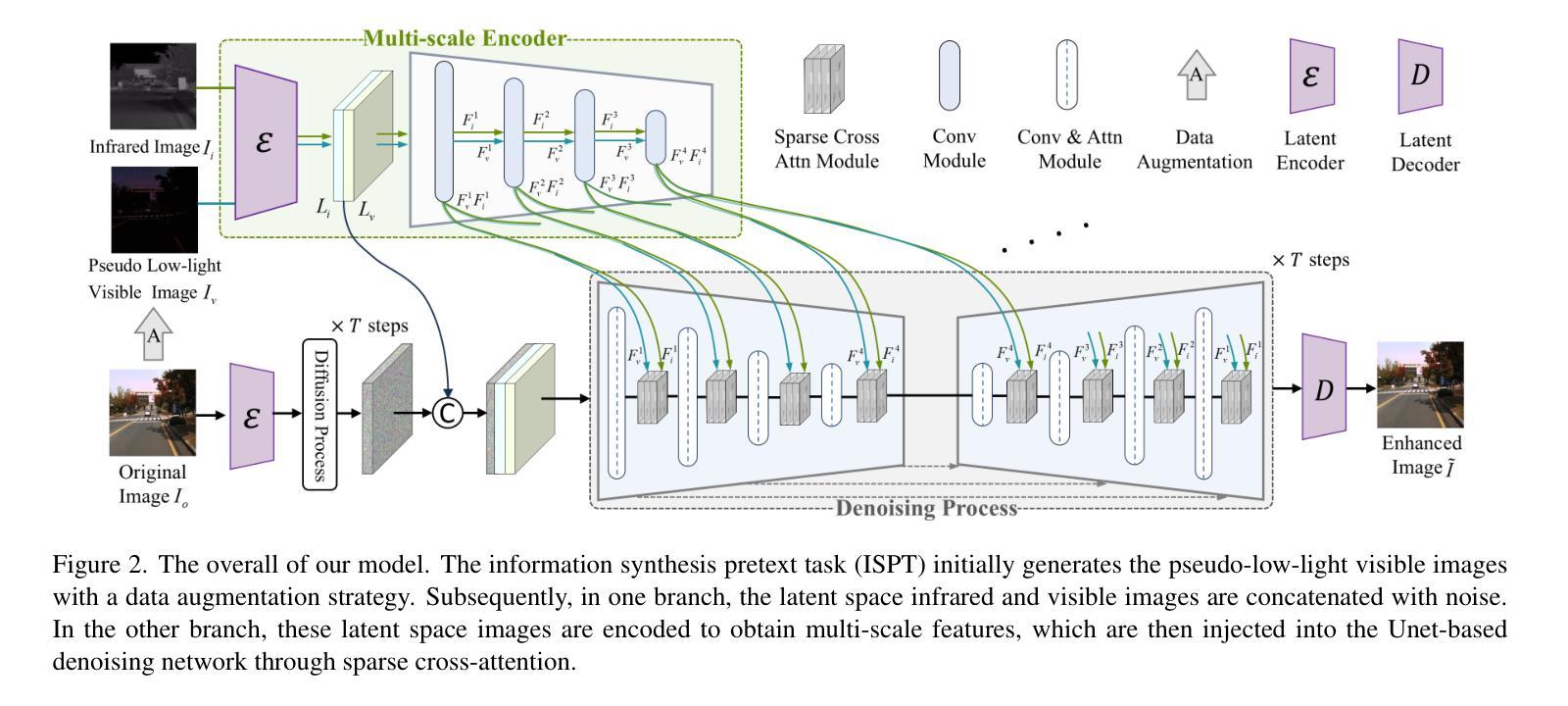



Noise Matters: Diffusion Model-based Urban Mobility Generation with Collaborative Noise Priors
Authors:Yuheng Zhang, Yuan Yuan, Jingtao Ding, Jian Yuan, Yong Li
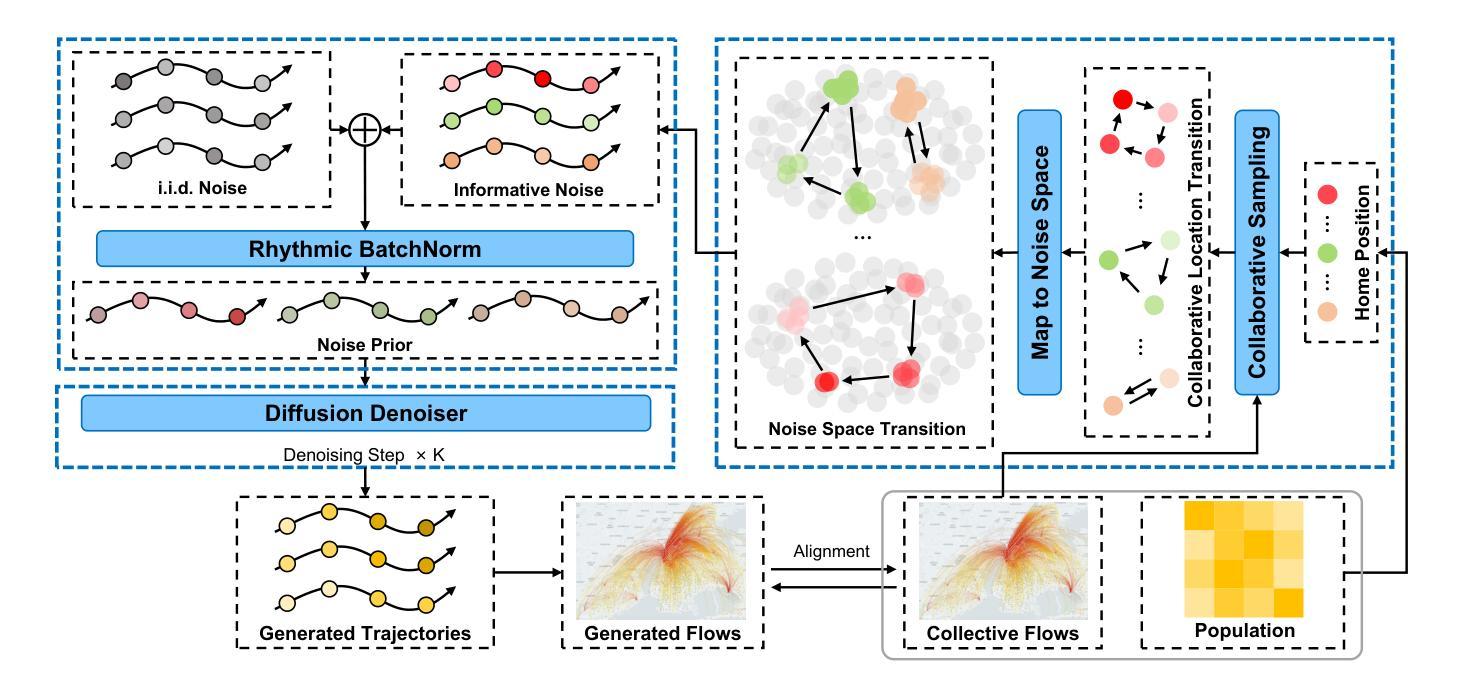
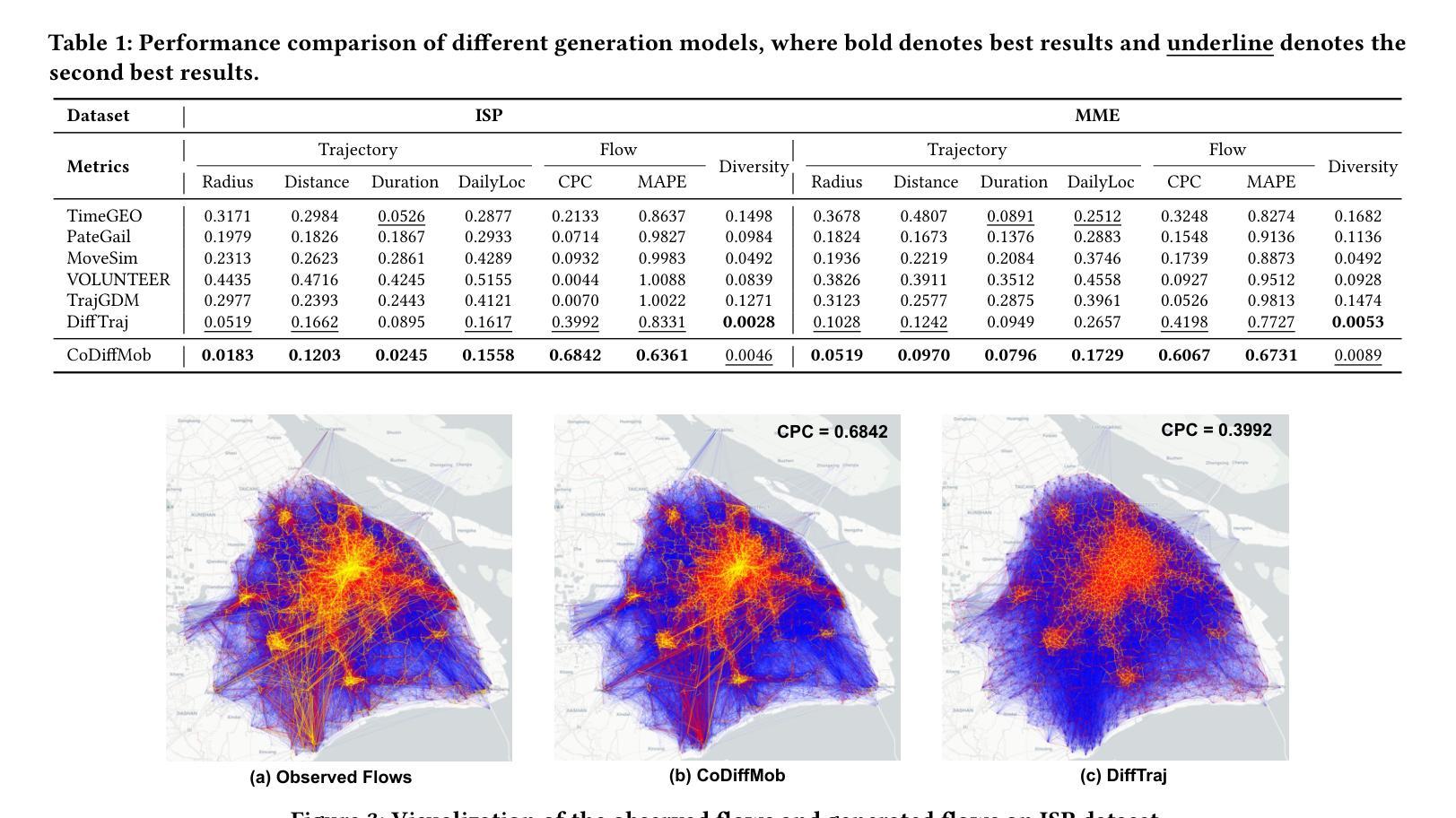
With global urbanization, the focus on sustainable cities has largely grown, driving research into equity, resilience, and urban planning, which often relies on mobility data. The rise of web-based apps and mobile devices has provided valuable user data for mobility-related research. However, real-world mobility data is costly and raises privacy concerns. To protect privacy while retaining key features of real-world movement, the demand for synthetic data has steadily increased. Recent advances in diffusion models have shown great potential for mobility trajectory generation due to their ability to model randomness and uncertainty. However, existing approaches often directly apply identically distributed (i.i.d.) noise sampling from image generation techniques, which fail to account for the spatiotemporal correlations and social interactions that shape urban mobility patterns. In this paper, we propose CoDiffMob, a diffusion model for urban mobility generation with collaborative noise priors, we emphasize the critical role of noise in diffusion models for generating mobility data. By leveraging both individual movement characteristics and population-wide dynamics, we construct novel collaborative noise priors that provide richer and more informative guidance throughout the generation process. Extensive experiments demonstrate the superiority of our method, with generated data accurately capturing both individual preferences and collective patterns, achieving an improvement of over 32%. Furthermore, it can effectively replace web-derived mobility data to better support downstream applications, while safeguarding user privacy and fostering a more secure and ethical web. This highlights its tremendous potential for applications in sustainable city-related research. The code and data are available at https://github.com/tsinghua-fib-lab/CoDiffMob.
随着全球城市化进程的推进,对可持续城市发展的关注日益增加,推动了关于公平、韧性和城市规划的研究,这些研究通常依赖于出行数据。网络应用程序和移动设备的普及为与出行相关的研究提供了宝贵的用户数据。然而,真实世界的出行数据成本高昂,并引发隐私担忧。为了在保护隐私的同时保留现实世界的移动关键特征,对合成数据的需求稳步增加。扩散模型的最新进展在生成移动轨迹方面显示出巨大潜力,因为它们能够模拟随机性和不确定性。然而,现有方法通常直接从图像生成技术中采用独立同分布(i.i.d.)噪声采样,忽略了时空关联和社会互动对城市出行模式的影响。在本文中,我们提出了CoDiffMob,这是一种带有协作噪声先验的城市移动性生成扩散模型。我们强调了噪声在扩散模型中生成移动性数据的关键作用。通过利用个体移动特征和整体人口动态,我们构建了新型协作噪声先验,为生成过程提供更丰富、更具信息量的指导。大量实验证明了我们方法的优越性,生成的数据准确捕捉了个体偏好和集体模式,实现了超过32%的改进。此外,它可以有效地替代网络派生的移动数据,以更好地支持下游应用程序,同时保护用户隐私并促进更安全、更道德的互联网发展。这凸显了其在可持续城市相关研究中的应用潜力。代码和数据可在https://github.com/tsinghua-fib-lab/CoDiffMob获得。
论文及项目相关链接
Summary
随着全球城市化的推进,对可持续城市的研究日益重视,涉及公平、韧性和城市规划等领域。由于真实世界移动数据成本高昂且存在隐私担忧,合成数据的需求逐渐增长。本文提出一种名为CoDiffMob的扩散模型,用于生成城市移动性数据,采用协作噪声先验技术,强调噪声在扩散模型中的重要性。该方法结合个体移动特性和群体动态,构建丰富的协作噪声先验,指导数据生成过程。实验表明,该方法能够准确捕捉个体偏好和集体模式,有效替代网络派生移动数据,保护用户隐私并促进更安全、更道德的网络建设。这为可持续城市相关研究提供了巨大潜力。
Key Takeaways
- 全球城市化推动了可持续城市研究的增长,涉及公平、韧性和城市规划等领域。
- 真实世界移动数据成本高昂且存在隐私担忧,合成数据需求增加。
- 现有扩散模型方法在处理城市移动轨迹生成时,未能充分考虑时空关联和社会互动。
- 本文提出的CoDiffMob模型利用协作噪声先验技术,强调噪声在扩散模型中的重要性。
- CoDiffMob模型结合个体移动特性和群体动态,构建丰富的协作噪声先验。
- 实验表明CoDiffMob模型能够准确捕捉个体偏好和集体模式,有效替代网络派生移动数据。
点此查看论文截图

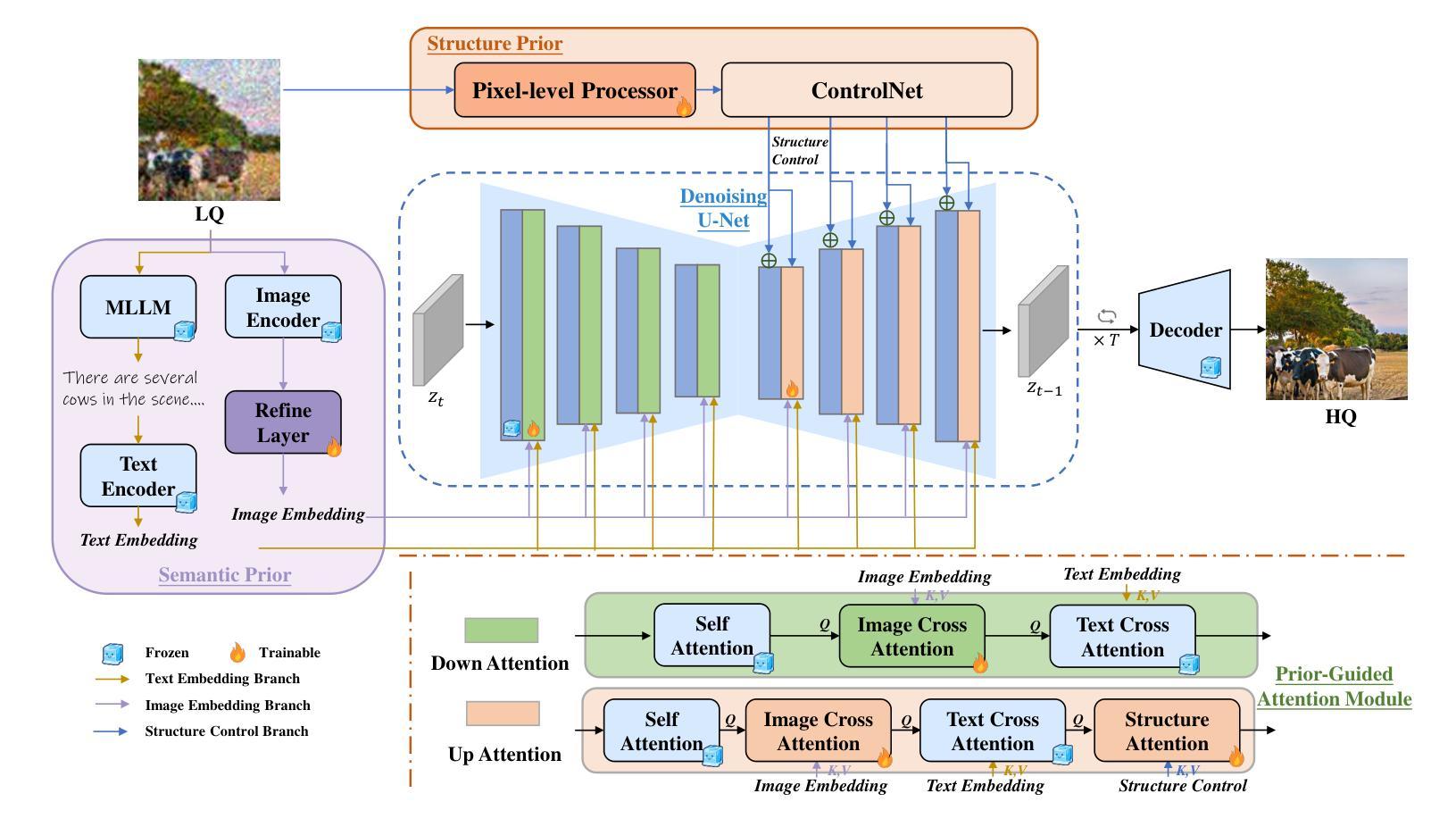
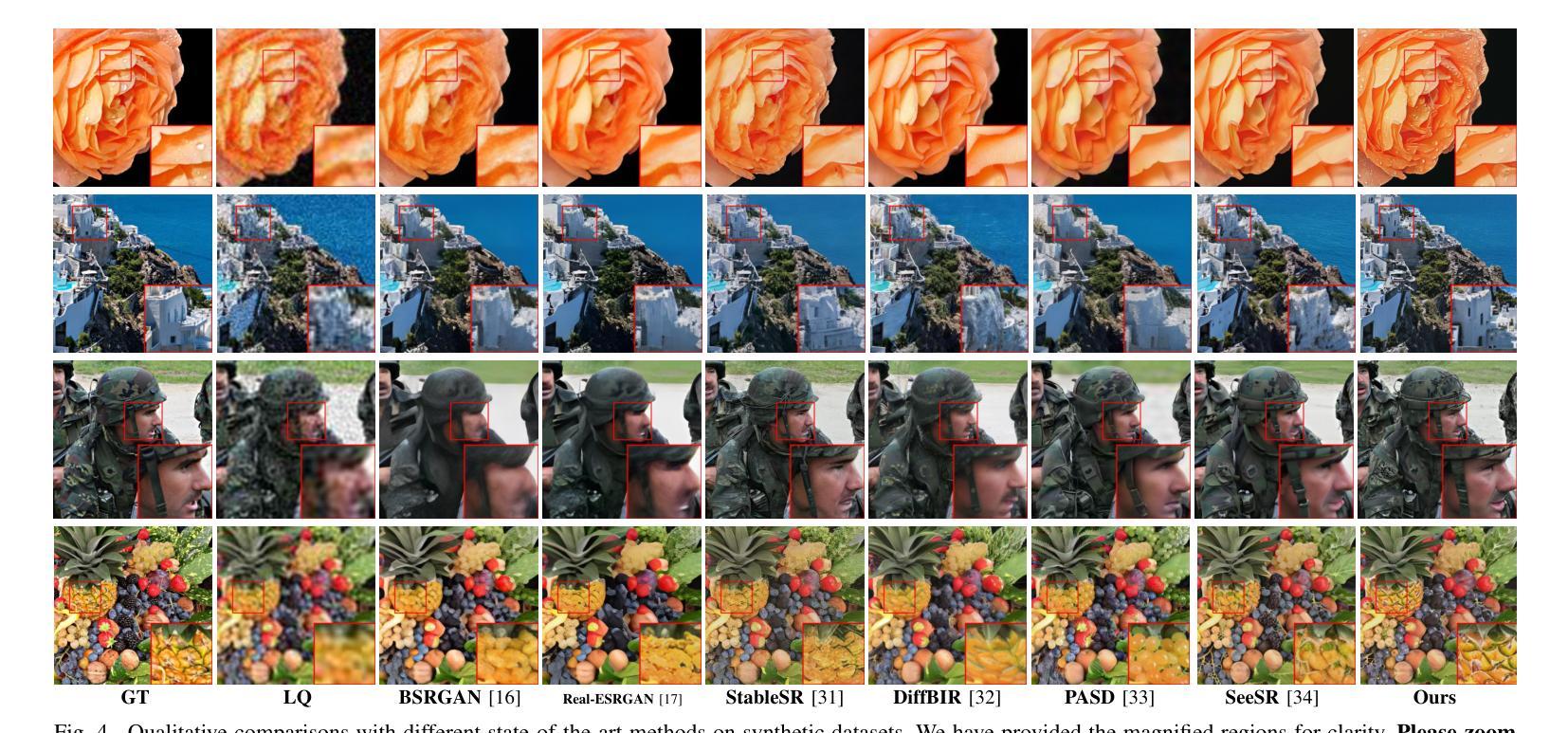
SSP-IR: Semantic and Structure Priors for Diffusion-based Realistic Image Restoration
Authors:Yuhong Zhang, Hengsheng Zhang, Zhengxue Cheng, Rong Xie, Li Song, Wenjun Zhang
Realistic image restoration is a crucial task in computer vision, and diffusion-based models for image restoration have garnered significant attention due to their ability to produce realistic results. Restoration can be seen as a controllable generation conditioning on priors. However, due to the severity of image degradation, existing diffusion-based restoration methods cannot fully exploit priors from low-quality images and still have many challenges in perceptual quality, semantic fidelity, and structure accuracy. Based on the challenges, we introduce a novel image restoration method, SSP-IR. Our approach aims to fully exploit semantic and structure priors from low-quality images to guide the diffusion model in generating semantically faithful and structurally accurate natural restoration results. Specifically, we integrate the visual comprehension capabilities of Multimodal Large Language Models (explicit) and the visual representations of the original image (implicit) to acquire accurate semantic prior. To extract degradation-independent structure prior, we introduce a Processor with RGB and FFT constraints to extract structure prior from the low-quality images, guiding the diffusion model and preventing the generation of unreasonable artifacts. Lastly, we employ a multi-level attention mechanism to integrate the acquired semantic and structure priors. The qualitative and quantitative results demonstrate that our method outperforms other state-of-the-art methods overall on both synthetic and real-world datasets. Our project page is https://zyhrainbow.github.io/projects/SSP-IR.
图像修复是计算机视觉中的一项重要任务,基于扩散模型的图像修复由于其能生成逼真的结果而受到广泛关注。修复可以被视为基于先验的受控生成。然而,由于图像退化的严重性,现有的基于扩散的修复方法无法充分利用来自低质量图像的先验信息,并且在感知质量、语义保真度和结构准确性方面仍然面临许多挑战。针对这些挑战,我们提出了一种新的图像修复方法SSP-IR。我们的方法旨在充分利用来自低质量图像的语义和结构先验,以指导扩散模型生成语义上忠实、结构上准确的自然修复结果。具体来说,我们结合了多模态大型语言模型的视觉理解能力(显式)和原始图像的视觉表示(隐式)来获取准确的语义先验。为了提取与退化无关的结构先验,我们引入了一个带有RGB和FFT约束的处理器,从低质量图像中提取结构先验,指导扩散模型,防止生成不合理的伪影。最后,我们采用多级注意力机制来整合获得的语义和结构先验。定性和定量结果表明,我们的方法在合成和真实世界数据集上的总体表现均优于其他最先进的方法。我们的项目页面是 https://zyhrainbow.github.io/projects/SSP-IR。
论文及项目相关链接
PDF To be published in IEEE TCSVT
Summary
本文介绍了基于扩散模型的图像恢复方法SSP-IR。该方法旨在从低质量图像中充分提取语义和结构先验,以指导扩散模型生成语义上忠实、结构上准确的自然恢复结果。通过整合多模态大型语言模型的视觉理解能力和原始图像的视觉表示,获取准确的语义先验。引入处理器提取结构先验,采用RGB和FFT约束,防止生成不合理的伪影。最后,采用多级注意力机制整合获取的语义和结构先验。实验结果表明,该方法在合成和真实世界数据集上均优于其他先进方法。
Key Takeaways
- 扩散模型在图像恢复中因其能产生真实结果而备受关注。
- 现有扩散模型在图像恢复中面临挑战,如感知质量、语义保真度和结构准确性。
- SSP-IR方法旨在从低质量图像中充分提取语义和结构先验。
- 该方法结合了多模态大型语言模型的视觉理解能力和原始图像的视觉表示。
- 引入处理器提取结构先验,采用RGB和FFT约束防止生成不合理伪影。
- 采用多级别注意力机制整合语义和结构先验。
点此查看论文截图