⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-15 更新
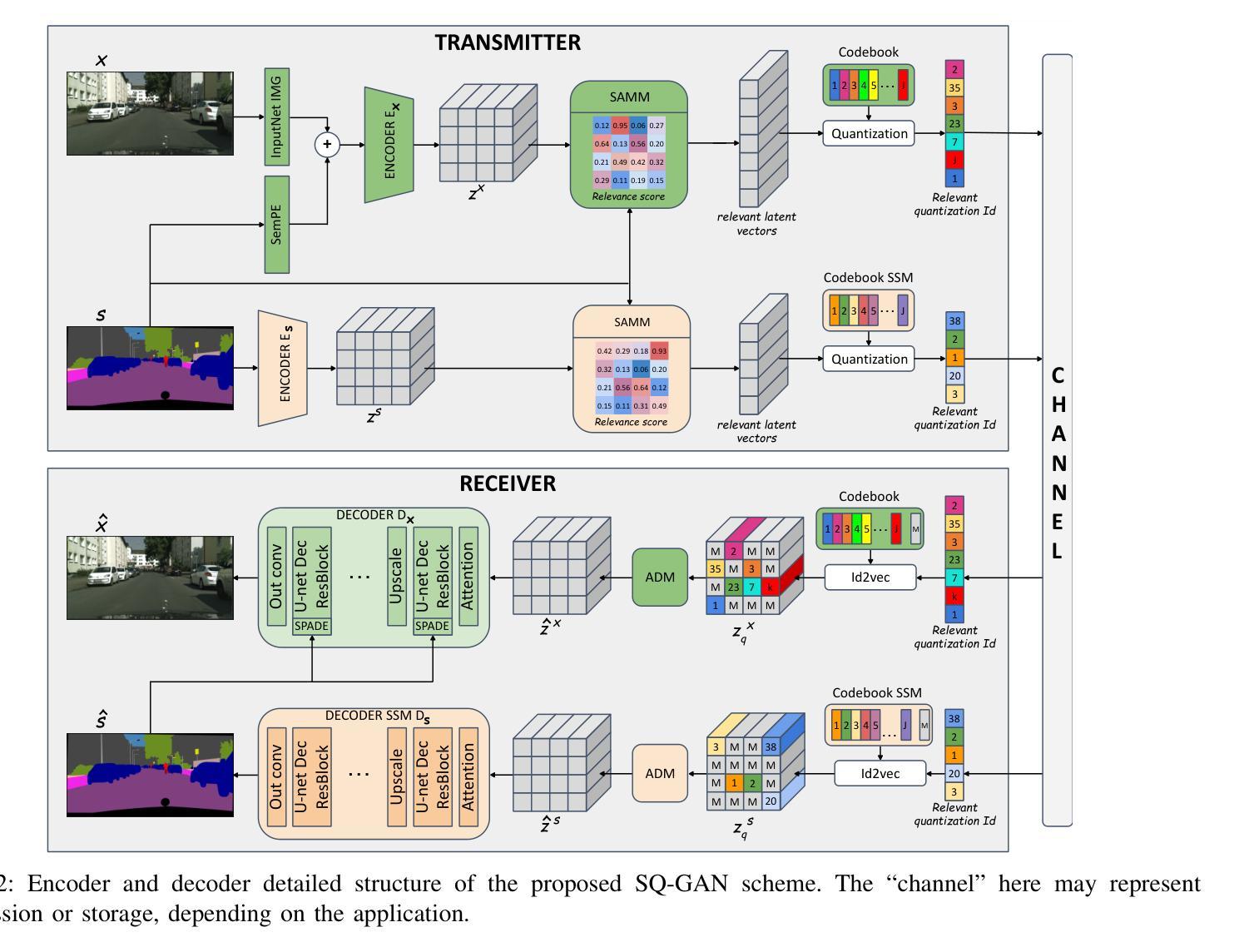
SQ-GAN: Semantic Image Communications Using Masked Vector Quantization
Authors:Francesco Pezone, Sergio Barbarossa, Giuseppe Caire
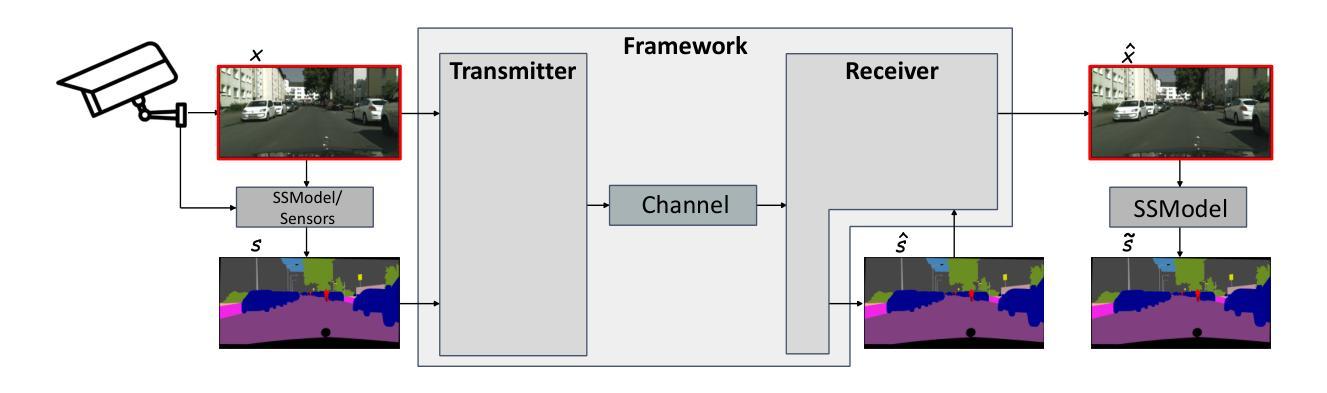
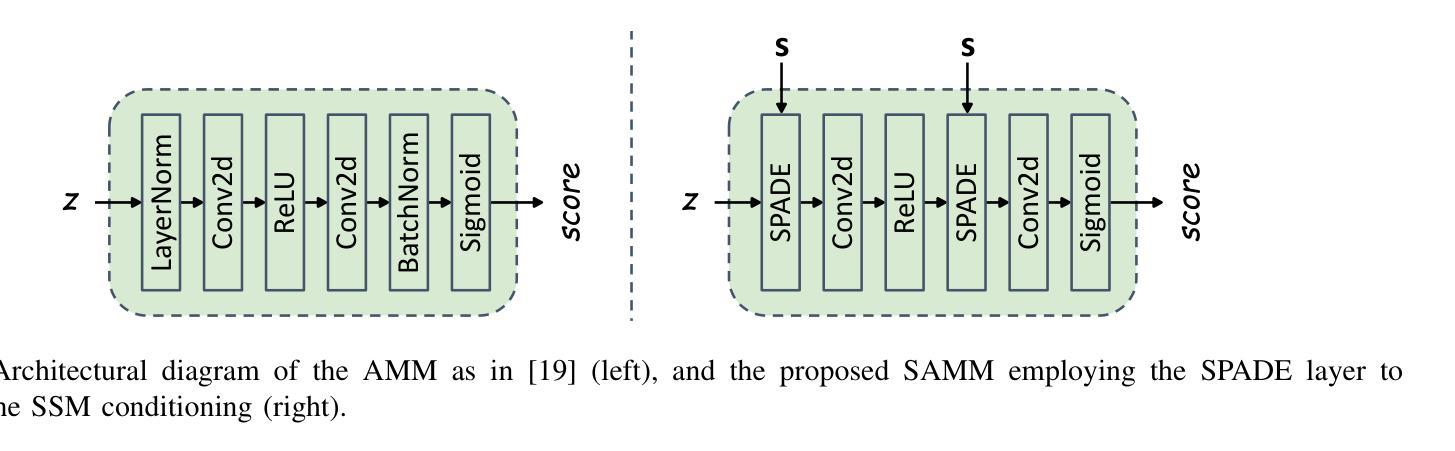
This work introduces Semantically Masked VQ-GAN (SQ-GAN), a novel approach integrating generative models to optimize image compression for semantic/task-oriented communications. SQ-GAN employs off-the-shelf semantic semantic segmentation and a new specifically developed semantic-conditioned adaptive mask module (SAMM) to selectively encode semantically significant features of the images. SQ-GAN outperforms state-of-the-art image compression schemes such as JPEG2000 and BPG across multiple metrics, including perceptual quality and semantic segmentation accuracy on the post-decoding reconstructed image, at extreme low compression rates expressed in bits per pixel.
本文介绍了语义掩码VQ-GAN(SQ-GAN),这是一种新型方法,通过集成生成模型来优化面向语义/任务导向通信的图像压缩。SQ-GAN采用现成的语义分割以及新开发的语义条件自适应掩码模块(SAMM),以选择性地对图像中的语义重要特征进行编码。在极低比特率(以每像素表示的位为单位)下,SQ-GAN在多个指标上都优于当前先进的图像压缩方案,如JPEG 2000和BPG,包括解码后重建图像的感知质量和语义分割准确性。
论文及项目相关链接
Summary
本文介绍了语义掩码VQ-GAN(SQ-GAN),这是一种结合了生成模型的新方法,旨在优化语义/任务导向通信的图像压缩。SQ-GAN利用现成的语义分割和一个新开发的语义条件自适应掩码模块(SAMM),有选择地对图像中的语义重要特征进行编码。在极端低比特率的压缩下,SQ-GAN在多个指标上超越了JPEG2000和BPG等当前领先的图像压缩方案,包括重建图像的感知质量和语义分割准确性。
Key Takeaways
- SQ-GAN是一种结合了生成模型的图像压缩新方法。
- SQ-GAN旨在优化语义/任务导向通信的图像压缩。
- SQ-GAN利用现成的语义分割和SAMM模块,有选择地编码图像中的语义重要特征。
- 在极端低比特率的压缩下,SQ-GAN在感知质量和语义分割准确性方面超越了现有图像压缩方案。
- SQ-GAN在多个指标上表现出卓越性能,包括压缩效率、图像质量和语义保留。
- SQ-GAN的引入为图像压缩领域带来了新的研究方向和可能性。
点此查看论文截图

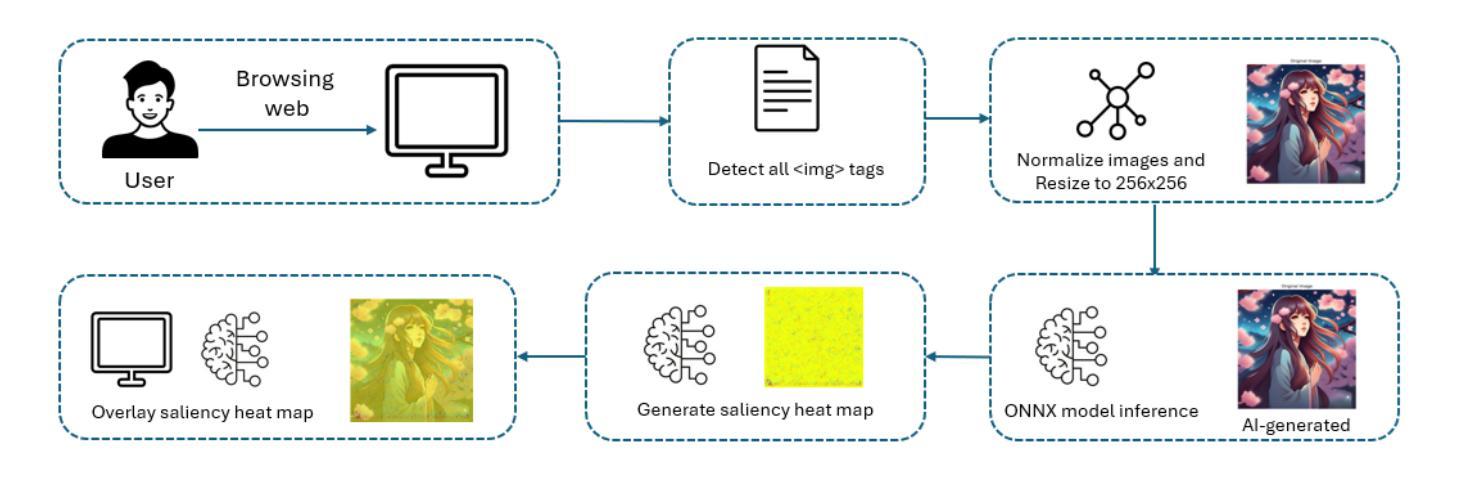
DejAIvu: Identifying and Explaining AI Art on the Web in Real-Time with Saliency Maps
Authors:Jocelyn Dzuong
The recent surge in advanced generative models, such as diffusion models and generative adversarial networks (GANs), has led to an alarming rise in AI-generated images across various domains on the web. While such technologies offer benefits such as democratizing artistic creation, they also pose challenges in misinformation, digital forgery, and authenticity verification. Additionally, the uncredited use of AI-generated images in media and marketing has sparked significant backlash from online communities. In response to this, we introduce DejAIvu, a Chrome Web extension that combines real-time AI-generated image detection with saliency-based explainability while users browse the web. Using an ONNX-optimized deep learning model, DejAIvu automatically analyzes images on websites such as Google Images, identifies AI-generated content using model inference, and overlays a saliency heatmap to highlight AI-related artifacts. Our approach integrates efficient in-browser inference, gradient-based saliency analysis, and a seamless user experience, ensuring that AI detection is both transparent and interpretable. We also evaluate DejAIvu across multiple pretrained architectures and benchmark datasets, demonstrating high accuracy and low latency, making it a practical and deployable tool for enhancing AI image accountability. The code for this system can be found at https://github.com/Noodulz/dejAIvu.
最近先进的生成模型(如扩散模型和生成对抗网络(GANs))的激增导致网上各种领域的AI生成图像数量惊人增长。虽然这些技术提供了民主化艺术创作等好处,但它们也带来了虚假信息、数字伪造和身份验证的挑战。此外,媒体和营销中未经授权使用AI生成的图像引发了在线社区的强烈反对。为了应对这一问题,我们推出了DejAIvu,这是一款Chrome网页扩展程序,它结合了实时AI生成图像检测与基于显著性的解释性,供用户在浏览网页时使用。DejAIvu使用经过ONNX优化的深度学习模型,自动分析网站上的图像(如Google Images),通过模型推理识别AI生成的内容,并通过叠加显著性热度图来突出显示与AI相关的特征。我们的方法融合了高效的浏览器内推理、基于梯度的显著性分析和无缝的用户体验,确保AI检测既透明又易于解释。我们还对DejAIvu进行了跨多个预训练架构和基准数据集的评估,证明了其高准确性和低延迟性,使其成为增强AI图像责任制的实用且可部署的工具。该系统的代码可在https://github.com/Noodulz/dejAIvu找到。
论文及项目相关链接
PDF 5 pages, 3 figures, submitted to IJCAI 2025 demo track
Summary
随着先进的生成模型如扩散模型和生成对抗网络(GANs)的兴起,网上出现了AI生成的图像泛滥现象。这虽带来了民主化的艺术创作等好处,但也引发了虚假信息、数字伪造和身份验证等挑战。为了解决这些问题,我们推出了DejAIvu,这是一款Chrome网页扩展程序,结合实时AI生成的图像检测和用户浏览时的显著性解释。DejAIvu使用优化的ONNX深度学习模型自动分析网站上的图像,通过模型推理识别AI生成的内容,并覆盖显著性热图以突出AI相关伪影。我们的方法融合了高效的浏览器内推理、基于梯度的显著性分析和无缝用户体验,确保AI检测既透明又易懂。评估结果显示,DejAIvu在多预训练架构和基准数据集上的准确率高、延迟低,是一个实用且可部署的增强AI图像责任工具。
Key Takeaways
- 先进的生成模型如扩散模型和GANs导致了网上AI生成图像的普及。
- AI生成图像带来了虚假信息、数字伪造和身份验证的挑战。
- DejAIvu是一款Chrome网页扩展程序,能实时检测AI生成的图像。
- DejAIvu通过结合深度学习模型、显著性热图和用户浏览行为来识别和分析AI生成的图像。
- DejAIvu具有高效浏览器内推理、基于梯度的显著性分析和无缝用户体验等特点。
- DejAIvu在多个预训练架构和基准数据集上的表现优秀,准确率高且延迟低。
点此查看论文截图